1. مقدمه
منطقه مرکزی پکن جایی است که عملکردهای پکن به عنوان مرکز مبادلات سیاسی، فرهنگی و بین المللی کشور بیشتر در آن قرار دارد و همچنین منطقه ای کلیدی برای حفظ مناطق تاریخی است [ 1 ]. منظر شهری (شامل منظر میراث تاریخی و زندگی مدرن) در این منطقه خاص در طول روند طولانی تاریخی توسعه آن ویژگی های متمایزی را شکل داده است که به طور شهودی منعکس کننده ویژگی های فرهنگی، صحنه تاریخی و جذابیت های زیبایی شناختی برای ساکنان شهر است. . با این حال، با تأثیر شهرنشینی و توسعه گردشگری، چشمانداز شهری منطقه مرکزی پکن دستخوش تغییرات شدیدی میشود و حفاظت و مدیریت منظر شهری در منطقه مرکزی پکن در حال حاضر با چالشهای جدی مواجه است.2 ، 3 ].
برای پاسخگویی به نیازهای حفاظت از منظر شهری و توسعه پایدار در منطقه مرکزی پکن، لازم است توزیع فضایی ویژگیهای معمولی منظر شهری (یعنی ویژگیهای طبیعی مانند آسمان، پوشش گیاهی و ویژگیهای مصنوعی مانند ساختمان ها، جاده ها و غیره). در ادبیات، دو نوع روش اصلی برای استخراج ویژگیهای منظر وجود دارد: روشهای مبتنی بر بررسی میدانی، و روشهای مبتنی بر سنجش از دور. بررسی میدانی و اندازه گیری با ابزارهای دستی معمولاً به مقدار قابل توجهی از منابع انسانی و مادی نیاز دارد [ 4 ، 5 ، 6 ، 7 ]. روش های مبتنی بر سنجش از دور در به دست آوردن توزیع فضایی چشم انداز در یک منطقه بزرگ کارآمد هستند [8 ، 9 ]. با این حال، تصاویر هوایی یا ماهوارهای معمولی نمیتوانند اطلاعات جانبی و نما ویژگیهای منظره را بدست آورند [ 10 ]، در حالی که فناوری اخیراً پررونق فتوگرامتری مایل [ 11 ] با مشکل کمبود داده در منطقه مرکزی پکن، به دلیل برقراری پرواز ممنوع، مواجه است. منطقه با رواج خدمات مبتنی بر مکان، تصاویر نمای خیابان در دسترس هستند و در سال های اخیر توجه فزاینده ای را با توجه به رانندگی مستقل [ 12 ]، مطالعات محیط شهری [ 13 ] و تحقیقات منظر شهری [ 14 ، 15 ] به خود جلب کرده اند.]. در مقایسه با عکسهای هوایی و تصاویر ماهوارهای، تصاویر نمای خیابان «مردممحور» هستند و پتانسیل کسب اطلاعات بیشتر را فراهم میکنند [ 16 ] و برای استخراج ویژگیهای منظره دقیق در مناطق پیچیده منطقه هسته پکن مناسب هستند.
با این وجود، اطلاعات غنی و متنوع با جزئیات در مورد چشم انداز شهری تعبیه شده در تصاویر نمای خیابان، نیازمندی های بالاتری را برای روش های استخراج ویژگی های منظره ایجاد می کند. روشهای سنتی مبتنی بر تحلیل تصویر، مانند روشهای مبتنی بر پیکسل [ 15 ]، روشهای مبتنی بر شی [ 17 ]، و روشهای مبتنی بر صحنه [ 18 ]، از ویژگیهای دست ساز برای مشخص کردن ویژگیهای منظر شهری استفاده میکردند، اما نتوانستند استخراج کنند. ویژگیهای معنایی سطح بالا از دادههای نمای خیابان. با پیشرفتهای اخیر در شبکههای عصبی عمیق (DNN)، مدلهای مختلف مبتنی بر DNN برای بخشبندی معنایی پیشنهاد شدهاند [ 19 ، 20 ، 21 ، 22 ، 23 ، 24 .، 25 ]، که می تواند به طور خودکار ویژگی هایی را استخراج کند که برای وظایف تقسیم بندی طراحی شده اند [ 26 ]، که چنین روش هایی را برای مدیریت سناریوهای پیچیده، به ویژه در تصاویر نمای خیابان، انتخاب های بهتری می کند [ 27 ، 28 ].
به لطف اثربخشی تقسیمبندی معنایی، چندین محقق تلاش کردهاند تا ویژگیهای منظره را در تصاویر نمای خیابان استخراج کنند. گونگ و همکاران [ 12 ، 13 ] سه ویژگی معمولی منظر (یعنی پوشش گیاهی، ساختمان و آسمان) را از دادههای نمای خیابان Google با استفاده از PSPNet [ 29 ] استخراج کرد و از آنها برای محاسبه ضریب نمای درختی (TVF)، ضریب نمای ساختمان (BVF) استفاده کرد. و فاکتور نمای آسمان (SVF) در مرکز شهر هنگ کنگ. میدل و همکاران [ 30 ] شش ویژگی منظره را از دادههای نمای خیابان Google استخراج کرد تا مورفولوژی سطح خیابان و ترکیب ویژگیهای شهری را که توسط یک عابر پیاده تجربه میشود استخراج کند. یه و همکاران [ 31 ] چندین ویژگی منظر شهری را با استفاده از SegNet استخراج کرد [ 21] از داده های نمای خیابان Baidu در مرکز شانگهای، برای تخمین کیفیت بصری خیابان های شهری. سوئل و همکاران [ 32 ] یک چارچوب چندوجهی مبتنی بر یادگیری عمیق جدید را برای استفاده مشترک از تصاویر ماهواره ای و سطح خیابان برای اندازه گیری درآمد، ازدحام بیش از حد و محرومیت محیطی در مناطق شهری پیشنهاد کرد. اخیرا ژانگ و همکاران. [ 33] TBMask R-CNN را پیشنهاد کرد تا ساختمانهای به سبک سنتی چینی در جاده کمربندی پنجم پکن را از دادههای Tencent Street View استخراج کند و درک بصری عابران پیاده از ساختمانهای سنتی را کمیسازی کند. با این حال، اطلاعات مربوط به مناطق تاریخی چین در مجموعه داده های قبلی نادر است یا وجود ندارد، و استخراج ویژگی های چشم انداز تاریخی را غیرممکن می کند. علاوه بر این، روشهای مبتنی بر معنایی-بخشبندی موجود، به دلیل تردد زیاد مردم و ترافیک، کوچههای باریک، جزئیات متعدد و شرایط نوری متغیر، از تنوع بالای محتوای پیچیده معنایی در مناطق تاریخی رنج میبرند.
در جدیدترین مطالعات، یک مکانیسم توجه برای بهبود عملکرد مدلها در سناریوهای پیچیده، با افزایش بخش مهم دادههای ورودی و محو کردن بقیه ایجاد شد [ 34 ]. با الهام از ابزار کلاسیک غیر محلی، یک شبکه عصبی غیرمحلی نامتقارن (ANNN) برای بهبود نتیجه تشخیص تصویر پیشنهاد شد [ 35 ]. ژائو و همکاران [ 22] یک شبکه توجه فضایی نقطهای (PSANet) را برای جمعآوری اطلاعات زمینهای از همه موقعیتها در نقشههای ویژگی، با اتصال هر موقعیت با همه موقعیتهای دیگر از طریق یک نقشه توجه آموختهشده خودسازگاری، پیشنهاد کرد. اگرچه مدلهای مبتنی بر توجه به عملکرد پیشرفتهای در سناریوهای پیچیده دست یافتهاند، اما معمولاً به مقدار زیادی داده برچسبدار برای آموزش مدل نیاز دارند، حتی بیشتر از یک شبکه تقسیمبندی معنایی معمولی. علاوه بر این، اجرای مکانیسم توجه نیز باعث خروجی ناپایدار شده و بنابراین نیاز به تکرارهای بیشتری در مرحله آموزش دارد. بنابراین، تا آنجا که می دانیم، روش های مبتنی بر توجه برای استخراج ویژگی های چشم انداز استفاده نشده است. علاوه بر این، هیچ مجموعه داده موجود به طور خاص برای استخراج ویژگی های منظره در مرکز پکن و مجموعه داده های موجود (به عنوان مثال،
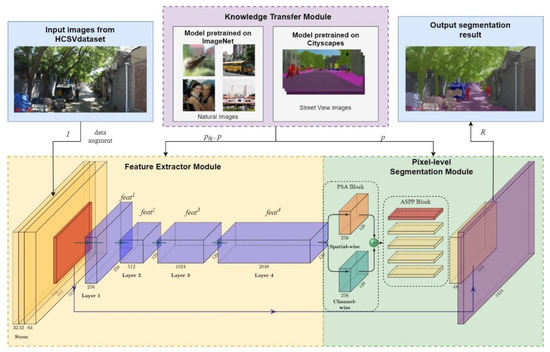
برای پرداختن به این چالشها، در این مقاله، ما یک مجموعه داده کوچک و در عین حال جامع از نمای خیابان (HCSV) ساختیم که از برچسبهای خوب برای هر ویژگی زمین معمولی در منطقه اصلی تشکیل شده است. علاوه بر این، ما فناوری یادگیری انتقال، بلوک خودتوجهی قطبی شده (PSA) و بلوک هرم فضایی آتروس (ASPP) را برای بهبود عملکرد مدلهای DNN، در رابطه با محیط پیچیده با حاشیهنویسیهای نسبتاً محدود، معرفی کردیم. در نهایت، روش خود را بر روی مجموعه داده HCSV ارزیابی کردیم و آن را با چندین شبکه تقسیمبندی پیشرفته مقایسه کردیم. تا آنجا که ما می دانیم، این اولین بار است که یک روش استخراج خودکار ویژگی های منظره به طور خاص برای مناطق تاریخی در چین، مانند منطقه هسته پکن ایجاد شده است. ما مشارکت های اصلی خود را به شرح زیر خلاصه می کنیم:
-
ما یک مجموعه داده جدید برای منطقه مرکزی پکن می سازیم.
