1. مقدمه
الگوی گروه ساختمانی در کارتوگرافی معمولاً به الگوی توزیع فضایی ساختمان ها در فضای نقشه برداری اشاره دارد. الگوی توزیع فضایی معمولاً با اندازه، فاصله و جهت ساختمان ها تعیین می شود [ 1 ، 2 ]. شناخت الگوهای گروه ساختمانی می تواند اطلاعات ساختاری را ارائه دهد که به انتخاب و پارامترسازی عملگرهای تعمیم نقشه کمک می کند [ 3 ، 4 ]]. به عنوان پیش نیاز تعمیم نقشه (یعنی رویه ای که از عملگرهای تعمیم برای حل تضادهای فضایی موجودیت ها و استخراج نقشه های مقیاس کوچکتر از نقشه های مقیاس بزرگتر استفاده می کند)، شناخت الگوهای گروه ساختمانی با توسعه نقشه برداری توجه گسترده ای را به خود جلب کرد و به تدریج به یکی تبدیل شد. از مسائل اساسی علم اطلاعات جغرافیایی [ 5 ، 6 ، 7 ].
تشخیص گروه های ساختمانی یک کار چالش برانگیز است زیرا الگوهای گروه ساختمانی اغلب وابسته به مقیاس هستند و با توزیع ساختمان (به عنوان مثال، فواصل، جهت گیری های نسبی و روابط توپولوژیکی بین ساختمان ها) متفاوت هستند [ 8 ، 9 ]]. با این حال، روشهای مختلفی برای شناسایی الگوهای گروهی برای تعمیم نقشه توسعه داده شد. ایده زیربنایی این روش ها شامل یافتن گروه های ساختمانی بالقوه و تعیین گروه های ساختمانی بهینه است. این روش ها را می توان به دو نوع دسته بندی کرد. روش خوشه بندی یک الگوی بالقوه را با مقایسه روابط فضایی بین ساختمان های مجاور تشکیل می دهد. روش دیگر به دست آوردن الگوهای گروهی از طریق تطبیق قالب است. روشهای خوشهبندی معمولاً از نمودارها برای مدلسازی ساختمانها و مجاورتهای آنها بر اساس مثلثسازی Delaunay محدود (CDT) استفاده میکنند [ 10 ، 11 ]]. در یک نمودار، گرهها ساختمانها را نشان میدهند، یالها روابط مجاورت بین ساختمانها را نشان میدهند و یالها با مقادیر شباهت فضایی وزن میشوند. تشابه ساختمان، مانند فواصل اروپایی، از جمله نزدیکترین فاصله [ 12 ]، فاصله متوسط [ 13 ] و فاصله مرئی [ 14 ]، رایج ترین اندازه گیری های شباهت هستند. علاوه بر این، شکل، مساحت و جهت ساختمان ها نیز برای اندازه گیری شباهت استفاده می شود [ 15 ، 16 ، 17 ، 18]. روشهای تطبیق الگو نیز مورد توجه گستردهای قرار میگیرند، زیرا میتوان از آنها برای شناسایی انواع خاصی از الگوهای گروهی استفاده کرد. رویکرد الگو ابتدا پارامترهای قالب را تعریف می کند، سپس الگوی گروه بالقوه را تعیین می کند، و در نهایت با هم مقایسه می شود که آیا این دو مطابقت دارند یا خیر. الگوهای شناسایی شده با استفاده از این روش شامل الگوهای تراز خط مرکزی [ 5 ]، الگوهای هم ترازی خطی [ 19 ] و الگوهای تراز جاده [ 20 ] است. علاوه بر روش های تقسیم بندی نمودار [ 16 ]، روش های یادگیری ماشین مانند شبکه های عصبی کانولوشن [ 21 ]، جنگل تصادفی [ 22 ] و SVM [ 23 ]] نیز برای تشخیص گروه های ساختمانی استفاده می شوند. با این حال، روشهای ذکر شده در بالا فقط اطلاعات هندسی ساختمانها را در نظر میگیرند و به معنایی ساختمان (یعنی توابع ساختمان) نمیپردازند، که منجر به تفاوتهای زیادی بین نتایج گروهبندی و نتایج دستی میشود.
