1. مقدمه
بازسازی صحنه های داخلی سه بعدی، به عنوان مثال، ناوبری داخلی، پذیرش تکمیل ساخت و ساز، و طراحی داخلی، توجه فزاینده ای را به خود جلب کرده است. از آنجایی که هندسه فیزیکی ساختمان ها اغلب با نقشه اصلی آن متفاوت است، بازسازی یک مدل سه بعدی واقعی برای فضای داخلی ساختمان یک نیاز رایج است. با توجه به اینکه محیط های داخلی شامل چندین ساختار مسطح هستند، تقسیم بندی صفحه سه بعدی یک انتخاب مناسب برای بازسازی صحنه سه بعدی است [ 1 ، 2 ]]. در ساختمان های مصنوعی، سازه های مسطح به طور منظم با یکی از روابط زیر منطبق می شوند: موازی، متعامد، همسطح، و برابری زاویه ای. استفاده مناسب از این ویژگی های هندسی می تواند به طور قابل توجهی دقت و استحکام بخش بندی هواپیمای سه بعدی داخلی را بهبود بخشد. با این حال، روش های کمی اطلاعات قبلی را برای محدود کردن تنظیمات معرفی کرده اند. روشهای سنتی استخراج سطحی (به عنوان مثال، رشد منطقه (RG) [ 3 ]، تبدیل Hough (HT) [ 4 ]) از این ویژگیهای هندسی بهره نمیبرند، اما به شدت بر کیفیت نقطه-ابر متکی هستند. اگرچه اجماع نمونه تصادفی (RANSAC) [ 5] به ما اجازه می دهد که چنین اطلاعات ساختاری را معرفی کنیم، به پارامترهایی که تنظیم می شوند بسیار حساس است. بنابراین، سنسورهای با نویز بالا، مانند سنسورهای RGB-D کم هزینه [ 6 ، 7 ]، که برای کاربردهای داخلی محبوب هستند، برای رویکردهای کلاسیک مناسب نیستند.
این مقاله یک رویکرد سریع و قوی را برای تقسیمبندی هواپیمای سه بعدی داخلی توسعه میدهد. برخلاف استراتژیهای سنتی، رویکرد ما سطوح را با برجستگی جهتهای عادی بازسازی میکند. دو مرحله اصلی در روش پیشنهادی وجود دارد. ابتدا، تقسیم بندی فضایی را بر اساس تحلیل برجسته جهات عادی انجام می دهیم. سپس ساختارهای فضایی به سرعت به صفحات محدود بریده می شوند. دوم، ما مدل انرژی مرتبه بالا را برای بهینه سازی تقسیم بندی بر اساس روابط توپولوژیکی چند سطحی هدایت می کنیم. این مرحله استحکام را بهبود می بخشد و خطر تقسیم بیش از حد را کاهش می دهد.
سه سهم عمده روش پیشنهادی به شرح زیر است:
(1) این روش شمارشپذیر جهتهای عادی اصلی را در یک فضای بسته به نفع سطوح خوشهبندی سریع معرفی میکند.
(2) این روش روابط توپولوژیکی چند سطحی را با سه نمونه اولیه از مراحل مختلف توسعه میدهد و یک مدل هزینه-انرژی با مرتبه بالا برای موارد داخلی طراحی میکند تا تقسیمبندی را بهینه کند و دقت و استحکام را بهبود بخشد.
(3) مدلهای سهبعدی دقیق بهدستآمده در خانهها بهطور خودکار تا حد زیادی حذف میشوند. بنابراین، روش ما یک مدل 3 بعدی داخلی دقیق برای سایت های ساخت و ساز تولید می کند.
2. آثار مرتبط
تقسیم بندی نقطه-ابر برای دهه ها مورد مطالعه و بررسی قرار گرفته است. تحقیقات را می توان تقریباً به چهار دسته تقسیم کرد: برازش مدل، RG، خوشه بندی ویژگی ها، و روش های بهینه سازی انرژی جهانی. این بخش به طور خلاصه کارهای مربوط به تقسیم بندی صفحه را بررسی می کند.
روشهای مبتنی بر برازش مدل . RANSAC [ 5 ] و HT [ 4 ] روشهای متداول مبتنی بر برازش [ 8 ] هستند که از اشکال هندسی اولیه (کره، مخروط، صفحه و استوانه) برای تقسیمبندی دادههای نقطه-ابر استفاده میکنند. ابرهای نقطه ای با نمایش های ریاضی یکسان به عنوان یک شی گروه بندی می شوند. محققان اخیراً عملکرد RANSAC را از نظر استحکام و کارایی بهبود بخشیده اند. به عنوان مثال، لی و همکاران. [ 9 ] یک روش RANSAC بهبود یافته را بر اساس سلولهای تبدیل با توزیع نرمال برای جلوگیری از صفحات جعلی (تقسیمبندی بیش از حد) برای تقسیمبندی صفحه پیشنهاد کرد. حمید لکزاییان [ 10] روش Gridded-RANSAC را پیشنهاد کرد که از مفاهیم شبکه برای سازماندهی مجموعه دادههای ذاتا سازمانیافته برای تسریع بخشبندی استفاده میکند. لینا و همکاران [ 11 ] پیشنهاد استفاده از بردارهای معمولی برای شتاب دادن به RANSAC برای استخراج صفحات از ابرهای نقطه ای را ارائه کرد. برای تسریع سرعت محاسبه و افزایش بیشتر قابلیت اطمینان الگوریتم HT، Tian et al. [ 12 ] یک روش جدید برای تقسیمبندی ویژگیهای مسطح از ابرهای نقطهای سازمانیافته بر اساس HT و octree دو بعدی پیشنهاد کرد.
