1. مقدمه
1.1. زمینه و انگیزه
تنها در مناطق شهری در ایالات متحده، در سال 2017، ازدحام منجر به 8.8 میلیارد ساعت زمان سفر اضافی، 3.3 میلیارد گالن سوخت اضافی خریداری شده و هزینه کلی 166 میلیارد دلار شد [ 1 ]. تصویر مشابهی در اروپا به نظر می رسد، با هزینه تراکم تقریباً 110 میلیارد یورو در سال، از نظر تأخیر [ 2 ]، در حالی که تحرک شهری 40٪ از کل انتشار CO 2 از حمل و نقل جاده ای را تشکیل می دهد [ 3 ]. انتظار میرود این امر در دهههای بعدی پیچیدهتر شود، با روندهایی مانند شهرنشینی که در بیشتر نقاط جهان رایج است [ 4 ]]. افزایش جمعیت مستلزم مسائلی مانند پراکندگی شهری، بار بیشتر در شبکه های حمل و نقل و افزایش سطح انتشار است. راهحلهای مختلف تحرک هوشمند برای این مشکلات در حال توسعه و آزمایش در مناطق شهری است، با مفهوم شهرهای هوشمند رایجتر [ 5 ]]. با این حال، راهحلهای جدید اغلب به ابزارهای ارزیابی جدید نیاز دارند و راهحلهای هوشمند تحرک نیز از این قاعده مستثنی نیستند. انعطافپذیری بالاتری که توسط دیجیتالیسازی فعال میشود مستلزم آن است که سطح معینی از تفکیک توسط مدلها و ابزارهای ارزیابی، که نمیتوانند توسط مدلهای حملونقل ماکروسکوپی سنتی، یعنی مدلهایی که مجموع جریانهای افراد/وسایل نقلیه را در نظر میگیرند، قاببندی شوند. این امر موجی از مدلهای مبتنی بر فعالیت و عامل (ABM) را برانگیخت که منجر به افزایش اتکا به دادهها و پیچیدگی میشود که مانع جذب آنها و کند کردن تحقیقات میشود [ 6 ]. سایر عوامل بازدارنده، برای مثال، فقدان مجموعه مهارتها و ابزارهای اختصاصی برای مدیریت افزایش پیچیدگی پردازش داده یا نیازهای محاسباتی بالاتر است.
از طریق ABM ها، می توان تصمیمات تحرک را تا سطح فردی (عامل) شبیه سازی کرد. این امکان مدلسازی و پیشبینی رفتار مسافرتی را فراهم میکند که به ویژگیهای اجتماعی-اقتصادی و ویژگیهای فردی حساس است، تا سطحی که با استفاده از مدلهای چهار مرحلهای سنتی قابل دستیابی نیست. علاوه بر این، نمایندگان بر اساس عملکرد عرضه حمل و نقل، انتخاب های تقاضای سفر را انجام می دهند، که به عنوان مثال، اجازه می دهد تا به طور ضمنی تقاضای القایی ایجاد کند [ 7 ]]. این ویژگیها از قبل از بحران COVID-19 مرتبط بودند و منصفانه است که فرض کنیم همهگیری تغییرات در رفتار حرکتی را سرعت میبخشد. علاوه بر این، راهحلهای تحرک انعطافپذیرتر و پیچیدهتر در حال توسعه هستند یا در حال حاضر در شهرهای سراسر جهان مستقر شدهاند، مانند، به عنوان مثال، وسایل نقلیه خودکار، برنامههای Mobility as a Service (MaaS) و راهحلهای micromobility. اثرات هر یک، و همچنین ترکیبی از آنها، بر تقاضای حمل و نقل هنوز به طور یکسان مشخص نشده است، که به نوبه خود، مدلهای کل را برای ارزیابی و پیشبینیهای آینده بهینه نمیکند.
محدودیتهای قابل توجهی از ABMها به میزان اتکا به دادهها و پیچیدگی تنظیمات آنها مربوط میشود. جمعیت عوامل در یک ABM شامل تمام ساکنان منطقه مورد مطالعه است و برخی از ویژگی های مربوط به هر فرد، مانند ساختار خانوار، سن، جنسیت، وضعیت شغلی و غیره را شرح می دهد. این نوع مجموعه داده به دلیل بیش از بیش از نگرانی های قانونی حریم خصوصی ( https://www.fsd.tuni.fi/en/services/data-management-guidelines/anonymisation-and-identifiers/; قابل دسترسی در 28 دسامبر 2021) و باید از نظرسنجی های تحرک و آمارهای مربوطه ساخته شود. در حالی که ابزارهایی برای ساخت این مجموعه دادهها از قبل وجود دارد و در پاراگرافهای بعدی بررسی خواهد شد، معمولاً خروجی هنوز به درجه دقت مورد نیاز اکثر ABMهای پیشرفته نمیرسد و زمانی که به آن میرسد، به لطف بهرهبرداری از روشهای اضافی و به ندرت است. منابع داده های موجود
هدف این مقاله پر کردن شکافی در ادبیات مربوط به تخصیص یک جمعیت مصنوعی به شبکهای از ابعاد دلخواه، یعنی به وضوح انتخابی، تنها با بهرهبرداری از دادههای در دسترس عموم است. این با یک روش جدید برای تخصیص جمعیت مصنوعی که از دادههای کاربری زمین و NACE بهرهبرداری میکند ( https://ec.europa.eu/competition/mergers/cases/index/nace_all.html ) به دست میآید.دسترسی به 28 دسامبر 2021) حاشیه هایی برای حفظ ثبات در الگوهای محل سکونت-محل کار. نتیجه یک رویکرد سیستماتیک است، یعنی هیچ قسمتی را بدون جزئیات باقی نمی گذارد، بسیار قابل تکرار است و به گونه ای طراحی شده است که انعطاف پذیر و چابک باشد. به طور خاص، سطح تفکیک را می توان آزادانه طراحی کرد، در حالی که کد پیاده سازی این روش به صورت منبع باز و در صورت نیاز قابل تنظیم است.
در این مقاله، ما یک نمای کلی از وضعیت هنر در مورد تولید و تخصیص یک جمعیت مصنوعی ارائه میکنیم. ما نشان میدهیم که چگونه روشها و ابزارهای موجود، در حالی که از دادههای در دسترس عموم استفاده میکنند، لزوماً نتایجی را در سطح تفکیک فضایی مطلوب ایجاد نمیکنند. بنابراین، نویسندگان استدلال میکنند، این روشی را میطلبد که از دادههای عمومی برای انجام تخصیص فضایی که جمعیتهای مصنوعی را با ABMs مرتبط میکند، بهرهبرداری میکند.
1.2. بررسی ادبیات
ABM ها به مجموعه داده ای نیاز دارند که نشان دهنده جمعیت ساکن، کار، مطالعه و سفر در منطقه مدل شده باشد. روشها و ابزارهای مختلفی برای ساختن یک نسخه ترکیبی آماری نماینده جمعیت واقعی پیشنهاد شدهاند. یکی از ابزارها روش به روز رسانی متناسب تکراری (IPU) است که در [ 8 ] شرح داده شده است. IPU نمونه ای از افراد تفکیک شده و توزیع کلی از ویژگی های مربوطه را در قطعنامه های جغرافیایی خاص پردازش می کند. به عنوان مثال، مطالعه موردی در [ 8] جمعیتی بالغ بر 4.5 میلیون نفر را برای منطقه بزرگ مونیخ تولید کرد. با این حال، مانند اغلب موارد، همه متغیرها به عنوان ورودی در دسترس نبودند و متغیرها، مانند محل کار یا محل سکونت از طریق نمونه گیری مونت کارلو تخصیص داده شدند. هنوز، این فرآیند در مقاله به تفصیل ذکر نشده است. کار در [ 9] افراد و خانواده ها را با الگوریتم سنتز مبتنی بر تناسب اندام ترکیب می کند و یک مطالعه موردی در آتلانتیک کانادا ایجاد می کند. داده های ورودی، فایل میکروداده استفاده عمومی سلسله مراتبی سرشماری کانادا و سرشماری کانادا بود. جمعیت مصنوعی بهدستآمده با متغیرهای زیر مشخص میشود: جنسیت، سن، قومیت، مهاجر، شهروندی، اندازه خانوار، تصدی، نوع مسکن و درآمد خانوار. با این حال، این متغیرها برای برآورده کردن الزامات ABM بسیار کم هستند، زیرا متغیرهای مربوطه، مانند محل سکونت، محل کار، اما همچنین بخش شغل و/یا وضعیت، وجود ندارند. ابزار دیگری برای تولید جمعیت مصنوعی از خاطرات سفر و حاشیه سرشماری SimPop [ 10 ] است.]، که به رویکردهایی مانند تولید مبتنی بر مدل و کالیبراسیون از طریق بازپخت شبیه سازی شده اجازه می دهد. علاوه بر این، SimPop را می توان برای سناریوهای بسیار بزرگ، حتی در سطح کشور استفاده کرد. در [ 10 ] نشان داده شده است که جمعیت مصنوعی کل اتریش را تولید می کند. با این حال، هیچ نقطه لنگر، به عنوان مثال، یک مکان کلیدی در زندگی و برنامه یک فرد، هنگامی که صحبت از محل کار یا تحصیل می شود، ایجاد نمی شود.
اطلاعات در مورد الگوهای فضایی مسکن در [ 11]، که در آن از روش برازش تناسبی دو سطحی (IPF) استفاده میشود، ساکنان را به هر ساختمان اختصاص میدهد در حالی که از دادههایی مانند نوع مسکن و درآمد خانوار بهرهبرداری میکند. همانطور که در بالا توضیح داده شد، این درجه از دقت در واقع در ادبیات نادر است. با این حال، این به قیمت استفاده از داده هایی است که به ندرت در دسترس هستند، مانند میانگین قیمت تراکنش یا ایجاد ظرفیت. علاوه بر این، در این مورد، درجه دقت ممکن است به طور غیر ضروری برای تنظیم ABM در زمینه مدلسازی تقاضای حملونقل بالا باشد. در نهایت، ادبیات موجود نشان میدهد که IPU از نظر تولید جمعیت بهتر از IPF عمل میکند، زیرا دومی اجازه تطبیق توزیع مشترک را هم در سطح فردی و هم در سطح خانوار نمیدهد [ 10 ]]. علاوه بر این، بهبودهای بیشتر الگوریتم IPU در زمان پیشنهاد شده است. به عنوان مثال، در [ 12 ]، الگوریتم IPU به روز می شود تا بتواند محدودیت ها را در وضوح های جغرافیایی متعدد در هنگام تولید یک جمعیت مصنوعی کنترل کند. بخش وسیعی از ادبیات بر تولید جمعیت های مصنوعی تمرکز دارد: مروری بر ابزارها و روش های مرتبط در [ 13 ] ارائه شده است. در ادامه، تنها آثاری که بر روی تخصیص نقاط لنگر (مثلاً مدرسه یا محل کار) تمرکز دارند، بیشتر مورد تجزیه و تحلیل قرار خواهند گرفت.
