


چرخه حیات توسعه سیستم (SDLC) فعالیتها و نقاط عطف در طراحی، توسعه، آزمایش و استقرار برنامههای کاربردی نرمافزار و سیستمهای اطلاعاتی را مشخص و هدایت میکند. انتخاب های مختلفی از SDLC برای انواع مختلف برنامه های کاربردی نرم افزاری و سیستم های اطلاعاتی و ترکیب تیم های توسعه و ذینفعان موجود است. در حالی که انتخاب یک SDLC برای ساختن برنامه های کاربردی سیستم اطلاعات جغرافیایی (GIS) شبیه به انواع دیگر برنامه های نرم افزاری است، تصمیمات حیاتی در هر مرحله از چرخه عمر توسعه GIS (GiSDLC) باید سوالات اساسی مربوط به ذخیره سازی را در نظر بگیرد. ، دسترسی و تجزیه و تحلیل داده های (جغرافیایی) مکانی برای برنامه هدف. هدف این مقاله معرفی ملاحظات مختلف در GiSDLC از دیدگاه مدیریت دادههای مکانی (جغرافیایی) است. مقاله اول چندین فرآیند و انواع (جغرافیایی) فضایی و همچنین روشهای مختلف کاربردهای GIS را معرفی می کند. سپس مقاله به معرفی مختصری از یک SDLC، از جمله توضیح نقش دادههای مکانی (جغرافیایی) در SDLC میپردازد. در نهایت، این مقاله از دو برنامه کاربردی موجود در دنیای واقعی به عنوان مثال برای برجسته کردن ملاحظات مهم در GiSDLC استفاده میکند.
- معرفی
- چرخه عمر توسعه سیستم ها
- سیستم مدیریت داده های ترافیک بایگانی شده
- خلاصه
سیستم های اطلاعات جغرافیایی (GIS) به سیستم های اطلاعاتی اطلاق می شود که داده های مکانی (جغرافیایی) را دستکاری می کنند. فرآیند دستکاری دادهها میتواند از تجمیع دادههای ساده تا روشهای پیچیده فضایی و یادگیری ماشینی باشد. نمونه ای از فرآیند تجمیع داده ها، محاسبه میانگین دمای روزانه هر مکان روی نقشه است. یک روش تحلیل فضایی از اصولی در آمارهای فضایی برای مدلسازی داده ها در فضا برای درک فرآیند تولید داده یا پیش بینی ها استفاده می کند، به عنوان مثال کریجینگ (Cressie 1990) و رگرسیون وزنی جغرافیایی (Brunsdon et al. 1996). یک روش یادگیری ماشین، مشابه روشهای تحلیل فضایی، از ویژگیهای (جغرافیایی) فضایی در دادهها برای استنتاج یا پیشبینی با استفاده از دادههای موجود برای دادههای دیده نشده بهرهبرداری میکند. در این مقاله،
برنامههای کاربردی GIS (نرمافزار) سنتی اغلب GISهای عمومی و همهمنظوره هستند که از انواع فرآیندهای (جغرافیایی) فضایی برای تجزیه و تحلیل و تجسم دادههای (جغرافیایی) مکانی در قالبهای مختلف بر روی یک رایانه محلی پشتیبانی میکنند. پیشرفتهای اخیر در قدرت محاسباتی و ابزارهای توسعه نرمافزار، طیف گستردهای از برنامههای GIS، از جمله برنامههای قدرتمند GIS عمومی و برنامههای کاربردی سفارشیشده برای مأموریتهای خاص (مثلاً تجسم دادههای ترافیک) را قادر ساخته است. به طور کلی، برنامه های GIS را می توان بر اساس ویژگی های منابع محاسباتی آنها (به عنوان مثال، ذخیره سازی داده ها، قدرت محاسباتی، دسترسی به شبکه) به عنوان برنامه های کاربردی دسکتاپ یا مبتنی بر ابر طبقه بندی کرد. برنامه های دسکتاپ، مانند ArcGIS Desktop و QGIS Esri اغلب نیازی به اتصال به اینترنت ندارند، اما فقط می توانند مقدار کمی از داده ها را به دلیل داشتن یک رایانه مدیریت کنند. قدرت محاسباتی و ذخیره سازی محدود است. در مقابل، برنامههای کاربردی مبتنی بر ابر، مانند ArcGIS Online Esri میتوانند دادههای بزرگ (اغلب در یک خوشه کامپیوتری بزرگ) را پردازش کنند، اما نیاز به دسترسی به شبکه (چه اینترنت یا یک شبکه سازمانی خصوصی) دارند.
