

کلید واژه ها:
خدمات پردازش وب ; کاربردهای علمی مبتنی بر گردش کار ; محاسبات با کارایی بالا ؛ عوامل ؛ سری زمانی ؛ تحلیل و پیش بینی ؛ بهینه سازی چند جانبی
1. مقدمه
-
با استفاده از منابع یک محیط محاسباتی توزیع شده، که در آن ناهمگونی هر سال در حال افزایش است، و تعامل با مدیران منابع محلی (LRMs) واقع در گره های منابع [ 9 ]،
-
توسعه برنامه های کاربردی مبتنی بر گردش کار، تشکیل ترکیبی از خدمات وب ارائه شده توسط پروژه های تحقیقاتی مختلف، و اجرای گردش کار در یک محیط محاسباتی توزیع شده، که مستلزم دسترسی انعطاف پذیرتر و ساده تر به منابع HPC است [ 10 ]،
-
پشتیبانی از طیف وسیعی از استانداردهای باز مختلف، مانند رابط محاسباتی ابری باز (OCCI) [ 11 ]، فرمت مجازی سازی باز (OVF) [ 12 ]، استانداردهای بنیاد زمین فضایی منبع باز (OSGeo) [ 13 ] و باز کنسرسیوم جغرافیایی (OGC) [ 14 ]،
-
اجرای سایر عملیات سیستم، به عنوان مثال، برنامه ریزی محاسبات و توزیع بار محاسباتی با رعایت سیاست های اداری تامین منابع.
2. رویکرد پیشنهادی: روش ها و ابزارها
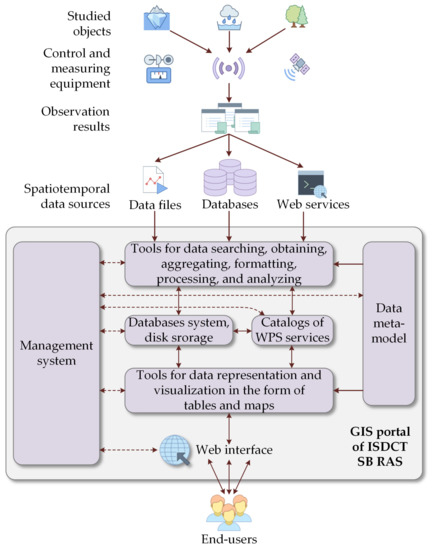
2.1. ایجاد خودکار و استفاده از خدمات WPS در پورتال GIS
-
رابط وب کاربر،
-
زیرسیستم برای یکپارچه سازی مداوم،
-
طراح مدل،
-
طراح خدمات WPS،
-
زیر سیستم اجرا،
-
دانش محور،
-
پایگاه داده محاسباتی
-
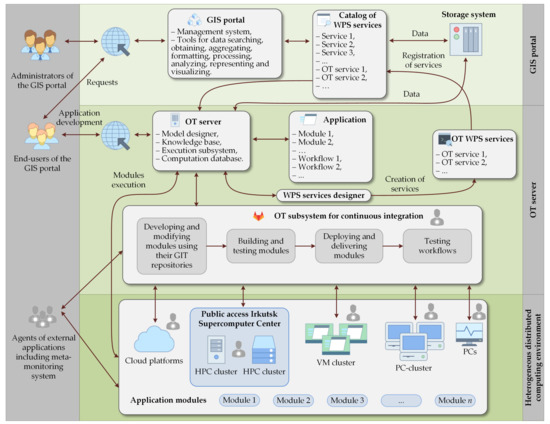
توسعه یا اصلاح ماژول های کاربردی، و همچنین ساخت، استقرار، تحویل و آزمایش آنها در منابع محیط محاسباتی با ابزارهای زیرسیستم OT برای یکپارچه سازی مداوم،
-
توصیف یک مدل محاسباتی که شامل مشخصات ماژول و روابط بین ماژول ها با استفاده از طراح مدل است،
-
ایجاد گردش کار بر روی مدل محاسباتی
-
فایل های پیکربندی مخزن،
-
فایل های گزارش عملیات ذخیره سازی انجام شده در مخزن،
-
یک فایل فهرستی که مکان فایل ها را توصیف می کند،
-
فایل های کاربر نهایی
-
توسعه و اصلاح ماژول ها با استفاده از مخازن GIT آنها،
-
ساخت و تست ماژول ها،
-
استقرار و ارائه ماژول ها،
-
تست گردش کار
-
مرحله 1. سرویس WPS یک درخواست از کاربر نهایی دریافت می کند.
