1. مقدمه
تشخیص تغییر فرآیندی است برای شناسایی تغییرات اشیاء در یک منطقه در دو زمان مختلف [ 1 ]. در حال حاضر، به طور گسترده ای در ارزیابی آسیب بلایای طبیعی، نظارت بر استفاده از زمین، تشخیص و درمان پزشکی، اندازه گیری زیر آب و سایر زمینه ها استفاده می شود. تشخیص تغییر سنتی عمدتاً برای تصاویر سنجش از راه دور با وضوح بسیار بالا (VHR) استفاده میشود. بیشتر روشهای تشخیص تغییرات اولیه، روشهای مقایسه مستقیم پیکسلی هستند، مانند روش مقایسه مستقیم، روش تبدیل تصویر، و روش مقایسه پس از طبقهبندی [ 2 ، 3 ، 4 ، 5 ].]. ماهیت این روش ها استخراج اطلاعات تغییر از طریق مقایسه پیکسل به پیکسل است که کاربرد خوبی در تشخیص اولیه تغییر تصویر با وضوح پایین دارد. با این حال، این روش به نویز، خطا و عوامل دیگر حساس است، با استحکام ضعیف و نرخ تشخیص کاذب بالا.
برای استخراج بهتر انواع ویژگی های زمین در تصاویر، بسیاری از محققان از فناوری یادگیری ماشینی برای دستیابی به دقت تشخیص تغییرات بالاتر با محاسبات ریاضی دقیق تر، مانند ماشین های بردار پشتیبان [ 6 ، 7 ]، روش های درخت تصمیم [ 8 ، 9 ] استفاده می کنند. ]، و روش های جنگل تصادفی [ 10 ، 11 ]. برای انطباق با توسعه تشخیص تغییر تصویر با وضوح فضایی بالا، سنجش از دور، بر اساس استراتژی تجزیه و تحلیل تصویر شی گرا، با کمک مجموعه های سطح [ 12 ]، میدان های تصادفی مارکوف [ 13 ]، زمینه های تصادفی شرطی [ 14 ]و روشهای دیگر، بسیاری از محققین تصاویر مراحل مختلف را طبقهبندی میکنند و سپس اطلاعات شیء مختلف را با هم مقایسه و تجزیه و تحلیل میکنند تا نتایج تغییر دو فاز تصویر را به دست آورند. اگرچه این نوع روش می تواند اطلاعات تغییر کامل را استخراج کند، اما به وضوح تصویر بالا نیاز دارد و توانایی تعمیم کمی دارد. در سالهای اخیر، با توسعه سریع یادگیری عمیق و فناوری دادههای بزرگ، روشهای تشخیص تغییر تصویر سنجش از دور مبتنی بر شبکههای عصبی پیچیده [ 15 ]، مانند STANet [ 16 ]، DASNet [ 17 ]، SSCDNet [ 18 ]، و SRCDNet [ 19]، به تدریج تبدیل به جریان اصلی شده اند. با توجه به ساختار پیچیده و تعداد زیاد محاسبات در شبکه های یادگیری عمیق، شبکه می تواند به طور خودکار تغییرات اشیاء را تشخیص دهد و در مقایسه با سایر استراتژی های تشخیص، دقت و مقیاس پذیری آن به طور قابل توجهی بهبود می یابد. همچنین تا حدی از مشکلات تفسیر سنجش از دور سنتی، مانند ماده خارجی همولوگ جزئی و هتروسطیفی اجتناب میکند. اگرچه دقت و تعمیم بهبود یافته است، روش تشخیص تغییر مبتنی بر یادگیری عمیق به عواملی مانند اندازه نمونه، ظرافت نمونه و وضوح تصویر حساس تر است. عملکرد مدل در تصاویر مختلف متفاوت است و افکت تشخیص اغلب از افکت ایده آل عقب است. برای بهبود دقت تشخیص شبکه تشخیص تغییر در تصاویر مختلف، یکی از سادهترین و مستقیمترین روشها، اصلاح نتایج تشخیص به صورت تعاملی است. در گذشته، تصحیح نتایج پیشبینیشده اغلب به مداخله دستی متکی بود و فرآیند اصلاح پیچیده و طولانی بود. علاوه بر این، زمان و هزینه های نیروی کار تعامل نیز نسبتاً بالا بود. بنابراین، ما قصد داریم یک مکانیسم تعاملی جدید را برای ساده کردن فرآیند تصحیح نتایج تشخیص تغییر و اصلاح نتایج تشخیص تغییر برای بهبود کارایی بررسی کنیم.
تقسیم بندی تعاملی روشی برای اصلاح نتایج تشخیص با وارد کردن اطلاعات تعامل خارجی است. در گذشته، این روش معمولاً برای آموزش مدلهای تقسیمبندی تصویر نیمه نظارت شده استفاده میشد [ 20 ، 21 ]. در طول آموزش مدل، کاربر علامت هایی را روی نمونه ها می کشید تا جهت آموزش مدل را هدایت کند. این روش میتواند برچسبگذاری نمونههای اصلی را کاهش دهد و دقت آموزشی مدلهای تقسیمبندی تصویر بدون نظارت یا نیمهنظارتشده را بهبود بخشد. در سالهای اخیر، با ظهور روشهای یادگیری عمیق، بسیاری از محققان روشهای تقسیمبندی تعاملی مبتنی بر یادگیری عمیق را مطالعه کردهاند. سوفیوک [ 22] اطلاعات کلیک را در یک شبکه تقسیم بندی تصویر یکپارچه کرد، از یادگیری عمیق برای استخراج ویژگی های کلیک های تعاملی کاربر و اشیاء تصویر استفاده کرد و محدوده تقسیم بندی را اصلاح کرد. ژانگ [ 23 ] یک الگوریتم تقسیم بندی هدف تعاملی مبتنی بر یک شبکه دو مرحله ای را پیشنهاد کرد، که اطلاعات تعاملی را با تعامل نقاشی انعطاف پذیر تولید می کند و نتایج را کامل تر و پالایش می کند. کسترخون [ 24] یک الگوریتم حاشیه نویسی نمونه هدف نیمه خودکار را پیشنهاد کرد. با توجه به چارچوب هدف ارائه شده توسط کاربر، از شبکه عصبی دایره ای برای تکرار رئوس چند ضلعی شی هدف در قاب استفاده می شود تا نتایج تقسیم بندی دقیق تری به دست آید. این روشهای تقسیمبندی تعاملی مبتنی بر یادگیری عمیق نه تنها میتوانند برای آموزش مدلهای تقسیمبندی تصویر نیمهنظارتشده اعمال شوند، بلکه میتوانند نتایج تشخیص موجود را نیز تغییر دهند. بنابراین، این روش تقسیمبندی تعاملی با استفاده از یادگیری عمیق میتواند مشکل تصحیح نتایج تشخیص دست و پا گیر را حل کند.
