1. مقدمه
کتیبه های استخوان اوراکل (OBI) از همان اوایل سلسله شانگ در چین ثبت شد [ 1 ]. این فیلمنامه شامل برخی از قدیمیترین شخصیتهای جهان و اولین شکل شخصیتهای شناخته شده در چین و شرق آسیا است. شخصیتهای OBI تأثیر عمیقی بر شکلگیری و توسعه حروف چینی دارند، که معمولاً روی استخوانهای حیوانات یا پوسته لاکپشت به منظور پیشگویی pyromantic [ 2 ، 3 ، 4 ]، همانطور که در شکل 1 نشان داده شده است، حک میشوند .
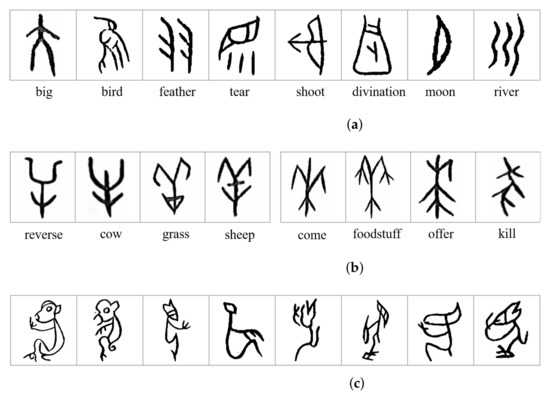
شکل 2 a کاراکترهای OBI را نشان می دهد که مربوط به برخی از کلمات رایج امروزی است. میتوان دید که شخصیتهای OBI با کشیدن اشکال و خطوط بر اساس ویژگیهای شکل اشیا نوشته میشدند، که یکی از ابتداییترین روشهای نگارهنگاری مورد استفاده مردم باستان بود. تا به امروز، باستان شناسان بیش از 4500 کاراکتر OBI را کشف کرده اند، اما معانی نیمی از این شخصیت ها هنوز شناسایی نشده است [ 5 ]. در گذشته کارشناسان با استفاده از مقایسه و تجزیه و تحلیل دستی، معنای شخصیت های OBI را بر اساس تجربیات موجود شناسایی می کردند که موثر بود، اما نیاز به زمان و تلاش داشت. علاوه بر این، از آنجایی که شخصیت های OBI توسط گروه های مختلف مردم باستان از چندین دوره تاریخی حک شده بود [ 2]، شخصیتها از نظر شکل، مقیاس و جهتگیری تنوع زیادی داشتند. به عنوان مثال، هشت کاراکتر نشان داده شده در شکل 2 ب دارای حروف بسیار مشابه هستند، اما نشان دهنده هشت کلمه با معانی بسیار متفاوت هستند. در مقابل، شکل 2 c هشت کاراکتر OBI را نشان میدهد که به روشهای مختلف نوشته شدهاند، با این حال، همه آنها معنای مشابهی از میمون را بیان میکنند. اینها چالش های بزرگی در شناخت شخصیت های OBI ایجاد می کنند.
اخیراً برخی روشهای خودکار برای شناسایی OBI پیشنهاد شدهاند که در میان آنها استخراج ویژگی بیشترین استفاده را دارد. لباس آندریاس و همکاران [ 6 ] تحلیلی از شخصیتهای استخوان اوراکل برای حیوانات از دیدگاه شناختی ارائه کرد. یانگ [ 7 ] یک نظریه گراف را برای شناسایی OBI پیشنهاد کرد که ایده اصلی آن در نظر گرفتن یک کاراکتر کتیبه به عنوان یک گراف بدون جهت و استخراج ویژگی های توپولوژیکی برای تشخیص بود. در کار لی و همکاران [ 8 ]، یک روش توصیف دینامیکی تعاملی انسان-رایانه پیشنهاد شد که OBI را با بردار سکته مغزی-بخش ها-بردار و عناصر ضربه توصیف می کند. یک توصیفگر فوریه بر اساس هیستوگرام انحنای (FDCH) توسط لو و همکاران پیشنهاد شد. [ 9] برای نشان دادن شخصیت های اوراکل. Gu [10 ] OBI را به ارقام توپولوژیکی تبدیل کرد و ارقام توپوگرافی را کدگذاری کرد. منگ [ 11 ، 12 ] از تبدیل Hough برای استخراج ویژگیهای خط کاراکترهای OBI استفاده کرد که منجر به دقت تشخیص کتیبه نزدیک به 90٪ شد. اگرچه رویکردهای مبتنی بر استخراج ویژگی می توانند به هدف شناسایی کاراکترهای OBI دست یابند، اما آنها فقط برای انواع داده های ساده یا مجموعه داده های کوچک مناسب هستند.
فناوری هوش مصنوعی (AI) دارای پتانسیل قوی در تشخیص OBI است و برخی از محققان از تشخیص الگو و یادگیری عمیق در وظایف تشخیص استفاده کردند. فناوری طبقهبندی ماشین بردار پشتیبانی (SVM) [ 13 ، 14 ] برای تشخیص کاراکترهای OBI و رسیدن به دقت 88٪ استفاده شد. گائو و همکاران [ 15 ] از شبکه هاپفیلد برای تشخیص کاراکترهای فازی OBI استفاده کرد و بالاترین میزان دقت 82 درصد بود. گوو و همکاران [ 3] یک نمایش سلسله مراتبی جدید را پیشنهاد کرد که یک نمایش سطح پایین مرتبط با گابور و یک نمایش سطح میانی مربوط به رمزگذار پراکنده را ترکیب کرد. آنها این روش را با شبکه های عصبی کانولوشن (CNN) ترکیب کردند و به دقت 89.1 درصد در تشخیص دست یافتند. اگرچه فناوریهای تشخیص OBI مبتنی بر یادگیری عمیق، مقیاسپذیری خوبی در مجموعه دادههای بزرگ دارند، دقت تشخیص کلی هنوز باید بهبود یابد. در این مقاله، ما رویکردهای جدیدی را برای بهبود دقت تشخیص OBI با استفاده از CNN بررسی میکنیم. مشارکت های عمده ما به شرح زیر خلاصه می شود:
-
ما یک مجموعه داده به نام OBI-100 با 100 کاراکتر کلاس OBI ایجاد کردیم که انواع مختلفی از شخصیت ها مانند حیوانات، گیاهان، بشریت، جامعه و غیره را پوشش می دهد و در مجموع 4748 نمونه دارد. هر نمونه در مجموعه داده با دقت از دو فرهنگ لغت قطعی [ 16 ، 17 ] انتخاب شد. با توجه به تنوع سبک های نوشتاری OBI باستانی، ما همچنین از چرخش، تغییر اندازه، اتساع، فرسایش و سایر تغییرات برای افزایش مجموعه داده به بیش از 128000 تصویر استفاده کردیم. مجموعه داده اصلی را می توان در https://github.com/ShammyFu/OBI-100.git (در 10 دسامبر 2021 در دسترس) یافت.
