1. مقدمه
استفاده گسترده از دستگاه های داخلی سیستم موقعیت یابی جهانی (GPS) به سمت گسترش خدمات مبتنی بر مکان (LBS) [ 1 ] و متعاقباً به سمت رشد تصاعدی در بازار LBS بلادرنگ [ 2 ، 3 ] هدایت شده است. پیشرفت های اخیر با تمرکز بر داده های بزرگ مکانی و زمانی و محاسبات مکانی مانند شهرهای هوشمند [ 4 ]، نظارت و ارزیابی محیطی [ 5 ]، خدمات مبتنی بر مکان [ 6 ، 7 ، 8 ]]، و اینترنت اشیا (IoT) بر مدیریت موثر داده های جغرافیایی مرجع تکیه می کنند. داده های جغرافیایی شامل اطلاعاتی است که هم در زمان و هم در مکان جمع آوری می شوند. این اطلاعات شامل اطلاعات مکان، زمان و در نهایت سرعت است [ 9 ]. حسگرهای مختلف مقیاس های بزرگی از داده ها را در فرکانس های بسیار بالا منتقل می کنند که در نتیجه پردازش داده های پویا در مقیاس بزرگ در زمان واقعی انجام می شود و مفهوم نمایه سازی و پرس و جو پیوسته را معرفی می کند. رویکردهای جستجوی فضایی پیوسته باید از انواع جستجوهای پیچیده با استفاده از تکنیک های نمایه سازی پیشرفته پشتیبانی کند. یک سری از گسترشهای زمانی با نمایش دوگانه دادههای مبتنی بر شی، مبتنی بر میدان، و جغرافیایی در روشهای مدلسازی اولیه GIS پیشنهاد شد [ 10 ]]. از این رو، پرس و جو مداوم کارآمد بر روی اشیاء متحرک به دلیل ظهور محاسبات تلفن همراه و همه جا حاضر، به عنوان یک فرآیند ضروری برای کاربردهای محاسباتی فضایی متعدد تکامل یافته است. پرس و جوهای فضایی و زمانی در سناریوهای مختلف مانند رویکردهای کنترل ترافیک، سیستم های اطلاعات جغرافیایی (GIS) و اشیاء آگاه از مکان مفید هستند [ 11 ].]. در این مقاله، ما پرس و جوی پیوسته K-nearest همسایه (CKNN) را مطالعه می کنیم، یک کلاس ضروری از پرس و جوهای مکانی-زمانی که K-نزدیک ترین همسایگان (KNN) را در میان مجموعه ای از اشیاء متحرک در هر مهر زمانی بررسی می کند. نمونه ای از پرس و جوی CKNN یافتن دو تاکسی عابر پیاده نزدیک بر اساس سرعت ارائه شده و مکان ترافیک عابر پیاده است. در دهه گذشته، اکثر رویکردهای پرس و جوی CKNN در یک ساختار نمایه سازی فضایی و فواصل زمانی گسسته ادغام شدند که مجموعه kNN را بر اساس مکان آنها در زمان تولید پرس و جو برمی گرداند. این جستجوی فوری بر اساس محاسبات استاتیک فاصله ممکن است یک مجموعه نتایج قدیمی را بازگرداند زیرا ممکن است اشیاء در این مدت در حال حرکت باشند. با این حال، مکان آنها همراه با ارزیابی پرس و جو به روز نشد، که دقت نتایج پرس و جو را کاهش داد. از این رو،12 ].
از آنجایی که دستگاهها و سرویسهای آگاه از مکان در یک سیستم مکانی آگاه از زمان توزیع میشوند، احتمالاً بسیاری از پرسوجوهای CKNN به طور همزمان پردازش میشوند. کاهش عملکرد سرور آسان است و پاسخگویی به سوالات طولانی است. با توجه به ماهیت بلادرنگ برنامه های کاربردی آگاه از مکان، تاخیرهای قابل توجه پاسخ دادن به سوالات را بی فایده می کند. بنابراین، الگوریتمهای جدید پردازش پرس و جو که عملکرد و مقیاسپذیری را مدیریت میکنند باید مجموعه دیگری از پرسوجوهای CKNN را شامل شوند. بسیاری از راه حل های موجود برای مشکل انتقال شی پرس و جو KNN برای رسیدگی به حجم زیادی از داده ها توسعه نیافته اند. بنابراین، هزینه های ساخت نمایه سازی گران است و متعاقباً بر زمان پاسخ پرس و جو تأثیر می گذارد، زیرا مطمئناً از یک تنظیم متمرکز پیروی می کند که در آن هر دو درخواست به روز رسانی نگهداری می شوند. و پردازش صورت می گیرد [ 13 ,14 ]. پرس و جوهای پیوسته برای جریان های داده در زمینه های فضایی که توسط آثار موجود مورد تجزیه و تحلیل قرار می گیرد، عمدتاً بر اساس روش های بای پس بولی یا تقریبی است که یک عدد تصادفی یا نتیجه تقریبی ارائه می دهد [ 15 ]. فناوری پردازش پرس و جو CKNN در تحقیقات پایگاه داده نگرانی است که بسیاری از محققان بر آن تاکید دارند. بسیاری از برنامه های کاربردی بلادرنگ مانند کنترل توزیع ترافیک، میدان نبرد دیجیتال، خدمات ناوبری شخصی و سایر سیستم هایی که کاربران تلفن همراه را به هم متصل می کنند، دارد. بنابراین، دسترسی به اطلاعات مکانی و اشیاء فضایی محدود به پرس و جو از اشیاء در یک شبکه جاده ای است [ 16 ]]، که شامل چالشهای زیادی است که عمدتاً به پیچیدگی ویژگیهای شبکه فضایی مانند شناسایی گره و هرس شی برای ارزیابی پرس و جو مربوط میشود.
هدف اصلی این مطالعه افزایش کارایی و دقت یک پرس و جوی CKNN بر روی اجسام متحرک با استفاده از شاخص های فضایی توزیع شده است. علاوه بر این، این کار با هدف استخراج موثر اطلاعات شی از شاخص های توزیع شده بر اساس الگوریتم های عملی و فناوری هرس کارآمد برای مدیریت چالش های پرس و جو مستمر است. این مقاله عملکردهای پرس و جوی CKNN را بررسی و بهینه سازی می کند تا از محدودیت های کار قبلی ذکر شده در بالا جلوگیری کند. برای مطالعه تجربی، سناریوهای مختلفی را در نظر گرفتیم، فاصله بین دو شی به عنوان کوتاهترین مسیر بین آنها در شبکه تعریف میشود. مجموعه CKNN یک نقطه پرس و جو برای مهر زمانی باید به طور کامل تعریف شود. به منظور کاهش قابل توجه جستجوی تکراری و هزینه محاسباتی، ما روشی طراحی کردیم که از اطلاعات سرعت نسبی جسم متحرک استفاده میکند و تعدادی تکرار را محدود به دو میکند. فاصله بین دو شی متحرک در هر مهر زمانی تنها به عنوان یک عملیات جدول زمانی ارائه می شود و با استفاده از این رویکرد به راحتی محاسبه می شود. کار ما کمبودهای قابل توجه کارهای مربوط به گذشته را برطرف می کند و روش دقیق و کارآمدتری برای مشکل CKNN ارائه می دهد. طرح کلی این مقاله به شرح زیر است:
-
ما یک رویکرد نمایهسازی جدید، یعنی رویکرد نمایهسازی فضای زمانی سرعت (VeST)، برای پرسوجوی پیوسته، عمدتاً K-نزدیکترین همسایه پیوسته (CKNN) و جستارهای محدوده پیوسته پیشنهاد میکنیم.
