1. مقدمه
تفکیک نامهای محلی به ابهامزدایی از نام مکانها مربوط میشود و در برخی موارد، ارجاعات دیگری به مکانها مانند اشکال صفت و اهریمنی که در اسناد متنی آورده شده است را نیز در نظر میگیرد. نام مکان ها ابتدا از طریق یک مدل شناسایی نهاد نامگذاری شده (NER) شناسایی می شوند و سپس ابهام زدایی با مرتبط کردن یک موقعیت منحصر به فرد در سطح زمین به هر یک از مراجع مکان، به عنوان مثال، با اختصاص مختصات جغرافیایی به دست می آید. از آنجایی که مراجع مکان بسیار مبهم هستند، وظایف حل متضاد به طور قابل توجهی چالش برانگیز هستند. هنگام حل نام های نامی در اسناد متنی، سه نوع ابهام خاص باید حل شود [ 1 ، 2 ]:
-
ابهام جغرافیایی/جغرافیایی زمانی اتفاق میافتد که یک نام مکان توسط مکانهای مختلف به اشتراک گذاشته شود. به عنوان مثال، نام کنت می تواند مربوط به شهرستان کنت ، دلاور ، ایالات متحده ، یا کنت نیو کنت ، ویرجینیا ، ایالات متحده باشد.
-
ابهام جغرافیایی/غیر جغرافیایی زمانی اتفاق میافتد که از واژههای زبان رایج برای شناسایی نام مکانها استفاده میشود، یعنی زمانی که همان نام توسط یک مکان و همچنین توسط یک غیرمکان به اشتراک گذاشته میشود. به عنوان مثال، کلمه شارلوت می تواند به مکان خاص شهرستان شارلوت ، ویرجینیا ، ایالات متحده یا به نام یک شخص اشاره داشته باشد. کلمه منهتن همچنین می تواند به یک نوشیدنی کوکتل یا مکان خاص منهتن ، نیویورک ، ایالات متحده اشاره کند .
-
ابهام مرجع، که زمانی به وجود میآید که یک مکان را میتوان با چندین نام ارجاع داد. به عنوان مثال، موتور سیتی نامی است که معمولاً برای اشاره به دیترویت ، میشیگان ، ایالات متحده استفاده می شود.
مشکل (2) باید توسط مدل NER که ارجاعات مکان را در اسناد متنی شناسایی میکند، حل شود، در حالی که مشکلات (1) و (3) باید در هنگام تلاش برای مرتبط کردن مکانهای فیزیکی بدون ابهام به مراجع شناسایی شده در متن حل شوند (مثلاً ، با استفاده از مختصات ژئوفضایی به صورت طول و عرض جغرافیایی).
چندین برنامه می توانند از نتایج روش های تفکیک نام نامی استفاده کنند. اینها شامل سازماندهی و تجسم اسناد بر اساس معیارهای فضایی است، به عنوان مثال با گروه بندی اسناد در خوشه های مربوطه و/یا نقشه برداری از اطلاعات کدگذاری شده متنی [ 2 ]. مثال دیگر به بهبود ارائه نتایج در موتورهای جستجو مربوط می شود، به عنوان مثال از طریق نمایه سازی جغرافیایی، رتبه بندی، و/یا خوشه بندی نتایج جستجو [ 3 ، 4 ، 5 ، 6 ]. یکی دیگر از کاربردهای احتمالی مربوط به حمایت از مطالعات در زمینه هایی مانند علوم اجتماعی محاسباتی یا علوم انسانی دیجیتال است [ 7 ]]، به عنوان مثال تجزیه و تحلیل و پردازش داده های جغرافیایی استخراج شده از مجموعه اسناد متنی. علاوه بر این، وضوح مراجع مکان می تواند به عنوان یک جزء کمکی برای موقعیت جغرافیایی اسناد کامل استفاده شود [ 8 ]، با توجه به اینکه نام های موجود در اسناد متنی می توانند سرنخ هایی را در مورد منطقه جغرافیایی کلی مورد بحث ارائه دهند.
بیشتر سیستمهای توسعهیافته قبلی برای تفکیک نام نامها در متن مبتنی بر اکتشافی هستند (مثلاً مکانهایی با تراکم جمعیت بالا را ترجیح میدهند، یا فاصله جغرافیایی – فضایی بین مکانهای مختلف ارجاعشده در یک واحد متنی را به حداقل میرسانند)، همچنین با تکیه بر پایگاههای دانش خارجی (یعنی روزنامهنگاران) برای تصمیمگیری مکانی که برای ارتباط با هر مرجع مناسبتر است. ارجاعهای مکانهایی که در متن با آن مواجه میشوند، ابتدا با مدخلهای مشابه موجود در روزنامه [ 9 ، 10 ] مقایسه میشوند و برای مثال، ورودیهای تطبیقی مربوط به مکانهای پرجمعیت را میتوان مورد پسند قرار داد، زیرا مستعد استفاده در توصیفهای متنی هستند. [ 11 ، 12]. روشهایی که از اکتشافیهای چندگانه بهعنوان ویژگیهای ادغامشده در تکنیکهای یادگیری ماشین نظارت شده استاندارد استفاده میکنند نیز در برخی از مطالعات [ 13 ، 14 ، 15 ، 16 ] در نظر گرفته میشوند ، در حالی که مطالعات جدیدتر کاربرد روشهای مدلسازی زبان را در نظر میگیرند [ 17،18 ] . اخیراً، استفاده از تکنیکهای یادگیری عمیق نتایج پیشرفتهای را برای تکلیف تفکیک نامها به همراه داشت [ 19 ، 20 ، 21 ، 22 ].
این مقاله یک روش جدید را برای تفکیک نام نامها معرفی میکند که از یادگیری عمیق برای مدلسازی عناصر متنی استفاده میکند، با ترکیب واحدهای حافظه کوتاهمدت دو طرفه (LSTM) با جاسازیهای متنی از پیش آموزشدیده شده (یعنی ویژگیهای استاتیک استخراجشده با استفاده از تعبیهها از زبان). مدلها (ELMo) [ 23 ] یا روشهای نمایش رمزگذار دوطرفه از ترانسفورماتورها (BERT) [ 24 ]. ما بر روی ابهامزدایی از مراجع مکانهایی که قبلاً شناسایی شدهاند، تمرکز کردیم، و اشاره کردیم که بسیاری از رویکردهای NER وجود دارد که به راحتی میتوان برای شناسایی دقیق نام مکانها در متن استفاده کرد (به عنوان مثال، بستههای نرمافزاری مانند spacy.io دارای مدلهای قوی برای شناسایی موجودیت هستند).
مدلی که ما پیشنهاد می کنیم چندین ورودی متنی، به طور خاص تر مرجع نام مکان، جمله ای که مرجع در آن رخ می دهد و پاراگراف مربوطه را ترکیب می کند. این مدل همچنین خروجیهای متعددی را که به یکدیگر متصل هستند، به ویژه یک خروجی اولیه مربوط به مختصات جغرافیایی، همراه با یک خروجی طبقهبندی جایگزین مربوط به مناطق درشت روی سطح زمین در نظر میگیرد (یعنی مدل یک هدف طبقهبندی چند کلاسه را با پیشبینی ترکیب میکند. مناطق، همراه با یک هدف رگرسیون مرتبط با پیشبینی مختصات طول و عرض جغرافیایی). مناطق طبقهبندی با استفاده از یک پیکسلسازی isoLatitude مساحت سلسله مراتبی (HEALPix) [ 25 ] ایجاد میشوند.] روشی که سلولهای مساحت مساوی را تولید میکند که با تقسیم یک سطح کروی که سطح زمین را به صورت بازگشتی نشان میدهد به دست میآید. خروجی شبکه مربوط به مختصات جغرافیایی فضایی، که مقادیر خود را از توزیع احتمال مرتبط با خروجی طبقهبندی میگیرد، به یک تابع تلفات مربوط به فاصله دایره بزرگ متصل میشود. این مقدار با از دست دادن آنتروپی متقابل برای خروجی طبقهبندی چند طبقه ترکیب میشود، و به طور مشترک هر دو بخش را بهینه میکند تا امیدواریم پیشبینی مختصات جغرافیایی برای هر مرجع مکان بهبود یابد. علاوه بر این، ما با استفاده از اطلاعات مربوط به خواص ژئوفیزیکی (به عنوان مثال، ارتفاع، توسعه زمین، حداقل فاصله از مناطق آبی، و درصد پوشش گیاهی)، در تلاش برای بهبود بیشتر عملکرد، آزمایش کردیم.
مدل پیشنهادی با استفاده از سه مجموعه داده معروف که به طور گسترده در مطالعات قبلی مورد استفاده قرار میگرفتند، بهویژه Local-Global Lexicon ، جنگ شورش ، و بدنه SpatialML مورد آزمایش قرار گرفت . کد منبع پشتیبانی از آزمایشها نیز در یک مخزن Github در دسترس عموم قرار گرفت ( https://github.com/barbarainacioc/toponym-resolution(دسترسی در 10 نوامبر 2021)). در مجموع، نتایج تجربی ما نشان میدهد که رویکرد پیشنهادی میتواند از نتایج بهدستآمده در مطالعات قبلی در مجموعه دادههای مشابه پیشی بگیرد. علاوه بر این، ما انواع مختلف رویکرد پیشنهادی را آزمایش کردیم (به عنوان مثال، مقایسه تعبیههای ELMo و BERT) و برای درک تأثیر اندازه دادههای آموزشی بر نتایج، سناریویی را نیز انتخاب کردیم که در آن نمونه دادهای بزرگتر برای مدل استفاده میشود. آموزش. نمونههای جدید اضافه شده به مجموعه اصلی از نمونهای تصادفی از مقالات ویکیپدیا انگلیسی استخراج شدهاند، با بهرهگیری از ساختار پیوند ویکیپدیا برای جمعآوری گسترههایی از متن مربوط به مراجع مکان (یعنی با در نظر گرفتن گسترههای متنی که به صفحات ویکیپدیا مرتبط با جغرافیا پیوند داده میشوند. مختصات مکانی). نتایج نشان میدهد که افزایش دادههای آموزشی تنها نتایج را به طور جزئی بهبود میبخشد.
بقیه مقاله به شرح زیر سازماندهی شده است: بخش 2 کارهای مرتبط را توصیف می کند و مجموعه های مورد استفاده در این پروژه را ارائه می دهد. بخش 3 مدل پیشنهادی را شرح می دهد. بخش 4 ارزیابی تجربی دنبال شده، شامل روش ارزیابی و همچنین نتایج به دست آمده را نشان می دهد. در نهایت، بخش 5 نتیجه گیری های ما را نشان می دهد و ایده هایی را برای کار آینده ترسیم می کند.
2. کارهای مرتبط
این بخش مطالعات قبلی مرتبط را ارائه میکند که به تفکیک نام نامها با تکنیکهای مختلف، بهویژه روشهای مبتنی بر اکتشاف ( بخش 2.1 )، روشهای ترکیب اکتشافی با یادگیری نظارتشده ( بخش 2.2 )، روشهای با استفاده از شبکههای ژئودزیکی همراه با مدلهای زبانی ( بخش 2.3 )، و در نهایت ارائه میشود. روش های اعمال نفوذ یادگیری عمیق ( بخش 2.4 ). در نهایت، بخش 2.5 بدنههایی را که در آزمایشهای توصیفشده در این کار مورد استفاده قرار گرفتند، توصیف میکند.