اگرچه RANSAC و HT به طور گسترده در وظایف بخشبندی استفاده شدهاند، این رویکردها دارای کاستیهای ذاتی هستند. اول، هر دوی آنها به انتخاب پارامتر برای مدلسازی مبتنی بر بخش حساس هستند. اگرچه بسیاری از مطالعات بر روی تراکمهای مختلف نقطه-ابر متمرکز شدهاند، هنوز دستیابی به یک روش خودسازگاری واقعی دشوار است. علاوه بر این، RANSAC برای داده های نقطه-ابر با حجم داده های کوچک و اطلاعات هندسی سطح کمتر مناسب است. در غیر این صورت، عملکرد الگوریتم ضعیف است [ 13 ]. کاستی های کلیدی روش HT پیچیدگی های زمانی و/یا مکانی است که کاربرد آن را محدود می کند. بسیاری از نویسندگان [ 14] HT و RANSAC را مقایسه کرد و نشان داد که HT در زمان محاسباتی زمانی که برای مجموعه دادههای بزرگ مناسب است کارایی کمتری دارد. در مقایسه با RANSAC و HT، رویکرد پیشنهادی نیازی به تنظیم پارامترهای زیادی ندارد، که نشان میدهد به انتخاب پارامتر حساس نیست.
روشهای مبتنی بر رشد منطقه . روش های مبتنی بر RG معمولا یک دانه را انتخاب می کنند و سطح بذر را تولید می کنند. سپس از این سطح به عنوان منطقه شروع استفاده می شود و شباهت های هر نقطه در همسایگی با سطح دانه مقایسه می شود تا ابرهای نقطه گسسته در اطراف هر سطح بذر گروه بندی شوند. اینها به طور مداوم به سمت بیرون گسترش می یابند تا در نهایت به تقسیم بندی کامل دست یابند. بسته به اصل الگوریتم، این روش باید نقاط مجاور را بدست آورد و اطلاعات مشخصه مرتبط را محاسبه کند، که منجر به راندمان محاسباتی پایین می شود. Anh-VuVo و همکاران. [ 13] از الگوریتم RG برای تقسیم تقریبی نمایش وکسلی مبتنی بر octree ابر نقطه ورودی برای تسریع در محاسبات استفاده کرد. با این حال، محدود کردن فرآیند تحویل با استفاده از قوانین رشد خاص نمیتواند به آسانی ویژگیهای همه اولیههای موجود در دادهها را برآورده کند. بنابراین، بهبود کارایی آشکار نیست. علاوه بر این، نتایج حاصل از RG تحت تأثیر انتخاب اولیه سطح بذر قرار می گیرد، در حالی که انتخاب نامناسب به آسانی باعث خطاهای تقسیم بندی قابل توجهی می شود. بسیاری از محققان بر بهبود دقت این رویکرد تمرکز کرده اند. به عنوان مثال، لو و همکاران. [ 15] یک الگوریتم تقسیمبندی نقطه-ابر مبتنی بر سوپر وکسل را پیشنهاد کرد که مرزهای نادرست و تقسیمبندی ناهموار را در روشهای موجود بهبود میبخشد. یکی از تفاوت های روش پیشنهادی با روش RG این است که نیازی به قضاوت در مورد نرمال ها به صورت جداگانه ندارد، که بر گلوگاه کارایی غلبه می کند.
روشهای مبتنی بر خوشهبندی ویژگیها . روشهای مبتنی بر خوشهبندی ویژگیها در درجه اول از ویژگیهای ساختار هندسی یا ویژگیهای توزیع فضایی ابرهای نقطهای برای خوشهبندی آنها و به دست آوردن بخشبندی استفاده میکنند. هولز و همکاران [ 16 ] به تقسیمبندی صفحهای بیدرنگ ابرهای نقطهای با استفاده از بردار عادی سطح، که میتواند اشیاء هدف برجسته را در صحنههای ابر نقطهای در زمان واقعی درک کند، پی برد. وو و همکاران [ 17] یک رویکرد تقسیمبندی خوشهبندی اقلیدسی صاف بر اساس الگوریتم سنتی خوشهبندی اقلیدسی پیشنهاد کرد. این با اضافه کردن محدودیت آستانه هموارسازی از تقسیمبندی بیش از حد یا کمتر از آن جلوگیری میکند. روشهای مبتنی بر خوشهبندی ویژگی از نظر انتخاب ویژگی انعطافپذیر هستند. ویژگی های خاص را می توان بر اساس تفاوت بین ابرهای نقطه ای انتخاب کرد که به آن دقت بالایی می دهد. با این حال، این روش الزامات خاصی برای تعاریف همسایگی دارد و به نویز حساس است [ 18]. علاوه بر این، به شدت به ویژگی ها وابسته است، که نشان می دهد کیفیت انتخاب ویژگی به طور قابل توجهی بر اثر تقسیم بندی نهایی تأثیر می گذارد. با این حال، ابعاد بیشتر یک ویژگی، بازده محاسباتی کمتری را به همراه دارد. در مقابل، رویکرد ما یک پارامتر از پیش تعیینشده بر اساس دانش قبلی را برای یک رویکرد کارآمدتر و قویتر معرفی میکند. در حال حاضر، با روشهای یادگیری عمیق که به طور گسترده برای مدیریت ابرهای نقطه معرفی شدهاند، بسیاری از محققان پیشنهاد کردهاند که از شبکههای عصبی برای تقسیمبندی ابرهای نقطه [ 19 ] و اجرای بازسازی سه بعدی [ 20 ] استفاده کنند. یکی از مزایای یادگیری ویژگی های مرتبه بالا این است که شبکه همیشه سازگاری خوبی دارد. بسیاری از شبکه ها می توانند داده های ناقص را مدیریت کنند، به عنوان مثال، نویز [ 21]، و برخی از آنها پتانسیل تعمیر اشکال را دارند، به عنوان مثال، GAN ها [ 22 ]. با این حال، بیشتر شبکههای عصبی از تعداد زیادی نمونه برچسبگذاری سود میبرند. یعنی، نمونهها عملکرد روشهای مبتنی بر یادگیری را به شدت محدود میکنند.
