

کشف و دسترسی به دادههای مکانی یک چالش مهم برای جامعه علوم زمین است، زیرا روزانه مقادیر زیادی داده تولید میشود. در این مقاله، ما یک سیستم هوشمند کشف دادههای مکانی مبتنی بر وب را گزارش میکنیم که ارتباط دادهها را از رفتار کاربر ابرداده استخراج و استفاده میکند. به طور خاص، (1) سیستم بسط و پیشنهاد معنایی پرس و جو را برای کمک به کاربران در یافتن داده های مرتبط تر، فعال می کند. (2) رتبهبندی یادگیری ماشینی برای ارائه رتبهبندی بهینه جستجو بر اساس تعدادی از ویژگیهای رتبهبندی شناساییشده که میتواند ترجیحات جستجوی کاربران را منعکس کند، استفاده میشود. (3) یک ماژول توصیه ترکیبی طراحی شده است تا به کاربران اجازه دهد داده های مرتبط را با در نظر گرفتن ویژگی های ابرداده و رفتار کاربر کشف کنند. (4) یک طراحی رابط کاربری گرافیکی یکپارچه برای هدایت سریع و شهودی مصرف کنندگان داده به منابع داده مناسب توسعه داده شده است. به عنوان اثبات مفهوم، ما بر روی یک دامنه اقیانوس شناسی به خوبی تعریف شده تمرکز می کنیم و از کشف داده های اقیانوس شناسی به عنوان مثال استفاده می کنیم. آزمایشها و یک مثال جستجو نشان میدهد که سیستم پیشنهادی میتواند تجربه جستجوی دادههای جامعه علمی را با ارائه گسترش پرس و جو، پیشنهاد، رتبهبندی بهتر جستجو و توصیه داده از طریق یک رابط کاربر پسند بهبود بخشد.
کلید واژه ها:
پایگاه دانش ؛ جستجوی معنایی ; رفتار کاربر ؛ فراداده ; رتبه بندی جستجو ؛ توصیه ; اطلاعات بزرگ
1. مقدمه
اقیانوس جهانی چندین نقش حیاتی در سیستم آب و هوای فیزیکی زمین ایفا می کند. اقیانوس ها بیش از نیمی از تشعشعات خورشیدی ورودی به سیستم آب و هوایی را دریافت می کنند، و خنک کننده تبخیری باعث تعادل بیشتر انرژی خورشیدی جذب شده توسط اقیانوس ها می شود و آنها را به منبع اصلی بخار آب و گرما برای جو تبدیل می کند [ 1 ]. جریان های موجود در اقیانوس ها می توانند آب را در فواصل بسیار دور منتقل کنند و گرما و سایر ویژگی های اقیانوس را از یک منطقه جغرافیایی به منطقه دیگر منتقل کنند. انتقال انرژی به سمت قطب توسط اقیانوس در کاهش گرادیان دمای قطب به استوا مهم است. انتقال افقی و عمودی انرژی توسط اقیانوس همچنین می تواند ماهیت آب و هوای منطقه ای را با کنترل دمای محلی سطح دریا تغییر دهد [ 2 ]]. رویدادهای شدید آب و هوایی مرتبط با اقیانوس (به عنوان مثال، طوفان های هاروی، ایرما، و ماریا) منجر به بلایای طبیعی متعدد در ایالات متحده و در سراسر جهان شده است که منجر به سطوح فاجعه بار آسیب به جامعه و محیط زیست ما شده است. برای ردیابی دقیق، پیشبینی و ارزیابی عواقب این بلایا و برای افزایش آمادگی در برابر بلایا و واکنش اضطراری، ماهوارهها و دادههای اقیانوسشناسی درجا با وضوح زمانی نزدیک به زمان واقعی و مکانی بسیار مهمتر از همیشه شدهاند.
با این حال، کشف و دسترسی به داده های اقیانوس شناسی به روشی که به طور دقیق و کارآمد نیازهای کاربران را برآورده کند، چالش مهمی برای جامعه علمی اقیانوس [ 3 ] است. به عنوان مثال، مشکلات فعلی که محققان در کشف و دسترسی به کاربردی ترین داده های رصدی در ناسا با آن مواجه هستند، پیامدهای زیانباری برای رویارویی با چالش های تغییرات آب و هوایی و محیطی دارد که در برنامه استراتژیک ناسا در سال 2011 شناسایی شده است [ 4 ]. در حال حاضر، مشاهدات ماهوارهای مورد نیاز جامعه علمی برای ارزیابی و بهبود شبیهسازیهای مدل کمتر مورد استفاده قرار میگیرد، زیرا یافتن دادههای مناسب در میان پتابایت دادههای موجود بسیار دشوار است [ 5 ].]. از آنجایی که حجم داده ها تنها به عنوان تابعی از زمان در حال افزایش است، به یک پارادایم جدید دسترسی بازتر و کاربرپسندتر به داده نیاز است [ 6 ].
در این زمینه، بسیاری از پورتال های آنلاین برای بهبود دسترسی به داده های اقیانوس شناسی ساخته شده اند. به عنوان مثال، مرکز بایگانی فعال توزیع شده اقیانوسشناسی فیزیکی ناسا (PO.DAAC) دادههای فیزیکی ماهوارههای اقیانوسشناسی را به جامعه علوم زمین ارائه میکند. در واقعیت، دانشمندان همچنان محدود به استفاده از مجموعه دادههایی هستند که برای آنها آشناست و اغلب دانش کمی از وجود مجموعه دادههایی دارند که میتواند مناسبتر برای مدل یا کاربرد آنها باشد، به دلیل ناکارآمدی موتورهای جستجوی مکانی فعلی [ 7 ]. ]. به طور خاص، یافتن داده های مکانی مناسب به طور کارآمد و دقیق از سه جنبه چالش برانگیز است.
- (1)
-
فقدان بافت معنایی جستجوی مبتنی بر کلمه کلیدی به طور گسترده در پورتال های داده های مکانی عملیاتی پذیرفته شده است. از آنجایی که جستجوی کلمه کلیدی از تطبیق رشته ها بدون در نظر گرفتن بافت معنایی، دقت و یادآوری استفاده می کند، تضمین دو اندازه گیری مهم برای ارتباط جستجو دشوار است [ 8 ]. به عنوان مثال، هنگام جست و جوی «دمای سطح دریا» با استفاده از جستجوی کلیدواژه، پرس و جو به عنوان یک جستار بولی «دریا و سطح و دمای دریا» تفسیر می شود. نتایج جستجو احتمالاً حاوی عبارات “دریا”، “سطح” و “دما” در محتوای متنی خود هستند، اما ممکن است به اسنادی که حاوی مخفف رایج آن “sst” باشند، منجر نشود.
- (2)
-
تنها رتبه بندی بر اساس ویژگی های منفرد. معمولاً صدها یا حتی هزاران مجموعه داده مربوط به پرس و جو داده شده وجود دارد. موتورهای جستجوی فعلی در بیشتر پورتال های داده های مکانی، تمایل دارند تا کاربران نهایی را بر روی یک ویژگی داده واحد (مثلاً وضوح فضایی) متمرکز کنند [ 9 ]. PO.DAAC چندین ویژگی را برای رتبه بندی نتایج جستجو فراهم می کند، از جمله محبوبیت همیشه، محبوبیت ماهانه، وضوح فضایی شبکه، و غیره. تجربه کاربر [ 10 ].