در [ 14 ]، دو روش تولید مصنوعی (یکی مبتنی بر نمونه و دیگری غیر نمونه ای) بر روی بخشی از جمعیت فرانسوی آزمایش شده است. با این حال، تمرکز مقاله مقایسه بین روششناسی است و جزئیات کمی در مورد دادههای ورودی و خروجی قابل دستیابی ارائه میشود، در حالی که هیچ تخصیص فضایی پس از انجام نشده است. کار در [ 15 ] متغیرهای کاربری زمین را در تولید جمعیت مصنوعی اضافه میکند و نتایج نشان میدهد که افزودن چنین متغیرهایی توانایی چارچوببندی تفاوتهای ظریف، مانند، بهعنوان مثال، تفاوت در الگوهای تحرک بین مناطق روستایی و شهری را بهبود میبخشد. در [ 16]، تخصیص مدارس و محل های کار بر اساس فرضیات مختلف برای مقابله با کمبود داده های مربوط به الگوهای ثبت نام و رفت و آمد انجام می شود. در حالی که از نظر تحصیلات، سن و مسافت عامل اصلی تعیین کننده ثبت نام بودند، محل های کار به طور تصادفی در داخل شهرستان ها اختصاص داده شدند (هنوز به نحوی که حواشی کل سرشماری را برآورده کند).
یک رویکرد متفاوت برای تخصیص جمعیت در [ 17 ] پیشنهاد شده است، جایی که یک جمعیت مصنوعی از موسسات (به عنوان مثال، مکان های تجاری) ابتدا برای یک مدل ABM (پلت فرم SimMobility) ساخته می شود. سپس نویسندگان پیشنهاد میکنند که چنین نتایجی ممکن است برای تخصیص نقاط لنگر به جمعیت مورد سوء استفاده قرار گیرند، زیرا تمام اطلاعات مربوطه مدلسازی شدهاند. با این حال، برخی از داده های مورد نیاز به ندرت در دسترس هستند، مانند، به عنوان مثال، مکان تاسیس، نوع صنعت، اندازه اشتغال، و مساحت طبقه اشغال شده. مقاله [ 18 ] نیز بهره برداری از سطوح طبقه را همراه با داده های کارت هوشمند حمل و نقل عمومی گزارش می دهد.
در [ 19 ]، نمونه اولیه شهرهای مختلف، جمعیت ها و الگوهای تحرک برای ایجاد سناریوهای مختلف ساخته شده است. به طور خاص، جمعیت نمونه اولیه با اختصاص ویژگی های فضایی بر اساس ویژگی های کاربری زمین ساخته می شود. با این حال، این مقاله نه الگوهای بین محل سکونت و محل کار را بررسی میکند و نه جزئیاتی را که چگونه یک مدل برای پر کردن این شکاف به کار میرود (توجه داشته باشید که یک مدل گرانشی برخی از تخمینهای مبدا و مقصد بین مناطق را محاسبه میکند و سپس آنها را از طریق فاکتور فاصله، در نظر گرفته شده مرتبط میکند. به عنوان امپدانس، برای ایجاد مقداری از سفر. جزئیات بیشتر را می توان در [ 20 ] یافت]). سپس مشخص نیست که چگونه راه حل در واقع الگوهای رفت و آمد را بازتولید می کند. علاوه بر این، از آنجایی که انتساب جمعیت مصنوعی در هسته [ 19 ] نیست، روش شناسی آنها به تفصیل بیان نشده است. کار دیگری که از یک مدل گرانشی برای تخصیص مکانهای کار استفاده میکند [ 21 ] است، اما تمرکز خارج از حوزه حملونقل منجر به یک رویکرد سادهسازی شد که در آن فقط فاصله و ظرفیت در نظر گرفته شد. همچنین در این مطالعه ظرفیت مؤسسات به عنوان داده های مکانی در دسترس نبود. با این حال، رویکرد در [ 21 ] جالب است زیرا تلاش میکند با فقدان نرمافزار منبع باز اختصاصی با یک برنامه متنباز کدگذاری شده در R مقابله کند، که ویژگیای است که این مقاله نیز اجرا میکند، البته با تمرکز محدودتر. به همین ترتیب، [ 22] فقط اندازه شرکت و مسافت را برای تعیین تکلیف در نظر می گیرد. در [ 23 ]، ارتباط بین شغل و ویژگی های فردی، مانند سطح تحصیلات یا جنسیت، مدل شده است. با این حال، از خود [ 23 ]، مشخص نیست که آیا موارد فوق در آنچه به عنوان یک مدل گرانشی تجربی توصیف میشود، مورد بهرهبرداری قرار گرفته است یا خیر. Paper [ 24 ] در این مسیر یک گام فراتر می رود و یک مدل مبتنی بر سودمندی ایجاد می کند که ویژگی های شخصی فرد را به محل کار (شامل انتخاب کار از خانه نیز می پردازد). با این حال، این امر با در دسترس بودن یک بررسی قابل اعتماد فعالیت خانوار و سوابق بیمه بیکاری ایالتی با جزئیات مکان های اشتغال امکان پذیر شد. رویکرد در [ 23 ، 24] در همان جهتی است که تخصیص NACE در این مقاله اجرا شده است. از سوی دیگر، سطح تفکیک فضایی به دست آمده در این مطالعه (500×500 متر) به دلیل مقیاس های مختلف منطقه مورد مطالعه بسیار کمتر از [ 23 ، 24 ] است.
مطالعه اخیر دیگری که به مسئله انتساب محل کار برای جمعیت های مصنوعی می پردازد [ 25 ] است، که در آن یک ماتریس صنعت مبدا-مقصد برای تخصیص احتمالات محل کار به جمعیت مصنوعی برای منطقه بزرگ بوستون مورد سوء استفاده قرار می گیرد. در حالی که این رویکرد امکان بهره برداری از الگوهای مشاهده شده را به جای فرض مدل های نظری فراهم می کند، چنین ماتریس های صنعت مبدا-مقصد به ندرت در دسترس هستند. به طور مشابه، مرجع [ 26 ] از دادههایی مانند الگوهای رفتوآمد، ماتریسهای OD رفت و آمد و مسافت طی شده برای انجام تخصیص مکانهای کاری برای یک جمعیت مصنوعی از طریق توزیع چندجملهای بهرهبرداری میکند. کاغذ [ 27]، در عوض، سوابق مربوط به مشاغل و تعداد کارکنان مرتبط، علاوه بر توزیع محل سکونت و محل کار بین مناطق سرشماری را به کار می گیرد. با این حال، مقیاس فضایی [ 27 ] با مقیاس این مطالعه قابل مقایسه نیست زیرا بر کل جمعیت ایالات متحده تمرکز دارد. این به نوبه خود مستلزم مناطق تجزیه و تحلیل بزرگتر است، که در دسترس بودن توزیع محل سکونت-محل کار را توضیح می دهد. یک رویکرد کمی متفاوت در [ 28 ] اتخاذ شده است، جایی که تعادل شغل-مسکن از طریق یک روش مبتنی بر ابزار ارزیابی میشود. در حالی که این کار سناریوهای مختلفی را ارزیابی می کند که در آن محل سکونت و محل کار در پکن انتخاب می شود، تمرکز بر یافتن توزیع بهینه شغل-مسکن به جای چارچوب بندی توزیع واقعی محل کار است.
نمای کلی خوبی از وضعیت فعلی هنر در [ 29 ] ارائه شده است، که با ایجاد جمعیت مصنوعی و تقاضای مسافرتی که تنها با داده های باز و در دسترس عموم است، وضعیت هنر را گسترش می دهد. خط لوله توسعه یافته نیز در [ 30 ] آزمایش شد. کار در [ 29 ] مورد خوبی در مورد اینکه چرا تحقیق در این زمینه مورد نیاز است، یعنی اینکه چگونه سایر رویکردهای فعلی به ندرت به طور سیستماتیک آزمایش می شوند و به سختی قابل انتقال هستند، ارائه می دهد. در حالی که هدف و مشارکت مشابه هستند، برخی از چالشها در مقاله ارائه شده مطرح شدهاند که در کار مذکور به آنها پرداخته نشده است. به عنوان مثال، در [ 29]، داده های مربوط به ماتریس های رفت و آمد آشکارا در دسترس بودند و می توانستند به عنوان پراکسی استفاده شوند. این مورد در مکان های دیگر (از جمله استونی) نیست، جایی که سایر اطلاعات آماری (مثلاً حاشیه های NACE) باید به جای آن مورد بهره برداری قرار گیرد. علاوه بر این، اطلاعات مربوط به مشاغل دارای سطح بالایی از جزئیات در [ 29 ] است، در حالی که در این مقاله دوباره اطلاعات آماری و دادههای کاربری زمین به عنوان پروکسی برای تخصیص مکانهای کار مورد بهرهبرداری قرار میگیرند. در نهایت، بررسی های سفر خانوار در [ 29 ، 30 ] مورد بهره برداری قرار گرفت] ورودیهای کافی برای اجازه ارتباط بین ویژگیهای اجتماعی-اقتصادی و مسافتهای رفتوآمد/لنگرها را داشت (در نتیجه، ساخت برنامههای فعالیت روزانه برای جمعیت مصنوعی را تسهیل میکند). در کار ما اینطور نبود. بنابراین، روش گزارش شده در این مقاله با [ 29 ] متفاوت است و نیاز به ماتریس OD و ورودی های قابل اعتماد در نظرسنجی خانوار را دور می زند، حتی اگر انگیزه کار و اهداف مشابه باشند. هر دو اثر تلاش میکنند یک خط لوله قابل اجرا ساده و تا حد امکان تکرارپذیر ارائه دهند که فقط بر اساس دادههای در دسترس عموم ساخته شده است. با توجه به دانش نویسندگان، به غیر از [ 29 ] و مقاله ارائه شده، هیچ اثر دیگری روش های مشابه را بررسی نمی کند یا وضعیت هنر را به روشی مشابه به چالش می کشد.