روشهای جهانی مبتنی بر بهینهسازی انرژی . روشهای جهانی مبتنی بر بهینهسازی انرژی، تقسیمبندی صفحه را به عنوان یک مسئله بهینهسازی انرژی فرموله میکنند. فام و همکاران [ 23 ] وظایف استخراج صفحه را به عنوان یک تابع انرژی جهانی بیان کرد که صفحات استخراج شده را مجبور می کند متعامد یا موازی با یکدیگر باشند تا به طور قوی صفحات زیرین را در یک صحنه پیدا کنند. دونگ و همکاران [ 24 ] همه وکسل ها را به هم مرتبط کرد و قوانینی را بین آنها برای محاسبه انرژی کلی ایجاد کرد. سپس از تئوری گراف برای اعمال برش نمودار و دستیابی به حداقل حالت انرژی استفاده کردند. لین و همکاران [ 2] کمینه سازی گرادیان L0 را برای برازش صفحه اعمال کرد تا نسبت بالایی از نویز و نقاط پرت را در بر بگیرد. در مقایسه با روشهای دیگر، بهینهسازی انرژی میتواند دادههای با سطوح نویز بالا را بهتر مدیریت کند [ 25 ]. با این حال، این روش به محاسبات قابل توجهی در هنگام انجام بخشبندی صفحه نیاز دارد و بیشتر به نتایج تقسیمبندی اولیه نیاز دارد [ 25 ]. بنابراین، رویکرد پیشنهادی روابط اولیه را ایجاد میکند، قوانین را ایجاد میکند و تعامل را برای تأثیرگذاری بر نتایج تقسیمبندی بهینه میکند.
3. روش شناسی
3.1. انگیزه
از آنجایی که ساختمانهای ساخت بشر دارای محدودیتهای ساختاری قوی هستند، یک محدودیت معمولی مدل جهانی منهتن [ 26 ] است که در میان مدلهای فرضی محبوب برای بخشبندی و بازسازی فضاهای داخلی است. مدل جهان منهتن بیان می کند که تمام سطوح در جهان با سه جهت غالب، به طور معمول مربوط به محورهای X، Y و Z هستند. یعنی جهان تکه تکه محور و مسطح است. قابل توجه است که مدل اصلی جهان منهتن برای ساختارهای پیچیده مناسب نیست، بنابراین محدودیت به مدل جهان چند منهتن تبدیل شده است. فقدان محدودیتهای زاویهای نقص اصلی مدلهای منهتن و جهان چندمنهتن است. بنابراین، Monszpart و همکاران. [ 26] محدودیت های زاویه ای را معرفی کرد و مدل کلی جهان منهتن را استخراج کرد و لین و همکاران. [ 27 ] یک مدل محدودیت جهتی بر اساس جهت بردارهای عادی پیشنهاد کرد. با الهام از این مدلهای محدودیت و ترکیب با ویژگیهای صحنههای داخلی (جهت بردارهای معمولی را میتوان خسته کرد)، ما تقسیمبندی ابرهای نقطهای را به خوشههای قابل شمارش بر اساس تحلیل برجستگی جهتها پیشنهاد میکنیم. ما یک جهت برجسته را به عنوان جمع آوری حداقل بیش از 5٪ از نقاط در یک خوشه نمونه تعریف می کنیم. برای معرفی رویکرد پیشنهادی، ابتدا گردش کار کلی روش خود را در شکل 1 ارائه می کنیم.
3.2. تقسیم بندی مبتنی بر وکسل و روابط توپولوژیکی
چه اسکن لیزری داخلی، چه تطبیق متراکم تصویر، یا SLAM، روشهای موجود در فضای داخلی جمعآوری نقطه ابری میتوانند دادههای ابری متراکم و بسیار زائد را به دست آورند که پردازش دادهها را زمانبر میکند. بنابراین، ابتدا ابرها را با استفاده از سوپر وکسل ها تقسیم بندی می کنیم، یعنی ویژگی های یک وکسل را در بر می گیرد تا فرآیندهای زیر را تسریع کنیم. آزمایشهای ما از روش تقسیمبندی مبتنی بر وکسل توصیفشده توسط لین و همکاران استفاده کردند. [ 22 ]. رزولوشن وکسل را بر روی تنظیم می کنیم برای حفظ جزئیات بیشتر اشیاء در صحنه های داخلی. این همچنین تضمین می کند که نقاط در یک وکسل تا حد امکان دارای ویژگی های مشابه هستند. تنظیم وضوح بسیار کوچک، به عنوان مثال، سطح سانتی متر، اطلاعات به طور قابل توجهی تکه تکه ایجاد می کند. یکی از مزایای اصلی روش Lin این است که وکسل ها می توانند عبور از مرزهای اشیا را محدود کنند. قابل توجه است، این اثر به طور قابل توجهی جهت های عادی وکسل ها را که نزدیک به مرزها هستند، بهبود می بخشد. بردار معمولی voxel v از بردار نرمال مجموعه نقطه محاسبه می شود (یعنی نقطه i∈ و بردار نرمال مربوطه است ) موجود در v به عنوان،
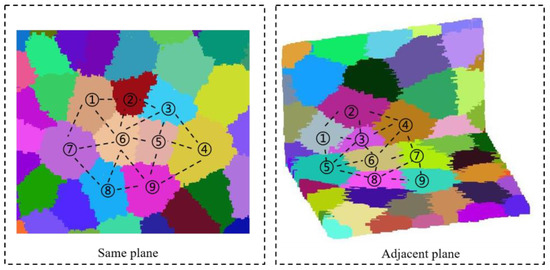
بر اساس تقسیم بندی سوپر وکسل، ما رابطه توپولوژیکی بین وکسل هایی که از نمونه های بعدی و بهینه سازی جهانی پشتیبانی می کنند، برقرار می کنیم. رابطه توپولوژیکی بین وکسل ها با نشان داده می شود . ما یک رابطه توپولوژیکی مرتبط بین دو وکسل بر اساس مجاورت آنها تشکیل می دهیم. شکل 2 وکسل ها را در امتداد دو نوع دیوار مختلف با روابط توپولوژیکی تا حدی مرتبط نشان می دهد. به عنوان مثال، وکسل شماره 6 در نمودار سمت چپ دارای این است روابط موقعیت مکانی voxel v با مختصات فضایی موقعیت مرکزی نشان داده می شود . پس از آن، بردار توصیف-ویژگی از وکسل به عنوان به دست می آید
3.3. تجزیه و تحلیل برجستگی جهت دار در محیط های داخلی
بردار معمولی voxel v را می توان برای آمار بر روی نیمه کره گاوسی پیش بینی کرد. بطور شهودی، بردار نرمال اثر تجمع قابل توجهی دارد و هر خوشه یک جهت برجسته را منعکس می کند، همانطور که در شکل 3 الف مشاهده می شود. راهبردهای آماری می توانند به آسانی نقاط پرت را در نیم کره گاوسی که به صورت نقاط توخالی در شکل نشان داده شده اند حذف کنند. برای بهبود توضیحات و درک، یک voxel v که به عنوان یک نقطه پرت در نظر گرفته می شود به عنوان نشان داده می شود .