با این حال، تحقیقات در مورد تشخیص تغییر تعاملی هنوز در مراحل اولیه است. اکثر مطالعات موجود در مورد تشخیص تغییر تعاملی بر آموزش مدلهای طبقهبندی نیمه نظارت شده برای کاهش برچسبگذاری نمونههای اصلی تمرکز دارند [ 25 , 26 , 27 , 28]. این نوع استراتژی تعامل فقط می تواند دقت مدل را بهبود بخشد یا تعداد نمونه های برچسب گذاری شده دستی را کاهش دهد، اما نمی تواند نتایج تشخیص تغییر را دو بار تغییر دهد. درجه تعامل محدود است و تغییر نتایج تشخیص موجود دشوار است. در حال حاضر، مطالعات تشخیص تغییر تعاملی کمی بر اساس یادگیری عمیق وجود دارد، بنابراین تحقیق در مورد این جنبه ارزش کاوش را دارد. در زمینه تقسیمبندی تصویر، ماهیت روش تقسیمبندی تعاملی مبتنی بر یادگیری عمیق، انتقال اطلاعات تعاملی ارائهشده توسط کاربر به شبکه عصبی است. به عنوان مثال، برخی از محققان فاصله اقلیدسی را از تمام نقاط پیکسل تا نقاط تعامل به عنوان نقشه تعامل می گیرند و آن را و تصویر اصلی را به عنوان ورودی اولیه شبکه می گیرند [ 29 ,30 ]. این روش نه تنها تعامل را ساده می کند، بلکه دقت قطعه بندی بالایی را تضمین می کند. برای سادهتر کردن بیشتر فرآیند تعامل، برخی از محققان لایه تعامل را به طور جداگانه [ 31 ] در هم میپیچانند و وزن لایه تعامل و نقشه ویژگی تصویر را به عنوان ورودی بعدی اضافه میکنند. در مقایسه با روش قبلی، این روش تأثیر تعامل کاربر را افزایش می دهد. روش بالا برای اصلاح نتیجه پیشبینی با معرفی وزن کلیک، یک ایده تعاملی برای روش تشخیص تغییر ما بر اساس یادگیری عمیق ارائه میکند.
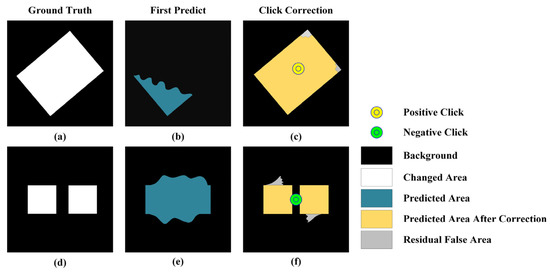
بنابراین، برای تعمیق بیشتر میزان تعامل انسان و رایانه در یک شبکه تشخیص تغییر مبتنی بر یادگیری عمیق، کلیکها را در شبکه تشخیص تغییر وارد میکنیم، وزن کلیکهای مثبت و منفی را به لایه فاصله شبکه اضافه میکنیم و برای دستیابی به اثر استفاده از کلیک ها برای تغییر نتایج پیش بینی، ویژگی ها را دوباره استخراج کنید. بنابراین، یک شبکه تشخیص تغییر تعاملی (ICD) برای تصاویر سنجش از راه دور VHR بر اساس یک شبکه عصبی پیچیده عمیق تحقق مییابد. شکل 1روند تصحیح نتیجه را بر اساس شبکه ICD نشان می دهد. وصله بنفش در سمت چپ، وصلهای است که باید قبل از پیشبینی اصلاح شود، و وصله سبز رنگ سمت راست، پچ اصلاحشده است. در میان آنها، ساختمان های سمت چپ ردیف اول به طور کامل پیش بینی نشده اند. پس از افزودن کلیک های مثبت (نقطه زرد در شکل 1 )، که می تواند وصله هایی را که به طور کامل پیش بینی نشده اند، جبران کند، ساختمان کامل پیش بینی می شود. در عین حال، تصویر سمت چپ ردیف دوم دارای تشخیص نادرست است و پچ nonbuilding پیش بینی می شود. پس از افزودن کلیک های منفی (نقطه آبی در شکل 1 )، که می تواند وصله های خطای پیش بینی را حذف کند، قسمت پیش بینی اضافی حذف می شود.
2. مواد و روشها
برای تحقق تشخیص تغییر تعاملی مبتنی بر یادگیری عمیق، ما دو پیشرفت را در شبکه تشخیص تغییر اصلی انجام دادیم. (1) ما روند آموزش را اصلاح می کنیم. در فرآیند آموزش، فرآیند تولید کلیکهای مثبت و منفی معرفی میشود تا هر نسل از مدل دارای کلیک مطابق با نتایج پیشبینی مدل نسل قبلی باشد. (2) ما ساختار شبکه را اصلاح می کنیم. وزن کلیک های مثبت و منفی به لایه فاصله شبکه اضافه می شود. استخراج ویژگی ثانویه انجام می شود و نتایج پیش بینی اصلاح شده به دست می آید.
2.1. ساختار شبکه تشخیص تغییر تعاملی
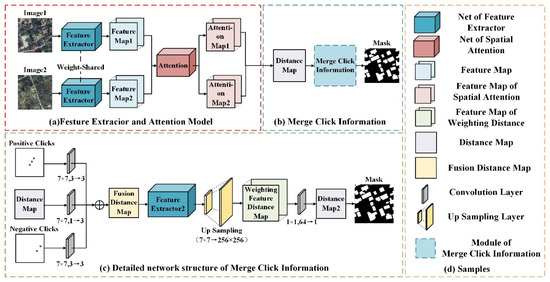
ما یک شبکه تشخیص تغییر تعاملی را پیشنهاد میکنیم و کلیکهای مثبت و منفی را معرفی میکنیم تا شبکه بتواند نتایج پیشبینی اولیه را با توجه به این کلیکها تغییر دهد و در نتیجه به اثر تقسیمبندی تعاملی دست یابد. شکل 2 ساختار شبکه رویکرد ICD را نشان می دهد.