-
ما یک ساختار شاخص چندلایه فشرده بر روی یک تنظیم توزیع شده طراحی می کنیم و یک الگوریتم جستجوی CKNN را برای نتایج دقیق با استفاده از فرآیند شناسایی سلول نامزد پیشنهاد می کنیم.
-
ما یک چشم انداز جامع از مدل نمایه سازی و تکنیک پرس و جو اتخاذ شده ارائه می دهیم.
-
ما مجموعه ای جامع از آزمایش ها را انجام دادیم، نتایج خود را با رویکردهای موجود مقایسه کردیم و از تکنیک های توزیع مختلف استفاده کردیم.
بقیه این مقاله به شرح زیر سازماندهی شده است. ما کار مرتبط را برای جستارهای پیوسته KNN و اشیاء متحرک در شبکه های جاده ای در بخش 2 بررسی می کنیم. بخش 3 مقدمات و رویکرد پیشنهادی را تشریح می کند. بخش 4 رویکرد نمایه سازی مکانی-زمانی سرعت، از جمله معماری، مرحله ساخت نمایه، و پردازش پرس و جو توزیع شده را ارائه می کند. بخش 5 مجموعه داده ها و نتایج شبیه سازی را در مورد عملکرد روش ما پوشش می دهد. در بخش 6 ، مقاله را با دستورالعمل هایی برای کار آینده به پایان می رسانیم.
2. بررسی ادبیات
پارادایم های نمایه سازی و پرس و جو از اجسام متحرک (MO) را می توان با توجه به واحد پایه ساختار شاخص، مانند شاخص های مبتنی بر شبکه، شاخص های درخت مانند و شاخص های ترکیبی، به کلاس های مختلفی طبقه بندی کرد [ 17 ]. پیچیدگی رویکردهای مرتبط با مکان، به طور کلی، و پردازش پیوسته MO به عوامل مختلفی مانند داده ها و تنوع وابسته است. دادههای نمایهسازیشده بهطور پیوسته نوسان بیشتری دارند و حجم قابلتوجهی از دادهها وجود دارد. دگرگونی های خودهمبستگی داده ها در عنصر مکانی-زمانی اجسام متحرک به آرامی در طول زمان رخ می دهد، بدون در نظر گرفتن محدودیت های کار مربوط به CKNN، از جمله عدم قطعیت سرعت که در بسیاری از کارهای مربوط به سرعت نامشخص اجسام متحرک وجود دارد، که صرفاً بر روی فضاهای اقلیدسی متمرکز است. [ 18، 19 ]. با این حال، با ارزیابی اشیاء روی یک شبکه جاده، دقت مکان [ 20 ] مربوط به ارزیابی مجدد پرس و جوی تکراری اضافی است. مقدار فازی از تکرارهای جستجوی CKNN رخ میدهد، و مقدار قابلتوجهی از الگوریتمهای جستجو بر اساس تعداد نامشخصی از تکرارها برای یافتن ناحیه KNN است که منجر به هزینههای ارتباطی اضافی [ 18 ] در یک محیط توزیعشده میشود. توزیع اریب داده ها بر روی گره ها به دلیل توزیع غیریکنواخت در فضا، اجراها را کاهش می دهد.
یک جستار پیوسته K-nearest همسایه (k-NN) چندین سرویس مبتنی بر مکان را پشتیبانی می کند و به طور پیوسته داده های K-nearest شی را به محیط پرس و جو برمی گرداند. بسیاری از رویکردهای فعلی به این موضوع بر روی تنظیمات متمرکز متمرکز شدهاند که نشاندهنده مقیاسپذیری کمتر برای پرداختن به مجموعه دادههای مهم و پراکنده است. در [ 21]، نویسندگان یک راه حل کارآمد و توزیع شده برای پرس و جوهای kNN پیشنهاد کردند، به طوری که اشیاء می توانند برای پردازش داده های گسترده تر جابجا شوند. راه حل پیشنهادی شامل یک شاخص مبتنی بر شبکه جدید به نام Block Grid Index (BGI) و یک روش جستجوی توزیع شده KNN مبتنی بر BGI بود. BGI یک نمایه در حافظه مبتنی بر شبکه لایه ای توزیع شده برای پرس و جوهای KNN است که در STORM ساخته شده است. از این فرض شروع میشود که اجسام متحرک متعلق به ناحیهای هستند که در سلولهای هم اندازه بدون همپوشانی تقسیم میشوند و هر سلول، اشیاء متحرک خود را نمایه میکند. هیچ الگوی از پیش تعریف شده ای برای حرکت اجسام وجود ندارد. حداقل و حداکثر تعداد از پیش تعریف شده از اشیاء در هر بلوک وجود دارد. هر بلوک دارای یک عدد N است. چند مزیت برای رویکرد آنها وجود دارد. راه اندازی و نگهداری BGI در یک محیط توزیع شده آسان است. الگوریتم پرس و جو می تواند نتایج را پس از دو تکرار جستجو برگرداند و عملکرد پرس و جو k-NN را بهبود بخشد. اثربخشی راه حل آنها از طریق آزمایش های گسترده بر روی میلیون ها گره ثابت شده است.
تمرکز بسیاری از برنامه های کاربردی با اشیاء پویا، پردازش پرس و جوهای k-NN است. اکثر رویکردهای فعلی برای تنظیمات متمرکز طراحی شده اند که در آن پرس و جوها در همان سرور برای رسیدگی به این مشکل پردازش می شوند. اگر نگوییم غیرقابل تصور، مقیاس کردن تنظیمات توزیع شده برای رسیدگی به حجم زیادی از داده ها و جستجوهای همگام سازی که به طور فزاینده ای در چنین برنامه هایی یافت می شوند، چالش برانگیز است. برای پرداختن به این موضوع، Ziqiang و همکاران. [ 22] مجموعه ای از توضیحات را پیشنهاد کرد که می تواند پردازش توزیع شده مقیاس پذیر پرس و جوهای k-NN را حفظ کند. مهمتر از همه، آنها یک ساختار شاخص ترکیبی جدید به نام شاخص نوار پویا (DSI) معرفی کردند که بهتر برای توزیع های مختلف داده تنظیم می شد. ساختار به خوشهها تقسیم شد و آن را برای پردازش توزیعی مناسب ساخت. آنها همچنین الگوریتم جستجوی K-NN مبتنی بر DSI (DKNN) را توصیه کردند. DKNN کارآمدتر و قابل پیش بینی تر از روش های سنتی است، زیرا از تعداد نامشخص تکرارهای بالقوه گران جلوگیری می کند. DSI و DKNN در بالای Apache S4، یک رسانه جریان توزیع شده منبع باز اجرا شدند. به منظور مطالعه ویژگی های DSI و DKNN، آنها یک مطالعه تجربی جامع را برای بررسی چارچوب و مقایسه آن با سه رویکرد اساسی نمایه سازی و پرس و جو انجام دادند.
