1. مقدمه
اخیراً، از آنجایی که هر کسی می تواند در هر زمان و در هر مکان با استفاده از دستگاه های تلفن همراه به پلتفرم های رسانه های اجتماعی دسترسی داشته باشد، حجم زیادی از متن ها و عکس ها برای برقراری ارتباط با دیگران در وب به اشتراک گذاشته شده است. مردم آزادانه افکار و احساسات خود را از طریق متن و عکس در شبکه های اجتماعی بیان می کنند. در کنار این روند، نحوه دریافت اطلاعات مربوط به جاذبه های سفر و به اشتراک گذاری تجربیات گردشگران نیز در حال تغییر است. بیشتر و بیشتر گردشگران تجربیات خود را در قالب متن، عکس و ویدیو در رسانه های اجتماعی به اشتراک می گذارند که به عنوان منبع اطلاعاتی برای گردشگران بالقوه عمل می کند [ 1 ]]. داده های ارسال شده در خدمات شبکه های اجتماعی (SNS) به طور پیوسته توجه اجتماعی را به خود جلب می کند زیرا محتوای تولید شده توسط کاربر (UGC) است. صنعت گردشگری همچنین به دادههای UGC توجه میکند تا روندهای جدید گردشگری را شناسایی کند و تصویری از جاذبههای گردشگری درک شده توسط گردشگران را تحلیل کند [ 2 ]. به طور خاص، تصویر جاذبههای توریستی زمانی که مردم مقصد گردشگری خود را انتخاب میکنند و سازمانهای بازاریابی مقصد (DMO) بازاریابی گردشگری را انجام میدهند، نقش مهمی ایفا میکند [ 3 ، 4 ، 5 ، 6 ].
در گذشته DMO ها نقش پیشرو در شکل دادن به تصویر مقاصد گردشگری داشته اند. با این حال، با توجه به محبوبیت پلت فرم های رسانه های اجتماعی در سال های اخیر، تشخیص داده شده است که تصویر جاذبه های گردشگری هم توسط UGC و هم محتوای ایجاد شده توسط DMO ها شکل می گیرد [ 7 ]. در میان UGCها، یک عکس نقش مهمی در شکلگیری تصویر جاذبههای توریستی ایفا میکند، زیرا به صورت بصری مکانها را بازتولید میکند [ 8 ]. یک عکس تصویر ذهنی عناصر فیزیکی تجربه شده توسط عکاسان را منعکس می کند. علاوه بر این، عکس ثبت یک لحظه برای بیان تصویری ذهنی از یک مکان به صورت تصویری است [ 9]. بنابراین، از آنجایی که این عکسها شامل ترجیحات بصری گردشگران برای یک منطقه خاص هستند، میتوانند ترجیحات واقعی گردشگران را مستقیماً منعکس کنند تا چند متخصص [ 10 ]. علاوه بر این، گردشگران بالقوه تمایل دارند از مکانهای توریستی بازدید کنند که در معرض آنها قرار گرفتهاند و از تصاویر بصری که روی آنها نمایش داده شدهاند عکس میگیرند [ 11 ].
با توجه به ارزش عکسها، مطالعات بیشتر و بیشتر تلاش کردهاند عکسهای گرفته شده توسط گردشگران را بر روی SNS تجزیه و تحلیل کنند و عوامل جذابی را که در شکلگیری تصویر یک مقصد گردشگری نقش دارند، کشف کنند [ 1 ، 4 ، 6 ، 12 ، 13 ، 14 .]. با این حال، به دلیل محدودیت در فناوریها، مطالعات بر روی تصاویر مقصد گردشگری (TDI) با استفاده از عکسهای UGC با چالشهایی از نظر حجم دادهها و تفسیر نتایج مواجه میشوند. پرکاربردترین روش آنالیز دستی است که در آن محققین عکس های جمع آوری شده خود را مشاهده کرده و به صورت دستی آنها را در دسته های خاص طبقه بندی می کنند. از آنجایی که این روش یک فرآیند کار فشرده است، محدودیتی برای تعداد عکس های قابل تجزیه و تحلیل وجود دارد که تجزیه و تحلیل جامع جاذبه های گردشگری را دشوار می کند.
همانطور که فناوری های بینایی کامپیوتری توسعه یافته اند، چندین مطالعه TDI را از تعدادی عکس SNS با استفاده از روش های یادگیری عمیق شناسایی کرده اند [ 15 ، 16 ، 17 ، 18 ، 19 ، 20 .]. با این حال، آنها در طبقه بندی عکس هایی که نشان دهنده ویژگی های منحصر به فرد جاذبه های گردشگری است، محدودیت هایی دارند. آنها از دسته های عکس از پیش تعیین شده مانند Places365 یا ImageNet استفاده می کنند که برای اهداف عمومی طراحی شده اند، بنابراین برای شناسایی منحصر به فرد بودن جاذبه های فردی مناسب نیستند. برای غلبه بر این محدودیت ها، کانگ و همکاران. و یون و کانگ تصاویر را با ایجاد یک دسته بندی عکس گردشگری با توجه به یک منطقه خاص و آموزش مدل با مجموعه داده های آموزشی برای هر دسته تجزیه و تحلیل کردند [ 21 ، 22 ].
اگرچه این مطالعات موجود نتایج ارزشمندی را با ترکیب عکسهای UGC و یک مدل یادگیری عمیق برای استخراج تصاویر مقصد گردشگری ارائه کردهاند، اما مطالعات هنوز در مراحل ابتدایی خود هستند. به طور خاص، مطالعات در مورد استخراج ویژگی های متمایز جاذبه های گردشگری فردی محدود است. آنها بر تجزیه و تحلیل TDI یک ملت یا یک شهر به جای جاذبه های گردشگری فردی متمرکز شده اند. در حالی که آنها تا حدی جاذبههای توریستی منفرد موجود در منطقه را بررسی میکنند، دستهبندیهای آنها برای طبقهبندی عکس که بر اساس مقیاس ملی یا مقیاس شهری است، برای کشف ویژگیهای منحصربهفرد جاذبههای گردشگری فردی مناسب نیست.
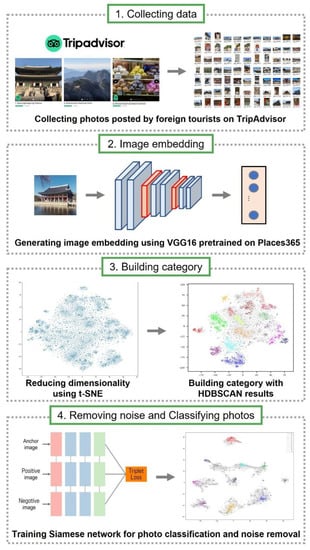
برای حل این مشکل، روشی را برای ساخت خودکار دستهها برای طبقهبندی عکس با استفاده از خوشهبندی و شبکه سیامی پیشنهاد میکنیم. این امر بار فرآیند ایجاد دسته بندی های مربوط به هر جاذبه گردشگری را کاهش می دهد. علاوه بر این، روش خوشهبندی مزیت ایجاد مقولهها را بر اساس شیوهای مبتنی بر دادهها فراهم میکند. چارچوب ما از چهار بخش زیر تشکیل شده است. ابتدا عکس های تریپ ادوایزر را در بررسی های ارسال شده توسط گردشگران خارجی در سئول جمع آوری کردیم. دوم، ما تصاویر جداگانه را به عنوان بردارهای 512 بعدی با استفاده از یک شبکه VGG16 از قبل آموزش دیده با Places365 جاسازی کردیم و این بردارها را با t-SNE به دو بعدی کاهش دادیم. سوم، ایجاد یک دسته بر اساس محتوای بصری که اغلب در عکس های گرفته شده توسط گردشگران ظاهر می شود. خوشه ها از طریق تجزیه و تحلیل HDBSCAN استخراج شدند و آنها یک دسته تصویر از یک جاذبه تنظیم شدند. در نهایت، یک شبکه سیامی برای حذف عکسهای نویز درون خوشه و طبقهبندی عکسها بر اساس دستهبندی اعمال شد.