شکل 2 a ماژول استخراج ویژگی و مکانیسم توجه را نشان می دهد. ماژول استخراج ویژگی ResNet18 است که شامل لایه جمعبندی جهانی و لایه کاملاً متصل نیست. تصاویر زمانی دوگانه وزن یکسانی در استخراج ویژگی دارند و PAM [ 16ماژول ] در ماژول مکانیسم توجه استفاده می شود که می تواند روابط مکانی-زمانی دقیق تر، جهانی را استخراج کند. پس از استخراج اطلاعات ویژگی های دو تصویر، بین این دو تفاوت قائل می شویم و نقشه فاصله ویژگی اولیه را به دست می آوریم. در شبکه متداول تشخیص تغییر، نتیجه پیش بینی نهایی را می توان با فیلتر کردن آستانه نمودار فاصله ویژگی در نتایج فوق به دست آورد. با این حال، در ICD تشخیص تغییر تعاملی، اطلاعات کلیک نمودار فاصله ویژگی را نیز ترکیب می کنیم. شکل 2 ب موقعیت همجوشی کلیک ها را نشان می دهد. تولید و ادغام کلیک ها در بخش 2.2 توضیح داده شده است.
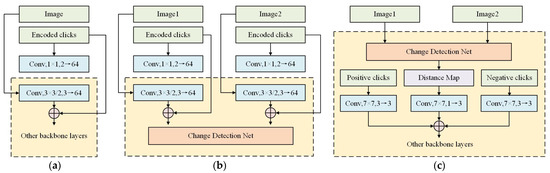
شکل 2 c یک ساختار شبکه دقیق را نشان می دهد که اطلاعات کلیک را یکپارچه می کند. از نظر حالت فیوژن، ما به شکل 3 a در Conv1s در کاغذ [ 22 ] مراجعه می کنیم، که عملیات کانولوشن را روی کلیک ها و تصاویر انجام می دهد تا آنها را به یک کانال تبدیل کند، آنها را فیوز می کند و در نهایت استخراج ویژگی را به صورت یکپارچه انجام می دهد. در ICD، از آنجایی که شبکه یک ساختار جریانی دوگانه است، اگر کلیک ها و تصاویر در ابتدا ادغام شوند ( شکل 3)ب)، تأثیر کلیک ها هنگام محاسبه تفاوت بین دو عکس، یکدیگر را جبران می کند. بنابراین، کلیک ها نمی توانند همراه با تصاویر در ابتدا وارد شبکه شوند. از آنجایی که نقطه ای که باید با کلیک ها اصلاح شود، ناحیه تغییر بین دو تصویر است، با نقشه فاصله شروع می کنیم (ماژول بنفش در شکل 3)ج) نشان دهنده تغییر و ادغام کلیک ها با این قسمت. ابتدا یک عملیات پیچیدگی 7×7 روی نقشه فاصله مشخصه انجام می شود و 1 کانال به 3 کانال برای تناسب با تعداد کلیک کانال تبدیل می شود. در مرحله بعد، عملیات پیچیدگی 7 × 7 بر روی نقشه های کلیک مثبت و منفی انجام می شود تا دو بعد با نقشه فاصله ویژگی یکسان شود. سپس با اضافه کردن وزن های نقشه فاصله ویژگی و کلیک های مثبت و منفی، نقشه فاصله همجوشی X به دست می آید که اطلاعات کلیک را یکپارچه می کند. سپس X برای دور جدیدی از استخراج ویژگی به یک شبکه استخراج ویژگی جدید فرستاده می شود و نتیجه استخراج ویژگی نمونه برداری می شود تا از 7×7 به 256×256 برسد و نقشه فاصله ویژگی جدید X’ به دست می آید. سرانجام،
در فرآیند بالا، ما ResNet را پس از ادغام کلیک وصل کردیم تا اطلاعات اصلاحی که توسط کلیکها آورده شده را بهتر استخراج کنیم. با این حال، برخلاف روش تقسیمبندی تعاملی شبکه تک جریانی، در شبکه دو جریانی مانند ICD، اطلاعات تغییر دو تصویر چندین بار قبل از ترکیب کلیک استخراج و پردازش میشود. اگر استخراج ویژگی دوباره در این زمان انجام شود، اثر ممکن است بهتر از ترکیب ویژگی کانولوشن نباشد. بنابراین، برای تأیید اثربخشی استخراج ویژگی ثانویه، آزمایشهای مربوطه را در بخش 3.2 انجام دادیم .
2.2. تولید خودکار کلیک ها
در فرآیند آموزش، با شروع از مدل نسل دوم، باید به طور خودکار کلیکها را با توجه به نتایج پیشبینی آخرین مدل انتخاب کنیم تا مرجعی بیدرنگ برای آموزش این دور از قابلیت تصحیح کلیک ارائه کنیم. الگوریتم 1 مراحل تولید خودکار کلیک ها را نشان می دهد.
| الگوریتم 1 الگوریتم تولید خودکار کلیک ها. |
ورودی: آخرین نسل مدل، نمونه های آموزشی دو فازی A، B و برچسب مربوطه.
خروجی: کلیک های مثبت و کلیک های منفی برای نتایج آموزشی مدل فعلی. |
1: از مدل برای پیش بینی نمونه های آموزشی استفاده کنید و نتایج پیش بینی را بدست آورید.
2: نتایج پیش بینی را با برچسب ها مقایسه کنید تا مناطقی را که باید با کلیک های مثبت و منفی اصلاح شوند مشخص کنید. این مناطق به شرح زیر تعریف می شوند:
- (1)
-
منفی کاذب: بخشی از ناحیه تغییر که پیش بینی نشده است.
- (2)
-
مثبت کاذب: قسمتی از ناحیه بدون تغییر که پیش بینی شده است.
3: برای کاهش محدوده هدف، خوردگی مورفولوژیکی را روی منفی کاذب و مثبت کاذب انجام دهید.
4: از اجزای متصل برای تقسیم پیکسل های False Negative و False Positive به خوشه های مختلف استفاده کنید و مجموعه های خوشه ای FNSet و FPSet را به دست آورید .
5: اولین N ناحیه بزرگ maxN(FNSet) و maxN(FPSet) FNSet و FPSet را با توجه به تعداد پیکسل ها تعیین کنید.
6: مرکز را در maxN (FNSet) و maxN (FPSet) به عنوان کلیک های مثبت در نظر بگیرید.و کلیک های منفی به ترتیب. |
7: کلیک های مثبت و کلیک های منفی نمونه های آموزشی را به روز کنید.