علاوه بر تمایز در منابع محاسباتی، برنامههای GIS میتوانند روشهای مختلفی بر اساس طراحی استراتژیهای تعامل انسان و رایانه (HCI) خود داشته باشند، مانند برنامههای GIS موبایل، برنامههای GIS وب و APIهای GIS آنلاین (رابط برنامهنویسی کاربردی). ). برنامه های کاربردی موبایل GIS برنامه های نرم افزاری هستند که بر روی دستگاه های تلفن همراه اجرا می شوند و مهمتر از همه، می توانند از خدمات مبتنی بر مکان (LBS) برای حل یک مشکل عملی (مثلاً ثبت مسیرهای متحرک) بهره برداری کنند. به عنوان مثال، Esri Collector یک برنامه GIS تلفن همراه است که جمع آوری داده ها را با استفاده از یک دستگاه تلفن همراه امکان پذیر می کند. برنامه های Web GIS در یک مرورگر وب، چه در یک دستگاه تلفن همراه یا دسکتاپ، اجرا می شوند. مزیت اصلی برنامه های Web GIS این است که مرورگرهای وب در انواع مختلف دستگاه ها وجود دارند. و از این رو کاربران نیازی به نصب نرم افزارهای اضافی ندارند. برنامه های کاربردی وب GIS اغلب به یک GIS ابری باطن نیاز دارند. یک وب GIS که توسط یک GIS ابری پشتیبانی میشود، میتواند طیف گستردهای از عملکردها را پشتیبانی کند، مانند تجسم دادههای نقشه موجود یا ارائهشده توسط کاربر و انجام فرآیندهای (جغرافیایی) فضایی پیچیده. نمونه ای از برنامه های Web GIS CARTO است که به کاربران امکان سفارشی سازی مجموعه داده ها و انتشار نقشه های تعاملی در وب را می دهد. Google Maps هم یک برنامه GIS موبایل و هم وب است که اطلاعات موقعیت مکانی، از جمله ترافیک، شبکههای جادهای و نقاط مورد علاقه را در دستگاههای تلفن همراه یا در وب نمایش میدهد. API های آنلاین GIS فرآیندهای محاسباتی هستند که روی یک سرور اجرا می شوند. آنها را می توان در اینترنت با استفاده از پروتکل های خاص (مانند، خدمات RESTful مطابق با معماری نرم افزار REpresentational State Transfer (REST) است. به عنوان مثال، مؤسسه علوم فضایی دانشگاه کالیفرنیای جنوبی یک API پیشبینی کیفیت هوا ارائه میکند و Google خدمات کدگذاری جغرافیایی خود را به عنوان یک API آنلاین در دسترس قرار میدهد.
برنامههای GIS همچنین میتوانند با انواع دادههای مکانی (جغرافیایی) پشتیبانیشده آنها، که اغلب توانایی فرآیندهای (جغرافیایی) فضایی برنامهها و روشهای کاربرد را تعیین میکنند، متمایز شوند. به عنوان مثال، فرض کنید یک برنامه GIS نیاز به تولید هفتگی مقادیر کیفیت هوا به صورت فضایی از مکان های نقطه ای دارد. سپس بهترین روش یک برنامه مبتنی بر ابر (یا سرور) با استفاده از پایگاه داده فضایی است. اگر برنامه شامل فرآیندهای (جغرافیایی) فضایی پیچیدهتری نسبت به تجمیع دادهها باشد، معماری نرمافزار روی ابر باید بتواند میزبان کتابخانههای برنامهنویسی (جغرافیایی) فضایی یا چارچوبهای یادگیری ماشینی باشد، بهعنوان مثال، جریان تنسور (Lin et al. 2018)
دو نوع داده مکانی (جغرافیایی) رایج عبارتند از نوع داده برداری و نوع داده شطرنجی. داده های برداری هندسه چیزهای (ژئو) فضایی را با استفاده از نقاط، خطوط و چندضلعی ها نشان می دهد. همچنین، دادههای برداری اغلب همراه با یک جزء جدولی هستند که فراداده هندسی (ویژگیها) را توصیف میکند. فرمتهای برداری محبوب عبارتند از: شکل فایل Esri (Esri 1998)، GeoJSON، و کنسرسیوم فضایی باز (OGC)، متن خوب شناخته شده، دودویی شناخته شده، و KML (زبان نشانهگذاری Keyhole). شکل فایل Esri هندسه اشیاء و ویژگی های آنها (به عنوان مثال، نام مکان، آدرس) را ذخیره می کند. GeoJSON یک فرمت برداری سبک است که بیشتر برای وب GIS و سایر برنامه های GIS که مجموعه داده های کوچکی را مدیریت می کنند، می باشد. متن شناخته شده و باینری شناخته شده فرمت های داده رایج برای پایگاه داده های فضایی (به عنوان مثال، PostGIS) هستند که از OGC سرچشمه می گیرند. تعاریف آنها در ISO/IEC 13249-3 آمده است: استاندارد 2016 KML (در حال حاضر توسط OGC نگهداری میشود) شامل هندسهها و ویژگیهای شی و نحوه نمایش این هندسهها در یک برنامه کاربردی است (به عنوان مثال، Google Earth و Google Maps Android Software Development Kit). داده های برداری به اندازه فایل کوچک و نمایش نقطه، اسکلت و مرز اشیاء (جغرافیایی) مکانی دقیق اجازه می دهد.
برخلاف داده های برداری که به صراحت اطلاعات هندسی را ذخیره می کنند، داده های شطرنجی از یک ساختار شبکه ای برای نمایش چیزهای فضایی با استفاده از یک سطح پیوسته بر روی فضا استفاده می کنند. هر سلول در شبکه بخشی از فضا را پوشش میدهد و میتواند شامل مجموعهای از متغیرها به عنوان ابرداده سلول باشد. رایج ترین نوع داده های جغرافیایی شطرنجی، تصاویر است، مانند تصاویر ماهواره ای و عکس های هوایی. فرمت های شطرنجی استاندارد عبارتند از GeoTIFF و NetCDF (شبکه فرم داده مشترک). GeoTIFF یک استاندارد فراداده برای توصیف تصاویر جغرافیایی ارجاع شده در فرمت فایل تصویر برچسب شده (TIFF) است. NetCDF از داده های چند بعدی پشتیبانی می کند و شامل مجموعه ای از قالب ها و کتابخانه ها برای نمایش و دسترسی به داده های چند بعدی است. NetCDF معمولاً در جامعه علوم زمین برای ذخیره پدیده های مختلف فضایی و زمانی استفاده می شود. دادههای رستری این مزیت را دارند که نمایش دادههای آن در مقایسه با دادههای برداری محدود به یک مرز از پیش تعریفشده نیست. اکثر کتابخانه های پردازش تصویر (به عنوان مثال، OpenCV) می توانند با در نظر گرفتن هر سلول شطرنجی به عنوان پیکسل تصویر، داده های شطرنجی را مدیریت کنند.