2. بررسی ادبیات
2.1. تجزیه و تحلیل جاذبه های گردشگری با استفاده از عکس های UGC
با محبوبیت دستگاه های تلفن همراه و ظهور پلتفرم های رسانه های اجتماعی، تصاویر جاذبه های گردشگری از طریق عکس ها و روایت های به اشتراک گذاشته شده به صورت آنلاین شکل می گیرند. تصاویر به اشتراک گذاشته شده از جاذبه های گردشگری به طور مداوم از فردی به فرد دیگر درک و بازتولید می شوند [ 12 ]. از آنجایی که محتوای ارسال شده در پلتفرم های رسانه های اجتماعی در معرض دید بسیاری از افراد قرار می گیرد، آنها تمایل دارند به مقاصد یا جاذبه هایی سفر کنند که اغلب در SNS ظاهر می شوند. این تصاویر بصری به DMO ها اجازه می دهد تا بینشی در مورد رفتارها و ادراکات گردشگران برای بازاریابی کسب کنند. در مقایسه با ابزارهای بازاریابی موجود، این نوع بازاریابی به عنوان یک ابزار مؤثر شناخته می شود که به سرعت بر فرآیند تصمیم گیری یک گردشگر تأثیر می گذارد و در عین حال هزینه ها را کاهش می دهد [ 13 ].]. با توجه به ارزش این گونه عکس ها، مطالعات روزافزونی در صدد تحلیل عکس های گرفته شده توسط گردشگران و کشف عوامل جذاب مقاصد گردشگری است. قبل از ظهور روش یادگیری عمیق در زمینه گردشگری، روش غالب در تجزیه و تحلیل عکس ها مشاهده مستقیم آنها یک به یک است که یک روش دستی است. آگوستی و همکاران و دین فرآیند شکل گیری تصویر گردشگری در یک منطقه خاص را از طریق تجزیه و تحلیل این عکس ها شناسایی کردند [ 1 ، 12 ]. استپچنکووا و همکاران تفاوت بین تصویر تولید شده توسط گردشگران و تصویر ارائه شده توسط DMO ها را تجزیه و تحلیل کرد [ 14]. در مورد مشاهده مستقیم بصری، که نیاز به یک فرآیند کار فشرده دارد، تجزیه و تحلیل جامع مقاصد گردشگری دشوار است زیرا محدودیتی برای حجم عکس های قابل تجزیه و تحلیل وجود دارد. علاوه بر این، محدودیت دیگری نیز وجود دارد که نتایج تحقیق ممکن است به محققین وابسته باشد.
با توسعه سریع فناوریهای بینایی کامپیوتری و پردازش تصویر در سالهای اخیر، مطالعات متعددی که حجم زیادی از عکسها را با استفاده از مدلهای یادگیری عمیق تجزیه و تحلیل میکنند، در زمینه گردشگری در حال ظهور هستند. اکثر مطالعات از یک شبکه عصبی کانولوشن (CNN) برای حل مشکل طبقه بندی تصویر استفاده کرده اند. این مطالعات عکسها را بر اساس دستهبندیهای خاص طبقهبندی کرده و ادراک گردشگران از مناطق خاص را بر اساس نسبتهای طبقهبندی آنها آشکار کرده است.
اکثر مطالعات عکس های توریستی را با استفاده از یک مدل از پیش آموزش دیده با Places365 تجزیه و تحلیل کردند که یک مجموعه داده تخصصی در مسائل طبقه بندی مکان است [ 15 ، 16 ، 17 ، 18 ، 19 ، 20 ]. با این حال، طبق گفته کیم و همکاران، هنگام استفاده از یک مدل از پیش آموزشدیده، مشکل طبقهبندی اشتباه اشیاء یا صحنههای منحصربهفردی وجود دارد که در عکسهای جاذبههای گردشگری محلی ظاهر میشوند [ 17 ].]. برای غلبه بر این محدودیت، مطالعات دیگری که مدلها را به مجموعه دادههای آموزشی تخصصی در زمینههای تحقیقاتی منتقل کردهاند، پدید آمدهاند. کانگ و همکاران و یون و کانگ تصاویر گردشگری را در یک منطقه خاص از طریق یادگیری انتقالی یک مدل یادگیری عمیق پس از ساخت دستهها و مجموعه دادههای تخصصی در آن منطقه بدون استفاده از یک مدل از پیش آموزشدیده تجزیه و تحلیل کردند [ 21 ، 22 ]. این مطالعات که از دستهبندیها برای طبقهبندی تصاویر گردشگری استفاده کردهاند، از این نظر محدودیتهایی دارند که تشخیص درست ویژگیهای جاذبههای گردشگری محلی دشوار است و ساخت مجموعه دادههای آموزشی به صورت دستی زمان و تلاش زیادی میبرد.
2.2. کاربرد تعبیه و خوشه بندی تصویر مبتنی بر یادگیری عمیق
خوشه بندی، یکی از متدولوژی های یادگیری بدون نظارت نماینده، ما را قادر می سازد تا الگوها و ساختارهای پنهان در داده ها را کشف کنیم. برای انجام تجزیه و تحلیل خوشهبندی، فرآیند استخراج ویژگیهای تصویر و تبدیل آنها به بردار مورد نیاز است. قبل از ظهور روش یادگیری عمیق، الگوریتمهای جاسازی تصویر که نقاط مشخصه ثابت را از تصویر استخراج میکنند، مانند تبدیل ویژگی تغییرناپذیر مقیاس (SIFT)، ویژگیهای قوی سریع (SURF)، و ویژگیهای ابتدایی مستقل باینری قوی (BRIEF)، در این فرآیند استفاده شده است [ 23]. با توسعه سریع فناوری بینایی کامپیوتری، رمزگذارهای خودکار مبتنی بر CNN و مدل تعبیهشده مبتنی بر شبکه CNN به طور گسترده مورد استفاده قرار گرفتهاند. روشهای اخیر، تصاویر را از طریق نقشههای ویژگی در شبکه CNN که از قبل روی مجموعه دادههای خاصی مانند Places365 یا ImageNet آموزش دیدهاند، به بردار تبدیل میکنند [ 24 ]. خوشه بندی تصویر راهی برای کشف ساختارها یا الگوهای پنهان داده در زمینه های مختلف فراهم می کند.
تاپسوی و همکاران چهره های تعبیه شده بر اساس یک مدل یادگیری عمیق برای تعیین تعداد کاراکترهای ظاهر شده در ویدیو، سپس تعداد خوشه ها را از طریق تجزیه و تحلیل خوشه سلسله مراتبی شناسایی و تعداد کاراکترها را استخراج کرد [ 25 ]. گو و همکاران گرایشهای مد نیویورک را با جاسازی تصاویر مد خیابانی و بهکارگیری خوشهبندی سلسله مراتبی تجمعی بر حسب سال شناسایی کرد [ 26 ]. Castellano و Vessio تصویر اثر هنری را با شبکه DenseNet121 به یک بردار ویژگی تبدیل کردند، خوشهبندی K-means و رمزگذار خودکار را برای یافتن خوشه اعمال کردند و سبک نقاشی اثر هنری را از طریق نتایج خوشه تجزیه و تحلیل کردند [ 27 ].
