

در علوم سیستم زمین (ESS)، داده های مکانی به طور فزاینده ای برای تحقیقات تاثیر و تصمیم گیری استفاده می شود. برای حمایت از تصمیم ذینفعان، کیفیت داده های مکانی و تضمین آن نقش عمده ای ایفا می کند. ما مفاهیم و یک گردش کار را برای اطمینان از کیفیت دادههای ESS ارائه میکنیم. مفاهیم و گردش کار ما در طول چرخه عمر داده های تحقیق طراحی شده و شامل معیارهایی برای باز بودن، عادلانه بودن داده ها (قابل یافتن، در دسترس بودن، قابلیت همکاری، قابل استفاده مجدد)، بلوغ داده ها و کیفیت داده ها است. مفاهیم بلوغ داده های موجود، ماتریس های بلوغ (خاص جامعه) را توصیف می کنند، به عنوان مثال، برای داده های هواشناسی. این مفاهیم انواع معیارهای بلوغ را به سطوح گسسته اختصاص می دهند تا ارزیابی داده ها را تسهیل کنند. علاوه بر این، استفاده از اعداد سطح با درک آسان، تشخیص سریع دادههای بسیار بالغ را ممکن میسازد. و از این رو قابلیت استفاده مجدد را آسان تر می کند. در اینجا، ما یک ماتریس سررسید اصلاحشده برای دادههای ESS شامل فهرستی جامع از معیارهای FAIR پیشنهاد میکنیم. برای تقویت سازگاری با رویکرد ماتریس بلوغ توسعهیافته، ماتریس کیفیت دادههای مکانی را ایجاد کردیم که سطوح بلوغ دادهها را به معیارهای کیفیت مرتبط میکند. سپس سطوح بلوغ و کیفیت به مراحل چرخه عمر داده ها اختصاص داده می شود. با اجرای معیارهای باز بودن و ماتریس برای بلوغ و کیفیت داده ها، ما یک گردش کار تضمین کیفیت (QA) ایجاد می کنیم که شامل فعالیت ها و نقش های مختلف است. برای حمایت از محققان در به کارگیری این گردش کار، ما یک پرسشنامه تعاملی را در ابزار RDMO (سازماندهنده مدیریت دادههای پژوهشی) پیادهسازی میکنیم تا به طور مشترک همه فعالیتهای QA را مدیریت و نظارت کنیم. این می تواند به عنوان طرحی برای QA خاص مورد استفاده برای سایر مجموعه های داده عمل کند.
کلید واژه ها:
تضمین کیفیت ؛ بلوغ داده ها ; ماتریس بلوغ ; کیفیت داده های مکانی ؛ نمایشگاه
1. مقدمه
کیفیت دادههای مکانی یک زیرشاخه اصلی در علوم سیستم زمین (ESS) است که نشاندهنده ارتباط ارائه اطلاعات کیفی دقیق برای نتایج دادههای علمی است [ 1 ]. دانش کیفیت داده ها، و بنابراین در دسترس بودن اطلاعات با کیفیت معنی دار، کلیدی برای تسهیل استفاده و استفاده مجدد از داده ها، به ویژه برای تصمیم گیری و ارائه داده های عادلانه است [ 2 ، 3 ]. گردش کار ایجاد و دستکاری داده های علمی با استانداردهای با کیفیت بالا مطابقت دارد [ 4 ]. با این حال، نظارت و گزارش اطلاعات با کیفیت کافی هنوز یک چالش مبرم در مدیریت داده های تحقیقاتی (RDM) است. اطلاعات با کیفیت اغلب فقط در پایان چرخه عمر داده های تحقیق ایجاد و ارائه می شود (cp. [ 2])، یا در یک مرحله اضافی از چرخه عمر داده [ 5 ]. بنابراین، اطلاعات کیفی مربوطه برای نتایج و مشکلات موقت، به عنوان مثال، در روشها یا پیادهسازیهای کاربردی وجود ندارد و تنها در مراحل نهایی قابل شناسایی است. برای تقویت شفافیت، تکرارپذیری و ارائه دادههای باز و عادلانه، ارائه اطلاعات با کیفیت برای چنین نتایج موقت و مراحل گردش کار، به ویژه برای گردشهای کاری پیچیده علمی ضروری است. با این حال، برای جلوگیری از از دست دادن اطلاعات و اشتباهات هنگام ایجاد اطلاعات با کیفیت، جنبه های اتوماسیون باید در نظر گرفته شود. رویکردهای فعلی در مدیریت اطلاعات کیفیت (نیمه خودکار) اغلب در ارائه اطلاعات ساختاریافته، در بهترین حالت استاندارد شده، با کیفیت برای استفاده در فرآیندهای دیجیتال بعدی بینیاز هستند (صفحه 2 ، 4 ).، 6 ، 7 ]). این امر از جمله به بازنگری و توسعه جدید استانداردها منجر می شود، به عنوان مثال، ISO 19157-1 [ 8 ] و ISO 19157-3.
در حالی که رویکردهایی برای شاخص های باز بودن و عادلانه بودن از قبل وجود دارد، مفاهیم کیفیت انضباطی یا رویکردهای ترکیبی از جمله جنبه های انضباطی و عمومی به سختی یافت می شود یا نیازهای محقق را برای اطلاعات با کیفیت بالا برآورده نمی کند. به عنوان مثال، GeoDCAT-AP [ 9 ] یک پروفایل کاربردی داده پیوندی مدرن برای ابرداده داده های مکانی شامل چندین جنبه کیفی فراهم می کند. با این حال، اجرای یک لیست جامع از عناصر کیفیت (به عنوان مثال، از ISO 19157:2013 [ 10 ]) هنوز در آغاز است. در ESS، محققین برای ارزیابی دادههای ورودی بالقوه، به عنوان مثال، مناسب بودن برای استفاده، و خروجیهای تحقیقاتی، به عنوان مثال، برای بررسی اعتبار، به معیارهای کیفی برای دادههای مکانی نیاز دارند.
تضمین کیفیت (QA) در پروژههای علمی دادهمحور بر حصول اطمینان و گزارشدهی تمرکز میکند که ایجاد دادههای کاربردی و جریانهای کاری دستکاری منجر به کیفیت داده مناسب میشود [ 11 ]. بنابراین، ما یک گردش کار QA عمومی برای نظارت و گزارش اطلاعات با کیفیت برای دادههای مکانی از ابتدا پیشنهاد میکنیم. مفهوم گردش کار QA ما از چرخه عمر داده های تحقیق به عنوان مفهوم اساسی برای ساختاردهی فعالیت های QA عمومی و انضباطی، نقش های مرتبط، و پیوند دادن شاخص ها و معیارها استفاده می کند ( شکل 1).). ما مفاهیم میان رشتهای شناخته شده و اثبات شده، مانند شاخصهای FAIR و رویکرد دادههای باز 5 ستاره تیم برنرز لی را شامل میشویم و یک الگوی سادهسازی شده با تمرکز بر ارائهدهنده داده، متصدی داده، و ناشر داده را اجرا میکنیم. علاوه بر این، ما این رویکردها را با مفاهیم انضباطی، مانند مدل ماتریس بلوغ دادهها و مفهوم کیفیت دادهها برای اطلاعات جغرافیایی، تطبیق و ترکیب میکنیم. بنابراین، ما یک مفهوم گردش کار مفصل با فعالیتهای خاص برای هر مرحله از چرخه عمر دادهها و اقدامات ساختاریافته برای نظارت و گزارش کیفیت دادهها با توجه به جنبههایی مانند اتوماسیون و سازگاری با رویکردهای چند رشتهای ارائه میکنیم.
چرخه زندگی داده های پژوهشی ساده شامل مراحل زیر است: جمع آوری، پردازش، تجزیه و تحلیل، انتشار، بایگانی و استفاده مجدد (برای پروژه های ESS در [ 12 ] اعمال می شود). از دیدگاه یک پروژه علمی، مرحله جمع آوری نقطه شروع فعالیت های RDM است و بایگانی داده ها نقطه پایانی را نشان می دهد. مرحله استفاده مجدد معمولاً شروع یک تکرار چرخه حیات جدید را نشان می دهد، به عنوان مثال، اجرای مرحله جمع آوری یک پروژه تحقیقاتی دوم با استفاده از داده های منتشر شده یا آرشیو شده از پروژه اول. شکل 1 شامل تمام اجزای مفهوم گردش کار QA توسعه یافته مربوط به چرخه عمر داده های تحقیق است.
1.1. مجموعه داده نمونه
ما از مجموعه داده معروف مدل تخصیص تولید فضایی (SPAM) 2010 به عنوان یک مجموعه داده نمونه رایج برای ESS استفاده می کنیم [ 13 ، 14 ]. مجموعه دادههای SPAM یک محصول داده مبتنی بر جامعه را توصیف میکند که آمار محصول را با سیستمهای کشاورزی مختلف تفکیک میکند ( شکل 2 ): تولید با نهادههای زیاد آبیاری، تولید نهادههای زیاد دیم، تولید با نهادههای کم دیم، و تولید معیشتی دیم. با استفاده از چندین ورودی و یک رویکرد آنتروپی متقابل، خروجی مدل منجر به یک شبکه جهانی 5 قوس دقیقهای از موارد زیر میشود:
-
منطقه فیزیکی: منطقه برای یک محصول در سلول شبکه.
-
منطقه برداشت: سطح فیزیکی با شدت محصول ضرب می شود تا برداشت های متعدد ممکن در هر کرت در نظر گرفته شود.
-
عملکرد: تولید محصول در هر منطقه برداشت شده – عملکرد کل میانگین وزنی چهار سیستم مختلف کشاورزی است.
-
تولید: سطح برداشت ضرب در عملکرد – برابر است با کل زیست توده عملکرد.