در مجموع، روش کاربردهای GIS دامنه وسیعی دارد. انواع داده های پشتیبانی شده و فرآیندهای (جغرافیایی) فضایی می توانند از تجسم داده های نقطه ای ساده تا تشخیص تصاویر پیچیده متفاوت باشند. طیف گسترده ای از روش ها و قابلیت ها، استفاده از یک روش واحد برای طراحی، توسعه، آزمایش و استقرار برنامه های کاربردی GIS (یعنی چرخه عمر توسعه سیستم، SDLC، برای برنامه های GIS) را چالش برانگیز می کند. به طور خاص، SDLC ها باید شامل ملاحظات ابزار، مشکل، دامنه و افراد (ذینفعان) یک برنامه GIS باشند. با این وجود، همه برنامههای GIS نیاز به مصرف، پردازش و تولید دادههای مکانی (جغرافیایی) دارند. از این رو، این مدخل بر تصمیمات حیاتی در هر مرحله از چرخه عمر توسعه GIS (GiSDLC) در رابطه با الزامات ذخیره سازی، دسترسی، و تجزیه و تحلیل داده های (جغرافیایی) مکانی برای برنامه هدف. ادامه این مقاله با هدف معرفی ملاحظات مختلف در GiSDLC، از جمله طراحی، توسعه، آزمایش و استقرار برنامه کاربردی، از منظر ذخیرهسازی، دسترسی و تحلیل دادهها است. بخش 2 مقدمه کوتاهی برای SDLC، از جمله توضیح نقش داده های (جغرافیایی) مکانی در هر مرحله SDLC ارائه می دهد. بخش 3 از دو برنامه کاربردی موجود در دنیای واقعی به عنوان مثال برای برجسته کردن ملاحظات مهم در هر مرحله از GiSDLC استفاده می کند. بخش 4 یک خلاصه کلی ارائه می دهد. از جمله توضیح نقش داده های (جغرافیایی) مکانی در هر مرحله SDLC. بخش 3 از دو برنامه کاربردی موجود در دنیای واقعی به عنوان مثال برای برجسته کردن ملاحظات مهم در هر مرحله از GiSDLC استفاده می کند. بخش 4 یک خلاصه کلی ارائه می دهد. از جمله توضیح نقش داده های مکانی (جغرافیایی) در هر مرحله SDLC. بخش 3 از دو برنامه کاربردی موجود در دنیای واقعی به عنوان مثال برای برجسته کردن ملاحظات مهم در هر مرحله از GiSDLC استفاده می کند. بخش 4 یک خلاصه کلی ارائه می دهد.
چرخه حیات توسعه سیستم (SDLC) فعالیت ها و نقاط عطف در توسعه سیستم های اطلاعاتی را تعریف می کند. به طور کلی، یک SDLC می تواند شامل پنج تا ده فاز باشد. به عنوان مثال، یک SDLC هفت فازی شامل مراحل شناسایی مشکل، برنامه ریزی، طراحی، توسعه، آزمایش، استقرار و نگهداری است. برای حفظ یک بحث مختصر، بدون از دست دادن کلیت، این مدخل بر روی یک SDLC پنج فازی، شامل مراحل طراحی، توسعه، آزمایش، استقرار، و تعمیر و نگهداری (که در آن مراحل شناسایی مشکل، برنامهریزی و طراحی ترکیب میشوند، تمرکز دارد. یک فاز طراحی). علاوه بر فازهای SDLC، یک روش یا مدل SDLC اجرای این فازها را هدایت می کند. در حالی که انتخاب یک SDLC برای برنامه های GIS شبیه به سایر برنامه های نرم افزاری است. هر مرحله از چرخه عمر توسعه GIS (GiSDLC) باید توجه بیشتری به داده ها و فرآیندهای (جغرافیایی) مکانی مورد نیاز داشته باشد. این بخش ابتدا دو متدولوژی SDLC نماینده (یعنی مدل آبشار و چابک) را توضیح میدهد که میتواند برای GiSDLC استفاده شود و سپس هر مرحله SDLC را با تمرکز بر دادهها و فرآیندهای (جغرافیایی) مکانی توصیف میکند.
2.1 روش SDLC
انواع SDLC ها در جامعه مهندسی نرم افزار به سازمان ها، تیم های توسعه و پروژه های مختلف مانند Waterfall، Agile، Spiral و V شکل پیشنهاد شده است. روشهای سنتی شامل مدل آبشار، یک روش متوالی است که نیاز به تکمیل تمام فعالیتها در هر مرحله قبل از انتقال به فاز بعدی دارد (مک کورمیک 2012)، و مدل چابک، یک روش تکراری که شامل تکرارهای زیادی است که هر یک زیر مجموعهای از فعالیتها را برای هر یک تکمیل میکند. فاز (ادکی 2015). روشهای دیگر اغلب در سناریوهای خاص استفاده میشوند. به عنوان مثال، مدل V شکل عمدتاً برای پروژههای کوچک و متوسط است، جایی که الزامات کاملاً از پیش تعریف شده است. این بخش به معرفی فرآیند مدل Waterfall و Agile و مقایسه مزایا و معایب آنها می پردازد.
