

جرایم یک نگرانی رایج اجتماعی است که بر کیفیت زندگی و رشد اقتصادی تأثیر می گذارد. علیرغم کاهش جهانی آمار جرم و جنایت، انواع خاصی از جرم و احساس ناامنی، اغلب افزایش یافته است و سازمانهای ایمنی و امنیتی را پیشروی میکنند که نیاز به استفاده از رویکردهای جدید و سیستمهای پیشرفته برای پیشبینی و پیشگیری بهتر از رویدادها دارند. استفاده از فنآوریهای مکانی، همراه با دادهکاوی و تکنیکهای یادگیری ماشین، پیشرفتهای قابلتوجهی در جرمشناسی مکان میدهد. در این مطالعه، دادههای پلیس رسمی پورتو، در پرتغال، بین سالهای 2016 و 2018، با استفاده از روشهای تحلیل فضایی، که امکان شناسایی الگوهای فضایی و نقاط داغ مربوطه را فراهم میکند، ارجاع جغرافیایی و درمان شد. سپس، فرآیندهای یادگیری ماشین برای کاوی الگوی فضا-زمان اعمال شد. با استفاده از تحلیل رگرسیون کمند، برای متغیرهای جرم و جنایت معنی دار بود، با جنگل تصادفی و درخت تصمیم که از انتخاب متغیر مهم حمایت می کرد. در نهایت، توییتهای مربوط به ناامنی جمعآوری شد و مدلسازی موضوع و تحلیل احساسات انجام شد. این روشها با هم به تفسیر الگوها، پیشبینی و در نهایت عملکرد پلیس و متخصصان برنامهریزی کمک میکنند.
کلید واژه ها:
تحلیل فضایی ; یادگیری ماشینی ؛ جرم شناسی مکان ; تحلیل احساسات ؛ مدل سازی موضوع ; کشور پرتغال
1. مقدمه
جرم به هر عملی گفته می شود که غیرقانونی باشد. وجود جرم و مهمتر از آن احساس ناامنی که ممکن است مستقیماً از آن ناشی شود، کیفیت زندگی و پایداری جوامع را تحت تأثیر قرار می دهد. برنامههای سیاست و برنامهریزی مرتبط مانند اهداف توسعه پایدار سازمان ملل، برنامه شهرهای امنتر زیستگاه سازمان ملل، شاخص رفاه OECD [ 1 ] یا گزارشهای انسجام اتحادیه اروپا [ 2 ] به وضوح بر نیاز به ایجاد فضاهای شهری تأکید میکنند که ساکنان آن احساس امنیت و امنیت کنند. از این نظر، مدتهاست ثابت شده است که واکنش های سنتی مبارزه با جرم و جنایت به خودی خود کافی نیست [ 3]. از دهه 1970، به ویژه در دو دهه اخیر، پارادایمهای پلیسی از واکنش به پیشگیری، و از تحلیل صرف عامل و عوامل اجتماعی زمینهای برای در نظر گرفتن عوامل شهری مرتبط با فضا، زمان و ایجاد فرصتها تغییر کرده است.
بنابراین، اصول جرم شناسی محیطی [ 4 ، 5 ، 6 ] بر سه ایده اصلی استوار است. اول اینکه رفتار مجرمانه به طور قابل توجهی تحت تأثیر ماهیت زمینهای محیطی است که در آن رخ میدهد، به عنوان مثال، مسائل مکانی [ 5 ]، زیرا دارای ویژگیهای فردی است که جرم را تشدید یا کاهش میدهد. ثانیاً، توزیع الگوهای جرم تصادفی نیست، زیرا نتیجه چنین شرایط سرزمینی است که در مکان و زمان متفاوت است. سوم، با تغییر ویژگی ها و همچنین با هدایت منابع (پلیس، طراحی شهری یا مداخلات اجتماعی یا فرهنگی) به این مکان های داغ، کاهش قابل توجهی در ناامنی حاصل می شود.
گسترش مدلسازی رایانهای، سیستمهای اطلاعات جغرافیایی و فنآوریهای مکانی [ 7 ، 8 ، 9 ] به پیشرفتهای قابلتوجهی در زمینه مرجع جغرافیایی جرم، نقشهبرداری و نقطه داغ اجازه داده است. چنین استفاده ای از داده های مکانی و تجزیه و تحلیل برای بهبود عملکرد و پیشگیری به عنوان پلیس نقطه داغ [ 10 ، 11 ]، پلیس مبتنی بر مکان [ 12 ] یا حتی GIS پزشکی قانونی [ 13 ]، بخشی از آنچه Couldren et al. [ 14] پارادایم جدید «پلیس هوشمند» نامیده اند، که همچنین خواستار ادغام و اشتراک دانش بیشتر بین سازمان های پلیس و مؤسسات تحقیقاتی مانند دانشگاه ها است. از یک سو، روشهای پیشرفتهتر بهعنوان نحو فضایی [ 15 ]، و همچنین الگوریتمهای داده کاوی و یادگیری ماشین برای درک الگوهای فضایی و حتی پیشبینی رخدادها، با استفاده از روشهای خطی یا مدلهای بیزی استفاده میشوند [ 16 ، 17 ، 18 ]. اینها شامل، اما نه محدود به، الگوریتم جنگل تصادفی (RF) [ 19 ]، درخت تصمیم [ 20 ، 21 ]، K-نزدیکترین همسایه (KNN) [ 22 ، 23 ]، ماشین بردار پشتیبانی (SVM) [24 ] یا شبکه های عصبی مصنوعی (ANN) [ 25 ]. از سوی دیگر، نویسندگانی مانند بنیستر و همکاران. [ 26 ] اخیراً به وابستگی فزاینده نتایج به دست آمده از داده های بزرگ و الگوریتم های مدل سازی هشدار داده اند، که در آن “علیت مرده است، همبستگی پادشاه است” [ 26 ] (ص. 323)، زیرا آنها “روش را بر معنا با اتخاذ یک غیر” برتری می دهند. رویکرد انتقادی به ویژگیهای مکانی و زمانی دادهها» [ 26 ] (ص. 323). علاوه بر این، از ادبیات مشخص است که استفاده از این تکنیک ها در برخی کشورها رواج بیشتری دارد، در حالی که سایر کشورها هنوز در مراحل اولیه پلیس مکان محور هستند، با فرهنگ دانشگاهی و نهادی پایین نقشه برداری جرم و یا حتی ارجاع جغرافیایی جرم. [ 27].
در نتیجه، این پیشرفتها باید بهدرستی در زمینههای محلی شکل گرفته و درک شوند. اول، تأثیری که فناوریهای جدید و این ظرفیت بیسابقه برای مدیریت دادهها و تجزیه و تحلیل فضایی میتواند بر پلیسهای مبتنی بر شواهد داشته باشد باید مورد توجه قرار گیرد. دوم، اینکه چگونه میتوانند فراتر از محاسبات بروند و به مشارکت جامعتر در حمایت از تصمیمگیری، در راستای اشتراک و جابجایی مسئولیتها که توسط مدلهای جدید پلیس ارتقا مییابد [ 28 ]. سوم، همانطور که Andresen و Weisburd [ 12 ] پیشنهاد میکنند، چگونه چنین نظریهها، روشها و مدلهایی خارج از مکانهایی که بیشتر آنها توسعه و آزمایش شدهاند، یعنی خارج از کلانشهرهای بزرگتر و همچنین در کشورهای پیرامونی، رفتار میکنند.
در این مقاله، این پرسشها در یک مطالعه موردی در پورتو، پرتغال مورد بررسی قرار میگیرند. در لبه غربی اروپا و اخیراً با غلبه بر یک بحران عمیق مالی، پرتغال به عنوان یکی از امن ترین کشورهای جهان در نظر گرفته می شود که چهارمین جایگاه جهانی را در شاخص صلح جهانی [ 29 ] در اختیار دارد و یکی از پایین ترین نرخ قربانیان در اروپا را ارائه می دهد. 30 ]، و همچنین وضعیت تهدید متوسط [ 31 ]. در عین حال، ترس بالایی از جرم را نشان می دهد [ 32 ]، چیزی که ممکن است در این واقعیت منعکس شود که یکی از بالاترین نرخ افسران پلیس به ازای هر ساکن در اروپا را دارد [ 33 ]. علاوه بر این، هنوز فرهنگ نقشه برداری، ارجاع جغرافیایی و تحلیل فضایی کم جرم در کشور وجود دارد.27 ] و نمونه های بسیار کمی از مدل سازی جرم با استفاده از الگوریتم های مبتنی بر فضا وجود دارد [ 34 ، 35 ، 36 ].
این مقاله با استفاده از ثبتهای رسمی دادههای جرم از پلیس امنیت عمومی پورتو از دوره پیش از همهگیری بین ژانویه 2016 تا دسامبر 2018، با ترکیب تجزیه و تحلیل فضایی با یادگیری ماشینی برای ایجاد یک مدل پیشبینی تجربی، به ادبیات فعلی در مورد مدلسازی جرم جغرافیایی کمک میکند. . بیش از استفاده از خود تکنیکها، تولید دانش مبتنی بر شواهد و فضا برای ایمنی شهری در زمانی که منابع محلی اغلب کمیاب نیاز به مدیریت صحیح و ادغام با برنامهریزی و برنامههای سرزمینی دارند، حیاتی تلقی میشود. زندگی و پایداری
2. یادگیری ماشینی، تحلیل احساسات و مدلسازی موضوع در نقطه داغ و پیشبینی جرم
محبوبیت اخیر تحقیقات جرمشناسی مکان همراه با پیشرفتهای فنآوری قرن بیست و یکم، امکان «ادبیات نوپایی از رویکردهای الگوریتمی به پیشبینی نقطه داغ جرم خاص زمان و مکان» را فراهم کرد [ 26 ] (ص. 323)، جایی که Big داده ها باید به عنوان «ابزار جدید عمیق ادراک اجتماعی» [ 37 ] (ص. 7) شناخته شوند. در چند سال اخیر این موضوع حتی شدیدتر شده است. رویکردهای یادگیری ماشین به طور گسترده ای در زمینه های مختلف مانند علوم شهری، حمل و نقل و پیش بینی جریان عابر پیاده، مراقبت های بهداشتی، زیست شناسی، باستان شناسی، امور مالی و حتی هنر استفاده شده است [ 38 ، 39 ]. آنها برای نظارت بر فعالیت های غیرقانونی استفاده شده اند [ 40 ، 41] و مدل سازی و پیش بینی جرم، با نویسندگان اغلب روش های مختلف [ 42 ، 43 ، 44 ، 45 ، 46 ].
به عنوان مثال، لین و همکاران. [ 42 ]، که در تایوان کار می کرد، یک روش مبتنی بر داده مبتنی بر نظریه پنجره های شکسته را برای پیش بینی کانون های جرم و جنایت در حال ظهور، بهبود عملکرد مدل با انباشت داده ها با مقیاس های زمانی مختلف، پیشنهاد کرد. از همه روشهای آزمایششده، الگوریتمهای یادگیری عمیق، جنگل تصادفی و بیز ساده پیشبینیهای بهتری ارائه کردند. برای ژانگ و همکاران. [ 43]، با این حال، نتایج بر اساس داده های جرم تاریخی و استفاده از نقاط مورد علاقه محیط ساخته شده و تراکم شبکه جاده های شهری به عنوان متغیرهای کمکی برای بهبود عملکرد، نشان می دهد که مدل حافظه کوتاه مدت یادگیری عمیق (LSTM) بهتر از سایرین عمل می کند. در مطالعه اخیر دیگری در مورد الگوهای فضا-زمان سرقت در منهتن، جایی که یک نمونه اولیه کاربردی برای جستجوی پارکینگ ایمنتر ایجاد شد، Matijosaitiene و همکاران. [ 44 ] کشف کردند که مدل های خطی بهتر عمل می کنند. پینتو و همکاران با مقایسه پنج ناحیه شهر نیویورک. [ 45 ] همچنین نشان داد که رگرسیون خطی چند متغیره دقت بهتری در پیشبینی نوع جرم ارائه شده به دست میدهد، اما درختهای تصمیم در پیشبینی ناحیه محل وقوع جرم بهترین بودند.
