1. مقدمه
در مناطق زلزله خیز، ارزیابی عملکرد لرزه ای سازه های موجود برای برآورد خسارات احتمالی ناشی از زلزله آینده بسیار مهم است. رویکردهای بسیاری با سطوح مختلف جزئیات برای تعیین یا برآورد حساسیت لرزه ای سازه های موجود ابداع شده است. این رویکردها شامل غربالگری خیابان، ارزیابی اولیه جامع تر، و ارزیابی مبتنی بر کد [ 1 ] است. در روش شناسی هر سه گروه، پارامترهای کلیدی مشابهی وجود دارد. کارشناسان این حقایق را در محل در رویکرد سنتی تعیین می کنند. این تحقیقات سنتی، بسته به تعداد ساختارهایی که باید بررسی شوند، چالش برانگیز هستند.
تعیین دوره ارتعاش اساسی ساختمان برای طراحی زلزله و ارزیابی خطر لرزه ای حیاتی است. دوره ساخت با جرم و سختی سازه تعیین می شود. ممکن است با استفاده از مقدار ویژه یا تحلیل فشار آور بر روی مدل عددی ساختمان محاسبه شود. با این حال، هنگام انجام مطالعات ارزیابی آسیبپذیری لرزهای در مقیاس شهری، عملکرد لرزهای صدها یا هزاران سازه باید برآورد شود [ 2 ]. بنابراین استفاده از تحلیل کامپیوتری برای محاسبه دوره ارتعاش هر سازه در محدوده شهری مورد مطالعه عملی نیست. در نتیجه، مدل های ساده ممکن است برای تعیین دوره ساختمان در رابطه با ارتفاع ساختمان استفاده شود [ 3]. روشهای سنتی بررسی میدانی ممکن است برای اندازهگیری ارتفاع هر سازه در یک ساختمان بزرگ زمان زیادی طول بکشد. در نتیجه، فناوری پیشرفته مانند برنامه های سنجش از راه دور باید برای ارزیابی ارتفاع ساختمان استفاده شود [ 4 ].
دوره ارتعاش اساسی ساختمان یک معیار مهندسی زلزله حیاتی در طراحی مقاوم در برابر زلزله و ارزیابی عملکرد لرزه ای است. اکثر رویکردهای طراحی استاتیک از یک طیف طراحی برای محاسبه نیروی جانبی لرزه ای مربوطه استفاده می کنند. در نتیجه، قدرت زلزله تابعی از دوره ارتعاش اساسی ساختمان است [ 5 ، 6 ]. دوره پایه را می توان بر اساس مدل سازی یا روابط تجربی ساده شده در کدهای طراحی لرزه ای محاسبه کرد. معادلات تجربی برای کاربردهای ارزیابی سریع ترجیح داده می شوند [ 7 ].
موجودی ساختمان بر اساس سنجش از دور ممکن است با استفاده از انواع فرمت های داده جمع آوری شود. امکان به دست آوردن عوامل ساختمانی ارزیابی ریسک حیاتی مانند سال ساخت، ارتفاع ساختمان و مساحت ساختمان وجود دارد. در عین حال، منابع انسانی ممکن است به سمت ارزیابی ریسک، تجزیه و تحلیل و تفسیر نتایج هدایت شوند. این داده ها ممکن است توسط الگوریتم های یادگیری ماشین خودکار برای ارزیابی سریع و پیشرفته خطر و سایر تحقیقات ارزیابی آسیب پذیری لرزه ای مورد استفاده و ارزیابی قرار گیرند.
استخراج خودکار و نیمه اتوماتیک ساختمان و تعیین ارتفاع ساختمان برای برنامه ریزی شهری، مدل سازی سه بعدی شهر، پایش شهری، ارزیابی ریسک ساختمان قبل از فاجعه، مدیریت بلایا و سایر کاربردهای مکانی ضروری است [ 8 ، 9 ، 10 ]. در چند سال اخیر، دادههای سنجش از دور مانند هوایی، ماهوارههای نوری، و تشخیص و محدوده نور (LiDAR) برای استخراج ساختمان و تعیین ارتفاع کارآمد هستند [ 8 ، 9 ، 11 ]. استخراج لبه/خط [ 12 ]، عملگرهای مورفولوژیکی [ 13 ] و تجزیه و تحلیل تصویر مبتنی بر شی (OBIA) [ 14 ]رویکردهای ] در استخراج ساختمان مبتنی بر تصویر استفاده شده است. در تعیین ارتفاع ساختمان با روشهای مبتنی بر تصویر، روشهای مبتنی بر سایه [ 9 ، 15 ] و رویکردهای تعیین ارتفاع از یک مدل سطح دیجیتال (DSM) تولید شده از جفتهای تصویر استفاده شده است [ 16 ]. اگرچه روش های مبتنی بر تصویر در استخراج ساختمان موفق هستند، اما ساختار پیچیده مناطق شهری، وجود پوشش گیاهی و مشکل سایه، موفقیت روش ها را در تعیین ارتفاع ساختمان کاهش می دهد [ 17 ].
استخراج ساختمان به طور مستقیم از ابر نقطه LiDAR برای بازسازی ساختمان سه بعدی انجام می شود. در این رویکرد، سقفهای ساختمانی مسطح با استفاده از روشهای تبدیل Hough و اتفاق نظر نمونه تصادفی (RANSAC) [ 18 ، 19 ، 20 ، 21 ، 22 ] و منطقه در حال رشد [ 23 ، 24 ] یا تقسیمبندی مبتنی بر قانون [ 19 ] استخراج میشوند. ویژگی های هندسی نقاط اگرچه این روشها که ساختمانها را مستقیماً از ابر نقطهای گسترده استخراج میکنند، از نظر کاربردی قابل مدیریت هستند، اما تغییراتی مانند استخراج اجسام مسطح غیرساختمانی به عنوان سقف ساختمان و عدم توانایی استخراج سقفهای منحنی ساختمان را دارند.25 ، 26 ].
