

سیستمی برای تراز کردن موجودات جغرافیایی از منابع بزرگ ناهمگن


1
مرکز تحقیقات ادینبورگ، تحقیق و توسعه فناوری هوآوی انگلستان، ادینبورگ EH3 8BL، انگلستان
2
موسسه زبان، شناخت و محاسبات، دانشکده انفورماتیک، دانشگاه ادینبورگ، ادینبورگ EH8 9AB، انگلستان
*
نویسنده ای که مسئول است باید ذکر شود.
دریافت: 18 دسامبر 2021/بازبینی شده: 20 ژانویه 2022/پذیرش: 25 ژانویه 2022/تاریخ انتشار: 28 ژانویه 2022
چکیده
:
تراز کردن نقاط مورد علاقه (POI) از منابع داده های جغرافیایی ناهمگن یک کار مهم است که به گسترش داده های نقشه با اطلاعات مجموعه داده های مختلف کمک می کند. این وظیفه چندین چالش از جمله تفاوت در سلسله مراتب نوع، برچسب ها (فرمت های مختلف، زبان ها و سطوح جزئیات) و انحراف در مختصات را به همراه دارد. مقیاس پذیری یکی دیگر از مسائل مهم است، زیرا مجموعه داده های مقیاس جهانی ممکن است ده ها یا صدها میلیون موجودیت داشته باشند. در این مقاله، ما سیستم همترازی نهادهای جغرافیایی (GLEAN) را برای تطبیق کارآمد مجموعه دادههای جغرافیایی بزرگ بر اساس پارتیشن بندی فضایی با حاشیه قابل تطبیق پیشنهاد میکنیم. به طور خاص، ما یک معیار تشابه متن را بر اساس ارتباط بافت محلی نشانههای مورد استفاده در ترکیب با جاسازیهای جمله معرفی میکنیم. سپس به یک مدل تعبیهشده از نوع مقیاسپذیر میرسیم. در نهایت، ما نشان میدهیم که سیستم پیشنهادی ما میتواند به طور موثری همترازی مجموعههای داده بزرگ را مدیریت کند و در عین حال کیفیت همترازیها را با استفاده از معیار تشابه موجودیت پیشنهادی بهبود بخشد.
1. مقدمه
در سالهای اخیر، تعداد زیادی از نقاط مورد علاقه (POI) در پایگاههای اطلاعاتی جغرافیایی گنجانده شده است [ 1 ]. شبکه های اجتماعی مانند فیس بوک میزبان صفحات بسیاری از مشاغل هستند و پست ها حاوی مجموعه ای از مشاغل هستند. شرکت های مسافرتی مانند تریپ ادوایزر میزبان مجموعه ای از جاذبه های گردشگری هستند. همه این POI ها با مکان های جغرافیایی خاصی مرتبط هستند. ارائه دهندگان خدمات نقشه (مانند Google Maps، Tomtom، Here Maps) مجموعه داده های خود را، اغلب با کمک جمع سپاری، گسترش و غنی می کنند (به عنوان مثال، ویژگی «افزودن مکان گمشده به Google Maps» گوگل ( https://support.google.com /maps/answer/6320846(دسترسی در 10 دسامبر 2021)). با گسترش ویکیپدیا، تعداد مقالات مربوط به موجودات جغرافیایی که مختصات را جاسازی میکنند نیز افزایش مییابد. به طور مشابه، نمودارهای دانش (KGs) مانند Wikidata، DBpedia و YAGO نیز شامل تعداد فزایندهای از موجودیتهای جغرافیایی با مختصات هستند [ 2 ]. این KG ها همچنین حاوی اطلاعات تکمیلی هستند که ممکن است برای کاربردهای نقشه ها ارزشمند باشند.
تراز کردن نهادهای جغرافیایی از منابع مختلف به اطلاعات کامل تر در مورد یک نهاد جغرافیایی معین کمک می کند و با افزودن موجودیت های گمشده، مجموعه داده های موجود را به روز می کند. متأسفانه، تطبیق یک موجود جغرافیایی مشابه در مجموعه داده های منبع مختلف دشوار است زیرا هیچ شناسه جهانی وجود ندارد [ 3 ، 4 ].
یک چالش این است که مجموعه دادههای جغرافیایی مختلف اغلب دارای ناسازگاریها، افزونگیها، ابهامات و تضادها هستند [ 5 ]، از جمله تفاوت در مجموعه ویژگیهای موجودیت، قالبها و مقادیر آنها. اگرچه نهادهای جغرافیایی معمولاً دارای ویژگیهایی مانند برچسب ، دسته ( نوع )، آدرس و مختصات هستند.، این ویژگی ها می توانند در بین مجموعه داده ها تفاوت داشته باشند. به طور خاص، مختصات ممکن است سطوح مختلفی از دقت داشته باشند، آدرسها را میتوان در قالبهای مختلف ذخیره کرد، برچسبها میتوانند به زبانهای مختلف باشند و سطوح مشخصی متفاوتی داشته باشند، و ممکن است استفاده ناسازگاری از اختصارات و کلمات اختصاری وجود داشته باشد. به عنوان مثال، یک آدرس داده شده ممکن است ” 2 Semple St., Edinburgh, Midlothian, Scotland, UK ” در یک مجموعه داده و ” 2 Semple Street, Edinburgh, United Kingdom ” در دیگری باشد. یک برچسب ممکن است ” باغ وحش ادینبورگ ” یا به سادگی ” باغ وحش ” باشد، زیرا اطلاعات شهر ممکن است قبلاً در آدرس و مختصات ذخیره شده باشد. در این زمینه، نشانه « ادینبورگ” هنگام اندازه گیری شباهت برچسب ها مهم نیست. با این حال، هنگام اندازه گیری شباهت بین ” دوک ادینبورگ میخانه ” و ” دوک ولینگتون پاب “، همان نشانه بسیار مرتبط است.
یکی دیگر از منابع اصلی تضاد این واقعیت است که مجموعه داده های مختلف اغلب از دسته ها (انواع) متفاوتی از موجودیت های جغرافیایی استفاده می کنند. این انواع اغلب در سلسله مراتبی که می توانند بسیار متفاوت باشند، با درجات مختلفی از دانه بندی، ساختارهای سلسله مراتبی و نام انواع ساختار یافته اند. تطبیق سلسله مراتب نوع مجموعه داده های مختلف می تواند یک فرآیند چالش برانگیز باشد، به خصوص زمانی که برخی از سلسله مراتب ها بسیار بزرگ هستند. بازدارندگی دستی.
همه تفاوت های ذکر شده در بالا چالش های عمده ای را برای مشکل هم ترازی موجودیت جغرافیایی ایجاد می کند. بهعلاوه، مشکل همترازی موجودیت میتواند موارد استفاده آفلاین و آنلاین داشته باشد که چالشهای بیشتری برای خود ایجاد میکند. در حالت آفلاین، دو مجموعه داده بزرگ باید در مقیاس جهانی با یکدیگر مطابقت داده شوند. یک مثال عملی خوب از چنین موردی زمانی است که یک ارائهدهنده خدمات مکان میخواهد مجموعه دادههای POI خود را با ترکیب مجموعه دادهای که از یک ارائهدهنده نقشه خارجی به دست آمده است، گسترش دهد. در این راهاندازی، ممکن است بین دو مجموعه داده همپوشانی وجود داشته باشد و همه موجودیتهای هر یک از مجموعههای داده قابل تطبیق نیستند. همچنین متداول است که مجموعه داده هایی که تراز می شوند ناهمگن هستند و دارای سطوح مختلف ناقصی هستند. برخی از تفاوت های اصلی بین مجموعه داده ها می تواند در سلسله مراتب نوع آنها، برچسب ها،
علاوه بر این، یافتن مسابقات در مقیاس جهانی می تواند چالش برانگیز باشد. در این سناریو، مجموعه دادهها ممکن است به راحتی دهها یا صدها میلیون موجودیت داشته باشند، که منجر به چهار میلیارد جفت تطبیق احتمالی میشود. پارتیشن بندی فضایی یک راه مفید برای مقابله با این مشکل فراهم می کند، زیرا موجودیت ها را می توان از نظر جغرافیایی به پارتیشن هایی با اندازه های قابل مدیریت جدا کرد. با این حال، پارتیشن بندی فضایی با چالش هایی مواجه می شود، زیرا مختصات ممکن است وجود نداشته باشند یا دقیق نباشند، و جعبه های مرزی (bboxes) ممکن است در دسترس نباشند. بسته به نوع موجودیت، فاصله معمولی بین مختصات موجودیت های منطبق می تواند از چند متر (مثلاً رستوران ها) تا چند کیلومتر (مثلاً شهرها) متغیر باشد.
تراز نهادی نه تنها برای غنی سازی داده های آفلاین بلکه برای تطبیق آنلاین نیز مورد نیاز است. در این مورد، ما باید یک موجودیت جدید را با موجودیت های جغرافیایی موجود در یک مجموعه داده معین مطابقت دهیم. یک برنامه معمول برای این مورد استفاده، افزودن موجودیتهای تولید شده توسط کاربر (مثلاً مالک کسبوکار) به مجموعه دادهها است، که در آن لازم است قبل از افزودن موجودیت جدید، بررسی شود که آیا موجودیت جدید قبلاً وجود دارد یا خیر، تا از تکراری شدن جلوگیری شود. یکی دیگر از برنامههای کاربردی جستجوی موجودیتهای POI است که در آن کاربر ممکن است اطلاعاتی را ارائه کند که چهار ویژگی موجودیت جغرافیایی جستجو شده را پوشش میدهد. مورد دوم باید به POI های موجود در سرویس جستجو نگاشت شود تا بتواند درخواست کاربر را برآورده کند. در هر دو مورد، چالشهای ایجاد شده توسط تفاوتهای بین مقادیر ویژگیهای تولید شده توسط کاربر و مجموعهای از موجودیتهای مورد جستجو مشابه چالشهایی است که از همترازی آفلاین مجموعه دادههای جغرافیایی ناهمگن است. با این حال، تاخیر کم یک نیاز حیاتی در مورد آنلاین است، زیرا کاربران انتظار دارند نتایج در کسری از ثانیه برگردانده شوند.
در این مقاله، ما بر روی امتیازدهی تراز و اطمینان از مقیاس پذیری در مورد آفلاین تمرکز می کنیم. با این حال، همانطور که در بخش 5.3 مورد بحث قرار گرفت، این رویکرد همچنین میتواند برای پشتیبانی از پرونده آنلاین تطبیق داده شود . مشارکت های این مقاله به شرح زیر است.
-
ما یک سیستم همترازی جدید را طراحی کردیم که از ویژگیهای اصلی موجودیتهای جغرافیایی استفاده میکند: برچسب ، دسته (یا نوع )، آدرس و مختصات . GLEAN ابتدا معیارهای شباهت فردی را برای هر یک از ویژگی ها محاسبه می کند، سپس آنها را در یک معیار تشابه نهایی برای جفت موجودیت های بررسی شده ترکیب می کند. سپس این شباهت هم ترازی با یک آستانه برای تصمیم گیری در مورد تطابق مقایسه می شود.
-
ما استفاده از ارتباط بافت محلی نشانه ها را با رمزگذارهای جملات چند زبانه ترکیب کردیم تا شباهت مؤلفه برچسب را محاسبه کنیم.
-
ما از روشهای جاسازی بدون نظارت و تنزل نوع برای امتیازدهی مولفههای نوع استفاده کردیم.
-
ما یک پارتیشن بندی حاشیه سازگار مقیاس پذیر در مجموعه داده های موجودیت های جغرافیایی در مقیاس بزرگ به منظور بهبود مقیاس پذیری سیستم تراز خود اعمال کردیم.
-
ما تأثیر مشارکت خود را در امتیاز شباهت همترازی و مقیاسپذیری رویکرد تطبیق آفلاین خود ارزیابی کردیم.
باقی مانده از مقاله به شرح زیر سازماندهی شده است. بخش 2 کارهای مرتبط را مورد بحث قرار می دهد. بخش 3 مسئله تحقیقی را که در این مقاله به دنبال حل آن هستیم، معرفی می کند. بخش 4 اجزای GLEAN را شرح می دهد. بخش 5 معماری کلی GLEAN را توصیف می کند که اجزای آن را در یک سیستم واحد جمع می کند. بخش 6 نتایج ارزیابی عملکرد را بر اساس اجرای فرسایش در رابطه با اجزای فردی پیشنهادی ما ارائه میکند. در نهایت، بخش 7 مشارکت های مقاله را جمع بندی می کند و آن را برای جهت گیری های تحقیقاتی آینده باز می کند.
2. کارهای مرتبط
آثار بسیار کمی در مورد همسویی نهادهای جغرافیایی از منابع ناهمگن وجود دارد. همانطور که توسط دنگ و همکاران توضیح داده شده است. [ 6 ]، مشکل هم ترازی موجودیت جغرافیایی به سه حوزه اصلی تقسیم شده است. حوزه اول بر ویژگی های هندسی یا مکانی داده ها تمرکز دارد [ 4 ]. ناحیه دوم ویژگی های توصیفی و سایر ویژگی های غیر مکانی را هدف قرار می دهد [ 7 ، 8 ]. ناحیه سوم، که این کار بخشی از آن است، هر دو چارچوب ویژگی فضایی و غیر مکانی را ترکیب می کند. در مورد ما، برچسب، آدرس و دسته (نوع) را به عنوان ویژگی های غیر مکانی و مختصات را به عنوان ویژگی های فضایی در نظر می گیریم.
صفرا و همکاران [ 9 ] یکی از اولین رویکردها را پیشنهاد کرد که روشهای موجود را برای تطبیق فقط مکان برای ترکیب ویژگیهای مکانی و غیرمکانی گسترش میدهد. شفلر و همکاران [ 3 ] از ویژگیهای فضایی بهعنوان یک فیلتر اساسی استفاده کرد و متعاقباً برچسبهای موجودیت را برای مطابقت با POI از مجموعه دادههای شبکه اجتماعی ترکیب کرد. مک کنزی و همکاران [ 10 ] از مدلهای چند ویژگی وزندار برای یافتن ترازهای موجودیت استفاده کرد: وزنها با استفاده از رگرسیون لجستیک دو جملهای تخصیص داده میشوند. لیو و همکاران [ 11 ] یک شباهت فضایی-متنی top-k را برای یافتن محتمل ترین جفت ترازهای نامزد پیشنهاد کرد. نواک و همکاران [ 12] یک نمودار با گرههایی که نشاندهنده POI هستند و یالهایی که همترازیهای احتمالی را نشان میدهند، ایجاد کرد و استراتژیهای تطبیق مبتنی بر نمودار را برای حل مشکل تطبیق تضاد دادههای POI ابداع کرد. پورویس و همکاران رویکرد [ 13 ] با استفاده از ترکیب خطی از ویژگیهای برچسب، نوع و مختصات از طریق آنتروپی اطلاعات، نمونهها را مطابقت داد.