-
ارزش تولید: قیمت محصول به ازای هر سلول شبکه – قیمت ها در سطح جهانی هماهنگ شده و از میانگین قیمت بین المللی محصولات سازمان غذا و کشاورزی (FAO) گرفته شده است.
مقاله و مکمل در [ 15 ] اطلاعات دقیقی را در مورد SPAM2010 و منشأ و کیفیت مجموعه داده توصیف می کند و مقایسه ای با سایر مجموعه داده های منطقه ای ارائه می دهد. شکل 2 گردش کار پیچیده ایجاد مجموعه داده SPAM2010 را به عنوان یک نمودار منشأ ساده شده توصیف می کند. مدل SPAM از چندین مجموعه داده ورودی دسترسی باز، مانند قیمت های تولیدکننده FAO-STAT [ 16 ] یا مناطق حفاظت شده پایگاه داده جهانی [ 17 ]، به عنوان ورودی استفاده می کند. همه این مجموعه دادههای ورودی ( شکل 2 ، مستطیلهای قرمز در سمت چپ) از قبل پردازش شدهاند، به عنوان مثال، تبدیل، فیلتر یا تجمیع شدهاند ( شکل 2 ، کادرهای آبی در کنار ورودیها). مجموعه داده های حاصل ( شکل 2، وسط کادرهای قرمزی که با نام “SPAM” + <موضوع> شروع میشوند، به عنوان ورودی برای مدل SPAM (جعبه آبی در سمت راست) که مجموعه دادههای SPAM2010 را ایجاد میکند، استفاده میشود.
1.2. کارها و مفاهیم مرتبط
از آنجایی که وعده کیفیت به عنوان پایه ای برای علم عمل می کند، در موارد استفاده از روش ها و رویکردهای پذیرفته شده برای ایجاد داده های با کیفیت بالا، کیفیت داده ارتباط نزدیکی با باز بودن، عادلانه بودن و بلوغ داده دارد [ 2 ، 4 ، 18 ]. در اینجا، ما این مفاهیم را بهعنوان بلوکهای ساختمانی برای گردش کار QA خاص ESS توصیف میکنیم که با مفاهیم بینرشتهای شروع میشود، و سپس مفاهیم انضباطی مانند معیارهای کیفیت ISO شروع میشود.
1.2.1. اقدامات باز بودن
باز بودن داده ها را می توان با طرح استقرار 5 ستاره برای داده های باز توسط تیم برنرز لی [ 19 ] ارزیابی کرد. اول، مجوز داده ها را پوشش می دهد، به عنوان مثال، استفاده از داده ها نیاز به ذکر منبع دارد، یا استفاده محدود به مشاهده است، و تغییر مجاز نیست. یک مثال شناخته شده برای طبقه بندی مجوزهای داده، مجوزهای خلاقانه مشترک [ 20 ] است. دوم، ارائه دادهها از جمله پیوندهایی به منابع دیگر را پوشش میدهد که جمعآوری اطلاعات بهم پیوسته قابل خواندن توسط ماشین را تسهیل میکند، و در پایان ارزیابی بافت داده را تسهیل میکند. پنج ستاره به صورت زیر تعریف می شوند، در حالی که مجموعه داده ای که الزامات چند ستاره را برآورده می کند، شرایط تعریف شده برای ستاره های کمتر را نیز برآورده می کند:
| * | داده های موجود در وب تحت مجوز باز؛ |
| ** | داده های ارائه شده به عنوان داده های ساخت یافته؛ |
| *** | داده های موجود در قالب باز غیر اختصاصی؛ |
| **** | استفاده از URI برای نشان دادن چیزها، به طوری که پیوند به داده ها امکان پذیر باشد. |
| ***** | برای ارائه زمینه، داده ها را به داده های دیگر پیوند دهید. |
1.2.2. نشان عادلانه
در حالی که مفهوم برنرز لی بر جنبه های معنایی مانند ساختار، استفاده از URI و پیوند تمرکز دارد، اصول FAIR جنبه های بیشتری را پوشش می دهد. اصول FAIR-قابلیت یافتن، دسترس پذیری، قابلیت همکاری و قابلیت استفاده مجدد- حداقل شیوه هایی را برای تقویت قابلیت استفاده از داده ها تعریف می کند [ 21 ]. گروه کاری مدل بلوغ داده RDA FAIR [ 22] یک مدل بلوغ با اشاره به اصول FAIR متشکل از شاخص ها، اولویت ها و روش های ارزیابی پیشنهاد می کند. این مدل شامل 41 شاخص است که بر اساس اولویت ها به دو دسته اساسی، مهم یا مفید طبقه بندی شده اند. برای فعال کردن ارزیابی پیشرفت برای هر شاخص، گروه کاری پنج سطح بلوغ شاخص را توسعه داد، شاخصها و اولویتها را در حوزههای FAIR خلاصه کرد (F, A, I, R) و شش سطح انطباق را از سطح 0 (نه FAIR) پیشنهاد کرد. به سطح 5 (تقاضا به طور کامل برآورده شده است). بر اساس آن مفهوم، پروژه FAIRsFAIR [ 23 ] از زیرمجموعهای از شاخصهای RDA FAIR استفاده میکند و 17 معیار را برای پرداختن به جنبههایی مانند اندازهگیری خودکار و اکوسیستم FAIR ( جدول 1 ) توسعه داده است [ 24 ].]. اگرچه کار آنها هنوز در حال پیشرفت است، معیارهای FAIR نقطه شروع ارزشمندی از دیدگاه ESS هستند.
1.2.3. مدل سازی بلوغ داده ها
یک مفهوم QA سالم و قابل استفاده به عنوان بخشی از اقدامات خوب RDM به پارامترهای قابل اندازه گیری بلوغ داده ها نیاز دارد. بلوغ داده یک مفهوم ثابت برای قابل مشاهده کردن نتایج ارزیابی QA است. در چندین مورد، محققان از بلوغ دادهها بهعنوان بخش مرکزی در گردش کار اصلی خود برای تنظیم و انتشار اطلاعات کیفیت داده استفاده میکنند [ 18 ]، و بلوغ را به عنوان بخشی از گزارشهای QA، به عنوان مثال، برای مجموعه دادههای آب و هوا [ 25 ] اجرا میکنند. علاوه بر این، مفاهیم مدلسازی بلوغ از رویکردهای موقت به فرآیندهای مدیریت شده در حال تکامل هستند [ 26 ]. همان نویسنده مروری بر دیدگاههای مختلف بلوغ فعالیتهای مدیریت داده، فعالیتهایی که محتوا، دسترسی و قابلیت استفاده از دادهها و ابردادههای آن را حفظ و بهبود میبخشد، ارائه میکند.27 ]. همانطور که ما بر روی دادههای مکانی تمرکز میکنیم، سه دیدگاه بلوغ به بهترین وجه مناسب هستند: بلوغ علمی مجموعه داده، بلوغ محصول مجموعه داده، و بلوغ سرپرستی مجموعه دادهها.
شکل 3 تمام رویکردهای مدل بلوغ در نظر گرفته شده از جمله مفهوم ما را نشان می دهد. سطوح آمادگی فناوری ناسا (TRL) به عنوان پایه ای عمل می کند و شامل تلاش اولیه برای ماتریسی است که بر اساس سطوح بلوغ و توضیحات مرتبط ساخته شده است. مراجع. [ 28 و 29 ] نسخه اول و به روز شده را با در نظر گرفتن سطوح و بر اساس توضیحات سخت و نرم افزار توصیف می کند. مرجع. [ 30 ] این مفهوم را تطبیق داد و یک ماتریس بلوغ را برای ارزیابی کامل بودن سوابق داده های اقلیمی و پیاده سازی مفهوم داده های آب و هوایی چند دهه ای پیشنهاد کرد [ 31 ]]. این ماتریس شش دسته (“حوزه های موضوعی”) – آمادگی نرم افزار، ابرداده، مستندات، اعتبارسنجی محصول، دسترسی عمومی، و ابزار – را در شش سطح بلوغ (ردیف) توصیف می کند. سطوح 1 و 2 با اهداف تجزیه و تحلیل و تحقیق مرتبط است. در سطوح 3 و 4 یک قابلیت عملیاتی اولیه از جمله اولین استفاده در تصمیم گیری به دست می آید. سطوح 5 و 6 (قابلیت عملیاتی کامل) باید برای تصمیم گیری قابل اعتماد بر اساس داده ها بدست آید. مرجع. [ 32 ] از این مفهوم برای یک مورد استفاده اقتباس شده (ماتریس بلوغ سیستم) استفاده می کند و یک زیر ماتریس دقیق برای عدم قطعیت ایجاد می کند که بر اساس اعتبار سنجی محصول است. مرجع. [ 33 ] همچنین از مفهوم ماتریس بلوغ از [ 30 ] استفاده می کند] برای یک ماتریس بلوغ سرپرستی با ساختار 5 سطحی و حوزه های موضوعی گسترده (نویسندگان آن را مؤلفه های کلیدی می نامند). با ساده کردن ماتریس بلوغ سیستم در [ 32 ]، ر. [ 34 ] ماتریس بلوغ کیفیت (QMM) را برای نیازهای مرکز محاسبات آب و هوایی آلمان بایگانی بلند مدت توسعه داد. آنها بر روی توصیف مجموعه داده ها تمرکز می کنند و ماتریس را به پنج سطح بلوغ کاهش می دهند – مفهوم، تولید / پردازش، همکاری پروژه / استفاده مورد نظر، بایگانی طولانی مدت، و مراحل تأثیر / استفاده مجدد. علاوه بر این، آنها معیارهایی را توصیف می کنند که ارزیابی تناسب برای استفاده را با پیروی از اصول داده های FAIR و سایر استانداردها و توصیه های مرتبط تسهیل می کند. مرکز صلاحیت KomFor برای داده های تحقیقاتی در زمین و علوم محیطی [ 35] تقریباً از همان اصطلاحات سطح بلوغ استفاده می کند، و بنابراین آنها ارتباط را با علوم سیستم زمین نشان می دهند.