ما فکر می کنیم که تعداد جهت های عادی در صحنه های داخلی محدود است. بنابراین، ما از یک رویکرد خوشهبندی برای افزایش این تعداد و بخشبندی بیشتر فضا استفاده میکنیم. ما از رویکرد mini-batch K-means [ 28 ] برای تقسیم مجموعههای جهت عادی، که یک مجموعه داده محدب هستند، به کلاسهای K استفاده میکنیم. سوگیری بین یک نقطه به مرکز خوشهبندی در درجه اول از خطاهای تصادفی در مشاهدات ناشی میشود. بنابراین، این تعصبات از نظر یک مرکز خوشهبندی، توزیع نرمال دارد با انحراف معیار مانند،
این ویژگی می تواند از روش های K-means برای دستیابی به نتایج عالی بهره مند شود. برای شروع فرآیند K-means، تقریباً K = 30 را تنظیم می کنیم و سپس یک ثابت معقول را تکرار می کنیم . آستانه K از شناخت ها و تجربیات صحنه های داخلی تولید می شود [ 2 ].
شکل 3 b نتایج پردازش شده از خوشه بندی K-means را در نیم کره گاوسی نشان می دهد (توجه داشته باشید: رنگ های مختلف در شکل 3 b,c نشان دهنده خوشه های مختلف هستند). جهت طبیعی دو سوپر وکسل در سطوح مخالف به صورت ظاهر می شود زیرا ما دیدگاه را در اتاق تنظیم می کنیم. بنابراین، همانطور که در شکل 3 ج مشاهده می شود، تعداد جهت های عادی را بیشتر کاهش دادیم. شکل 4 تقسیم بندی را در یک فضای داخلی با استفاده از جهت های معمولی برجسته نشان می دهد. برخی از اشتباهات در تقسیم بندی دیده می شود مانند نقاط سبز رنگ در که باید قرمز باشد. خط تقسیم دو خوشه نامشخص است. بنابراین، نتایج حاصل از K-means همیشه بهینه نیستند. با این حال، ما می توانیم تقریباً تمام این خطاها را در استراتژی های بهینه سازی جهانی بعدی حذف کنیم. برای تسهیل پردازش بعدی (تنظیمسازی و بازسازی)، ما تقسیمبندی نمونهای را با استفاده از روابط توپولوژیکی مبتنی بر وکسل انجام دادیم، همانطور که در شکل 5 مشاهده میشود .
دو مورد خاص باید در تقسیم بندی نمونه در نظر گرفته شود که به راحتی باعث ایجاد مشکلات زیربخشی می شود. این شامل (I) دو صفحه موازی بسیار نزدیک به یکدیگر و (II) عدم تمایز در تفاوت بین دو جهت عادی است. شکل 6 a موقعیت اول را نشان می دهد، جایی که رابطه شبه اتصال بین وکسل ها زمانی ایجاد می شود که فاصله d بین دو صفحه کمتر از آستانه داده شده باشد. (= 2.5 برابر تراکم نقطه در موارد ما) یا نقاط نویز بین دو صفحه وجود دارد. موضوع دوم در شکل 6 c نشان داده شده است، که در آن تفاوت زاویه ای دو جهت عادی در پردازش K-means قابل توجه نیست. برای پرداختن به این مشکلات، ما هواپیماهایی را برای هر خوشه با سطح دقیق تری تنظیم می کنیم. . شکل 6 b,d دو مثال مرتبط قبل و بعد از پردازش را نشان می دهد. فرآیند اعتبار سنجی به صورت موازی انجام می شود زیرا هر یک از آزمایشات w (یکی از خوشه ها را کنترل می کند) مستقل از دیگران است که باعث افزایش پردازش مستقیم می شود. پیاده سازی ما از رابط برنامه نویسی برنامه OpenMP برای توزیع آزمایش های جداگانه و بررسی رشته های مختلف استفاده می کند.
3.4. بهینه سازی انرژی جهانی
نقاط نویز قابل توجهی در ابرهای نقطه وجود دارد. اگرچه استراتژیهایی برای جهتهای عادی مبتنی بر وکسل و برجسته میتوانند استحکام پردازش دادهها را بهبود بخشند، برخی از وکسلها ناگزیر حاوی گوشهها و نقاط مرزی هستند که به طور قابلتوجهی دقت برآوردهای عادی را کاهش میدهند [ 29 ]. این بخش به موارد پرت مانند مشکل جهانی بهینهسازی انرژی میپردازد. تقسیمبندی حقیقت-زمینی به عنوان حالت انرژی بهینه، یعنی E = 0 تعریف شد. سپس قوانین مختلفی را برای قضاوت و مجازات روابط بین اولیهها تعریف کردیم. ما در نهایت برش نمودار [ 30 ] را برای محاسبه نتایج تقسیم بندی بهینه معرفی کردیم.