لو و همکاران [ 14 ] یک چارچوب کامل ترکیبی POI، از ارائه داده تا تأیید داده ها را پیشنهاد کرد. آنها همچنین از اطلاعات ویژگی های POI برای مطابقت با POI ها استفاده کردند. با این حال، این چارچوب ابتدا با نگاشت طبقه بندی انواع قبل از مقایسه POI آغاز شد. این با این فرض انجام می شود که طبقه بندی انواع از منابع داده های مختلف سازگار و بدون نویز هستند. علاوه بر این، اگرچه Low و همکاران. [ 14] ادعا کرد که در مقیاس بزرگ از چارچوب ترکیبی خود استفاده می کند، حداکثر مقیاس مجموعه داده استفاده شده از 12000 POI تجاوز نمی کند. محدودیت مقیاس پذیری عمدتاً به دلیل مداخله دستی متخصصان انسانی در مرحله تأیید است. در نهایت، این کار به مسائل مربوط به چند زبانه بودن برچسب ها یا ارتباط بافت محلی نشانه ها پرداخت.
همچنین تلاش هایی برای همسویی نهادهای جغرافیایی در جامعه داده های پیوندی صورت گرفته است. SLIPO [ 15 ] یک گردش کار یکپارچه سازی داده را پیشنهاد کرد، که شامل یک جزء ترکیبی بر اساس انطباق توابع شباهت خاص POI Fagi [ 16 ] است. این رویکرد بر دادههای رابطهای موجود متکی بود، اما جزئیاتی را در مورد تابع امتیازدهی همترازی ارائه نکرد و به چالشهای خاص تراز کردن موجودیتهای جغرافیایی از منابع داده ناهمگن اشاره نکرد.
یو و همکاران [ 17 ] هستی شناسی های مورد استفاده در زبان هستی شناسی وب 2 (OWL-2) ( https://www.w3.org/TR/owl2-overview/(در 10 دسامبر 2021 قابل دسترسی است)) و Description Logic (DL) برای ایجاد چارچوب ترکیبی داده های خود. هستی شناسی برای نمایش مجموعه داده های فضایی و هندسه ها و توپولوژی های مربوطه استفاده شد. DL برای اجرای قوانین خط مشی مورد استفاده قرار گرفت، که یا از داده ها و/یا اسناد پشتیبان استخراج شده بودند یا از کارشناسان آن منطقه تهیه شده بودند. یک مکانیسم استدلال پس از فیلتر کردن POI بر اساس پروکسی مکان و شباهت آدرس اعمال شد. مرحله استدلال هسته اصلی این چارچوب است و برای ساختن قوانین و ترتیب اجرای آنها به منابع زیادی تکیه کرده است. اگرچه این ترکیب خودکار داده ها را فراهم می کند، اما به شدت به انواع مختلف دانش به شرح زیر بستگی دارد. منشأ داده و پیش پردازش آن ایده ای در مورد صحت آن ارائه می دهد. قوانین کسب و کار نیازهای کاربر را از نظر طراحی پایگاه داده را در بر می گیرد. روش های آماری برای تصمیم گیری در مورد شباهت فضایی POI ها صرفا بر اساس مختصات آنها استفاده شد. قوانین اعتبار سنجی متنی از منابع اطلاعات مکانی (تصاویر ماهواره ای، نمای خیابان، و غیره) برای اعتبارسنجی اطلاعات POI استفاده می کنند. احتمال ترجیح ایده ای در مورد اینکه چقدر احتمال دارد که نتایج تولید شده نیازهای کاربران را برآورده کند، ارائه کرد. همه این دسته بندی قوانین به طور مستقل با استفاده از سه گانه مرتبط و ایجاد موارد جدید اجرا شد. این چارچوب همانطور که توضیح داده شد امیدوارکننده است، با این حال، روی هیچ مجموعه داده در مقیاس متوسط تا بزرگ آزمایش نشده است. علاوه بر این، یکی از انواع قوانین به در دسترس بودن اطلاعات مختصات برای انجام فیلترهای خاص متکی بود. قوانین اعتبار سنجی متنی از منابع اطلاعات مکانی (تصاویر ماهواره ای، نمای خیابان، و غیره) برای اعتبارسنجی اطلاعات POI استفاده می کنند. احتمال ترجیح ایده ای در مورد اینکه چقدر احتمال دارد که نتایج تولید شده نیازهای کاربران را برآورده کند، ارائه کرد. همه این دسته بندی قوانین به طور مستقل با استفاده از سه گانه مرتبط و ایجاد موارد جدید اجرا شد. این چارچوب همانطور که توضیح داده شد امیدوارکننده است، با این حال، روی هیچ مجموعه داده در مقیاس متوسط تا بزرگ آزمایش نشده است. علاوه بر این، یکی از انواع قوانین به در دسترس بودن اطلاعات مختصات برای انجام فیلترهای خاص متکی بود. قوانین اعتبار سنجی متنی از منابع اطلاعات مکانی (تصاویر ماهواره ای، نمای خیابان، و غیره) برای اعتبارسنجی اطلاعات POI استفاده می کنند. احتمال ترجیح ایده ای در مورد اینکه چقدر احتمال دارد که نتایج تولید شده نیازهای کاربران را برآورده کند، ارائه کرد. همه این دسته بندی قوانین به طور مستقل با استفاده از سه گانه مرتبط و ایجاد موارد جدید اجرا شد. این چارچوب همانطور که توضیح داده شد امیدوارکننده است، با این حال، روی هیچ مجموعه داده در مقیاس متوسط تا بزرگ آزمایش نشده است. علاوه بر این، یکی از انواع قوانین به در دسترس بودن اطلاعات مختصات برای انجام فیلترهای خاص متکی بود. همه این دسته بندی قوانین به طور مستقل با استفاده از سه گانه مرتبط و ایجاد موارد جدید اجرا شد. این چارچوب همانطور که توضیح داده شد امیدوارکننده است، با این حال، روی هیچ مجموعه داده در مقیاس متوسط تا بزرگ آزمایش نشده است. علاوه بر این، یکی از انواع قوانین به در دسترس بودن اطلاعات مختصات برای انجام فیلترهای خاص متکی بود. همه این دسته بندی قوانین به طور مستقل با استفاده از سه گانه مرتبط و ایجاد موارد جدید اجرا شد. این چارچوب همانطور که توضیح داده شد امیدوارکننده است، با این حال، روی هیچ مجموعه داده در مقیاس متوسط تا بزرگ آزمایش نشده است. علاوه بر این، یکی از انواع قوانین به در دسترس بودن اطلاعات مختصات برای انجام فیلترهای خاص متکی بود.
نهاری و همکاران [ 18 ] یک معیار تشابه برای تفکیک موجودیت فضایی بر اساس مدل دانه بندی داده ها پیشنهاد کرد. دانه بندی بر اساس تقسیمات اداری یا ویژگی های جغرافیای طبیعی بود. اندازهگیری تشابه و روشهای مسدود کردن آنها بر روابط تقسیم اداری و ماهیت سلسله مراتبی مدل دانهبندی تکیه داشت. از سوی دیگر، رویکرد ما کاملاً مستقل از چنین ساختارهایی است و میتواند بر روی هر مجموعه داده اعمال شود، تا زمانی که شامل اجزای لازم (یعنی مختصات) باشد.
PlacERN [ 19 ] از یک رویکرد عصبی برای محاسبه شباهت بین یک جفت موجودیت جغرافیایی استفاده کرد که شامل همان چهار مؤلفه تحت پوشش در این مقاله بود. آنها از گسسته سازی استفاده کردند [ 20] فاصله بین یک جفت یا مختصات به عنوان جاسازی موقعیت جغرافیایی. برای رمزگذاری آدرس و برچسب، آنها از جاسازی کلمات و کاراکترهای جداگانه استفاده کردند. برای رمزگذاری دستهها، آنها به سادگی از جاسازیهای دستهبندی با مجموع جاسازیهای کلمات که نام دسته را تشکیل میدهند، استفاده کردند. تمام تعبیههای رمزگذاریشده همه مؤلفهها در نهایت با استفاده از یک ژنراتور به اصطلاح میل ترکیبی و به دنبال آن یک پرسپترون چند لایه، که امتیاز شباهت را به دست میدهد، ترکیب میشوند. در حالی که این رویکرد راهحلهای جالبی را از نظر ترکیب اجزای مختلف با هم در یک معیار تشابه ارائه میدهد، به جفتهای مشروح زیادی از موجودیتهای منطبق و غیر منطبق برای آموزش مدل نیاز دارد. این یک محدودیت قوی در بسیاری از تنظیمات، از جمله تنظیمات ما است. از سوی دیگر، رویکرد ما میتواند با نظارت کم یا بدون نظارت، همترازی ایجاد کند. علاوه بر این، معیارهای برچسب و آدرس آنها، ارتباط محلی توکنها را در نظر نمیگرفت، زیرا شبکه فقط فاصله جفتی بین موجودیتها را به عنوان ورودی جغرافیایی در نظر گرفت. علاوه بر این، استفاده از جاسازی نام دسته به تنهایی برای شباهت نوع نمی تواند به اندازه کافی سلسله مراتب نوع بسیار ناهمگن را مدیریت کند، به ویژه در مواردی که دو سلسله مراتب دارای سطوح بسیار متفاوتی از دانه بندی هستند که نیاز به نگاشت های 1-N زیادی دارند.
سهگل و همکاران [ 21 ] روشی را برای حل و فصل نهادهای جغرافیایی پیشنهاد کرد که از ویژگیهای برچسب، مختصات و نوع (اما بدون آدرس) استفاده میکرد. این ویژگیها در یک معیار تشابه ترکیبی قرار گرفتند. رویکرد هر مؤلفه نسبتاً ساده است، با استفاده از: (1) شباهتهای جاکارد و جارو-وینکلر برای برچسب، (2) فاصله معکوس برای مختصات، و (3) آمار در مورد همزمانی جفتهای نوع در یک تمرین. داده برای نوع نمرات با یک طبقه بندی ترکیب شدند (لجستیک رگرسیون، پرسپترون رای، و SVM) که یک مقدار باینری تولید می کند که نشان می دهد موجودیت ها مطابقت دارند یا نه. یکی از محدودیت های این رویکرد این است که نیاز به وجود داده های آموزشی دارد که در بسیاری از موارد در دسترس نیستند و ساخت آن می تواند بسیار پرهزینه باشد.
اخیراً، ر. [ 6 ] رویکردی را پیشنهاد کرد که بر مؤلفههای مشخصه یکسانی متکی است، اما علاوه بر این از معیاری برای مؤلفه آدرس پشتیبانی میکند. به طور کلی، مؤلفه برچسب از فاصله ویرایش نرمال شده Levenshtein استفاده می کند. مولفه مختصات مشابه سهگل و همکاران بود. [ 21 ] اما از معکوس فاصله استفاده کرد که به یک تابع نمایی متصل شده بود تا اطمینان حاصل شود که در محدوده بین 0 و 1 قرار می گیرد. یک معیار تشابه بر اساس سطوح سلسله مراتبی گره های تطبیق ابداع شد. جزء آدرس شباهت کسینوس بین بردارهای TF-IDF هر آدرس را نشان می دهد.
کار اخیر دیگر [ 22 ] نیز بر همان چهار مؤلفه ویژگی [ 6 ] تکیه داشت. معیارهای شباهت اجزای برچسب، مختصات و آدرس مشابه هستند اما چند تفاوت وجود دارد. مؤلفه برچسب از برچسب گذاری نقش معنایی (SRL) برای فیلتر کردن نشانه های نامربوط قبل از محاسبه شباهت برچسب استفاده می کند. مانند [ 6 ]، مؤلفه مختصات نیز معیارهای ویژه ای برای اشیاء خط و ناحیه داشت. مؤلفه نوع نیز به نگاشت بین دو سلسله مراتب نوع متکی بود، اما امتیازها بر اساس حداقل تعداد مراحلی بود که هر دو سلسله مراتب را برای یافتن یک نگاشت طی می کردند. هرچه مراحل مورد نیاز بیشتر باشد، شباهت کمتری داشت. تفاوت مهم دیگر این است که [ 22] از محدودیتهای تعیین چندگانه استفاده میکرد: اینها قوانینی بودند که در آن شرایط، ترکیب الزامات هستند. این الزامات به ارضای حداقل آستانه برای هر یک از اجزای ویژگی اشاره دارد.
شباهت اصلی بین رویکردهای مورد بحث در بالا و کار ما در این مقاله، استفاده از همان چهار مؤلفه ویژگی است. با این حال، هیچ یک از کارهای قبلی به مشکل بزرگ کردن فرآیند هم ترازی در مقیاس جهانی پرداختند. آنها سلسله مراتب نوع پیچیده را نیز در نظر نگرفتند، با همه رویکردها متکی بر نگاشت های دستی ساخته شده از قبل موجود. در رویکردمان، ما یک معیار تشابه برچسب پیچیدهتر داریم که میتواند برچسبهای مشابه را در زبانهای مختلف شناسایی کند و از زمینه مرتبط محلی نشانهها استفاده کند. برای اصلاح بیشتر نمرات تراز محاسبه شده قبلی، رویکرد ما همچنین از مجموعه ای از قوانین پس از پردازش در آخرین مرحله ترازسازی استفاده می کند. بخش پس پردازش از همان ایده رویکردهای تطبیق مبتنی بر ویژگی که قبلا ذکر شد پیروی می کند ([6 ، 22 ])، اما در معیارهای در نظر گرفته شده، شرایط تصمیم گیری آنها و ترکیبات نهایی متفاوت است.
به طور خلاصه، تمام این جنبه ها توسط آثار قبلی که در بالا مورد بحث قرار گرفت در نظر گرفته نشد. علاوه بر این، ما مشکل تطبیق موجودیتهای ناقص (آدرس از دست رفته یا دادههای مختصات) را بررسی میکنیم و از آمار نوع برای تنظیم امتیازهای مختصات به اندازه موجودیتها استفاده میکنیم.