در مدل Waterfall، هر فاز باید قبل از شروع فاز بعدی به طور کامل تکمیل شود. فرآیند بررسی در پایان هر مرحله تعیین می کند که آیا پروژه در مسیر صحیح قرار دارد یا خیر. مدل Waterfall یک راه آسان برای مدیریت پروژه توسعه فراهم می کند زیرا هر فاز دارای یک تحویل خاص و یک بررسی است
روند. بنابراین، معمولاً برای پروژههایی که نیازمندیها را میتوان به وضوح تعریف کرد و به خوبی درک کرد، به خوبی کار میکند. با این حال، یک نقطه ضعف این است که وقتی یک پروژه در مرحله آزمایش است، تغییر چیزی که در مراحل قبلی به خوبی فکر نشده بود دشوار است. هیچ نرم افزار یا نسخه ی نمایشی تا اواخر چرخه عمر تولید نشده است، بنابراین روش Waterfall برای پروژه های طولانی مدت و پیچیده مناسب نیست. یکی دیگر از اشکالات مدل آبشار این است که تعاملات ذینفعان بسیار کمی در کل چرخه عمر دخیل است، به این معنی که محصول تنها زمانی می تواند به ذینفعان نشان داده شود که در پایان چرخه آماده باشد (Mahalakshmi and Sundararajan 2013).
روش چابک نوعی توسعه نرم افزار افزایشی با چرخه های سریع و تکراری است. به طور خاص، کل فرآیند توسعه برنامه به چندین چرخه کوچک (اغلب زیاد) تقسیم می شود. تیم توسعه هر مرحله را در مراحل طراحی، توسعه، آزمایش و استقرار برنامه در هر چرخه انجام می دهد. در پایان هر چرخه، تیم باید یک زیرمجموعه مورد توافق از محصول را تحویل دهد و ذینفعان میتوانند کار در حال پیشرفت را ببینند. یکی از نقاط قوت مدل چابک این است که ذینفعان به طور فعال در سراسر پروژه شرکت می کنند. به این ترتیب، تیم توسعه فرصت هایی برای درک واقعی دیدگاه سهامداران با بررسی های خود پس از هر چرخه دارد. مدل Agile همچنین امکان تغییرات در تکرار بعدی را فراهم می کند. که فرصتی برای اصلاح و اولویت بندی مجدد محصول کلی به طور مداوم فراهم می کند. با این حال، داشتن تعاملات مداوم با سهامداران ممکن است منجر به مدیریت ارتباطات پیچیده شود. فقدان چشم انداز نهایی یا ایجاد تغییرات زیاد ممکن است پروژه را به هم ریخت. همچنین، اسناد ضعیفی وجود خواهد داشت زیرا تعاملات با ذینفعان به دلیل ماهیت ارتباطات مکرر، بیشتر شفاهی است.
2.2 SDLC در مورد داده های مکانی (جغرافیایی).
در مرحله طراحی، تیم توسعه تجزیه و تحلیل نیازمندی ها را با ذینفعان انجام می دهد، ابزارهای نرم افزاری (مانند زبان های برنامه نویسی، چارچوب ها و معماری نرم افزار، کتابخانه های نرم افزار و معماری سیستم) را انتخاب می کند و محیط محاسباتی را تعیین می کند (مثلا دسکتاپ در مقابل ابر. برنامه های مبتنی بر). در مورد برنامه های کاربردی GIS، تصمیمات حیاتی باید سه سوال اساسی در مورد داده های مکانی (جغرافیایی) و فرآیندهای مورد نیاز برای برنامه مورد نظر را در نظر بگیرند:
- انواع و اندازه های مورد نیاز داده های (ژئو) مکانی (به عنوان ورودی و خروجی سیستم) چیست؟
- فرآیندهای (ژئو) فضایی مورد نیاز چیست؟
- زمان پاسخ مطلوب برای هر فرآیند (جغرافیایی) فضایی چقدر است؟
این سه سوال به هم مرتبط هستند. انواع دادههای مکانی (جغرافیایی) مورد نیاز اغلب فرآیندهای (جغرافیایی)مکانی قابل اجرا و اندازههای بالقوه داده را تعیین میکنند که تأثیر قابلتوجهی بر زمان پاسخ فرآیند دارند. پاسخ به این سوالات به شناسایی معماری نرم افزار و محیط محاسباتی مناسب کمک می کند
.
در مرحله توسعه، تیم توسعه برنامه ها را مطابق با الزامات ذکر شده در مرحله طراحی می سازد. یک استراتژی توسعه متداول این است که به طور مستقل هر ماژول نرم افزار را با استفاده از ورودی، فرآیند و خروجی از پیش تعریف شده از مرحله طراحی برای ساخت چندین ماژول به
صورت موازی و آزمایش آنها به طور جداگانه در فاز بعدی توسعه دهیم. به عنوان مثال، یک راه ترجیحی برای توسعه برنامه های GIS، جداسازی ماژول پیش پردازش و آماده سازی داده ها از ماژول تجزیه و تحلیل است. در مورد یک برنامه GIS برای پیشبینی کیفیت هوا، ماژول پیشبینی میتواند قالب ورودی و سیستم مختصات را پیشبینی کند و تمام جمعآوری، تمیز کردن و تبدیل دادهها را به ماژول پیش پردازش واگذار کند.
