

کلید واژه ها:
پیش بینی مسیر ; ترانسفورماتور ; پرس و جو انحراف تصادفی
1. مقدمه
-
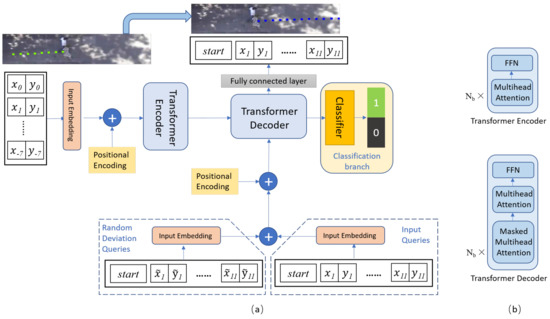
اول، ما یک چارچوب آموزشپذیر موثر و سرتاسری را پیشنهاد میکنیم که بر اساس چارچوب ترانسفورماتور ساخته شده است که با یک جستجوی انحراف تصادفی برای پیشبینی مسیر تعبیه شده است. با بهره گیری از توانایی خود تصحیح معرفی شده توسط پرس و جو انحراف تصادفی، استحکام شبکه ترانسفورماتور موجود افزایش می یابد. برای جزئیات، ما یک ماسک توجه برای حل مشکلات تخصیص بین پرسوجوهای ورودی موازی و پیشبینی متوالی طراحی میکنیم.
-
دوم، ما یک استراتژی همآموزشی مبتنی بر شاخه طبقهبندی برای بهبود اثر آموزشی ارائه میکنیم. کل طرح به طور مشترک توسط ضرر اصلی و فقدان طبقه بندی آموزش داده می شود که می تواند دقت نتایج را بهبود بخشد. نتایج تجربی در مقایسه با روشهای پیشرفته نشان میدهد که روش پیشنهادی میتواند مسیر قابل قبولی را با دقت بالاتر پیشبینی کند.
2. کارهای مرتبط
3. مواد و روشها
3.1. فرمول مسأله
رمزگذاری موقعیتی: شبکه ترانسفورماتور ماهیت متوالی داده های سری زمانی مورد استفاده در مدل مبتنی بر LSTM را کنار می گذارد، اما وابستگی های زمانی را با مکانیزم توجه به خود مدل می کند. بنابراین، ورودی داده های تعبیه شده است شامل تعبیه مسیر فضایی است و جاسازی موقعیت زمانی . با پیروی از تنظیمات مشابه در [ 18 ]، جاسازی موقعیت با توابع سینوس و کسینوس تعریف می شود. هر بعد از رمزگذاری موقعیتی بر اساس یک سینوسی با فرکانس های مختلف از نظر زمانی متفاوت است تا 10000 · ، که یک مهر زمانی منحصر به فرد را برای خطا تضمین می کند.
3.2. ترانسفورماتور رمزگذار-رمزگشا
ترانسفورماتور مکانیزمی است که در آن یک مدل یاد می گیرد با تمرکز انتخابی بر روی داده های داده شده، پیش بینی کند. در حالی که توجه به خود مکانیزم توجهی است که در آن مدل از بخش مشاهده شده نمونه استفاده می کند و بقیه را پیش بینی می کند. ورودی های یک ماژول توجه شامل Q (ورودی های جاسازی پرس و جو)، K (ورودی های جاسازی کلید) و V (ورودی های جاسازی ارزش) است. بنابراین، خروجی مجموع وزنی بردارهای مقدار است، که در آن وزن تخصیص داده شده به هر V توسط حاصلضرب نقطه مقیاس شده Q و K مربوطه تعیین می شود.
توجه چند سر جزء اصلی ترانسفورماتور است. برخلاف توجه ساده، مکانیسم چند سر ورودی را به بخشهای کوچک زیادی تقسیم میکند، حاصل ضرب نقطهای مقیاسشده هر زیرفضا را به صورت موازی محاسبه میکند و در نهایت تمام خروجی توجه را به هم متصل میکند.
جایی که ماتریس های وزن در پرس و جوها، کلیدها، مقادیر و خروجی هستند. همه این وزنه ها قابل تمرین هستند.
در هر زیر لایه، توجه چند سر دارای یک شبکه پیشخور (FFN) است. ترتیب در FFN یک تبدیل خطی [ 18 ]، فعال سازی Relu [ 39 ] و یک تبدیل خطی دیگر است. ترک تحصیل برای کاهش بیش از حد تناسب، سرعت بخشیدن به تمرین و افزایش عملکرد استفاده می شود.
