1. مقدمه
فرسایش شدید خاک باعث افزایش رسوب خاک و کاهش شدید ظرفیت ذخیره و تامین آب مخازن خواهد شد. تجزیه و تحلیل قبلی نشان داد که 30 درصد از زمین های زراعی ایالات متحده دارای نرخ فرسایش بیش از حد خاک هستند [ 1 ]. فرسایش خاک یکی از موضوعات اصلی در کشاورزی، حفاظت از منابع طبیعی و سایر زمینه های مرتبط از اواخر دهه 1920 بوده است [ 2 ]. یک روند قابل توجه در مطالعه فرسایش خاک، توسعه مدلهای مختلف اندازهگیری و پیشبینی برای مکانها و کاربردهای مختلف، مانند AGNPS (مدل آلودگی غیر نقطهای کشاورزی [ 3 ])، CRAMS (مواد شیمیایی، رواناب و فرسایش از سیستمهای مدیریت کشاورزی [ 4 ] بود. ])، EPIC (ماشین حساب تأثیر فرسایش بهره وری [5 )، SWRRBWQ (شبیه ساز برای منابع آب در حوضه های روستایی-کیفیت آب [ 6 ])، WEPP (پروژه پیش بینی فرسایش آب [ 7 ])، و USLE (معادله جهانی از دست دادن خاک [ 8 ، 9 ]). USLE علیرغم اینکه اولین مدل توسعه یافته است، هنوز یک مدل تجربی پرکاربرد است و در سطوح ملی و بین المللی برای برآورد تلفات خاک در سراسر جهان استفاده شده است [ 10 ].
شش عامل مهم در مدل USLE وجود دارد، از جمله ضریب فرسایش بارندگی (ضریب Rm )، ضریب فرسایش پذیری خاک (ضریب Km )، فاکتور طول شیب (ضریب L)، ضریب شیب شیب (عامل S)، ضریب مدیریت پوشش (عامل C) و عامل تمرین پشتیبانی (عامل P). نتیجه مدل USLE میانگین تلفات سالانه خاک (Am ) را نشان می دهد. با این حال، محاسبه USLE زمین لغزش، فرسایش خندقی، فرسایش بستر رودخانه یا ساحل، و رسوبات رسوب را مستثنی می کند [ 11 ، 12 ، 13]. در بین عوامل USLE، ضریب C (از 0 تا 1) مربوط به کاربری زمین/پوشش زمین (LULC) است. بنابراین، ممکن است تفاوت هزار برابری در برآورد فرسایش خاک ایجاد کند (001/0 در مقابل 1).
خلاصه ای از مطالعات گذشته فرسایش خاک در یک حوضه آبخیز تایوان نشان داد که نرخ فرسایش خاک محاسبه شده از 1 تا 3310 تن در هکتار در سال متغیر است [ 14 ]. مطالعه دیگری همچنین نشان داد که توزیع غیریکنواخت عوامل USLE ممکن است باعث اختلاف قابل توجهی در برآورد فرسایش خاک شود [ 15 ]. بنابراین، توسعه یک استراتژی برای استخراج عوامل سازگارتر و قابل اعتمادتر در هنگام استفاده از مدل USLE برای ارزیابی تلفات خاک ضروری است.
این مطالعه بر ارزیابی فاکتور C متمرکز بود. به طور سنتی، فاکتور C بر اساس آزمایش های نمودار یا تحقیقات درجا تعیین می شد [ 9 ]. با این حال، چنین کارهایی بیش از حد وقت گیر و غیراقتصادی بودند که در همه جا کاربرد نداشتند [ 16 ]. رنارد و همکاران [ 17 ] تابعی را برای شبیهسازی آزمایشهای مزرعهای طولانیمدت با استفاده از فاکتور فرعی کاربری قبلی، فاکتور فرعی تاج پوشش، عامل فرعی پوشش سطح، زیر عامل زبری سطح و خاک- استخراج کرد. زیر عامل رطوبت برای ارزیابی فاکتور C. اگرچه تابع مشتق شده کارایی آزمایش های مزرعه ای طولانی مدت را بهبود بخشید، اما کارهای میدانی قابل توجهی هنوز اجتناب ناپذیر بود. امروزه، اتصال ضریب C با نقشه LULC با استفاده از جدول جستجو یک استراتژی موثر است.18 ]. با این حال، این استراتژی توسط دوره به روز رسانی نقشه محدود شده است، و بنابراین ارزیابی فرسایش چند زمانی خاک دشوار است. به طور مشابه، به جای نقشه LULC، یک نتیجه سری زمانی را می توان با استفاده از تصاویر سنجش از دور ماهواره ای و تکنیک های طبقه بندی نظارت شده به دست آورد [ 19 ، 20 ]. محدودیتها در اینجا این است که برای ارزیابی دقت طبقهبندی تصویر به نقاط حقیقت زمینی نیاز است و نتایج نسبت به نقشه LULC تولید شده از کار میدانی پایینتر است. انجام تجزیه و تحلیل رگرسیون برای اتصال ویژگی های به دست آمده از تصاویر سنجش از راه دور (به عنوان مثال، شاخص گیاهی تفاوت نرمال شده، NDVI) با فاکتور C یکی دیگر از رویکردهای رایج است [ 21 ، 22 ].]. مجدداً، روابط توسعه یافته ممکن است حاشیه خطای زیادی داشته باشد، در ارائه هیچ معنای فیزیکی ناکام باشد، و ممکن است به فنولوژی پوشش گیاهی و شرایط خاک حساس باشد [ 23 ]. با توجه به مقایسه بالا، جدول 1 رویکردهای معمولی برای تخمین ضریب C را خلاصه می کند.