8: بازگشت کلیک های مثبت و کلیک های منفی . |
در فرآیند آموزش اولیه، چون تصویر مرجعی برای اصلاح وجود ندارد، کلیک های مثبت و منفی را خالی تنظیم می کنیم. پس از تکمیل آموزش مدل نسل اول، تمام نمونه های آموزشی بر این اساس پیش بینی می شوند و نتایج پیش بینی ( شکل 4 a1) با برچسب اصلی ( شکل 4 a2) مقایسه می شود تا قسمتی که واقعا تغییر کرده است، مشخص شود، اما نه پیش بینی شده ( شکل 4 a3)، و بخشی که در واقع بدون تغییر است، اما پیش بینی شده است ( شکل 4 a4). دو قسمت مربوط به قسمت هایی است که برای کلیک های مثبت و منفی باید اصلاح شوند.
سپس برای تصحیح کل جمعیت نقاط در ناحیه مورد تصحیح و اجتناب از وضعیتی که نقاط انتخاب شده در مرز قرار دارند، باید خوردگی مورفولوژیکی را روی ناحیه استخراج شده انجام دهیم و کلیک را اصلاح و باریک کنیم. -محدوده استخراج حکاکی مورفولوژیکی به پیچیدن تصویر اصلی و گرفتن حداقل مقدار محلی اشاره دارد. می تواند ناحیه لکه را از مرز کاهش دهد و لکه های کوچک آواری را از بین ببرد. اندازه هسته کانولوشن مورد استفاده در عملیات اچینگ ما 3×3 است، تعداد تکرارها 3 است و اثر خوردگی در شکل 4 ب نشان داده شده است. شکل 4 b1 نقاط قبل از خوردگی را نشان می دهد و نتایج پس از عملیات خوردگی در شکل 4 نشان داده شده است.b2.
در مرحله بعد، با توجه به اجزای متصل، پیکسل ها در این دو به خوشه های مختلف تقسیم می شوند و N خوشه های بالایی با توجه به تعداد پیکسل ها تعیین می شوند. برای جلوگیری از موقعیتی که در آن خوشه به دلیل اتصال نواحی مختلف بیش از حد بزرگ است، هنگام گرفتن اجزای متصل از الگوریتم seed 4-connected استفاده می کنیم. پس از آن، برای انتخاب سریع مراکز این مناطق، از الگوریتم استخراج مرکز استفاده می کنیم که می تواند سرعت محاسبه و دقت موقعیت را محاسبه کند. ابتدا از الگوریتم Canny [ 32 ] برای استخراج مرز هر نقطه خوشه استفاده می کنیم. پس از استخراج مرز، نقاط مرزی باید در جهت عقربه های ساعت مرتب شوند. نقطه مرکزی میانگین را انتخاب کنید Oاز نقاط مرزی به عنوان نقطه گوشه ثابت و سپس یک نقطه دیگر O”در جهت افقی در سمت چپ Oبرای تولید بردار افقی OO”→. سپس از تمام نقاط مرزی عبور کنید پمن، و تمام زوایای بین را محاسبه کنید OO” →و Oپمن→(معادلات (1) – (3)). در نهایت، پس از مرتب سازی زاویه از کوچک به بزرگ، نقاط مرزی مرتب شده در جهت عقربه های ساعت را می توان به دست آورد.
پس از مرتبسازی نقاط مرزی در جهت عقربههای ساعت، مرکز N ناحیهای که باید اصلاح شوند را میتوان انتخاب کرد. فرض کنید ناحیه ای که باید تصحیح شود، هر چند ضلعی n ضلعی باشد آمن( ایکسمن، yمن) (i = 1,2…,n) به عنوان راس ( شکل 4 ج). مساحت هر مثلث است σمن. مرکز جرم است جیمن( ایکسمن، yمن). مساحت چند ضلعی S است و مرکز آن G(x,y) است. فرمول محاسبه در معادلات (4) – (9) نشان داده شده است.
پس از انتخاب کلیک ها، کلیک های مثبت و منفی هر نمونه با توجه به شعاع مشخصی ایجاد می شود. از آنجایی که دقت نمودار فاصله اقلیدسی معمولی ( شکل 4 d1) به اندازه نقطه جامد با شعاع معین ( شکل 4 d2) [ 22 ] دقیق نیست، آن را بهبود دادیم (معادله (10)) به طوری که رنگ هر کدام مرکز کلیک عمیق ترین است، در امتداد شعاع به سمت بیرون کاهش می یابد و به رنگ پس زمینه در شعاع باز می گردد ( شکل 4 d3). این روش می تواند وزن تاثیر لبه کلیک را کاهش دهد و محدوده اصلاح را دقیق تر کند. آزمایش در بخش 3.2 توضیح داده شده است .
2.3. شاخص ارزیابی
در حال حاضر، شاخص ارزیابی شبکه تشخیص تغییر موجود، که دقت کلی نتایج پیشبینی را از طریق محاسبه چند زاویهای ارزیابی میکند، بهبود یافته است. نشانگرهای دقت تشخیص تغییر متعارف شامل دقت، دقت، فراخوانی و امتیاز F1 است.. دقت نسبت تعداد نمونه های تقسیم شده صحیح به تعداد تمام نمونه ها است. هرچه مقدار دقت بزرگتر باشد، پیکسل های بیشتری به درستی شناسایی می شوند. دقت نسبت تعداد نمونه های مثبت شناسایی شده به تعداد نمونه های مثبت واقعی است. هرچه دقت بالاتر باشد، نمونه های مثبت شناسایی شده توسط مدل دقیق تر است. یادآوری نسبت تعداد نمونه های مثبت شناسایی شده به تعداد کل نمونه های مثبت است. هرچه فراخوان بیشتر باشد، مدل می تواند نمونه های مثبت بیشتری پیدا کند. امتیاز F1 میانگین هارمونیک دقت و یادآوری است که شاخص مهمی برای ارزیابی عملکرد مدل است. هر چه امتیاز F1 بالاتر باشداست، توانایی تشخیص بهتر مدل به عنوان یک کل است. برای محاسبه شاخص های فوق به فرمول های (11)-(14) مراجعه کنید:
که در آن TP تعداد نمونه هایی است که مقدار تشخیص آنها با مقدار واقعی یکسان است و مقدار تشخیص آنها مثبت است، TN تعداد نمونه هایی است که مقدار تشخیص آنها با مقدار واقعی یکسان است و مقدار تشخیص آنها منفی است، FP برابر است با تعداد نمونه هایی که مقدار تشخیص آنها با مقدار واقعی متفاوت است و مقدار تشخیص آنها مثبت است و FN تعداد نمونه هایی است که مقدار تشخیص آنها با مقدار واقعی متفاوت است و مقدار تشخیص آنها منفی است.
