

هدف جریان های ترافیکی (مانند ترافیک وسایل نقلیه، مسافران و دوچرخه ها) آشکارسازی پدیده های جریان ترافیکی است که توسط مشارکت کنندگان ترافیک در فعالیت های ترافیکی ایجاد می شود. مطالعات مختلف در مورد جریان های ترافیکی به شدت بر داده های ترافیکی با کیفیت بالا متکی هستند. دادههای مسیر GPS تاکسی دادههای موقعیت مکانی هستند که شامل طول جغرافیایی، طول جغرافیایی و زمان میشوند. این دادهها برای تحلیل جریان ترافیک، برنامهریزی، طرحبندی زیرساختها و توصیههایی برای ساکنان شهری حیاتی هستند. یک نقشه شهر را می توان با توجه به مختصات طول و عرض جغرافیایی به شبکه های متعدد تقسیم کرد و داده های جریان ترافیک مسافران را که از داده های مسیر تاکسی به دست می آید استخراج کرد. با این حال، داده های تصادفی از دست رفته به دلیل آب و هوا و خرابی تجهیزات رخ می دهد. بنابراین، انتساب مؤثر دادههای جریان ترافیک از دست رفته یک موضوع داغ است. این مطالعه مدل شبکه انتساب متخاصم مولد فضایی-زمانی (ST-GAIN)را برای حل الحاق جریان مسافران ترافیکی پیشنهاد میکند. یک بازی خصمانه با چندین ژنراتور و یک تمایز ایجاد می شود. مولد برخی از اجزای بردار داده ترافیک منطقه ای و دامنه زمانی را که از شبکه استخراج می شود مشاهده می کند. این به طور موثر مقادیر از دست رفته دادههای جریان ترافیک مکانی-زمانی مسافر را نسبت میدهد. دادههای تجربی، دادههای دقیق مسیر تاکسی کونمینگ هستند، و نتایج تجربی نشان میدهد که روش پیشنهادی از پنج روش پایه در مورد دقت انتساب بهتر عمل میکند. قابل توجه است و امکان استفاده مؤثر از مدل را برای پیشبینی جریان مسافر در برخی مناطق که دادههای ترافیکی به دلایلی نمیتوان جمعآوری کرد یا دادههای ترافیکی بهطور تصادفی گم شده است را پیشنهاد میکند.
کلید واژه ها:
شبکه ترافیک شهری ; انتساب داده ها ; باز شدن تانسور یادگیری عمیق ؛ شبکه متخاصم مولد ; بازیابی جریان ترافیک
1. مقدمه
با توجه به توسعه سریع حمل و نقل هوشمند، مقادیر زیادی از دادههای جریان ترافیک مکانی-زمانی ارزشمند، از جمله دادههای مسیر GPS برای تاکسیها، اتوبوسها و موتورسیکلتهای مشترک تولید میشوند [ 1 ]. چندین محقق داده های مسیر عظیم را برای ارزیابی جریان های ترافیکی مختلف و شرایط لحظه ای جاده در یک منطقه یا دوره خاص تجزیه و تحلیل کرده اند. الگوهای سفر ساکنان شهری برای هدایت برنامه ریزی حمل و نقل شهری، ساخت زیرساخت ها و مصرف مورد بررسی قرار گرفته است [ 2 ]. با این حال، داده های مسیر ممکن است به دلیل شرایط آب و هوایی، خرابی سیستم موقعیت یابی، و انسداد ساختمان دارای مقادیر گم شده باشند که در نتیجه داده های جمع آوری شده ناقص است که ممکن است تجزیه و تحلیل و مدیریت ترافیک را گمراه کند.
ایجاد کمبود در داده های ترافیکی یک پدیده رایج است. محققان معمولاً متغیرهایی را بدون مقادیر از دست رفته به عنوان متغیرهای کامل و با مقادیر گمشده به عنوان متغیرهای ناقص معرفی می کنند. سه نوع مشکل داده های از دست رفته شناسایی شده است [ 3]: (1) به طور تصادفی از دست رفته (MCAR) به این معنی است که دلیل گم شدن داده ها به داده ها (متغیرهای ناقص و کامل) مربوط نمی شود. (2) گم شدن به صورت تصادفی (MAR) نشان می دهد که نبود داده کاملاً تصادفی نیست و به سایر متغیرهای کامل بستگی دارد. و (3) از دست رفتن تصادفی نیست (MNAR) به این معنی است که داده های از دست رفته در متغیر ناقص به متغیر ناقص بستگی دارد. تغییرات در داده های جریان ترافیک در مناطق مجاور می تواند بر یکدیگر تأثیر بگذارد. به عنوان مثال، جریان ترافیک در یک منطقه مجاور یک منطقه داده از دست رفته تحت تأثیر قرار می گیرد. همانطور که در شکل 1 الف نشان داده شده است، مقدار جریان از دست رفته بخش جاده س3در دوره تی4با مقدار جریان بخش جاده مجاور همبستگی دارد س2و س3در دوره تی4. جریان ترافیک در حوزه زمانی قبلی در یک منطقه خاص بر دامنه زمانی بعدی در منطقه تأثیر می گذارد. همانطور که در شکل 1 ب نشان داده شده است، عدم وجود جریان در دوره های پیوسته تی4و تی5در بخش جاده س1مربوط به جریان در دوره ها است تی1به تی3. بنابراین، داده های جریان ترافیک در اکثر موارد MAR هستند. برای دستیابی به حمل و نقل هوشمند در مناطق شهری، استفاده از روش انتساب داده ها و تجزیه و تحلیل همبستگی داده های جریان ترافیک گمشده بسیار مهم است.
انتساب داده راهی برای مقابله با مقادیر گمشده در یک مجموعه داده است که معمولاً از همبستگی عناصر شناخته شده در مجموعه داده برای استنباط و پر کردن مقادیر گمشده و بهبود کیفیت مجموعه داده برای به دست آوردن نتایج بهتر و دقیقتر از تجزیه و تحلیل دادهها استفاده میکند [ 4 ]. . تکنیک های زیادی برای حل داده های مختلف جریان ترافیک گمشده پیشنهاد شده است. بیشتر روش های انتساب داده های ترافیکی از همبستگی مکانی، زمانی یا مکانی-زمانی بین داده ها استفاده می کنند. چندین روش آماری [ 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 , 13] و مدل هایی پیشنهاد شده است. آماری که معمولاً برای انتساب استفاده می شود شامل میانگین، میانگین وزنی یا میانه برای داده های عددی و مقدار بزرگترین دسته برای داده های طبقه بندی می شود. برخی از مدل های پیش بینی [ 14 ، 15 ، 16 ، 17 ، 18 ] با استفاده از اطلاعات مقادیر موجود، مقدار گمشده را پیش بینی می کنند. مدلهای رگرسیون [ 19 ، 20 ، 21 ، 22 ، 23 ] برای انتساب متغیرهای عددی و مدلهای طبقهبندی استفاده میشوند [ 24 ، 25 ] استفاده می شود.] برای متغیرهای طبقه بندی استفاده می شود. محققان از همبستگی مکانی-زمانی داده های ترافیک برای ساختن یک مدل انباشت تانسور جریان مرتبه سوم استفاده کرده اند. تانسور با ابعاد مکانی و زمانی برای فاکتورسازی تانسور [ 26 ] برای مقدار گمشده استفاده شده است. اکثر محققان از تانسورهای جریان برای جفت کردن همبستگیهای مکانی-زمانی [ 27 ، 28 ، 29 ] دادههای ترافیک استفاده کردهاند و دریافتند که دادههای گمشده با استفاده از فاکتورسازی تانسور نسبت به اکثر روشهای مبتنی بر آماری برتری دارد. تکنیکهای یادگیری ماشین، بهویژه مدلهای یادگیری عمیق شبکههای عصبی، در سالهای اخیر به طور فزایندهای برای محاسبه دادههای ترافیک از دست رفته مورد استفاده قرار گرفتهاند و نتایج خوبی ارائه میدهند [ 30 ]]. یون و همکاران [31 ] ابتدا از یک مدل شبکههای متخاصم مولد (GAN) [ 32 ] برای انتساب دادهها استفاده کرد و مدل شبکههای انتساب متخاصم مولد (GAIN) را پیشنهاد کرد، که به دقت انتساب بالایی در مقادیر گمشده در بردار داده دست یافت.