- (3)
-
عدم ارتباط داده ها روابط پنهانی بین داده های میزبانی شده توسط موتور جستجو وجود دارد. به عنوان مثال، پس از اینکه کاربر روی یک داده کلیک می کند، باید از آخرین نسخه داده های کلیک شده مطلع شود که اغلب از دقت بهتری برخوردار است. علاوه بر این، دانشمندان سیستم زمین اغلب نیاز دارند تحقیقات خود را با استفاده از پارامترهای فیزیکی متعدد به هم متصل کنند زیرا اکتشافات مهم و پیشرفت کلی علم اغلب از حوزه یک رشته فراتر می رود [ 11 ].
برای پرداختن به چالشهای فوق، ما یک سیستم کشف دادههای مکانی مبتنی بر وب هوشمند را پیشنهاد میکنیم که ارتباط دادهها را از فراداده، رفتار کاربر و هستیشناسی استخراج و استفاده میکند. مشارکتهای سیستم پیشنهادی به شرح زیر است: (1) سیستم بسط و پیشنهاد معنایی پرس و جو را برای کمک به کاربران در یافتن دادههای مرتبطتر ممکن میسازد. (2) رتبهبندی یادگیری ماشینی برای ارائه رتبهبندی بهینه جستجو بر اساس تعدادی از ویژگیهای رتبهبندی شناساییشده که میتواند ترجیحات جستجوی کاربران را منعکس کند، استفاده میشود. (3) یک ماژول توصیه ترکیبی طراحی شده است تا به کاربران اجازه دهد داده های مرتبط را با در نظر گرفتن ویژگی های ابرداده و رفتار کاربر کشف کنند. (4) یک طراحی رابط کاربری گرافیکی یکپارچه برای داده های سریع و شهودی مصرف کنندگان به منابع داده مناسب توسعه داده شده است. به عنوان اثبات مفهوم،
2. کارهای مرتبط
کار قبلی سعی کرده است مشکل معنایی را از طریق ایجاد دستی هستی شناسی ها حل کند [ 12 ]. پیوندها و مفاهیم (مثلاً چندمعنایی و مترادف) اغلب برای ارائه زمینه معنایی برای یک پرس و جو مورد استفاده قرار می گیرد. هستی شناسی های جغرافیایی مانند وب معنایی زمین و اصطلاحات محیطی (SWEET) [ 13 ] مفاهیم و روابط در حوزه جغرافیایی را به تصویر می کشد. European INSPIRE (زیرساخت اطلاعات فضایی در جامعه اروپایی) یک رویکرد جستجوی مبتنی بر معنایی مبتنی بر هستی شناسی را پیاده سازی کرد [ 14 ]]. مشکل ایجاد دستی هستیشناسیها این است که بهروز نگهداشتن آنها بسیار سخت است. رویکرد دیگری برای این چالش از طریق تکنیکهای خوشهبندی اسناد و کاهش ابعاد مانند تحلیل معنایی پنهان (LSA) [ 15 ] و تخصیص دیریکله پنهان (LDA) [ 16 ] اعمال شده است. لی، گودچایلد [ 7 ] یک الگوریتم جستجوی معنایی جغرافیایی ایجاد کردند که LSA را در حوزه وسیع علم زمین ادغام میکند، و Hu، Janowicz [ 17 ]] مدل سازی موضوع را با استفاده از LDA در پورتال های مکانی انجام داد. مزیت این راه حل ها در خودکار بودن و استقلال انسانی و زبانی آنهاست. با این حال، این رویکرد مستعد سروصدا است و درک یا تعامل مستقیم برای انسان دشوار است. بنابراین، ما رویکردی برای کشف روابط معنایی پنهان با استخراج سیاهههای جستجوی کاربر پیشنهاد میکنیم.
اگرچه الگوریتمهای رتبهبندی مختلفی توسط پورتالهای دادههای مکانی موجود، مانند فرکانس سند معکوس فرکانس (TF-IDF) و Okapi BM25 [ 18 ] اتخاذ میشوند، همه آنها فقط بر روی اندازهگیری همپوشانی بین پرس و جو کاربر و محتوای فراداده تمرکز دارند. تلاشهایی برای بهبود رتبهبندی مبتنی بر کلیدواژه با انجام تحلیل معنایی انجام شده است، اما جنبههای دیگر دادهها که میتوانند با علاقه جستجوی کاربران مرتبط باشند، نادیده گرفته میشوند، مانند زمانی که دادهها منتشر شدند [ 7 ، 17 ]. مارتینز و کالادو [ 19 ] از یادگیری ماشینی برای رتبه بندی اسناد روزنامه پرس و جو جغرافیایی استفاده می کنند. شاو، شی [ 20] از Foursquare یک الگوریتم جستجوی فضایی با استفاده از یادگیری ماشینی برای استنتاج مکان کاربران پیشنهاد کرد. با توجه به نیازهای منحصربهفرد کشف دادههای مکانی، بنابراین ما چند ویژگی مرتبط با رتبهبندی را پیشنهاد میکنیم و یک رویکرد یادگیری ماشینی را برای یادگیری خودکار یک تابع برای وزن کردن ویژگیهای رتبهبندی اعمال میکنیم.
با پیشرفت فنآوریهای معنایی، یک رویکرد نوظهور برای اتصال دادهها انتشار دادهها بهعنوان «دادههای پیوندی» است [ 21 ]. یک مثال خوب در حوزههای مکانی، پروژه GeoLink EarthCube است [ 22]. GeoLink به کاربران این امکان را میدهد که دادهها را با کلیک بر روی یک ویژگی فراداده (به عنوان مثال، ابزار) مرور کنند تا دادههای مرتبطی را که دارای مقدار مشخصه یکسانی هستند، مشاهده کنند. یک مسئله این است که نیاز به انتشار داده ها با استفاده از استانداردهای معنایی مانند چارچوب توصیف منابع (RDF) دارد. علاوه بر این، ممکن است داده های زیادی مربوط به داده های کلیک شده وجود داشته باشد که می تواند بسیار زیاد باشد. سیستم توصیهکننده در بسیاری از محصولات تجاری (به عنوان مثال، نتفلیکس) به موفقیت چشمگیری دست یافته است. معمولاً فهرستی از توصیهها را به یکی از دو روش تولید میکند – از طریق فیلتر مشارکتی و مبتنی بر محتوا [ 23 ]. وکنر و همکاران [ 24] یک سیستم توصیه مبتنی بر LSA را پیشنهاد کرد. به عنوان یک تلاش اولیه در حوزههای مکانی، بنابراین ما یک روش توصیه ترکیبی برای اندازهگیری ارتباط دادهها با چند ویژگی فراداده شناساییشده همراه با رفتار مرور کاربران را پیشنهاد میکنیم.
این مقاله همچنین نحوه ادغام سه قابلیت فوق را در یک سیستم کشف داده و نحوه پشتیبانی هر یک از آنها توسط اجزای مختلف سیستم مورد بحث قرار می دهد. هدف کلی افزایش کارایی اکتشاف داده و توانمندسازی جوامع کاربران نوظهور برای کشف و دسترسی آسان به داده های متناسب با تلاش هایشان است.