به طور خلاصه، در ادبیات، مرحله کوچک اما حیاتی اختصاص یک جمعیت مصنوعی به واحدهای فضایی تفکیکشده به نظر میرسد یا بر دادههای بسیار دقیق تکیه میکند، مثلاً درباره شرکتها و الگوهای رفتوآمد، یا به حاشیههای کل و توزیعهای احتمال محدود میشود. یکی از نمونههای متعدد ABM مورد دوم در [ 31 ]، اثری است که از MATSim بهرهبرداری میکند. این مقاله گزارش می دهد که چگونه محل سکونت و محل کار به طور تصادفی در مناطقی با کاربری منسجم اختصاص داده شده است (به عنوان مثال، هیچ سکونتی به مناطق کاربری زمین بدون ساختمان های مسکونی اختصاص داده نمی شود). در واقع [ 31] به عنوان مثال بسیار مرتبط است زیرا صراحتاً هدف آن استفاده از دادههای در دسترس عموم برای ساخت مدل است. با این حال، این راه حل در مواردی که فقط داده های بسیار مجموعی در دسترس است، امکان پذیر نیست (به عنوان مثال، در مطالعه موردی ارائه شده در زیر، که در آن مجموع کارگران فقط در سطح منطقه در دسترس بود).
در نهایت، حتی اگر برخی از ابزارها توابع یا افزونههایی را برای اختصاص نقاط لنگر تعبیه کرده باشند (مثلاً ct-ramp ( https://www.ct-ramp.com/ دسترسی به 28 دسامبر 2021))، برخی دیگر این کار را ندارند (مانند SimMobility MT) ( https://github.com/smart-fm/simmobility-prod/wiki/Introduction-to-SimMobilityدسترسی به 28 دسامبر 2021)) و دومی برای اجرای این تکلیف به روش های چابک نیاز دارد. روش پیشنهادی مستقل از هر نرم افزار ABM است و می تواند بدون توجه به مدلی که مورد بهره برداری قرار می گیرد مورد استفاده قرار گیرد. روش ارائه شده در این مقاله تصور میشود که هم کمتر به دادههای شرکتها/ ماتریسهای رفت و آمد OD وابسته است و هم به اندازه کافی زیرک برای ادغام ورودیهای اضافی است. علاوه بر این، طبق دانش نویسندگان، تنها راه حلی است که فقدان آمار تفکیک شده را با معرفی فیلدهای NACE جبران می کند.
آنچه جدول 1 سعی می کند به طور شهودی نشان دهد این است که هیچ مطالعه دیگری که در ادبیات وجود دارد، به انجام تکلیف محل کار با حداقل داده ها به اندازه مورد پیشنهادی هدف ندارد. پس از آن باید واضح تر به نظر برسد که چگونه ارائه یک رویکرد سیستماتیک برای مقابله با چالش تخصیص نقاط لنگر به یک جمعیت مصنوعی، که فقط از داده های عمومی استفاده می کند، ممکن است به پیشرفته ترین تکنولوژی اجازه دهد تا بیشتر به سمت ABM حرکت کند. با کاوش در ادبیات، بدیهی است که هیچ رویکردی به محققان اجازه نمیدهد تا جمعیتهای مصنوعی را برای ABM به روشی رسمی، کارآمد و سریع تطبیق دهند و در عین حال از مجموعهای از حداقل دادههای در دسترس عموم، حاشیههای کل و ویژگیهای کاربری زمین، صرف نظر از ابزارهای بهره برداری شده این شکاف تحقیقاتی است که این مقاله سعی دارد پر کند.
1.3. ساختار کاغذ
ساختار مقاله به شرح زیر است. در بخش 2 ، روش پیشنهادی توضیح داده شده و به تفصیل شرح داده شده است، در بخش 3 ، یک مطالعه موردی اجرا شده برای شهر تالین، استونی، معرفی شده است، در حالی که نحوه اجرای روش پیشنهادی را شرح می دهد. در بخش 4 ، مجموعه داده حاصل ارائه شده و در برابر توزیع های آماری موجود اعتبار سنجی می شود. بخش 5 شامل بحثی در مورد چگونگی پر کردن نتایج بهدستآمده شکاف شناساییشده در مقدمه است، در حالی که جهتهای تحقیقات آینده نیز برجسته شدهاند. در نهایت، در بخش 6 ، خلاصه ای کوتاه از کار ارائه شده ارائه شده و نتیجه گیری بیان شده است.
2. مواد و روشها
همانطور که قبلاً بحث شد، تولید یک جمعیت مصنوعی تمام نقاط لنگر مورد نیاز برای طراحی یک مدل مبتنی بر فعالیت را چارچوب نمیدهد. در واقع، یک مرحله میانی مورد نیاز است: تخصیص فضایی جمعیت به سطحی از تفکیک که برای اجرای مورد نیاز مناسب باشد. ورودی این مرحله، جمعیت مصنوعی تولید شده و برای روش پیشنهادی، دادههای آماری مانند دادههای کاداستر، آمار صنعت، و کل حاشیههای کارکنان یا دانشجویان است که در شکل 1 گزارش شده است. خروجی این مرحله جمعیت مصنوعی ادغام شده با نقاط لنگر، ورودی برای تولید تقاضای مبتنی بر فعالیت است. خروجی ها به طور گسترده در SimMobility، Preday آزمایش شده اند، اما باید با هر مدل تولید تقاضای مبتنی بر فعالیت مطابقت داشته باشند.
سهم جدید این مقاله اساساً بر بخش برجسته شده در شکل 1 ، یعنی تخصیص فضایی نقاط لنگر، تمرکز میکند، در حالی که فرض میکنیم دیگر روشهای پیشرفته برای سایر اجزا به کار گرفته شدهاند.
قبل از ارائه روش پیشنهادی، ما به طور خلاصه مرتبط ترین روش موجود در ادبیات [ 19 ] را خلاصه می کنیم که برای ساخت نمونه های اولیه شهرهای مختلف با جمعیت نمونه اولیه آنها، که در آن ویژگی های فضایی بر اساس ویژگی های کاربری زمین و فاصله اختصاص داده شده است، توسعه داده شده است. الگوریتم ارائه شده در [ 19 ] را می توان به صورت زیر خلاصه کرد.
اول، وزن برای کلاس های سلولی مختلف به صورت زیر تعریف می شود:
جایی که وزن کلاس X = { L,H,C,I,E,O } است که به این صورت تعریف میشود: مسکونی کم ( L )، بسیار مسکونی ( H )، تجاری ( C )، صنعتی ( I )، تحصیلات ( E ) و زمین باز ( O). سلول ها ممکن است بر اساس مطالعه موردی در دست تعریف شوند و منعکس کننده توزیع های مختلف الگوهای کاداستر باشند. اگر ابعاد سلول ها بسیار متفاوت است، توصیه می شود که منطقه اشغال شده را در محاسبه وزن سلول اضافه کنید. فرمول زیر در عوض برای سلول هایی با ابعاد مساوی (بدون توجه به بعد واقعی) تصور شد. سپس، وزن سلول ها در هر زیرمنطقه (یعنی سطح ناحیه دوم اداری) با توجه به:
جایی که i سلول ها را نمایه می کند، s زیرمنطقه ها را نمایه می کند و مجموعه ای از سلول ها در زیر ناحیه s است. با وزن دهی سلول ها در برابر کل در هر زیرمنطقه، این روش برای هر تعداد و نوع کلاس های کاداستر قابل استفاده می شود. تعداد محل کار در هر سلول در یک زیرمنطقه، ، سپس با ضرب وزن نرمال شده در تعداد کل کارگران در یک زیرمنطقه محاسبه می شود :
در نهایت، فاصله برای تخصیص آخرین مایل محل کار به جمعیت استفاده می شود. این روش امکان انجام تخصیص جمعیت مصنوعی را با تکیه بر دادههایی که معمولاً در دسترس عموم هستند، مانند دادههای کاربری زمین، فراهم میکند. درجه تفکیک که به دست می آید در واقع برای ساخت مدل های دقیق مبتنی بر فعالیت کافی است، زیرا بعد سلول ها را می توان به طور دلخواه تعریف کرد. با این حال، این روش بررسی نمیکند که چگونه یک تکلیف نهایی مبتنی بر مدل گرانشی برای محل کار انجام میشود، یا اینکه آیا هر نوع سازگاری فضایی بیشتر یا الگوهای رفتوآمد در سراسر زیرمنطقهها در جریان کار در نظر گرفته میشود. بنابراین، مشخص نیست که رابطه محل سکونت و محل کار از طریق روش ارائه شده چقدر نزدیک است. با گنجاندن تکلیف NACE، کار ما سعی می کند بر روی چنین چارچوبی بنا شود تا عواملی غیر از کاربری زمین و مسافت را در بر گیرد. علاوه بر این، توصیف تخصیص گرانش و نتایج باید قابلیت انتقال و تکرارپذیری روش پیشنهادی را تقویت کند.
2.1. واگذاری زمینه های NACE به جمعیت
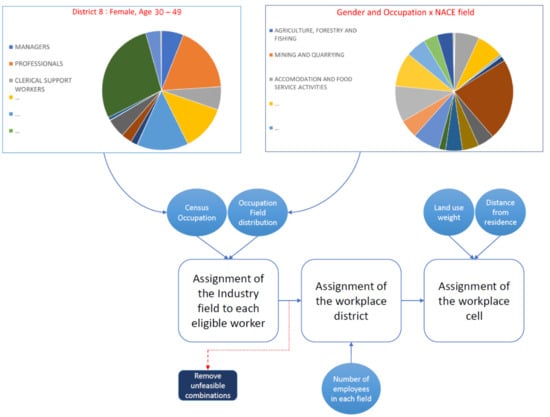
اولین مرحله پیشنهادی شامل بهرهبرداری از دادههای سرشماری برای به دست آوردن توزیع کارگران بر اساس وضعیت شغلی و کلاسهای NACE آنها (یا NAICS آنها ( https://www.census.gov/naics/ دسترسی به 28 دسامبر 2021) یا موارد مشابه است. بر اساس جنسیت، سن و منطقه محل سکونت (همانطور که از سرشماری ملی ثبت شده است – طبقه بندی EMTAK، نسخه ملی طبقه بندی NACE، مورد بهره برداری قرار گرفت). این تکلیف از طریق توزیع های احتمالی مانند شغل بر حسب سن، جنسیت و منطقه محل سکونت اجرا می شود. در پایان مأموریت، ترکیبات غیرقابل اجرا یا بسیار بعید، مانند مدیران 20 ساله، باید با تخصیص مجدد وضعیت شغلی حذف شوند. این فرآیند در شکل 2 نشان داده شده است .