3.4.1. وکسل های پرت
تعداد زیادی وکسل پرت در مجموعه داده های واقعی وجود دارد که به صورت نقاط توخالی در شکل 3 الف نشان داده شده است. ما می توانیم این پرت ها را به دو دسته تشخیص دهیم. یکی این است که جهت عادی یک وکسل به طور قابل توجهی با همسایگانشان متفاوت است و دیگری وکسل های “شبح” است. برای اهداف تقسیم بندی، ما باید نوع اول پرت ها را تعمیر کنیم و نوع دوم را هرس کنیم. از آنجایی که اولین نوع پرت ها به دلیل نویز و لبه های گوشه ایجاد می شوند، نقاط مفید زیادی در چنین وکسل هایی وجود دارد که نیازی به حذف مستقیم ندارند.
3.4.2. رابطه بین اولیه های مختلف
ما یک گراف ایجاد کردیم تا همه موارد اولیه را بر اساس روابط توپولوژیک به هم متصل کنیم [ 31 ]. وکسل به عنوان اولیه اصلی عمل می کند و شبکه ارتباط اولیه مرتبط در بخش قبل توضیح داده شد. بنابراین، این بخش با معرفی انواع ابتدایی دیگر (ابتدایی های صفحه و نقطه) شبکه رابطه را غنی و کامل می کند. ما ابتدا اتصالات بین وکسل ها و صفحه متناظر آنها را برقرار کردیم، نقاط را از نوع اول وکسل دورافتاده آزاد کردیم و پیوندهای نقطه به نقطه و نقطه به وکسل را ساختیم. شکل 7نمودار شماتیکی از روابط چند سطحی برای موارد اولیه را نشان می دهد. لبه هایی که دو اولیه را به هم متصل می کنند نه تنها روابط توپولوژیک را نشان می دهند بلکه تعاملات بین اولیه را نیز بیان می کنند. چنین نیروهایی هم بزرگی و هم جهت دارند، که به طور منطقی نشان می دهد که اثرات نزدیک به نوع اولیه است. در مقایسه با وکسل اولیه، صفحه اولیه دارای خواص قطعی تری است. با این حال، نقطه ابتدایی برعکس است.
3.4.3. فرمولاسیون تابع انرژی
ما مسئله تقسیمبندی-بهینهسازی را بهعنوان بهینهسازی برچسبگذاری با یک تابع انرژی جهانی [ 24 ] در نظر میگیریم تا خطاهای هندسی، سازگاری فضایی و پتانسیلهای مرتبه بالا را متعادل کنیم. بنابراین، ما تابع انرژی را به صورت،
جایی که و اندازه گیری هزینه داده را به ترتیب به عنوان مجموع خطاهای هندسی از وکسل و نقطه اولیه نشان می دهد. ، ، و عبارتهای ارزان قیمتی هستند که ناسازگاری برچسب بین موارد اولیه متصل (voxel–voxel، point–point و point–voxel) را جریمه میکنند. و نشان دهنده پتانسیل های مرتبه بالا مربوط به تعداد برچسب ها است که به اصطلاح هزینه لیبل است. اصطلاح هزینه داده نشان دهنده پتانسیل های وکسل است ، با برچسب . با توجه به اصل روش پیشنهادی، متعلق به هواپیمای با عنوان ; در غیر این صورت حذف یا آزاد می شود. پتانسیل ها را محاسبه می کنیم با یک تابع هسته گاوسی به صورت
جایی که نشان دهنده میانگین فاصله بین نقاط ( ) به هواپیما مربوطه ، آستانه مناسب برای یک هواپیما است، و یک پارامتر تنظیم کننده برای بهبود اثرات وکسل اولیه در نوبت اول است. این مربوط به پتانسیل های یکنواخت نقطه است با برچسب اولیه . سپس بیشتر تعریف می کنیم مانند،
جایی که 1 و 0 به ترتیب نشان می دهد که به هواپیما تعلق دارد یا نیست. این برنامه نقطه ایزوله را جریمه می کند و ادغام آن در هواپیماهای همسایه را تشویق می کند.
اصطلاح کم هزینه برای ارتقای سازگاری فضایی طراحی شده است. این نشان دهنده پتانسیل های زوجی از و . بنابراین، برنامه یال هایی را که دو برچسب مختلف را به هم مرتبط می کنند جریمه می کند. سپس می توانیم محاسبه کنیم ، ، و مانند،
راهبردهای تنبیه شامل دانش قبلی قوی است. بنابراین، اگر واحدهای مجاور دارای برچسب های متفاوتی باشند و ، مجازات ها شدیدتر می شود و خطاهای هندسی کاهش می یابد. علاوه بر این، ما یک قانون اجباری را تنظیم کردیم که برچسب برای یک امتیاز می تواند به برچسب تبدیل شود ، که متعلق به voxel است ، اما برعکس مجاز نیست. Voxel primitive به دلیل افزایش قابلیت اطمینان، اطلاعات قطعی تری نسبت به نقطه اولیه دارد. این به عنوان مدل پاتس [ 32 ] برای جریمه کردن برچسب های مختلف با هزینه 1 عمل می کند.
اصطلاح هزینه برچسب تعداد برچسب ها را جریمه می کند. حالت ایده آل این است که در یک محدوده خاص، انواع شی محدود است، و انواع کمتری ترجیح داده می شود، که برای کار ما معتبر است. با این حال، جدا از استراتژیهای دیگر، ما انتظار نداشتیم تعداد برچسبها به صفر نزدیک شود، بلکه در عوض برابر با یک ثابت باقی بماند. ، که تعداد خوشه های پردازش K-means است. از آنجایی که تعداد جهتهای عادی در یک محیط داخلی محدود است، حالت شدید بهینهسازی انرژی این است که ما فقط داریم برچسب ها. شکل 8 بخشی از نتایج تقسیمبندی را قبل و بعد از بهینهسازی انرژی نشان میدهد که مشکل بیشبخشبندی را نشان میدهد.