برای بهبود تحقیقات قبلی در مورد این موضوع، هدف این مطالعه ساخت مدلی بین ضریب C و دادههای جغرافیایی مرتبط (شامل اما نه محدود به آنهایی که از تصاویر سنجش از دور به دست میآیند) با استفاده از رویکرد داده کاوی بود. اگر بتوان یک مدل معتبر از دادههای رسمی جمعآوریشده در سالهای قبل ساخت، آنگاه میتوان مدل را برای پیشبینی فاکتورهای C برای سالهای بعد صرفاً با بهروزرسانی تصاویر سنجش از دور، به کار برد، بنابراین بدون نیاز به بهروزرسانی LULC، به تحلیل چندزمانی دست یافت. نقشه هر سال علاوه بر این، با استفاده از این چارچوب جدید برای ارزیابی و پیشبینی فاکتورهای C بر اساس عوامل مکانی، میتوانیم نرخ فرسایش خاک را در مقیاس بزرگ، مانند مقیاس حوضه، بهتر تخمین بزنیم. همانطور که در جدول 1 نشان داده شده استما از نقشه رسمی LULC و جدول جستجو برای تعیین فاکتورهای C در این مطالعه استفاده کردیم. سپس یک مدل RF برای پیشبینی مقادیر ضریب C از فاکتورهای مکانی برای استفاده در مدل USLE ساخته شد.
بقیه مقاله به شرح زیر سازماندهی شده است. بخش 2 منطقه مورد مطالعه، داده های مکانی و الگوریتم داده کاوی را معرفی می کند. بخش 3 مدل سازی فاکتور C و نتایج برآورد فرسایش خاک و بحثی را با تمرکز بر مشکل عدم تعادل طبقاتی (داده های نامتعادل) ارائه می دهد. در نهایت، بخش 4 این مقاله را به پایان میرساند و جهات احتمالی تحقیقات آینده را ارائه میکند.
2. روش ها
برای پرداختن به هدف تحقیق، لازم است یک استراتژی برای استخراج عوامل سازگارتر و قابل اعتمادتر هنگام استفاده از مدل USLE برای ارزیابی تلفات خاک ایجاد شود. با توسعه سریع فناوریهای مکانی و در دسترس بودن دادهها، پتانسیل زیادی برای بهبود مدلسازی USLE بر اساس دادههای مکانی، مانند تصاویر سنجش از راه دور و لایههای داده سیستم اطلاعات جغرافیایی (GIS) وجود دارد تا تخمین دقیقتری از تلفات خاک بدست آید. مقیاس منطقه ای، به ویژه برای مطالعات طولانی مدت و چند زمانی. انواع داده ها، پردازش داده ها و تجزیه و تحلیل داده کاوی در زیر بخش های زیر توضیح داده شده است.
2.1. منطقه مطالعه
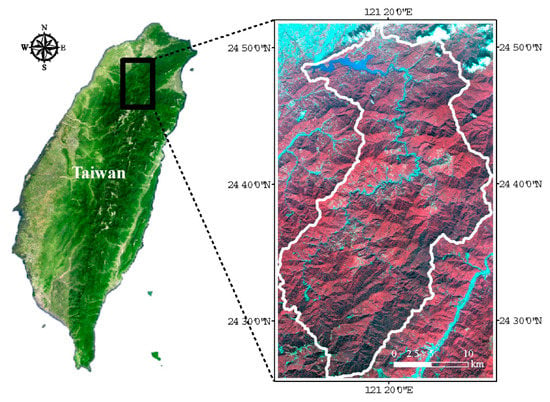
منطقه کوهستانی به مساحت 760 کیلومتر مربع از حوزه آبخیز مخزن شیمن در شمال تایوان به عنوان منطقه مورد مطالعه انتخاب شد ( شکل 1 ). ارتفاع منطقه مورد مطالعه تقریباً از 250 تا 3500 متر بالاتر از سطح دریا است که از یک مدل ارتفاعی دیجیتال 10 متری (DEM) اندازه گیری می شود. زمین به شدت از شمال به جنوب افزایش می یابد و شیب های تند در حوضه آبخیز همه جا وجود دارد. میانگین بارندگی سالانه حدود 2500 میلی متر است. 13 سازندهای زمین شناسی و شش نوع خاک در منطقه مورد مطالعه وجود دارد [ 24 ]. پوشش اصلی زمین جنگل (طبیعی و مصنوعی) است و فعالیت کشاورزی کمی در آن وجود دارد.
حوضه آبریز مخزن شیمن یکی از مخازن اصلی تایوان است که آب آشامیدنی بیش از سه میلیون نفر در سه شهر شمالی را تامین می کند. با این حال، بارندگی شدید ناشی از طوفانهایی مانند طوفان Aere در آگوست 2004، ممکن است مقدار زیادی زباله و چوب رانش ایجاد کند که در نتیجه کمبود آب و مشکلات مدیریت منابع آب ایجاد میکند. از این رو، یک پروژه بلند مدت پایش پوشش زمین از سال 2004 تا 2009 با استفاده از فناوری های سنجش از دور برای حمایت از منابع آب و مدیریت تامین آب اجرا شد [ 25 ]. بر اساس دادههای مکانی جمعآوریشده، این مطالعه بیشتر اثربخشی مدل USLE را با مدلسازی ضریب C در حوضه آبخیز مخزن شیهمن برای تخمین نرخهای فرسایش چند زمانی خاک بررسی کرد.