-
مرحله 2. سرویس WPS پارامترهای ورودی موجود در درخواست را بررسی می کند. اگر این پارامترها درست باشند، انتقال به مرحله بعدی انجام می شود. در غیر این صورت یک پیغام خطا به کاربر نهایی برمی گرداند و عملیات آن به پایان می رسد.
-
مرحله 3. سرویس WPS یک فایل XML با وضعیت اجرای درخواست تولید می کند. علاوه بر این، نشانی اینترنتی فایل XML را نشان می دهد که حاوی نتایج اجرای درخواست یا مسیر سیستم پایگاه داده در صورت تبادل داده بین ماژول ها با استفاده از فایل های متنی است.
-
مرحله 4. سرویس WPS عملیات زیر را اجرا می کند: تولید یک کار محاسباتی برای OT، فراخوانی زمانبندی محاسبات، انتقال کار تولید شده و پارامترهای ورودی درخواست به زمانبند با استفاده از یک API تخصصی، تکمیل کار.
2.2. تکنیک و ابزار برای پیش بینی دمای هوا
SF بر اساس تعیین همبستگی بین قطعات مقایسه شده است. الگوریتم 1 شبه کد یک الگوریتم عملیات SF را نشان می دهد.
| الگوریتم 1. الگوریتم عملیات SF. |
| 1 تابع 2 اگر سپس 3 برگردان 0; 4 پایان اگر 5 اگرسپس 6 بازگشت 1; 7 دیگر 8 بازگشت 0; 9 پایان اگر 10 تابع پایان |
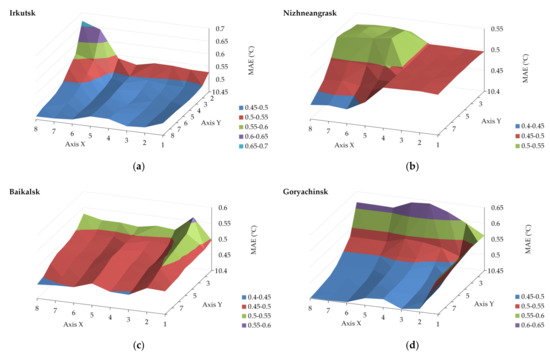
مقادیر پارامترها از برای به حداقل رساندن خطای پیش بینی تنظیم می شوند. پارامترهای تنظیمشده طول مجاز سریهای زمانی و ضریب همبستگی و همچنین محدودیتهای ماژولهای اختلاف دمای هوا، تابش خورشیدی کل، سرعت باد و جهت باد را تعیین میکنند. برای تنظیم این پارامترها، مجموعه ای از ترکیبات مقادیر پارامتر را به طور تصادفی از دامنه های پارامتر انتخاب می کنیم. سپس پیش بینی می کنیم با استفاده از PF الگوریتم 2 شبه کد یک الگوریتم عملیات PF را نشان می دهد، جایی که .
| الگوریتم 2. الگوریتم عملیات PF. |
| 1 تابع 2 ; 3 برای از جانب به افزایش 4 اگر ( یا ) سپس 5 ، ، ; 6 اگر ( ) سپس 7 ; 8 ; 9 پایان اگر 10 پایان اگر 11 بعدی ; 12 اگر ( ) سپس 13 ; 14 دیگر 15 ; 16 پایان می یابد اگر 17 بازگشت ; 18 تابع پایانی |
ما میانگین خطای مطلق (MAE) را برای اندازه گیری خطاهای پیش بینی انتخاب می کنیم. در مورد ما، MAE به صورت زیر تعریف می شود:
-
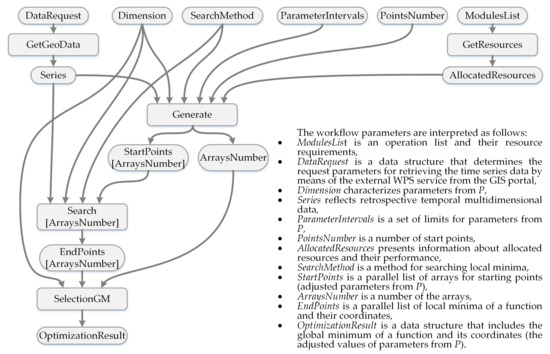
تولید مجموعه از نقاط شروع،
-
توزیع نقاط شروع بین منابع محیط محاسباتی،
-
نزول موازی از نقاط شروع به بهینه محلی با استفاده از روش نلدر مید،
-
انتخاب بهینه جهانی از جانب .