2.1. روش های اکتشافی برای تفکیک نام های نامی
اکثر سیستمهایی که قبلاً برای تفکیک نام نامها توسعه داده شدهاند، مبتنی بر اکتشاف هستند و از منابع دانش خارجی برای دسترسی به مجموعهای از دادهها در مورد مکانهای روی سطح زمین (مثلاً انواع مکانها، نامهای جایگزین، ردپای جغرافیایی-فضایی، یا تراکم جمعیت) استفاده میکنند. ، درمیان دیگران). سیستمهای مبتنی بر اکتشافی معمولاً از انواع دادههای ذکر شده استفاده میکنند تا تصمیم بگیرند که کدام یک از مکانهای ممکن، در مجموعهای از نامزدهای بازیابی شده از روزنامه، با نام مکان ارائهشده در متن مطابقت دارد [ 11 ، 12 ، 14 ، 26 ، 27 ].
علاوه بر اطلاعات خارجی، همچنین میتوان جنبههای زبانی را در شکلگیری اکتشافات ابهامزدایی نامها در نظر گرفت [ 12 ، 27 ]. در کار اصلی در این منطقه، لایدنر [ 12 ] هم از اکتشافات زبانی (یعنی استنباط قواعد و الگوها از محتوای متنی) و هم از اکتشافات فرازبانی (یعنی استفاده از منبع خارجی دانش) استفاده کرد. به عنوان مثال، یکی از اکتشافی های در نظر گرفته شده توسط لایدنر مبتنی بر یک واجد شرایط است که الگوهایی مانند ( ) یا که در و محدودیت جغرافیایی را برای مکانهای نامزد احتمالی (یعنی مکانهایی با همان نامی که در حال حل شدن است) با توجه به هر دو نام نامی ارزیابی میکند، مختصات جغرافیایی را بر اساس مهار جغرافیایی-مکانی تعریف میکند (به عنوان مثال، اختصاص دادن به لندن مختصات پایتخت انگلستان در صورتی که الگوی شناسایی شده مربوط به لندن (بریتانیا) باشد، یا مختصات شهر در انتاریو اگر الگوی شناسایی شده به لندن ، انتاریو ، کانادا اشاره دارد.). لیدنر همچنین از اکتشافات فرازبانی مانند اکتشاف مبتنی بر اختصاص دادن نام نامی به مکان نامزد با تراکم جمعیت بالاتر استفاده کرد. مثال دیگر اکتشافی یک حس در هر گفتمان است که در نظر میگیرد اگر یک نام مفروض چندین بار در متن بدون سرنخهای زمینهای اضافی وجود داشته باشد، و اگر یک مکان نامزد بسیار برجسته باشد (مثلاً مربوط به یک شهر پایتخت باشد) احتمال بالاتری وجود دارد که همان نام نامبرده اشاره به آن نامزد داشته باشد (به عنوان مثال، اگر پاریس در متن وجود دارد، همیشه مختصات پاریس، پایتخت فرانسه را در نظر بگیرید، و مکان های دیگری به نام پاریس را تعیین نکنید).
Leidner [ 12 ] همچنین در مورد ترکیبات ترکیبی از هر دو نوع اکتشافی گزارش داد، به عنوان مثال، با در نظر گرفتن همبستگی متنی-فضایی و با فرض اینکه شباهت متنی در زمینههای وقوع باید به شدت با مجاورت فضایی مرتبط باشد. برای مثال، اگر نامهای پاریس و ورسای در یک گستره متنی کوچک (یعنی در مجاورت متنی) وجود داشته باشند، احتمالاً نام پاریس با پاریس، پایتخت فرانسه مرتبط است.
یک روش اکتشافی اخیر که در زمینه ژئوکدگذار GeoTxt توسعه یافته است (یعنی یک رابط برنامه نویسی کاربردی انعطاف پذیر که برای استخراج و ابهام زدایی نام های نامی در اسناد متنی کوچک استفاده می شود)، توسط کریم زاده و همکاران گزارش شده است. [ 14]. این سیستم با تمرکز انحصاری بر ابهامزدایی از مراجع مکان شناسایی شده، از منابع موجود برای تشخیص نامهای نامی در متن استفاده میکند. در طول تفکیک نام نامها، برای هر ذکر، سیستم از یک فهرست سفارشی روی روزنامه GeoNames استفاده میکند تا مجموعهای از مکانهای نامزد را بازیابی کند و به هر یک از آنها امتیاز خاصی اختصاص دهد. این امتیاز از ترکیبی از ویژگیهای متعدد حاصل میشود که شامل افزایش تراکم جمعیت یا شاخصهای نوع مکان خاص (مانند تقسیمات اداری، مناطق، قارهها، نهادهای سیاسی مستقل، مکانهای پرجمعیت، یا انواع تأسیسات (مانند استادیوم، ایستگاه قطار، کالج) میشود. )، درمیان دیگران). علاوه بر این، GeoTxt همچنین اکتشافات ابهامزدایی اضافی را براساس همروی نامهای نامی در متن در نظر میگیرد و از ایده حداقلی فضایی استفاده میکند.قبلا توسط Leidner [ 12 ] نیز گزارش شده بود. دو مورد از این اکتشافیها به روابط سلسله مراتبی بین نامها مربوط میشوند (به عنوان مثال، اگر یک رابطه مهاری نسبت به یک فضای جغرافیایی یکسان توسط دو نام محلی مشترک باشد، یا به نامهای مکان بلافاصله متوالی (مثلاً ترکیبی از ایالت، شهر) و یا مربوط به نامها باشد. به طور جداگانه در متن نشان داده شده است). سومین اکتشافی مربوط به مجاورت فضایی است و هدف آن به حداقل رساندن فاصله متوسط بین مکان پیشبینیشده یک نام و مکان دیگر نامهای همزمان در متن است.
2.2. ترکیب اکتشافی از طریق یادگیری نظارت شده
چندین مطالعه قبلی از رویکردهای نظارت شده استفاده کردهاند که اکتشافیها را، مانند مواردی که در بخش قبل به آنها اشاره شد، بهعنوان ویژگیهای تکنیکهای یادگیری ماشین استاندارد در نظر میگیرند [ 13 ، 15 ، 16 ].
به عنوان مثال، الهام گرفتن از مطالعات قبلی مرتبط با موجودیت کلی، سانتوس و همکاران. [ 16] ترکیبی از ویژگیهای چندگانه، مانند برجستگی مکان، شباهتهای بین مکانهای نامزد احتمالی و زمینه مرتبط با مرجع مکان (مثلاً مقایسه توصیفهای نامزدها در برابر متن اطراف ذکر) و شباهتهای نامزدها به نامهای دیگر موجود را بررسی کرد. در متن. یک مدل یادگیری رتبهبندی از مجموعهای از نمونههای مرتبط با ابهامزدایی صحیح آموزش داده میشود و، هنگام پردازش مراجع مکان در متنهای دیده نشده قبلی، از مدل برای تخصیص یک رتبه به هر مکان نامزد، با توجه به احتمال مطابقت آن با ابهام زدایی صحیح مکان با بالاترین رتبه در نهایت با ذکر مکان حل می شود.
روش هایی مانند روش های لیبرمن و سامت [ 15 ] یا سانتوس و همکاران. [ 16 ] به طور طبیعی می تواند انواع مختلفی از ویژگی ها را در خود جای دهد، و از نیاز به تنظیم دستی پارامتر اجتناب می کند. همچنین میتوان ویژگیها را با روشهای یادگیری بازنمایی مبتنی بر یادگیری عمیق ترکیب کرد (به عنوان مثال، Canwen و همکاران اخیراً استفاده از شبکههای LSTM را برای نشان دادن ذکر مکان همراه با زمینههای چپ و راست آنها توصیف کردهاند، و این نمایشها را با ویژگیهای دیگر در یک موجودیت پیوند دهنده ترکیب میکنند. روشی برای مرتبط کردن نامهای مکان در توییتها به ورودیهای یک پایگاه داده نقاط مورد علاقه [ 28]). با این حال، همانطور که در مورد مطالعات بررسی شده در بخش قبل، این روش ها به در دسترس بودن منابع خارجی مانند روزنامه ها بستگی دارد [ 9 ، 10 ]. یکی از معایب استفاده از روزنامهها این است که این منابع معمولاً ناقص و قدیمی هستند، بنابراین تأثیر مستقیمی بر نتایج سیستمهایی که از آنها استفاده میکنند میگذارد و باعث میشود آنها نتوانند با نامهای مکان جدید و بومی سروکار داشته باشند.
2.3. روشهای ترکیب شبکههای ژئودزیکی و مدلهای زبان
برخی از مطالعات قبلی روشهای تفکیک نام نامی را پیشنهاد کردهاند که از نیاز به اطلاعات خارجی در قالب روزنامهها اجتناب میکنند، در عوض از مدلهای زبانی مرتبط با مناطق مختلف استفاده میکنند تا پیشبینی کنند که کدام منطقه بیشتر با مرجع مکان مورد تجزیه و تحلیل مطابقت دارد [ 7 ، 17 ]. ، 18 ]. اکثر این روشها از شبکههای ژئودزیکی برای تقسیم فضای جغرافیایی به چندین منطقه استفاده میکنند و فرض میکنند که حتی کلمات زبان رایج (و نه فقط نام مکانها) اغلب میتوانند از نظر جغرافیایی نشاندهنده باشند.
مجموعه ای از گفته های متنی، که مختصات جغرافیایی- فضایی مربوطه برای آنها مشخص است، با هر یک از مناطق در یک شبکه ژئودزیکی مرتبط است. این عبارات متنی برای آموزش یک مدل زبان برای هر یک از مناطق استفاده می شود (به عنوان مثال، یک مدل زبان مولد n- gram، یا در عوض یک مدل تمایز بر اساس رگرسیون لجستیک یا برخی روش های یادگیری ماشین دیگر). وضوح شبکه معمولاً با توجه به تعداد گفته های متنی موجود نیز تطبیق داده می شود و می توان از شبکه های چند وضوحی نیز استفاده کرد. با توجه به مرجع مکان و بافت اطراف آن، می توان با انتخاب منطقه ای که مدل زبانی آن با متن مرجع به اضافه بافت مطابقت دارد، پیش بینی کرد و سپس مختصات مرکز منطقه را در نظر گرفت.
وینگ و بالدریج [ 29 ] در یک مطالعه اساسی به دنبال روششناسی فوقالذکر، استفاده از شبکههای ژئودزیکی را برای مکانیابی کل اسناد متنی بررسی کردند. نویسندگان سطح زمین را گسسته کردند سلولهای شبکه درجه، که واگراییهای Kullback–Liebler را به هر سلولی که یک سند داده میشود، بر اساس مدلهای زبان یونی گرام که برای هر سلول از مقالات ویکیپدیا در موقعیت جغرافیایی آنها آموخته شده است، اختصاص میدهد. اسپریوسو و بالدریج [ 18 ] این ایده را بیشتر تصحیح کردند و یک روش تفکیک نام نامی مبتنی بر متن را پیشنهاد کردند که به عنوان ورودی مدل زبان، از پنجرههای بافتی متشکل از بیست کلمه از هر طرف هر کلمه در متن استفاده میکند. در ادامه این خط از تحقیقات، Wing [ 7 ] در مورد آزمایشهایی با استفاده از شبکههای ژئودزیکی با وضوح چندگانه (به عنوان مثال، بر اساس پارتیشنبندی درخت kd)، همراه با مدلهای رگرسیون لجستیک متمایز به جای مدلهای زبان یونی گرم تولیدی، برای هر دو سند جغرافیایی گزارش کرد. کدگذاری و تفکیک نام های نامی.