همانطور که داده های بزرگ جغرافیایی رونق می گیرد، می توان ساختارهای شهری را از طریق عملکردهای مختلف ساختمان استنباط شده با استفاده از یکپارچه سازی داده های فضایی چند منبعی (مانند POI ها، داده های رسانه های اجتماعی، GPS و داده های مسیر) درک کرد. با پشتیبانی از روش های یادگیری ماشین، استخراج توابع ساختمان از داده های بزرگ جغرافیایی به عنوان یک روند جدید مهم ظاهر شد [ 24 ]. مقیاس تحقیق در مورد عملکرد ساختمان عمدتاً بر بلوک ساختمانی یا سطح جامعه [ 25 ، 26 ] و سطح ساختمان [ 27 ، 28 ] متمرکز است.]. با این حال، این دو عملکرد ساختمان برای استفاده روزانه به عنوان نقشه مناسب نیستند. به طور خاص، واحد تشخیص در سطح بلوک ساختمان برای کاربران برای درک دقیق صحنههای ساختمان بسیار بزرگ است، در حالی که واحد تشخیص در مقیاس سطح ساختمان برای درک صحنههای ساختمان در سطوح بالا بسیار کوچک است. علاوه بر این، چنین تحقیقاتی اطلاعات هندسی ساختمان ها را در نظر نمی گیرد که منجر به کمبود اطلاعات الگوی ساختمان می شود. این نتایج نگاشت می تواند فرآیند تشخیص گروه ساختمان را محدود کند. داده های بزرگ جغرافیایی فرصت جدیدی را برای محققان نقشه کشی در حوزه های فنی، روش شناختی و هنری ارائه می دهد [ 29 ]]. روش تشخیص ترکیب اطلاعات عملکرد ساختمان و ویژگیهای هندسی ممکن است نتایج گروهبندی دقیقتر و معقولتری را به همراه داشته باشد.
بقیه این مقاله به شرح زیر سازماندهی شده است: مطالعه موردی و مجموعه داده های تجربی در بخش 2 توضیح داده شده است . بخش 3 شرح مفصلی از یک سری مراحل در روش پیشنهادی ارائه می دهد. آزمایشات متشکل از نرم افزار، پیاده سازی، نتایج تشخیص و بحث در بخش 4 ارائه شده است. در نهایت نتیجه گیری ارائه شده است.
2. منطقه مطالعه و داده ها
منطقه مورد مطالعه ما در شهر چنگدو چین واقع شده است که بزرگترین شهر در جنوب غربی چین است ( شکل 1). مواد مطالعه در تحقیق ما شامل ردپای ساختمان، شبکههای جادهای و تراکم کاربر Tencent در زمان واقعی (RTUD) است. مجموعه دادههای ساختمان و شبکههای جادهای توسط مؤسسه تحقیقاتی برنامهریزی شهری و طراحی استان در استان سیچوان، چین ارائه شده است. این مجموعه داده شامل 546 ساختمان در شکل فایل ESRI است. آنها توسط شبکه های جاده ای به چندین بلوک تقسیم می شوند. این ساختمان ها در نقشه های الکترونیکی به واحدهای منطقه ای دسته بندی می شوند. دادههای RTUD اطلاعات مکان دستگاههای پایانه هوشمند را با استفاده از محصولات Tencent، از جمله Tencent QQ، WeChat، Tencent Maps و سایر برنامههای تلفن همراه که خدمات مبتنی بر مکان (LBS) ارائه میکنند، ثبت میکند. یک خزنده وب برای ضبط این داده ها هر دو ساعت در وب سایت Tencent ( http:ur.tencent.com) ساخته شده است.، قابل دسترسی در 5 ژوئن 2020). با توجه به اینکه افراد معمولاً در روزهای کاری و روزهای غیر کاری فعالیتهای متفاوتی دارند، ما دادههای RTUD را در یک روز کاری (5 ژوئن 2020) و یک روز غیر کاری (6 ژوئن 2020) در منطقه مورد مطالعه خود برای استنتاج عملکردهای ساختمان انتخاب کردیم. علاوه بر این، ما از نقشه های Baidu و تصاویر Google Earth برای تأیید نتایج آزمایشی استفاده کردیم. داده های شبکه جاده دانلود شده از نقشه AutoNavi برای بحث در مورد نتایج تعمیم استفاده شد. نقشه AutoNavi یک نقشه الکترونیکی است که به طور گسترده در زندگی روزمره برای ناوبری رانندگی استفاده می شود.
3. روش شناسی
روش پیشنهادی شامل یک سری مراحل است که در جدول 1 نمایش داده شده است و در زیر به تفصیل توضیح داده شده است.
مرحله 1. اولین گام، ترسیم توزیع تراکم کاربر با استفاده از داده های تراکم کاربر Tencent است. این مجموعه داده خام از نقاطی در یک فایل شیپ تشکیل شده است و هر نقطه شامل تعداد کاربر است. برخی از نقاط شامل تعداد کاربران غیرعادی هستند که چندین برابر بیشتر از نقاط همسایه است. با این حال، ساختمان های نزدیک به این نقاط مشابه ساختمان های نزدیک به نقاط مجاور خود هستند. پس از حذف دستی دادههای غیرعادی، توزیعهای چگالی کاربر با استفاده از ابزار چگالی هسته ArcMap تولید میشوند. ما توزیع تراکم کاربر را برای هر نقطه زمانی ترسیم می کنیم.