2.3. کاربرد شبکه سیامی با جاسازی تصویر
شبکه Siamese به ویژه در تحقیقات مراقبت های پزشکی، چاپ کف دست، تشخیص چهره، ردیابی اشیا و غیره استفاده می شود که در آن به دست آوردن حجم زیادی از داده ها دشوار است. برای حل این مشکلات از شبکه Siamese استفاده شده است. هنگامی که دو یا چند تصویر ورودی داده می شود، شبکه Siamese شباهت بین آنها را می آموزد و آن را به صورت فاصله عددی بیان می کند. یعنی اگر تصاویر ورودی شبیه به هم باشند فاصله نزدیک است و اگر تصاویر ورودی متفاوت باشد فاصله دور می شود. همین اصل را می توان برای طبقه بندی تصاویر در زمینه های مختلف اعمال کرد.
شروف و همکاران یک مدل FaceNet که با از دست دادن سه گانه برای تشخیص چهره بر اساس ساختار شبکه سیامی آموخته شده بود [ 28 ]. مدل FaceNet یک تصویر چهره ورودی را در 128 بعد جاسازی میکند و سپس بین عکسهای صورت یک فرد و عکسهایی که این کار را نمیکنند، از طریق فاصله بین بردارهای تعبیهشده تمایز قائل میشود. ژونگ و همکاران یک مدل تشخیص چاپ کف دست با استفاده از شبکه سیامی مبتنی بر شبکه VGG16 [ 29 ] توسعه داد.]. در این مطالعه، آنها از شبکه سیامی برای تبدیل یک تصویر متنی طولانی که به عنوان داده ورودی داده شده است به یک بردار 500 بعدی استفاده کردند و فواصل بین دو بردار تصویر متن طولانی را برای تعیین یکسان بودن آنها مقایسه کردند. محمود و همکاران مدلی برای تشخیص زودهنگام آلزایمر با استفاده از شبکه سیامی مبتنی بر شبکه VGG-16 [ 30 ] ایجاد کرد. آنها مدلی را با استفاده از مجموعه داده های MRI که بر اساس شدت آلزایمر به چهار نوع طبقه بندی شده بود آموزش دادند و با مقایسه فاصله بین جاسازی ها، پیشرفت آلزایمر را طبقه بندی کردند. برتینتو و همکاران یک مدل ردیابی شی را بر اساس شبکه سیامی توسعه داد [ 31]. آنها تصویری را که شامل شی مورد ردیابی و تصویری برای یافتن شیء است را در شبکه سیامی جاسازی کردند و با مقایسه شباهت بین جاسازیها، مکان یک شی خاص را در تصویر شناسایی کردند. به این ترتیب، این مطالعات به طور گسترده مورد استفاده قرار می گیرند، به ویژه در مواردی که ایمن کردن مجموعه داده های کافی مانند چاپ طولانی کف دست، تشخیص چهره و تشخیص بیماری دشوار است. حتی در زمینه گردشگری، اگر مقیاس هدف تحقیق به یک منطقه توریستی خاص محدود شود، ممکن است تامین اطلاعات کافی دشوار باشد. بنابراین، این مطالعه همچنین قصد دارد از مدل شبکه سیامی برای بهبود عملکرد طبقهبندی با مجموعه دادههای حجم نسبتاً کم استفاده کند.
3. مواد و روشها
3.1. فرآیند تحقیق
فرآیند تحلیل این مطالعه در شکل 1 نشان داده شده است . ابتدا عکسهای ارسال شده در تریپ ادوایزر را استخراج کردیم و سپس عکسهای ارسال شده توسط گردشگران خارجی را انتخاب کردیم، بدون در نظر گرفتن کرهایهایی که از کشور مبدا ناشر و زبان استفاده شده در نوشتن نقد استفاده میکردند. دوم، با استفاده از یک شبکه VGG16 که از قبل روی مجموعه داده Places365 آموزش داده شده بود، تصاویر منفرد را به عنوان بردارهای ویژگی 512 بعدی جاسازی کردیم. سوم، هر بردار را با t-SNE به دوبعدی کاهش دادیم، از HDBSCAN برای خوشهبندی این عکسها استفاده کردیم و آن را به عنوان یک دسته تصویر تنظیم کردیم. چهارم، ما از شبکه Siamese برای حذف تصاویر نویز موجود در دستهها و طبقهبندی عکسها بر اساس دستهبندی استفاده کردیم.
3.2. جمع آوری داده ها
تریپادوایزر ( www.tripadvisor.com ، قابل دسترسی در 19 سپتامبر 2021) بزرگترین پلت فرم اطلاعات سفر در جهان با بیش از 260 میلیون کاربر ماهانه است [ 32 ]]. تریپ ادوایزر نظراتی را ارائه می دهد که توسط بازدیدکنندگان از جاذبه های گردشگری، هتل ها و رستوران های سراسر جهان نوشته شده است. هنگامی که وارد تریپ ادوایزر می شوید و کشور یا شهر را جستجو می کنید، می توانید اطلاعاتی در مورد جاذبه های گردشگری محبوب، اقامتگاه ها، رستوران ها و فعالیت های آن منطقه پیدا کنید. اگر مردم سئول را در تریپ ادوایزر جستجو کنند، می توانند فهرستی از جاذبه های گردشگری معروف سئول را تحت عنوان «جاذبه های برتر در سئول» بیابند. اگر مردم بر روی هر جاذبه گردشگری کلیک کنند، می توانند نظرات ارسال شده توسط گردشگرانی که از جاذبه های گردشگری بازدید کرده اند را بررسی کنند. در هر بررسی، آنها می توانند نام مستعار کاربر، منطقه مبدا، تعداد پست ها، رتبه بندی ستاره ها، عنوان نقد، تاریخ بازدید، نوع بازدید، متن متنی، عکس های پیوست شده و تاریخ ایجاد را شناسایی کنند. در این مطالعه، ما نظرات “کاخ Gyeongbokgung” و “Insadong” را با استفاده از Python جمعآوری کردیم و عکسهای پیوست شده به بررسی، تاریخ بازدید و دادههای ملیت ناشر را جمعآوری کردیم. «کاخ گیونگبوکگونگ» یک کاخ متعلق به سلسله چوسون است که در مرکز شهر قرار دارد و یکی از پربازدیدترین مکانهای گردشگران خارجی است. «اینسادونگ»، منطقهای متمایز با ترکیبی از گالریها، رستورانهای سنتی، ساختمانهای مدرن و خیابانهای خرید، نیز مکانی محبوب برای گردشگران خارجی است. در این مطالعه، ما فقط عکس های ارسال شده توسط گردشگران خارجی را با استفاده از فیلتر زبان و اطلاعات مبدا بازدیدکنندگان انتخاب کردیم. از آنجایی که تعداد گردشگران ورودی در سال 2020 به دلیل COVID-19 به شدت کاهش یافت، همه داده های قبل از سال 2020 استفاده شد. «کاخ گیونگبوکگونگ» یک کاخ متعلق به سلسله چوسون است که در مرکز شهر قرار دارد و یکی از پربازدیدترین مکانهای گردشگران خارجی است. «اینسادونگ»، منطقهای متمایز با ترکیبی از گالریها، رستورانهای سنتی، ساختمانهای مدرن و خیابانهای خرید، نیز مکانی محبوب برای گردشگران خارجی است. در این مطالعه، ما فقط عکس های ارسال شده توسط گردشگران خارجی را با استفاده از فیلتر زبان و اطلاعات مبدا بازدیدکنندگان انتخاب کردیم. از آنجایی که تعداد گردشگران ورودی در سال 2020 به دلیل COVID-19 به شدت کاهش یافت، همه داده