بهینهسازی یک تابع چند انتها با استفاده از روش چند شروع بر روی منابع ناهمگن با ویژگیهای محاسباتی مختلف انجام میشود. نقطه شروع توزیع در منابع یک مشکل غیر ضروری است. ما باید مشکل زیر را حل کنیم:
جایی که تعدادی هسته است، تعدادی از نقاط شروع است، تعداد متوسطی از عملیات ابتدایی است که برای یافتن حداقل SF محلی از یک نقطه شروع لازم است، تعدادی از نقاط شروع است که در هسته اول پردازش خواهند شد ، تعدادی عملیات ابتدایی است که توسط هسته i در واحد زمان پردازش می شود، سربار هسته i است که به تعداد نقاط شروع پردازش شده بستگی دارد و ارزیابی یک گردش کار است.
3. نتایج و بحث
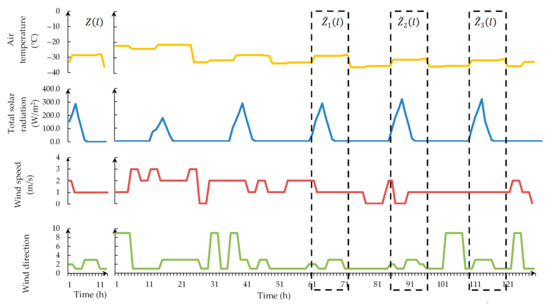
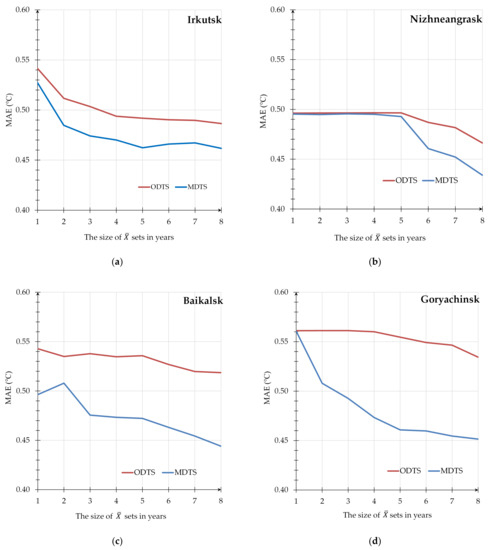
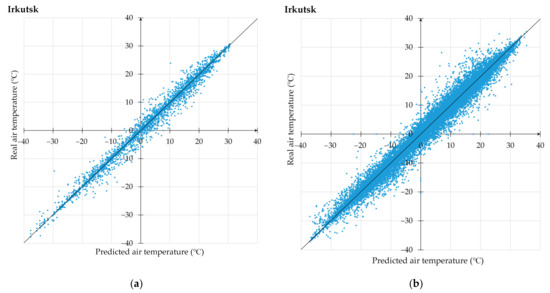
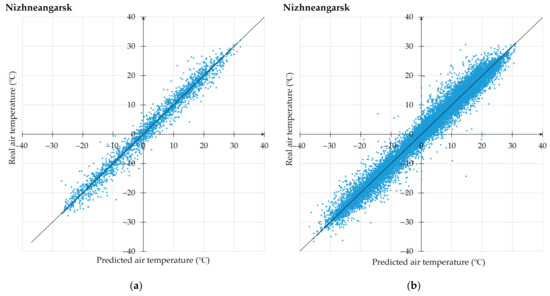
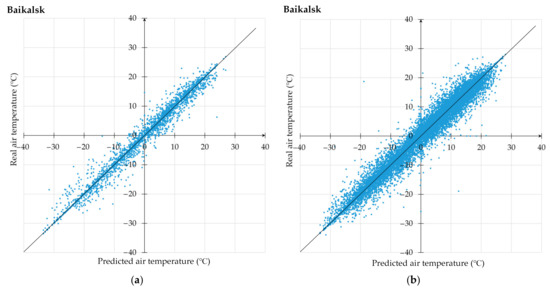
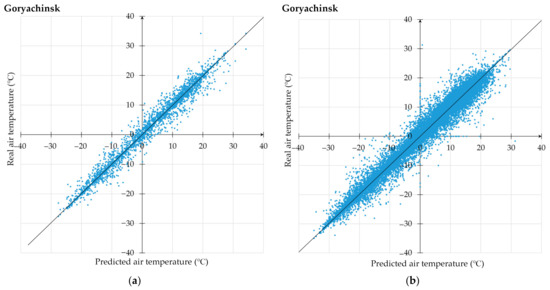
3.1. استفاده از تکنیک پیشنهادی برای پیشبینی دمای هوا
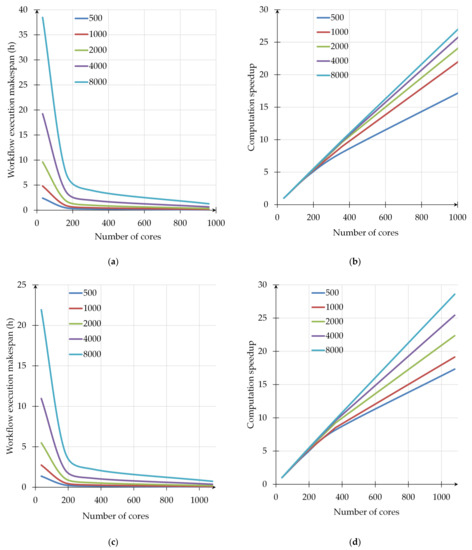
3.2. تجزیه و تحلیل جامع آزمایشات محاسباتی
-
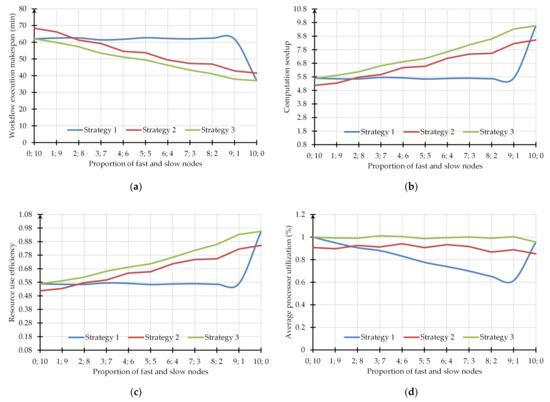
راه اندازی تعداد مساوی کار در هر گره توسط یک کاربر.