با این حال، دقت پیشبینی شبکه ICD را نمیتوان تنها با استفاده از شاخص دقت-ارزیابی شبکه تشخیص تغییر موجود به درستی ارزیابی کرد. از یک طرف، هنگام ارزیابی دقت سیستم، تمام کلیکها به طور خودکار توسط الگوریتم شبیهسازی میشوند و موقعیت تصحیح لزوما مناسب نیست، بنابراین اثر تصحیح محدود است. از سوی دیگر، شبکه ICD با شبکه تشخیص تغییر معمولی متفاوت است. نه تنها باید از صحت نتایج پیشبینی کلی اطمینان حاصل کند، بلکه از اثربخشی توانایی تصحیح کلیک نیز باید اطمینان حاصل کند. با این حال، سیستم ارزیابی صحت موجود فقط می تواند صحت اولی را تأیید کند و دومی را نمی توان به طور مؤثر ارزیابی کرد. برای ارائه یک سیستم ارزیابی دقیق تر برای شبکه ICD،
محدوده تصحیح کلیک به شاخص مورد استفاده برای ارزیابی اثر تصحیح کلیک اشاره دارد که به دو نوع تقسیم می شود: محدوده تصحیح کلیک مثبت و محدوده تصحیح کلیک منفی. آنها برای ارزیابی توانایی اصلاح کلیک های مثبت و منفی استفاده می شوند.
کلیک مثبت برای پر کردن و تصحیح ناحیه تغییر پیش بینی نشده استفاده می شود و موقعیت اصلی اصلاح آن در ناحیه تغییر واقعی است. در این راستا، محدوده تصحیح کلیک را به عنوان نسبت تعداد پیکسل های تغییر یافته جدید اضافه شده در ناحیه تغییر واقعی کلیک اصلاح شده به تعداد واقعی پیکسل های تغییر یافته اصلاح شده تعریف می کنیم، همانطور که در رابطه (15) نشان داده شده است:
جایی که سیلمنجک_منمترپrovهمترهnتیپoسمنتیمنvهمحدوده تصحیح کلیک های مثبت است، N تعداد نمونه ها در تمام مجموعه های اعتبارسنجی است، سیorrهجتیمنon_سیساعتآngه_منnتعداد پیکسل های تغییر یافته در منطقه تغییر واقعی است که کلیک در آن قرار دارد (ناحیه زرد در شکل 5 ج)، Orمنgn_سیساعتآngه_منnتعداد پیکسل های تغییر یافته در ناحیه تغییر واقعی است که کلیک قبل از تصحیح در آن قرار دارد (ناحیه آبی در شکل 5 ب)، و Lآبهل_سیساعتآngهتعداد واقعی پیکسل ها در ناحیه ای است که کلیک در آن قرار دارد ( شکل 5 یک ناحیه سفید). محدوده تصحیح کلیکهای مثبت نشاندهنده توانایی اصلاح کلیکهای مثبت است، یعنی نسبت ناحیهای که باید پس از اصلاح کلیک مثبت اصلاح شود.
- 2.
-
محدوده تصحیح کلیک منفی
یک کلیک منفی برای حذف و تصحیح ناحیه پیش بینی خطا در ناحیه بدون تغییر استفاده می شود و موقعیت اصلاح اصلی در ناحیه بدون تغییر واقعی است. در این راستا، ما محدوده تصحیح کلیک کلیکهای منفی را به عنوان نسبت تعداد پیکسلهای بدون تغییر جدید اضافه شده در ناحیه بدون تغییر واقعی که کلیک اصلاحی در آن قرار دارد به تعداد واقعی پیکسلهای بدون تغییری که باید اصلاح شوند، تعریف میکنیم، همانطور که در معادله نشان داده شده است. (16):
جایی که سیلمنجک_منمترپrovهمترهnتیnهgآتیمنvهمحدوده تصحیح کلیک منفی است، N تعداد نمونهها در تمام مجموعههای اعتبارسنجی است، سیorrهجتیمنon_Unسیساعتآngه_Oتوتیتعداد پیکسل های بدون تغییر در ناحیه بدون تغییر واقعی است که کلیک اصلاحی در آن قرار دارد (ناحیه سیاه در شکل 5 )، Orمنgn_Unسیساعتآngه_Oتوتیتعداد پیکسل های بدون تغییر در ناحیه بدون تغییر واقعی است که کلیک تصحیح قبل از تصحیح در آن قرار دارد (منطقه سیاه در شکل 5 e)، و Lآبهل_Unسیساعتآngهتعداد واقعی پیکسل های بدون تغییر است که کلیک اصلاحی در آن قرار دارد (منطقه سیاه در شکل 5 د). محدوده تصحیح کلیک منفی نشان دهنده توانایی اصلاح کلیک های منفی است، یعنی نسبت ناحیه ای که باید پس از اصلاح کلیک منفی اصلاح شود.
2.4. عملکرد از دست دادن
در تشخیص تغییر، عدم تعادل دسته یک مشکل رایج است، زیرا تفاوت زیادی در مقدار اطلاعات بین اطلاعات بدون تغییر و اطلاعات تغییر یافته در این دو تصویر وجود دارد و اطلاعات تغییر یافته عموماً تنها بخش کوچکی از تمام اطلاعات را به خود اختصاص می دهد. چنین مشکلاتی را می توان با تنظیم تابع ضرر برای دستیابی به تعادل اطلاعات در حال تغییر تنظیم کرد.
ضایعات متوازن دسته ای (BCL) یک بهبود در تابع ضرر مقایسه سنتی است که می تواند اطلاعات بدون تغییر و تغییر یافته را متعادل کند. فرمول محاسبه در معادلات (17) – (19) نشان داده شده است:
جایی که، نجتعداد پیکسل های تغییر یافته است، نتوتعداد پیکسل های بدون تغییر است، LoسسآLLنتیجه ضرر است، Y حقیقت زمین است، D نقشه فاصله، m برابر 2، i شماره ردیف است و 1≤من≤منمترآgه ساعتهمنgساعتتی، j شماره ستون و است 1≤j≤منمترآgه wمندتیساعت، b شماره دسته و 1≤ب≤بآتیجساعت سمنzه.
3. نتایج
3.1. مجموعه داده ها
در ادامه، از مجموعه داده منبع باز WHU [ 33 ] و LEVIR-CD [ 16 ] استفاده می کنیم.] برای آزمایش مجموعه داده ساختمان WHU توسط تیم تحقیقاتی دانشگاه ووهان پیشنهاد شده است. داده ها تصاویر هوایی هستند که در سال های 2011 و 2016 به دست آمده اند. منطقه آزمایشی کرایست چرچ، نیوزیلند است. مساحت کل تصویر 20.5 کیلومتر مربع و وضوح 0.2 متر است. از آنجایی که تصویر اصلی برای ورود مستقیم به مدل یادگیری عمیق بسیار بزرگ است، تصویر اصلی به اندازههای 256 × 256 برش داده میشود و سپس 7431 جفت نمونه به دست آوردیم. با این حال، به دلیل برش تصویر اصلی، نسبت نمونه های مثبت (نمونه دارای تغییر ویژگی زمین) و منفی (نمونه بدون تغییر ویژگی زمین) شکسته شده است. طبق آمار، 5541 نمونه منفی وجود دارد، در حالی که نمونه های مثبت تنها 1890 مورد است.