استفاده از تصاویر ماهوارهای یا هوایی و دادههای LiDAR بهوسیله همجوشی در مطالعات استخراج ساختمان دوبعدی برای مدیریت بلایا یا سایر کاربردهای مکانی بسیار رایج است. حذف ویژگی زمین از داده های LiDAR و فیلتر کردن پوشش گیاهی از باندهای طیفی تصویر، دقت استخراج ساختمان را افزایش می دهد [ 27 ، 28 ]. OBIA رویکرد ارجح در تصاویر نوری و مطالعات همجوشی LiDAR برای استخراج ساختمان به دلیل استفاده ترکیبی از ویژگی های هندسی، طیفی و توپوگرافی است [ 29 ، 30 ، 31 ، 32 ].
اگرچه مجموعه دادههای ترکیبی نتایج موفقیتآمیزی به دست میدهند، داشتن مجموعه دادههای تصویری LiDAR و اپتیک که متعلق به یک فیلد هستند همیشه امکانپذیر نیست. مطالعاتی وجود دارد که در آن استخراج ردپای ساختمان دو بعدی فقط بر روی مشتقات LiDAR انجام می شود. در این مطالعات، ساختمانهای استخراجشده با مقدار آستانه DSM مشتقشده از LiDAR نتایج بهتری نسبت به دادههای DSM مبتنی بر تصویر [ 33 ] به دست آوردند و ردپای ساختمان با موفقیت از DSM مشتقشده از LiDAR و مدل زمین دیجیتال (DTM) با طبقهبندی مبتنی بر قانون OBIA استخراج شد. [ 34 ]. علاوه بر این، بر اساس داده های LiDAR DSM و DTM، ردپای سقف ساختمان استخراج شده و انواع ساختمان با طبقه بندی کننده های OBIA و RF طبقه بندی شدند [ 35]. ارتباط آن نوع داده ها در استخراج ساختمان، قابلیت استفاده از ردپای ساختمان به دست آمده، و ارتفاعات در ارزیابی خطرات لرزه ای سازه ها، علیرغم کار قبلی بر روی استخراج ساختمان با استفاده از مشتقات LiDAR مورد مطالعه قرار نگرفته است [ 30 ، 34 ].
بنابراین، هدف اصلی این مطالعه ارائه دادههایی بوده است که میتوان از راه دور برای مهندسین سازه به دست آورد تا محاسبات اولیه را برای عملکرد لرزهای سازههای موجود انجام دهند. بنابراین، ما از شش مرحله برای استفاده از مشتقات مختلف LiDAR شطرنجی و دستیابی به هدف مقاله استفاده می کنیم. (i) تقسیم بندی OBIA برای استخراج ساختمان. (ب) بررسی اساسی ترین پارامترها برای استخراج ساختمان. (iii) بررسی روشهای مختلف یادگیری ماشین برای استخراج ساختمان؛ (IV) کاوش تقسیم داده های مختلف برای طبقه بندی بهتر ساختمان. (v) برآورد ارتفاع ساختمان. و (vi) تخمین مساحت ردپای ساختمان.
مقاله در پنج بخش ساختار یافته است. پس از مقدمه، بخش مواد و روش ها دنبال می شود که در آن جزئیاتی در مورد منطقه مورد مطالعه، داده ها و روش های مورد استفاده ارائه شده است. روش شناسی از بخش های مختلف ساخته شده است. آماده سازی داده های سنجش از دور، که در آن تقسیم بندی تصویر و آماده سازی داده ها توضیح داده شده است. طبقه بندی یادگیری ماشین و ارزیابی دقت؛ و استخراج ساختمان و محاسبه ارتفاع و مساحت ردپا. در ادامه، نتایج ارائه شد، با بحث و نتیجه گیری پشتیبانی شد.
2. مواد و روشها
2.1. منطقه مطالعه
منطقه مورد مطالعه (300 هکتار) از یک منطقه شهری با مجموع 312 ساختمان در بخش غربی شهر اسکوپیه، پایتخت مقدونیه شمالی تشکیل شده است ( شکل 1 ). منطقه مورد مطالعه به دو قسمت تقسیم می شود که رودخانه واردار به عرض تقریبی 60 متر است. در سمت چپ منطقه مورد مطالعه، ساختمانهای شبکهای مسکونی متراکم و کم ارتفاع با حداکثر 10 متر و در سمت راست، ساختمانهای مسکونی و تجاری بالاتر با حداکثر ارتفاع 70 متر قرار دارند. منطقه مورد مطالعه عموماً مسطح است و ارتفاع سطح منطقه مورد مطالعه از 250 تا 327 متغیر است، در حالی که ارتفاع زمین از 250 تا 325 است. علاوه بر ساختمانها، منطقه مورد مطالعه شامل درختان فراوان، سه پل و یک رودخانه به عرض 20 متر از دو طرف است.
منطقه مورد مطالعه در یک منطقه لرزه خیز با سابقه زمین لرزه های مخرب واقع شده است. بنابراین، یک زلزله کم عمق، 6.1 ریشتر با درجه شدت IX (مقیاس مرکالی) در سال 1963 شهر را لرزاند، جایی که این فاجعه منجر به خسارات جانی و مالی قابل توجهی شد. بیش از 1000 نفر کشته، 4000 زخمی و بیش از 200000 آواره شدند. تقریباً 80 درصد شهر ویران شد و بسیاری از ساختمانهای عمومی، مدارس، بیمارستانها و مکانهای تاریخی به شدت آسیب دیدند. در زمانهای اخیر، در سال 2016، زلزلهای قوی با بزرگی ML5.3 پایتخت را لرزاند [ 36 ].