اخیراً، DeLozier و همکاران. [ 17 و 30 ] سیستم TopoCluster را توصیف کرد که از مدل های زبانی به روشی کمی متفاوت استفاده می کند. به طور خاص، نویسندگان از آمار مکانی استفاده کردند [ 31] برای استخراج هر کلمه در واژگان یک احتمال هموار جغرافیایی. سپس با یافتن نقاط قویترین همپوشانی برای یک نام و کلمات اطراف آن، تفکیک نام نامها انجام شد. با جزئیات بیشتر، با توجه به مجموعه مرجعی از اسناد موقعیت جغرافیایی، یک مدل زبان محلی غیر هموار برای اندازه گیری ارتباط هر کلمه با هر سند استفاده می شود. این روش میتواند مستقیماً از مکانهای اسناد مرجع استفاده کند یا بهطور اختیاری، این مکانها را میتوان در سلولهای شبکه ژئودزیکی ادغام کرد. Getis محلی – Ord Gi آمار [ 31 ]، همراه با هسته Epanichnikov که فواصل زیاد بین جفت مکان ها را جریمه می کند، برای اندازه گیری قدرت ارتباط بین کلمات و مناطق جغرافیایی استفاده می شود، که در نتیجه ماتریسی از آمار با سلول های شبکه به عنوان ستون و هر کلمه به عنوان یک بردار ردیف (یعنی Gi آمار را میتوان بهعنوان احتمال تجمیع و هموار شده جغرافیایی مشاهده هر کلمه در نقاط خاصی از فضای جغرافیایی مشاهده کرد. برای ابهامزدایی از یک نام، نویسندگان کلمات نام نامی را از کلمات غیر نامی در یک پنجره بافت اطراف جدا میکنند (یعنی 15 کلمه در هر طرف، فیلتر کردن کلمات تابع)، و در نهایت مجموع وزنی تمام Gi را محاسبه میکنند. ارزش برای همه کلمات مرکز از سلول با بالاترین مقدار را می توان به عنوان ابهام زدایی برای نام ورودی برگرداند.
مطالعات فوق نشان داد که رویکردهای مبتنی بر متن میتوانند نتایج برتر را بدون مراجعه مجدد به روزنامهنگاران به دست آورند و نتایج خوبی را نسبت به مجموعههای متشکل از مقالات خبری بینالمللی و متون تاریخی گزارش کنند.
2.4. تکنیک های یادگیری عمیق برای تفکیک نام های نامی
مطالعات اخیر روشهای یادگیری عمیق را برای تفکیک نامها، فرمولبندی تکلیف بهعنوان یک مسئله پیوند دهنده موجودیت خاص [ 28 ]، یا گسترش روشهای مبتنی بر شبکههای ژئودزیکی، مانند مواردی که در بخش 2.3 به آنها اشاره شد ، در جهت جایگزینی مدلهای زبان سادهتر با رویکردهای مبتنی بر شبکه های عصبی عمیق [ 19 ، 20 ، 22 ].
به عنوان مثال، آدامز و مک کنزی [ 19] یک رویکرد در سطح کاراکتر مبتنی بر شبکه های عصبی کانولوشن برای متن چند زبانه کدگذاری جغرافیایی را تشریح کرد. این مدل دنباله ای از کاراکترهای UTF-8 را به عنوان ورودی دریافت می کند که هر کدام به صورت یک بردار یک داغ کدگذاری می شوند و یک سری عملیات کانولوشن زمانی و حداکثر ادغام روی آن اعمال می شود. این عملیات منجر به یک نمایش برداری برای متن ورودی می شود که سپس تبدیل های متعددی برای آن اعمال می شود. در نهایت، لایه خروجی یک طبقه بندی منطقه را پیش بینی می کند، به عنوان مثال، بر اساس یک شبکه ژئودزیکی درشت. استفاده از شبکههای عصبی کانولوشنال در سطح کاراکتر به نویسندگان این امکان را میدهد که از نیاز به قوانین نشانهسازی خاص زبان اجتناب کنند. با این حال، آزمایشها نشان داد که مدل مبتنی بر کاراکتر همیشه بهترین نتایج را به دست نمیآورد (یعنی، نتایج بهتری را میتوان اغلب با مدلهای SVM با استفاده از n به دست آورد.ویژگی های گرم). نویسندگان به این نتیجه رسیدند که کلمات فردی گاهی اوقات می توانند شاخص های جغرافیایی خوبی باشند.
در مطالعه اخیر دیگری، Gritta و همکاران. [ 20 ] سیستم CamCoder را ارائه کرد ، که سعی میکند با شناسایی سرنخهای واژگانی با توسل به واژههای زمینه اطراف ذکر، ارجاعات مکانی را ابهام کند. یک نمایش برداری پراکنده توسط نویسندگان پیشنهاد شده است، با عنوان MapVec ، که یک توزیع برای احتمالات جغرافیایی قبلی مرتبط با مکان ها (به عنوان مثال، بر اساس مختصات مکان و تعداد جمعیت) رمزگذاری می کند. به طور خاص، دادههای ژئومکانی خارجی بر روی یک شبکه ژئودزیکی با وضوح تصویر پیشبینی میشوند. درجه (به عنوان مثال، برای هر مکان ذکر شده در یک پنجره زمینه، و برای هر یک از نامزدهای مبهم آن در روزنامه، نویسندگان از شمارش جمعیت برای تخمین احتمال قبلی استفاده میکنند و آن را به سلول شبکه مربوطه اضافه میکنند)، که در مرحله بعدی به شکل یک بردار ویژگی 1 بعدی (یعنی MapVec ). سیستم CamCoder اطلاعات واژگانی و جغرافیایی متناظر با ورودی های زیر را ترکیب می کند: موجودیت هدف برای ابهام زدایی، هرگونه اشاره به مکان ها (به استثنای کلمات متن)، هر کلمه متنی (به استثنای اشاره به مکان)، و MapVecبردار ویژگی ورودیهای متنی (یعنی سه ورودی اول از شمارش قبلی) به لایههای جداگانهای وارد میشوند که کانولوشنها را با عملیات جمعبندی حداکثر جهانی ترکیب میکنند تا کلماتی را که نشاندهنده مکانهای خاص هستند، شناسایی کنند. بردار ویژگی MapVec به نوبه خود به یک لایه کاملاً متصل ارائه می شود. پس از آن، چهار بردار بهدستآمده به صورت جداگانه به لایه متراکم دیگری منتقل میشوند و به دنبال آن نتایج آنها ترکیب میشوند. این نمایش در نهایت به یک لایه خروجی تحویل داده می شود، که با آن مدل یک مکان را بر اساس طبقه بندی به مناطق تعریف شده توسط یک شبکه ژئودزیکی پیش بینی می کند. نویسندگان مجموعه گستردهای از آزمایشها را با مجموعههای متعدد گزارش کردند که نشان میدهد رویکرد کامل از CNNs+ MapVec استفاده میکند.در آن زمان به بهترین نتایج دست یافت. ویژگیهای MapVec زمانی که در سایر رویکردهای یادگیری ماشینی (مثلاً جنگلهای تصادفی) استفاده میشوند، مؤثر باقی میمانند، و همچنین وقتی با مدلهای مبتنی بر شبکههای عصبی مکرر ترکیب میشوند، عملکرد را بهبود میبخشند.
2.5. مجموعه هایی از مطالعات قبلی که در کار ما به کار گرفته شده اند
این بخش مجموعه دادههای پیشنهادی قبلی را توصیف میکند که برای ارزیابی روش ما نیز استفاده شدهاند، بهویژه جنگ شورش [ 30 ]، واژگان محلی-جهانی [ 32 ]، و پیکرههای SpatialML [ 33 ]. این سه مجموعه داده مجزا تا حد زیادی در زمینه مطالعات قبلی در این منطقه مورد استفاده قرار گرفتهاند [ 11 ، 16 ، 17 ، 20 ، 30 ، 34 ] که حوزههای متمایز را پوشش میدهند.
لیبرمن و همکاران [ 32 ] مجموعه Local-Global Lexicon (LGL) را ارائه کرد که از 588 مقاله استخراج شده از روزنامه هایی که کوچک و از نظر جغرافیایی توزیع شده اند، تشکیل شده است. این مجموعه عمداً برای به چالش کشیدن سیستمهای تفکیک نام نامها ساخته شده است، زیرا از مقالات خبری محلی، بهویژه از شهرهای کوچک با نامهای مبهم تشکیل شده است. به عنوان مثال، پاریس یک نام نامی بسیار مبهم است و این مجموعه داده خاص حاوی مقالات استخراج شده از روزنامه های محلی مانند The Paris Post-Intelligencer ( پاریس ، تنسی )، The Paris News ( پاریس، تگزاس )، و The Paris Beacon-News ( پاریس ، ایلینوی). این مجموعه اکنون ( https://raw.githubusercontent.com/geoai-lab/EUPEG/master/corpora/lgl.xml (دسترسی در 10 نوامبر 2021)) در پلت فرم معیار EUPEG [ 35 ، 36 ] برای تفکیک نام نامها در دسترس است. .
به نوبه خود، مجموعه جنگ شورش (WOTR) ( https://github.com/utcompling/WarOfTheRebellion (دسترسی در 10 نوامبر 2021)) حاوی 1644 متن تاریخی است که از آرشیوهای نظامی مرتبط با جنگ داخلی آمریکا استخراج شده است، که در آن گزارش ها، دستورات نظامی و مکاتبات دولتی غالب است. فرآیند حاشیه نویسی مربوط به این اسناد تاریخی توسط DeLozier و همکاران شرح داده شده است. [ 30]، که همچنین ارزیابی دیگری از سیستمهای تفکیک نام نامهای موجود در مجموعه را ارائه کرد، و علاوه بر این، روشهای مشابه را نسبت به سایر مجموعهها برای مقایسه نتایج ارزیابی کرد. نویسندگان به این نتیجه رسیدند که WOTR با چالش برانگیزترین پیکره مورد بررسی مطابقت دارد، به عنوان مثال، سیستم هایی که به نتایج عملکرد کلی پایین تری نسبت به مجموعه واژگان محلی-جهانی دست می یابند ، که تا آن زمان چالش برانگیزترین مورد در نظر گرفته می شد.
سرانجام، مجموعه SpatialML ( https://catalog.ldc.upenn.edu/LDC2011T02 (دسترسی در 10 نوامبر 2021)) از کنسرسیوم داده های زبانی، متشکل از 428 سند انگلیسی از کمپین ارزیابی ACE 2005، از جمله اخبار مجله، در دسترس است. ، پخش اخبار، پخش گفتگوها، ورودی های وبلاگ وب و پست های گروه های خبری. علاوه بر پیکره، SpatialML همچنین به طرح مبتنی بر XML اشاره دارد که در حاشیه نویسی داده ها استفاده می شود، جایی که مراجع مکان ظاهر شده در متن با یک برچسب PLACE همراه با یک ویژگی LATLONG ترکیب می شوند که مختصات جغرافیایی طول و عرض جغرافیایی را در بر می گیرد.
اکثر روش های بررسی شده در بخش های قبلی حداقل یکی از این سه مجموعه داده را برای ارزیابی استفاده کردند. بخش 4 مقاله حاضر یک توصیف آماری برای مجموعه داده های مختلف ارائه می دهد (به عنوان مثال، جدول 1 را ببینید )، همچنین روش ما را در مقابل نتایج گزارش شده قبلی قرار می دهد.