در مرحله آزمایش، تیم توسعه از سناریوهای مختلفی برای آزمایش اپلیکیشن ساخته شده استفاده می کند. به عنوان مثال، مرحله آزمایش شامل پردازش مقادیر زیادی از داده ها از انواع مختلف در سیستم عامل های مختلف یا اشتباه کردن عمدی کاربران هنگام اجرای برنامه است. برای کاربردهای GIS
، دادههای آزمایشی باید شامل دادههای (جغرافیایی) مکانی از سیستمها و مقیاسهای مختصات مختلف باشد تا از تبدیل صحیح و یکپارچهسازی دادههای (جغرافیایی) مکانی از منابع ناهمگن اطمینان حاصل شود. مرحله آزمایش باید نشان دهد که برنامه ساخته شده می تواند سناریوهای معمولی و غیرمنتظره (مانند خطا در داده های ورودی) را مدیریت کند.
در مرحله استقرار، تیم توسعه اپلیکیشن ساخته شده را با چارچوب های نرم افزاری، کتابخانه ها و معماری های مورد نیاز در یک محیط تولید یکپارچه می کند و دسترسی برنامه را برای ذینفعان فراهم می کند. تیم توسعه معمولاً یک بسته نصبی برای برنامه ساخته شده در سیستم عامل مورد نظر ایجاد می کند (مثلاً Windows Installer برای Microsoft Windows) و گاهی اوقات نیاز دارد بسته نصب را در بازار برنامه (مثلاً Apple App Store) منتشر کند.
پس از استقرار یک برنامه، تیم توسعه باید اطمینان حاصل کند که برنامه همچنان به کار خود ادامه می دهد. به عنوان مثال، برای یک برنامه مبتنی بر ابر، سرور باید بدون هیچ گونه خرابی پاسخگو باشد. همچنین، در هر مرحله، تیم توسعه نیاز به ایجاد مستندات برنامه برای تسهیل فرآیند توسعه، فعال کردن تعمیر و نگهداری در آینده و ارائه کتابچه راهنمای عملیات دارد. نیازهای عملیاتی اضافی ممکن است شامل انتشار اسناد برای عموم باشد تا طیف وسیعی از کاربران (مانند دانشمندان داده و دانشمندان زمینشناسی) بتوانند به برنامهها و همچنین ارائه پشتیبانی فنی دسترسی داشته باشند و از آنها استفاده کنند (به Yang et al. 2019 مراجعه کنید).
3. مطالعه موردی: سیستم مدیریت داده های ترافیک بایگانی شده
سیستم مدیریت داده های ترافیکی بایگانی شده (ADMS) (Anastasiou et al. 2019) یک انبار داده حمل و نقل بزرگ است که توسط مرکز سیستم های رسانه ای یکپارچه دانشگاه کالیفرنیای جنوبی (IMSC) با مشارکت اداره حمل و نقل متروپولیتن لس آنجلس (LA Metro) توسعه یافته است. و METRANS. ADMS داده های حسگر ترافیک در مقیاس بزرگ و با وضوح بالا (هم مکانی و هم زمانی) را از انواع مقامات حمل و نقل در کالیفرنیای جنوبی، از جمله وزارت حمل و نقل کالیفرنیا (Caltrans)، وزارت حمل و نقل لس آنجلس (LADOT) ترکیب و تجزیه و تحلیل می کند. گشت بزرگراه کالیفرنیا (CHP) و حمل و نقل لانگ بیچ (LBT). این مجموعه داده شامل داده های تاریخی و بلادرنگ است. داده های بلادرنگ دارای نرخ به روز رسانی به اندازه هر 30 ثانیه برای حسگرهای بزرگراه و ترافیک شریانی هستند (14, 500 لوپ آشکارساز) که 4300 مایل را پوشش می دهد، 2000 اتوبوس و قطار مکان یابی خودکار وسایل نقلیه (AVL). دادههای بلادرنگ همچنین شامل حوادثی مانند تصادفات، خطرات ترافیکی، بسته شدن جادهها (تقریباً 400 مورد در روز) توسط اداره پلیس لسآنجلس (LAPD) و CHP و مترهای سطح شیبدار میشود. ADMS در 9 سال گذشته به طور مداوم مجموعه داده ها را جمع آوری و بایگانی می کند. ADMS، با رشد سالانه 15 گیگابایت، عظیمترین انبار داده حسگر ترافیک است که تاکنون در کالیفرنیای جنوبی ساخته شده است. این بخش برنامه های کاربردی در ADMS را توضیح می دهد و روش SDLC مورد استفاده در فرآیند کلی توسعه ADMS را مورد بحث قرار می دهد. بسته شدن جاده ها (تقریباً 400 در روز) توسط اداره پلیس لس آنجلس (LAPD) و CHP و مترهای سطح شیب دار گزارش شده است. ADMS در 9 سال گذشته به طور مداوم مجموعه داده ها را جمع آوری و بایگانی می کند. ADMS، با رشد سالانه 15 گیگابایت، عظیمترین انبار داده حسگر ترافیک است که تاکنون در کالیفرنیای جنوبی ساخته شده است. این بخش برنامه های کاربردی در ADMS را توضیح می دهد و روش SDLC مورد استفاده در فرآیند کلی توسعه ADMS را مورد بحث قرار می دهد. بسته شدن جاده ها (تقریباً 400 در روز) توسط اداره پلیس لس آنجلس (LAPD) و CHP و مترهای سطح شیب دار گزارش شده است. ADMS در 9 سال گذشته به طور مداوم مجموعه داده ها را جمع آوری و بایگانی می کند. ADMS، با رشد سالانه 15 گیگابایت، عظیم ترین انبار داده حسگر ترافیک است که تاکنون در کالیفرنیای جنوبی ساخته شده است. این بخش برنامه های کاربردی در ADMS را توضیح می دهد و روش SDLC مورد استفاده در فرآیند کلی توسعه ADMS را مورد بحث قرار می دهد.