چنین یافتههایی باید به این معنا باشد که در نظر گرفتن شرایط مکان خاص، به جای محاسبات جهانی (یک روش برای همه رویکردها)، باید استفاده از این الگوریتمها را هدایت کند. در واقع، نویسندگان از روشهای یادگیری ماشینی برای استخراج دانش و پیشبینی روند دادههای جرم با عوامل اجتماعی، شهری و اقتصادی مبتنی بر مکان استفاده کردهاند. میتال و همکاران [ 46 ]، برای مثال، از یادگیری ماشینی در زمینه هندی برای پیشبینی علیت بین نرخ جرم، مانند دزدی، سرقت و دزدی، با شاخصهای اقتصادی استفاده کرد و در آن مورد مشاهده کرد که بیکاری بزرگترین متغیر توضیحی است.
همچنین ادغام این مدلها با تجزیه و تحلیل فضایی با استفاده از سیستمهای اطلاعات جغرافیایی (GIS)، به عنوان راهی برای شفافسازی الگوهای فضا-زمان، کشف عوامل تعیینکننده فضایی و به طور کلی بهبود رویکرد نقطه داغ جغرافیایی و مکانمحور جرمشناسی مدرن است. محل. به عنوان مثال، بوگومولوف و همکاران. [ 47 ] از دادههای کلان رفتاری جمعآوری شده از تلفنهای همراه در ترکیب با اطلاعات اولیه جمعیتشناختی برای پیشبینی اینکه آیا مناطقی در لندن مستعد تبدیل شدن به کانون جرم و جنایت هستند یا خیر، با دقت 70% استفاده کردند. آزمایشات ژو و همکاران [ 48] با استفاده از رویکرد ترکیبی از الگوریتمهای غیرخطی، درختهای تصمیمگیری افزایش گرادیان (GBDT) و مدلهای GIS، به نتایج مشابهی دست پیدا میکنند، و نرخهای کارایی و دقت بالا را آشکار میکنند تا تأثیر بیش از هزار عامل از جمعیت، مسکن، تحصیلات را ارزیابی کنند. ، اقتصاد، اجتماعی و شهرسازی. GBDT، در این مورد، بهتر از روشهای دیگر مانند رگرسیون لجستیک (LR)، ماشینهای بردار پشتیبان (SVM)، شبکههای عصبی مصنوعی (ANN) یا جنگل تصادفی (RF) عمل کرد.
چنین مدلهای پیشبینی جرم خاص منطقه، مانند Boni و همکاران. [ 49 ] که آنها را نام بردند، باید عدم تجانس جغرافیایی الگوهای جرم و جنایت را تشخیص دهند، چیزی که با قانون تمرکز جرم ویزبورد [ 50 ] مطابقت دارد. در مورد Boni، یادگیری آماری سلسله مراتبی و چند وظیفهای برای پیشبینی جرایم در سطح کد پستی، از طریق مدلهای محلیسازی شده که در آن پراکندگی با اشتراکگذاری اطلاعات در مناطق کاهش مییابد، استفاده شد. برای مثال، ژانگ و همکاران، پیشبینی مکانی-زمانی از طریق رمزگذاری رویدادهای جرم خاص منطقه نیز اعمال شد. [ 51 ] و باپی و همکاران. [ 52]، نتایجی را مطابق با قانون Weisebud نشان می دهد. اولین مورد از روشهای آماری مبتنی بر هیستوگرام، تجزیه و تحلیل متمایز (LDA) و K-نزدیکترین همسایهها (KNN)، مقایسه الگوها با ویژگیهای همسایگی و فاصله زمانی تا تعطیلات مهم استفاده کرد و با تنظیم دقیقتر دادههای زمانی، عملکرد بیشتری را مشاهده کرد. دومی از خوشهبندی فضایی مبتنی بر چگالی سلسله مراتبی برنامهها با نویز (HDBSCAN) برای استخراج نقاط داغ از کانونهای جرم برای دستههای مختلف جرم و سپس محاسبه فاصله فضایی بین مرکزهای خوشهای (یعنی نقاط داغ کانونهای جرم) به عنوان ویژگی برای طبقهبندیکنندهها استفاده کرد. . در این مورد LR و SVM دقت بیشتری نسبت به RF نشان دادند. مانند نتایج تجزیه و تحلیل فضایی، این نتایج مربوط به منطقه خاص و مبتنی بر فضا از یادگیری ماشینی را می توان تا حدی نمایش داد،53 ].
نکته دیگری که مورد بحث است، چگونگی گنجاندن دادههای غیرساختیافته مربوط به ادراکات، روالها و احساسات کلی ساکنان شهر است. فراتر از نظرسنجی ها، تحقیقات به طور فزاینده ای به داده های تلفن همراه به عنوان پروکسی برای الگوهای فعالیت [ 47 ، 54 ] و همچنین به طور گسترده در رسانه های اجتماعی، ایجاد تجزیه و تحلیل احساسات، یعنی بر اساس احساسات ناشی از مطالعه پیام های فردی، توجه کرده است. بسیاری از اینها به دلیل استفاده قابل توجه در بسیاری از کشورها، در دسترس بودن رایگان داده ها و این واقعیت که توییت ها اغلب با مختصات مکانی و زمانی مرتبط هستند، از داده های توییتر به عنوان منبع استفاده کرده اند [ 55 ، 56 ، 57 ، 58 ، 59 .]. در ایالات متحده، گربر [ 55 ] نشان داد که چگونه استفاده از دادههای توییتر، از طریق تجزیه و تحلیل زبانی و مدلسازی موضوع آماری، عملکرد مدلهای پیشبینی را برای 19 نوع از 25 نوع جرم، در مقایسه با رویکرد درون یابی استاندارد بر اساس تراکم هسته، بهبود بخشید. برآورد کردن. در هند، Thanh و همکاران. [ 56 ] دریافتند که تجزیه و تحلیل احساسات مبتنی بر دادههای توییتر به نتایجی منتهی شد که با دادههای نرخ واقعی جرم مطابقت داشت، در حالی که وانگ و همکاران. [ 57 ] نشان میدهد که چگونه مدلی شامل تحلیل معنایی خودکار پستهای توییتر همراه با کاهش ابعاد و پیشبینی از طریق مدلسازی خطی از مدلهای پایه بهتر عمل میکند. با استفاده از دادههای توییتهای مجرمانه، Siriaraya و همکاران. [ 58] همچنین از تحلیل احساسات برای کشف ویژگیهای منفی مناطق فضایی مرتبط با جرایم مختلف استفاده کرد و مجدداً بر ارتباط یک پایه جغرافیایی در چنین تحلیلی تأکید کرد.
برخلاف تحلیل احساسات، نمونههای زیادی یافت نشد که از مدلسازی موضوعی بر روی دادههای مرتبط با جرم استفاده کرده باشند [ 60 ، 61 ]. این روش از تکنیک های آماری یادگیری ماشین برای شناسایی الگوها (به عنوان یک توصیف شفاهی) در یک مجموعه یا مقدار زیادی از متن بدون ساختار استفاده می کند. به عنوان مثال، Pandey و همکاران. [ 60 ] گزارش های جرم و جنایت از لس آنجلس را تجزیه و تحلیل کرد و انسجام موضوع را در برابر تمرکز فضایی در آزمون قانون تمرکز جرم ارزیابی کرد. یافتههای آنها نشان میدهد که تخصیص دیریکله نهفته (LDA) موضوعات مرتبط با جرم و جنایت را با انسجام و غلظت جرم بالاتر ایجاد میکند، در حالی که فاکتورسازی ماتریس غیرمنفی (NMF) انسجام را بهبود میبخشد، اما غلظت فضایی آنچنان بالا نبود.
همانطور که بنیستر و همکاران. [ 26 ] نشان میدهد، مطالعاتی مانند اینها همگی دارای محدودیتهای دادهای مربوط به بازنمایی دادههای رسانههای اجتماعی هستند، اما همچنین در ارتباط با دقت دادههای جرم جغرافیایی و زمانی مورد استفاده قرار میگیرند [ 62 ]. تحقیقات بیشتری در مورد مدلهایی مورد نیاز است که میتوانند با استفاده از GIS و دادههای رسمی جرم جغرافیایی-زمانی، با پیشرفت در تکنیکهای یادگیری ماشین و دادهکاوی، از تحلیلهای مکانی دقیق عبور کنند.
3. داده ها و روش ها
3.1. زمینه مطالعه موردی
مطالعه موردی این تحقیق شهر پورتو در پرتغال می باشد. دومین شهر کشور، پس از پایتخت لیسبون، پورتو خانه حدود 240000 نفر است [ 63 ]. تشخیص های اخیر، پورتو را به عنوان یکی از شهرهایی با بالاترین میزان جرم و جنایت در پرتغال معرفی کرده است که به ویژه جرایم علیه اموال (مانند سرقت خودرو، جیب بری، سرقت از ساختمان ها) را ثبت می کند. علیه مردم (به ویژه تمامیت جسمانی بلکه خشونت خانگی، تهدید یا اجبار)؛ جرایم علیه جامعه (مانند جعل یا رانندگی در حالت مستی) و جرایم متفرقه (مانند قاچاق مواد مخدر) [ 27 ] (ص 64). به عنوان یک مقصد گردشگری اصلی در اروپا، این کشور همچنین مستعد افزایش جرایم خیابانی غیرخشونت آمیز در ماه های تابستان است [ 31 ]]. تعداد کل جرایم ثبت شده در سال در طول دهه گذشته در پورتو تا حدودی کاهش یافته است (از حدود 16 به 14 هزار)، اما این شهر همچنین ساکنان خود را به حومه های پیرامونی از دست داده است که منجر به تعداد کم و بیش ثابت 65 رویداد جنایی شده است. در هر هزار نفر جمعیت [ 64 ].
3.2. منابع اطلاعات
دادههای جرم مورد استفاده در این مطالعه، دادههای محرمانهای هستند که توسط پلیس ایمنی عمومی پورتو به طور هدفمند در اختیار تیم تحقیقاتی قرار گرفتهاند، زیرا تنها دادههای جرم عمومی در دسترس در پرتغال، کل دادههای شهرداری است. این مجموعه داده محدود و بدون ارجاع جغرافیایی شامل یک صفحه گسترده است که توسط پلیس گردآوری شده است که شامل تاریخ، ساعت، نوع شناسی، محله و نام خیابان همه جرایم گزارش شده در داخل محدوده شهر بین ژانویه 2016 تا دسامبر 2018 می باشد. به حدود 42 هزار ورودی. تنها 4 درصد از داده ها اطلاعات کافی برای ارجاع جغرافیایی نداشتند. بقیه، پس از تمیز کردن گسترده پایگاه داده (عمدتاً نام خیابان ها، که یکپارچه نبودند)، توسط تیم تحقیقاتی در بخش های خیابان، با در نظر گرفتن تقسیمات محله، ارجاع جغرافیایی شد.