روشهای آماری اغلب از سوابق تاریخی دادههای ترافیک استفاده میکنند تا مقادیر از دست رفته را درج کنند، که نمیتوانند عمیقاً همبستگیهای مکانی و زمانی دادههای ترافیک را بررسی کنند و بنابراین عملکرد پایینتری دارند. روشهای مدلسازی از تجزیه تانسور یا یادگیری عمیق برای استخراج همبستگی بین دادههای ترافیک از ابعاد مختلف استفاده میکنند که معمولاً نتایج بهتری نسبت به روشهای آماری به دست میآورد. روش مدل مبتنی بر یادگیری عمیق نسبت به روش های تجزیه مدل آماری و تانسوری عملکرد بهتری داشته است. اگرچه یادگیری عمیق در مقایسه با سایر روشها برای دادههای جریان ترافیک از دست رفته به خوبی عمل میکند، محققان هنوز با مشکل عدم استفاده کامل از اطلاعات ویژگی همبستگی بین زمان مجاور و فضای مجاور دادههای جریان ترافیک مواجه هستند. به ویژه، هنگام ساخت تانسور جریان،
در این مقاله، با هدف مسئله گم شدن تصادفی در تانسور جریان، یک الگوریتم انتساب جریان مسافر ترافیک تحت فرض MAR پیشنهاد میکنیم. ما نقاط دریافت را در دادههای مسیر GPS تاکسی برای ساخت تانسور جریان مسافر استخراج میکنیم ن∈آرمن×j×سدر یک دوره پیوسته از ناحیه یکنواخت تقسیم شده؛ من*jنشان دهنده تقسیم شبکه ای منطقه مورد مطالعه است. داده ها در هر شبکه نشان دهنده دوره زمانی جاری (تقسیم دوره زمانی، به عنوان مثال، 11:00 تا 12:00 به عنوان یک دوره زمانی)، تعداد نقاط تحویل در این منطقه به عنوان جریان مسافر ترافیک در نظر گرفته می شود، و همچنین وضعیت جریان ترافیک. نتغییر جریان را در طول زمان در دوره های زمانی متوالی در داخل توصیف می کندمن*jمناطق. توزیع ترافیک در نقاط حمل و نقل در داده های مسیر GPS تاکسی نشان دهنده تغییرات جریان ترافیک در یک منطقه است. همانطور که در نشان داده شده است شکل 2 نشان داده شده است، یک دوره نمایندگی سه روزه (7، 10، 12، سپتامبر 2019) را در بخشی از منطقه تحقیقاتی انتخاب می کنیم و توزیع نقاط برداشت و رها کردن را در شبکه جغرافیایی واقعی تجسم می کنیم که نشان می دهد انتخاب نقاط سقوط و صعود تصادفی هستند و نقاط سقوط متمرکز تر از نقاط تحویل هستند. تعداد نقاط دریافت در هر شبکه نه تنها پراکنده تر است، بلکه نقاط انتقال منطقه ای نیز بیشتر جریان می یابد که منعکس کننده توزیع تقاضای جریان مسافر است. بنابراین، انتخاب جریان نقاط دریافت میتواند توزیع تصادفی تقاضای مسافر در منطقه را با دقت بیشتری شبیهسازی کند. این توزیع تصادفی باعث میشود که بیشتر شبکههایی که تقسیم میکنیم دارای تعداد معینی از مقادیر جریان باشند، با اجتناب از این که فقط بخش کوچکی از شبکهها دارای مقادیر جریان باشند. منجر به توزیع بیش از حد متمرکز مقادیر جریان در شبکه ها می شود، بنابراین استخراج همبستگی مکانی-زمانی جریان مسافر را دشوار می کند. ما با معرفی و بهبود ایده انتساب دادهها در شبکه GAIN، مدل ST-GAIN بر اساس ویژگیهای مکانی-زمانی را پیشنهاد میکنیم. مشکل جایگزینی داده های از دست رفته در تانسور جریان با به حداقل رساندن تابع تلفات به یک مشکل تولید داده تبدیل می شود. بهبود این مدل به شرح زیر است: مشکل جایگزینی داده های از دست رفته در تانسور جریان با به حداقل رساندن تابع تلفات به یک مشکل تولید داده تبدیل می شود. بهبود این مدل به شرح زیر است: مشکل جایگزینی داده های از دست رفته در تانسور جریان با به حداقل رساندن تابع تلفات به یک مشکل تولید داده تبدیل می شود. بهبود این مدل به شرح زیر است:
(1) مدل جدید همبستگی مکانی-زمانی بردار داده جریان را مشاهده می کند. تانسور جریان با استفاده از حالتهای مختلف در ماتریسهای جریان مختلف باز میشود. ژنراتورهای چندگانه با پارامترهای وزنی مختلف برای شبیه سازی مولفه های برداری در ماتریس های جریان مختلف استفاده می شود. ماتریس جریان برای به دست آوردن یک تانسور جریان جدید بازیابی می شود. نتایج تجربی نشان میدهد که ST-GAIN میتواند دادههای از دست رفته را جایگزین کند و نتیجهای نزدیک به توزیع جریان ترافیک مکانی-زمانی واقعی مسافران ایجاد کند.
(2) به عنوان بخشی از تابع بهینهسازی هدف، یک ضرر همبستگی سفارشی به آیتم ضرر مدل ST-GAIN اضافه میکنیم. نتایج آزمایشهای فرسایش نشان میدهد که این عبارت از دست دادن همبستگی عملکرد انتساب مدل را بهبود میبخشد.
بقیه این مقاله به شرح زیر سازماندهی شده است. بخش 2 کار مرتبط را مرور می کند و انگیزه مطالعه را توضیح می دهد. بخش 3 روش ST-GAIN پیشنهادی را شرح می دهد. بخش 4 مجموعه داده های تجربی، روش ارزیابی و نتایج تجربی را ارائه می دهد. بخش 5 مقاله را به پایان می رساند و موضوعاتی را برای تحقیقات بیشتر پیشنهاد می کند.
2. بررسی ادبیات
در حال حاضر، روشهای انتساب محققین برای دادههای جریان ترافیک گمشده در فضا و زمان عمدتاً شامل روشهای انتساب بر اساس آمار، روشهای انتساب بر اساس مدلهای فاکتورسازی تانسور و روشهای انتساب بر اساس مدلهای یادگیری عمیق است.
2.1. انتساب داده ها بر اساس روش های آماری
مازومدر و همکاران [ 5 ] یک روش ماتریس کامل را پیشنهاد کرد که از یک الگوریتم محدب برای به حداقل رساندن خطای بازسازی در هنجار هسته استفاده میکرد تا مقادیر گمشده در تکمیل ماتریس را درک کند. رویستون و وایت [ 6 ] یک انتساب چندگانه توسط معادله زنجیره ای (MICE) را پیشنهاد کردند که از رگرسیون خطی برای انجام انتساب چندگانه بر روی داده های ناقص استفاده می کرد. استخوون و همکاران [ 7 ] یک روش انتساب تکراری (missForest) را بر اساس یک جنگل تصادفی پیشنهاد کرد. شی و همکاران [ 8 ] یک تحلیل مولفه اصلی بیزی و روش حداقل مربعات محلی را برای تخمین مقادیر گمشده پیشنهاد کرد. شا و همکاران [ 9] یک روش ترکیبی برای انتساب داده های ترافیک گمشده بر اساس C-means فازی (FCM) پیشنهاد کرد [ 10 ] پیشنهاد کرد که با ترکیب با سایر روش های تکمیل بهینه شده است. تأثیر حالتهای چندگانه دادههای جریان ترافیک در نظر گرفته میشود. هونگ و همکاران [ 11 ] از روش هموارسازی نمایی و روش وزن دهی داده های خطوط مجاور برای ترمیم مشکل گمشده در داده های جریان ترافیک استفاده کرد. سونگ و همکاران [ 12 ] از یک رویکرد یادگیری تطبیقی برای یادگیری یک مدل رگرسیون احتمالی برای هر تاپل داده استفاده کرد و هر تاپل از مدل رگرسیون مربوطه برای پیشبینی مقادیر از دست رفته استفاده کرد. تانگ و همکاران [ 13] یک مدل ترکیبی پیشنهاد کرد که سیستم استنتاج فازی مبتنی بر شبکه تطبیقی و مجموعه ناهموار فازی را ترکیب میکند تا دادههای ترافیکی گمشده را نسبت دهد.
جریان ترافیک گمشده بر اساس روش های آماری از داده های تاریخی برای محاسبه مقادیر گمشده فعلی استفاده می کند. عملکرد این روش ها به تخمین پیشینی توزیع داده در مجموعه داده بستگی دارد. با این حال، در بسیاری از موارد، توزیع واقعی دادههای جریان ترافیک ناشناخته است، که منجر به عملکرد انتساب ضعیف میشود.