-
بر اساس چارچوبهای عصبی کانولوشنال LeNet، AlexNet و VGGNet، مدلهای جدیدی را با تنظیم پارامترهای شبکه و اصلاح لایههای شبکه تولید کردیم. این مدل های جدید با استراتژی های بهینه سازی مختلف آموزش و آزمایش شدند. از میان صدها تلاش مدل مختلف، ده مدل CNN با بهترین عملکرد برای شناسایی مجموعه دادههای 100 کلاسی OBI انتخاب شدند.
-
مدلهای پیشنهادی به نتایج تشخیص عالی در مجموعه دادههای OBI، با بالاترین میزان دقت 99.5 درصد دست یافتند که بهتر از سه مدل شبکه کلاسیک و بهتر از روشهای دیگر در ادبیات است.
2. مواد و روشها
2.1. آماده سازی مجموعه داده
2.1.1. اکتساب نمونه
از آنجایی که شخصیت های OBI بر روی پوسته لاک پشت و استخوان های حیوانات حک شده اند، مردم معمولاً آنها را به عنوان مجموعه های کاغذی یا الکترونیکی با مالش یا گرفتن عکس ذخیره می کنند. دادههای خام در مجموعه داده ما از دو فرهنگ لغت OBI اسکن شده کلاسیک [ 16 ، 17 ] میآیند، که هر دو در زمینه OBI قطعی هستند.
مجموعه داده اصلی شامل 100 کلاس از نمونه کاراکترهای اوراکل است که کوچکترین دسته شامل 20 نمونه و بزرگترین کلاس دارای 134 نمونه است که مجموعاً 4748 تصویر کاراکتر دارد. به منظور اطمینان از تنوع مجموعه داده، دستههای کاراکتری که انتخاب میکنیم شامل علوم انسانی، حیوانات، گیاهان، محیط طبیعی و فعالیتها و غیره میشود. علاوه بر این، با توجه به اینکه برخی از شخصیتهای OBI دارای انواع غیراستاندارد زیادی هستند، تعداد زیادی از این موارد را انتخاب میکنیم. کاراکترها تا حد امکان برای اطمینان از اینکه مجموعه داده به واقعیت نزدیکتر است. این مجموعه داده OBI-100 نام دارد. پس از انجام این قسمت از مجموعه داده های اصلی، کامل و تنوع مجموعه داده را از طریق پیش پردازش، تقویت و عادی سازی افزایش می دهیم.
2.1.2. پیش پردازش مجموعه داده
برای بازیابی دقیقتر مشخصات نوشتاری OBI، نمونههای اصلی را همانطور که در شکل 3 نشان داده شده است، از قبل پردازش میکنیم .
-
حذف نویز: از آنجایی که نمونه های OBI از کتاب های الکترونیکی اسکن شده هستند، نویز گاوسی در تصاویر معرفی شده است. ما ابتدا روش غیر محلی (NLM) [ 18 ] را برای حذف نویز انتخاب کردیم. برای یک پیکسل در یک تصویر، این روش مناطق مشابه آن پیکسل را بر حسب بلوک های تصویر پیدا می کند و سپس مقادیر پیکسل را در این مناطق به طور میانگین می گیرد و مقدار اصلی این پیکسل را با مقدار متوسط جایگزین می کند [ 19 ] که می تواند به طور موثری حذف نویز گاوسی
-
باینریزه سازی: از آنجایی که تصاویر OBI مورد استفاده برای تشخیص فقط به مقادیر پیکسل سیاه و سفید نیاز دارند، نمونه های حذف شده را به نمونه های خاکستری تبدیل کرده و سپس آنها را بایناریزه می کنیم.
-
نرمال سازی اندازه: برای ثابت نگه داشتن اندازه همه تصاویر بدون از بین بردن قسمت های اطلاعات مفید آنها، اندازه تصویر را تغییر دادیم. . برای تصاویر غیرمربع اصلی، ابتدا قسمت خالی لبه را با پیکسل های سفید پر کردیم و سپس آنها را به اندازه مورد نیاز تغییر دادیم.
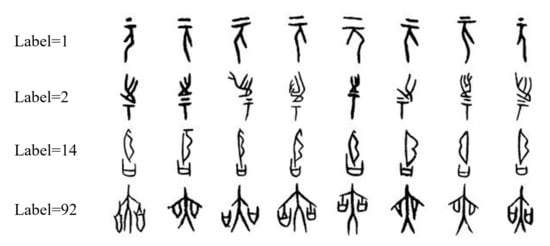
ما نمونه هایی از مجموعه داده های از پیش پردازش شده را در شکل 4 نشان می دهیم .