هنگامی که تخصیص فیلد NACE (یا معادل آن) انجام شد، مقدار در جمعیت مصنوعی با تعداد کل کارکنان در شهر بررسی می شود، به عنوان مثال توسط سرشماری تجاری ثبت شده است. در واقع، ما باید در نظر بگیریم که جمعیت مصنوعی، در حالی که نماینده جمعیت کلی است، ممکن است برخی از توزیعها را بسته به توزیعهایی که بر اساس آن کالیبره شده است، نادرست نشان دهد [ 10 ]. این ممکن است در برخی از زمینههای NACE یا در برخی از مناطق/زیرمنطقهها به مجموع اریبها منجر شود. علاوه بر این، ممکن است اتفاق بیفتد که مجموعه داده NACE و ثبت کسب و کار با یکدیگر سازگار نباشند.
2.2. واگذاری زیرمنطقه
درصورتیکه هیچ تناقضی بین مجموعههای داده شناسایی نشود، ناحیه حاوی محل کار برای هر فرد اختصاص داده میشود تا مجموع هر فیلد NACE برآورده شود. تخصیص با استخراج نمونههای تصادفی بر اساس میدان NACE توزیع احتمال در هر منطقه کار انجام میشود. فیلد NACE بر اساس سن، جنسیت و محل سکونت از طریق توزیع شغل اختصاص داده می شود. بنابراین، پیوند قویتری بین این متغیرها و ناحیه کاری در مقایسه با پیوندی که صرفاً با بهرهبرداری از مجموعها برای استخراج توزیع در حالی که با مجموع حاشیههای کارکنان مطابقت دارد، به دست میآید. در ادامه، الگوریتم 1 این مرحله اول را خلاصه می کند. فهرست احتمالات 1توزیع مشاغل را بر اساس حاشیه سرشماری نشان می دهد در حالی که فهرست احتمالات 2 پل مشاغل را با زمینه های NACE نشان می دهد. در مورد دوم، تمام فیلدهای NACE که ناهماهنگ هستند در زیر «سایر» دسته بندی می شوند. تابع نمونه R ( https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/sample در 28 دسامبر 2021 قابل دسترسی است) برای اعمال توزیع های مختلف بر اساس سن (A)، جنسیت (G) مورد سوء استفاده قرار می گیرد. منطقه محل سکونت (DoR) و وضعیت دانشجویی (S)؛ * مقادیر ترکیب های مختلفی از ویژگی های فردی را نشان می دهد که مربوط به توزیع های مختلف است.
| الگوریتم 1 تخصیص NACE (فردی، توزیع شغلی {A، G، DoR، S}، توزیع NACE {G، O}) |
| 1: حلقه: فردی i <- جمعیت |
| 2: اگر ({A i , G i , DoR i , S i } == {A, G, DoR, S} و شغل == NA |
| 3: شغل<-نمونه(فهرست مشاغل، اندازه = 1، فهرست احتمالات 1 ) |
| 4: NACE<-sample(لیست فیلدهای NACE، اندازه = 1، فهرست احتمالات 2 ) |
| 5: در غیر این صورت |
| 6: تکلیف NACE (فردی، توزیع شغلی {A*، G*، DoR*، S*}، |
| 7: توزیع NACE {G*، O*} |
برای خوشه «سایر»، ابتدا فاصله بین هر سلول محل اقامت و زیرمنطقه دیگر را محاسبه می کنیم. ) سپس اولین کشش گرانشی زیرمنطقه، یعنی تعداد کارمندانی که قبلاً به یک میدان NACE دیگر اختصاص داده نشده اند، در نظر گرفته می شود و احتمال کار هر فرد در یکی از مناطق. به صورت زیر محاسبه می شود:
جایی که j ناحیه کاری است، تعداد کارمندان منطقه مذکور است و من سلول محل اقامت است.
علیرغم اینکه این روش ممکن است مقداری سر و صدا به تعداد کل مشاغل در یک منطقه اضافه کند، یکپارچگی فضایی حفظ می شود، به عنوان مثال، افراد از یک طرف شهر کمتر در سمت دیگر شهر کار می کنند. با این حال، این مرحله برای مقایسه این تخصیص با زمینه های منسجم NACE لازم است. علاوه بر این، همانطور که در مطالعه موردی نشان داده خواهد شد، تعداد کارمندانی که به این روش در هر زیرمنطقه تخصیص داده شده اند، نسبتاً با داده های دنیای واقعی سازگار است. در اینجا شایان ذکر است که کار ارائه شده چگونه سعی می کند بر اساس [ 19 ] بنا شود و چه تفاوت هایی دارد. مرحله اصلی، مرحله تخصیص NACE است که در شکل 2 خلاصه شده استو در الگوریتم گزارش شده؛ با ایجاد یک همبستگی محل سکونت و محل کار، ارتباط فاکتور فاصله به شدت کاهش می یابد و ممکن است پویایی های متفاوتی قاب شود. به عنوان مثال، سهم کارگرانی که رفت و آمدهای بسیار طولانی دارند، مسلماً به این شکل بهتر است، زیرا حاشیه کلی آنها تعریف شده است. در [ 19 ]، در عوض، به نظر می رسد مسیرهای طولانی تر به شدت جریمه شده اند. این نحوه اجرای مراحل زیر را تغییر میدهد (به عنوان مثال، معادله (5) یک کلاس را قبل از محاسبه احتمال کار در یک سلول خاص اختصاص میدهد).
تفاوت کلیدی دیگر در گزارش نکردن نتایج مراحل مختلف و فقط توصیف خط لوله در ضمیمه است (تمرکز کار مذکور تخصیص فضایی نیست). بنابراین، تکرارپذیری روش مانع می شود و درجه پایایی نتایج هرگز ارزیابی نمی شود. با گزارش هر قسمت، دادههای ورودی و الگوریتم مورد استفاده و مهمتر از آن نتایج یک مورد استفاده واقعی که در برابر دادههای تلفن همراه تأیید شده است، هدف این مقاله اثبات امکانسنجی روش و قابلیت اطمینان نتایج و پر کردن این شکاف است.
2.3. آخرین مایل تکلیف
هنگامی که منطقه اختصاص داده شد، ما به هر فرد طبقه سلولی را که محل کار در آن قرار دارد اختصاص می دهیم. این مرحله اساسا تضمین می کند که توزیع کاربری زمین توسط تخصیص مبتنی بر مدل گرانشی که به عنوان آخرین مرحله انجام می شود، منحرف نمی شود. احتمال کار برای هر فردی که محل کار او در منطقه مورد نظر است در یکی از طبقات سلولی برابر است با:
جایی که وزن (محاسبه بر اساس مقصد استفاده از زمین رایج در هر سلول، همانطور که در دادههای کاداستر ثبت شده است)، i کلاس (بسیار مسکونی، کم مسکونی، نوع مشاغل و خدمات، و نوع تولیدی)، j ناحیه در نظر گرفته شده است، و X تعداد سلول های ناحیه است. هنگامی که کلاس سلول و زیرمنطقه کاری به یک فرد اختصاص داده می شود، سلول کاری صرفاً بر اساس فاصله از سلول محل سکونت اختصاص داده می شود. :
که در آن n سلول محل اقامت و m یکی از سلول های کلاس تعریف شده در ناحیه j است.
شایان ذکر است که تا آخرین مرحله، فاکتورهای فاصله فقط برای تنظیمات جزئی، یعنی (الف) به عنوان نماینده ای برای توزیع های غیرواقعی NACE (محاسبه میانگین فاصله بین سلول محل سکونت و هر سلول در ناحیه هدف) استفاده شده است. ) و (ب) به عنوان یک عامل اصلاحی برای تخصیص زیر ناحیه (با در نظر گرفتن فاصله بین سلول محل اقامت و سلول های کلاس هدف). با این حال، معابر فوق از میدانهای NACE و دادههای کاربری زمین برای افزایش نمایندهگی انتساب در صورت امکان، قبل از متوسل شدن به فاصله برای تخصیص آخرین مایل، بهرهبرداری میکنند. در واقع، زمینه کار باید یک متغیر معرف بیشتر از مسافت باشد، زیرا به ندرت فردی آزادی انتخاب محل کار خود را با دقت 500×500 متر دارد، در حالی که عواملی مانند حقوق و دستمزد، نوع شغل و غیره بسیار مهمتر هستند. مهم است که مشخص شود که فاصله، بهویژه زمانی که فیلدهای NACE مورد بهرهبرداری قرار میگیرند، تنها برای تخصیص سلول آخرین مایل (در شبکه 500×500 متر) و تنها پس از در نظر گرفتن وزن سلولها محاسبه میشود. بنابراین، روش پیشنهادی، با بهرهبرداری از آمار کاربری اراضی و NACE،منجر به توزیع غیر واقعی کارگرانی که تصمیم به کار در نزدیکی محل سکونت دارند، نمی شود. یک مثال در بخش 4 ارائه خواهد شد .
در نهایت، شایان ذکر است که چارچوب پیشنهادی به اندازه کافی منعطف است که در صورت وجود منبع داده مناسب، امکان ادغام سایر عوامل غیر از بخش اشتغال را فراهم می کند، در حالی که فرآیند کلی را از نظر نیازهای داده ساده و صرفه جویی می کند. . برای مثال، میتوان گرههای اصلی حملونقل عمومی را در محاسبه وزن گنجاند یا کلاسهای کاربری اضافی را در نظر گرفت (به عنوان مثال، یک کار جالب در این جهت [ 32 ] است).