مرحله 2. پس از ترسیم توزیع تراکم کاربر، نمونه هایی را برای محاسبه میانگین تراکم کاربر هر نوع ساختمان انتخاب می کنیم. در منطقه مورد مطالعه ما، انواع ساختمان ها شامل ساختمان های مسکونی، اداری و تجاری است. اطلاعات عملکردی مربوط به این ساختمانها از نقاط مورد علاقه (POI) و نماهای خیابان در Baidu Maps به دست آمد. ما نمونههایی را برای هر نوع ساختمان بر اساس Google Earth، نقشههای Baidu و نظرسنجیها انتخاب میکنیم. سپس، میانگین تراکم کاربری هر نوع ساختمان با استفاده از رابطه (1) [ 24 ] به دست می آید.
که در آن k نشان دهنده k نوع توابع است، مترکمترکتعداد نمونه است، نk ، wنک،�تراکم کاربر نمونه ها را نشان می دهد و t نشان دهنده زمان فعالیت کاربران Tencent است.
مرحله 3. هدف این مرحله استنتاج توابع ساختمان با استفاده از الگوریتم زمان تابش پویا (DTW) است. با توجه به اینکه منحنی اوج فعالیت هر نوع ساختمان در مرحله 2 به دست آمد، ما فقط باید منحنی اوج فعالیت ساختمان پیش بینی شده را با نمونه ها مقایسه کنیم تا عملکرد ساختمان های پیش بینی شده را تشخیص دهیم. یعنی تشابه آنها مشخص شود. DTW [ 30] روش مناسبی برای اندازه گیری شباهت بین دو سری زمانی است و در زمینه داده کاوی سری های زمانی کاربرد فراوانی دارد. DTW فرض می کند که اگر نقاط دو دنباله به درستی مطابقت داشته باشند، فاصله آنها (فاصله اقلیدسی) به حداقل می رسد. حداقل فاصله را می توان شباهت دو دنباله در نظر گرفت. در این مطالعه از سری زمانی نمونه ها به عنوان الگوی مرجع استاندارد R استفاده می کنیم که یک بردار M بعدی است. R = {R(1)، R(2)، ……، R(m)، ……، R(M)}. هر جزء نشان دهنده میانگین مقدار چگالی کاربر در هر نقطه زمانی است. توالی میانگین تراکم کاربر هر ساختمان پیش بینی شده به عنوان یک الگوی آزمایشی T عمل می کند که ممکن است یک بردار N بعدی باشد. T = {T(1)، T(2)، ……، T(m)، ……، T(N)}. الگوریتم DTW برای مقایسه سری های زمانی هر ساختمان پیش بینی شده با توالی هر نوع نمونه استفاده می شود.
مرحله 4. برای بهبود کارایی پردازش، نقشه توپوگرافی ساختمان ها توسط یک شبکه جاده به مجموعه ای از بلوک های ساختمانی تقسیم می شود. این به این دلیل است که هر دو ساختمان برای شناسایی روابط مجاورت در طول پردازش داده ها باید با هم مقایسه شوند. اگر مجموعه داده خیلی بزرگ باشد، پیمایش زمان قابل توجهی خواهد داشت. بنابراین، هر بلوک ساختمانی یک واحد درمان جداگانه در پردازش بعدی است. سپس، دو نوع مثلث Delaunay محدود (CDT) برای هر بلوک جداگانه ایجاد می شود ( شکل 2 ). اولین نوع CDT برای تمام ساختمانها در هر بلوک جداگانه محاسبه میشود ( شکل 2 a). نوع دیگری از CDT، یعنی مثلث های ساختمانی زوجی، فقط برای هر جفت ساختمان مجاور محاسبه می شود ( شکل 2).ب). اولین نوع CDT باید ابتدا ایجاد شود تا روابط مجاورت بین ساختمان ها را تشخیص دهد. اگر دو ساختمان مجاور هم باشند، مثلث های ساختمانی زوجی آنها ایجاد می شود. قبل از ایجاد یک CDT، بهتر است برای جلوگیری از تولید مثلث های باریک، نقاط اضافی را در بخش های خط چندضلعی های ساختمانی و جاده ها در یک فاصله اضافه کنید [ 31 ].
مرحله 5. مقادیر شاخص ساختمان های مجاور بر اساس دو نوع مثلث بندی محدود دلون محاسبه می شود. شاخص هایی شامل رابطه مجاورت (معادله (2))، طول خط اسکلت (معادله (3))، میانگین فاصله ساختمان های مجاور (معادله (4))، شاخص پیوستگی فضایی ( SCI ) (معادله (5) ) جهت دو ساختمان مجاور و زاویه مسیر (معادله (6)) در یک فرآیند ردیابی بر اساس مثلث ها تعریف می شوند. همه این مقادیر شاخص به جز زوایای مسیر در ماتریس ها ذخیره می شوند. فرمول محاسبه هر شاخص در زیر توضیح داده شده است.
