

اندازه، حجم، تنوع و سرعت داده های مکانی جمع آوری شده توسط ژئوسنسورها، افراد و سازمان ها به سرعت در حال افزایش است. زیرساختهای دادههای مکانی (SDI) برای تسهیل اشتراکگذاری دادههای ذخیرهشده در یک محیط توزیعشده و همگن ادامه دارند. استخراج اطلاعات و دانش سطح بالا از این مجموعه داده ها برای حمایت از تصمیم گیری بدون شک نیازمند یک روش نسبتاً پیچیده برای دستیابی به نتایج مطلوب است. انواع تکنیک های داده کاوی فضایی برای استخراج دانش از داده های مکانی توسعه یافته اند که روی سیستم های متمرکز به خوبی کار می کنند. با این حال، استفاده از آنها برای داده های توزیع شده در SDI برای استخراج دانش همچنان یک چالش باقی مانده است. این مقاله یک راه حل خلاقانه را پیشنهاد می کند، بر اساس محاسبات توزیع شده و فناوری های وب سرویس جغرافیایی برای استخراج دانش در یک محیط SDI. رویکرد پیشنهادی، سرویس وب کشف دانش (KDWS) نامیده میشود، که میتواند به عنوان یک لایه در بالای SDIها برای ارائه به کاربران دادههای مکانی و تصمیمگیرندگان امکان استخراج دانش از دادههای فضایی ناهمگن عظیم در SDIs استفاده شود. با پیشنهاد و آزمایش یک معماری سیستم برای KDWS، این مطالعه به انجام تکنیکهای داده کاوی مکانی به عنوان یک چارچوب سرویسگرا در بالای SDIها برای کشف دانش کمک میکند. ما خوشهبندی فضایی، طبقهبندی و استخراج قوانین انجمن را در یک محیط کارآمد پیادهسازی و آزمایش کردیم. علاوه بر پیاده سازی رابط، یک نمونه اولیه سیستم مبتنی بر وب برای استخراج دانش از داده های واقعی ژئودموگرافیک در شهر تهران طراحی شد.
کلید واژه ها:
داده کاوی مکانی ; وب سرویس کشف دانش ; هادوپ ; زیرساخت های داده های مکانی
1. مقدمه
در دسترس بودن زیرساختهای دادههای مکانی (SDI) و خدمات متقابل فرصتی را برای ایجاد جامعهای فراهم میکند که با نوآوری مبتنی بر دادهها توانمند میشود. در حال حاضر، بیش از 150 هزار مجموعه داده فقط در زیرساخت INSPIRE در دسترس هستند [ 1 ]. پیشرفتهای اخیر در فناوریهایی مانند تلفنهای هوشمند و سنسورهای جغرافیایی، علاوه بر پارادایمهایی مانند اطلاعات جغرافیایی داوطلبانه (VGI)، دادههای شهروند محور، اطلاعات جمعسپاری جغرافیایی، و جوامع منبع باز، دسترسی به دادهها را در جامعه ما افزایش میدهد [ 2 ]. ، 3 ، 4]. در این زمینه، اتحادیه اروپا (EU) مردم، کسبوکارها و سازمانها را تشویق میکند تا برای تصمیمگیری بهتر در حوزههای مختلف، دادههای خود را آزادانه و آزادانه نگهداری و منتشر کنند. با توجه به مزایا، نیاز فوری به پرداختن به مشکل استخراج دانش از این داده های حجیم وجود دارد [ 5 ، 6 ، 7 ]. در این وضعیت ایدهآل، دادههای مکانی برای بسیاری از کسبوکارها و برنامهها بسیار مهم باقی میمانند [ 8 ].
علاقه فزاینده ای به روش های داده کاوی فضایی (SDM) وجود دارد [ 9 ، 10 ]. SDM فرآیند کشف بینش جالب و ناشناخته قبلی اما بالقوه مفید از داده های بزرگ مکانی است. اخیراً، ادبیات قابل توجهی بر روشها، الگوریتمها، ابزارها و چارچوبهای مرتبط با SDM متمرکز شده است. الگوهای استخراج [ 11 ، 12 ]، طبقهبندی [ 13 ]، تشخیص پرت [ 14 ]، خوشهبندی [ 15 ]، رگرسیون [ 16 ]، ارتباط و پیشبینی [ 17 ، 18 ]] پرکاربردترین تکنیک هایی هستند که برای استخراج دانش از داده های مکانی به کار گرفته شده اند.
علیرغم تلاشهای قابل توجه در تکنیکهای SDM و الگوریتمهای کارآمد، چالش حیاتی ماهیت توزیعشده دادههای مکانی است. در یک محیط توزیع شده، داده های مرتبط اغلب در ماشین های فیزیکی جداگانه قرار می گیرند. این بدان معنی است که برای انجام روش های SDM، معمولاً تمام داده های مورد نیاز باید به طور سنتی در یک مخزن داده جمع آوری شوند [ 6 ]. با این حال، این یک فرآیند زمانبر است که به چارچوبهای پردازش کلان داده قابل اعتماد، مقیاسپذیر، قابل تعامل و توزیع شده نیاز دارد.
اگرچه تعداد زیادی خدمات وب فضایی (SWS) برای جمعآوری، ذخیرهسازی، بهروزرسانی، نقشهبرداری و پردازش دادههای مکانی توسعه یافتهاند، اما توجه بسیار کمی به روشهای SDM با استفاده از معماری سرویسگرا استاندارد (SOA) شده است. استخراج دانش از داده های مکانی توزیع شده بر اساس SWS ها، پایه ای برای SDM توزیع شده در یک محیط SDI فراهم می کند. SWS مجموعهای از اجزای نرمافزاری است که بر اساس SOA برای پشتیبانی از تعامل ماشین به ماشین برای مدیریت دادههای مکانی روی یک شبکه طراحی شدهاند. ایده کلی برای استخراج دانش فضایی، استفاده از SWS قابل همکاری در بالای یک پلت فرم بزرگ داده مکانی است. خوشبختانه، با ظهور چارچوب های مدرن کلان داده، محدودیت های عملکرد سیستم های پردازش سنتی بهبود یافته است.19 ].
برای استخراج دانش از داده های فضایی توزیع شده در SDIs، در این مقاله، راه حلی مبتنی بر SWS پیشنهاد شده است. ما راه حل خود را سرویس وب کشف دانش (KDWS) می نامیم، که می تواند به عنوان یک لایه در بالای SDI ها استفاده شود تا به کاربران داده های مکانی و تصمیم گیرندگان امکان استخراج دانش از داده های فضایی ناهمگن عظیم در SDI ها را ارائه دهد. این مطالعه با پیشنهاد و استفاده از یک معماری سیستم برای KDWS، به اجرای تکنیکهای دادهکاوی مکانی به عنوان یک چارچوب سرویسگرا در بالای SDI کمک میکند. این فرصت را فراهم می کند تا به جای تمرکز بر نحوه اجرای الگوریتم های SDM، روی آنچه معمولاً از داده ها می خواهیم تمرکز کنیم.
بقیه مطالعه به شرح زیر سازماندهی شده است: ابتدا، ابعاد پس زمینه تحقیق شامل چارچوب های پردازش داده های بزرگ، SDM و SWS مورد بررسی قرار می گیرد (به بخش 2 مراجعه کنید ). در بخش 3 ، اجزای مورد استفاده برای راه حل پیشنهادی توضیح داده شده است. در بخش 4 ، مراحل اجرای چارچوب پیشنهادی مشخص شده است. در نهایت، در بخش 5 ، ویژگی های چارچوب توسعه یافته مورد بحث قرار می گیرد و نتیجه گیری ارائه می شود.
2. پس زمینه
در دسترس بودن رو به رشد داده های مکانی از منابع مختلف، امکانات زیادی را برای کشف دانش ارزشمند ارائه می دهد. اگرچه SDI برای فرآیندهای مبتنی بر داده های توزیع شده و به اشتراک گذاری داده های فضایی مناسب است، اما هنوز برای استخراج دانش در یک محیط متقابل سازگار نشده است [ 20 ]. تأیید شده است که بازیابی دانش از دادههای فضایی عظیم، ناهمگن و توزیعشده به یک پایه نرمافزاری منحصربهفرد و اکوسیستم معماری نیاز دارد [ 19 ]]. با این حال، برخی محدودیتها و مشکلات مانند ذخیرهسازی دادههای مرسوم، فناوریهای محاسباتی، ناهمگونی و نگرانیهای قابلیت همکاری دادههای مکانی منجر به تاخیر در توسعه چنین اکوسیستم معماری شد. توصیف جامع تری از این چالش ها را می توان در مطالعه انجام شده توسط [ 21 ] یافت.
مطالعات اخیر (نگاه کنید به [ 19 ، 22 ، 23 ]) نشان دادهاند که چارچوبهای پردازش موازی و توزیعشده، برآوردن الزامات عملکرد برای مدیریت دادههای فضایی بزرگ در مقیاس بزرگ را ممکن میسازد. در این زمینه، Apache Hadoop، یک چارچوب منبع باز برای محاسبات قابل اعتماد، مقیاس پذیر و توزیع شده به عنوان پلتفرم های قدرتمندی که برای مقابله با چالش های کلان داده سازگار شده است، پدیدار شده است ( https://hadoop.apache.org/). Hadoop با استفاده از مدلهای برنامهنویسی ساده، قادر است حجم زیادی از دادهها را به طور کارآمد در میان خوشههای کامپیوتری ذخیره و مدیریت کند. این به گونه ای طراحی شده است که از سرورهای منفرد به هزاران دستگاه افزایش یابد که هر کدام محاسبات محلی و ذخیره سازی را ارائه می دهند. مفهوم اصلی چارچوب به دو بخش جدا شده است، سیستم فایل توزیع شده Hadoop (HDFS) برای ذخیره داده ها و مدل برنامه نویسی MapReduce برای فرآیند داده هایی که معمولاً در HDFS ذخیره می شوند [ 24 ]. آپاچی اسپارک، یک محاسبات توزیع شده در حافظه، چارچوب دیگری است که یک انتزاع داده جدید به نام مجموعه داده های توزیع شده انعطاف پذیر (RDD) ارائه می دهد. RDD ها مجموعه ای از اشیاء هستند که در یک خوشه از ماشین ها تقسیم شده اند ( https://spark.apache.org/). تا به امروز، چندین مطالعه بررسی کردهاند که چارچوبهای Hadoop و Spark محاسباتی با کارایی بالا برای بازیابی الگوها و دانش از حجم عظیمی از دادههای مکانی فراهم میکنند. پارک، کو و سونگ (2019) [ 25 ] روشی را برای دریافت داده های فضایی بزرگ با استفاده از یک تکنیک موازی در یک محیط خوشه ای پیشنهاد کردند. اس لی و همکاران (2016) [ 26 ] یک چارچوب مبتنی بر HDFS با پشتیبانی بومی برای انواع داده های مکانی-زمانی و عملیات به نام ST-Hadoop معرفی کرد. Apache Sedona (سابق GeoSpark) یکی دیگر از چارچوب های محاسباتی خوشه ای برای پردازش داده های فضایی در مقیاس بزرگ است ( https://sedona.apache.org/). Sedona Apache Spark و SparkSQL را با مجموعهای از Spatial RDDs و SpatialSQL گسترش میدهد که دادههای فضایی در مقیاس بزرگ را در ماشینها بارگیری، پردازش و تحلیل میکنند [ 27 ]. عملکردهایی از جمله پارتیشن بندی داده های مکانی، نمایه سازی فضایی، و پیوستن فضایی با چندین API را فراهم می کند که به کاربران اجازه می دهد اشیاء فضایی ناهمگن را از فرمت های مختلف داده بخوانند. GeoMesa همچنین یک مجموعه منبع باز مبتنی بر Spark است که پرس و جو و تجزیه و تحلیل مکانی در مقیاس بزرگ را در سیستم های محاسباتی توزیع شده امکان پذیر می کند ( https://www.geomesa.org/). این پایگاه داده NoSQL را برای ذخیره سازی گسترده داده های نقطه، خط و چند ضلعی فراهم می کند. از طریق GeoServer، ادغام با طیف گسترده ای از استانداردهای OGC موجود مانند خدمات نقشه وب (WMS) و سرویس ویژگی وب (WFS) را تسهیل می کند.