3. چارچوب سیستم
3.1. معماری
این سیستم از سه جزء اصلی تشکیل شده است: رابط کاربری گرافیکی وب (GUI)/خدمات، پایگاه دانش و موتور هوشمند ( شکل 1).). کاربران از طریق رابط کاربری گرافیکی وب با سیستم تعامل دارند در حالی که لاگ های وب را تولید می کنند. پایگاه دانش ابرداده، دادههای رفتار کاربر و مدلهای یادگیری ماشینی را ذخیره میکند. موتور هوشمند شامل چهار جزء فرعی است: تحلیلگر پروفایل، رتبهبندی، ماشینحساب شباهت معنایی و توصیهکننده. تحلیلگر پروفایل دادههای رفتار کاربر را از لاگهای وب خام به طور منظم استخراج کرده و در پایگاه دانش ذخیره میکند. ماشین حساب معنایی شباهت معنایی بین پرس و جوهای مختلف جستجوی کاربر را بر اساس الگوی دسترسی کاربر محاسبه می کند که از رتبه بندی و توصیه کننده پشتیبانی می کند. رتبهبندی شاخص فراداده را جستجو میکند و فهرستی بهینه از نتایج رتبهبندیشده را بر اساس چند ویژگی رتبهبندی از پیش تعریفشده، یک مدل رتبهبندی از قبل آموزشدیدهشده توسط ماشین، و نتایج شباهت معنایی تولید میکند.
3.2. اجزای سیستم
3.2.1. رابط کاربری گرافیکی وب سیستم
رابط کاربری گرافیکی وب سیستم طراحی کاربر محور را اتخاذ می کند و رابطی را برای تعاملات کاربر با موارد زیر فراهم می کند: (الف) ورودی محدودیت های جستجو. (ب) نتایج رتبه بندی شده؛ ج) کاوش داده ها بر اساس توصیه ها. و (د) پیمایش از طریق پیشنهاد پرس و جو برای یافتن مجموعه داده های مربوطه.
سه پانل برای کمک به کاربران در کشف و دسترسی بهتر داده ها اضافه شده است: (الف) پانل “پرس و جوهای مرتبط” برای نمایش پرس و جوهای کاربر از نظر معنایی مشابه ارائه شده است. (ب) پانل “رتبه بندی مبتنی بر یادگیری ماشین” برای ارائه نتایج مرتبط تر برای کاربران نهایی ایجاد شده است. (ج) پانل «دادههای مرتبط» پس از انتخاب کاربر یک مجموعه داده خاص اضافه میشود. دانشمندان دامنه میتوانند از این سه قابلیت برای شناسایی سریع مجموعه دادههای موجود و هدایت به سرویس دانلود داده استفاده کنند. وب سرویس های این سه جزء نیز برای پشتیبانی از ارتباط با سایر برنامه ها توسعه یافته اند.
3.2.2. دانش محور
پایگاه دانش شامل سه بخش است: فراداده، رفتار کاربر و مدلهای یادگیری ماشینی. ابرداده توصیف داده ها است و در یک موتور جستجوی متن کامل نمایه می شود. رفتار کاربر نتایج لاگ کاوی تحلیلگر پروفایل است که زمینه را برای رتبهبندی، محاسبهگر تشابه معنایی و توصیهکننده فراهم میکند. مدلهای یادگیری ماشینی شامل مدل رتبهبندی از پیش آموزشدیده، ماتریس همروند تاریخچه جستجوی کاربر و جریان کلیک، و مدل توصیه فیلتر مشارکتی از قبل آموزشدیده شده است.
3.2.3. موتور هوشمند
به عنوان مهمترین جزء سیستم، موتور هوشمند از چهار جزء فرعی تشکیل شده است: تحلیلگر پروفایل، رتبهبندی، محاسبهگر تشابه معنایی و توصیهگر. تحلیلگر پروفایل لاگ کاوی را انجام می دهد و الگوی دسترسی کاربر را در پایگاه دانش به طور دوره ای به روز می کند. در زمان پرس و جو، موتور هوشمند ورودی جستجو را دریافت می کند و جستجو را با نمایه ابرداده هماهنگ می کند. سپس بازده جستجوی نمایه ابرداده مجدداً توسط رتبهبندی رتبهبندی میشود. با توجه به پرس و جوی کاربر، ماشین حساب شباهت می تواند لیستی از پرس و جوهای کاربر بسیار مرتبط را تولید کند. هنگامی که کاربران دادهای را در نتایج رتبهبندی شده انتخاب میکنند، توصیهکننده فهرستی از دادههای مرتبط را ارائه میدهد.
3.2.4. آنالایزر پروفایل
تحلیلگر پروفایل الگوی دسترسی کاربر را از لاگ های وب خام استخراج می کند. گردش کار پردازش گزارش دارای چهار مرحله است: شناسایی کاربر، تشخیص خزنده، شناسایی جلسه و بازسازی ساختار ( شکل 2 ). مرحله شناسایی کاربر، هر کاربر را از طریق آدرس IP و مرورگر وب شناسایی می کند. مرحله تشخیص خزنده گزارشهای وب ایجاد شده توسط فعالیتهای رباتیک را شناسایی و حذف میکند. شناسایی جلسه، دنبالهای از گزارشهای وب هر کاربر را به جلساتی تقسیم میکند که بازدیدهای منفرد آن کاربر را نشان میدهد. مرحله بازسازی جلسه، اقدامات کاربر را با توجه به اطلاعات صفحه قبلی گزارش وب به هم متصل می کند. جزئیات بیشتر را می توان در Jiang, Li [ 25 ] یافت.
دو نوع خروجی از تحلیلگر پروفایل وجود دارد: تاریخچه جستجوی کاربر و جریان کلیک. تاریخچه جستجوی کاربر به درخواست جستجو شده توسط کاربر معین در یک دوره زمانی از پیش تعریف شده اشاره دارد. Clickstream مخفف مجموعه ای از کلیک های ماوس است که هنگام بازدید از یک وب سایت انجام می شود. این اطلاعات برای پشتیبانی از سایر اجزای موتور هوشمند در پایگاه دانش نگهداری می شود.
3.2.5. ماشین حساب شباهت معنایی
ماشین حساب شباهت شباهت معنایی بین پرس و جوهای کاربر را محاسبه می کند. فرض بر این است که اگر دو پرسوجو مشابه باشند، (1) در تاریخچه جستجوی کاربران متمایز، فراوانتر میشوند. (2) داده های کلیک شده نیز در زمینه رفتارهای کاربر در مقیاس بزرگ مشابه هستند. بر اساس این فرض، LSA برای کشف پیوندهای پنهان بین عبارات مرتبط با معنایی ( شکل 3) به ماتریس هموقوع پرس و جو تاریخچه جستجوی کاربر و جریان کلیک اعمال میشود .). نتایج هر دو طرف به طور مستقل نمره گذاری می شوند و برای حذف نویز منحصر به فرد برای هر طرف قطع می شوند. مقادیر شباهت حاصل از 0 (یعنی بدون رابطه) تا 1 (یعنی یکسان) متغیر است. نتایج شباهت در پایگاه دانش ذخیره می شود و به طور دوره ای به روز می شود. جزئیات بیشتر را می توان در Jiang, Li [ 26 ] یافت. اصطلاحات بسیار مرتبط به همراه مقادیر شباهت مرتبط با آنها را می توان برای بسط و پیشنهاد پرس و جو استفاده کرد.