3. بیان مشکل
مشکل تحقیقی که در این مقاله به دنبال آن هستیم در این بخش معرفی شده است. اجازه دهید E1و E2مجموعه داده های دو نهاد جغرافیایی باشد. E1و E2در مقیاس بزرگ فرض می شوند: هر یک از آنها حداقل ده ها میلیون موجودیت دارد. هر موجود جغرافیایی ei∈E1و ej∈E2با ویژگی های زیر مشخص می شود. اول، ویژگی های برچسب liو ljاز نهادها eiو ejبه ترتیب از یک نام و/یا مجموعه ای از نام مستعار ساخته می شوند. اینها می توانند به هر زبانی باشند. دوم، صفات نوع tiو tjاز نهادها eiو ejبه ترتیب، نام و سطح طبقه بندی را نشان می دهد که نهادهای مربوطه در آن قرار دارند eiو ejمتعلق به در E1و E2سلسله مراتب نوع مربوطه E1و E2سلسله مراتب انواع ذکر شده است T1و T2، به ترتیب. سوم، صفات آدرس aiو ajحاوی اطلاعات آدرس کامل نهادها باشد eiو ej، به ترتیب، به عنوان یک سند متنی واحد. با این حال، بیشتر از E1و E2نهادها اطلاعات بیشتری در مورد مختصات خود دارند. ویژگی های مجموعه مختصات ciو cjاز نهادها eiو ejبه ترتیب از عرض و طول جغرافیایی ساخته می شوند. آنها ممکن است به صورت اختیاری شامل اطلاعات جعبه محدود شوند.
ما این را فرض می کنیم E1و E2ناهمگن هستند. این بدان معنی است که برای هر ei∈E1و ej∈E2:
-
liو ljممکن است ساختارهای متفاوتی داشته باشند (یعنی برچسب ها ممکن است به روش های مختلف نوشته شوند، به طور بالقوه شامل بخش های عمومی تر هستند، و قطعات ممکن است به طور متفاوتی مرتب شوند). liو ljهمچنین ممکن است به زبان های مختلف موجود باشد (گاهی اوقات، هیچ زبانی با هم تداخل دارند).
-
T1و T2ممکن است درجات مختلفی از دانه بندی، ساختارهای سلسله مراتبی و نام انواع داشته باشد.
-
aiو ajممکن است فرمت های متفاوتی داشته باشد و با سطوح مختلف ناقصی همراه باشد. علاوه بر این، آنها ممکن است حاوی اطلاعات بیشتر/کمتر مرتبط باشند.
-
ciو cjممکن است مقداری از یکدیگر دور باشند و یکی از آنها نیز ممکن است در دسترس نباشد. تعداد کمی از نهادهایی که دارند ci/ cjموجود شامل اطلاعات جعبه مرزی است.
برای جمع بندی مشکل تحقیق خود، با توجه به دو نهاد ei∈E1و ej∈E2، ما قصد داریم بررسی کنیم که آیا آنها همان موجودیت جغرافیایی دنیای واقعی را نشان می دهند: ei≡ej. برای رسیدگی به این مشکل، نمرات شباهت فردی را استخراج می کنیم که از اطلاعات موجود در هر ویژگی استفاده می کند. سپس امتیازهای به دست آمده را در یک نمره هم ترازی وزنی ترکیب می کنیم که با یک آستانه مقایسه می شود تا تصمیم بگیریم که آیا eiو ejهمخوانی داشتن. بخش 4 روشها/مکانیسمهای دقیق را برای استخراج امتیازات اجزای جداگانه ارائه میکند، در حالی که بخش 5 همه این مؤلفهها را در سیستم یکپارچه GLEAN، که در سناریوی همترازی آفلاین اعمال میشود، جمعآوری میکند.
4. اجزای GLEAN
در این قسمت اجزای GLEAN را به تفصیل شرح می دهیم. ما ابتدا معیار مربوط به توکن بافت محلی را در بخش 4.1 ارائه می کنیم. این به این دلیل است که ما از این اندازه گیری هم در برچسب ها و هم در محاسبه شباهت های اجزاء استفاده می کنیم. سپس امتیاز کلی شباهت POI و نمرات ترکیب آن را در بخش 4.2 شرح می دهیم . در بخش 4.3 ، قوانین پس از پردازش مورد استفاده برای پالایش امتیازهای جفت لبه را مورد بحث قرار می دهیم.
4.1. ارتباط رمز زمینه محلی
در رویکرد همترازی ما، ارتباط بافت محلی هنگام محاسبه شباهتهای برچسب بسیار مهم است، زیرا نشانههای مشابه ممکن است سطوح مختلفی از ارتباط را در زمینههای جغرافیایی مختلف داشته باشند. یک بافت جغرافیایی توسط یک منطقه جغرافیایی معین تعریف می شود و شامل موجودیت های موجود در منطقه می شود. این کار با در نظر گرفتن الحاق ویژگی های متنی موجودیت در نظر گرفته شده (مثلاً برچسب/نام مستعار یا آدرس) به عنوان یک سند واحد انجام می شود. d∈D، که در آن D مجموعه ای از اسناد (موجودات) موجود در یک زمینه جغرافیایی است.
سپس ارتباط محلی یک نشانه را به عنوان فرکانس سند معکوس آن (IDF) در زمینه محلی همانطور که در معادله ( 1 ) تعریف شده است، تعریف می کنیم.
IDF(t,D)=log(|D||d∈D:t∈d|)
سپس می توان از این مقادیر مربوط محلی برای محاسبه شباهت بین ویژگی های متن استفاده کرد. در رویکرد خود، ما دو معیار مرتبط محلی را اتخاذ میکنیم: (1) شباهت محلی جاکارد با وزن IDF (LIDFJ) (معادله ( 2 )) و (2) میانگین گنجاندن کلمه با وزن IDF (معادله ( 3 )). A و B دو مجموعه از نشانه های پیش پردازش شده را از یک ویژگی متنی معین (مثلاً برچسب، آدرس) نشان می دهند که به ترتیب متعلق به دو موجودیت مقایسه شده است.
JD(A,B)=(∑t∈A∩BIDF(t,D)∑t∈A∪BIDF(t,D))ψ
ED(A,B)=∑t∈Ae(t)IDF(t,D)∑t∈AIDF(t,D)×∑t∈Be(t)IDF(t,D)∑t∈BIDF(t,D)
همانطور که در رابطه ( 2 ) اشاره شد، یک ثابت اضافه می کنیم ψکه امتیاز نهایی را در اندازه گیری LIDFJ تنظیم می کند. در عمل، توزیع امتیاز خام LIDFJ معمولاً پایینتر از روشهای تعبیهشده است، بنابراین ممکن است استفاده از برخی موارد ضروری باشد. 0<ψ<1برای افزایش نمرات
شکل 1 نشان می دهد که چگونه یک نشانه ” کنیسه ” بسته به بافت جغرافیایی آن می تواند ارتباط متفاوتی داشته باشد. در مناطقی که تقریباً اندازه آنها یکسان است، ادینبورگ (تصویر سمت راست) در مقایسه با اورشلیم غربی ، دارای موجودیت های بسیار کمتری با نماد ” کنیسه " است. این بدان معناست که این نشانه زمانی که در صفت(های) متنی وجود دارد، برای موجودیتهای واقع در ادینبورگ بیشتر از آنهایی که در اورشلیم غربی قرار دارند، مرتبط است. از این رو، این فرکانس پایین به معنای LIDF بالاتر و ارتباط بیشتر است. به عبارت دیگر، اگر دو نهاد در ادینبورگ نماد ” کنیسه ” را به اشتراک بگذارند، احتمال اینکه آنها با یکدیگر مطابقت داشته باشند بسیار بیشتر از این است که در غرب اورشلیم نیز همین اتفاق بیفتد.
4.2. نمرات تراز
امتیاز هم ترازی ϕاز یک جفت موجودیت ei∈E1و ej∈E2، از چهار جزء تشکیل شده است: برچسب ( λ، نوع ( θ)، نشانی ( α) و فاصله جغرافیایی ( γ). امتیاز نهایی به صورت مجموع وزنی نمرات شباهت هر یک از مؤلفه ها محاسبه می شود. برای یک جفت موجودیت معین eiو ejنمره نهایی آن در رابطه ( 4 ) تعریف شده است.
ϕ(ei,ej)=wλλ(ei,ej)+wθθ(ei,ej)+wαα(ei,ej)+wγγ(ei,ej)+b
وزنه ها wλ، wθ، wα، wγو بایاس b را می توان با رگرسیون خطی یاد گرفت اگر داده های برچسب دار کافی ارائه شود. روش دیگر، دیگر روش های رگرسیون پیچیده تر نیز می تواند استفاده شود. در تنظیم مشکل ما، دادههای برچسبگذاری شده در دسترس نیستند و رویکردهای پیچیدهتر یادگیری ماشینی امکانپذیر نیستند. بنابراین، در این مقاله، ما به مشکل ترکیب بهینه امتیازات مؤلفهها نمیپردازیم، و در عوض بر روی خود معیارهای تشابه مؤلفهها تمرکز میکنیم. این توابع امتیازدهی شباهت مؤلفه ها λ، θ، αو γدر بخش 4.2.1 ، بخش 4.2.2 ، بخش 4.2.3 و بخش 4.2.4 ارائه شده است.
4.2.1. مولفه برچسب
جزء برچسب متکی بر دو بخش مختلف است که مکمل یکدیگر هستند. یکی رمزگذار جملات چند زبانه است که می تواند تطبیق بین زبانی را انجام دهد. به عنوان یک مدل توالی، میتواند تفاوتهای معنایی ناشی از توالیهای مختلف را توضیح دهد. بخش دیگر شباهت محلی IDF-Jacard است که می تواند از ارتباط توکن ها در یک زمینه جغرافیایی خاص استفاده کند.
امتیاز نهایی بازگردانده شده برای مؤلفه برچسب، حداکثر دو جزء فرعی آن است. جزئیات نحوه محاسبه هر دو امتیاز در بخش 4.2.1.3 و بخش 4.2.1.4 توضیح داده شده است. قبل از محاسبه این امتیازات، ابتدا پیش پردازش برچسب و ترتیب قطعات برچسب را به ترتیب در بخش 4.2.1.1 و بخش 4.2.1.2 انجام می دهیم.
4.2.1.1. پیش پردازش برچسب
همه برچسبها و نامهای مستعار از تکنیکهای پیشپردازش استاندارد استفاده میکنند که شامل کاهش کاراکترها و حذف علائم نگارشی است. کاهش کاراکترها مهم است زیرا منابع داده مختلف ممکن است از حروف متفاوت برای برخی کلمات استفاده کنند. با این حال، رمزگذارهای جملات مانند MUSE به حروف کوچک و بزرگ حساس هستند و نمرات شباهت بین جفتهای جملات کوچکتر میتواند تفاوتهای ظریف کمتری داشته باشد، زیرا گاهی اوقات کلمات در موارد مختلف ممکن است معنای متفاوتی داشته باشند. بنابراین، برای برخی از جفت برچسبها (به عنوان مثال، برچسبهای اصلی و برچسبهای انگلیسی اصلی، در صورتی که زبان اصلی نباشد)، ما انتخاب میکنیم تا شباهت بین برچسبها را با پوشش اصلی محاسبه کنیم.
ما همچنین حداکثر تعداد نام مستعار داریم که باید در نظر گرفته شوند ( η)، به منظور اطمینان از اینکه محاسبه امتیاز شباهت برچسب خیلی طول نمی کشد. علاوه بر این، برای جلوگیری از پیچیدگی درجه دوم هنگام محاسبه شباهت، شباهت بین همه جفتهای نام مستعار از دو موجودیت را محاسبه نمیکنیم. در عوض، ما یک برچسب اصلی (به طور کلی به زبان محلی) برای هر موجودیت داریم و فقط شباهت نام مستعار را با برچسب اصلی موجودیت دیگر محاسبه می کنیم. بهطور استثنایی، ما شباهتهای نام مستعار را برای برچسبهای انگلیسی (اگر انگلیسی زبان اصلی نباشد) محاسبه میکنیم. شایان ذکر است که در مورد ما، برچسب های اصلی قبلاً در HuaweiPD تعریف شده اند و در ویکی پدیا اولین برچسب rdfs: یک موجودیت به زبان مادری کشور (یا یکی از زبان های مادری آن) به عنوان برچسب اصلی استفاده می شود.
علاوه بر این، برخی از برچسب ها نه تنها حاوی نام نهاد بلکه اطلاعات اضافی در مورد محلی سازی آن نیز هستند. این اطلاعات اغلب پس از کاما (“)، خط تیره (یعنی “-“) یا بین پرانتز در انتهای برچسب اضافه می شود. این می تواند اندازه گیری شباهت بین برچسب های نشان داده شده در زیر را بسیار دشوار کند.
فواره راس ، باغ های خیابان پرینس وست، ادینبورگ → فواره راس
فواره راس ( ادینبورگ) → فواره راس
برای در نظر گرفتن این مبادله هنگام پیش پردازش برچسب ها، ما برچسب اصلی را نگه می داریم، اما همچنین یک رشته حذف شده اضافه می کنیم، جایی که قسمت های عمومی تر شناسایی شده توسط کاراکترهای ویژه که قبلا توضیح داده شد را حذف می کنیم. مرحله پیش پردازش برچسب در GLEAN به عنوان توکن مجموعه تابع زمانی که ورودی ها برچسب هستند، و به عنوان توکنیز تابع زمانی که آنها آدرس هستند ، ادغام می شود. در مقایسه با tokenset ، tokenize ممکن است شامل پیش پردازش خاص آدرس، مانند مدیریت اختصارات باشد. برای برچسب نهاد li، تابع tokenset مجموعه ای از توکن های نوشتن را خروجی می دهد.
یکی از مشکلات در این رویکرد این است که فرض میکند قسمتهای خاصتر برچسب قبل از عمومیتر قرار میگیرند. این همیشه درست نیست، و ما به راهی برای شناسایی این موارد و مرتب کردن مجدد قطعات برچسب نیاز داریم تا اطمینان حاصل کنیم که آنها همیشه سازگار هستند. این همان چیزی است که در پاراگراف زیر توضیح می دهیم (به عنوان مثال، بخش 4.2.1.2 ).
4.2.1.2. لیبل سفارش قطعات
برای اطمینان از اینکه اشتباهاً شباهت را برای بخشهای کلیتر برچسب محاسبه نمیکنیم، مرتب کردن قطعات برچسب بسیار مهم است. ما قسمتهای یک برچسب را بهعنوان رشتههای فرعی تعریف میکنیم که میتوان آن را با تقسیم کردن برچسب به «» یا «-» به دست آورد (از جمله فاصله قبل و بعد از «-» برای جلوگیری از تقسیم کلمات خط فاصله). در مثال زیر، قطعات برچسب از کمتر به خاص تر مرتب شده اند. اگر روش strip down را که قبلا توضیح داده شد به کار ببریم، در نهایت به اشتباه آن را به جای ” بنای یادبود جورج بوکانان " به " ادینبورگ ” تبدیل می کنیم . به همین دلیل است که مثال زیر باید به یک نمایش استاندارد بازآرایی شود، که در مورد ما از بیشتر به کمتر خاص است.