شبکههای حسگر مقیاس بزرگی از دادههای بسیار پویا که دائماً بهروز میشوند را تولید میکنند که به صورت بستههایی در جریان داده ارسال میشوند. فرکانس بالا و ماهیت پیوسته جریان داده، یادگیری از مشاهدات اولیه را دشوار می کند. مقاله بولانگ و همکاران. [ 23] یک نمای کلی به روز از تجزیه و تحلیل بصری داده های جریان جغرافیایی و جهانی ارائه کرد و چارچوبی را پیشنهاد کرد که توسط شکاف های مشخص شده در بررسی ایجاد شده است. این چارچوب شامل یک نمونه اولیه دادهای بود که دادههای نظارت حسگر را نشان میداد، یک مدل کاربر که پرس و جوهای کاربر را مدیریت میکرد و دانش دامنه سازماندهی میکرد، یک نمونه اولیه طراحی برای الگوهای کشفشده و تجسمهای مربوط به آنها، و همچنین یک مدل بصری برای پردازش دادههای رندر. مدل مفهومی به این نتیجه رسید که جریان بازخورد حسگر به ابزارهایی نیاز دارد که بتواند نمایشگرهای سری زمانی چند متغیره را مدیریت کند. مدلهای طراحی نشان داد که مدلهای ارزشمند متعدد نسبتها، انحرافات و دادهها را با هم ترکیب میکنند. مدل کاربر بر لزوم رسیدگی به دادههای از دست رفته، ناهماهنگیهای فرکانس بالا و تغییرات بررسی تاکید کرد.
بسیاری از اشیاء و بسیاری از سوالات ثابت محیط آگاه از فضا را مشخص می کند. هم چیزها و هم سوالات ثابت می توانند در طول زمان موقعیت خود را تغییر دهند. در مقاله شیائوپینگ و همکاران. [ 24]، آنها موضوع بررسی پرس و جوهای شبکه عصبی کانولوشنال (CNN) در پایگاه داده فضا-زمان را بررسی کردند. برای حفظ عملکرد پاسخ های پرس و جو CNN، یک الگوریتم اجرای مشترک (SEA-CNN) معرفی شد. SEA-CNN ارزیابی های اضافی را با اجرای مشترک ترکیب می کند تا هزینه به روز رسانی پاسخ به سوالات را کاهش دهد. در ارزیابی افزایشی، تنها سوالاتی که تحت تاثیر حرکت اجسام قرار می گیرند، مورد بررسی مجدد قرار می گیرند. هر پرس و جو با منطقه جستجو بر اساس پاسخ به پرس و جو قبلی برای کاهش زمان ارزیابی مرتبط است. پرس و جوهای سازگاری در یک جدول جستجوی استاندارد در مدل اجرای مشترک گروه بندی می شوند. بنابراین، موضوع بررسی پرس و جوهای متعدد با اتصال محلی بین جدول جستجو و جدول شی حل می شود. SEA-CNN نیز یک چارچوب کلی قابل استفاده است. در درجه نخست، SEA-CNN هیچ استنتاجی در مورد حرکت یک جسم (به عنوان مثال، سرعت، مدار) نمی کند. آنها یک تحلیل نظری از SEA-CNN در مورد هزینه های پیاده سازی، نیازهای حافظه و پیامدهای پارامترهای قابل تنظیم ارائه کردند. تجربه گسترده نشان داد که SE-CNN مقیاس پذیرتر و کارآمدتر از فناوری CNN مبتنی بر درخت R در مورد تعداد IO و هزینه CPU است.
شبکههای حسگر بیسیم به طور گسترده در کاربردهای متعددی مانند نظارت بر محیطزیست، مدیریت تولید، مدیریت داراییهای تجاری، اتوماسیون حمل و نقل و صنعت پزشکی مورد استفاده قرار گرفتهاند. در مقاله Hua و همکاران. [ 25] موضوع جالبی را بررسی می کنند. نظارت مستمر از جمع آوری میانگین k خوانش حسگرها در شبکه های حسگر بزرگ. با توجه به مجموعه ای از حسگرها که اندازه گیری آنها تکامل می یابد، آنها می خواهند میانگین k اندازه گیری را ثابت نگه دارند. هدف بهینه سازی کاهش هزینه های گزارش شبکه است. هدف این است که مرکز داده را از قرائتهای فعلی با حفظ حداکثر تعداد سنسورها مطلع کنیم. آنها یک درخت گزارش خواندن، یک چارچوب طبقه بندی برای جمع آوری داده ها و تجزیه و تحلیل را برای رسیدگی به این موضوع توصیه می کنند. آنها همچنین چندین روش گزارشدهی اقتصادی را با نظارت مستمر k منابع با خواندن درخت گزارش توسعه میدهند. اول، یک روش استاندارد نمونه برداری با استفاده از درخت گزارش خوانی می تواند چشم انداز با کیفیت خوبی ارائه دهد. دوم، آنها روشی را برای تعیین مرزها پیشنهاد کردند که تقریباً می تواند کیفیت را تضمین کند. سرانجام، آنها یک رویکرد کند را آزمایش کردند که می تواند محاسبات میانی را به طور قابل توجهی کاهش دهد. برای بررسی ویژگی های روش پیشنهادی، آنها شبیه سازی سیستماتیک را با استفاده از مجموعه داده های مصنوعی ارزیابی کردند.
فرآیند جستجوی پیوسته K نزدیکترین همسایه (CKNN) نزدیکترین k اشیاء را برای مجموعه ارائه شده از اشیاء متحرک می گیرد. نتایج ثابتی را در زمان واقعی با اشیا و نقاط پرس و جو برای نظارت بر انتقال می دهد. فرآیندهای فعلی پرس و جو CKNN معمولاً دارای نگهداری فهرست، به روز رسانی نتایج بلادرنگ و هزینه های پرس و جو هستند که ممکن است مشکل را به طور کامل حل نکنند. برای پرداختن به این موضوع، یو و همکاران. [ 26] یک الگوریتم جستجوی اضافی را توصیه کرد. از روش تخمین تصادفی (RE) برای پردازش پرس و جوهای CKNN برای مقادیر زیادی از اجسام متحرک استفاده می کند. در ترکیب با یک الگوریتم جستجوی افزایشی برای پردازش نمایه سازی CKNN و پرس و جو بر روی حجم عظیمی از اشیاء متحرک، رویکرد RE می تواند به سرعت یک منطقه جستجوی مناسب برای یک پرس و جو پیوسته ایجاد شده بر روی نتایج قبلی پرس و جو را تعیین کند. در مقایسه با سایر رویکردهایی که پرس و جوی مداوم را در یک منطقه دو بعدی مورد علاقه هدف قرار می دهند، این استراتژی به دقت تخمین بالاتری برای شناسایی تعداد آیتم ها در یک منطقه خاص دست یافت که به طور قابل توجهی کارایی پردازش پرس و جو پیوسته kNN را بهبود بخشید.
حیاتی ترین بخش یک سیستم واکنش اضطراری زمان است. بنابراین، ذخیره فوری دادههای دقیق جدید در پایگاه داده، بازیابی سریع دادهها، حفظ ترتیب زمانی و تقویت سیستم، همه در زمان واقعی، ضروری است. یکی دیگر از عناصر حیاتی نظارت بر تهدیدهای محیطی، فعال کردن پرس و جوهای بلادرنگ مبتنی بر ویژگی های مدرن است. ما همچنین به سریع ترین دسترسی به آخرین داده ها نیاز داریم. علاوه بر این، دادههای بیدرنگ جمعآوریشده از حسگرها به کنترل سریع و کارآمد برای انحراف از اشباع حافظه مرکزی نیاز دارند. سروین و همکاران [ 27] روشهای نمایهسازی را برای پشتیبانی از پرسشهایی که دادههای معاصر را هدف قرار میدهند، پیشنهاد کرد. راهحل نمایهسازی پیشنهادی برای دادههای بیدرنگ حسگرهای ثابت بود. دومی داده های زمان واقعی و فضایی بود که از طریق حسگرهای فعال جمع آوری شد. در نهایت، آنها یک راه حل کلی برای مدیریت اشباع حافظه در زمان واقعی با توجه به اهمیت داده ها ارائه کردند.