پیشرفتها در SOA چشمانداز روشنی را برای مدیریت دادههای فضایی توزیعشده و ناهمگن ارائه کرده است [ 28 ، 29 ، 30 ، 31 ، 32 ]. SOA به عنوان سبک، مفهوم یا پارادایم معماری نرمافزاری تعریف میشود که شامل اصولی مانند اتصال آزاد، قابلیت استفاده مجدد، قابلیت همکاری، مقیاسپذیری، چابکی، انعطافپذیری و مستقل از فناوری با استفاده از مؤلفههای استاندارد و مدولار به نام سرویس است [ 33 ، 34 ].]. به طور کلی، عملکرد و رفتار طراحی سرویس بر اساس مشخصات رابط پیاده سازی می شود. انواع داده ها، عملیات، اتصال پروتکل حمل و نقل و محل سرویس دهی شبکه، مهمترین ویژگی هایی هستند که مشخصات رابط را توصیف می کنند. تا به امروز، برای مدیریت بهتر داده های جغرافیایی بر اساس SOA، مجموعه ای از استانداردها توسط OGC توسعه یافته است. این استانداردها که به عنوان خدمات وب OGC (OWS) شناخته می شوند، می توانند در گروه های مختلفی مانند مدل های داده، رمزگذاری، جستجو، ذخیره سازی، پردازش، نقشه برداری و انتشار داده های مکانی طبقه بندی شوند [ 28 ، 29 ، 32 ].]. علاوه بر این، مجموعه ای از SWS هر ساله توسعه یافته است که توسط گروه های کاری OGC بررسی می شود. میتوان انتظار داشت که در سالهای آینده، SWS جنبههای مختلف مدیریت دادههای مکانی را در نظر بگیرد و پارادایم SOA به طور فزایندهای در علم، سیستمها و جوامع جغرافیایی استفاده شود [ 20 ، 35 ، 36 ]. در بررسی خدمات GIS ترکیبی، چاو (2011) [ 35] تغییر پارادایم GIS “از یک معماری ایزوله به یک چارچوب قابل همکاری، از یک راه حل مستقل به یک رویکرد توزیع شده، از فرمت های داده های اختصاصی فردی تا تبادل مشخصات باز داده ها، از یک پلت فرم دسکتاپ به یک محیط اینترنت” را برجسته کرد. بر اساس مطالعات قبلی و روند اخیر در فناوریها، به نظر میرسد یک تغییر پارادایم از سیستمهای GI به GI-Services رخ خواهد داد. خدمات GI همچنین ممکن است در سالهای اخیر از سیستمهای GI در جوامع دانشگاهی، صنعتی و تجاری مهمتر شود ( شکل 1 ).
کشف دانش فضایی مبتنی بر وب سرویس می تواند برای رسیدگی به مسائل قابلیت همکاری کشف دانش فضایی در یک محیط SDI استفاده شود. تعدادی از مطالعات [ 37 ، 38 ، 39 ، 40 ، 41 ، 42 ] استفاده از SOA را برای داده کاوی، یادگیری ماشینی (ML)، هوش تجاری (BI) و پردازش تحلیلی آنلاین (OLAP) پیشنهاد کرده اند. زوریلا و گارسیا-سایز (2013) [ 42] یک معماری نرم افزاری مبتنی بر SOA را برای استخراج دانش مفید و جدید با استفاده از تکنیک های داده کاوی به منظور به دست آوردن الگوهایی که می توانند در فرآیند تصمیم گیری استفاده شوند، تشریح کرد. معماری در 5 لایه شامل لایه داده، مؤلفه سازمانی، خدمات، فرآیند تجاری و لایه ارائه ارائه شده است. لایه سرویس به عنوان یک وب سرویس ارائه می شود که به راحتی از هر برنامه مشتری قابل دسترسی است. ویژگی اصلی آن این است که مبتنی بر استفاده از الگوهایی است که به سؤالات تعریف شده قبلی پاسخ می دهد. این الگوها وظایف فرآیند کشف دانش در پایگاههای داده (KDD) را جمعآوری میکنند تا روی مجموعه دادهای که توسط کاربر نهایی ارسال میشود، انجام شود. مدودف و همکاران (2017) [ 43] تعدادی از روش های داده کاوی را به عنوان WS پیاده سازی کرد و از آنها در ابزار داده کاوی مبتنی بر وب استفاده کرد. ایده اصلی تحقیق ارائه گردش کار علمی برای استخراج الگوهای مفید از مجموعه داده های بزرگ بر اساس مؤلفه خدمات است. در اینجا، گردش های کاری علمی اجازه می دهد تا مدل مناسبی از فرآیند داده کاوی را که تعدادی از روش های مختلف را پوشش می دهد، بسازید. با استفاده از Apache Hadoop، Kusumakumari، Sherigar، Chandran و Patil (2017) [ 44 ] یک الگوریتم زمان کارآمد برای استخراج مجموعه آیتمهای مکرر در دادههای جریان بلادرنگ پیشنهاد میکنند. آنها مشاهده کردند که Hadoop برای استخراج الگوهای متداول به خوبی کار می کند. آنها به این نتیجه رسیدند که استفاده از روش پیشنهادی مشابه در چارچوب MapReduce به طور قابل توجهی زمان اجرا را کاهش می دهد. امیدی پور و همکاران (2018) [ 20] نشان داد که مجموعه ای از روش های SDM مبتنی بر سرویس وب برای پاسخگویی به الزامات جامعه GIS ضروری است. برای تسهیل روش های SDM توزیع شده، آنها (نگاه کنید به [ 20 ]) یک زیرساخت دانش فضایی عمومی (SKI) پیشنهاد کردند که در آن SWS نقش محوری در مطالعه آنها دارد.
اگرچه تحقیقات گستردهای بر روی یکپارچهسازی تکنیکهای DM بر اساس SOA انجام شده است، توجه بسیار کمی به استفاده از روشهای SDM به عنوان یک رویه WS قابلعملیات داده شده است. در حال حاضر از مطالعات مختلف به خوبی ثابت شده است که در سال های اخیر، پیشرفت قابل توجهی در سیستم های GIS موازی و توزیع شده رخ داده است. سوالی که می توان به آن پرداخت این است که چگونه می توان دانش مفید را از داده های فضایی ناهمگن و توزیع شده با استفاده از خدمات متقابل و استاندارد استخراج کرد. همانطور که [ 21 ] ذکر شد، ناهمگونی نیازمند قابلیت همکاری و استانداردهایی در میان ابزارهای پردازش داده است. بنابراین، یک رویکرد جدید برای کشف دانش فضایی مورد نیاز است که با چالشهای قابلیت همکاری مقابله کند.
3. راه حل پیشنهادی
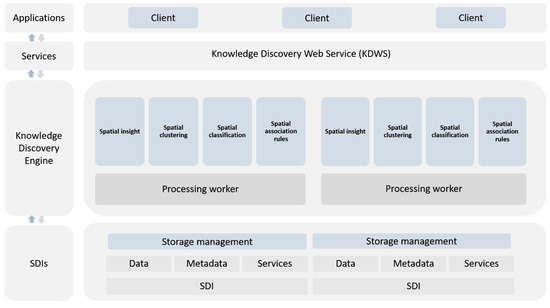
راه حل پیشنهادی قابلیتهای تکنیکهای SOA و SDM را در یک موتور محاسباتی موازی و متقابل ادغام میکند تا فرآیند استخراج دانش از SDI را تسهیل کند. شکل 2معماری کلی راه حل پیشنهادی را ارائه می دهد. این معماری شامل چهار لایه اصلی برای ارائه قابلیت ها و قابلیت های مطلوب است: (1) لایه SDI مسئول یکپارچه سازی داده های توزیع شده و ناهمگن از SDI های مختلف با استفاده از فناوری های مدرن ذخیره سازی کلان داده است. (2) یک لایه موتور کشف دانش از تکنیکهای دادهکاوی فضایی با کارایی بالا در میان خوشههایی از رایانهها به نام کارگران پردازشگر پشتیبانی میکند. (3،4) تعامل یکپارچه و متقابل بین مشتریان و لایه های پایین ارائه شده توسط KDWS. در بخش های بعدی، توضیحات مفصلی از اجزای معماری شرح داده شده است.