سایر مجموعههای داده شامل دادههای سرشماری، بهدستآمده از موسسه آمار ملی پرتغال [ 63]، گزارش از آخرین سرشماری جمعیت یا داده های جدیدتر، در صورت وجود. این شامل بیش از 150 شاخص در سطح بلوک شهری، مربوط به داده های ساختمان (مانند نوع ساختمان، سن و نوع کاربری) بود. داده های مسکن (مانند اندازه، نوع شناسی، شرایط و اشغال)؛ داده های جمعیت (مانند سن، جنس یا تحصیلات)؛ داده های خانواده (نوع، اندازه، تعداد فرزندان) و داده های شغلی. داده های شهری و کاربری زمین یا از منابع رسمی شهرداری پورتو یا نقشه خیابان باز در زمانی که نقشه اول در دسترس نبود، بازیابی شد. این شامل کاربری زمین و نقاط مورد علاقه است. اتصال، شبکه جاده و داده های سیگنال ترافیکی؛ و همچنین محل استقرار کلانتری ها و دوربین های مداربسته.
توییتها برای مدلسازی موضوع و تحلیل احساسات با استفاده از Snscrape [ 65 ] استخراج شدند. شعاع 1 کیلومتری از تمام نقاط داده جرم برای استخراج توییت ها در نظر گرفته شد و مجموعه خاصی از اصطلاحات مربوط به جرم در انگلیسی و پرتغالی جستجو شد. بر اساس تجزیه و تحلیل ادبیات، مجموعه ای از اصطلاحات مرتبط با جرم تهیه شد. این فهرست شامل بیش از پنجاه اصطلاح مرتبط با جرم است.
3.3. روش شناسی
سه نوع روش روش شناختی برای شناسایی الگوی جرم در شهر، پیشبینی میزان جرم و سپس پیشبینی جرم بهصورت رخداده/عدم وقوع استفاده شد. اینها تجزیه و تحلیل جغرافیایی، مدلسازی یادگیری ماشین و پردازش زبان طبیعی (NLP) بودند.
برای درک الگوهای جرم و جنایت، ابزارهای تحلیل فضایی با استفاده از ArcGIS 10.7.1 روی مجموعه داده اعمال شد. پس از ادغام همه مجموعه داده ها و پیش پردازش و پاکسازی مجموعه داده ادغام شده نهایی، ورودی های جرم با در نظر گرفتن مختصات خیابان ارجاع داده شدند و سپس با تخمین تراکم هسته (KDE) ترسیم شدند، یک تکنیک درونیابی که اغلب در تجزیه و تحلیل جرم استفاده می شود، زیرا نتایج دقیق تری ارائه می دهد. و به راحتی توسط ذینفعان قابل درک است [ 66 ، 67 ]. اگرچه توافق نظر در مورد اینکه کدام پارامترها باید استفاده شود [ 68 ] وجود ندارد، نویسندگان حمایت کرده اند که این یک روش بسیار مفید برای توصیف تغییرات کوچک محلی است [ 69 ]]. به همین دلیل، و همچنین برای اندازه کوچکتر شهرهای پرتغال، اندازه سلول 50 متر آزمایش شد. این کوچکتر از مواردی است که اخیراً در ادبیات نقشه برداری جنایی استفاده شده است، به عنوان مثال 63 متر [ 67 ]، 90 متر [ 70 ] یا 100 متر [ 71 ]، اما مطابق با تحقیقات قبلی برای پرتغال [ 72 ] است. نتایج با افسران پلیس ایمنی عمومی پورتو تأیید شد. تجزیه و تحلیل نقاط داغ بیشتر در حال ظهور انجام شد [ 73 ]، به عنوان مثال، یک تکنیک داده کاوی که نشان می دهد کدام نقاط گرم و سرد در طول مکان و زمان حفظ یا تغییر کرده اند. با در نظر گرفتن اندازه سلول بزرگتر از یک شبکه توری ماهی استفاده شد.
با در نظر گرفتن این اطلاعات، از یک الگوریتم جنگل تصادفی برای پیشبینی مقادیر هر مکان یک مکعب فضا-زمان استفاده شد. این ابزار برای هر مکان در مکعب دو مدل میسازد و سپس مقادیر فاز زمانی آینده را پیشبینی میکند. برازش مدل با مقدار ریشه پیش بینی میانگین مربعات خطا (RMSE) تعیین می شود. زمانی که برای هر مکان مکعب فضا-زمان دو مدل رگرسیون جنگلی تصادفی ساخته می شود، از تکنیک “پنجره” استفاده می شود. مدل از مقادیر واقعی و سپس پیش بینی شده برای پیش بینی مقادیر برای مراحل زمانی آینده استفاده می کند. مدل با RMSE کوچکتر به عنوان بهترین مدل مناسب از بین دو مدل برای هر مکان مکعب فضا-زمان انتخاب می شود.
پس از درک الگوی نقطهای جرایم ثبتشده، تحلیلهای مختلف یادگیری ماشین بر اساس روشهای نظارت شده برای تعیین تأثیر عوامل بافتی شهری، ریختشناسی و اجتماعی-اقتصادی انجام شد. انتخاب متغیر، به منظور انتخاب مناسب ترین زیرمجموعه پیش بینی کننده ها برای مدل، در نتیجه اجتناب از نویز، پیچیدگی و مسائل چند خطی، با استفاده از رگرسیون LASSO (حداقل انقباض مطلق و عملگر انتخاب) [ 74 ] انجام شد.]. سپس، برای مدلسازی جرم، که در آن نرخ جرم به یک هدف دوتایی تبدیل شد – 0 در صورت عدم وقوع جرم و 1 در صورت وقوع حداقل یک جرم – از چهار روش طبقهبندی مختلف برای پیشبینی کلاسهای جرم 0 “بدون جرم رخ نخواهد داد” یا 1 استفاده شد. “حداقل یک جنایت رخ خواهد داد”. رگرسیون لجستیک اول، که در آن از تابع سیگموئید برای ترسیم پیشبینیها به احتمالات استفاده میشود، که در آن جریمه L-1 برای انجام انتخاب متغیر اضافه میشود (یعنی از بین تعداد زیادی متغیر اولیه، فقط مهمترین متغیرهای جرم را انتخاب میکند). که ضرایب متغیرهای کمتر کمک کننده را به صفر کاهش می دهد. دوم، درختان تصمیم، یک روش یادگیری نظارت شده ناپارامتریک که در آن یک مدل با تقسیم سوابق دادهها ساخته میشود تا زمانی که همه یا بیشتر رکوردها به برچسبهای کلاس مربوطه خود 0 «هیچ جرمی رخ نخواهد داد» یا 1 «حداقل یک جرم رخ خواهد داد» طبقهبندی میشود. درختان تصمیم با “هرس” برگ ها و شاخه های مسئول طبقه بندی اعمال می شوند.75 ] برای جلوگیری از برازش بیش از حد مدل مبتنی بر درخت. برازش بیش از حد زمانی اتفاق میافتد که مدل الگوهای بسیار خوبی را در دادههای آموزشی یاد میگیرد و بنابراین، عملکرد مدل بالایی را در دادههای آموزشی نشان میدهد. با این حال، قادر به تعمیم الگوهای آموخته شده بر روی یک داده جدید نیست. سوم، جنگل تصادفی، که در آن تعداد زیادی درخت تصمیم گیری منفرد، ساخته شده از نمونه های گرفته شده از مجموعه آموزشی، در نظر گرفته می شوند، که هر کدام یک کلاس را پیش بینی می کنند و سپس یک روش مجموعه ای، کلاسی را که بیشترین رای را دارد به عنوان پیش بینی مدل تعیین می کند. 76 ، 77]. برای ساخت و آموزش مدل جنگل تصادفی، علاوه بر انتخاب تصادفی نمونههای بوت استرپ، یک تقسیم تصادفی روی ویژگیها نیز انجام میشود. چهارم، ماشین بردار پشتیبان (SVM)، که هدف آن اختصاص ابرصفحه هایی است که به طور خاص نقاط داده را طبقه بندی می کنند، به عنوان مثال، آنهایی که بیشترین تفاوت را بین نقاط داده در هر دو گروه دارند [ 78 ].
در نهایت، از دو روش پردازش زبان طبیعی، مدلسازی موضوع و تحلیل احساسات استفاده شد. اولی، از طریق تخصیص دیریکله پنهان (LDA) [ 79 ]، متن را در یک سند به یک موضوع خاص طبقه بندی می کند. برای هر سند d ، هر کلمه w را پردازش می کند و p (موضوع t | سند d ) را محاسبه می کند ، یعنی نسبت کلمات موجود در سند d که به مبحث t اختصاص داده شده اند . سپس p (کلمه w |موضوع t )، یعنی نسبت تکالیف به مبحث t بر تمام اسنادی که از کلمه w می آیند.. از سوی دیگر، تحلیل احساسات متن را برای شناسایی و استخراج اطلاعات ذهنی مرتبط با احساسات مثبت یا منفی استخراج می کند [ 80 ]. یک رویکرد این است که از یادگیری ماشین و عملکردهای مختلف برای ساختن طبقهبندیکنندهای استفاده کنیم که بتواند متن احساسی را تشخیص دهد. مورد دیگر، که شامل آموزش داده نمیشود، مبتنی بر واژگان است و از اصطلاحات مختلفی استفاده میکند که با امتیاز قطبیت مشروح شدهاند. هر دو رویکرد را می توان در یک رویکرد ترکیبی سوم ادغام کرد. اگرچه در این تحقیق از دو روش LDA و تحلیل احساسات به طور جداگانه به عنوان افزودنی های ارزشمند به یکدیگر استفاده شده است.
4. الگوی جنایت پورتو بین سال های 2016 و 2018
4.1. الگوی آماری
بین سالهای 2016 و 2018، سوابق رسمی پلیس حاوی کمی بیش از 42 هزار ورودی است که از این تعداد حدود 1600 مورد (3.8٪) به دلیل کمبود اطلاعات در ثبت احوال یا در مورد جرمی که قربانی در آن است، نمیتواند در سطح خیابان ارجاع داده شود. نمی تواند مکان دقیق را بداند (به عنوان مثال، سرقت کیف پول). مجموع جرایم ثبت شده اندکی افزایش یافته است، از حدود 13 هزار در سال 2016، به 14 هزار در سال 2017 و به حدود 14500 در سال 2018. مطابق با گرایش های ملی گزارش شده در جاهای دیگر [ 27 ]]، در پورتو رایج ترین انواع جرایم جرایم علیه میراث/اموال (64٪؛ از جمله به عنوان زیرمجموعه های اصلی سرقت خودرو و سرقت کیف پول) و جرایم علیه مردم (18٪؛ از جمله تخلف علیه تمامیت جسمانی، خشونت خانگی یا تهدید و اجبار). به دنبال آن جرایم علیه زندگی در جامعه (مانند رانندگی در حالت مستی یا قاچاق اسلحه) و جرایم متفرقه (مانند قاچاق مواد مخدر یا رانندگی بدون گواهینامه) وجود دارد. هر کدام حدود 8 درصد سایر انواع جرایم، علیه هویت فرهنگی، علیه حیوانات خانگی یا علیه دولت، کمتر از 2 درصد است.
در طول روز ( شکل 1 الف)، وقوع جرم به تدریج از ساعت 8 صبح به بعد افزایش می یابد، بین ساعت 6 بعد از ظهر تا 8 بعد از ظهر به اوج خود می رسد، سپس دوباره به تدریج کاهش می یابد، که نشان می دهد غروب ها بیش از هر زمان دیگری از روز در معرض جرم و جنایت هستند. در طول سال ( شکل 1 ب)، تعداد کلی جرایم ثبت شده در هر ماه نسبتا ثابت است (بین 3200 تا 3700)، با بالاترین اعداد بین ماه مه و سپتامبر، چیزی که مطابق با ارزیابی های قبلی کشور است [ 31 ].]. روزهایی که کمترین جنایات گزارش شده مربوط به جشن های کریسمس و سال نو (20، 25 و 31 دسامبر و 2 ژانویه) است، در حالی که بیشترین تعداد جرایم گزارش شده مربوط به تعطیلات دیگر است: 24 ژوئن، روز تعطیلات شهرداری پورتو در شب 23) یا 1 نوامبر، یک تعطیلات مذهبی جشن گرفته می شود.