3.2.6. رتبه بندی
ماژول رتبه بندی برای بهبود رتبه بندی نتایج جستجو طراحی شده است ( شکل 4). هنگامی که کاربر یک پرس و جو را ارسال می کند، سپس بر اساس نتایج برگشتی ماشین حساب شباهت معنایی به یک پرس و جو معنایی تبدیل می شود. به عنوان مثال، پرس و جو “دمای سطح دریا” به “دمای سطح دریا یا sst” تبدیل می شود. سپس نمایه جستجو K نتایج برتر را برای پرس و جو معنایی برمی گرداند. پس از آن، استخراج کننده ویژگی ویژگی های رتبه بندی را برای هر یک از نتایج جستجو استخراج می کند. ویژگیهای رتبهبندی شامل امتیاز ارتباط مبتنی بر متن، شباهت فضایی، شماره نسخه، سطح پردازش، تاریخ انتشار، وضوح مکانی، وضوح زمانی، محبوبیت همیشه، محبوبیت ماهانه و محبوبیت کاربر است. هنگامی که همه ویژگی ها آماده شدند، نتایج K برتر در یک مدل رتبه بندی از پیش آموزش دیده رتبه بندی RankSVM قرار می گیرند، که در نهایت بازیابی K برتر را مجدداً رتبه بندی می کند.
3.2.7. توصیه کننده
ماژول توصیه برای پیشبینی دادههایی که کاربران ممکن است به آن علاقهمند باشند، توسعه داده شده است. توصیهها بر اساس دو نوع معیار ارائه میشوند: محتوای فراداده و رفتار کاربر. هدف شناسایی مشابه ترین داده ها بر اساس داده هایی است که مشاهده می شود. شکل 5گردش کار الگوریتم توصیه را شرح می دهد. در محاسبات مبتنی بر محتوای فراداده، پس از وزندهی، ویژگیهای فراداده (به عنوان مثال، موضوع، سطح پردازش، وضوح مکانی) به سه دسته مکانی-زمانی، ترتیبی و طبقهبندی تقسیم میشوند. الگوریتم های شباهت مربوطه برای هر دسته طراحی شده است. در روش مبتنی بر رفتار کاربر، ماتریس همرویداد دادهها با توجه به جلسات کاربر از دادههای رفتار کاربر ساخته میشود و سپس LSA برای محاسبه شباهت اعمال میشود. شهود این است که اگر دو داده در جلسات وب کاربران متمایز به طور مکرر با هم اتفاق بیفتند، احتمالاً مشابه یکدیگر هستند. در نهایت از میانگین وزنی این دو روش برای رتبه بندی نتایج توصیه ها استفاده می شود.
3.3. پیاده سازی
3.3.1. داده ها
فراداده های آزمایشی ما از همه فراداده های سطح مجموعه در دسترس عموم از PO.DAAC می آیند. PO.DAAC صدها مجموعه داده منحصربهفرد مرتبط با اقیانوسهای جهان را توزیع میکند، از جمله آنهایی که در مناطق باد اقیانوس، توپوگرافی، دما، گردش خون، شوری و یخ دریا هستند. وسعت و تعداد مجموعه داده ها در هر دامنه یک چالش کلیدی برای ارتباط جستجو از دیدگاه کاربر است. به عنوان مثال، همانطور که در جدول 1 نشان داده شده است ، کاتالوگ دمای سطح دریا (SST) شامل 205 مجموعه داده است که چندین رشته را پوشش می دهد.
مجموعه داده های SST یک منبع ضروری برای نظارت و درک تغییرات آب و هوا و تغییرات آب و هوا هستند. از لحاظ تاریخی، اندازه گیری های SST از کشتی ها انجام شده است. دادههای کشتی در پایگاههای دادهای مانند مجموعه دادههای جامع بینالمللی اقیانوس-اتمسفر (ICOADS) گردآوری شدهاند که به نوبه خود ورودی اصلی مجموعه دادههای آب و هوایی بلندمدت را تشکیل میدهند. شناورهای لنگردار و متحرک منبع اصلی دیگر داده های SST درجا هستند، به ویژه در مناطق دورافتاده مانند اقیانوس جنوبی، جایی که شناورهای ARGO پوشش بسیار بهبود یافته ای را ارائه می دهند. بر فراز اقیانوس آرام استوایی، پروژه متراکم اقیانوس اتمسفر استوایی (TAO) – آرایه مثلث شبکه شناور فرا اقیانوسی (TAO-TRITON) اندازه گیری های کلیدی را برای نظارت بر ظهور و تکامل رویدادهای ال نینو فراهم می کند [ 27 ]]. داده های درجا همچنین مرجع اولیه برای کالیبراسیون تخمین های SST مبتنی بر ماهواره هستند [ 28]. تخمین های مبتنی بر ماهواره از اندازه گیری های مادون قرمز (IR) و طول موج های مایکروویو استفاده می کنند. مشاهدات مایکروویو نسبت به اندازهگیریهای IR نسبت به ابرها حساسیت کمتری دارند، اما به پراکندگی توسط باران حساستر هستند و وضوح فضایی پایینتری دارند. برای تحقیقات آب و هوایی، طولانیترین مجموعه داده مبتنی بر ماهواره، OI SSTv2 NOAA است که از سال 1981 تا کنون گسترش یافته است، با اندازهگیریهای IR با وضوح بسیار بالا (AVHRR) به عنوان دادههای منبع اولیه. گروه SST با وضوح بالا (GHRSST) یک ماموریت چتر است که توسعه محصولات داده SST چند طیفی را برای جوامع عملیاتی و آب و هوا هماهنگ می کند. در حال حاضر، یکی از طولانیترین محصولات GHRSST جهانی، آنالیز SST با وضوح فوقالعاده بالا (MUR) است، یک مجموعه داده شبکهای 0.01 درجه که توسط JPL، ناسا توسعه یافته و از سال 2002 تا کنون را پوشش میدهد.29 ].
آزمایشهای ما با استفاده از یک سال سابقه جستجو از موتور جستجوی دادههای PO.DAAC، که نزدیک به 120 میلیون رکورد در 30 گیگابایت است، اجرا شد. این لاگهای وب در قالب Apache Common Log، پرکاربردترین فرمت گزارش که توسط W3C نگهداری میشود، هستند. هر گزارش وب دارای چندین فیلد از جمله آدرس IP مشتری، تاریخ/زمان درخواست، صفحه درخواستی، کد HTTP و بایت های ارائه شده است.
3.3.2. پیاده سازی سیستم
این سیستم با استفاده از جاوا 8، جاوا اسکریپت، HTML 5 و CSS توسعه یافته است. فریم ورک Angular JS JavaScript در توسعه frontend استفاده میشود، که دارای یک تابع پیوند داده است که هر زمان که مدل تغییر کرد، view را بهروزرسانی میکند، و همچنین هر زمان که نما تغییر کرد، مدل را بهروزرسانی میکند. ارتباط بین backend و frontend از رابط های وب سرویس استاندارد RESTful استفاده می کند که توسط Apache CXF و Tomcat فعال شده اند. Elasticsearch به عنوان فهرست جستجوی متن کامل استفاده می شود. الگوریتم LSA در ماشین حساب شباهت معنایی و الگوریتم RankSVM در رتبهبندی با Spark MLlib پیادهسازی شدهاند.