3.1. مولفه لایه SDIs
جزء لایه SDIs جزء اصلی برای یکپارچه سازی داده های مکانی است. این مؤلفه اجازه می دهد تا داده ها از SDI های مختلف برای استخراج، تبدیل و بارگذاری (ETL) در یک سیستم ذخیره سازی داده های بزرگ مدرن یکپارچه شوند. به طور خاص، مؤلفه مسئول بارگذاری منابع مختلف داده در یک خوشه HDFS است. HDFS برای پشتیبانی از فایلهای بسیار بزرگ (ترابایت) طراحی شده است، و برای برنامههایی که از معنایی «نوشتن-یک بار-خواندن-خیلی» پیروی میکنند و به «خواندن» نیاز دارند تا در سرعتهای پخش جریانی برآورده شوند، به خوبی مورد رضایت است. این با اهداف داده کاوی در SDI مطابقت دارد. یک خوشه HDFS در درجه اول از یک NameNode تشکیل شده است که ابرداده سیستم فایل را مدیریت می کند و DataNodes که داده های واقعی را ذخیره می کند (معماری اصلی / برده). در داخل، یک فایل به یک یا چند بلوک تقسیم می شود، و این بلوک ها در مجموعه ای از DataNodes ذخیره می شوند. برای ارائه قابلیت اطمینان، هر فایل را به صورت دنباله ای از بلوک ها نگهداری می کند. NameNode و DataNodes دارای وب سرورهای داخلی هستند که نظارت بر وضعیت خوشه را آسان می کند. شرح جامع معماری HDFS را می توان در معماری Hadoop HDFS موجود در وب سایت رسمی یافت.
در راه حل پیشنهادی، فرآیند مذکور توسط یک ابزار مدیریت ذخیره سازی مدیریت می شود. این گستره وسیعی از فرمتهای دادههای مکانی از جمله مبتنی بر XML، مبتنی بر JSON، CSV و سایر فرمتهای برداری سنتی را در یک HDFS ارائه میکند. در حال حاضر، با استفاده از ابزارهای ETL درون حافظه، میتوان حجم بسیار زیادی از دادهها را به طور کارآمد مدیریت کرد. لازم به ذکر است که ETL فضایی مبتنی بر فراداده می تواند برای ادغام منابع داده SDI در HDFS با استفاده از خدمات وب OGC استفاده شود.
3.2. موتور کشف دانش
موتور کشف دانش یک جزء پردازشی هسته ای برای استخراج دانش از یک پلت فرم بزرگ داده مکانی است. برای جلوگیری از تاخیر زمانی کم، لایه از راه حل های محاسباتی موازی یا خوشه ای استفاده می کند. این لایه همچنین به کاربران اجازه می دهد تا اشیاء فضایی ناهمگن را از فرمت های داده های مختلف بخوانند و وظایف پردازش فضایی موازی را اجرا کنند. در این راستا می توان از چارچوب های محاسباتی موازی متن باز مبتکرانه مانند GeoSpark استفاده کرد. اجزای اصلی GeoSpark مجموعهای از RDDهای فضایی (SRDD) را ارائه میکنند که مجموعهای از دادهها فقط خواندنی است که میتواند در زیر مجموعهای از ماشینهای خوشه اسپارک تقسیم شود. در راه حل پیشنهادی، هر پارتیشن به یک پردازشگر اختصاص داده می شود. اگرچه تکنیک های داده کاوی بسیار متنوع هستند، رایج ترین و پرکاربردترین تکنیک ها بر اساس [6 ، 9 ، 10 ] و [ 45 ] در راه حل پیشنهادی پیاده سازی شده اند. تکنیک ها یا الگوریتم های در نظر گرفته شده در موتور کشف دانش در بخش های زیر توضیح داده شده است. علاوه بر روشهای کلی دادهکاوی، تلاشهایی برای پیادهسازی روشهای دادهکاوی صریح فضایی صورت گرفته است.
3.2.1. خوشه بندی فضایی
الگوریتمهای خوشهبندی فضایی از جمله پرکاربردترین گروههای روشهای SDM هستند. ایده اصلی خوشهبندی فضایی این است که اشیاء مکانی را در دستههای K خلاصه کنیم به طوری که شباهت درون خوشهای و بین خوشهای به ترتیب به حداکثر و حداقل برسد [ 14 ، 46 ، 47 ]. چندین الگوریتم پارتیشن بندی، سلسله مراتبی و خوشه بندی مبتنی بر چگالی توسط مؤلفه موتور کشف دانش پشتیبانی می شوند ( جدول 1 را ببینید ). از آنجایی که این الگوریتمها فقط با شباهت ویژگیها سروکار دارند، روش خوشهبندی صریح فضایی توسط [ 46] اجرا شده است. با استفاده از این روش می توان علاوه بر گروه بندی اشیاء جغرافیایی، نقاط گرم و سرد و همچنین نقاط پرت فضایی را شناسایی کرد.
3.2.2. طبقه بندی فضایی
طبقه بندی فضایی یک روش داده کاوی است که برای یافتن مدلی استفاده می شود که یک برچسب کلاس را برای اشیاء جغرافیایی بر اساس روابط مکانی توصیف و اختصاص می دهد [ 54 ، 55 ]. بسته به هدف، زمینه و در دسترس بودن داده ها، این فرآیند می تواند با استفاده از الگوریتم های نظارت شده یا بدون نظارت [ 56 ] انجام شود. طبقه بندی نظارت شده در دو مرحله، یادگیری و آزمایش انجام می شود [ 57 ، 58]. در مرحله اول، بخش هایی از مجموعه داده به عنوان مجموعه داده های آموزشی انتخاب می شوند و سپس از الگوریتم های مختلف برای ساخت یک طبقه بندی کننده استفاده می شود. در مرحله تست، طبقهبندی کننده برای پیشبینی برچسبهای کلاس و آزمایش مدل استفاده میشود. یک قانون مشتق شده از مجموعه ای از داده های آموزشی را می توان با استفاده از دو معیار ارزیابی کرد: پوشش و دقت. اگرچه در اکثر الگوریتم ها، روابط فضایی در نظر گرفته نمی شود، برخی از محققین نیز الگوریتم هایی را برای در نظر گرفتن روابط فضایی پیشنهاد کرده اند [ 54 ، 55 ]. الگوریتم های طبقه بندی توسط مؤلفه موتور کشف دانش ارائه شده در جدول 2 پشتیبانی می شوند .
3.2.3. معادن قانون انجمن فضایی
استخراج قوانین تداعی فضایی یکی از جالبترین روشهای مورد استفاده در SDM است [ 9 ، 18 ، 26 ]. این تکنیک نوعی فرآیند کاوی است که برای کشف روابط مفید، تداعی ها یا الگوهایی که به صراحت در پایگاه داده های فضایی ذخیره نمی شوند، استفاده می شود. یک قانون تداعی فضایی را می توان به صورت X→Y تعریف کرد که در آن نمایش X و Y مجموعه محمول را نشان می دهد [ 17 ، 18]. دو مرحله اصلی برای یافتن قوانین مفید وجود دارد. ابتدا، تمام ترکیبات اشیاء جغرافیایی که با حداقل فرکانس مشخص رخ می دهند باید پیدا شوند. سپس بر اساس مجموعه اقلام مکرر شناخته شده، قوانین ارزیابی می شوند. Apriori پرکاربردترین الگوریتم قانون کاوی انجمن برای یافتن مجموعه آیتم های مکرر است. از آنجایی که تعداد قوانین شناسایی احتمالی معمولاً خیلی زیاد است، یک مقدار آستانه توسط کاربر برای تعیین اهمیت قوانین تداعی فضایی شناسایی شده (قوانین قوی) داده می شود. سه روش متداول برای ارزیابی اهمیت قوانین شناسایی شده وجود دارد: حمایت، اعتماد، و بالا بردن [ 9 ، 17 ].
3.3. لایه خدمات
برای ایجاد یک تعامل یکپارچه و متقابل بین کاربران نهایی و مؤلفه موتور استخراج دانش، یک وب سرویس به نام KDWS توسعه داده شد. از نقطه نظر عملیاتی، یک مشتری یک سری پارامترها را به درخواست خود واگذار می کند و یک وظیفه SDM را به موتور استخراج دانش اختصاص می دهد. سپس موتور استخراج دانش، دانش فضایی استخراج شده را بر اساس پارامترهای دریافت شده توسط کاربر به کاربر ارائه می کند. در این زمینه، دانش فضایی به خروجی متقابل تکنیک های SDM ارائه شده توسط KDWS اشاره دارد.
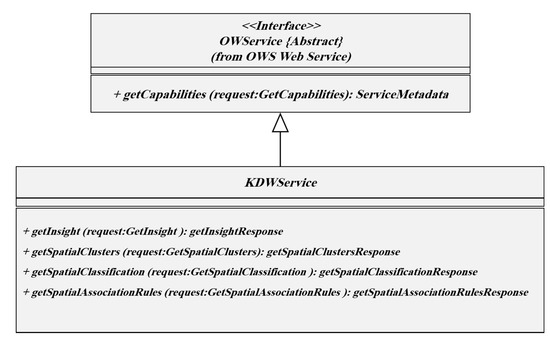
مهمترین مفاهیم مورد استفاده در KDWS عبارتند از سرویس، رابط و عملیات. سرویس مجموعه ای از رابط های ارائه شده توسط یک موجودیت است. سرویس های مختلف عملکردهای متفاوتی دارند که مستقل و قابل تفکیک هستند. به عنوان مثال، خدمات مختلف مانند بازیابی، نقشه برداری و پردازش به عنوان خدمات جداگانه در نظر گرفته می شوند. برای اجرای یک فرآیند (در اینجا استخراج دانش از داده های مکانی)، روش ارجاع درخواست ها به یک شی (در اینجا به معنی سرور) توسط یک رابط مشخص می شود. در ساده ترین حالت، رابط KDWS نام عملیات، لیست پارامترها و مقادیر مجاز برای استخراج دانش از پایگاه داده را توصیف می کند. در ارتباط با KDWS، عملیات مختلفی انتظار می رود که توسط رابط سرویس تعریف می شوند. رابط سرویس KDWS نشان داده شده درشکل 3 بر اساس زبان مدلسازی یکپارچه (UML) است.
نمودار کلاس نشان می دهد که KDWS عملیات GetCapabilities را از رابط OWS به ارث می برد و سه عملیات به نام های GetInsight، GetSpatialClusters، GetSpatialClassification و GetSpatialAssociationRules را اضافه می کند. لازم به ذکر است که استانداردهای OGC/ISO مربوط به نماد UML برای تعریف مشخصات رابط KDWS استفاده شده است. با توجه به تنوع گسترده تکنیک های SDM، ایجاد یک طرحواره واحد که بتواند ساختارها و پارامترهای مختلف را به عنوان یک رابط ارائه دهد، بسیار دشوار است، اگر نگوییم غیرممکن است. بنابراین، هر الگوریتم داده کاوی به عنوان یک رابط جداگانه تعریف می شود. اگرچه عملیات سرویس پیشنهادی با سایر سرویسهای OGC، مانند سرویس پردازش وب (WPS)، سرویس پوشش وب (WCS) و WFS متفاوت است، شباهتهای زیادی با رابطهای مشترک وجود دارد. از این رو،60 ]. عملیات درخواست در KDWS بر اساس استاندارد OGC 05-008 پیاده سازی شده است. بنابراین، درخواست می تواند بر اساس HTTP GET، کدگذاری KVP یا بر اساس HTTP POST انجام شود. در سرویس، با توجه به پارامترهای مشخص شده توسط کاربر، خروجی قابل تعامل و استاندارد ارائه می شود.
