

بسیاری از سیستم های پشتیبانی تصمیم فضایی به دلیل عدم اعتماد، تخصص فنی و منابع، در عمل از مشکلات پذیرش کاربر رنج می برند. یادگیری ماشینی خودکار اخیراً به افراد غیرمتخصص این امکان را داده است که بدون نیاز به دانش و منابع متخصص فراوان، مدلهای یادگیری ماشینی را در صنعت کشف و به کار ببرند. این مقاله ادبیات اخیر را از 136 مقاله مرور میکند و یک چارچوب کلی برای ادغام سیستمهای پشتیبانی تصمیمگیری فضایی با یادگیری ماشین خودکار به عنوان فرصتی برای کاهش موانع اصلی پذیرش کاربر پیشنهاد میکند. چالشهای کیفیت داده، تفسیرپذیری مدل، و سودمندی عملی به عنوان ملاحظات کلی برای پیادهسازی سیستم مورد بحث قرار میگیرند. فرصتهای تحقیقاتی مربوط به مدلهای صریح فضایی در AutoML، و منابع آگاه، مشارکتی/متصل، و سیستم های انسان محور نیز برای رسیدگی به این چالش ها مورد بحث قرار گرفته اند. این مقاله استدلال میکند که ادغام یادگیری ماشین خودکار در سیستمهای پشتیبانی تصمیمگیری فضایی نه تنها میتواند به طور بالقوه پذیرش کاربر را تشویق کند، بلکه میتواند برای تحقیقات در هر دو زمینه مفید باشد – پل زدن پیشرفتهای فنی و مرتبط با انسان برای تقویت پیشرفتهای آینده در سیستمهای پشتیبانی تصمیم فضایی و یادگیری ماشین خودکار. .
کلید واژه ها:
فضایی ؛ پشتیبانی تصمیم گیری ؛ یادگیری ماشینی ؛ اتوماسیون ؛ چارچوب ; سیستم ; SDSS _ AutoML _ GIS
1. مقدمه
پیشرفتها در جمعسپاری [ 1 ]، ابتکارات دادههای باز [ 2 ]، و استانداردهای منبع باز [ 3 ] دادههای مکانی را در دسترس عموم قرار دادهاند. سیستمهای پشتیبانی تصمیم مکانی (SDSS) دادههای مکانی و غیر مکانی را برای تصمیمگیریهای مهم ذخیره، مدیریت و پردازش میکنند، مانند انتخاب مکانهای تجاری، قرار دادن زیرساختهای ترافیکی، و اجرای سیاستهای بهداشت عمومی [ 4 ]. با این حال، بسیاری از SDSS ها به دلیل عدم اعتماد، تخصص فنی و منابع توسط تصمیم گیرندگان پذیرفته نمی شوند [ 5 ، 6 ]]. اخیراً، یادگیری ماشین خودکار (AutoML) مورد توجه جامعه پژوهشی و رسانه ها قرار گرفته است. AutoML اتوماسیون و یادگیری ماشینی (ML) را با تولید مدلهایی با كمك انسانی كم، ادغام میكند كه تحت شرایط خاص و بودجههای محاسباتی به خوبی عمل میكنند [ 7 ]. این باعث کاهش تلاش و تخصص فنی مورد نیاز برای پردازش و مدلسازی دادهها میشود، که اکثریت زمان صرف شده برای تجزیه و تحلیل دادهها را تشکیل میدهد [ 8 ]. همانطور که شرکت های فناوری پیشرو محصولات AutoML را در سال های 2017 تا 2018 منتشر کردند [ 9 ، 10 ، 11]، مدلهای ML به طور گستردهتری توسط افراد غیرمتخصص استفاده میشوند و پیادهسازی آن هزینه کمتری دارد. با افزایش اخیر دسترسی به AutoML، منابع برای پیاده سازی و نگهداری SDSS را می توان کاهش داد و پذیرش SDSS توسط تصمیم گیرندگان را بهبود بخشید.
این مقاله مروری سیستماتیک از ادغام AutoML و SDSS ارائه میکند، که به دنبال پاسخ به سه سؤال تحقیق است: (R1) طبق تحقیقات اخیر، SDSS و AutoML چه مشکلاتی را میتوانند حل کنند؟ (R2) چگونه می توان AutoML را در SDSS ادغام کرد؟ و (R3) چالش ها و فرصت های SDSS با AutoML برای بهبود پذیرش کاربر چیست؟ اگرچه مقالات بررسی موجود در AutoML و SDSS به طور جداگانه وجود دارد [ 4 , 12 , 13]، مقالات مروری متمرکز بر ادغام AutoML و SDSS از جستجوی اولیه در مورد موضوعات AutoML و SDSS با هم در ادبیات یافت نشد. این مقاله سه مشارکت تحقیقاتی زیر را برای پاسخ به این سؤالات ارائه میکند: (C1) یک مرور سیستماتیک که روشهای اخیر، نتایج، برنامههای کاربردی و مشکلات احتمالی در SDSS و AutoML (C2) را بررسی میکند. چارچوبی مبتنی بر ادبیات اخیر برای پیادهسازی AutoML در SDSS و (C3) خلاصه ای از فرصت های تحقیقاتی کلیدی و چالش های SDSS با AutoML در رابطه با پذیرش کاربر.
بخش 2 فرآیند انتخاب و بررسی ادبیات را شرح می دهد. بخش 3 به طور خلاصه ادبیات انتخاب شده از بخش 2 را خلاصه و تجزیه و تحلیل می کند تا مروری بر مقالات، موضوعات و گرایش های مهم ارائه دهد. بخش 4 ادبیات انتخاب شده را برای پیشینه و نظریه عمیق تر نظریه AutoML و SDSS گذشته و اخیر، مشکلات و کاربردها برای پاسخ به سؤال تحقیق 1 مرور می کند. چارچوب SDSS با AutoML در بخش 5 برای پاسخ به سؤال تحقیق 2 مورد بحث قرار می گیرد. همراه با ملاحظات کلیدی، چالش های پیاده سازی، و فرصت های تحقیقاتی برای پاسخ به سوال تحقیق 3 که به پذیرش کاربر مربوط می شود. در نهایت، بخش 6مقاله را با خلاصهای از بخشهای قبلی و پیامدهای آینده تحقیق بر روی SDSS با AutoML به پایان میرساند.
2. روش ها
این مقاله از یک فرآیند دو مرحله ای برای پاسخ به سه سوال تحقیقی که در مقدمه توضیح داده شده است استفاده کرد ( شکل 1 ). این بخش فرآیندی را شامل میشود که شامل جمعآوری ادبیات تحقیقاتی مربوط به AutoML و SDSS، سپس خلاصهسازی، تجزیه و تحلیل و بحث درباره ادبیات جمعآوریشده برای پاسخ به سه سؤال تحقیق میشود. یک نمای کلی از ادبیات یافت شده از بکارگیری فرآیند توصیف شده در این بخش در بخش 3 موجود است .
2.1. مرحله اول: جستجوی ادبیات
اولین گام شامل جستجوی متون اخیر AutoML و SDSS بود. مقالات مجلات بررسی شده با کلمات کلیدی (فقط عناوین) در 382 پایگاه داده تحقیقاتی (مانند Scopus، arxiv، Web of Science و غیره) با استفاده از Summon 2.0 بین 1 ژانویه 2019 و 24 سپتامبر 2022 جستجو شدند [ 14 ]. سپس این مقالات با بررسی عنوان و چکیده مقالات مرتبط با AutoML/SDSS که فقط مقالات مروری هستند، به صورت دستی فیلتر شدند. از آنجایی که بسیاری از مقالات مروری اخیر ادبیات، تحولات AutoML [ 12 ، 13 ، 15 ، 16 ، 17 ] و SDSS [ 4 ، 18 ، 19 ، 20 ، 21 را پوشش می دهند.] در 5 سال گذشته، از مقالات سه سال گذشته برای جلوگیری از اطلاعات قدیمی و تمرکز بر جدیدترین تحقیقات استفاده شده است. بنابراین، مقالات AutoML و SDSS که مرور ادبیات نبودند یا در اوایل سال 2019 منتشر شده بودند، حذف شدند. مقالات فیلتر شده به صورت دستی (17 AutoML، 18 SDSS) در سه سال گذشته برای کشف 101 مرجع اضافی برای موضوعات AutoML و SDSS با استفاده از استراتژی جستجوی گلوله برفی، که شامل بررسی مقالات فیلتر شده به صورت دستی برای موضوعات فرعی اصلی (مثلاً، انتخاب ویژگی، خوشه بندی فضایی، خطوط لوله یادگیری ماشین، و غیره) برای شناسایی مراجع مکمل مهم برای AutoML و SDSS [ 22 ]]. هدف از شناسایی مقالات تکمیلی پوشش موضوعات اصلی SDSS و AutoML قبل از سال 2019 بود و به سه سال گذشته محدود نشد.
2.2. مرحله دوم: بررسی و بحث
مرحله دوم شامل پاسخ به سؤالات تحقیق با استفاده از مقالات و منابع مرتبط گردآوری شده از مرحله اول بود. مسائل مشابه قابل حل توسط AutoML و SDSS بر اساس اهداف مطالعه (به عنوان مثال، پیش بینی خطر زمین لغزش، شبیه سازی الگوهای کاربری زمین، و غیره) شناسایی شد و برای پاسخ به سوال تحقیق 1 خلاصه شد: (R1) SDSS و AutoML چه مشکلاتی را می توانند بر اساس حل کنند. به تحقیقات اخیر؟ یک چارچوب کلی برای SDSS با AutoML برای پاسخ به سوال تحقیق 2 ایجاد شد: (R2) چگونه می توان AutoML را در SDSS ادغام کرد؟شباهتهای بخش روششناسی از مقالات مروری در مرحله اول، و مراجع مربوطه، برای شناسایی مؤلفههای AutoML و SDSS مورد بررسی قرار گرفت. سپس مؤلفههای AutoML و SDSS بر اساس رویکردهای عمومی AutoML/SDSS از مقالات مروری/ مراجع مربوطه و مشکلات فضایی شناسایی شده از پاسخ به سؤال تحقیق یک به هم متصل شدند. در نهایت، فرصتها و چالشهای مقالات مروری و مراجع مربوطه در مرحله اول شناسایی و مورد بحث قرار گرفت تا به سؤال تحقیق 3 پاسخ داده شود: (R3) چالشها و فرصتهای SDSS با AutoML برای بهبود پذیرش کاربر چیست؟ چالشها و فرصتها با مقایسه شباهتها و تفاوتها بین نتایج، بحث، محدودیتها و سایر بخشها/مرجعات مرتبط پیدا شد.
3. نتایج جستجو
در مجموع 136 مقاله SDSS و AutoML برای بررسی یافت شد. در مجموع از 18 مقاله SDSS و 17 مقاله AutoML به عنوان منابع اولیه برای بررسی پیشرفت های مهم اخیر استفاده شد، در حالی که 63 مقاله SDSS، 21 مقاله AutoML، و 17 مقاله AutoML/SDSS (مقالاتی که هم AutoML و هم SDSS را به عنوان موضوع دارند) با استفاده از این منابع اولیه پیدا شد. منابع اولیه (بین سالهای 2019 و 2022) بهعنوان منابع تکمیلی برای بررسی ادبیات بنیادی در اوایل سال 2022 مهم بودند، زیرا از جدیدترین بررسیهای ادبیات تشکیل شدهاند تا یک نمای کلی از پیشرفت قابل توجه تحقیقات تا به امروز ارائه کنند، در حالی که منابع تکمیلی ( قبل از سال 2022) از منابع اولیه برای محدود کردن موضوعات فرعی حیاتی برای AutoML و SDSS شناسایی شدند. تعداد مقالات در سال بین سالهای 1990 و 2018 ثابت بوده است (انتخاب تکمیلی)،شکل 2 ). مقالاتی با موضوعات AutoML و SDSS کاملاً جدید بودند و تنها پس از سال 2020 دیده شدند. کلیدواژههای اصلی بر موضوعات دادهها، سیستمهای فضایی/برنامهریزی، یادگیری ماشین و مدلها/تحلیل متمرکز بودند ( شکل 3 ). مقالات قابل توجه بر اساس تعداد استنادها در شکل 4 و شکل 5 مشاهده می شود ، جایی که داده های استناد با استفاده از OpenCitations Corpus در 25 سپتامبر 2022 [ 23 ] پیدا شد. این مقالات که بر اساس موضوع و منبع گروه بندی شده اند، در مقایسه با سایر مقالات همان گروه، تعداد ارجاعات بسیار بیشتری داشتند. مقالات قابل توجه اولیه SDSS دارای بیش از 15 استناد بودند [ 4 ، 19 ، 24 ، 25]. مقالات اولیه قابل توجه AutoML بیش از 25 استناد داشتند [ 12 ، 26 ، 27 ]. مقالات تکمیلی قابل توجه SDSS بیش از 500 استناد داشتند [ 28 ، 29 ]. مقالات تکمیلی قابل توجه AutoML بیش از 1000 نقل قول داشتند: [ 30 ، 31 ، 32 ]. مقالات تکمیلی قابل توجه با موضوعات AutoML و SDSS به دلیل تازگی، نقل قول های بسیار کمتری داشتند و فقط بیش از 5 نقل قول داشتند [ 33 ، 34 ، 35 ].
4. نتایج را بررسی کنید
سوال تحقیق 1 را به یاد بیاورید: (R1) طبق تحقیقات اخیر، SDSS و AutoML چه مشکلاتی را می توانند حل کنند؟ این بخش با مرور و خلاصه ادبیات منتخب از بخش 3 از طریق مروری دقیق بر SDSS، AutoML و مشکلات، روشها، کاربردها و رویکردهای مرتبط با آنها در تحقیقات اخیر، به سوال تحقیق 1 میپردازد.
4.1. سیستم های پشتیبانی تصمیم گیری فضایی (SDSS)
اصطلاح SDSS از سال 1985 برای توصیف نرم افزار طراحی شده برای پشتیبانی از تصمیم گیری استفاده شده است که کاربران را قادر می سازد تا مسائل فضایی ساختاریافته یا نیمه ساختار یافته را برای راه حل های بالقوه تجزیه و تحلیل کنند [ 65 ]. SDSS مدرن از نرم افزار راه حل محور به چارچوب های انسان محور تغییر کرد که ویژگی ها و ایده هایی از سیستم های اطلاعات جغرافیایی (GIS) [ 66 ] و سیستم های پشتیبانی برنامه ریزی (PSS) [ 67 ] را در خود جای داد. SDSS چارچوبهایی هستند که مجموعهای از ابزارهای طراحیشده برای اطلاعرسانی تصمیمگیری مربوط به مسائل فضایی را در بر میگیرند که عموماً از سه جزء تشکیل شدهاند [ 4 ، 18 ، 19 ، 24 ، 36 .]: (1) داده های مکانی (2) اطلاعات مکانی و (3) دانش مکانی.