2.1.3. افزایش داده ها
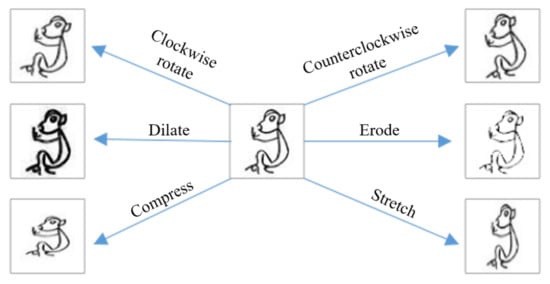
تعداد ناکافی نمونهها در مجموعه داده منجر به دقت تشخیص پایین میشود، بنابراین ما مجموعه داده را برای بهبود اثربخشی کار تشخیص گسترش میدهیم. با توجه به تصادفی بودن یک کاراکتر زمانی که چندین بار نوشته می شود، زاویه یا ضخامت نوشتن کاراکتر ممکن است تغییر کند. بنابراین، همانطور که در شکل 5 برای هر نمونه نشان داده شده است، چندین تبدیل برای تولید تصاویر جدید انجام می دهیم.
-
چرخش: با چرخاندن تصاویر اصلی در جهت عقربههای ساعت یا خلاف جهت عقربههای ساعت، تصاویر جدیدی ایجاد کنید. زاویه چرخش به طور تصادفی از 0 تا 15 درجه انتخاب می شود.
-
فشرده سازی/کشش: شکل کاراکترهای روی تصاویر را با کشش یا فشرده سازی، با استفاده از نسبت کشش 1 به 1.5 و نسبت فشرده سازی 0.67 به 1 تنظیم کنید. .
-
اتساع/فرسایش: گشاد یا فرسایش خطوط کاراکترهای OBI [ 20 ] برای تولید نمونه های جدید. با توجه به اندازه کوچک تصویر، خوردگی مستقیم باعث از بین رفتن بسیاری از ویژگی ها می شود. ابتدا تصویر را بزرگ کردیم، سپس عملیات خوردگی را اجرا کردیم و در نهایت اندازه تصویر را تغییر دادیم برای به دست آوردن بهترین اثر خوردگی
-
تبدیل ترکیبی: علاوه بر شش تبدیل فردی که در بالا توضیح داده شد، ما همچنین بیست ترکیب از تبدیل ها را برای نمونه ها اعمال می کنیم. یعنی تصویر چندین بار با انتخاب دو یا چند روش فوق تغییر شکل میدهد تا نمونههای جدید مربوطه تولید شود.
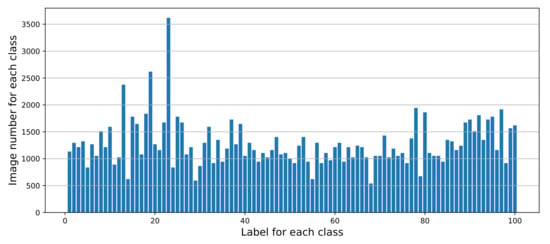
پس از عملیات تقویت، هر تصویر اصلی 26 تصویر تبدیل شده مربوطه را تولید می کند. تعداد کل نمونه ها با 27 برابر افزایش به 128196 ( ). کوچکترین کلاس شامل حدود 540 تصویر و بزرگترین دسته دارای بیش از 3600 تصویر است. این توزیع تعداد هر دسته را در مجموعه داده OBI در شکل 6 نشان می دهد.
2.2. آماده سازی مدل ها
2.2.1. پس زمینه CNN
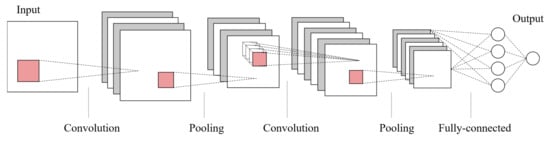
شبکه عصبی کانولوشنال (CNN) [ 21 ] یک شبکه عصبی پیشخور چند لایه است که می تواند ویژگی ها و ویژگی ها را از داده های ورودی استخراج کند. در حال حاضر CNN نقش مهمی در یادگیری عمیق ایفا می کند، زیرا می تواند نگاشت غیرخطی را از تعداد بسیار زیادی داده (تصاویر یا صداها) حتی در ورودی های پیچیده با ابعاد بالا یاد بگیرد. علاوه بر این، قابلیت یادگیری بازنمایی یک CNN را قادر میسازد تا اطلاعات ورودی را با توجه به ساختار سلسله مراتبی خود با طبقهبندی ثابت ترجمه طبقهبندی کند. به طور خاص، یک CNN آموزش دیده می تواند تصویر اصلی را در هر لایه از شبکه تغییر دهد تا یک امتیاز کلاسی مطابق با آن تصویر ورودی در انتهای شبکه ایجاد کند [ 22 ].
به طور کلی، همانطور که در شکل 7 نشان داده شده است ، ساختار اصلی CNN از یک لایه ورودی، چندین لایه کانولوشن، و لایه های ادغام، و همچنین چندین لایه کاملا متصل و یک لایه خروجی تشکیل شده است.