برای استخراج دانش از دادههای مکانی، عملیاتهای مختلف در KDWS پشتیبانی میشوند که در بخشهای زیر توضیح داده شده است.
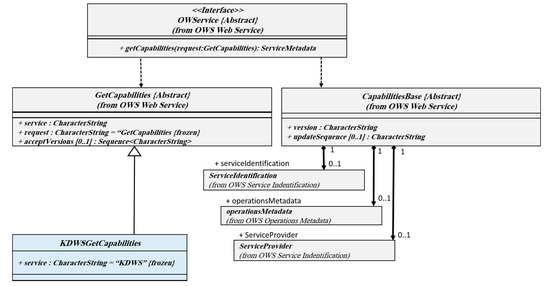
3.3.1. عملیات GetCapabilities
به منظور درک نحوه استفاده از KDWS، یک سری اطلاعات فراداده در قالب یک قالب قابل همکاری (به عنوان مثال، سند XML) مورد نیاز است. این سند نه تنها شامل درخواستهای معتبر KDWS است، بلکه به ارائهدهندگان خدمات و سایر مؤلفههای سرویس، مانند توضیحات عملیات، الگوریتمهای SDM پشتیبانیشده، پارامترها، سطوح دسترسی، اطلاعات سرصفحه و مجموعه دادههای موجود نیز اشاره دارد. در حالی که یک وب سرور درخواستی از مشتری دریافت می کند، این اطلاعات فراداده در قالبی قابل همکاری برای مشتری ارسال می شود. شکل 4 نمودار کلاس UML GetCapabilities را نشان می دهد.
همانطور که در رابط بالا نشان داده شده است، علاوه بر به ارث بردن کلاس های مبتنی بر OGC، فراداده KDWS کلاس های جدیدی را برای توصیف و ارائه ابرداده های مربوط به عملیات GetCapabilities اضافه کرده است.
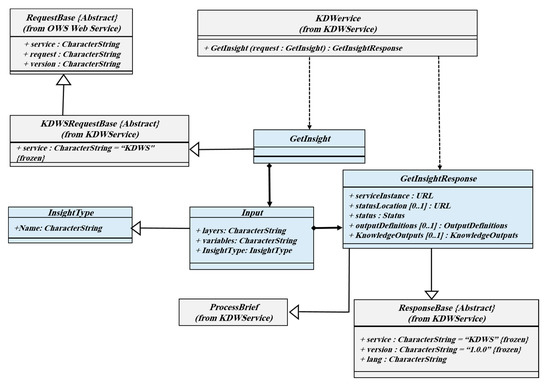
3.3.2. عملیات GetInsight
عملیات GetInsight یک نمای کلی از داده های جغرافیایی ارائه می دهد. در اینجا، بینش می تواند خلاصه، توزیع و رابطه بین متغیرها باشد. به طور کلی، مشتری می خواهد خلاصه ای از داده های جغرافیایی در قالب های مختلف مانند تصویر، JSON و XML داشته باشد. کمیتکنندههایی مانند میانگین، میانه و همچنین معیارهای تغییرپذیری مهمترین معیارهایی هستند که در عملیات مورد تأکید قرار میگیرند. توزیع داده و ارتباط بین متغیرها نیز در عملیات GetInsight مورد انتظار است. خلاصه سازی، روابط و توزیع مهم ترین انواع بینش هستند که در عملیات GetInsight پیاده سازی شده اند. شکل 5 نمودار کلاس عملیات GetInsight را نشان می دهد.
3.3.3. عملیات GetSpatialClusters
در GetSpatialClusters، مشتری الگوریتم، مجموعه داده، متغیرهای مرتبط و قالب پاسخ را انتخاب می کند. در درخواست GetSpatialClusters، خروجی الگوریتم به صورت پیش فرض با فرمت JSON ارائه می شود، بنابراین می توان از آن مجددا استفاده کرد و به اشتراک گذاشت. دریافت خروجی به صورت XML یا GML امکان پذیر است. نمودار کلاس عملیات GetSpatialClusters در شکل 6 نشان داده شده است .
3.3.4. عملیات GetSpatialClassification
پیادهسازی الگوریتمهای طبقهبندی فضایی در قالب خدمات وب پیچیدهتر از سایر الگوریتمهای SDM است. دلیل آن را باید در مراحل جداگانه آموزش و تست پایه ریزی کرد. برای رسیدگی به این پیچیدگی در رابط سرویس KDWS، می توان بخشی از مجموعه داده را برای آزمایش و یادگیری مدل در نظر گرفت. به عنوان مثال، 20 درصد از مجموعه داده را می توان به صورت تصادفی به عنوان داده های آزمایشی در نظر گرفت و پس از اجرای الگوریتم، مدل را محاسبه کرد. تعداد پارامترهای اجباری و اختیاری بسته به الگوریتم مورد استفاده متفاوت است. الگوریتم های بدون نظارت در عملیات GetSpatialClassification نیز پشتیبانی می شوند. نمودار کلاس عملیات GetSpatialClassification در شکل 7 نشان داده شده است .
3.3.5. عملیات GetSpatialAssociationRules
یکی از جالب ترین عملیات های پشتیبانی شده در KDWS GetSpatialAssociationRules است. قوانین پنهان را در مجموعه ای از مجموعه داده های فضایی شناسایی می کند. معمولاً بسیاری از قوانین شناسایی شده ممکن است چندان مهم نباشند، بنابراین سرویس پیشنهادی قوانین استخراج شده را با دو معیار ارزیابی مهم ارائه می دهد: پشتیبانی و اطمینان. لذا در تمامی قواعد استخراج شده ارزش و ملاک پذیرش قواعد انجمن مشخص خواهد شد. مانند عملیات ذکر شده، خروجی دانش استخراج شده در درخواست فوق را می توان در قالب قابل همکاری متفاوت دریافت کرد، بنابراین می توان از آن استفاده مجدد و به اشتراک گذاشت. شکل 8 یک نمودار کلاسی از عملیات GetSpatialAssociationRules را نشان می دهد.
3.4. لایه برنامه های کاربردی
این بالاترین لایه معماری پیشنهادی است. استفاده از KDWS دانش قابل استفاده و قابل همکاری را فراهم می کند که می تواند در برنامه های مختلف مورد استفاده قرار گیرد. به طور کلی، بسیاری از سازمانها، بازارها و تصمیمات صنعتی نیازمند دانش فضایی هستند. بنابراین، راه حل پیشنهادی می تواند زیرساخت دانش فضایی نرم را در یک محیط تعاملی و مشارکتی فراهم کند. برای مثال، برخی از سازمانها میتوانند برای به اشتراک گذاشتن دانش استخراجشده توسط سرویسهای KDWS خود با هم مشارکت کنند و در طی فرآیندهای تصمیمگیری فضایی، یک محیط مشارکتی ایجاد کنند. علاوه بر خروجی های سرویس مبادله، برخی از سازمان ها ممکن است خدمات خود را با دیگران به اشتراک بگذارند. در این شرایط سازمان های مربوطه می توانند با توجه به نیاز خود از قابلیت های خدماتی استفاده کنند. در اینگونه موارد، یک رجیستری خدمات می تواند توصیفی از KDWS و داده های مکانی و الگوریتم های موجود ارائه دهد. سپس، الگوریتم های کشف دانش فضایی به عنوان یک گردش کار اجرایی مورد استفاده قرار می گیرند. در نهایت، یک زنجیره خدمات KDWS می تواند ایجاد شود تا دانش فضایی استخراج شده را برای تولید دانش سطح بالا پیوند دهد.
4. اجرا و نتایج
برای بررسی قابلیت های چارچوب، سناریو تعریف شده و قابلیت های راه حل پیشنهادی مشخص می شود. در این سناریو، اطلاعات مربوط به داده های ژئودموگرافیک به عنوان خدمات وب استاندارد در SDI های محلی مختلف منتشر می شود. هدف استخراج دانش مفید از این مجموعه داده ها از طریق راه حل پیشنهادی است. در این سناریو، دانش فضایی به خروجی تکنیک های SDM ارائه شده توسط KDWS اشاره دارد.
یک رویکرد مطالعه موردی برای به دست آوردن درک دقیق از چارچوب پیشنهادی اتخاذ شد. مجموعه داده استفاده شده مربوط به سه منطقه تهران (مناطق: 3، 6 و 11) می باشد. این مناطق معرف سطوح مختلف کیفیت زندگی هستند که در بخش های شمالی، مرکزی و جنوبی شهر قرار دارند ( شکل 9 را ببینید ). از منظر اقتصادی-اجتماعی، طبقات اجتماعی مختلفی در شهر زندگی میکنند که از آن جمله میتوان به طبقه مرفه (بالا) در بخش شمالی، نیمه مرفه در بخش مرکزی (وسط) و طبقه محروم (پایین) در بخش جنوبی اشاره کرد.
شکل 9 موقعیت ولسوالی های انتخاب شده و تراکم جمعیت را در بلوک های سرشماری نشان می دهد. این بلوک ها شامل 3184 واحد می باشد. شاخص های اجتماعی-اقتصادی و ژئودموگرافیک مربوط به این بلوک ها در یک شبکه توزیع شده ذخیره می شود که توسط مراجع مختلف منتشر شده است. شاخص ها در جدول 3 نشان داده شده است.
4.1. گردش کار پیاده سازی
این بخش مراحل پیاده سازی برای استخراج دانش از داده های فضایی توزیع شده را شرح می دهد. همانطور که در شکل 10 نشان داده شده است ، گردش کار پیاده سازی شامل سه مرحله اصلی به شرح زیر است:
4.1.1. بلع داده ها
در این مرحله، داده های مکانی از SDI های مختلف بارگذاری شده و در سیستم های ذخیره سازی داده مبتنی بر HDFS ادغام می شوند. در اینجا، بسیار مهم است که بدانیم چگونه داده ها، ابرداده ها، و خدمات مکانی موجود در SDI های مختلف در راه حل سازماندهی می شوند. برای شبیه سازی چنین محیطی، Oracle VirtualBox، یک نرم افزار مجازی سازی بین پلتفرمی ( https://www.virtualbox.org/ )، برای ایجاد سه ماشین مجازی استفاده شد. برای هر ماشین، تخصیص منابع، سرور پایگاه داده (اینجا، PostgreSQL)، سرور GIS (اینجا، Geoserver)، و تنظیمات مربوط به شبکه پیکربندی شده است. GeoNode ( https://geonode.org/)، یک سیستم مدیریت محتوای جغرافیایی، برای مدیریت آسان داده ها، ابرداده ها، و انتشار سرویس های مختلف OGC از جمله WMS، WFS، و خدمات کاتالوگ برای وب (CSW) استفاده شد. پس از انتشار داده ها به عنوان خدمات OGC، داده ها باید در HDFS مورد نظر ارائه شده توسط چارچوب Hadoop ذخیره شوند. با استفاده از GeoKettle، یک ابزار ETL فضایی مبتنی بر فراداده، داده های ژئودموگرافیک ذخیره شده در HDFS مورد نظر.