جزء داده های مکانی، داده ها را به عنوان ورودی برای جزء اطلاعات مکانی مدیریت و پردازش می کند، که داده ها را با سازماندهی و ارائه آن برای نیازهای تصمیم گیری به اطلاعات تبدیل می کند (به عنوان مثال، مدل سازی، تجسم) [ 21 ، 68 ، 69 ]. رویکردهای مورد استفاده در مولفه اطلاعات فضایی شامل تجزیه و تحلیل تصمیم گیری معیارهای چندگانه (MCDA) [ 46 ]، تجزیه و تحلیل نقطه داغ [ 70 ]، رگرسیون فضایی [ 71 ]، اتوماتای سلولی (CA) [ 72 ]، مدل سازی مبتنی بر عامل (ABM) [ 47 ] و بهینه سازی ازدحام ذرات (PSO) [ 48]. این اطلاعات به عنوان ورودی برای مؤلفه دانش عمل میکند که کاربران را قادر میسازد تا با اطلاعات تعامل داشته باشند و اطلاعات را برای تولید دانش بررسی کنند [ 20 , 37 , 38 , 39 , 73 ]. دانش برای حمایت از تصمیمات یا کمک به بهبود داده ها یا اجزای اطلاعات استفاده می شود [ 4 ، 24 ]. رویکردهای تولید دانش شامل برنامه ریزی مشارکتی [ 19 ]، دانش شهروندی [ 73 ] و همکاری جغرافیایی [ 74 ] است.]. اگرچه دادههای مکانی و اجزای اطلاعات بر دادههای مکانی تمرکز میکنند، ممکن است شامل دادههای غیرمکانی تکمیلی نیز باشند. هر مؤلفه SDSS شامل چندین مؤلفه فرعی است که ویژگی ها و عملکردهای خاص مولفه را نشان می دهد. اجزای عمومی SDSS، اجزای فرعی و تعاملات آنها در شکل 6 مشاهده می شود. جزء داده های مکانی شامل اجزای فرعی مرتبط با داده ها (به عنوان مثال، جمع آوری داده ها، ذخیره سازی، دسترسی، اسناد، پردازش، و غیره) است که به عنوان ورودی برای جزء اطلاعات مکانی عمل می کند. مؤلفه اطلاعات مکانی شامل چندین مؤلفه فرعی است (مانند نظارت، مدلسازی، تجسم، گزارشدهی و غیره) که دادههای مکانی را به اطلاعات تبدیل میکند (مثلاً معیارهای معنادار در طول نظارت، نمودارها/نقشهها برای تجسم، خلاصههای متنی خودکار برای گزارش، و غیره) که می تواند تجزیه و تحلیل، تفسیر شود، و در نهایت، بیشتر به ورودی برای مؤلفه دانش تبدیل شود. مؤلفه دانش شامل مؤلفههای فرعی مرتبط با عمل (مانند ارتباطات، همکاری، کاوش و غیره) است که منجر به تغییر دادههای مکانی یا مؤلفههای اطلاعات مکانی میشود. و/یا اقدامی برای اجرا یا حمایت از یک تصمیم. این سه مؤلفه با هم کار می کنند تا بینش عملی را از ترکیب داده ها، اطلاعات و دانش ارائه شده توسط SDSS ایجاد کنند.
علیرغم بسیاری از مطالعات در SDSS [ 4 ]، چالشهای مربوط به پذیرش کم کاربران [ 5 ، 39 ، 40 ] (به عنوان مثال، آگاهی در سراسر رشتهها، عدم پذیرش/اعتماد پزشک، منابع/آموزش گران)، شواهد مفید بودن [ 18،38 ] وجود دارد . (به عنوان مثال، اثبات سودمندی/موفقیت عملی برای پزشکان، ارزش افزوده در مقابل منابع مورد نیاز)، سازگاری [ 21 ] (به عنوان مثال، تعادل بین ویژگی دامنه و قابلیت تعمیم، کاربرد در زمینه ها/مشکلات مشابه)، همکاری [ 36 ] (به عنوان مثال، ارتباط بین بازیگران غیر فنی و فنی، ترجمه نیازهای تصمیم گیری به مدل ها/ابزارها) و قابلیت تفسیر [ 6 ]] (به عنوان مثال، اطلاعات بیش از حد/پیچیده برای کاربران غیر فنی، شفافیت فرآیندها/ورودی ها/خروجی ها). بحث در مورد شکاف های بین تحقیق و عمل SDSS یک موضوع مهم باقی مانده است، با بسیاری از مطالعات که مشارکت اولیه و همکاری بین تصمیم گیرندگان، سهامداران و جامعه را تشویق می کند [ 5 ، 36 ، 41 ]. با گذشت زمان، تحقیقات SDSS، که عمدتاً بر کاربردها، مطالعات موردی و بررسیها متمرکز بود، پس از سال 2004 شروع به افزایش کرد و بین سالهای 2010 تا 2020 ثابت ماند، با رشد اخیر مطالعات مربوط به علوم/تحلیل شهری، شهرهای هوشمند/برنامهریزی شهری و دوقلوهای دیجیتال [ 75 ].
4.2. یادگیری ماشین خودکار (AutoML)
AutoML را می توان به عنوان اتوماسیون یادگیری ماشینی، ترکیبی از دو اصطلاح توصیف کرد: (1) اتوماسیون (خودکار)، برای عمل مستقل، عملکرد یا کار بدون دخالت انسان [ 76 ] و (2) یادگیری ماشین (ML)، حوزه هوش مصنوعی (AI) بر الگوریتمهای رایانهای متمرکز است که میتوانند از طریق تجربه بهبود یابند [ 77 ]. رویکردهای فعلی AutoML معمولاً شامل بهینهسازی اجزا در فرآیند ML (به عنوان مثال، استخراج/ایجاد ویژگیها، تنظیم/ایجاد مدلها) با توجه به محدودیتها (مانند رسیدن به عملکرد یا محدودیتهای زمانی مورد نظر) است [ 13 ]]. این رویکردهای بهینه سازی از معیارهایی (به عنوان مثال، دقت، خطا) استفاده می کنند که کیفیت اجزای خروجی (مثلاً ویژگی ها، مدل ها) را تعیین می کند. مدلها شامل رگرسیون خطی/لجستیک [ 78 ، 79 ]، بیز ساده (NB) [ 80 ]، درختهای تصمیمگیری (DT) [ 49 ]، جنگلهای تصادفی [ 30 ]، خوشهبندی k-means [ 32 ]، ماشینهای بردار پشتیبان (SVM) هستند. [ 31 ]، شبکه های عصبی (NN) [ 81 ] و الگوریتم های ژنتیک (GA) [ 50 ]. یک رویکرد AutoML عمومی در شکل 7 دیده می شود، که در آن دو فرآیند اصلی (بهینه سازی ویژگی و بهینه سازی مدل) در بین رویکردهای مختلف AutoML که در ادبیات دیده می شود مشترک هستند. فرآیند بهینهسازی ویژگی، دادهها را به مجموعهای از ویژگیهای اطلاعاتی تبدیل میکند که میتوانند برای مدلسازی یک نتیجه خاص مورد استفاده قرار گیرند، جایی که این ویژگیها بر اساس معیاری که کیفیت هر ویژگی را اندازهگیری میکند بهینه هستند (مثلاً میزان اطلاعرسانی یا متفاوت بودن هر ویژگی) . سپس فرآیند بهینهسازی مدل، ویژگیهای بهینهشده را میگیرد و بر اساس مدلهای موجود و پارامترهای الگوریتم مدل/بهینهسازی مرتبط ارائه شده، مدلهای با کارایی بالا تولید میکند. عملکرد مدل با معیاری از کیفیت مدل اندازه گیری می شود که الگوریتم بهینه سازی مدل را هدایت می کند (به عنوان مثال، دقت یا خطا بین داده های آموزش و آزمایش).
اگرچه AutoML AutoML را برای افراد غیرمتخصص بیشتر در دسترس قرار داده است [ 7 ، 82 ]، مسائلی در وابستگی به داده ها [ 12 ، 26 ] (به عنوان مثال، کیفیت پایین داده، داده های در دسترس، سوء استفاده از داده)، زمان و کارایی [ 17 ، 83 ] وجود دارد. (به عنوان مثال، عملکرد در مقابل زمان اجرا قابل قبول، اندازه مجموعه داده ها، جامعیت فضای جستجو)، به روز رسانی/قابلیت استفاده مجدد [ 13 ، 42 ، 43 ، 84 ] (به عنوان مثال، به روز رسانی مدل موجود با داده های جدید، سازگاری عملکرد، راه حل های قابل تکرار)، و تفسیرپذیری [ 12 ، 85 ، 86] (به عنوان مثال، چرا مدل ها بهتر/بدتر عمل می کنند یا اقدامات خاصی انجام می دهند). از آنجایی که فرآیندهای ML به طور فزایندهای خودکار میشوند و برای حل مشکلات عملی در صنعت به کار میروند ، بسته کردن شکاف بین متخصصان/متخصصان حوزه و متخصصان ML اخیراً موضوع مورد توجه بوده است . بسیاری از تحقیقات AutoML بر یادگیری نظارت شده متمرکز شده است، اما تحقیقات اخیر برای مقابله با طیف وسیع تری از مشکلات ML مانند یادگیری بدون نظارت، پیش بینی سری های زمانی، و تشخیص ناهنجاری متفاوت است [ 87 ، 88 ].
4.3. مسائل فضایی در SDSS و ML
مشکلات فضایی، که معمولاً در SDSS مورد مطالعه قرار میگیرند، در تحقیقات AutoML قبل از سال 2020 رایج نبودند، زمانی که بسیاری از مطالعات بر روی مشکلات عمومی مانند پیشبینی و بهینهسازی، بدون در نظر گرفتن اثرات فضایی تمرکز داشتند. با این حال، برنامه های کاربردی ML برای مشکلات فضایی رایج تر هستند [ 89 ، 90 ]، و اخیراً در SDSS ادغام شده اند [ 21 ، 91 ]. این بخش مشکلات فضایی را شناسایی میکند که با رویکردهای SDSS یا ML برای تکمیل تعداد بسیار کمتری از مطالعات متمرکز بر SDSS و AutoML مورد مطالعه قرار گرفتهاند. از آنجایی که AutoML فرآیندهای ML را خودکار می کند، بررسی مطالعاتی که از ML برای حل مشکلات فضایی استفاده می کنند مرتبط است. خلاصه ای از مشکلات فضایی در SDSS و برنامه ها و رویکردهای بررسی شده در نشان داده شده استجدول 1 ، و با جزئیات بیشتر در بخش 4.3.1 تا بخش 4.3.5 بررسی شده است.
4.3.1. تخمین فضایی
مشکلات تخمین فضایی شامل محاسبه مقادیر مجهول در مکان های مختلف است که شامل درون یابی مکانی [ 92 ]، پیش بینی [ 93 ] و پوشش [ 94 ] می شود. این مسائل برای ایجاد سطوح از نمونه ها (به عنوان مثال، کریجینگ [ 29 ])، پیش بینی مقادیر آینده در مکان های مختلف، و محاسبه مقادیر بر اساس مکان حل می شوند. نمونههای اخیر شامل محاسبه خطر بیماری [ 95 ]، پیشبینی خطر بلایا [ 96 ]، و ایجاد شاخص کاربری زمین [ 97 ] با استفاده از رویکردهای MCDA، رگرسیون فضایی (به عنوان مثال، رگرسیون وزندار جغرافیایی (GWR) [ 98 ) است.])، ML (به عنوان مثال، SVM، RF، NN)، و ML دارای وزن جغرافیایی (GW-ML) (به عنوان مثال، NN و RF دارای وزن جغرافیایی) [ 99 ، 100 ]. راهحلهای تخمین فضایی اغلب با خطا (مثلاً ریشه میانگین مربعات خطا (RMSE)، منفیهای واقعی، مجموع مربع خطا (SSE)) و دقت (به عنوان مثال، امتیاز F1، سطح زیر منحنی ROC (AUC)، حساسیت، ویژگی ارزیابی میشوند. ) معیارهایی که مقادیر برآورد شده را با مقادیر واقعی از داده های دنیای واقعی مقایسه می کنند [ 51 ]. چالشها در مشکلات تخمین فضایی شامل نیاز به مقادیر بیشتری از دادههای حقیقت زمینی و در نظر گرفتن عوامل/متغیرها/مقیاسهای اضافی است [ 93 ].
4.3.2. بهینه سازی فضایی
بهینه سازی فضایی شامل قرار دادن فضایی [ 101 ] و مسیریابی [ 102 ] موجودیت ها است. حل مسائل بهینهسازی فضایی به تعیین مکان بهینهتر تسهیلات و زیرساختهای مهم (به عنوان مثال، مشکلات انتخاب مکان یا مکان تأسیسات [ 52 ])، و مسیرهای حملونقل کارآمد (به عنوان مثال، مسیریابی وسیله نقلیه [ 103 ] و مشکلات فروشنده دوره گرد [ 104 ] کمک میکند. ]). نمونههای اخیر شامل انتخاب تسهیلات بیمارستانی [ 105 ]، قرار دادن زیرساخت انرژی [ 106 ]، مسیریابی تحویل [ 107 ] و کنترل خودکار ترافیک [ 108 ] است.] با استفاده از GA، MCDA و PSO. علاوه بر معیارهای خطا و دقت، راه حل های بهینه سازی فضایی با معیارهای چند معیاره [ 109 ] (به عنوان مثال، مجموع وزنی، تحلیل حساسیت) و چند هدفه [ 53 ] (به عنوان مثال، گسترش، حجم زیاد، همگرایی) ارزیابی می شوند که شاخص های مهم داده ها را در نظر می گیرند. ، ورودی متخصص و جامعیت فضای جستجو. چالشها در مسائل بهینهسازی فضایی شامل اثرات زمانی، اهداف چندگانه و راندمان محاسباتی است [ 52 ، 110 ].
4.3.3. خوشه بندی فضایی
خوشهبندی فضایی شامل گروهبندی موجودیتها در فضا (به عنوان مثال، شاخصهای محلی تداعی فضایی (LISA) [ 111 ]، تجزیه و تحلیل نقطه داغ، خوشهبندی فضایی مبتنی بر چگالی برنامههای کاربردی با نویز (DBSCAN) [ 112 ]) و زمان (به عنوان مثال، خوشهبندی مکانی و زمانی است. [ 113 ]، SaTScan [ 114 ]، K-means [ 32 ])، که در آن موجودیت های درون گروه ها مشابه و موجودیت های خارج از گروه های مختلف متفاوت هستند [ 115 ]. این گروهها برای شناسایی مناطق جالب (مانند مناطق با جرم بالا [ 116 ] یا منابع طبیعی بالقوه [ 117 ]) و بازههای زمانی (مانند مناطق انتقال بیماری در زمانهای خاص [ 118 ) استفاده میشوند.]). کاربردهای جدیدتر شامل خوشه بندی داده های مکانی-زمانی با حجم و سرعت بالا (به عنوان مثال، رسانه های اجتماعی، جمع سپاری) است [ 119 ، 120 ]. راه حل های خوشه بندی فضایی با معیارهای آماری [ 121 ] (به عنوان مثال، نسبت احتمال، همبستگی خودکار، اهمیت) و شباهت [ 54 ] (به عنوان مثال، فاصله اقلیدسی، همبستگی پیرسون) ارزیابی می شوند. چالشهای خوشهبندی فضایی شامل خوشههایی با شکل نامنظم، دادههای ابعادی بالا، انتخاب روابط/وزنهای فضایی، وضوح، تعاملات شی، و ارزیابی کمی در مقابل بصری [ 113 ، 122 ، 123 ] است.
4.3.4. شبیه سازی فضایی
شبیه سازی فضایی به تقلید از پدیده های دنیای واقعی یا فرضی در فضا و زمان اشاره دارد [ 124 ]. شبیه سازی فضایی تجزیه و تحلیل را در مواردی که داده ها به سختی به دست می آیند (به عنوان مثال، تفکیک مکانی/زمانی دقیق تر، پدیده های فرضی/آینده) امکان پذیر می سازد [ 47 ]. رویکردها شامل مدلهای دامنه خاص (به عنوان مثال، مدلهای عملکرد محصول [ 125 ]، مدلهای هیدرودینامیکی سیال [ 126 ])، CA و ABM هستند. نمونههای اخیر عبارتند از یادگیری تقویتی (RL)، ABM و CA برای شبیهسازی کنترل چراغ راهنمایی [ 127 ]، گسترش آتشسوزی [ 128 ] و رشد شهری پایدار [ 129 ]. راه حل های شبیه سازی فضایی با دامنه خاص ارزیابی می شوند (به عنوان مثال، تاخیر ترافیک کل [127 ]، عملکرد کل محصول [ 125 ]، ترکیب چشمانداز/اندازههای وصله [ 130 ]) معیارهایی که برای راهنمایی مشاهدات تجربی استفاده میشوند. چالشهای شبیهسازی فضایی شامل اعتبارسنجی مدل، پیچیدگی بیش از حد، عدم سازماندهی، تکرارپذیری، منابع محاسباتی و فقدان مبنای نظری است [ 131 ].