2.2. داده ها
در این مطالعه از مشتقات LiDAR برای استخراج ساختمان استفاده می کنیم. بنابراین، داده های اولیه در این مطالعه سنجش از دور LiDAR است. داده های LiDAR از آژانس کاداستر مقدونیه شمالی به دست آمده است. جمع آوری داده ها با یک پلت فرم هوایی، Cessna 402B و سیستم حسگر Riegl VQ-780i انجام شد. جمع آوری داده ها در تاریخ 3 می 2019، در آسمان صاف و دمای هوا 11 درجه سانتی گراد انجام شد. فاصله نمونه برداری از زمین داده های LiDAR 5 نقطه بر متر مربع است ( شکل 2 ).
نقشههای تفاوت DSM، DTM، شدت، تعداد بازگشت (NOR) و DSM-DTM با وضوح فضایی 30 سانتیمتری تولید شده از یک ابر نقطه LiDAR برای استخراج ردپای ساختمان و تعیین ارتفاع آنها استفاده شد. برای تولید مشتقات LiDAR، ابتدا نقاط نویز با اعمال یک فیلتر پرت آماری (SOR) به ابر نقطه اصلی حذف شدند. با استفاده از داده های فیلتر شده، نقشه های DSM، شدت و NOR با درونیابی خطی تولید شد. نقاط زمین با استفاده از الگوریتم شبیه سازی پارچه فیلترینگ (CSF) به ابر نقطه برای تولید DTM [ 37 ] استخراج شد. پارامترهای CSF به عنوان توپوگرافی: مسطح، وضوح پارچه: 0.5، حداکثر تکرار: 1000، و آستانه طبقه بندی: 0.1 در استخراج نقاط زمین تنظیم شد. نمونه هایی از داده های مشتق شده LiDAR در اینجا آورده شده استشکل 3 .
2.3. مواد و روش ها
روش در این مطالعه از سه مرحله مختلف ساخته شده است. (i) آماده سازی داده های سنجش از دور؛ (ب) طبقه بندی یادگیری ماشینی؛ و (iii) استخراج ساختمان و محاسبه ارتفاع. نمودار جریان متدولوژی ها در شکل 4 آورده شده است ، در حالی که جزئیات هر بخش در بخش های بعدی توضیح داده خواهد شد.
2.3.1. آماده سازی مجموعه داده ها و تجزیه و تحلیل تصویر
مرحله اولیه در فرآیند OBIA قطعه بندی تصویر است. در این سطح، هدف تولید اشیاء تصویری معنی دار از لایه های تقسیم شده است. در OBIA، پرکاربردترین رویکرد تقسیمبندی، تقسیمبندی چند رزولوشن (MRS) است. فرآیند تقسیمبندی در این رویکرد در سطح پیکسل آغاز میشود و فرآیند ادغام بر اساس ناهمگونی فضایی و طیفی مورد عکس انتخاب شده با اشیاء تصویر اطراف اتفاق میافتد [ 38 ]]. برای ساخت اشیاء تصویری بهینه با استفاده از رویکرد MRS، کاربر باید مقیاس، شکل، فشردگی و وزن لایه را تعیین کند. پارامتر scale اندازه یا ناهمگنی اشیاء تصویری را که ایجاد می شود را تعیین می کند. هنگامی که پارامتر مقیاس روی یک مقدار بزرگ تنظیم می شود، اشیاء تصویر بزرگ ایجاد می شوند و بالعکس. پارامتر شکل، با مقادیری از 0 تا 1، برای محاسبه وزن توابع فضایی و طیفی در ضریب ادغام استفاده می شود. در محاسبه تابع شکل، پارامتر فشردگی بر فشردگی و صافی اشیاء تصویر تولید شده تأثیر می گذارد. وزن لایه ها ارتباط لایه های تقسیم بندی را در مقایسه با لایه های دیگر نشان می دهد [ 39 ]. برای تعیین پارامترهای تقسیم بندی بهینه، از روش آزمون و خطا بر اساس تحلیل بصری استفاده کردیم [40 ]. ترکیبهای مختلف شدت، DSM، تفاوت DSM-DTM، تعداد بازگشتها، و لایههای شیب برای تولید اشیاء ساختمانی بهینه آزمایش شدند. بهترین نتیجه جداسازی با ترکیب تفاوت DSM-DTM و DSM به دست آمد. پارامترهای تقسیم بندی بهینه برای این ترکیب به صورت مقیاس: 25، شکل: 0.2، و فشردگی: 0.5 تعیین شد. پس از تقسیم بندی، متغیرهای مورد استفاده در مرحله طبقه بندی برای اشیاء ایجاد شده تعیین شدند. در این مرحله از مقادیر میانگین لایه های ورودی، متغیرهای هندسی اشیا و متغیرهای بافتی محاسبه شده از لایه های ورودی استفاده شد. در نتیجه تجزیه و تحلیل دیداری مشخص شد که 25 متغیر برای طبقه بندی مناسب هستند ( جدول 1).). سپس تمامی اشیاء تولید شده به دو دسته ساختمانی و غیر ساختمانی برچسب گذاری شدند. در این مرحله سقف ها را هدف گرفتیم تا ردپای ساختمان ها را استخراج کنیم ( شکل 5 ). فرآیند برچسبگذاری با استفاده از تصاویر با وضوح بالا از Google Earth، یک عکس ارتو با وضوح فضایی 50 سانتیمتر و دامنههای تپه انجام شد. برای بررسی تأثیر اندازه مجموعه داده آموزشی بر استخراج ردپای ساختمان، مجموعه داده برچسبگذاری شده با استفاده از برنامه آماری R به طور تصادفی به دو مجموعه داده مختلف، 70 درصد قطار، 30 درصد آزمون و 30 درصد قطار، 70 درصد آزمون تقسیم شد.