3. تخصیص فضایی: مطالعه موردی تالین
3.1. توضیحات عمومی و در دسترس بودن داده ها
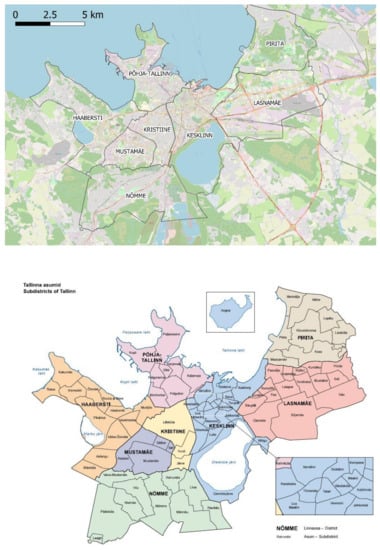
این روش در اینجا در یک مطالعه موردی مربوط به شهر تالین، استونی استفاده می شود. تالین یک پایتخت اروپایی است که با یک شبکه اتوبوس و واگن برقی کارآمد و یک بندر مهم که به جریان های بالایی از حمل و نقل و مسافران خدمات می دهد، مشخص می شود. همچنین در یکی از محورهای TEN-T (Rail Baltica) قرار دارد. نقشه هایی که ولسوالی ها و نواحی فرعی را نشان می دهد در شکل 3 ارائه شده است.
سال مرجع انتخاب شده 2015 است، با انگیزه این واقعیت که یک بررسی سفر [ 33 ]، که شامل خاطرات سفر بود، در طول آن سال ثبت شد. در سال 2015، این شهر 414000 نفر سکنه داشت که پرجمعیت ترین منطقه در بین هشت ناحیه لاسنامیه و مستامه است. آمارها و توزیعهای مربوطه، مانند جنسیت در هر سن، هم از پایگاه داده آماری ملی ( www.stat.ee ؛ قابل دسترسی در 28 دسامبر 2021) و هم از سوابق شهرداری [ 34 ] بهدست آمد.
ما در ضمیمه A یک نمای کلی از تمام داده های موجود را که می توان استفاده کرد گزارش می کنیم. اساساً، همه منابع داده بهصورت آزاد و رایگان در دسترس بودند، به استثنای مجموعههای محل کار که برای فرآیند استخراج نیاز به هزینه داشتند. شایان ذکر است که همانطور که در بخش 2 بحث شد ، منابع داده غیرعمومی (به عنوان مثال، داده های تلفن همراه، آدرس شرکت، فضای طبقه، آمار تفکیک شده، ODهای رفت و آمد، و غیره) یا هر داده ای که اجازه انجام وظایف پیچیده تر را می دهد در نظر گرفته نشده است. در این مطالعه.
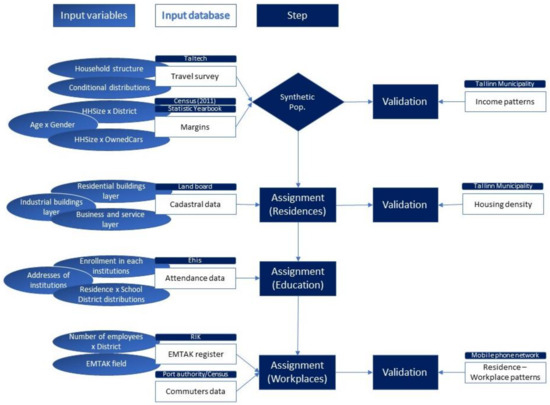
فرآیندی که برای تولید و اعتبارسنجی مجموعه داده نهایی برای شهر تالین دنبال شد در شکل 4 خلاصه شده است ، جایی که هر مرحله به ورودی های مورد نیاز گره خورده است.
همانطور که در شکل 4 مشاهده می شود ، کار بر روی جمعیت مصنوعی چهار مرحله اصلی را دنبال می کند که برای هر کدام منابع و متغیرهای مورد بهره برداری گزارش شده است. علاوه بر این، در سمت راست، دادههای مورد استفاده برای اعتبار سنجی فهرست شدهاند که دوباره منابع را برجسته میکند. برای اینکه مدلسازی تصمیمگیری را پیشنهاد کند، اعتماد به نتایج بسیار مهم است و میتوان آن را از طریق اعتبار سنجی، که یک گام کلیدی در هر تجزیه و تحلیل است، تقویت کرد، حتی بیشتر از آن زمانی که از حداقل مجموعهای از دادهها مانند این مورد سوء استفاده میشود. شکل 4 همچنین سعی می کند ماهیت ماژولار بودن فرآیند را برجسته کند.
3.2. توضیحات عمومی و در دسترس بودن داده ها
به منظور تولید جمعیت مصنوعی که بعداً اختصاص داده می شود، بسته SimPop انتخاب شد [ 10 ]. با این حال، باید مشخص شود که چگونه انتخاب SimPop کاربرد رویکرد ارائه شده را محدود نمی کند، زیرا اساساً هر روش دیگری که قادر به تولید جمعیت مصنوعی باشد می تواند برای تولید ورودی های مورد نیاز مورد سوء استفاده قرار گیرد. برای جزئیات بیشتر در مورد ابزار SimPop، خوانندگان علاقه مند می توانند به [ 10 ] مراجعه کنند. علیرغم اینکه این گام اول یک نسخه اولیه از جمعیت مصنوعی را تولید میکند، اما هنوز برای استفاده به عنوان ورودی برای مدل تقاضای مبتنی بر فعالیت آماده نیست، زیرا هنوز فاقد متغیرهای کلیدی مانند مکانهای آموزشی و محل کار است. همانطور که از شکل 1 پیداست، این متغیرها از طریق مرحله میانی “تخصیص فضایی” مدلسازی میشوند و به نقاط لنگر کلیدی مورد نیاز برای تکرار الگوهای سفر معمولی منجر میشوند. با این حال، نقاط لنگر نمی توانند گنجانده شوند زیرا به درستی توسط دفتر خاطرات سفر ثبت نشده اند. علاوه بر این، توزیع محل سکونت باید بیشتر تفکیک میشد، زیرا هر عامل باید به منطقهای اختصاص داده شود که به مدلسازی انتخابهای تحرک او اجازه دهد (مثلاً 500×500 متر). در واقع، نمیتوان مدلهای انتخابی را برای مناطقی به بزرگی زیرمجموعهها اعمال کرد، در حالی که این امکان وجود دارد که درجه دقت در محدوده پیادهروی باشد. یک جمعیت مصنوعی تفکیکشدهتر یافت میشود که بهترین دقت را دارد در حالی که سطوح خوبی از دقت را حفظ میکند (همانطور که در [ 35 ] ثابت شد).
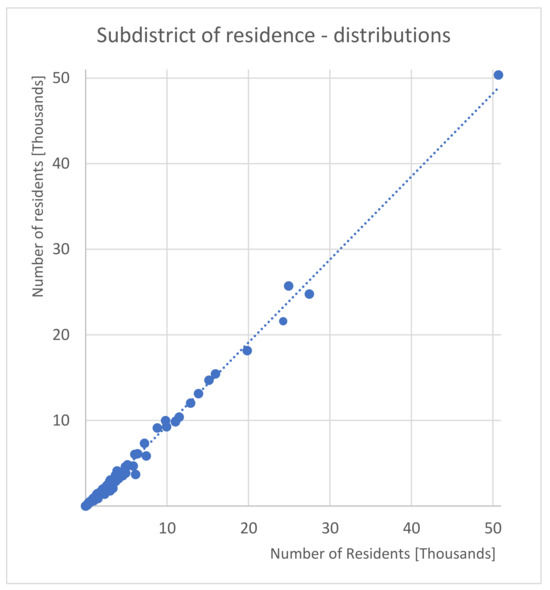
ما در شکل 5 اولین نسخه از جمعیت مصنوعی را گزارش میکنیم که از استفاده از ابزار SimPop حاصل شده است، جایی که ممکن است مشاهده شود که دو جمعیت (واقعی، یعنی از سرشماری، و مصنوعی) از نظر اندازه خانوار و توزیع فضایی تقریباً کاملاً مطابقت دارند. در سراسر مناطق فرعی تالین. این در واقع به این دلیل اتفاق میافتد که کالیبراسیون نهایی از طریق بازپخت شبیهسازی شده روی این دو متغیر (که برای مطالعه موردی مهمتر از مثلاً جنسیت × سن تلقی میشدند) انجام شد.توزیع). علاوه بر این، با توجه به ساختار نظرسنجی، متوسط درآمد هر عضو خانواده بیشتر با ساختار خانوار مرتبط بود تا فرد. بنابراین، از آنجایی که درآمد متغیر کلیدی دیگری برای یک ABM است، توزیع دقیقتر اندازه خانوار بر کالیبراسیون بر روی متغیرهای فردی ترجیح داده شد. جزئیات بیشتر در مورد جمعیت مصنوعی در بخش 4 ارائه شده است .
3.3. تخصیص فضایی – محل کار
برای اجرای تخصیص فضایی محل کار، یک مجموعه داده جمعآوری شده از مرکز ثبتها و سیستمهای اطلاعاتی استونی (RIK) بهدست آمد.
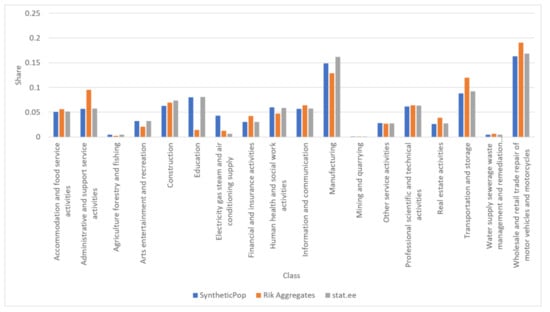
چنین مجموعهای با مجموعهای از مجموعههای پیچیدهتر گزارششده در ادبیات، با جمعآوری و ناشناسسازی متفاوت است. در واقع، تنها مجموع حواشی برای تعداد کارکنان در هر میدان EMTAK در سطح منطقه مورد بهره برداری قرار گرفت. در این بخش، به هر فرد یک محل کار در یک سلول در شبکه اختصاص داده می شود، بدون اینکه او را به ساختمان یا آدرس خاصی اختصاص دهد. توزیع های مورد بهره برداری در شکل 6 و شکل 7 گزارش شده است.