-
بارگیری گره های رایگان از صف کار مشترک. این استراتژی در عمل توسط متا زمانبندی های معروفی مانند GridWay و Condor DAGMan و همچنین LRMها برای منابع همگن، به عنوان مثال LSF [ 54 ] استفاده می شود.
-
راه اندازی تعداد کارها در هر گره متناسب با عملکرد گره با در نظر گرفتن زمان اجرای کار ارزیابی شده در این گره. ما این استراتژی را در OT با استفاده از سیستم فرا مانیتورینگ برای پیشبینی زمان اجرای کار بر روی گرههایی که توسط عواملی که نتایج آزمایش ماژول برنامه در این گرهها را در نظر گرفتهاند، اجرا و اعمال کردیم.
-
استفاده از حداقل یک گره آهسته بر سرعت اجرای گردش کار، سرعت محاسبات و کارایی استفاده از منابع در هنگام اعمال استراتژی اول تأثیر منفی می گذارد. در همان زمان، مقادیر متوسط استفاده از CPU نزدیک به 1 هنگام استفاده از محیط محاسباتی که به طور کامل از گرههای همگن تشکیل شده بود، به دست آمد.
-
در استراتژی دوم، نمونههای بیشتری از جستجوی ماژول تولید شد. همه موارد شامل صف کشیدن قبل از راه اندازی بود. علاوه بر این، انتقال داده ها و بررسی وضعیت اجرا برای هر نمونه ضروری بود. بنابراین، استراتژی دوم با سربار بیشتر مشخص شد. این سربارها در مقایسه با استراتژی های دیگر، عوامل اصلی افزایش طول اجرای گردش کار بودند.
-
مزایای استراتژی سوم به دلیل توزیع بار محاسباتی بر روی منابع بر اساس عملکرد آنها به دست آمد. سرعت محاسبات نشان داده شده با افزایش تعداد گره های سریع استفاده شده و کارایی استفاده از آنها نزدیک به 1 مقیاس پذیری خوب محاسبات توزیع شده را تعیین می کند.
4. نتیجه گیری
-
پشتیبانی از فناوری شبکه داده های درون حافظه (IMDG) [ 55 ] برای برنامه های توسعه یافته در OT برای ارائه پردازش داده های مکانی-زمانی در RAM گره های محیط محاسباتی توزیع شده ناهمگن،
-
اصلاح سیستم فرامانیتورینگ با توجه به خودکارسازی شناسایی و عیبیابی جزئی عیوب در عملکرد نرمافزار و سختافزار سیستم برای بهبود قابلیت اطمینان پردازش دادههای مکانی-زمانی مبتنی بر IMDG.
-
توسعه یک مبدل اضافی برای اطمینان از سازگاری با زبان رایج گردش کار (CWL) [ 56 ] برای جلوگیری از توسعه مجدد جریان های کاری مشابه و در نتیجه کاهش زمان آزمایش ها.