3.1 برنامه های کاربردی در ADMS
ADMS یک معماری چند لایه است که بر روی پلت فرم ابری IMSC اجرا می شود (شکل 1). معماری چند لایه شامل لایه جمع آوری داده، لایه مدیریت داده، لایه تجزیه و تحلیل آفلاین و آنلاین، لایه یادگیری و هوش، لایه سرویس و لایه ارائه است. با هم، معماری چند لایه از انواع مختلفی از برنامه های کاربردی که نیاز به پردازش داده های مکانی (جغرافیایی) دارند پشتیبانی می کند. به عنوان مثال، IMSC رویکردها و برنامه های کاربردی مبتنی بر داده های مکانی (جغرافیایی) را برای پیش بینی ترافیک (Li et al. 2018) و برآورد قابلیت اطمینان عملکرد وسایل نقلیه عمومی (Nguyen et al. 2018) در بالای زیرساخت AMDS توسعه داده است. هر دو برنامه در لایه یادگیری و هوش قرار دارند و برای دسترسی به دادههای ورودی مورد نیاز و آمادهسازی دادهها در قالبی خاص، به ماژولهای پاکسازی و تبدیل دادهها در لایههای دیگر متکی هستند. معماری چند لایه ADMS انعطافپذیر است و نگهداری آن آسان است، زیرا هر لایه دارای یک فرمت ورودی و خروجی ساختار یافته از پیش تعریف شده است. هر لایه شامل اجزای مدولار شده است که می تواند به سرعت در صورت در دسترس بودن فناوری های جدید بدون بازسازی کل زیرساخت به روز شود.
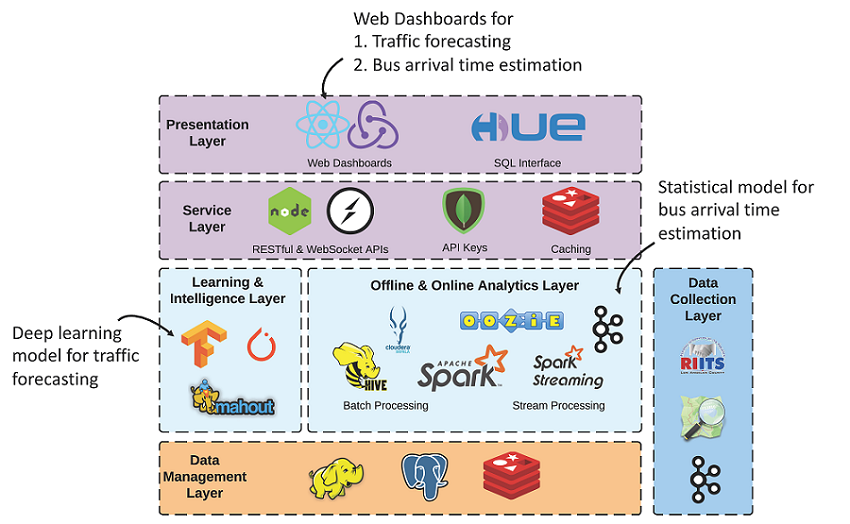
شکل 1. معماری چند لایه در ADMS (سیستم مدیریت داده های ترافیک بایگانی شده). منبع: نویسندگان
برنامه پیش بینی ترافیک (لی و همکاران 2018) یک شبکه عصبی پیچیده گراف (GCRNN) است که وابستگی زمانی پیچیده و وابستگی توپولوژیکی جریان ترافیک را برای پیش بینی ترافیک مدل می کند. این برنامه میتواند ترافیک را در وضوحهای مختلف مکانی (مثلاً مناطق منفرد، بخشهای جاده یا حسگرها) و زمانی (مثلاً 5 دقیقه و 30 دقیقه آینده) پیشبینی کند. در طول زمان پیشبینی، برنامه بهروزرسانیهای ترافیکی بلادرنگ را از صف پیام از لایه تحلیل آفلاین و آنلاین مصرف میکند، که تغذیه مداوم داده برای پیشبینی ساعتی را تضمین میکند. سپس یک ماژول در لایه مدیریت داده نتایج پیش بینی را ذخیره می کند. یک API در لایه سرویس، نتایج ذخیره شده پیش بینی را مصرف می کند و نتایج را به داشبورد Web GIS در لایه ارائه می دهد.