برای شروع بهینه سازی انرژی، همه اولیه ها دارای برچسب های اولیه بر اساس انواع اولیه خود پس از تقسیم بندی نمونه صفحات هستند. بر اساس تئوری گراف [ 32 ]، این رئوس (به عنوان مثال، اولیه) به صورت مجزا وجود ندارند، اما از طریق یال ها (ارتباط روابط توپولوژیکی) تعامل دارند. یعنی برای هر رأس، برچسب آن چندین احتمال دارد که هم به ویژگی های خودش و هم به اولیه های مجاور بستگی دارد. ما هزینه انرژی را برای هر ترکیب ممکن (از جمله موارد اولیه)، روابط پیوندی، و محدوده هزینه برچسب را محاسبه کردیم. ما متعاقباً از رویکرد برش نمودار [ 31 ] برای به دست آوردن ترکیب بهینه استفاده کردیم. هدف تعیین استراتژی بود که تضمین کند کل انرژی به حداقل می رسد.
4. آزمایش ها و تجزیه و تحلیل
4.1. توضیحات مجموعه داده
چهار مجموعه داده از صحنه های داخلی برای تأیید تجربی اثربخشی رویکرد پیشنهادی استفاده شد. اطلاعات صریح در مورد این چهار مجموعه داده در جدول 1 خلاصه شده است. TUB1 و TUB2 از مجموعه دادههای معیار معیار مدلسازی داخلی هستند که توسط انجمن بینالمللی فتوگرامتری و سنجش از دور (ISPRS) [ 33 ] ارائه شده است. ابر نقطه TUB1 در یکی از ساختمانهای دانشگاه فنی براونشوایگ آلمان با استفاده از سیستم Viametris iMS3D ضبط شد. ابر نقطه TUB2 در همان ساختمان با استفاده از حسگر Zeb-Revo ثبت شد. این مجموعه داده ها شامل چندین اتاق و فضاهای راهرو عمومی است که در شکل 9 و شکل 10 مشاهده می شود.. بنابراین، آنها شامل ساختارهای مختلف دیوار توپولوژیکی هستند. اگرچه بسیاری از موارد مختلف (سه پایه، صندلی، میز و قفسه کتاب) در صحنه ها وجود دارد، اما آنها اشیاء اصلی در حالت کل ساختار طبقه نیستند. مجموعه داده های آزمایشگاهی و دفتری به ترتیب با یک اسکنر لیزری زمینی Faro3D (TLS) و یک حسگر موبایل ارزان قیمت RGB-D جمع آوری شدند، همانطور که در شکل 11 و شکل 12 مشاهده می شود.. از آنجایی که این مجموعه داده ها بر روی فضای داخلی اتاق متمرکز شده اند، اثاثیه زیادی وجود دارد. مجموعه داده آزمایشگاهی فقط شامل مجموعه های نقطه-ابر ثبت شده زوجی است که از مکان های مختلف گرفته شده است. بنابراین، چندین سوراخ در ابرهای نقطه به دلیل انسداد وجود دارد. ما توجه می کنیم که ساختار فضایی ناقص چالش هایی را برای بخش بندی صفحه ایجاد می کند. علاوه بر این، فراوانی مبلمان خطر تقسیم بیش از حد را افزایش می دهد. شکل 12 نشان می دهد که مجموعه داده آفیس پیچیده ترین محیط را در تست ها دارد. به غیر از مبلمان بزرگ (میز و صندلی)، اشیاء کوچک زیادی (کتاب، صفحه نمایش، فنجان و غیره) وجود دارد. با توجه به سنسورهای کم هزینه، ابرهای نقطه ای با کیفیت پایین مرتبط، روش پیشنهادی را با چالش های دقیق تری ارائه می کنند.
4.2. معیارهای ارزیابی
ما از چهار معیار برای ارزیابی عملکرد رویکرد پیشنهادی استفاده کردیم: دقت صفحه (PP)، فراخوان هواپیما (PR)، نرخ پایینبخشی (USR)، و نرخ تقسیمبندی بیش از حد (OSR). PP به عنوان نسبت تعداد صفحات به درستی تقسیم شده به تعداد کل صفحات قطعه بندی شده، و فراخوان صفحه (PR) به عنوان نسبت تعداد صفحات به درستی تقسیم شده به تعداد کل صفحات در حقیقت زمین تعریف می شود. [ 18 ] همانطور که،
جایی که تعداد صفحات به درستی تقسیم بندی شده است و N S و تعداد کل صفحات در تقسیم بندی و حقیقت زمین به ترتیب است. یک صفحه به درستی قطعه بندی شده به عنوان همپوشانی صفحه مرجع مربوطه در حقیقت زمین حداقل 80٪ [ 25 ] تعریف می شود. علاوه بر این، ما از USR و OSR برای ارزیابی درجات تقسیم بندی نادرست استفاده کردیم که به صورت زیر محاسبه می شود:
جایی که تعداد هواپیماهای شناسایی شده است که بیش از یک صفحه از حقیقت زمین همپوشانی دارند و تعداد صفحاتی را در حقیقت زمین نشان می دهد که با چندین هواپیمای شناسایی شده همپوشانی دارند. ما به صورت دستی حقیقت پایه را برای هر مجموعه داده تولید کردیم تا مقایسه ها و ارزیابی های کمی و کیفی انجام دهیم. اشاره شد که حقیقت زمین هواپیما با ساختار دیوار اصلی و مبلمان کمی بزرگتر بود که عمدتاً بر تقسیم استفاده از فضا تأثیر می گذاشت.