دو رویکرد متفاوت در طبقه بندی مجموعه داده ها با الگوریتم های یادگیری ماشین دنبال شد. ابتدا ساختمان ها با استفاده از متغیرهای ارائه شده در جدول 1 استخراج شدندبرای دو مجموعه داده به طور تصادفی تقسیم شده است. سپس الگوریتمهای ML با استفاده از ده متغیر مهم با توجه به اهمیت متغیر محاسبهشده به ترتیب با میانگین کاهش دقت (MDA) و میانگین کاهش در جینی (MDG) که معیارهای اهمیت متغیر تصادفی هستند، روی مجموعههای داده اعمال شد. الگوریتم جنگل شاخص MDA اجازه استفاده از نمونههای مشاهدهای خارج از کیسه (OOB) را میدهد که در توسعه درخت برای محاسبه اهمیت متغیر استفاده نمیشوند. تفاوت بین خطای OOB به دلیل مجموعه داده آزمایشی ایجاد شده توسط جایگشت تصادفی مقادیر متغیر مختلف و خطای OOB محاسبه شده از مجموعه داده اصلی را در نظر می گیرد. مهم ترین متغیر در شاخص MDA متغیری است که هنگام حذف از مجموعه داده، دقت را بیشتر کاهش می دهد. اندازه گیری MDG معیاری است که نشان می دهد چگونه هر متغیر مورد استفاده در طبقه بندی به همگنی در گره ها و برگ ها در جنگل تصادفی تولید شده توسط داده های آموزشی کمک می کند. اگر متغیر مهم باشد، گره های کلاس مختلط را به گره های تک کلاسی خالص تقسیم می کند. متغیر با مقدار MDG بالا از اهمیت بالایی برخوردار است.
2.3.2. طبقه بندی یادگیری ماشین و ارزیابی دقت
داده های حل شده بیشتر برای تجزیه و تحلیل آماری و پیش بینی در Weka استفاده شد. یک نرم افزار چند منظوره که برای اعمال الگوریتم های یادگیری ماشین توسعه یافته است. جنگل تصادفی (RF)، درخت تصادفی (RT) و جنگل بهینه شده (OF) برای طبقهبندی ساختمان ارزیابی شدهاند. بخش های OBIA از دو کلاس، ساختمان ها و غیر ساختمان ها آموزش دیده اند ( شکل 5 D).
RT یک طبقه بندی کننده نظارت شده است که یک مجموعه داده تصادفی را برای ساختن درخت تصمیم تولید می کند. تقسیم بهینه در تمام متغیرهای درخت برای تقسیم هر گره استفاده می شود. درختان تصادفی گروه هایی از پیش بینی کننده های درختی هستند [ 41 ]. از سوی دیگر، طبقهبندیکننده RF با استفاده از پیشبینیهای تولید شده توسط مجموعهای از درختان تصمیم، طبقهبندیهای قابل اعتمادی را ارائه میکند [ 42 ]. از آنجایی که RF و RT میتوانند گرههای زیادی داشته باشند که اغلب در افزایش دقت مجموعه جنگل مفید نیستند، عدنان و همکاران. [ 43]، تکنیکی را برای انتخاب یک زیرجنگل کوچک پیشنهاد کرد. آنها استفاده از الگوریتم های ژنتیک را برای انتخاب زیرجنگل های بهینه/تقریباً بهینه پیشنهاد کردند. این سه استراتژی مدلسازی به دلیل سادگی و توانایی استفاده از مدل با دادههای مختلف انتخاب شدند. مدلهای مورد استفاده با استفاده از چندین معیار ارزیابی دقت مورد آزمایش قرار گرفتند.
میانگین خطای مطلق (MAE)، یک مقایسه مبتنی بر خطا بین مقادیر پیشبینیشده و مشاهدهشده، برای اندازهگیری عملکرد مدل در طول پردازش مدل [ 44 ]، و خطای مطلق نسبی (RAE) برای اندازهگیری عملکرد مدل پیشبینیکننده استفاده شده است. REF [ 45 ]،
که در آن O i مقدار مشاهده شده و P i مقدار پیش بینی شده است.
علاوه بر این، برای تجزیه و تحلیل دقت، از آمار ارزیابی استاندارد برای طبقه بندی باینری استفاده شد. به عنوان مثال، پارامترهای مثبت درست (TP) (یک کلاس به درستی شناسایی شده)، مثبت کاذب (FP) (یک کلاس به اشتباه شناسایی شده است؛ یک خطای کمیسیون) و منفی کاذب (FN) (یک کلاس از قلم افتاده است، یک خطای حذف) در نظر گرفته شده است. توجه. TP، FN و FP به ترتیب نشان دهنده شناسایی کامل، عدم شناسایی و شناسایی بیش از حد هستند. سپس دقت (P)، یادآوری (R) و امتیاز F (F) محاسبه شد. دقت (یعنی ارزش پیشبینی مثبت) صحت ساختمانهای استخراجشده و نحوه برخورد الگوریتم با FP (معادله (3)) را توصیف میکند، در حالی که یادآوری (یعنی حساسیت) میزان تشخیص ساختمان و نحوه عملکرد الگوریتم با FN را توصیف میکند. معادله (4)). امتیاز F میانگین هارمونیک یادآوری و دقت است و دقت کلی را با در نظر گرفتن خطاهای کم کاری و حذف گزارش می دهد (معادله (5)). از ماتریس سردرگمی، آمار کاپا نیز محاسبه شد [46 ]. مشخصه عملکرد گیرنده (ROC) و منحنی فراخوان دقیق (PRC) در برابر مدلهای مورد بررسی برای بررسی دقت آنها برای طبقهبندی ساختمان اعمال شد. ROC و PRC برای ارزیابی عملکرد مدل تحلیلی طراحی شده اند [ 47 ]. بنابراین، از نواحی زیر منحنی ها می توان برای تخمین دقت کلی مدل استفاده کرد. مقدار ایده آل برای مقادیر ROC و PRC 1 است.