ماتریس رابطه مجاورت نشان می دهد که آیا ساختمان ها از نظر توپولوژیکی مجاور هستند یا خیر و بر اساس اینکه آیا ساختمان ها مثلث های مشترکی در CDT دارند یا خیر به دست می آید:
جایی که i = 1 : nمن=1:�و j = 1 : n�=1:�ساختمان های درون یک بلوک را نشان می دهد و آرمن ، جآرمن،�یک متغیر بولی است. جایی که آرمن ، ج= 1آرمن،�=1نشان میدهد که منمنو j�مجاور هستند و آرمن ، ج= 0آرمن،�=0نشان میدهد که منمنو j�مجاور نیستند
خط اسکلت توسط نقاط میانی اضلاع مثلثی که دو ساختمان مجاور را به هم پیوند می دهند تشکیل می شود ( شکل 3 ). طول یک خط اسکلت به صورت زیر بدست می آید:
جایی که لمن ، ج ، کلمن،�،کنشان دهنده فاصله بین دو نقطه وسط اضلاع یک مثلث است کککه دو ساختمان مجاور را به هم پیوند می دهد، Lمن ، ج= ∑لمن ، ج ، ک�من،�=∑لمن،�،کنشان دهنده طول مجموع خط اسکلت بین دو ساختمان مجاور است و Lمن ، ج= 0�من،�=0اگر دو ساختمان منمنو j�همانطور که در رابطه (2) به دست می آید، مجاور نیستند.
میانگین فاصله ساختمان های مجاور بر اساس خط اسکلت به صورت زیر بدست می آید [ 13 ]:
جایی که ساعتمن ، ج ، کساعتمن،�،کارتفاع مثلث را نشان می دهد ککبا پایه ای که در هر چند ضلعی ساختمان مجاور قرار می گیرد، لمن ، ج ، کلمن،�،کنشان دهنده فاصله بین دو نقطه وسط اضلاع مثلث است کککه دو ساختمان مجاور را، همانطور که از رابطه (3) به دست می آید، به هم مرتبط می کند Dمن ، ج= ∞�من،�=∞اگر دو ساختمان منمنو j�همانطور که در رابطه (2) به دست می آید، مجاور نیستند. اگر مثلث تیز یا راست باشد، ساعتمن ، ج ، کساعتمن،�،کارتفاع از سمت مشترک با ساختمان است. اگر مثلث منفرد باشد، ساعتمن ، ج ، کساعتمن،�،ککوتاه ترین ضلع مثلثی است که دو ساختمان را به هم متصل می کند ( شکل 3 ).
شاخص پیوستگی فضایی ( SCI ) ساختمان های مجاور نسبت خط اسکلت به فاصله به صورت زیر است:
جایی که اسسیمنمن ، جاسسیمنمن،�پیوستگی فضایی بین ساختمان های i و j است، Lمن ، ج�من،�نشان دهنده طول خط اسکلت دو ساختمان همانطور که در رابطه (3) توضیح داده شده است، و Dمن ، ج�من،�نشان دهنده فاصله دو ساختمان مجاور همانطور که در رابطه (4) توضیح داده شده است.
زوایای آزیموت دو ساختمان مجاور بر اساس دو نوع مثلث دلونای محدود به دست آمده است. محاسبه این شاخص در ادبیات [ 15 ] به تفصیل شرح داده شده است. سه مرحله برای محاسبه زاویه آزیموت دو ساختمان مجاور وجود دارد ( شکل 4 ).
زاویه مسیر در ساختمان میانی منمنزاویه تشکیل شده توسط جهت ساختمان است ( b u i l dمن ngمن – 1, b u i l dمن ngمنبتومنلدمن��من-1،بتومنلدمن��من) و جهت ساختمان ( b u i l dمن ngمن, b u i l dمن ngمن + 1بتومنلدمن��من،بتومنلدمن��من+1) در مسیر. هر چه زاویه به صفر نزدیکتر باشد، الگوی خطی بهتر است.
جایی که αمن ، ج ، ک�من،�،کزاویه آزیموت یک مثلث را نشان می دهد ککبا پایه ای که در هر دو ساختمان مجاور می افتد و لمن ، ج ، کلمن،�،کنشان دهنده فاصله بین دو نقطه وسط دو ضلع مثلث است ککهمانطور که از رابطه (4) به دست می آید، دو ساختمان مجاور را به هم مرتبط می کند.