4.3. نتایج تجربی و تحلیل کیفی
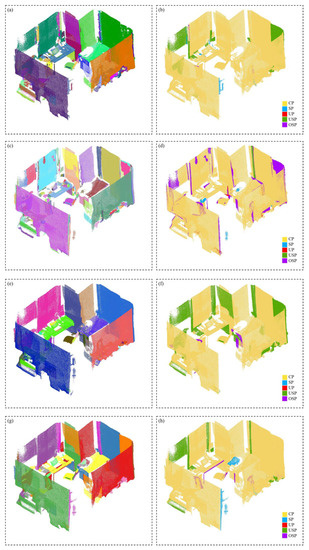
شکل 13 ، شکل 14 ، شکل 15 و شکل 16 نتایج تقسیم بندی صفحه را برای همه مجموعه داده ها و مقایسه های کیفی مرتبط نشان می دهد. نتایج روش پیشنهادی در شکلهای فرعی (الف)، حقایق پایه برای هر مجموعه داده در شکلهای فرعی (ب) نشان داده شده است، و مقایسههای کیفی برای هر مجموعه داده در زیرشکلهای (ج) آمده است. روش پیشنهادی نتایج تقسیمبندی ایدهآل را بهدست میآورد زیرا شکلهای فرعی (a) برای همه آزمایشها از نظر دقت تقسیمبندی مشابه شکلهای فرعی (b) هستند. از شکلهای فرعی (c)، وظایف تقسیمبندی صفحه بیش از 80 درصد موفقیتآمیز بود. جدول 2عملکرد کمی روش پیشنهادی را برای همه آزمایش ها نشان می دهد. دقت قطعهبندی هواپیما بیش از 87 درصد و امتیاز F-1 بیش از 0.84 در سه مجموعه داده اول بود. برای مجموعه داده Office، دقت و امتیاز F-1 به ترتیب به 72.7% و 0.73 کاهش یافت که دلیل آن محیط پیچیده و کیفیت نامناسب نقطه-ابر است. برای تقسیم بندی های نادرست، استراتژی پیشنهادی به طور قابل توجهی خطر تقسیم بیش از حد را کاهش داد. اگرچه نرخهای زیربخشبندی معنیدار نبودند، اما به کاهش نرخهای بیشبخشبندی کمک کردند و نرخهای سازگاری کلی را بهبود بخشیدند.
برای انجام تحلیلهای کیفی خاص، تفاوتهای اصلی بین نتایج تقسیمبندی این مقاله و حقیقت پایه را نشان میدهیم. نواحی زرد، قرمز، آبی، سبز و بنفش نمایانگر صفحه به درستی تقسیمبندی شده (CP)، صفحه شناسایی نشده (UP)، سطوح کاذب (SPs)، صفحه زیر بخشدار (USP) و صفحه بیش از بخش (OSP) هستند. به ترتیب. USP ها در همه آزمایش ها رخ می دهند. با این حال، مشکلات OSP ها تنها در TUB2 آشکار است. مهمترین OSP در TUB2 نشان میدهد که چنین اشتباهاتی توسط صفحات خمشی پیوسته و بزرگ ایجاد میشوند. از آنجایی که اینها قبلاً اطلاعات اولیه سطحی دارند که بسیار قوی است، تغییر برچسب ها در طول بهینه سازی انرژی دشوار است. مهم ترین مشکل USP در مجموعه داده های Office است، همانطور که در شکل 16 مشاهده می شودج این به شدت به دادههای با کیفیت پایین مربوط میشود، که یک مشکل لایهبندی روی دیوارها ایجاد میکند و نشان میدهد که آنها باید به دو قسمت در حقیقت زمین جدا شوند ( شکل 16 ب با دیوارهای سبز و زرد را ببینید). برای مسائل UP، روش ما تقریباً به طور کامل از چنین مشکلاتی جلوگیری می کند، به جز چگالی های نقطه ای که در صفحات کوچک بسیار کم هستند، همانطور که در شکل 14 مشاهده می شود . تقسیمبندیهای نادرست مربوط به SPها ناچیز هستند زیرا جهتهای عادی در کره گاوسی برجسته نیستند و میتوانند تقریباً به طور کامل در طول پردازش حذف شوند.
4.4. مقایسه و ارزیابی کمی
برای ارزیابی بیشتر عملکرد روش پیشنهادی، آن را با رویکردهای پیشرفته مقایسه کردیم. ما سه روش پیشرفته را به عنوان معیار برای تقسیمبندی صفحه انتخاب کردیم، از جمله Global-L 0 (GL 0 )، RANSAC کارآمد، و RG، همانطور که در چهار مجموعه داده اعمال میشود. GL 0 یک رویکرد مناسب برای هواپیما است که اخیراً پیشنهاد شده است که از نظر سرعت و استحکام عملکرد بسیار خوبی دارد. RANSAC و RG کارآمد هر دو روشهای رایج تشخیص صفحه هستند. به عنوان یک مقایسه منصفانه، آزمایشها سه تابع معیار را به صورت داخلی بازتولید نکردند، بلکه از آثار اصلی و یک کتابخانه سوم معروف بودند. به طور خاص، ما GL 0 را با استفاده از برنامه های Lin و همکاران پیاده سازی کردیم. [ 2]، و دو مورد دیگر از ماژول کتابخانه در CGAL [ 5 ، 34 ] بودند. علاوه بر این، ما یک تنظیم پارامتر معقول را برای دستیابی به عملکرد بهینه اتخاذ کردیم. جدول 3 این روش ها را از نظر دقت، فراخوان، USR، OSR و زمان اجرا مقایسه می کند. روش پیشنهادی بهترین دقت و نتایج فراخوان را در تمام مجموعه دادههای آزمایش شده به دست آورد. RG و GL 0 از نظر دقت و یادآوری عملکرد خوبی داشتند، اما GL 0بهتر بود. با این حال، RG نسبت به روشهای دیگر به نویز حساستر بود. نرخ دقت به دلیل ابر نقطه با کیفیت پایین به شدت به 24.3٪ در مجموعه داده Office کاهش یافت. اگرچه سایر رویکردها (از جمله رویکرد ما) نیز تحت تأثیر نویز قرار دارند، اما این موضوع چندان قابل توجه نبود. نتایج برای RANSAC از نظر دقت به خوبی نبود. با این حال، آن را به نمایش گذاشته استحکام عالی. RG بهترین عملکرد USR را به دست آورد. با این حال، بدترین هزینه به دلیل عملکرد OSR آن بود. از آنجایی که GL 0 و روش ما هر دو با استفاده از بهینهسازی انرژی جهانی پردازش شدند، OSR مشکل اصلی نبود. جدول 3 بیشتر زمان اجرا CPU را با بهترین عملکرد روش پیشنهادی نشان می دهد. با توجه به اصول الگوریتمی، RG زمانبرترین روش بود.