-
ما تکنیکهای یادگیری تبدیل و یک بلوک توجه PSA را برای بهبود عملکرد شبکه در محیطهای پیچیده و سناریوهای نمونه کوچک معرفی میکنیم. و
-
ما روش پیشنهادی را در مجموعه داده HCSV تأیید میکنیم و آن را با سایر روشهای پیشرفته یادگیری عمیق در منطقه هسته پکن مقایسه میکنیم.
این مقاله به صورت زیر سازماندهی شده است: بخش 2 منطقه مورد مطالعه و مجموعه داده پیشنهادی را توصیف می کند و سپس روش شناسی در بخش 3 ارائه می شود . بخش 4 آزمایش مفصلی را انجام می دهد. بخش 5 مجموعه داده پیشنهادی را مورد بحث قرار می دهد و بهترین معماری تقسیم بندی را برای منطقه هسته پکن بررسی می کند. در نهایت، این مقاله را در بخش 6 به پایان میرسانیم .
2. مجموعه داده های Historical Core Street View (HCSV).
در این بخش، مجموعه داده های نمای خیابان Historical-Core پیشنهادی خود را با روشن کردن منطقه مورد مطالعه و روش حاشیه نویسی داده ها معرفی می کنیم.
2.1. منطقه مطالعه
به عنوان پایتخت پنج سلسله امپراتوری (لیائو، جین، یوان، مینگ و چینگ) و پایتخت فعلی، پکن، واقع در شمال دشت چین شمالی، مساحتی معادل 16410.54 کیلومتر مربع (کیلومتر مربع) را پوشش می دهد. منطقه مسکونی سنتی پکن به عنوان یک میراث فرهنگی جهانی با ارزش تاریخی، فرهنگی و اجتماعی بی نظیر شناخته شده است. منطقه ای با غلظت بالایی از ساختمان های تاریخی و کوچه ها در مناطق مسکونی سنتی در پکن، یعنی منطقه هسته پکن، به عنوان انتقال دهنده تاریخ و فرهنگ چین در نظر گرفته می شود و نماینده معمولی یک منطقه تاریخی چینی در نظر گرفته می شود. تلاش های زیادی برای حفاظت و مدیریت این منطقه توسط دولت محلی انجام شده است.
در طول مطالعه بر روی منطقه مرکزی پکن، متوجه شدیم که کل منطقه را می توان به ترتیب به سه دسته تقسیم کرد: خیابان مدرن، مسکونی مدرن و کوچه باستانی. به عنوان یکی از قدیمیترین بلوکهای مسکونی و معروفترین جاذبه در منطقه مرکزی پکن، لین لوگو جنوبی شامل کوچههای تاریخی متعدد (مثلاً Maoer Hutong) است و توسط خیابانهای مدرن احاطه شده است (مثلاً خیابان Di’anmenwai). بنابراین، خیابان Di’anmenwai و Mouer Hutong به عنوان مناطق مورد مطالعه برای پوشش مناظر اصلی نشان داده شده در منطقه مرکزی انتخاب شدند. جزئیات در شکل 1 زیر نشان داده شده است.
2.2. مجموعه داده
با توسعه خدمات نقشه دنیای واقعی در چین، چندین ارائهدهنده نقشهبرداری اینترنتی محلی مانند Baidu و Tencent تصاویر نمای خیابان را به طور گسترده در دسترس قرار دادهاند که اطلاعات نمای خیابان را از منظر عابر پیاده نشان میدهد و بنابراین منبع داده جدیدی برای مطالعه ارائه میکند. از منظر شهری بر اساس دادههای نمای خیابان، مجموعه دادههای مختلفی برای اهداف مختلف ایجاد شدهاند و ما آنها را با توجه به حجم تصویر، دستهها و مکانها در جدول 1 خلاصه میکنیم.
بدیهی است که بیشتر این مجموعه داده ها دارای هزاران تصویر حاشیه نویسی برای آموزش مدل های یادگیری عمیق مدرن هستند. مجموعه داده ImageNet [ 36 ] به عنوان بزرگترین مجموعه داده بصری در جهان، بیش از 14 میلیون تصویر دارد که همه به طور جامع در 20 هزار دسته شرح داده شده است. اگرچه نمیتواند مستقیماً برای یک کار پاییندستی مانند تقسیمبندی معنایی آموزش ببیند، به دلیل حجم گسترده اطلاعات بصری رایج، به طور گسترده برای روش پیشآموزشی استفاده شده است. مجموعه داده CamVid [ 37 ]، که دارای 701 تصویر با برچسب متراکم است که از دنبالههای ویدیویی به دست آمده است، یکی از متداولترین مجموعههای داده درک صحنه جاده برای مطالعه اولیه در بخشبندی معنایی بود. مجموعه داده Cityscapes [ 38] شامل 5000 تصویر نمای خیابان با حاشیه نویسی دقیق از 50 شهر در اروپا از فریم های ویدئویی رانندگی انتخاب شده است. برای غنی سازی بیشتر سناریوها برای درک صحنه، مجموعه داده ADE20k حاوی بیش از 20000 تصویر حاشیه نویسی با 150 دسته مختلف است. از سوی دیگر، مجموعه داده COCO شامل 123 هزار تصویر است و حاشیهنویسی را برای بخشبندی پانوپتیک در سال 2018 منتشر کرد که دارای 171 دسته مختلف است [ 39 ]. با این حال، این مجموعه داده شامل چندین صحنه داخلی و خارجی است و بر روی سناریوهای خیابان تمرکز نمی کند. در مقابل، چند مجموعه داده به طور خاص برای سناریوهای خیابانی اعلام شد، از جمله مجموعه داده Bdd100k [ 40 ] و مجموعه داده ApolloScapes [ 41 ].
اگرچه این مجموعه دادهها تصاویر مشروح زیادی را در یک سناریوی خیابانی ارائه کردهاند، هنوز هم پیشرفتهایی وجود دارد که میتوان به خاطر وظیفه استخراج ویژگیهای منظر شهری انجام داد. اول، اکثر مجموعههای داده موجود، دادههای نمای خیابان را با ضبط ویدیوهای رو به جلو در امتداد یک خیابان به دست میآورند، که میتواند برای کارهایی مانند رانندگی خودکار مفید باشد، اما به دلیل فقدان اطلاعات چند نمای (یا پانوراما) نمیتواند نیازهای استخراج منظره را برآورده کند. جدای از آن، هیچ یک از مجموعه داده های موجود حاوی اطلاعات ویژگی های منظره منحصر به فرد (به عنوان مثال، ساختمان های سنتی و جزئیات متغیر و غیره) برای منطقه تاریخی چین نیست. بنابراین، ما ابتدا تصاویر مربوط به منظره خیابان را جمع آوری کردیم، و سپس یک پلت فرم حاشیه نویسی تقسیم بندی معنایی راه اندازی کردیم و اولین مجموعه داده نمای خیابان را برای منطقه اصلی در پکن ساختیم.
مجموعه داده HCSV توسعهیافته، مجموعه دادههای موجود را از نظر ارائه نماهای مختلف از تصاویر نمای خیابان و حاشیهنویسی آنها با یک مجموعه کلاس خاص در مورد ویژگیهای منظره در منطقه هسته پکن تکمیل میکند. این مجموعه داده شامل 127 تصاویر حاشیه نویسی در سطح پیکسل است که از خیابان Di’anmenwai و Maoer Hutong گرفته شده است، که شامل سه سناریو معمولی (یعنی خیابان مدرن، مسکونی مدرن، و کوچه باستانی) از منظر شهری در منطقه مرکزی پکن است.
تصاویر موجود در مجموعه داده HCSV از سرویس نقشه بایدو، که یک رابط برنامه نویسی کاربردی (API) برای پرس و جو و دانلود تصاویر نمای خیابان با پارامترهای متعدد، به عنوان مثال، اندازه، مختصات، عنوان، زمین و میدان دید (FOV) فراهم می کند، به دست آمده است. . به طور خاص، تصاویر نمای خیابان (با وضوح 512 × 1024) را در چهار جهت (با زاویه گام 0 درجه و عناوین 0 درجه، 90 درجه، 180 درجه و 270 درجه، با FOV تنظیم شده روی 90 درجه) جمع آوری کردیم. ) برای هر نقطه نمونه در امتداد خیابان ها یا کوچه ها در فواصل 20 متری. پس از جمعآوری دادهها، فرآیند پاکسازی دادهها با استفاده از روش هش میانگین برای شناسایی و حذف تمام تصاویر تکراری اعمال شد.
برای حاشیه نویسی، ما یک پلت فرم ویرایشگر تقسیم بندی معنایی آنلاین (نشان داده شده در شکل 2 ) را بر اساس یک پروژه منبع باز ( https://github.com/Hitachi-Automotive-And-Industry-Lab/semantic-segmentation-editor ) توسعه دادیم که در اینجا قابل دسترسی است. 18 مه 2022) [ 42]. علاوه بر این، ما یک کلاس سفارشی ایجاد کردیم تا ویژگیهای منظر شهری متمایز را بهویژه برای مناطق تاریخی چین خلاصه کند. مجموعه کلاس ساده شد (ادغام اشیاء با معنایی مشابه، به عنوان مثال، علامت و چراغ راهنمایی) و گسترش یافت (توسعه معناشناسی، به عنوان مثال، طاق نماها و سایر ساخت و سازها در کلاس “ساختمان” گنجانده شد و ما کلاس های جدیدی مانند درهم و برهم را راه اندازی کردیم. ) از مجموعه اصلی کلاس Cityscapes. بنابراین، مجموعه داده ما می تواند چشم انداز را برای هر سناریوی معمولی در منطقه هسته پکن ترسیم کند، در حالی که سلسله مراتب دسته بندی ساده ای را در مقایسه با مجموعه داده های موجود حفظ می کند. دسته بندی های موجود در مجموعه داده ما در جدول 2 نشان داده شده است و ما ویژگی های منظره معمولی را برای هر دسته در شکل 3 نشان می دهیم.. این مجموعه داده HCSV برای تمام نیازهای تحقیقاتی به طور آشکار در دسترس خواهد بود.