برای آموزش و آزمایش مدل، داده ها به دو صورت 70-30 درصد و 30-70 درصد تفکیک شدند. در مجموع 5380 سگمنت در بخش بندی تولید شد. بنابراین، در تقسیمبندی دادههای 70 تا 30 درصد، 3766 شی برای آموزش و 1614 شی برای آزمایش استفاده شد. دقت با استفاده از اشیاء مستقل که بخشی از مجموعه آموزشی نبودند، ارزیابی شد.
2.3.3. پس پردازش
از آنجایی که بسیاری از ردپاهای ساختمان به عنوان بیش از یک شی در مرحله تقسیم بندی به دست آمدند، تکه های شی ردپای ساختمان به دست آمده در نتیجه مرحله طبقه بندی ادغام شدند. پس از مرحله استخراج ساختمان، از ساده سازی چند ضلعی برای نمایش بهتر ردپای ساختمان استفاده کردیم. بنابراین از الگوریتم سادهسازی نقطه حذف استفاده کردهایم و با توجه به وضوح مکانی دادهها، تحمل سادهسازی 50 سانتیمتر را اعمال کردهایم. پس از ساده سازی چند ضلعی ها، ناحیه استخراج شده و ردپای واقعی را با هم مقایسه کرده ایم. به عنوان ارجاع به منطقه ردپای واقعی، مناطق برآورد شده با مناطق استخراج شده به صورت دستی بر روی دامنه های تپه ابر نقطه مقایسه شد.
2.3.4. ارتفاعات ساختمان و منطقه ردپا
ارتفاع ساختمان از تفاوت DSM-DTM به دست آمد. چند ضلعی های ساختمانی استخراج شده از OBIA شامل مساحت سقف ساختمان است. در اینجا، میانگین ارتفاع ساختمان را از اختلاف DSM–DTM استخراج میکنیم. برای تخمین ارتفاع سقف، مقدار حداکثر ارتفاع را در هر ساختمانی که توسط اشیاء نشان داده می شود استخراج می کنیم. به این ترتیب سعی می کنیم هم ارتفاع از بدنه اصلی ساختمان و هم ارتفاع کل ساختمان را بدست آوریم. علاوه بر این، با تبدیل چند ضلعی ها به خطوط، ارتفاع ساختمان را برای بدنه ساختمان استخراج کرده ایم. پس از آن، اشیاء نقطه ای برای رأس خطوط ایجاد شدند، جایی که مقادیر ارتفاع از تفاوت های DSM-DTM استخراج شدند. یک نمایش بصری روی یک نمایه از ابر نقطه استفاده شده در شکل 6 آورده شده است. ارزیابی دقت نتایج بهدستآمده با مقایسه سطح استخراجشده و ارتفاع ساختمان با منطقه استخراجشده دستی از سایه تپه و ارتفاعات از دادههای LiDAR انجام شد. برای این منظور، پروفیل هایی را بر روی ابر نقطه استخراج کرده و ارتفاع بدنه اصلی و ارتفاع کل ساختمان را اندازه گیری کرده ایم.
3. نتایج
3.1. اهمیت متغیر
سه مجموعه داده مختلف برای مدل سازی هر تقسیم داده استفاده شده است. ابتدا از تمامی 25 متغیر برای طبقه بندی ساختمان ها استفاده کردیم. علاوه بر این، تکنیک های MDA و MDG برای انتخاب 10 متغیر برتر برای هر دو تقسیم داده استفاده شده است. متغیرهای انتخاب شده در شکل 7 و شکل 8 به ترتیب برای 70-30 درصد و 30-70 درصد تقسیم داده های آموزشی-آزمایی آورده شده است.
نتایج نشان میدهد که تفاوت بین دادههای DSM و DTM اساسیترین متغیر در همه موارد است، که MDA را بیش از 25 درصد در 70-30 و بیش از 35 درصد در تقسیم داده 30-70 درصد افزایش میدهد. متغیر G_Ang2_DSM در رتبه دوم قرار گرفت و می توان متوجه شد که اهمیت آن در انتخاب متغیر MDG نسبت به MDA مهمتر بود. همه متغیرهای برتر مشتقات Lidar بودند و هیچ یک از مشتقات OBIA مربوط به شکل اشیا انتخاب نشدند.
3.2. نتایج طبقه بندی
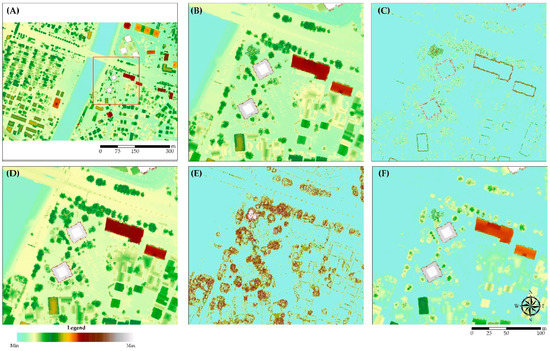
پس از انتخاب 10 متغیر برتر با استفاده از روشهای MDA و MDG، ما از سه مدل مختلف ML برای طبقهبندی شی به دو دسته ساختمانی و غیر ساختمانی استفاده کردهایم. بنابراین، ما سه مدل را برای سه مجموعه داده مختلف اعمال کردهایم و تقسیمبندی دادههای مختلف مانند 70-30 و 30-70 را به ترتیب برای آموزش و آزمایش بررسی کردیم. نتایج بصری در شکل 9 ارائه شده است. از تحلیل بصری می توان متوجه شد که ساختمان ها با دقت بالایی طبقه بندی شده اند. جدول 2 نتایج ارزیابی دقت طبقه بندی ساختمان را برای هر روش ML، با هر استراتژی انتخاب متغیر، برای 70٪ و 30٪ تقسیم داده های آموزش و آزمایش ارائه می دهد. RT آخرین از روش های ML انجام شد، در حالی که RF و OF نتایج مشابهی را نشان دادند.