مرحله 6. این مرحله شامل ایجاد گراف و تقسیم بندی نمودار است. قبل از تقسیم بندی نمودار، هر بلوک ساختمان ابتدا به عنوان یک نمودار مدل می شود، که در آن گره ها ساختمان ها را نشان می دهند و یال ها روابط مجاور دو ساختمان مجاور را با عملکرد یکسان نشان می دهند. سپس، لبههای نمودار با مقادیر شاخص حاصل از مرحله 5 وزنگذاری میشوند. در تقسیمبندی نمودار، الگوهای خطی به دلیل همگنی بالا، ابتدا شناسایی میشوند. بر اساس SCI و زاویه آزیموت، روش پیشنهادی در ادبیات [ 15] برای تشخیص الگوهای خطی اعمال می شود. پس از آن، لبه هایی با فواصل غیرعادی حذف می شوند تا گروه های ساختمانی نهایی به دست آید. به طور خاص، ابتدا جفت گرههایی که با لبهای متصل شدهاند که کمترین فاصله را وزن میکند، تعیین میشود، سپس تمام گرههای همسایه آنها پیدا میشود و انحراف استاندارد فواصل متعلق به گرههای همسایه بالا محاسبه میشود. اگر انحراف استاندارد از یک آستانه معین فراتر رود (مثلاً 0.2)، یال با حداکثر فاصله حذف میشود و انحراف استاندارد مجدداً محاسبه میشود تا مشخص شود آیا لبهای با حداکثر فاصله باید حذف شود یا خیر. پس از تکمیل فرآیند فوق، جفت گره با دومین فاصله کوتاه پیدا می شود و همان عملیات انجام می شود. لبه هایی که الزامات را برآورده نمی کنند حذف می شوند.
مرحله 7. برای ارزیابی کارایی رویکرد ما، یک ارزیابی تخصصی انجام شد. ما نتایج شناسایی شده با استفاده از روش پیشنهادی را با نتایج شناسایی شده به صورت دستی توسط کاربران مقایسه کردیم. چنین روش مقایسه ای به طور گسترده در تحقیقات تشخیص الگو استفاده می شود [ 22 ، 32]. برای ارزیابی توابع ساختمان شناسایی شده با استفاده از الگوریتم DTW، ما نتایج را با POIs نقشه Baidu مقایسه کردیم. داده های مرجع اعمال شده برای ارزیابی نتیجه تشخیص گروه ساختمان به صورت دستی بر اساس نقشه های Baidu و تصاویر Google Earth شناسایی می شوند. هنگام ارزیابی نتایج تشخیص گروه ساختمانی، چهار حالت مختلف میتواند وجود داشته باشد، از جمله الگوهای صحیح (یعنی الگوهای مدلسازیشده و الگوهای مرجع سازگار هستند)، الگوهای گنجاندن (یعنی یک الگوی مدلشده حاوی الگوهای مرجع متعدد است)، درون الگوها (یعنی یک الگوی مرجع شامل چندین الگوی مدل شده است)، و الگوهای همپوشانی (یعنی یک الگوی مدل شده با الگوی مرجع همپوشانی دارد). در اینجا، از دو معیار، از جمله صحت و کامل بودن، برای ارزیابی دقت نتایج تشخیص الگو استفاده شد. درستی به نسبت الگوهای صحیح به کل الگوهای استخراج شده اشاره دارد، در حالی که کامل بودن به نسبت الگوهای صحیح به الگوهای مرجع اشاره دارد. علاوه بر این، برای درک استحکام روش پیشنهادی بر اساس مطالعات مقایسهای، روشی بدون تشخیص تابع ساختمان (یک روش استاندارد CTD) نیز برای شناسایی گروههای ساختمانی در آزمایش ما استفاده شد. این روش شامل دومین مرحله اصلی استجدول 1 که از مرحله 4 تا 6 تشکیل شده است. این مراحل فقط از CTD برای محاسبه مقادیر شاخص ساختمان های مجاور بدون در نظر گرفتن توابع ساختمان استفاده می کنند. به طور خاص، در مرحله ایجاد نمودار، لبه هایی بین ساختمان های مجاور ایجاد می شود، صرف نظر از عملکرد آنها.
تمام آزمایش ها بر روی یک کامپیوتر شخصی با پردازنده مرکزی Intel (R) Core (TM) i7-7700 (واحد پردازش مرکزی) و حافظه 8 گیگابایتی انجام شد. تمام الگوریتم های پیشنهاد شده در بخش 3 با استفاده از C# در مایکروسافت ویندوز 10 (64 ×) تحقق یافتند. کتابخانه های مؤلفه و کتابخانه های ابزار ArcGIS Engine 10.1 برای توسعه الگوریتم های مرتبط استفاده شد.