ما از یک خوشه Hadoop با 5 گره داده استفاده کردیم که هر کدام یک پردازنده AMD Opteron با فرکانس 2.4 گیگاهرتز با 4 تا 8 هسته و 8 تا 16 گیگابایت رم داشتند. حدود 1.5 ساعت طول کشید تا فهرستبندی، پرسوجو از گزارشهای وب یکساله، و ساخت مدلهای مورد نیاز (یعنی ماتریسهای همزمانی تاریخچه جستجوی کاربر و جریان کلیک). پایگاه داده و مدل ها ماهانه به روز می شوند. فن آوری های مورد استفاده برای پیاده سازی سیستم پیشنهادی برای مجموعه داده های PO.DAAC عبارتند از: HDFS، Map/Reduce jobs، Spark، Elasticsearch و DC2 [ 30 ، 31 ]. این آزمایش بر روی پلت فرم ابری ناسا AIST، یک محیط محاسبات ابری ترکیبی که برای تحقیقات علمی ارائه شده است، انجام شد. کد منبع سیستم به همراه این مقاله به عنوان یک نرم افزار متن باز منتشر شده است ( https://github.com/mudrod/mudrod) تحت پروژه MUDROD [ 32 ].
3.4. سناریوی کاربر
پس از ورود کاربران به سیستم، آنها یک پرس و جو (به عنوان مثال، دمای اقیانوس) را در کادر جستجو تایپ می کنند ( شکل 6 ). عملکرد تکمیل خودکار در حین تایپ با پیش بینی بقیه کلماتی که کاربران قصد وارد کردن آنها را دارند کمک می کند. هنگامی که کاربران دکمه جستجو را فشار می دهند، لیستی از نتایج بازیابی می شود که دارای رتبه بندی پیش فرض رتبه بندی مبتنی بر یادگیری ماشین است. کاربران همچنین می توانند لیست را بر اساس معیارهای دیگر مانند محبوبیت و وضوح فضایی مرتب کنند. در سمت راست، لیستی از جستجوهای مرتبط نمایش داده می شود ( شکل 7). در این مورد خاص، جستارهای مشابه «دمای اقیانوس» عبارتند از «sst»، «دمای سطح دریا»، «ghrsst»، و غیره. کاربران می توانند برای کاوش مجموعه داده های دیگر، روی هر یک از این جستجوهای مرتبط کلیک کنند. اگر کاربران مایلند جزئیات بیشتری از یک مجموعه داده خاص در لیست جستجو بدانند، میتوانند روی ویژگی «نام» (به عنوان مثال، VIIRS_NPP-NAVO-L2P-v2.0) و اطلاعات بیشتری مانند نسخه، سطح پردازش، پوشش کلیک کنند. نمایش داده خواهد شد. با توجه به الگوریتم توصیه در پشت صحنه، مجموعه داده های مرتبط بالا در سمت راست فهرست شده اند ( شکل 8). در این مورد، مرتبط ترین مجموعه داده، نسخه 1.0 مجموعه “VIIRS_NPP-NAVO-L2P” است زیرا مجموعه داده ای که مشاهده می شود نسخه 2.0 آن است. یک سیستم نمایشی آنلاین در https://mudrod.jpl.nasa.gov/#/ در دسترس قرار گرفته است.
3.5. موارد استفاده
ملاحظات رایج برای استفاده از مجموعه داده های SST در تحقیقات اقلیمی و ارزیابی مدل عبارتند از (1) تفکیک مکانی و زمانی – آیا ویژگی هایی مانند جریان خلیج فارس و جبهه های آن با گرداب حل می شوند؟ (2) کمیت در حال اندازه گیری – آیا این دمای “پوست” یک لایه سطحی بسیار نازک است یا دمای عمده متر بالایی یا بیشتر؟ (3) سطح پردازش – آیا به دادههای شبکهبندی نشده سطح 2 نیاز داریم که حاوی فیلدهای دادههای جانبی و همچنین ویژگیهای خطای کامل برای هر پیکسل باشد؟ (4) تأخیر – آیا دادههای تقریباً همزمان مورد نیاز است؟ (5) پوشش مکانی و زمانی – آیا منطقه و دوره مورد مطالعه تحت پوشش است؟ (6) درون یابی مکانی – آیا داده ها به شیوه ای آماری درون یابی شده اند و این چه تاثیری بر واریانس مکانی و زمانی سیگنال های آب و هوا دارد؟
3.5.1. پیشنهاد پرس و جو
شکل 9نتایج پیشنهاد پرس و جو از پرس و جو “دمای سطح دریا” را نشان می دهد. “sst” و “Ocean temperature” دو عبارت اول در لیست “جستجوهای مرتبط” هستند که مقادیر مشابهی با یک دارند. “sst” مخفف رایج در جامعه علمی اقیانوس است. در زمینه داده های ماهواره اقیانوس شناسی که آزمایش در حال طراحی پیرامون آن است، «دمای اقیانوس» و «دمای سطح دریا» تقریباً مترادف هستند زیرا مجموعه داده های زیرسطحی/عمیق کمی در PO.DAAC وجود دارد. این واقعیت توسط مهندسان داده PO.DAAC تأیید شده است. با توجه به اینکه هدف بهبود کشف داده ها است، بنابراین این نتیجه معقول است. در واقع، اگر مجموعه دادههای زیرسطحی/عمیق بیشتری در PO.DAAC در دسترس باشد، روش پیشنهادی میتواند به طور خودکار شباهت را مطابق با الگوی دسترسی کاربر بهروزرسانی کند.26 ]. سومین پرس و جو “ghrsst” با مقدار شباهت 0.83 است. “ghrsst” مخفف The Group for High-Resolution Sea Surface Temperature (GHRSST) است که هدف آن توسعه نسل جدیدی از محصولات جهانی، چند سنسوری و با وضوح بالا نزدیک به زمان واقعی SST است. با توجه به کیفیتی که ghrsst ارائه می دهد، به یکی از محبوب ترین مجموعه داده های دمای سطح دریا تبدیل شده است. سایر ماموریت های SST گرا عبارتند از AQUA، AVHRR-Pathfinder، Resolution Imaging Spectroradiometer (MODIS)، Suomi National Polar-Morbiting Partnership (S-NPP)، TERRA، که می توان آنها را در جستجوهای مرتبط دیگر یافت.
3.5.2. رتبه بندی جستجو
شکل 10مقایسه نتایج جستجوی برتر “دمای سطح دریا” بین موتور جستجوی PO.DAAC و سیستم پیشنهادی است. با توجه به موضوع داده به رنگ نارنجی در وب سایت PO.DAAC و سبز در رابط کاربری سیستم، موضوعات دو داده اول در PO.DAAC عبارتند از: امواج اقیانوس، توپوگرافی سطح دریا، رادار، یخ دریا، در حالی که از سیستم پیشنهادی «دمای سطح دریا» و «پروفایل دما» هستند. این به دلیل رتبه بندی های متفاوتی است که توسط این دو سیستم استفاده می شود. PO.DAAC به طور پیش فرض از محبوبیت همیشگی برای رتبه بندی نتایج جستجو استفاده می کند. فقط به این دلیل که دادههای «امواج اقیانوس» بارگیری بیشتری نسبت به دادههای «دمای سطح دریا» دارند، آن دادههایی که ارتباط کمی دارند در بالاترین رتبهبندی قرار میگیرند. ضعف در نظر گرفتن تنها یک ویژگی داده با رتبهبندی مبتنی بر یادگیری ماشینی سیستم پیشنهادی برطرف شده است.
مثال دیگر ترتیب مجموعه داده «AVHRR Pathfinder Level 3 Daily Nighttime SST Version 5» و «AVHRR Pathfinder Level 3 Daily Nighttime SST Version 5.1» است. این دو مجموعه داده همان داده های AVHRR Pathfinder Level 3 Nighttime SST از نسخه های مختلف هستند. نسخه دوم نسخه جدیدتر با کیفیت بهتر است. فقط به این دلیل که نسخه قبلی بیشتر از نظر تاریخی بارگیری شده است، از جایگزینی آن بالاتر است. یک ارزیابی سیستماتیک بر اساس دقت در K و سود تجمعی کاهش یافته نرمال نشان می دهد که رویکرد یادگیری ماشینی از روش های دیگر مانند محبوبیت ماهانه بهتر عمل می کند [ 9 ].