بخشی از دادههای مکانی-زمانی موجود به دلیل پیشرفت در فناوری جمعآوری دادههای تلفن همراه و دستگاههای آگاه از مکان در حال افزایش است. پردازش بیدرنگ دادههای فضایی بزرگ به یکی از مرزهای بررسی در سیستمهای اطلاعات جغرافیایی (GIS) تبدیل شده است. هدف آن کاهش پیچیدگی به روز رسانی داده ها با استفاده از ساختارهای نمایه سازی فضایی توزیع شده خاص است که داده های بسیار پویا را مدیریت می کند. ژانگ و همکاران به منظور پردازش پرس و جوی مستمر در جریان داده های مکانی. [ 17] پسوندی را برای Apache Storm پیشنهاد کرد که یک سیستم محاسباتی بلادرنگ توزیع شده منبع باز است. آنها از یک استراتژی اتصالات فضایی بین مجموعه داده های متحرک با یک شاخص فضایی توزیع شده استاتیک ثانویه برای پردازش پرس و جوهای مداوم استفاده کردند. با این حال، تکنیکهای پارتیشنبندی مبتنی بر شبکه پیشنهادی تنها بر روی دادههای نقطهای ۲ بعدی متمرکز شدهاند. علاوه بر این، چنین تکنیکهای نمایهسازی در کاربردهای فضایی به دلیل دادههای پویا و توزیعهای پرسوجو بیاثر بودند. ما یک حالت رویکرد نمایه سازی جدید برای پرس و جوهای محدوده برای رسیدگی به این مسائل پیشنهاد کرده ایم. ما یک ساختار شاخص چندلایه فشرده بر روی یک تنظیم توزیع شده طراحی می کنیم و یک الگوریتم جستجوی CKNN را برای نتایج دقیق و کارآمد پیشنهاد می کنیم.
3. مقدمات
ما برخی از تعاریف و نمادهای مورد استفاده در این مقاله را نشان می دهیم. جدول 1 نمادهای اصلی استفاده شده در این مقاله را فهرست می کند. ما تنظیماتی را در نظر گرفتیم که در آن N جسم در یک فضای دو بعدی با سرعت های مختلف حرکت می کنند که در آن X_Vel و Y_Vel به ترتیب سرعت مطابق با محور X و Y هستند. اجسام متحرک به عنوان اشیاء نقطه ای و فضایی که در آن حرکت می کنند به عنوان یک فضای اقلیدسی دو بعدی مدل سازی شدند. اشیاء اغلب به روز رسانی در مورد مکان خود را به گره اصلی نمایه سازی ارسال می کنند. به روز رسانی ها به صورت سه گانه ارسال شدند (obj_ID، x_loc، y_loc)، که در آن obj_ID شماره شناسایی منحصر به فرد شی است، x_loc نشان دهنده موقعیت طول جغرافیایی، و y_loc نشان دهنده موقعیت عرض جغرافیایی شی است.
تعریف 1.
اجسام متحرک، MO : یک جسم متحرک با یک دنباله مجزا از تاپل ها به شکل {obj_id,(x_loc, y_loc ), (x_vel, y_vel), t)} نمایش داده می شود که در آن obj_id شناسه شی است, (x_loc, y_loc ) مکان فعلی را نشان می دهد، (x_vel، y_vel) سرعت حرکت جسم است و t زمان فعلی است.
تعریف 2.
به روز رسانی ها: در یک زمینه پردازش داده های مکانی پویا، اشیاء متحرک به طور مداوم به روز رسانی های مکان جدید خود را ارسال می کنند تا آنها را در ساختار نمایه سازی منعکس کنند. به منظور اطمینان از دقت، ایندکس باید بتواند حجم زیادی از به روز رسانی ها را به سرعت پردازش کند تا پاسخ هایی با دقت بالا، همچنین با طول بازه های پرس و جوی متفاوت، ارائه دهد.
تعریف 3.
پرسوجوهای فضایی : پرسوجوهای فضایی بیشتر در تعداد پویا از برنامههای کاربردی ایجاد و استفاده میشوند. انتظار می رود که چنین درخواست هایی توسط کاربران بر اساس تجزیه و تحلیل داده های زمان واقعی یا تقریباً واقعی پاسخ داده شود. انواع مختلفی از پرس و جوهای فضایی وجود دارد. در این کار، ما بر پرس و جوهای فضایی پیوسته kNN تمرکز می کنیم.
(الف) نقطه پرس و جو: یک نقطه پرس و جو توسط شناسه کاربر (صادرکننده درخواست) تعریف می شود. کاربر باید برای تعیین منطقه و مجموعه kNN در ایندکس قرار گیرد.
(ب) K-nearest Neighbor Query، kNN query: با توجه به یک نقطه پرس و جو در فضا، یک پرس و جو kNN باید k-امین نزدیکترین اشیا به نقطه پرس و جو را بازیابی کند.
ج) پرس و جوهای پیوسته K-نزدیکترین همسایه، پرس و جو CKNN: با توجه به یک نقطه پرس و جو در فضا، یک پرس و جو CKNN باید به طور پیوسته k اشیایی را که نزدیکترین آنها به نقطه پرس و جو هستند ردیابی کند. اشیاء مورد علاقه، همچنین به نام اشیاء کاندید، و/یا نقطه پرس و جو ممکن است در طول ارزیابی پرس و جو در حال حرکت باشند، به این معنی که مکان ها به طور مداوم به روز می شوند.
4. روش پیشنهادی
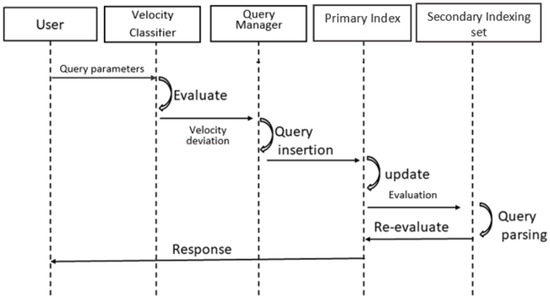
این مقاله یک روش نمایهسازی وابسته به سرعت را برای دادههای شی متحرک بر اساس طبقهبندی سرعت مشابه با استفاده از معادله انحراف استاندارد در توزیع سرعت پیشنهاد میکند، که منجر به دو دیدگاه زیرمکانی مجزا برای جلوگیری از چولگی دادهها و تکرارهای جستجوی غیرمفید میشود. ما یک شاخص مبتنی بر منطقه برای اشیاء دائماً در حال حرکت در هر صحنه در یک محیط توزیع شده طراحی کردیم. ما یک الگوریتم برای انتخاب نامزدهای پرس و جو پویا در CKNN [ 28 ] پیشنهاد کردیم. VeST با ترکیب نمایه سازی زمان-مکان با سرعت سفارشی شد. هنگامی که یک پرس و جو جدید تولید شد، ابتدا با استفاده از مراحل مختلف از طریق شاخص [ 24 ] ارزیابی شد] به منظور یافتن بهترین حجم جستجو برای پرس و جوها برای کاهش هزینه به روز رسانی فهرست. شاخص Velocity SpatioTemporal (VeST) یک نتیجه پرس و جو شبیه به گره های فضایی نقشه برداری شده به دست آورد. از روش ورودی سفارشی برای وارد کردن لیست اشیاء و درخت مربوطه استفاده کرد. این رویکرد عملکرد ساختمان سازه شاخص از جمله زمان ساخت شاخص و همچنین اندازه را بهبود بخشید و هزینه های به روز رسانی شاخص را کاهش داد. شکل 1نمودار Sequence پردازش پرس و جو را نشان می دهد. در جایی که یک پرسوجوی CKNN تولید میشد، طبقهبندیکننده Velocity سرعتهای واقعی اشیاء را برای محاسبه انحراف استاندارد و تعیین آستانه برای راهاندازی پارتیشنبندی وابسته به سرعت آنالیز میکرد. سپس مدیر پرس و جو ابتدا پردازش پرس و جو را از طریق ساختار فهرست جهانی آغاز کرد. پرس و جو بر این اساس بر روی گره های توزیع شده شاخص ارزیابی و به روز شد تا پاسخ پرس و جو ایجاد شود.