4. نتایج و بحث
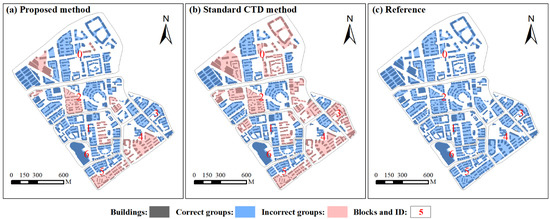
شکل 5 نتایج تشخیص گروه ساختمانی را که با استفاده از روش های مختلف استخراج شده است نشان می دهد. ساختمانهایی که با الگوهای دریچهدار آبی پوشانده شدهاند به درستی گروهبندی شدهاند، در حالی که ساختمانهایی که با نقشههای مرجع ناسازگار هستند با الگوهای دریچهدار قرمز پوشیده شدهاند. از نظر بصری، روش پیشنهادی در شناخت الگوهای مختلف گروه ساختمانی موثر است. ساختمان ها از نظر منطقه مسکونی به طور منطقی گروه بندی می شوند. این ساختمان های مسکونی به گروه های متفاوتی از دیگر انواع ساختمان های کاربردی تقسیم می شوند. در مقایسه، نتایج شناسایی شده با استفاده از روش استاندارد CTD تا حد زیادی از الگوهای مرجع منحرف شد. بسیاری دیگر از انواع عملکردی ساختمان ها در گروه های مشابه ساختمان های مسکونی گروه بندی می شوند. این به این دلیل است که آنها به یکدیگر نزدیک هستند.
نتایج ارزیابی دقت تشخیص الگوی ساختمان در جدول 2 خلاصه شده است. به طور کلی، روش پیشنهادی میتواند گروههای ساختمانی را با مقادیر صحت و مقادیر بالای 81 درصد تشخیص دهد که نشان میدهد نتایج تشخیص به خوبی با دادههای مرجع مطابقت دارد. به طور خاص، روش پیشنهادی میتواند دقت بالایی در بلوکهای 0، 1، 3 و 6 به دست آورد، در حالی که در بلوکهای 4 و 5 ضعیف عمل میکند. بیشتر این خطاها به دلیل تقسیمبندی بیش از حد است، زیرا فاصله بین ساختمانها در همان فاصله است. گروه بزرگتر از بین گروه ها است. این نشان می دهد که فاصله بین ساختمان ها مهم ترین عامل در تشخیص گروهی در برخی موارد نیست. در مقایسه، روش استاندارد CTD در اکثر بلوکهای ساختمانی به جز بلوک 6 ضعیف عمل میکند. از آنجایی که هیچ اطلاعات عملکردی وجود ندارد که به عنوان یک محدودیت عمل کند، به راحتی منجر به زیربخشبندی میشود.
شکل 6 نتایج نگاشت تراکم کاربر Tencent را برای زمان های مختلف در منطقه مورد مطالعه ما نشان می دهد. این نتایج نقشه برداری نشان می دهد که تراکم کاربر Tencent به طور قابل توجهی در طول زمان متفاوت بوده است. به عبارت دیگر فضای فعالیت افراد در طول زمان به خصوص در روزهای کاری و غیر کاری متفاوت است. بنابراین، می توان با توجه به این تغییرات، عملکردهای ساختمان را استنباط کرد.
شکل 7 تغییرات زمانی میانگین تراکم کاربر Tencent را در منطقه مورد مطالعه در طی دو روز نشان می دهد. واضح است که نوسانات دوره ای آشکار برای منحنی تراکم کاربر متوسط ساختمان های تجاری در طول دو روز رخ داده است. تقریباً هیچ کس در ساختمان های تجاری در اواخر شب وجود ندارد. تغییرات زمانی در میانگین تراکم کاربری ساختمانهای مسکونی تفاوت جزئی بین روزهای هفته و روزهای استراحت را نشان داد. برعکس، میانگین تراکم کاربری ساختمان های اداری در دو روز به طور قابل توجهی متفاوت بود. این به این دلیل است که اکثر مردم در تعطیلات آخر هفته از محل کار خود دور می مانند.
شکل 8 نتایج تشخیص عملکرد ساختمان را نشان می دهد. دقت تشخیص کلی به 87.91٪ می رسد. به طور مشخص دقت شناسایی ساختمان های مسکونی، تجاری و اداری به ترتیب 70/91 درصد، 77/96 درصد و 82/47 درصد است. دقت تشخیص کلی بالاتر از روش های پیشنهادی در ادبیات است [ 24 ، 27 ]]. دلیل اصلی این امر این است که دو روش توابع ساختمان را با استفاده از ادغام داده های مسیر جاده شناسایی کردند. با این حال، این داده ها نمی توانند به طور دقیق تغییرات در تراکم جمعیت را به همان شیوه ای که داده های تراکم کاربر Tencent منعکس می کنند، منعکس کنند. بالاترین دقت در تشخیص ساختمان های تجاری احتمالاً به این دلیل است که منحنی های تراکم کاربر به دست آمده از این نوع ساختمان نسبت به دو نوع ساختمان دیگر واضح تر است ( شکل 7).). کمترین دقت در تشخیص ساختمان های اداری به این دلیل است که منحنی های فعالیت تراکم کاربر در ساختمان های اداری بسیار شبیه منحنی های ساختمان های مسکونی است که باعث می شود برخی از ساختمان های مسکونی به عنوان ساختمان های اداری شناسایی شوند. علاوه بر این، بسیاری از ساختمان ها در بلوک 0 و بلوک 2 به عنوان ساختمان های رسمی شناخته می شوند. با مقایسه نقشه های Baidu و تصاویر Google Earth، متوجه شدیم که این ساختمان های مسکونی به عنوان ساختمان های اداری استفاده می شوند که تشخیص آنها از ساختمان های اداری را دشوار می کند. یکی دیگر از دلایل احتمالی این امر این است که همهگیری کووید-19 منجر به محدودیتهای محل کار، قرنطینه و قرنطینههای انتخابی شد و باعث شد برخی افراد از خانه کار کنند.