4.3.5. بینش فضایی
مشکلات بینش فضایی بر تفسیر و تجسم دادههای مکانی و خروجیهای مدل تمرکز میکنند، که معمولاً شامل رگرسیون فضایی [ 132 ]، رابطهای تعاملی [ 133 ] و نقشهها [ 134 ] است. گنجاندن ویژگیهای بینش مکانی در SDSS به دادهها و مدلها کمک میکند تا دانش مفید برای تصمیمگیری را تولید کنند (به عنوان مثال، رابط گرافیکی برای مشاهده و دستکاری تعاملی دادهها و مدلهای مکانی [ 135 ]، نقشههای وب نمایش دادههای مکانی یا نتایج مدل [ 136 ]، ضرایب نشاندهنده متغیر اثرات در مدل ها [ 55 ]). نمونه های اخیر شامل رگرسیون فضایی برای شناسایی عوامل کاهش آلودگی است [ 137]، وب GIS برای ایجاد تعاملی مدل های حوضه [ 138 ]، و ابزارهای تجسم تعاملی برای کاوش و تجزیه و تحلیل خطوط لوله AutoML [ 139 ]. راهحلهای بینش فضایی با متغیرها (به عنوان مثال، اهمیت ویژگی [ 56 ]، ضرایب [ 28 ])، تفسیرپذیری [ 57 ] (به عنوان مثال، شاخصهای شناختی، شاخصهای توضیح)، و رویکردهای تجربی [ 140 ] ارزیابی میشوند.] (به عنوان مثال، تست قابلیت استفاده، نظرسنجی های کنترل شده کاربر، مشاهده بینش کاربر) برای بررسی اثربخشی ابزارهای تعاملی/تجسم برای تولید بینش مفید. چالشهای بینش فضایی شامل اندازهگیری سودمندی، انتخاب/توجیه روشهای ارائه مناسب، مدیریت کلان داده/پیچیدگی، و شخصیسازی در مقابل تعمیمپذیری است [ 58 ، 140 ، 141 ].
4.4. SDSS با AutoML
تحقیقات مربوط به SDSS با AutoML اخیراً، پس از سال 2020 شروع به ظهور کرده است. روشهای AutoML در کاربردهای مختلفی در زمینههای کشاورزی به کار گرفته شد (به عنوان مثال، پیشبینی محصول [ 59 ، 142 ، 143 ]، طبقهبندی محصولات [ 60 ])، علوم زیست محیطی (به عنوان مثال، ارزیابی اثرات زیست محیطی [ 144 ]، برآورد خطر غرقابی [ 145 ]، تخمین ذخیره آب [ 33 ]، نقشه برداری پتانسیل آب [ 146 ]، پیش بینی هواشناسی [ 147 ]، پیش بینی رفتار اقیانوس [ 148 ]) ، زمین شناسی (به عنوان مثال، محل چاه نفت [ 149 ]، تخمین زبری خاک [35 ]، تخمین رطوبت خاک [ 34 ]، تخمین خطر زمین لغزش [ 61 ، 150 ]، حمل و نقل (به عنوان مثال، بازرسی بهداشت جاده [ 151 ])، و بهداشت عمومی (به عنوان مثال، پیش بینی نرخ خشونت [ 62 ]). اکثر مطالعات از تلفیقی از منابع دادههای مکانی استفاده میکنند که تصاویر ماهوارهای، حسگرها و نظرسنجیها رایجترین و دادههای جمعیتشناختی اجتماعی کمترین رایجترین آنها هستند. خلاصه ای از SDSS با رویکردها و کاربردهای AutoML در جدول 2 نشان داده شده است .
روشهای AutoML بررسیشده به چهار رویکرد تعمیمیافته گروهبندی شدند: (1) مجموعهسازی، (2) بیزی، (3) شبکههای عصبی، و (4) تکاملی. برجستهترین رویکرد AutoML، مجموعهبندی بود، که شامل ترکیبی از الگوریتمهای متعدد برای دستیابی به عملکرد بهتر نسبت به الگوریتمهای فردی است [ 152 ]. این با رویکردهای بیزی دنبال می شود که بر اساس قضیه بیز است و از مشاهدات گذشته برای هدایت پیش بینی های آینده استفاده می کند [ 83 ، 153 ]. رویکردهای شبکه عصبی شامل بهینهسازی معماری شبکههای عصبی برای ساخت مدلهای یادگیری عمیق است که به عملکرد بالایی دست مییابند [ 154 ]]. در نهایت، رویکردهای تکاملی از الگوریتمهایی استفاده میکنند که تکنیکهای مبتنی بر انتخاب طبیعی را بر روی جمعیتی از مدلها، مانند جهش، تولید مثل، و انتخاب تقلید میکنند تا مدلهای تکاملیافته بهینه را پیدا کنند که عملکرد بهتری را به دست آورند [ 155 ].
روشها و نرمافزارهای بررسی شده AutoML عبارتند از Auto-Sklearn، ابزار بهینهسازی خط لوله مبتنی بر درخت (TPOT)، H2O، Autogluon، جستجوی معماری عصبی (NAS) و Alpha3DM. Auto-Sklearn از ترکیبی از بهینه سازی بیزی، فرا یادگیری، و ساخت مجموعه برای انجام تنظیم هایپرپارامتر و انتخاب الگوریتم استفاده می کند [ 156 ]. TPOT از برنامه ریزی ژنتیکی برای بهینه سازی و تولید خطوط لوله ML مبتنی بر درخت استفاده می کند [ 157 ]. H2O از جستجوی تصادفی و مجموعههای پشتهای برای تولید مدل نهایی استفاده میکند که تنوع مدلهای کاندید را ارزیابی میکند، که در برخی شرایط، بهتر از بهینهسازی بیزی یا رویکردهای مبتنی بر الگوریتم ژنتیک هستند [ 158 ].]. Autogluon مدلهای مجموعهای را به مدلهای جداگانه تقطیر میکند، با استفاده از یک استراتژی افزایش دادهها بر اساس نمونهگیری Gibss، برای تولید مدلهای نهایی که سریعتر و در برخی موارد دقیقتر از آموزش مدلهای جداگانه توسط خودشان یا مدلهای ترکیبی هستند [ 159 ]. NAS ساخت معماریهای شبکه عصبی را برای ساخت مدلهای یادگیری عمیق با استراتژیهای جستجو، فضاها و تکنیکهای مختلف تخمین عملکرد خودکار میکند، که میتواند برای شبکههای بیزی و شبکههای حافظه کوتاهمدت (LSTM) اعمال شود [ 154 ].]. AlphaD3M با مدلسازی متا داده، وظایف و خطوط لوله ML به عنوان حالتها در یک مدل یادگیری عمیق، از یادگیری تقویتی متا با بازی خود استفاده میکند، که به AlphaD3M اجازه میدهد سریعتر از رویکردهای AutoML مانند Auto-Sklearn و TPOT باشد، در حالی که با شفاف توضیح داده میشود. عملیات ویرایش خط لوله ML [ 160 ].
5. بحث
دو سوال تحقیق را به خاطر بیاورید: (R2) چگونه می توان AutoML را در SDSS ادغام کرد؟ و (R3) چالش ها و فرصت های SDSS با AutoML برای بهبود پذیرش کاربر چیست؟ بخش 5.1 با استفاده از مفاهیم موجود در ادبیات بررسی شده از بخش 4 برای تشکیل چارچوبی برای SDSS با AutoML و بحث در مورد ملاحظات کلیدی هنگام اعمال چارچوب، به سؤال تحقیق 2 پاسخ میدهد. بخش 5.2 – بخش 5.3 با شناسایی و بحث در مورد چالش های پیاده سازی و فرصت های تحقیقاتی در SDSS با AutoML مربوط به پذیرش کاربر SDSS به سؤال تحقیق 3 پاسخ می دهد.
5.1. SDSS با چارچوب AutoML
تحقیقات اخیر در SDSS الگوریتمهای ML و مدلهای دیگری را که میتوانند توسط AutoML خودکار شوند، برای حل مشکلات فضایی برای تبدیل دادههای مکانی به اطلاعات مکانی ترکیب کردهاند. با استفاده از مفهوم عمومی AutoML در شکل 7 به اجزای SDSS در شکل 6 ، AutoML را می توان با قاب بندی این مسائل فضایی به عنوان مسائل بهینه سازی در SDSS ادغام کرد. با اشاره به مؤلفههای SDSS در شکل 6 ، AutoML به طور خودکار دادههای مکانی را به اطلاعات مکانی پردازش میکند، و نقشی بین این دو مؤلفه SDSS دارد، اما مؤلفه دانش مکانی را ندارد زیرا به فرآیندهای انسان محور (مانند ارتباطات، اکتشاف، همکاری) وابسته است. ). با توجه به مسئله فضایی x ، راه حل های بالقوهS و متریک Q (اندازهگیری چگونگی حل مسئله فضایی توسط راهحلها)، AutoML میتواند به طور خودکار جوابهای تقریباً بهینه را تقریب کند. اس˜برای x بر اساس متریک Q در محدودیت های از پیش تعریف شده (به عنوان مثال، محدودیت های زمانی، عملکرد مطلوب). به عنوان مثال، یک مشکل تخمین فضایی x می تواند طبقه بندی این باشد که آیا پیکسل ها در مختصات مختلف کاربری شهری یا روستایی دارند. متریک Q میتواند معیاری باشد برای اینکه چند پیکسل به درستی بر اساس نمونههای واقعی پیکسلهای کاربری زمین شهری/روستایی پیشبینی شدهاند، در حالی که راهحلهای بالقوه S میتواند مجموعهای از مدلهای مناسب (مانند کریجینگ، DT، NN) باشد که میتواند شهری/را پیشبینی کند. پیکسل کاربری اراضی روستایی راه حل نزدیک به بهینه اس˜دقیق ترین مدل از S بر اساس Q است، با استفاده از یک الگوریتم بهینه سازی (به عنوان مثال، GA، PSO) تحت محدودیت ها (به عنوان مثال، حداکثر تکرار / زمان اجرا). در MCDA، راهحلهای بالقوه S نیز میتوانند طرحهای وزنی متفاوتی باشند. با اشاره به اجزای AutoML در شکل 7 ، چارچوبی برای ادغام AutoML در SDSS ایجاد شده است، همانطور که در شکل 8 مشاهده می شود ، جایی که AutoML به طور خودکار داده های مکانی را با حل مسائل فضایی مختلف به اطلاعات مکانی پردازش می کند. به طور کلی، این چارچوب به سه ملاحظات کلیدی نیاز دارد که ممکن است برای حل مسائل جغرافیایی در مقیاس وسیعتر نیز قابل اجرا باشد:
-
مشکلات فضایی : با توجه به زمینه و بازیگران در تصمیم گیری، چه مشکلات فضایی باید حل شود؟
-
معیارها: چه معیارهایی برای ارزیابی و اندازه گیری مسئله(های) فضایی تعریف شده مناسب هستند؟
-
راه حل های بالقوه : با مسئله(های) فضایی و متریک(های) داده شده، راه حل های بالقوه برای حل مسئله(های) فضایی چیست؟
5.1.1. ملاحظات کلیدی 1: مشکلات فضایی
با توجه به زمینه و بازیگران در تصمیم گیری، مشکلات فضایی باید تعریف شوند تا تصمیمات در حال ارزیابی را منعکس کنند [ 161 ]. در ابتدا، تعیین انواع تصمیمات مورد ارزیابی ممکن است به تعریف رفتار تصمیمات کمک کند. انواع اصلی تصمیمات بر اساس [ 162 ] عبارتند از:
-
مستقل : تصمیماتی که توسط یک تصمیم گیرنده با مسئولیت و اختیار کامل گرفته می شود.
-
متوالی وابسته : تصمیماتی که تا حدی توسط یک تصمیم گیرنده و تا حدی توسط طرف دیگر گرفته می شود.
-
وابستگی متقابل تلفیقی : تصمیمات حاصل از مذاکره و تعامل بین تصمیم گیرندگان.
سپس، سه مرحله اصلی مربوط به فرآیند تصمیمگیری همانطور که توسط [ 163 ] شرح داده شد، میتواند در تعریف مشکلات فضایی کمک بیشتری کند:
-
هوش : بررسی داده های مکانی برای شناسایی مشکلات فضایی که نیاز به تصمیم گیری دارند و فرصت تغییر دارند.
-
طراحی : تعیین تصمیمات ممکن و جایگزین و توسعه رویکردهایی برای ارزیابی و درک تصمیمات.
-
انتخاب : انتخاب از طیف تصمیمات ممکن و جایگزین پس از ارزیابی و درک هر تصمیم.
پس از در نظر گرفتن نوع تصمیمات، تصمیمات احتمالی و رویکردهای انتخاب/ارزیابی تصمیمات ممکن، مشکل فضایی ممکن است بهتر به عنوان یک یا چند (اما نه محدود به) از مشکلات فضایی کلی زیر که در بخش 4.3 بررسی شده است، تعریف شود :
-
تخمین فضایی : محاسبه مقادیر مجهول در فضا (به عنوان مثال، پیشبینی، پوشش).
-
بهینه سازی فضایی : بهینه سازی موجودیت ها در فضا (به عنوان مثال، قرار دادن، مسیریابی).
-
خوشه بندی فضایی : سازماندهی موجودیت ها در فضا (به عنوان مثال، گروه بندی، طبقه بندی، منطقه بندی).
-
شبیه سازی فضایی : شبیه سازی پدیده ها در فضا (به عنوان مثال، فیزیک، شبیه سازی های نظری).
-
بینش فضایی : تفسیر و اکتشاف پدیده ها و موجودات در فضا (به عنوان مثال، نقشه های تعاملی، تجسم ها، نمودارها).
بسته به تغییر مورد نظر از تصمیم و رویکرد ارزیابی طراحی شده، تصمیمات می توانند ساده یا پیچیده باشند. یک تصمیم ساده ممکن است فقط نیازمند تعریف یک مشکل فضایی باشد. به عنوان مثال، شناسایی کانون های جرم برای گشت های پلیس را می توان به عنوان یک مشکل خوشه بندی فضایی تعریف کرد. یک تصمیم واحد پیچیدهتر ممکن است نیاز به تعریف یک یا ترکیبی از مسائل فضایی مختلف داشته باشد. به عنوان مثال، تجزیه و تحلیل اثرات مداخلات بهداشتی ممکن است نیاز به شناسایی مناطق مداخله (یک مشکل خوشهبندی فضایی) و شبیهسازی اثرات هر مداخله جایگزین بر روی مناطق مداخله (یک مشکل شبیهسازی فضایی) داشته باشد. ملاحظات در این بخش به معنای نقطه شروعی برای کمک به ساختار تصمیم گیری به عنوان مشکلات فضایی است.161 ].
5.1.2. ملاحظات کلیدی 2: معیارها
پس از تعریف مسئله فضایی برای حل، معیارهای مورد استفاده برای اندازه گیری و ارزیابی راه حل های بالقوه برای هر مسئله فضایی باید تعیین شود. در نظر گرفتن وظیفه مورد نیاز برای حل مسائل فضایی تعریف شده مهم است. برای ML و آمار، وظایف زیر در میان مطالعات رایج است [ 51 ، 164 ، 165 ]:
-
رگرسیون : تخمین یا پیشبینی مقادیر هدف مستمر با توجه به عوامل دیگر (مثلاً محاسبه خطر زمین لغزش، پیشبینی تعداد برخوردهای ترافیکی).
-
طبقهبندی : شناسایی مقادیر هدف گسسته (گروهها یا دستهها) با توجه به عوامل دیگر (به عنوان مثال، پیشبینی انواع کاربری زمین، شناسایی انواع ساختمان).
-
خوشهبندی : سازماندهی نهادها به گروهها یا دستهها بر اساس ویژگیها (به عنوان مثال، شناسایی مناطق جرم، مناطق بیماری).
در نظر گرفتن وظایف برای حل مسائل فضایی به شناسایی معیارهای مورد نیاز برای ارزیابی هر مسئله فضایی کمک می کند. هر متریک هدف خاصی دارد و برای اندازه گیری عملکرد وظایف خاص مناسب است. به عنوان مثال، معیارهای RMSE و ضرایب همبستگی برای ارزیابی وظایف رگرسیون استفاده می شود، در حالی که از دقت و امتیازات F1 برای ارزیابی وظایف طبقه بندی استفاده می شود. به عنوان مثال، معیارهای مربوط به وظایف ذکر شده در بالا در جدول 3 ارائه شده است. مرجع. [ 51 ] مجموعه جامع تری از معیارهای رگرسیون و طبقه بندی را ارائه می دهد، در حالی که [ 54 ، 166 ، 167 ] مرورهای دقیق تری از معیارهای مختلف خوشه بندی ارائه می دهد.