لایه کانولوشن برای استخراج ویژگی ها از داده های ورودی طراحی شده است که حاوی هسته های کانولوشنی زیادی است. هر عنصر از هسته مربوط به یک ضریب وزن و یک بردار بایاس است. پارامترهای لایه کانولوشن شامل اندازه هسته، اندازه گام و روش padding است [ 23 ]. این سه عامل به طور مشترک اندازه نقشه ویژگی خروجی لایه کانولوشن را تعیین می کنند [ 24 ]. با معرفی یک تابع فعال سازی، CNN می تواند به طور موثر مسائل غیرخطی مختلف را حل کند. تابع فعال سازی ویژگی های نورون فعال شده را حفظ کرده و به لایه بعدی نگاشت می کند. به طور معمول، CNN ها از تابع یکسو کننده خطی (واحد خطی اصلاح شده، ReLU) استفاده می کنند [ 25] به عنوان تابع فعال سازی برای کمک به بیان ویژگی های پیچیده، که می تواند به صورت فرموله شود . پس از استخراج ویژگی [ 26 ] توسط لایه کانولوشن، نقشه ویژگی خروجی برای انتخاب ویژگی و فیلتر اطلاعات به لایه ادغام منتقل می شود. لایه pooling در واقع تابع نمونه برداری را پیاده سازی می کند و ایده اصلی آن استخراج ویژگی ها با گرایش خاصی است. به عنوان مثال، حداکثر ادغام مربوط به ویژگی های برجسته تر است، در حالی که ادغام متوسط مربوط به ویژگی های صاف تر است. لایه کاملا متصل ویژگی های استخراج شده را به صورت خطی ترکیب می کند تا خروجی را به دست آورد. لایه خروجی از یک تابع لجستیک یا یک تابع نمایی نرمال شده برای خروجی برچسب طبقه بندی یا احتمال استفاده می کند. معمولاً از تابع softmax [ 27 ] برای محاسبه امتیازات کلاس به صورت زیر استفاده می شود:
در انتخاب ساختار شبکه، چندین مدل اصلی را بر روی مجموعه داده OBI-100 آموزش دادیم، از جمله LeNet، AlexNet، VGGNet، ResNet-50، و Inception. با این حال، پس از آزمایش های اولیه، مشخص شد که نتایج ResNet-50 و Inception رضایت بخش نیستند (نرخ دقت آنها هر دو کمتر از 70٪ است). بنابراین، ما سه چارچوب شبکه با عملکرد قویتر و بازده آموزشی بالاتر را انتخاب کردیم: LeNet، AlexNet و VGGNet. بر اساس این سه مدل، ساختار شبکه را تنظیم کردیم، پارامترها را اصلاح کردیم و از روشهای بهینهسازی مختلف برای یافتن مدلهایی با عملکرد بهتر استفاده کردیم. پس از آزمایش صدها ترکیب، ده مدل را انتخاب کردیم که عملکرد خوبی داشتند. جدول 1 پیکربندی این ده مدل بهبود یافته را خلاصه می کند.
2.2.2. مدل های بهبود یافته LeNet
LeNet [ 28] یکی از معرف ترین مدل ها برای تشخیص ارقام دست نویس است. این شامل دو بخش است: (1) یک رمزگذار کانولوشن متشکل از دو لایه کانولوشن و دو لایه ادغام. (ii) یک بلوک متراکم متشکل از سه لایه کاملاً متصل. برای وظایف طبقه بندی OBI، ما دو مدل بهبود یافته بر اساس LeNet به نام های L1 و L2 را پیشنهاد می کنیم. برای دو مدل، ساختار هفت لایه اصلی را به یک ساختار شش لایه تنظیم کردیم و عمق لایه کانولوشن و اندازه فیلتر را تنظیم کردیم. به طور خاص، ابعاد خروجی لایههای کانولوشن و لایههای کاملاً متصل مدل L1 اساساً مشابه مدل اصلی LeNet است، اما لایه کاملاً متصل با عمق 120 مستقیماً به آخرین لایه کاملاً متصل با عمق 100 متصل است. در مدل L2، ما از یک هسته پیچشی با ابعاد بالاتر استفاده کردیم. هسته کانولوشن، و لایه کانولوشن دوم از یک 64 بعدی استفاده می کند هسته پیچیدگی به علاوه در هر دو مدل از روش max pooling استفاده شده است. پارامترهای padding لایه های کانولوشن L1 را روی مقدار VALID قرار می دهیم ، به این معنی که اندازه نقشه ویژگی خروجی پس از کانولوشن تغییر می کند. با این حال، پارامترهای مربوط به مدل L2 روی SAME تنظیم شده است، به این معنی که اندازه تصویر پس از پیچیدگی بدون تغییر باقی میماند. از طریق این استراتژی های تنظیم، مدل L1 16 نقشه ویژگی را با اندازه ورودی وارد می کند به لایه کاملا متصل، و L2 ورودی 64 نقشه با اندازه .
2.2.3. مدل های بهبود یافته الکس نت
AlexNet [ 25 ] مدل برنده در رقابت ImageNet در سال 2012 است که از پنج لایه کانولوشن، سه لایه max-pooling، دو لایه نرمال سازی دسته ای، دو لایه کاملا متصل و یک لایه softmax تشکیل شده است. برای AlexNet، ما سه شبکه بهینهسازی شده برای طبقهبندی کاراکترهای OBI به نامهای A1، A2 و A3 پیشنهاد میکنیم. این سه مدل دارای تعداد لایه های کانولوشن و لایه های تلفیقی متفاوتی هستند و چهار لایه کانولوشن اول دقیقاً ساختار مشابهی دارند. به طور خاص، مدل A2 دارای سه لایه کانولوشنال با 256 بعدی است. هسته های کانولوشن و یک لایه ترکیبی نسبت به مدل A1. در مقایسه با مدل A2، مدل A3 نه تنها عمق شبکه را بهبود می بخشد، بلکه از هسته های پیچشی با ابعاد بالاتر نیز استفاده می کند. علاوه بر این، ما از حداکثر استراتژی ادغام برای همه شبکه ها استفاده می کنیم. حداکثر لایه های ادغام در مدل A1 استفاده می شود هسته ها، در حالی که در مدل های A2 و A3 استفاده می کنند هسته ها در A1 و A3، لایه Pooling بین آخرین لایه کانولوشن و قسمت کاملاً متصل اضافه می شود، در حالی که آخرین لایه کانولوشن مدل A2 مستقیماً به اولین لایه کاملاً متصل متصل می شود.
2.2.4. مدل های بهبود یافته VGGNet
مانند AlexNet و LeNet، VGGNet [ 29 ] را می توان به دو بخش تقسیم کرد: اولی که عمدتاً از لایه های کانولوشنال و ادغامی تشکیل شده است و دومی شامل لایه های کاملاً متصل است. بخش کانولوشنال شبکه چندین بلوک VGG را به صورت متوالی به هم متصل می کند و یک بلوک VGG متشکل از دنباله ای از لایه های کانولوشن است و به دنبال آن یک لایه ادغام حداکثر برای نمونه برداری فضایی. آخرین شبکه از سه لایه کاملاً متصل و یک لایه softmax تشکیل شده است. با انباشتن مکرر کوچک کرنل ها و حداکثر لایه های ادغام، VGGNet قابلیت های قابل توجهی را در استخراج ویژگی نشان می دهد.