از آنجایی که تعداد کل نمونه ها پس از پردازش به طور قابل توجهی کاهش یافت، داده ها را افزایش دادیم، به طور تصادفی همه نمونه ها را با چرخش 90 درجه، 180 درجه و 270 درجه در جهت عقربه های ساعت تبدیل کردیم و در مجموع 7086 نمونه به دست آوردیم. در نهایت، نمونهها را بهصورت تصادفی به مجموعه آموزشی، مجموعه تأیید و مجموعه آزمون تقسیم کردیم و 4960 نمونه آموزشی، 1417 نمونه تأیید و 709 نمونه آزمایش بهدست آمد. اطلاعات اولیه داده ها در جدول 1 نشان داده شده است و داده های نمونه جزئی بریده شده در شکل 6 نشان داده شده است.
مجموعه داده های تشخیص تغییر ساختمان LEVIR-CD توسط تیم دانشگاه هوانوردی و فضانوردی پکن پیشنهاد شده است. بازه زمانی داده ها از سال 2002 تا 2018 است و منطقه آزمایشی 20 منطقه مختلف در تگزاس است. با توجه به بازه زمانی زیاد داده ها و تغییرات فصلی زیاد، «تغییرات شبه» زیادی ناشی از عوامل رشد طبیعی در مجموعه داده ها وجود دارد. تصویر اصلی نیز به اندازه 256 × 256 برش داده شد و سپس 10192 جفت نمونه به دست آوردیم. برای حفظ نسبت نمونه مثبت و منفی 4:1، تمام نمونه های مثبت (4538 جفت) را استخراج و تعداد مناسبی از نمونه های منفی (1135 جفت) را به طور تصادفی از بین نمونه های منفی انتخاب کردیم.
ما همچنین داده ها را افزایش دادیم، به طور تصادفی همه نمونه ها را با چرخش 90 درجه، 180 درجه و 270 درجه در جهت عقربه های ساعت تبدیل کردیم و در مجموع 11376 نمونه به دست آوردیم. در نهایت نمونه ها را به صورت تصادفی به مجموعه آموزشی، مجموعه تایید و مجموعه تست بر اساس 7:2:1 تقسیم کردیم و 7942 نمونه آموزشی، 2269 نمونه تایید و 1135 نمونه تست به دست آمد. اطلاعات اولیه داده ها در جدول 2 و داده های نمونه جزئی بریده شده در شکل 7 نشان داده شده است.
3.2. تست دقت
در این بخش، آزمایشهای ابلیشن را روی شبکههای ICD انجام دادیم. ما آزمایشهایی را بر روی مجموعه داده WHU و مجموعه داده LEVIR-CD روی شبکه با استفاده از نقاط گرادیان بدون استخراج ویژگی ثانویه (Gradient_No_Res)، با استفاده از شبکه از نقاط جامد با استخراج ویژگی ثانویه (Disc_Res) و شبکه با استفاده از نقاط گرادیان با استخراج ویژگی ثانویه انجام دادیم. (Gradient_Res)، و ما شاخصهای دقت را زیر 0، 1، 5 و 10 کلیک در آزمایش ارزیابی کردیم.
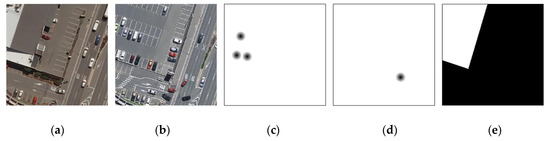
مجموعه داده اصلی شامل سه پوشه A، B و Label است که مربوط به تصویر فاز 1، تصویر فاز 2 و برچسب تغییر ساختمان واقعی است ( شکل 8 a,b,e). بر این اساس، ما دو پوشه جدید C و D را که مربوط به کلیک های مثبت و منفی هستند اضافه کردیم ( شکل 8 c,d). قبل از شروع آموزش، باید کلیک ها را مقداردهی اولیه کنیم، که به معنای تولید برچسب سفید خالص تک کانال مربوطه است. در فرآیند آموزش، هر نسل جدید کلیک های مثبت و منفی نمونه های فعلی را به روز می کند. زمانی که کلیک های تمامی نمونه های آموزشی به روز شد، دوره بعدی آموزش شروع می شود.
بر اساس چارچوب یادگیری عمیق PyTorch، ما تمام داده ها و کدهای آموزشی را در یک واحد با سرور سیستم Ubuntu16.04.4 مستقر کردیم. پردازنده سرور Core i7-8700k، حافظه 32 G، حافظه ویدیویی GTX2080Ti-12G و دارای چهار کارت گرافیک مستقل NVIDIA 2080Ti-GPU است. در فرآیند آموزش مدل، نرخ یادگیری را 1 × 10-4 قرار می دهیمو نسل های تکرار تا 200. پس از آموزش، دقت مدل را با 0، 1، 5 و 10 کلیک مثبت و منفی آزمایش کردیم. در طول تست، مرکز 10 ناحیه اول را که باید تصحیح شوند، به عنوان محل کلیک انتخاب می کنیم. اگر تعداد مناطقی که باید اصلاح شوند کمتر از 10 باشد، به اولین ناحیه بزرگی که باید اصلاح شود برمی گردیم و پس از انتخاب تمام مراکز نواحی اصلاح شده، به انتخاب نقاط ادامه می دهیم. با توجه به اصل به حداقل رساندن فاصله بین آخرین نقطه و نقطه انتخاب شده در منطقه و تمام نقاط مرزی، نقاط باقی مانده در مناطق باقی مانده انتخاب شدند. نتایج تجربی در جدول 3 نشان داده شده است.