علاوه بر این، ما یک ماسک توجه برای جلوگیری از حضور پوزیشن ها به موقعیت های بعدی طراحی می کنیم. این پوشش تضمین می کند که پیش بینی موقعیت i می تواند فقط به خروجی های شناخته شده در موقعیت های قبل از i بستگی داشته باشد . ماتریس ماسک به لایه softmax توجه به خود در رمزگشا اضافه می شود، به عنوان مثال، .
جایی که تعیین می کند که آیا پرس و جو قبل از پرس و جو است . پرس و جوهای بعد از مهر زمان فعلی ماسک می شوند تا پیش بینی فقط بر اساس داده های فعلی و قبلی باشد.
3.3. پرس و جو انحراف تصادفی
3.4. هدف نهایی
ضرر نهایی برای شبکه به صورت زیر تعریف می شود:
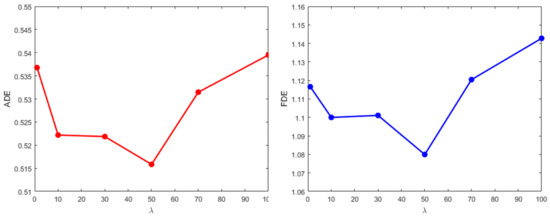
جایی که تعادل بین دو هدف را حفظ می کند. برای آموزش 50 تنظیم شده است.
4. نتایج
4.1. تنظیم آزمایش
-
مجموعه داده ها؛ به دنبال تحقیقات قبلی مرتبط، روش پیشنهادی را روی دو مجموعه داده عمومی ارزیابی میکنیم: ETH [ 40 ] و UCY [ 41 ]. این مجموعه داده ها شامل 5 دنباله ویدیویی (Hotel، ETH، UCY، ZARA1 و ZARA2) است که در مجموع از 1536 عابر پیاده با الگوهای حرکتی و تعاملات اجتماعی مختلف تشکیل شده است. مردم به صورت موازی راه می روند، به صورت گروهی حرکت می کنند، در گوشه ای می چرخند، هنگام راه رفتن رودررو از برخورد اجتناب می کنند. اینها سناریوهای رایجی هستند که شامل رفتارهای اجتماعی می شوند. این سکانس ها در 25 فریم در ثانیه (fps) ضبط می شوند و شامل 4 پس زمینه صحنه مختلف می باشند.
-
معیارهای؛ میانگین خطای جابجایی (ADE)، میانگین مربعات خطای کلی نقاط برآورد شده در مسیر پیش بینی شده و مسیر حقیقت زمین. خطای جابجایی نهایی (FDE)، فاصله بین مقصد نهایی پیشبینیشده و مقصد نهایی حقیقت زمین. آنها را می توان از نظر ریاضی به صورت زیر تعریف کرد:
4.2. آزمایش بر روی ETH و UCY Dataset
4.3. مطالعه ابلیشن
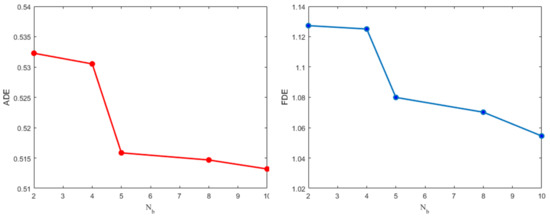
4.3.1. تأثیر بر تعداد مختلف بلوک رمزگذار-رمزگشا
4.3.2. تأثیر بر پارامترهای کلیدی مختلف
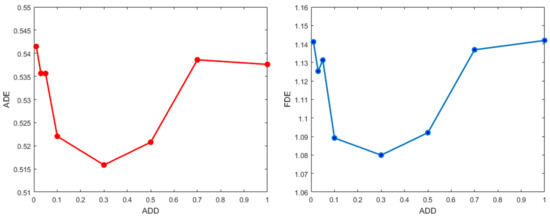
4.3.3. تأثیر بر فاصله تفکیک دقت مختلف
5. نتیجه گیری ها
منابع
- الهی، ع. گوئل، ک. راماناتان، وی. Robicquet، A. لی، اف. Savarese، S. Social LSTM: پیش بینی مسیر انسان در فضاهای شلوغ. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. [ Google Scholar ]
- ژانگ، پی. اویانگ، دبلیو. ژانگ، پی. ژو، جی. ژنگ، N. SR-LSTM: اصلاح وضعیت برای LSTM به سمت پیشبینی مسیر عابر پیاده. در مجموعه مقالات کنفرانس IEEE/CVF 2019 در مورد دید رایانه و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019. [ Google Scholar ]
- بیسانو، ن. ژانگ، بی. Conci، N. گروه LSTM: پیشبینی مسیر گروهی در سناریوهای شلوغ . Springer: Cham، سوئیس، 2018. [ Google Scholar ]
- هوین، م. علاقبند، جی. پیش بینی مسیر با جفت کردن صحنه-LSTM با حرکت انسانی LSTM. در مجموعه مقالات سمپوزیوم بین المللی در محاسبات بصری، دریاچه تاهو، NV، ایالات متحده، 7 تا 9 اکتبر 2019. [ Google Scholar ]
- منه، اچ. علاقبند، جی. صحنه-LSTM: مدلی برای پیش بینی مسیر انسان. arXiv 2018 , arXiv:1808.04018. [ Google Scholar ]