3. روش پیشنهادی تفکیک نام های نامی
بخش های زیر شرح مفصلی از تکنیک های به کار گرفته شده در روش پیشنهادی ارائه می دهد. بخش 3.1 شبکه های عصبی مکرر، یعنی واحدهای حافظه کوتاه مدت (LSTM) مورد استفاده در مدل ما را مرور می کند، و همچنین از جاسازی کلمه ELMo پشتیبانی می کند. بخش 3.2 رویکردهای خاصی را برای نمایش متن از طریق جاسازی کلمه، یعنی ELMo و BERT در نظر می گیرد. در نهایت، بخش 3.3 رویکرد تفکیک نام نامهای ما را توصیف میکند، که مشکل را به عنوان یک کار پیشبینی مدلسازی میکند که توسط یک شبکه عصبی عمیق، که معماری آن به تفصیل توضیح داده شده است، پرداخته میشود.
3.1. شبکه های عصبی مکرر
یک شبکه عصبی بازگشتی (RNN) از مدلسازی توالیها پشتیبانی میکند، بنابراین به طور طبیعی برای وظایف پردازش زبان طبیعی (NLP) که شامل دنبالهای از کاراکترها یا کلمات است، اعمال میشود [ 37 ].
نمایش دنبالههای ورودی با طول اختیاری (مثلاً دنبالههایی از بردارها که عبارات متنی را کد میکنند) توسط یک RNN مجاز است، برای مثال تبدیل آنها به یک نمایش برداری با اندازه ثابت که ویژگیهای دنباله ورودی را حفظ میکند. به طور کلی، یک RNN را می توان به صورت بازگشتی از طریق یک تابع تعریف کرد که بردار حالت را می پذیرد به عنوان ورودی (یعنی یک بردار متناظر با حالت قبلی)، همراه با یک بردار ورودی برای وضعیت فعلی ، یک بردار حالت جدید را برمی گرداند . بردار حالت بعد توسط یک تابع نگاشت می شود به بردار که شبیه بردار خروجی حالت فعلی است . ساختار فوق مجموعه تاریخ مربوط به تمام حالات قبلی را در نظر می گیرد . پس از پردازش آخرین بردار ورودی، یک نمایش فراگیر برای کل دنباله ورودی را می توان از بردار خروجی نهایی، یا با یک عملیات ادغام (مثلا، حداکثر ادغام) اعمال شده بر روی دنباله بردارهای خروجی به دست آورد.
یک RNN دو جهته نیز می تواند تعریف شود، به دنبال ایده هایی که قبلا ذکر شد، اما در این مورد، اتصال دو واحد RNN (به عنوان مثال، الحاق بردارهای خروجی) است که ورودی ها را در جهات مخالف پردازش می کند (یعنی از چپ به راست و از راست-). به سمت چپ). بنابراین، خروجی هر موقعیت می تواند اطلاعاتی را با ترکیب حالت های گذشته (عقب) و آینده (به جلو) رمزگذاری کند. چندین واحد RNN یا دو جهته RNN نیز میتوانند در شبکههای عصبی عمیق، با استفاده از خروجیهای تولید شده توسط یک RNN به عنوان ورودی به لایه RNN بعدی دیگر، کنار هم قرار گیرند.
ایدههای کلی فوقالذکر را میتوان در عمل از طریق معماریهای مختلف پیادهسازی کرد، در بسیاری از موارد با تکیه بر مکانیزمهای دروازهای که یادگیری تحت نظارت را با تنظیم بهروزرسانیهای گرادیان تسهیل میکنند. واحدهای حافظه کوتاه مدت بلند مدت (LSTM) شاید رایج ترین نمونه از معماری RNN بتنی باشد [ 38 ]. در این حالت، هنگام پردازش هر بردار ورودی، یک مکانیسم دروازه ای تصمیم می گیرد که سلول حافظه چه مقدار از ورودی جدید را دریافت کند و چه مقدار از محتوای سلول حافظه فعلی را سلول حافظه فراموش کند. به دنبال نماد گلدبرگ [ 37 ]، واحدهای LSTM را می توان به طور رسمی همانطور که در معادله ( 1 ) نشان داده شده است، تعریف کرد.
هنگام در نظر گرفتن هر موقعیت ورودی j ، حالت مربوط به الحاق دو بردار است و ، به ترتیب یک جزء حافظه و یک جزء حالت پنهان (معادله ( 1a )). سه مولفه دروازهای مسئول تنظیم جریان اطلاعات، بهویژه دروازههای ورودی، فراموشی و خروجی هستند که به ترتیب با متغیرهای i ، f و o نمایش داده میشوند (معادله ( 1d – 1f )، که در آن پارامترهای W مختلف مطابقت دارند. ماتریس وزن قابل یادگیری). مقادیر گیت از ترکیب خطی ورودی جریان جمع آوری می شود و حالت قبلی و از یک تابع فعال سازی سیگموئید عبور کرد. ترکیبی خطی از و یک کاندید بهروزرسانی z را تعیین میکند که تابع فعالسازی مماس هذلولی (معادله ( 1g )) برای آن اعمال میشود. بعد، جزء حافظه با در نظر گرفتن دروازه فراموشی، که مقدار حافظه قبلی را که باید حفظ شود، و گیت ورودی، که کنترل می کند چه مقدار از به روز رسانی پیشنهادی باید حفظ شود، کنترل می کند، به روز می شود (معادله ( 1b )). در نهایت، ارزش ، در مورد خروجی (معادله ( 1h ))، با در نظر گرفتن محتوای حافظه محاسبه می شود ، از یک تابع مماس هذلولی عبور می کند و توسط دروازه خروجی کنترل می شود (معادله ( 1c ) ، که در آن نماد ⊙ نشان دهنده یک محصول از نظر عنصر است.
امروزه LSTMها بلوک اصلی بسیاری از مدلهای مختلف برای NLP هستند و خواننده برای توضیح دقیقتر به آموزش گلدبرگ [ 37 ] ارجاع داده میشود.
3.2. بازنمایی متن از طریق جاسازی های متنی کلمه
هنگام استفاده از یادگیری ماشینی در وظایف NLP، نمایش کلمات و قطعات طولانیتر متن یک جنبه ضروری است. یک رویکرد رایج شامل استفاده از روشهای جاسازی کلمه برای نشان دادن عناصر متنی است، به گونهای که اطلاعات زبانی/معنای را به دست میآورد. خواننده برای معرفی این روش ها به اسمیت [ 39 ] و به لیو و همکاران ارجاع داده می شود. [ 40 ] یا کیو و همکاران. [ 41 ] برای توضیحات عمیق تر.
بیشتر رویکردهای جاسازی کلمه (به عنوان مثال، الگوریتم های درون بسته محبوب word2vec [ 42]) از شبکه های عصبی ساده برای نگاشت کلمات به بردارهای اعداد واقعی متراکم استفاده کنید، که در آن هر کلمه واژگانی با یک بردار نشان داده می شود و کلماتی که در زمینه های مشابه ظاهر می شوند احتمالاً بردارهای مشابهی دارند (یعنی فاصله بین کلمات جاسازی شده با آنها مرتبط است. شباهت معنایی). جاسازی کلمات متنی فراتر از ایده فوق الذکر نگاشت ورودی های واژگان به بردارهای متراکم است، و بازنمایی هایی را در نظر می گیرد که به بافت اطراف بستگی دارد (یعنی بازنمایی های پویا کلمه، در تقابل با نگاشت ایستا از کلمات به بردارها)، و بنابراین بهتر می توانند کلمات چند معنایی را مدیریت کنند. در مطالعه خود، ما از دو مورد از این روشها استفاده کردیم، بهویژه Embeddings from Language Models (ELMo) و Representations Encoder Bidirectional from Transformers (BERT).
به طور خلاصه، پیترز و همکاران. [ 23 ] تعبیههایی از مدلهای زبانی (ELMo) را بهعنوان رویکردی برای ایجاد جاسازیهای متنی از پیش آموزشدیدهشده برای کلمات ارائه کرد. برای متنی کردن بازنمودهای کلمه، ELMo کل جملات را با استفاده از یک مدل زبان عصبی (یعنی مدلی که میتواند توزیعهای احتمال را به دنبالههای کلمات اختصاص دهد) بررسی میکند که برای پیشبینی محتملترین کلمه بعدی با توجه به دنبالهای از کلمات آموزش داده شده است. مدل زبانی که توسط ELMo استفاده میشود با نمایش کلمات بر اساس کاراکترهایی که آنها را تشکیل میدهند (یعنی از طریق یک شبکه عصبی کانولوشنال ساده) شروع میشود و سپس بر پشتهای چند لایه از LSTMهای دو جهته تکیه میکند، همانطور که قبلا در بخش 3.1 توضیح داده شد.، برای تولید بازنمایی کلمه متنی. بنابراین، هنگام ایجاد تعبیههای کلمه، ELMo از کلمات قبلی و زیر به عنوان اطلاعات متنی استفاده میکند. برای به دست آوردن نمایشی برای هر کلمه، ELMo حالت پنهان هر لایه LSTM دو طرفه را در پشته محاسبه می کند و سپس مجموع وزنی این بردارها را محاسبه می کند.
با الهام گرفتن از ELMo، Devlin و همکاران. [ 24 ] بازنمایی رمزگذار دو جهته از ترانسفورماتورها (BERT) را با استفاده از یک مدل زبان مبتنی بر معماری عصبی ترانسفورماتور [ 43 ] به جای تکیه بر LSTMs (یعنی مدلسازی متن از طریق رمزگذارهای ترانسفورماتور، که از لایههای توجه به جای تکرار متوالی استفاده میکنند) پیشنهاد کرد. در تقابل با مدل های RNN جهت دار همانطور که در بخش 3.1 توضیح داده شد ، که ورودی متن را به صورت متوالی می خواند، رمزگذارهای ترانسفورماتور کل دنباله کلمات را یکجا می خوانند. بنابراین، این مدلها را میتوان دو جهته در نظر گرفت، هرچند میتوان گفت که آنها غیر جهته هستند.
بلوک ساختمانی اساسی مدل ترانسفورماتور مورد استفاده در BERT از دو لایه فرعی تشکیل شده است، یعنی یک لایه خود توجه و یک لایه متراکم پیشخور. این بلوک ها در یک معماری عمیق در کنار هم چیده شده اند. مدل به عنوان ورودی دنباله ای از قطعات کلمه را دریافت می کند (یعنی BERT واژگانی متشکل از چند کلمه کامل همراه با قطعات فرعی را در نظر می گیرد که می تواند در نمایش کلمات کمیاب استفاده شود) و هر یک از آنها به عنوان یک بردار نشان داده می شود. ، کلمه قطعه را همراه با موقعیت آن در دنباله نشان می دهد. هر لایه رمزگذار یک مکانیسم توجه به خود را روی ورودی اعمال میکند (یعنی رمزگذار را قادر میسازد تا کلمات دیگر موجود در دنباله ورودی را هنگام رمزگذاری یک کلمه خاص در نظر بگیرد)، نتیجه را از طریق یک لایه پیشخور پردازش میکند، و خروجی را به لایه رمزگذار بعدی این مدل از طریق یک هدف مدلسازی زبان پوشانده آموزش داده میشود، که در آن یک ماسک به 15 درصد از نشانههای ورودی اعمال میشود، پس از آن خروجی موقعیت کلمات پوشانده شده برای پیشبینی کلمات مربوطه استفاده میشود. این هدف آموزشی با یک کار پیشبینی جمله بعدی تکمیل میشود، جایی که به مدل یک جفت جمله داده میشود و آموزش داده میشود تا تشخیص دهد که چه زمانی مورد دوم از جمله اول پیروی میکند. هدف دوم این است که اطلاعات بلندمدت یا عملگرایانه بیشتری به دست آورد. که در آن به مدل یک جفت جمله داده می شود و آموزش داده می شود تا تشخیص دهد که چه زمانی مورد دوم از جمله اول پیروی می کند. هدف دوم این است که اطلاعات بلندمدت یا عملگرایانه بیشتری به دست آورد. که در آن به مدل یک جفت جمله داده می شود و آموزش داده می شود تا تشخیص دهد که چه زمانی مورد دوم از جمله اول پیروی می کند. هدف دوم این است که اطلاعات بلندمدت یا عملگرایانه بیشتری به دست آورد.