4.2. الگوی مکانی و زمانی
شکل 2یک KDE را برای پورتو، بر اساس مقادیر بخشهای خیابان نشان میدهد. قانون تمرکز جرم تایید شده است، زیرا بخش ها و مناطق خاصی از شهر بیش از سایرین مستعد وقوع جرم هستند. این امر به ویژه در منطقه مرکز شهر (بیشترین تمرکز) در داخل و اطراف خیابان اصلی عابر پیاده/خرید شهر، خیابان سانتا کاتارینا، و میدان اصلی که تالار شهر در آن واقع شده است (خیابان آلیادوس)، هر دو نزدیک به شب شهر اتفاق می افتد. ناحیه. در نقاط دیگر، تمرکز قابل توجهی نیز در لبه شمالی شهر، جایی که بزرگترین پردیس دانشگاه و بیمارستان اصلی شهر واقع شده است، و در خیابان های اصلی دیگر مانند خیابان Boavista (در غرب شهر)، خیابان Campo Alegre (غرب شهر) رخ می دهد. مرکز)، خیابان Constituição (شمال مرکز شهر)،
تجزیه و تحلیل نقطه داغ با در نظر گرفتن سطل فضا-زمان 3 ماهه انجام شد ( شکل 3). مرکز شهر بهعنوان مهمترین نقطه از نظر آماری شهر تأیید میشود، که برای نود درصد یا بیشتر از مراحل زمانی، از جمله مرحله زمانی نهایی (به ترتیب کانون تشدید و پایدار) یک کانون است. مناطق بواویستا و کامپو آلگره دارای مکانهای کانونی متوالی (یک اجرای بدون وقفه از سطلهای هات اسپات آماری قابل توجه در آخرین مراحل زمانی)، یا نقاط پراکنده (مکانی در نقطهای دوباره و سپس خارج از کانون هستند). یک الگوی کانونی پایدار کوچک در شمال در اطراف محوطه بیمارستان/دانشگاه مشاهده می شود. نکته قابل توجه منطقه پراکنده و به ویژه کانون جدید (یعنی مکانی که از نظر آماری یک کانون مهم برای مرحله زمانی نهایی است و قبلاً هرگز از نظر آماری کانون مهم نبوده است) در غرب مرکز شهر در اطراف وسط خیابان بواویستا است.
4.3. پیش بینی
با استفاده از خوشهبندی، یک ابزار یادگیری ماشینی بدون نظارت، میتوان الگوهای طبیعی خوشهها را در دادهها شناسایی کرد. برای به دست آوردن خوشه های فضایی جرم با توجه به داده های سرشماری، دومی با داده های جرم و جنایت با استفاده از تکنیک پیوستن فضایی ادغام شد (به عنوان مثال، داده های جرم-سرشماری ادغام شده به عنوان ورودی در الگوریتم خوشه بندی استفاده می شود). سپس تجزیه و تحلیل خوشهبندی DBSCAN انجام شد، که در آن اپسیلون = 533 متر (شعاع بهینه برای تجزیه و تحلیل خوشهای) با روش “زانو” تعریف شد در حالی که فاصله خوشهای را در برابر طیف وسیعی از مقادیر اپسیلون ممکن ترسیم کرد.
سپس برای پیشبینی تعداد جرایم، از ابزار پیشبینی تصادفی جنگل در ArcGIS استفاده شد. با استفاده از توسعه Breiman [ 81 ] از الگوریتم جنگل تصادفی، مدل مقادیر هر مکان مکعب فضا-زمان را پیشبینی میکند، در این مورد در اندازه سلول 500 متر انجام میشود. پیشبینی جنایات برای دوازده ماه پس از مجموعه دادهها، از ژانویه 2019 تا دسامبر 2019 انجام شد . شکل 4 شمارش جرم پیشبینیشده را در مجموعه دادههای آزمایشی دیده نشده نشان میدهد. شمارش جنایات پیشبینیشده از 0 تا 746 در هر مربع متفاوت است، با بیشترین تراکم جرم در مرکز شهر و سپس در امتداد محورهای اصلی همانطور که قبلاً شناسایی شده بود. یک مکان جدید نیز نشان داده شده است.
5. یادگیری ماشینی برای پیش بینی جرم
برای استفاده از روشهای یادگیری ماشین برای پیشبینی جرم، همه مجموعههای داده به صورت مکانی به هم پیوستند: دادههای جرم، دادههای سرشماری درباره ساختمانها، خانهها، جمعیت، دادههای خانواده و شغل، دادههای کاربری شهری و زمین با نقاط مورد علاقه، اتصال، شبکه جادهها و علائم راهنمایی و رانندگی، مکان ایستگاه های پلیس و دوربین های مدار بسته.
5.1. انتخاب ویژگی با رگرسیون کمند
رگرسیون کمند به دادههای جرم پورتو برای انتخاب زیرمجموعهای از پیشبینیکنندهها که از نظر جرم مهمترین هستند، اعمال شد. داشتن پیشبینیکنندههای کمتری که قدرت پیشبینی قویتری دارند، خطای پیشبینی را کاهش میدهد و زمان و منابع محاسباتی را به حداقل میرساند و همچنین از برازش بیش از حد مدل پیشبینی جلوگیری میکند. رگرسیون کمند از جریمه L1 استفاده می کند که اجازه می دهد ضرایب رگرسیون برای پیش بینی های بی اهمیت و کم اهمیت به صفر کاهش یابد. نسبت تمرین و مجموعه تست استفاده شده برای رگرسیون کمند بر این اساس 67% و 33% بود. ضریب رگرسیون مثبت نشان می دهد که با افزایش مقدار متغیرهای پیش بینی کننده، مقدار متغیر پاسخ نیز تمایل به افزایش دارد. در حالی که یک ضریب رگرسیون منفی نشان می دهد که با افزایش متغیر پیش بینی کننده، متغیر پاسخ تمایل به کاهش دارد. متغیرهای «جمعیت با تحصیلات پایین» و «درصد جوانان» دارای ضرایب مثبت هستند و بنابراین با افزایش این متغیرها، میزان جرم و جنایت افزایش مییابد. در حالی که متغیرهای «جمعیت با تحصیلات عالی (مدرک دانشگاهی)»، «خانوادههای مؤسسهای»، «جمعیت فعلی (مرد)»، «مسکنهای خانوادگی کلاسیک محل سکونت معمولی با 1 یا 2 اتاق»، «عمدتا ساختمانهای مسکونی» و وجود دوربین های مداربسته دارای ضرایب منفی هستند و بنابراین با افزایش این متغیرها میزان جرم و جنایت کاهش می یابد.
5.2. طبقه بندی
طبقهبندی یک کار یادگیری ماشینی است که رکوردها را با پیشبینی و تخصیص برچسبها به کلاسها طبقهبندی میکند. روشهای زیادی در طبقهبندی وجود دارد که در این مطالعه از الگوریتمهای طبقهبندی مختلف استفاده شده است. برای اهداف طبقه بندی، هدف، یعنی نرخ جرم، به یک متغیر باینری تبدیل می شود، که در آن 0 به معنای “بدون جرم رخ نخواهد داد” و 1 به معنای “حداقل یک جرم رخ خواهد داد”.
ابتدا، رگرسیون لجستیک با مجازات L1 برای شناسایی متغیرهایی که با جرم به عنوان یک هدف باینری مرتبط هستند، اعمال شد. برای آموزش و آزمایش مدل رگرسیون لجستیک، رکوردهای موجود در مجموعه داده ها به 70 درصد قطار و 30 درصد مجموعه آزمون تقسیم شدند. استفاده از جستجوی شبکهای با اعتبارسنجی متقاطع در طیفی از پارامترهای فوق به ما امکان داد بهترین آلفا = 0.151 را برای مجازات L1 تنظیم کنیم که مهمترین متغیرها را برای حضور جرم گزارش شده انتخاب میکند. «ساختمان های با سازه دیوار در بنایی با صفحه»، «ساختمان های ساخته شده قبل از سال 1919»، «جمعیت فعلی (مرد)»، «ساختمان های ساخته شده بین سال های 1946 تا 1960»، «ساختمان های ساخته شده بین سال های 2006 تا 2011» و دوربین مدار بسته دارای ضرایب منفی و بنابراین، احتمال وقوع جرم را کاهش می دهد. در حالی که “خانه های خانوادگی کلاسیک مسکونی معمولی با 1 یا 2 اتاق”،
برای ساخت مدل طبقهبندی SVM، جستجوی شبکهای با اعتبارسنجی متقاطع بر روی طیف وسیعی از پارامترهای فوق به ما این امکان را میدهد تا بهترین هسته = rbf، پارامتر منظمسازی C = 1 و پارامتر گاما = 0.1 را تنظیم کنیم.
مدلهای پیشبینی جرم نیز با استفاده از درخت تصمیم و جنگل تصادفی با تنظیم فراپارامترها و با استفاده از جستجوی شبکهای با اعتبارسنجی متقاطع و همچنین ماشین بردار پشتیبان ساخته شدند. درخت تصمیم و جنگل تصادفی متغیرهای مهم زیر را شناسایی کردند: «ساختمان ها (کلاسیک)»، «ساکنان دارای دوره اول آموزش پایه» و «جمعیت فعلی (مرد)». مقایسه مدل جدول 1توصیه می کند که جنگل تصادفی بهترین دقت عملکرد مدل = 0.832، فراخوانی = 0.99، دقت = 0.79 و امتیاز F1 = 0.89 را دارد. جنگل تصادفی همچنین مجموعه ای از متغیرهای مهم برای جرم را فراهم می کند. بنابراین، مدل رگرسیون لجستیک مجموعه مفصلی از متغیرهای مهم جرم و تأثیر (مثبت یا منفی) این متغیرها بر جرم را ارائه میکند، اگرچه بر اساس متریک دقیق عملکرد ضعیفی دارد.
5.3. پردازش زبان طبیعی (NLP)
برای تجزیه و تحلیل فعالیت اجتماعی و بعد نظر در رابطه با جرم و جنایت، توییتهایی از توییتر با استفاده از کتابخانه Snscrape، یک سرویس شبکه اجتماعی در پایتون جمعآوری شد. طول و عرض جغرافیایی نقاط داده جرم برای استخراج توییت ها در شعاع 1 کیلومتری اطراف مکان های جرم استفاده شده است. برای تلاش و ارتباط با الگوی جرم، در اولین تکرار آزمایشی، توییتهای مرتبط با کلماتی مانند سرقت، سرقت، آتشسوزی، خرابکاری، خشونت و غیره در انگلیسی و پرتغالی جستجو شد. اینها تنها مقدار کمی از تعداد کل توییتهای موجود در این منطقه را نشان میدهند، که ممکن است نشان دهد کاربران برای گزارش در مورد موضوعات مرتبط با جرم وارد سیستم نمیشوند. در این مورد، حدود 1300 توییت جمع آوری شد که بیشتر آنها در واقع به منابع رسانه ای مرتبط بودند.