3. روش شناسی
معماری روش پیشنهادی یعنی PALESNet در شکل 4 نشان داده شده است. با هدف استخراج ویژگیهای چشمانداز شهری منطقه هسته پکن، به ویژه با تعداد محدودی از نمونهها، شبکه پیشنهادی از سه بخش تشکیل شده است: یک ماژول استخراج ویژگی، یک ماژول تقسیمبندی در سطح پیکسل، و یک ماژول انتقال دانش. برای تشخیص انواع مختلف ویژگیهای منظره در منطقه هسته پکن، استخراج کننده ویژگی ابتدا ویژگیها را از تصاویر نمای خیابان ورودی استخراج میکند. سپس، ماژول تقسیمبندی سطح پیکسل، نمایش معنایی چند مقیاسی را از ویژگیهایی که قبلاً استخراج شدهاند، یاد میگیرد و هر ویژگی چشمانداز را بخشبندی میکند. در این ماژول، بلوک PSA برای تشخیص موثرتر ویژگی های منظره، به ویژه در یک محیط پیچیده، استفاده می شود، در حالی که بلوک ASPP برای گرفتن ویژگی های چند مقیاسی استفاده می شود. علاوه بر این،
اجازه دهید منتصویر نمای خیابان را از HCSV نشان دهید و اجازه دهید yبرچسب ویژگی های چشم انداز باشد. نمودار جریان این مطالعه را می توان به صورت زیر خلاصه کرد:
-
اول، تصویر منبرای به دست آوردن گروهی از بردارهای ویژگی، وارد ماژول استخراج ویژگی می شود اف={fهآتی1، fهآتی2 ،fهآتی3 ،fهآتی4}.
-
بعد، بردار ویژگی افدر ماژول تقسیمبندی سطح پیکسل برای شناسایی هر دسته از ویژگیهای منظر شهری، جایی که بلوک PSA و بلوک ASPP برای ساختن پیادهسازی میشوند، استفاده میشود. افتمایز بیشتر و استخراج ویژگی های چند مقیاسی، به ترتیب. سپس تلفات آنتروپی متقاطع (CEL) با توجه به خروجی شبکه محاسبه می شود آرو برچسب y. علاوه بر این، یک الگوریتم تقویت داده برای افزایش نمونه آموزشی و افزایش استحکام مدل استفاده میشود.
-
در مرحله آموزش، ماژول انتقال دانش برای مقداردهی اولیه پارامترهای شبکه فعال می شود پ={په،پس}، جایی که پهپارامتر استخراج کننده ویژگی و پسمخفف پارامتر ماژول تقسیم بندی است. پارامتر اولیه پاز مدل به خوبی آموزش دیده با دانش مجموعه داده های موجود می آید [ 36 ، 38 ].
3.1. استخراج کننده ویژگی
برای شناسایی هر ویژگی منظره در منطقه هسته پکن، ما نیاز به استخراج ویژگیها از تصاویر نمای خیابان داشتیم. بسیاری از مطالعات قبلی ثابت کرده اند که CNN عمیق (DCNN) توانایی قوی برای استخراج ویژگی دارد، و بنابراین ما استخراج کننده ویژگی خود را بر اساس ResNet-r50 [ 43 ] ساختیم. علاوه بر این، یک روش افزایش داده برای به دست آوردن نمونه های آموزشی بیشتر قبل از تصاویر نمای خیابان معرفی شد منورودی به شبکه هستند که شامل عملیات برش و تغییر اندازه تصادفی، چرخش تصادفی و اعوجاج تصادفی است. جدا از افزایش حجم نمونه، روش افزایش داده ها می تواند با ارائه نمونه های تصادفی، استحکام شبکه را افزایش دهد.
برای افزایش عمق CNN های سنتی، ضمن غلبه بر مشکلات ناپدید شدن گرادیان و انفجار گرادیان، ResNet توسط معماری به نام بلوک باقیمانده ( شکل 5 ) تشکیل شده است، که از یک اتصال میانبر برای انتقال ورودی استفاده می کند. ایکسمستقیم به خروجی خروجی بلوک باقیمانده به شرح زیر است:
جایی که دبلیو1، دبلیو2، و دبلیو3به ترتیب وزن لایه های پیچشی را نشان می دهد، در حالی که σتابع واحد خطی اصلاح شده (ReLU) [ 44 ] است. اتصال میانبر می تواند نقشه برداری هویت را به طور موثرتری نسبت به CNN های ساده انجام دهد و بنابراین می تواند مشکل تخریب را که عمق شبکه را محدود می کند حل کند. علاوه بر این، معماری باقیمانده می تواند از پدیده ناپدید شدن گرادیان با حمل گرادیان در سراسر وسعت DCNN [ 45 ] جلوگیری کند.
پس از حذف لایه ادغام متوسط و لایه کاملاً متصل از ResNet-r50 اصلی، یک نوع ResNet برای استخراج ویژگی به دست آمد. استخراج کننده ویژگی ما از پنج مرحله تشکیل شده است. برای اولین مرحله ساقه، 7 اصلی ×7 لایه پیچشی ResNet با سه لایه جایگزین شده است 3×3لایه های پیچیدگی، همانطور که در شکل 6 نشان داده شده است. دلیل جایگزینی کاهش هزینه محاسبات هسته کانولوشن بزرگ بود. به عنوان مثال، 7 ×7 هسته با کفیلترها 5.4 برابر گرانتر از هسته 3 × 3 با همان تعداد فیلتر است. برای پرداختن به بیان کمتر ناشی از کاهش اندازه هسته، سه 3 ×برای استخراج ویژگی های بیشتر، 3 لایه کانولوشن به صورت سریال روی هم چیده شده اند. در مورد ما، مرحله ساقه اصلاح شده فقط دارد (2×3×3×32+3×3×64)/(7×7×64)=0.37برابر محاسبه مرحله پایه اصلی.
بعد از مرحله ساقه چهار مرحله لایه باقیمانده قرار دارد که به ترتیب از 3، 4، 6 و 3 بلوک باقیمانده تشکیل شده است. توجه داشته باشید که هر بلوک به تدریج عمیق می شود و در پایان به عمق 2048 می رسد. ویژگی خروجی fهآتی4استخراج ویژگی 1/8 اندازه تصویر ورودی اصلی است.
3.2. ماژول تقسیم بندی سطح پیکسل
ماژول تقسیمبندی برای تشخیص هر ویژگی چشمانداز در مقیاس متغیر (یعنی مقیاس بین ویژگیهای مختلف و تغییر مقیاس ناشی از فواصل مختلف) طراحی شده است که در مناطق تاریخی چین کاملاً رایج است. علاوه بر این، ماژول تقسیمبندی برای تشخیص ویژگیهای مختلف در محیط پیچیده مورد نیاز است، که ناشی از شرایط نوری ناهموار، جریان ترافیک بالا و کوچههای باریک است. بنابراین، ما PSA را برای تشخیص ویژگیها در محیط پیچیده و استفاده از استخر هرم فضایی آتروس (ASPP) برای ترکیب ویژگیهای چند مقیاسی معرفی کردیم.
3.2.1. خود توجه قطبی شده
بلوک PSA میتواند وابستگی دوربرد را به تصویر بکشد و ویژگیها را در نقشههای ویژگی متمایزتر کند، و یک مدل بسیار سبک وزن است که نیازی به هزینههای گزافی در رابطه با حافظه و محاسبه ندارد و در عین حال وضوح بالایی را در محاسبه توجه حفظ میکند. همانطور که شکل 7 نشان می دهد، PSA شامل دو زیر ماژول است: ماژول خودتوجهی فقط کانال و ماژول خودتوجهی فقط فضایی.
هدف ماژول خودتوجهی فقط برای کانال گرفتن وابستگی دوربرد از طریق نقشه توجه کانال و برجسته کردن ویژگیهای خاص کلاس است که میتواند با استفاده از فرمول زیر محاسبه شود:
که در آن X یک ویژگی ورودی به اندازه C × H × W را نشان می دهد و fاسجینشان دهنده تابع سیگموئید است. این دبلیوآ، دبلیوب، و دبلیوج1 هستند ×1 لایه پیچیدگی، به ترتیب، φ1، φ2دو عملگر تغییر شکل تانسور هستند و σتابع SoftMax است. این پجساعت(ایکس)نقشه توجه کانال است و ×” عملیات ماتریس نقطه-محصول است.
به طور مشابه، ماژول خودتوجهی فقط فضایی نیز 1 اعمال می شود ×ابتدا 1 پیچیدگی و سپس نتیجه را تغییر شکل می دهد. برخلاف شاخه فقط کانال، تابع ادغام جهانی fجیپپس از اولین پیچیدگی، برای فشرده سازی اطلاعات اضافی و به دنبال آن تابع SoftMax اتخاذ می شود. σ. سپس، عملیات نقطه-محصول ماتریس بین دو تانسور داخلی اعمال می شود. در نهایت یک تابع سیگموئید fاسجیبرای به دست آوردن نقشه نهایی توجه فضایی استفاده می شود پسپ(ایکس). فرمول را می توان به صورت زیر توصیف کرد:
یکی دیگر از ویژگی های برجسته افبعد از ماژول خودتوجهی فقط کانال و ماژول خودتوجهی فقط فضایی ایجاد می شود. در این مقاله، ساختار موازی PSA را انتخاب کردیم که می توان آن را به صورت زیر توصیف کرد:
جایی که ⊙جساعتو ⊙سپبه ترتیب عملگرهای ضرب کانالی و فضایی هستند و “+” عملگر جمع عنصر را نشان می دهد. در مورد ما، خروجی استخراج کننده ویژگی، به عنوان مثال، fهآتی4، از طریق بلوک PSA برای به دست آوردن یک ویژگی متمایزتر قرار داده شد fهآتی“=اف(fهآتی4)هم از نظر فضایی و هم از نظر کانال، که می تواند از رمزگشایی بعدی در سناریوی پیچیده در منطقه هسته پکن سودمند باشد.