2.2. پیش پردازش مواد و داده ها
برای اتصال داده های مکانی به فاکتور C، در مجموع هشت ویژگی (همانطور که در جدول 2 ذکر شده است ) در مدل سازی در نظر گرفته شد. ارتفاع، شیب، NDVI، شاخص گیاهی تنظیم شده با خاک (SAVI)، کوتاه ترین فاصله تا جاده ها، کوتاه ترین فاصله تا رودخانه ها، زمین شناسی و نوع خاک. برخلاف مطالعاتی که از بسیاری از ویژگی ها استفاده می کنند، ما فقط از هشت ویژگی استفاده کردیم زیرا تحقیقات نشان داده است که کاهش ویژگی می تواند عملکرد مدل را بهبود بخشد [ 26 ]. همچنین به دلیل نیاز به حداکثر کردن تعداد نقاط داده ای که می توانند توسط نرم افزار R پردازش شوند، از ویژگی های کمتری استفاده کردیم (به بخش 2.3 مراجعه کنید.). هدف از پیش پردازش سه مورد است، از جمله جمع آوری داده ها، برچسب گذاری، و استخراج ویژگی. برخی از ویژگی های مشتق شده را می توان با تجزیه و تحلیل فضایی از داده های اصلی به دست آورد. به عنوان مثال، اطلاعات ارتفاع و شیب را می توان از DEM استخراج کرد. همانطور که برای تصاویر ماهواره ای چند زمانی فهرست شده در جدول 3 ، این مطالعه سال به سال شاخص های NDVI و SAVI را برای اهداف مدل سازی تولید کرد. معادلات (1) و (2) معادلات NDVI و SAVI را نشان میدهند، جایی که NIR و RED به ترتیب تابش یا بازتاب نوارهای مادون قرمز نزدیک و قرمز را نشان میدهند و L نشاندهنده ضریب تصحیح خاک است که معمولاً روی 0.5 تنظیم میشود [ 27 ].]. با این حال، توپوگرافی کوهستانی ممکن است پاسخ های طیفی را تحریف کند به طوری که همان گونه های پوشش زمین واقع در مناطق فوتوتروپیک و آفلیوتروپیک ممکن است تغییرات قابل توجهی داشته باشند. برای کاهش اثر توپوگرافی، این مطالعه یک تصحیح معمولی Minnaert [ 28 ] را برای اصلاح پاسخهای طیفی بر اساس یک فرض غیرلامبرتی قبل از استخراج ویژگیهای رویشی اعمال کرد. مشابه استفاده از تصاویر DEM و SPOT، بقیه داده ها، مانند اطلاعات فاصله تا جاده ها و رودخانه ها، با تجزیه و تحلیل فضایی تولید شدند. علاوه بر این، داده های برداری به ابعاد 10×10 متر شطرنجی شدند تا با یکدیگر سازگار باشند.
که در آن NIR و RED تابش یا بازتاب نوارهای مادون قرمز نزدیک و قرمز هستند و L ضریب تصحیح خاک است (0.5).
پس از استخراج و مونتاژ ویژگی، یک جدول جستجو برای تخصیص مقادیر فاکتور C به نقشه رسمی LULC 2004 (تنها نقشه موجود در طول دوره مطالعه) استفاده شد. مقادیر نقطه فاکتور C بر اساس تحقیقات Jhan [ 29 ] و Lin [ 30 ] بود که به نوبه خود بر اساس کتابچه راهنمای طراحی دفتر حفاظت از خاک و آب تایوان بود. بدون انجام آزمایشهای متعدد در زمینه برای تعیین فاکتورهای C در مکانهای مختلف، جدول جستجو بهترین گزینه بعدی را برای تخصیص مقادیر ضریب C معتبر به کلاسهای LULC مختلف در منطقه مورد مطالعه ارائه میکند. همانطور که از شکل 2 مشاهده می شود23 کلاس کاربری اراضی به 12 کلاس مختلف فاکتور C اختصاص داده شد. هر چه ضریب C بیشتر باشد، پوشش زمین کمتر و فرسایش خاک بیشتر می شود. مطابقت بین کلاس های LULC و کلاس های فاکتور C در جدول 4 خلاصه شده است. داده های مکانی و مقادیر ضریب C مربوط به هر سلول شبکه در منطقه مورد مطالعه استخراج و به عنوان یک مجموعه داده تحلیلی (که در اینجا مجموعه داده جمعیت نامیده می شود) که توسط الگوریتم داده کاوی (پس از نمونه برداری) استفاده می شود جمع آوری شد تا یک C- ایجاد شود. مدل عاملی این مدل برای تجزیه و تحلیل چند زمانی تغییر فاکتور C و فرسایش خاک استفاده می شود.
2.3. تجزیه و تحلیل داده کاوی
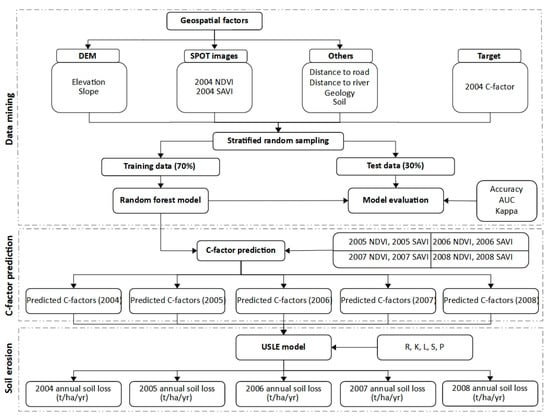
برای استخراج اطلاعات مفید، ناشناخته و بالقوه از مجموعه داده گسترده، داده کاوی یک رویکرد کارآمد است [ 31 ، 32 ]. جنگل های تصادفی (RF)، یکی از الگوریتم های محبوب داده کاوی پیشنهاد شده توسط بریمن [ 33 ]، عملکرد عالی در تجزیه و تحلیل بسیاری از مسائل پیچیده سنجش از راه دور دارد [ 34 ، 35 ، 36 ، 37 ]. روش بکارگیری الگوریتم داده کاوی برای ساخت مدل ضریب C برای تخمین فرسایش خاک در شکل 3 نشان داده شده است.. ما از دادههای مکانی بهدستآمده از تصاویر GIS و SPOT و نقشه رسمی LULC 2004 (از بررسیهای میدانی) برای ساخت مدل فاکتور C با استفاده از بسته تصادفی Forest() نرمافزار R استفاده کردیم. در میان رویههای داده کاوی، الگوریتم RF یک رویکرد نظارت شده است که درختهای تصمیمگیری چندگانه (DT)، تجمع بوت استرپ (کیسهبندی) و تکنیکهای اعتبارسنجی متقابل داخلی را اتخاذ میکند. تمام نتایج مبتنی بر درخت را در بهترین مدل برای تجزیه و تحلیل ادغام می کند [ 33 ]. در سال های اخیر توجه بیشتری به الگوریتم RF در حوزه ژئو انفورماتیک شده است. بلژیک و دراگوت [ 34] کاربرد و جهت آینده آن را در سنجش از دور بررسی کرد. با این وجود، ساخت مدل فاکتور C بر اساس الگوریتم RF و دادههای مکانی به ندرت تاکنون انجام شده است. مزیت اصلی الگوریتم RF این است که می تواند از مشکل بیش از حد برازش برای بهبود دقت پیش بینی جلوگیری کند [ 38 ]]. الگوریتم RF از معیارهایی مانند شاخص جینی، افزایش اطلاعات (IG) یا آنتروپی برای ارزیابی درجه ناخالصی داده های ورودی گسسته یا عددی استفاده می کند. هرچه شاخص جینی یک ویژگی کوچکتر باشد، اولویت باید برای ساخت یک گره شرطی و نادیده گرفتن سایر ویژگی ها انتخاب شود. الگوریتم RF تکرارهای متعددی را انجام می دهد و به طور تصادفی مجموعه داده های آموزشی (از نظر تعداد داده ها و تعداد ویژگی ها) را به زیر مجموعه های زیادی تقسیم می کند تا درختان زیادی بسازد و نتایج بهتری نسبت به روش DT ایجاد کند. مراحل دقیق را می توان در Guo و همکاران مشاهده کرد. [ 39 ].