2.2. انتساب داده ها بر اساس مدل های فاکتورسازی تانسور
تان و همکاران [ 19 ] برای اولین بار یک روش انتساب داده ترافیک مبتنی بر تانسور را پیشنهاد کرد. بر اساس ایده تانسورهای جفت شده، ژو و همکاران. [ 27 ] یک روش انتساب بهبود یافته بر اساس ماتریس جفت شده و فاکتورسازی تانسور (CMTF) برای بازیابی داده های ترافیک گمشده پیشنهاد کرد. وو و همکاران [ 33 ] یک چارچوب فاکتورسازی تانسور بهبود یافته CP (CANDECOMP/PARAFAC) را پیشنهاد کرد که عملکرد انتساب دادههای با نرخ از دست رفته بالا را تا حد زیادی بهبود بخشید. لی و همکاران [ 28 ] از مدل تکمیل تانسور برای محاسبه داده های ترافیک گمشده استفاده کرد که به طور غیرمستقیم مدل پیش بینی جریان ترافیک را بهبود بخشید. کای و همکاران [ 29] از نقاط حساس شهری برای معرفی اطلاعات مربوطه برای محاسبه در مناطق گمشده بر اساس CMTF استفاده کرد. یان و همکاران [ 20 ] یک الگوریتم انتساب مبتنی بر فاکتورسازی تانسور باقیمانده را پیشنهاد کرد که رگرسیون خطی و فاکتورسازی CP را با هم ترکیب کرد و دقت انتساب را تا حد زیادی بهبود بخشید. چن و همکاران [ 21 ] یک مدل تانسور خودرگرسیون با رتبه پایین پیشنهاد کرد که از ساخت یک تانسور مرتبه سوم متغیر با زمان برای گرفتن ثبات کلی داده های ترافیک استفاده می کند و به طور تجربی اثربخشی آن را در سناریوهای گمشده مختلف نشان داد.
مدل انتساب جریان ترافیک مبتنی بر فاکتورسازی تانسور به طور کلی ویژگیهای داخلی دادههای ترافیک را استخراج میکند و شباهت و الگوی توزیع دادهها را تحلیل میکند. با این حال، روشهای موجود مستلزم باز کردن تانسور اصلی در یک ماتریس در فرآیند بازیابی تانسور است که منجر به از بین رفتن همبستگی برخی از الگوها در تانسور ترافیک ساختهشده و در نتیجه کاهش دقت انباشته میشود.
2.3. انتساب داده ها بر اساس مدل های یادگیری عمیق
چه و همکاران [ 24 ] واحدهای بازگشتی دروازهدار را بر اساس شبکه عصبی بازگشتی (RNN) [ 34 ] برای محاسبه در دادههای سری زمانی اضافه کرد. کائو و همکاران [ 25 ] یک حافظه کوتاه مدت دو طرفه (LSTM) برای ضبط اطلاعات داده قبل و بعد از نقطه زمانی فعلی پیشنهاد کرد و عملکرد انباشت داده را بهبود بخشید. لی و همکاران [ 14 ] بردار ورودی را تجزیه کرد و LSTM و ماشین بردار پشتیبان را با هم ترکیب کرد تا دادههای سری زمانی را از طریق یک روش چند نمایشی نسبت دهد. لو و همکاران [ 15 ] پیشنهاد استفاده از شبکه GAN را برای انجام انتساب مقدار گمشده برای سری های زمانی چند متغیره با تعداد زیادی مقادیر گمشده ارائه کرد. وانگ و همکاران [ 16] یک روش انتساب داده جریان ترافیک شبکه جاده ای مبتنی بر GAN را پیشنهاد کرد. ژانگ و همکاران [ 22 ] از LSTM برای ساخت یک مدل دنباله به دنباله استفاده کرد و از ساختار رمزگذار-رمزگشا برای انتساب داده سری های زمانی استفاده کرد. لو و همکاران [ 17 ] یک شبکه واحد مکرر دروازه دار از نوع GAN و RNN را برای ساخت یک شبکه GAN سرتاسری ترکیب کرد و ماتریس اطلاعات مکان نقاط از دست رفته داده را برای تلقی داده های سری زمانی اضافه کرد. چن و همکاران [ 35 ] روشی را پیشنهاد کرد که از داده های موازی و GAN برای افزایش تلفیق داده های ترافیکی استفاده می کرد. وانگ و همکاران [ 23] ویژگیهای زمانی و مکانی حجم ترافیک را در نظر گرفت و روش رگرسیون رگرسیونی معادله پرسپترون-چند متغیری را پیشنهاد کرد که پرسپترون چندلایه و MICE را ترکیب میکرد و استفاده از MICE به تنهایی برای انتساب را بیشتر بهبود بخشید. وانگ و همکاران [ 36 ] یک شبکه نموداری دو جهته چند وجهی جدید را پیشنهاد کرد که به طور جامع شرایط ترافیک را از نماهای همبستگی زمانی مختلف توصیف میکند و با در نظر گرفتن تعاملات بین نماهای همبستگی زمانی، تابع ضرر را بهبود میبخشد و ثابت میکند که روش پیشنهادی برای ترافیک مناسب است. نسبت جریان با الگوهای گمشده پیچیده یانگ و همکاران [ 18] شبکههای متخاصم مولد توجه دوطرفه قابل یادگیری مکانی-زمانی را برای تلفیق دادههای ترافیکی برای بهبود عملکرد انتساب پیشنهاد کرد. وانگ و همکاران [ 37 ] از یک تحلیل سری زمانی خاص برای استخراج الگوهای تناوبی استفاده کرد و یک روش تجزیه ماتریسی جدید را برای توصیف روند دادههای جریان ترافیک پیشنهاد کرد. در نهایت، مدل ساخته شده با ادغام یک روش جدید شبکه عصبی دندریتیک، دقت انتساب را تا حد زیادی بهبود بخشید.
روشهای انتساب دادهها مبتنی بر یادگیری عمیق معمولاً عملکرد انتساب عالی بر روی دادههای مکانی-زمانی دارند و میتوانند به خوبی با قوانین توزیع آنها مطابقت داشته باشند. با این حال، زمانی که مجموعه داده بیش از حد بزرگ باشد، یا مدل بسیار پیچیده باشد، منجر به زمان طولانی آموزش و مشکل بیش از حد برازش خواهد شد.
3. مدل انتساب جریان های مسافربری بر اساس داده های ناقص جریان
ما مدل ST-GAIN را برای باز کردن تانسور جریان مرتبه سوم در ماتریسهای جریان مختلف با استفاده از حالتهای مختلف پیشنهاد میکنیم. علاوه بر این، ما از سه ژنراتور برای شبیه سازی و تولید مولفه های برداری در یک ماتریس جریان با حالت های مختلف استفاده می کنیم. ماتریس های جریان تولید شده توسط ژنراتورهای متعدد با استفاده از ترکیب وزن به یک تانسور جریان جدید تبدیل می شوند. این تانسور جریان جدید را می توان پس از یادگیری توزیع داده های تانسور اصلی به عنوان یک تانسور شبیه سازی شده در نظر گرفت. مدل ST-GAIN میتواند تأثیر متقابل جریان مسافران ترافیکی در مناطق مختلف را بیاموزد و همبستگی بین جریان مسافر در مناطق و دورههای مختلف را تعیین کند. بنابراین، این مدل یک مدل همبستگی مکانی-زمانی است.
3.1. تجزیه و تحلیل همبستگی
با توجه به مختصات طول و عرض جغرافیایی، منطقه مورد مطالعه به شبکه هایی به طول و عرض 500 متر تقسیم می شود. ما تعداد نقاط برداشت را در هر شبکه در دوره های زمانی مختلف محاسبه می کنیم. سپس به طور تصادفی چند شبکه مجاور را استخراج می کنیم (مثلاً شبکه 611 و چهار شبکه مجاور آن را در بالا، پایین، چپ و راست انتخاب می کنیم) و جریان ترافیک مسافران را در 24 ساعت در همان روز تعیین می کنیم. شکل 3 یک همبستگی فضایی قوی بین تعداد نقاط جمع آوری در پنج شبکه را نشان می دهد و روند جریان پنج شبکه مجاور در دوره های مختلف روز نه تنها بسیار مشابه است، بلکه مقادیر جریان نیز بسیار نزدیک است. اکثر دوره های زمانی مشابه
علاوه بر یک همبستگی مکانی قوی، یک همبستگی زمانی بین تعداد نقاط برداشت وجود دارد. شکل 4 تعداد نقاط برداشت در شبکه 634 را در زمان های مختلف در پنج روز کاری نشان می دهد. یک همبستگی زمانی بین تعداد نقاط پیک آپ در روزهای مختلف مشاهده می شود. روند منحنی ها مشابه است و مقادیر جریان در همان دوره زمانی در روزهای مختلف نیز در بیشتر موارد بسیار نزدیک است.