منابع
- ماخونکو، NI; بلوسوف، SA; تاراسووا، EA؛ پلوتنیکوا، YA فناوری اطلاعات و ارتباطات در پایش محیطی تغییرات آب و هوا. IOP Conf. سر. محیط زمین. علمی 2021 , 808 , 012045. [ Google Scholar ] [ CrossRef ]
- بیچکوف، IV; روژنیکوف، جنرال موتورز؛ Hmelnov، AE; فدوروف، RK; Madzhara, TI; پوپووا، نظارت دیجیتال AK دریاچه بایکال و منطقه ساحلی آن. در مجموعه مقالات دومین کارگاه علمی-عملی فناوری اطلاعات: الگوریتم ها، مدل ها، سیستم ها (ITAMS 2019)، ایرکوتسک، روسیه، 20 سپتامبر 2019؛ CEUR-WS Proc.: آخن، آلمان، 2019؛ جلد 2463، ص 13-23. در دسترس آنلاین: https://ceur-ws.org/Vol-2463/paper2.pdf (دسترسی در 29 اکتبر 2021).
- لگا، م. کاسازا، م. تتا، ر. Zappa، CJ ارزیابی اثرات زیست محیطی: یک چارچوب چند سطحی و چند پارامتری برای آب های ساحلی. بین المللی جی. سوست. توسعه دهنده طرح. 2018 ، 13 ، 1041-1049. [ Google Scholar ] [ CrossRef ]
- پل، پ. آیتال، PS; Bhuimali، A. کالیشانکار، تی. ساودرا، MR; آرمو، سیستمهای اطلاعات جغرافیایی PSB و سنجش از راه دور: کاربردها در سیستمهای محیطی و مدیریت. بین المللی جی. مناگ. فنی Soc. علمی 2020 ، 5 ، 11-18. [ Google Scholar ] [ CrossRef ]
- دندان های نیش.؛ دا خو، ال. زو، ی. آهاتی، ج. پی، اچ. یان، جی. Liu, Z. یک سیستم یکپارچه برای نظارت و مدیریت محیطی منطقه ای بر اساس اینترنت اشیا. IEEE Trans. Ind. اطلاع رسانی. 2014 ، 10 ، 1596-1605. [ Google Scholar ] [ CrossRef ]
- کوسول، ن. شلستوف، آ. Skakun، S. Grid و فن آوری های وب حسگر برای نظارت بر محیط زیست. علوم زمین آگاه کردن. 2009 ، 2 ، 37-51. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- برونیگ، ام. بردلی، PE; جان، م. کوپر، پی. مزروب، ن. روش، ن. الدوری، م. استفاناکیس، ای. جدیدی، م. تحقیقات مدیریت داده های جغرافیایی: پیشرفت و جهت گیری های آینده. ISPRS Int. Geo-Inf. 2020 ، 9 ، 95. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لی، کالیفرنیا؛ Gasster، SD; پلازا، آ. چانگ، CI; Huang, B. تحولات اخیر در محاسبات با کارایی بالا برای سنجش از راه دور: بررسی. IEEE J. Sel. بالا. Appl. 2011 ، 4 ، 508-527. [ Google Scholar ] [ CrossRef ]
- دراگان، آی. فورتیش، TF; Iuhasz، G. نیگل، ام. Petcu، D. بکارگیری اصول خود* در محیط های ابری ناهمگن. در رایانش ابری ؛ Antonopoulos, N., Gillam, L., Eds. Springer: Cham, Switzerland, 2017; شابک 978-3-319-85443-4. [ Google Scholar ]
- هوانگ، اف. یانگ، اچ. تائو، جی. Zhu, Q. پلت فرم زنجیره خدمات محاسبات جغرافیایی با کارایی بالا مبتنی بر گردش کار جهانی. داده های بزرگ زمین 2020 ، 4 ، 409-434. [ Google Scholar ] [ CrossRef ]
- رابط محاسبات ابری باز OGF. در دسترس آنلاین: https://www.occi-wg.org/doku.php (در 29 اکتبر 2021 قابل دسترسی است).
- فرمت مجازی سازی باز DMTF. در دسترس آنلاین: https://www.dmtf.org/standards/published_documents/DSP0243_1.0.0.pdf (در 29 اکتبر 2021 قابل دسترسی است).
- بنیاد زمین فضایی منبع باز. در دسترس آنلاین: https://www.osgeo.org/ (دسترسی در 29 اکتبر 2021).
- مدلهای Castronova، AM به عنوان خدمات وب با استفاده از استاندارد سرویس پردازش وب کنسرسیوم فضایی باز (ogc) (wps). محیط زیست مدل نرم افزار 2013 ، 41 ، 72-83. [ Google Scholar ] [ CrossRef ]
- فورستر، تی. شفر، بی. براونر، جی. Jirka, S. ادغام خدمات پردازش وب ogc در برنامه های کاربردی بازار انبوه جغرافیایی. در مجموعه مقالات کنفرانس بین المللی سیستم های اطلاعات جغرافیایی پیشرفته و خدمات وب، کانکون، مکزیک، 1-7 فوریه 2009. IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2009; صص 98-103. [ Google Scholar ] [ CrossRef ]
- GeoServer. در دسترس آنلاین: https://geoserver.org/ (دسترسی در 29 اکتبر 2021).