با توجه به محدودیت اندازه حافظه R، تنها حدود 4٪ از مجموعه داده جمعیت را می توان وارد کرد و در مدل سازی استفاده کرد (303682 امتیاز از 7592062 امتیاز). بنابراین، ما از روش نمونهگیری تصادفی طبقهای برای انتخاب همان درصد نقاط داده از هر یک از 12 کلاس عامل C (که در اینجا به عنوان مجموعه داده نمونه یا مجموعه داده ورودی نامیده میشود) استفاده کردیم، همانطور که در جدول 5 نشان داده شده است. توجه داشته باشید که مجموعه داده ورودی بسیار نامتعادل است، با 92.5٪ از داده ها از کلاس C = 0.01 (جنگل ها). درصد بقیه کلاس های فاکتور C از نزدیک به 0٪ تا 2.9٪ متغیر است.
پس از نمونه برداری، 70 درصد از مجموعه داده ورودی به عنوان داده های آموزشی استفاده شد و برای ایجاد مدل C-factor وارد الگوریتم RF شد. 30 درصد باقیمانده داده های آزمون بود و برای ارزیابی عملکرد مدل استفاده شد. هنگامی که مدل اعتبار سنجی شد، برای ایجاد نقشه های فاکتور C از سال 2004 تا 2008 در مجموعه داده های جمعیت اعمال شد. در نهایت، ضریب C و سایر عوامل USLE در مدل USLE برای محاسبه نرخ فرسایش خاک از سال 2004 ترکیب شدند. تا سال 2008 ( برای جزئیات به بخش 2.4 مراجعه کنید).
داده های مقوله ای و عددی دو نوع داده جغرافیایی اصلی هستند. بسته randomForest() R از شاخص جینی برای تقسیم گره ها به منظور کاهش ناخالصی در هر گره استفاده می کند [ 40 ]. ما در این مطالعه از 1000 درخت استفاده کردیم و در هر تقسیم سه متغیر مورد آزمایش قرار گرفت. شاخص جینی مجموعه داده D در رابطه (3) تعریف شده است، که در آن m تعداد دسته ها، n i تعداد نقاط داده در دسته i و N تعداد کل نقاط داده است. اگر یک تقسیم دودویی بر روی ویژگی A انجام شود ، شاخص جینی با توجه به تقسیم در رابطه (4) تعریف شده است، که در آن D1 و D2 مجموعه داده های پس از تقسیم هستند [ 41 ].].
برای تأیید مدل فاکتور C مبتنی بر داده کاوی، این مطالعه ماتریس سردرگمی (یا ماتریس خطا)، دقت کلی ( OA )، ضریب کاپا و سطح زیر منحنی (AUC) منحنی مشخصه عملکرد گیرنده (ROC) را محاسبه کرد. برای ارزیابی کمی دقت کلی به درصد نمونه هایی که به درستی طبقه بندی شده اند همانطور که در رابطه (5) نشان داده شده است، اشاره دارد، که در آن M عنصر موجود در ماتریس سردرگمی را نشان می دهد. M کل حاصل جمع M است . M دیاگ مجموع M روی خط مورب است. Nc تعداد برچسب ها است. و من و جشاخص های سطر و ستون هستند. ضریب کاپا در رابطه (6) نشان داده شده است که قابلیت اطمینان نتایج مدلسازی را نشان می دهد. وقتی ضریب کاپا نزدیک به 1 باشد، تطابق عالی بین پیش بینی و مشاهده را نشان می دهد. در مقابل، نتایج بدتر از تخصیص تصادفی زمانی است که یک مقدار کاپا منفی ظاهر شود.
2.4. محاسبات USLE
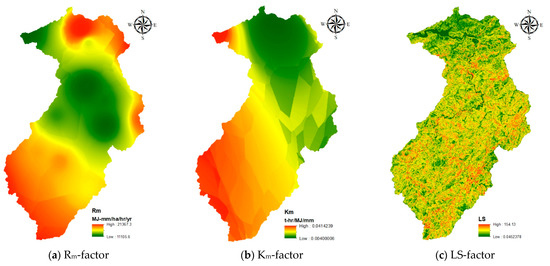
معادله USLE در معادله (7) نشان داده شده است، و معانی همه عوامل USLE در جدول 6 آمده است. اگرچه هدف این مطالعه ارزیابی فاکتور C است، اما سایر عوامل USLE نیز برای تخمین تلفات سالانه خاک مورد نیاز است. برای این عوامل، این مطالعه به دنبال تحقیقات چن و همکاران بود. [ 14 ] و لیو و همکاران. [ 42 ] برای تولید لایههای فرسایشپذیری بارندگی، فرسایشپذیری خاک، طول شیب و لایههای شیب شیب. ما همچنین فرض کردیم که ضریب تمرین پشتیبانی 1 است. نقشه های توزیع فاکتور Rm – و Km – تولید شده در شکل 4 a ,b نشان داده شده است و ضرایب L- و S به عنوان یک فاکتور توپوگرافی (LS-factor) ترکیب شده اند. ) نشان داده شده درشکل 4 ج.