3.5.3. توصیه
شکل 11 نتایج توصیه شده یک مجموعه داده انتخاب شده را نشان می دهد – “AVHRR_SST_METOP_B-OSISAF-L2P-v1.0″، که دمای سطح دریا زیر پوست سطح 2P GHRSST از رادیومتر با وضوح بسیار بالا پیشرفته (AVHRR) در Metop-B است. ماهواره های تولید شده توسط OSI SAF. سه مجموعه داده اول مجموعه داده های AVHRR SST از پلتفرم های ماهواره ای مختلف، سطوح پردازش و نسخه ها هستند. چهارمین و پنجمین مورد، داده های حسگر AVHRR هستند که به ترتیب توسط سازمان اروپایی بهره برداری از ماهواره های هواشناسی (EUMETSAT) و دفتر اقیانوس شناسی نیروی دریایی ایالات متحده (NAVO) تولید شده اند. عملکرد توصیه به کاربران اجازه می دهد تا داده های مربوطه را راحت تر کاوش کنند، که به نوبه خود به یافتن مطلوب ترین داده ها در زمان بیشتری کمک می کند.
4. نتیجه گیری و بحث
این مقاله معماری و روششناسی MUDROD را معرفی میکند، یک موتور جستجوی دادههای مکانی مبتنی بر وب هوشمند که هدف آن بهبود کشف دادهها با استخراج و استفاده از ارتباط دادهها از فراداده و رفتار کاربر است. برای کمک به کاربران در یافتن و کاوش داده های مرتبط تر، یک ماشین حساب شباهت معنایی برای پشتیبانی از بسط پرس و جو و پیشنهاد طراحی شده است. برای کمک به کاربران در یافتن مرتبطترین دادهها، یک رتبهبندی مبتنی بر یادگیری ماشین ایجاد شده است تا رتبهبندی بهینه جستجو را بر اساس چند ویژگی رتبهبندی شناساییشده ارائه دهد. علاوه بر این، یک توصیهکننده ترکیبی استفاده میشود تا به کاربران اجازه دهد دادههای مرتبط را با در نظر گرفتن ویژگیهای ابرداده و رفتار کاربر کشف کنند. برای بهبود تجربه جستجوی کاربران،
در سیستم فعلی چندین محدودیت وجود دارد. یکی این است که سیستم فقط می تواند گزارش های وب را در حالت دسته ای پردازش کند، به این معنی که علاقه جستجوی کاربران توسط سیستم در زمان واقعی قابل یادگیری نیست. ما قصد داریم تابع ورود به سیستم بلادرنگ را ادغام کنیم زیرا در بسیاری از موارد بسیار مهم است [ 33 ]. به عنوان مثال، در طول یک طوفان، مرتبط ترین داده ها باید با ادامه یک منطقه طوفان تغییر کند. محدودیت دیگر این است که مدل رتبهبندی با استفاده از قضاوتهای مربوط به خبرگان از قبل آموزش داده شده است، که هم زمانبر و هم کار فشرده است. ما در حال بررسی روشهایی برای استفاده از رفتار کاربر برای ایجاد خودکار دادههای آموزشی برای الگوریتم رتبهبندی یادگیری ماشین هستیم [ 34]. آخرین نگرانی در مورد شناسایی ویژگی رتبه بندی است. در حالی که ویژگی ها منعکس کننده شهود و بحث ما با کارشناسان حوزه هستند، به احتمال زیاد این ویژگی ها مطلوب نیستند. ما قصد داریم در کارهای آینده ویژگی های بیشتری (به عنوان مثال، شباهت زمانی) اضافه کنیم. علاوه بر این، یک الگوریتم درک پرس و جو که می تواند پرس و جوی چند عبارتی را برای فعال کردن جستجوی معنایی بهتر تجزیه کند، به طور فعال در حال توسعه است.
قدردانی ها
این پروژه توسط NASA AIST (NNX15AM85G) و NSF (IIP-1338925 و ICER-1540998) تامین می شود. این تحقیقات تا حدی در آزمایشگاه پیشرانه جت، موسسه فناوری کالیفرنیا، تحت قراردادی با سازمان ملی هوانوردی و فضایی انجام شد.
مشارکت های نویسنده
چاووی یانگ ایده اصلی تحقیق را مطرح کرد و به Yongyao Jiang و Yun Li در مورد الگوریتم ها توصیه کرد. Yongyao Jiang شباهت معنایی و الگوریتم رتبه بندی را توسعه داد. یون لی الگوریتم توصیه را توسعه داد. Yongyao Jiang، Yun Li، Chaowei Yang و Fei Hu گردش کار را توسعه دادند و سیستم را پیاده سازی کردند. ادوارد ام. آرمسترانگ، دیوید مورونی، توماس هوانگ و کریستوفر جی. فینچ بازخورد قابل توجهی برای توسعه سیستم ارائه کردند. Lewis J. McGibbney و Frank Greguska کار را به عنوان یک پروژه منبع باز بسته بندی و مستند کردند. یونگ یاو جیانگ، یون لی، چاووی یانگ و فی هو مقاله را نوشتند. ادوارد ام. آرمسترانگ، توماس هوانگ و دیوید مورونی مقاله را اصلاح کردند.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- هارتمن، اقلیم شناسی فیزیکی جهانی DL ; الزویر: آمستردام، هلند، 2015. [ Google Scholar ]
- فن، ی. گینیس، آی. هارا، تی. اثر برهمکنش باد-موج-جریان بر شارهای تکانه هوا-دریا و پاسخ اقیانوس در طوفان های استوایی. J. Phys. اقیانوسگر. 2009 ، 39 ، 1019-1034. [ Google Scholar ] [ CrossRef ]
- دواراکوندا، ر. پالانیسامی، جی. ویلسون، BE; Green, JM Mercury: مدیریت ابرداده قابل استفاده مجدد، سیستم کشف داده و دسترسی. علوم زمین Inf. 2010 ، 3 ، 87-94. [ Google Scholar ] [ CrossRef ]
- ناسا برنامه راهبردی ناسا 2011. در دسترس آنلاین: https://www.nasa.gov/pdf/516579main_NASA2011StrategicPlan.pdf (در 7 آوریل 2017 قابل دسترسی است).