5. مدل نمایه سازی مکانی-زمانی سرعت
ما یک مدل شاخص فضایی برای پرس و جو پیوسته پیشنهاد کردهایم. مدل پیشنهادی با ترکیب نمایه سازی مکانی-زمانی با سرعت سازماندهی شده است. شکل 2 معماری شاخص مکانی-زمانی سرعت پیشنهادی (VeST) را برای پرس و جوی شی متحرک CKNN نشان می دهد.
5.1. معماری جلیقه
شاخص مکانی-زمانی سرعت ما شامل دادههای مکان-زمان و سرعت بود. سرعت اجسام متحرک را تجزیه و تحلیل کرد و سپس داده های آنها را در یک ساختار ترکیبی توزیع شده فهرست کرد. VeST به گونه ای طراحی شد که دارای دو بخش اصلی، اولیه و ثانویه باشد. یک پارادایم اولیه/ثانویه نشان می دهد که یک سرور برای کار به عنوان گره اولیه پیکربندی شده است. سپس هدایت شد تا تمام پرسشهای نوشته شده را به دست آورد. سپس گره اولیه کوئریها را اجرا و ثبت کرد، که سپس به گرههای ثانویه فرستاده شد تا دادههای یکسان را در تمام اجزای همتای خود هدایت و نگهداری کنند. در ساختار اولیه/ثانویه، توابع نوشتن در سطح اولیه و توابع خواندن در سطح ثانویه اجرا شدند [ 29 ]]. بنابراین، تمام درخواستهای جستجو در ابتدا به گره اصلی رسیدند، یک صف از ارسالها حفظ شد و تابع خواندن صرفاً در پشت انجام عملیات نوشتن انجام شد. یک مشکل رایج در پیکربندی اولیه/ثانویه وجود دارد، که همچنین زمانی که صف گره اولیه بیش از حد بزرگ می شود که نمی توان آن را حفظ کرد، مشاهده می شود. این معماری فرو می ریزد و گره های ثانویه شروع به رفتار به عنوان گره های اولیه می کنند.
5.2. فاز پارتیشن بندی مبتنی بر سرعت
مرحله تقسیم بندی مبتنی بر سرعت به کاهش هزینه های زمانی و کارآمدتر کردن سیستم کمک می کند همانطور که در مطالعه قبلی خود ارائه و اثبات کردیم [ 28 ]. این سیستم سرعت اشیاء را برای دسته بندی موجودیت ها به کلاس های مختلف ارزیابی می کند.
طبقه بندی مبتنی بر سرعت دو کلاس ایجاد کرد، یکی برای کلاس اشیاء سریع و دیگری برای کلاس اشیاء کند. انتخاب بر اساس یک معادله از پیش تعیین شده انجام شد که انحراف سرعت یک شی بلادرنگ را بر اساس توزیع اشیا تخمین زد. سرعت کل ( ) با استفاده از معادله ( 1 ) محاسبه می شود، که در آن n تعداد کل اشیاء در یک زمان معین است، و سرعت جسم است. برای تعیین سرعت استفاده می شود ، که در معادله ( 2 ) مشخص شده است. در نهایت، برای به دست آوردن استفاده می شود با استفاده از معادله ( 3 )، که آستانه بین اجسام سریع و کند است. این پارتیشن دسترسی بیش از حد به موجودیت ها را در یک مکان ذخیره می کند. علاوه بر این، دوره جستجو و هزینه های تقسیم یا ادغام را کاهش می دهد.
شکل 3 ساختار مدل نمایه سازی، اشیاء آن، رفتار و عملیات آنها را نشان می دهد. کلاس “DataAnalysis” حاوی ویژگی های فضایی پرس و جو و انحراف سرعت است که توسط شی “VelocityClassifer” به منظور تقسیم بندی اشیا بر اساس سرعت آنها ایجاد شده است. پارامتر k یک پرس و جو CKNN برای پردازش عملیات جستجوی تکراری بر روی پارتیشنهای ساختار نمایه پس از تقسیم فضایی منطقه استفاده شد.
5.3. فازهای ساختمان شاخص
مقیاس بزرگ داده های مکانی به طور مداوم در طول زمان تولید می شود و کاربران می توانند انواع مختلفی مانند تاکسی، مردم یا اتوبوس داشته باشند. از این رو یک نقشه هش برای ذخیره ساختار کلید-مقدار یکپارچه شد. نقشه های هش برای مقادیر کم داده و حفظ تحولات مکرر مناسب هستند. سوابق مناطقی را که کاربر بازدید کرده است و ویژگیهای اضافی که دادههای مربوطه مانند نوع کاربر را ایجاد میکند جمعآوری میکند: (id، [مسیر]، نوع). نقشه هش یک تکنیک جستجوی نامحدود، یک اسکن خطی را اختصاص می دهد. بنابراین، پیچیدگی زمانی یک پرس و جو O(m) است.
5.4. پردازش پرس و جو توزیع شده
همانطور که در شکل 4 نشان داده شده است، ما استفاده از یک ساختار چند لایه را برای پلت فرم پردازش توزیع شده پیشنهاد کردیم .. ماژول های پردازش توزیع شده از سه لایه تشکیل شده اند، یک لایه اول برای گره نمایه سازی اولیه، یک لایه دوم برای مجموعه مجموعه نمایه سازی ثانویه، و یک لایه پارتیشن بندی داده های مکانی. گره های منفرد شاخص خود را برای تمام رکوردهای رزرو شده محلی در لایه نمایه سازی ثانویه ایجاد کردند. بنابراین، هر گره فهرست کوتاهی از داده های اشیاء داشت. ابتدا یک پرس و جو برای هر گره پخش شد و سپس مشتقات یکپارچه شدند. بنابراین، هر گره دارای تعداد کمتری از لیست های طولانی بود. تحت روش ارزیابی پرس و جو استاندارد، یک پرس و جو ابتدا به گره ای که لیست را برای یک لیست مختصرتر حفظ می کند، هدایت می شود، که سپس کل لیست خود را به گره حاوی لیست اصلی [ 30 ] ارسال می کند.