طبق چارچوب VGGNet، ما پنج CNN بهبودیافته برای تشخیص کاراکتر OBI، از جمله V11، V13، V16، V16-2، و V19 میسازیم. ساختار کلی این مدل ها از مدل های لایه های مختلف در چارچوب VGGNet اقتباس شده است که عمدتاً با افزودن یا حذف لایه ها در بلوک های VGG، تنظیم عمق هسته کانولوشن و تنظیم عمق لایه های کاملاً متصل به دست می آید. به عنوان مثال، در مقایسه با ساختار معمولی 11 لایه در VGGNet، یک لایه کانولوشن به هر یک از بلوک های VGG اول و دوم در V11 اضافه می شود، در حالی که بلوک چهارم VGG حاوی دو لایه کانولوشن در ساختار 11 لایه معمولی حذف می شود. V11.
2.3. مواد و روش ها
روش آزمایشی تشخیص در این بخش بر اساس مدل های CNN پیشنهاد شده در بخش 2.2 و مجموعه داده OBI-100 ارائه شده در بخش 2.1 طراحی شده است.. در آزمایشهای ما، دقت تشخیص روی مجموعه داده OBI یکی از مهمترین شاخصها برای ارزیابی عملکرد این مدلها است. بنابراین، هدف ما آموزش مدل های شبکه دقیق است. اثر آموزش به عواملی مانند ساختار مدل آموزشدیده، مجموعه دادههای شرکتکننده در آموزش، تنظیمات فراپارامتر و روش بهینهسازی مورد استفاده مرتبط است. بنابراین، رویکردهای تقسیم مجموعه داده، استراتژیهای تنظیم پارامتر و روشهای بهینهسازی مورد استفاده برای آزمایشها را در بخشهای زیر معرفی میکنیم. مدل های ارائه شده در این مقاله با استفاده از TensorFlow و فرآیند پیش پردازش تصویر با استفاده از OpenCV پیاده سازی شده است.
2.3.1. بخش مجموعه داده
کل OBI-100 به یک مجموعه آموزشی، یک مجموعه اعتبار سنجی و یک مجموعه تست با نسبت تقریباً 8:1:1 تقسیم می شود. مجموعه آموزشی برای تناسب مدل برای پیشبینی یا طبقهبندی استفاده میشود. دادههای مجموعه اعتبارسنجی به جستجوی ترکیبهای فراپارامتر بهینه کمک میکند، در حالی که مجموعه آزمون برای ارزیابی عملکرد تعمیم مدل انتخابشده استفاده میشود. برای اینکه هر دسته از کاراکترهای OBI به طور یکنواخت در هر یک از زیرمجموعه های داده فوق گنجانده شوند، از فرآیند تقسیم زیر استفاده می کنیم: ابتدا، نمونه های کل مجموعه داده OBI-100 از پیش پردازش شده را 50 بار قبل از تقسیم آنها به زیر مجموعه های مختلف با هم مخلوط می کنیم. . در مرحله دوم، 90٪ از تصاویر مجموعه نمونه به طور تصادفی انتخاب شده و در پوشه “قطار” قرار می گیرند، در حالی که تصاویر ” بقیه” در پوشه “تست” قرار می گیرند. ما نتایج تقسیم را بررسی می کنیم تا مطمئن شویم که هر یک از 100 کلاس در زیر مجموعه های فوق گنجانده شده است. ثالثاً، روش های تقویت داده ارائه شده دربخش 2.1.3 برای گسترش تعداد نمونه ها در هر پوشه انجام می شود. چهارم اینکه 10 درصد از نمونه های پوشه «قطار» به صورت تصادفی به عنوان مجموعه اعتبار سنجی انتخاب می شوند و بقیه به عنوان مجموعه آموزشی نهایی استفاده می شوند. در نهایت، تمام فایل های نمونه داده به عنوان فایل “H5” ذخیره می شوند تا در طول آموزش بارگذاری شوند.
2.3.2. تنظیم پارامتر
تنظیم پارامتر عمدتاً شامل دو جنبه است، یکی استراتژی مقداردهی اولیه وزن شبکه، و دیگری طرح پیکربندی هایپرپارامتر برای آموزش مدل. انتخاب یک پیکربندی اولیه مناسب تأثیر بسیار مهمی بر کل فرآیند آموزش دارد. به عنوان مثال، هایپرپارامترهای معقول می توانند از ورود پیش از موعد شبکه به لایه خاصی از اشباع جلو (یا عقب) جلوگیری کنند. روش های مقدار دهی اولیه وزن معمولاً شامل مقداردهی اولیه صفر، مقداردهی اولیه تصادفی و مقداردهی اولیه He [ 30 ] است]. پس از آزمایشهای زیاد، ما بهطور تجربی از He Initialization استفاده میکنیم و بایاس اولیه را روی 0.1 قرار میدهیم. از نظر فراپارامترهای آموزشی، دوره آموزشی تمامی شبکه های ما روی 100 تنظیم شده است و برای آموزش مدل از روش پلکانی گسسته استفاده می شود که نرخ یادگیری در ابتدا روی 0.1 تنظیم شده و هر 20 دوره به نصف کاهش می یابد. علاوه بر این، اندازه دسته ای مجموعه داده آموزشی را به مقدار (32، 64، 96، 128، 160، 196، 224، 256) تنظیم کردیم. ما از ترکیب پارامترهای مختلف برای انجام آزمایشها استفاده کردیم و فرآیند آموزش و اثرات این مدلها را مشاهده کردیم و سپس طرحهای پیکربندی پارامتر بهینه را انتخاب کردیم.