در ادامه، کاربرد مطالعه موردی تالین با استفاده از روش توصیف شده در بخش 2 ارائه شده است. اول، از دادههای سرشماری در دسترس عموم، میتوان توزیعهای کارگران در حوزه EMTAK را بر اساس شغل (که به نوبه خود به جنسیت، سن و منطقه سکونت مرتبط است) بدست آورد. این مورد برای اختصاص یک میدان به هر فرد در جمعیت مصنوعی مورد سوء استفاده قرار می گیرد، در حالی که در توزیع فضایی نقش های حرفه ای سازگاری دارد. شکل 6منطبقات به دست آمده در بین شغل و جمعیت کلی را گزارش می دهد. باید دوباره مشخص شود که چگونه جمعیت مصنوعی ممکن است کمی با جمعیت واقعی در برخی مناطق یا در برخی ویژگی ها متفاوت باشد. این به دلیل ماهیت تصادفی تخصیص است و بسته به حاشیههایی که جمعیت بر اساس آن کالیبره میشود. بنابراین مهم است که بررسی شود که حاشیه ها با سرشماری مطابقت دارند. در این مورد، رشتههای شغلی بر اساس سن، جنسیت و منطقه محل سکونت تخصیص داده شد و میتوان نتیجه گرفت که میزان سازگاری رضایتبخش است. هنگامی که تخصیص فیلدهای EMTAK انجام شد، مجموع در جمعیت مصنوعی ناشی از دادههای سرشماری با مجموع موجود در مجموعه داده RIK مقایسه میشود و ناسازگاریها شناسایی میشوند. به عنوان مثال، کارگران “آموزش و پرورش” 14 نفر هستند،شکل 7 ). سپس همه موارد پرت به عنوان “دیگر” دسته بندی می شوند و زمینه آنها در تعیین منطقه محل کار مورد سوء استفاده قرار نمی گیرد. در حالی که، برای فیلدهایی که توزیع آنها بین دو مجموعه داده مطابقت دارد، در عوض امکان بهره برداری از توزیع وجود دارد.
هنگامی که مجموعه داده EMTAK بین RIK و پایگاههای سرشماری منسجم شد، هم تخصیص میدان EMTAK و هم منطقه محل کار با اعمال توزیعهای ثبتشده انجام میشود (همانطور که در بخش 2 توضیح داده شده است). بنابراین، تمرکز بر آخرین مایل خواهد بود که به شرح زیر اجرا می شود:
-
ابتدا، وزنهایی بر اساس کلاس هر سلول تخصیص داده میشود، که امکان محاسبه وزن کل برای تمام سلولهای هر ناحیه را نیز فراهم میکند.
-
سپس نسبت i بین وزن هر سلول و مجموع وزنهای ناحیه طبق رابطه (2) محاسبه میشود.
برای کارگران EMTAK که مجموع آنها بین داده های RIK و سرشماری منسجم است، از نسبت i برای اختصاص سلول محل کار استفاده می شود. سپس از فیلدهای فاصله و EMTAK برای تخصیص زیرمنطقه، یعنی ناحیه کاری، استفاده میشود، که امکان قاببندی الگوهای رفتوآمد منسجم و واقعی را فراهم میکند. برای سایر کارگران، انتساب سلولی ساده به طور بالقوه بیش از حد کج تلقی می شد و انتساب ناحیه کاری بر اساس سرشماری یا توزیع EMTAK پیش از پیش ممکن نبود.
بنابراین، برای جلوگیری از اینکه افراد تنها بر اساس وزن سلول در سمت دیگر شهر کار کنند، از الگوریتم اکتشافی زیر استفاده میشود:
-
فاصله بین هر سلول محل سکونت و هر منطقه، که به عنوان میانگین بین تمام فواصل بین سلول در دست و آنهایی که در منطقه گنجانده شده است، محاسبه می شود (نمونه ای در شکل 8 a را ببینید).
-
برای هر جفت سلول (یکی محل سکونت و دیگری محل کار واجد شرایط)، نسبت بین فاصله آنها و میانگین فاصله بین سلول های محل سکونت و تمام سلول های دیگر در منطقه محاسبه می شود.
-
هر منطقه کشش گرانشی خود را دارد که بر اساس تعداد کارمندان در میدان های باقی مانده (“سایر”) محاسبه می شود. در این حالت، احتمال کار در یک منطقه از طریق رابطه (4) محاسبه می شود. حتی اگر نویز خاصی به تعداد کل مشاغل در زمینه “سایر” اضافه شود، یکپارچگی فضایی حفظ می شود (مناطق دور شانس کمتری برای انتخاب دارند). علاوه بر این، نشان داده خواهد شد که چگونه تعداد کل کارکنان “سایر” در هر منطقه کاملاً ثابت است.
-
کلاس سلول محل کار بر اساس توزیع طبقات سلولی در منطقه از طریق رابطه (5) محاسبه می شود.
-
هنگامی که هم ناحیه و هم کلاس برای محل کار تخصیص یافتند، تخصیص سلول نهایی به سادگی از طریق معادله (6) انجام می شود. شکل 8 ب نشان می دهد که چگونه تخصیص سلول نهایی در هر کلاس انجام می شود.
توجه داشته باشید که فاصله به عنوان یک عامل تنها به عنوان یک آیتم اصلاحی در هنگام اختصاص ناحیه محل کار (عامل اصلی کشش گرانشی تعداد مشاغل یا توزیع واقعی EMTAK) و برای تعیین آخرین مایل در نظر گرفته می شود. علاوه بر این، هنگام تخصیص منطقه کاری، فاکتور فاصله فقط برای زمینههایی در نظر گرفته میشود که اطلاعات مکانی قابل اعتمادی برای آنها در دسترس نبود. موارد فوق فقط از طریق داده های مکانی مربوط به تعداد ساختمان ها در هر سلول و مقصد اصلی آنها و آمار کل در سطح منطقه در مورد تعداد کارکنان در هر فیلد EMTAK (در صورت امکان) انجام شد.
شکل 8 ب آخرین مرحله روش را نشان می دهد که شامل تخصیص فاصله است. افراد ساکن در سلول قرمز قبلاً بر اساس حواشی سرشماری و فیلدهای NACE به منطقه کاری و بر اساس وزن نسبی و احتمال نتیجه به یک طبقه سلولی منصوب شده اند. سپس، پس از اینکه محل کار به عنوان یکی از محل های بنفش تعریف شد، فاصله به عنوان پروکسی نهایی استفاده می شود. در واقع، از آنجایی که سلول های بنفش در نوع تولیدی قرار می گیرند و وزن بالایی دارند، تعداد کارگران در سلول های دور در مرز شرقی بیشتر از کارگران بخش غربی و شمالی منطقه (نزدیک ترین ها) است. به سلول قرمز محل سکونت).
4. نتایج
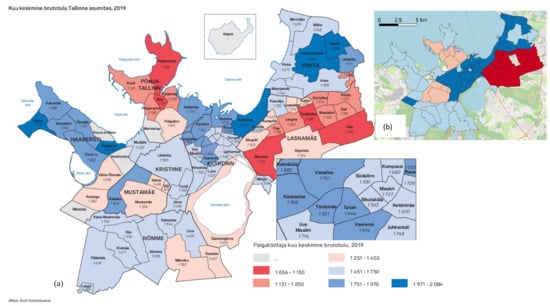
در ادامه، مروری بر توزیعهای مربوطه در مجموعه داده نهایی ارائه میکنیم و بررسی میکنیم که چگونه آنها با دادههای دنیای واقعی مطابقت دارند. همانطور که از شکل 9 مشاهده می شود ، توزیع درآمد برای جمعیت مصنوعی به طور معقولی، حداقل از نظر کیفی، با توزیع واقعی مطابقت دارد. تنها نادرستی ها برای نواحی کوچک به دلیل تعداد بسیار کم ساکنان ظاهر می شود (مساله مشابهی در مورد مناطق کوچکتر نیز در [ 8 ] گزارش شده است). برای ناشناس ماندن مجموعه داده مصنوعی، متغیر درآمد به ازای هر عضو خانواده به چهار سطح (بالا، متوسط، پایین و در دسترس) تبدیل شد. تعداد کل خودروها بر اساس حاشیه های موجود در [ 36 ] اختصاص داده شد]، به دنبال توزیع احتمال بر اساس متغیرهای خانوار.
همانطور که گفته شد، مدلهای مبتنی بر فعالیت به سطحی از تفکیک فضایی نیاز دارند که توسط دادههای سرشماری چارچوب بندی نشده و از طریق ابزارهایی مانند SimPop قابل تکرار نیستند. در مطالعه موردی ما، شهر تالین به 628 سلول 500 × 500 متر تقسیم شده است که سپس به عنوان بسیار مسکونی (HR)، مسکونی کم (LR)، نوع مشاغل و خدمات (OW) و نوع تولیدی (MW) طبقهبندی میشوند. بر اساس برخی از کلاس های تعریف شده در [ 19 ]، داده های کاداستر، و مقاصد مختلف برای ساختمان ها در هر سلول، همانطور که در شکل 10 نشان داده شده است.
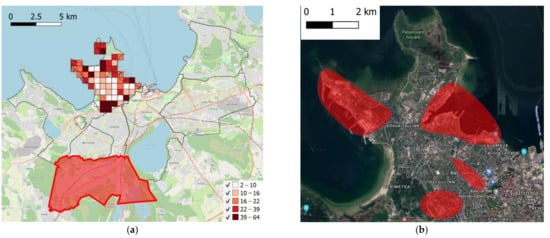
به نظر می رسد مقادیر تک سلولی برای ساکنان دقیقاً مطابق با مقادیر ثبت شده (اما به طور عمومی به اشتراک گذاشته نشده، تا جایی که می دانیم) توسط سرشماری شهر مطابق شکل 11 باشد. همانطور که مشاهده می شود، سلول های آبی تیره در تصویر سمت چپ با سلول های سمت راست همپوشانی دارند.