3.2. ساخت مدل
مدل GAIN بر اساس چارچوب GAN است و هر دو یک اصل اساسی دارند. در GAIN وظیفه مولد پر کردن داده های از دست رفته است و وظیفه تمایز کننده تشخیص پر بودن یا واقعی بودن داده ها است، یعنی هر عنصر را در ماتریس داده طبقه بندی و ارزیابی می کند. تمایزکننده میزان خطای طبقهبندی را به حداقل میرساند و مولد نرخ خطای طبقهبندی متمایزکننده را به حداکثر میرساند زیرا این یک شبکه متخاصم است. در GAIN، لازم است که تمایزکننده را با ماتریس اشاره (یک مکانیسم اشاره) بر روی ماتریس داده ها برای به دست آوردن نتایج دقیق و اطمینان از اینکه مولد نمونه هایی نزدیک به توزیع داده های واقعی تولید می کند، ارائه شود. نمادهای درگیر در مدل ST-GAIN در جدول 1 توضیح داده شده است.
این مدل از سه مولد و یک تفکیک کننده تشکیل شده است. هدف از سه مولد مشاهده مولفه های برداری در آ، ب، و سیماتریس ها و تولید بردارهای جدید برای تشکیل ماتریس ها (the آ، ب، و سیمجموعه های ماتریس را می توان به عنوان مجموعه ماتریس تانسور جریان مرتبه سوم در نظر گرفت ناز حالت های مختلف آشکار می شود). برای اطمینان از اینکه ژنراتور مولفه های برداری را در ماتریس ها برای ابعاد مختلف در تانسور مشاهده و یاد می گیرد. ن، تمایز دهنده داده های ترکیبی را از سه مولد برای طبقه بندی دریافت می کند و تعیین می کند که داده های تولید شده واقعی یا پر شده باشند. بنابراین، چهار شبکه عصبی عمیق با استفاده از یک فرآیند خصمانه آموزش داده می شوند.
ما از ضریب همبستگی برای تعریف تابع تلفات جزئی ژنراتور استفاده می کنیم تا خطای داده های تولید شده توسط مدل را به حداقل برسانیم. ضریب همبستگی میزان همبستگی بین متغیرها را اندازه گیری می کند. مقادیر از 1- تا 1 متغیر هستند. هر چه به 1 نزدیک تر باشند، همبستگی قوی تر است و هر چه به 0 نزدیک تر باشد، همبستگی ضعیف تر است. سه نوع ضرایب همبستگی [ 38] معمولاً استفاده می شوند: ضریب همبستگی پیرسون (PCC)، ضریب همبستگی اسپیرمن و ضریب همبستگی کندال. دو مورد آخر بر اساس رتبه داده ها هستند. معمولاً برآوردگرهای مبتنی بر رتبه برای مجموعه داده های کوچک و آزمون های فرضیه خاص مناسب هستند. PCC برای متغیرهای پیوسته با توزیع نرمال مناسب است. معمولاً دادههای جریان ترافیک در مناطق مجاور در هر دوره از نظر مکان و زمان پیوسته هستند. برای آزمایش اینکه آیا دادههای ترافیکی مورد استفاده در آزمایش با توزیع نرمال مطابقت دارند یا خیر، دورههای زمانی معرف 8:00، 12:00، و 18:00 را برای هر یک از سه روز استخراج میکنیم و محاسبه میکنیم که آیا مسافر ترافیک در جریان است یا خیر. منطقه تقسیم تحقیقاتی هر دوره زمانی با توزیع نرمال مطابقت دارد. ما از آزمون KS استفاده می کنیم [ 39] در آزمون توزیع تجربی و از ماژول تست kstest در پایتون استفاده کنید (تست فرضیه: توزیع نرمال زمانی برآورده می شود که مقدار بازگشتی p بیشتر از 0.05 باشد). مقادیر p عبارتند از 0.12، 0.22، 0.25، 0.6، 0.24، 0.11، 0.61، 0.76، 0.16، هر دوره بزرگتر از آستانه 0.05 برای برآورده کردن فرضیه توزیع نرمال است. بنابراین PCC برای بازسازی تابع تلفات ژنراتور در مدل GAIN معرفی شده است. شکل 5 معماری کلی را نشان می دهد و نشان می دهد که معماری مدل عمدتاً از سه مولد و یک تشخیص دهنده و همچنین فرآیند ترکیب، ورودی و خروجی داده ها تشکیل شده است.
فرآیند انتساب داده ها به چهار مرحله تقسیم می شود: (1) ما تانسور اصلی جریان ترافیک مسافر را می سازیم نو سایر تانسورهای جریان D، آرو م، که دارای ابعاد مشابه هستند ن. (2) ما تانسورها را ترکیب می کنیم D، آر، و م، سپس تانسور جریان را شبیه سازی کنید D*=D⊙م+(1–م)⊙آربا عناصر از دست رفته، و آشکار D*به مجموعه های ماتریس جریان آ، ب، و سیبا استفاده از حالت های مختلف مجموعه ماتریس ماسک مربوط به آ، ب، و سیمجموعه های ماتریس با باز کردن به دست می آیند مبا استفاده از حالت های مختلف (3) ترکیب می کنیم آ، ب، و سیبه صورت افقی با ماتریس ماسک متناظر خود و بردارها را یکی یکی بشکنید تا به ژنراتورهای مربوطه منتقل شود تا بردارهای خروجی ژنراتورها به دست آید. سپس خروجی های سه ژنراتور را با هم ترکیب می کنیم تا تانسور به دست آید D“. (4) در نهایت، D“و اچ ساعتمنnتیتانسورها (همان اصل ساعتمنnتیماتریس در GAIN) به صورت افقی در تشخیصگر ترکیب می شوند و خروجی نهایی تانسور ماسک پیش بینی است. م“.
3.3. تابع هدف مدل
تابع هدف مدل ST-GAIN شامل یک تابع تلفات مولد و یک تابع ضرر تفکیک کننده است. این تضمین میکند که دادههای بدون مقادیر از دست رفته تولید شده توسط مولد مشابه دادههای اصلی هستند و همبستگی بین دو مجموعه داده نیز باید بالا باشد. بنابراین، یک اصطلاح ضرر همبستگی بر اساس عبارت زیان مولد در مدل GAIN اصلی به مدل پیشنهادی اضافه میشود. PCC را بین داده های تولید شده و اصلی محاسبه می کند. نماد را تعریف می کنیم £جیبه عنوان تابع از دست دادن ژنراتور، و £جیشامل سه بخش به نام £جی1، £جی2و £جی3، به ترتیب. نماد مترمنعنصری در تانسور است م; مترمن“عنصر در است م“; y نشان دهنده مقدار اصلی است. yمن“نشان دهنده ارزش تولید شده است. x نشان دهنده داده های اصلی است. f نشان دهنده داده های تولید شده است. r تعداد عناصر است. ایکسمن،fمنمقادیر مشاهده شده نقطه i مربوط به x و f هستند. ایکس^میانگین x است . f^میانگین f است ; و αیک هایپرپارامتر است. تابع تلفات ژنراتور به صورت تعریف شده است
£جی=£جی1+£جی2∗α+£جی3،
£جی1=–1متر∑(1–مترمن)لog(مترمن“)،
£جی2=1n∑من=1n(y–yمن“)2،
£جی3=1–∑من=1rایکسمن–ایکس^fمن–f^∑من=1rایکسمن–ایکس^2∑من=1rfمن–f^2،
£جی1کیفیت انتساب داده ها را ارزیابی می کند. هر چه مقدار آن کوچکتر باشد، احتمالی که متمایز کننده ارزیابی می کند بیشتر است مترمن=0مانند مترمن=1و بالعکس. £جی2نشان دهنده خطای بازسازی است که برای ارزیابی تفاوت بین مقدار خروجی ژنراتور و مقدار اصلی استفاده می شود. هر چه مقدار آن کوچکتر باشد، مقدار بازسازی شده به مقدار واقعی نزدیکتر است. £جی3عبارت از دست دادن همبستگی است که همبستگی بین خروجی توزیع داده توسط مولد و توزیع داده اصلی را ارزیابی می کند. هرچه مقدار آن کوچکتر باشد، همبستگی بین دو مجموعه داده قوی تر است. αآن را تضمین می کند £جی2دارای همان ترتیب قدر است £جی1و £جی3. مترمننشان می دهد که آیا عنصر موقعیت در تانسور مبرای عنصر موقعیت مربوط به تانسور وجود ندارد D(0 به معنای از دست دادن، 1 به معنای از دست ندادن است)، و مترمن“مقدار خروجی تفکیک کننده است که نشان دهنده احتمال این است که هر عنصر تولید شده توسط مولد داده اصلی است.