تجزیه و تحلیل دقت در مورد خطاهای طبقه بندی نتایج مشابهی را نشان می دهد که در آن نتایج RF و OF مشابه هستند و RT عملکرد بهتری دارند. همانطور که انتظار می رفت، 70 درصد از داده های آموزشی با خطاهای کمی کمتر سودمندتر بود. با این حال، این مورد برای RF نبود، جایی که با انتخاب متغیر MDA و MDG، RT خطاهای کمتری را با مجموعه دادههای آموزشی جزئیتر نشان داد. با این وجود، خطاهای RT در تمام سناریوها به طور قابل توجهی بیشتر از دو روش ML دیگر بود. در مورد آمار کاپا، بالاترین مقادیر با استفاده از RF، سپس OF و RT به ترتیب مشاهده شد ( شکل 10 ).
3.3. ارتفاعات ساختمان و منطقه ردپا
با تجزیه و تحلیل بصری، به این نتیجه رسیدیم که چند ضلعی ها را می توان بدون از دست دادن داده های اساسی با تحمل ساده سازی 50 سانتی متر ساده کرد. نتایج در شکل 11 آورده شده است، جایی که خطوط آبی نشان دهنده بخش های ساختمان ساده شده است. مشاهده می شود که بخش های ساده شده بهتر نمایانگر سقف ساختمان ها هستند. پس از آن، مساحت ساختمانهای سادهشده را با مساحت محاسبهشده دستی ساختمانها بر روی دادههای هیلشید که سقفها را میتوان دید، مقایسه کردیم. مقایسه نتایج و مناطق واقعی نشان داد که روششناسی تمایل دارد مساحت را تقریباً 6% کوچکتر از ردپای واقعی ساختمان تخمین بزند. علاوه بر این، RMSE 30.4 متر مربع است .
دو داده مختلف ارتفاع ساختمان از بالای ساختمان و بدنه اصلی ساختمان استخراج شده است. برای بالای ساختمان، از حداکثر مقدار پیکسل اختلاف DSM–DTM استفاده کردیم. برای بدنه اصلی ساختمان، از مقادیر میانگین پیکسل و اختلاف DSM–DTM در رأس چند ضلعی های ساختمان استفاده کرده ایم. نتایج نشان داد که میانگین درصد اختلاف بین حداکثر واقعی و ارتفاع تخمینی ساختمانها 8/0 درصد، با حداکثر اختلاف 3/4 درصد و حداقل اختلاف 01/0- درصد است. RMSE 0.25 متر بود.
برای بدنه ساختمان اصلی، اختلاف صدک بین ارتفاع واقعی و پیش بینی شده با استفاده از مقادیر میانگین پیکسل 7٪ و RMSE 1.47 متر بود، در حالی که با استفاده از مقادیر میانگین راس، اختلاف 2.5٪ با RMSE 1.17 به دست آمد. متر با استفاده از مقدار راس میانگین توانستیم نتایج را با دقت بهتری به دست آوریم. در مقایسه با روش مقدار میانگین پیکسل، روش اول تمایل دارد ارتفاع ساختمان ها را کمتر از مقادیر واقعی تخمین بزند ( شکل 12 ).
4. بحث
این مطالعه استخراج اطلاعات موجودی ساختمان از داده های سنجش از دور استخراج شده از داده های LiDAR را نشان می دهد. نتایج نشان می دهد که اطلاعات ساختمانی خاص مانند مساحت ردپا، ارتفاع کل و ارتفاع بدنه اصلی ساختمان را می توان از داده های بررسی شده با دقت بالایی استخراج کرد. این با استفاده از الگوریتم های ML و انتخاب دقیق متغیر به دست آمد. در مرحله انتخاب متغیر، متغیر اختلاف DSM-DTM به عنوان مهمترین پارامتر در همه مجموعه دادهها بهدست آمد. به این دلیل که منطقه مورد مطالعه دارای توپوگرافی مسطح است، بنابراین تفاوت ارتفاع بین ساختمان ها و زمین و اشیاء کوچک برای طبقه بندی متمایز است. مشاهده شده است که شدت، DSM، شیب، و لایههای تفاوت DSM-DTM که به عنوان ورودی در مطالعه استفاده میشوند، جزو ده پارامتر ضروری در تمام مجموعههای داده هستند. مشاهده شده است که این لایه ها که به عنوان مشتقات LiDAR تولید می شوند، متغیرهای ضروری برای استخراج ساختمان هستند. در تحلیل اهمیت متغیرها مشاهده شده است که تأثیر متغیرهای بافتی تولید شده از داده های DSM و شیب بر استخراج ساختمان زیاد است. به طور خاص، متغیر G-Ang2_DSM به عنوان دومین متغیر مهم در تمام مجموعه داده ها تعیین شد. متغیرهای بافتی در تشخیص ساختمانها و درختان از یکدیگر ضروری بودند، در حالی که این ویژگیها در ساختمانها منظمتر، اما در درختان نامنظمتر هستند. در تحلیل اهمیت متغیرها مشاهده شده است که تأثیر متغیرهای بافتی تولید شده از داده های DSM و شیب بر استخراج ساختمان زیاد است. به طور خاص، متغیر G-Ang2_DSM به عنوان دومین متغیر مهم در تمام مجموعه داده ها تعیین شد. متغیرهای بافتی در تشخیص ساختمانها و درختان از یکدیگر ضروری بودند، در حالی که این ویژگیها در ساختمانها منظمتر، اما در درختان نامنظمتر هستند. در تحلیل اهمیت متغیرها مشاهده شده است که تأثیر متغیرهای بافتی تولید شده از داده های DSM و شیب بر استخراج ساختمان زیاد است. به طور خاص، متغیر G-Ang2_DSM به عنوان دومین متغیر مهم در تمام مجموعه داده ها تعیین شد. متغیرهای بافتی در تشخیص ساختمانها و درختان از یکدیگر ضروری بودند، در حالی که این ویژگیها در ساختمانها منظمتر، اما در درختان نامنظمتر هستند.