انتخاب معیارها نه تنها باید با مشکل فضایی تعریف شده، بلکه با رفتار و ویژگی های داده های مکانی مورد استفاده مطابقت داشته باشد. توجه به این نکته مهم است که هر معیار دارای مزایا و اخطارهای خاص خود است [ 51 ، 53 ، 166 ]. به عنوان مثال، زمانی که داده ها دارای کلاس های نامتعادل هستند، معیارهای دقت سوگیری دارند (به عنوان مثال، 90٪ داده ها کلاس A و تنها 10٪ کلاس B هستند). این باعث می شود که مدل های طبقه بندی عملکرد بالایی داشته باشند اگر اکثریت بزرگی از خروجی طبقه بندی شامل کلاس غالب باشد. در این مورد، امتیاز F1 معیار مناسب تری برای محاسبه عدم تعادل طبقاتی است.
5.1.3. نکته کلیدی 3: راه حل های بالقوه
هنگامی که مسائل فضایی و معیارهای مرتبط تعریف میشوند، راهحلهای بالقوه برای مطابقت با این مسائل و معیارها را میتوان تعیین کرد. مسائل و معیارهای فضایی یک هدف ساختاریافته برای رویکردهای AutoML ایجاد میکنند، جایی که راهحلهای بالقوه اغلب مدلها یا الگوریتمهای ممکن برای روشهای AutoML برای انتخاب هستند. راهحلهای بالقوه باید دادههای فضایی ورودی مربوط به مسائل فضایی تعریفشده را بپذیرند، در حالی که به معیارهای انتخابی اجازه میدهند خروجیها را به روشی اندازهگیری کنند که در بین راهحلهای بالقوه مختلف قابل مقایسه باشد. بنابراین، چند ملاحظات برای راه حل های بالقوه شامل [ 121 ، 168 ، 169 ] است:
-
اندازه داده ها : داده ها چقدر بزرگ یا کوچک هستند.
-
تفسیرپذیری: آیا راهحلهای بالقوه نیاز به تفسیر دارند یا صرفاً خروجیهایی برای استفاده تولید میکنند (مثلاً شناسایی متغیرهای مهم در مقابل عملکرد پیشبینی) .
-
محدودیت های منابع : محدودیت های زمان، محاسبات و تخصص (به عنوان مثال، زمان اجرا مدل ها، آموزش برای تفسیر نتایج).
-
فرکانس بهروزرسانی : هر چند وقت یکبار راهحلهای بالقوه نیاز به ارزیابی مجدد دارند (مثلاً دادههای ورودی جدید، تنظیمات مدل/الگوریتم جدید).
مشابه انتخاب معیارها، راهحلهای بالقوه عموماً نکات و مزایای خاص خود را دارند [ 170 ]. به عنوان مثال، عملکرد شبکه های عصبی به طراحی معماری عصبی وابسته است [ 154 ]، در حالی که مدل های بدون نظارت تمایل دارند در مجموعه داده های بزرگتر عملکرد بهتری داشته باشند [ 169 ]. با این حال، تفاوت بین تعیین راهحلهای بالقوه و معیارها در این است که با توجه به متریک مناسب و قدرت محاسباتی کافی، یک فضای جستجوی جامع را میتوان تعریف کرد و انتخاب راهحلهای بالقوه انعطافپذیرتر میشود [ 171 ]. در موارد پیچیدهتر، راهحلهای بالقوه نیز ممکن است اجازه داشته باشند که برای تشکیل راهحلهای بالقوه جدید ترکیب شوند [ 172 ].
5.2. چالش های پیاده سازی
این بخش چالش های پیاده سازی SDSS با AutoML را مورد بحث قرار می دهد زیرا آنها به پذیرش کاربر و موانع آن مربوط می شوند. بخش 5.2.1 موضوع وابستگی به کیفیت داده را مورد بحث قرار می دهد که به دلیل نیاز به مدل متخصص و دانش مدیریت داده، مانعی فنی برای پذیرش کاربر ایجاد می کند. بخش 5.2.2 تفسیرپذیری مدل را مورد بحث قرار میدهد، جایی که خروجیهای مدل باید برای کاربران غیر فنی (مثلاً تصمیمگیرندگان، عموم مردم) توضیح داده شود، زیرا این شفافیت تا حد زیادی بر اعتماد کاربر SDSS، یک مانع اصلی پذیرش کاربر، تأثیر میگذارد. مهمتر از همه، سودمندی SDSS و شواهدی برای اثبات سودمندی یک چالش بزرگ رایج در بین همه SDSS است و ممکن است به شدت بر نیاز کاربر به SDSS تأثیر بگذارد. این در بخش 5.2.3 مورد بحث قرار گرفته است.
5.2.1. کیفیت داده
SDSS و AutoML برای تولید مدلها برای تولید اطلاعات مفید به دادهها متکی هستند که به دلیل نیاز به تخصص دامنه در مدیریت دادهها و مدلسازی مناسب، مانعی فنی برای کاربران ایجاد میکند. کیفیت داده ها یک عامل مهم در مدل سازی است، زیرا تعیین می کند که داده ها برای اهداف SDSS یا مدل سازی AutoML مناسب هستند. داده ها شامل نویز [ 12 ] (به عنوان مثال، خطاها، ناقص بودن)، سطوح مختلف جزئیات [ 173 ] (به عنوان مثال، کل، مقیاس)، و خطرات [ 174 ] (به عنوان مثال، سوء استفاده، اخلاقیات). از آنجایی که حدود 60 درصد از زمان صرف آماده سازی داده ها می شود [ 8]، چالش این است که منابع را توزیع کنیم تا اطمینان حاصل شود که داده های مورد استفاده متنوع (به عنوان مثال، فراگیر، شفاف)، نماینده (مانند پوشش و جزئیات کافی) و قابل اعتماد (مثلاً حداقل خطاها) برای اهداف مورد نظر در طول زمان هستند [ 26 ] ].
5.2.2. تفسیرپذیری مدل
پیشبینیها یا اقدامات از مدلها در نهایت برای کاربران غیر فنی در تصمیمگیری توضیح داده میشوند (به عنوان مثال، مشتریان، جامعه)، که اعتماد، شفافیت و انصاف را بهبود میبخشد [ 86 ]. بسیاری از مطالعات AutoML بررسی شده عملکرد مدل را اندازه گیری می کنند، اما اغلب بر تفسیرپذیری تمرکز نمی کنند – چرا مدل ها بهتر/بدتر عمل می کنند یا اقدامات خاصی انجام می دهند [ 12 ، 26 ]. مدلهای بررسیشده در مطالعات SDSS قابلیت تفسیر را در نظر میگیرند، اما اغلب برای تصمیمگیرندگان پیچیدهتر از آن هستند که از آن استفاده کنند یا با ذینفعان ارتباط برقرار کنند [ 24 ].]. بهبود قابلیت تفسیر به دلیل اعتماد و دانش مفید از ارتباطات بهتر منجر به پذیرش بیشتر کاربر می شود. چالش دیگر ایجاد تعادل بین منابع موجود، عملکرد مدل و تفسیرپذیری مدل نسبت به مسائل فضایی خاص است.
5.2.3. شواهد مفید بودن
شواهد مفید بودن، که بر پذیرش کاربر تأثیر میگذارد، اغلب در مطالعات SDSS و AutoML مورد بررسی قرار نمیگیرد. بدون معیارها/بررسی سودمندی، اثبات ارزش افزوده SDSS یا AutoML در عمل دشوار است. این منجر به مشکلاتی مانند مشکل در تمایز پیادهسازیهای SDSS [ 6 ]، پذیرش کم کاربر SDSS [ 18 ]، عملکرد متناقض AutoML [ 13 ]، و مدلهای AutoML غیرقابل استفاده مجدد [ 84 ] میشود. SDSS همچنین در زمینهها و حوزههای کاربردی مختلف (به عنوان مثال، کشاورزی، جنگلداری، مدیریت محیطزیست) استفاده میشود که نیازمندیها و کاربران مختلفی دارند که نیاز به تنظیمات و توجه ویژه در کنار SDSS عمومی دارند [ 4 ].]. یک چالش مهم طراحی روشهایی برای اندازهگیری موفقیت عملی با بررسی کاربرد پیادهسازیهای SDSS/AutoML برای تصمیمگیریهای دنیای واقعی و حوزهها و زمینههای کاربردی مختلف است – ارزیابی نه تنها عملکرد، بلکه اینکه چگونه SDSS با AutoML مستقیماً بر تصمیمگیری تأثیر میگذارد.
5.3. فرصت های پژوهشی
این بخش فرصت های تحقیقاتی را برای رسیدگی به چالش های بخش 5.2 مورد بحث قرار می دهد، جایی که هر فرصت یک یا چند چالش را پوشش می دهد ( شکل 9 ). بخش 5.3.1 AutoML فضایی را مورد بحث قرار می دهد، که اغلب در ادبیات AutoML بررسی شده در نظر گرفته نمی شد، اما می تواند موانع فنی را برای مدل سازی فضایی برای کاربران SDSS کاهش دهد. نیاز به رویکردهای آگاه از منابع در بخش 5.3.2 شناسایی شده است تا تنوع کاربران را در محیطهای مختلف با محدودیت منابع افزایش دهد. بخش 5.3.3به مشکل سیستمهای قابل استفاده مجدد و قابل مقایسه میپردازد، در حالی که تعمیمپذیری و ویژگی را متعادل میکند، تا به کاربران اجازه میدهد تا به راحتی SDSSهای مختلف را بر اساس استانداردها و جوامع مشترک در حوزهها و زمینههای عملی مختلف اتخاذ کنند. در نهایت، یک مانع عمده برای پذیرش کاربر شامل ترجمه ورودی/خروجی های پیچیده در SDSS است که می تواند با تحقیق در طراحی سیستم انسان محور، که در بخش 5.3.4 مورد بحث قرار گرفته است، بهبود یابد .
5.3.1. AutoML فضایی
بسیاری از رویکردهای رایج AutoML در مطالعات بررسی شده، الگوهای داده های مکانی را هنگام برخورد با مشکلات فضایی در نظر نمی گیرند. اگرچه AutoML میتواند مدلهای غیرمکانی را خودکار کند، اکثریت SDSS از مدلهای فضایی استفاده میکنند و این موانع در دانش فنی برای کاربران ایجاد میکند. اگر الگوهای فضایی در داده ها وجود داشته باشد (به عنوان مثال، خوشه بندی و پراکندگی در فضا)، آنگاه این فرض که مشاهدات مستقل از یکدیگر هستند نقض می شود و داده ها وابستگی مکانی دارند [ 175 ]. استراتژیهای فضایی (به عنوان مثال، نمونهگیری فضایی [ 63 ]، مدلهای محلی [ 176 ]) میتوانند در رویکردهای AutoML برای عملکرد بالقوه یا دستاوردهای کارآیی ادغام شوند، در حالی که مشکلات پارامترهای مکانی (مانند انتخاب همسایگان یا باندهای فاصله [ 64 ]]) می تواند در بسیاری از روش های بهینه سازی AutoML مناسب باشد. یک فرصت تحقیقاتی شامل ترکیب رویکردهای صریح فضایی در AutoML برای SDSS برای بهبود عملکرد/کارایی مدلسازی و کاهش انتخاب پارامتر دلخواه بدون تأثیر شدید بر قابلیت تفسیر [ 25 ] است.
5.3.2. رویکردهای آگاه از منابع
از آنجایی که SDSS و AutoML از رویکردهای مدلسازی و تجسم مختلف استفاده می کنند، منابع موجود (مثلاً، مقدار/کیفیت داده، قدرت پردازش سرور، متخصصان داده/دامنه) تعیین می کنند که آیا یک پیاده سازی برای اهداف مورد نظرش عملی و عملی است یا خیر. تنوع کاربران SDSS به این معنی است که محیط های آنها متفاوت است، جایی که یک محدودیت عمده محدودیت منابع در هنگام پذیرش SDSS است (به عنوان مثال، قدرت محاسباتی، زیرساخت ابری، دانش مدل سازی). در AutoML، طراحی فضای جستجو (به عنوان مثال، محدوده مدل ها/پارامترها) و معیارهای توقف بهینه سازی (به عنوان مثال، محدودیت های تکرار، رسیدن به عملکرد مطلوب) به تحمل زمان، داده های موجود، و قدرت محاسباتی بستگی دارد [ 17 ]]. به طور مشابه، SDSS به منابع سخت افزاری و نرم افزاری وابسته است، اما همچنین شامل منابع انسانی (به عنوان مثال، توسعه دهندگان نرم افزار، تصمیم گیرندگان، مشاوران) است که برای طراحی ویژگی ها و اهداف سیستم ارتباط و همکاری دارند [ 36 ]. فرصت دیگر، توسعه رویکردهای پیاده سازی آگاه از منابع برای SDSS با AutoML با متعادل کردن منابع موجود و نتایج مورد نظر (به عنوان مثال، کیفیت داده، تفسیرپذیری/عملکرد مدل) است.
5.3.3. سیستم های مشارکتی و متصل
استفاده مجدد از بسیاری از SDSS به دلیل توسعه برای اهداف دامنه خاص مشکل است [ 18 ]، در حالی که مدل های AutoML به دلیل فضاهای جستجوی متفاوت و رویکردهای بهینه سازی [ 12 ] برای بازتولید مشکل هستند. مشکلات قابلیت استفاده مجدد/تکرارپذیری مانع همکاری و ارتباطات می شود، زیرا پیاده سازی های SDSS و مدل های AutoML از استانداردهای قابل مقایسه (مثلاً معیارها، عملکرد، ویژگی ها) و قابلیت انتقال (مثلا استفاده مجدد برای مشکلات مشابه/منطقه جغرافیایی مختلف) پیروی نمی کنند [ 6 ، 27 ، 43 ، 45 ]. استانداردسازی پیادهسازیهای SDSS و مدلهای AutoML، SDSS با AutoML را قادر میسازد تا آسانتر در بین مسائل مختلف فضایی مقایسه/استفاده شود [ 4 ]]، و در بین مطالعات و سازمان ها به اشتراک گذاشته شد [ 36 ]. این استانداردها SDSS های مختلف با پیاده سازی های AutoML را قادر می سازند تا به هم متصل شوند، که شفافیت داده ها و تحقیقات، در دسترس بودن و قابلیت همکاری را بهبود می بخشد (به عنوان مثال، پلت فرم های وب [ 177 ]، رابط های برنامه نویسی [ 178 ]، داده های باز [ 69 ]). سومین فرصت شامل توسعه استانداردهای متقابل برای اتصال SDSS با پیاده سازی های AutoML در یک شبکه برای به اشتراک گذاری داده/اطلاعات/دانش برای کاهش افزونگی و تکرار است، در حالی که قابلیت استفاده و همکاری بین ذینفعان، تصمیم گیرندگان و سایر بازیگران را بهبود می بخشد.
5.3.4. طراحی سیستم انسان محور
قابلیت استفاده و تفسیرپذیری اغلب در تحقیقات SDSS و AutoML با تمرکز بر عملکرد نادیده گرفته می شود. هنگامی که ورودی ها و خروجی ها پیچیده هستند، موانع برای ترجمه اطلاعات برای دانش تصمیم گیری مفید، مانع از کاربران غیر فنی (به عنوان مثال، تصمیم گیرندگان، سهامداران، سیاست گذاران) و پذیرش کمتر کاربر می شود [ 179 ]. با این حال، یک معاوضه بین سادگی و دقت وجود دارد، جایی که بهبود سهولت استفاده و شفافیت در حالی که پیچیدگی به حداقل می رسد مورد نظر است [ 36 ، 180 ]. SDSS با AutoML همچنین نیاز به متعادل کردن ویژگی دامنه (به عنوان مثال، راه حل های سفارشی متناسب با یک مشکل فضایی خاص) و سازگاری (به عنوان مثال، راه حل های انعطاف پذیر قابل استفاده برای انواع مشکلات فضایی) دارد [ 18 ]]. آخرین فرصت، تلاش برای اصول طراحی سیستم انسان محور و طراحی مشترک برای SDSS با AutoML است، که در آن ملاحظات دقیقی در مورد ویژگیهای کاربر و مشکل فضایی، پیچیدگیها و تعاملات برای افزایش پذیرش، تجربه و سودمندی عملی کاربر انجام میشود.