2.3.3. روش های بهینه سازی
علاوه بر تنظیم مجموعه ای از پارامترهای آموزشی مناسب، به منظور بهبود بیشتر اثر آموزشی شبکه، برخی از روش های بهینه سازی را نیز اعمال کردیم.
-
نرمال سازی دسته ای [ 31 ]: نرمال سازی دسته ای، ورودی هر دسته کوچک را به یک لایه عادی می کند، که تأثیر تثبیت فرآیند یادگیری دارد و می تواند زمان آموزش مورد نیاز برای آموزش شبکه های عمیق را به میزان قابل توجهی کاهش دهد. در آزمایش ما، هنگام استفاده از این روش بهینهسازی، لایه نرمالسازی دستهای قبل از هر تابع فعالسازی اضافه میشود تا توزیع دادهها به توزیع نرمال شده بازگردد، به طوری که مقدار ورودی تابع فعالسازی در ناحیهای قرار میگیرد که تابع فعالسازی است. نسبت به ورودی حساس تر است.
-
ترک تحصیل [ 32]: با حذف تصادفی گرههای شبکه در طول فرآیند آموزش، یک مدل واحد میتواند تعداد زیادی معماری مختلف را شبیهسازی کند که به آن روش حذف میگویند. این یک هزینه محاسباتی بسیار کم و یک رویکرد منظم سازی بسیار موثر برای کاهش بیش از حد برازش شبکه های عصبی عمیق و بهبود عملکرد تعمیم ارائه می دهد. وقتی از این روش در آزمایشهای ما استفاده میشود، به هر لایه کاملاً متصل یک لایه حذفی اضافه میکنیم که با غیرفعال کردن برخی از نورونها با مقدار احتمال مشخص (صفر کردن خروجی نورونها) وابستگی متقابل بین گرههای عصبی در شبکه را کاهش میدهد. در آزمایش خود، مدل ها را با تنظیم مشترک مقدار احتمال لایه حذف و مقدار اندازه دسته ای آموزش می دهیم. ابتدا سعی می کنیم مقدار احتمال لایه های حذفی را روی مقدار (0.1، 0.2، 0.3، 0) قرار دهیم. 4، 0.5، 0.6، 0.7، 0.8، 0.9، 1). دوم، از طریق آزمایشهای متعدد، بهترین ترکیبی از مقادیر انصرافی و اندازه دستهای را انتخاب میکنیم.
-
Shuffle: برای حذف تأثیر احتمالی ترتیبی که دادههای آموزشی به شبکه وارد میشوند و بیشتر تصادفی بودن نمونههای دادههای آموزشی را افزایش میدهیم، روش مخلوط را در آزمایشهای ارزیابی مدل معرفی میکنیم. به طور خاص، زمانی که این روش اعمال میشود، ما تمام نمونههای آموزشی را در هر دوره آموزشی جدید به هم میزنیم، و سپس هر دسته دادههای مختلط شده را وارد شبکه میکنیم.
3. نتایج
برای یافتن مدلهایی با عملکرد پایدار و دقت تشخیص کاراکتر OBI بالا در بین ده مدل پیشنهادی CNN، ما سه نوع آزمایش زیر را انجام دادیم و هر مجموعه از نتایج تجربی را مشاهده کردیم.
-
ما با افزایش تعداد دورههای آموزشی، تغییرات در مقدار از دست دادن تمرین، نرخهای دقت در مجموعه آموزشی و مجموعه اعتبارسنجی مدلهای مختلف را در طول فرآیند آموزش مشاهده کردیم. علاوه بر این، با مقایسه دقت آموزش و صحت اعتبارسنجی، میتوان اثر یادگیری کلی مدلهای مربوط به هر دوره را استنباط کرد. این موارد در بخش 3.1 مورد بحث قرار گرفته است.
-
برای مدلهای مختلف، تأثیر ترکیبهای چندگانه مقدار اندازه دستهای و مقدار احتمال خروج را بر دقت تشخیص مجموعه اعتبارسنجی آزمایش میکنیم. در مقایسه، ترکیب بهینه این دو پارامتر به عنوان استراتژی تنظیم برای آزمایش عملکرد نهایی مدل مربوطه انتخاب میشود. نتایج به طور عمده در بخش 3.2 تجزیه و تحلیل شده است.
-
از سه جنبه افزایش داده، تنظیم ساختار مدل، و اجرای بهینهسازی، ما اثرات روشهای مختلف بهبود را بر یادگیری مدل و تشخیص OBI ارزیابی میکنیم. نتایج و بحث ها در بخش 3.3 ارائه شده است.
3.1. مشاهده فرآیند آموزش
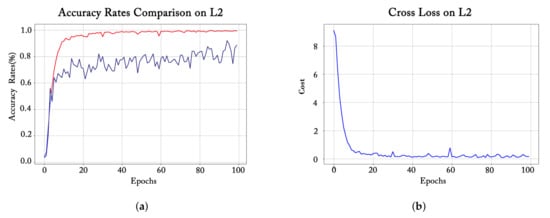
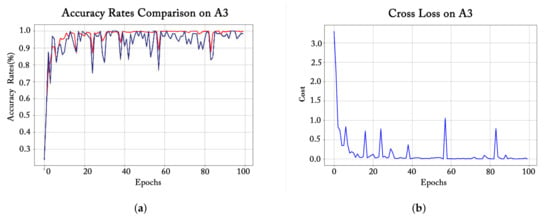
همانطور که در شکل 8 ، شکل 9 و شکل 10 نشان داده شده است، برای سه گروه از مدل های بهبود یافته مربوط به سه چارچوب اصلی CNN، از هر گروه یکی را برای مشاهده فرآیند آموزشی مربوطه انتخاب کردیم . برای هر نمودار سمت چپ، خط آبی نشان دهنده دقت اعتبارسنجی (دقت تشخیص در مجموعه اعتبارسنجی)، و خط قرمز به دقت آموزش (دقت تشخیص در مجموعه آموزشی) اشاره دارد. هر شکل در سمت راست رابطه بین از دست دادن تمرین و دوره های آموزشی را نشان می دهد.