برنامه تخمین زمان رسیدن اتوبوس (Nguyen و همکاران 2018) از مقادیر زیادی از مجموعه داده های مسیر اتوبوس تاریخی ذخیره شده در HDFS و PostGIS در لایه مدیریت داده استفاده می کند. این برنامه از قابلیت پردازش موازی آفلاین در لایه تجزیه و تحلیل برای تولید آمار زمان ورود تاریخی برای مسیرهای اتوبوس جداگانه برای تخمین تاخیر برای هر ایستگاه اتوبوس در زمانهای مختلف روز استفاده میکند. مانند برنامه پیش بینی ترافیک، نتایج تخمین در لایه مدیریت داده با یک API در لایه سرویس ذخیره می شود تا دسترسی عمومی را از داشبورد Web GIS فراهم کند. علاوه بر تخمین زمان رسیدن، داشبورد Web GIS همچنین با مصرف API موقعیت اتوبوس در لایه سرویس، مکانهای اتوبوس را در زمان واقعی نمایش میدهد.
هر دو برنامه نیاز به دسترسی به داده های ترافیکی آفلاین و در زمان واقعی دارند. برنامه پیشبینی ترافیک به یک چارچوب یادگیری ماشینی نیاز دارد، در حالی که برنامه تخمین عملکرد گذرگاه بر یک فرآیند جمعآوری داده ساده بر روی چند ترابایت داده تاریخی متکی است. در ساخت این برنامهها،
تیم توسعه، ماژولهای جداگانه را بر روی لایههای جداگانه بهطور مستقل با استفاده از ورودی، فرآیند ماژول و خروجی پیشبینیشده میسازد و آزمایش میکند، که نمونهسازی سریع و تشخیص خطاهای احتمالی را ممکن میسازد.
3.2 SDLC ADMS
SDLC ADMS عموماً از مدل Agile پیروی می کند که در آن فرآیند توسعه شامل چندین تکرار است. در اولین تکرار، تیم توسعه، عملکرد اولیه هر لایه را ایجاد میکند تا اطمینان حاصل کند که خط لوله داده از لایه جمعآوری داده تا لایه ارائه، برای پشتیبانی از یک برنامه کاربردی سرتاسر کارایی دارد. در تکرار بعدی، تیم توسعه قابلیتهای جدیدی را به هر لایه اضافه میکند تا از برنامههای پیچیده پشتیبانی کند. در هر تکرار، تیم توسعه هر لایه را به صورت متوالی میسازد. در اینجا، ما به طور خلاصه در مورد استراتژی ADMS SDLC بحث می کنیم.
در تکرار اول، هدف این است که یک ADMS کاملاً کاربردی داشته باشیم، اما تنها چند فید داده مهم را مدیریت کنیم که بتواند تخمین زمان رسیدن اتوبوس را پشتیبانی کند. الزامات تعیین شده شامل 1) جمع آوری داده های LA Metro برای سرعت و حجم واقعی خودرو از هزاران حسگر ترافیک و مکان اتوبوس از صدها اتوبوس، و 2) ذخیره داده های جمع آوری شده بر اساس نوع استفاده از آنها. دادههای جمعآوریشده اخیر (مثلاً ماهها) به عملیات مکانی مکرر (مثلاً پیوستن فضایی) نیاز دارند. دادههای جمعآوریشده در زمان واقعی (مثلاً دقیقه) به دسترسی سریع به دادهها نیاز دارد. داده های تاریخی طولانی مدت نیاز به عملیات ادغام و فیلتر کردن داده ها دارند که می توانند مجموعه داده های بزرگی را مدیریت کنند.
پس از مرحله طراحی، تیم لایه جمع آوری داده ها را با چند آداپتور مدوله شده حیاتی پیاده سازی می کند. پیادهسازی آداپتور مدولهشده به سیستم اجازه میدهد تا به راحتی فیدهای دادههای جدید (مثلاً اطلاعات آب و هوا در محلهها) را با آداپتورهای اضافی در تکرار بعدی Agile در خود جای دهد. خروجی این لایه جمع آوری داده ها، جریان های داده از منابع مختلف داده است. سپس تیم توسعه الزامات را برای پیادهسازی لایه مدیریت داده، از جمله سیستمهای ذخیرهسازی دادههای تخصصی برای دسترسی، دنبال میکند. ذخیره (redis)، و 3) تمام داده های تاریخی که به محاسبات توزیع شده برای تجمع و فیلتر کردن داده ها نیاز دارند (Hadoop Distributed File System، HDFS). بعد، تیم توسعه چارچوب اولیه را برای لایه سرویس، لایه یادگیری و هوش، و لایه ارائه میسازد تا با استقرار برنامههای سرتاسر سازگار شود. لایه سرویس شامل چندین API دسترسی به داده برای مصرف داده ها در ADMS است (از جمله نتایج برنامه های کاربردی مستقر در لایه یادگیری و هوش، به عنوان مثال، تخمین زمان رسیدن اتوبوس). لایه ارائه شامل داشبوردهای وب و نقشه هایی برای تجسم و انتشار داده های ADMS و خروجی از مدل های یادگیری ماشین است. تخمین زمان رسیدن اتوبوس). لایه ارائه شامل داشبوردهای وب و نقشه هایی برای تجسم و انتشار داده های ADMS و خروجی از مدل های یادگیری ماشین است. تخمین زمان رسیدن اتوبوس). لایه ارائه شامل داشبوردهای وب و نقشه هایی برای تجسم و انتشار داده های ADMS و خروجی از مدل های یادگیری ماشین است.