1.2.4. معیارهای کیفیت داده
کیفیت داده ها یکی از جنبه های کلیدی در استفاده صحیح از داده ها است. به دنبال [ 1 ]، یکی از دستاوردهای عمده برای داده های تحقیقات فضایی، افزایش آگاهی از کیفیت داده ها و اهمیت آن است که توسط تعداد فزاینده ای از پروژه های تحقیقاتی که تناسب برای استفاده و کیفیت خارجی را ارزیابی می کنند، مورد توجه قرار می گیرد. اگرچه [ 1 ] مشکلات قابل توجهی را در ارزیابی تناسب برای استفاده با استفاده از ابرداده های موجود شناسایی کرد، رفر. [ 36 ] این یافته ها را با مصاحبه با کاربران داده های مکانی زیربنا می دهد. آنها بر ضرورت معیارهای کیفیت داده در ابرداده تأکید می کنند – اگرچه معمولاً در عمل اعمال نمی شوند – و بر اهمیت استفاده از استانداردها و طرحواره ها، مانند سری ISO 19xxx یا Dublin Core [ 37 ] تأکید می کنند.
معیارهای مناسب کیفیت داده ارزیابی برازش محتوا را برای استفاده تسهیل می کند. ISO 19157:2013 [ 10 ] اجرای ساختاری معیارهای کیفیت داده برای داده های مکانی را ارائه می دهد که اغلب در طرحواره های مبتنی بر XML مرتبط پیاده سازی می شوند. با این حال، کیفیت داده را می توان به عنوان داده های پیوندی نیز توصیف کرد، به عنوان مثال، با استفاده از واژگان کیفیت داده (DQV [ 38 ]). مزیت DQV ویژگی های قابل گسترش و باز بودن آن است که به اندازه کافی برای چندین مورد استفاده انعطاف پذیر است. با این حال، دادههای رایج این است که واژگان با کیفیت و جنبههای فضایی مانند دقت موقعیت یا سازگاری توپولوژیکی باید اضافه شوند و به عنوان نمایه DQV توصیف شوند.
2. روش ها – مفهوم تضمین کیفیت ESS
ما یک مفهوم گردش کار QA خاص ESS را برای دادههای تحقیقات فضایی پیشنهاد میکنیم که باز بودن و نشانههای عادلانه، مدلسازی بلوغ دادهها و معیارهای کیفیت دادههای مکانی را یکپارچه میکند. گردش کار توسعهیافته ما شامل شاخصها، اقدامات، فعالیتها و نقشهای مسئول است که در صورت امکان با مراحل چرخه عمر دادهها مرتبط یا حداقل با آنها سازگار است.
ما پنج سطح داده را به مجموعه مراحل چرخه عمر داده ها برای بایگانی اختصاص می دهیم ( جدول 2 ). مرحله استفاده مجدد در اینجا نادیده گرفته می شود، زیرا معمولاً شروع مرحله جمع آوری یک پروژه بعدی را نشان می دهد، به عنوان مثال، پروژه پیگیری. هر سطح به عنوان مجموعه ای از شرایط سطح جداگانه برای باز بودن، بلوغ داده ها و کیفیت داده ها توصیف می شود ( جدول 2). برای تخصیص سطح مطابق به یک مجموعه داده، مجموعه داده باید شرایط را برای هر سه جنبه برآورده کند. علاوه بر این، برای تسهیل یک تفسیر سریع، ما شرایط سطح را با مخفف جنبه (“Open”، “DM” و “DQ” برای باز بودن، بلوغ داده و کیفیت داده)، جداکننده صدا “4” و نام فاز، به عنوان مثال، “DM4processing”. ما محدودههایی را برای هر شرایط سطح از پیش تعریف میکنیم، ارائهدهندگان داده، متصدیان داده، یا ناشران داده را تسهیل میکنیم تا آنها را با نیازهای مورد استفاده خود تطبیق دهند (مثلاً Open4archiving تعریف میکند که یک مجموعه داده حداقل دادههای باز 4 ستاره است). هنگامی که یک گروه تحقیقاتی یک پروژه دادهمحور را شروع میکند، معمولاً قوانین داخلی، به عنوان مثال، نهادی یا انضباطی، و توصیههایی در مورد استفاده از داده ایجاد میکند.
گردش کار QA برای ارائه چندین مرحله QA برای هر مرحله از چرخه عمر داده (طبق سطوح جدول 2 ) ایجاد شده است. هر مرحله شامل تعدادی فعالیت و تصمیم است که می توان به یکی از سه نقش مورد استفاده اختصاص داد. نمودار جریان زیر ( شکل 4 ) طرح گردش کار QA را که چرخه عمر داده را از بالا به پایین دنبال می کند با نقش ها نشان می دهد: ارائه دهنده داده (سبز)، متصدی داده (فیروزه ای) و ناشر داده (بنفش). رنگ فعالیت ها (مستطیل ها) و تصمیم گیری ها (لوزی ها) نقش های تعیین شده را نشان می دهد. این طرح شامل یک فرآیند کنترل کیفیت از پیش تعریف شده است که به تفصیل در شکل 5 توضیح داده شده است .
بخشهای زیر شرایط سطح را برای باز بودن و عادلانه بودن جنبههای QA عمومی توصیف میکنند ( بخش 2.1.1 و بخش 2.1.2 ). جنبه های QA ویژه رشته برای بلوغ داده ها و کیفیت داده ها به تفصیل در بخش 2.1.1 و بخش 2.1.2 پوشش داده شده است . علاوه بر این، بخش 3 ارزیابی نمونه ای از تمام جنبه های QA برای نمونه مجموعه داده ESS انتخاب شده ارائه می دهد (به بخش 1.1 مراجعه کنید ).
2.1. تضمین کیفیت عمومی
2.1.1. اقدامات باز بودن
از آنجایی که طرح استقرار 5 ستاره تیم برنرز لی برای داده های باز ( بخش 1.2.1 ) بیشتر با الزامات مورد استفاده ESS مطابقت دارد، ما از اقدامات موجود برای ارزیابی باز بودن داده ها استفاده می کنیم. از این رو، مجوز داده ها و میزان دسترسی به داده ها و پیوند به سایر نهادها را ارزیابی می کنیم. با این حال، ما مفهوم نوع مجوز باز را به مجوزهای بالقوه محدود تعمیم می دهیم تا امکان استفاده گسترده تر از مفهوم QA خود را فراهم کنیم، به عنوان مثال، مجوزهایی با دسترسی کامل به داده محدود به اعتبار دادن به ایجاد کننده داده، فعالیت های گردش کار QA را مختل نمی کند (به بخش مراجعه کنید. 2.3 ).
برای باز بودن، ما سه شرط سطح مختلف را پیشنهاد می کنیم: Open4usage، Open4publication، و Open4archiving ( جدول 2 را مقایسه کنید ). یک مجموعه داده باید با الزامات یک شرط سطح برای استفاده در فاز مربوط به چرخه عمر داده مطابقت داشته باشد. ما تعاریف شرایط سطح را همانطور که در جدول 3 نشان داده شده است، پیشنهاد می کنیم .
2.1.2. نشان عادلانه
اهمیت عادلانه بودن داده های مکانی قبلاً در جامعه تحقیقاتی ESS به خوبی تأیید شده است. معیارهای FAIRsFAIR توسعه یافته توسط جامعه ( بخش 1.2.2 ) شامل معیارهای رایج قابل خواندن توسط ماشین برای داده ها و ابرداده های آن است. این معیارها را میتوان برای دادههای تحقیقاتی خاص ESS اعمال کرد و یک ارزیابی عادلانه جامع ارائه داد، که سازگاری با پروژهها یا رشتههای دیگر را تسهیل میکند. علاوه بر این، امکان ادغام این معیارها در مفاهیم بلوغ داده وجود دارد ( بخش 2.2.1 ).
2.2. تضمین کیفیت ویژه رشته
2.2.1. مدل سازی بلوغ داده ها
QMM مجموعه بزرگ و مفیدی از الزامات را برای داده های مورد استفاده و تولید شده در موارد استفاده ESS فراهم می کند. بلوغ را در سطح معقولی از جزئیات توصیف می کند و اطلاعاتی را در مورد نیازها و پیشرفت ها روشن می کند/افزودن می کند. بنابراین، ما از QMM استفاده می کنیم ([ 34 ]، به بخش 1.2.3 مراجعه کنید) در گردش کار QA ما. از آنجایی که مفهوم QMM به داده های آب و هوا و موضوعات مرتبط محدود می شود، ما این مفهوم را برای برآورده کردن الزامات عمومی ESS تطبیق می دهیم. بنابراین، از منظر ESS، ما اصلاحات زیر را پیشنهاد میکنیم: (1) ساده کردن ماتریس برای تناسب با روالهای پژوهشگر، (ب) به طور صریح معیارهای FAIRsFAIR را یکپارچه میکند تا حالت FAIR مجموعه داده مرتبط را قابل مشاهدهتر کند، (iii) گسترش/توسعه QMM مفهومی برای تسهیل استفاده از دادههای تحقیقات فضایی، و (IV) تسهیل مجموعهای از حوزههای موضوعی خاص ESS. اگرچه معیارهای FAIRsFAIR را می توان با ورودی های QMM موجود ترسیم کرد، ما پیوندی از هر دو مفهوم را برای اطمینان از دیده شدن و سازگاری با رویکردهای مشابه پیاده سازی می کنیم.