3. نتایج و بحث
نتایج این تحقیق به صورت جداول، نمودارها و معیارهای آماری در زیر بخش های زیر ارائه شده است.
3.1. مدلسازی عوامل پوششی
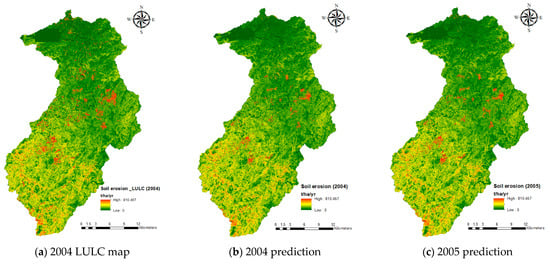
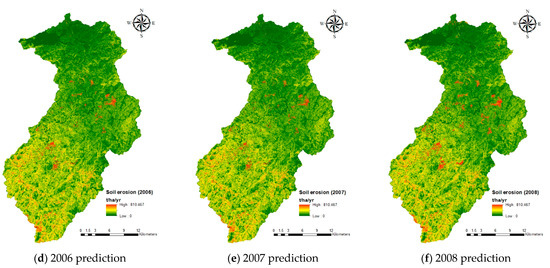
با توجه به پیش پردازش داده ها و روش های مطالعه شرح داده شده در بخش های قبلی، مدل RF فاکتور C با استفاده از داده های آموزشی ساخته شد و با داده های آزمون آزمایش شد. فاکتورهای C از نقشه رسمی LULC 2004 (تنها نقشه موجود در طول دوره مطالعه) بودند و نتایج در جدول 7 نشان داده شده است. برخلاف مطالعه قبلی [ 30]، که تنها از هر کلاس فاکتور C حداکثر 100 نقطه استفاده می کرد و فرسایش خاک را به طور قابل ملاحظه ای بیش از حد تخمین می زد، ما سعی کردیم تعداد نقاط داده ای را که می توان برای آموزش مدل RF پردازش کرد با توجه به محدودیت اندازه حافظه R به حداکثر برسانیم. در نتیجه، 4 درصد از کل نقاط داده (مجموعه مجموعه داده) استفاده شد (303682 امتیاز از 7592062 امتیاز انتخاب شد). نتیجه مجموعه داده آموزشی نشان می دهد که OA = 1، Kappa = 1، و AUC = 1 (ماتریس سردرگمی در اینجا برای جلوگیری از افزونگی نشان داده نشده است). این نشان می دهد که مدل RF می تواند به درستی تمام 212578 نقطه داده در مجموعه داده آموزشی را تشخیص دهد. در مقابل، جدول 7نشان می دهد که نتیجه مجموعه داده آزمایشی دارای معیارهای قابل توجه کمتری است. در حالی که OA هنوز بسیار بالا است (0.9516)، کاپا فقط 0.5741 است و AUC 0.7804 است. با استفاده از این مدل RF، ما نقشه های توزیع فاکتور C را از سال 2004 تا 2008 با استفاده از تصاویر SPOT پیش بینی کردیم. نقشه های حاصل در شکل 5 b–f نشان داده شده است.
شکل 5 a توزیع واقعی فاکتور C را از نقشه رسمی LULC 2004 نشان می دهد. شباهت بین پیش بینی ( شکل 5 b-f) و عامل C مرجع مشهود است. پیکسل های قرمز (مقادیر ضریب C بالا) همه نقشه ها در امتداد دره رودخانه مرکزی در نزدیکی مرکز و بخش های پایینی حوضه جمع می شوند. با این حال، برخی از ضریب C را نمی توان به طور قابل اعتماد تشخیص داد، و برخی از خطاها و خطاها رخ داده است. همانطور که در ستون 4 (سایه دار) جدول 7 نشان داده شده است ، قابل توجه ترین روند یک سوگیری پیش بینی نسبت به کلاس C = 0.01 است که جنگل های طبیعی و مصنوعی را نشان می دهد. این نتیجه منعکس کننده اکثریت قریب به اتفاق کلاس C = 0.01 در نمونه (92.5٪) هنگام ساخت مدل RF است ( جدول 5).). از این رو، مدل RF تمایل دارد پیکسل ها را در کلاس C = 0.01 طبقه بندی کند. به دلیل این سوگیری نسبت به مقدار ضریب C پایین (0.01)، میانگین 2004 فاکتور C پیش بینی شده توسط مدل RF تنها 0.0115 است ( جدول 8 )، که کمتر از میانگین واقعی 0.0164 (نقشه رسمی LULC 2004) است. . به همین ترتیب، میانگین فاکتورهای C پیشبینیشده نیز در سالهای بعدی از سال 2005 تا 2008 کمتر است.