3.2.2. بلوک ASPP
همانطور که در بالا بحث شد، مقیاس ویژگی های چشم انداز در منطقه هسته پکن متغیر است. بنابراین، ما بلوک ASPP را به شبکه خود معرفی کردیم، که نتایج امیدوارکنندهای را در مدلهای تقسیمبندی معنایی چندگانه نشان داده است [ 23 ، 29 ]. همانطور که در شکل 8 نشان داده شده است ، بلوک ASPP می تواند ویژگی های چند مقیاسی تولید شده توسط استخراج کننده ویژگی و محاسبه شده توسط بلوک PSA قبلی را استخراج کند.
بلوک ASPP از چهار تنظیمات مختلف فیلد گیرنده تشکیل شده است. لایه اول از یک لایه کانولوشن با اندازه هسته 1 تشکیل شده است ×1، به دنبال آن یک لایه معمولی دسته ای و یک لایه فعال سازی ReLU. برای بقیه لایه ها، اندازه هسته لایه کانولوشن روی 3 تنظیم شد ×3، با نرخ اتساع به ترتیب 16، 24 و 36. پیچ خوردگی آتروس با نرخ های اتساع مختلف منجر به میدان های دریافتی متفاوتی می شود که ویژگی های چند مقیاسی را به طور موثر و کارآمد به تصویر می کشد، زیرا به پارامترهای کمتری نسبت به عملیات پیچشی معمولی نیاز دارد (مثلاً پیچش با اندازه هسته 16). ×16) برای دستیابی به یک میدان پذیرای بزرگتر. ویژگی قبلی fهآتی“بیشتر از طریق لایه های فوق به صورت موازی و به هم پیوسته برای تشکیل ویژگی خروجی مورد سوء استفاده قرار می گیرد. fهآتی*. سرانجام، fهآتی*با استفاده از روش نمونهگیری دوخطی، چهار برابر میشود.
در نهایت، ویژگی fهآتی*برای به دست آوردن اطلاعات معنایی هر ویژگی منظره در تصویر نمای خیابان رمزگشایی می شود مندر سطح پیکسل با الهام از آخرین کارهای سری DeepLab، ویژگی های سطح پایین fهآتی1با fهآتی*بعد از 1 ×1 گلوگاه پیچیدگی، برای بازیابی جزئیات فضایی در تصاویر نمای خیابان، و سپس به صورت دوخطی با ضریب 4 نمونه برداری می شود. از طریق ترکیب 3 مورد ×3 و 1 ×1 لایه پیچیدگی، نقشه تقسیم بندی نهایی در سطح پیکسل ویژگی های چشم انداز به دست می آید.
3.3. ماژول یادگیری انتقال
استخراج ویژگیهای چشمانداز با دقت در سناریوهای پیچیده در منطقه هسته پکن، بهویژه با تعداد محدود نمونههای برچسبگذاری شده، یک مشکل چالش برانگیز برای اکثر روشهای تقسیمبندی معنایی موجود است. برای حل این مشکل، ما فناوری یادگیری انتقال را معرفی کردیم، که می تواند دانش را از مجموعه داده های موجود مربوطه به شبکه پیشنهادی ما انتقال دهد.
ImageNet به عنوان بزرگترین مجموعه داده بصری در جهان، دارای مقادیر بسیار زیادی از تصاویر در مورد موارد رایج است، در حالی که Cityscapes (که در بخش 2.2 ذکر شد ) ویژگی های مشترک زیادی در صحنه های شهری مدرن به اشتراک می گذارد، و بنابراین ما می توانیم از هر دو آنها برای غنی سازی دانش در زمینه های شهری استفاده کنیم. شبکه پیشنهادی بنابراین، ما یک استراتژی یادگیری انتقال دو مرحله ای را در این مقاله معرفی کردیم.
3.3.1. انتقال دانش از ImageNet
استخراجکننده ویژگی برای استخراج ویژگیهای سطح پایین تعبیهشده در تصاویر، مانند ویژگی مرزی، که همیشه ویژگیهای مشابهی را در زمینههای مختلف تصاویر (یعنی تصاویر طبیعت و تصاویر نمای خیابان) به اشتراک میگذارند، استفاده میشود. بنابراین، امکان انتقال دانش مشترک در حوزههای تصویری ناهمگن وجود دارد.
در مورد ما، انتقال دانش به معنای انتقال پارامترها از یک شبکه آموزش دیده به شبکه هدف است که حوزه ها و وظایف داده مشابه اما متفاوتی دارد. اجازه دهید Dمنمترgنشان دهنده دامنه صحنه های رایج ImageNet و تیfوظیفه استخراج ویژگی برای موارد معمولی باشد و اجازه دهید Dساعتجسv، تیf“دامنه را در HCSV و وظیفه استخراج ویژگی مورد انتظار را برای ویژگی های چشم انداز نشان می دهد. فرآیند انتقال را می توان به شرح زیر توصیف کرد:
جایی که پfهپارامترهای مدل استخراج ویژگی را نشان می دهد که توسط ImageNet برای اهداف استخراج ویژگی آموزش داده شده است، و پfه“پارامترهای استخراج کننده ویژگی ما است. پس از این پیشرفت انتقال، پارامترهای استخراجکننده ویژگی پیشنهادی توسط مدل از پیش آموزشدیده (با همان معماری) در ImageNet مقداردهی اولیه میشوند و بنابراین قبل از آموزش واقعی روی مجموعه داده HCSV، دانش موارد معمولی در تصاویر طبیعی را دریافت میکنند. چنین دانشی می تواند عملکرد استخراج کننده ویژگی را در یک موقعیت نمونه محدود تقویت کند.
3.3.2. انتقال دانش از مناظر شهری
برای غنیسازی دانش صحنههای شهری مدرن برای شبکه پیشنهادی، دانش تعبیهشده در مجموعه دادههای Cityscapes را منتقل کردیم. فرآیند انتقال دانش را می توان به شرح زیر توصیف کرد:
جایی که اسهgجسو اسهgساعتجسvبه ترتیب وظیفه تقسیم بندی اشیاء در Cityscapes و ویژگی های منظره در HCSV را نشان می دهد. پو پ“پارامترهای شبکه پیشنهادی را برای کار مشخص کنید اسهgجسو اسهgساعتجسv.
هنگامی که شبکه اطلاعاتی در مورد ویژگی های عمومی اقلام معمولی و همچنین ویژگی های خیابان های کلان شهر به دست آورد، مجموعه داده پیشنهادی HCSV سپس برای آموزش شبکه ها برای یادگیری ویژگی های خاص در منطقه مرکزی پکن استفاده شد. شایان ذکر است که لایه 1، لایه 2 و لایه 3 استخراج کننده ویژگی پس از فریز شده است تیrآnسfهr2، برای رزرو توانایی ثبت ویژگی های مشترک و همچنین تسریع روند اتصال، به ویژه در این وضعیت نمونه محدود.
4. نتایج تجربی
در این بخش ابتدا مجموعه داده ها و الگوریتم های مقایسه به کار رفته در آزمایش های زیر نشان داده شده است. سپس جزئیات پیاده سازی و معیارهای ارزیابی به اختصار ارائه می شود. در نهایت نتایج آزمایش ها به تفصیل مورد تجزیه و تحلیل قرار می گیرد.
4.1. مجموعه داده
در این آزمایش، مجموعه داده پیشنهادی HCSV برای ارزیابی عملکرد روش ما و مقایسه بین آن و سایر مدلهای تقسیمبندی مبتنی بر CNN استفاده شد. همانطور که در بخش 2 مورد بحث قرار گرفت ، مجموعه داده HCSV شامل 127 تصویر نمای خیابان با حاشیه نویسی دستی در منطقه مرکزی پکن، با اندازه 512 است. ×1024. این تصاویر به طور کامل حاشیه نویسی شده و با دقت انتخاب شده اند تا سناریوهای محیطی (مانند خیابان های عریض، کوچه های باریک، مناطق مسکونی شلوغ و غیره) ارائه شده در منطقه مورد مطالعه را پوشش دهند. در آزمایشهای ما، نسبت نمونههای مورد استفاده برای آموزش، اعتبارسنجی و مجموعههای آزمایشی 8:1:1 تنظیم شد.
4.2. روشهای مقایسه ای
برای تأیید اعتبار روش ما، سه مدل بخشبندی پیشرفته برای مقاصد مقایسه انتخاب و به طور خلاصه معرفی شدند:
- 1
-
شبکه کاملاً کانولوشن (FCN): FCN [ 19 ] لایه های کاملاً متصل را با یک لایه کانولوشن 1 × 1 در انتهای معماری عمومی CNN جایگزین می کند. ما این شبکه کلاسیک را بهعنوان خط پایه معرفی کردیم که شامل هیچ گونه اصلاح اضافی (به عنوان مثال، مکانیسم توجه، بلوک ASPP و غیره) نیست.
- 2
-
شبکه عصبی غیرمحلی نامتقارن (ANNN): با الهام از ابزارهای غیر محلی کلاسیک، ANNN [ 35 ] به عنوان یک بلوک پیشخور ساده برای محاسبه فیلترهای غیرمحلی توسعه داده شد که می تواند مستقیماً وابستگی های دوربرد را در حالی که ورودی متغیر حفظ می کند، ضبط کند. اندازه است و به راحتی با سایر عملیات ترکیب می شود. بلوکهای ساختمانی مبتنی بر ANNN برای معماریهای بینایی کامپیوتری متمرکز بر کارایی (مانند طبقهبندی و تقسیمبندی ویدئو) به کار گرفته شدهاند.