ماتریس بلوغ پیشنهادی ما 5 سطح بلوغ ( جدول 2 ) را همراه با 4 معیار، 9 جنبه و معیارهای مشخص، شامل تمام 17 معیار FAIRsFAIR ( جدول 1 ) توصیف می کند. علاوه بر این، ما چهار شرط سطح را برای بلوغ داده پیشنهاد می کنیم که با سطوح بلوغ داده 2 تا 5 منطبق است: پردازش DM4، تجزیه و تحلیل DM4، انتشار DM4، و بایگانی DM4 ( جدول 2 را ببینید ). سطح 1 بلافاصله پس از ایجاد داده می رسد. برای رسیدن به سطح بلوغ بالاتر، مجموعه داده باید معیارهای مطابق با آن را برآورده کند (به زیر مراجعه کنید). معیارها از [ 34 ] انتخاب و اقتباس می شوند و برای تمایز آنها از معیارهای کیفیت داده ها ( بخش 2.3.2 ) که در مفهوم ما نیز گنجانده شده اند، تغییر نام داده می شوند. جدول 4معیارها و جنبه های بلوغ داده ها را خلاصه می کند.
اولین هدف اصلاح (به بالا مراجعه کنید) ساده کردن استفاده از QMM در مفهوم QA ما است. QMM چندین معیار را در بر می گیرد که به مدل سیستم اطلاعات بایگانی باز اشاره دارد (OAIS، ISO 14721:2012 [ 39 ]). برای گردش کار QA ارائه شده در اینجا، حفظ طولانی مدت داده ها فقط یک جنبه جزئی را پوشش می دهد. بنابراین، ما تصمیم گرفتیم که جنبه های خاص OAIS را حذف کنیم. بهعلاوه، بهدلیل دلایل افزونگی بهویژه برای مورد استفاده از ESS، اقدامات بیشتری را حذف کردیم ( پیوست A را ببینید).
پس از اولین تکرار توسعه ماتریس بلوغ ESS، ماتریس را با مرتب کردن مجدد محتوای سطح برای دیدگاه ESS (هدف سوم/چهارمین اصلاح) بازبینی کردیم و یک ورودی ماتریس واحد برای هر معیار FAIRsFAIR ایجاد کردیم تا عادلانه بودن داده ها را تقویت کنیم. هدف اصلاح دوم). در اینجا، ما فقط بخش ماتریس اصلاح شده را برای یکپارچگی معیار در جدول 5 به عنوان مثال درج می کنیم. بخشهای ماتریس اصلاحشده فنی، دسترسی و اعتبارسنجی معیارها در پیوست A ارائه شدهاند ( جدول A1 ، جدول A2 و جدول A3 ).
ماتریس بلوغ اصلاح شده برای یکپارچگی معیار ( جدول 5) از دو جنبه تشکیل شده است. در اینجا به دلایل زیر چندین تغییر و تغییرات سطح اعمال کردیم. (i) از آنجایی که ابرداده از قبل برای داده های سطح 2 مورد نیاز است، استفاده زودتر از استانداردهای مخزن انضباطی و هدف نسبت به پیشنهاد در QMM قویاً توصیه می شود. (ii) بیشتر مجموعه داده های جغرافیایی و ابرداده های مربوطه قبلاً دیجیتالی شده اند یا در ابتدای پروژه دیجیتالی خواهند شد. بنابراین، ابرداده ها باید در مراحل اولیه تر از QMM اصلی قابل خواندن توسط ماشین باشند تا کار مشترک را تقویت کنند. (iii) ابردادههای عمومی قبلاً برای مجموعههای داده در سطح 2 ارائه شدهاند. برای جلوگیری از تغییرات پیچیده و مستعد خطا (فرمت)، ما قویاً توصیه میکنیم از یک زبان نمایش رسمی دانش زودتر از QMM در کار مشارکتی (سطح 3) استفاده کنید. (IV) استفاده از منابع معنایی برای محصولات با کیفیت بالا و استفاده آتی از داده ها ضروری است. برای حمایت از این موضوع، ما نیاز به استفاده از مفاهیم معنایی در سطوح پایین تر از QMM داریم. (v) اهمیت منابع معنایی به شدت با استفاده از داده های مرتبط و پیوند به محتوای مرتبط همراه است. از این رو، همه شاخصهای معنایی و مرتبط با دادههای مرتبط باید در یک سطح بلوغ استفاده شوند. (vi) اطلاعات منشأ تحقیقات شفاف و در نهایت تکرارپذیری را تقویت می کند. چندین ابزار خودکار ردیابی منشأ در حال حاضر وجود دارد و میتوان آنها را به راحتی هنگام ادغام با RDM در مراحل اولیه استفاده کرد. این ابزارها حتی می توانند پارامترهای زمان اجرا را ردیابی کنند. بنابراین، اطلاعات منشأ باید در قالبی کاملاً تعریف شده از ابتدای ایجاد مدل در سطح 2 به جای سطح 4، همانطور که در QMM اصلی پیشنهاد شده است، جمع آوری شود.
ماتریس بلوغ برای فنی بودن معیار ( جدول A1 در ضمیمه A ) شامل سه قالب جنبه، نسخه سازی و واژگان کنترل شده است. در اینجا، ما چندین معیار را حذف کردیم (مربوط به OAIS، به بالا مراجعه کنید) و یک معیار FAIRsFAIR را برای تقویت تکرارپذیری اضافه کردیم. سطح FsF-R1.3-02D (داده ها در قالب فایل توصیه شده توسط جامعه پژوهشی هدف موجود هستند) از سطح 4 به سطح 3 تغییر کرده است. مجموعه داده های فضایی عمدتاً در قالب های دیجیتالی و برای جلوگیری از تبدیل های مستعد خطا در دسترس هستند. استانداردهای جامعه به خوبی تعریف شده باید در سطح 3 همکاری استفاده شود.
معیارهای دسترسی و اعتبارسنجی ( جدول A2 و جدول A3 در پیوست A ) تغییرات سطحی برای معیارهای خاص ندارند. با این حال، برخی از اقدامات برای ساده کردن استفاده از ماتریس بلوغ داده حذف شده است. قابلیت دسترسی معیار گزینههایی برای بازیابی دادهها و فراداده را پوشش میدهد، در حالی که اعتبارسنجی معیار شامل خطاهای احتمالی و ویژگیهای آماری دادهها است.
2.2.2. ماتریس کیفیت داده های مکانی
مفاهیم باز بودن و عادلانه توصیف شده قبلی، مفاهیم رایج داده های تحقیق را توصیف می کنند و می توانند در چندین حوزه علمی به کار روند. ماتریس بلوغ دادهها برخی از جنبههای خاص رشته ESS را پوشش میدهد، اما میتواند به راحتی در حوزههای دیگر اعمال/تطبیق شود. برای اندازه گیری کیفیت داده ها، ما باید جنبه های فضایی را در نظر بگیریم. بنابراین ما مفهوم یک ماتریس کیفیت دادههای مکانی را پیشنهاد میکنیم که کلاسهای کیفیت دادههای خاص ESS را برای دادههای تحقیقات فضایی بهعنوان یک بعد با سطوح معرفیشده قبلی ( جدول 2 ) به عنوان بعد دوم ترکیب میکند.
ISO 19157:2013 [ 10 ] طیف وسیعی از جنبهها و معیارهای کیفی دادههای مکانی را ارائه میدهد که به صورت کلاسهای داده و زیر کلاسها ساختار یافتهاند. ما کلاسهای کیفیت داده ISO، زیر کلاسهای مرتبط و اقداماتی را برای توسعه سطوح کیفیت دادهها به طور خاص ترسیم میکنیم. یک سطح چندین معیار مورد نیاز را با مقادیر مرتبط خلاصه می کند که به نیازهای جامعه ESS می پردازد و ویژگی های داده های مکانی را منعکس می کند.
هنگام اعمال مفهوم سطح توسعه یافته ما ( بخش 2 )، مجموعه داده بلافاصله پس از ایجاد به سطح 1 می رسد. برای رسیدن به سطح بالاتر، اطلاعات کیفیت داده باید در دسترس باشد و ارزش(های) کیفیت داده شده باید شرایط سطح معیارهای کیفیت مربوطه را برآورده کند. کیفیت داده برای سطوح 2 و 3 مهم است زیرا تعامل مستقیمی بین ارائه دهندگان داده و کاربران داده وجود دارد – و اطلاعات کیفی باید برای چندین طرف در دسترس و قابل درک باشد، به عنوان مثال، تسهیل ارزیابی تناسب برای استفاده. سطوح 4 و 5 برای اهداف انتشار و تحقیقات تأثیر / آرشیو استفاده می شود. در مورد دوم، گروه پژوهشی هدف اغلب شرایط سطح را برای برآوردن نیازهای پروژه خاص یا مورد استفاده خود تطبیق می دهد.
در اینجا، ما یک مثال برای سطوح و شرایط سطح خاص ESS ارائه میدهیم و سطح هر عنصر کیفیت را با توجه به سریهای زمانی جهانی دادههای کاربری زمین تعریف میکنیم ( قسمت 1.1 ). جدول 6 کلاس های کیفیت داده ها و زیر کلاس ها را با توضیحات کوتاه و سطوح مرتبط ارائه می کند. به عنوان مثال، یک مقدار داده شده برای دقت موقعیت خارجی مطلق مورد نیاز است و باید از آستانه تعریف شده برای انطباق سطح 3 فراتر رود. با تمرکز بر استفاده ساده از گردش کار QA توسعه یافته، ما مقادیر آستانه سخت گیرانه تری را برای سطوح بالاتر فرض نمی کنیم. بنابراین، اگر یک مجموعه داده با سطح 3 در دقت موقعیت خارجی مطلق مطابقت داشته باشد، الزامات سطح 4 و 5 نیز برآورده می شوند.
پیوست B مجموعه ای اصلاح شده از معیارهای ISO 19157:2013 [ 10 ] را برای هر زیر کلاس کیفیت داده ارائه می دهد ( جدول A4 ، جدول A5 ، جدول A6 ، جدول A7 ، جدول A8 و جدول A9 ). اصلاحات شامل انتخاب معیارهای کیفیت داده برای هر طبقه و معیارهای اضافه شده برای فراکیفیت است.