-
برچسب اصلی : ادینبورگ، ردیف کندل میکر، کلیسای گریفریرز، بنای یادبود جورج بوکانان
-
برچسب دوباره سفارش داده شده : بنای یادبود جورج بوکانان، کلیسای گریفریرز، کندل میکر رو، ادینبورگ
یکی از راههای تشخیص اینکه قسمتهای مختلف برچسب چقدر خاص هستند، بررسی آنها با آدرس نهاد است. احتمال ظاهر شدن قسمت های عمومی تر در آدرس بیشتر از قسمت های خاص تر است. برای مثال قبلی ما، آدرس ” 26A Candlemaker Row, Edinburgh EH1 2QQ, United Kingdom ” نشان می دهد که ” Edinburgh ” و ” Candlemaker Row ” بخش های کلی تری هستند. از آنجایی که اینها در ابتدای برچسب هستند، میتوانیم ترتیب را معکوس کنیم تا از سازگاری لازم اطمینان حاصل کنیم. این به عنوان اولین مرحله از ترتیب مجدد برچسب انجام می شود. اگر هیچ قسمت برچسبی در آدرس موجود نباشد یا بیش از یک قسمت در آدرس موجود نباشد، ترتیب مجدد برچسب آماری اعمال می شود.
مرتب سازی مجدد برچسب آماری فرکانس های قطعات برچسب را در یک زمینه جغرافیایی معین، مانند پارتیشن استخراج می کند و از آن فرکانس ها برای مشاوره در مورد ویژگی قطعه استفاده می کند. قسمتهای کمتکرار به احتمال زیاد خاصتر هستند. در مثال ما، میتوانیم POIهای دیگری را با برچسبهایی که حاوی « کلیسای گریفریرز » هستند، مانند نمونههای زیر، پیدا کنیم، اما هیچ POI دیگری با « بنای یادبود جورج بوکانان » وجود ندارد.
« ادینبورگ، ردیف کندل میکر، کلیسای گریفریرز »
« ادینبورگ، ردیف کندل میکر، کلیسای گریفریرز، زندان کوونانترز »
“ ادینبورگ، ردیف کندل میکر، کلیسای گریفریرز، لج به علاوه، اسکله دروازه ”
سپس به هر قسمت از برچسب یک مقدار فرکانس قسمت معکوس محلی (LIPF) اختصاص داده می شود. این ایده تا حدودی شبیه به ارتباط محلی نشانهها است که در بخش 4.1 بحث شد ، جایی که یک منطقه جغرافیایی تعریف شده است. با این حال، در این مورد، فرکانس ها برای کل قسمت های برچسب به جای توکن های جداگانه محاسبه می شوند.
اگر برچسبی با قطعات خاص تری شروع شود، انتظار می رود که LIPF قطعات به ترتیب کاهشی باشد. این بدان معناست که اگر یک برچسب مقادیر LIPF افزایشی برای قطعات خود داشته باشد، احتمالاً در جهت معکوس است. حداقل آستانه نرخ افزایش LIPF به منظور اطمینان از اینکه افزایش LIPF قابل توجه است و تصادفی رخ نداده است استفاده می شود. برچسب فقط در صورتی معکوس می شود که قطعات برچسب دارای مقادیر LIPF یکنواخت در حال افزایش باشند که آستانه نرخ افزایش را برآورده کند. آستانه نرخ افزایش LIPF بالاتر محافظهکارانهتر است و میتواند تعداد برچسبهایی را که به اشتباه مرتب شدهاند کاهش دهد، اما تعداد برچسبهای معکوسشده را نیز افزایش میدهد.
4.2.1.3. رمزگذار جملات چند زبانه
همسویی نهادهای جغرافیایی در مقیاس جهانی نه تنها به دلیل اندازه بالقوه بزرگ مجموعه داده ها، بلکه به دلیل زبان های مختلف مورد استفاده، چالش هایی را ایجاد می کند. بسیاری از کشورها چندین زبان رسمی دارند و مجموعه دادههای مختلف ممکن است همیشه دارای برچسبهایی به یک زبان نباشند. بنابراین استفاده از معیارهای شباهت که می تواند شباهت ها را در زبان های مختلف شناسایی کند، مهم است. به همین دلیل است که سیستم ما از قدرت رمزگذارهای جملات چند زبانه از پیش آموزش دیده استفاده می کند.
در سیستم ما، ما از رمزگذار جملات جهانی گوگل استفاده میکنیم، زیرا بسیار مقیاسپذیر است و در کار شباهت متن بسیار خوب عمل میکند. دارای نسخه چند زبانه (MUSE) [ 23 ، 24 ] است که در حال حاضر از 16 زبان پشتیبانی می کند ( https://tfhub.dev/google/universal-sentence-encoder-multilingual/3 (در 6 اکتبر 2021 در دسترس قرار گرفته است)). این تقریباً به تعداد زبانهای موجود در مجموعه دادههای ما نیست ( جدول 1 را ببینید)، اما برخی از رایجترین زبانها را پوشش میدهد. ما همچنین سعی کردیم از LaBSE [ 25 ] استفاده کنیم که از زبان های بسیار بیشتری پشتیبانی می کند (109 ( https://tfhub.dev/google/LaBSE/1(دسترسی در 6 اکتبر 2021))). با این حال، به طور قابل توجهی کندتر از MUSE است و در معیار تشابه متنی معنایی [ 25 ] به خوبی عمل نمی کند (دارای حدود 10٪ کمتر از پیرسون ρدر مورد وظیفه).
ما هر یک از برچسبها/نام مستعار هر موجودیت را از دو منبع داده برای تراز کردن از قبل پردازش میکنیم و از MUSE برای کدگذاری جاسازیهای جمله آنها استفاده میکنیم که دو ماتریس جاسازی را ایجاد میکنند. شباهت موجودیت های زوجی بین موجودیت های دو مجموعه داده با انجام یک ضرب ماتریس بین دو ماتریس تعبیه شده محاسبه می شود. محاسبه این مقدار بسیار کمتر از سایر بخشهای امتیاز تراز است و همراه با شباهت جاسازی نوع برای فیلتر اولیه تعداد نامزدها استفاده میشود. این در بخش 5 مورد بحث قرار گرفته است .
ما شباهت جاسازی جمله برچسب را تعریف می کنیم λemb(ei,ej)بین نهادها eiو ejو نشان دهنده تعبیه جمله MUSE موجودیت است eiبرچسب liمانند eMUSE(li)(ر.ک معادله ( 5 )).
λemb(ei,ej)=eMUSE(li)⋅eMUSE(lj)
4.2.1.4. شباهت وزنی ارتش اسرائیل
اگرچه استفاده از مدل های از پیش آموزش دیده به ما امکان می دهد از مجموعه بزرگ و منابع محاسباتی مورد استفاده برای آموزش آنها بهره مند شویم، اما آنها از ارتباط محلی کلمات آگاهی ندارند. بسیار مهم است که ارتباط محلی یک کلمه معین را در زمینه جغرافیایی در نظر بگیریم. این ارتباط محلی ممکن است به طور چشمگیری متفاوت باشد. به عنوان مثال، کلمه ” ادینبورگ ” ممکن است در متن لندن هنگام تطبیق ” میخانه دوک ادینبورگ” بسیار مرتبط باشد زیرا یک کلمه نادر است، در حالی که در بافت شهر ادینبورگ، نشانه ” ادینبورگ ” ظاهر می شود. اغلب اوقات و باید هنگام مطابقت با ” گالری ملی اسکاتلند ادینبورگ ” ارتباط کمی داشته باشد.
به عنوان مثال، اگر شباهت LIDFJ را بین « گالری ملی » و « گالری ملی اسکاتلند ادینبورگ » در زمینه مرکز ادینبورگ محاسبه کنیم، شباهت زیاد است (917/0) زیرا « اسکاتلندی » و « ادینبورگ » ارتباط محلی پایینی دارند. با این حال، اگر از رمزگذارهای جملات استفاده کنیم که در زمینه کلی گسترده آموزش داده شده اند، شباهت بسیار کم خواهد بود (در MUSE 0.539 است).
بنابراین، در رویکرد خود، ما از LIDFJ برای تکمیل شباهت جاسازیهای جمله با اتخاذ یک معیار تشابه بر اساس رویکرد ارتباط بافت محلی شرح داده شده در بخش 4.1 استفاده میکنیم. امتیاز نهایی برچسب λ(ei,ej)با در نظر گرفتن نمره تعبیه جمله ( λemb) و امتیاز LIDFJ ( λLIDFJ). در این کار، همانطور که در رابطه ( 6 ) نشان داده شده است، به سادگی از حداکثر بین این دو استفاده کردیم:
λ(ei,ej)=max(λemb(ei,ej),λLIDFJ(ei,ej)),
که در آن مولفه امتیاز LIDFJ در معادله ( 7 ) تعریف شده است:
λLIDFJ(ei,ej)=JD(tokenset(li),tokenset(lj)).
به یاد می آوریم که تابع tokenset برچسب ها را همانطور که در بخش 4.2.1.1 توضیح داده شده از قبل پردازش می کند و مجموعه ای از نشانه های ترکیبی خود را خروجی می دهد.
4.2.2. کامپوننت را تایپ کنید
برای یک جفت موجودیت eiو ej، نمره جزء نوع θ(ei,ej)با ترکیب نمره تعبیه نوع محاسبه می شود θemb(ei,ej)و یک جزء تنزل نوع θtd(ei,ej)همانطور که در معادله ( 8 ) تعریف شده است. امتیاز جزء نوع θنمره جزء نوع است θembمنهای نمره تنزل نوع θtd.
θ(ei,ej)=θemb(ei,ej)−θtd(ei,ej)
θemb(ei,ej)بدون نظارت آموخته می شود و می تواند نمرات شباهت ظریف را محاسبه کند. در حالی که θtdبرای کاهش کاستی ناشی از اندازه گیری تعبیه با ایجاد جفت های گسست سطح بالا استفاده می شود. این دو امتیاز شباهت به ترتیب در بخش 4.2.2.1 و بخش 4.2.2.2 مورد بحث قرار گرفته است.
4.2.2.1. Embeddings را تایپ کنید
ایجاد نقشه برای دو سلسله مراتب بسیار متفاوت و بالقوه پیچیده و پر سر و صدا می تواند یک کار بسیار چالش برانگیز باشد. در بسیاری از موارد، مانند مجموعه دادههای شرح داده شده در جدول 1 ، یافتن همترازیها به صورت دستی میتواند غیرممکن باشد، زیرا کلاسها و انواع متعددی از یک منبع وجود دارد که میتوانند به چندین نوع دیگر در بخشهای مختلف سلسله مراتب منبع دیگر نگاشت شوند. علاوه بر این، در بسیاری از موارد، نگاشت های مختلف ممکن است سطح اطمینان یکسانی نداشته باشند، و تولید آنها به صورت دستی بسیار دشوار است.
بنابراین، در رویکرد خود، یک روش بدون نظارت را برای یادگیری تعبیههای نوع پیشنهاد میکنیم. مزایای نمایش انواع به عنوان جاسازی بسیار زیاد است. اولاً، محاسبه شباهتهای بین انواع را میتوان به راحتی با محصول نقطهای و هنگام مقایسه انجام داد M1×M2انواع از منابع مختلف شباهت بین هر جفت ممکن از انواع را می توان به راحتی با ضرب ماتریس محاسبه کرد. علاوه بر این، تعبیهها میتوانند سطوح اطمینان متفاوتی را در نگاشتها نشان دهند، زیرا شباهتها به عنوان نزدیکی بین نمایشهای انواع در فضای جاسازی کدگذاری میشوند. این همچنین امکان محاسبه شباهت بین جفت های نامرئی از انواع را فراهم می کند.
برای یادگیری تعبیهها، به دادههای آموزشی نیاز داریم. تولید دادههای با کیفیت بالا احتمالاً نیازمند نظارت انسانی است و این میتواند بسیار پرهزینه باشد. در رویکرد ما، استفاده از جفتهای همترازی با اطمینان بالا را از یک اجرای تراز قبلی پیشنهاد میکنیم که در آن جزء نوع خاموش است. سپس جفتهای نوع از آن همترازیهای با اطمینان بالا به عنوان مثالهای مثبت استفاده میشوند و نمونههای منفی با خراب کردن موارد مثبت ایجاد میشوند.
مجموعه مثال های مثبت را به این صورت تعریف می کنیم D+و منفی ها به عنوان D−. سپس داده های آموزشی به صورت تعریف می شوند D={(1,(t1,t2))|t1,t2∈D+}∪{(0,(t1,t2))|t1,t2∈D−}، جایی که موارد مثبت دارای برچسب هستند y=1و منفی ها y=0.
مدل تعبیه نوع معادل DistMult [ 26 ] بدون تعبیه رابطه است. نوع امتیاز تعبیه θemb(ر.ک. معادله ( 9 )) حاصل ضرب نقطه ای از نوع بردارهای تعبیه شده است. e(ti)و e(tj)، جایی که tiو tjانواع موجودیت ها هستند eiو ej، به ترتیب.
θemb(ei,ej)=e(ti)⋅e(tj)
این مدل به گونه ای آموزش داده شده است که امتیاز را برای مثال های مثبت به حداکثر برساند و برای نمونه های منفی آن را به حداقل برساند. این کار با به حداقل رساندن تابع ضرر L (ر.ک معادله ( 10 )) که از آنتروپی متقاطع باینری استفاده می کند، انجام می شود. به عنوان محدودیت، بردارهای embeddings هستند L2-نرمال شده، یعنی |e(t)|2=1,∀t∈T1∪T2.
L(D)=∑y,(t1,t2)inDylog(s(t1,t2))+(1−y)log(1−s(t1,t2))
این روش بدون نظارت برای تولید داده های آموزشی می تواند به راحتی تعداد زیادی نمونه مثبت با کیفیت نسبتا بالا ایجاد کند. ممکن است مثبت کاذب وجود داشته باشد، زیرا در بیشتر مجموعههای داده میتواند موجودیتهایی از انواع مختلف وجود داشته باشد که نباید تراز شوند، اما از آنجایی که آنها بسیار نزدیک به یکدیگر قرار دارند و برچسبها و آدرسهای مشابهی دارند، در نهایت در ترازهای با اطمینان بالا قرار میگیرند.
نمونه هایی از این موارد عبارتند از: ایستگاه اتوبوس و خیابان ، شهر و ایستگاه راه آهن . ایستگاههای اتوبوس اغلب به نام خیابانها نامگذاری میشوند و مکان بسیار مشابهی دارند و تنها چیزی که اشاره میکند نباید با نوع آنها مطابقت داشته باشند. با توجه به اینکه فرآیند تولید داده های آموزشی انواع را نادیده می گیرد و این نوع مثبت کاذب تکراری است، مدل تعبیه نوع در نهایت به یادگیری اختصاص شباهت زیاد بین آنها می پردازد.