با توجه به نتایج تجربی، دقت Gradient_Res باید بهتر از Gradient_No_Res و Disc_Res باشد. با افزایش تعداد کلیکها، امتیاز F1 Gradient_Res در WHU و LEVIR-CD میتواند به ترتیب 4.3% و 4.2% افزایش یابد، که ثابت میکند که دقت پیشبینی-نتیجه را میتوان تا حد زیادی از طریق تعامل کاربر بهبود بخشید. برای محدوده تصحیح کلیک، با افزایش تعداد کلیک ها، مقدار محدوده تصحیح کلیک پایدارتر می شود. هنگامی که تعداد کلیک ها به 10 می رسد، محدوده تصحیح کلیک مثبت (CR_positive) Gradient_Res در WHU و LEVIR-CD به ترتیب 0.779 و 0.815 است، که نشان می دهد یک کلیک مثبت متوسط می تواند 80٪ از حفره های تشخیص را در ناحیه مربوطه پر کند. ، در حالی که محدوده تصحیح کلیک منفی مربوطه (CR_negative) 0.546 و 0.655 است،
تفاوت بین Disc_Res و Gradient_Res در این است که کلیکهای استفاده شده توسط اولی نقاط جامد هستند، در حالی که کلیکهایی که توسط دومی استفاده میشوند، نقاط گرادیان هستند. با توجه به نتایج تجربی، توانایی تصحیح کلیک Gradient_Res بهتر از Disc_Res است. امتیاز F1 Disc_Res در WHU و LEVIR-CD در مقایسه با Gradient_Res به ترتیب 3.4% و 2.9% افزایش می یابد که باید به ترتیب 0.9% و 1.3% کمتر باشد. از نظر محدوده تصحیح کلیک، محدوده تصحیح کلیک مثبت Disc_Res در WHU و LEVIR-CD به ترتیب 0.876 و 0.835 است که بالاتر از Gradient_Res 0.097 و 0.020 است و محدوده تصحیح کلیک منفی 0.507 و 0 است. به ترتیب، که از Gradient_Res 0.039 و 0.123 کمتر هستند. اگرچه تفاوت کمی در شاخص های مختلف بین دو روش وجود دارد، اما در فرآیند استفاده واقعی، قابلیت تصحیح کلیک Disc_Res به اندازه Gradient_Res پایدار نیست. چه یک کلیک مثبت یا یک کلیک منفی، دامنه تاثیر کلیک های آن بیشتر از Gradient_Res است (شکل 9 b1-b6,c1-c6. بنابراین، در مورد همان شعاع، توانایی تصحیح نقطه گرادیان بالاتر از نقطه جامد است.
از نظر ساختاری Gradient_Res بهتر از Gradient_No_Res است و تفاوت آنها در این است که اولی دارای یک عملیات استخراج ویژگی ResNet اضافی در ماژول کلیک فیوژن است. با توجه به نتایج تجربی، توانایی تصحیح کلیک Gradient_Res بهتر از Gradient_No_Res است. امتیاز F1 Gradient_No_Res در WHU و LEVIR-CD در مقایسه با Gradient_Res به ترتیب 1.4% و 0.9% افزایش می یابد که به ترتیب باید 2.9% و 3.3% کمتر باشد. از نظر محدوده تصحیح کلیک: محدوده تصحیح کلیک مثبت Gradient_No_res در WHU و LEVIR-CD به ترتیب 0.352 و 0.495 است که کمتر از Gradient_Res 0.427 و 0.320 است و محدوده تصحیح کلیک منفی به ترتیب 0.355 و 0.47 است. که کمتر از Gradient_Res 0.191 و 0.179 هستند. آنها فاصله بسیار واضحی بین امتیاز F1 و محدوده تصحیح کلیک دارند. در فرآیند استفاده واقعی، اثر تصحیح Gradient_No_Res به مراتب کمتر از Gradient_Res است. به طور خاص، محدوده تصحیح کلیک مثبت باریک و نادرست است (شکل 9 d3)، و تصحیح کلیک منفی ناقص است ( شکل 9 d6). با این حال، پس از افزودن استخراج ویژگی ثانویه، توانایی تصحیح آن تا حد زیادی بهبود خواهد یافت. به طور خاص، کلیکهای مثبت میتوانند بهطور خودکار ناحیه مورد اصلاح را تکمیل کنند (( شکل 9 b3)، و کلیکهای منفی میتوانند به طور موثر تکههای چسب را جدا کنند ( شکل 9 b6). بنابراین، استخراج ویژگی ثانویه در ماژول همجوشی کلیک میتواند باعث بهبود قابلیت تصحیح کلیک ها
به طور خلاصه، Gradient_Res که از نقاط گرادیان و استخراج ویژگی های ثانویه استفاده می کند، ساختار شبکه بهینه است و کاربران می توانند به طور موثر منطقه را با افزودن کلیک های مثبت و منفی تغییر دهند. نتایج آزمایش مجموعه داده LEVIR-CD تحت شبکه ICD در شکل 10 نشان داده شده است ، که در آن تمام نواحی تغییر یافته با یک کادر قرمز مشخص شده اند و ماسک اصلی، ماسک نتیجه و برچسب نشان دهنده نتیجه پیش بینی اولیه است، نتیجه تصحیح کلیک کنید و برچسب تغییر واقعی، به ترتیب. شکل 10 a6-c6) تأثیر استفاده از کلیکهای مثبت را نشان میدهد تا خانههایی که به طور کامل پیشبینی نشدهاند، پیشبینی کامل را به دست آورند، که نشان میدهد یک کلیک مثبت میتواند به طور مؤثر جای خالی پیشبینی را پر کند. شکل 10b6,d6 اثر تقسیم بندی با کلیک منفی جزئی را بر روی خانه های چسب دار نشان می دهد. مشاهده میشود که کلیکهای منفی در شکل میتواند شکافهای بین خانهها را بدون تأثیر بر شکل خانهها تقسیم کند.
4. بحث
4.1. بحث در مورد آزمایش
ما یک شبکه تشخیص تغییر تعاملی (ICD) را بر اساس یادگیری عمیق پیشنهاد کردیم. با افزودن وزن کلیک به لایه فاصله شبکه تشخیص تغییر، شبکه می تواند مداخله تعامل خارجی را برای دستیابی به اثر بازنگری در نتایج پیش بینی اولیه بپذیرد. می تواند دقت نتیجه پیش بینی را بهبود بخشد و بار کاری مداخله انسانی را کاهش دهد. در مقایسه با شبکه اصلی تشخیص تغییر، کاربران فقط باید تعداد کمی کلیک مثبت و منفی اضافه کنند تا نتایج دقت بالاتری نسبت به شبکه اصلی داشته باشند.
از نظر ساختار شبکه، ماژول کلیک-فیوژن را با اشاره به شبکه تقسیمبندی تعاملی یک ساختار تک جریانی طراحی کردیم، کلیکهای مثبت و منفی را در نقشه فاصله شبکه تشخیص تغییر جریان دوگانه ادغام کردیم و تفاوت ایجاد شده را مقایسه کردیم. با انجام استخراج ویژگی ثانویه پس از ادغام کلیک ها. با توجه به نتایج تجربی، ماژول کلیک-فیوژن برای استخراج ویژگی ثانویه دارای توانایی تصحیح بهتری است، که نشان می دهد عملیات استخراج ویژگی بیشتر در لایه ویژگی می تواند اثر تصحیح کلیک ها را بهبود بخشد.