روند آموزش مدل L2 (یکی از مدل های بهبود یافته LeNet) در نشان داده شده است شکل 8 نشان داده شده است. میتوانیم ببینیم که در 10 دوره اول آموزش، ارزش از دست دادن تمرین به شدت کاهش مییابد و دقت تمرین بهطور چشمگیری افزایش مییابد، که نشان میدهد این مدل به طور موثر یاد میگیرد. از دوره 10 تا 40، افت تمرین همچنان روند نزولی را نشان می دهد تا زمانی که پس از 40 دوره تثبیت شود، که با تغییر دقت تمرین نیز مطابقت دارد. با این حال، اگرچه میزان دقت اعتبارسنجی نیز در حال افزایش است، اما هنگام نزدیک شدن به 100 دوره، میزان دقت مجموعه آموزشی نزدیک به 1 است، در حالی که میزان دقت در مجموعه اعتبارسنجی کمتر از 90٪ است و همچنان به نوسان ادامه می دهد، که نشان می دهد فقط آموزش برای 100 دوره نمی تواند مدل L2 را به طور کامل همگرا کند.
برای مدل A3 (یکی از مدلهای بهبود یافته AlexNet) در شکل 9 ، نرخهای دقت در مجموعه آموزشی و مجموعه اعتبارسنجی اساساً یک روند ثابت را حفظ میکنند. به طور خاص، در ده دوره اول آموزش، هر دو منحنی به سرعت بالا می روند. پس از 10 دوره، دقت تمرین به تدریج به 100٪ تمایل پیدا می کند و صاف می شود، در حالی که منحنی صحت اعتبارسنجی همچنان دارای نوسانات زیادی است. این نشان می دهد که یادگیری مدل A3 علیرغم دقت بالای تشخیص در 100 دوره به اندازه کافی پایدار نیست.
روند آموزش مدل V16 (یکی از مدل های بهبود یافته VGGNet) در شکل 10 نشان داده شده است . از این دو نمودار، به وضوح می توان مشاهده کرد که در مدل V16، هر دو میزان دقت آموزش و اعتبارسنجی با نوسانات بسیار شدید در 40 دوره اول افزایش می یابد و این نوسانات در منحنی از دست دادن تمرین نیز رخ می دهد. با این حال، پس از دوره 40، منحنیهای دقت آموزش و اعتبارسنجی حدود 100٪ هموار میشوند و دقت آموزش کمی بالاتر از دقت اعتبارسنجی است. از این نتیجه میگیریم که مدل V16 فقط به 40 دوره برای همگرایی نیاز دارد و عملکرد تشخیص خوبی دارد.
3.2. ارزیابی اثر پارامتر
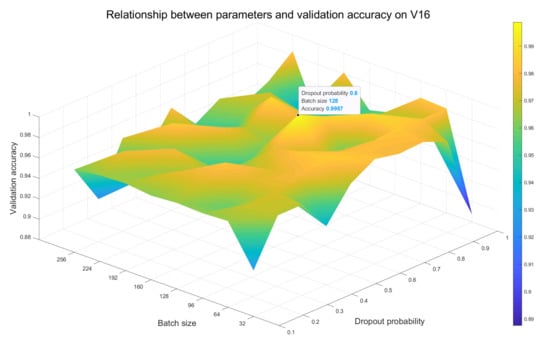
ما سایر پارامترهای شبکه را بدون تغییر نگه می داریم و مقادیر اندازه دسته و احتمال انصراف را به صورت تداعی تنظیم می کنیم تا دقت تشخیص را در مجموعه اعتبارسنجی مدل مشاهده کنیم، جایی که مقدار اندازه دسته از آن گرفته شده است (32، 64، 96، 128). ، 160، 192، 224، 256) و احتمال ترک تحصیل از (0.1، 0.2، 0.3، 0.4، 0.5، 0.6، 0.7، 0.8، 0.9، 1) گرفته شده است. نمودارهای سطحی رابطه بین اندازه دسته، احتمال حذف و میزان دقت اعتبارسنجی در مدل های L2، A3 و V16 به ترتیب در شکل 11 ، شکل 12 و شکل 13 به دست آمده است. برای علامت گذاری نقطه ای با بیشترین دقت در هر سطح از یک نقطه سیاه استفاده می کنیم و مختصات x و y مربوطه را در کنار آن نقطه مشخص می کنیم.
با توجه به تغییر رنگ نمودارهای سطحی، می توان استنباط کرد که هر چه تغییرات سیستم رنگ شدیدتر باشد، تأثیر انتخاب های مختلف مقادیر اندازه دسته و احتمال افت بر روی مدل ها بیشتر است. از شکل 11 می بینیم که نواحی آبی و زرد آشکاری وجود دارد که نشان می دهد دقت مدل L2 بیشتر تحت تأثیر این دو پارامتر قرار می گیرد و به دنبال آن مدل A3 در شکل 12 قرار دارد. سیستم رنگی نقشه سطح در شکل 13مربوط به مدل V16 به آرامی تغییر می کند، بنابراین حداقل تحت تأثیر دو پارامتر قرار می گیرد. علاوه بر این، بالاترین نقطه ترکیب بهینه اندازه دسته و مقادیر احتمال انصراف را نشان می دهد. برای مدل های L2 و A3، تنظیم اندازه دسته و مقادیر احتمال انصراف روی 64 و 0.5 انتخاب بهینه است، در حالی که برای مدل V16 باید به ترتیب روی 128 و 0.6 تنظیم شود.