برای رسیدگی به این مشکل، یک مکانیسم تنزل نوع را شامل میکنیم که هدف آن کاهش امتیاز نوع برای آن موارد است.
4.2.2.2. Demotion را تایپ کنید
تنزل نوع متکی بر فهرستی از جفتهای ناهمگونی است که شامل انواعی از سلسله مراتب دو منبع و استدلال فرعی بر سلسله مراتب است. این استدلال اجازه می دهد تا از عدم پیوستگی بین جفت انواع سطح بالا استفاده شود، که از آن می توان جدایی زوجی همه اجداد آنها را استنباط کرد. این فرآیند ایجاد جفت های تنزل سطح بالا را ساده می کند Pdemو آنها را قابل درک تر و مدیریت آسان تر می کند. با آنها می توانیم نتیجه بگیریم P+demحاوی Pdemبه علاوه همه بدیهیات عدم پیوستگی استنباط شده بر اساس سلسله مراتب.
یکی از مشکلات این نوع رویکرد این است که نمی توان از آن در سلسله مراتب اشتباه استفاده کرد. این می تواند هنگام تراز کردن مجموعه داده ها با بدیهیات نادرست subClassOf ، مانند Wikidata، مشکل ساز باشد. مثال شکل 2 مسائلی را که ممکن است باعث این امر شود را نشان می دهد. اصل پارک ⊑ ArchitecturalStructure اشتباه است و اگر یک جفت عدم پیوستگی ArchitecturalStructure ∩ AdministrativeRegion = ∅ اضافه شود، به استنتاج های اشتباه منجر می شود. در این صورت، نوادگان هر دو کلاس نیز از هم گسسته خواهند شد، که شامل بدیهیات نادرست Park ∩ NationalPark = ∅ و NationalPark ∩ می شود.پارک ملی = ∅.
برای توضیح چنین مشکلی، و همچنان اجازه دادن به ساده سازی ارائه شده با استفاده از استدلال، امکان افزودن جفت های تبلیغاتی سطح بالا را در نظر می گیریم. Ppro(که از آن مجموعه جفت استنباط شده است P+proرا می توان مشتق کرد) که تنزل ها را خنثی می کند. علاوه بر آن، از رمزگذارهای جملات نیز برای محاسبه شباهت برچسب نوع و خنثی سازی تنزل جفت هایی با شباهت بالای یک آستانه معین استفاده می کنیم. tλ.
هر زمان که یک موجودیت با انواع جفت شود ti,tjشامل هر گونه جفت ناپیوستگی انواع استنباط شده و هیچ جفت تبلیغاتی انواع استنباط شده ای نیست (به عنوان مثال، (ti,tj)∈P+dem−P+pro) سپس نمره شباهت نوع آن کاهش می یابد ρ. تابع تنزل نوع θtd(ei,ej)در معادله ( 11 ) تعریف شده است.
θtd(ei,ej)={ρ0,if(ti,tj)∈P+dem−P+prootherwise.
4.2.3. جزء آدرس
یکی از چالشهای اصلی هنگام تطبیق آدرسها، فرمتهای مختلفی است که ممکن است وارد شوند. علاوه بر این، برخی از آدرسها ممکن است کاملتر از بقیه باشند و برخی از آنها مانند استان و کدپستی فاقد بخشهایی مانند استان و کد پستی باشند، مانند مثالهای زیر.
“ 2 Semple St., EH3 8BL, Edinburgh, Midlothian, Scotland, UK ”
“ 2 Semple Street, EH3 8BL Edinburgh, United Kingdom ”
در رویکرد خود، ما از شباهت محلی ژاکارد با وزن IDF (LIDFJ) برای تطبیق آدرس ها استفاده می کنیم. مزیت LIDFJ این است که می تواند ارتباط بخش های مختلف آدرس را در نظر بگیرد. بهعنوان مثال، به سیستم همترازی اجازه میدهد تا تشخیص دهد که « Midlothian »، « Scotland »، « UK »، « بریتانیا »، « خیابان » و « St » نشانههای چندان مرتبطی در زمینه محلی نیستند، زیرا اغلب اتفاق میافتند. از سوی دیگر، کدپستی و نام خیابان اهمیت بیشتری دارند. در نتیجه، تا زمانی که این قطعات کمتر با هم مطابقت داشته باشند، امتیاز شباهت بالا باقی خواهد ماند. امتیاز جزء آدرس α(ei,ej)در معادله ( 12 ) تعریف شده است، به طوری که aiو ajآدرس نهادها هستند eiو ej، به ترتیب. α(ei,ej)شبیه است به λLIDFJاما از یک تابع متفاوت برای به دست آوردن مجموعه نشانه ها استفاده می کند. به طور خاص، تابع tokenize ممکن است شامل پیش پردازش خاص آدرس، مانند مدیریت اختصارات، در مقایسه با مجموعه نشانههای تابع باشد .
α(ei,ej)=JD(tokenize(ai),tokenize(aj))
محدودیت این رویکرد این است که بر موجودیت هایی متکی است که مختصاتی دارند تا سیستم هم ترازی بتواند تشخیص دهد که آنها به یک بافت جغرافیایی تعلق دارند. اگر موجودیت ها در یک زمینه جغرافیایی شناخته نشده باشند، نمی توان از این رویکرد استفاده کرد.
4.2.4. مولفه فاصله جغرافیایی
هدف مولفه فاصله جغرافیایی تبدیل فاصله واقعی بین موجودیت ها به یک معیار تشابه است. γ∈[0,1]. را γامتیاز باید نشان دهد که یک جفت موجودیت با توجه به نوع آنها چقدر نسبتا نزدیک است. به عنوان مثال، فرودگاه های با فاصله 1 کیلومتر باید امتیاز بالایی داشته باشند، در حالی که رستوران هایی که در فاصله 1 کیلومتری از یکدیگر قرار دارند باید امتیاز پایینی داشته باشند. در یک سیستم هم ترازی جغرافیایی که شامل انواع موجودات جغرافیایی (از ایستگاه های اتوبوس تا کشورها) می شود، فاصله قابل قبول بین موجودیت های منطبق می تواند از چند متر تا صدها کیلومتر متغیر باشد.
این بدان معناست که ما نمیتوانیم به طور یکسان با همه نهادها با اندازههای جغرافیایی متفاوت رفتار کنیم و باید امتیاز فاصله را با توجه به ویژگیهای موجودیتها تطبیق دهیم. جعبه های محدود کننده دقیقاً نوع اطلاعات مورد نیاز ما را ارائه می دهند. هر چه موجودیت بزرگتر باشد (از این رو جعبه مرزی آن)، تحمل فاصله باید بزرگتر باشد. مشکل، همانطور که در بخش 5 توضیح داده شد ، این است که بسیاری از نهادها فاقد اطلاعات جعبه مرزی هستند. بنابراین، برای حدس زدن اندازه یک موجودیت بر اساس نوع آن، مجدداً به آمار اندازه جعبه محدود تکیه می کنیم. امتیاز فاصله γسپس همانطور که در معادله ( 13 ) توضیح داده شده است، محاسبه می شودd(ci,cj)فاصله ژئودزیکی بین مختصات است ciو cjاز نهادها eiو ej، به ترتیب. Δbboxiاندازه جعبه مرزی مورب از است ei. پارامتر m حداکثر فاصله ای است که برای آن γمی تواند مقدار غیر صفر داشته باشد. پارامتر p تعیین می کند که چقدر سختگیرانه است γاندازه گیری باید این باشد: یک p بزرگتر منجر به همگرایی سریعتر می شود γبه صفر در آزمایشات خود استفاده می کنیم m=100و p=25.
γ(ei,ej)=(1−d(ci,cj)mΔbboxi)p
4.3. قوانین پس پردازش
مجموعه ای از قوانین اصلاح ممکن است در مرحله نهایی تراز به منظور بهبود عملکرد کلی ترازها استفاده شود. این برای پرداختن به موارد لبه ای است که حل آنها دشوار است و با تنظیم امتیازهای تراز انجام می شود. ایده این است که قوانینی با مجموعه ای از شرایط منطقی ایجاد کنیم که بتواند امتیاز مثبت های کاذب لبه را کاهش دهد و امتیاز منفی های کاذب را ارتقا دهد. این کار با اعمال مجموعه ای از بررسی ها بر روی سه ویژگی (یعنی برچسب، نوع و فاصله) یک جفت انجام می شود. مرحله پس پردازش پس از دریافت امتیازهای ترازهای ترکیبی از مؤلفههای Fallback و Partition انجام میشود و تصمیم میگیرد که آیا یک امتیاز همترازی تنزل رتبه، ارتقا یا حفظ شود.
اگر موارد لبه طبقهبندیشده اشتباه برچسبگذاریشده در دسترس باشد، میتوان یک طبقهبندی کننده را بر روی ویژگیهایی مانند امتیاز ویژگی یا معیارهای سفارشی آموزش داد. با این حال، در مورد ما، چنین دادههایی در دسترس نبود و تصمیم گرفتیم از شرایط قوانین دستی ساخته شده برای ارزیابی مستقل ویژگیهای برچسب، نوع و فاصله جغرافیایی استفاده کنیم. قوانین میتوانند از امتیازات مؤلفهها مجدداً استفاده کنند و آستانههای خاصی را نسبت دهند یا معیارهای سفارشی ایجاد کنند تا جنبههایی را که توسط امتیازهای همترازی پوشش نمیدهند، ثبت کنند.
شرط برچسب بررسی می کند که آیا شباهت جاکارد مبتنی بر توکن دو موجودیت حداقل آستانه معینی را برآورده می کند یا خیر. شرط نوع بررسی می کند که آیا عمیق ترین سطح سلسله مراتبی که در آن انواع از دو نهاد جفت می شود، حداقل آستانه عمق آن را برآورده می کند یا خیر. شرایط فاصله جغرافیایی بررسی می کند که آیا فاصله ژئودزیکی بین آنها حداقل آستانه فاصله را برآورده می کند یا خیر.
در صورتی که هیچ یک از این شرایط برآورده نشود، با کم کردن یک مقدار معین، امتیاز هم ترازی کاهش می یابد. برعکس، اگر همه شرایط برآورده شود، آنگاه امتیاز با محاسبه مجدد و جایگزینی امتیاز همترازی جفت ارتقا مییابد. آستانه سه ویژگی، و همچنین ارزش تنزل، به منظور تکمیل بهترین نقاط ضعف بالقوه معیار امتیاز هم ترازی و به حداکثر رساندن بهبود عملکرد، بهینه سازی شده است.
در عمل، ما مقادیری را آزمایش میکنیم که احتمال بیشتری برای افزایش عملکرد کلی GLEAN در استاندارد طلایی ما دارند. آستانه برچسب ها در محدوده 0.5 تا 1 با یک مرحله 0.1 تغییر می یابد. آستانه فاصله در این مجموعه انتخاب می شود {0.1,0.2,0.5,1.0,2.0}، که بر حسب کیلومتر اندازه گیری می شوند. تطبیق ویژگی نوع Boolean است و تنها در صورتی تطابق نوع را در نظر میگیرد که انواع در عمیقترین یا دومین سطح عمیقترین سطح کمعمقترین سلسله مراتب نوع بین منابع مطابقت داشته باشند. با این حال، نمرات تطبیق نوع متفاوت است: 1. برای تطبیق عمیق ترین سطح و 2/3برای دومین سطح تطبیق عمیق. مقدار تنزل نوع در مجموعه انتخاب شده است {0.001,0.005,0.01,0.02,0.05,0.1}. ما تمام ترکیبهای ممکن این آستانهها را آزمایش میکنیم و ترکیبی را انتخاب میکنیم که بهترین مبادله را از نظر دقت و یادآوری فراهم میکند. عملکرد بر روی داده های استاندارد طلا آزمایش می شود (لطفاً برای جزئیات بیشتر در مورد ارزیابی عملکرد به بخش 6 مراجعه کنید).
5. معماری سیستم تراز نهادهای جغرافیایی (GLEAN).
هدف GLEAN تراز کردن دو مجموعه داده بزرگ تا حد امکان کارآمد است. از آنجایی که مجموعه دادهها ممکن است فاقد اطلاعات مختصات باشند، ما دو رویکرد اصلی را طراحی میکنیم، یکی برای رسیدگی به موجودیتها با مختصات و دیگری برای رسیدگی به موجودیتهای بدون مختصات. ما هر دو را به ترتیب در بخش 5.1 و بخش 5.2 با جزئیات بیشتر مورد بحث قرار می دهیم . معماری کلی گردش کار آفلاین GLEAN در شکل 3 نشان داده شده است .
5.1. تطبیق مبتنی بر پارتیشن
رویکرد تطبیق مبتنی بر پارتیشن از مختصات موجودیتها برای دستهبندی آنها به پارتیشنهای جغرافیایی استفاده میکند که حداکثر تعداد موجودیتها را شامل میشود. ایده این است که موجودیت هایی که باید مطابقت داده شوند باید در یک پارتیشن قرار گیرند. علاوه بر این، تطبیق موجودیتها از دو منبع در برابر یکدیگر توسط دستهای در پارتیشنهای جداگانه بسیار کارآمدتر از تطبیق کل مجموعه موجودیتها به طور همزمان است.
پارتیشن بندی را می توان با استفاده از هر روش پارتیشن بندی فضایی پیشرفته انجام داد. در مورد ما، از ساختار چهار درختی استفاده می کنیم. اجازه دهید P1و P2مجموعه ای از موجودیت ها از E1و E2به ترتیب موجود در پارتیشن: P1⊂E1و P2⊂E2. ما تعداد موجودیت های موجود در هر پارتیشن را به محدود می کنیم NW، مانند |P1|×|P2|<=NW. پارتیشن ها به صورت بازگشتی تقسیم می شوند تا زمانی که همه پارتیشن ها این شرایط را برآورده کنند.
ما روش پارتیشن بندی چهاردرختی کلاسیک را تغییر می دهیم تا یک حاشیه m قابل تطبیق را شامل شود تا اطمینان حاصل شود که جفت موجودیت های منطبق در پارتیشن های مختلف قرار ندارند. هنگام انتخاب حاشیه m یک معاوضه وجود دارد زیرا حاشیه های کوچک ممکن است منجر به جفت های تطبیق بیشتر از دست رفته شود، اما m بزرگتر همپوشانی بزرگی بین پارتیشن ها ایجاد می کند که روند هم ترازی را کند می کند. وجود واحدهای بزرگ (مانند کشورها، شهرها) که موقعیت مختصات ممکن است بسیار متفاوت باشد، به متر بزرگ نیاز دارد.(به ده ها یا صدها کیلومتر می رسد). چنین حاشیه های بزرگی امکان پذیر نیست، به ویژه در مناطق متراکم (مانند منهتن) زیرا ممکن است موجودیت های زیادی در چنین حاشیه بزرگی وجود داشته باشد. به همین دلیل، روش پارتیشن بندی ما حاشیه های بزرگتری را در مناطق پراکنده اجازه می دهد، در حالی که به تدریج آن را با یک نرخ کاهش می دهد. Rm<1در مناطق متراکم تر، به منظور اطمینان از رسیدن به آستانه در حداکثر تعداد موجودیت ها. کاهش حاشیه زمانی آغاز می شود که حداکثر تعداد مورد نیاز موجودیت ها باشد NWنمی تواند برآورده شود و نسبت بین حاشیه و مورب پارتیشن از یک آستانه خاص فراتر می رود.