- Baranski، B. رایانش شبکه ای را فعال می کند خدمات پردازش وب. در مجموعه مقالات ششمین روز اطلاعات جغرافیایی، مونستر، آلمان، 16-18 ژوئن 2008; IfGI Prints: مونستر، آلمان، 2008; جلد 32، ص 243–256. موجود به صورت آنلاین: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.470.8333&rep=rep1&type=pdf (در 29 اکتبر 2021 قابل دسترسی است).
- یو، پی. ژانگ، ام. Tan, Z. یک سیستم گردش کار ژئوپردازش برای نظارت بر محیط زیست و مدل سازی یکپارچه. محیط زیست مدل نرم افزار 2015 ، 69 ، 128-140. [ Google Scholar ] [ CrossRef ]
- Iosifescu-Enescu، I.; ماتیس، سی. گکونوس، سی. Iosifescu-Enescu، CM; Hurni، L. معماریهای مبتنی بر ابر برای ژئوپورتالهای وب مقیاسپذیر خودکار به سمت Cloudification GeoVITe Geoportal دانشگاهی سوئیس. ISPRS Int. Geo-Inf. 2017 ، 6 ، 192. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- وانگ، ی. جیانگ، جی. ژانگ، اچ. دونگ، ایکس. وانگ، ال. رنجان، ر. Zomaya، AY یک الگوریتم موازی مقیاسپذیر برای مدلهای گردش عمومی اتمسفر در یک خوشه چند هستهای. ژنرال آینده. Comp. سیستم 2017 ، 72 ، 1-10. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هوانگ، اف. کراوات، بی. تائو، جی. تان، ایکس. Ma، Y. روششناسی و بهینهسازی برای اجرای الگوریتمهای جغرافیایی موازی مبتنی بر خوشه با مطالعه موردی. خوشه. محاسبه کنید. 2019 ، 23 ، 673-704. [ Google Scholar ] [ CrossRef ]
- کانگ، اس. لی، ک. مقیاس خودکار پردازش تصویر مبتنی بر جغرافیا در یک محیط محاسبات ابری OpenStack. Remote Sens. 2016 , 8 , 662. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، ز. دی، ال. برگس، آ. تولیس، جی. Magill, AB Geoweaver: زیرساخت سایبری پیشرفته برای مدیریت گردشهای کاری هوش مصنوعی زمینشناسی ترکیبی. ISPRS Int. Geo-Inf. 2020 ، 9 ، 119. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- فئوکتیستوف، آ. گورسکی، اس. سیدوروف، آی. بیچکوف، آی. چرنیخ، آ. Edelev، A. توسعه مشارکتی و استفاده از کاربردهای علمی در ابزار Orlando: یکپارچه سازی، تحویل، و استقرار. اشتراک. محاسبه کنید. Inf. علمی 2020 ، 1087 ، 18-32. [ Google Scholar ] [ CrossRef ]
- بیچکوف، آی. فئوکتیستوف، آ. گورسکی، اس. ادلف، آ. سیدوروف، آی. کاسترومین، آر. فرفروف، ای. فدوروف، آر. مهندسی ابر رایانه برای حمایت از تصمیم گیری در مورد انعطاف پذیری سیستم های انرژی. در مجموعه مقالات چهاردهمین کنفرانس بین المللی IEEE در مورد کاربرد فناوری های اطلاعات و ارتباطات، تاشکند، ازبکستان، 7 تا 9 اکتبر 2020؛ IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2020؛ صص 1-6. [ Google Scholar ] [ CrossRef ]
- چرنیخ، آ. بیچکوف، آی. فئوکتیستوف، آ. گورسکی، اس. سیدوروف، آی. کاسترومین، آر. ادلف، آ. زورکالزف، وی. Avetisyan، A. کاهش عدم قطعیت در توسعه و به کارگیری برنامه های کاربردی علمی در یک محیط محاسباتی یکپارچه. برنامه. محاسبه کنید. نرم. 2020 ، 46 ، 483-502. [ Google Scholar ] [ CrossRef ]
- بیچکوف، IV; روژنیکوف، جنرال موتورز؛ فدوروف، RK; Khmelnov، AE; Popova، AK فناوری نظارت بر محیط زیست دیجیتال قلمرو طبیعی بایکال. در مجموعه مقالات سومین کارگاه علمی-عملی فناوری اطلاعات: الگوریتمها، مدلها، سیستمها (ITAMS 2020)، ایرکوتسک، روسیه، 3 سپتامبر 2020؛ CEUR-WS Proc.: آخن، آلمان، 2020؛ جلد 2677، ص 1-7. در دسترس آنلاین: https://ceur-ws.org/Vol-2677/paper1.pdf (دسترسی در 29 اکتبر 2021).