6. تنظیمات و نتایج تجربی
این بخش تنظیمات شبیه سازی رویکرد پیشنهادی، تجزیه و تحلیل داده های اکتشافی و نتایج ارزیابی را توضیح می دهد. ما از یک مجموعه داده ردیابی GPS تاکسی منبع باز [ 7 ] استفاده کردیم. مجموعه داده شامل بیش از 100000 داده تاکسی در شهر شنژن با سوابق مختلف بود. مجموعه داده شامل شناسه شی، مکان در محور x، مکان در محور y، سرعت در محور x، سرعت در محور y و زمان صدور بهروزرسانی بود.
6.1. محیط شبیه سازی
آزمایشها روی دستهای از گرهها با واحد پردازش Intel Core i7-8500y @ 3.00 گیگاهرتز و حافظه دسترسی تصادفی 16 گیگابایت انجام شد. تنظیمات شبیه سازی به کار گرفته شده در طول دوره اکتشافی در جدول 2 نشان داده شده است.
6.2. تجزیه و تحلیل داده های اکتشافی
شکل 5 مکان نمونه برداری شده از اجسام متحرک در شهر را نشان می دهد. محل تاکسی ها نیز طرح کلی شبکه راه های شهر را ترسیم کرده است. شکل 6 اجسام را پس از طبقه بندی آنها بر اساس سرعت آنها با توجه به انحراف سرعت واقعی نشان می دهد. شکل 6 a نمایش بصری اجسام آهسته با نقاط قرمز را نشان می دهد، در حالی که شکل 6 b اشیاء سریع حرکت را با نقاط سبز نشان می دهد.
حجم کل مجموعه داده های مورد استفاده 46.9 مگابایت بود. داده ها از طریق OpenSourceMap با دامنه فضایی 10000 × 10000 برای شهر شنژن [ 31 ] تولید شد. جدول 3خلاصه مجموعه داده را نشان می دهد. مجموعه داده شامل شش ستون و 1025486 سطر بود که تنها یک سطر حاوی مقادیر تهی بود. ستون اول نشان دهنده شناسه هر شی بود که حداقل شناسه شی 0 و حداکثر شناسه 10928 بود. ستون های دوم و سوم برای مکان X_loc و Y_Loc به ترتیب با توجه به محورهای X و Y بودند که نشان دهنده طول و طول جغرافیایی بودند. عرض جغرافیایی؛ در حالی که X_Vel و Y_Vel نشان دهنده سرعت در محورهای X و Y هستند. حداکثر سرعت ثبت شده در محور X 25/33 و در محور Y 19/33 بود. آخرین ستون، “زمان” حاوی مهرهای زمانی ردیابی بود.
شکل 7 توزیع ویژگی های مختلف مجموعه داده را نشان می دهد. شکل 7 ب توزیع سرعت را در محور X و Y نشان می دهد. بیشتر نقاط بین 30- تا 30 متر بر ثانیه قرار دارند. شکل 7 ب تعداد اشیاء در هر شکاف زمانی را از 0 تا 7199 نشان می دهد. می توان مشاهده کرد که زمان بین 0 تا 1000 بیشترین تعداد اشیاء و 6000 تا 7000 کمترین تعداد اشیاء را شامل می شود. شکل 7 c تعداد اجسام را با توجه به سرعت روی محور X نشان می دهد. شکل 7 d تعداد اجسام را با توجه به سرعت روی محور Y نشان می دهد. در هر دو توزیع سرعت محور X و Y، حداکثر تعداد بین 10- تا 10 بود.
6.3. نتایج تجربی
ما آزمایش های گسترده ای را روی مجموعه داده ارائه شده در بخش قبل انجام دادیم. ما شبیهسازیها را انجام دادیم و نمودارهای مختلفی را برای نمایش عملکرد رویکرد پیشنهادی از منظر فرضیههای کاری ترسیم کردیم. با هدف بررسی اینکه رویکرد پیشنهادی چقدر سریعتر از رویکردهای مرسوم از نظر زمان پردازش است، زمان پرس و جو را برای فواصل پرس و جوی مختلف برای جستجوی CKNN مقایسه کردیم که در آن k روی 7 تنظیم شده بود. زمان استفاده از روش پیشنهادی را مقایسه کردیم. و اسپارک آپاچی برای ارتقای بیشتر اجراها و استفاده از رویکرد مرسوم. همانطور که در شکل 8 مشاهده می شودبرای فواصل پرس و جو 100 (یعنی تعداد پرس و جوهایی که به صورت موازی شبیه سازی کردیم برابر با 100 بود)، رویکرد پیشنهادی 13.59 برابر سریعتر از رویکرد رقیب بود. اثر طول بازه پرس و جو بر میانگین زمان در شکل 8 نشان داده شده است . همانطور که می بینیم، میانگین زمان رویکرد VeST برای تمام فواصل پرس و جو کمتر از 0.005 ثانیه بود.
ما سه الگوی توزیع داده های مختلف را از یک مجموعه داده برای آزمایش خود شبیه سازی کردیم. در اصلی ترین الگوی توزیع (گاوسی)، 70 درصد از اشیا توزیع گاوسی [ 32 ] را در سراسر شبکه دنبال کردند. ما از معادله ( 4 ) برای تولید یک توزیع گاوسی برای 70% اشیا استفاده کردیم. اشیاء باقی مانده به طور یکنواخت توزیع شدند. الگوی توزیع دوم (یکنواخت) شامل اشیایی بود که از توزیع یکنواخت در سراسر شبکه پیروی می کردند. در الگوی توزیع سوم، اشیا از توزیع Zipf پیروی کردند. همه اشیا به یک مربع واحد نرمال شدند.
شکل 9 زمان ساخت VeST را با تغییر تعداد اشیا و الگوی توزیع آنها نشان می دهد. اگر پارامترهای بیشتر تغییر نمی کردند، زمان ساخت شاخص تقریباً به صورت خطی با افزایش تعداد اشیا افزایش می یابد. همانطور که ما یک الگوی گاوسی متمرکز بهتر ساختیم، فرآیندهای تقسیم و ادغام اضافی در لایه R-tee برای این مورد وجود داشت. در نتیجه، زمان ساخت در بیشتر موارد در بین سه الگوی توزیع بالاترین بود.