برای کاهش خطای طبقهبندی، ما با نمونهبرداری موقتی از تکنیک کلاس اکثریت آزمایش کردیم که تنها از 2٪ داده از کلاس اکثریت (کلاس C = 0.01) استفاده کرد در حالی که نرخ نمونه 4٪ از اقلیت C- دیگر را حفظ کرد. کلاس های فاکتور درصد نقاط داده از هر یک از 12 کلاس عامل C در مجموعه داده ورودی قبلاً در جدول 5 نشان داده شده است. مجدداً، نتیجه مجموعه داده آموزشی یک طبقهبندی کامل از OA = 1، Kappa = 1، و AUC = 1 را نشان میدهد (دوباره، ماتریس سردرگمی در اینجا برای جلوگیری از افزونگی نشان داده نشده است). نتیجه مجموعه داده آزمایشی ( جدول 9 ) نشان می دهد که OA = 0.9230، Kappa = 0.6484، و AUC = 0.7807. در مقایسه با جدول 7، می بینیم که OA از 0.9516 به 0.9230 کاهش می یابد، کاپا از 0.5741 به 0.6484 افزایش می یابد و AUC تقریباً ثابت می ماند. با استفاده از تنها 2٪ داده از کلاس C = 0.01، میانگین C-factor های پیش بینی شده از سال 2004 تا 2008 از 0.0124 تا 0.0133 متغیر است ( جدول 8) بالاتر از مورد 4% و نزدیکتر به میانگین واقعی مقدار فاکتور C. به عبارت دیگر، کاهش نرخ نمونه گیری از 4% به 2% ضریب کاپا را به هزینه OA افزایش می دهد. به طور همزمان، کاهش نرخ نمونه گیری نیز پیش بینی ها را به مقدار مرجع (حقیقت زمینی) نزدیک می کند. اگرچه ما روش نمونهگیری تصادفی طبقهای را برای به دست آوردن نمونهای نماینده از تمام کلاسهای عامل C اتخاذ کرده بودیم، اما به طور کامل از مشکل دادههای نامتعادل جلوگیری نکرد. در بخش بعدی نحوه نمونه برداری از طبقه اکثریت بر برآوردهای فرسایش خاک تأثیر می گذارد.
3.2. برآورد فرسایش خاک
تا سال 2017، مدل USLE تنها روش برای تخمین میزان تلفات خاک در مقررات فنی حفاظت از خاک و آب در تایوان [ 43 ] بود. با ترکیب لایه های فاکتور Rm- ، Km- و LS ( شکل 4 ) با لایه فاکتور C ( شکل 5 )، مدل USLE در این مطالعه برای تخمین میزان فرسایش خاک استفاده شد. نتیجه بر اساس نقشه رسمی LULC 2004 در ستون دوم جدول 10 فهرست شده است.(116.3 تن در هکتار در سال). ارزیابی های چند زمانی از سال 2004 تا 2008 بر اساس مدل های RF (4٪ و 2٪) در ستون های 3-7 همان جدول سال به سال نشان داده شده است. با مقایسه نتایج برای سال 2004 (ستونهای 2 و 3)، مدلهای RF نرخ فرسایش خاک کمتر از حد انتظار (واقعی) تولید میکنند (88.2 و 95.1 در مقابل 116.3 تن در هکتار در سال). به طور مشابه، نرخ فرسایش خاک در سالهای بعدی از 2005 تا 2008 کمتر است. با استفاده از مدل RF 2 درصد، نقشههای فرسایش خاک پیشبینیشده را در شکل 6 b–f برای سالهای 2004 تا 2008 تهیه کردیم، در حالی که نقشه فرسایش خاک بر اساس نقشه رسمی LULC 2004 در شکل 6 الف نشان داده شده است. به این ترتیب، شباهت زیادی بین پیش بینی ها ( شکل 6 b-f) و مقدار مرجع ( شکل 6) وجود دارد.الف) مشهود است. پیکسلهای قرمز (نرخ فرسایش خاک بالا) همه نقشهها در نزدیکی مرکز و بخشهای پایینتر حوضه جمع میشوند که نشاندهنده نتایج مدلسازی خوب است. نتایج مدل RF 4% مشابه است، اما برای جلوگیری از افزونگی آنها را در اینجا لحاظ نکردیم.
چن و همکاران [ 14 ] جدولی از مقادیر محاسبه شده فرسایش خاک حوضه آبخیز مخزن شیمن را از مطالعات قبلی تهیه کرد. جدول نشان می دهد که فرسایش خاک از 1 تا 3310 تن در هکتار در سال متغیر است. نتایج ما نزدیک به انتهای پایین محدوده فرسایش خاک است. در مقابل، تنها مطالعه ای که از روشی مشابه با این مطالعه استفاده می کند [ 30 ]، که نه عامل تصمیم گیری، از جمله ماتریس هم رخداد سطح خاکستری (GLCM) را به عامل C مرتبط می کند، تنها از هر C- حداکثر 100 نقطه استفاده می کند. کلاس عامل این مطالعه به ضریب کاپا 0.758 دست یافت، اما فرسایش خاک را 359.4-629.9 تن در هکتار در سال برآورد کرد.
بر اساس پین های فرسایش نصب شده در حوضه آبخیز مخزن شیمن [ 44 ] و اندازه گیری های جمع آوری شده از 8 سپتامبر 2008 تا 10 اکتبر 2011، عمق فرسایش خاک از 2.17 تا 13.03 میلی متر در سال متغیر بود [ 37 ]. متوسط عمق فرسایش 6.5 میلی متر در سال است که اگر وزن واحد خاک 1.4 تن در متر مکعب فرض شود، معادل 90.6 تن در هکتار است [ 42 ]. بنابراین، نتایج ما با اندازهگیریهای پین فرسایش قابل مقایسهتر است. به طور خاص، نشان می دهد که نرخ نمونه برداری 4 درصد فرسایش خاک را دست کم می گیرد، در حالی که نرخ نمونه برداری 2 درصد فرسایش خاک را بیش از حد برآورد می کند.