برخی از معیارهای کیفیت داده ها به داده های مرجع اضافی نیاز دارند که به آنها حقیقت زمینی نیز گفته می شود. برای دقت موقعیتی خارجی مطلق و دقت موقعیتی دادههای شبکهای، یک حقیقت فضایی برای ارزیابی مجموعه داده فعلی مورد نیاز است. علاوه بر این، برای ارزیابی دقت اندازهگیری زمانی، به یک مرجع زمانی نیاز داریم، و ارزیابی اعتبار زمانی به تاریخها، بازههای زمانی معتبر و/یا وضوح نیاز دارد. برای ارزیابی سازگاری، باید مفاهیم معتبر ارائه شود. برای سازگاری مفهومی، برخی از مفاهیم استاندارد، به عنوان مثال، چند ضلعی های غیر همپوشانی با ویژگی های متقابل منحصر به فرد، می تواند مورد استفاده قرار گیرد یا پذیرفته شود. ارزیابی سازگاری دامنه مستلزم استفاده از یک توصیف دامنه موضوعی است که می تواند به عنوان هستی شناسی یا واژگانی از ویژگی های معتبر یا محدوده ارزش برای داده های کمی ارائه شود. برای ارزیابی سازگاری قالب، ما به تعاریف قالب مرتبط نیاز داریم که به عنوان فهرستی از قالبهای معتبر یا توضیحات مفصلی از فرمتهای خاص ارائه شود. برای ارزیابی صحت طبقهبندی موضوعی و ارزیابی صحت ویژگی غیرکمی و دقت ویژگی کمی، یک حقیقت پایه کلاسها مورد نیاز است.
برای کیفیت داده، ما پنج شرط سطح را در نظر می گیریم: DQ4usage، DQ4processing، DQ4analysis، DQ4publication و DQ4archiving ( جدول 2 را مقایسه کنید ). بر خلاف معیارهای بلوغ داده ها، معیارهای کیفیت داده به مقادیر آستانه برای همه شرایط سطح نیاز دارند. جدول 7 یک نمای کلی از اقدامات برای کلاس کامل بودن با نرخ مجاز 5 درصد داده های اضافی و گمشده ارائه می دهد. با این حال، این نرخ را می توان برای موارد استفاده دیگر تطبیق داد.
مفهوم کاربردی ISO 19157:2013 مجموعه ای جامع از کلاس های کیفیت داده ها، زیر کلاس ها و معیارها را ارائه می دهد. بدیهی است که اعمال هر معیار برای هر مورد استفاده امکان پذیر نیست. به عنوان مثال، اگر یک مجموعه داده یک سری زمانی نباشد، اطلاعات مربوط به کیفیت زمانی مورد نیاز نیست. علاوه بر این، برای مجموعه دادههای مورد استفاده در موارد استفاده بدون اطلاعات حقیقت پایه، اگرچه حقیقت پایه برای ارزیابی یک معیار کیفیت داده خاص ضروری است، معیار مربوطه را میتوان بدون شکست در ارزیابی کلی مجموعه داده نادیده گرفت.
2.3. نقش ها، فعالیت ها و توضیحات در طول چرخه زندگی داده ها
بخش 2.1 قبلی و بخش 2.2 جنبه هایی را که در گردش کار QA ترکیب می کنیم، توضیح می دهند. با استفاده از این اطلاعات، بخشهای زیر فعالیتها، نقشهای مسئول، و اسناد سطح را برای هر مرحله شرح میدهند. برای درک بهتر فعالیت ها و نقش های مرتبط، جدول 8 ، جدول 9 ، جدول 10 ، جدول 11 ، جدول 12 ، جدول 13 و جدول 14 از رنگ های پس زمینه یکسانی برای مراحل و نقش ها استفاده می کنند که در شکل 4 و شکل 5 استفاده شده است.
2.3.1. فاز مقدماتی
قبل از شروع فعالیتهای مدیریت داده، نظارت و گزارشدهی در طول چرخه عمر دادهها، ارائهدهندگان داده، متولیان داده و ناشران داده باید معیارها و شرایط سطح باز بودن، بلوغ دادهها و کیفیت دادهها را بسته به ویژگیهای پروژه یا مورد استفاده تعریف کنند. جدول 8 تمام فعالیت های لازم را خلاصه می کند.
2.3.2. فرآیند کنترل کیفیت از پیش تعریف شده
کنترل کیفیت به عنوان یک فرآیند از پیش تعریف شده را می توان چندین بار در گردش کار QA یافت: در مرحله جمع آوری، مرحله پردازش و مرحله تجزیه و تحلیل. کنترل کیفیت با انتخاب و اعمال یک روش QA مناسب، شامل معیارها و تعاریف آستانه ارزش شروع می شود. نتایج برای ارزیابی اینکه آیا مجموعه داده برای مرحله بعدی در چرخه عمر داده آماده و قابل استفاده است یا خیر استفاده می شود. بسته به فاز، شاخص ها و نتایج باید به ابرداده ها اضافه شوند. جدول 9 شامل فعالیت های فرآیند کنترل کیفیت است.
2.3.3. فاز جمع آوری
در ESS، مرحله جمع آوری معمولی شامل سه مرحله اصلی برای QA است: جمع آوری اولیه، کنترل کیفیت، و رسیدگی به بلوغ داده ها. مجموعه اولیه شامل داده ها و کشف فراداده و جمع آوری و استخراج فراداده مربوط به داده های مکانی است. سپس، متصدی داده باید تصمیم بگیرد که آیا یک مرحله کنترل کیفیت مفید است یا خیر. کنترل کیفیت در صورتی از اهمیت ویژه ای برخوردار است که قابل اعتماد بودن داده ها را نتوان ارزیابی کرد، به عنوان مثال، با ابرداده یا شهرت یک ارائه دهنده داده، یا اگر تولید کننده داده ها داده ها را با مشاهده، به عنوان مثال، استفاده از روش های سنجش از راه دور جمع آوری کند.
بلوغ داده یا ارزیابی کیفیت دادهها میتواند شرایط سطح 2 پردازش DM4 یا پردازش DQ4 را به دلیل وجود ابرداده یا داده معیوب انجام دهد. در حالت اول، متصدی داده باید جمع آوری و غنی سازی فراداده را تکرار کند. در حالت دوم، یک مجموعه داده جدید باید کشف و جمع آوری شود.
اگر مقادیر بلوغ داده و کیفیت داده برای شرایط سطح بین پردازش DM4 و انتشار DM4، یا پردازش DQ4 و انتشار DQ4 قرار گیرند، داده ها می توانند به مرحله پردازش منتقل شوند. در صورتی که هم شرایط DM4publication و DQ4publication (سطح 4) برآورده شود و داده ها را می توان برای انتشار آماده کرد. این امر به ویژه در مورد داده های جمع آوری شده از حسگرها توسط ارائه دهنده داده صدق می کند.
جدول 10 نقش ها، فعالیت ها و شرح آنها را برای مرحله جمع آوری فهرست می کند.
2.3.4. فاز پردازش
QA خاص ESS در مرحله پردازش معمولاً از سه مرحله تشکیل شده است: مدلسازی و ایجاد داده، به ترتیب، پردازش داده، کنترل کیفیت متوسط، و رسیدگی به بلوغ دادهها. مدلسازی و ایجاد داده، گردش کار و/یا پردازش مدل مورد استفاده را توصیف میکند، که میتواند شامل تعدادی دلخواه از مراحل مدلسازی/پردازش مرتبط باشد. متصدی داده می تواند یک ارزیابی کنترل کیفیت متوسط را با مجموعه ای از بررسی های ساده کیفیت توصیه کند. این امر شناسایی و رد نتایج نامناسب – در مراحل اولیه پردازش داده – بلافاصله پس از مدلسازی داده را تسهیل میکند.
با نتایج ارزیابی کیفیت و بلوغ داده ها، متصدی داده می تواند تصمیم بگیرد که آیا داده ها برای مرحله تجزیه و تحلیل مناسب هستند یا خیر. اگر شرایط DM4analysis یا DQ4 Analysis برآورده نشود، ارائهدهنده داده دو گزینه دارد: (1) تنظیم گردش کار مدل یا خود گردش کار مدل مورد نیاز برای بهبود نتایج. (ii) دادههای ورودی جدید را جمعآوری کنید، زیرا دادههای ورودی استفادهشده با گردش کار مدل مطابقت ندارند. اگر بلوغ داده ها و ارزیابی کیفیت داده ها الزامات تجزیه و تحلیل DM4 و تحلیل DQ4 (سطح 3) را برآورده کند، داده ها می توانند برای تجزیه و تحلیل بیشتر در مرحله تجزیه و تحلیل استفاده شوند. جدول 11 یک نمای کلی از نقش ها، فعالیت ها و توضیحات مرحله پردازش را ارائه می دهد.
2.3.5. فاز تحلیل
مرحله تجزیه و تحلیل گردش کار QA شامل سه مرحله اصلی است: تجزیه و تحلیل داده ها، کنترل کیفیت، و رسیدگی به بلوغ داده ها. تجزیه و تحلیل داده های مکانی معمولاً شامل آزمون های دقیق است. با این حال، اگر نتایج تجزیه و تحلیل محدود به اهداف مورد استفاده/پروژه نباشد و مدل به طور مستقیم مکانیسمها/الگوریتمهای کنترل کیفیت را شامل شود، ارزیابی کنترل کیفیت جداگانه میتواند حذف شود.
اگر بلوغ داده یا کیفیت داده الزامات DM4publication یا DQ4publication را برآورده نکند، ارائه دهنده داده دو گزینه دارد. اول، روش های تجزیه و تحلیل را می توان برای برآوردن معیارهای لازم منطبق یا گسترش داد. دوم، مرحله پردازش باید با تغییرات در مدل یا ورودی های مرتبط تکرار شود. اگر بلوغ و کیفیت داده ها شرایط انتشار DM4 و انتشار DQ4 (سطح 4) را داشته باشد، می توان از داده ها برای انتشار استفاده کرد.