- 3
-
شبکه توجه فضایی نقطهای (PSANet): با هدفی مشابه برای گرفتن وابستگیهای بافت دوربرد مانند ANNN، PSANet [ 22 ] از یک بلوک جدید تجمع اطلاعات دو جهته نقطهای برای گرفتن اطلاعات متنی و درج این بلوک استفاده میکند. به FCN معمولی. این شبکه در آن زمان بهترین عملکرد را در مجموعه دادههای مختلف از جمله Cityscapes و ADE20K به دست آورده بود که اثربخشی و عمومیت آن را نشان میداد، و بنابراین برای نشان دادن بهروزترین شبکههای یکپارچه توجه انتخاب شد.
به طور خلاصه، یک شبکه کلاسیک (FCN) به عنوان شبکه تقسیمبندی پایه استفاده شد، در حالی که دو مدل (ANNN و PSANet) بهعنوان شبکههای یکپارچه توجه مبتنی بر CNN مورد استفاده قرار گرفتند که میتواند برای تشخیص ویژگی منظر مفید باشد.
4.3. معیارهای تنظیم و ارزیابی آزمایشی
آزمایشها با استفاده از PyTorch 1.6.0 با کتابخانه Python 3.7 بر روی دستگاه مجهز به Intel Xeon E3-1200 (QuadCore)، 32 گیگابایت رم و Nvidia GeForce GTX Titan X (رم 12 گیگابایت) انجام شد. در آزمایشها، همه مدلها بر اساس یک پلتفرم معیار یکپارچه، MMSegmentation ساخته شدند، که یک طراحی مدولار برای ساخت یک چارچوب تقسیمبندی معنایی سفارشی ارائه میکرد، در حالی که از چندین چارچوب تقسیمبندی معنایی معاصر برای رقابت منصفانه پشتیبانی میکرد [ 46 ]]. ما همان استخراج کننده ویژگی (یعنی ستون فقرات ResNet-r50) را برای همه مدل های مقایسه اعمال کردیم. پارامترهای مورد استفاده در ماژول انتقال ImageNet به طور رسمی توسط PyTorch ارائه شده است. تکرار فرآیند آموزش در ماژول انتقال Cityscapes روی 40000 در مجموعه داده Cityscapes و سپس به 20000 برای آموزش با مجموعه داده HCSV تنظیم شد. ما پارامترها را برای همه مدلهای مقایسه با استفاده از بهینهساز SGD با حرکت 0.9 و سیاست نرخ یادگیری چند که از 0.01 به 0.0001 کاهش یافت، بهینه کردیم، جایی که کاهش وزن روی 0.0005 تنظیم شد.
برای ارزیابی عملکرد روشهای مقایسهای، از چهار معیار: دقت کلی ( aAcc )، تقاطع روی اتحادیه ( IoU ) برای هر کلاس، میانگین تقاطع بر اتحادیه ( mIoU ) و دقت میانگین ( mAcc ) برای ارزیابی استفاده شد. دقت تقسیم بندی این شاخص ها به صورت زیر محاسبه شدند:
جایی که ایکسمنjتعداد کلاس پیکسل را نشان می دهد منبه عنوان کلاس پیش بینی شده است j. اجازه دهید nتعداد کلاس ها باشد و متعداد کل پیکسل ها باشد، در حالی که نمنکل پیکسل های کلاس تعیین شده را نشان می دهد من.
برای ارزیابی کارایی، تأثیرات نظری و عملی در نظر گرفته شده است. تعداد پارامتر مدل و عملیات ممیز شناور ( FLOPs ) به عنوان شاخص های نظری استفاده می شود. حافظه و توان محاسباتی مورد نیاز هر مدل را می توان با استفاده از این شاخص ها به صورت جداگانه ارزیابی کرد. در میان آنها، FLOP ها به شرح زیر محاسبه می شوند:
جایی که اچو دبلیوارتفاع و عرض نقشه های ویژگی ورودی و کاندازه اندازه هسته فرآیند کانولوشن است. سیمنnو سیoتوتیبه ترتیب کانال نقشه های ویژگی ورودی یا خروجی را نشان می دهد. در مورد ارزیابی کارایی عملی، ما اشغال حافظه GPU و سرعت فرآیند پیشبینی را ثبت کردیم.
4.4. نتایج مربوط به مجموعه داده HCSV
برای مقایسه منصفانه با سایر مدلهای تقسیمبندی معنایی تحت دانش قبلی، دانش یکسانی را برای همه روشها با ماژول یادگیری انتقال قبل از آزمایش انتقال دادیم، و بنابراین تفاوت اصلی در معماری شبکهها بود. جدول 3نتایج کمی را برای معیارهای مقایسه همه روش ها ارائه می دهد. میتوانیم ببینیم که FCN کلاسیک بدون توجه به عملکرد نسبی با ANNN که یک بلوک توجه غیرمحلی را ادغام میکند، دست یافت و با اختلاف زیادی از PSANet بهتر عمل کرد. این نشان میدهد که استراتژیهای مختلف توجه تأثیر زیادی بر نتیجه خواهند داشت و استراتژی توجه قبلی برای کار استخراج ویژگیهای چشمانداز در منطقه هسته پکن مناسب نیست. دلیل احتمالی عملکرد نامطلوب ANNN و PSANet این است که آنها به اطلاعات نسبتاً بیشتری برای تقسیم بندی در یک محیط پیچیده مانند منطقه هسته پکن نیاز دارند، که در یک وضعیت نمونه کوچک حتی بدتر خواهد بود. روش ما،
اگرچه ویژگی های چشم انداز مختلفی در منطقه مرکزی پکن وجود دارد، اما می توان آنها را در سه سناریو معمولی خلاصه کرد: خیابان مدرن، سناریوی مسکونی مدرن و سناریوی کوچه باستانی. نتایج تقسیم بندی برای هر روش مقایسه در هر سناریوی معمولی در شکل 9 نشان داده شده است ، و ما نتایج تقسیم بندی دسته به دسته را در شکل 10 ارائه می دهیم.. همانطور که می بینیم، در سناریوی مسکونی مدرن، همه مدل ها به نتایج معقولی دست یافتند، که نشان دهنده اثربخشی روش یادگیری انتقال است که با موفقیت دانش منظر شهری را از ImageNet و Cityscapes منتقل کرد. در این سناریوی خاص، انواع مختلفی (گلدان در جاده، سه چرخه و غیره) از کلاس “بهم ریختگی” وجود دارد که منجر به یک تقسیم بندی ناپایدار می شود. مشاهده میشود که فقط روش ما گلدان را از جمعیت متمایز میکند، که نشان میدهد روش ما میتواند نمایشهای ویژگیهای جدید را مؤثرتر از سایرین بیاموزد. دلیل احتمالی این است که استراتژی منجمد در استخراج کننده ویژگی، فضای پارامتر را محدود کرده و باعث شده است که شبکه در مرحله آموزش راحتتر همگرا شود.
در سناریوی خیابانی مدرن، مشاهده میشود که FCN عملکرد بهتری در ویژگیهای منظر با مساحت بزرگتر (مانند جاده، آسمان، عابر پیاده، و پوشش گیاهی و غیره) دارد، اما در صورت مواجهه با ویژگیهای غیر متعارف (مثلاً ناقص) اتوبوس سمت چپ)، مستعد شکست بود. نتایج PSANet و ANNN پراکنده و ناپیوسته بودند اما می توانستند اشیاء غیرمنتظره را تشخیص دهند. ما معتقدیم که این شکاف عملکرد ناشی از اجرای مکانیسم توجه است، که میتواند با محاسبه رابطه بین موقعیتهای مختلف در تصویر، ویژگیهای متمایز را ثبت کند. با این حال، مدل مبتنی بر توجه قبلی نمی تواند روابط پیچیده را در چنین موقعیت های متغیر مدیریت کند. از سوی دیگر، روش ما از ماژول PSA برای استفاده کامل از وضوح هم از نظر مکانی و هم از نظر کانال استفاده می کند.
در مورد سناریوی کوچه باستانی، این سناریو به دلیل طراحی شهری، شرایط نوری پیچیده و انواع مختلف بهم ریختگی، پیچیدهترین سناریو بود. جدای از محیط فیزیکی پیچیده، چالشی برای هر مدل نیز در مسئله نمونه محدود ظاهر شد که حاوی دانش غیرقابل جایگزینی است و تقاضای بالاتری را برای یادگیری و نمایش ویژگی ها ایجاد می کند. از شکل بالا، می بینیم که FCN تحت تأثیر سایه روی دیوار قرار گرفته است، و PSANet تمایل دارد که برچسب اشتباه (وسیله نقلیه غیر موتوری) را به سه چرخه اختصاص دهد (به دلیل غیرقانونی بودن آن به عنوان شلوغ شناخته می شود). علاوه بر ترکیب مزیت توانایی استخراج ویژگی چند مقیاسی بلوک ASPP و ظرفیت نمایش ماژول توجه PSA، روش ما توانایی یادگیری ویژگی را با تحمیل و منجمد کردن دانش قبلی در شبکه با ماژول یادگیری انتقال افزایش داد. بنابراین، روش پیشنهادی در یک محیط پیچیده به نتیجه قویتری دست یافت.