هدف تمایزگر این است که تشخیص دهد کدام قسمت از داده های تولید شده، داده های اصلی و کدام بخش، داده های پر شده است. مقدار نشان دهنده احتمال این است که موقعیت داده های تولید شده، داده های اصلی یا داده های پر شده باشد. بنابراین از تابع تلفات متقاطع آنتروپی استفاده می شود. اصطلاح ضرر آن به این صورت تعریف می شود
£D=–1متر∑مترمنلog(متر“من)+(1–مترمن)لog(1–مترمن“)،
هر چه ارزش آن کمتر باشد £D، خروجی تفکیک کننده نزدیک تر است مترمن“به ارزش واقعی است مترمنو بالعکس.
3.4. توضیحات الگوریتم
مراحل الگوریتم برای انتساب داده ها با استفاده از مدل ST-GAIN در زیر توضیح داده شده است و شبه کد الگوریتم در الگوریتم 1 توضیح داده شده است.
| الگوریتم 1: شبه کد ST-GAIN |
|
ورودی: ن،م،آر
خروجی: داده های تکمیل شده D“
Initialize: عصرها E، سایر پارامترهای هایپر
1. برای ه=1به E انجام دهید
2. تکرار کنید
3. دمن∈D“،ساعتمن∈اچ
4. تشخیص دهنده بهینه سازی D
5. م“←خوراک D (دمن،ساعتمن) // داده های ورودی دمن،ساعتمنبه متمایز کننده D ، D برمی گردد م“
6. D با استفاده از Adam به روز شد // تشخیص دهنده D را با استفاده از بهینه ساز Adam به روز کنید
7. آ،ب،سی= تقسیم ابعاد ( ن،م،آر)
8. آ“←Feed Generator1 (آ)
9. ب“←فید Generator2 (ب)
10. سی“←فید Generator3 (سی)
11. D“=جonvهrتیتیoتیهnسorس(آ∗آ‘،ب∗ب‘،ج∗سی‘)⊙(1–م)+ن⊙م
12. Generator1, Generator2, Generator3 با استفاده از Adam به روز شد
13. تا زمانی که تمام شود
14. پایان برای
|
گام1:داده های ترافیکی نقاط تاکسی را در یک منطقه مشخص در یک بازه زمانی خاص استخراج کنید و تانسور را بسازید. ن( 38∗35∗168)، جایی که 38∗35مختصات طول و عرض جغرافیایی ناحیه مستطیلی مشخص شده را نشان می دهد. منطقه به طور مساوی به یک شبکه تقسیم شده است 38*35و 168 نشان دهنده 168 دوره متوالی است (هر ساعت یک بخش زمانی است).
گام2:به طور تصادفی 20٪ از نقاط را در تانسور تنظیم کنید نصفر کنید (با مقادیر 0 جایگزین کنید) و یک تانسور نقطه گمشده تصادفی بسازید Dاز همان ابعاد ن. یک تانسور بسازید ماز همان ابعاد نو استفاده کنید 0/1مقادیر مطابق با مقادیر موجود در مبرای تعیین اینکه آیا ارزش هر موقعیت در نمفقود است یا خیر یک تانسور نویز تصادفی بسازید آربا همان ابعاد ن; مقدار ورودی را تنظیم کنید D*( برای توضیحات بیشتر به بخش 3.3 مراجعه کنید ).
گام3:متمایز کننده برای دریافت داده های ترکیبی آموزش دیده است جیسآمترپلهتولید شده از سه ژنراتور مولد و متمایز کننده شبکه های عصبی کاملاً متصل هستند. تمایزگر از تابع از دست دادن آنتروپی متقابل برای تشخیص خام بودن یا پر بودن داده ها استفاده می کند که معادل مقدار m در تانسور ماسک پیش بینی است. م.
گام4:ژنراتور را آموزش دهید. سه مولد بردارهای داده مجموعه های ماتریس جریان را دریافت می کنند آ، ب، و سیپس از اینکه ماژول های مختلف تانسور جریان را باز کردند D“و بردارهای متناظر آنها از مجموعه های ماتریس ماسک. از آخرین مقدار خروجی تشخیصگر به روز شده استفاده کنید و سپس آن را با ماتریس های ماسک مربوطه ترکیب کنید آ، ب، و سی. فینال را تنظیم کنید جیسآمترپله=آ∗جی1+ب∗جی2+ج∗جی3، ( جی1، جی2، و جی3مقادیر خروجی ژنراتور مربوطه را نشان می دهد، که در آن آ+ب+ج=1،آ>=0،ب>=0،ج>=0. مقادیر وزنی a ، b ، و c با بهینه سازی پیوسته آیتم از دست دادن تعریف شده تعیین می شود £جی.
گام5:به طور مداوم تلفات خصمانه سه مولد (G) و تشخیص دهنده (D) را بهینه سازی کنید تا احتمال پیش بینی صحیح را به حداکثر برسانید. مو احتمال پیش بینی را به حداقل برسانید م. از شبکه ST-GAIN بهینه برای آموزش استفاده کنید و تانسور مکانی-زمانی با مقادیر از دست رفته را در شبکه وارد کنید تا داده های از دست رفته را درج کنید.
4. آزمایش و نتایج
عملکرد مدل ST-GAIN با یک مطالعه فرسایشی و مقایسه با روشهای پایه ارزیابی شد. ما دادههای جریان مسافران ترافیک را تحت MAR به عنوان داده ورودی مدل میسازیم. با انجام هر آزمایش 10 بار و با استفاده از اعتبار سنجی 5 متقاطع. ما RMSE، MAE و R را گزارش می کنیم 2به عنوان معیار عملکرد به همراه انحرافات استاندارد آنها در 10 آزمایش.
4.1. مجموعه داده و تنظیمات آزمایشی
مجموعه داده مورد استفاده در این آزمایش دادههای مسیر GPS (طول جغرافیایی، طول جغرافیایی، و نقطه تحویل) 7457 تاکسی در کونمینگ (7 تا 13 سپتامبر 2019) است. محدوده طول و عرض جغرافیایی منطقه مورد مطالعه می باشد 102∘628“∼102∘798“E و 24∘865“∼ 25∘135“N. تعداد نقاط برداشت در ساعت در هر شبکه به عنوان جریان مسافر استفاده می شود و یک تانسور مرتبه سوم ایجاد می کند. ناز 38∗35∗168. همه آزمایشهای ما روی 64 هسته پردازنده Intel i7-9800X با فرکانس 3.80 گیگاهرتز × 16 با 512 گیگابایت رم و پردازنده گرافیکی NVIDIA GeForce RTX 2080Ti انجام شد. سیستم عامل و پلتفرم های نرم افزاری Ubutu 18.04، Pytorch r1.8 و Python 3.6 هستند. هایپرپارامتر αروی 100 تنظیم شده است. پارامترهای روش های پایه به عنوان تنظیمات در مقالات اصلی نامیده می شوند.
4.2. معیارهای ارزیابی
ما به طور تصادفی 10 تا 60٪ از عبارت های عددی را از تانسور مرتبه سوم حذف می کنیم. نبرای شبیه سازی مقادیر از دست رفته ریشه میانگین مربعات خطا (RMSE)، میانگین خطای مطلق (MAE) و ضریب تعیین (R) 2) برای ارزیابی عملکرد انتساب استفاده می شود. آنها با استفاده از معادلات (6) – (8) محاسبه می شوند. هر چه مقادیر RMSE و RAE کوچکتر باشند، تفاوت بین مقادیر پر شده و واقعی کمتر است. هر چه R نزدیکتر باشد 2مقدار 1 است، عملکرد مدل بهتر است:
RMSE=1n∑من=1n(ایکس(من)–y(من))2،
MAE=1n∑من=1n∣ایکس(من)–y(من)∣،
آر2=1–∑من=1nایکس(من)–y(من)2∑من=1ny^–y(من)2،
جایی که ایکس(من)نشان دهنده مقدار پیش بینی شده است، y(من)نشان دهنده ارزش واقعی است، y^مقدار متوسط را نشان می دهد و n تعداد مقادیر پیش بینی شده را نشان می دهد.