- کازانووا، اچ. لگراند، ا. زاگورودنوف، دی. Berman, F. Heuristics for Scheduling Parameter Sweep Applications in Grid Environments. در مجموعه مقالات نهمین کارگاه محاسباتی ناهمگن (HCW) (شماره گربه PR00556)، کانکون، مکزیک، 1 مه 2000. IEEE: نیویورک، نیویورک، ایالات متحده آمریکا، 2000; صص 349-363. [ Google Scholar ] [ CrossRef ]
- GridWay Metascheduler. در دسترس آنلاین: https://www.gridway.org (در 29 اکتبر 2021 قابل دسترسی است).
- تاننباوم، تی. رایت، دی. میلر، ک. لیونی، ام. کندور—یک برنامهریز شغلی توزیعشده. در Beowulf Cluster Computing با لینوکس . استرلینگ، تی.، اد. انتشارات MIT: کمبریج، MA، ایالات متحده آمریکا، 2002; صص 307-350. [ Google Scholar ]
- Lientz، BP; سوانسون، ای بی. تامپکینز، جنرال الکتریک ویژگی های نگهداری نرم افزار کاربردی. اشتراک. ACM 1978 ، 21 ، 466-471. [ Google Scholar ] [ CrossRef ]
- Chatfield, C. Time-Series Forecasting , 1st ed.; CRC Press: نیویورک، نیویورک، ایالات متحده آمریکا، 2000; پ. 280. [ Google Scholar ] [ CrossRef ]
- De Gooijer، JG; Hyndman، RJ 25 سال پیش بینی سری های زمانی. بین المللی J. پیش بینی. 2006 ، 22 ، 443-473. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کیسی، دی. سنت هیلر، آ. الجابی، ن. پیشبینی دمای آب با استفاده از مدلهای رگرسیونی و تصادفی. در مجموعه مقالات پنجاه و هفتمین کنگره سالانه انجمن منابع آب کانادا، مونترال، QC، کانادا، 16-18 ژوئن 2004. در دسترس به صورت آنلاین: https://www.researchgate.net/profile/Daniel-Caissie/publication/274071811_Prediction_of_water_temperatures_using_regression_and_stochastic_models/links/551434800cf2edagression_and_stochastic_models/links/551434800cf2edagression-and_4800cf2edagression . اکتبر 2021).
- صمدی، م. مجللی، ف. پیشبینی دمای هوا با استفاده از مدلهای سری زمانی و الگوریتمهای مبتنی بر عصبی. جی. ریاضی. آمار 2007 ، 3 ، 44-48. [ Google Scholar ] [ CrossRef ]
- شرف، ع. روی، SR تحلیل مقایسه ای پیش بینی دما با استفاده از روش های رگرسیون و شبکه عصبی پس انتشار. در مجموعه مقالات دومین کنفرانس بین المللی روندها در الکترونیک و انفورماتیک (ICOEI)، Tirunelveli، هند، 11-12 مه 2018؛ صص 739-742. [ Google Scholar ] [ CrossRef ]
- Tran، TTK؛ باتنی، SM; کی، اس جی. وثوقی فر، ح. مروری بر شبکه های عصبی برای پیش بینی دمای هوا. Water 2021 , 13 , 1294. [ Google Scholar ] [ CrossRef ]
- سیفوئنتس، جی. مارولاندا، جی. بلو، ا. Reneses، J. پیش بینی دمای هوا با استفاده از تکنیک های یادگیری ماشین: مروری. Energies 2020 , 13 , 4215. [ Google Scholar ] [ CrossRef ]
- اسمیت، کارشناسی; مک کلندون، RW; Hoogenboom, G. بهبود پیشبینی دمای هوا با شبکههای عصبی مصنوعی. آکادمی جهانی علوم، مهندسی و فناوری. بین المللی جی. کامپیوتر. برق خودکار کنترل. Inf. مهندس 2007 ، 1 ، 3146-3153. [ Google Scholar ] [ CrossRef ]
- هیوگی، پی. بهرا، ع. ترواتی، م. پریرا، ای. قهرمانی، م. پالمیری، اف. لیو، ی. شبکه عصبی کانولوشنال زمانی (TCN) برای پیش بینی آب و هوای موثر با استفاده از داده های سری زمانی از ایستگاه آب و هوای محلی. محاسبات نرم. 2020 ، 24 ، 16453-16482. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاروان، ز. Suykens, J. Transductive LSTM برای پیشبینی سریهای زمانی: برنامهای برای پیشبینی آب و هوا. شبکه عصبی 2020 ، 125 ، 1-9. [ Google Scholar ] [ CrossRef ]