جدا از تجزیه و تحلیل کیفی، ما نتایج تقسیمبندی را برای هر نوع ویژگی چشمانداز بیشتر بررسی کردیم. همانطور که در جدول 4 نشان داده شده استمیتوان مشاهده کرد که ویژگیهای متمایز که دارای مساحت نسبتاً بزرگتر و ویژگیهای یکپارچهکننده در تصاویر هستند (یعنی آسمان، جاده، پوشش گیاهی و ساختمان) نتایج بخشبندی بهتری را با همه شبکههای آزمایششده در مقایسه با دستههای پیچیدهای داشتند که تکهتکه هستند. و متنوع (به عنوان مثال، بهم ریختگی، شخص، و پیاده روها). علاوه بر این، PSANet و ANNN در برخی از ویژگی های پیچیده مانند درهم و برهمی از FCN بهتر عمل کردند، که پتانسیل مکانیسم توجه را اثبات می کند. با این حال، به دلیل پیچیدگی بیشتر، روشهای موجود نتوانستند نمایش ویژگی را با نمونههای محدود بیاموزند و این منجر به نتایج تقسیمبندی ناراضی برای دستههای مختلف شد. در مقابل، روش ما بهترین دقت را در اکثر دسته ها به دست آورد. برای ویژگی های متمایز، همه مدلها به نتایج مشابهی دست یافتند و روش ما به یک مزیت جزئی (با عملکرد بهتر 2-3٪) دست یافت. از سوی دیگر، برای ویژگیهای پیچیده، شبکه پیشنهادی با اختلاف زیادی (حدود 7 تا 10 درصد) از روشهای دیگر بهتر عمل کرد. این نتایج اثربخشی ماژول PSA را به ویژه برای سازماندهی مجدد ویژگی های پیچیده نشان می دهد.
ما همچنین آزمایشهای تحلیل کارایی را بر روی CNNهای کاندید انجام دادیم که شامل میلیونها پارامتر (M)، استفاده از حافظه (MByte، Mb)، عملیات ممیز شناور گیگا در ثانیه (GFLOPs) و سرعت استنتاج (فریمها در هر) بود. دوم، FPS). تمام آزمایش ها در یک محیط انجام شد. همانطور که در جدول 5 نشان داده شده استPSANet پیچیده ترین شبکه با بیشترین پارامتر (50.57 میلیون) است که در شرایط نمونه کوچک تأثیر منفی بر توانایی یادگیری ویژگی خواهد داشت. با این حال، ANNN کارآمدتر (37.66 میلیون پارامتر)، نمی تواند رابطه بین ویژگی های مشابه را به طور کامل نشان دهد. در مقابل، پارامترهای PALESNet پیشنهادی (43.42 میلیون) در مقایسه با FCN معمولی (40.93 میلیون)، که پتانسیل کامل مکانیسم توجه را درک می کند، تنها اندکی افزایش یافته است، در حالی که از عوارض جانبی پیچیدگی اضافی یا بیش از حد جلوگیری می کند. سازش در کارایی دلیل این امر این است که ماژول PSA در هنگام محاسبه توجه از نظر فضایی و کانالی، ابعاد مخالف را “بر هم می زند”، که منجر به استفاده از پارامتر کمتر بدون افت عملکرد می شود.
4.5. مطالعه فرسایش PALESNet
روش ما شامل یادگیری انتقال، یک بلوک PSA و بلوک ASPP برای تقسیم بندی دقیق در ناحیه هسته پکن با مجموعه داده پیشنهادی HCSV بود. برای تأیید بیشتر اعتبار هر ماژول در PALESNet پیشنهادی، یک آزمایش فرسایش را به شرح زیر طراحی کردیم: در آزمایش فرسایش، هر ماژول ذکر شده در روش ما به صورت جداگانه تجزیه و تحلیل شد تا تأثیر آن بر کل شبکه بررسی شود. شایان ذکر است که FCN به عنوان خط پایه مورد استفاده قرار گرفت که شامل یک ماژول یادگیری انتقال، بلوک PSA یا بلوک ASPP نبود.
در این آزمایش، PALESNet پیشنهادی تنها یک بلوک ASPP بیشتر در مقایسه با خط پایه داشت. بنابراین، می توان از آن برای ارزیابی اثر ASPP استفاده کرد. هر مدل برای 40000 تکرار در مجموعه داده HCSV آموزش داده شد. همانطور که در جدول 6 مشاهده می شود، یادگیری انتقال می تواند به طور قابل توجهی عملکرد همه مدل ها را بهبود بخشد که کارایی این فناوری را ثابت کرد. به طور دقیق تر، mIoU با FCN، PSANet و ANNN به ترتیب 17.13، 12.49 درصد و 17.24 درصد بهبود یافت. برای روش ما، 19.18٪ افزایش یافته است که نشان می دهد روش ما پتانسیل یادگیری اطلاعات بیشتر از روش یادگیری انتقال را دارد. برای بلوک ASPP، مشاهده میشود که روش ما حدود 2% از خط پایه بهتر عمل کرده است، صرف نظر از اینکه یادگیری انتقال درگیر بوده یا نه، که کارایی بلوک ASPP را ثابت میکند.
همانطور که در جدول 7 نشان داده شده است ، ما عملکرد مدل را با و بدون مکانیسم توجه ارزیابی کردیم. ماژول PSA mIoU، mAcc و aAcc مجموعه داده HCSV را به ترتیب 1.71٪، 1.24٪ و 0.8٪ بهبود بخشید. این نشان میدهد که بلوک PSA میتواند نتایج را با تمرکز بر ویژگیهای یکسان برای هر کلاس و انتقال این اطلاعات به مدل تقسیمبندی بعدی، به طور قابل ملاحظهای بهبود بخشد.
به طور خلاصه، با فناوری یادگیری انتقال، بلوک PSA و بلوک ASPP، روش ما می تواند حداکثر استفاده را از اطلاعات موجود در مجموعه داده های از پیش آموزش دیده، و همچنین نمونه های محدود با محیط های پیچیده در منطقه هسته پکن داشته باشد. بنابراین، روش ما میتواند بهطور مؤثری یک نقشه تقسیمبندی دقیقتر ایجاد کند.
5. بحث
در این بخش، ما ابتدا عملکرد همگرایی را برای همه شبکههای مقایسهای در طول فرآیند آموزش تجزیه و تحلیل میکنیم و ضرورت مجموعه دادههای HCSV پیشنهادی را بیشتر مورد بحث قرار میدهیم. در نهایت، به طور خلاصه تجزیه و تحلیل می کنیم که چرا روش ما به بهترین عملکرد در آزمایش دست یافت و بینش هایی را در مورد طراحی شبکه برای یک مجموعه داده کوچک ارائه می دهیم.
منحنی های تلفات و متریک در مرحله آموزش در شکل 11 نشان داده شده است. همانطور که می بینیم، FCN اصلی، که از معماری توجه برخوردار نبود، در مرحله آخر آموزش (پس از 280 دوره) نتوانست سود زیادی برای متریک mAcc و aAcc به دست آورد. از سوی دیگر، معیارهای روشهای مجهز به توجه به طور مداوم در طول کل فرآیند آموزش افزایش یافت. این ممکن است نشان دهد که مکانیسم توجه می تواند از ویژگی های قابل استفاده بیشتری برای یادگیری شبکه استفاده کند. با این حال، معرفی مکانیسم توجه، همگرایی مدل را دشوارتر کرد، که منجر به لرزش افت و منحنی متریک شد. برای کاهش این مشکل، اطلاعات چند مقیاسی را با بلوک ASPP ترکیب کردیم و چند لایه را در شبکه ثابت کردیم (به بخش 3.3.2 مراجعه کنید.) در طول آموزش نهایی، برای تثبیت و تسریع روند همگرایی. در نتیجه، منحنی متریک PALESNet ما بسیار هموارتر از PSANet بود و سرعت همگرایی مدل ما به طور قابل توجهی سریعتر از ANNN بود.
همانطور که قبلاً ذکر کردیم، مجموعه داده های موجود مناطق منحصر به فردی را که شامل بناهای تاریخی متعددی است، مانند منطقه هسته پکن، پوشش نمی دهد. بنابراین، مجموعه داده پیشنهادی HCSV میتواند یک منبع داده جدید برای آموزش و ارزیابی مدلهای یادگیری عمیق برای مطالعات مرتبط فراهم کند. تا آنجا که ما می دانیم، ما اولین کسی هستیم که یک مجموعه داده به طور خاص برای این منطقه تاریخی در این منطقه شهری ایجاد می کنیم. روشهای فعلی نمیتوانند نتایج مناسبی را بدون آموزش روی مجموعه داده HCSV ایجاد کنند. علاوه بر این، برای کمک به تحقیقات و حفظ مناظر در پکن، حتی ممکن است در سناریوهای دیگر مورد استفاده قرار گیرد. معماری تاریخی الگوی مشابهی در چین دارد و مدلهای از قبل آموزشدیده شده در مجموعه دادههای HCSV میتوانند سریعتر با سایر بلوکهای تاریخی و فرهنگی همگرا شوند.
در مقایسه، متوجه شدیم که روش ما بهترین عملکرد را هم در دقت کلی و هم در بیشتر کلاس به کلاس به دست آورده است. این عملکرد فوقالعاده ممکن است به دلیل ساختار هرمی فضایی ناخوشایند آن باشد که میتواند اطلاعات بافت غنی را به تصویر بکشد و به درک ویژگیهای پیچیده سطح کمک کند. دلیل عملکرد ناامیدکننده شبکههای اخیر با مکانیسم توجه میتواند پیچیدگی و تنوع دادههای HCSV باشد که ممکن است شبکهها را گمراه کرده و منجر به روابط نادرست بین مکانهای مختلف شود.
در مورد بهترین روشهای تقسیمبندی معنایی برای هسته تاریخی در پکن، ما معتقد بودیم که این به حجم تصاویر حاشیهنویسی برای آموزش بستگی دارد. هنگامی که مقادیر محدودی از داده های برچسب دار وجود دارد، یک شبکه با ظرفیت کم عملکرد تعمیم یافته بهتری خواهد داشت. به عنوان مثال، Fast-SCNN [ 47 ] میتواند نتایج بخشبندی امیدوارکنندهای را بر روی Cityscapes بدون نیاز به فرآیند پیشآموزشی تولید کند، و نمونههای آموزشی محدود در مقایسه با DCNNهای با ظرفیت بالا تأثیر کمتری خواهند داشت. با این حال، روشهای مجهز به مکانیسم توجه، به ویژه شبکههای مبتنی بر ترانسفورماتور تازه پدید آمده [ 48 ، 49 ]]، نمی تواند دانش کافی برای تشخیص ویژگی های سطحی پیچیده و ایجاد روابط مناسب با استفاده از نمونه های حاشیه نویسی محدود را بیاموزد [ 50 ]. یکی دیگر از دلایل احتمالی برای بهترین عملکرد روش پیشنهادی، دستیابی به تعادل بین ظرفیت شبکه و مقدار داده است.