- یانگ، سی. یو، م. هو، اف. جیانگ، ی. Li, Y. استفاده از رایانش ابری برای رسیدگی به چالشهای بزرگ دادههای مکانی. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 61 ، 120-128. [ Google Scholar ] [ CrossRef ]
- Overpeck، JT; Meehl، GA; استخوانی، اس. ایسترلینگ، DR چالش های داده های آب و هوا در قرن بیست و یکم. Science 2011 ، 331 ، 700-702. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لی، دبلیو. Goodchild، MF; Raskin, R. Towards geospatial semantic search: بهره برداری از روابط معنایی پنهان در داده های جغرافیایی. بین المللی جی دیجیت. زمین 2014 ، 7 ، 17-37. [ Google Scholar ] [ CrossRef ]
- جیانگ، ی. شیا، جی. پورتال Liu, K. Polar CI: موتور کشف منابع قطبی مبتنی بر ابر. در رایانش ابری در علوم اقیانوسی و جوی ؛ Vance, TC, Merati, N., Yang, C., Yuan, M., Eds.; مطبوعات دانشگاهی: آمستردام، هلند، 2016; صص 163-185. [ Google Scholar ]
- جیانگ، ی. لی، ی. یانگ، سی. هو، اف. آرمسترانگ، ای.ام. هوانگ، تی. مورونی، دی. مک گیبنی، ال جی؛ Finch، CJ به سوی کشف دادههای مکانی هوشمند: چارچوب یادگیری ماشین برای رتبهبندی جستجو. بین المللی جی دیجیت. زمین 2017 ، 1-16. [ Google Scholar ] [ CrossRef ]
- گوس، ا. Ipeirotis، PG; لی، بی. طراحی سیستم های رتبه بندی هتل ها در موتورهای جستجوی سفر با استخراج محتوای تولید شده توسط کاربر و جمع سپاری. علامت. علمی 2012 ، 31 ، 493-520. [ Google Scholar ] [ CrossRef ]
- NRC. فرصت های تحقیقاتی جدید در علوم زمین ; انتشارات آکادمی ملی: واشنگتن، دی سی، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- الجده، ک. کورایم، م. گرینگر، تی. راسل، سی. افزایش پرس و جو از طریق کشف معنایی اصطلاحات مخصوص دامنه. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2014 در مورد داده های بزرگ (Big Data)، واشنگتن، دی سی، ایالات متحده آمریکا، 27-30 اکتبر 2014. صص 808-815. [ Google Scholar ]
- وب معنایی زمین و اصطلاحات محیطی (SWEET). در دسترس آنلاین: https://www.researchgate.net/publication/250346856_Semantic_Web_for_Earth_and_Environmental_Terminology_SWEET (دسترسی در 10 مه 2017).
- گونای، ا. آکچای، او. Altan, MO ساخت یک ژئوپورتال حمل و نقل عمومی مبتنی بر معنایی مطابق با موضوع داده شبکه حمل و نقل INSPIRE. علوم زمین Inf. 2014 ، 7 ، 25-37. [ Google Scholar ] [ CrossRef ]
- دومایس، تحلیل معنایی نهفته ST. آنو. Rev. Inf. علمی تکنولوژی 2004 ، 38 ، 188-230. [ Google Scholar ] [ CrossRef ]
- Blei، DM; Ng، AY؛ جردن، MI تخصیص دیریکله نهفته. Adv. عصبی Inf. روند. سیستم 2002 ، 1 ، 601-608. [ Google Scholar ]
- هو، ی. یانوویچ، ک. پراساد، س. گائو، S. هماهنگی موضوع فراداده و جستجوی معنایی برای پورتال های جغرافیایی مبتنی بر داده های پیوندی: مطالعه موردی با استفاده از ArcGIS Online. ترانس. GIS 2015 ، 19 ، 398-416. [ Google Scholar ] [ CrossRef ]
- گورملی، سی. Tong, Z. Elasticsearch: The Definitive Guide: A Distributed Real Time Search and Analytics Engine ; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2015. [ Google Scholar ]
- مارتینز، بی. Calado, P. یادگیری رتبه بندی برای بازیابی اطلاعات جغرافیایی. در مجموعه مقالات ششمین کارگاه آموزشی بازیابی اطلاعات جغرافیایی، زوریخ، سوئیس، 18 تا 19 فوریه 2010. پ. 21. [ Google Scholar ]
- شاو، بی. شی، جی. سینها، س. Hogue, A. یادگیری رتبه بندی برای جستجوی مکانی و زمانی. در مجموعه مقالات ششمین کنفرانس بین المللی ACM در جستجوی وب و داده کاوی، رم، ایتالیا، 4 تا 8 فوریه 2013. صص 717-726. [ Google Scholar ]
- داده های مرتبط – داستان تاکنون. در دسترس آنلاین: https://eprints.soton.ac.uk/271285/ (دسترسی در 10 مه 2017).
- کریسنادی، ا. هو، ی. یانوویچ، ک. هیتزلر، پی. آرکو، آر. کاربات، اس. چندلر، سی. چیتام، ام. فیلس، دی. Finin، T. هستی شناسی اقیانوس شناسی مدولار GeoLink. در مجموعه مقالات چهاردهمین کنفرانس بین المللی وب معنایی، بیت لحم، PA، ایالات متحده آمریکا، 11-15 اکتبر 2015; ص 301-309. [ Google Scholar ]
- بوبادیلا، جی. اورتگا، اف. هرناندو، ا. Gutiérrez, A. بررسی سیستم های توصیه کننده. بدانید. سیستم مبتنی بر 2013 ، 46 ، 109-132. [ Google Scholar ] [ CrossRef ]
- وکنر، بی. ریشتر، آ. Mittlböck، M. از geoportals تا پورتال دانش جغرافیایی. ISPRS Int. J. Geo-Inf. 2014 ، 2 ، 256-275. [ Google Scholar ] [ CrossRef ]
- جیانگ، ی. لی، ی. یانگ، سی. آرمسترانگ، ای.ام. هوانگ، تی. مورونی، دی. بازسازی جلسات از کشف داده ها و گزارش های دسترسی برای ایجاد یک پایگاه دانش معنایی برای بهبود کشف داده ها. ISPRS Int. J. Geo-Inf. 2017 ، 5 ، 54. [ Google Scholar ] [ CrossRef ]
- جیانگ، ی. لی، ی. یانگ، سی. لیو، ک. آرمسترانگ، ای. هوانگ، تی. مورونی، دی. Finch, C. یک روش جامع برای کشف روابط معنایی بین واژگان جغرافیایی با استفاده از کشف دادههای اقیانوسشناسی به عنوان مثال. بین المللی جی. جئوگر. Inf. علمی 2017 ، 31 ، 2310-2328. [ Google Scholar ] [ CrossRef ]
- مک فادن، ام جی پیدایش و تکامل ال نینو 1997-98. علوم 1999 ، 283 ، 950-954. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- UCAR. مجموعه داده های SST: جدول نمای کلی و مقایسه. 2014. در دسترس آنلاین: https://climatedataguide.ucar.edu/climate-data/sst-data-sets-overview-comparison-table (در 10 مه 2017 قابل دسترسی است).
- مارتین، ام. داش، پ. ایگناتوف، آ. بنزون، وی. بگز، اچ. براسنت، بی. کایولا، ج.-ف. کامینگز، جی. دانلون، سی. Gentemann, C. Group for Resolution High Resolution Temperature Seface Sea (GHRSST) زمینه های تجزیه و تحلیل بین مقایسه ها. بخش 1: مجموعه چند محصولی GHRSST (GMPE). Deep Sea Res. قسمت دوم 2012 ، 77 ، 21-30. [ Google Scholar ] [ CrossRef ]
- لی، ی. جیانگ، ی. هو، اف. یانگ، سی. هوانگ، تی. مورونی، دی. Fench, C. استفاده از محاسبات ابری برای افزایش سرعت استخراج ورود به سیستم دسترسی کاربر. In Proceedings of the OCENS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 سپتامبر 2016. صص 1-6. [ Google Scholar ]
- جین، بی. آهنگ، دبلیو. ژائو، ک. وی، ایکس. هو، اف. Jiang, Y. یک سیستم تجزیه و تحلیل آماری مکانی-زمانی با کارایی بالا و مبتنی بر بستر ابر مکانی-زمانی. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 165. [ Google Scholar ] [ CrossRef ]
- استخراج و استفاده از ارتباط مجموعه داده از فراداده های مجموعه داده اقیانوس شناسی (MUDROD)، معیارهای استفاده و بازخورد کاربر برای بهبود کشف و دسترسی به داده ها. در دسترس آنلاین: https://adsabs.harvard.edu/abs/2015AGUFMIN51B1809J (دسترسی در 10 مه 2017).