های قبل از سال 2020 استفاده شد. «کاخ گیونگبوکگونگ» یک کاخ متعلق به سلسله چوسون است که در مرکز شهر قرار دارد و یکی از پربازدیدترین مکانهای گردشگران خارجی است. «اینسادونگ»، منطقهای متمایز با ترکیبی از گالریها، رستورانهای سنتی، ساختمانهای مدرن و خیابانهای خرید، نیز مکانی محبوب برای گردشگران خارجی است. در این مطالعه، ما فقط عکس های ارسال شده توسط گردشگران خارجی را با استفاده از فیلتر زبان و اطلاعات مبدا بازدیدکنندگان انتخاب کردیم. از آنجایی که تعداد گردشگران ورودی در سال 2020 به دلیل COVID-19 به شدت کاهش یافت، همه داده های قبل از سال 2020 استفاده شد. همچنین مکانی محبوب برای گردشگران خارجی است. در این مطالعه، ما فقط عکس های ارسال شده توسط گردشگران خارجی را با استفاده از فیلتر زبان و اطلاعات مبدا بازدیدکنندگان انتخاب کردیم. از آنجایی که تعداد گردشگران ورودی در سال 2020 به دلیل COVID-19 به شدت کاهش یافت، همه داده های قبل از سال 2020 استفاده شد. همچنین مکانی محبوب برای گردشگران خارجی است. در این مطالعه، ما فقط عکس های ارسال شده توسط گردشگران خارجی را با استفاده از فیلتر زبان و اطلاعات مبدا بازدیدکنندگان انتخاب کردیم. از آنجایی که تعداد گردشگران ورودی در سال 2020 به دلیل COVID-19 به شدت کاهش یافت، همه داده های قبل از سال 2020 استفاده شد.
3.3. جاسازی تصویر
برای تجزیه و تحلیل داده های تصویر با استفاده از یادگیری عمیق، لازم است تصویر را در یک فضای تعبیه شده نگاشت کنید. در این حالت، هنگامی که یک بردار با ترتیب مقادیر پیکسلی یک تصویر اصلی در یک ردیف ایجاد میشود، تعیین شباهت بین تصاویر از طریق اندازهگیری فاصله دشوار است، زیرا بردار حالتی را که در آن الگوی بصری یکسان در مکانهای مختلف وجود دارد، منعکس نمیکند. در تصویر. به عنوان جایگزینی برای این، می توان از روشی برای استخراج الگوی بصری یک تصویر و جاسازی آن به عنوان یک وکتور استفاده کرد.
در این مطالعه، ما از یک مدل جاسازی مبتنی بر CNN استفاده کردیم که در آن بردارها با انعکاس محتوای بصری عکس تولید شدند. بنابراین، بردارهایی که محتوای بصری مشابهی دارند در فضای تعبیه نزدیک به هم قرار می گیرند و بالعکس. فاصله نزدیک بین بردارها به این معنی است که محتوای بصری تصاویر اصلی مشابه است. مدل طبقهبندی تصاویر مبتنی بر CNN تا حد زیادی به دو بخش تقسیم میشود: یکی یادگیری ویژگیهای تصاویر و دیگری طبقهبندی تصاویر بر اساس ویژگیها. اولی از یک لایه کانولوشن، یک تابع فعال سازی و یک لایه ادغام تشکیل شده است، در حالی که دومی از یک لایه کاملاً متصل و یک لایه softmax تشکیل شده است. از آنجایی که در فرآیند جاسازی نیازی به بخش دوم نیست، ما لایه کاملاً متصل در بالای مدل CNN را با یک لایه Global Max Pooling جایگزین کردیم. در این مطالعه، ما از یک شبکه VGG16 که از قبل بر روی مجموعه داده Places365 آموزش داده شده بود برای جاسازی استفاده کردیم. Places365 یک مجموعه داده معیار است که با استخراج 365 دسته از مجموعه داده های Place که در مجموع از 10 میلیون عکس تشکیل شده است، ایجاد شده است.33 ]. از آنجایی که این مطالعه سعی در تجزیه و تحلیل عکس های گرفته شده در جاذبه های گردشگری دارد، از یک مدل از پیش آموزش دیده با Places365 استفاده شد.
3.4. کاهش ابعاد و خوشه بندی
کارکردهای اصلی این فرآیند استخراج محتوای بصری است که اغلب در عکس های گرفته شده توسط گردشگران ظاهر می شود و از آنها به عنوان یک دسته بندی استفاده می کند. ابتدا با t-SNE بعد 512 را به 2 بعدی کاهش دادیم. دوم، ما از الگوریتم خوشهبندی HDBSCAN برای خوشهبندی این تعبیهها استفاده کردیم. نتایج خوشهبندی ترجیح بصری گردشگران را برای یک جاذبه گردشگری که TDI را تشکیل میدهد، نشان داد.
t-SNE یکی از روشهای غیرخطی است که برای کاهش دادههای پربعد به دو یا سه بعدی بر اساس توزیع احتمال و تجسم آن طراحی شده است [ 34 ]. این روش با تکمیل مشکلات تعبیه همسایه تصادفی [ 35 ] توسعه یافت و بر حفظ ساختار محلی هنگام کاهش ابعاد متمرکز است. در اینجا، حفظ ساختار محلی به معنای کاهش داده ها است به طوری که می توان رابطه را حتی پس از اینکه نقاطی که در بعد بالا به یکدیگر نزدیک هستند به بعد پایین پیش بینی کرد، حفظ شود. در معادله (1) نشان دهنده احتمال اشاره به داده است و موجود در ابعاد بالا با یکدیگر همسایه هستند. در معادله (2) نشان دهنده این احتمال است که و ، که نقاط کم بعدی مربوط به و ، در مجاورت یکدیگر قرار دارند. تابع هزینه t-SNE با واگرایی Kullback-Leibler محاسبه می شود، تابعی که تفاوت بین توزیع احتمال هر دو بعد بالا و پایین را در معادله (3) محاسبه می کند [ 36 ].
: احتمال مشترک که و همسایگان در ابعاد بالایی هستند
: احتمال مشترک که و همسایگان در ابعاد پایین هستند
: نقاط داده با ابعاد بالا
: نقاط داده کم بعدی همتایان و
ما از الگوریتم HDBSCAN برای شناسایی خوشه ها در فضای جاسازی و استفاده از آنها به عنوان یک دسته استفاده کردیم. HDBSCAN از خوشه بندی فضایی مبتنی بر چگالی با نویز (DBSCAN)، یک الگوریتم خوشه بندی مبتنی بر چگالی [ 37 ] تکامل یافته است. DBSCAN خوشه ای از نقاط را با چگالی معین در کل فضای نقطه داده پیدا می کند [ 38 ]. در اینجا، چگالی معین به عنوان مقدار Eps که شعاع و را نشان می دهد، تعریف می شود ، که حداقل تعداد نقاط داده موجود در Eps است. DBSCAN دو اشکال دارد، اولی حساس بودن به پارامترها و دومی این که نمی تواند خوشه هایی با چگالی متفاوت پیدا کند زیرا آستانه هایی را برای چگالی تعیین می کند. HDBSCAN الگوریتمی است که کاستی های DBSCAN را جبران می کند و مفهوم خوشه بندی سلسله مراتبی را به DBSCAN اضافه می کند. از آنجایی که HDBSCAN خوشه ها را تنها با تعریف حداقل مقدار داده بدون استفاده از مقدار ثابت Eps پیدا می کند، می تواند خوشه های مختلف با مقادیر چگالی متفاوت را استخراج کند.