راه دیگر برای به حداقل رساندن موضوع مورد بحث در بالا، انجام یک پارتیشن بندی جداگانه برای موجودیت های بزرگی است که به حاشیه های بزرگتر نیاز دارند. از آنجایی که این نهادها نیز نادرتر هستند (به طور کلی مناطق اداری بسیار کمتری نسبت به POI وجود دارد)، اطمینان از آن آسان تر است. |P1|×|P2|≤NWاگر نهادها را فقط به مناطق اداری محدود کنیم.
پس از انجام پارتیشن بندی، تطبیق برای هر پارتیشن به طور جداگانه انجام می شود. از آنجایی که ممکن است بین آنها همپوشانی وجود داشته باشد، برای ادغام نتایج حاصل از پارتیشنهای مختلف در یک خروجی تراز منفرد، به یک مرحله اضافی در پایان نیاز داریم. انتخاب نامزدها برای فرآیند تطبیق در هر پارتیشن همانطور که در شکل 4 نشان داده شده است انجام می شود . هر موجودیتی که مختصات نقطهای در جعبه کراندار قرار گرفته یا ناحیه پارتیشن را قطع میکند (از جمله حاشیه) انتخاب میشود.
هنگامی که مجموعه ای از نهادهای نامزد از P1و P2انتخاب می شوند، تطبیق بین موجودیت های دو منبع شروع می شود، به دنبال فرآیندی که در شکل 5 نشان داده شده است. ایده این است که یک پیش فیلتر کردن نهادهای نامزد انجام شود. ابتدا، شباهتهای جاسازی نوع و جاسازی برچسب محاسبه میشوند، زیرا نسبتاً ارزان هستند. این امتیازات سپس برای فیلتر کردن جفتهای با امتیاز پایین استفاده میشوند و فقط موجودیتهای کاندید برتر را حفظ میکنند . P2برای هر موجودیت از P1. متعاقباً، بخشهای باقیمانده امتیازات مؤلفههای دیگر را میتوان برای آن محاسبه کرد |P1|×kجفت نهاد نامزد این تضمین میکند که محاسبات گرانتر، مانند LIDFJ، فقط انجام میشوند |P1|×kبجای |P1|×|P2|. این به طور قابل توجهی روند امتیاز دهی را به طور معمول سرعت می بخشد |P2|≫k.
پس از محاسبه امتیاز نهایی، k P2نامزدهای هر کدام P1موجودیت مجدداً رتبه بندی می شوند و زوج ها با امتیاز تراز نهایی ϕ>tϕبازگردانده می شوند؛ جایی که tϕیک آستانه تراز است.
5.2. تطبیق بازگشتی
تطبیق مبتنی بر پارتیشن فقط به همترازی موجودیتهایی میپردازد که حاوی مختصات جغرافیایی هستند. رویکرد تطبیق بازگشتی از آن نهادها بدون هیچ نوع اطلاعات مختصاتی مراقبت می کند. این رویکرد عمدتاً به اطلاعات برچسب و آدرس برای بازیابی نامزدها متکی است و هنگام محاسبه نمره نهایی مؤلفه های مختصات را نادیده می گیرد. wγ= 0).
بازیابی نامزدها شامل یک بازیابی فازی به تدریج محدود کننده در هر دو فیلد آدرس و برچسب است. عبارات جستجو برای ویژگیهای برچسب و آدرس به ترتیب از ترکیب همه برچسبها و نامهای مستعار موجود و اتحاد همه آدرسهای مختلف تشکیل شدهاند. سختی تطابق با حداقل درصد نشانههای جستجویی که باید توسط یک نهاد جغرافیایی مطابقت داده شوند، تعریف میشود. مهم است که با الزامات تطبیق دقیق شروع کنید تا اطمینان حاصل شود که تعداد نامزدها کم است. اگر هیچ نامزدی برگردانده نشود، الزامات تطابق فازی به تدریج کاهش مییابد تا زمانی که تعداد کافی کاندید برگردانده شوند.
5.3. بحث در مورد سناریوی تراز آنلاین
سیستم ما همچنین می تواند برای پرونده آنلاین، که در آن یک نیاز اضافی مربوط به تأخیر سرویس وجود دارد، سازگار شود. برای برآوردن الزامات تاخیر کم، چند مرحله وجود دارد که می توان از قبل محاسبه کرد و برخی از فیلترها را می توان برای هرس زودهنگام نامزدها معرفی کرد. میتوان مختصات موجودیتهای نامزد را در کادر محدود کننده موجودیت درخواستشده (یا اندازه متوسط جعبه مرزی نوع آن در صورتی که نهاد یک مورد ندارد) به اضافه تحمل افزایش حاشیه مورد نیاز باشد. وزن های LIDF را می توان برای پارتیشن های از پیش تعریف شده از پیش محاسبه کرد و تعداد جفت های نامزد را می توان با استفاده از محدودیت های نوع و مختصات محدود کرد.
6. آزمایشات
در آزمایشهای خود، ما یک مطالعه فرسایشی را برای تجزیه و تحلیل تأثیر مؤلفههای مختلف امتیاز همترازی پیشنهاد شده در این مقاله انجام میدهیم. ما همچنین آزمایشهایی را در زمان اجرا آفلاین در برنامه همترازی مجموعه دادههای ناهمگن خود اجرا میکنیم.
6.1. مجموعه داده ها
در آزمایشهای خود، از دو مجموعه داده برای فرآیند همترازی استفاده میکنیم: مجموعه دادههای خصوصی Huawei (یعنی HuaweiPD) و Wikidata. آمار مربوط به آنها در جدول 1 توضیح داده شده است. هر دو مجموعه داده بسیار بزرگ هستند و تعداد کل موجودیت ها به ترتیب صدها و ده ها میلیون است. سلسله مراتب بسیار متفاوت است. HuaweiPD فقط 744 نوع دارد که در یک درخت سازماندهی شده اند، در حالی که Wikidata دارای یک سلسله مراتب پیچیده تر و ریزدانه انبوه گراف غیر چرخه مستقیم (DAG) با بیش از دو میلیون نوع است. در این تنظیمات خاص، میتوان نگاشتهای 1:N و N:M بین دو سلسله مراتب وجود داشته باشد که یک نوع در یک سلسله مراتب اغلب به چندین نوع در بخشهای مختلف سلسله مراتب دیگر نگاشت میشود. در اصل، نهادهای ویکی داده اطلاعات آدرس ندارند، اما یک آدرس را می توان به صورت پویا بر اساس روابط P281 ( کدپستی )، P131 ( مکان ) و P17 ساخت.( کشور ). با این حال، این ویژگی ها بسیار ناقص هستند و کیفیت آدرس های ساخته شده پایین است. بنابراین، برای ترازهای Wikidata-HuaweiPD، ما ترجیح دادیم از مؤلفه آدرس استفاده نکنیم.
تعداد بسیار کمی اطلاعات جعبه محدود دارند: 1.0402٪ در HuaweiPD و 0.1084٪ در Wikidata. در هر دو مجموعه داده، بیشتر موجودیت ها دارای مختصات نقطه هستند: 100٪ HuaweiPD و 95.338٪ از Wikidata. فقدان اطلاعات مختصات برای تقریباً 5 درصد از نهادهای ویکی داده، اهمیت استراتژی پیشنهادی ما را آشکار می کند.
ما از یک استاندارد طلایی مشروح برای بازیابی نتایج عملکرد استفاده می کنیم. ما بهطور تصادفی مجموعهای از 1942 را از Wikidata انتخاب کردیم و بهصورت دستی هر موجودیت را با 0 تا N موجودیت HuaweiPD مشابه حاشیهنویسی کردیم. ما دقت، دقت، یادآوری و امتیاز F1 را برای هر مجموعه محاسبه میکنیم و نتایج را با توجه به نسبت آنها با مجموعه داده اصلی ترکیب میکنیم.
6.2. نتایج و بحث
6.2.1. مطالعه ابلیشن
دو تا از بیشتر سیستمهای همترازی موجودیتهای جغرافیایی مرتبط [ 6 ، 22 ] پیادهسازی و مجموعه دادههای خود را بهطور عمومی به اشتراک نمیگذارند. بنابراین نمی توان مقایسه مستقیم با آنها انجام داد. با این حال، همانطور که در کار مرتبط (به عنوان مثال، بخش 2 ) مورد بحث قرار گرفت، رویکرد ما یک معیار تشابه برچسب بسیار پیچیدهتر دارد، که میتواند برچسبهای چندزبانه را مدیریت کند و همچنین ارتباط محلی نشانهها را در نظر بگیرد. علاوه بر این، رویکردهای قبلی بر نگاشت های دستی بین سلسله مراتب نوع تکیه می کنند، که در مورد ما در دسترس نیست و با توجه به اندازه سلسله مراتب، ایجاد آنها غیرممکن است ( جدول 1 را ببینید). لو و همکاران، 2021 [ 14] کد موجود را دارد، اما برای اجرای آن در مجموعه داده های ما (که بسیار بزرگتر از مجموعه داده های حاوی چند هزار موجودیت مورد استفاده در کارشان هستند) برخی از ویژگی های پیشنهاد شده در مقاله ما را می طلبد. علاوه بر این، سه اثر مرتبط نیز به مسائل اصلی تحت پوشش کار ما، یعنی مشکل مقیاسپذیری و استفاده از ارتباط محلی نشانهها برای بهبود معیارهای تشابه متن، و چند زبانه بودن برچسبها، توجه نمیکنند. بنابراین، ما یک مطالعه فرسایشی را انتخاب کردیم، که در آن تأثیر هر ویژگی پیشنهادی را می توان به صورت جداگانه با اجرای نسخه های مختلف سیستم با ویژگی های حذف شده و مقایسه نتایج اندازه گیری کرد. جدول 2نتایج حاصل از مطالعه فرسایش را نشان می دهد و شرح نسخه های ارزیابی شده و قطعات تراشیده شده در زیر نشان داده شده است:
-
GLEAN : سیستم کامل بدون قطعات فرسوده.
-
LIDFJ : شباهت محلی-IDF Jaccard با امتیاز برچسب که منحصراً بر رمزگذار جملات چند زبانه تکیه دارد حذف می شود.
-
MLSE : رمزگذار جملات چند زبانه با استفاده از LIDFJ به عنوان نمره برچسب حذف می شود.
-
TypeComp : کل مؤلفه نمره نوع حذف می شود (هر دو مؤلفه جاسازی و کاهش). این به این معنی است که تراز به دست آمده به طور کامل انواع را نادیده می گیرد.
-
TypeDem : تنزل نوع با امتیازات نوع که منحصراً بر تعبیهها تکیه دارد حذف میشود.
-
TypeGD : امتیاز فاصله جغرافیایی مبتنی بر نوع حذف می شود و امتیازات مؤلفه دیگر وابسته به نوع نیستند.
شایان ذکر است که هنگام حذف MLSE، امتیاز به کمترین میزان کاهش می یابد. یکی از دلایل این امر این است که LIDFJ می تواند کاملاً محدود کننده باشد زیرا برای تطابق کامل به توکن ها نیاز دارد. دلیل مهم دیگر این است که همراه با شباهت تعبیهشده نوع، تنها معیار محاسبهشده برای همه جفتهای تطبیق ممکن است، و حذف آن به این معنی است که رتبهبندی مجدد k ممکن است شامل بسیاری از امیدوارکنندهترین منطبقها نباشد. در نتایج، ما همچنین میتوانیم ببینیم که معرفی LIDFJ به طور قابلتوجهی یادآوری را بهبود میبخشد. این باعث میشود که سیستم قادر به تطبیق نهادهایی باشد که برچسبهای آنها فقط تا حدی مطابقت دارند، در حالی که فقط کمی دقت را کاهش میدهد.
ما همچنین می توانیم اهمیت مولفه تنزل نوع را مشاهده کنیم. جزء تعبیههای نوع به خودی خود نتایج را در مقایسه با عدم استفاده از امتیاز نوع بهبود نمیبخشد، اما در ترکیب با تنزل نوع، میتواند دقت و یادآوری را به طور قابل ملاحظهای بهبود بخشد.
زمان اجرا برای GLEAN همانطور که در ردیف اول جدول 2 گزارش شده است حدود یک روز (23 ساعت) بود، با فرآیند هم ترازی مبتنی بر پارتیشن در مجموع 403,453 پارتیشن اجرا شد و در مجموع 3,979,183 تراز ایجاد کرد. این سیستم در پایتون پیاده سازی شد و بر روی دستگاه 72 هسته ای Intel Xeon Gold 6154 3.00 گیگاهرتز با 128 گیگابایت رم اجرا شد.
6.2.2. نمونه هایی از تراز GLEAN
شکل 6 دو مثال برای جفت های منطبق و غیر منطبق از POI، به عنوان خروجی تراز GLEAN، همراه با امتیازات برچسب، نوع و مختصات مربوطه آنها را نشان می دهد. این جفت ها به ترتیب از Wikidata و HuaweiPD هستند. از آنجایی که موجودیت های ویکی داده اطلاعات آدرس دقیقی ندارند، شباهت ویژگی آدرس در تراز جفت ها در نظر گرفته نمی شود. مثال سمت چپ یک POI Wikidata و یک HuaweiPD POI را نشان میدهد که یک نهاد جغرافیایی را نشان میدهند. امتیاز تراز نهایی بیانگر اطمینان بالای GLEAN در مورد شباهت “Q1427870” و “HuaweiID-X” است. مولفه تشابه برچسب شباهت برچسب ها را به دست آورده است، حتی اگر 100٪ مطابقت نداشته باشند. به طور خاص، سخت است که با ” Stadtbibliothek Leverkusen” و ” Stadtbibliothek ” به عنوان اولی دارای یک نشانه اضافی ” Leverkusen ” است که نشان دهنده شهری است که این POI در آن واقع شده است. رمزگذار جملات چند زبانه 0.714 را به عنوان شباهت برچسب خروجی می دهد. از سوی دیگر، مؤلفه LIDFJ وزن کم را به نشانه « Leverkusen » و وزن بالاتری را به « Stadtbibliothek » اختصاص میدهد که منجر به امتیاز بالاتر برچسب میشود. علاوه بر این، POI “HuaweiID-X” یک “کتابخانه” است اما طبقه بندی نوع HuaweiPD انواع آن را به عنوان Business , Company , Business Services مشخص می کند.. اگرچه طبقه بندی نوع HuaweiPD گیج کننده است، شباهت تعبیه نوع بالا 0.9862 است. این بدان معنی است که GLEAN به لطف رویکرد تعبیه نوع بدون نظارت، علیرغم اینکه برچسبهای نوع بسیار متفاوت هستند، میتواند تطابق نوع را تشخیص دهد.