جدول 12 یک نمای کلی از فعالیت ها در مرحله تحلیل ارائه می دهد.
2.3.6. فاز انتشار
در مرحله انتشار گردش کار QA، داده ها در ساختار و قالب مناسب در دسترس عموم قرار می گیرند. در ESS، دادههای علمی معمولاً در یک مخزن معروف منتشر میشوند و به یک نشریه علمی مرتبط میشوند. جدول 13 نمای کلی از فعالیت های انتشارات و نقش های درگیر را ارائه می دهد. پس از انتشار داده ها، ناشر داده تصمیم می گیرد که آیا داده ها باید بایگانی شوند یا خیر. اگر بلوغ یا کیفیت دادهها با شرایط بایگانی DM4 و بایگانی DQ4 مطابقت نداشته باشد، دادهها لازم نیست بایگانی شوند و گردش کار QA به پایان میرسد. در غیر این صورت، اگر الزامات DM4archiving و DQ4archiving (سطح 5) برآورده شود، مجموعه داده را می توان بایگانی کرد.
2.3.7. مرحله بایگانی
مرحله بایگانی آخرین مرحله در چرخه عمر داده است. اگر داده ها به عنوان یک منبع ارزشمند برای تحقیقات بیشتر (احتمالاً تأثیر) ارزیابی شوند، به این نتیجه می رسیم. در ESS، چندین مخزن انضباطی در دسترس بودن طولانی مدت داده ها را تسهیل می کنند. تمام فعالیت ها و توضیحات در جدول 14 ارائه شده است.
3. نتایج – کاربرد برای مجموعه داده کاربری زمین
3.1. ارزیابی باز بودن برای مجموعه داده SPAM2010
SPAM2010 تحت مجوز Creative Commons Attribution 4.0 بین المللی (CC BY 4.0 [ 40 ]) مجوز دارد. با توجه به طرح استقرار 5 ستاره، ما SPAM2010 را به عنوان داده باز سه ستاره (3.5) رتبه بندی می کنیم، که به شرح زیر توجیه می شود: SPAM2010 به عنوان داده های ساخت یافته (2 ستاره) ارسال می شود، و در دو قالب باز غیر اختصاصی در دسترس قرار می گیرد. CSV و GeoTIFF (سه ستاره). ابرداده را می توان از طریق مخزن هاروارد Dataverse دانلود کرد [ 14]. برخی از عناصر فراداده حاوی پیوندهایی با استفاده از URI برای نشان دادن اهداف هستند. از این رو، در این موارد می توان آن را به عنوان داده باز 4 ستاره رتبه بندی کرد و برای سایر موارد فقط می تواند داده های باز 3 ستاره (نتیجه کلی 3.5) رتبه بندی شود. با این حال، SPAM2010 سطح 5 ستاره را از دست می دهد، که به پیوندهایی به منابع دیگر برای ارائه زمینه نیاز دارد، به عنوان مثال، واژگان برای محصولات، واحدهای استفاده شده، نامگذاری ستون.
3.2. ارزیابی شاخص FAIR برای مجموعه داده SPAM2010
مجموعه داده های SPAM2010 رویکردی برای ارائه مجموعه داده ارائه می دهد که به طور فزاینده ای در جامعه ESS مورد استفاده قرار می گیرد. چنین مجموعههای داده معمولاً در یک مخزن مرکزی میزبانی میشوند که مفهوم FAIR را به درستی پیادهسازی میکند. بنابراین، مجموعه داده های SPAM2010 اکثر معیارهای ارزیابی شده FAIRsFAIR را اجرا می کنند ( جدول 15 ). با این حال، برای بهبود ارزیابی برای FsF-I3-01M (فراداده شامل پیوندهای بین داده ها و موجودیت های مرتبط با آن است)، ابرداده باید شامل پیوندهایی به داده های ورودی، ORCID [ 41 ] برای مشارکت کنندگان، یا ROR [ 42 ] باشد.] برای سازمان. علاوه بر این، ابرداده ها اطلاعات منشأ را پوشش نمی دهند (FsF-R1.2-01M – فراداده شامل اطلاعات منشأ مربوط به ایجاد یا تولید داده است). علاوه بر این، FsF-R1.3-01M (فراداده از استاندارد توصیه شده توسط جامعه پژوهشی هدف داده پیروی می کند) تنها تا حدی با ارائه ابرداده ساختار یافته به عنوان هسته دوبلین پشتیبانی می شود. با این حال، استانداردهای خاص دامنه، مانند ISO 19115-1:2014 [ 43 ] یا GeoDCAT [ 9 ]، استفاده نمی شوند.
3.3. ارزیابی بلوغ داده برای مجموعه داده SPAM2010
ارزیابی بلوغ مجموعه داده SPAM2010 به ارزیابی فراداده [ 14 ]، صفحه وب مرتبط با توضیحات مفصل [ 13 ] و انتشارات همراه [ 15 ] نیاز دارد. جدول 16 نتایج ارزیابی را برای هر معیار نشان می دهد. SPAM2010 بیشتر به سطوح بلوغ 4 یا 5 می رسد. استثناهای معدود با رتبه بندی در سطح 1 یا 2 بیشتر به محتوای ابرداده (یکپارچگی معیار) اشاره دارد. منشأ، توصیف تاریخچه داده ها، و کیفیت داده ها در فراداده توضیح داده نشده است، اما در انتشار یا در وب سایت SPAM2010 گنجانده شده است. علاوه بر این، ارجاع به داده های ورودی در ابرداده وجود ندارد. برای دسترسی به معیار، جمعهای چک وجود ندارد.
3.4. ارزیابی کیفیت داده برای مجموعه داده SPAM2010
ابرداده SPAM2010 شامل جنبه های کیفیت داده نمی شود. از این رو، کیفیت دادهها را بر اساس دادهها و انتشارات علمی مرتبط، با یک ارزیابی ترکیبی دستی و مبتنی بر ابزار ارزیابی میکنیم.
چندین کلاس را نمی توان به دلایل مختلف ارزیابی کرد: (i) دقت موقعیتی فاقد یک حقیقت اساسی برای ارزیابی است. (ii) مجموعه داده یک سری زمانی نیست، به عنوان مثال، معیارهای کیفیت زمانی قابل ارزیابی نیستند. (iii) برای دقت موضوعی ، به دادههای حقیقت پایه خاصی نیاز داریم که توسط تولیدکنندگان داده SPAM2010 ارائه نشده است. آماری برای طبقه بندی اشتباه یا صحت ویژگی های کمی، به عنوان مثال، عملکرد محصول، وجود ندارد، و ما نمی توانیم ویژگی های غیر کمی مانند واحد اداری یا مرجع زمانی را ارزیابی کنیم.
با این حال، ما می توانیم کلاس های دیگر را ارزیابی کنیم. معیارهای سازگاری منطقی همه برآورده شده اند. همه موارد با مفهوم (الزامی برای سطح 2 یا بالاتر)، دامنه (الزامی برای سطح 4 یا 5) و قالب (الزامی برای سطح 4 یا 5) مطابقت دارند. مجموعه داده شامل برشها، خودتقاطعها، یا خود همپوشانیها (ذاتی دادههای شطرنجی، مورد نیاز در سطح 5) نیست. علاوه بر این، هنگام ارزیابی کامل بودن ، مجموعه داده هیچ داده گمشده ای ندارد – هر سلول دارای مقادیری برای هر محصول است. دادههای شطرنجی همچنین حاوی دادههای اضافی نیستند ( جدول 7 ، مورد نیاز برای سطح 3 یا بالاتر).
اطمینان و همگنی در فراکیفیت در SPAM2010 داده نشده است. با توجه به بازنمایی، تعداد امتیاز در هر منطقه حدود 1/100 کیلومتر مربع ، تعداد واحدهای زمانی 1 و تعداد واحدهای موضوعی 42 (زراعت) است. ما فرض می کنیم که این مقادیر با مشخصات ناشر داده مطابقت دارند. از این رو، نمایندگی الزامات سطح 4 را برآورده می کند.
عنصر قابلیت استفاده در [ 10 ] به خوبی تعریف نشده است، همچنین به دلیل گستره وسیعی از امکانات [ 45 ]. حتی در مورد این تعداد زیاد، اطلاعات قابلیت استفاده در ابرداده ارائه نشده است. با این حال، وبسایت خانواده محصولات هرزنامه (به بخش 1.1 مراجعه کنید ) مجموعهای از موارد استفاده بالقوه و همچنین فهرستی از انتشارات با استفاده از دادههای هرزنامه را ارائه میدهد.
در مجموع، SPAM2010 تعداد محدودی از عناصر کیفیت داده را ارائه می دهد. معیارهای به دست آمده با سطح 5 مطابقت دارند. کاربران بالقوه داده ممکن است الزامات کیفیت داده خود را داشته باشند و بنابراین می توانند به داده ها اعتماد کنند، به عنوان مثال، به دلیل شهرت ارائه دهنده داده، یا توصیفات روش شناسی ارائه شده در مواد تکمیلی نشریه و در وبسایت.
4. بحث/نتیجه گیری
برای پشتیبانی از اعمال گردش کار QA ارائه شده در طول چرخه عمر داده، پیشنهاد می کنیم از یک نرم افزار مدیریتی استفاده کنید که ردیابی، نظارت و گزارش کلیه فعالیت ها و مسئولیت ها را تقویت می کند. سازماندهنده مدیریت دادههای تحقیق (RDMO [ 46 ]) یک نرمافزار منبع باز است که عمدتاً برای برنامهریزی، سازماندهی و پیادهسازی سیستماتیک مدیریت دادهها پیادهسازی میشود. RDMO مکانیسم هایی را برای انتشار فهرستی از سوالات، گزینه ها، شرایط و وظایف فراهم می کند. بنابراین، ما یک پرسشنامه گردش کار QA را اجرا کردیم و فعالیت های QA را به وظایف و ارزیابی های بلوغ و کیفیت را به سوالات ترسیم کردیم.