3.5. حذف داده های نویز و طبقه بندی عکس ها
ممکن است به نظر برسد که نتایج خوشهبندی میتواند جایگزین طبقهبندی عکس شود زیرا خوشهها از محتوای بصری مشابهی تشکیل شدهاند. با این حال، از آنجایی که HDBSCAN بر اساس چگالی کار میکند، دقت خوشهبندی در لبه خوشهای که چگالی نسبتاً پایینی نسبت به هسته دارد پایین است. این مسئول دو مشکل است. اول، عکس های نویز که به خوشه مربوط نمی شوند ممکن است گنجانده شوند. دوم، نقاط نویز واقع در اطراف مرز خوشه ممکن است در واقع نویز نباشند.
برای رسیدگی به این مشکلات، ما یک شبکه سیامی را برای طبقه بندی عکس های آموزش دیده با مجموعه داده های خودمان که از عکس های گرفته شده در منطقه تحقیقاتی تشکیل شده است، پیاده سازی کردیم. شبکه سیامی شامل بیش از دو زیرشبکه یکسان است که قادر به یادگیری الگوها از بردارهای ورودی هستند [ 39 ]. خروجی های تولید شده از طریق یک شبکه سیامی شباهت بین تصاویر را منعکس می کند. اگرچه مدل عکسهای مختلفی را بهعنوان ورودی دریافت میکند، وزنها در زیرشبکهها بهطور یکسان بهروزرسانی میشوند، زیرا با تابع از دست دادن ترکیب میشوند. این تثبیت وزن به این معنی است که تصاویر بصری مشابه در نزدیکی یکدیگر قرار دارند و بالعکس.
در این مطالعه، از دست دادن سه گانه به عنوان تابع هزینه برای آموزش شبکه سیامی و از روش نیمه سخت در بین روش های کاوی سه گانه استفاده شد. تابع ضرر سه گانه سه نوع داده ورودی را دریافت می کند: لنگر، مثبت و منفی. سه راه برای ساخت داده های ورودی وجود دارد: سه قلوهای آسان، سه قلوهای سخت و سه قلوهای نیمه سخت. شروف و همکاران نشان داد که مدل آموزش دیده با استفاده از روش سه قلوهای نیمه سخت در بین آنها برتر است [ 28 ]. شکل 2 معماری مدل مورد استفاده در مطالعه را نشان می دهد.
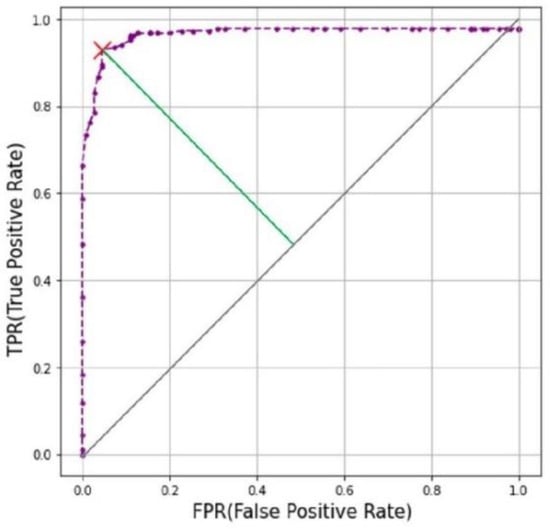
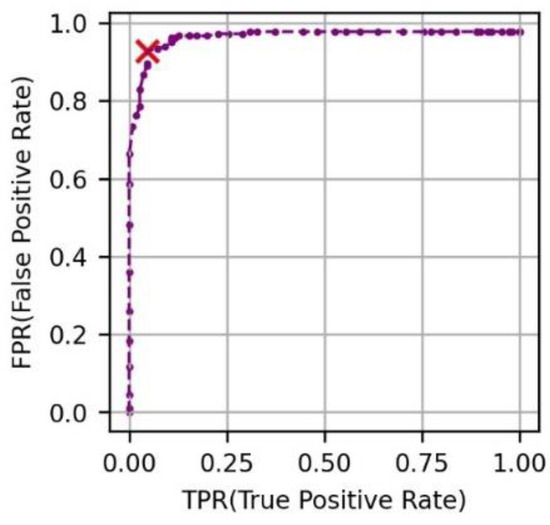
شبکه سیامی یاد می گیرد که تصاویر با محتوای بصری مشابه را در فضای برداری نزدیک به یکدیگر قرار دهد و بالعکس. بر اساس این اصل می توان عکس ها را طبقه بندی کرد و نویزها را تشخیص داد. برای این، یک مجموعه هدف، یک مجموعه نویز و یک مجموعه مرجع مورد نیاز است. مجموعه هدف مجموعهای از عکسهای هدف است که باید بر اساس موارد دستهبندی طبقهبندی و برچسبگذاری شوند. مجموعه نویز مجموعه ای از عکس های نویز است که به دسته بندی تعلق ندارند. مجموعه مرجع از نمونه تصاویر هر دسته تشکیل شده است. مجموعههای تست و مجموعههای مرجع به گونهای ساخته شد که از تعداد عکسهای مشابهی برای هر دسته تشکیل شده باشد. مجموعه نویز با تعداد عکس های مشابه مجموعه تست ساخته شده است. طبقه بندی عکس و حذف نویز از طریق چهار مرحله زیر انجام می شود: اول، فاصله بین عکس هدف و عکس متعلق به مجموعه مرجع به ترتیب محاسبه می شود. دوم، برچسب پیشبینی تصویر هدف به عنوان برچسب عکس مرجع با حداقل فاصله در معادله (4) اختصاص داده میشود. این فرآیندها برای تمام تصاویر هدف تکرار می شوند. سوم، فاصله بین یک عکس نویز و عکس متعلق به مجموعه مرجع به ترتیب محاسبه می شود. این مرحله برای همه عکسهای موجود در مجموعه نویز تکرار میشود. در نتیجه، عکس های نویز را می توان با تعیین آستانه برای حداقل فاصله حذف کرد. چهارم، دقت پیشبینی با تغییر حداقل آستانه فاصله با استفاده از منحنی ROC ارزیابی شد. آستانه نقطه نشان دهنده بهترین دقت انتخاب شد. منحنی ROC نموداری است که نشان می دهد چگونه عملکرد سیستم طبقه بندی با توجه به آستانه های مختلف تغییر می کند. در این مطالعهمحورهای X و Y منحنی ROC عبارتند از نرخ مثبت واقعی (TPR) و نرخ مثبت کاذب (FPR). TPR درصد مواردی است که برچسب واقعی با برچسب پیش بینی شده در هدف تعیین شده در معادله (5) مطابقت دارد. FPR درصد مواردی است که نویز در معادله (6) به عنوان نویز طبقه بندی نشده است. آستانه بهینه مقدار دورترین نقطه از Y = X در بین نقاط روی منحنی ROC در شکل 3 است.