مثال سمت راست در شکل 6 یک POI Wikidata و یک HuaweiPD POI را نشان میدهد که شبیه به هم هستند (با در نظر گرفتن برچسبها و فاصله آنها)، اما به موجودیتهای جغرافیایی مختلف در دنیای واقعی اشاره دارند. حتی با وجود اینکه امتیاز همترازی GLEAN برای این جفت بالا است (به دلیل سهم امتیازهای برچسب و فاصله)، هنوز از آستانه پایینتر است. تعبیه نوع GLEAN اجازه می دهد تا امتیازات کمتری را برای انواع بی همتا تعیین کنید: شهرداری پرتغال ، شهر پرتغال و حمل و نقل ، ایستگاه راه آهن ، حومه یا شهری. علاوه بر این، تنزل نوع فعال می شود و امتیاز همترازی جفت کاهش می یابد (0.05) تا شباهت کلی کاهش یابد. تنزل رتبه به دلیل جفت گسست در سطح بالا بین حمل و نقل و نهاد قلمرو اداری (Q56061) (که توسط هر دو شهرداری پرتغال ، شهر پرتغال شمرده می شود) فعال می شود. این مثال مزایای کاهش نوع و رویکرد تعبیه نوع را نشان می دهد.
6.2.3. مقیاس پذیری GLEAN
در آزمایشهای مقیاسپذیری، تأثیر پارامترهای سیستم (به عنوان مثال، رتبهبندی k ، تعداد نامهای مستعار ) را ارزیابی میکنیم.η، حداکثر تعداد موجودیت های ویکی داده در هر پارتیشن NWو حاشیه پارتیشن m ) در زمان اجرا تراز. ما همچنین تأثیر این پارامترها را بر تعداد همترازیها با شباهت بیشتر یا مساوی 0.950 اندازهگیری میکنیم که آن را «همترازیهای بالقوه خوب» مینامیم. تعداد «همترازیهای بالقوه خوب» برای تخمین تعداد همترازیهای واقعاً خوب استفاده میشود، زیرا حاشیهنویسی دستی همه همترازیهای تولید شده کار دشواری است، و برای نشان دادن مبادله بین زمان اجرا و پوشش ترازها عمل میکند.
به یاد میآوریم که k تعداد موجودیتهای نامزد از پیش فیلتر شده پس از اعمال شباهتهای تعبیهشده برچسب و نوع ارزان است ( شکل 5 را ببینید). پارامتر ηحداکثر تعداد نام مستعار برچسب موجودیت است که در فرآیند هم ترازی در نظر گرفته شده است. حاشیه پارتیشن m ( شکل 4 ) حاشیه بر حسب متر است که بین پارتیشن ها همپوشانی ایجاد می کند. برای این آزمایش ها یک پارامتر جدید تعریف می کنیم NW، که به حداکثر تعداد موجودات ویکی داده در یک پارتیشن معین اشاره دارد. این به طور مستقیم بر تعداد پارتیشن های تولید شده با بزرگتر تأثیر می گذارد NWدر نتیجه پارتیشن های بزرگتر کمتری ایجاد می شود.
اجرای سیستم با تنظیمات پارامترهای متعدد در کل مجموعه داده امکان پذیر نیست زیرا این کار خیلی طول می کشد. بنابراین، ما تأثیر پارامترهای k را ارزیابی می کنیم ، η، م ، و NWدر مقیاس پذیری برای زیر مجموعه های مجموعه داده ما. ما آزمایشها را روی جعبه مرزی تعریفشده با مختصات جنوب غربی و شمال شرقی (54،-1) (58،7) برای k اجرا میکنیم ، ηو m که شامل 6509 Wikidata و 21451 موجودیت HuaweiPD است. برای تعداد موجودیت ها در هر پارتیشن ( NW) آزمایش، زیرمجموعه بزرگتری از داده ها مورد نیاز است، و کادر محدود (53،-3) (59،9) حاوی 233300 Wikidata و 1،471،205 موجودیت HuaweiPD استفاده می شود.
شکل 7 تاثیر چهار پارامتر k را نشان می دهد ، η، م و NWدر زمان اجرا تراز نمودارها نشان می دهد که مقادیر بالای k و NWمی تواند بسیار گران باشد نمودار k رتبه بندی مجدد (بالا به چپ) اهمیت فرآیند امتیازدهی نشان داده شده در شکل 5 را در کاهش تعداد جفت های نامزد برای هر یک از اجزای گران تر امتیاز تراز (مانند LIDFJ) نشان می دهد. این نقش مهمی در بهبود مقیاس پذیری کلی سیستم ایفا می کند. به طور مشابه، تعداد موجودیتها در هر پارتیشن (پایین-راست) برای اطمینان از اینکه فرآیند همترازی کلی میتواند در مدت زمان معقولی اجرا شود، با محدود کردن تعداد موجودیتهایی که در یک زمان معین با یکدیگر مطابقت دارند، بسیار مهم است.
تعداد نمودار نام مستعار نشان می دهد که ηمحدودیت نیز برای کنترل زمان اجرا مهم است. با این حال، تاثیر آن بر زمان اجرا به شدت k و نیستNWاز آنجایی که اکثریت قریب به اتفاق موجودیت ها چندین نام مستعار ندارند (HuaweiPD به طور متوسط 0.086 نام مستعار در هر نهاد و Wikidata 3.58 است). این امکان استفاده از بزرگتر را فراهم می کند ηمقادیر، که می تواند به ویژه در مواردی که مجموعه داده ها دارای برچسب ها و نام مستعار زیادی در چندین زبان هستند، همانطور که در جدول 1 مشاهده می شود، مهم باشد.
نمودار حاشیه پارتیشن m (پایین-چپ) تأثیر متوسطی بر زمان اجرا دارد تا زمانی که به مساحت کلی پارتیشن اضافه نکند. این را می توان با مرحله کاهش حاشیه توضیح داده شده در بخش 5.1 کنترل کرد. در این آزمایش، حداکثر نسبت بین حاشیه و مورب پارتیشن به بی نهایت تنظیم شد تا اطمینان حاصل شود که مقادیر حاشیه انتخاب شده در فرآیند پارتیشن بندی کاهش نمی یابد.
شکل 8 تأثیر همان چهار متغیر را در تعداد “هم ترازهای بالقوه خوب” شناسایی شده نشان می دهد. قابل توجه است که حتی برای مقادیر k rerank کوچک ، تعداد جفت ترازها بسیار کمتر از مقادیر بالاتر نیست. افزایش k از 5 به 640 تعداد جفت ها را حدود 6.9٪ افزایش می دهد در حالی که زمان اجرا حدود 8 برابر بیشتر است.
تعداد نمودار نام مستعار (بالا سمت راست) نشان می دهد که مزایای افزایش ηبرای بزرگتر کاهش می یابد ηارزش های. این به این دلیل است که تعداد نهادهایی با تعداد زیادی نام مستعار نسبتاً کم است و بیشتر آنها جاذبه های گردشگری محبوب یا مناطق اداری سطح بالا مانند شهرها و کشورها هستند. نمودار حاشیه پارتیشن (پایین-چپ) اهمیت اضافه کردن حاشیه به پارتیشن را نشان می دهد. تعداد “ترازهای بالقوه خوب” در ابتدا با شروع به اضافه شدن حاشیه شامل موجودیت های واقع در پارتیشن های همسایه افزایش می یابد، اما قبل از اینکه حاشیه به 10 کیلومتر برسد شروع به افزایش می کند. این نشاندهنده اهمیت افزودن حاشیه به منظور از دست ندادن جفتهای موجودات منطبق است که در طرف مقابل مرزهای پارتیشن قرار دارند، اما مزایای حاشیههای بسیار بزرگ کاهش مییابد زیرا تعداد بسیار کمی از جفتهای موجودیت منطبق میتوانند از یکدیگر بسیار دور باشند. . تغییر حاشیه از 100 به 3200 نتیجه افزایش بیش از 13 درصدی در تعداد جفتهای «همترازی بالقوه خوب» و افزایش 38 درصدی در زمان اجرا است. از طرف دیگر، هنگام تغییر حاشیه از 3200 به 12800، زمان اجرا 154٪ افزایش می یابد در حالی که تعداد ترازها تنها 3.4٪ بیشتر است.
تعداد موجودیت ها در هر نمودار پارتیشن (پایین-راست) نشان می دهد که افزایش تعداد پارتیشن ها (کاهش NW) تأثیر قابل توجهی در افزایش تعداد “هم ترازهای بالقوه خوب” تولید شده دارد. زیرا با پارتیشنهای بیشتر، طول کل حاشیه افزایش مییابد و در نتیجه تعداد جفتهای منطبق واقع در پارتیشنهای مختلف نیز افزایش مییابد. علاوه بر این، در مناطق متراکم، حاشیه باید کاهش یابد، که همچنین تعداد ترازهای از دست رفته را افزایش می دهد. هنگام کاهش NWاز 65536 به 512، تعداد ترازهای ایجاد شده 18 درصد کاهش می یابد. با این حال، همان کاهش در NWزمان اجرا را به حدود 10 درصد از زمان اجرا اولیه کاهش می دهد.
به طور کلی، نتایج این آزمایشها نشان میدهد که GLEAN میتواند بهطور چشمگیری مقیاسپذیری را بهبود بخشد، و همترازی مجموعههای داده بزرگ را در مقیاس جهانی امکانپذیر میکند. با این حال، این به قیمت یادآوری است، زیرا سیستم جفت ترازهای بیشتری را از دست می دهد زیرا پارامترها برای کاهش زمان اجرا تغییر می کنند. با این حال، همانطور که قبلا بحث شد، از دست دادن یادآوری در مقایسه با بهبود زمان اجرا جزئی است. GLEAN هنوز یک مبادله جذاب بین عملکرد و مقیاس پذیری ارائه می دهد.
7. نتیجه گیری
در این مقاله، ما GLEAN را پیشنهاد کردیم، یک رویکرد مقیاسپذیر برای تراز کردن نهادهای جغرافیایی (یعنی POI) از منابع مختلف بر اساس چهار ویژگی (برچسب، مختصات، نوع و آدرس). رویکرد ما میتواند منابع ناقص و سلسلهمراتب نوع پیچیده را مدیریت کند و از ارتباط بافت محلی نشانهها و برچسبهای چند زبانه استفاده کند. روش آفلاین از پارتیشن بندی حاشیه تطبیقی برای فعال کردن ترازهای مقیاس پذیر مجموعه داده های بزرگ در مقیاس جهانی استفاده می کند.
مطالعه فرسایشی ما نقش مهم رمزگذار جملات چندزبانه را در افزایش کیفیت تراز، به ویژه یادآوری نشان میدهد. این مطالعه همچنین اهمیت شباهت محلی-IDF Jaccard (LIDFJ) را در بهبود یادآوری GLEAN نشان داده است. از طریق این مطالعه، ما همچنین مزایای تعبیه نوع و تنزل نوع را در بهبود دقت و یادآوری شناسایی کردیم.
علاوه بر این، ما مقیاس پذیری GLEAN را از نظر زمان اجرا هم ترازی ارزیابی کردیم. نتایج نشان میدهد که پارتیشنبندی برای بهبود مقیاسپذیری و امکان تراز کردن در مقیاس جهانی بسیار مهم است، با افزودن حاشیه پارتیشن به کاهش تعداد ترازهای از دست رفته با تأثیر جزئی بر زمان اجرا کمک میکند. نشان داده شد که استفاده از نوع جاسازی و شباهت جاسازی برچسب به نامزدهای تراز هرس اولیه در کاهش زمان اجرا بسیار موثر است. سیستم پیشنهادی ما برای هم ترازی نهادهای جغرافیایی از منابع ناهمگن در مقیاس بزرگ با موفقیت در عمل برای تراز کردن داده های مورد استفاده در تولید استفاده شد.
یکی از جهتگیریهای کاری بالقوه در آینده، اعمال مفهوم ارتباط نشانه بافت محلی در یک شبکه ترانسفورماتور برای رمزگذاری متن (مثلاً برچسبها و آدرسها) در ترکیب با مختصات موجودات جغرافیایی است. این به نمایش توکن اجازه می دهد تا به مختصات رمزگذاری شده نیز توجه کند. یکی دیگر از جهتگیریهای تحقیقاتی جالب، یادگیری بدون نظارت یا با نظارت ضعیف بازنمایی نهادهای جغرافیایی است. ایده این است که بتوانیم مدلی را یاد بگیریم که بتواند برچسب، نوع، آدرس و اطلاعات مختصات موجود را رمزگذاری کند، بدون اینکه نیاز به مقادیر زیادی داده برچسبگذاری شده باشد.
مشارکت های نویسنده
مفهوم سازی، آندره ملو; روش شناسی، آندره ملو، بتیسام ار-رحمدی و جف زی. نرم افزار، آندره ملو; اعتبار سنجی، آندره ملو و بتیسام ار رحمدی. تحلیل رسمی، آندره ملو; تحقیق، آندره ملو؛ سرپرستی داده ها، آندره ملو و بتیسام الرحمدی. نوشتن – آماده سازی پیش نویس اصلی، آندره ملو و بتیسام الرحمدی. نوشتن-بررسی و ویرایش، آندره ملو، بتیسام ار-رحمدی و جف زی. تجسم، آندره ملو و بتسام الرحمدی. نظارت، آندره ملو و جف زی پان. مدیریت پروژه، جف زد. تامین مالی، جف زی پان. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق هیچ بودجه خارجی دریافت نکرد.
بیانیه هیئت بررسی نهادی
قابل اجرا نیست.
بیانیه رضایت آگاهانه
قابل اجرا نیست.