شکل 10 تأثیر اندازه فاصله پرس و جو را بر زمان CPU VeST و رویکردهای رقیب تجزیه و تحلیل می کند. این پیشنهاد با رویکرد IMA پیشنهاد شده توسط موراتیدیس و همکاران مقایسه شد. [ 33 ] و با رویکرد CKNN پیشنهاد شده در [ 34]. روش IMA بر خلاف رویکرد VeST، که در آن از تعداد ناشناخته تکرار اجتناب میکنیم، مبتنی بر ارزیابیهای جستجوی فوری فوری kNN است. هنگامی که به روز رسانی مکان اشیاء رخ می دهد، الگوریتم IMA دوباره پرس و جو KNN عکس فوری را ارزیابی کرد. در آزمایشهای ما، فاصله بهروزرسانی IMA (UI) یک بار روی 5 واحد زمانی و سپس به 10 واحد زمانی تنظیم شد تا هر دو مورد را بررسی کرده و آن را با الگوریتم VeST مقایسه کنیم. الگوریتم IMA با فواصل به روز رسانی 5 و 10 واحد زمانی به ترتیب IMA (UI = 5) و IMA (UI = 10) نامیده می شود. از سوی دیگر، الگوریتم CKNN بازه زمانی را به زیر بازههای غیرمجاز تقسیم کرد. این زیر بازه ها به طور متوالی در مکان یابی KNN های موجودیت پرس و جو ارزیابی شدند. آزمایشها نشان داد که هزینه CPU با افزایش اندازه بازه پرس و جو برای همه الگوریتمها افزایش مییابد. این به این دلیل است که اندازه پرس و جو قابل توجه اشیاء اضافی را برای رویکرد جستجوی پیوسته KNN در نظر گرفته و بهروزرسانیهای مکان گسسته بهتری از اشیاء را جمعآوری میکند. در نتیجه، الگوریتم IMA به پرس و جوهای KNN عکس فوری بیشتری نیاز داشت (هم برای UI = 5 و هم برای UI = 10). بنابراین، زمان CPU در هر دو مورد UI = 5 و UI = 10 بیشتر بود. الگوریتم KNN در مقایسه با IMA عملکرد بهتری را نشان داد زیرا زمان را به مُهرهای زمانی متوالی تقسیم میکرد. با این حال، به زمان بیشتری برای جستجوی کامل KNN نیاز داشت و فرض میکرد که اجسام با سرعت ثابت حرکت میکنند، که غیرواقعی بود. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد. الگوریتم IMA به پرس و جوهای KNN عکس فوری بیشتری نیاز داشت (هم برای UI = 5 و هم برای UI = 10). بنابراین، زمان CPU در هر دو مورد UI = 5 و UI = 10 بیشتر بود. الگوریتم KNN در مقایسه با IMA عملکرد بهتری را نشان داد زیرا زمان را به مُهرهای زمانی متوالی تقسیم میکرد. با این حال، به زمان بیشتری برای جستجوی کامل KNN نیاز داشت و فرض میکرد که اجسام با سرعت ثابت حرکت میکنند، که غیرواقعی بود. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد. الگوریتم IMA به پرس و جوهای KNN عکس فوری بیشتری نیاز داشت (هم برای UI = 5 و هم برای UI = 10). بنابراین، زمان CPU در هر دو مورد UI = 5 و UI = 10 بیشتر بود. الگوریتم KNN در مقایسه با IMA عملکرد بهتری را نشان داد زیرا زمان را به مُهرهای زمانی متوالی تقسیم میکرد. با این حال، به زمان بیشتری برای جستجوی کامل KNN نیاز داشت و فرض میکرد که اجسام با سرعت ثابت حرکت میکنند، که غیرواقعی بود. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد. به زمان بیشتری برای جستجوی کامل KNN نیاز داشت و فرض میکرد که اجسام با سرعت ثابت حرکت میکنند، که غیرواقعی بود. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد. به زمان بیشتری برای جستجوی کامل KNN نیاز داشت و فرض میکرد که اجسام با سرعت ثابت حرکت میکنند، که غیرواقعی بود. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد.
شکل 11 اثر اندازه فاصله پرس و جو را بر دقت رویکردهای مختلف نشان می دهد. دقت نسبت واحدهای زمانی است که در آن نتیجه پرس و جو پیوسته KNN بازیابی شده صحیح است، همانطور که با استفاده از رابطه ( 5 ) تعیین می شود که در آن kNNreal تعداد رکوردهای مجموعه نتایج بدست آمده است، و kNNreal تعداد واقعی k نزدیکترین همسایگان به است. نقطه پرس و جو به منظور تعریف مقدار پارامتر k بهینه برای جلوگیری از نویز یا مشکلات عدم تناسب، در این سناریوی تجربی، k را بر اساس انحراف استاندارد اشیاء برابر با 7 قرار دادیم تا یک مثال گویا ایجاد کنیم.
با توجه به به روز رسانی مداوم مکان اشیاء، دقت برای IMA و kNN به ترتیب زیر 60٪ و 90٪ بود. حتی زمانی که فاصله پرس و جو بزرگتر بود (UI = 10) به 20٪ رسید زیرا به روز رسانی مکان شی در این رویکردها قرار بود گسسته باشد. بنابراین، دو نمونه زمانی بهروزرسانی متوالی نتایج پرس و جوی نادقیق را به دست میآورند. در مقابل، دقت الگوریتم VeST بدون توجه به طول بازه پرس و جو تقریباً برابر با 100٪ بود.
7. بحث
این مقاله چالش های مربوط به پرس و جوهای مداوم بر روی اشیاء متحرک را بررسی می کند. سهم این مقاله چهارگانه است. اول، ارائه یک رویکرد جدید برای پرس و جو مستمر. دوم، توضیح ساختار شاخص چند لایه. و سوم، تکنیک پرس و جو و مرحله نهایی از تکنیک های توزیع مختلف برای بررسی تأثیر رویکرد پیشنهادی استفاده می کند. در این بخش چگونگی پرداختن به شکاف های شناسایی شده توسط چارچوب پیشنهادی مورد بحث قرار می گیرد.
اولین شکاف مربوط به ارائه یک رویکرد جدید برای پرس و جوی مداوم با پیشنهاد یک رویکرد نمایه سازی جدید، یعنی رویکرد نمایه سازی فضای زمانی سرعت (VeST)، برای پرس و جو پیوسته، عمدتاً K-نزدیکترین همسایه پیوسته (CKNN) و پرس و جوهای محدوده پیوسته برطرف شد. شکاف دوم مربوط به توضیح ساختار شاخص چندلایه با طراحی یک ساختار شاخص چندلایه فشرده بر روی یک تنظیم توزیع شده و پیشنهاد یک الگوریتم جستجوی CKNN برای نتایج دقیق با استفاده از فرآیند شناسایی سلول نامزد پرداخته شد. سومین شکاف مربوط به تکنیک پرس و جو با ارائه یک چشم انداز جامع از مدل نمایه سازی ما و تکنیک پرس و جو اتخاذ شده برطرف شد. شکاف چهارم و آخر مربوط به استفاده از تکنیک های مختلف توزیع برای بررسی تأثیر رویکرد پیشنهادی است. ما مجموعه ای جامع از آزمایش ها را انجام دادیم، نتایج خود را با رویکردهای موجود مقایسه کردیم و از تکنیک های توزیع مختلف استفاده کردیم. این روش پیشنهادی هزینه به روز رسانی را کاهش داد و زمان پاسخ و دقت پرس و جو را بهبود بخشید. مجموعه داده در تمام ارقام یکسان بود، اما با نمایش های متفاوت، که یک مجموعه داده در دنیای واقعی بود که یک سیستم ردیابی GPS تاکسی بود که در شهر شنژن ثبت شده بود. ما ویژگی های داده را برای ارائه توضیحات جامع داده ها نشان دادیم. ما همچنین نتایج آزمایشهای پیشنهادی خود را روی مجموعه داده ارائه کردهایم. ما سه مدل توزیع داده مختلف را از