ما نتایج تقسیمبندی را از چهار رویکرد و تفاوتهای بالا با حقیقت زمینی متناظر بهعنوان تحلیلی عمیقتر در مورد عملکرد روش پیشنهادی نشان میدهیم. همانطور که در شکل 17 ، شکل 18 ، شکل 19 و شکل 20 مشاهده می شود، ما همچنین از UP، SP، USP و OSP برای توصیف تقسیم بندی های نادرست استفاده کردیم . ستون های سمت چپ (a)، (c)، (e)، و (g) نشان دهنده نتایج تقسیم بندی از روش پیشنهادی، RG، RANSAC، و GL 0 است.، به ترتیب. روش پیشنهادی بهتر از روشهای معیار عمل کرد، بهویژه زیرا تلاش میکرد تا به طور کامل از مشکل UP که خطر از دست دادن اطلاعات را دارد، اجتناب کند. به عنوان یک مزیت از استراتژی بهینه سازی جهانی، OSP یک مشکل عمده در GL 0 یا روش های پیشنهادی نبود. USP یکی از مهم ترین مشکلات در روش های پیشنهادی، RANSAC و GL 0 بود . با این وجود، روش پیشنهادی به طور چشمگیری عملکرد قطعهبندی صفحه داخلی را از نظر کارایی و سازگاری بهبود بخشید.
4.5. بحث
تحلیل های کمی و کیفی نشان می دهد که روش پیشنهادی از نظر دقت، استحکام و کارایی قابل اجرا است. ما بیشتر مزایا و محدودیتهای روش پیشنهادی را برای نشان دادن پتانسیل از دیدگاههای نمای بالا تحلیل کردیم. یک مزیت این است که نتایج تقسیم بندی مبتنی بر سوپر وکسل به طور قابل توجهی پردازش را تسریع می کند زیرا حداقل واحد کنترل از یک نقطه به یک وکسل تغییر می کند. با توجه به اینکه وکسل ها می توانند عبور از مرزهای شی را محدود کنند، جهت های عادی دقیق تری از ساختارهای وکسل به دست می آیند. یکی از جذابترین مراحل، ارائه یک آستانه از پیش تعیینشده است که بر اساس جهتهای برجسته قابل شمارش در یک صحنه داخلی است. اول، این آستانه از پیش تعیین شده می تواند نتایج خوشه بندی را افزایش دهد و از دسته های گسسته جلوگیری کند.
در مرحله بعد، مسئله بهینهسازی تقسیمبندی را در فضای انرژی جهانی بررسی میکنیم و رویکرد برش نمودار را برای متعادل کردن عوامل مختلف و تعیین ترکیب بهینه معرفی میکنیم. قابل توجه است، از آنجایی که بهینه سازی انرژی تفاوت ها را مجازات می کند، مشکلات OSP را می توان بیشتر در تست ها بررسی کرد. چارچوب ما بیشتر سه نوع رابطه را برای پیوند دادن سه نوع اولیه و ایجاد قوانینی برای تعاملات آنها معرفی می کند. این عملیات به بخشبندیها اجازه میدهد تا یک ثبات معقول را حفظ کنند و از ادغام بیش از حد بین اولیهها جلوگیری کنند.
عملکرد جامع روش پیشنهادی بهتر از سه روش معیار بوده و دارای دو محدودیت زیر است. اول، از آنجایی که رویکرد مربوط به جهتهای برجسته است، نرخهای تغییر جهت ناچیز، قطعهبندی لبههای منظم و ایجاد صفحات دقیق را دشوار میکند ( شکل 21 را ببینید ). دوم، اگرچه تعداد از پیش تعیین شده جهت های برجسته یک صحنه داخلی می تواند مزایای زیادی ایجاد کند، برخی از اهداف کوچک از بین خواهند رفت. بنابراین پارامترهایی که مربوط به جهات برجسته هستند باید به طور کامل در نظر گرفته شوند.
5. نتیجه گیری ها
این مقاله یک چارچوب خودکار برای تقسیم بندی ابرهای نقطه جمع آوری شده در محیط های داخلی پیشنهاد می کند. دو ستون رویکرد ارائهشده عبارتند از (I) جهتهای عادی محدود برای ترویج خوشهبندی سریع صفحه و (II) سه نوع اولیه با سطوح مختلف با روابط توپولوژیک برای پشتیبانی از پردازش بهینهسازی جهانی. این دو رویکرد به بهبود ثبات جهانی و تسریع محاسبات کمک می کند. برخلاف روشهای سنتی تقسیمبندی سطحی، ما نه نیازی به تایید یک مدل ریاضی برای برازش دادهها داریم و نه نیازی به رشد نقاط به صورت جداگانه. بنابراین، روش پیشنهادی نه تنها در سرعت مفید است، بلکه به طور موثر از تلههای محاسبه از حداقلهای محلی جلوگیری میکند. در مرحله بعد، برای تضمین صحت و درستی،
آزمایشات جامعی برای ارزیابی روش پیشنهادی انجام شد. نتایج نشان میدهد که این روش برای رسیدگی به بخشبندی صفحه در صحنههای داخلی مناسب است. مقایسهها نشان میدهد که در چنین محیطهایی، روش پیشنهادی نسبت به روشهای معیار برجسته است. با این وجود، هنوز محدودیت هایی وجود دارد. بنابراین، تحقیقات آینده باید به مسائل مربوط به بهبود بیشتر سازگاری نتایج بپردازد.























بدون دیدگاه