بیانیه در دسترس بودن داده ها
داده ها به دلیل محدودیت های تجاری در دسترس نیست.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- Goodchild، M. شهروندان به عنوان حسگرها: دنیای جغرافیای داوطلبانه. ژئوژورنال 2007 ، 69 ، 211-221. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ویمن، اس. Bernard, L. ادغام داده های مکانی در زیرساخت های داده های مکانی با استفاده از داده های پیوندی. بین المللی جی. جئوگر. Inf. علمی 2016 ، 30 ، 613-636. [ Google Scholar ] [ CrossRef ]
- شفلر، تی. شیرو، آر. Lehmann, P. Matching Points of Interest از سایت های مختلف شبکه های اجتماعی. در مجموعه مقالات سی و پنجمین کنفرانس سالانه آلمان در مورد پیشرفت در هوش مصنوعی، زاربروکن، آلمان، 24-27 سپتامبر 2012. Springer: برلین/هایدلبرگ، آلمان، 2012; ص 245-248. [ Google Scholar ] [ CrossRef ]
- بیری، سی. دویتشر، ی. کانزا، ی. صفرا، ای. Sagiv، Y. یافتن اشیاء متناظر هنگام ادغام چندین مجموعه داده جغرافیایی-مکانی. در مجموعه مقالات سیزدهمین کارگاه بین المللی سالانه ACM در سیستم های اطلاعات جغرافیایی، نیویورک، نیویورک، ایالات متحده آمریکا، 3 تا 6 نوامبر 2005. صص 87-96. [ Google Scholar ] [ CrossRef ]
- سمال، ع. ست، SC; Cueto، K. یک رویکرد مبتنی بر ویژگی برای ترکیب منابع جغرافیایی. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 459-489. [ Google Scholar ] [ CrossRef ]
- دنگ، ی. لو، ا. لیو، جی. Wang, Y. تطبیق نقطه مورد علاقه بین مجموعه داده های مختلف جغرافیایی. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 435. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- کیم، جی. واسردانی، م. Winter, S. تطبیق شباهت برای یکپارچه سازی اطلاعات مکانی استخراج شده از توضیحات مکان. بین المللی جی. جئوگر. Inf. علمی 2017 ، 31 ، 56-80. [ Google Scholar ] [ CrossRef ]
- لی، ایکس. موری، پی. راث، دی. ادغام معنایی در متن: از نام های مبهم تا موجودیت های قابل شناسایی. AI Mag. 2005 ، 26 ، 45-58. [ Google Scholar ] [ CrossRef ]
- صفرا، ای. کانزا، ی. ساگیو، ی. Doytsher, Y. یکپارچه سازی داده ها از نقشه ها در وب جهانی. در مجموعه مقالات وب و سیستم های اطلاعات جغرافیایی بی سیم، ششمین سمپوزیوم بین المللی، W2GIS 2006، هنگ کنگ، چین، 4-5 دسامبر 2006. Carswell, JD, Tezuka, T., Eds. Springer: برلین/هایدلبرگ، آلمان، 2006; جلد 4295، ص 180–191. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مک کنزی، جی. یانوویچ، ک. آدامز، ب. تطبیق چند ویژگی وزنی نقاط مورد علاقه تولید شده توسط کاربر. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، نیویورک، نیویورک، ایالات متحده آمریکا، 5-8 نوامبر 2013. صص 440-443. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، اس. چو، ی. متعجب.؛ فنگ، جی. Zhu, X. جستجوی تشابه فضایی-متنی Top-k. در مجموعه مقالات مدیریت اطلاعات عصر وب – پانزدهمین کنفرانس بین المللی، WAIM 2014، ماکائو، چین، 16-18 ژوئن 2014; Li, F., Li, G., Hwang, S., Yao, B., Zhang, Z., Eds. Springer: برلین/هایدلبرگ، آلمان، 2014; جلد 8485، ص 602–614. [ Google Scholar ] [ CrossRef ]
- نواک، تی. پیترز، آر. Zipf، A. تطبیق نقاط مورد علاقه مبتنی بر نمودار از مجموعه دادههای جغرافیایی مشترک. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 117. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پورویس، بی. مائو، ی. رابینسون، دی. آنتروپی و کاربرد آن در سیستم های شهری. Entropy 2019 ، 21 ، 56. [ Google Scholar ] [ CrossRef ] [ PubMed ] [ نسخه سبز ]
- کم، آر. تکلر، زد. Cheah, L. چارچوب تلفیقی نقطه مورد علاقه (POI) پایان به پایان. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 779. [ Google Scholar ] [ CrossRef ]
- الکساکیس، م. آتاناسیو، اس. کوواراس، ی. پاترومپاس، ک. Skoutas، D. SLIPO: یکپارچه سازی داده های مقیاس پذیر برای نقاط مورد علاقه. در مجموعه مقالات دومین کارگاه بین المللی ACM SIGSPATIAL در مورد دسترسی به داده های جغرافیایی و API های پردازش، سیاتل، WA، ایالات متحده آمریکا، 3 نوامبر 2020. [ Google Scholar ] [ CrossRef ]
- جیانوپولوس، جی. اسکوتاس، دی. مارولیس، تی. کاراگیاناکیس، ن. Athanasiou، S. FAGI: چارچوبی برای ترکیب داده های RDF جغرافیایی. در مجموعه مقالات حرکت به سوی سیستمهای اینترنتی معنادار: کنفرانسهای OTM 2014، آمانتیا، ایتالیا، 27 تا 31 اکتبر 2014. Meersman, R., Panetto, H., Dillon, T., Missikoff, M., Liu, L., Pastor, O., Cuzzocrea, A., Sellis, T., Eds. Springer: برلین/هایدلبرگ، آلمان، 2014; صص 553-561. [ Google Scholar ]
- یو، اف. غرب، جی. آرنولد، ال. مک میکین، دی. Moncrieff, S. ادغام خودکار داده های مکانی با استفاده از فناوری های وب معنایی. در مجموعه مقالات کنفرانس چند کنفرانسی هفته علوم کامپیوتر استرالیا، کانبرا، استرالیا، 1 تا 6 فوریه 2016. انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2016. صص 1-10. [ Google Scholar ] [ CrossRef ]
- نهاری، م.ک. قدیری، ن. برائانی دستجردی، ع. Sack, J. یک معیار تشابه جدید برای وضوح موجودیت فضایی بر اساس مدل دانه بندی داده ها: مدیریت ناسازگاری ها در توضیحات مکان. Appl. هوشمند 2021 ، 51 ، 6104-6123. [ Google Scholar ] [ CrossRef ]
- کوسو، وی. Barbosa, L. پیوند دادن رکوردهای مکان با استفاده از رمزگذارهای چند نمای. محاسبات عصبی Appl. 2021 ، 33 ، 12103-12119. [ Google Scholar ] [ CrossRef ]
- جیانگ، ایکس. د سوزا، EN; پسرانقادر، ع. هو، بی. نقره، DL; Matwin, S. TrajectoryNet: یک نمایش مسیر GPS جاسازی شده برای طبقه بندی مبتنی بر نقطه با استفاده از شبکه های عصبی مکرر. در مجموعه مقالات بیست و هفتمین کنفرانس بین المللی سالانه علوم کامپیوتر و مهندسی نرم افزار، مارکهام، ON، کانادا، 6 تا 8 نوامبر 2017؛ IBM Corp.: Foster City، CA، USA، 2017; صص 192-200. [ Google Scholar ]
- سهگل، وی. گتور، ال. Viechnicki، PD Entity Resolution در یکپارچه سازی داده های مکانی. در مجموعه مقالات چهاردهمین سمپوزیوم بینالمللی سالانه ACM در زمینه پیشرفتها در سیستمهای اطلاعات جغرافیایی، آرلینگتون، ویرجینیا، ایالات متحده آمریکا، 10–11 نوامبر 2016. انجمن ماشین های محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2006; صص 83-90. [ Google Scholar ] [ CrossRef ]
- لی، سی. لیو، ال. دای، ز. لیو، ایکس. روش تطبیق نقطه مورد نظر منبعیابی متفاوت با در نظر گرفتن محدودیتهای متعدد. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 214. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یانگ، ی. سر، دی. احمد، ع. گو، ام. قانون، ج. ثابت، ن. Ábrego، GH; یوان، اس. تار، سی. سانگ، ی. و همکاران رمزگذار جملات جهانی چند زبانه برای بازیابی معنایی. arXiv 2019 ، arXiv:1907.04307. [ Google Scholar ]
- چیدامبارام، م. یانگ، ی. سر، دی. یوان، اس. سانگ، ی. استروپ، بی. Kurzweil, R. یادگیری بازنمایی جملات چندزبانی از طریق یک مدل رمزگذار دوگانه چند کاره. arXiv 2018 , arXiv:1810.12836. [ Google Scholar ]
- فنگ، اف. یانگ، ی. سر، دی. آریواژگان، ن. وانگ، دبلیو. تعبیه جملات BERT زبانی. arXiv 2020 ، arXiv:2007.01852. [ Google Scholar ]
- یانگ، بی. Yih، SWt; او، X. گائو، جی. دنگ، ال. تعبیه نهادها و روابط برای یادگیری و استنتاج در پایگاه های دانش. در مجموعه مقالات کنفرانس بینالمللی نمایشهای یادگیری (ICLR) 2015، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 7 تا 9 مه 2015. [ Google Scholar ]
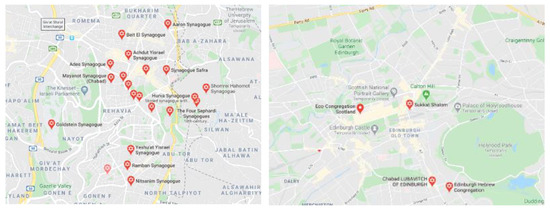
شکل 1. فراوانی ” کنیسه ” در زمینه های جغرافیایی اورشلیم غربی ( سمت چپ ) و ادینبورگ ( راست ).
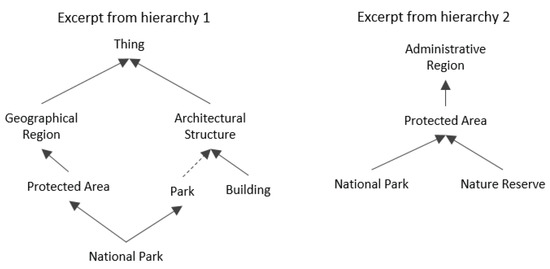
شکل 2. مثالی از بدیهیات زیر کلاس اشتباه در یک سلسله مراتب که منجر به استدلال اشتباه می شود.
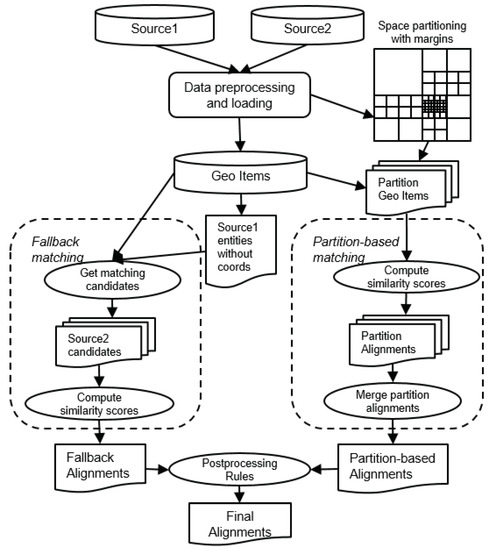
شکل 3. معماری GLEAN در سناریوی تطبیق آفلاین.
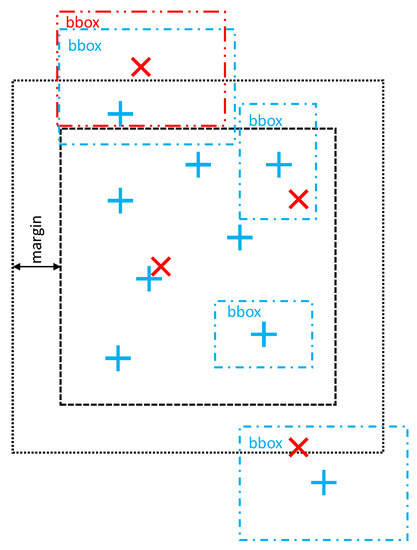
شکل 4. نمونه ای از انتخاب موجودیت های کاندید برای تطبیق مبتنی بر پارتیشن.
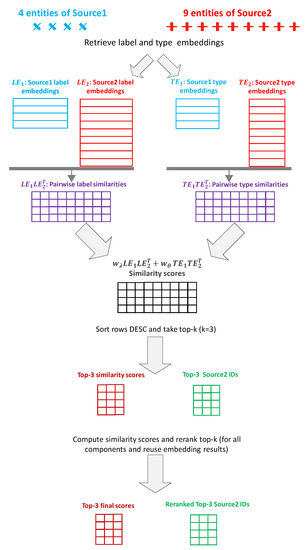
شکل 5. فرآیند امتیازدهی با استفاده از برچسب و جاسازی نوع برای هرس زودهنگام نامزدهای تراز.

شکل 6. نمونه هایی از جفت های POI منطبق ( سمت چپ ) و غیر منطبق ( راست ) که از اجرای GLEAN به دست آمده است.
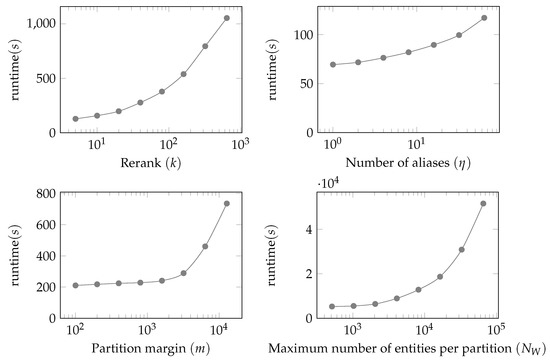
شکل 7. ارزیابی تأثیر متغیرهای k ( بالا سمت چپ )، تعداد نام مستعار η( بالا سمت راست )، حاشیه پارتیشن m ( پایین-چپ ) و حداکثر تعداد موجودات در هر پارتیشن ندبلیو( پایین سمت راست ) در زمان اجرا تراز.
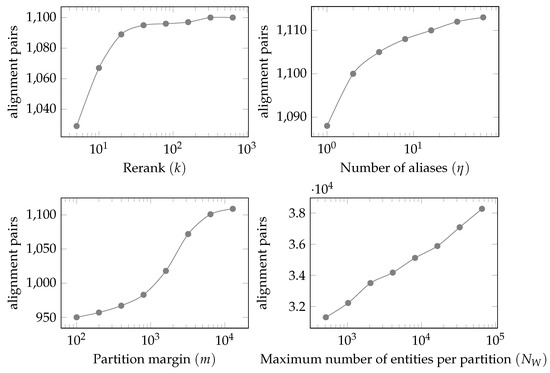
شکل 8. ارزیابی تاثیر رتبه مجدد k ( بالا سمت چپ )، تعداد نام های مستعار η( بالا سمت راست )، حاشیه پارتیشن m ( پایین-چپ ) و حداکثر تعداد موجودات در هر پارتیشن ندبلیو( پایین سمت راست ) روی کیفیت ترازها.


بدون دیدگاه