یک مجموعه داده شبیهسازی کردیم تا عملکرد رویکرد پیشنهادی برای توزیعهای دادههای مختلف با تعداد متفاوتی از اشیاء را بررسی کنیم. نتایج ما را با رویکردهای موجود مقایسه کرد و از تکنیکهای توزیع مختلف استفاده کرد. این روش پیشنهادی هزینه به روز رسانی را کاهش داد و زمان پاسخ و دقت پرس و جو را بهبود بخشید. مجموعه داده در تمام ارقام یکسان بود، اما با نمایش های متفاوت، که یک مجموعه داده در دنیای واقعی بود که یک سیستم ردیابی GPS تاکسی بود که در شهر شنژن ثبت شده بود. ما ویژگی های داده را برای ارائه توضیحات جامع داده ها نشان دادیم. ما همچنین نتایج آزمایشهای پیشنهادی خود را روی مجموعه داده ارائه کردهایم. ما سه مدل توزیع داده مختلف را از یک مجموعه داده شبیهسازی کردیم تا عملکرد رویکرد پیشنهادی برای توزیعهای دادههای مختلف با تعداد متفاوتی از اشیاء را بررسی کنیم. نتایج ما را با رویکردهای موجود مقایسه کرد و از تکنیکهای توزیع مختلف استفاده کرد. این روش پیشنهادی هزینه به روز رسانی را کاهش داد و زمان پاسخ و دقت پرس و جو را بهبود بخشید. مجموعه داده در تمام ارقام یکسان بود، اما با نمایش های متفاوت، که یک مجموعه داده در دنیای واقعی بود که یک سیستم ردیابی GPS تاکسی بود که در شهر شنژن ثبت شده بود. ما ویژگی های داده را برای ارائه توضیحات جامع داده ها نشان دادیم. ما همچنین نتایج آزمایشهای پیشنهادی خود را روی مجموعه داده ارائه کردهایم. ما سه مدل توزیع داده مختلف را از یک مجموعه داده شبیهسازی کردیم تا عملکرد رویکرد پیشنهادی برای توزیعهای دادههای مختلف با تعداد متفاوتی از اشیاء را بررسی کنیم. این روش پیشنهادی هزینه به روز رسانی را کاهش داد و زمان پاسخ و دقت پرس و جو را بهبود بخشید. مجموعه داده در تمام ارقام یکسان بود، اما با نمایش های متفاوت، که یک مجموعه داده در دنیای واقعی بود که یک سیستم ردیابی GPS تاکسی بود که در شهر شنژن ثبت شده بود. ما ویژگی های داده را برای ارائه توضیحات جامع داده ها نشان دادیم. ما همچنین نتایج آزمایشهای پیشنهادی خود را روی مجموعه داده ارائه کردهایم. ما سه مدل توزیع داده مختلف را از یک مجموعه داده شبیهسازی کردیم تا عملکرد رویکرد پیشنهادی برای توزیعهای دادههای مختلف با تعداد متفاوتی از اشیاء را بررسی کنیم. این روش پیشنهادی هزینه به روز رسانی را کاهش داد و زمان پاسخ و دقت پرس و جو را بهبود بخشید. مجموعه داده در تمام ارقام یکسان بود، اما با نمایش های متفاوت، که یک مجموعه داده در دنیای واقعی بود که یک سیستم ردیابی GPS تاکسی بود که در شهر شنژن ثبت شده بود. ما ویژگی های داده را برای ارائه توضیحات جامع داده ها نشان دادیم. ما همچنین نتایج آزمایشهای پیشنهادی خود را روی مجموعه داده ارائه کردهایم. ما سه مدل توزیع داده مختلف را از یک مجموعه داده شبیهسازی کردیم تا عملکرد رویکرد پیشنهادی برای توزیعهای دادههای مختلف با تعداد متفاوتی از اشیاء را بررسی کنیم. که یک مجموعه داده واقعی بود که یک سیستم ردیابی GPS تاکسی بود که در شهر شنژن ثبت شده بود. ما ویژگی های داده را برای ارائه توضیحات جامع داده ها نشان دادیم. ما همچنین نتایج آزمایشهای پیشنهادی خود را روی مجموعه داده ارائه کردهایم. ما سه مدل توزیع داده مختلف را از یک مجموعه داده شبیهسازی کردیم تا عملکرد رویکرد پیشنهادی برای توزیعهای دادههای مختلف با تعداد متفاوتی از اشیاء را بررسی کنیم. که یک مجموعه داده واقعی بود که یک سیستم ردیابی GPS تاکسی بود که در شهر شنژن ثبت شده بود. ما ویژگی های داده را برای ارائه توضیحات جامع داده ها نشان دادیم. ما همچنین نتایج آزمایشهای پیشنهادی خود را روی مجموعه داده ارائه کردهایم. ما سه مدل توزیع داده مختلف را از یک مجموعه داده شبیهسازی کردیم تا عملکرد رویکرد پیشنهادی برای توزیعهای دادههای مختلف با تعداد متفاوتی از اشیاء را بررسی کنیم.
عوامل مختلفی می توانند بر عملکرد رویکرد VeST پیشنهادی تأثیر بگذارند. یک عامل تعداد نزدیکترین همسایگان است. یکی دیگر از عوامل موثر بر عملکرد، سرعت حرکت اجسام است. رویکرد پیشنهادی مبتنی بر تقسیمبندی سرعت اشیاء قبل از نمایهسازی فضایی است. از آنجایی که ویژگی سرعت در پیشنهاد ما ضروری است و بر انجام نمایه سازی و عملکرد پرس و جو تأثیر می گذارد، ما پراکندگی این اطلاعات را از دیدگاه های مختلف نشان دادیم تا نحوه تغییر آن را نشان دهیم که باید در نظر گرفته شود. در آینده می توان از روش های تحلیلی برای تخمین توزیع سرعت و شبکه های سلسله مراتبی استفاده کرد.
8. نتیجه گیری
ما یک مدل رویکرد نمایهسازی جدید، یعنی رویکرد نمایهسازی فضای زمانی سرعت (VeST)، برای پرسوجو پیوسته، عمدتاً K-نزدیکترین همسایه پیوسته (CKNN) و پرسوجوهای محدوده پیوسته پیشنهاد کردیم. ما یک ساختار شاخص چندلایه فشرده بر روی یک تنظیم توزیع شده طراحی کردیم و یک الگوریتم جستجوی CKNN را برای نتایج دقیق با استفاده از فرآیند شناسایی سلول نامزد پیشنهاد کردیم. ما یک چشم انداز جامع از مدل نمایه سازی و تکنیک پرس و جو اتخاذ شده ارائه کردیم. ما مجموعه ای جامع از آزمایش ها را انجام دادیم، نتایج خود را با رویکردهای موجود مقایسه کردیم و از تکنیک های توزیع مختلف برای بررسی زمان ساخت سازه شاخص در سناریوهای مختلف استفاده کردیم. برای فواصل پرس و جو برابر با 100، رویکرد پیشنهادی 13.59 برابر سریعتر از روش سنتی بود. علاوه بر این، میانگین زمان رویکرد VeST برای تمام فواصل پرس و جو کمتر از 0.005 بود. این روش پیشنهادی زمان پاسخ و دقت پرس و جو را بهبود بخشید. دقت الگوریتم VeST بدون توجه به طول بازه پرس و جو تقریباً برابر با 100٪ بود. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد. تأثیر استفاده از روش های تحلیلی و شبکه های سلسله مراتبی را می توان در آینده برای افزایش نتایج بررسی کرد. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد. تأثیر استفاده از روش های تحلیلی و شبکه های سلسله مراتبی را می توان در آینده برای افزایش نتایج بررسی کرد. نتایج شبیهسازی نشان داد که الگوریتم ارائهشده در تمام موارد در حالی که به طور پیوسته ویژگی سرعت پویا را در نظر میگیرد از رقبای خود پیشی میگیرد. تأثیر استفاده از روش های تحلیلی و شبکه های سلسله مراتبی را می توان در آینده برای افزایش نتایج بررسی کرد.














بدون دیدگاه