در شکل 5 ، این توییتها به صورت فضایی ترسیم شدهاند، و میتوان مشاهده کرد که بیشترین تعداد توییتها در داخل و اطراف مرکز شهر و، بهویژه، در جنوبتر در منطقه تفریحی شبانه Ribeira، مطابق با تداوم و تشدید نقاط داغ جنایات گزارششده قبلی است. شناسایی شده و همچنین مناطقی که بیشترین پیش بینی در آنها بود. همچنین قابل توجه است که غلظت در Campo Alegre (غرب مرکز شهر) و در محله اجتماعی Cerco (شرق مرکز شهر)، مکانهای کانونی موقت نیستند، اما با تراکم جرم قابل توجهی روبرو هستند.
5.3.1. مدلسازی موضوعی (LDA)
مدلسازی موضوعی نوعی مدلسازی آماری است که «موضوعاتی» را که در مجموعهای از اسناد وجود دارد، شناسایی میکند. تخصیص دیریکله نهفته (LDA) روش مدلسازی موضوعی است که در این تحقیق مورد استفاده قرار گرفته است. پس از پاکسازی دادهها (پایهبندی، ریشهسازی و بردارسازی) و تنظیم فراپارامترها با استفاده از جستجوی شبکه و اعتبارسنجی متقاطع، مدل LDA اجرا شد و مقدار احتمال Log 56491- و گیجی 134.68 محاسبه شد. موضوعات با وزن های مختلف توییت ها محاسبه شد ( شکل 6و از این موضوعات، نگرانی های ساکنان قابل درک است. هر چه وزن بیشتر باشد، کلمه در کلمه ابر بزرگتر است. همانطور که در بالا مشاهده شد، مردم عادی ممکن است مستقیماً در مورد جرم توییت نکنند. به نظر می رسد روزنامه ها بیشتر این کار را در پورتو انجام می دهند. بنابراین کلماتی مانند دزدی، دزدی، باطری، خشونت در تاپیک ها زیاد دیده نمی شود. برعکس، کلمات دیگری که بیشتر با احساس ناامنی مرتبط هستند، از جمله جنایت، پلیس، دستگیری پلیس، زندان، قتل، نفوذ، افراد یا جراحت، در موضوعات مربوطه خود اهمیت بالایی دارند (برخی از موضوعات غیرمثل “thcmbzzbo” یا “mgruq” در این شکل ظاهر می شود. این می تواند از املای نادرست یا “زبان شخصی” استفاده شده در توییت ها مشتق شود. اگر اصطلاحی معنی ندارد و مخفف یا اصطلاح عامیانه شناخته شده نیست، در طول پیش پردازش متن حذف شده است).
5.3.2. تحلیل احساسات
تحلیل احساسات، استخراج متنی است که اطلاعات ذهنی از احساسات/عقیده را که می تواند مثبت یا منفی باشد، شناسایی و استخراج می کند. برای این تحلیل از روش مبتنی بر واژگان AFINN استفاده شد. AFINN لیستی از کلمات است که برای ظرفیت با عدد صحیح بین منهای پنج (منفی) و به علاوه پنج (مثبت) رتبه بندی شده اند. شکل 7 ابر کلمه ای از احساسات مثبت و منفی موجود در تحلیل توییتر را نشان می دهد. توییتهایی که شامل کلماتی مانند عشق، خدا، برد، کتاب یا عالی هستند در مثبتترین احساسات فرکانس بالایی دارند، در حالی که توییتهایی مانند زندان، محکوم، کشتهشده و توهینآمیز بیشترین احساسات منفی را ایجاد میکنند.
شکل 8 نشان می دهد که توییت ها عمدتاً دارای احساسات منفی (مقادیر منفی) هستند، مطابق با آنچه در بالا مورد بحث قرار گرفت. منفی ترین بخش ها در واقع کمی خارج از نقاط اصلی جرم و جنایت ثبت شده در مرکز شهر، در جنوب شرقی (در محله های فونتینها و کامپو 24 د آگوستو) و در شمال غربی (در اطراف استادیوم اصلی فوتبال شهر) توییت می شوند. احساسات منفی نیز در وسط خیابان Boavista، به سمت غرب، کانون جدید دیده می شود. برعکس، مثبت ترین احساسات (2 که حداکثر در مقیاس [-5؛ 5] یافت می شود) در مناطق غیر جرم و جنایت، مانند منطقه لردلو، منطقه تجاری/صنعتی شمال غرب و اطراف پارک شهر شرقی، واقع شده است. در حاشیه شرقی شهر
6. بحث و نتیجه گیری
تکامل مستمر در 20 سال گذشته ظرفیت نقشهبرداری و مدلسازی فناوریهای مکانی، توانایی بیسابقهای برای درک روابط بین جرم و مکان را فراهم کرده است. این امر به طور قطع بر ارتباط جرم شناسی زیست محیطی به عنوان یک رشته و کمک های فوری آن به تصمیم گیری در زمینه پیشگیری، مدیریت شهری و حمایت از سیاست های انسجام و کیفیت زندگی (به معنای عام) و همچنین از نظر پلیس تاکید کرده است. و برنامه ریزی در مقیاس خرد (به معنای خاص تر). متفق القول شده است که روش های داده محور [26; 46] به طور موثر به کاهش ناامنی (واقعی و درک شده) کمک می کند، و در این میان، ادراک جغرافیایی از الگوها بسیار مهم است [ 82 ].
از یک طرف، جرم و جنایت الگوهای متمرکز و به طور کلی پایدار را در طول زمان نشان می دهد، که برای پورتو مفاد قانون تمرکز جرم ویزبورد [ 50 ] را تایید می کند.] و اصول فضایی جرم شناسی محیطی. تمرکز اصلی در ناحیه مرکز شهر رخ میدهد، که به مناطق کانونی پایدار، متوالی اما در حال تشدید تقسیم میشود، در حالی که سایر غلظتهای کوچکتر نیز مشخص شدهاند، از جمله مکان کانون جدید. پیشبینی تعداد جرایم، با نشان دادن این محورها بهعنوان محورهایی با پتانسیل بالاتر برای وقوع و همچنین کشف مکانهای دیگری که ممکن است روند صعودی را نشان دهند، این روند را دنبال میکند. همراه با درک زمانی (اوج در اواخر بعد از ظهر، و افزایش ماه مه تا سپتامبر) این می تواند در تخصیص منابع و در ایجاد برنامه های پیشگیری بسیار مرتبط باشد.
بدیهی است که این تجزیه و تحلیل با استفاده از دادههای پیش از همهگیری، تنها نوع موجود در زمان نگارش، انجام شده است، بنابراین پیشبینی جرم در مرحله بعد و مقایسه با مقادیر واقعی به منظور ارزیابی بیشتر کارایی این مدل انجام خواهد شد. با این حال، همانطور که توضیح داده شد، مدل با استفاده از 30 درصد از دادههای دست نخورده برای مقایسه با واقعیت اصلی اعتبارسنجی شد، و به نظر میرسد که هم با روندهای مورد انتظار و هم با دیدگاههای ذینفعان پلیس از قلمرو که در طول این تحقیق مورد مشورت قرار گرفتهاند، مطابقت دارد. . بهعلاوه، دادهها توسط گزارش خود جرم سوگیری دارند (همه جرایم گزارش نمیشوند)، و همه جرایم از همه نوعشناسی در پیشبینی و در کانون در نظر گرفته شدند. بنابراین تجزیه و تحلیل دقیق بر اساس دسته بندی جرم نیز برای برآوردن نیازهای مختلف برنامه ریزی و پیشگیری از اهمیت بالایی برخوردار است. همانطور که توسط نویسندگان دیگر بحث شده است [83 ]، تحلیل جغرافیایی الگوهای جرم مشروط به سطح جغرافیای مورد استفاده و نحوه ارائه اطلاعات مکانی جرم و جنایت، در این مورد تنها توسط بخشهای خیابانی است که در برخی مکانها نیز نشان داده شده است که عملکرد بدتری نسبت به طبیعی دارند. خیابان ها در تبیین وقایع جنایی [ 15]. در واقع، Space Syntax اغلب در پیشبینی جرم مورد استفاده قرار گرفته است و میتواند در تحقیقات آینده برای آزمایش بیشتر یا بهبود نتایج ارائه شده در اینجا مورد استفاده قرار گیرد. علاوه بر این، نمایش بصری الگوهای جرم، به عنوان مثال در تخمین تراکم هسته، به تنظیمات پارامتر، به عنوان اندازه سلول و باند فاصله بسیار حساس است. با این حال، تکرار اولیه انجام شده در این مقاله اهمیت مدلسازی آماری و فضایی را آشکار کرده است، زیرا مبتنی بر دانشی است که اغلب در اختیار مؤسسات نیست، اما در عین حال نتایجی را تولید میکند که به راحتی با آن ارتباط برقرار میکند، قابل درک است و قابل درک است. تایید شده توسط ذینفعان ثابت شده است که مشارکت های فرا رشته ای با دانشگاه ها و مراکز تحقیقاتی می تواند سنگ بنای پلیس اطلاعاتی و مکان محور باشد.
با این وجود، از سوی دیگر، اگرچه نقشهبرداری جرم با پشتیبانی ترکیبی از تحلیلهای جغرافیایی و آماری ضروری است [ 84 ، 85 ]، نویسندگان خواستار تجمیع هوشمندتر دادهها [ 86 ] هستند، به عنوان مثال، یک رویکرد یکپارچه و کل نگر که شامل موارد اضافی، گاهی اوقات منابع داده های غیرساختارمندی که منعکس کننده بافت اقتصادی، مورفولوژیکی، اجتماعی، ادراکی یا فرهنگی مناطق شهری برای بهینه سازی بهتر سیاست های پیشگیری، برنامه ریزی و انسجام هستند [ 87 ، 88 ، 89 ]]. در این تحقیق، روشهای یادگیری ماشینی، مانند درخت تصمیم و جنگل تصادفی، همسو با رگرسیون کمند، این ابعاد را با هم ترسیم کردند و متغیرهایی را نشان دادند که از نظر مکانی و آماری، به نظر میرسد که قرابت بیشتری با افزایش نرخ جرم گزارششده دارند. اینها شامل درصد جمعیت با سطح تحصیلات پایین و درصد جوانان است. برعکس، مکانهایی که دارای نرخهای بالاتر جمعیت با مدرک دانشگاهی، دوربینهای مداربسته بیشتر و تعداد مردان بیشتری در جمعیت هستند، به نظر میرسد ارتباط کمتری با میزان جرم و جنایت دارند. تراکم ساختمانی و تمرکز خانه ها بسته به روش می تواند به عنوان یک کاتالیزور برای و علیه نرخ جرم ظاهر شود. با این حال، حتی اگر مدل پیشبینی تصادفی جنگل بهترین نتایج عملکرد را نشان داد (یادآوری = 0.99 و دقت = 0.79)،
به طور کلی، این نتایج با تحقیقات قبلی مطابقت دارد. تراکم بیشتر، محلههای قابل پیادهروی، تحصیلات عالی و مرد بودن با ترس کمتری از جرم مرتبط است، در حالی که ویژگیهای خانه یک رابطه صریح را نشان نمیدهند [ 90 ]. جمعیت خیابان به طور قوی و مثبت با جرم و جنایت، به ویژه زنان، مرتبط است، همانطور که آسیب های متمرکز در سطح جامعه [ 89 ] و حضور نوجوانان پرخطر [ 91 ] وجود دارد.]. این مطالعات همچنین توجه به متغیرهای اثربخشی جمعی را جلب می کند. این به طور مستقیم در این تحقیق مورد بررسی قرار نگرفت، اما مدلسازی موضوعی (LDA) دادههای توییتر، اگرچه این دادهها از نظر کاربران، مضامین و اندازه اطلاعات نیز محدود هستند (و از این رو نمیتوان آنها را به عنوان یک جایگزین کلی برای نظرسنجیها در نظر گرفت. مصاحبهها و کارگاههای آموزشی با ساکنان) توانست راهی سریع برای ایجاد اولین تکرار از احساس ساکنان در مورد شهر ارائه دهد. همانطور که انتظار می رفت، احساسات عمدتاً در بحث ناامنی منفی است، نزدیک به مناطق با نرخ بالاتر جرم گزارش شده (مرکز شهر و بواویستا) اما همچنین مناطقی که به شدت مورد انگ هستند و توجه رسانه ها را جلب می کنند (مانند محله اجتماعی Cerco) . کلماتی مانند “پلیس”، “قتل”، “جراحت” یا “کشته شده” احساسات منفی را در این مکان ها نشان می دهد.