- چاندرا، آر. گوان، تی. پانوگانتی، اس. میتال، تی. باتاچاریا، U. برا، ا. Manocha، D. پیش بینی مسیر و رفتار عوامل جاده با استفاده از خوشه بندی طیفی در نمودار-LSTMs. arXiv 2019 ، arXiv:1912.01118. [ Google Scholar ] [ CrossRef ]
- تائو، سی. جیانگ، کیو. دوان، ال. Luo، P. LSTM آگاه از زمینه پویا و استاتیک برای پیشبینی حرکت چند عاملی. در مجموعه مقالات کنفرانس اروپا در زمینه بینایی رایانه، گلاسکو، انگلستان، 23 تا 28 اوت 2020. [ Google Scholar ]
- چنگ، کیو. وانگ، سی. روشی برای پیشبینی مسیر بر اساس الگوریتم فیلتر کالمن و الگوریتم ماشین بردار پشتیبانی. در مجموعه مقالات کنفرانس سیستم های هوشمند چینی 2017 (CISC)، مودانجیانگ، چین، 14 تا 15 اکتبر 2017؛ صص 495-504. [ Google Scholar ]
- چن، اف. چن، ز. بیسواس، س. لی، اس. راماکریشنان، ن. Lu, C. گراف شبکه های کانولوشن با فیلتر کالمن برای پیش بینی ترافیک. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی (SIGSPATIAL)، سیاتل، WA، ایالات متحده آمریکا، 3 تا 6 نوامبر 2020. [ Google Scholar ]
- دندوفر، پی. اوشپ، ا. Leal-Taixé, L. Goal-GAN: پیش بینی مسیر چندوجهی بر اساس برآورد موقعیت هدف. در مجموعه مقالات کنفرانس آسیایی بینایی رایانه، کیوتو، ژاپن، 30 نوامبر تا 4 دسامبر 2020. [ Google Scholar ]
- صادقیان، ع. کوساراجو، وی. صادقیان، ع. هیروس، ن. Savarese، S. SoPhie: GAN توجه برای پیش بینی مسیرهای منطبق با محدودیت های اجتماعی و فیزیکی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 15 تا 20 ژوئن 2019. [ Google Scholar ]
- فرناندو، تی. دنمن، اس. سریدهران، اس. Fookes، C. GD-GAN: شبکههای متخاصم مولد برای پیشبینی مسیر و تشخیص گروهی در جمعیت. در مجموعه مقالات کنفرانس آسیایی در مورد چشم انداز رایانه، پرت، استرالیا، 2 تا 6 دسامبر 2018. [ Google Scholar ]
- جواد، ع. ژان برنارد، اچ. جولین، پی. راههای اجتماعی: یادگیری توزیعهای چندوجهی مسیرهای عابر پیاده با GAN. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی رایانه و تشخیص الگو (CVPRW)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019. [ Google Scholar ]
- گوپتا، ا. جانسون، جی. فی فی، ال. ساوارس، اس. الهی، ع. گان اجتماعی: مسیرهای قابل قبول اجتماعی با شبکه های متخاصم مولد. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018. [ Google Scholar ]
- حداد، س. وو، ام. وی، اچ. لام، پیش بینی مسیر عابر پیاده آگاه از موقعیت SK با مدل توجه مکانی-زمانی. در مجموعه مقالات بیست و چهارمین کارگاه زمستانی بینایی رایانه (CVWW)، Stift Vorau، اتریش، 6 تا 8 فوریه 2019. [ Google Scholar ]
- یو، جی. ژو، ام. وانگ، ایکس. پو، جی. چنگ، سی. چن، بی. یک شبکه توجه آگاه از زمینه پویا و استاتیک برای پیشبینی مسیر. ISPRS Int. J. Geo-Inf. 2020 ، 10 ، 336. [ Google Scholar ] [ CrossRef ]