شایان ذکر است که پروژه بلندمدت پایش پوشش زمین و زمین لغزش [ 25] از سال 2004 تا 2009 نشان داد که تنها طوفان Aere در سال 2004 باعث تخریب قابل توجه زمین و حرکت توده ای در این دوره شد. مقدار زیادی زباله و چوب رانده شده به مخزن شیمن سرازیر شد. کدورت زیاد آب باعث شد تا سیستم توزیع آب به مدت 18 روز بی سابقه خاموش شود. از آن زمان وضعیت مشابهی رخ نداده است. حذف پوشش اراضی در حوزه آبخیز دلیلی است که فرسایش خاک محاسبه شده بر اساس نقشه رسمی LULC 2004 به 116.3 تن در هکتار در سال می رسد. پس از طوفان Aere، با تثبیت زمین و رشد مجدد پوشش گیاهی برای ایجاد پوشش جدید زمین، فرسایش خاک به میزان قابل توجهی کاهش یافت. این توضیح می دهد که چرا فرسایش خاک اندازه گیری شده بین سال های 2008 و 2011 تنها 90.6 تن در هکتار است ( جدول 10 ).
طبق جدول 10 ، هر دو مدل فاکتور C 4% و 2% اوج فرسایش خاک را در سال 2004 پیشبینی میکنند و به دنبال آن کاهش تدریجی تا یک بازگشت کوچک در سال 2008 وجود دارد. این با بازیابی پوشش گیاهی در منطقه مورد مطالعه مطابقت دارد. 2005 تا 2007 و افزایش بارندگی توسط طوفان های Kalmaegi، Sinlaku و Jangmi در سال 2008 [ 45 ]. با این حال، تفاوت در نرخ فرسایش خاک آن طور که انتظار می رود از سال به سال مشخص نیست. با این وجود، این نتایج تأیید می کند که امکان توسعه یک مدل داده کاوی چند زمانی برای فاکتور C و فرسایش خاک مربوطه وجود دارد.
3.3. بحث
اگرچه نتایج این مطالعه امکان ساخت یک مدل داده کاوی برای عامل C USLE را نشان میدهد، نتایج مدلسازی تحت تأثیر نرخ نمونهگیری اکثریت کلاس (کلاس C = 0.01) قرار گرفت. در ابتدای مطالعه، ما از روش نمونهگیری تصادفی طبقهای (به جای روش نمونهگیری تصادفی ساده) استفاده کردیم تا اطمینان حاصل کنیم که هر کلاس (طبقه) از مجموعه دادههای جامعه (کل نقاط داده) نشان داده شده است. این به جلوگیری از تحلیل نادرست کمک کرد، اما مشکل عدم تعادل طبقاتی را به طور کامل حل نکرد. بنابراین، ما نمونه برداری پایین از طبقه اکثریت (کلاس C = 0.01) را به 2٪ آزمایش کردیم و سایر طبقات اقلیت را با نرخ نمونه 4٪ نگه داشتیم. نتیجه بهتر همانطور که با ضریب کاپا بالاتر نشان داده شد (اما به قیمت OA کمتر) به دست آمد. برای بررسی اینکه آیا میتوان عملکرد طبقهبندی را بیشتر بهبود بخشید، ما یک نمونهگیری موقتی پایین از تکنیک طبقه اکثریت (شبیه به نمونهگیری زیر نمونه تصادفی) برای مجموعه داده جمعیت با نرخهای نمونهگیری 1% و 0.5% اعمال کردیم. ترکیب درصد حاصل از هر یک از 12 کلاس عامل C در مجموعه داده ورودی قبلاً درجدول 5 . پس از ساخت مدلهای RF مربوطه، نتایج کلی در جدول 11 خلاصه شده است که OA، ضریب کاپا، AUC، نرخ مثبت واقعی همه کلاسهای اقلیت ترکیبی، نرخ مثبت واقعی کلاس اکثریت، میانگین C- را نشان میدهد. فاکتور نقشه LULC، میانگین ضریب C پیش بینی شده در سال 2004، نرخ فرسایش خاک پیش بینی شده در سال 2004، نرخ فرسایش خاک پیش بینی شده در سال 2008، و نرخ فرسایش خاک اندازه گیری شده توسط پین های فرسایش.
مشخص شد که استراتژی نمونه گیری پایین به خوبی کار می کند. با کاهش نرخ نمونه گیری کلاس اکثریت، ضریب کاپا از 0.574 به 0.732 و AUC از 0.780 به 0.891 افزایش می یابد. علاوه بر این، نرخ مثبت واقعی تمام طبقات اقلیت با هم از 0.43 به 0.70 افزایش می یابد. با این حال، دقت کلی با کاهش نمونه از 0.952 به 0.846 کاهش می یابد، و نرخ مثبت واقعی طبقه اکثریت از 0.99 به 0.94 کاهش می یابد.
در ابتدا به نظر می رسد که 0.5% بهترین نرخ نمونه گیری در این مطالعه است، اما میانگین ضریب C چیز دیگری را نشان می دهد. مقدار ضریب C از 0.0115 در 4٪ شروع می شود و سپس به 0.0130 در 2٪ و 0.0156 در 1٪ تبدیل می شود و به تدریج به مقدار مرجع 0.0164 نزدیک می شود. با این حال، میانگین ضریب C به طور ناگهانی به 0.0115 در 0.5٪ کاهش می یابد و دوباره از مقدار مرجع منحرف می شود. بنابراین، با قضاوت از میانگین ضریب C، 1٪ بهترین نرخ نمونه گیری در طبقه اکثریت است.