6. نتیجه گیری
این مقاله تحقیقات اخیر را برای ادغام SDSS و AutoML برای پاسخ به سه سوال مورد بررسی قرار می دهد: (R1) طبق تحقیقات اخیر SDSS و AutoML چه مشکلاتی را می توانند حل کنند؟ (R2) چگونه می توان AutoML را در SDSS ادغام کرد؟ و (R3) چالش ها و فرصت های SDSS با AutoML برای بهبود پذیرش کاربر چیست؟ برای پاسخ به سوال (R1)، مسائل مربوط به SDSS و AutoML از ادبیات اخیر در پنج دسته مسئله فضایی (تخمین، بهینهسازی، خوشهبندی، شبیهسازی و بینش) سازماندهی شدند و بر اساس کاربرد تحقیق و روشهای فضایی خلاصه شدند. یک چارچوب کلی برای SDSS با AutoML برای پاسخ به سؤال (R2) با شناسایی و اتصال مؤلفههای عمومی SDSS و AutoML از مقالات پژوهشی منتخب پیشنهاد شد. جایی که SDSS به طور خودکار داده ها را با حل مسائل فضایی به اطلاعات پردازش می کند. برای پاسخ به سوال (R3)، چالشهایی در رابطه با کیفیت دادهها، تفسیرپذیری مدل، و شواهد سودمندی مورد بحث قرار گرفت، در حالی که فرصتهای تحقیقاتی نیز برای رسیدگی به این چالشها در رابطه با موضوع پذیرش کاربر در SDSS مورد بحث قرار گرفت. هنگام پیادهسازی SDSS با AutoML، منابع موجود برای نگهداری دادهها با کیفیت/کمیت مناسب برای اهداف تصمیمگیری توزیع میشود، در حالی که اطمینان حاصل میشود که مدلها و سیستمها قابل تفسیر، قابل مقایسه و عملکرد خوبی هستند. یک فرصت شامل ترکیب مدلهای صریح فضایی است که معمولاً توسط SDSS استفاده میشود، در تحقیقات AutoML برای کمک به بهینهسازی، استانداردسازی و مقایسه مدلهای مورد استفاده در SDSS. فرصت های دیگر شامل توسعه استانداردها، رویکردها، و اصولی برای سیستم های آگاه از منابع، مشارکتی/متصل و انسان محور. این پیشرفتها از هدف SDSS با AutoML پشتیبانی میکنند، که کمک به تصمیمگیری شامل همکاری بین بازیگران مختلف و تنظیمات منابع مختلف است. از آنجایی که در تحقیقات اخیر SDSS و AutoML مسائل مربوط به انسان (مثلاً تفسیرپذیری، قابلیت استفاده، سودمندی) و فنی (مثلاً تکرارپذیری، قابلیت استفاده مجدد، مقایسه) به وجود میآیند، ادغام SDSS با AutoML جنبههای فنی AutoML را در بر میگیرد (مثلاً خطوط لوله / معیارهای استاندارد شده) در تحقیقات SDSS، در حالی که ملاحظات مربوط به انسان از SDSS (به عنوان مثال، پیچیدگی راه حل، ارزیابی سناریو) در تحقیقات AutoML را نیز شامل می شود. SDSS با AutoML نه تنها به بهبود پذیرش کاربر SDSS کمک می کند، اما با تقویت رویکردهایی که هم مسائل مربوط به انسان و هم مسائل فنی را در نظر می گیرند، به نفع تحقیقات SDSS و AutoML هستند. الزامات، اجرا و پذیرش کاربر SDSS در زمینههای مختلف مطالعاتی (مثلاً، علوم محیطی، بهداشت عمومی) متفاوت است، و کار آینده برای کاوش SDSS با AutoML برای هر رشته تحصیلی ممکن است ارزش بیشتری برای تحقیقات SDSS و AutoML ایجاد کند.
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| ABM | مدل سازی مبتنی بر عامل |
| هوش مصنوعی | هوش مصنوعی |
| AUC | مساحت زیر منحنی ROC |
| AutoML | یادگیری ماشین خودکار |
| CA | اتوماتای سلولی |
| DBSCAN | خوشه بندی فضایی مبتنی بر چگالی برنامه های کاربردی با نویز |
| DT | درختان تصمیم |
| GA | الگوریتم های ژنتیک |
| GIS | سیستم های اطلاعات جغرافیایی |
| GW-ML | یادگیری ماشین با وزن جغرافیایی |
| GWR | رگرسیون وزنی جغرافیایی |
| لیزا | شاخص های محلی تداعی فضایی |
| LSTM | حافظه کوتاه مدت بلند مدت |
| MAE | به معنای خطای مطلق |
| MCDA | تجزیه و تحلیل تصمیم گیری چند معیاره |
| ML | فراگیری ماشین |
| MSE | خطای میانگین مربعات |
| NAS | جستجوی معماری عصبی |
| NB | بیز ساده لوح |
| NN | شبکه های عصبی |
| PSO | بهینه سازی ازدحام ذرات |
| PSS | سیستم های پشتیبانی برنامه ریزی |
| RL | یادگیری تقویتی |
| RMSE | ریشه میانگین مربعات خطا |
| SDSS | سیستم های پشتیبانی تصمیم گیری فضایی |
| SSE | مجموع مربعات خطا |
| SVM | ماشین های بردار پشتیبانی می کند |
| TPOT | ابزار بهینه سازی خط لوله مبتنی بر درخت |
منابع
- نیو، اچ. سیلوا، EA داده کاوی جمعسپاری شده برای فعالیت شهری: بررسی منابع داده، کاربردها و روشها. ج. طرح شهری. توسعه دهنده 2020 , 146 , 04020007. [ Google Scholar ] [ CrossRef ]
- رویجر، ای. Meijer، A. داده های دولت باز به عنوان یک فرآیند نوآوری: درس هایی از یک آزمایش آزمایشگاهی زنده. اجرای عمومی. مدیریت Rev. 2020 , 43 , 613-635. [ Google Scholar ] [ CrossRef ]
- Riehle, D. نوآوری های منبع باز. کامپیوتر 2019 ، 52 ، 59-63. [ Google Scholar ] [ CrossRef ]
- کینان، PB; Jankowski، P. سیستم های پشتیبانی تصمیم فضایی: سه دهه بعد. تصمیم می گیرد. سیستم پشتیبانی 2019 ، 116 ، 64–76. [ Google Scholar ] [ CrossRef ]
- Geertman, S. PSS: Beyond the Implementation Gap. ترانسپ Res. بخش A سیاست سیاست. 2017 ، 104 ، 70-76. [ Google Scholar ] [ CrossRef ]
- جیانگ، اچ. گیرتمن، اس. Witte, P. اجتناب از مشکلات سیستم پشتیبانی برنامه ریزی؟ آنچه حکمرانی هوشمند می تواند از شکاف پیاده سازی سیستم پشتیبانی برنامه ریزی بیاموزد. محیط زیست طرح. ب مقعد شهری. علوم شهر 2020 ، 47 ، 1343-1360. [ Google Scholar ] [ CrossRef ]
- یائو، کیو. وانگ، ام. چن، ی. دای، دبلیو. لی، YF; تو، WW; یانگ، کیو. Yu, Y. حذف انسان از برنامه های یادگیری: نظرسنجی در مورد یادگیری ماشین خودکار. arXiv 2019 ، arXiv:1810.13306. [ Google Scholar ]
- مونسون، کارشناسی ارشد مطالعه ای در مورد اهمیت و زمان صرف شده برای مراحل مختلف مدل سازی. ACM SIGKDD Explor. Newsl. 2012 ، 13 ، 65-71. [ Google Scholar ] [ CrossRef ]
- Google LLC. Cloud AutoML—مدلهای یادگیری ماشین سفارشی. 2020. در دسترس آنلاین: https://cloud.google.com/automl (در 20 سپتامبر 2020 قابل دسترسی است).
- شرکت مایکروسافت. یادگیری ماشین خودکار | مایکروسافت آژور. 2020. در دسترس آنلاین: https://azure.microsoft.com/en-ca/services/machine-learning/automatedml/ (در 20 سپتامبر 2020 قابل دسترسی است).
- Amazon.com، Inc. Amazon SageMaker. 2020. در دسترس آنلاین: https://aws.amazon.com/sagemaker/ (در 20 سپتامبر 2020 قابل دسترسی است).
- او، X. ژائو، ک. چو، ایکس. AutoML: بررسی وضعیت موجود. بدانید. سیستم مبتنی بر 2021 , 212 , 106622. [ Google Scholar ] [ CrossRef ]
- Escalante، یادگیری ماشین خودکار HJ – مروری کوتاه در پایان سالهای اولیه. در طراحی خودکار الگوریتم های یادگیری ماشین و جستجو ؛ Pillay, N., Qu, R., Eds.; سری محاسبات طبیعی; انتشارات بین المللی Springer: چم، سوئیس، 2021; ص 11-28. [ Google Scholar ] [ CrossRef ]
- ProQuest LLC. منابع مشتری ProQuest Summon 2.0. 2022. در دسترس آنلاین: https://support.proquest.com/s/article/ProQuest-Summon-2-0-Customer-Resources?language=en_US (در 21 نوامبر 2022 قابل دسترسی است).
- بوداچ، آر. نیکمون، م. شرایبر، پ. زهرادنیکوا، بی. Janáčová، D. بررسی اجمالی یادگیری ماشین خودکار. وید پراس ماتر. فک اسلوو. فنی دانشگاه 2019 ، 27 ، 107–112. [ Google Scholar ] [ CrossRef ]
- Weng, Z. از یادگیری ماشین معمولی تا AutoML. جی. فیزی. Conf. سر. 2019 ، 1207 ، 012015. [ Google Scholar ] [ CrossRef ]
- چن، YW; آهنگ، س. Hu, X. تکنیکهای یادگیری ماشین خودکار. ACM SIGKDD Explor. Newsl. 2021 ، 22 ، 35-50. [ Google Scholar ] [ CrossRef ]
- گیرتمن، اس. استیلول، جی. علم پشتیبانی برنامه ریزی: تحولات و چالش ها. محیط زیست طرح. ب مقعد شهری. علوم شهر 2020 ، 47 ، 1326-1342. [ Google Scholar ] [ CrossRef ]
- فلاک، جی. شرستا، ر. تقویت مشارکت با استفاده از سیستم های پشتیبانی برنامه ریزی تعاملی: یک بررسی سیستماتیک. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 49. [ Google Scholar ] [ CrossRef ]
- پان، اچ. گیرتمن، اس. Deal, B. انفورماتیک شهری چه چیزی را به فناوری پشتیبانی برنامه ریزی اضافه می کند؟ محیط زیست طرح. ب مقعد شهری. علوم شهر 2020 ، 47 ، 1317-1325. [ Google Scholar ] [ CrossRef ]
- قفل، O.; بین، ام. پتیت، سی. به سوی توسعه مشارکتی تکنیکهای یادگیری ماشین در سیستمهای پشتیبانی برنامهریزی – یک مثال سیدنی. محیط زیست طرح. ب مقعد شهری. علوم شهر 2020 ، 48 ، 484-502. [ Google Scholar ] [ CrossRef ]
- نیازی، م. آیا بررسی های سیستماتیک ادبیات بهتر از بررسی های غیررسمی ادبیات در حوزه مهندسی نرم افزار است؟ مطالعه موردی اولیه. عرب J. Sci. مهندس 2015 ، 40 ، 845-855. [ Google Scholar ] [ CrossRef ]
- پرونی، س. Shotton، D. Open Citations، یک سازمان زیرساخت برای بورسیه باز. مقدار. علمی گل میخ. 2020 ، 1 ، 428-444. [ Google Scholar ] [ CrossRef ]
- پان، اچ. Deal، B. گزارش در مورد عملکرد و قابلیت استفاده از برنامه ریزی سیستم های پشتیبانی – به سوی یک درک مشترک. Appl. تف کردن مقعدی سیاست 2020 ، 13 ، 137-159. [ Google Scholar ] [ CrossRef ]
- دو، پ. بای، ایکس. تان، ک. زو، ز. سمت، ع. شیا، جی. دروغ.؛ سو، اچ. لیو، دبلیو. پیشرفتهای چهار روش یادگیری ماشین برای مدیریت دادههای فضایی: مروری. J. Geovisualization Spat. مقعدی 2020 ، 4 ، 13. [ Google Scholar ] [ CrossRef ]
- وارینگ، جی. لیندوال، سی. Umeton, R. Automated Machine Learning: مروری بر آخرین هنر و فرصت ها برای مراقبت های بهداشتی. آرتیف. هوشمند پزشکی 2020 , 104 , 101822. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- زولر، MA Huber، MF Benchmark و Survey of Automated Machine Learning Frameworks. جی آرتیف. هوشمند Res. 2021 ، 70 ، 409-472. [ Google Scholar ] [ CrossRef ]
- Taylor, R. تفسیر ضریب همبستگی: یک بررسی اساسی. J. تشخیص. پزشکی سونوگر. 1990 ، 6 ، 35-39. [ Google Scholar ] [ CrossRef ]
- الیور، MA; Webster, R. Kriging: A Method of Interpolation for Geographical Information Systems. بین المللی جی. جئوگر. Inf. سیستم 1990 ، 4 ، 313-332. [ Google Scholar ] [ CrossRef ]
- بریمن، ال. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ]
- Noble, WS ماشین بردار پشتیبان چیست؟ نات. بیوتکنول. 2006 ، 24 ، 1565-1567. [ Google Scholar ] [ CrossRef ]
- استاینلی، D. K-Means Clustering: A Half-Century Synthesis. برادر جی. ریاضی. آمار روانی 2006 ، 59 ، 1-34. [ Google Scholar ] [ CrossRef ]
- Sun، AY; Scanlon، BR; ذخیره، H.; Rateb, A. بازسازی کل ذخیره آب GRACE از طریق یادگیری ماشین خودکار. منبع آب Res. 2021 ، 57 ، e2020WR028666. [ Google Scholar ] [ CrossRef ]
- باباییان، ا. Paheding، S. صدیق، ن. Devabhaktuni، VK; Tuller, M. برآورد رطوبت خاک منطقه ریشه از اطلاعات خاک و سنجش از راه دور با ترکیب داده های چندحسگر و یادگیری ماشین خودکار. سنسور از راه دور محیط. 2021 ، 260 ، 112434. [ Google Scholar ] [ CrossRef ]
- سینگ، آ. کومار، جی. رای، AK; Beg, Z. یادگیری ماشینی برای تخمین زبری سطح از تصاویر ماهواره ای. Remote Sens. 2021 , 13 , 3794. [ Google Scholar ] [ CrossRef ]
- شیندلر، ام. دیونیزیو، آر. کینگهام، اس. چالش های ابزارهای تصمیم-حمایت فضایی در برنامه ریزی شهری: درس هایی از شهرهای نیوزلند. ج. طرح شهری. توسعه دهنده 2020 , 146 , 04020012. [ Google Scholar ] [ CrossRef ]