- فرناندو، تی. دنمن، اس. سریدهران، اس. Fookes, C. Soft+ hardwired توجه: یک چارچوب lstm برای پیشبینی مسیر انسان و تشخیص رویداد غیرعادی. شبکه عصبی 2018 ، 108 ، 466-478. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- واسوانی، ع. Shazeer, N. پارمار، ن. Uszkoreit، J. جونز، ال. گومز، آ. قیصر، ال. Polosukhin، I. توجه تمام چیزی است که شما نیاز دارید. در مجموعه مقالات سی و یکمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صفحات 6000–6010. [ Google Scholar ]
- فن، ز. گونگ، ی. لیو، دی. وی، ز. وانگ، اس. جیائو، جی. دوان، ن. ژانگ، آر. Huang, X. Mask Attention Networks: Rethinking and Strengthen Transformer. در مجموعه مقالات کنفرانس بخش آمریکای شمالی انجمن زبانشناسی محاسباتی (NAACL)، آنلاین. 6–11 ژوئن 2021؛ صفحات 1692-1701. [ Google Scholar ]
- کاریون، ن. ماسا، اف. سینایو، جی. یوسونیر، ن. کریلوف، آ. Zagoruyko، S. تشخیص اجسام انتها به انتها با ترانسفورماتورها. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، گلاسکو، بریتانیا، 23 تا 28 اوت 2020؛ صص 213-229. [ Google Scholar ]
- چن، ایکس. وو، ی. وانگ، ز. لیو، اس. لی، جی. توسعه مبدل ترانسفورماتور جریانی بلادرنگ برای تشخیص گفتار در مجموعه داده در مقیاس بزرگ. arXiv 2020 ، arXiv:2010.11395. [ Google Scholar ]
- دوسوویتسکی، آ. بیر، ال. کولسنیکوف، آ. وایسنبورن، دی. ژای، ایکس. Unterthiner، T. دهقانی، م. مایندرر، م. هیگلد، جی. گلی، اس. و همکاران یک تصویر ارزش 16 × 16 کلمه دارد: ترانسفورماتورها برای تشخیص تصویر در مقیاس. arXiv 2020 ، arXiv:2010.11929. [ Google Scholar ]
- پارمار، ن. واسوانی، ع. Uszkoreit، J. قیصر، ال. Shazeer, N. کو، ا. تران، دی. ترانسفورماتور تصویر. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین (ICML)، استکهلم، سوئد، 10 تا 15 ژوئیه 2018؛ صفحات 4052-4061. [ Google Scholar ]
- دونگ، ال. خو، اس. Xu, B. تبدیل کننده گفتار: مدل توالی به دنباله بدون تکرار برای تشخیص گفتار. در مجموعه مقالات کنفرانس بین المللی آکوستیک، گفتار و پردازش سیگنال (ICASSP)، کلگری، AB، کانادا، 15 تا 20 آوریل 2018؛ صص 5884–5888. [ Google Scholar ] [ CrossRef ]
- گلاتی، ع. کین، جی. چیو، سی. پارمار، ن. ژانگ، ی. یو، جی. هان، دبلیو. وانگ، اس. ژانگ، ز. وو، ی. و همکاران Conformer: ترانسفورماتور کانولوشن تقویت شده برای تشخیص گفتار. Proc. Interspeech 2020 ، 2020 ، 5036–5040. [ Google Scholar ] [ CrossRef ]
- جولیاری، ف. حسن، من. کریستانی، م. گالاسو، F. شبکه های ترانسفورماتور برای پیش بینی مسیر. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی تشخیص الگو (ICPR)، میلان، ایتالیا، 10 تا 15 ژانویه 2021. [ Google Scholar ]
- سیتز، ام جی; دیتریش، اف. Köster, G. اثر گام برداشتن بر مسیرهای عابر پیاده. فیزیک یک آمار مکانیک. برنامه آن است. 2015 ، 421 ، 594-604. [ Google Scholar ] [ CrossRef ]
- کاراموتا، سی. کلودل، جی. جیاکومینی، سی. گرودن، سی. لونگو، جی. پیکولوتو، پی. بررسی تکنیکهای تشخیص، مدلهای ریاضی و نرمافزار شبیهسازی در دینامیک عابر پیاده. ترانسپ Res. Procedia 2017 ، 25 ، 551-567. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بولتس، ام. Seyfried, A. جمع آوری مسیرهای پیاده. محاسبات عصبی 2013 ، 100 ، 127-133. [ Google Scholar ] [ CrossRef ]