در عمل، ELMo و BERT کمی مفصل تر هستند و خواننده برای توضیح عمیق تر به انتشارات اصلی ارجاع داده می شود [ 23 ، 24 ]. در آزمایشهای خود، از مدلهای انگلیسی از پیش آموزشدیده در دسترس عموم استفاده کردیم، یعنی (i) مدل اصلی ELMo با در نظر گرفتن حالتهای پنهان LSTM با ابعاد 4096 و اندازه خروجی 512، و (ii) نسخه محفظهای از BERT اصلی. .
3.3. معماری عصبی برای تفکیک نام های نامی
مدل تشخیص نام نامی ما نمایشی از نام نامی ایجاد میکند که باید ابهامزدایی شود (یعنی هر مرجع مکانی را که قبلاً در یک سند متنی شناسایی شده بود پردازش میکند) همراه با بافت اطراف آن، و از آن برای ایجاد یک طبقهبندی منطقه بر اساس یک شبکه ژئودزیکی استفاده میکند. سپس توزیع احتمال از خروجی دسته بندی چند کلاسه برای بدست آوردن مختصات جغرافیایی (یعنی طول و عرض جغرافیایی) برای نام نام استفاده می شود.
سه توالی مختلف از کلمات به عنوان ورودی مدل ارائه شده است، به طور خاص (i) مکان ذکر شده، (ii) مجموعه کلمات اطراف ذکر (یعنی یک پنجره ثابت، در سمت چپ و راست دهانه متن). ، شامل 50 نشانه کلمه است و اغلب برای ثبت جملات و مرتبط ترین زمینه کافی است، و (iii) یک متن پاراگراف، که همچنین با یک پنجره ثابت از 512 نشانه تعریف شده است (یعنی حداکثر اندازه دنباله در نظر گرفته شده در BERT). هر دو ورودی جمله و پاراگراف، زمینه اطراف ذکر را در جهت های راست و چپ در نظر می گیرند. هر یک از سه ورودی ابتدا از طریق مکانیزم جاسازی کلمه متنی (یعنی با استفاده از ELMo یا BERT) به دنباله ای از بردارها تبدیل می شوند و سپس این بردارها توسط یک LSTM دو جهته پردازش می شوند.
ما به ترتیب با ارائه پاراگراف ذکر شده به شبکه عصبی (یعنی ارائه زمینه کلی سند) و یک پنجره متنی کوچکتر حاوی ذکر (به عنوان مثال) کلی و نزدیکترین زمینه اطراف موجودیت را در نظر می گیریم. ، گستره ای از متن که تقریباً با یک جمله مطابقت دارد). در هر دو مورد، زمینه ممکن است سرنخ هایی در مورد مکان ذکر ارائه دهد، به عنوان مثال، از طریق نام های دیگر. حتی کلمات رایج زبان موجود در متن اطراف ممکن است ویژگی های مناطق جغرافیایی خاص را به تصویر بکشند.
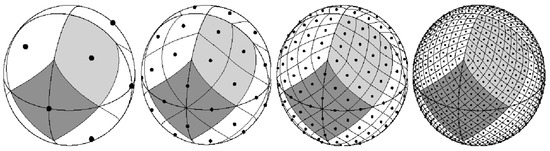
شبکه ژئودزیکی مورد استفاده برای پشتیبانی از هدف طبقهبندی چند کلاسه از طریق طرح پیکسلسازی isoLatitude منطقه مساوی سلسله مراتبی (HEALPix ( https://healpix.sourceforge.io (دسترسی در 10 نوامبر 2021)) ساخته شده است، پیشنهاد شده توسط Górski و همکاران. [ 25 ] و در مطالعات قبلی مربوط به کدگذاری جغرافیایی اسناد استفاده شده است [ 44 ]. به طور خلاصه، الگوریتم HEALPix یک نمایش کروی از سطح زمین را تقسیم بندی می کند و سلول هایی با مساحت مساوی مربوط به مناطق مجزا تولید می کند. پارتیشن ها به صورت سلسله مراتبی از بخش های بازگشتی جمع آوری می شوند و تعداد بخش های بازگشتی برای اجرا (یعنی وضوح مورد نظر) می تواند توسط کاربر تعریف شود. طرح پارتیشن بندی در شکل 1 نشان داده شده است، که شبکه حاصل از تقسیمات مربوط به پارامترهای وضوح چندگانه را با تفاوت در تعداد سلول های تولید شده نشان می دهد. تعداد نواحی تولید شده (یعنی سلول ها در شبکه ژئودزیکی) طبق رابطه ( 2 ) تعریف می شود، که در آن مربوط به قطعنامه مورد نظر است.
در زمینه این کار، پارامتر وضوح به ثابت شد ، که مربوط به در نظر گرفتن حداکثر 786432 منطقه است ( ). این وضوح به گونهای انتخاب شده است که اندازه منطقه به اندازه کافی بزرگ باشد تا نمونههای کافی از نامهای نامگذاری در برخی مناطق را در خود جای دهد. در عمل، با توجه به اینکه اکثر مناطق ممکن است با هیچ نمونه ای در مجموعه آموزشی مرتبط نباشند، تعداد کلاس ها بسیار کمتر خواهد بود.
مروری بر روش پیشنهادی در شکل 2 آورده شده است. سه ورودی متنی ابتدا از طریق جاسازیهای متنی ELMo یا BERT نشان داده میشوند (یعنی هر یک از این گزینهها را در آزمایشهای جداگانه آزمایش کردیم)، و دنبالههای بردارها توسط واحدهای LSTM دو جهته سفارشی، با ابعاد 512 پردازش میشوند. بردارهای حالت پنهان (یعنی 1024 مقدار، با توجه به استفاده از LSTM های دو جهته) و که از توابع فعال سازی مماس هذلولی جریمه شده، به جای توابع تانژانت سیگموئیدی لجستیک یا تانژانت هذلولی منظم استفاده می کنند (یعنی معادله ( 3 ) را ببینید). استفاده از تانژانت هذلولی جریمه شده، همانطور که در رابطه ( 3 ) نشان داده شده است، برای اولین بار توسط ایگر و همکاران پیشنهاد شد. [ 45]، که نتایج بهبود یافته را در سراسر انواع وظایف پردازش زبان طبیعی مشاهده کرد.
دنباله ای از حالات تولید شده توسط هر LSTM دو جهته از طریق عملیات max-pooling خلاصه می شود و سپس سه بردار حاصل به هم متصل می شوند تا یک نمایش فراگیر برای ورودی ها تشکیل دهند. سپس این نمایش توسط یک لایه کاملاً متصل پردازش میشود، که نواحی HEALPix را پیشبینی میکند (یعنی توزیع احتمال را بر روی مناطق احتمالی HEALPix ایجاد میکند) از طریق یک تابع فعالسازی soft-max. این بردار احتمال کلاس HEALPix یکی از خروجی های مدل است (یعنی یک تابع تلفات متقابل آنتروپی طبقه ای بر روی این نتیجه محاسبه می شود)، و به طور همزمان برای تخمین مختصات جغرافیایی مربوطه نیز استفاده می شود. به طور خاص، مقادیر احتمال به توان سوم افزایش یافته و مجدداً عادی می شوند (یعنی توزیع اوج بیشتری از نتایج Soft-max ساخته می شود، با تاکید بر محتمل ترین ناحیه)، و سپس نتایج به عنوان وزن توسط یک طرح درون یابی استفاده می شود که یک ماتریس مختصات مرکز را در نظر می گیرد (یعنی یک ماتریس ثابت که حاوی مختصات مرکز هر کلاس HEALPix است، که در آن هر ردیف مربوط به یک متمایز است. کلاس). از نظر عملی، ما حاصل ضرب را بین بردار احتمال تنظیم شده مجدد و ماتریس مختصات مرکز برای تخمین مختصات محاسبه می کنیم و نتیجه به دست آمده به تابع تلف دوم متصل می شود که فاصله دایره بزرگ بین پیش بینی شده و زمین را محاسبه می کند. مختصات حقیقت بنابراین، آموزش مدل شامل به حداقل رساندن توابع از دست دادن ترکیبی مرتبط با هر یک از خروجی ها است، که هر یک به طور متقابل فرآیند یادگیری را هدایت می کنند و امیدواریم به نتایج کلی بهتر کمک کنند. و سپس نتایج به عنوان وزن توسط یک طرح درون یابی که یک ماتریس مختصات مرکز را در نظر می گیرد (یعنی یک ماتریس ثابت که شامل مختصات مرکز هر کلاس HEALPix است، که در آن هر ردیف مربوط به یک کلاس مجزا است) استفاده می شود. از نظر عملی، ما حاصل ضرب را بین بردار احتمال تنظیم شده مجدد و ماتریس مختصات مرکز برای تخمین مختصات محاسبه می کنیم و نتیجه به دست آمده به تابع تلف دوم متصل می شود که فاصله دایره بزرگ بین پیش بینی شده و زمین را محاسبه می کند. مختصات حقیقت بنابراین، آموزش مدل شامل به حداقل رساندن توابع از دست دادن ترکیبی مرتبط با هر یک از خروجی ها است، که هر یک به طور متقابل فرآیند یادگیری را هدایت می کنند و امیدواریم به نتایج کلی بهتر کمک کنند. و سپس نتایج به عنوان وزن توسط یک طرح درون یابی که یک ماتریس مختصات مرکز را در نظر می گیرد (یعنی یک ماتریس ثابت که شامل مختصات مرکز هر کلاس HEALPix است، که در آن هر ردیف مربوط به یک کلاس مجزا است) استفاده می شود. از نظر عملی، ما حاصل ضرب را بین بردار احتمال تنظیم شده مجدد و ماتریس مختصات مرکز برای تخمین مختصات محاسبه می کنیم و نتیجه به دست آمده به تابع تلف دوم متصل می شود که فاصله دایره بزرگ بین پیش بینی شده و زمین را محاسبه می کند. مختصات حقیقت بنابراین، آموزش مدل شامل به حداقل رساندن توابع از دست دادن ترکیبی مرتبط با هر یک از خروجی ها است، که هر یک به طور متقابل فرآیند یادگیری را هدایت می کنند و امیدواریم به نتایج کلی بهتر کمک کنند. یک ماتریس ثابت که شامل مختصات مرکز هر کلاس HEALPix است که در آن هر ردیف مربوط به یک کلاس مجزا است. از نظر عملی، ما حاصل ضرب را بین بردار احتمال تنظیم شده مجدد و ماتریس مختصات مرکز برای تخمین مختصات محاسبه می کنیم و نتیجه به دست آمده به تابع تلف دوم متصل می شود که فاصله دایره بزرگ بین پیش بینی شده و زمین را محاسبه می کند. مختصات حقیقت بنابراین، آموزش مدل شامل به حداقل رساندن توابع از دست دادن ترکیبی مرتبط با هر یک از خروجی ها است، که هر یک به طور متقابل فرآیند یادگیری را هدایت می کنند و امیدواریم به نتایج کلی بهتر کمک کنند. یک ماتریس ثابت که شامل مختصات مرکز هر کلاس HEALPix است که در آن هر ردیف مربوط به یک کلاس مجزا است. از نظر عملی، ما حاصل ضرب را بین بردار احتمال تنظیم شده مجدد و ماتریس مختصات مرکز برای تخمین مختصات محاسبه می کنیم و نتیجه به دست آمده به تابع تلف دوم متصل می شود که فاصله دایره بزرگ بین پیش بینی شده و زمین را محاسبه می کند. مختصات حقیقت بنابراین، آموزش مدل شامل به حداقل رساندن توابع از دست دادن ترکیبی مرتبط با هر یک از خروجی ها است، که هر یک به طور متقابل فرآیند یادگیری را هدایت می کنند و امیدواریم به نتایج کلی بهتر کمک کنند. ما حاصلضرب بین بردار احتمال تنظیم شده مجدد و ماتریس مختصات مرکز را محاسبه می کنیم تا مختصات را تخمین بزنیم، و نتیجه به دست آمده سپس به تابع ضرر دوم متصل می شود که فاصله دایره بزرگ بین مختصات پیش بینی شده و حقیقت زمین را محاسبه می کند. بنابراین، آموزش مدل شامل به حداقل رساندن توابع از دست دادن ترکیبی مرتبط با هر یک از خروجی ها است، که هر یک به طور متقابل فرآیند یادگیری را هدایت می کنند و امیدواریم به نتایج کلی بهتر کمک کنند. ما حاصلضرب بین بردار احتمال تنظیم شده مجدد و ماتریس مختصات مرکز را محاسبه می کنیم تا مختصات را تخمین بزنیم، و نتیجه به دست آمده سپس به تابع ضرر دوم متصل می شود که فاصله دایره بزرگ بین مختصات پیش بینی شده و حقیقت زمین را محاسبه می کند. بنابراین، آموزش مدل شامل به حداقل رساندن توابع از دست دادن ترکیبی مرتبط با هر یک از خروجی ها است، که هر یک به طور متقابل فرآیند یادگیری را هدایت می کنند و امیدواریم به نتایج کلی بهتر کمک کنند.