4.3. نتایج مطالعه Ablation
مدل ST-GAIN از سه مولد و یک اصطلاح ضرر همبستگی استفاده می کند £جی3برای تعیین تلفات جزئی ژنراتور، و از ماتریس اشاره [ 31 ] استفاده می کند. را £جی3آیتم، یک ژنراتور، دو ژنراتور و اشاره ( ماتریس اشاره ) به ترتیب حذف می شوند تا اهمیت ساختار کامل ST-GAIN را تأیید کنند. تانسور نبا 20% مقادیر گمشده استفاده شده است.
جدول 2 نتایج مطالعه فرسایش را فهرست می کند. مدل ST-GAIN عملکرد انتساب بهینه را دارد. مقدار RMSE (MAE) آن 6% (15%) کمتر از ST-GAIN- است. £جی38% (10%) کمتر از ST-GAIN-G و 11% (19%) کمتر از ST-GAIN-2G. علاوه بر این، R 2مقدار ST-GAIN دارای بیشترین R است 2ارزش، اگرچه خیلی بالاتر از سه مدل دیگر بالا نیست. اگرچه hint به بهبود عملکرد قابل توجهی در معماری مدل GAIN [ 31 ] دست یافته است، جدول 2 نشان می دهد که مدل ST-GAIN- hint تقریباً در عملکرد در مقایسه با مدل ST-GAIN کامل یکسان است. RMSE، MAE و R آنها 2مقادیر تقریبا مشابه هستند با توجه به ارجاع به معماری مدل GAIN، مدل ST-GAIN ما همچنان از مکانیزم اشاره برای یکپارچگی مدل استفاده می کند. با این حال، اشاره بهبود عملکرد محدودی برای مدل ما دارد.
شکل 6 و شکل 7 معیارهای ارزیابی را برای سه ژنراتور با وزن های مختلف نشان می دهد (به ترتیب a، b و c وزن خروجی ژنراتورها را نشان می دهند. جی1، جی2، و جی3). بهینه RMSE، MAE و R 2مقادیر زمانی بدست می آیند که آ=0.2، ب=0.5، و ج=0.3(یعنی جی1وزن 0.2 است جی2وزن 0.5 است و جی3وزن 0.3)، نسبت وزن از جی2بالاتر از آن است جی1و جی3. وزن b افزایش مییابد تا مشخص شود که آیا این کار عملکرد انتساب را بهبود میبخشد یا خیر. با این حال، عملکرد انتساب افزایش نمی یابد، اما زمانی که کاهش می یابد ب=0.7. بنابراین، افزایش نسبت وزنی جی2ژنراتور عملکرد مدل را بهبود نمی بخشد. به عبارت دیگر، سه ژنراتور که بردار را در ماتریس های جریان تانسور جریان یکسان دریافت می کنند، در حالت های مختلف به عنوان داده ورودی باز می شوند. از آنجایی که عناصر داخلی مجموعه های مختلف ماتریس پس از باز شدن درجات مختلفی از همبستگی دارند، هر ژنراتور برای هر ماتریس جریان استفاده می شود. تنظیم وزن مناسب، عملکرد انباشت را بهینه می کند.
ما آزمایشهای گستردهای را با تنظیم مقادیر مختلف وزنهای مربوطه سه ژنراتور برای آزمایش تغییرات عملکرد انتساب انجام میدهیم. شکل 8 تغییرات مقدار RMSE را هنگام تغییر وزن متغیرهای سه تایی a , b و c نشان می دهد. زمانی که a ، b و c به ترتیب به مقدار وزن بهینه نزدیک شوند، RMSE به مقدار بهینه خواهد رسید.
4.4. مقایسه مدل های مختلف
جدول 3 عملکردهای انتساب مدل ST-GAIN و پنج الگوریتم پایه را فهرست می کند: CP [ 33 ]، GAIN [ 31 ]، Matrix-Complete [ 5 ]، MICE [ 6 ] و missForest [ 7 ]. داده های ورودی به الگوریتم های GAIN، Matrix-Complete، MICE و missForest ماتریسی هستند که از ترکیب افقی ماتریس جریان ساعتی در منطقه مورد مطالعه (معادل ماتریس باز شده از حالت های تانسور ) به دست می آیند.ن). همانطور که از جدول 3 مشاهده می شود ، مدل ST-GAIN کمترین RMSE و MAE و بالاترین R را دارد. 2مقدار در بین همه مدلها، نشان میدهد که روش پیشنهادی نسبت به روشهای پایه برای انتساب مجموعه داده ترافیک با 20 درصد مقادیر گمشده، بهتر عمل میکند.
شکل 9 ، شکل 10 و شکل 11 تغییرات معیارهای ارزیابی (RMSE، MAE و آر2) برای پنج روش پایه و شبکه ST-GAIN برای نرخ های مختلف از دست دادن (10٪، 20٪، 30٪، 40٪، 50٪ و 60٪). عملکرد همه الگوریتمها با افزایش نرخ اشتباه کاهش مییابد. ST-GAIN به طور مداوم از سایر روشهای پایه در کل محدوده نرخ اشتباه بهتر عمل میکند، که نشاندهنده استحکام بالا و عملکرد نسبتاً پایدار مدل پیشنهادی، بهویژه در نرخ خطای بالاتر است.
برای درک بهتر ST-GAIN، آزمایشهای زیر را انجام میدهیم که در آن تعداد ابعاد زمانی را تغییر میدهیم. شکل 12 ، شکل 13 و شکل 14 تغییرات در معیارهای ارزیابی را نشان می دهد که ابعاد زمانی s تانسور جریان ورودی ما نمتفاوت است، که نشان می دهد تانسور ساخته شده است ندارای ابعاد زمانی مختلف (دوره های زمانی 24، 48، 72، 96، 120، 144، 168 پیوسته). ارقام نشان میدهند که ST-GAIN با مقایسه با دو معیار رقابتی (GAIN و missForest) نسبت به تعداد ابعاد زمانی قوی است. با افزایش ابعاد زمانی تنظیم شده در آزمایش، بهبود ST-GAIN به طور قابل توجهی بالاتر از دو معیار دیگر است.
5. بحث و نتیجه گیری
این مقاله مدل جدید ST-GAIN را بر اساس شبکه GAIN برای القای عناصر گمشده در دادههای جریان مسافری ترافیک مکانی-زمانی، که معمولاً مقادیر گمشده تصادفی دارد، پیشنهاد میکند. این روش، دادههای جریان مسافربری را به یک تانسور جریان مرتبه سوم تبدیل میکند و آن را با استفاده از حالتهای مختلف به سه ماتریس جریان باز میکند. از سه ژنراتور برای مشاهده و یادگیری مولفه های برداری در ماتریس های مختلف استفاده می شود و هر کدام بردارهای جدیدی را برای تشکیل یک ماتریس جریان تولید می کنند. وزن خروجی هر ژنراتور بهطور جداگانه تعیین میشود تا دادههای تولید شده پس از ترکیب سه ژنراتور برای بهبود همبستگی دادههای جریان مسافر ترافیک در ابعاد مکانی-زمانی به دست آید. ما از PCC برای تعریف یک اصطلاح تلفات همبستگی به عنوان بخشی از ضرر مولد استفاده کردیم تا اطمینان حاصل کنیم که داده های به دست آمده از ژنراتور مشابه داده های واقعی هستند. نتایج تجربی تأیید کرد که مدل ST-GAIN از پنج روش انتساب پایه برای پر کردن مقادیر گمشده با استفاده از تانسور جریان بهتر عمل میکند.