چنین یافتههایی به وضوح اهمیت مدلهای توضیحی و پیشبینیکننده را در حمایت از تصمیم نشان میدهند و ممکن است تعریف سیاستهای مکان خاص را هدایت کنند، اما باید با احتیاط به آنها نزدیک شد. ظرفیت تجزیه و تحلیل الگوی بینشی است و قطعاً باید بخشی از تشخیص و نظارت منطقه باشد. با این حال، تحقیقات نباید به همین جا ختم شود، و وابستگی به داده های بزرگ نیز در صورت از بین رفتن معنی، “خطرات” بزرگی را پنهان می کند [ 26 ]]. اول به این دلیل که همبستگی به معنای علیت نیست، و دوم، زیرا همانطور که در بالا بحث شد، از آنجایی که مکانهای مقیاس خرد سیستمهای پیچیده شهری و اجتماعی هستند، متغیرهای مهم مرتبط با مسائل شخصی و ادراکی (مثلا آنهایی که به کارایی جمعی یا فضای قابل دفاع مربوط میشوند) ممکن است در محاسبات گم شود یا اصلاً محاسبه نشود. الگوریتمها و روشهای جهانی باید با مدلسازی و درک فضایی عمیقتر جایگزین شوند و نتایج مدل باید موضوع نقد باشد. پس از شناسایی نقاط داغ، مرحله دوم تجزیه و تحلیل باید عمیقتر به فضای شهری بپردازد و به دنبال محسوس و ناملموس باشد و درک کند که چگونه متغیرهای قابل اندازهگیری در مقیاس خرد همبستگی دارند، اما همچنین به بررسی موارد غیرقابل اندازهگیری فوری، به عنوان تیمهای پلیس جامعه یا CPTED. در دهه های اخیر انجام داده اند.
منابع
- سازمان همکاری اقتصادی و توسعه. زندگی چطوره؟ انتشارات OECD: پاریس، فرانسه، 2020. [ Google Scholar ]
- منطقه من، اروپای من، آینده ما – گزارش هفتم در مورد انسجام اقتصادی، اجتماعی و سرزمینی . کمیسیون اروپا: لوکزامبورگ، 2017.
- برانتینگهام، PL; Brantingham، PJ پیشگیری از جرم موقعیتی در عمل. می توان. J. Criminol. 1990 , 32 , 17. [ Google Scholar ] [ CrossRef ]
- اندرسن، کارشناسی ارشد جرم شناسی محیطی: تکامل، نظریه و عمل . Routledge: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- ویزبرد، دی. اک، جی. براگا، آ. Telep، CW; Cave, B. Place Matters: Criminology for the Twenty and First Century ; انتشارات دانشگاه کمبریج: نیویورک، نیویورک، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- ورتلی، آر. تاونزلی، ام. جرم شناسی محیطی و تجزیه و تحلیل جرم ؛ Routledge: نیویورک، نیویورک، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- لایتنر، ام. مدلسازی جرم و نقشهبرداری با استفاده از فناوریهای جغرافیایی ؛ Springer Science & Business Media: برلین، آلمان، 2013. جلد 8. [ Google Scholar ]
- چینی، اس. Ratcliffe, J. GIS and Crime Mapping ; جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- کنان، م. سینگ، ام. سیستم اطلاعات جغرافیایی و نقشه برداری جرم ؛ CRC Press: Boca Raton، FL، ایالات متحده، 2020. [ Google Scholar ]
- براگا، آ. پاپاکریستوس، ا. هورو، دی. اثرات پلیس نقاط داغ بر جرم و جنایت. کمبل سیست. Rev. 2012 , 8 , 1-96. [ Google Scholar ] [ CrossRef ]
- ویزبرد، دی. پلیس نقاط داغ Telep، CW: آنچه می دانیم و آنچه باید بدانیم. J. Contemp. جنایت. عدالت 2014 ، 30 ، 200-220. [ Google Scholar ] [ CrossRef ]
- اندرسن، MA; ویزبورد، دی. پلیس مکان محور: مسیرهای جدید، چالش های جدید. سیاسی بین المللی J. 2018 , 41 , 310-313. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- المز، GA; رودل، جی. Conley, J. Forensic GIS: نقش فناوریهای زمین فضایی برای بررسی جرم و ارائه شواهد . Springer: Dordrecht، هلند، 2014; جلد 11. [ Google Scholar ]
- Coldren، JR; هانتون، ا. مدرس، م. معرفی پلیس هوشمند: مبانی، اصول و عمل. پلیس Q. 2013 ، 16 ، 275-286. [ Google Scholar ] [ CrossRef ]
- Attig, S. The Organic Pattern of Space: A Space Syntax Analysis of Natural Streets and Street Segments for Measuring Crime and Traffic Incidents (پایان نامه). 2019. در دسترس آنلاین: https://urn.kb.se/resolve?urn=urn:nbn:se:kth:diva-264938 (در 1 آوریل 2022 قابل دسترسی است).
- جردن، MI; میچل، یادگیری ماشینی TM: روندها، دیدگاه ها و چشم اندازها. Science 2015 ، 349 ، 255-260. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ژائو، ایکس. تانگ، جی. مدلسازی همبستگیهای زمانی-مکانی برای پیشبینی جرم. در مجموعه مقالات ACM 2017 در کنفرانس مدیریت اطلاعات و دانش، سنگاپور، 6 تا 10 نوامبر 2017؛ صص 497-506. [ Google Scholar ]
- باباکورا، ا. سلیمان، MN; یوسف، MA روش بهبود یافته الگوریتم های طبقه بندی برای پیش بینی جرم. در مجموعه مقالات سمپوزیوم بین المللی 2014 در بیومتریک و فناوری های امنیتی (ISBAST)، کوالالامپور، مالزی، 26 اوت 2014؛ IEEE: Piscataway، NJ، ایالات متحده؛ صص 250-255. [ Google Scholar ]
- آلوس، ال جی؛ ریبیرو، HV; رودریگز، پیشبینی جرم FA از طریق معیارهای شهری و یادگیری آماری. فیزیک یک آمار مکانیک. برنامه آن است. 2018 ، 505 ، 435-443. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ایوان، ن. آهیشاکیه، ای. Omulo، EO; Taremwa، D. پیشبینی جرم با استفاده از الگوریتم طبقهبندی درخت تصمیم (J48). بین المللی جی. کامپیوتر. Inf. تکنولوژی 2017 ، 6 ، 188-195. [ Google Scholar ]
- نصریدینوف، آ. Ihm, SY; پارک، YH یک مدل طبقهبندی مبتنی بر درخت تصمیم برای پیشبینی جرم. در همگرایی فناوری اطلاعات ; Springer: Dordrecht، هلند، 2013; صص 531-538. [ Google Scholar ]
- Tayal، DK; جین، ا. آرورا، اس. آگاروال، اس. گوپتا، تی. Tyagi، N. کشف جرم و شناسایی جنایتکاران در هند با استفاده از تکنیک های داده کاوی. AI Soc. 2015 ، 30 ، 117-127. [ Google Scholar ] [ CrossRef ]
- سیورنجانی، س. سیواکوماری، س. Aasha, M. پیشبینی و پیشبینی جرم در تامیلنادو با استفاده از رویکردهای خوشهبندی. در مجموعه مقالات کنفرانس بین المللی 2016 در مورد روندهای فناوری نوظهور (ICETT)، کولام، هند، 21 تا 22 اکتبر 2016؛ IEEE: Piscataway، NJ، ایالات متحده؛ صص 1-6. [ Google Scholar ]
- کیانمهر، ک. الحاج، ر. اثربخشی ماشین بردار پشتیبان برای پیشبینی نقاط داغ جرم. Appl. آرتیف. هوشمند 2008 ، 22 ، 433-458. [ Google Scholar ] [ CrossRef ]
- Memon، QA; محبوب، س. بررسی و تحلیل جرم با استفاده از شبکه های عصبی. در مجموعه مقالات هفتمین کنفرانس بین المللی چند موضوعی، 2003. INMIC 2003، اسلام آباد، پاکستان، 8-9 دسامبر 2003; IEEE: Piscataway، NJ، ایالات متحده؛ صص 346-350. [ Google Scholar ]
- بنیستر، جی. O’Sullivan، A. بیتس، ای. مکان و زمان در جرم شناسی مکان. نظریه. Criminol. 2019 ، 23 ، 315-332. [ Google Scholar ] [ CrossRef ]
- سارایوا، م. آمانته، ا. مارکز، تی. فریرا، م. Maia، C. Perfis territoriais de kriminalidade در پرتغال (2009–2019). Finisterra 2021 ، 56 ، 49-73. [ Google Scholar ] [ CrossRef ]
- Freilich، JD; نیومن، GR Situational Crime Prevention دایره المعارف تحقیقات آکسفورد جرم شناسی و عدالت کیفری ; انتشارات دانشگاه آکسفورد: آکسفورد، بریتانیا، 2017. [ Google Scholar ]
- برنامه آموزش فردی شاخص جهانی صلح 2021: سنجش صلح در دنیای پیچیده. 2021. در دسترس آنلاین: https://www.visionofhumanity.org/wp-content/uploads/2021/06/GPI-2021-web-1.pdf (در 1 آوریل 2022 قابل دسترسی است).
- گرانژیا، اچ. کروز، او. تکسیرا، آر. Alves، P. Vulnerabilidades urbanas: O caso da kriminalidade associada às ourivesarias na cidade do Porto. کشیش لاتیت. 2013 ، 7 ، 69-89. [ Google Scholar ]
- گزارش امنیت کشور 2020. در دسترس آنلاین: https://www.osac.gov/Country/Portugal/Content/Detail/Report/3e50b674-78b2-4997-8950-188df6d2cadf (در 1 آوریل 2022 قابل دسترسی است).
- Tulumello, S. Segurança urbana: Tendências globais, contradições Portugueseas e tempos de crise. Cid. Em Reconstrução. Leituras Círitcas 2018 ، 2008–2018 ، 73–80. [ Google Scholar ]
- یورواستات آمار جرم و عدالت کیفری. 2016. در دسترس آنلاین: https://ec.europa.eu/eurostat/statistics-explained/index.php/MainPage (در 1 آوریل 2022 قابل دسترسی است).