: برچسب پیش بینی شده روی عکس مورد نظر
t : جاسازی تصویر یک تصویر هدف
: تعبیه از تصویر نمونه از آیتم دسته .
: تابع فاصله اقلیدسی بین و
: برچسب واقعی یک عکس
: برچسب پیش بینی شده یک عکس
شکل 3. مثالی از منحنی ROC.
4. نتایج
4.1. کاخ Gyeongbokgung
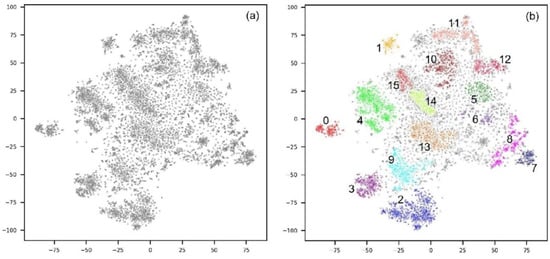
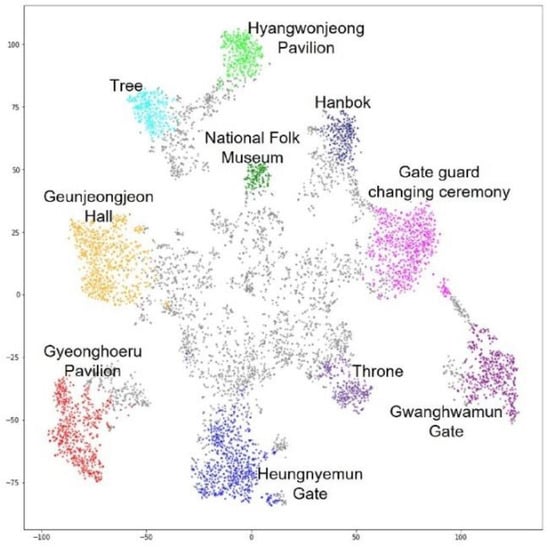
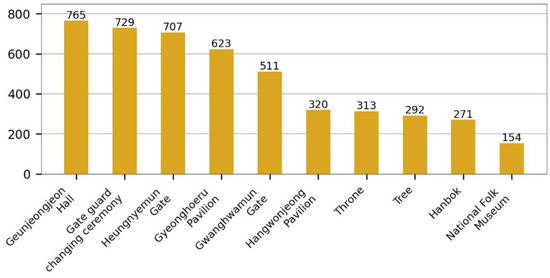
در مجموع 9940 عکس در 10655 بررسی ثبت شده در تریپ ادوایزر در صفحه ‘کاخ Gyeongbokgung’ جمع آوری شد. از مجموع 9940 عکس، 8188 عکس را انتخاب کردیم به جز 715 بررسی که به زبان کره ای نوشته شده بودند. یک مدل VGG16 که از قبل با Places365 آموزش داده شده بود، هر عکس را در یک بردار 512 بعدی جاسازی کرد و t-SNE وکتورها را به دو بعدی کاهش داد. ما HDBSCAN را برای خوشهبندی این بردارها در چندین گروه پیادهسازی کردیم. نتیجه در شکل 4 نشان داده شده است و تعداد عکس ها برای هر خوشه در جدول 1 نشان داده شده است . 16 خوشه ایجاد شد و 3824 نقطه به عنوان نویز طبقه بندی شد.
پس از بررسی عکس ها در هر خوشه، دو اقدام انجام دادیم. اول، اگر بیش از دو خوشه وجود داشت که حاوی محتوای بصری یکسانی بود، آنها را در یکی ادغام کردیم. ثانیاً، اگر هیچ شباهتی بین تصاویری که یک خوشه را تشکیل می دادند وجود نداشت، آن خوشه حذف می شد زیرا در نظر گرفتن آنها به عنوان یک خوشه معنادار دشوار است. خوشه های 7 و 8 در یک خوشه ادغام شدند زیرا هر دو از عکس های “تخت” تشکیل شده بودند. خوشههای 10 و 12 نیز در یک خوشه ترکیب شدند، زیرا هر دو شامل عکسهایی از «مراسم تعویض نگهبان دروازه» بودند. خوشه های 14 و 15 نیز در یک خوشه ادغام شدند زیرا هر دو از عکس های “دروازه هئونگنیمون” به یک شکل تشکیل شده بودند. از سوی دیگر، خوشه های 11، 12 و 13 برای ایجاد یک دسته استفاده نشدند، زیرا هر خوشه از عکس های متفاوتی تشکیل شده بود.
شبکه Siamese ما را قادر می سازد تا عکس ها را بر اساس دسته بندی قبلی تولید شده طبقه بندی کنیم و عکس های نویز را حذف کنیم. برای این منظور، ما یک شبکه سیامی مبتنی بر شبکه VGG16 را با استفاده از مجموعه داده عکس قصر Gyeongbokgung آموزش دادیم. در این فرآیند، مجموعه داده آموزشی از عکسهای هر خوشه به جز عکسهایی که به اشتباه در خوشهها گنجانده شده بودند، تشکیل شد. جدول 2 تعداد عکس های موجود در مجموعه داده های آموزشی را برای هر دسته نشان می دهد.
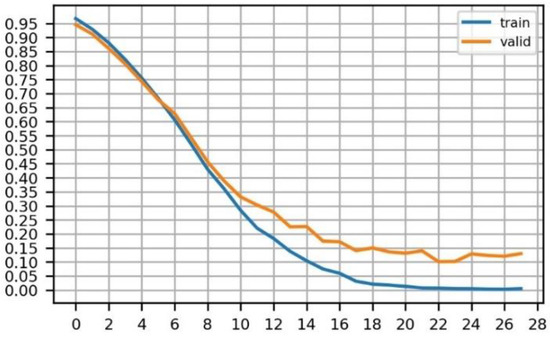
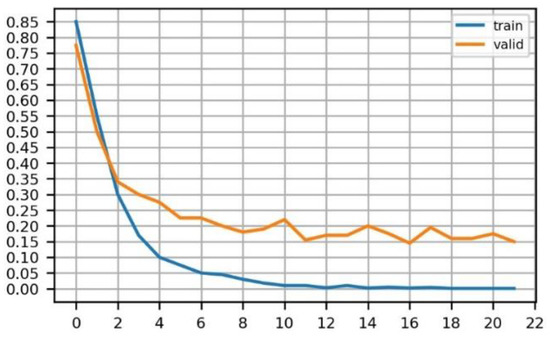
برای بهبود توانایی مدل برای استخراج الگو از طریق غیر خطی، دو لایه کانولوشن به ساختار اصلی شبکه VGG16 اضافه شد. مدل مورد استفاده در این فرآیند دارای وزنه هایی بود که از قبل روی Places365 آموزش داده شده بودند. این وزن ها با مجموعه داده های خود ما به خوبی تنظیم شده بودند. شکل 5 تغییر مقدار ضرر را در فرآیند آموزش مدل نشان می دهد. برای جلوگیری از برازش بیش از حد، ما مدل را تا دوره 18 آموزش دادیم.