4.1.2. مدیریت محاسبات توزیع شده
در این مرحله تمام داده های مورد نیاز به درستی در قالب فایل های HDFS محلی ذخیره می شوند. برای استفاده بهینه از قابلیتهای پردازش موازی، لازم است دادهها را در ماشینهای جداگانه پارتیشن بندی کنیم. علاوه بر این، پردازش مورد نیاز برای استخراج دانش باید به واحدهای محاسباتی مختلف (گره کارگر) تقسیم شود. در مدیریت پارتیشن بندی و پردازش موازی چالش هایی وجود دارد. متأسفانه، ابزارهای ذخیره سازی بومی Hadoop، داده ها را بدون در نظر گرفتن مشخصه های مکانی (یعنی انواع داده ها، شاخص های مکانی و عملیات هندسی) به چند پارتیشن تقسیم می کنند. برای پارتیشن بندی داده های لازم بر اساس ویژگی های فضایی، GeoSpark ( https://sedona.apache.org/)، یک سیستم محاسباتی خوشه ای برای پردازش داده های مکانی در مقیاس بزرگ، استفاده شد. این RDD، ساختار دادههای اصلی در آپاچی اسپارک را گسترش میدهد تا دادههای مکانی بزرگ را در یک خوشه مجزا جای دهد. داده ها در SRDD ها بر اساس توزیع داده های مکانی تقسیم بندی می شوند و اشیاء فضایی نزدیک به احتمال زیاد در همان پارتیشن قرار می گیرند. مدیریت مکان داده های پارتیشن بندی شده (مسیر مربوط به داده ها) و محاسبات مختلف (وظایف) در چندین ماشین چالش دیگری است. برای پیگیری دقیق محل ذخیره داده ها در HDFS توزیع شده، از ابزاری به نام “Cluster management” استفاده شد. با استفاده از یک تابع mapper، رقابت های توزیع شده را در گره هایی که داده های پارتیشن بندی شده در آن قرار دارند یکپارچه می کند.
کتابخانه های پایتون مانند PyClustering [ 61 ]، PySAL [ 62 ] و Scikit-Learn [ 63 ] برای اجرای وظایف داده کاوی مکانی استفاده می شوند. علاوه بر این، GeoPandas، یک پروژه پایتون منبع باز که از انواع دادههای مکانی ( https://geopandas.org/ ) پشتیبانی میکند، برای اجرای الگوریتمهای طبقهبندی استفاده شد. علاوه بر کتابخانه های ذکر شده، از پیاده سازی پایتون خالص برای استخراج قوانین انجمن فضایی و سایر عملکردها استفاده شد.
4.1.3. KDWS
تعامل یکپارچه و متقابل بین مشتریان و وظایف کشف دانش توزیع شده توسط KDWS ارائه می شود. قابلیت های به دست آمده توسط KDWS قبلا ذکر شد (به بخش 3.3 مراجعه کنید ).
چارچوب توسعه وب جنگو در فرآیند پیاده سازی چارچوب وب نمونه اولیه ( https://www.djangoproject.com/ ) استفاده شد. این اجازه می دهد تا یکپارچه سازی ماژول های سیستم بر اساس یک رویکرد آزادانه جفت شده [ 64 ].
همانطور که در شکل 11 نشان داده شده است ، قابلیت های مختلف راه حل پیشنهادی در یک نمونه اولیه سیستم مبتنی بر وب پیاده سازی شده است. این قابلیت ها با عملیات KDWS که قبلا ذکر شد به دست می آیند.
4.2. نتایج
پروتکل درخواست پاسخ HTTP به مشتریان اجازه می دهد تا با نمونه اولیه پیاده سازی شده ارتباط برقرار کنند. مشتری یک پیام درخواست HTTP را بر اساس HTTP GET یا HTTP POST به سرور ارسال می کند. یک سری اطلاعات فراداده حاوی پارامترهای معتبر درخواست/پاسخ KDWS است که توسط عملیات GetCapabilities ارائه شده است (به بخش 3.3.1 مراجعه کنید ). بر اساس وظایف کشف دانش مورد نیاز، مشتری الگوریتم، مجموعه داده، متغیرهای مرتبط و قالب پاسخ را انتخاب می کند. در ادامه یک نمونه درخواست KVP نشان داده شده است.
https://127.0.0.1:8000/KDWS?service=KDWS&version=1.0.0&request=getSpatialclusters&algorithm=k-means&dataset=geodemographic&variables=literacy,income&outputformat=application/json .
نتایج GetSpatialClusters برای مجموعه داده های مورد استفاده در منطقه مورد مطالعه در شکل 9 نشان داده شده است. همانطور که در شکل 12 نشان داده شده است ، بلوک های آماری همگن منطقه مورد مطالعه بر اساس متغیرهای مختلف از جمله درآمد، اشتغال، نرخ طلاق و نرخ باسوادی به عنوان خوشه های فضایی مختلف شناسایی شدند. در شکل، نواحی سبز و آبی به صورت خوشه ای و همچنین قرمز هستند و بنفش نقاط پرت است.
شکل 13 نتایج عملیات GetSpatialClassification اعمال شده بر روی داده های ژئودموگرافی منطقه مورد مطالعه را نشان می دهد. هدف طبقه بندی بلوک های آماری به طبقات جداگانه بر اساس شاخص های اجتماعی و اقتصادی است. به دلیل کمبود داده های آموزشی، از الگوریتم طبقه بندی K-NN استفاده شد. در نتیجه مشابه ترین ویژگی های فضایی در قالب کلاس ها از سایر ویژگی ها جدا شد و در شکل 13 ارائه شده است.
با اعمال عملیات GetAssociationRules، روابط بین متغیرهای مختلف به عنوان مجموعه ای از قوانین ارتباطی ارائه می شود. نمونه های زیر از جمله قوانینی هستند که برای ارزیابی حمایت و اطمینان از آنها ارائه شده است.
قانون 1: نرخ سواد='(0.96-1]’ رایانه و ماشین='(0.71-0.85]’ اندازه خانواده='(2.9-3.5]’ بار وابستگی='(0.2-0.4]’ 398 ==> درآمد سالانه (م ریال ایران)='(153 -171)’ 376 <supp:(0.125) conf:(0.94)>
قانون 2: نرخ طلاق='(0-0.052]’ درآمد سالانه (M ریال ایران) ='(153-171]’ رایانه و ماشین='(0.72-0.86]’ بار وابستگی='(0.2-0.4]’ 478 ==> نرخ سواد='(0.96-inf)’ 435 <supp:(0.15) conf:(0.91)>
در قانون اول، اگر نرخ باسوادی بیش از 96 درصد باشد، 71 تا 85 درصد خانوارها رایانه و ماشین شخصی دارند، تعداد خانواده بین 2.9 تا 3.5 و بار وابستگی بین 0.2-0.4 است، پس میانگین درآمد سالانه خانوارهای ساکن در این بلوک ها بین 153 تا 171 میلیون ریال ایران خواهد بود. مقادیر حمایت و اطمینان برای این قانون به ترتیب 0.125 و 0.94 بود.
شکل 14 عوارض اجزاء (شرایط) را به ترتیب در قانون دوم نشان می دهد. بر اساس این قانون، بلوکهای سرشماری با نرخ طلاق کمتر از 5.2 درصد و درآمد سالانه بین 153 تا 171 میلیون ریال و خانوارهای دارای رایانه و خودرو شخصی بین 71 تا 85 درصد و بار مسئولیت بین 0.2 تا 0.4 دارای افراد باسواد هستند. نرخ بیش از 96٪.
5. بحث و نتیجه گیری
هدف از مطالعه حاضر ارائه چارچوبی برای استخراج دانش از داده های فضایی توزیع شده در بالای SDI ها بود. این چارچوب تکنیک های SOA و SDM را برای فعال کردن فرآیندهای استخراج دانش فضایی ادغام می کند. در این زمینه، معماری را معرفی کردیم که شامل چهار لایه اصلی است. لایه داده برای ادغام داده های فضایی توزیع شده و ناهمگن استفاده می شود. لایه موتور کشف دانش از تکنیک های داده کاوی فضایی با کارایی بالا در سراسر خوشه های رایانه پشتیبانی می کند و لایه KDWS قابلیت همکاری را برای برنامه ها فراهم می کند. بر این اساس، یک وب سرویس پیاده سازی شده است که از تکنیک های SDM در ذخیره سازی داده های مدرن و یک پلت فرم محاسباتی موازی به نام KDWS پشتیبانی می کند. رابط های KDWS بر اساس استانداردهای قابلیت همکاری اجرا می شوند که از مهم ترین تکنیک های SDM شامل خوشه بندی فضایی، طبقه بندی و استخراج قوانین انجمن پشتیبانی می کنند. علاوه بر پیادهسازی رابط، رویههای این مطالعه برای استخراج دانش مفید از بخشی از دادههای ژئودموگرافیک تهران اجرا شد. ادغام تکنیکهای SDM مبتنی بر SOA و محاسبات توزیعشده، کارایی بالا و سرویسهای فضایی فضایی را ارائه میکند که میتواند در بسیاری از برنامهها استفاده شود.
یافتهها باید سهم مهمی در زمینههای خدمات وب جغرافیایی، SDI و کشف دانش جغرافیایی (GKD) داشته باشند. در مقایسه با روشهای سنتی SDM، راهحل پیشنهادی امکان اجرای تکنیک SDM را به روشی پویا، آسانتر و بسیار سریعتر میدهد. با توجه به اجزای متقابل چارچوب پیشنهادی، این روش به ویژه در اشتراک دانش فضایی مفید است. این بدان معنی است که یک تصمیم گیرنده می تواند از ترکیبی از عملیات KDWS برای پاسخ به سؤالات بدون ساختار استفاده کند، همچنین امیدوار است که ارکستراسیون یا آهنگسازی خدمات برای به دست آوردن دانش ارزشمندتر باشد. یافته های این مطالعه نشان می دهد که می توان از تکنیک های SDM مبتنی بر وب برای کشف دانش جغرافیایی استفاده کرد.