علاوه بر مناطق HEALPix و مختصات ژئوفضایی، ما سعی کردیم ویژگیهای زمین ژئوفیزیکی مرتبط با مناطق پیشبینیشده HEALPix را تخمین بزنیم، به این امید که مدل را بیشتر به سمت پیشبینیهای مکان صحیح هدایت کنیم. مشابه آنچه برای پیشبینی مختصات ژئوفضایی ساخته شد، از مقادیر احتمال کلاس تنظیمشده به عنوان وزنهای درونیابی، همراه با ماتریسی که ویژگیهای زمین ژئوفیزیکی را در مختصات مرکز هر سلول HEALPix کد میکند، استفاده کردیم. مجموعه ای از بردارهای ستونی، یکی برای هر ویژگی، با مقادیر عددی برای هر یک از مناطق مختلف HEALPix ایجاد شد. سپس خواص ژئوفیزیکی پیشبینیشده با ارزشهای دارایی واقعی مرتبط با مکان واقعی نام، با استفاده از توابع تلفات اضافی مربوط به تفاوت مطلق مقایسه شد.
ما از الگوریتم بهینهسازی آدام برای آموزش مدل از طریق انتشار مجدد استفاده کردیم، با یک خطمشی نرخ یادگیری چرخهای که نرخ یادگیری را در طول آموزش تنظیم میکند [ 46 ]، بر اساس چرخهای بین یک مرز پایینتر از و یک کران بالایی از . با توجه به این واقعیت که توابع آنتروپی متقاطع، فاصله دایره بزرگ و توابع از دست دادن خطای مطلق مقادیری را در محدوده های مختلف تولید می کنند، ما سهم هر تابع را در تلفات ترکیبی وزن کردیم (یعنی وزن 100 به یک به آن داده شد. آنتروپی متقاطع طبقهای در رابطه با مقادیر دیگر، از طریق مجموعهای از آزمایشهای اولیه که تأثیر این پارامتر را ارزیابی میکند، و همچنین نتایج بهتری را هنگام ترکیب آنتروپی متقاطع و توابع کاهش فاصله دایره بزرگ تأیید میکند. یک استراتژی توقف زودهنگام (یعنی راهی برای منظمسازی که برای غلبه بر تناسب بیش از حد مورد استفاده قرار میگیرد، که در آن فرآیند آموزش زمانی که عملکرد مدل بهبود نمییابد متوقف میشود) نیز به کار گرفته شد، که آموزش را مجبور میکند زمانی که از دست دادن ترکیبی در دادههای آموزشی متوقف شد، متوقف شود. برای پنج دوره متوالی بهبود نیافته است.
4. ارزیابی تجربی
این بخش در مورد ارزیابی تجربی مدل ارائه شده در این کار گزارش می دهد. بخش 4.1 هم روش ارزیابی و هم مجموعه کامل آزمایشهایی را که انجام شده است شرح میدهد. به نوبه خود، بخش 4.2 نتایج به دست آمده و تجزیه و تحلیل آنها را ارائه می دهد، در حالی که بخش 4.3 یک بحث خلاصه در مورد یافته های کلیدی و محدودیت های اصلی ارائه می دهد.
4.1. روش ارزیابی تجربی
با استفاده از معماری عصبی عصبی و روش کلی شرح داده شده در بخش 3.3 ، که در شکل 2 نیز نشان داده شده است، آزمایش هایی را با چندین رویکرد جایگزین انجام دادیم، یعنی شامل استفاده از (i) ELMo، (ii) BERT، (ii) داده های ویکی پدیا برای تقویت نمونه های آموزشی، و (iii) اطلاعات خارجی مربوط به خواص ژئوفیزیکی. در ادامه توضیح کوتاهی برای هر یک از این گزینه ها ارائه می شود.
-
مدلهای ELMo – این با رویکرد پایه ما مطابقت دارد، از شبکههای عصبی بازگشتی همانطور که در بخش 3.2 توضیح داده شد ، و از روش ELMo برای ایجاد تعبیههای متنی هنگام نمایش ورودیهای متنی استفاده میکند.
-
مدلهای BERT – برای مشاهده تأثیر استفاده از روشهای مختلف نمایش متن، ELMo را با تعبیههای متنی کلمه BERT جایگزین کردیم. این رویکرد خاص، بر اساس معماری عصبی ترانسفورماتور و همچنین در بخش 3.2 شرح داده شده است، قبلا نشان داده شده است که نتایج برتر را در طیف وسیعی از وظایف NLP ارائه می دهد.
-
مدل های ویکی پدیا— برای درک تأثیر اندازه مجموعه داده آموزشی، مجموعه جدیدی شامل مقالات تصادفی جمع آوری شده از ویکی پدیای انگلیسی ایجاد کردیم. ما پیوندهای موجود به سمت صفحات مرتبط با مختصات جغرافیایی را شناسایی کردیم و متن مقاله منبع، متن ابرپیوند (یعنی مرجع مکان تولید شده به طور خودکار)، و مختصات جغرافیایی هدف را جمع آوری کردیم. این دادهها برای ایجاد نمونههای آموزشی اضافی مورد استفاده قرار گرفتند، که سپس برای مطابقت با مناطق HEALPix موجود در مجموعه اصلی فیلتر شدند. بنابراین، ویکیپدیا برای تقویت نمونههای آموزشی موجود، بدون تغییر فضای طبقهبندی منطقه هر مجموعه استفاده شد. آزمایشها با جاسازیهای ELMo یا BERT، در تنظیماتی که شامل دادههای ویکیپدیا بود، انجام شد. در مجموع 15،
-
مدلهایی که ویژگیهای ژئوفیزیکی را ادغام میکنندما همچنین با استفاده از اطلاعات اضافی مربوط به ویژگیهای زمین ژئوفیزیکی مرتبط با هر یک از مناطق HEALPix، یعنی توسعه زمین (به عنوان مثال، کمی سازی میزان نفوذناپذیر/توسعه یافته در مقابل زمین طبیعی، استنتاج شده از مجموعه دادههای پوشش زمین تاریخی در مورد آزمایشات با پیکره WOTR، و از منابع مدرن در موارد باقی مانده)، درصد پوشش گیاهی، ارتفاع زمین، و حداقل فاصله از مناطق آبی. ما این اطلاعات را از مجموعه دادههای شطرنجی عمومی جمعآوری کردیم، و آن را با استفاده از تکنیکی مشابه با درونیابی مختصات جغرافیایی در مدل گنجاندیم. به طور خاص، ما هر یک از چهار ویژگی ژئوفیزیکی را به عنوان مقادیر واقعی رمزگذاری کردیم، و سپس بردارهای ستونی با مقادیر مربوط به اندازه گیری های مربوط به مختصات مرکز هر کلاس HEALPix ایجاد کرد. سپس ما یک محصول نقطهای را بین هر یک از بردارهای ستون و بردار احتمال کلاس HEALPix تنظیمشده محاسبه کردیم، که منجر به تخمینهایی برای خواص ژئوفیزیکی شد. توابع تلفات اضافی در مدل گنجانده شد که مربوط به تفاوت مطلق بین مقادیر پیشبینیشده و ارزشهای واقعی است. شهود اصلی پشت این مجموعه آزمایشها به این موضوع مربوط میشود که ببینیم آیا ویژگیهای ژئوفیزیکی زمین، که احتمالاً در متن پیرامون منابع مکان توصیف شدهاند، میتواند وظیفه پیشبینی مختصات جغرافیایی را هدایت کند یا خیر. مانند مورد قبلی، آزمایشها تحت این تنظیم با جاسازیهای کلمه متنی ELMo یا BERT انجام شد. سپس ما یک محصول نقطهای را بین هر یک از بردارهای ستون و بردار احتمال کلاس HEALPix تنظیمشده محاسبه کردیم، که منجر به تخمینهایی برای خواص ژئوفیزیکی شد. توابع تلفات اضافی در مدل گنجانده شد که مربوط به تفاوت مطلق بین مقادیر پیشبینیشده و ارزشهای واقعی است. شهود اصلی پشت این مجموعه آزمایشها به این موضوع مربوط میشود که ببینیم آیا ویژگیهای ژئوفیزیکی زمین، که احتمالاً در متن پیرامون منابع مکان توصیف شدهاند، میتواند وظیفه پیشبینی مختصات جغرافیایی را هدایت کند یا خیر. مانند مورد قبلی، آزمایشها تحت این تنظیم با جاسازیهای کلمه متنی ELMo یا BERT انجام شد. سپس ما یک محصول نقطهای را بین هر یک از بردارهای ستون و بردار احتمال کلاس HEALPix تنظیمشده محاسبه کردیم، که منجر به تخمینهایی برای خواص ژئوفیزیکی شد. توابع تلفات اضافی در مدل گنجانده شد که مربوط به تفاوت مطلق بین مقادیر پیشبینیشده و ارزشهای واقعی است. شهود اصلی پشت این مجموعه آزمایشها به این موضوع مربوط میشود که ببینیم آیا ویژگیهای ژئوفیزیکی زمین، که احتمالاً در متن پیرامون منابع مکان توصیف شدهاند، میتواند وظیفه پیشبینی مختصات جغرافیایی را هدایت کند یا خیر. مانند مورد قبلی، آزمایشها تحت این تنظیم با جاسازیهای کلمه متنی ELMo یا BERT انجام شد. توابع تلفات اضافی در مدل گنجانده شد که مربوط به تفاوت مطلق بین مقادیر پیشبینیشده و ارزشهای واقعی است. شهود اصلی پشت این مجموعه آزمایشها به این موضوع مربوط میشود که ببینیم آیا ویژگیهای ژئوفیزیکی زمین، که احتمالاً در متن پیرامون منابع مکان توصیف شدهاند، میتواند وظیفه پیشبینی مختصات جغرافیایی را هدایت کند یا خیر. مانند مورد قبلی، آزمایشها تحت این تنظیم با جاسازیهای کلمه متنی ELMo یا BERT انجام شد. توابع تلفات اضافی در مدل گنجانده شد که مربوط به تفاوت مطلق بین مقادیر پیشبینیشده و ارزشهای واقعی است. شهود اصلی پشت این مجموعه آزمایشها به این موضوع مربوط میشود که ببینیم آیا ویژگیهای ژئوفیزیکی زمین، که احتمالاً در متن پیرامون منابع مکان توصیف شدهاند، میتواند وظیفه پیشبینی مختصات جغرافیایی را هدایت کند یا خیر. مانند مورد قبلی، آزمایشها تحت این تنظیم با جاسازیهای کلمه متنی ELMo یا BERT انجام شد. که احتمالاً در متن پیرامون مراجع مکان توضیح داده شده است، می تواند وظیفه پیش بینی مختصات جغرافیایی را هدایت کند. مانند مورد قبلی، آزمایشها تحت این تنظیم با جاسازیهای کلمه متنی ELMo یا BERT انجام شد. که احتمالاً در متن پیرامون مراجع مکان توضیح داده شده است، می تواند وظیفه پیش بینی مختصات جغرافیایی را هدایت کند. مانند مورد قبلی، آزمایشها تحت این تنظیم با جاسازیهای کلمه متنی ELMo یا BERT انجام شد.