تیم توسعه از تخمین زمان رسیدن اتوبوس برای آزمایش خط لوله داده انتها به انتها و تجسم وب در مرحله آزمایش استفاده می کند. به طور خاص، مرحله آزمایشی که پیاده سازی الزامات تعیین شده در مرحله طراحی را کامل کرده است. در مرحله استقرار، تیم توسعه برنامه را برای عموم مردم باز می کند و کتابچه راهنمای کاربر و فیلم های آموزشی تولید می کند. در مرحله تعمیر و نگهداری، تیم توسعه میزبان ساعات اداری هفتگی برای کمک به حل مشکلات کاربر است. تیم توسعه همچنین نرمافزاری را برای نظارت بر وضعیت ADMS نصب میکند و اطمینان حاصل میکند که ADMS تقریباً 100٪ زمان کار دارد تا دادههای بلادرنگ مصرف کند و نتایج تقریباً بیدرنگ به طور مداوم تولید کند.
در تکرار دوم، تیم توسعه همان SDLC را در تکرار اول با ملاحظات اضافی برای طراحی، توسعه، آزمایش، استقرار و حفظ برنامه پیشبینی ترافیک تکرار میکند. برای مثال، نیاز تکرار دوم شامل پشتیبانی از یک چارچوب یادگیری ماشینی پیشرفته در لایه یادگیری و هوش است. به طور کلی، توسعه ADMS و مزایای استفاده از مدل AGILE به طوری که ذینفعان می توانند پس از هر بار تکرار، یک برنامه پایان به انتها را بررسی کنند. در طول هر تکرار، تیم توسعه میتواند قابلیتهای اضافی (ماژولهای محاسباتی) را در هر لایه معماری ADMS اضافه کند.
این مقاله انواع مختلف کاربردهای GIS و ملاحظات در چرخه عمر توسعه GIS را از منظر ذخیره، دسترسی و تحلیل دادههای مکانی (جغرافیایی) معرفی میکند. این مقاله همچنین دو برنامه کاربردی موجود در دنیای واقعی را برای برجسته کردن ملاحظات مهم در هر مرحله از GiSDLC به نمایش گذاشت.
Anastasiou، CJ Lin، C. He، Y.-Y. چیانگ و سی. شهابی. (2019). Admsv2: یک معماری مدرن برای مدیریت و تجزیه و تحلیل داده های حمل و نقل. در کارگاه بین المللی ACM SIGSPATIAL در مورد پیشرفت در شهرهای تاب آور و هوشمند، 2019.
Brunsdon، C.، AS Fotheringham، و ME Charlton. (1996)، رگرسیون وزندار جغرافیایی: روشی برای کاوش غیرایستایی فضایی. تحلیل جغرافیایی , 28(4):281-298.
کلارک، کی سی (2010). شروع کار با سیستم های اطلاعات جغرافیایی پیرسون، 2010. ISBN 9780131494985.
Cressie, N. (1990). ریشه های کریجینگ. زمین شناسی ریاضی، 22(3):239-252.
Edeki, C. (2015) روش شناسی توسعه نرم افزار چابک. مجله اروپایی ریاضیات و علوم کامپیوتر، 2 (1)، 2015.
ESRI. (1998). توضیحات فنی شکل اسری. گزارش فنی، ESRI.
لی، ی.، آر. یو، سی. شهابی و ی. لیو. (2018). شبکه عصبی بازگشتی کانولوشنال انتشار: پیشبینی ترافیک مبتنی بر داده در کنفرانس بین المللی بازنمایی های یادگیری، 2018.
لین، ی.، ن. ماگو، ی. گائو، ی. لی، ی.-ای. چیانگ، سی. شهابی، و جی ال آمبیت. (2018). بهرهبرداری از الگوهای مکانی-زمانی برای پیشبینی دقیق کیفیت هوا با استفاده از یادگیری عمیق در ACM SIGSPATIAL، صفحات 359-368.
Mahalakshmi M. and M. Sundararajan. (2013). روش شناسی سنتی sdlc در مقابل اسکرام{یک مطالعه تطبیقی. مجله بین المللی فناوری های نوظهور و مهندسی پیشرفته، 3 (6): 192-196.
مک کورمیک، ام (2012). روش شناسی آبشار در مقابل چابک MPCS.
نگوین، ک.، جی. یانگ، ی. لین، جی. لین، ی.-ای. چیانگ و سی. شهابی. (2018). تجزیه و تحلیل داده های اتوبوس مترو لس آنجلس با استفاده از مسیر GPS و داده های برنامه (مقاله آزمایشی). در مجموعه مقالات بیست و ششمین کنفرانس بین المللی ACM SIGSPATIAL در زمینه پیشرفت در سیستم های اطلاعات جغرافیایی، صفحات 560-563.
یانگ، سی.، ام. یو، ی. لی، ف. هو، ی. جیانگ، کیو. لیو، دی. شا، ام. ژو، و جی. گو. (2019). تجزیه و تحلیل داده های زمین بزرگ: یک نظرسنجی داده های بزرگ زمین ، 3 (2): 83-107.
- نقاط قوت و ضعف روش های مختلف کاربرد GIS را مورد بحث قرار دهید
- انواع داده های رایج مورد استفاده در برنامه های GIS را شرح دهید
- در مورد ابزارهای نرم افزاری رایج برای ساخت برنامه های GIS بحث کنید
- مراحل تک تک چرخه عمر توسعه سیستم را توضیح دهید
- دو روش متداول چرخه عمر توسعه سیستم را توضیح دهید
- سوالات مهم را در هر مرحله از چرخه عمر توسعه سیستم های اطلاعات جغرافیایی شناسایی کنید


بدون دیدگاه