با بازگشت به نتایج گروه بندی در شکل 5 ، متوجه می شویم که روش پیشنهادی با توجه به اینکه تنها یک گروه خطا وجود دارد، عملکرد رقابتی برای گروه بندی ساختمان های تجاری دارد. در مقابل، سه گروه نادرست با استفاده از روش استاندارد CTD شناسایی شده است. برای گروه بندی ساختمان های اداری، نتایج گروه بندی روش پیشنهادی همه صحیح است، در حالی که نتایج شناسایی شده با روش استاندارد CTD همه اشتباه هستند. این رویکرد به اشتباه ساختمان های اداری و مسکونی را در گروه های مشابه گروه بندی کرد. هیچ کدام از این روش ها ساختمان های مسکونی شناسایی شده به عنوان ساختمان های اداری را به درستی گروه بندی نکردند.
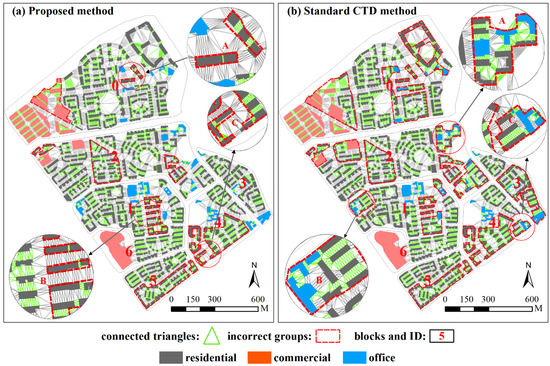
شکل 9 مثلث های باقیمانده را در طول روش تقسیم بندی (مرحله 6) نشان می دهد. مثلث های سبز نشان دهنده روابط مجاورت بین ساختمان ها هستند. این شکل درک روشنی از اینکه چرا برخی از روابط حذف می شوند، در حالی که برخی دیگر حفظ می شوند، ارائه می دهد. این به این دلیل است که شاخصهای مورد استفاده در فرآیند تقسیمبندی نمودار از مثلثهایی که ساختمانها را به هم متصل میکنند، مشتق شدهاند. هنگام انجام تقسیم بندی یک نمودار، اگر رابطه مجاورت دو ساختمان (یعنی دو گره) حذف شود، مثلث های متصل کننده دو ساختمان نیز حذف می شوند. از این شکل، متوجه شدیم که دو دلیل برای روش پیشنهادی برای تقسیم بیش از حد وجود دارد. اول، فاصله بین ساختمانها در یک گروه بسیار متفاوت است ( شکل 9 a(A))، و برخی از آنها بیشتر از فاصله بین گروهها هستند.شکل 9 a (B,C)). علاوه بر این، فاصله غیرعادی باعث یک مقدار پیوستگی کم می شود ( شکل 9 a(A)). در مقابل، روش استاندارد CTD اطلاعات عملکرد را به عنوان یک محدودیت به جز دلایل بالا در نظر نمی گیرد، که منجر به شناسایی گروه های خطای بیشتری می شود. با این حال، این ساختمانها با عملکردهای متفاوت به یکدیگر نزدیک هستند، که منجر به گروهبندی تمام ساختمانها با هم میشود ( شکل 9 b(B,C)). علاوه بر این، بدون کمک اطلاعات معنایی، تقسیم ساختمانهای مدرسه به گروههای ساختمانی با عملکردهای مختلف دشوار است ( شکل 9 ب (A)).