الگوریتمهای ML مورد بررسی در چند سال اخیر به طور مکرر برای کاربردهای مختلف مورد استفاده قرار گرفتهاند [ 48 ]. در حالی که همه الگوریتم های بررسی شده عملکرد خوبی را نشان دادند، نتایج نشان می دهد که RF و OF بهتر از RT عمل می کنند که بالاترین خطاها و کمترین مقادیر کاپا ناشی از طبقه بندی ساختمان را ایجاد می کند. RF و OF نتایج نسبتا مشابهی را با تفاوت های ناچیز نشان دادند. با توجه به دو تقسیم دادههای مورد بررسی در این مطالعه، میتوان نتیجه گرفت که روش مورد استفاده میتواند نتایج خوبی را حتی با یک مجموعه داده کوچک ارائه دهد. به عنوان مثال، در 70٪ آموزش و 30٪ مجموعه داده آزمایشی، OF به 99.1٪ CCI منجر شد، در حالی که در 30٪ -70٪، 98.8٪. به طور مشابه، امتیاز F برای RF و OF با 70٪ تمرین 0.98، در حالی که با 30٪، 0.97 بود.
ارتفاع ساختمان در این تحقیق به دو صورت مختلف تعریف شد. اولی کل ارتفاع ساختمان از سطح زمین تا نقطه اوج سقف است که به عنوان ارتفاع سقف (H) ذکر شده است. دومی ارتفاع از سطح زمین تا نوک پوشش سقف است که به عنوان ارتفاع اصلی بدنه (h) ذکر شده است ( شکل 6 ).). ارتفاع دوم در مهندسی سازه معنادارتر است زیرا نشان دهنده ارتفاع آخرین دال از سطح زمین است. سقف ساختمان و ارتفاع بدنه اصلی به صورت خودکار برای ارتفاع ساختمان محاسبه شده است. حداکثر ارتفاع در چند ضلعی های ساختمان به طور خودکار از لایه اختلاف DSM-DTM برای ارتفاع سقف به دست آمد. هنگامی که مقادیر H با مقادیر ارتفاع بدست آمده به صورت دستی مقایسه می شوند، مشاهده می شود که مقدار RMSE 0.25 متر است. این نتیجه نشان می دهد که روش اعمال شده می تواند ارتفاع سقف ساختمان را با دقت بالایی بدست آورد. برای استخراج ارتفاعات بدنه اصلی ساختمان از دو رویکرد متفاوت استفاده شد. اولین مورد، مقدار متوسط ارتفاع است که در داخل چند ضلعی ردپای ساختمان قرار می گیرد. مورد دیگر، مقدار میانگین ارتفاع زیر نقاط رأس چند ضلعی ساختمان است. هنگامی که مقادیر h بهدستآمده با هر دو روش با مقادیر ارتفاع بهدستآمده بهصورت دستی مقایسه شد، مقادیر RMSE برای ارتفاع متوسط و ارتفاع راس بهترتیب 1.47 متر و 1.17 متر بهدست آمد. بنابراین می توان نتیجه گرفت که نتایج به دست آمده با ارتفاع راس از دقت بالاتری نسبت به ارتفاع متوسط برخوردار است. از طرفی مشاهده می شود که مقادیر ارتفاع اصلی بدنه با دقت کمتری نسبت به ارتفاع سقف به دست می آید. در روش استخراج ساختمان به کار رفته در مطالعه، چند ضلعی های متعلق به ردپای مرزهای ساختمان استخراج می شوند. این حاشیه خطا یک نتیجه مورد انتظار است، زیرا میانگین تمام ارتفاعات در چند ضلعی در مقادیر ارتفاع محاسبه شده بر اساس ارتفاع متوسط محاسبه می شود. از آنجایی که ساختمان های منطقه مورد مطالعه دارای انواع سقف های مسطح، شیروانی، شیبدار و هرمی هستند.
در کاربردهای ارزیابی ایمنی سریع سازه با استفاده از داده های سنجش از دور، مرحله دوم پس از استخراج ارتفاع ساختمان، تخمین دوره ارتعاش اساسی ساختمان ها است. برای این تخمین معمولاً از معادلات تجربی که دوره ساختمان را در رابطه با ارتفاع ساختمان پیش بینی می کنند استفاده می شود [ 49 ]. برای درک اینکه آیا ارتفاعات ساختمانی استخراج شده در این مطالعه به اندازه کافی برای استفاده در ارزیابی ایمنی سریع لرزه ای دقیق هستند یا خیر، رویکرد زیر ممکن است اعمال شود. مقادیر RMSE محاسبه شده در این مطالعه 0.25 متر برای ارتفاع سقف و 1.47 متر و 1.17 متر برای ارتفاع بدنه اصلی است. اگر این اعداد در یکی از معادلات تخمین دوره ساختمان قرار داده شوند، برای مثال، T= 0.0195H [ 7مشاهده می شود که تأثیر این مقادیر RMSE بر دوره ساختمان به 0.005 ثانیه برای ارتفاع سقف و 0.03 و 0.02 برای ارتفاع بدنه اصلی بسیار محدود خواهد بود. از آنجایی که این تفاوتهای دوره حداقل بوده و تأثیر آنها بر محاسبات نیروی زلزله ناچیز است، صحت نتایج این مطالعه را میتوان با توجه به ماهیت ارزیابی سریع ایمنی سازه با استفاده از دادههای سنجش از دور معقول دانست.