- موتوکو، بی. بوئربوم، ال. مادوریرا، AM نقش سیستمهای پشتیبانی برنامهریزی در انتقال خطمشی ملی و ترجمه خطمشی در شهرهای ثانویه. بین المللی طرح. گل میخ. 2019 ، 24 ، 293-307. [ Google Scholar ] [ CrossRef ]
- ارسکین، MA; گرگ، دی جی؛ کریمی، ج. اسکات، JE تصمیم-عملکرد فردی با استفاده از سیستمهای پشتیبانی تصمیم فضایی: توانایی استدلال جغرافیایی و دیدگاه مناسب تکلیف-فناوری درک شده. Inf. سیستم جلو. 2019 ، 21 ، 1369–1384. [ Google Scholar ] [ CrossRef ]
- پونت، EP; Geertman، SCM; افروز، AE; Witte، PA; پتیت، سی جی زندگی یک صحنه است و ما بازیگران آن هستیم: ارزیابی سودمندی برنامهریزی تئاترهای پشتیبانی برای برنامهریزی شهر هوشمند. محاسبه کنید. محیط زیست سیستم شهری 2020 ، 82 ، 101485. [ Google Scholar ] [ CrossRef ]
- پیج، جی. مورتبرگ، U. دستونی، گ. فریرا، سی. ناستروم، اچ. کلانتری، ز. سیستم پشتیبانی برنامه ریزی منبع باز برای برنامه ریزی منطقه ای پایدار: مطالعه موردی شهرستان استکهلم، سوئد. محیط زیست طرح. ب مقعد شهری. علوم شهر 2020 ، 47 ، 1508-1523. [ Google Scholar ] [ CrossRef ]
- هوپر، پی. بولانژ، سی. آرسینیگاس، جی. فاستر، اس. بولتر، جی. پتیت، سی. بررسی پتانسیل سیستمهای پشتیبانی برنامهریزی برای پر کردن شکاف تحقیق و ترجمه بین بهداشت عمومی و برنامهریزی شهری. بین المللی J. Health Geogr. 2021 ، 20 ، 36. [ Google Scholar ] [ CrossRef ]
- Escalante، HJ; تو، WW; گیون، آی. نقره، DL; ویگاس، ای. چن، ی. دای، دبلیو. Yang, Q. AutoML @ NeurIPS 2018 Challenge: Design and Results. در مسابقه NeurIPS ’18 ; Escalera, S., Herbrich, R., Eds.; سری Springer در مورد چالش ها در یادگیری ماشین. انتشارات بین المللی Springer: Cham، سوئیس، 2020; ص 209-229. [ Google Scholar ] [ CrossRef ]
- حلواری، ت. نورمینن، JK; Mikkonen، T. تست استحکام سیستمهای AutoML. الکترون. Proc. نظریه. محاسبه کنید. علمی 2020 ، 319 ، 103-116. [ Google Scholar ] [ CrossRef ]
- Karmaker، SK; حسن، م.م. اسمیت، ام جی. خو، ال. ژای، سی. Veeramachaneni، K. AutoML تا به امروز و فراتر از آن: چالش ها و فرصت ها. کامپیوتر ACM. Surv. 2021 ، 54 ، 175. [ Google Scholar ] [ CrossRef ]
- هانوسک، ام. بلوم، ام. کینتز، ام. آیا AutoML می تواند از انسان ها بهتر عمل کند؟ در ارزیابی مجموعه داده های محبوب OpenML با استفاده از معیار AutoML. در مجموعه مقالات دومین کنفرانس بین المللی 2020 در زمینه هوش مصنوعی، رباتیک و کنترل، قاهره، مصر، 12 تا 14 دسامبر 2020؛ ص 29-32. [ Google Scholar ] [ CrossRef ]
- گرین، آر. دیویلر، آر. لوتر، ج. تجزیه و تحلیل تصمیم گیری چند معیاره مبتنی بر GIS ادی، BG. Geogr. Compass 2011 , 5 , 412-432. [ Google Scholar ] [ CrossRef ]
- کروکس، آ. قلعه، سی. Batty، M. چالشهای کلیدی در مدلسازی مبتنی بر عامل برای شبیهسازی جغرافیایی-فضایی. محاسبه کنید. محیط زیست سیستم شهری 2008 ، 32 ، 417-430. [ Google Scholar ] [ CrossRef ]
- وهاب، MNA; نفتی مزیانی، س. اطیابی، ع. بررسی جامع الگوریتم های بهینه سازی ازدحام. PLoS ONE 2015 ، 10 ، e0122827. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Quinlan, JR Decision Trees and Decision-Aking. IEEE Trans. سیستم مرد سایبرن. 1990 ، 20 ، 339-346. [ Google Scholar ] [ CrossRef ]
- Jaramillo، JH; بهادوری، جی. Batta, R. در مورد استفاده از الگوریتم های ژنتیک برای حل مسائل مکان. محاسبه کنید. اپراتور Res. 2002 ، 29 ، 761-779. [ Google Scholar ] [ CrossRef ]
- ناصر، م.ز. علوی، معیارهای خطای AH و شاخصهای تناسب عملکرد برای هوش مصنوعی و یادگیری ماشین در مهندسی و علوم. آرشیت. ساختار. ساخت و ساز 2021 . [ Google Scholar ] [ CrossRef ]
- فراهانی، رض. عسگری، ن. حیدری، ن. حسینی نیا، م. Goh, M. پوشش مشکلات در مکان تاسیسات: یک بررسی. محاسبه کنید. مهندسی صنعتی 2012 ، 62 ، 368-407. [ Google Scholar ] [ CrossRef ]
- ریکلمه، ن. فون لوکن، سی. باران، ب. معیارهای عملکرد در بهینه سازی چند هدفه. در مجموعه مقالات کنفرانس محاسباتی آمریکای لاتین 2015 (CLEI)، آرکیپا، پرو، 19 تا 23 اکتبر 2015. صص 1-11. [ Google Scholar ]
- Grabusts, P. The Choice of Metrics for Clustering Algorithms. محیط زیست تکنولوژی منبع. Proc. بین المللی علمی تمرین کنید. Conf. 2011 ، 2 ، 70-76. [ Google Scholar ] [ CrossRef ]
- چی، جی. Zhu، J. مدل های رگرسیون فضایی برای تجزیه و تحلیل جمعیت شناختی. مردمی Res. Policy Rev. 2008 , 27 , 17-42. [ Google Scholar ] [ CrossRef ]
- وی، پی. لو، ز. Song, J. Variable Importance Analysis: A Comprehensive Review. Reliab. مهندس سیستم Saf. 2015 ، 142 ، 399-432. [ Google Scholar ] [ CrossRef ]
- کاروالیو، دی وی؛ پریرا، EM; کاردوسو، JS تفسیرپذیری یادگیری ماشین: بررسی روشها و معیارها. Electronics 2019 , 8 , 832. [ Google Scholar ] [ CrossRef ]
- آندرینکو، ن. آندرینکو، جی. گاتالسکی، پی. تجسم فضایی-زمانی اکتشافی: مروری تحلیلی. J. Vis. لنگ محاسبه کنید. 2003 ، 14 ، 503-541. [ Google Scholar ] [ CrossRef ]
- کاسیماتی، ع. اسپژو-گارسیا، بی. دارا، ن. Fountas، S. پیشبینی محتوای قند انگور تحت ویژگیهای کیفیت با استفاده از دادههای شاخص گیاهی تفاوت عادی و یادگیری ماشین خودکار. Sensors 2022 , 22 , 3249. [ Google Scholar ] [ CrossRef ]
- کای یون، ال. Burnside، NG; سامپایو دی لیما، آر. lPeciña، MV; سپ، ک. Cabral Pinheiro، VH; د لیما، BRCA چارچوب یادگیری ماشین خودکار در سیستمهای هواپیمای بدون سرنشین: بینشهای جدید در مورد رویکردهای شناسایی شیوههای مدیریت کشاورزی. Remote Sens. 2021 , 13 , 3190. [ Google Scholar ] [ CrossRef ]
- Bruzón، AG; مغرور-فونز، پی. مغرور-فنز، اف. مارتین-گونزالس، اف. نوویلو، سی جی; فرناندز، آر.آر. وازکز-جیمنز، آر. Alarcón-Paredes، A.; آلونسو-سیلوریو، GA؛ کانتو رامیرز، کالیفرنیا؛ و همکاران ارزیابی حساسیت زمین لغزش با استفاده از چارچوب AutoML. بین المللی جی. محیط زیست. Res. بهداشت عمومی 2021 ، 18 ، 10971. [ Google Scholar ] [ CrossRef ]
- D’Orazio، V. Lin, Y. پیشبینی تضاد در آفریقا با سیستمهای یادگیری ماشین خودکار. بین المللی تعامل داشتن. 2022 ، 48 ، 714-738. [ Google Scholar ] [ CrossRef ]
- وانگ، جی اف. استین، ا. گائو، بی بی. Ge, Y. مروری بر نمونه برداری فضایی. تف کردن آمار 2012 ، 2 ، 1-14. [ Google Scholar ] [ CrossRef ]
- گتیس، ع. Aldstadt, J. ساخت ماتریس وزن های فضایی با استفاده از یک آمار محلی. Geogr. مقعدی 2004 ، 36 ، 90-104. [ Google Scholar ] [ CrossRef ]
- هاپکینز، LD; آرمسترانگ، ذخیرهسازی دادههای تحلیلی و کارتوگرافی MP: رویکردی دو لایه به سیستمهای پشتیبانی تصمیمگیری فضایی. در مجموعه مقالات هفتمین سمپوزیوم بین المللی کارتوگرافی به کمک کامپیوتر، واشنگتن، دی سی، ایالات متحده آمریکا، 11 تا 14 مارس 1985. [ Google Scholar ]
- لانگلی، پی. Goodchild، MF; مگوایر، دی جی; Rhind، DW سیستم های اطلاعات جغرافیایی و علوم ; جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2005. [ Google Scholar ]
- گیرتمن، اس. استیلول، جی. سیستم های پشتیبانی برنامه ریزی در عمل . Springer Science & Business Media: Cham, Switzerland, 2012. [ Google Scholar ]
- آلوا، پ. یانسن، پی. Stouffs، R. Geospatial Tool-Chains: Planning Support Systems for Organisation Teams. بین المللی جی آرچیت. محاسبه کنید. 2019 ، 17 ، 336-356. [ Google Scholar ] [ CrossRef ]
- ژانگ، جی. ژانگ، دبلیو. گوهاتاکورتا، اس. بوچوی، ن. توسعه یک سیستم پشتیبانی برنامه ریزی مبتنی بر جریان بر اساس داده های باز برای شهر آتلانتا. محیط زیست طرح. ب مقعد شهری. علوم شهر 2019 ، 46 ، 207–224. [ Google Scholar ] [ CrossRef ]
- گتیس، ع. Ord, JK تجزیه و تحلیل ارتباط فضایی با استفاده از آمار فاصله. در دیدگاه های تحلیل داده های مکانی ; Anselin, L., Rey, SJ, Eds. پیشرفت در علوم فضایی؛ Springer: برلین/هایدلبرگ، آلمان، 2010; صص 127-145. [ Google Scholar ] [ CrossRef ]
- بخش، MD; مدلهای رگرسیون فضایی گلدیچ، KS ; انتشارات SAGE: لندن، بریتانیا، 2018. [ Google Scholar ]
- Itami، RM شبیه سازی دینامیک فضایی: نظریه اتوماتای سلولی. Landsc. طرح شهری. 1994 ، 30 ، 27-47. [ Google Scholar ] [ CrossRef ]
- شرستا، ر. Flacke، J. استفاده از علم شهروندی برای پیشبرد فناوری پشتیبانی از تصمیمات فضایی تعاملی: یک تحلیل سوات. در آرشیو بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی . Copernicus GmbH: گوتینگن، آلمان، 2019؛ جلد XLII. [ Google Scholar ] [ CrossRef ]
- Maceachren، AM; بروور، I. توسعه چارچوب مفهومی برای همکاری جغرافیایی با قابلیت بصری. بین المللی جی. جئوگر. Inf. علمی 2004 ، 18 ، 1-34. [ Google Scholar ] [ CrossRef ]
- دانیل، سی. پتیت، سی. ترسیم گذشته و آیندههای احتمالی سیستمهای پشتیبانی برنامهریزی: نتایج یک تحلیل شبکه استنادی. محیط زیست طرح. ب مقعد شهری. علوم شهر 2022 ، 49 ، 1875-1892. [ Google Scholar ] [ CrossRef ]
- گل نراقی، ف. Kuo، سیستم های کنترل خودکار پیش از میلاد ، ویرایش 9. Wiley: Hoboken، NJ، ایالات متحده، 2009. [ Google Scholar ]
- ساموئل، AL برخی از مطالعات در یادگیری ماشین با استفاده از بازی چکرز. IBM J. Res. توسعه دهنده 1959 ، 3 ، 210-229. [ Google Scholar ] [ CrossRef ]
- سبر، GAF; لی، تحلیل رگرسیون خطی AJ . جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2012. [ Google Scholar ]
- Kleinbaum، DG; کلین، ام. مقدمه ای بر رگرسیون لجستیک. در رگرسیون لجستیک: یک متن خودآموز . Kleinbaum, DG, Klein, M., Eds. آمار زیست شناسی و سلامت؛ Springer: New York, NY, USA, 2010; صص 1-39. [ Google Scholar ] [ CrossRef ]
- Rish، I. مطالعه تجربی طبقهبندیکننده سادهلوح بیز. در مجموعه مقالات کارگاه آموزشی IJCAI 2001 در مورد روشهای تجربی در هوش مصنوعی، سیاتل، WA، ایالات متحده آمریکا، 4 تا 6 اوت 2001. [ Google Scholar ]
- هینتون، جنرال الکتریک چگونه شبکه های عصبی از تجربه یاد می گیرند. علمی صبح. 1992 ، 267 ، 144-151. [ Google Scholar ] [ CrossRef ]
- سانتو، SKK؛ حسن، م.م. اسمیت، ام جی. خو، ال. ژای، سی. Veeramachaneni، K. دیدگاه طبقهبندی سطح عاقلانه در مورد یادگیری ماشینی خودکار تا به امروز و فراتر از آن: چالشها و فرصتها. arXiv 2020 ، arXiv:2010.10777. [ Google Scholar ]
- فیورر، ام. کلاین، ا. اگنزپرگر، ک. Springenberg، JT; بلوم، م. Hutter, F. Auto-Sklearn: یادگیری ماشین خودکار کارآمد و قوی. در یادگیری ماشین خودکار ؛ Hutter, F., Kotthoff, L., Vanschoren, J., Eds. انتشارات بین المللی Springer: چم، سوئیس، 2019; صص 113-134. [ Google Scholar ] [ CrossRef ]
- مادرید، جی جی. ژایر اسکالانته، اچ. مورالس، EF; تو، WW; یو، ای. سان هوسویا، ال. گیون، آی. Sebag, M. Towards AutoML in Presence of Drift: First Results. arXiv 2018 , arXiv:1907.10772. [ Google Scholar ]
- مولنار، سی. یادگیری ماشینی قابل تفسیر. 2020. در دسترس آنلاین: https://christophm.github.io/interpretable-ml-book/ (در 20 سپتامبر 2020 قابل دسترسی است).