سه مجموعه داده معروف، که قبلاً در بخش 2.5 توضیح داده شد ، برای حمایت از ارزیابی مقایسه ای جایگزین های مدل سازی مختلف، به ویژه (i) مجموعه واژگان محلی-جهانی (LGL) [ 32 ]، (ii) پیکره SpatialML [ 33 ] استفاده شد. ]، و (iii) مجموعه جنگ شورش (WOTR) [ 30]. اسناد درون این مجموعهها منابع متفاوتی دارند (یعنی گزارشهای تاریخی، مقالات خبری از روزنامههای محلی و اخبار بینالمللی)، که طبیعتاً با ویژگیهای اسناد کمی متفاوت نیز مطابقت دارند. به عنوان مثال، SpatialML عمدتاً بر اساس مقالات خبری بینالمللی است که احتمالاً گستردهتر و با ارجاعات نام عمومیتر از سایر مجموعههای داده است. جدول 1 یک توصیف آماری از مجموعه داده های مختلف، از جمله جنبه هایی مانند طول متوسط سند یا تعداد نام های نامی در هر سند را ارائه می دهد.
ما سعی کردیم شرایط تجربی مطالعات قبلی را شبیهسازی کنیم، که امکان مقایسه عملکرد و نتایج مدل را فراهم کرد. دقیقاً همان تقسیمبندی دادههایی که توسط نویسندگان به اشتراک گذاشته شد در آزمایشها با مجموعه WOTR استفاده شد (یعنی همان تقسیم اسناد به مجموعههای داده آموزشی و آزمایشی). در مورد LGL و SpatialML، داده ها به طور تصادفی با در نظر گرفتن 90٪ از اسناد برای آموزش، و 10٪ اضافی برای آزمایش تقسیم شدند (یعنی مجموعه داده های آموزشی و آزمایشی فقط حاوی مراجع مکان ارائه شده در اسناد مختلف بودند). نتایج اندازه گیری شده روی مجموعه داده های LGL و SpatialML به طور مستقیم با نتایج گزارش شده در مطالعات قبلی قابل مقایسه نیستند، اگرچه تفاوت های بزرگ با این وجود باید نشان دهنده باشد.
برای محاسبه مناطق HEALPix بر روی سطح زمین، همانطور که در بخش 3.3 توضیح داده شد ، و برای تبدیل بین مختصات طول و عرض جغرافیایی و مناطق HEALPix، از کتابخانه هلپی پایتون ( https://pypi.org/project/healpy/ ) استفاده کردیم. مشاهده شده در 10 نوامبر 2021)). بازنمایی محتوای متن از طریق جاسازیهای متنی کلمه متکی بر ELMo از پیش آموزشدیده ( https://allennlp.org/elmo (دسترسی در 10 نوامبر 2021)) و BERT ( https://github.com/google-research/bert ( مشاهده شده در 10 نوامبر 2021)) مدل ها. مدل یادگیری عمیق پیشنهادی به نوبه خود از طریق کتابخانه keras Python ( https://keras.io (دسترسی در 10 نوامبر 2021) اجرا شد.
برای ارزیابی عملکرد پیشبینی مختصات جغرافیایی مربوط به هر نام، فاصله بین مختصات ژئوفضایی پیشبینیشده و حقیقت زمین با استفاده از فرمولهای ژئودزیکی وینسنتی محاسبه شد [ 47 ].] (یعنی یک روش شناخته شده برای محاسبه کوتاه ترین فواصل جغرافیایی بین جفت نقاط روی سطح زمین، با دستیابی به دقت در 0.5 میلی متر). از اندازهگیریهای خطای فردی (یعنی از فواصل بین تخمینها و حقیقت زمین)، میانگین و میانه فاصله بر حسب کیلومتر و همچنین دقت (یعنی درصد نتایج صحیح) در آستانهای در فاصله محاسبه شد. مقادیر مربوط به 161 کیلومتر. تمام معیارهای ذکر شده معمولاً در مطالعات قبلی مربوط به کدگذاری جغرافیایی اسناد یا تفکیک نام های نامی مورد استفاده قرار گرفته اند.
4.2. نتایج به دست آمده
جدول 2 نتایج بهدستآمده توسط مدل پایه ما (یعنی مدل با استفاده از ELMo) را خلاصه میکند، و آنها را با نتایج گزارششده در نشریات قبلی که از مجموعه دادههای یکسان و معیارهای ارزیابی استفاده کردهاند مقایسه میکند (یعنی مطالعات قبلی مانند مطالعات لیبرمن و همکاران همکاران [ 32] از مجموعه دادههای LGL و SpatialML نیز استفاده کردهاند، اما این نویسندگان در عوض عملکرد را از طریق معیارهای دقیق و یادآوری، از نظر یافتن مطابقت صحیح با ورودیهای روزنامه اندازهگیری کردهاند. مدل پیشنهادی به نتایج بسیار جالبی دست یافت که در بیشتر موارد از وضعیت قبلی پیشی گرفت. ما به طور خاص فاصلههای خطای متوسط بسیار کم را در مجموعه دادههای WOTR و LGL، با اختلاف منفی 281 و 463 کیلومتر، در مقایسه با بهترین نتایج قبلی، اندازهگیری کردیم. در پیکره SpatialML، یادگیری رتبه بندی سیستم از Santos و همکاران. هنوز هم بهترین خطای میانگین فاصله را ثبت می کند، اگرچه مدل ما به خطای میانگین فاصله بسیار بهتری رسیده است. توجه به این نکته مهم است که منابعی مانند ویکیپدیا یا روزنامههای تحت پوشش جهانی مانند GeoNames ( https://www.geonames.org(دسترسی در 10 نوامبر 2021))، در حاشیه نویسی مجموعه های تفکیک نامی استفاده شده است. از این رو، مختصات جغرافیایی-مکانی داده شده در حقیقت زمین اغلب دقیقاً با مختصات مرتبط با ورودی های خاص در این منابع مطابقت دارد. سیستمهایی که به تطابق روزنامهها متکی هستند، مانند سیستم یادگیری رتبهبندی از سانتوس و همکاران. می تواند تا حدودی از تنظیمات آزمایشی که در نظر گرفته شد، اندازه گیری فواصل به سمت مختصات ژئو فضایی حقیقت زمینی بهره مند شود. با این حال، بدون درگیر کردن تطبیق روزنامه، رویکرد ما به طور متوسط می تواند به نتایج بسیار دقیقی دست یابد.
جدول 3 نتایج بهدستآمده در مجموعه دوم آزمایشها را نشان میدهد که در آن ما جایگزینهای مدلسازی مختلف را آزمایش کردیم (به عنوان مثال، استفاده از BERT به جای ELMo، و در نظر گرفتن دادههای آموزشی اضافی یا ویژگیهای ژئوفیزیکی). نتایج نشان میدهد که روش نمایش متنی تأثیر جدی بر نتایج دارد، با جاسازیهای متنی BERT که نتایج بهتری را در تمام مجموعههای داده به دست میآورد (یعنی به طور متوسط، بهبود 41 کیلومتر برای میانگین خطا، 0.3 کیلومتر برای خطای متوسط. ، و افزایش 3.9٪ به میزان دقت@161 )، به جز در خطای میانه روی مجموعه داده SpatialML (یعنی جدول 3)نشان میدهد که همه گزینههای مختلف با در نظر گرفتن دقت عددی دو رقم اعشاری، فاصله خطای میانهای را در مجموعه داده SpatialML به دست آوردند.
افزایش اندازه دادههای آموزشی با نمونههای آموزشی بیشتر جمعآوریشده از ویکیپدیا، اگرچه بهطور مداوم انجام نمیشود، اما اغلب منجر به بهبود جزئی در نتایج میشود. به عنوان مثال، در پیکره LGL و هر دو با تعبیههای ELMo یا BERT، افزایش میانگین خطا، افزایش در اندازهگیری دقت @161 و کاهش جزئی در خطای میانه مشاهده شد. لازم به ذکر است که دادههای ویکیپدیا ویژگیهای بسیار متفاوتی با اسناد مرتبط با مجموعههای مختلف (مثلاً گزارشهای تاریخی یا مقالات خبری) دارند، که شاید مانع از نتایج شوند. آزمایشهای آینده احتمالاً میتوانند به جای افزایش مجموعه نمونههای آموزشی، پیشآموزش مدل را با دادههای ویکیپدیا و به دنبال آن تنظیم دقیق در مجموعههای خاص دامنه در نظر بگیرند.
در مورد آزمایشهای مربوط به اطلاعات ژئوفیزیکی، هم با تعبیههای ELMo یا BERT، ما فقط پیشرفتهای جزئی و ناسازگاری را نسبت به نتایج ثبت کردیم. در مجموعه دادههای WOTR و SpatialML، به نظر میرسد که مدل از افزودن اطلاعات ژئوفیزیکی سود میبرد، در حالی که در مجموعه LGL مدل ادغام اطلاعات ژئوفیزیک بدتر عمل میکند. در کار آینده، ما قصد داریم یک ارزیابی عمیق تر در مورد سهم خواص ژئوفیزیکی مختلف انجام دهیم، همچنین تخصیص خواص ژئوفیزیکی حقیقت زمین به مناطق HEALPix را بهبود ببخشیم.