- فریرا، جی. جوائو، پی. مارتینز، جی.ای.اس برای تجزیه و تحلیل جرم-جغرافی برای مدل های پیش بینی. الکترون. J. Inf. سیستم ارزشیابی 2012 ، 15 ، 36-49. [ Google Scholar ]
- João, P. Modelo Preditivo de Criminalidade: Georeferenciação ao Concelho de Lisboa. پایان نامه کارشناسی ارشد، Universidade Nova de Lisboa، لیسبون، پرتغال، 2009. [ Google Scholar ]
- رودریگز، TMF; ایناسیو، AA; آراجو، دی. پاینهو، ام. هنریکس، آر. Cabral، PdCB; اولیویرا، تی. Neto، MdC SIM4SECURITY. در کنگره پنجم Português de Demografia ; مدل پیش بینی و تحلیل فضایی برای امنیت داخلی پرتغال 2030; Fundação Calouste Gulbenkian: لیسبون، پرتغال، 2016. [ Google Scholar ]
- اینس، ام. رابرتز، سی. پریس، ا. راجرز، دی. ده «رای» واکنش اجتماعی: استفاده از رسانههای اجتماعی برای تحلیل تأثیرات «پس از رویداد» قتل لی ریگبی. ترور خشونت سیاسی 2018 ، 30 ، 454-474. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هو، اس. گائو، اس. وو، ال. خو، ی. ژانگ، ز. کوی، اچ. گونگ، X. طبقهبندی تابع شهری در سطح بخش جاده با استفاده از دادههای مسیر تاکسی: یک رویکرد شبکه عصبی کانولوشنال گراف. محاسبه کنید. محیط زیست سیستم شهری 2021 ، 87 ، 101619. [ Google Scholar ] [ CrossRef ]
- وو، اچ. لین، ا. زینگ، ایکس. آهنگ، دی. Li، Y. شناسایی عوامل محرک اصلی تغییر کاربری زمین شهری از محصولات پوشش زمین جهانی و داده های POI با استفاده از روش جنگل تصادفی. بین المللی J. Appl. زمین Obs. Geoinf. 2021 ، 103 ، 102475. [ Google Scholar ] [ CrossRef ]
- ابوحف، م. کو، س. Gueaieb، W. ابیلمونا، آر. هارب، ام. پاسخ به فعالیت های غیرقانونی در امتداد سواحل کانادا با استفاده از یادگیری تقویتی. در مجموعه مقالات IEEE Instrumentation & Measurement Magazine، کاتانیا، ایتالیا، 12 آوریل 2021؛ جلد 24، ص 118-126. [ Google Scholar ] [ CrossRef ]
- پتروسیان، GA جلوگیری از ماهیگیری غیرقانونی، گزارش نشده و غیرقانونی (IUU): یک رویکرد موقعیتی. Biol. حفظ کنید. 2015 ، 189 ، 39-48. [ Google Scholar ] [ CrossRef ]
- Lin، YL; چن، TY; Yu, LC استفاده از یادگیری ماشینی برای کمک به پیشگیری از جرم. در مجموعه مقالات ششمین کنگره بین المللی IIAI در انفورماتیک کاربردی پیشرفته 2017 (IIAI-AAI)، هاماماتسو، ژاپن، 9 تا 13 ژوئیه 2017؛ IEEE: Piscataway، NJ، ایالات متحده؛ ص 1029–1030. [ Google Scholar ]
- ژانگ، ایکس. لیو، ال. شیائو، ال. جی، جی. مقایسه الگوریتمهای یادگیری ماشین برای پیشبینی نقاط داغ جرم. دسترسی IEEE 2020 ، 8 ، 181302–181310. [ Google Scholar ] [ CrossRef ]
- Matijosaitiene، I.; مک داوالد، ای. جونجا، وی. پیشبینی فضاهای پارکینگ ایمن: رویکرد یادگیری ماشینی به دادههای شهری و جرم و جنایت. پایداری 2019 ، 11 ، 2848. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پینتو، ام. وی، اچ. کوناته، ک. Touray، I. بررسی عوامل مؤثر بر داده های جرم و جنایت نیویورک با ابزارهای یادگیری ماشین. جی. کامپیوتر. علمی Coll. 2020 ، 36 ، 61-70. [ Google Scholar ]
- میتال، م. گویال، ال.ام. Sethi، JK; Hemanth، DJ نظارت بر تأثیر بحران اقتصادی بر جرم و جنایت در هند با استفاده از یادگیری ماشین. محاسبه کنید. اقتصاد 2019 ، 53 ، 1467-1485. [ Google Scholar ] [ CrossRef ]
- بوگومولوف، آ. لپری، بی. استایانو، جی. الیور، ن. پیانسی، اف. پنتلند، آ. روزی روزگاری یک جنایت: به سوی پیشبینی جرم از روی اطلاعات جمعیتی و تلفن همراه. در مجموعه مقالات شانزدهمین کنفرانس بین المللی تعامل چندوجهی، استانبول، ترکیه، 12 تا 16 نوامبر 2014; ص 427-434. [ Google Scholar ]
- ژو، جی. لی، ز. ما، جی جی. جیانگ، اف. کاوش عوامل تأثیرگذار پنهان بر فعالیت های جرم و جنایت: رویکرد داده های بزرگ. دسترسی IEEE 2020 ، 8 ، 141033–141045. [ Google Scholar ] [ CrossRef ]
- البونی، م. مدلهای پیشبینی جرم ویژه منطقه MS Gerber. در مجموعه مقالات پانزدهمین کنفرانس بینالمللی IEEE در مورد یادگیری ماشین و کاربردها (ICMLA)، آناهیم، کالیفرنیا، ایالات متحده آمریکا، 18 تا 20 دسامبر 2016؛ IEEE: Piscataway، NJ، ایالات متحده؛ صص 671-676. [ Google Scholar ]
- ویزبورد، دی. قانون تمرکز جرم و جرم شناسی مکان. جرم شناسی 2015 ، 53 ، 133-157. [ Google Scholar ] [ CrossRef ]
- ژانگ، Q. یوان، پی. ژو، Q. یانگ، زی. ویژگیهای مکانی-زمانی ترکیبی مبتنی بر پیشبینی نقاط داغ جنایت. در مجموعه مقالات بیستمین کنفرانس بین المللی IEEE در سال 2016 در مورد کار مشترک با پشتیبانی رایانه در طراحی (CSCWD)، نانچانگ، چین، 4 تا 6 مه 2016؛ IEEE: Piscataway، NJ، ایالات متحده؛ صص 97-101. [ Google Scholar ]
- باپی، FK; جونیور، ع. متوین، اس. پیش بینی جرم با استفاده از ویژگی های فضایی. در مجموعه مقالات کنفرانس کانادایی هوش مصنوعی، تورنتو، کانادا، 8 تا 11 مه 2018؛ اسپرینگر: چم، سوئیس؛ صص 367-373. [ Google Scholar ]
- Chen, Y. Crime Mapping با استفاده از یادگیری ماشین و وب GIS. Ph.D. پایان نامه، دانشگاه ایالتی کالیفرنیا، نورتریج، کالیفرنیا، ایالات متحده آمریکا، 2019. [ Google Scholar ]
- او، ال. پائز، آ. جیائو، جی. آن، پ. لو، سی. مائو، دبلیو. طولانی، D. جمعیت محیطی و سرقت-سرقت: تجزیه و تحلیل فضایی با استفاده از داده های تلفن همراه. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 342. [ Google Scholar ] [ CrossRef ]
- گربر، ام. پیشبینی جرم با استفاده از توییتر و تخمین چگالی هسته. تصمیم می گیرد. سیستم پشتیبانی 2014 ، 61 ، 115-125. [ Google Scholar ] [ CrossRef ]
- وو، تی. شارما، آر. کومار، آر. پسر، LH; فام، بی تی؛ تین بوی، دی. پریادرشینی، ط. سرکار، م. Le, T. تشخیص میزان جرم و جنایت با استفاده از رسانههای اجتماعی مکانهای مختلف جرم و برچسبگذاری بخشی از گفتار توییتر با خوشهبندی قهوهای. جی. اینتل. سیستم فازی 2020 ، 38 ، 4287-4299، (پیش چاپ). [ Google Scholar ] [ CrossRef ]
- وانگ، ایکس. گربر، ام اس; Brown, DE پیشبینی خودکار جرم با استفاده از رویدادهای استخراج شده از پستهای توییتر. در مجموعه مقالات کنفرانس بینالمللی محاسبات اجتماعی، مدلسازی رفتاری-فرهنگی و پیشبینی، کالج پارک، MD، ایالات متحده آمریکا، 3 تا 5 آوریل 2012. اسپرینگر: برلین، هایدلبرگ؛ ص 231-238. [ Google Scholar ]
- سیریارایا، پ. ژانگ، ی. وانگ، ی. کاوایی، ی. میتال، م. Jeszenszky، P. Jatowt، A. شاهد جنایت از طریق توییت: ابزار تحقیق جرم بر اساس رسانه های اجتماعی. در مجموعه مقالات بیست و هفتمین کنفرانس بینالمللی ACM SIGSPATIAL در مورد پیشرفتها در سیستمهای اطلاعات جغرافیایی، شیکاگو، IL، ایالات متحده آمریکا، 5 تا 8 نوامبر 2019؛ صص 568-571. [ Google Scholar ]
- ال هاناچ، اچ. Benkhalifa، M. WordNet مبتنی بر تحلیل احساسات جنبه ضمنی برای شناسایی جرم از توییتر. بین المللی J. Adv. محاسبه کنید. علمی Appl. 2018 ، 9 ، 150-159. [ Google Scholar ] [ CrossRef ]
- پاندی، آر. Mohler, GO ارزیابی مدلهای موضوع جرم: انسجام موضوع در مقابل تمرکز جرم فضایی. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در زمینه اطلاعات و انفورماتیک امنیتی (ISI)، میامی، فلوریدا، ایالات متحده آمریکا، 9 تا 11 نوامبر 2018؛ IEEE: Piscataway، NJ، ایالات متحده؛ صص 76-78. [ Google Scholar ]
- کوانگ، دی. برانتینگهام، پی جی. برتوزی، مدل سازی موضوع جرم و جنایت AL. علوم جنایی 2017 ، 6 ، 12. [ Google Scholar ] [ CrossRef ]
- تامپسون، ال. جانسون، اس. اشبی، م. پرکینز، سی. Edwards, P. UK داده های جرم منبع باز: دقت و امکانات برای تحقیق. کارتوگر. Geogr. Inf. علمی 2015 ، 42 ، 97-111. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- موسسه ملی استاتیکا شاخص های اصلی Instituto Nacional de Estatistica (INE)، لیسبون، پرتغال. 2012. در دسترس آنلاین: https://www.ine.pt/xportal/xmain?xpid=INE&xpgid=inemain (در 1 آوریل 2022 قابل دسترسی است).
- سارایوا، م. Amante، A. Geografia do bem-estar: Insegurança: O caso dos crimes contra as pessoas no Grande Porto. در جغرافیای دو پورتو ؛ فرناندس، آر.، اد. جلد کتاب: پورتو، پرتغال، 2020; ص 202-211. ISBN 9789898898517. [ Google Scholar ]
- GitHub—JustAnotherArchivist/Snscrape: یک وب سایت اجتماعی. در دسترس آنلاین: www.github.com/JustAnotherArchivist/snscrape (در 1 آوریل 2022 قابل دسترسی است).
- چینی، اس. تامپسون، ال. Uhlig, S. ابزار نقشه برداری کانون برای پیش بینی الگوهای فضایی جرم. امن J. 2008 , 21 , 4-28. [ Google Scholar ] [ CrossRef ]
- کالینیچ، م. کریسپ، تخمین چگالی کرنل JM (KDE) در مقابل تجزیه و تحلیل نقطه داغ – تشخیص نقاط داغ جنایی در شهر سانفرانسیسکو. در مجموعه مقالات بیست و یکمین کنفرانس علوم اطلاعات جغرافیایی، لوند، سوئد، 12 تا 15 ژوئن 2018. [ Google Scholar ]
- اک، جی. چینی، اس. کامرون، جی. Wilson, R. Mapping Crime: Understanding Hotspots ; دفتر برنامه های دادگستری وزارت دادگستری ایالات متحده: واشنگتن، دی سی، ایالات متحده آمریکا، 2005.