6. نتیجه گیری و کار آینده
خدمات نقشه آنلاین به سرعت در حال تکامل با تصاویر نمای خیابان، چشم اندازی جدید برای مشاهده منظر شهری و وضعیت محیطی، به ویژه برای منطقه با ویژگی های چشم انداز متنوع در منطقه مرکزی پکن، ارائه می دهد. برای پرداختن به سوال کمبود داده، این مقاله مجموعه داده کوچک و در عین حال جامع History-Core Street View را برای تحقیقات مرتبط ارائه میکند. علاوه بر این، ما یک روش مبتنی بر DNN با فناوری یادگیری تبدیل، یک بلوک توجه PSA و یک بلوک ASPP برای انجام استخراج دقیق ویژگیهای منظره برای مناطق تاریخی چین پیشنهاد کردیم. برای کاهش اثرات منفی ناشی از مشکل نمونه محدود، ماژول یادگیری انتقال میتواند دانش را از مجموعه دادههای موجود به شبکه پیشنهادی منتقل کند تا به تمایز ویژگیهای یکسان در مجموعه داده HCSV کمک کند. علاوه بر این، بلوک توجه PSA میتواند ویژگیهای پیچیده را تشخیص دهد، در حالی که بلوک ASPP میتواند ویژگیهای چند مقیاسی را استخراج کند و بنابراین، میتواند به مدل کمک کند تا ویژگیهای منظره را با دقت بیشتری، به ویژه در یک محیط پیچیده استخراج کند. در مقایسه با سایر روشهای پیشرفته، یعنی ANNN و PSANet، شبکه ما بالاترین دقت را با mIoU 63.7٪ در مجموعه داده HCSV به دست آورد.
در آینده، فناوری اخیر با نظارت ضعیف و ترانسفورماتور را بیشتر بررسی خواهیم کرد و روشهای موثر استخراج ویژگیهای منظره را توسعه خواهیم داد که میتواند انواع بیشتری از ویژگیها را با دقت بالاتر در یک محیط پیچیده و موقعیت نمونه کوچک تشخیص دهد. علاوه بر این، روش پیشنهادی میتواند به سایر مناطق تاریخی چین مانند شهر باستانی Fenghuang و Lilong در شانگهای نیز ارتقا یابد تا از حفاظت از مناظر سنتی با ارائه دادههای بررسی ویژگیهای زمین به بخشهای مربوطه حمایت شود.
مشارکت های نویسنده
مفهوم سازی، سیمینگ یین و شیان گو. روش، سیمینگ یین. اعتبار سنجی، سیمینگ یین. تحلیل رسمی، سیمینگ یین. منابع، جی جیانگ; مدیریت داده، سیمینگ یین. نوشتن – آماده سازی پیش نویس اصلی، سیمینگ یین. نوشتن-بررسی و ویرایش، Xian Guo و Jie Jiang. نظارت، شیان گو. مدیریت پروژه، جی جیانگ؛ کسب بودجه، جی جیانگ. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این مطالعه توسط برنامه ملی تحقیق و توسعه کلیدی چین (2021YFE0117500)، پروژه آموزش استعدادهای هرمی دانشگاه مهندسی عمران و معماری پکن (JDYC20200322)، صندوق های تحقیقات بنیادی برای دانشگاه مهندسی عمران و معماری پکن (X20) پشتیبانی شد.
بیانیه هیئت بررسی نهادی
قابل اجرا نیست.
بیانیه رضایت آگاهانه
قابل اجرا نیست.
بیانیه در دسترس بودن داده ها
داده های ارائه شده در این مطالعه به درخواست نویسنده مسئول در دسترس است.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- شان، JX حفاظت از مناطق تاریخی و فرهنگی ; انتشارات دانشگاه تیانجین: تیانجین، چین، 2015. (به زبان چینی) [ Google Scholar ]
- Cai، تجزیه و تحلیل XF و مقررات در مورد سبک و ویژگی شهر. دکتری پایان نامه، دانشگاه Tongji، شانگهای، چین، 2006. [ Google Scholar ]
- مانگی، من؛ یو، ز. کلوار، س. علی لشاری، زهرا. تحلیل تطبیقی روندهای توسعه شهری مناطق شهری پکن و کراچی. پایداری 2020 ، 12 ، 451. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Wherrett, JR ایجاد مدل های ترجیحی چشم انداز با استفاده از تکنیک های نظرسنجی اینترنتی. Landsc. Res. 2000 ، 25 ، 79-96. [ Google Scholar ] [ CrossRef ]
- ورمولن، اف. کی، اس جی. برگرز، جی.-جی. کورسی، سی. بررسی منظر شهری در ایتالیا و مدیترانه . کتاب های آکسبو: آکسفورد، انگلستان، 2012; ISBN 9781842174869. [ Google Scholar ]
- Ahern, J. پایداری و انعطافپذیری منظر شهری: نوید و چالشهای ادغام اکولوژی با برنامهریزی و طراحی شهری. Landsc. Ecol. 2013 ، 28 ، 1203-1212. [ Google Scholar ] [ CrossRef ]
- لی، ز. هان، ایکس. لین، ایکس. لو، ایکس. تحلیل کمی اثربخشی منظر بر اساس مدلسازی معادلات ساختاری: شواهد تجربی از خیابانهای تجاری سبک چینی جدید. الکس. مهندس J. 2021 , 60 , 261-271. [ Google Scholar ] [ CrossRef ]
- لیو، ی. وانگ، آر. لو، ی. لی، ز. چن، اچ. کائو، ام. ژانگ، ی. Song، Y. محیط طبیعی در فضای باز، انسجام اجتماعی محله و سلامت روان: با استفاده از مدلسازی معادلات ساختاری چندسطحی، متریکهای چشمانداز خیابان و سنجش از دور. شهری برای. سبز شهری. 2020 , 48 , 126576. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. آموزش دوره بررسی منظره بر اساس تفسیر تصویر سنجش از دور شناسایی* را تمرین کنید. آموزش. علمی عمل تئوری. 2018 ، 18 ، 1411-1423. [ Google Scholar ] [ CrossRef ]
- تانگ، جی. طولانی، Y. اندازه گیری کیفیت بصری فضای خیابان و تغییرات زمانی آن: روش شناسی و کاربرد آن در منطقه هوتونگ در پکن. Landsc. طرح شهری 2019 , 191 , 103436. [ Google Scholar ] [ CrossRef ]
- خو، ز. وو، ی. Lu، XZ; جین، XL تجسم عکس واقع گرایانه از پاسخ های دینامیکی لرزه ای خوشه های ساختمان شهری بر اساس عکاسی هوایی مایل. Adv. مهندس به اطلاع رساندن. 2020 ، 43 ، 17. [ Google Scholar ] [ CrossRef ]
- راویندران، آر. سانتورا، ام جی; جمالی، MM، تشخیص و ردیابی چند شیء، بر اساس DNN، برای وسایل نقلیه خودمختار: یک بررسی. IEEE Sens. J. 2021 , 21 , 5668–5677. [ Google Scholar ] [ CrossRef ]
- گونگ، FY؛ Zeng، ZC; ژانگ، اف. لی، XJ; نگ، ای. نورفورد، LK نقشه برداری از آسمان، درخت و عوامل نمای ساختمان دره های خیابان در یک محیط شهری با تراکم بالا. ساختن. محیط زیست 2018 ، 134 ، 155-167. [ Google Scholar ] [ CrossRef ]
- لیانگ، جی. گونگ، جی. سان، ج. ژو، جی. لی، دبلیو. لی، ی. لیو، جی. Shen, S. تخمین خودکار فاکتور نمای آسمان از عکسهای نمای خیابان – رویکرد دادههای بزرگ. Remote Sens. 2017 , 9 , 411. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چنگ، ال. چو، اس اس. Zong، WW; لی، سی. وو، جی. لی، ام سی استفاده از تصاویر نمای خیابان Tencent برای درک بصری از خیابان ها. ISPRS Int. J. Geo-Inf. 2017 ، 6 ، 265. [ Google Scholar ] [ CrossRef ]
- راندل، AG; بادر، MD; ریچاردز، کالیفرنیا؛ Neckerman، KM; Teitler، JO استفاده از نمای خیابان گوگل برای ممیزی محیط های محله. صبح. J. قبلی پزشکی 2011 ، 40 ، 94-100. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- لی، XJ; راتی، سی. سیفرلینگ، I. کمی کردن سایه درختان خیابان در منظر شهری: مطالعه موردی در بوستون، ایالات متحده، با استفاده از نمای خیابان گوگل. Landsc. طرح شهری. 2018 ، 169 ، 81-91. [ Google Scholar ] [ CrossRef ]
- لی، XJ; ژانگ، CR; بازیابی اطلاعات کاربری شهری در سطح بلوک ساختمانی لی، WD بر اساس تصاویر نمای خیابان گوگل. GIScience Remote Sens. 2017 ، 54 ، 819-835. [ Google Scholar ] [ CrossRef ]
- لانگ، جی. شلهامر، ای. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. صص 3431–3440. [ Google Scholar ]
- رونبرگر، او. فیشر، پی. Brox، T. U-net: شبکه های کانولوشن برای تقسیم بندی تصاویر زیست پزشکی. در مجموعه مقالات کنفرانس بین المللی محاسبات تصویر پزشکی و مداخله به کمک کامپیوتر، مونیخ، آلمان، 5 تا 9 اکتبر 2015. صص 234-241. [ Google Scholar ]
- بدرینارایانان، وی. کندال، ا. Cipolla، R. SegNet: معماری رمزگذار-رمزگشای پیچیده پیچیده برای تقسیم بندی تصویر. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 2481-2495. [ Google Scholar ] [ CrossRef ]