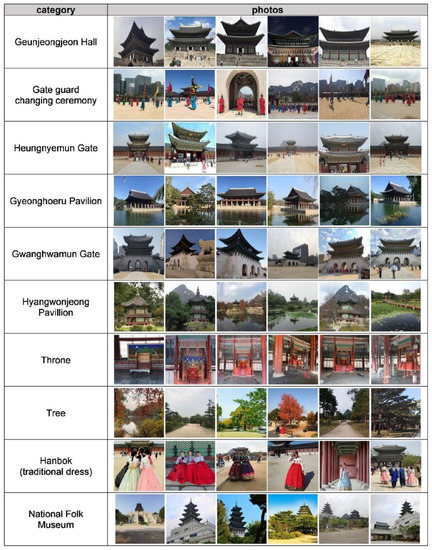
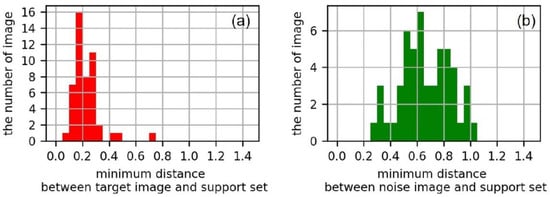
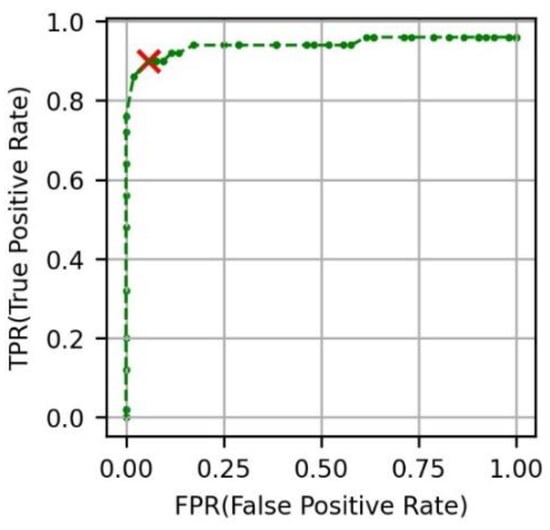
برای حذف عکس های نویز، لازم بود مقدار آستانه بهینه از منحنی ROC شناسایی شود. شکل 6 a حداقل فاصله بین عکس هدف و مجموعه مرجع را به عنوان هیستوگرام نشان می دهد. شکل 6 ب حداقل فاصله بین عکس هدف و مجموعه مرجع را به عنوان هیستوگرام نشان می دهد. شکل 7 منحنی ROC را نشان می دهد و 0.4 که آستانه دورترین نقطه از Y = X است که با رنگ قرمز X در نمودار نشان داده شده است، به عنوان مقدار بهینه انتخاب شد. شکل 7 نیز نشان می دهد که TPR 0.928 و FPR 0.045 بوده که مربوط به دقت مدل است. در مقایسه با شکل 4 ب، شکل 8نشان می دهد که نقاط داده متعلق به یک خوشه به هم نزدیک بوده و فاصله بین خوشه های مختلف از هم دورتر بوده است. شکل 9 و شکل 10 به ترتیب تعداد عکسها و عکسهای نمونه را نشان میدهند که در نهایت بر اساس موارد در یک دسته طبقهبندی شدهاند.
4.2. اینسادونگ
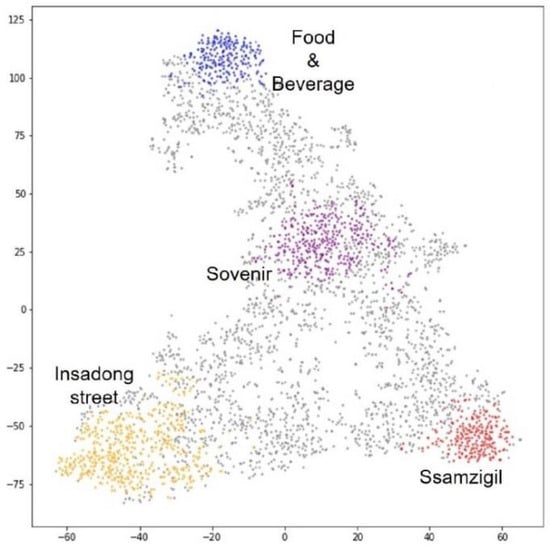
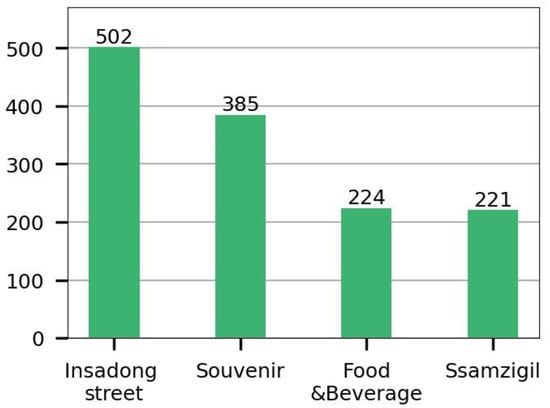
6410 نظر در صفحه “اینسادونگ” تریپ ادوایزر ثبت شده است. از این تعداد، 3695 عکس از 5915 نقد نوشته شده به زبان خارجی جمع آوری شد. هر عکس به عنوان یک بردار 512 بعدی تعبیه شد، با استفاده از t-SNE به دو بعد کاهش یافت و با استفاده از HDBSCAN خوشهبندی شد. شکل 11 نتیجه را نشان می دهد و جدول 3 تعداد عکس ها را برای هر خوشه نشان می دهد. از مجموع 3659 نقطه، 2568 به عنوان نویز طبقه بندی شدند و 5 خوشه در شکل 11 ایجاد شد.ب از آنجایی که 134 عکس متعلق به خوشه 4 نشان دهنده محتویات بصری مختلف مانند نشانه ها، سوغاتی ها، نقاشی های دیواری، پرتره ها و غذا است، این خوشه در رده ساختمان در نظر گرفته نشد. در نهایت چهار دسته به شرح زیر ایجاد شد: “Ssamzigil”، “خیابان Insadong”، “غذا و نوشیدنی” و “Souvenir”.
شبکه سیامی برای طبقه بندی عکس ها بر اساس دسته بندی های قبلی تولید شده و حذف عکس های نویز استفاده شد. برای این منظور، شبکه سیامی را بر روی مجموعه داده عکس Insadong آموزش دادیم. در این زمان، مجموعه داده های آموزشی با استفاده از عکس های تشکیل شده از هر خوشه به جز عکس هایی که به اشتباه در خوشه ها گنجانده شده بودند، سازماندهی شد. جدول 4 تعداد عکس های موجود در مجموعه داده های آموزشی را برای هر دسته نشان می دهد. مدل مورد استفاده در Insadong نیز بر اساس شبکه VGG16 بود. با این حال، بر خلاف مدل مورد استفاده در “کاخ Gyeongbokgung”، ما چهار لایه بالایی مدل را بدون لایه های کانولوشن اضافی تنظیم کردیم. از آنجایی که ‘Insadong’ مجموعه داده آموزشی کوچکتری نسبت به ‘Gyeongbokgung Palace’ داشت، ممکن است بیش از حد برازش ایجاد شود. شکل 12تغییر ارزش تلفات را در طول آموزش مدل نشان می دهد و مدل آموزش دیده تا دوره 10 برای جلوگیری از برازش بیش از حد استفاده شد.