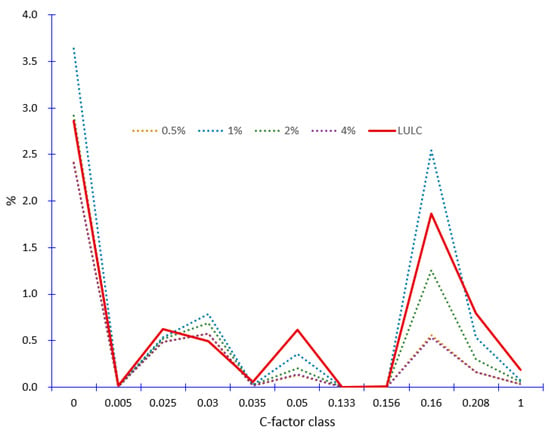
نتیجه غیرمنتظره میانگین ضریب C در شکل 7 بیشتر بررسی شده استکه در آن ترکیب درصدی پیشبینیشده از چهار نرخ نمونهگیری مختلف برای همه طبقات اقلیت ترسیم شد. خط قرمز ترکیب درصد “واقعی” را از نقشه رسمی LULC در سال 2004 نشان می دهد. همانطور که در شکل نشان داده شده است، تفاوت در کلاس C = 0.16 بین نقشه LULC و نرخ های مختلف نمونه گیری تعیین می کند که میانگین نهایی C-factor چقدر دقیق است. همانطور که نرخ نمونه برداری از 4% به 2% و 1% کاهش می یابد، درصد مربوط به کلاس C = 0.16 نزدیک می شود و سپس از نقشه LULC پیشی می گیرد. هنگامی که نرخ نمونهگیری بیشتر به 0.5٪ کاهش مییابد، درصد کلاس C = 0.16 مسیر را معکوس میکند و به همان سطح نرخ نمونهگیری 4٪ کاهش مییابد. این توضیح میدهد که چرا نرخ نمونهگیری 0.5 درصد میانگین فاکتور C بهتری را به همراه نداشت، حتی اگر معیارهای دیگر آن (مانند OA، Kappa، و AUC) برتر بودند.
در نهایت، اگر نرخ های پیش بینی شده فرسایش خاک را با نرخ اندازه گیری شده توسط پین های فرسایش مقایسه کنیم، به نتیجه متفاوت دیگری می رسیم. نرخ نمونه برداری 2 درصد نرخ فرسایش خاک 93.2 تن در هکتار را پیش بینی می کند که نزدیک ترین نرخ اندازه گیری شده 90.6 تن در هکتار در سال است. در این سناریو 2% بهترین نرخ نمونه گیری است. بهترین نرخ های نمونه گیری تحت معیارهای مختلف برای مقایسه آسان در جدول 11 نشان داده شده است.
نتایج ارائه شده در بالا نشان می دهد که به غیر از مشکل عدم تعادل طبقاتی، عوامل دیگری مسئول عملکرد مدل سازی این مطالعه هستند. استفاده از معیارهای ارزیابی کلی (مانند OA، Kappa و AUC) در این مطالعه کاملاً مناسب نیست و میتواند گمراهکننده باشد. از آنجایی که هدف ما یک رویکرد دو مرحلهای برای مدلسازی فاکتور C و در نهایت فرسایش خاک بود، نرخ فرسایش خاک پیشبینیشده مهمترین شاخص است. یک مجموعه داده متعادلتر همیشه نتیجه مدلسازی بهتری را از نظر از دست دادن خاک به همراه نمیآورد و ما 2 درصد را بهترین نرخ نمونهگیری در این مطالعه در نظر میگیریم.
4. نتیجه گیری
برخلاف مطالعات قبلی، این تحقیق مدلهای فاکتور C را بر اساس تکنیکهای داده کاوی برای بهبود ارزیابی فرسایش خاک در حوزه آبخیز مخزن شیمن در شمال تایوان توسعه داد. هشت داده جغرافیایی انتخاب و در مدلسازی مورد استفاده قرار گرفت. شاخصهای رویشی چند زمانی (NDVI و SAVI) که از تصاویر ماهوارهای چندطیفی به دست میآیند، با اصلاح توپوگرافی تصحیح شدند تا تغییرات در طول زمان کاهش یابد و تشعشعات سطحی اهداف مشابه بهتر مشخص شود. مدلهای فاکتور C که با استفاده از الگوریتم دادهکاوی مبتنی بر RF ساخته شدهاند، با USLE برای تخمین تلفات فضایی و زمانی خاک از سال 2004 تا 2008 استفاده شدند. نتایج با مطالعات گذشته و اندازهگیری پینهای فرسایش مقایسه شد. آنها عملکرد طبقه بندی امیدوارکننده ای را نشان دادند.
مشخص شد که نرخ فرسایش خاک در سال 2004 به دلیل تخریب بیسابقه طوفان Aere در سال 2004، بالاترین میزان بود. از آنجایی که پوشش گیاهی حوضه آبخیز پس از طوفان برای ایجاد پوشش جدید زمینی دوباره رشد کرد، نرخ فرسایش خاک تا سال 2008 به طور پیوسته کاهش یافت. ، هنگامی که موجی از بارندگی به دلیل طوفان های Kalmaegi، Sinlaku و Jangmi رخ داد. این روند با موفقیت توسط مدلهای RF ثبت شد، که امکانسنجی تحلیل چند زمانی را نشان میدهد. علاوه بر این، با استفاده از یک نمونه برداری موقتی پایین از تکنیک طبقه اکثریت (با نرخ نمونه برداری 2٪)، نرخ فرسایش خاک 93.2 تن در هکتار پیش بینی شد، بسیار نزدیک به 90.6 تن در هکتار اندازه گیری شده توسط پین های فرسایشی نصب شده در حوضه
علاوه بر این، این مطالعه موردی از مشکل داده های نامتعادل را ارائه می دهد که با سایر مشکلات داده های نامتعادل متفاوت است زیرا مجموعه داده های متعادل تر همیشه نتیجه مدل سازی بهتری را به همراه ندارد. بهترین نرخ نمونه گیری از طبقه اکثریت بر اساس معیارهای مختلف به شرح زیر خلاصه می شود:
به طور خلاصه، نتایج نشان میدهد که چارچوب جدید پیشنهادی برای ارزیابی و پیشبینی فاکتورهای C و فرسایش خاک بر اساس عوامل مکانی هم قابل اجرا و هم کاربردی است. این روش همچنین عملکرد طبقه بندی امیدوارکننده ای دارد حتی زمانی که با مشکل داده های نامتعادل مواجه می شود. مشکل داده های نامتعادل را نمی توان به راحتی با حذف رکوردها از کلاس اکثریت از بین برد. بنابراین، تحقیقات آینده برای بهبود عملکرد مدل و برآورد فرسایش خاک ضروری است.






بدون دیدگاه