علاوه بر ارزیابیهای سطح بالا از نظر خطاهای فاصله کلی، ما همچنین سعی کردیم موارد خاصی را که در آن مدلها به درستی یا نادرست انجام شدهاند، در تلاش برای شناسایی الگوها در نتایج تجزیه و تحلیل کنیم. جدول 4 ارجاعات نام مکان را نشان می دهد که از هر یک از مجموعه داده ها گرفته شده است، که برای آن مدل پایه (یعنی مدلی که از جاسازی های ELMo استفاده می کند، بدون داده های آموزشی ویکی پدیا و استفاده از ویژگی های زمین فیزیکی) کمترین یا بالاترین فاصله را ایجاد کرده است. مکانهایی که خطای پیشبینی پایینی داشتند شامل نامهای شیطانی (به عنوان مثال، انگلیسی در پیکره SpatialML، حلوفصل به انگلستان ، بریتانیامکان با خطای کوچک 2.44 کیلومتر)، یا مکانهای کوچکی که از طریق نامهای محلی مشخص شدهاند (به عنوان مثال، مورد دریاچه بزرگ اوون در مجموعه WOTR). اینها احتمالاً در رویکردهایی که بر تطبیق روزنامهها تکیه میکنند، بهدرستی ابهامزدایی میکنند. ارجاعات نامی با خطای فاصله زیاد شامل اسامی بسیار مبهم (مثلاً Capital در پیکره SpatialML)، یا ارجاع به مناطق بزرگ (مثلاً آمریکای شمالی در مجموعه LGL) است. اگرچه جدول 4 فقط نمونه هایی را برای مدل پایه نشان می دهد، نتایج مشابهی نیز با سایر گزینه های مدل سازی به دست می آید (یعنی بسیاری از نام مکان های مشابه همچنان در لیست هایی که دارای خطاهای کمتر/بالا هستند دیده می شوند).
جدول 5 نتایج بهدستآمده با مدل پایه را نشان میدهد و نمونههایی از گفتههای متنی حاوی ارجاعات مکانی را به همراه مکانهای جغرافیایی-مکانی مربوط به پیشبینیها و حقیقت زمینی نشان میدهد. در هر مثال، نامها برجسته میشوند، و نقشه مربوطه مکان واقعی (نقاط سبز) و مکانهای پیشبینیشده (نقاط قرمز)، از جمله مطابقت بین این نقاط را نشان میدهد که با خطوط سیاه به تصویر کشیده شدهاند. موارد متمایز که در آن خطا در بین نقاط پیش بینی شده و واقعی یا کوچک یا به طور قابل توجهی بزرگ است نشان داده شده است. توجه داشته باشید که برخی از مثالها شامل نامهایی هستند که در مجاورت یکدیگر وجود دارند (مثلاً ممفیس ، تن.در مثال اول)، که می تواند سرنخ هایی در مورد مکان ها ارائه دهد. در مثال سوم، همه نامها دارای مکانهایی با خطاهای کوچک هستند که با فاصله متوسط نزدیک به 16.6 کیلومتر تعیین شدهاند، که در میان آنها اشاره به مکان کوچکی به نام پاریس نشان داده شده است (یعنی یک نام مکان مبهم معمول که مدل به خوبی با استفاده از کمک از زمینه اطراف).
4.3. بحث در مورد نتایج کلی
به طور کلی، نتایج بهدستآمده برتری روش پیشنهادی را نسبت به روشهای قبلی تأیید میکند و به طور قابلتوجهی بهتر از وضعیت قبلی هنر است.
قبلاً نشان داده شده بود که استفاده از جاسازی کلمات متنی برای طیف وسیعی از وظایف NLP مفید است، به ویژه هنگامی که شامل مقادیر نسبتاً کمی از داده های آموزشی مشروح شده است. نتایج ما بیشتر این مشاهدات را تأیید میکند، و بهویژه ما نتایج بهتری را با تعبیههای BERT در مقایسه با مدل پایه ما که از تعبیههای ELMo استفاده میکند، مشاهده کردیم. افزایش مجموعه دادههای آموزشی با نمونههای خارج از دامنه جمعآوریشده از ویکیپدیا، یا افزودن اطلاعات در مورد ویژگیهای زمین ژئوفیزیکی، نتایج را به میزان اندکی بهبود بخشید. با این حال، برای ارزیابی بیشتر سهم هر دوی این ایدهها، باید آزمایشهای بیشتری در نظر گرفته شود. به عنوان مثال، نمونه های بسیار بزرگتری از نمونه های ویکی پدیا را می توان برای گسترش مجموعه داده های آموزشی در نظر گرفت.
استفاده از اطلاعات خارجی برای گرفتن ویژگی های زمین یک جهت تحقیقاتی جالب توجه است که مایلیم آن را با جزئیات بیشتری دنبال و ارزیابی کنیم. به عنوان مثال، میتوانیم تخصیص اندازهگیریهای حقیقت زمین را به سلولهای HEALPix، با استفاده از آمار منطقهای به جای جمعآوری دادهها برای مختصات مرکز هر سلول، بهبود ببخشیم. چهار ویژگی متفاوتی که در آزمایشهای اولیه ما در نظر گرفته شدهاند، ممکن است همه به یک اندازه آموزنده نباشند، و منابع اطلاعاتی اضافی (مثلاً شطرنجیهایی که تراکم جمعیت انسانی را رمزگذاری میکنند، که به عنوان پیشین در بسیاری از سیستمهای تفکیک نام نامی استفاده میشود، یا اطلاعات مربوط به استفاده از زمین مشتق شده است. از OpenStreetMap) نیز می تواند در نظر گرفته شود. به جای محصولات سطح بالا که از سنجش از دور بدست می آیند،
همه آزمایشهای ما روی سختافزار نسبتاً متوسطی (مثلاً رایانههای شخصی استاندارد با پردازندههای گرافیکی Titan Xp، دارای 12 گیگابایت حافظه) انجام شد، همچنین زمان کوتاهی برای آموزش و ارزیابی مدل صرف شد (مثلاً، آموزش فقط چند ساعت طول میکشد، در هر یک از مجموعه داده های در نظر گرفته شده). این به این دلیل است که آموزش شامل بهروزرسانی تعداد نسبتاً کمی از پارامترها است، با توجه به اینکه مدلهایی که تعبیههای ELMo یا BERT را محاسبه میکنند ثابت نگه داشته میشوند (یعنی فقط لایههای LSTM دو طرفه ما و لایه پیشخور مرتبط با پیشبینیهای کلاس ، تنظیم می شوند). با این حال، برای کار آینده، آزمایش با تنظیم دقیق یک مدل BERT برای تفکیک نام نامها (بهعنوان مثال، بهجای پردازش لایههای دو طرفه LSTM که جداگانه محاسبه میشوند، مستقیماً از BERT استفاده کنید) جالب خواهد بود.
5. نتیجه گیری و کار آینده
این مقاله به مشکل وضوح نام نامی پرداخته و یک معماری شبکه عصبی جدید را که به طور خاص برای این کار طراحی شده است، پیشنهاد میکند. شبکه ورودیهای متنی متعددی را در نظر میگیرد که متناظر با نام نام ابهامزدایی بهعلاوه اطلاعات متنی مرتبط است، و از جاسازیهای متنی از پیش آموزشدیدهشده (ELMo یا BERT) برای نمایش متن استفاده میکند. علاوه بر این، شبکه عصبی همچنین خروجیهای متعددی را در نظر میگیرد و توزیع احتمال را بر روی مناطق جغرافیایی-فضایی درشت دانه پیشبینی میکند و سپس از این توزیع احتمال برای هدایت پیشبینی مختصات جغرافیایی-مکانی عرض و طول جغرافیایی منطبق با نام ورودی استفاده میکند.
ما آزمایشهای ارزیابی را با سه مجموعه داده که بهطور گسترده در مطالعات قبلی مورد استفاده قرار میگرفت، انجام دادیم و تأثیر جایگزینهای مدلسازی مختلف (به عنوان مثال، استفاده از BERT در مقابل تعبیههای ELMo، استفاده از دادههای آموزشی اضافی جمعآوریشده از ویکیپدیا، یا استفاده از اطلاعات خارجی در مورد ویژگیهای زمین ژئوفیزیکی برای هدایت آموزش مدلها را ارزیابی کردیم. ). به طور کلی، نتایج تجربی نشان میدهد که رویکرد پیشنهادی میتواند به وضوح از روشهای گزارششده قبلی در مجموعه دادههای مشابه پیشی بگیرد.
برای کار آینده، ممکن است جالب باشد که تعبیههای چند زبانه یا چند زبانه (مثلاً مدلهای BERT چند زبانه منتشر شده توسط Google) را بررسی کنیم تا از ایده استفاده از دادههای موجود در یک (مجموعه) زبان (مجموعهای از) معین پشتیبانی شود. ) و رویکردی را طراحی کنید که قادر به کار بر روی متون از زبان های متمایز باشد. علاوه بر ELMo و BERT، مدلهای متنی متعدد دیگری برای جاسازی کلمه وجود دارد که میتوان آنها را بررسی کرد [ 40 ، 41 ، 48 ، 49 ]، از قبل با مجموعه دادههای بزرگتر آموزش دید و/یا اهداف مدلسازی زبان اضافی را در نظر گرفت. یک مثال RoBERTa [ 50]، یک نسخه بهینه از BERT (یعنی آموزش داده شده با مینی دسته های بزرگتر، داده های بیشتر و برای مدت زمان بیشتر، در نظر گرفتن یک سیاست متفاوت برای تنظیم نرخ یادگیری، و حذف هدف قبل از آموزش در مورد پیش بینی موارد بعدی. جمله) که نشان داده شده است موثرتر است و نتایج پیشرفتهای را در طیف وسیعی از وظایف ایجاد میکند. نمونه های دیگر عبارتند از مدل هایی مانند LUKE [ 51 ] یا ERICA [ 52]، برای به تصویر کشیدن بهتر موجودیت ها و روابط بین موجودات در متن، از قبل آموزش داده شده است، و از این رو شاید در کارهایی که شامل سر و کار با نام های نامی است نیز بهتر عمل کند. شاید جالبتر از آن، بهجای استفاده از مدلهای تعبیه متنی از پیش آموزشدیده بهعنوان استخراجکننده ویژگی (یعنی در تولید نمایشهای ثابت که سپس به عنوان ورودی به LSTMهای دو جهته ارائه میشوند)، میتوانیم مدلهای تنظیم دقیق مستقیم مانند BERT را در نظر بگیریم. به وظیفه ابهام زدایی نام نامی. این جایگزین خاص از نظر محاسباتی سختتر خواهد بود، اگرچه شاید بتواند به نتایج بهتری نیز منجر شود.
همچنین گسترش بیشتر اعتبار سنجی تجربی، به عنوان مثال، استفاده از مجموعههای دیگر از منابع مختلف (به عنوان مثال، اسناد علمی، همانطور که در رقابت بر روی تفکیک نام نامها در چالش SemEval-2019 [ 21 ] استفاده میشود)، و مقایسه عملکرد رویکرد پیشنهادی در برابر مجموعه بزرگتری از سیستم های قبلی. یک امکان شامل ادغام رویکرد پیشنهادی در EUPEG [ 35 ، 36 ] است، یک پلتفرم معیار اخیر که برای ارزیابی سیستمهای تشخیص و ابهامزدایی نام نامها ایجاد شده است، که طیف وسیعی از مجموعهها و سیستمهای اسناد را ادغام میکند. با این حال، در نسخه فعلی، EUPEG از آموزش مدل با اطلاعاتی از مجموعههایی که در پلتفرم ادغام شدهاند، پشتیبانی نمیکند.





بدون دیدگاه