در برخی صحنه های واقعی، با استخراج سه ویژگی زمان، طول و عرض جغرافیایی داده های ترافیکی و تقسیم جغرافیای واقعی به شبکه ها، می توان اطلاعات ماتریس جریان ترافیک هر حوزه زمانی در منطقه را ساخت. اطلاعات جریان ترافیک هر دوره زمانی در یک محدوده خاص را می توان بدون اطلاعات ساختار شبکه ترافیک واقعی به دست آورد و اطلاع از وضعیت ترافیک هر زیر منطقه در منطقه جغرافیایی واقعی آسان تر است. علاوه بر این، زمانی که داده های ترافیک در برخی از پارتیشن ها به دست نمی آید یا داده ها به دلیل خرابی جمع کننده ها در برخی پارتیشن ها از بین می روند، مدل ST-GAIN می تواند به طور موثر داده های گمشده را نسبت دهد تا از داده های ترافیکی با کیفیت بهبودیافته استفاده شود. تحلیل و استفاده بعدی
در تحقیقات آینده، میتوانیم عملکرد انتساب مدل را به روشهای مختلف بهبود و تأیید کنیم. اولاً، دادههای جریان ترافیک همبستگی مکانی-زمانی را نشان میدهند و ارتباط نزدیکی با کمیت و نوع نقاط مورد علاقه در شهر دارند. مطالعات آتی میتواند بر بهبود عملکرد انتساب مدل پیشنهادی با ادغام دادههای نقطه مورد علاقه شهری با دادههای جریان ترافیک در شبکه و استخراج ویژگیها تمرکز کند. ثانیا، این مقاله فقط عملکرد انتساب دادههای جریان ترافیک را تحت سناریوهای گمشده تصادفی در نظر گرفت. با این حال، در سناریوهای واقعی، الگوهای گمشده مختلفی در داده ها وجود دارد. سازگاری کلی مدل ST-GAIN با سناریوهای مختلف داده از دست رفته را می توان در آینده بررسی و بهبود بخشید.
منابع
- ژانگ، ن. چن، اچ. چن، ایکس. چن، جی. پیشبینی استفاده از حمل و نقل عمومی توسط سنجش جمعیت و استخراج مسیر معنایی: مطالعات موردی. ISPRS Int. J. Geo-Inf. 2016 ، 5 ، 180. [ Google Scholar ] [ CrossRef ]
- چن، ی. یوان، پی. کیو، م. Pi، D. یک الگوریتم استخراج الگوی مکرر مسیر داخلی بر اساس توالی شبکه مبهم. سیستم خبره Appl. 2019 ، 118 ، 614-624. [ Google Scholar ] [ CrossRef ]
- کوچک، RJA; روبین، تجزیه و تحلیل آماری DB با داده های از دست رفته . پسران جان وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2019؛ جلد 793. [ Google Scholar ]
- جدهاو، ع. پرامود، دی. راماناتان، ک. مقایسه عملکرد روشهای انتساب دادهها برای مجموعه دادههای عددی. Appl. آرتیف. هوشمند 2019 ، 33 ، 913-933. [ Google Scholar ] [ CrossRef ]
- مازومدر، ر. هستی، تی. الگوریتم های منظم سازی طیفی برای یادگیری ماتریس های بزرگ ناقص. جی. ماخ. فرا گرفتن. Res. 2010 ، 11 ، 2287-2322. [ Google Scholar ] [ PubMed ]
- رویستون، پی. White, IR انتساب چندگانه توسط معادلات زنجیره ای (MICE): پیاده سازی در Stata. J. Stat. نرم افزار 2011 ، 45 ، 1-20. [ Google Scholar ] [ CrossRef ]
- استخوون، دی جی; بولمان، پی. بیوانفورماتیک 2012 ، 28 ، 112-118. [ Google Scholar ] [ CrossRef ]
- شی، اف. ژانگ، دی. چن، جی. کریمی، برآورد ارزش گمشده منابع انسانی برای دادههای ریزآرایه با تحلیل مؤلفههای اصلی بیزی و حداقل مربعات محلی تکراری. ریاضی. مشکل مهندس 2013 ، 2013 ، 162938. [ Google Scholar ] [ CrossRef ]
- شانگ، Q. یانگ، ز. گائو، اس. Tan, D. یک روش انتساب برای داده های ترافیک گمشده بر اساس FCM بهینه شده توسط PSO-SVR. J. Adv. ترانسپ 2018 ، 2018 ، 2935248. [ Google Scholar ] [ CrossRef ]
- تانگ، جی. ژانگ، جی. وانگ، ی. وانگ، اچ. لیو، اف. یک رویکرد ترکیبی برای ادغام روش انتساب مبتنی بر C-means فازی با الگوریتم ژنتیک برای تخمین حجم ترافیک گمشده. ترانسپ Res. قسمت C Emerg. تکنولوژی 2015 ، 51 ، 29-40. [ Google Scholar ] [ CrossRef ]
- منگ، اچ. چن، اس. تجزیه و تحلیل مقایسه ای روش های انتساب داده ها برای داده های جریان ترافیک از دست رفته. J. Transp. Inf. Saf. 2018 ، 36 ، 61-67. [ Google Scholar ]
- ژانگ، ا. آهنگ ها.؛ سان، ی. Wang, J. یادگیری مدل های فردی برای انتساب. در مجموعه مقالات سی و پنجمین کنفرانس بین المللی مهندسی داده IEEE 2019 (ICDE)، ماکائو، چین، 8 تا 11 آوریل 2019؛ صص 160-171. [ Google Scholar ]
- تانگ، جی. ژانگ، ایکس. یو، تی. Liu, F. گم شدن داده های ترافیکی با در نظر گرفتن فواصل تقریبی: یک ساختار ترکیبی که استنتاج مبتنی بر شبکه تطبیقی و مجموعه خشن فازی را ادغام می کند. فیزیک یک آمار مکانیک. Appl. 2021 ، 573 ، 125776. [ Google Scholar ] [ CrossRef ]
- لی، ال. ژانگ، جی. وانگ، ی. Ran، B. مقدار گمشده برای دادههای سری زمانی مرتبط با ترافیک بر اساس روش یادگیری چند نمایه. IEEE Trans. هوشمند ترانسپ سیستم 2018 ، 20 ، 2933-2943. [ Google Scholar ] [ CrossRef ]
- لو، ی. کای، ایکس. ژانگ، ی. Xu, J. انتساب سری زمانی چند متغیره با شبکه های متخاصم مولد. Adv. عصبی Inf. روند. سیستم 2018 ، 31 ، 1603-1614. [ Google Scholar ]
- وانگ، ال. لی، ام. Yan, JQ روش بازیابی اطلاعات جریان ترافیک شهری مبتنی بر شبکه متخاصم مولد. J. Sci. J. Transp. سیستم مهندس Inf. تکنولوژی 2018 ، 18 ، 63-71. [ Google Scholar ]
- لو، ی. ژانگ، ی. کای، ایکس. Yuan, X. E2gan: شبکه متخاصم مولد سرتاسر برای انتساب سری زمانی چند متغیره. در مجموعه مقالات بیست و هشتمین کنفرانس مشترک بین المللی هوش مصنوعی، ماکائو، چین، 10 تا 16 اوت 2019؛ صص 3094–3100. [ Google Scholar ]
- یانگ، بی. کانگ، ی. یوان، ی. هوانگ، ایکس. لی، اچ. ST-LBAGAN: شبکه های متخاصم مولد توجه دو طرفه فضایی-زمانی قابل یادگیری برای انتساب داده های ترافیک گمشده. سیستم مبتنی بر دانش 2021 ، 215 ، 106705. [ Google Scholar ] [ CrossRef ]
- تان، اچ. یانگ، ز. فنگ، جی. وانگ، دبلیو. ران، ب. تجزیه و تحلیل همبستگی برای روش انتساب داده های ترافیک مبتنی بر تانسور. Procedia-Soc. رفتار علمی 2013 ، 96 ، 2611-2620. [ Google Scholar ] [ CrossRef ]