- شوالیه، RF; هوگنبوم، جی. مک کلندون، RW; Paz، JA پشتیبان رگرسیون برداری با کاهش مجموعه های آموزشی برای پیش بینی دمای هوا: مقایسه با شبکه های عصبی مصنوعی. عصبی. محاسبه کنید. Appl. 2011 ، 20 ، 151-159. [ Google Scholar ] [ CrossRef ]
- پزشکی، ز. مزینانی، SM مقایسه شبکه های عصبی مصنوعی، منطق فازی و فازی عصبی برای پیش بینی بهینه سازی مصرف حرارتی ساختمان: یک بررسی. آرتیف. هوشمند Rev. 2019 , 52 , 495–525. [ Google Scholar ] [ CrossRef ]
- کرمی زاده، س. عبدالله، س.م. حلیمی، م. شایان، ج. رجبی، ام جی مزیت و اشکال عملکرد ماشین بردار پشتیبان. در مجموعه مقالات کنفرانس بین المللی 2014 کامپیوتر، ارتباطات و فناوری کنترل (I4CT)، لنکاوی، مالزی، 2 تا 4 سپتامبر 2014. صص 63-65. [ Google Scholar ] [ CrossRef ]
- بهاردواج، س. سریواستاوا، اس. گوپتا، جی. مدل مبتنی بر شباهت الگو برای پیشبینی سریهای زمانی. محاسبه کنید. هوشمند 2013 ، 31 ، 106-131. [ Google Scholar ] [ CrossRef ]
- دودک، جی. Pełka، P. روش های یادگیری ماشین مبتنی بر شباهت الگو برای پیش بینی بار میان مدت: یک مطالعه مقایسه ای. Appl. محاسبات نرم. 2021 ، 104 ، 107223. [ Google Scholar ] [ CrossRef ]
- مارتی، آر. Resende، MGC; Ribeiro، CC روش های چند شروع برای بهینه سازی ترکیبی. یورو جی. اوپر. Res. 2013 ، 226 ، 1-8. [ Google Scholar ] [ CrossRef ]
- نلدر، ج.ا. مید، آر. روش سیمپلکس برای کمینه سازی تابع. محاسبه کنید. J. 1965 , 7 , 308-313. [ Google Scholar ] [ CrossRef ]
- گاری، م. جانسون، دی. کامپیوترها و سختناپذیری . WH Freeman: San Francisco, CA, USA, 1979; ISBN 0716710447. [ Google Scholar ]
- بیچکوف، IV; Oparin، GA; Feoktistov، AG; سیدوروف، IA; بوگدانوا، وی.جی. گورسکی، SA کنترل چندعاملی سیستم های محاسباتی بر اساس فرا نظارت و شبیه سازی تقلیدی. اپتوالکترون. ساز. فرآیند داده 2016 ، 52 ، 107-112. [ Google Scholar ] [ CrossRef ]
- rp5.ru.برنامه آب و هوا. در دسترس آنلاین: https://rp5.ru/ (در 29 اکتبر 2021 قابل دسترسی است).
- کاسترومین، آر. بشارینا، او. فئوکتیستوف، آ. سیدوروف، I. رویکرد مبتنی بر ریز سرویس برای شبیه سازی تجهیزات سازگار با محیط زیست اشیاء زیرساخت با در نظر گرفتن داده های هواشناسی. Atmosphere 2021 , 12 , 1217. [ Google Scholar ] [ CrossRef ]
- مرکز ابر رایانه ایرکوتسک در دسترس آنلاین: https://hpc.icc.ru/ (در 29 اکتبر 2021 قابل دسترسی است).
- Estévez Ruiz، EP; کالونا چیکایزا، جنرال الکتریک؛ Jiménez Patiño، FR; لوپز لاگو، JC; Thirumuruganandham، الگوریتم های ضرب ماتریس متراکم SP و ارزیابی عملکرد HPCC در 81 گره IBM Power 8 Architecture. Computation 2021 , 9 , 86. [ Google Scholar ] [ CrossRef ]
- ژانگ، اچ. چن، جی. Ooi، BC; قهوهای مایل به زرد، KL; ژانگ، ام. مدیریت و پردازش داده های بزرگ در حافظه: یک نظرسنجی. IEEE Trans. بدانید. مهندسی داده 2015 ، 27 ، 1920-1948. [ Google Scholar ] [ CrossRef ]
- زبان گردش کار رایج در دسترس آنلاین: https://www.commonwl.org/ (در 29 اکتبر 2021 قابل دسترسی است).


بدون دیدگاه