- فایسترر، اف. توماس، جی. Bischl, B. Towards Human Centered AutoML. arXiv 2019 ، arXiv:1911.02391. [ Google Scholar ]
- بحری، م. سالوتاری، ف. پوتینا، ا. Sozio، M. AutoML: وضعیت هنر با تمرکز بر تشخیص ناهنجاری ها، چالش ها و جهت گیری های تحقیق. بین المللی J. Data Sci. مقعدی 2022 ، 14 ، 113-126. [ Google Scholar ] [ CrossRef ]
- الشارف، ع. آگاروال، ک. سونیا؛ کومار، م. Mishra, A. بررسی راه حل های ML و AutoML برای پیش بینی داده های سری زمانی. قوس. محاسبه کنید. مهندسی روش ها 2022 ، 29 ، 5297-5311. [ Google Scholar ] [ CrossRef ]
- Li، W. GeoAI: جایی که یادگیری ماشین و داده های بزرگ در علم GIS همگرا می شوند. جی. اسپات. Inf. علمی 2020 ، 20 ، 71-77. [ Google Scholar ] [ CrossRef ]
- یانوویچ، ک. گائو، اس. مک کنزی، جی. هو، ی. Bhaduri، B. GeoAI: تکنیکهای هوش مصنوعی صریح فضایی برای کشف دانش جغرافیایی و فراتر از آن. بین المللی جی. جئوگر. Inf. علمی 2020 ، 34 ، 625-636. [ Google Scholar ] [ CrossRef ]
- نیش، ز. جین، ی. یانگ، تی. گنجاندن هوش برنامه ریزی در یادگیری عمیق: ابزار پشتیبانی برنامه ریزی برای طراحی شبکه خیابانی. J. فناوری شهری. 2022 ، 29 ، 99-114. [ Google Scholar ] [ CrossRef ]
- مایرز، DE Spatial Interpolation: An Overview. ژئودرما 1994 ، 62 ، 17-28. [ Google Scholar ] [ CrossRef ]
- جیانگ، ز. بررسی روشهای پیشبینی فضایی. IEEE Trans. بدانید. مهندسی داده 2019 ، 31 ، 1645-1664. [ Google Scholar ] [ CrossRef ]
- Unwin, D. ادغام از طریق تجزیه و تحلیل پوشش. در دیدگاه های تحلیلی فضایی GIS ; Routledge: لندن، بریتانیا، 1996. [ Google Scholar ]
- داس، اس. لی، جی جی. آلستون، ا. Kharfen، M. برنامه ریزی برنامه های پیشگیری و مداخله ویژه منطقه برای HIV با استفاده از تحلیل رگرسیون فضایی. بهداشت عمومی 2019 ، 169 ، 41-49. [ Google Scholar ] [ CrossRef ]
- کاستاش، آر. پوپا، ام سی; تین بوی، دی. دیاکونو، دی سی؛ سیوبوتارو، ن. مینه، جی. فام، QB پیشبینی فضایی مناطق بالقوه سیل با استفاده از ترکیببندیهای جدید تصمیمگیری فازی، آمار دو متغیره و یادگیری ماشین. جی هیدرول. 2020 , 585 , 124808. [ Google Scholar ] [ CrossRef ]
- وارث، جی. براون، آ. آسمان، او. فلکنشتاین، ک. Hochschild، V. پیش بینی شاخص های اجتماعی-اقتصادی برای برنامه ریزی شهری با استفاده از تصاویر ماهواره ای VHR و تحلیل فضایی. Remote Sens. 2020 ، 12 ، 1730. [ Google Scholar ] [ CrossRef ]
- براندون، سی. فاثرینگهام، اس. چارلتون، ام. رگرسیون وزنی جغرافیایی. JR Stat. Soc. سر. D 1998 , 47 , 431-443. [ Google Scholar ] [ CrossRef ]
- خان، SN; لی، دی. Maimaitijiang، M. یک رویکرد جنگل تصادفی وزندار جغرافیایی برای پیشبینی عملکرد ذرت در کمربند ذرت ایالات متحده. Remote Sens. 2022 , 14 , 2843. [ Google Scholar ] [ CrossRef ]
- فنگ، ال. وانگ، ی. ژانگ، ز. Du, Q. شبکه عصبی دارای وزن جغرافیایی و زمانی برای پیشبینی عملکرد گندم زمستانه. سنسور از راه دور محیط. 2021 ، 262 ، 112514. [ Google Scholar ] [ CrossRef ]
- برونو، جی. Giannikos، I. مکان و GIS. در علم مکان یابی ; Laporte, G., Nickel, S., Saldanha da Gama, F., Eds. انتشارات بین المللی Springer: چم، سوئیس، 2015; ص 509-536. [ Google Scholar ] [ CrossRef ]
- سیستمهای پشتیبانی تصمیم فضایی Keenan، PB برای مسیریابی خودرو. تصمیم می گیرد. سیستم پشتیبانی 1998 ، 22 ، 65-71. [ Google Scholar ] [ CrossRef ]
- Keenan، P. مدلسازی مسیریابی خودرو در GIS. اپراتور Res. 2008 ، 8 ، 201. [ Google Scholar ] [ CrossRef ]
- لاپورت، جی. مارتلو، اس. مسئله فروشنده دوره گرد انتخابی. گسسته. Appl. ریاضی. 1990 ، 26 ، 193-207. [ Google Scholar ] [ CrossRef ]
- کاوه، م. کاوه، م. مسگری، ام اس; Paland، RS تصمیم گیری چند معیاره برای مکان بیمارستان – تخصیص بر اساس الگوریتم ژنتیک بهبود یافته. Appl. Geomat. 2020 ، 12 ، 291-306. [ Google Scholar ] [ CrossRef ]
- Diemuodeke، EO; آدو، ا. اوکو، COC؛ مولوگتا، ی. Ojapah، MM نقشه برداری بهینه سیستم های انرژی تجدیدپذیر ترکیبی برای مکان ها با استفاده از الگوریتم تصمیم گیری چند معیاره. تمدید کنید. انرژی 2019 ، 134 ، 461-477. [ Google Scholar ] [ CrossRef ]
- موسولینو، جی. ریندون، سی. پولمنی، ع. Vitetta، A. برنامه ریزی مکان مرکز توزیع شهری با سناریوهای تقاضای تجدید ذخایر متغیر: روش شناسی عمومی و آزمایش در یک شهر متوسط. ترانسپ سیاست 2019 ، 80 ، 157-166. [ Google Scholar ] [ CrossRef ]
- وانگ، ز. لی، ام. تانگ، ال. Huang, JS تحقیق و کاربرد الگوریتم کنترل سیگنال ترافیک تقاطع بر اساس مکان خودرو. بین المللی J. Commun. توزیع شبکه ها سیستم 2020 ، 24 ، 249-261. [ Google Scholar ] [ CrossRef ]
- دی مونتس، ا. تورو، PD; Droste-Franke، B. Stagl، IOaS ارزیابی کیفیت روشهای مختلف MCDA. در گزینه های جایگزین برای ارزیابی زیست محیطی ; Routledge: لندن، انگلستان، 2004. [ Google Scholar ]
- لی، ایکس. بله، AGO ادغام الگوریتم های ژنتیک و GIS برای جستجوی مکان بهینه. بین المللی جی. جئوگر. Inf. علمی 2005 ، 19 ، 581-601. [ Google Scholar ] [ CrossRef ]
- Anselin، L. نشانگرهای محلی انجمن فضایی-LISA. Geogr. مقعدی 1995 ، 27 ، 93-115. [ Google Scholar ] [ CrossRef ]
- خان، ک. رحمان، SU; عزیز، ک. فونگ، اس. ساراسوادی، S. DBSCAN: گذشته، حال و آینده. در مجموعه مقالات پنجمین کنفرانس بین المللی کاربردهای اطلاعات دیجیتال و فناوری های وب (ICADIWT 2014)، بنگلور، هند، 17 تا 19 فوریه 2014. ص 232-238. [ Google Scholar ] [ CrossRef ]
- انصاری، من; احمد، ع. خان، اس اس. بوشان، جی. میین الدین. خوشه بندی فضایی و زمانی: مروری. آرتیف. هوشمند Rev. 2020 , 53 , 2381–2423. [ Google Scholar ] [ CrossRef ]
- Kulldorff، M. یک آمار اسکن فضایی. اشتراک. آمار روشهای نظریه 1997 ، 26 ، 1481-1496. [ Google Scholar ] [ CrossRef ]
- Aldstadt, J. Spatial Clustering. در کتابچه راهنمای تحلیل فضایی کاربردی: ابزارها، روش ها و کاربردهای نرم افزاری ; Fischer, MM, Getis, A., Eds. Springer: برلین/هایدلبرگ، آلمان، 2010; صص 279-300. [ Google Scholar ] [ CrossRef ]
- ایرندگانی، ز. محمدی، ر. طالعی، م. بررسی اثرات زمانی و مکانی متغیرهای شهرسازی بر میزان جرم: رویکرد مبتنی بر Gwr و Ols. در آرشیو بین المللی فتوگرامتری، سنجش از دور و علوم اطلاعات فضایی . Copernicus GmbH: گوتینگن، آلمان، 2019؛ جلد XLII-4/W18، صفحات 559–564. [ Google Scholar ] [ CrossRef ]
- اوهانا-لوی، ن. بن گال، ا. پیترز، ا. ترمین، دی. لینکر، آر. برام، س. راوه، ا. Paz-Kagan, T. مقایسه ای بین مدل های خوشه بندی فضایی برای تعیین مناطق مدیریتی کوددهی N در باغات. دقیق کشاورزی 2020 ، 22 ، 99-123. [ Google Scholar ] [ CrossRef ]
- فیتزموریس، AG; لینلی، ال. ژانگ، سی. واتسون، ام. فرانسه، AM; Oster، AM روش جدید برای تشخیص سریع خوشههای فضایی-زمانی HIV که مداخله بالقوه را تضمین میکند. ظهور. آلوده کردن دیس 2019 ، 25 ، 988–991. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- لی، ام. کرویتورو، آ. Yue, S. GeoDenStream: یک روش خوشه بندی DenStream بهبود یافته برای مدیریت داده های موجودیت در جریان داده های جغرافیایی. محاسبه کنید. Geosci. 2020 , 144 , 104563. [ Google Scholar ] [ CrossRef ]
- پیترسون، کارشناسی; براونلی، MTJ؛ سلام، جی سی. Beeco، JA; سفید، DL؛ شارپ، RL; Cribbs، TW متغیرهای فضایی و زمانی برای درک الگوهای سفر بازدیدکنندگان: رویکرد مدیریت محور. J. بازآفرینی در فضای باز. تور. 2020 ، 31 ، 100316. [ Google Scholar ] [ CrossRef ]
- گروبسیچ، TH; وی، آر. موری، AT Spatial Clustering مرور و مقایسه: دقت، حساسیت و هزینه محاسباتی. ان دانشیار صبح. Geogr. 2014 ، 104 ، 1134-1156. [ Google Scholar ] [ CrossRef ]
- Surendran، MS بررسی روش های خوشه بندی فضایی. بین المللی J. Inf. تکنولوژی زیرساخت. 2012 ، 2 ، 15-24. [ Google Scholar ]
- فریتز، م. شوورمن، ن. رابرتسون، سی. Lear, S. A Scoping Review of Spatial Analysis Cluster Techniques for Point-Event Data. ژئوسپات. سلامت 2013 ، 7 ، 183-198. [ Google Scholar ] [ CrossRef ]
- اوسالیوان، دی. Perry، GLW Spatial Simulation: Exploring Pattern and Process . جان وایلی و پسران: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- سینکلر، TR; سلطانی، ع. مرو، ح. غانم، م. Vadez, V. ارزیابی جغرافیایی برای بهبودهای فیزیولوژیکی و مدیریتی محصول با مثال هایی با استفاده از مدل شبیه سازی ساده. Crop Sci. 2020 ، 60 ، 700-708. [ Google Scholar ] [ CrossRef ]
- چن، ال. ژانگ، پی. Lv، GP; شن، توزیع مکانی- زمانی ZY و تنوع عامل محدود کننده رشد جلبک: شبیه سازی سه بعدی برای بهبود مدیریت مخزن آب آشامیدنی. بین المللی جی. محیط زیست. علمی تکنولوژی 2019 ، 16 ، 7417–7432. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. خو، تی. نیو، ایکس. تان، سی. چن، ای. Xiong، H. STMARL: یک رویکرد یادگیری تقویتی چند عاملی فضایی-زمانی برای کنترل تعاونی چراغ راهنمایی. IEEE Trans. اوباش محاسبه کنید. 2022 ، 21 ، 2228-2242. [ Google Scholar ] [ CrossRef ]
- حسام، س. ولی زاده کامران، ک. مدیریت هوشمند وقوع و گسترش آتش جلو در GIS با استفاده از اتوماتای سلولی. مطالعه موردی: جنگل گلستان. ISPRS Int. قوس. فتوگرام از راه دور. حس اسپات. Inf. علمی 2019 ، XLII-4/W18 ، 475–481. [ Google Scholar ] [ CrossRef ]
- یو، دی. یانکسو، ال. بوجی، اف. شبیه سازی رشد شهری با هدایت محدودیت های اکولوژیکی در شهر پکن: روش ها و پیامدها برای برنامه ریزی فضایی. جی. محیط زیست. مدیریت 2019 ، 243 ، 402-410. [ Google Scholar ] [ CrossRef ]
- پارکر، دی سی؛ Meretsky، V. اندازهگیری نتایج الگو در یک مدل مبتنی بر عامل از اکسترنالهای اثر لبه با استفاده از متریکهای فضایی. کشاورزی اکوسیستم. محیط زیست 2004 ، 101 ، 233-250. [ Google Scholar ] [ CrossRef ]
- والنتین، جی. شبیهسازی فضایی: دیدگاه فضایی بر بومشناسی مبتنی بر فردی – مروری. Ecol. مدل. 2017 ، 350 ، 30-41. [ Google Scholar ] [ CrossRef ]
- Anselin, L. Under the Hood Issues in the Specification and Interpretation of Spatial Regression Models. کشاورزی اقتصاد 2002 ، 27 ، 247-267. [ Google Scholar ] [ CrossRef ]
- بیلی، TC GIS و سیستمهای ساده برای تحلیل بصری، تعاملی، فضایی. کارتوگر. J. 1990 , 27 , 79-84. [ Google Scholar ] [ CrossRef ]
- تاینر، JA اصول طراحی نقشه ; انتشارات گیلفورد: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- Rivest, S. Toward Better Support for Spatial Decisioning: تعریف ویژگی های پردازش تحلیلی روی خط فضایی (Solap). Geomatica 2001 ، 55 ، 539-555. [ Google Scholar ] [ CrossRef ]
- کراک، جی.ام. براون، A. نقشه کشی وب ; CRC Press: Boca Raton، FL، USA، 2003. [ Google Scholar ]
- وو، زی. چن، ی. هان، ی. که، تی. لیو، ی. شناسایی عوامل مؤثر در کنترل تغییرات فضایی فلزات سنگین در خاک حومه شهر با استفاده از مدلهای رگرسیون فضایی. علمی کل محیط. 2020 , 717 , 137212. [ Google Scholar ] [ CrossRef ]