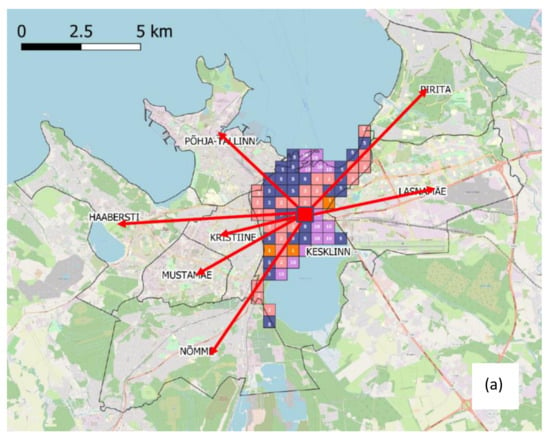
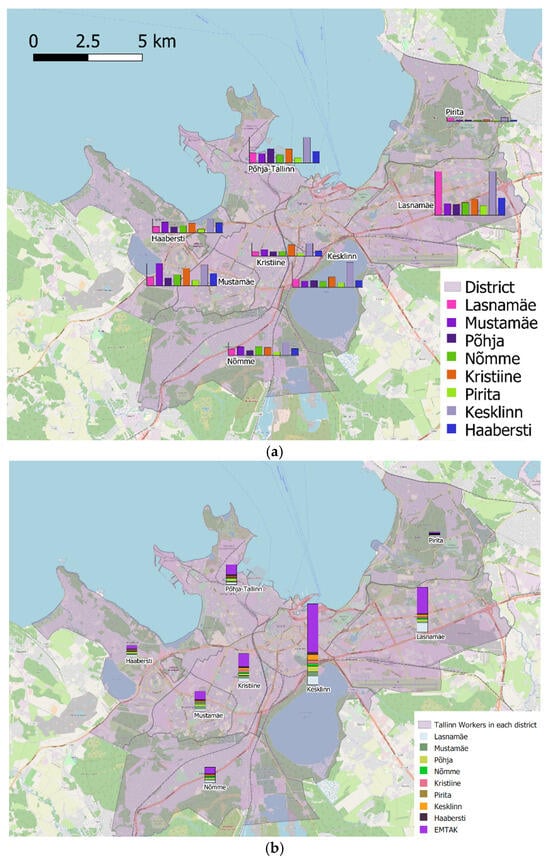
همانطور که در شکل 12 مشاهده می شود ، هنگامی که با یک الگوی زیرمنطقه محل کار واقع گرایانه ترکیب می شود، انتساب الگوهای بسیار منسجمی را در توزیع محل کار ایجاد می کند که با اولویت بندی کاربری زمین و استفاده از فاصله تنها به عنوان یک نماینده برای فیلتر کردن ترکیبات بعید به دست می آید.
به طور خاص، همانطور که از شکل 12 الف مشاهده می شود، ساکنان Läsnamäe، برای مثال، بیشتر در Läsnamäe و Kesklinn کار می کنند. از طرف دیگر ساکنان هابرستی تمایل دارند در هابرستی و کسکلین کار کنند. این روندهای مختلفی را که ممکن است مورد انتظار باشد نشان می دهد: منطقه محل سکونت در واقع سهم عادلانه ای از محل کار را جذب می کند در حالی که مناطق مرکزی همین کار را انجام می دهند. بنابراین، حرکات مورد انتظار در داخل شهر تکرار می شود و در عین حال کج بودن را به حداقل می رساند. شکل 12هدف b مقایسه کل کارکنان در هر منطقه با کل هر منطقه در مجموعه داده حاصل است. همانطور که از منظر کیفی می توان مشاهده کرد، انتساب سهام های مختلف را کاملاً صادقانه بازتولید می کند. لازم به ذکر است که داده هایی برای مقایسه کمی در دسترس نیست. افزودن عنصر گرانشی برای میدانهای غیر منسجم EMTAK، مجموع را منحرف نمیکند. به نظر می رسد توزیع بین سلول ها منسجم ترین الگوها را نیز بازتولید می کند.
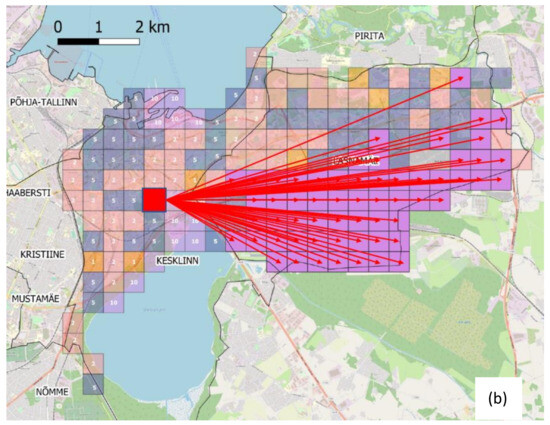
در شکل 13سلول های محل کار برای افراد ساکن در Nõmme و کار در Põhja-Tallinna گزارش شده است. شایان ذکر است که چگونه الگوی رفت و آمد در اینجا به طور صادقانه وضعیت کاربری زمین را نشان می دهد، حتی اگر یک مدل گرانشی اجرا شود. در واقع، مربعهای تیرهتر در بخش شمالی، مناطقی را در Põhja-Tallinna نشان میدهند که ساختمانهای بندر در آن قرار دارند، در حالی که مربعهای تاریکتر جنوبی نتیجه عنصر گرانشی اضافه شده است که مناطق نزدیک به مرکز شهر و نزدیک ایستگاه قطار را به تصویر میکشد. علاوه بر این، این الگو مخصوص رفت و آمد بین Põhja-Tallinna و Nõmme است زیرا توزیع محل سکونت/کار از طریق تخصیص میدانی EMTAK حفظ شده است. به این ترتیب، تمام اطلاعات موجود برای انتساب مورد سوء استفاده قرار می گیرد،
مقایسه نهایی با [ 37 ] انجام شد، مطالعه اخیری که الگوهای رفت و آمد در تالین را با بهره برداری از داده های شبکه تلفن همراه تلفن همراه بررسی می کند. دوره مرجع مطالعه می 2018 و درجه دقت در سطح منطقه بود. توجه داشته باشید که این دو مطالعه بر روی مجموعه دادههای بسیار متفاوتی ساخته شدهاند و دادههای خام از شبکه تلفن همراه برای نویسندگان در دسترس نبود. جدول 2 نتایج بهدستآمده با روش پیشنهادی انتساب محل کار و نتایج گزارش شده در [ 37 ] را ارائه میکند.
می توان مشاهده کرد که فرضیه های مطرح شده در مورد استفاده از زمین، مزارع EMTAK و فواصل، روند کلی را نشان می دهد، حتی مواردی مانند Pirita-Lasnamäe که 22٪ از نیروی کار ساکن را تشکیل می دهد. در جدول 2 ، درصدها نشان دهنده سهم کارگرانی است که از منطقه مبدا (ردیف ها) برای رسیدن به منطقه محل کار (ستون) حرکت می کنند. درصدها باید در بین ردیف ها مقایسه شوند (یعنی مجموع درصد هر ردیف به 100٪ می رسد). مقایسه با مقایسه الگوی بصری ناشی از جدول 2 و با مشاهده دلتای ناشی از دو مجموعه داده انجام می شود. فقط توزیع ها و نه مقادیر مطلق را می توان با هم مقایسه کرد زیرا در [ 37 ] هیچ مقدار مطلقی گزارش نشده است.
در جدول 3 ، تفاوت بین درصد در جدول 2 گزارش شده است. همانطور که می توان متوجه شد، بیشتر تفاوت ها زیر یا حدود 5٪ است. با این حال، الگویی از خطاها برای مواردی که کارگران در همان منطقه ساکن و کار میکنند ظاهر میشود، که به طور مداوم در [ 37 ] بالاتر است. این ممکن است تفسیرهای متفاوتی داشته باشد و دو فرضیه قابل قبول در نظر نویسندگان عبارتند از:
-
در این مطالعه، وزن فاصله باید برای محل کار در مجاورت محل سکونت بیشتر باشد. این یک الگوی غیرخطی را در ارتباط فاصله منعکس می کند. این فاصله بیش از سایر عوامل (کاربری زمین و میدان های EMTAK) برای سلول های اطراف محل سکونت وزن بیشتری دارد.
-
در [ 37 ]، محل های کار به عنوان متداول ترین شناسه سلولی ثبت شده بین ساعت 11:00 و 16:00 در طول روزهای کاری شناسایی می شوند. مواردی که این شناسه های سلولی مشابه محل سکونت باشد، مستثنی هستند. در حالی که این فیلتر کردن احتمالاً اکثر کارمندان خانه، افراد بازنشسته و افراد با برنامه کاری متفاوت را در بر می گیرد (رویکرد مشابه مطالعات دیگر مانند [ 38 ] است)، ممکن است در شناسایی برخی موارد دور از دسترس (مانند والدین در خانه بمانند) شکست بخورد. با یک برنامه ورزشی روتین). این امر منجر به برآورد بیش از حد افراد شاغل و ساکن در همان منطقه می شود.
فرضیه نویسندگان این است که حقیقت احتمالاً در این بین قرار دارد، با رویکرد ارائه شده در این مقاله در به تصویر کشیدن برخی از ترجیحات مربوط به یک محل کار نزدیک تر و رویکرد در [ 37 ] احتمالاً گرفتن برخی از ورودی های ناخواسته به دلیل ناشناس بودن داده ها. در نهایت، برخی اختلافات کوچک ممکن است به دلیل سال مرجع متفاوت (2015 و 2018) باشد. همانطور که در ادبیات [ 37 ، 38 ] ذکر شد، در حالی که داده های تلفن همراه منبع ارزشمندی از اطلاعات است، اعتبار مجموعه داده های حاصل به دلیل کمبود داده چالش برانگیز است. به نظر می رسد روش ارائه شده در این مقاله، جایگزینی برای زمانی که داده های تلفن همراه در دسترس نیست، این شکاف را نیز پر می کند.
به طور خلاصه، اعتبارسنجی الگوهای سکونت و محل کار، توزیع فضایی اندازههای مختلف خانوار، و توزیع جنسیت و سن در بین جمعیت امکانپذیر بود. بنابراین، هر مرحله از فرآیند با بهترین داده های موجود بررسی شد و نتایج امیدوارکننده تلقی شد.