اگرچه چارچوب پیشنهادی مزایایی را برای جوامع GIS فراهم می کند، اما شامل محدودیت های خاصی نیز می شود. در این مطالعه از بارگذاری دادههای SDI در HDFS که توسط ابزارهای ETL و همچنین کدگذاری دستی و اسکریپتهای متعدد استفاده میشود، استفاده شد. با این حال، تکرار چنین عملیات دستی فرآیندی زمانبر است، به خصوص زمانی که صدها یا هزاران خوشه وجود داشته باشد. در این راستا، اتوماسیون چنین عملیات دستی یک مکانیسم ضروری است. یکپارچه سازی داده های اتوماسیون و فرآیند ETL از طریق گردش کار یا یک رابط گرافیکی کاربر پسند می تواند این مشکل را حل کند. علاوه بر این، داده های جغرافیایی به ویژه در زمینه محیطی ذاتاً در مدل داده های شطرنجی ذخیره می شوند، اما این نوع مدل داده در سرویس توسعه یافته نادیده گرفته می شود. استراتژیهایی برای ارتقای عملکرد روششناسی باید در مطالعات آینده درگیر شوند. راه حل پیشنهادی می تواند برای پشتیبانی از سایر تکنیک های کاوی فضایی گسترش یابد. علاوه بر این، در حالی که این مطالعه بیشتر بر امکانسنجی استخراج دانش از SDI با استفاده از سرویسهای متقابل متمرکز است، سرعت و عملکرد این نوع از خدمات میتواند با استفاده از مجموعه دادههای حجیم (گیگابایت یا ترابایت از یک مجموعه داده فضایی) مقابله شود. به طور گسترده تر، تحقیقات نیز برای تعیین مشکلات معنایی داده های مکانی در راه حل پیشنهادی مورد نیاز است. برای ادغام دادههای فضایی ناهمگن و توزیعشده در زمینههای مختلف، چارچوب را میتوان با ژئوهستیشناسی در نظر گرفت تا روابط معنایی دادههای فضایی بزرگ را توصیف کند. علاوه بر این، در حالی که این مطالعه بیشتر بر امکانسنجی استخراج دانش از SDI با استفاده از سرویسهای متقابل متمرکز است، سرعت و عملکرد این نوع از خدمات میتواند با استفاده از مجموعه دادههای حجیم (گیگابایت یا ترابایت از یک مجموعه داده فضایی) مقابله شود. به طور گسترده تر، تحقیقات نیز برای تعیین مشکلات معنایی داده های مکانی در راه حل پیشنهادی مورد نیاز است. برای ادغام دادههای فضایی ناهمگن و توزیعشده در زمینههای مختلف، چارچوب را میتوان با ژئوهستیشناسی در نظر گرفت تا روابط معنایی دادههای فضایی بزرگ را توصیف کند. علاوه بر این، در حالی که این مطالعه بیشتر بر امکانسنجی استخراج دانش از SDI با استفاده از سرویسهای متقابل متمرکز است، سرعت و عملکرد این نوع از خدمات میتواند با استفاده از مجموعه دادههای حجیم (گیگابایت یا ترابایت از یک مجموعه داده فضایی) مقابله شود. به طور گسترده تر، تحقیقات نیز برای تعیین مشکلات معنایی داده های مکانی در راه حل پیشنهادی مورد نیاز است. برای ادغام دادههای فضایی ناهمگن و توزیعشده در زمینههای مختلف، چارچوب را میتوان با ژئوهستیشناسی در نظر گرفت تا روابط معنایی دادههای فضایی بزرگ را توصیف کند. به طور گسترده تر، تحقیقات نیز برای تعیین مشکلات معنایی داده های مکانی در راه حل پیشنهادی مورد نیاز است. برای ادغام دادههای فضایی ناهمگن و توزیعشده در زمینههای مختلف، چارچوب را میتوان با ژئوهستیشناسی در نظر گرفت تا روابط معنایی دادههای فضایی بزرگ را توصیف کند. به طور گسترده تر، تحقیقات نیز برای تعیین مشکلات معنایی داده های مکانی در راه حل پیشنهادی مورد نیاز است. برای ادغام دادههای فضایی ناهمگن و توزیعشده در زمینههای مختلف، چارچوب را میتوان با ژئوهستیشناسی در نظر گرفت تا روابط معنایی دادههای فضایی بزرگ را توصیف کند.
در کار آینده، استفاده از راه حل پیشنهادی از دیدگاه های مختلف شامل استخراج دانش، به اشتراک گذاری، و ترکیب می تواند در یک ژئوپورتال پیاده سازی یا ارزیابی شود. تمرکز بیشتر روی رویهها برای ادغام یا ترکیب سرویسهای مختلف KDWS میتواند یافتههای جالبی را ایجاد کند که میتواند در آینده بسیار مهم باشد. سوال مطرح شده توسط این مطالعه این است که چگونه می توان تکنیک های SDM مبتنی بر وب را ترکیب کرد و دانش مهم تری (دانش در مورد دانش) به دست آورد. یکی دیگر از زمینه های احتمالی تحقیقات آینده، بررسی راه حل SDM مبتنی بر وب برای یک مدل داده مبتنی بر شطرنجی است.
منابع
- کوتسف، آ. مینگینی، ام. توماس، آر. سیتل، وی. لوتز، ام. از زیرساختهای دادههای مکانی تا فضاهای داده – چشمانداز فناوری در مورد تکامل SDI اروپا. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 176. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- آندراچوک، م. مارشکه، ام. هینگز، سی. آرمیتاژ، دی. فنآوریهای گوشیهای هوشمند که از نظارت و پیادهسازی محیطی مبتنی بر جامعه حمایت میکنند: یک بررسی محدوده سیستماتیک. Biol. حفظ کنید. 2019 ، 237 ، 430-442. [ Google Scholar ] [ CrossRef ]
- بروولی، MA; مینگینی، ام. Zamboni، G. مشارکت عمومی در GIS از طریق برنامه های کاربردی تلفن همراه. ISPRS J. Photogramm. Remote Sens. 2016 , 114 , 306–315. [ Google Scholar ] [ CrossRef ]
- کانکانمگه، ن. Yigitcanlar، T. گونتیلکه، ا. Kamruzzaman, M. آیا جمع سپاری داوطلبانه می تواند خطر فاجعه را کاهش دهد؟ یک مرور نظام مند از ادبیات. بین المللی J. کاهش خطر بلایا. 2019 ، 35 ، 101097. [ Google Scholar ] [ CrossRef ]
- لی، دی. وانگ، اس. یوان، اچ. Li, D. نرم افزار و برنامه های کاربردی داده کاوی فضایی. وایلی اینتردیسیپ. Rev. Data Min. بدانید. کشف کنید. 2016 ، 6 ، 84-114. [ Google Scholar ] [ CrossRef ]
- میلر، اچ جی; هان، جی. داده کاوی جغرافیایی و کشف دانش . CRC Press: Boca Raton، FL، USA، 2014. [ Google Scholar ]
- ریستوسکی، پ. پاولهایم، اچ. وب معنایی در داده کاوی و کشف دانش: یک بررسی جامع. J. وب سمنت. 2016 ، 36 ، 1-22. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پاشووا، ال. باندرووا، تی. مروری کوتاه بر وضعیت فعلی زیرساختهای دادههای مکانی اروپا – تحولات و چشماندازهای مرتبط برای بلغارستان. ژئو اسپات. Inf. علمی 2017 ، 20 ، 97-108. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گروون، جی. لین، جی. Waters, N. Data Mining for Geoinformatics: Methods and Applications ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2014. [ Google Scholar ]
- پرومال، م. ولومانی، بی. صداسیوام، ع. راماسوامی، کی. رویکردهای داده کاوی فضایی برای GIS – مروری کوتاه. در فناوری اطلاعات و ارتباطات نوظهور برای پل زدن بر آینده – مجموعه مقالات چهل و نهمین کنوانسیون سالانه انجمن کامپیوتر هند CSI ; AISC: شیکاگو، IL، ایالات متحده آمریکا، 2015; جلد 2. [ Google Scholar ] [ CrossRef ]
- شیروژان، س. لیم، اس. تریدر، جی. لی، اچ. سپاسگزار، س. داده کاوی برای شناسایی الگوهای توزیع فضایی ارتفاعات ساختمان با استفاده از داده های هوابرد لیدار. Adv. مهندس به اطلاع رساندن. 2020 , 43 , 101033. [ Google Scholar ] [ CrossRef ]
- Thach، NN; Ngo، DB-T. Xuan-Canh، P. هونگ-تی، ن. Thi، BH; نهات دوک، اچ. Dieu، TB ارزیابی الگوی فضایی خطر آتش سوزی جنگل های استوایی در منطقه Thuan Chau (ویتنام) با استفاده از الگوریتم های یادگیری ماشین پیشرفته مبتنی بر GIS: یک مطالعه مقایسه ای. Ecol. به اطلاع رساندن. 2018 ، 46 ، 74-85. [ Google Scholar ] [ CrossRef ]
- جورجانوس، اس. گریپا، تی. نیانگ گادیاگا، ای. لینارد، سی. لنرت، ام. ونهویسه، اس. Kalogirou، S. جنگلهای تصادفی جغرافیایی: گسترش فضایی الگوریتم جنگل تصادفی برای پرداختن به ناهمگونی فضایی در سنجش از دور و مدلسازی جمعیت. Geocarto Int. 2019 ، 1-16. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ارنست، ام. Haesbroeck، G. مقایسه تکنیکهای تشخیص نقاط پرت محلی در دادههای چند متغیره فضایی. حداقل داده بدانید. کشف کنید. 2017 ، 31 ، 371-399. [ Google Scholar ] [ CrossRef ]
- Unternährer، J. مورت، اس. جوست، س. Maréchal، F. خوشه بندی فضایی برای ادغام گرمایش منطقه ای در سیستم های انرژی شهری: کاربرد در انرژی زمین گرمایی. Appl. انرژی 2017 ، 190 ، 749-763. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Blachowski, J. کاربرد روشهای رگرسیون فضایی GIS در ارزیابی فرونشست زمین در شرایط پیچیده معدن: مطالعه موردی معدن زغالسنگ Walbrzych (SW لهستان). نات. خطرات 2016 ، 84 ، 997-1014. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جایبابو، ی. وارما، جی. Govardhan، A. کاوی قواعد تداعی فضایی توپولوژیکی افزایشی و خوشهبندی از مجموعه دادههای جغرافیایی با استفاده از رویکرد احتمالی. J. King Saud Univ. محاسبه کنید. Inf. علمی 2018 ، 30 ، 510-523. [ Google Scholar ] [ CrossRef ]
- کومار، آر. جها، س. میتال، م. Goyal، LM تجزیه و تحلیل داده های فضایی با استفاده از استخراج قوانین انجمن در محیط های توزیع شده: چشم انداز حفظ حریم خصوصی. تف کردن Inf. Res. 2018 ، 26 ، 629-638. [ Google Scholar ] [ CrossRef ]
- الکاثیری، م. جوماروالا، ا. Potdar، M. داده کاوی چند بعدی جغرافیایی در یک محیط توزیع شده با استفاده از MapReduce. J. Big Data 2019 ، 6 ، 82. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- امیدی پور، م. تومانیان، ع. سامانی، NN به سوی زیرساخت دانش فضایی (SKI): درک فناوری. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی AGILE در علم اطلاعات جغرافیایی، لوند، سوئد، 12 تا 15 ژوئن 2018؛ در دسترس آنلاین: https://www.semanticscholar.org/paper/Towards-Spatial-Knowledge-Infrastructure-(-SKI-)-%3A-Omidipoor/823c974fbdf149e8412d0ae5fe692ef1284bdaf2 (دسترسی در 202 دسامبر).