با استفاده از پرسشنامه، ارائه دهندگان داده، ناشران داده و متولیان داده در مورد نحوه انجام فعالیت ها و مدیریت و نظارت بر تصمیمات و نتایج راهنمایی خواهند شد (تصویر صفحه نمونه در شکل 6 ). علاوه بر این، نوارهای پیشرفت نظارت بر پیشرفت کلی را تسهیل می کنند. علاوه بر پرسشنامه، نماهای استاندارد شده را می توان در RDMO تهیه کرد. کاربر می تواند در صورت درخواست، به این نماها نگاه کرده و آنها را به فرمت های مختلف صادر کند. این می تواند برای اتوماسیون بیشتر بر اساس پاسخ های خاص در پرسشنامه استفاده شود. چندین دانشگاه/کتابخانه (در حال حاضر عمدتا آلمانی) از RDMO برای ایجاد و مدیریت برنامه های مدیریت داده با بازخورد مثبت به جامعه RDMO استفاده می کنند. که زیربنای مناسب بودن نوع پرسشنامه به عنوان ابزاری برای QA همراه با پروژه است.
برای تسهیل ایجاد و استفاده مجدد از پرسشنامه و کاهش تلاش های دستی در رابط کاربری RDMO، ما یک اسکریپت پایتون را برای ایجاد خودکار پرسشنامه و مدیریت روابط وظایف، سوالات و غیره پیاده سازی کردیم. پرسشنامه و اسکریپت به صورت باز منتشر می شوند. پروژه منبع در GitHub [ 47 ].
در این مقاله، مفاهیم و یک گردش کار پیچیده برای تضمین کیفیت دادههای خاص ESS و همچنین پیادهسازی ارائه کردیم. ما چندین رویکرد QA موجود را با و بدون تمرکز دامنه خاص بررسی کردیم. نتایج با تجربیات ما در هدایت تولیدکنندگان داده ESS در QA مرتبط با نرم افزار ترکیب شد و به عنوان ورودی برای مفاهیم QA و گردش کار ما استفاده شد.
به طور کلی، این بحث وجود دارد که آیا همکاری با گروههایی که استانداردهای شناخته شده را برای ترکیب دادههای مکانی حفظ میکنند مؤثرتر است تا ایجاد روشها/جریانهای کاری که صرفاً به دادههای مکانی اختصاص داده شده است [ 48 ]. مرجع. [ 18 ] به مزایای تدوین دستورالعمل برای اطلاعات با کیفیت، به عنوان مثال، سند زنده در [ 2 ]، به عنوان یک تلاش جامعه اشاره می کند. بنابراین، جامعه یک اجماع ایجاد می کند که احتمالاً به مرحله اجرا گذاشته می شود.
ISO 19157:2013 [ 10 ] فهرست جامعی از عناصر کیفیت را پیاده سازی می کند. با این حال، استاندارد مشابهی برای معیارها/سطوح بلوغ دادهها وجود ندارد. کار آینده باید شامل گنجاندن عناصر بلوغ داده ها در طرحواره فراداده شود و بنابراین ارزیابی بلوغ و نتایج در دسترس و شفاف باشد.
در حال حاضر، تضمین کیفیت نمی تواند کاملاً خودکار باشد. با این حال، ما توسعه یک ابزار استخراج و ردیابی با پشتیبانی نرمافزار را برای بلوغ دادهها و عناصر کیفیت داده متصور هستیم. علاوه بر این، تجسمهای سبک وزن و کاربرپسند از اطلاعات با کیفیت (استخراج شده یا ردیابی شده) – به عنوان مثال، ارائه شده به عنوان داشبورد با نماهای خاص برای ارائهدهندگان داده، متصدیان داده، و ناشران دادهها – میتواند راهنمایی برای گردش کار تضمین کیفیت را تقویت کند.
کار آینده باید شامل تلاش بیشتر برای اتوماسیون فرآیندها باشد، زیرا این امر باعث تشویق به استفاده موثرتر/کارآمدتر میشود و از ایجاد مشکل در تولیدکنندگان داده توسط مسائل فنی جلوگیری میکند. معیارهای رسمی و قابل خواندن توسط ماشین را می توان برای ایجاد بررسی خودکار QA استفاده کرد. تعریف و پیوند مجموعه ای از آنها به مجموعه داده ها، انواع داده ها و ابرداده (عناصر) آنها می تواند کار دستی را به حداقل برساند. علاوه بر این، تولیدکنندگان داده را تسهیل میکند تا بر روی کنترل استفاده (صحیح) از استانداردهای فراداده تمرکز کنند (به عنوان مثال، تعریف اندازهگیری را در یک رجیستری کشف کنید و استفاده صحیح از عناصر مرتبط را بررسی کنید) یا استفاده از واژگان کنترلشده برای مقایسه ابردادههای با کیفیت.
علاوه بر این، تبدیل گردش کار به دیدگاه متصدی داده می تواند یک روش مدیریت عملی ارائه دهد. نماهای مرتبط در RDMO حتی میتوانند بدون نیاز به نرمافزار اضافی از کیوریشن پشتیبانی کنند.
منابع
- دیویلر، آر. استین، ا. Bédard، Y.; کریسمن، ن. فیشر، پی. Shi, W. سی سال تحقیق در مورد کیفیت داده های مکانی: دستاوردها، شکست ها و فرصت ها: سی سال تحقیق در مورد کیفیت داده های مکانی. ترانس. GIS 2010 ، 14 ، 387-400. [ Google Scholar ] [ CrossRef ]
- پنگ، جی. لاکانینا، سی. ایوانووا، آی. داونز، RR; راماپریان، اچ. گانسکه، آ. جونز، دی. باستین، ال. وایبورن، ال. باستراکوا، آی. و همکاران دستورالعملهای جامعه بینالمللی برای اشتراکگذاری و استفاده مجدد از اطلاعات کیفی مجموعه دادههای علوم زمین منفرد. به روز شده: 2022، نسخه: v01r02 20220326، Open Science Framework. 2021. در دسترس آنلاین: https://osf.io/xsu4p/ (در 22 مارس 2022 قابل دسترسی است).
- بلبل، ج. بوئرسما، ک. مولر، J.-P. کامپرنول، اس. لامبرت، جی.-سی. برکت، س. گیرینگ، آر. گوبرون، ن. دی اسمد، آی. کوهور، پی. و همکاران توسعه چارچوب تضمین کیفیت بر اساس شش محصول داده ECV جدید برای افزایش اعتماد به نفس کاربر برای کاربردهای آب و هوایی. Remote Sens. 2018 , 10 , 1254. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- RfII–شورای زیرساختهای اطلاعات علمی آلمان. چالش کیفیت داده ها توصیه هایی برای تحقیقات پایدار در چرخش دیجیتال ; دفتر مرکزی RfII: گوتینگن، آلمان، 2020. [ Google Scholar ]
- Rüegg، J. گریس، سی. باند-لامبرتی، بی. بوون، جی جی; فلزر، BS; مک اینتایر، NE; سورانو، PA; Vanderbilt، KL; Weathers, KC تکمیل چرخه حیات داده: استفاده از مدیریت اطلاعات در تحقیقات بومشناسی کلان سیستمها. جلو. Ecol. محیط زیست 2014 ، 12 ، 24-30. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کای، ال. Zhu, Y. چالشهای کیفیت داده و ارزیابی کیفیت داده در عصر کلان داده. CODATA 2015 ، 14 ، 2. [ Google Scholar ] [ CrossRef ]
- Hassenstein، MJ; وانلا، پی. کیفیت داده ها – مفاهیم و مسائل. دایره المعارف 2022 ، 2 ، 498-510. [ Google Scholar ] [ CrossRef ]
- ISO/DIS 19157-1. اطلاعات جغرافیایی-کیفیت داده-بخش 1: الزامات عمومی. در دسترس آنلاین: https://www.iso.org/standard/78900.html (در 22 مارس 2022 قابل دسترسی است).
- GeoDCAT-AP-نسخه 2.0.0. در دسترس آنلاین: https://semiceu.github.io/GeoDCAT-AP/drafts/latest/ (در 16 مارس 2022 قابل دسترسی است).
- سازمان بین المللی استاندارد سازی. اطلاعات جغرافیایی–کیفیت داده (ISO 19157:2013) ؛ دفتر حق چاپ ISO: ژنو، سوئیس، 2013. [ Google Scholar ]
- سازمان بین المللی استاندارد سازی. سیستم های مدیریت کیفیت – مبانی و واژگان (ISO 9000:2015) ؛ دفتر حق نشر ISO: ژنو، سوئیس، 2015. [ Google Scholar ]
- Henzen, C. GeoKur-Curation و تضمین کیفیت داده های تحقیقات محیطی برای مورد استفاده از داده های کاربری جهانی زمین. Zenodo 2021 ، 1-10. در دسترس آنلاین: https://geokur.geo.tu-dresden.de/ (دسترسی در 22 مارس 2022).
- صفحه اصلی مدل تخصیص تولید فضایی. در دسترس آنلاین: https://www.mapspam.info/ (در 16 مارس 2022 قابل دسترسی است).
- موسسه تحقیقات بین المللی سیاست غذایی دادههای آماری تولید محصول با تفکیک فضایی جهانی برای سال 2010 نسخه 2.0 . Harvard Dataverse: Harvard, MA, USA, 2019. [ Google Scholar ] [ CrossRef ]
- یو، کیو. شما، ال. Wood-Sichra، U. Ru، Y. جوگلکار، AKB; فریتز، اس. Xiong، W. لو، ام. وو، دبلیو. Yang, P. A Cultivated Planet in 2010—Part 2: The Global Gridded Agricultural-Production Maps. سیستم زمین علمی دادههای 2020 ، 12 ، 3545–3572. [ Google Scholar ] [ CrossRef ]
- قیمت های تولید کننده کشاورزی (جهانی-ملی-سالانه/ماهانه-FAOSTAT). در دسترس آنلاین: https://data.apps.fao.org/catalog/dataset/faostat-pp (در 22 مارس 2022 قابل دسترسی است).