برای حذف عکسهای نویز موجود در دسته، مقدار آستانه بهینه را از طریق منحنی ROC بررسی کردیم. شکل 13 a حداقل فاصله بین مجموعه تست و مجموعه مرجع را به صورت هیستوگرام نشان می دهد. شکل 13 ب حداقل فاصله بین مجموعه نویز و مجموعه مرجع را به صورت هیستوگرام نشان می دهد. شکل 14 منحنی ROC را نشان می دهد و 0.32، مقدار آستانه دورترین نقطه از Y = X، مربوط به X قرمز روی نمودار، به عنوان مقدار بهینه انتخاب شده است. شکل 14 نیز نشان می دهد که TPR 0.90 و FPR 0.057 بوده که مربوط به دقت مدل است. شکل 15 مدل آموزش دیده و نقاط داده طبقه بندی شده بر اساس آستانه را نشان می دهد. در مقایسه با شکل 11ب، شکل 15 نشان می دهد که نقاط داده متعلق به یک خوشه به یکدیگر نزدیک بوده و فواصل بین خوشه های مختلف از هم دورتر بوده است. شکل 16 و شکل 17 به ترتیب تعداد عکس ها و نمونه عکس ها را که در نهایت بر اساس دسته بندی طبقه بندی شده اند نشان می دهد.
5. بحث و نتیجه گیری
از آنجایی که ارزش عکس های ارسال شده توسط گردشگران در حوزه گردشگری اهمیت بیشتری پیدا می کند، رویکردهای جدیدی برای تجزیه و تحلیل عکس های توریستی با استفاده از فناوری یادگیری عمیق در حال تلاش است. روشهای تحقیقی که عکسهای گردشگری را با استفاده از فناوری یادگیری عمیق اخیر تجزیه و تحلیل میکنند، دوگانه هستند. روش اول این است که تصاویر گردشگری پس از طبقه بندی عکس های توریستی توسط دسته بندی های طبقه بندی عکس های از پیش تعیین شده مانند Places365 یا ImageNet تجزیه و تحلیل می شوند. روش دوم این است که تصاویر گردشگری با توجه به دسته بندی عکس های گردشگری که در مقیاس شهری یا ملی ایجاد شده است، تجزیه و تحلیل می شوند. در مورد اول، نقصی وجود دارد که عکسهای منحصربهفرد که در جاذبههای گردشگری خاص ظاهر میشوند را نمیتوان به درستی با دستهبندی طراحیشده برای اهداف عمومی طبقهبندی کرد. در مورد دوم،
هدف از این مطالعه پیشنهاد روشی برای ساخت خودکار یک دسته برای هر جاذبه با خوشهبندی عکسها و طبقهبندی آنها با شبکه سیامی، به جای طبقهبندی آنها به دستههای از پیش تعیینشده است. علاوه بر این، این مطالعه سعی دارد اعتبار روش پیشنهادی را با اعمال آن در دو جاذبه گردشگری معرف در سئول تأیید کند. این مطالعه چهار مرحله برای روشن کردن روش طبقهبندی عکس برای هر جاذبه گردشگری و تأیید اعتبار آن دارد. ابتدا عکسهای توریستی پیوست شده به نظرات ارسال شده توسط گردشگران خارجی در تریپ ادوایزر را جمعآوری کردیم. دوم، با استفاده از شبکه VGG16 که با Places365 از قبل آموزش داده شده بود، عکسها را بهعنوان بردار ویژگی در ابعاد 512 جاسازی کردیم و با استفاده از t-SNE آنها را به 2 بعد کاهش دادیم. سوم، برای ایجاد دستهبندی بر اساس محتوای بصری که اغلب در عکسهای گرفته شده توسط گردشگران ظاهر میشود، خوشهها از طریق تجزیه و تحلیل HDBSCAN استخراج شدند و به عنوان دستهبندی تصویری یک جاذبه تنظیم شدند. چهارم، ما نویزهای موجود در خوشه را از طریق شبکه سیامی حذف کردیم و با تأیید تعداد عکس های طبقه بندی شده در هر دسته، تصویر جاذبه های گردشگری را تجزیه و تحلیل کردیم.
با استفاده از روش پیشنهادی در این مطالعه، عکسهای Tripadvisor ارسال شده توسط گردشگران خارجی در “کاخ Gyeongbokgung” و “Insadong” در سئول، کره تجزیه و تحلیل شدند. کاخ Gyeongbokgung کاخی است که در زمان سلسله چوسون ساخته شده است و یکی از جاذبههای گردشگری معرف واقع در مرکز شهر سئول است. در کاخ Gyeongbokgung، 10 دسته به شرح زیر ایجاد شد: “تالار Geunjeongjeon”، “Gyeonghoeru Pavilion”، “Gyeongnyemun Gate”، “Hyangwonjeong”، “National Folk Museum”، “Trone”، “Hanbok (لباس سنتی کره ای)”، مراسم تعویض نگهبان دروازه و «درخت» «دروازه گوانگوامون». از این طریق میتوان بررسی کرد که کدام تصاویر مقصد «کاخ گیونگبوکگونگ» مورد علاقه گردشگران خارجی است. ‘اینسادونگ’ همچنین یکی از جاذبه های گردشگری در مرکز شهر سئول است. اینسادونگ منطقهای است که به عنوان مرکز نمایشگاهی برای هنرهای سنتی کرهای، عتیقهجات و سرامیکهای قدیمی شناخته میشود که نسل به نسل منتقل شدهاند. در اینسادونگ، چهار دسته ایجاد شد: “Ssamzigil”، “خیابان اینسادونگ”، “غذا و نوشیدنی” و “سوغاتی”. از این طریق می توان تشخیص داد که چه تصاویری از اینسادونگ مورد علاقه گردشگران خارجی است.
این مطالعه در سه جنبه زیر از مطالعات موجود متمایز می شود. اول، از آنجایی که ما بر اساس نتایج خوشهبندی دستهبندی میکنیم، ویژگیهایی که مقاصد گردشگری را جذاب میکنند، میتوانند به طور خاص و انعطافپذیرتر به شیوهای مبتنی بر داده شناسایی شوند. دوم، از آنجایی که ما نتایج تجزیه و تحلیل خوشهبندی را به عنوان دستهها تنظیم میکنیم، نیازی به ساخت دستی مجموعه داده آموزشی نیست. سوم، برای رسیدگی به کمبود داده، از یک شبکه سیامی استفاده میکنیم که میتواند عملکرد طبقهبندی را با مجموعه دادههای حجم نسبتاً کمی بهبود بخشد. در مورد حوزه گردشگری، اگر منطقه تحقیقاتی به یک جاذبه گردشگری خاص محدود شود، ممکن است محدودیتی برای مقدار داده های قابل استفاده وجود داشته باشد. با این حال، از آنجایی که داده های مورد استفاده در این مطالعه، عکس های ارسال شده در تریپ ادوایزر است، این احتمال وجود دارد که عکس های مختلف کمتر با هم ترکیب شوند زیرا دسته بندی ها به مقاصد گردشگری، جاذبه های گردشگری و فعالیت ها تقسیم می شوند. بنابراین، لازم است عکس های ارسال شده در تریپ ادوایزر را با عکس های سایر سایت های SNS که احتمالاً عکس های مختلفی را برای همان منطقه ارسال می کنند، مقایسه کنید. علاوه بر این، لازم است یک دسته ایجاد شده توسط روش پیشنهادی با یکی از روشهای موجود پیشنهاد شده توسط مطالعات قبلی مقایسه شود، که عکسهای توریستی را بر اساس دستههای عکس از پیش تعریفشده با استفاده از Places365 یا ImageNet طبقهبندی میکند.








بدون دیدگاه