- لی، ز. گی، ز. هوفر، بی. لی، ی. شیدر، اس. Shekhar, S. فناوری های پردازش اطلاعات جغرافیایی. در کتابچه راهنمای زمین دیجیتال ; اسپرینگر: سنگاپور، 2020؛ صص 191-227. [ Google Scholar ]
- جو، جی. لی، K.-W. سیستم پردازش داده های بزرگ جغرافیایی با کارایی بالا بر اساس MapReduce. ISPRS Int. J. Geo-Inf. 2018 ، 7 ، 399. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یائو، ایکس. موکبل، MF; اعرابی، ل. الدوی، ا. یانگ، جی. یون، دبلیو. Zhu، D. رویکرد مبتنی بر کدگذاری فضایی برای پارتیشن بندی داده های فضایی بزرگ در Hadoop. محاسبه کنید. Geosci. 2017 ، 106 ، 60-67. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اعرابی، ل. موکبل، MF; Musleh, M. St-hadoop: یک چارچوب کاهش نقشه برای داده های مکانی-زمانی. GeoInformatica 2018 ، 22 ، 785-813. [ Google Scholar ] [ CrossRef ]
- پارک، اس. کو، دی. Song, S. روش درج موازی و نمایه سازی برای مقدار زیادی از داده های مکانی-زمانی با استفاده از تکنیک شبکه چند سطحی پویا. Appl. علمی 2019 ، 9 ، 4261. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لی، اس. دراگیسویچ، اس. کاسترو، FA; سستر، ام. زمستان، اس. کولتکین، ا. استاین، الف. نظریه و روشهای مدیریت دادههای بزرگ جغرافیایی: بررسی و چالشهای تحقیق. ISPRS J. Photogramm. Remote Sens. 2016 ، 115 ، 119-133. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یو، جی. ژانگ، ز. Sarwat، M. مدیریت داده های فضایی در اسپارک آپاچی: چشم انداز geospark و فراتر از آن. GeoInformatica 2019 ، 23 ، 37–78. [ Google Scholar ] [ CrossRef ]
- Wagemann، J.; کلمنتز، او. مارکو فیگوئرا، آر. روسی، AP; Mantovani, S. خدمات وب جغرافیایی راه های جدیدی را برای دسترسی بر اساس درخواست و پردازش داده های زمین بزرگ بر اساس سرور هموار می کند. بین المللی جی دیجیت. زمین 2018 ، 11 ، 7-25. [ Google Scholar ] [ CrossRef ]
- Yue, P. خدمات وب جغرافیایی هوشمند مبتنی بر وب معنایی ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- یو، پی. دی، ال. یانگ، دبلیو. یو، جی. ژائو، پی. گونگ، جی. برنامه ریزی فرآیند مبتنی بر خدمات وب معنایی برای کاربردهای علوم زمین. بین المللی جی. جئوگر. Inf. علمی 2009 ، 23 ، 1139-1163. [ Google Scholar ] [ CrossRef ]
- ژانگ، اف. چن، ام. ایمز، DP; شن، سی. یو، اس. ون، ی. Lü, G. طراحی و توسعه یک سیستم بسته بندی سرویس گرا برای به اشتراک گذاری و استفاده مجدد از مدل های تجزیه و تحلیل جغرافیایی توزیع شده در وب. محیط زیست مدل. نرم افزار 2019 ، 111 ، 498–509. [ Google Scholar ] [ CrossRef ]
- Zhao, P. خدمات وب جغرافیایی: پیشرفت در قابلیت همکاری اطلاعات: پیشرفت در قابلیت همکاری اطلاعات ; IGI Global: Hershay، PA، USA، 2010. [ Google Scholar ]
- چاوز، JTF; de Freitas، SAA مروری بر ادبیات سیستماتیک برای معماری سرویس گرا و توسعه چابک. در مجموعه مقالات کنفرانس بین المللی علوم محاسباتی و کاربردهای آن، سن پترزبورگ، روسیه، 29 ژوئن 2019. [ Google Scholar ] [ CrossRef ]
- نیک نژاد، ن. اسماعیل، دبلیو. غنی، من. نظری، ب. بهاری، م. درک معماری سرویس گرا (SOA): مروری بر ادبیات سیستماتیک و دستورالعمل هایی برای بررسی بیشتر. Inf. سیستم 2020 . [ Google Scholar ] [ CrossRef ]
- Chow, TE Geography 2.0: A mashup view. در پیشرفت در GIS مبتنی بر وب، خدمات نقشه برداری و برنامه های کاربردی ؛ CRC Press: Boca Raton، FL، USA، 2011; صص 15-36. [ Google Scholar ]
- لی، اس. دراگیسویچ، اس. Veenendaal, B. پیشرفت در GIS مبتنی بر وب، خدمات نقشه برداری و برنامه های کاربردی . CRC Press: Boca Raton، FL، USA، 2011. [ Google Scholar ]
- لرتی، د. لیپی، م. Torroni، P. موازی سازی یادگیری ماشین به عنوان یک سرویس برای کاربر نهایی. ژنرال آینده. محاسبه کنید. سیستم 2020 ، 105 ، 275-286. [ Google Scholar ] [ CrossRef ]
- ریبیرو، ام. گرولینگر، ک. Capretz، MA Mlaas: یادگیری ماشین به عنوان یک سرویس. در مجموعه مقالات چهاردهمین کنفرانس بین المللی IEEE 2015 در مورد یادگیری ماشین و کاربردها (ICMLA)، میامی، FL، ایالات متحده آمریکا، 9 تا 11 دسامبر 2015؛ در دسترس آنلاین: https://ieeexplore.ieee.org/document/7424435 (در 28 دسامبر 2020 قابل دسترسی است).
- سان، ز. زو، اچ. Strang، K. تجزیه و تحلیل داده های بزرگ به عنوان یک سرویس برای هوش تجاری. در مجموعه مقالات کنفرانس کسب و کار الکترونیکی، خدمات الکترونیکی و جامعه الکترونیکی، دلفت، هلند، 13 تا 15 اکتبر 2015. در دسترس به صورت آنلاین: https://link.springer.com/chapter/10.1007/978-3-319-25013-7_16 (در 28 دسامبر 2020 قابل دسترسی است).
- وهرله، پی. میکل، ام. Tchounikine، A. معماری مبتنی بر خدمات شبکه برای عملکرد کارآمد انبارهای داده توزیع شده در Globus. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی شبکه های اطلاعاتی پیشرفته و برنامه های کاربردی (AINA’07)، آبشار نیاگارا، ON، کانادا، 21 تا 23 مه 2007. موجود به صورت آنلاین: https://www.semanticscholar.org/paper/OLAP-query-processing-for-partitioned-data-Bellatreche-Karlapalem/4719af2994bb45fd9dfd687eebaa2b829b9ab474 (در 28 دسامبر 2018 قابل دسترسی است).
- وو، ال. براش، جی. بارتولینی، سی. معماری سرویس گرا برای هوش تجاری. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد محاسبات و برنامه های کاربردی سرویس گرا (SOCA’07)، نیوپورت بیچ، کالیفرنیا، ایالات متحده آمریکا، 19 تا 20 ژوئن 2007. در دسترس آنلاین: https://dl.acm.org/doi/10.1109/SOCA.2007.6 (در 28 دسامبر 2020 قابل دسترسی است).
- زوریلا، م. García-Saiz, D. معماری سرویس گرا برای ارائه خدمات داده کاوی برای داده کاویان غیر متخصص. تصمیم می گیرد. سیستم پشتیبانی 2013 ، 55 ، 399-411. [ Google Scholar ] [ CrossRef ]
- مدودف، وی. کوراسووا، او. برناتاویچینه، جی. تریگیس، پی. مارسینکوویچیوس، وی. Dzemyda, G. یک راه حل جدید مبتنی بر وب برای مدل سازی فرآیندهای داده کاوی. شبیه سازی مدل. تمرین کنید. نظریه 2017 ، 76 ، 34-46. [ Google Scholar ] [ CrossRef ]
- کوسوماکوماری، وی. شریگر، دی. چاندران، آر. پتیل، N. الگوبرداری مکرر روی دادههای جریان با استفاده از Hadoop CanTree-GTree. Procedia Comput. علمی 2017 ، 115 ، 266-273. [ Google Scholar ] [ CrossRef ]
- گل محمدی، ج. زی، ی. گوپتا، جی. لی، ی. کای، جی. دتور، اس. Shekhar, S. مقدمه ای بر داده کاوی فضایی. 2018. در دسترس آنلاین: https://conservancy.umn.edu/handle/11299/216029 (در 28 دسامبر 2020 قابل دسترسی است).