- مناطق حفاظت شده (WDPA). در دسترس آنلاین: https://www.protectedplanet.net/en/thematic-areas/wdpa?tab=WDPA (در 22 مارس 2022 قابل دسترسی است).
- پنگ، جی. لاکانینا، سی. داونز، RR; گانسکه، آ. راماپریان، هنگ کنگ؛ ایوانووا، آی. وایبورن، ال. جونز، دی. باستین، ال. شی، سی. و همکاران دستورالعملهای جامعه جهانی برای مستندسازی، اشتراکگذاری و استفاده مجدد از اطلاعات کیفی مجموعههای داده دیجیتال فردی. اطلاعات علمی J. 2022 , 21 , 8. [ Google Scholar ] [ CrossRef ]
- داده های باز 5 ستاره. در دسترس آنلاین: https://5stardata.info/ (در 16 مارس 2022 قابل دسترسی است).
- درباره مجوزهای CC در دسترس آنلاین: https://creativecommons.org/about/cclicenses/ (در 16 مارس 2022 قابل دسترسی است).
- ویلکینسون، MD؛ دومانتیه، ام. آلبرسبرگ، آی جی; اپلتون، جی. آکستون، ام. باک، ا. بلومبرگ، ن. Boiten، J.-W. دا سیلوا سانتوس، LB; بورن، PE; و همکاران اصول راهنمای FAIR برای مدیریت و سرپرستی داده های علمی. علمی داده 2016 ، 3 ، 160018. [ Google Scholar ] [ CrossRef ] [ PubMed ] [ نسخه سبز ]
- گروه کاری مدل بلوغ داده های پژوهشی اتحاد FAIR مدل بلوغ داده عادلانه: مشخصات و دستورالعمل ها. Zenodo 2020 ، 1-47. [ CrossRef ]
- FAIRsFAIR. در دسترس آنلاین: https://fairsfair.eu/ (دسترسی در 16 مارس 2022).
- دواراجو، ع. هوبر، آر. موکرانه، م. هرتریش، پی. Cepinskas، L. دی وریس، جی. L’Hours، H.; دیویدسون، جی. White, A. FAIRsFAIR معیارهای ارزیابی اشیاء داده. Zenodo 2020 ، 1-25. [ Google Scholar ] [ CrossRef ]
- لاکانینا، سی. دوبلاس-ریس، اف. لارنیکول، جی. بوونتمپو، سی. Obregón، A. کاستا سوروس، ام. سن مارتین، دی. Bretonnière, P.-A.; پولاد، SD; رومانوا، وی. و همکاران چارچوب مدیریت کیفیت برای مجموعه داده های آب و هوا. CODATA 2022 ، 21 ، 10. [ Google Scholar ] [ CrossRef ]
- پنگ، جی. وضعیت ارزیابی بلوغ مباشرت داده ها – مروری. اطلاعات علمی J. 2018 ، 17 ، 7. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- شورای تحقیقات ملی. مدیریت داده های زیست محیطی در NOAA: آرشیو، سرپرستی و دسترسی . انتشارات آکادمی ملی: واشنگتن، دی سی، ایالات متحده آمریکا، 2007; پ. 12017. شابک 978-0-309-11209-3.
- سادین، اس آر. پوینلی، FP; روزن، آر. فناوری ناسا به سمت سیستمهای ماموریت فضایی آینده پیش میرود. فضانورد Acta. 1989 ، 20 ، 73-77. [ Google Scholar ] [ CrossRef ]
- سطوح آمادگی فناوری (TRLs). در دسترس آنلاین: https://esto.nasa.gov/trl/ (دسترسی در 16 مارس 2022).
- بیتس، جی جی. Privette، JL یک مدل بلوغ برای ارزیابی کامل بودن رکوردهای داده های آب و هوایی. Eos Trans. AGU 2012 ، 93 ، 441. [ Google Scholar ] [ CrossRef ]
- بیتس، جی جی. Privette، JL; کرنز، ای جی. نگاه، دبلیو. ژائو، ایکس. تولید پایدار رکوردهای آب و هوایی چند دهه ای: درس هایی از برنامه ثبت داده های آب و هوایی NOAA. گاو نر صبح. هواشناسی Soc. 2016 ، 97 ، 1573-1581. [ Google Scholar ] [ CrossRef ]
- شولز، جی. ارزیابی بلوغ سیستم. ارائه شده در کارگاه کوپرنیک در مورد الزامات مشاهده آب و هوا، ECMWF، Reading. 2015. در دسترس آنلاین: https://www.ecmwf.int/sites/default/files/elibrary/2015/13474-system-maturity-assesment.pdf (در 16 مارس 2022 قابل دسترسی است).
- پنگ، جی. Privette، JL; کرنز، ای جی. ریچی، NA; انصاری، س. چارچوب یکپارچه برای اندازهگیری شیوههای سرپرستی به کار رفته در مجموعه دادههای محیطی دیجیتال. اطلاعات علمی J. 2015 ، 13 ، 231-252. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هاک، اچ. توسن، اف. Thiemann, H. تناسب برای استفاده از اشیاء داده توصیف شده با ماتریس بلوغ کیفیت در مراحل مختلف تولید داده. اطلاعات علمی جی. 2020 , 19 , 45. [ Google Scholar ] [ CrossRef ]
- بهترین روش ها – تضمین کیفیت. در دسترس آنلاین: https://www.komfor.net/qa.html (در 16 مارس 2022 قابل دسترسی است).
- یانگ، ایکس. دمنده، JD; باستین، ال. سرسبز، وی. زبالا، ع. ماسو، جی. کورنفورد، دی. دیاز، پی. Lumsden, J. دیدگاهی یکپارچه از کیفیت داده در رصد زمین. فیل. ترانس. R. Soc. A 2013 , 371 , 20120072. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- شرایط فراداده DCMI. در دسترس آنلاین: https://www.dublincore.org/specifications/dublin-core/dcmi-terms/ (در 16 مارس 2022 قابل دسترسی است).
- داده ها در وب بهترین شیوه ها: واژگان کیفیت داده ها. در دسترس آنلاین: https://www.w3.org/TR/vocab-dqv/ (در 16 مارس 2022 قابل دسترسی است).
- سازمان بینالمللی استانداردسازی فضایی دادهها و سیستمهای انتقال اطلاعات – سیستم اطلاعات بایگانی باز (OAIS) – مدل مرجع (ISO 14721:2012) . دفتر کپی رایت ISO: ژنو، سوئیس، 2012.
- Attribution 4.0 International (CC BY 4.0). در دسترس آنلاین: https://creativecommons.org/licenses/by/4.0/ (در 16 مارس 2022 قابل دسترسی است).
- ORCID. در دسترس آنلاین: https://orcid.org/ (دسترسی در 16 مارس 2022).
- ROR. در دسترس آنلاین: https://ror.org/ (دسترسی در 16 مارس 2022).
- سازمان بین المللی استانداردسازی اطلاعات جغرافیایی – فراداده – قسمت 1: اصول (ISO 19115-1:2014) ; دفتر کپی رایت ISO: ژنو، سوئیس، 2014.
- AGROVOC. در دسترس آنلاین: https://www.fao.org/agrovoc/ (دسترسی در 16 مارس 2022).
- شکارچی، جی جی. واچوویچ، ام. Bregt، AK درک قابلیت استفاده از داده های مکانی. اطلاعات علمی J. 2003 , 2 , 79-89. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- RDMO – سازمان مدیریت داده های پژوهشی. در دسترس آنلاین: https://github.com/rdmorganiser/rdmo (در 16 مارس 2022 قابل دسترسی است).
- RDMO کاتالوگ ساز. در دسترس آنلاین: https://github.com/GeoinformationSystems/RDMOCatalogBuilder (در 16 مارس 2022 قابل دسترسی است).
- گروه کاری دامنه کیفیت داده های کنسرسیوم جغرافیایی باز. در دسترس آنلاین: https://www.ogc.org/projects/groups/dqdwg (در 22 مارس 2022 قابل دسترسی است).

شکل 1. چرخه عمر داده ها و جنبه های مفهوم گردش کار تضمین کیفیت توسعه یافته.
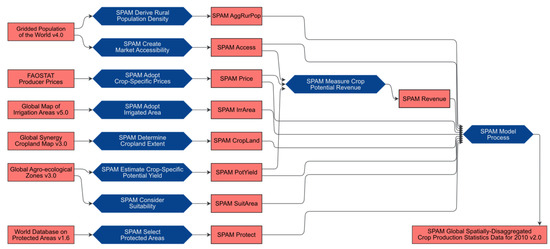
شکل 2. نمودار منشأ ساده شده سری داده های SPAM2010. مستطیل های قرمز مجموعه داده ها را توصیف می کنند و جعبه های آبی فرآیندها را توصیف می کنند.

شکل 3. جدول زمانی توسعه ماتریس بلوغ در مراجع. [ 28 ، 30 ، 32 ، 33 ، 34 ] از جمله مفهوم توسعه یافته ما.

شکل 4. گردش کار تضمین کیفیت در کنار چرخه عمر داده برای داده های تحقیقات فضایی. اختصارات: DQ – کیفیت داده، MD – فراداده، DM – بلوغ داده.

شکل 5. فرآیند از پیش تعریف شده کنترل کیفیت در گردش کار QA آشکار شده است ( شکل 4 ).

شکل 6. اجرای گردش کار QA به عنوان یک پرسشنامه RDMO.


بدون دیدگاه