3.3. بررسی اجمالی عملکرد مدل
از نتایج تجربی بالا، بهترین ترکیب اندازه دسته و مقادیر احتمال انصراف مورد استفاده برای آموزش هر مدل را بدست می آوریم. در آزمایش بعدی، از روشهای بهینهسازی ذکر شده در بخش 2.3.3 و پیکربندیهای ترکیبی فراپارامتر بهینه برای آموزش مدلهای کلاسیک و بهبود یافته پیشنهادی استفاده میکنیم. علاوه بر این، برای ارزیابی اثر افزایش دادهها برای مجموعه داده OBI-100، این مدلها نیز بر روی مجموعه دادههای غیرافزودهشده آموزش و آزمایش میشوند. یک نمای کلی از نتایج نهایی در جدول 2 ، جدول 3 و جدول 4 نشان داده شده است .
از جدول 2 ، جدول 3 و جدول 4از یک طرف، ما به سادگی می توانیم مشاهده کنیم که استراتژی افزایش داده ها به طور کلی می تواند دقت تشخیص مدل ها را افزایش دهد. به عنوان مثال، مدل L1 آموزشدیده بر روی مجموعه آموزشی غیرافزوده شده، حداکثر دقت 78.77 درصد را برای کار طبقهبندی سادهتر مجموعه آزمایشی تقویتنشده دریافت میکند، در حالی که مدل L1 آموختهشده در OBI-100 تقویتشده، دقت 95.35 درصد را در مقابل نمونههای بیشتر به دست میآورد. کار دشوار تشخیص نمونه تقویت شده از سوی دیگر، متوجه میشویم که در مقایسه با مدلهای اصلی سه چارچوب کلاسیک، شبکههای بهبودیافته عملکرد تشخیص بهتری را در مجموعه دادههای OBI تقویتشده نشان میدهند. به طور خاص، هنگام ادغام سه روش بهینهسازی، مدلهای L1 و L2 به ترتیب 13.02% و 11.47% عملکرد تشخیص بالاتری نسبت به LeNet اصلی دارند، در حالی که A1، A2، و مدل های A3 به ترتیب 5.09٪، 5.39٪ و 6.82٪ بهبود در دقت تشخیص نسبت به AlexNet اصلی دارند. علاوه بر این، خط پایه عملکرد مدلهای اصلی مبتنی بر VGGNet نسبتاً بالا است، اما مدل بهبودیافته همچنان منجر به افزایش عملکرد میشود. به عنوان مثال، دقت مدل بهینه V16 99.50٪ است در حالی که مدل اصلی VGG16 تنها به 97.75٪ می رسد.
علاوه بر این، افزودن روشهای بهینهسازی مناسب کمک زیادی به دقت تشخیص مدلها میکند. برای مثال، برای مدل V11 آموزشدیدهشده بر روی OBI-100 تقویتشده، حداکثر دقت تست تنها با استفاده از نرمالسازی دستهای به 91.20 درصد میرسد، و دقت پس از استفاده از بهینهسازی تصادفی به 91.80 درصد افزایش مییابد، و پس از آن به 94.66 درصد بهبود مییابد. استفاده از روش ترک تحصیل بهبود دقت مشابه را می توان به وضوح در نتایج تجربی هر مدل پیشنهادی مشاهده کرد.
برای هر گروه از مدل های پیشرفته، مشاهدات زیر را نیز انجام می دهیم. اولاً، مدل L1 مبتنی بر LeNet به طور قابل توجهی بهتر از مدل L2 است. از یک طرف بهترین حداکثر دقت تست مدل L1 بیشتر از مدل L2 است و از طرف دیگر فاصله بین حداکثر سرعت تست و میانگین سرعت تست مدل L1 مقدار کمتری از 0.5% که نشان می دهد اثر تمرینی مدل L1 پایدارتر است.
ثالثاً، از جدول 4 ، می توان دریافت که افزایش تعداد لایه های شبکه تأثیر مفیدی بر عملکرد شناسایی مدل های مبتنی بر VGGNet دارد. به طور خاص، V11، V13، و V16 با ساختارهای لایهای کاملاً متصل به ترتیب، بهترین نرخهای دقت 94.66، 95.85 درصد و 99.50 درصد را به صورت افزایشی دریافت میکنند. علاوه بر این، برای V16 و V16-2 با ساختارهای شبکه یکسانی از لایههای کانولوشنال و ادغام، مدل V16 با لایههای عمیقتر کاملاً متصل نسبت به مدل V16-2 3.9 درصد بهتر است. همچنین مشاهده میکنیم که حداکثر دقت در مدل V16 با دقت متوسط یکسان است، که نشان میدهد مدل V16 یادگیری ویژگی مؤثرتری را در مجموعه داده OBI-100 انجام میدهد.
در نهایت، از جدول 2 ، جدول 3 و جدول 4 ، به دست می آید که مدل V16 مبتنی بر VGGNet، برای یکی، بالاترین دقت 99.5٪ را در مجموعه داده OBI-100 به دست می آورد، برای دیگری، مقادیر دقت حداکثر و متوسط این مدل یکسان است، بنابراین بهترین مدل برای شناسایی مجموعه داده OBI-100 در آزمایشات ما است.
4. نتیجه گیری
در این کار از شبکه های عصبی کانولوشنال عمیق برای شناسایی شخصیت های اوراکل استفاده شده است. ما یک مجموعه داده استاندارد به نام OBI-100 ایجاد کردیم که شامل 100 کلاس از کاراکترهای OBI است. OBI-100 می تواند شکاف مجموعه داده های در دسترس عموم را در کاربردهای یادگیری عمیق در تحقیقات OBI پر کند. بر اساس سه چارچوب شبکه کانولوشنال معمولی، ده مدل بهبود یافته برای طبقه بندی شخصیت های OBI پیشنهاد شده است. از طریق تعداد زیادی آزمایش و انواع روشهای بهینهسازی، بهترین مدل به دقت 99.5 درصد در کار تشخیص OBI 100 کلاسه دست مییابد. کار ما نشان میدهد که کاراکترهای OBI را میتوان به طور عملی و مؤثر در شبکههای عصبی کانولوشنال عمیق شناسایی کرد و برنامههای کاربردی در این زمینه دارای چشمانداز تحقیقاتی گستردهای هستند.









بدون دیدگاه