- Anselin، L. شاخص های محلی ارتباط فضایی-LISA. Geogr. مقعدی 1995 ، 27 ، 93-115. [ Google Scholar ] [ CrossRef ]
- دوان، ال. خو، ال. گوا، اف. لی، جی. Yan, B. الگوریتم خوشهبندی فضایی مبتنی بر چگالی محلی با نویز. Inf. سیستم 2007 ، 32 ، 978-986. [ Google Scholar ] [ CrossRef ]
- آرتور، دی. Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding ; دانشگاه استنفورد: استنفورد، کالیفرنیا، ایالات متحده آمریکا، 2006. [ Google Scholar ]
- ژانگ، تی. راماکریشنان، ر. Livny، M. BIRCH: یک روش خوشهبندی داده کارآمد برای پایگاههای داده بسیار بزرگ. ACM Sigmod Rec. 1996 ، 25 ، 103-114. [ Google Scholar ] [ CrossRef ]
- Dhillon، IS; گوان، ی. Kulis، B. Kernel K-Means: Spectral Clustering and Normalized Cuts. در مجموعه مقالات دهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، نیویورک، نیویورک، ایالات متحده آمریکا، 22 تا 25 اوت 2004. [ Google Scholar ] [ CrossRef ]
- مرتق، ف. روش خوشهبندی سلسله مراتبی تجمعی لژاندر، پی وارد: کدام الگوریتمها معیار وارد را اجرا میکنند؟ J. Classif. 2009 ، 31 ، 274-295. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آنکرست، م. برونیگ، MM; کریگل، اچ.-پی. Sander, J. OPTICS: نقاط ترتیب برای شناسایی ساختار خوشه بندی. ACM Sigmod Rec. 1999 ، 28 ، 49-60. [ Google Scholar ] [ CrossRef ]
- استر، ام. کریگل، اچ.-پی. ساندر، جی. Xu, X. الگوریتم مبتنی بر چگالی برای کشف خوشهها در پایگاههای داده فضایی بزرگ با نویز . KDD: استانفورد، کالیفرنیا، ایالات متحده آمریکا، اوت 1996؛ جلد 96، ص 226–231. [ Google Scholar ]
- فرانک، آر. استر، ام. Knobbe، A. یک رویکرد چند رابطه ای به طبقه بندی فضایی. در مجموعه مقالات پانزدهمین کنفرانس بین المللی ACM SIGKDD در مورد کشف دانش و داده کاوی، پاریس، فرانسه، 28 ژوئن تا 1 ژوئیه 2019؛ KDD: استانفورد، کالیفرنیا، ایالات متحده آمریکا. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کوپرسکی، ک. هان، جی. استفانوویچ، ن. یک روش کارآمد دو مرحله ای برای طبقه بندی داده های مکانی. در مجموعه مقالات سمپوزیوم بین المللی در مورد مدیریت داده های فضایی (SDH’98)، ونکوور، BC، کانادا، 11-15 ژوئیه 1998. در دسترس آنلاین: https://www.semanticscholar.org/paper/An-Efficient-Two-Step-Method-for-Classification-of-Koperski-Han/c9e10cf4006690e6f3a3c05a151515d0c5a8ca6d (در 02 دسامبر 2013)
- فن، R.-E. چانگ، K.-W. هسیه، سی.-ج. وانگ، X.-R. لین، سی.-جی. LIBLINEAR: کتابخانه ای برای طبقه بندی خطی بزرگ. جی. ماخ. فرا گرفتن. Res. 2008 ، 9 ، 1871-1874. [ Google Scholar ]
- بریمن، ال. فریدمن، جی اچ. اولشن، RA; سنگ، CJ طبقه بندی و رگرسیون درختان ; مطبوعات CRC: Boca Raton، FL، USA، 1984; جلد 432، صص 151–166. [ Google Scholar ]
- گلدبرگر، جی. هینتون، جنرال الکتریک؛ Roweis، ST; سالاخوتدینوف، تحلیل مؤلفه های همسایگی RR. Adv. عصبی Inf. روند. سیستم 2004 ، 17 ، 513-520. [ Google Scholar ]
- Geurts، P. ارنست، دی. Wehenkel, L. درختان بسیار تصادفی. ماخ فرا گرفتن. 2006 ، 63 ، 3-42. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Whiteside, A. OGC Implementation Specification 06-121r3: OGC Web Services Common Specification ; کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2007. [ Google Scholar ]
- نوویکوف، A. PyClustering: کتابخانه داده کاوی. J. نرم افزار منبع باز. 2019 ، 4 ، 1230. [ Google Scholar ] [ CrossRef ]
- ری، اس جی. Anselin, L. PySAL: کتابخانه پایتون از روش های تحلیلی فضایی. در کتابچه راهنمای تحلیل کاربردی فضایی ; Springer: برلین/هایدلبرگ، آلمان، 2010; صص 175-193. [ Google Scholar ]
- پدرگوسا، اف. واروکو، جی. گرامفورت، آ. میشل، وی. تیریون، بی. گریزل، او. Dubourg, V. Scikit-learn: یادگیری ماشینی در پایتون. جی. ماخ. فرا گرفتن. Res. 2011 ، 12 ، 2825-2830. [ Google Scholar ]
- امیدی پور، م. جلوخانی نیارکی، م. معین مهر، ع. صادقی نیارکی، ع. چوی، اس.-ام. یک سیستم پشتیبانی تصمیم مبتنی بر GIS برای تسهیل فرآیند نوسازی شهری مشارکتی. خطمشی استفاده از زمین 2019 ، 88 ، 104150. [ Google Scholar ] [ CrossRef ]

شکل 1. تغییر پارادایم از سیستم های اطلاعات جغرافیایی (GI) به خدمات GI.
شکل 2. چارچوب پیشنهادی برای استخراج دانش از داده های مکانی.
شکل 3. نمودار کلاسی سرویس وب کشف دانش (KDWS).
شکل 4. رابط عملیات GetCapabilities.
شکل 5. رابط عملیات GetInsight.
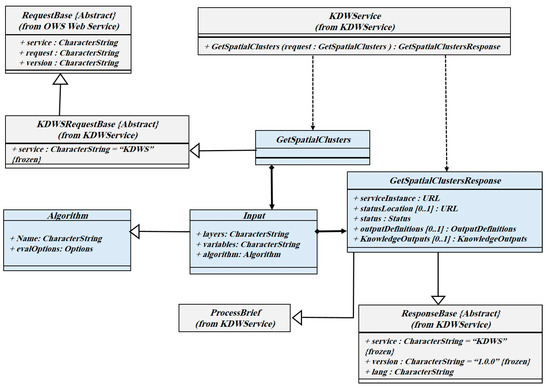
شکل 6. رابط عملیات GetSpatialClusters.
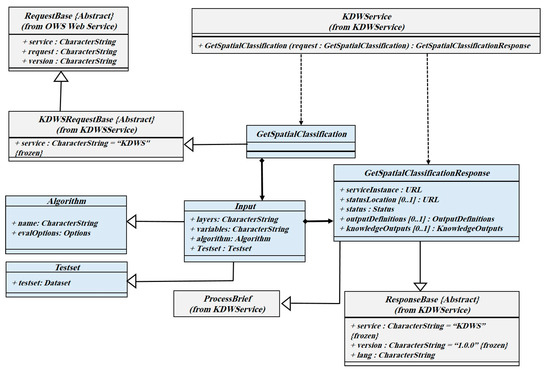
شکل 7. رابط عملیات GetSpatialClassification.
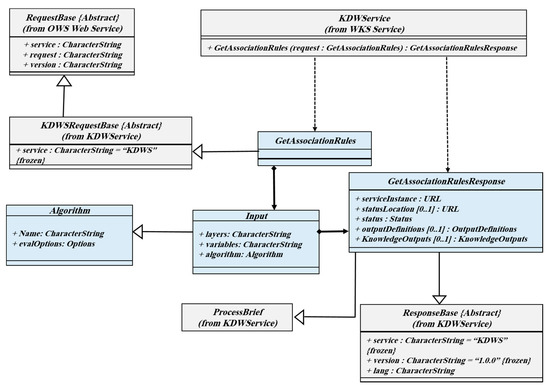
شکل 8. نمودار کلاس عملیات GetAssociationRules.
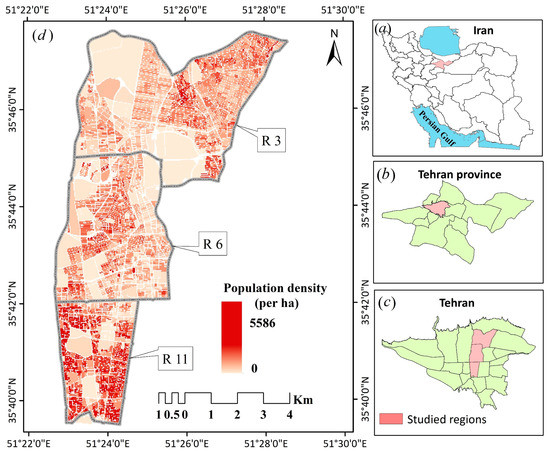
شکل 9. موقعیت منطقه مورد مطالعه. الف ) ایران، ب ) استان تهران، ج ) شهر تهران، و د ) مناطق 3، 6 و 11.

شکل 10. گردش کار پیاده سازی راه حل پیشنهادی.
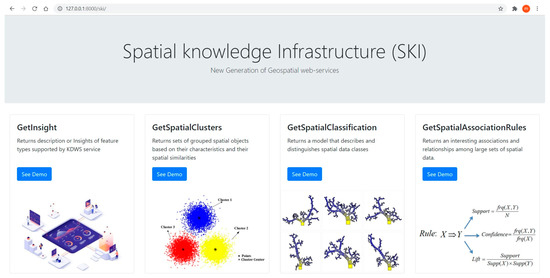
شکل 11. یک سیستم نمونه اولیه که برای استفاده از KDWS توسعه یافته است.
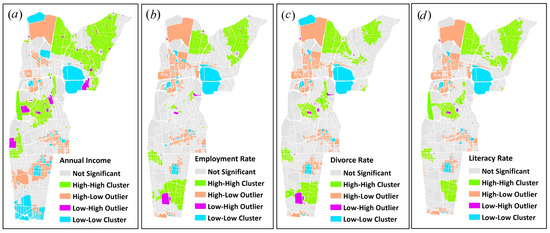
شکل 12. نمونه ای از خروجی عملیات GetSpatialClusters اعمال شده برای داده های ژئودموگرافیک تهران: ( الف ) درآمد سالانه، ( ب ) نرخ اشتغال، ( ج ) نرخ طلاق، و ( د ) نرخ باسوادی.

شکل 13. خروجی عملیات GetSpatialClassification اعمال شده در منطقه مورد مطالعه.
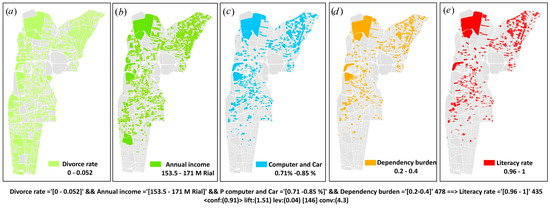
شکل 14. خروجی عملیات GetSpatialAssociationRules برای داده های ژئودموگرافیک اعمال می شود. ( الف ) نرخ طلاق، ( ب ) درآمد سالانه، ( ج ) کامپیوتر و ماشین، ( د ) بار وابستگی، و ( ه ) نرخ باسوادی.


بدون دیدگاه