- فنگ، Q. فلانگان، دی سی; انگل، کارشناسی; یانگ، ال. Chen، L. GeoAPEXOL، یک رابط GIS وب برای مدل توسعهدهنده محیطی سیاست کشاورزی (APEX) که هم شبیهسازی میدانی و هم حوزه آبخیز کوچک را امکانپذیر میکند. محیط زیست مدل. نرم افزار 2020 , 123 , 104569. [ Google Scholar ] [ CrossRef ]
- اونو، جی پی؛ کاستلو، اس. لوپز، آر. برتینی، ای. فریره، جی. Silva, C. PipelineProfiler: ابزار تجزیه و تحلیل بصری برای کاوش خطوط لوله AutoML. IEEE Trans. Vis. محاسبه کنید. نمودار. 2020 ، 27 ، 390-400. [ Google Scholar ] [ CrossRef ]
- North, C. Towards Measuring Visualization Insight. محاسبات IEEE. نمودار. Appl. 2006 ، 26 ، 6-9. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- هالیسی، تجسم نقشهکشی EJ: ارزیابی و بررسی معرفتشناختی. پروفسور Geogr. 2005 ، 57 ، 350-364. [ Google Scholar ] [ CrossRef ]
- کای یون، ال. سامپایو دی لیما، آر. Burnside، NG; Vahtmäe، E. کوتسر، تی. Sepp، K. به سمت تجزیه و تحلیل تصویر فراطیفی مبتنی بر یادگیری ماشین خودکار در تخمین محصول و زیست توده. Remote Sens. 2022 , 14 , 1114. [ Google Scholar ] [ CrossRef ]
- دیلمورات، ک. ساگان، وی. موس، S. پیشبینی عملکرد ذرت مبتنی بر هوش مصنوعی با استفاده از ترکیب دادههای فراطیفی و لیدار مبتنی بر وسایل نقلیه هوایی بدون سرنشین. ISPRS Ann. فتوگرام از راه دور. حس اسپات. Inf. علمی 2022 ، V-3-2022 ، 193-199. [ Google Scholar ] [ CrossRef ]
- گراسیس، اس. گیرالدز، ای. پازو رودریگز، م. ساودرا، Á. Taboada، J. AI رویکردهای ارزیابی اثرات زیست محیطی (EIAs) در بخش معدن و فلزات با استفاده از AutoML و مدلسازی بیزی. Appl. علمی 2021 ، 11 ، 7914. [ Google Scholar ] [ CrossRef ]
- گوا، ی. کوان، ال. آهنگ، ال. لیانگ، اچ. ساخت مدلهای هشدار اولیه سریع و تحلیل جامع برای غرقابی شهری بر اساس AutoML و مقایسه سه الگوریتم یادگیری ماشین دیگر. جی هیدرول. 2022 , 605 , 127367. [ Google Scholar ] [ CrossRef ]
- بای، ز. لیو، کیو. لیو، ی. نقشهبرداری پتانسیل آبهای زیرزمینی در منطقه هوبی چین با استفاده از روشهای یادگیری ماشین، یادگیری گروهی، یادگیری عمیق و روشهای AutoML. نات. منبع. Res. 2022 ، 31 ، 2549-2569. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. جین، Q. یو، تی. شیانگ، اس. کوانگ، کیو. پرینت، وی. Pan, C. پیش بینی هواشناسی فضایی-زمانی چندوجهی با شبکه عصبی عمیق. ISPRS J. Photogramm. Remote Sens. 2022 , 188 , 380-393. [ Google Scholar ] [ CrossRef ]
- اودونچا، اف. هو، ی. پالمز، پی. بورک، ام. فیلگوئیرا، آر. Grant, J. یک مدل LSTM فضایی-زمانی برای پیشبینی در مقیاسهای زمانی و مکانی چندگانه. Ecol. Informatics 2022 , 69 , 101687. [ Google Scholar ] [ CrossRef ]
- نیکیتین، نه؛ ریوین، آی. هواتوف، آ. ویچوژانین، پ. Kalyuzhnaya، AV ترکیبی و رویکردهای یادگیری ماشین خودکار برای توسعه میادین نفتی: مطالعه موردی میدان Volve، دریای شمال. محاسبه کنید. Geosci. 2022 ، 161 ، 105061. [ Google Scholar ] [ CrossRef ]
- مغرور-فونز، پی. Bruzón، AG; مغرور-فونز، اف. راموس-برنال، RN; Vázquez-Jiménez، R. ادغام آسیب پذیری و عوامل خطر برای ارزیابی خطر زمین لغزش. بین المللی جی. محیط زیست. Res. بهداشت عمومی 2021 ، 18 ، 11987. [ Google Scholar ] [ CrossRef ]
- Siriborvornratanakul، T. رفتار انسان در سیستمهای بازرسی سلامت جادهای مبتنی بر تصویر علیرغم AutoML در حال ظهور. J. Big Data 2022 , 9 , 96. [ Google Scholar ] [ CrossRef ]
- ساگی، او. Rokach, L. Ensemble Learning: A Survey. وایلی اینتردیسیپ. Rev. Data Min. بدانید. کشف کنید. 2018 ، 8 ، e1249. [ Google Scholar ] [ CrossRef ]
- اسنوک، جی. لاروچل، اچ. آدامز، بهینه سازی عملی بیزی الگوریتم های یادگیری ماشین RP. Adv. عصبی Inf. روند. سیستم 2012 ، 25 ، 1-9. [ Google Scholar ]
- السکن، تی. Metzen، JH; Hutter, F. Neural Architecture Search: A Survey. جی. ماخ. فرا گرفتن. Res. 2019 ، 20 ، 1997–2017. [ Google Scholar ]
- الصحاف، ح. بی، ی. چن، کیو. لنسن، ا. می، ی. سان، ی. تران، بی. ژو، بی. ژانگ، ام. نظرسنجی در مورد یادگیری ماشینی تکاملی. JR Soc. NZ 2019 ، 49 ، 205–228. [ Google Scholar ] [ CrossRef ]
- فیورر، ام. کلاین، ا. اگنزپرگر، ک. اسپرینگنبرگ، جی. بلوم، م. Hutter, F. یادگیری ماشین خودکار کارآمد و قوی. Adv. عصبی Inf. روند. سیستم 2015 ، 28 ، 1-9. [ Google Scholar ]
- اولسون، آر اس؛ بارتلی، ن. Urbanowicz، RJ; مور، JH ارزیابی ابزار بهینه سازی خط لوله مبتنی بر درخت برای خودکارسازی علم داده. در مجموعه مقالات کنفرانس محاسبات ژنتیکی و تکاملی، دنور، CO، ایالات متحده آمریکا، 20-24 ژوئیه 2016. ص 485-492. [ Google Scholar ]
- لدل، ای. پویریر، S. H2O AutoML: یادگیری ماشین خودکار مقیاس پذیر. در مجموعه مقالات کارگاه AutoML در ICML، وین، اتریش، 17 تا 18 ژوئیه 2020؛ جلد 2020. [ Google Scholar ]
- فکور، ر. مولر، جی دبلیو. اریکسون، ن. چودهری، پ. مدل های Smola، AJ سریع، دقیق و ساده برای داده های جدولی از طریق تقطیر افزوده. Adv. عصبی Inf. روند. سیستم 2020 ، 33 ، 8671-8681. [ Google Scholar ]
- دروری، آی. کریشنامورتی، ی. رامپین، آر. لورنکو، RdP; اونو، جی پی؛ چو، ک. سیلوا، سی. Freire، J. AlphaD3M: سنتز خط لوله یادگیری ماشین. arXiv 2021 ، arXiv:2111.02508. [ Google Scholar ]
- Sprague, RH چارچوبی برای توسعه سیستم های پشتیبانی تصمیم. MIS Q. 1980 , 4 , 1-26. [ Google Scholar ] [ CrossRef ]
- Keen، PG; Hackathorn، RD Decision Support Systems and Personal Computing ; MIT: کمبریج، MA، ایالات متحده آمریکا، 1979. [ Google Scholar ]
- Simon, HA علم جدید تصمیم مدیریت ; هارپر و برادرز: نیویورک، نیویورک، ایالات متحده آمریکا، 1960; پ. 50. [ Google Scholar ]
- عمران، ام جی; Engelbrecht، AP; سلمان، ع. مروری بر روش های خوشه بندی. هوشمند داده آنال. 2007 ، 11 ، 583-605. [ Google Scholar ] [ CrossRef ]
- هارکانت، اس. Phulpagar, BD A Survey on Clustering Methods and Algorithms. بین المللی جی. کامپیوتر. علمی Inf. تکنولوژی 2013 ، 4 ، 687-691. [ Google Scholar ]
- آمیگو، ای. گونزالو، جی. آرتیلس، جی. وردجو، اف. مقایسه معیارهای ارزیابی خوشهبندی بیرونی بر اساس محدودیتهای رسمی. Inf. Retr. 2009 ، 12 ، 461-486. [ Google Scholar ] [ CrossRef ]
- Maulik، U. Bandyopadhyay, S. ارزیابی عملکرد برخی از الگوریتمهای خوشهبندی و شاخصهای روایی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2002 ، 24 ، 1650-1654. [ Google Scholar ] [ CrossRef ]
- Vazquezl، MYL; پنافیل، آزمایشگاه. Muñoz، SXS؛ مارتینز، MAQ چارچوبی برای انتخاب مدل های یادگیری ماشین با استفاده از TOPSIS. در پیشرفت در هوش مصنوعی، نرم افزار و مهندسی سیستم ها ؛ پیشرفت در سیستم های هوشمند و محاسبات؛ اهرم، ت.، ویرایش; انتشارات بین المللی Springer: چم، سوئیس، 2021; صص 119-126. [ Google Scholar ]
- ماهش، بی. الگوریتم های یادگیری ماشین – مروری. بین المللی J. Sci. Res. 2020 ، 9 ، 381-386. [ Google Scholar ]
- میفیلد، اچ جی; اسمیت، سی. گالاگر، م. Hockings, M. ملاحظات برای انتخاب یک تکنیک یادگیری ماشینی برای پیش بینی جنگل زدایی. محیط زیست مدل. نرم افزار 2020 , 131 , 104741. [ Google Scholar ] [ CrossRef ]
- Sparks، ER; تالوالکار، ا. هاس، دی. فرانکلین، ام جی; جردن، MI; Kraska، T. جستجوی مدل خودکار برای یادگیری ماشینی در مقیاس بزرگ. در مجموعه مقالات ششمین سمپوزیوم ACM در رایانش ابری، ساحل Kohala، HI، ایالات متحده آمریکا، 27-29 اوت 2015. صص 368-380. [ Google Scholar ] [ CrossRef ]
- رئال، ای. لیانگ، سی. بنابراین، D. Le, Q. AutoML-Zero: تکامل الگوریتم های یادگیری ماشین از ابتدا. در مجموعه مقالات سی و هفتمین کنفرانس بین المللی یادگیری ماشین – PMLR، مجازی، 13 تا 18 ژوئیه 2020؛ صفحات 8007–8019. [ Google Scholar ]
- بیلجکی، اف. Heuvelink، GBM؛ لدوکس، اچ. Stoter, J. اثر خطای اکتساب و سطح جزئیات بر دقت تحلیل های فضایی. کارتوگر. Geogr. Inf. علمی 2018 ، 45 ، 156-176. [ Google Scholar ] [ CrossRef ]
- دیویلر، آر. Bédard، Y.; ژانسولین، آر. Moulin, B. Towards Spatial Data Quality Analysis Information To Towards Spatial Data Quality Analysis Tools for Experts assessing the fitness for use of space. بین المللی جی. جئوگر. Inf. علمی 2007 ، 21 ، 261-282. [ Google Scholar ] [ CrossRef ]
- گتیس، الف. خودهمبستگی فضایی. در کتابچه راهنمای تحلیل فضایی کاربردی: ابزارها، روش ها و کاربردهای نرم افزاری ; Fischer, MM, Getis, A., Eds. Springer: برلین/هایدلبرگ، آلمان، 2010; صص 255-278. [ Google Scholar ] [ CrossRef ]
- گیلاردی، ن. Bengio، S. مدل های یادگیری ماشین محلی برای تجزیه و تحلیل داده های فضایی. جی. جئوگر. Inf. تصمیم می گیرد. مقعدی 2000 ، 4 ، 11-28. [ Google Scholar ]
- Rouse، LJ; برگرون، اس جی; هریس، TM شرکت در وب جغرافیایی: نقشه برداری مشارکتی، شبکه های اجتماعی و GIS مشارکتی. در وب جغرافیایی: چگونه مرورگرهای جغرافیایی، نرم افزارهای اجتماعی و وب 2.0 به جامعه شبکه شکل می دهند . Scharl, A., Tochtermann, K., Eds. پردازش اطلاعات و دانش پیشرفته؛ Springer: لندن، انگلستان، 2007; صص 153-158. [ Google Scholar ] [ CrossRef ]
- زامبلی، پ. گبرت، اس. Ciolli، M. Pygrass: یک رابط برنامه نویسی کاربردی پایتون شی گرا (API) برای سیستم پشتیبانی تجزیه و تحلیل منابع جغرافیایی (GRASS) سیستم اطلاعات جغرافیایی (GIS). ISPRS Int. J. Geo-Inf. 2013 ، 2 ، 201-219. [ Google Scholar ] [ CrossRef ]
- ونک، جی. Geertman, S. بهبود پذیرش و استفاده از سیستم های پشتیبانی برنامه ریزی در عمل. Appl. تف کردن مقعدی سیاست 2008 ، 1 ، 153-173. [ Google Scholar ] [ CrossRef ]
- هنگ، اس آر؛ کاستلو، اس. D’Orazio، V. بنتون، سی. سانتوس، آ. لانگوین، اس. جونکر، دی. برتینی، ای. Freire, J. Towards Evaluating Exploratory Model Building Process with AutoML Systems. arXiv 2020 ، arXiv:2009.00449. [ Google Scholar ]
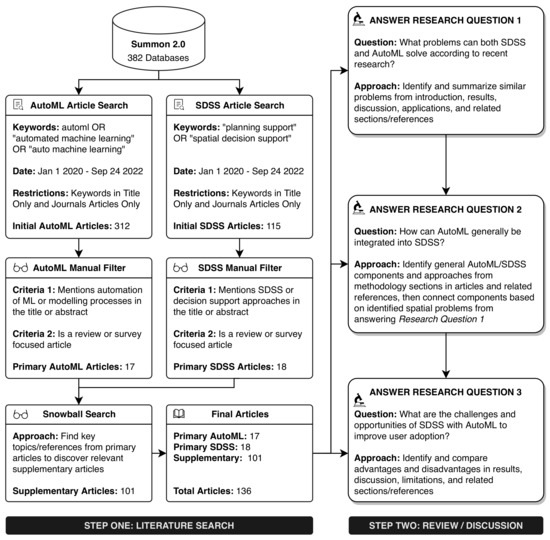
شکل 1. فرآیند دو مرحله ای برای پاسخ به سوالات تحقیق.
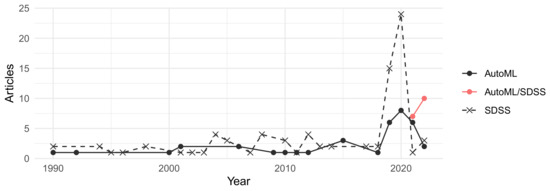
شکل 2. مقالات نهایی SDSS و AutoML در سال (n = 136).

شکل 3. ابر کلمه از 100 کلمه برتر در 136 چکیده و عنوان مقاله SDSS و AutoML.
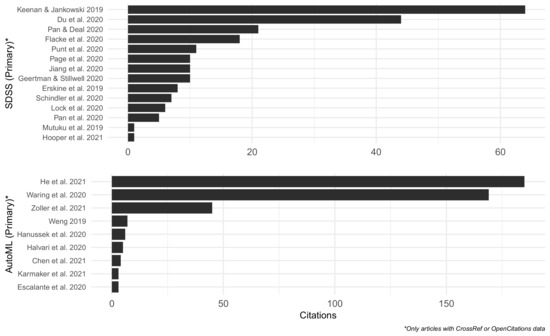
شکل 4. تعداد استناد به مقاله AutoML اولیه (17 = n) و SDSS (n = 18 ) [ 4 ، 6 ، 12 ، 16 ، 17 ، 18 ، 19 ، 21 ، 24 ، 25 ، 26 ، 27،37 ، , 39 , 40 , 41 , 42 , 43 , 44 , 45 ].
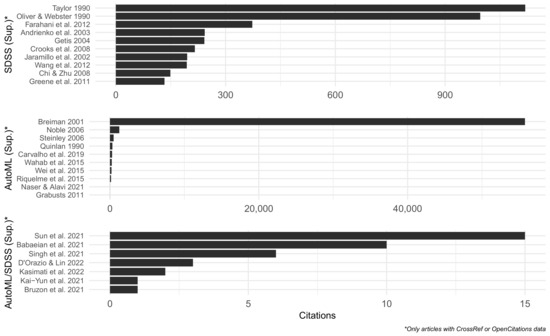
شکل 5. 10 مقاله تکمیلی برتر AutoML (n = 21)، SDSS (n = 63)، و AutoML/SDSS (n = 17) [ 28 ، 29 ، 30 ، 31 ، 32 ، 33 ، 34 ، 35 ، 46 . , 47 , 48 , 49 , 50 , 51 , 52 , 53 , 54 , 55 , 56 , 57 , 58 , 59 , 60 , 61 , 62 ,63 ، 64 ].
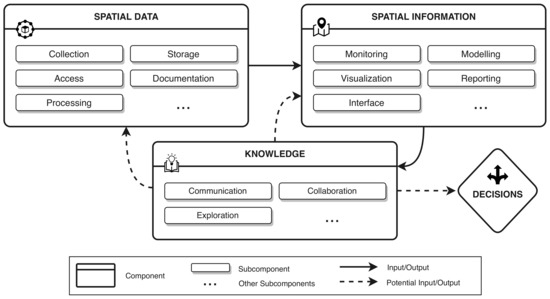
شکل 6. اجزای سیستم پشتیبانی تصمیم فضایی (SDSS).
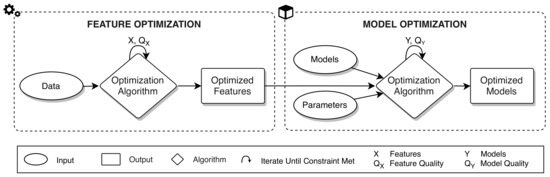
شکل 7. رویکرد یادگیری ماشینی خودکار عمومی (AutoML).
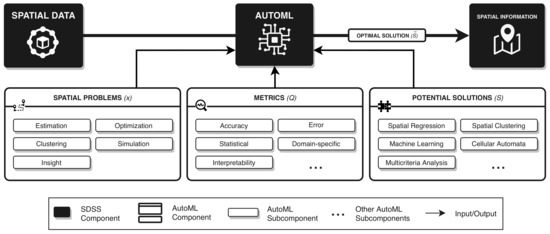
شکل 8. SDSS عمومی با چارچوب AutoML.
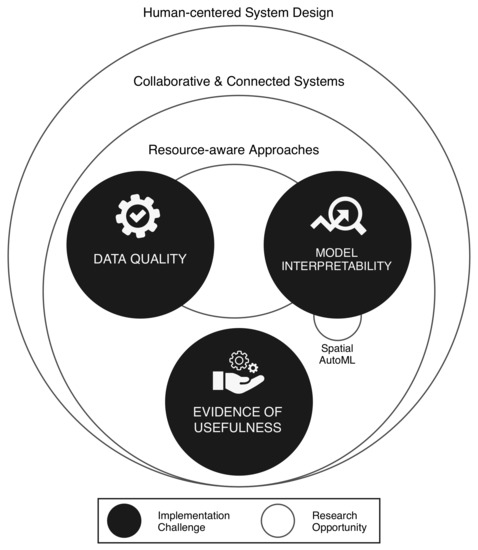
شکل 9. SDSS با فرصت های تحقیقاتی AutoML و چالش های پیاده سازی.


بدون دیدگاه