- گرودن، سی. کامپیسی، تی. کانال، ا. Tesoriere، G. Sraml، M. یک مطالعه متقابل در مورد جمع آوری داده های ویدئویی و تکنیک های ریزشبیه سازی برای تخمین سطح ایمنی عابر پیاده در یک فضای محدود. IOP Conf. سر. ماتر علمی مهندس 2019 , 603 , 042008. [ Google Scholar ] [ CrossRef ]
- ما، WC; هوانگ، DA; لی، ن. کیتانی، KM پیش بینی پویایی تعاملی عابران پیاده با بازی ساختگی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017. [ Google Scholar ]
- کوساراجو، وی. صادقیان، ع. مارتین، آر. رید، آی. رضاتوفیقی، ح. Savarese, S. Social-bigat: پیش بینی مسیر چندوجهی با استفاده از شبکه های توجه دوچرخه و گراف. arXiv 2019 , arXiv:1907.03395. [ Google Scholar ]
- سالزمن، تی. ایوانوویچ، بی. چاکروارتی، پ. Pavone, M. Trajectron++: پیشبینی مسیر مولد چند عاملی با دادههای ناهمگن برای کنترل. در مجموعه مقالات بینایی کامپیوتری و تشخیص الگو (CVPR)، سیاتل، WA، ایالات متحده آمریکا، 16-18 ژوئن 2020. [ Google Scholar ]
- پارت، ک. کریس، اس. الهی، الف. پیش بینی مسیر انسان در جمعیت: دیدگاه یادگیری عمیق. IEEE Trans. هوشمند ترانسپ سیستم 2021 . [ Google Scholar ] [ CrossRef ]
- ژو، اچ. Huynh، DQ; رینولدز، ام. مدل LSTM توجه مکان-سرعت-زمانی برای پیش بینی مسیر عابر پیاده. دسترسی IEEE 2020 ، 8 ، 44576–44589. [ Google Scholar ] [ CrossRef ]
- یو، سی. ما، ایکس. رن، جی. ژائو، اچ. یی، S. شبکه های ترانسفورماتور نمودار فضایی-زمانی برای پیش بینی مسیر عابر پیاده. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر، مجازی. 23–28 اوت 2020. [ Google Scholar ]
- خو، ی. پیائو، ز. گائو، اس. رمزگذاری تعامل جمعیت با شبکه عصبی عمیق برای پیشبینی مسیر عابر پیاده. در مجموعه مقالات کنفرانس IEEE 2018 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018. [ Google Scholar ]
- یی، اس. لی، اچ. وانگ، ایکس. درک رفتارهای عابر پیاده از گروههای جمعیت ساکن. در مجموعه مقالات کنفرانس IEEE 2015 در مورد دید رایانه و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. [ Google Scholar ]
- گلوروت، ایکس. بوردس، آ. Bengio، Y. شبکه های عصبی یکسو کننده پراکنده عمیق. در مجموعه مقالات کنفرانس بین المللی هوش مصنوعی و آمار (AISTATS)، Ft. Lauderdale، FL، USA، 11-13 آوریل 2011. [ Google Scholar ]
- پلگرینی، اس. اس، ا. شیندلر، ک. ون گول، ال. شما هرگز به تنهایی راه نخواهید رفت: مدل سازی رفتار اجتماعی برای ردیابی چند هدف. در مجموعه مقالات دوازدهمین کنفرانس بین المللی IEEE 2009، کیوتو، ژاپن، 27 سپتامبر تا 4 اکتبر 2009. ص 261-268. [ Google Scholar ]
- لرنر، آ. کریسانتو، ی. Lischinski، D. ازدحام به عنوان مثال. در انجمن گرافیک کامپیوتری ; وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2007; جلد 26، ص 655–664. [ Google Scholar ]



بدون دیدگاه