5. بحث
کار ارائه شده روشی را برای اختصاص مکان های کاری به جمعیت مصنوعی با استفاده از مقدار محدودی از داده های انبوه، بدون بهره برداری از منابع داده های پیشرفته تر مورد استفاده در ادبیات موجود، معرفی می کند. جدول 1 تفاوت در نیازهای داده ها و شکاف تحقیقاتی را که این مقاله به دنبال پر کردن آن است، نشان می دهد، یعنی اینکه آیا و چگونه می توان یک انتساب نقاط لنگر را انجام داد در حالی که فقط از کل برای یک جمعیت استفاده می کند. مهم است که تاکید شود که نتایج حتی ارزشمندتر هستند زیرا الگوهای رفت و آمد به وضوح 500 × 500 متر اختصاص داده شده است.
برای مطالعه موردی تالین، امکان ساخت یک الگوی رفت و آمد OD وجود داشت که به طور رضایت بخشی با روندهای مشاهده شده با تجزیه و تحلیل داده های تلفن همراه مطابقت داشته باشد ( جدول 2 ). علاوه بر این، همانطور که در شکل 13 نشان داده شده است ، موسسات و محل های کار با دقت خوبی شناسایی شدند و اساسا به جای مدل سازی یا دریافت آن به عنوان ورودی، مکان شرکت ها را تخمین زدند.
در اینجا بحث می شود که حجم محدود داده های مورد نیاز برای کارکرد روش و نتایج قابل اعتماد تنها شکاف تحقیقی نیست که مقاله پر می کند. با استفاده از روش برای یک مطالعه موردی واقعی و مقایسه آن با منبع داده دیگری ( جدول 2 ) این مقاله امکانسنجی و قابلیت اطمینان راهحل پیشنهادی را اثبات میکند. تلاش شد تا هر مرحله از خط لوله مدل سازی با جزئیات گزارش شود و کد استفاده شده و نتایج به عنوان منبع باز ارائه می شود. هدف در این مورد، تقویت تکرارپذیری و قابلیت انتقال است که در بخش 1 به عنوان برخی از محدودیتهای کنونی در جدیدترین فناوری شناسایی شد [ 29 ].]. مزیت اصلی روش پیشنهادی نسبت به روش های موجود در نیاز به داده بسیار سبک نهفته است. علاوه بر این، کد موجود به زبان R نوشته شده است و هر مرحله از طریق آن پیاده سازی می شود، بنابراین هیچ الزام خاصی در مورد توان محاسباتی، سیستم عامل یا محدودیت های حافظه ایجاد نمی شود. تمام داده های ورودی در قالب csv. هستند، بنابراین پیچیدگی پردازش داده ها مشکلی نیست. برای مطالعه موردی تالین، کد در طی چند (ده ها) دقیقه از طریق تکالیف اجرا می شود.
همچنین باید مشخص شود که چگونه جمعیت مصنوعی و تخصیص حاصله ارائه شده در این مقاله گام های کلیدی در تحلیل های گسترده تر هستند، همانطور که در شکل 1 پیشنهاد شده است . ABM که ممکن است بر اساس مجموعه دادههای ارائه شده ساخته شود، سپس میتواند برای انجام ارزیابی گستردهتر در رابطه با کارایی ترافیک، اشتراکهای مودال و دسترسی مورد بهرهبرداری قرار گیرد [ 31 ]. سپس می توان از این نتایج برای ارزیابی اثرات زیست محیطی و سطوح انتشار یا پیش بینی سناریوهای آینده مانند مواردی از جمله رانندگی خودکار استفاده کرد.
در حالی که نتایج دلگرمکننده به نظر میرسند و یک ورودی کارآمد برای ABM هستند (آنها در SimMobility MT آزمایش شدند)، برخی محدودیتها هنوز وجود دارند و ارزش بحث را دارند. عاملی که باید در حین مدلسازی در نظر گرفته شود، ماهیت اکتشافی تخصیص برای فیلدهای NACE طبقهبندی شده به عنوان «سایر» است. بسته به سهم این کارگران و پویایی رفت و آمد در مطالعه موردی، نتایج باید به دقت تجزیه و تحلیل شوند و احتمالاً از طریق معیارهای اضافی اعتبار سنجی شوند. این مشکل زمانی که چندین منبع داده مورد سوء استفاده قرار می گیرند کمتر مرتبط است [ 11 , 17 , 25 , 26 , 27 , 28 , 29] از آنجایی که تأیید اعتبار کمتر فشار می آورد.
علاوه بر این، فقدان دادههای تفکیکشدهتر اعتباری را که میتوان انجام داد محدود کرد. این امر اعتبار روش ارائه شده را نسبت به کارهایی که از داده های اضافی بهره می برند چالش برانگیزتر می کند [ 11 ، 17 ، 25 ، 26 ، 27 ، 28 ، 29 ]. تکرار این رویکرد به سایر مطالعات موردی با دادههای موجود بیشتر امکان کمیسازی درجه دقت بهدستآمده را فراهم میکند. برای به کارگیری روش ارائه شده برای مطالعه موردی دیگر می توان عملکرد آن را با هر یک از روش ها و ابزارهای شرح داده شده در بخش 1 مقایسه کرد.. به دلیل ماهیت مطالعه موردی تالین، یعنی فقدان ورودی های قابل اعتماد در محل کار در نظرسنجی خانوار و کمیاب بودن سایر داده ها (به جدول 1 مراجعه کنید )، امکان انجام ارزیابی عملکرد دقیق تری وجود نداشت.
جهتهای تحقیقاتی آینده که توسط این مقاله باز میشود، به چالشهای فعلی، مانند ظهور الگوهای کاری انعطافپذیر یا از راه دور، مربوط میشود. افزودن فیلدهای NACE باید امکان مدلسازی این الگوها را به موازات تخصیص محلهای کار فراهم کند. کارهای آینده که ممکن است با مجموعه داده یا روش ارائه شده انجام شود، زمینه های مختلف NACE مربوط به آمارهای مختلف کار از راه دور را مشاهده خواهد کرد و توانایی چارچوب بندی تغییرات در جریان واقعی افراد را در بین مناطق 500 × 500 متر ارزیابی می کند. سایر مسیرهای تحقیقاتی مربوط به ادغام ایستگاه های حمل و نقل عمومی در وزن فاکتورهای کاربری زمین یا تمرکز بر وزن فاکتور فاصله در مجاورت محل سکونت، برای بررسی اختلافات برجسته شده در بخش 4 است .. در نهایت، یک محدودیت مقاله این است که از وزن های گزارش شده در [ 19 ]، که برای یک شهر نمونه اولیه تصور شده است، بهره برداری می کند. توسعه آتی می تواند روش ارائه شده را برای مطالعه موردی مورد بررسی قرار دهد که در آن داده های کاربری دقیق زمین برای انجام کالیبراسیون وزن های مذکور ثبت می شود. علاوه بر این، سایر داده های تحرک باز، مانند خطوط حمل و نقل عمومی و ماتریس های اسکیم، می توانند دقت را بهبود بخشند، به عنوان مثال، با انحراف وزن سلول های خاص نزدیک به هاب های تحرک واقعی.
6. نتیجه گیری
این مقاله یک روش سیستماتیک برای اختصاص نقاط لنگر محل کار به یک جمعیت مصنوعی، با بهرهبرداری از دادههای کاربری زمین و مجموعه دادههای کل با مجموع کارکنان در هر زمینه NACE را توصیف میکند. تصور می شود که جمعیت حاصل برای تولید تقاضای مبتنی بر فعالیت به کار گرفته شود. روش طراحی شده بهعنوان زیرک، مدولار (یعنی به هیچ ابزار موجود محدود نمیشود)، و متکی به مجموعه دادههای عمدتاً باز و/یا مجموع طراحی شده است. سپس این مشارکت باید بهرهبرداری از مدلهای مبتنی بر عامل را آسانتر کند و جذب آنها را هم در ادبیات علمی و هم در مجموعههای حرفهای تقویت کند. راه حل توصیف شده قابل تکرار و بسیار قابل انتقال است، با قدرت اصلی در سادگی و اتکای کم آن به داده های موجود است. به خصوص، قابلیت انتقال با این واقعیت تضمین میشود که روش پیشنهادی فقط از دادههای باز در قالبی که معمولاً توسط نهادهای آماری ملی یا فراملی ثبت میشود بهرهبرداری میکند و هیچ مانع قابل پیشبینی نمیتواند از قبل شناسایی شود. شکاف پژوهشی پر شده شامل فقدان روش های انتساب محل کار برای جمعیت های مصنوعی، بر اساس داده های بسیار کمیاب و انبوه است. این مقاله هر گذر از چنین روشی را شرح می دهد و آن را بر روی یک شهر واقعی آزمایش می کند، نتایج را معتبر می کند و سطح دقت به دست آمده را ارزیابی می کند. مجموعه داده به دست آمده برای استفاده توسط محققین دیگر برای مدلسازی مبتنی بر فعالیت (یا هر جهت تحقیقاتی دیگر) مفصل است زیرا بهعنوان منبع باز در آدرس زیر به اشتراک گذاشته میشود: شکاف پژوهشی پر شده شامل فقدان روش های انتساب محل کار برای جمعیت های مصنوعی، بر اساس داده های بسیار کمیاب و انبوه است. این مقاله هر گذر از چنین روشی را شرح می دهد و آن را بر روی یک شهر واقعی آزمایش می کند، نتایج را معتبر می کند و سطح دقت به دست آمده را ارزیابی می کند. مجموعه داده به دست آمده برای استفاده توسط محققین دیگر برای مدلسازی مبتنی بر فعالیت (یا هر جهت تحقیقاتی دیگر) مفصل است زیرا بهعنوان منبع باز در آدرس زیر به اشتراک گذاشته میشود: شکاف پژوهشی پر شده شامل فقدان روش های انتساب محل کار برای جمعیت های مصنوعی، بر اساس داده های بسیار کمیاب و انبوه است. این مقاله هر گذر از چنین روشی را شرح می دهد و آن را بر روی یک شهر واقعی آزمایش می کند، نتایج را معتبر می کند و سطح دقت به دست آمده را ارزیابی می کند. مجموعه داده به دست آمده برای استفاده توسط محققین دیگر برای مدلسازی مبتنی بر فعالیت (یا هر جهت تحقیقاتی دیگر) مفصل است زیرا بهعنوان منبع باز در آدرس زیر به اشتراک گذاشته میشود:https://github.com/Angelo3452/Tallinn-Synthetic-Population . جزئیات بیشتر در بخش بیانیه در دسترس بودن داده ها ارائه شده است.








بدون دیدگاه