- یانسنبرگر، EM; Staufer-Steinnocher، P. تخمین چگالی هسته دوگانه به عنوان روشی برای توصیف تغییرات مکانی-زمانی در بازار خردهفروشی مواد غذایی اتریش فوقانی. در مجموعه مقالات هفتمین کنفرانس AGILE در علم اطلاعات جغرافیایی، هراکلیون، کرت، یونان، 29 آوریل – 1 مه 2004. [ Google Scholar ]
- Chainey، SP بررسی تأثیر اندازه سلول و اندازه پهنای باند بر روی نقشههای کانون جرم تخمین چگالی هسته برای پیشبینی الگوهای فضایی جرم. گاو نر Geogr. Soc. لیژ 2013 ، 60 ، 7–19. [ Google Scholar ]
- هو، ی. وانگ، اف. گین، سی. زو، اچ. یک چارچوب تخمین چگالی هسته مکانی-زمانی برای نقشهبرداری و ارزیابی نقاط داغ جرم و جنایت. Appl. Geogr. 2018 ، 99 ، 89-97. [ Google Scholar ] [ CrossRef ]
- Meneses، BM; ریس، ای. ریس، آر. Vale، MJ اثرات استفاده از زمین و پوشش زمین اطلاعات جغرافیایی تعمیم شطرنجی در تجزیه و تحلیل LUCC در پرتغال. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 390. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Ord، JK; Getis، A. آمار خودهمبستگی فضایی محلی: مسائل توزیع و یک برنامه کاربردی. Geogr. مقعدی 1995 ، 27 ، 286-306. [ Google Scholar ] [ CrossRef ]
- تبشیرانی، آر. انقباض و انتخاب رگرسیون از طریق کمند. JR Stat. Soc. سر. B (Methodol.) 1996 ، 58 ، 267-288. [ Google Scholar ] [ CrossRef ]
- دو، دبلیو. Zhan, Z. طبقهبندی درخت تصمیمگیری ساختمان در دادههای خصوصی. مهندسی برق و علوم کامپیوتر. 2002. در دسترس آنلاین: https://surface.syr.edu/eecs/8 (دسترسی در 1 آوریل 2022).
- Ho, TK جنگلهای تصمیم تصادفی. در مجموعه مقالات سومین کنفرانس بین المللی تجزیه و تحلیل و شناسایی اسناد، مونترال، QC، کانادا، 14-16 اوت 1995. IEEE: Piscataway، NJ، ایالات متحده؛ جلد 1، ص 278-282. [ Google Scholar ]
- Ho, TK روش زیر سرعت تصادفی برای ساخت جنگل های تصمیم. IEEE Trans. الگوی مقعدی ماخ هوشمند 1998 ، 20 ، 832-844. [ Google Scholar ]
- Wang, L. (ویرایش) ماشینهای بردار پشتیبانی: نظریه و کاربردها . Springer Science & Business Media: برلین، آلمان، 2005; جلد 177. [ Google Scholar ]
- Blei، DM; Ng، AY؛ جردن، MI تخصیص دیریکله نهفته. جی. ماخ. فرا گرفتن. Res. 2003 ، 3 ، 993-1022. [ Google Scholar ]
- لیو، بی. تحلیل احساسات و ذهنیت. هندب نات. لنگ پردازش 2010 ، 2 ، 627-666. [ Google Scholar ]
- بریمن، ال. پیش بینی کننده های بگینگ. ماخ فرا گرفتن. 1996 ، 24 ، 123-140. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Lasierra، FG شناسایی و مقابله با سطوح مختلف امنیت ذهنی 1. در ابعاد ناامنی در مناطق شهری ; باراباس، AT، اد. موسسه ملی بوداپست: بوداپست، مجارستان، 2018. [ Google Scholar ]
- سولیموسی، ر. باورز، ک. فوجیما، تی. ترسیم ترس از جنایت به عنوان یک تجربه روزمره وابسته به زمینه که در مکان و زمان متفاوت است. پا. Criminol. روانی 2015 ، 20 ، 193-211. [ Google Scholar ] [ CrossRef ]
- LeBeau، JL; لایتنر، ام. مقدمه: پیشرفت در تحقیق در مورد جغرافیای جرم و جنایت. پروفسور Geogr. 2011 ، 63 ، 161-173. [ Google Scholar ] [ CrossRef ]
- بانتینگ، RJ; چانگ، OY؛ کوئن، سی. هانکینز، آر. لنگستون، اس. وارنر، ا. یانگ، ایکس. لودربک، ER; روی، اس اس الگوهای فضایی سرقت و حمله شدید در شهرستان میامی-داد، 2007-2015. پروفسور Geogr. 2018 ، 70 ، 34-46. [ Google Scholar ] [ CrossRef ]
- هانت، پی. کیلمر، بی. روبین، جی. توسعه گزارش جرم اروپا: بهبود ایمنی و عدالت با داده های جرم و عدالت کیفری موجود . رند اروپا: کمبریج، بریتانیا، 2011. [ Google Scholar ]
- مشارکت در امنیت در فضاهای عمومی (PSPS). برنامه اقدام شهری دستور کار مشارکت امنیت در فضاهای عمومی. 2021. در دسترس آنلاین: https://ec.europa.eu/futurium/en/system/files/ged/final_action_plan_security_in_public_spaces.pdf (دسترسی در 1 آوریل 2022).
- ویزبرد، دی. سفید، سی. وودیچ، الف. آیا کارآیی جمعی در سطح جغرافیایی خرد اهمیت دارد؟ برادر J. Criminol. 2020 ، 60 ، 873-891. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویزبرد، دی. سفید، سی. سیم ها.؛ ویلسون، DB افزایش کنترلهای اجتماعی غیررسمی برای کاهش جرم و جنایت: شواهدی از مطالعه نقاط داغ جرم و جنایت. قبلی علمی 2021 ، 22 ، 509-522. [ Google Scholar ] [ CrossRef ]
- فاستر، اس. گیلز کورتی، بی. Knuiman، M. طراحی محله و ترس از جرم: یک بررسی اجتماعی-اکولوژیکی از همبستگی های ترس ساکنان در توسعه های جدید مسکن حومه شهر. Health Place 2010 ، 16 ، 1156-1165. [ Google Scholar ] [ CrossRef ]
- ویزبرد، دی. گراف، ای آر. یانگ، اس ام درک و کنترل نقاط داغ جرم: اهمیت کنترل های اجتماعی رسمی و غیررسمی. قبلی علمی 2014 ، 15 ، 31-43. [ Google Scholar ] [ CrossRef ]
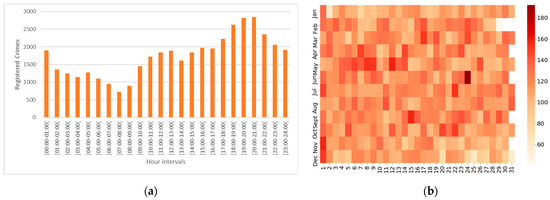
شکل 1. وقوع جرم ثبت شده پورتو بین سال های 2016 و 2018: ( الف ) بر حسب ساعت. ( ب ) بر اساس ماه و روز
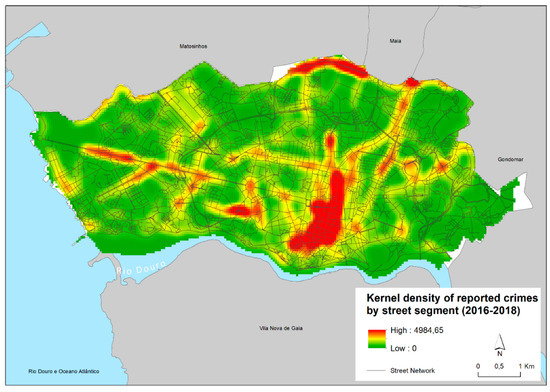
شکل 2. تخمین تراکم هسته پورتو از جرایم گزارش شده از سال 2016 تا 2018 بر اساس بخش خیابان
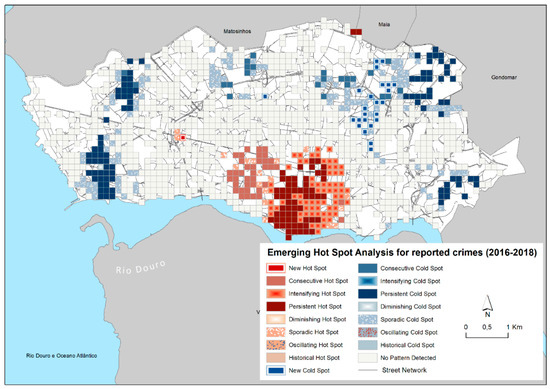
شکل 3. تجزیه و تحلیل کانون های نوظهور برای جنایات گزارش شده
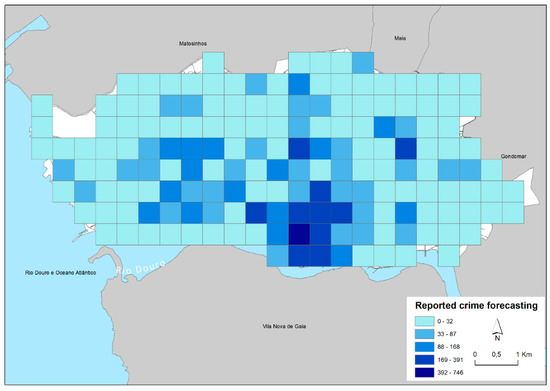
شکل 4. پیشبینی جنایت در پورتو بر اساس دادههای 2016 تا 2018
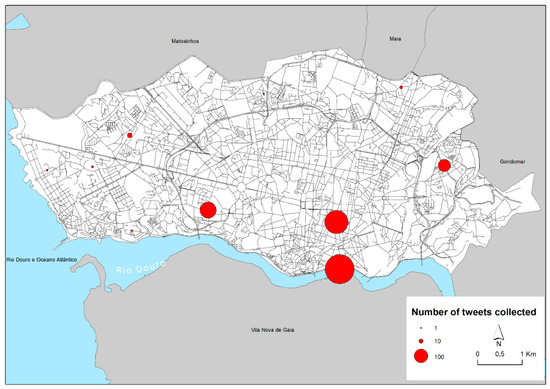
شکل 5. توزیع فضایی توییت های جمع آوری شده
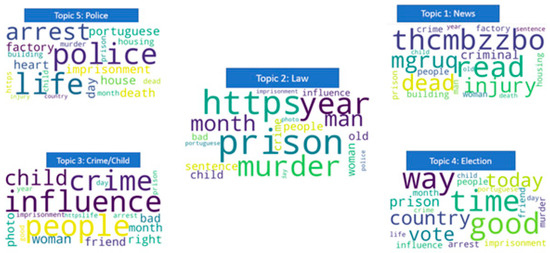
شکل 6. پنج موضوع حاصل از مدل سازی LDA (منبع: نویسندگان، بر اساس داده های توییتر).

شکل 7. ابرهای کلمه ای از مثبت ترین و منفی ترین احساسات بر اساس تجزیه و تحلیل احساسات توییت ها
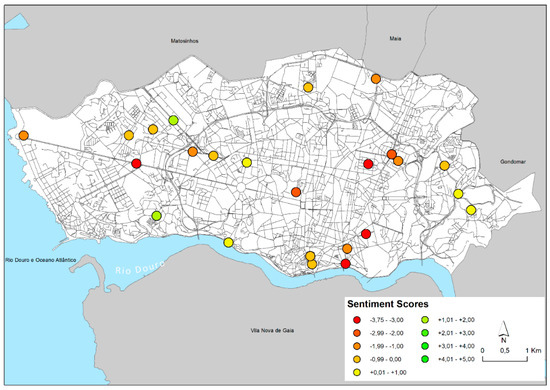
شکل 8. توزیع فضایی نمرات احساسات


بدون دیدگاه