- ژائو، اچ. ژانگ، ی. لیو، اس. شی، ج. لوی، سی سی; لین، دی. Jia, J. Psanet: شبکه توجه فضایی نقطهای برای تجزیه صحنه. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018؛ ص 267-283. [ Google Scholar ]
- چن، L.-C.; زو، ی. پاپاندرو، جی. شروف، اف. Adam, H. رمزگذار-رمزگشا با پیچیدگی قابل جداسازی آتروس برای تقسیم بندی تصویر معنایی. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018؛ ص 801-818. [ Google Scholar ]
- هوو، ایکس. زی، ال. او، جی. یانگ، ز. ژو، دبلیو. لی، اچ. Tian, Q. ATSO: بهینه سازی ناهمزمان معلم و دانش آموز برای تقسیم بندی تصویر نیمه نظارت شده. در مجموعه مقالات کنفرانس IEEE/CVF در مورد دید رایانه و تشخیص الگو (CVPR)، آنلاین، 19 تا 25 ژوئن 2021؛ ص 1235-1244. [ Google Scholar ]
- وانگ، اچ. زو، ی. آدم، اچ. یویل، ا. چن، ال.-سی. Max-deeplab: تقسیم بندی پانوپتیک انتها به انتها با ترانسفورماتورهای ماسک. در مجموعه مقالات کنفرانس IEEE/CVF در مورد دید رایانه و تشخیص الگو (CVPR)، آنلاین، 19 تا 25 ژوئن 2021؛ صص 5463–5474. [ Google Scholar ]
- یوان، XH; شی، ج.اف. Gu، LC مروری بر روشهای یادگیری عمیق برای تقسیمبندی معنایی تصاویر سنجش از دور. سیستم خبره Appl. 2021 ، 169 ، 14. [ Google Scholar ] [ CrossRef ]
- Yan، YL; Ryu, Y. کاوش نمای خیابان Google با یادگیری عمیق برای نگاشت نوع برش. Isprs J. Photogramm. Remote Sens. 2021 , 171 , 278–296. [ Google Scholar ] [ CrossRef ]
- ژانگ، اف. وو، ال. زو، دی. لیو، ی. سنجش اجتماعی از تصویرسازی سطح خیابان: مطالعه موردی در یادگیری الگوهای تحرک شهری فضایی-زمانی. ISPRS J. Photogramm. Remote Sens. 2019 ، 153 ، 48–58. [ Google Scholar ] [ CrossRef ]
- ژائو، اچ. شی، ج. Qi، X. وانگ، ایکس. شبکه تجزیه صحنه هرم جیا، جی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 2881-2890. [ Google Scholar ]
- میدل، ا. لوکاشیک، جی. زاکرزوسکی، اس. آرنولد، ام. Maciejewski، R. فرم شهری و ترکیب دره های خیابانی: یک داده های بزرگ انسان محور و رویکرد یادگیری عمیق. Landsc. طرح شهری 2019 ، 183 ، 122–132. [ Google Scholar ] [ CrossRef ]
- بله، ی. زنگ، دبلیو. شن، QM; ژانگ، XH; Lu, Y. کیفیت بصری خیابان ها: یک اندازه گیری پیوسته انسان محور بر اساس الگوریتم های یادگیری ماشین و تصاویر نمای خیابان. محیط زیست طرح. ب مقعد شهری. علوم شهر 2019 ، 46 ، 1439-1457. [ Google Scholar ] [ CrossRef ]
- سوئل، ای. بهات، اس. برائر، ام. فلکسمن، اس. عزتی، م. یادگیری عمیق چندوجهی از تصاویر ماهواره ای و سطح خیابان برای اندازه گیری درآمد، ازدحام بیش از حد و محرومیت محیطی در مناطق شهری. سنسور از راه دور محیط. 2021 ، 257 ، 11. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ژانگ، LY; پی، تی. وانگ، ایکس. وو، مگابایت؛ آهنگ، سی. Guo، SH; چن، وای جی، درک بصری شهری از ساختمانهای به سبک سنتی چینی را با تصاویر نمای خیابان تعیین میکند. Appl. علمی 2020 ، 10 ، 5963. [ Google Scholar ] [ CrossRef ]
- چنگ، بی. میسره، من. شوینگ، AG; کریلوف، آ. Girdhar, R. ترانسفورماتور ماسک توجه نقابدار برای تقسیم بندی تصویر جهانی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 21 تا 24 ژوئن 2022. [ Google Scholar ]
- زو، ز. خو، ام. بای، اس. هوانگ، تی. بای، X. شبکه های عصبی غیرمحلی نامتقارن برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF در بینایی کامپیوتر، سئول، کره، 27 اکتبر تا 2 نوامبر 2019؛ صص 593-602. [ Google Scholar ]
- دنگ، ج. دونگ، دبلیو. سوچر، آر. لی، ال.-جی. لی، ک. Fei-Fei, L. Imagenet: پایگاه داده تصویر سلسله مراتبی در مقیاس بزرگ. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، میامی، فلوریدا، ایالات متحده آمریکا، 20-25 ژوئیه 2009. صص 248-255. [ Google Scholar ]
- Brostow، GJ; Fauqueur, J.; Cipolla، R. کلاس های شیء معنایی در ویدئو: پایگاه داده حقیقت زمینی با کیفیت بالا. تشخیص الگو Lett. 2009 ، 30 ، 88-97. [ Google Scholar ] [ CrossRef ]
- کوردتس، ام. عمران، م. راموس، اس. رهفلد، تی. انزوایلر، م. بننسون، آر. فرانکه، یو. راث، اس. شیله، بی. مجموعه داده مناظر شهری برای درک معنایی صحنه شهری. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016؛ صص 3213–3223. [ Google Scholar ]
- لین، تی.-ای. مایر، م. بلنگی، اس. هیز، جی. پرونا، پی. رامانان، دی. دلار، پی. Zitnick، CL مایکروسافت کوکو: اشیاء مشترک در زمینه. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، زوریخ، سوئیس، 6 تا 12 سپتامبر 2014. صص 740-755. [ Google Scholar ]
- یو، اف. چن، اچ. وانگ، ایکس. Xian، W. چن، ی. لیو، اف. مدهوان، وی. Darrell, T. Bdd100k: مجموعه داده رانندگی متنوع برای یادگیری چندکاره ناهمگن. در مجموعه مقالات کنفرانس IEEE/CVF در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سیاتل، WA، ایالات متحده آمریکا، 14 تا 19 ژوئن 2020؛ صص 2636–2645. [ Google Scholar ]
- هوانگ، ایکس. چنگ، ایکس. گنگ، س. کائو، بی. ژو، دی. وانگ، پی. لین، ی. یانگ، آر. مجموعه داده آپولوسیپ برای رانندگی مستقل. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ ص 954-960. [ Google Scholar ]
- مشارکت کنندگان ویرایشگر تقسیم بندی معنایی. ویرایشگر تقسیم بندی معنایی در دسترس آنلاین: https://github.com/Hitachi-Automotive-And-Industry-Lab/semantic-segmentation-editor (در 18 مه 2022 قابل دسترسی است).
- او، ک. ژانگ، ایکس. رن، اس. Sun، J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو (CVPR)، لاس وگاس، NV، ایالات متحده، 27-30 ژوئن 2016. صص 770-778. [ Google Scholar ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE Imagenet طبقه بندی با شبکه های عصبی کانولوشن عمیق. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی سیستم های پردازش اطلاعات عصبی، دریاچه تاهو، نوادا، ایالات متحده آمریکا، 3-6 دسامبر 2012. صص 1097–1105. [ Google Scholar ]
- ویت، ا. ویلبر، ام جی; Belongie, S. شبکههای باقیمانده مانند مجموعهای از شبکههای نسبتا کم عمق رفتار میکنند. در مجموعه مقالات سی امین کنفرانس سیستم های پردازش اطلاعات عصبی، بارسلون، اسپانیا، 5 تا 10 دسامبر 2016. صص 550-558. [ Google Scholar ]
- مشارکت کنندگان MMSegmentation. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. در دسترس آنلاین: https://github.com/open-mmlab/mmsegmentation (در 18 مه 2022 قابل دسترسی است).
- پودل، RP; لیویکی، اس. Cipolla, R. Fast-scnn: شبکه تقسیم بندی معنایی سریع. arXiv 2019 ، arXiv:1902.04502. [ Google Scholar ]
- دوسوویتسکی، آ. بیر، ال. کولسنیکوف، آ. وایسنبورن، دی. ژای، ایکس. Unterthiner، T. دهقانی، م. مایندرر، م. هیگلد، جی. Gelly، S. یک تصویر ارزش 16×16 کلمه دارد: ترانسفورماتور برای تشخیص تصویر در مقیاس. در مجموعه مقالات کنفرانس بینالمللی نمایشهای یادگیری (ICLR)، آنلاین، 3 تا 7 مه 2021. [ Google Scholar ]
- لیو، ز. لین، ی. کائو، ی. متعجب.؛ وی، ی. ژانگ، ز. لین، اس. Guo, B. ترانسفورماتور Swin: ترانسفورماتور دید سلسله مراتبی با استفاده از پنجره های جابجا شده. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF در بینایی رایانه (ICCV)، مونترال، QC، کانادا، 11 تا 17 اکتبر 2021. [ Google Scholar ]
- لیو، ز. مائو، اچ. وو، سی.-ای. فایختنهوفر، سی. دارل، تی. Xie, S. A ConvNet برای سال 2020. در مجموعه مقالات کنفرانس IEEE/CVF در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 21 تا 24 ژانویه 2022. [ Google Scholar ]
















7 نظرات