- یان، جی. لی، اچ. بای، ی. Lin, Y. روش بازیابی و پیشبینی دادههای جریان ترافیک مکانی-مکانی بر اساس تجزیه تانسور. Appl. علمی 2021 ، 11 ، 9220. [ Google Scholar ] [ CrossRef ]
- چن، ایکس. لی، م. سونیر، ن. Sun، L. تکمیل تانسور خودبازگشتی با رتبه پایین برای انتساب داده های ترافیک مکانی-زمانی. IEEE Trans. هوشمند ترانسپ سیستم 2022 ، 23 ، 12301-12310. [ Google Scholar ] [ CrossRef ]
- ژانگ، YF; توربرن، پی جی. شیانگ، دبلیو. Fitch، P. SSIM – یک رویکرد یادگیری عمیق برای بازیابی دادههای حسگر سری زمانی از دست رفته. IEEE Internet Things J. 2019 ، 6 ، 6618–6628. [ Google Scholar ] [ CrossRef ]
- وانگ، ایکس. ممکن است.؛ هوانگ، اس. Xu, Y. محاسبه داده برای حجم ترافیک شناسایی شده آزادراه با استفاده از رگرسیون پرسپترون چند لایه. J. Adv. ترانسپ 2022 ، 2022 ، 4840021. [ Google Scholar ] [ CrossRef ]
- چه، ز. پوروشاتام، اس. چو، ک. سونتاگ، دی. Liu، Y. شبکههای عصبی بازگشتی برای سریهای زمانی چند متغیره با مقادیر گمشده. علمی Rep. 2018 , 8 , 6085. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کائو، دبلیو. وانگ، دی. لی، جی. ژو، اچ. لی، ال. Li، YB دو طرفه تکراری برای سری های زمانی. arXiv 2018 ، arXiv:1805.10572. [ Google Scholar ]
- ژائو، کیو. ژانگ، ال. Cichocki، A. بیزی فاکتورسازی CP تانسورهای ناقص با تعیین رتبه خودکار. IEEE Trans. الگوی مقعدی ماخ هوشمند 2015 ، 37 ، 1751-1763. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ژو، دبلیو. ژنگ، اچ. فنگ، ایکس. Lin, D. الگوریتم تکمیل تانسورهای جفت شده مبتنی بر چند منبع برای محاسبه ناقص داده های ترافیکی. در مجموعه مقالات یازدهمین کنفرانس بین المللی 2019 در زمینه ارتباطات بی سیم و پردازش سیگنال (WCSP)، شیان، چین، 23 تا 25 اکتبر 2019؛ صص 1-6. [ Google Scholar ]
- لی، کیو. تان، اچ. وو، ی. بله، ال. Ding، F. پیشبینی جریان ترافیک با دادههای گمشده که با روشهای تکمیل تانسور نسبت داده میشوند. دسترسی IEEE 2020 ، 8 ، 63188–63201. [ Google Scholar ] [ CrossRef ]
- کای، ال. وانگ، اچ. شا، سی. جیانگ، اف. ژانگ، ی. ژو، دبلیو. استخراج نقاط داغ شهری بر اساس ادغام داده های مکان چند منبعی. IEEE Trans. بدانید. مهندسی داده 2023 ، 35 ، 2061-2077. [ Google Scholar ] [ CrossRef ]
- دوان، ی. Lv، Y.; Kang, W. یک رویکرد مبتنی بر یادگیری عمیق برای انتساب داده های ترافیک. در مجموعه مقالات هفدهمین کنفرانس بین المللی IEEE در مورد سیستم های حمل و نقل هوشمند (ITSC)، چینگدائو، چین، 8 تا 11 اکتبر 2014. ص 912-917. [ Google Scholar ]
- یون، جی. جردون، جی. Schaar, M. Gain: گم شدن دادهها با استفاده از شبکههای متخاصم مولد. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین، استکهلم، سوئد، 10 تا 15 ژوئیه 2018؛ صص 5689–5698. [ Google Scholar ]
- دوست خوب، من. پوگت ابادی، ج. میرزا، م. شبکه های متخاصم مولد. اشتراک. ACM 2020 ، 63 ، 139-144. [ Google Scholar ] [ CrossRef ]
- وو، ی. تان، اچ. لی، ی. ژانگ، جی. Chen, X. روش فاکتورسازی CP ذوب شده برای تانسورهای ناقص. IEEE Trans. شبکه عصبی فرا گرفتن. سیستم 2018 ، 30 ، 751-764. [ Google Scholar ] [ CrossRef ]
- چو، ک. ون مرینبور، بی. گلچهره، سی. بهداناو، د. بوگارس، اف. شونک، اچ. Bengio، Y. آموزش نمایش عبارات با استفاده از رمزگذار-رمزگشا RNN برای ترجمه ماشینی آماری. arXiv 2014 ، arXiv:1406.1078. [ Google Scholar ]
- چن، ی. Lv، Y.; Wang، FY نسبت جریان ترافیک با استفاده از داده های موازی و شبکه های متخاصم مولد. IEEE Trans. هوشمند ترانسپ سیستم 2019 ، 21 ، 1624-1630. [ Google Scholar ] [ CrossRef ]
- وانگ، پی. ژانگ، تی. ژنگ، ی. Hu, T. یک شبکه گراف فضایی-زمانی دو جهته چند نمای برای منتسب کردن جریان ترافیک شهری. بین المللی جی. جئوگر. Inf. علمی 2022 ، 36 ، 1231-1257. [ Google Scholar ] [ CrossRef ]
- وانگ، پی. هو، تی. گائو، اف. وو، آر. گوو، دبلیو. Zhu، X. یک چارچوب مبتنی بر داده ترکیبی برای انتقال دادههای جریان ترافیک مکانی-زمانی. IEEE Internet Things J. 2022 , 9 , 16343–16352. [ Google Scholar ] [ CrossRef ]
- جین، ال. Li, Y. تجزیه و تحلیل چند ضرایب همبستگی و اجرای آنها در زبان R. آمار Inf. انجمن 2019 ، 34 ، 3–11. [ Google Scholar ]
- Yap، BW; Sim, CH مقایسه انواع مختلف تست های نرمال بودن. J. Stat. محاسبه کنید. شبیه سازی 2011 ، 81 ، 2141-2155. [ Google Scholar ] [ CrossRef ]

شکل 1. ویژگی های از دست رفته داده های جریان ترافیک منطقه ای. (مربع های سیاه نشان دهنده داده های از دست رفته است.) ( الف ) جریان به طور تصادفی در منطقه وجود ندارد. ( ب ) جریان از دست رفته در حوزه زمان پیوسته در منطقه.

شکل 2. توزیع نقاط حمل و نقل در بخش هایی از منطقه. (نقاط آبی نقطههای جمعآوری و نقاط قرمز نقاط رها شدن هستند).

شکل 3. تردد مسافران در زمان های مختلف روز در شبکه های مجاور.

شکل 4. تردد مسافران در شبکه 634 در زمان های مختلف در 5 روز کاری.
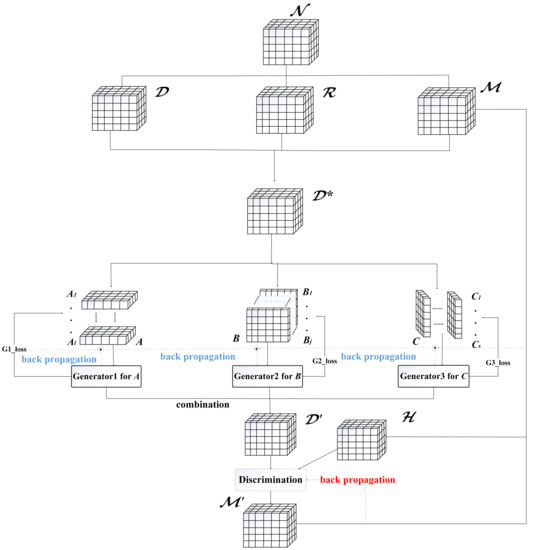
شکل 5. معماری مدل ST-GAIN.
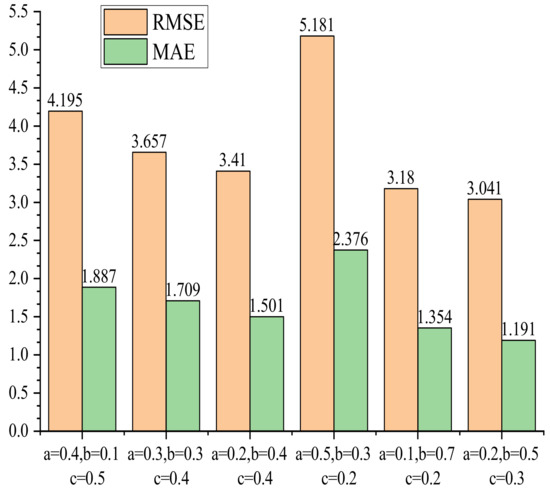
شکل 6. مقادیر RMSE و MAE برای وزن های مختلف ژنراتور.

شکل 7. R 2مقادیر برای وزن ژنراتورهای مختلف

شکل 8. RMSE تحت مقادیر مختلف متغیرهای سه تایی. ( a – c ) به ترتیب وزن خروجی ژنراتورهای G1، G2 و G3 را نشان می دهند.

شکل 9. MAE برای نرخ های مختلف از دست دادن.

شکل 10. RMSE برای نرخ های مختلف از دست دادن.

شکل 11. R 2برای نرخ های مختلف از دست دادن

شکل 12. RMSE برای ابعاد مختلف زمانی.

شکل 13. MAE برای ابعاد زمانی مختلف.

شکل 14. R 2برای ابعاد مختلف زمانی


بدون دیدگاه