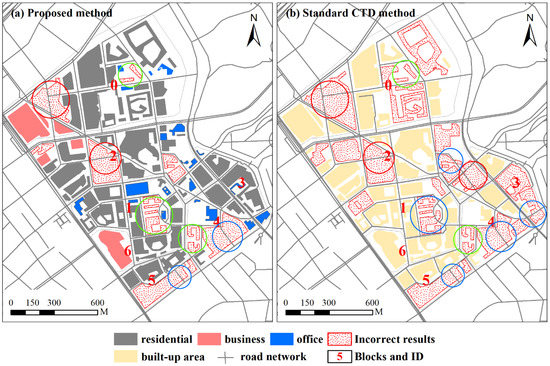
تعمیم نقشه یک کاربرد مهم پایین دستی برای تشخیص گروه ساختمان است. بنابراین، ما آزمایشی را برای آزمایش اینکه آیا نتایج شناسایی شده میتوانند مبنایی برای تعمیم نقشه بعدی تشکیل دهند، انجام دادیم. شکل 10 نتایج تعمیم به دست آمده از گروه های ساختمانی را نشان می دهد که با استفاده از روش پیشنهادی و روش مقایسه شناسایی شده اند. رویکرد تعمیم روشی است که در ادبیات پیشنهاد شده است [ 33 ]. نتایج تعمیم بر روی شبکه جاده نقشه AutoNavi برای نمایش قرار می گیرند. این شکل نشان می دهد که چگونه گروه بندی ساختمان بر کیفیت یک نقشه تأثیر می گذارد. اولاً، زیربخشبندی (یعنی الگوهای گنجاندن) به کاربران این امکان را میدهد که هنگام رفتن به مقصد، مسیرهای انحرافی بیشتری انجام دهند (مثلاً مناطق ساخته شده که با دایرههای قرمز مشخص شدهاند.شکل 10 ). دوم، نتایج تعمیم یافته الگوهای درون شناسایی شده با استفاده از روش تقسیمبندی بیش از حد، تأثیر زیادی بر ناوبری ندارد، زیرا تقسیمبندی بیش از حد بیشتر برای ساختمانهای درون جوامع مشابه اتفاق میافتد (به عنوان مثال، مناطق ساخته شده با دایرههای سبز در شکل 10 ) . سوم، نتایج تعمیمیافته گروههایی که با استفاده از روش استاندارد CTD شناسایی شدهاند، مانند نتایج زیربخشبندی هستند، که به انحرافهای بیشتری برای ناوبری نیاز دارند (مثلاً مناطق ساخته شده با دایرههای قرمز مشخص شده در شکل 10 ). نتایج تعمیم یافته نادرست حاصل از الگوهای همپوشانی (مثلاً مناطق ساخته شده با دایره های آبی در شکل 10)) می تواند باعث خطاهای ناوبری در هنگام رانندگی شود. این به این دلیل است که شکافهای بین این نتایج کلی شبیه جادههای رانندگی است. آنها در واقع مسیرهای پیاده روی در مجتمع های مسکونی هستند.
5. نتیجه گیری ها
به دلیل عدم وجود داده های معتبر، اکثر روش های سنتی گروه بندی ساختمان ها تنها ویژگی های هندسی ساختمان ها را در نظر می گیرند و در نتیجه نتایج گروه بندی رضایت بخشی به دست نمی آید. با پشتیبانی از دادههای بزرگ جغرافیایی، این مقاله روشی را برای ترکیب ویژگیهای هندسی ساختمان و اطلاعات عملکردی برای شناسایی گروههای ساختمانی پیشنهاد کرد. به طور خاص، رویکرد پیشنهادی شامل دو بخش، یعنی تشخیص عملکرد ساختمان و تشخیص گروه ساختمان است. دادههای تراکم کاربر Tencent و دادههای POI برای استنتاج توابع ساختمان بر اساس الگوریتم DTW استفاده شد. فقط ساختمان هایی با عملکرد یکسان را می توان با هم گروه بندی کرد. ما رویکردهای خود را با استفاده از مطالعه موردی تأیید کردیم. نتایج تجربی نشان میدهد که روشهای پیشنهادی میتوانند نتایج رضایتبخشی تولید کنند، با توجه به اینکه مقادیر صحت همه بالاتر از 81 است. 63 درصد برای منطقه مورد مطالعه. در مقابل، روش مقایسه اطلاعات تابع را به عنوان یک محدودیت در نظر نمی گیرد و منجر به شناسایی گروه های خطای بیشتری می شود. قابل ذکر است، زمانی که ساختمانهایی با عملکردهای متفاوت به یکدیگر نزدیک هستند، روش مقایسه، همه ساختمانها را با هم گروهبندی میکند. نتایج تعمیم به دست آمده از گروههای دارای اطلاعات عملکرد بیشتر با نیازهای استفاده روزانه از نقشه مطابقت دارد، زیرا میتواند تقسیم فضایی دقیقتری از ساختمانهای شهری را در اختیار کاربران قرار دهد.
آزمایشات بیشتری برای بهبود روش پیشنهادی مورد نیاز است، مانند آزمایش آن با اطلاعات معنایی بیشتر علاوه بر عملکردهای ساختمان (به عنوان مثال، ارتفاع ساختمان). همچنین برای کالیبره کردن خودکار پارامترها (به عنوان مثال، زاویه مسیر) مورد استفاده در استراتژی تقسیم بندی ارائه شده، کار بیشتری لازم است.











بدون دیدگاه