- Ranjan, R. جریان پردازش کلان داده در ابرهای مرکز داده. IEEE Cloud Comput. 2014 ، 1 ، 78-83. [ Google Scholar ] [ CrossRef ]
- آگیشتاین، ای. بریل، ای. دومایس، اس. بهبود رتبه بندی جستجوی وب با ترکیب اطلاعات رفتار کاربر. در مجموعه مقالات بیست و نهمین کنفرانس بین المللی سالانه ACM SIGIR در مورد تحقیق و توسعه در بازیابی اطلاعات، سیاتل، WA، ایالات متحده آمریکا، 6-11 اوت 2006. ص 19-26. [ Google Scholar ]
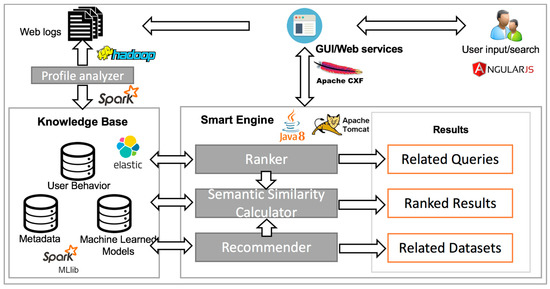
شکل 1. معماری سیستم.
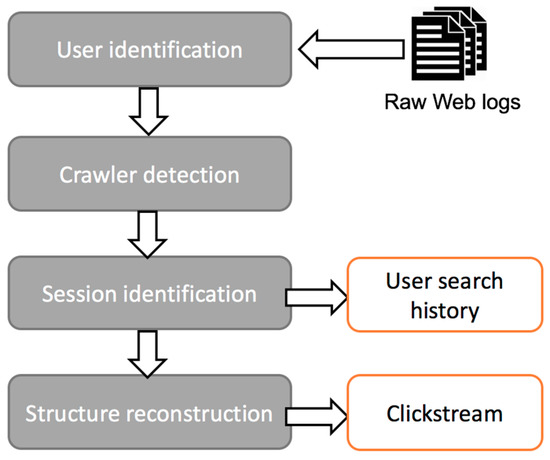
شکل 2. گردش کار تحلیلگر پروفایل.
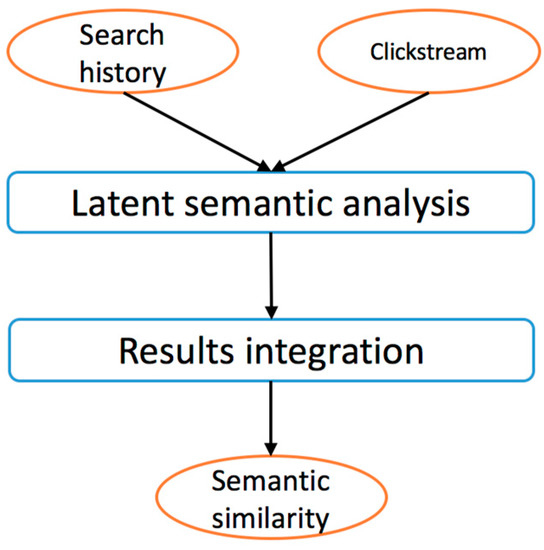
شکل 3. گردش کار ماشین حساب شباهت معنایی.
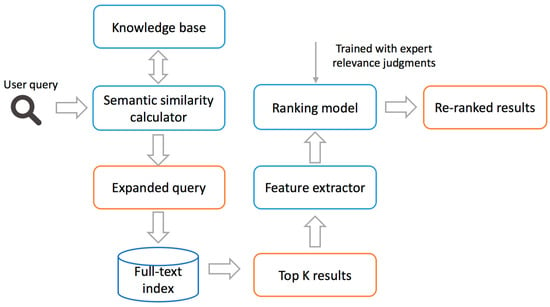
شکل 4. گردش کار رتبه بندی.
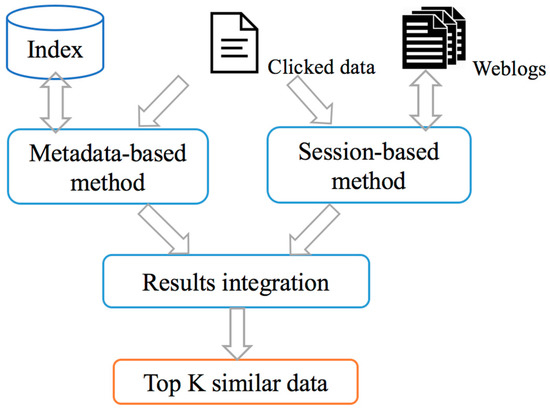
شکل 5. گردش کار توصیه کننده.
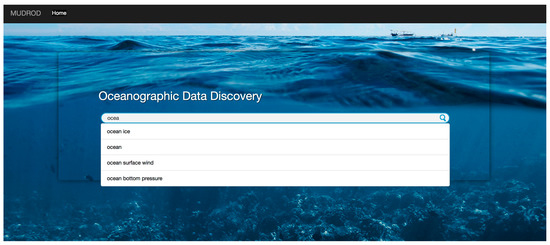
شکل 6. صفحه اصلی سیستم.

شکل 7. صفحه نتایج جستجو.
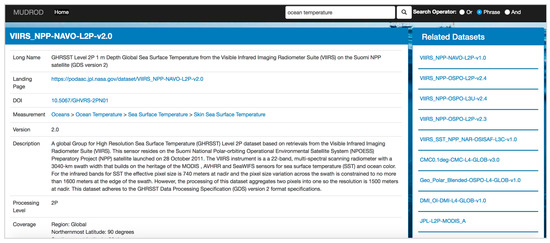
شکل 8. صفحه جزئیات مجموعه داده.

شکل 9. نتایج پیشنهادات پرس و جو.
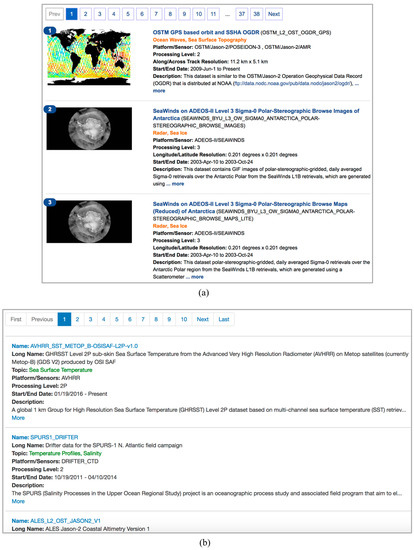
شکل 10. مقایسه بین سیستم پیشنهادی و نتایج جستجوی PO.DAAC. ( الف ) نتایج جستجوی برتر “دمای سطح دریا” PO.DAAC. ( ب ) نتایج جستجوی برتر “دمای سطح دریا” سیستم پیشنهادی.

شکل 11. نتایج پیشنهادی یک مجموعه داده انتخاب شده.



بدون دیدگاه