از نظر روش ترسیم کلیک، روش ترسیم کلیک موجود را بهبود دادیم و آن را روی مجموعه داده منبع باز WHU و مجموعه داده خانگی LEVIR-CD آزمایش کردیم. با توجه به نتایج تجربی، در مورد همان شعاع، اثر تصحیح کلی نقطه گرادیان بهتر از نقطه جامد است و پایداری تصحیح اولی بالاتر از دومی است.
ما از ساختار مدل بهینه برای آزمایش WHU و LEVIR-CD استفاده کردیم. نتایج نشان میدهد که امتیاز F1 مدل در WHU و LEVIR-CD میتواند به ترتیب 4.3 و 4.2 درصد افزایش یابد. محدوده تصحیح کلیک مثبت و منفی به ترتیب 0.779 و 0.815 و 0.546 و 0.655 است. این نشان میدهد که افزودن کلیکها میتواند به طور موثری دقت تشخیص را بهبود بخشد و ناحیه مورد اصلاح را اصلاح کند. علاوه بر این، دامنه تصحیح کلیک مثبت دو مدل بیشتر از دامنه اصلاح کلیک منفی است، بنابراین توانایی اصلاح کلیکهای مثبت قویتر از کلیکهای منفی است. علاوه بر این، ناحیه ای که باید از کلیک های منفی اصلاح شود معمولاً در مرز ناحیه تغییر واقعی قرار دارد.
4.2. سناریوی کاربردی
شبکه تشخیص تغییر تعاملی که ما پیشنهاد کردیم میتواند در بسیاری از سناریوها مانند تصحیح سریع نتایج پایش منابع طبیعی و تولید کارآمد نمونههای تشخیص تغییر استفاده شود. در سناریوهای تجاری واقعی مانند نظارت بر منابع طبیعی، به دلیل گستره وسیع وصله های نظارتی و تفاوت رنگ زیاد بین تصاویر، برای نتایج تشخیص تغییر مرسوم برای برآورده کردن استانداردهای کاربردی دشوار است. اغلب شامل تشخیص نادرست و عدم شناسایی نقاط نقشه است. اگر قرار است مورد استفاده قرار گیرد، باید به صورت دستی اصلاح شود. تصحیح دستی به عملیاتی مانند پر کردن سوراخ در وصله برداری، ترسیم مرز اشتباه، قطعهبندی وصله متصل و حذف پچ اشتباه نیاز دارد ( شکل 11).) یعنی کل فرآیند اصلاح نیاز به نیروی انسانی و زمان قابل توجهی دارد. با این حال، تشخیص تغییر تعاملی می تواند این فرآیندها را به طور موثر ساده کند و کاربر برای تکمیل تصحیح فقط باید کلیک هایی را به قسمت های خطا اضافه کند. بنابراین، شبکه تشخیص تغییر تعاملی میتواند به طور موثری کارایی تصحیح حاصل از روش تشخیص تغییر را بر اساس یادگیری عمیق در تجارت نظارت بر منابع طبیعی واقعی بهبود بخشد. علاوه بر این، برای تصحیح سریع نتایج تشخیص، از شبکه تعاملی تشخیص تغییر نیز می توان در تولید نمونه تشخیص تغییر استفاده کرد. میتوانیم برای تصحیح نتایج تشخیص تغییر با نقصهای جزئی کلیک کنیم و نتایج تصحیحشده میتوانند به عنوان نمونههای جدید تشخیص تغییر استفاده شوند.
4.3. جهت کمبود و بهبود آینده
اگرچه ICD می تواند الگوهای اشتباه را به طور موثر تصحیح کند، اما همچنان مشکلاتی دارد. به عنوان مثال، زمانی که کاربر کلیکهایی را در مکانی نادرست اضافه میکند، ممکن است تأثیر منفی بر نتیجه تشخیص داشته باشد. همانطور که در شکل 12 b1-b3 نشان داده شده است، هنگامی که کاربر کلیک های مثبت را به ناحیه بدون تغییر اضافه می کند، یک قضاوت نادرست دایره ای در مقیاس کوچک در موقعیت مربوطه رخ می دهد. در حالی که در شکل 12 c1-c3، اگر کاربر کلیک های منفی را به ناحیه تغییریافته اضافه کند، تصحیح خطا دشوار است، که نشان می دهد تأثیر کلیک های مثبت بیشتر از کلیک های منفی است. علاوه بر این، زمانی که ناحیه تصحیح در مرز پچ قرار دارد، اگر موقعیت کلیک دقیق نباشد، شکل مرز تحت تأثیر قرار میگیرد ( شکل 12).b4-b6 نتایج تصحیح دقیق را نشان می دهد، در حالی که شکل 12 c4-c6 نتایج تصحیح نادرست را نشان می دهد. بنابراین، اثر تصحیح ICD تا حدی به قضاوت کاربر بستگی دارد. اگر موقعیت کلیک نادرست یا نادرست باشد، تصحیح نتیجه تشخیص برای شبکه دشوار است.
علاوه بر این، در طول آزمایش، دستگاه به طور خودکار مرکز ناحیه مورد نظر را به عنوان مرکز کلیک ها در نظر می گیرد. در عملیات واقعی، کاربر با توجه به وضعیت واقعی کلیک را انتخاب می کند، یعنی ممکن است در برخی مناطق کلیک های دقیق تری وجود داشته باشد. بنابراین، اثر تصحیح نقاط انتخاب شده اغلب بهتر از تأثیر نقاط انتخاب شده توسط دستگاه است و دقت تصحیح در استفاده واقعی بالاتر از نتیجه آزمایش است.
بنابراین در تحقیقات آتی دو جهت بهبود خواهیم داشت. یکی این است که عملکرد کلیک را بهینه کنید تا در هنگام کلیک کردن در موقعیت اشتباه، روی نتایج تشخیص صحیح اصلی تأثیری نداشته باشد. مورد دیگر بهینه سازی الگوریتم انتخاب نقطه موجود است تا بتواند موقعیت تصحیح را با دقت بیشتری انتخاب کند و نتایج محاسبه شده در راستیآزمایی دقت مدل به وضعیت واقعی نزدیکتر باشد که نقطه به صورت دستی انتخاب شود.












بدون دیدگاه