علاوه بر این، برآورد مساحت ساختمان یک پارامتر با ارزش برای پایگاه داده موجودی ساختمان است که می تواند برای تخمین جرم طبقات و در صورت مشخص بودن تعداد طبقات، کل جرم ساختمان ها مورد استفاده قرار گیرد. از آنجایی که نیروی زلزله وارد بر یک ساختمان تابعی از جرم کل است، یک پارامتر حیاتی برای ارزیابی ایمنی لرزه ای در مقیاس شهری است.
تخمین سال ساخت ساختمان از حوصله این مطالعه خارج است. همانطور که در مقدمه ذکر شد، سال ساخت نیز یک پارامتر مهم در پایش سلامت سازه است. برای این کار، داده های اضافی مورد نیاز است زیرا مجموعه داده مورد استفاده در مطالعه ارائه شده در یک تاریخ جمع آوری شده است. مطالعات قبلی از تصاویر ماهواره ای نوری با وضوح بالا از دو سال مختلف استفاده کرده اند [ 49 ]. بنابراین، مطالعات آتی باید سال ساخت ساختمان ها و سایر اطلاعات مربوطه را در نظر بگیرد.
5. نتیجه گیری ها
بسیاری از انواع داده ها ممکن است برای جمع آوری فهرستی از ساختمان ها بر اساس سنجش از دور استفاده شوند. ارزیابی ریسک حیاتی عناصر ساختمان مانند سال ساخت، ارتفاع ساختمان و اندازه ساختمان ممکن است تعیین شود. اهداف اولیه این مطالعه برای ارائه اطلاعات مورد نیاز مهندسین سازه برای انجام محاسبات لازم برای عملکرد لرزه ای سازه های موجود ایجاد شده است. بنابراین، ما از مشتقات LiDAR برای طبقهبندی ساختمانها با استفاده از الگوریتمهای یادگیری ماشین و تخمین اطلاعات حیاتی، مانند مساحت ردپا و ارتفاعات مختلف ساختمانها، مانند ارتفاع بدنه اصلی و پشت بام، استفاده کردیم. اگرچه این مطالعه چندین هدف بررسی شده دارد، مهم ترین نتیجه این است که داده های مشتقات LiDAR را می توان برای استخراج اطلاعات موجودی ساختمان حساس استفاده کرد. نتایج مطالعه از نظر استخراج دادههای مختلف از یک مجموعه داده امیدوارکننده است. همانطور که در برخی از برنامه ها، زمان برای اقدام محدود است، و استخراج سریع موجودی ساختمان بسیار مهم است. نکته کلیدی این است که نتایج دقیقی را می توان با مقدار کمی داده های آموزشی تولید کرد که از نظر زمانی مفید است. نتایج را می توان در بسیاری از کاربردها، اما مهمتر از همه، در ارزیابی ایمنی سازه استفاده کرد. برای تکمیل داده های لازم برای چنین کاربردهایی، سال ساخت ساختمان مورد نیاز است و برای مطالعات آتی در نظر گرفته شده است. برای مطالعات آتی می توان شکل و همچنین متریال ساختمان را نیز در نظر گرفت. و استخراج سریع موجودی ساختمان بسیار مهم است. نکته کلیدی این است که نتایج دقیقی را می توان با مقدار کمی داده های آموزشی تولید کرد که از نظر زمانی مفید است. نتایج را می توان در بسیاری از کاربردها، اما مهمتر از همه، در ارزیابی ایمنی سازه استفاده کرد. برای تکمیل داده های لازم برای چنین کاربردهایی، سال ساخت ساختمان مورد نیاز است و برای مطالعات آتی در نظر گرفته شده است. برای مطالعات آتی می توان شکل و همچنین متریال ساختمان را نیز در نظر گرفت. و استخراج سریع موجودی ساختمان بسیار مهم است. نکته کلیدی این است که نتایج دقیقی را می توان با مقدار کمی داده های آموزشی تولید کرد که از نظر زمانی مفید است. نتایج را می توان در بسیاری از کاربردها، اما مهمتر از همه، در ارزیابی ایمنی سازه استفاده کرد. برای تکمیل داده های لازم برای چنین کاربردهایی، سال ساخت ساختمان مورد نیاز است و برای مطالعات آتی در نظر گرفته شده است. برای مطالعات آتی می توان شکل و همچنین متریال ساختمان را نیز در نظر گرفت. برای تکمیل داده های لازم برای چنین کاربردهایی، سال ساخت ساختمان مورد نیاز است و برای مطالعات آتی در نظر گرفته شده است. برای مطالعات آتی می توان شکل و همچنین متریال ساختمان را نیز در نظر گرفت. برای تکمیل داده های لازم برای چنین کاربردهایی، سال ساخت ساختمان مورد نیاز است و برای مطالعات آتی در نظر گرفته شده است. برای مطالعات آتی می توان شکل و همچنین متریال ساختمان را نیز در نظر گرفت.















بدون دیدگاه