

طراحی و توسعه راه حل اینترنتی دوربین های هوشمند برای تشخیص رویدادهای پیچیده در تشخیص رفتار خطر COVID-19
چکیده

کلید واژه ها:
اینترنت اشیا ؛ COVID-19 ؛ پخش ویدئو ؛ تشخیص رویداد پیچیده ؛ دوربین هوشمند ؛ پردازش لبه
1. مقدمه
- –
-
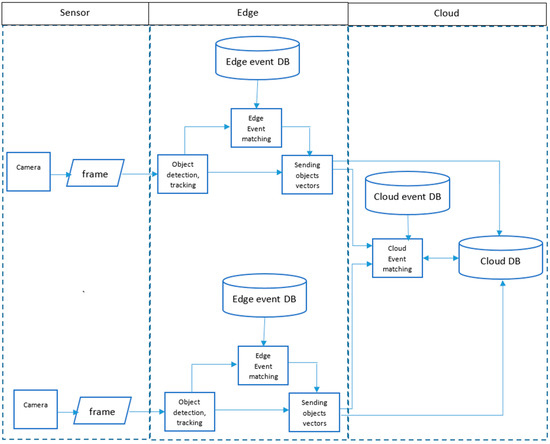
طراحی و توسعه یک معماری لبه و محاسبات ابری یکپارچه برای تشخیص رویدادهای پیچیده با استفاده از اینترنت قابل همکاری دوربین های هوشمند. این معماری انعطافپذیر به ما امکان میدهد اشیاء را از دوربینهای منفرد شناسایی کرده و آنها را در یک رویداد پیچیده در بخش محاسبات ابری ادغام کنیم.
- –
-
برای پیاده سازی معماری یکپارچه محاسبات ابری و لبه IoSC برای شناسایی رفتارهای مخاطره آمیز انجام شده توسط افراد که ممکن است منجر به انتشار احتمالی COVID-19 شود. رفتارهای ریسک رویدادهای پیچیده در نظر گرفته می شوند و با استفاده از مدل معماری شناسایی می شوند و در زمان واقعی به شبکه ابری گزارش می شوند.
- –
-
برای نشان دادن اینکه مدل تشخیص شی چقدر بر تعداد رویدادهای از دست رفته تأثیر میگذارد، مدلهای تشخیص شی مبتنی بر منطقه و رگرسیون را برای رویدادهای ساده مقایسه کردیم.
2. پس زمینه
3. روش تشخیص رویداد پیچیده
3.1. تشخیص و ردیابی شی
ردیابی اشیا فرآیند یافتن اشیاء مشابه در فریم های ویدئویی و شناسایی آنها است. این یک بخش اساسی از تشخیص رویداد پیچیده است و اشیاء را در فریم های متوالی شناسایی می کند تا امکان تشخیص روابط زمانی بین رویدادها در فریم ها را فراهم کند. روش های مختلفی برای ردیابی اشیا در فریم های ویدئویی وجود دارد. پیشرفتها در تشخیص اشیا، ردیابی با تشخیص را به یکی از محبوبترین روشهای ردیابی تبدیل کرده است. ردیابی عمیق آنلاین و بیدرنگ (DeepSORT) یکی از الگوریتمهایی است که در ردیابی خودرو [ 50 ]، ردیابی عابر پیاده [ 51 ]، ردیابی توپ [ 52 ] استفاده میشود.] و غیره الگوریتم فقط فریم های قبلی و فعلی را در نظر می گیرد تا یک شناسه به شی شناسایی شده اختصاص دهد. لازم نیست هر بار کل ویدیو را پردازش کند. هدف به حداقل رساندن تابع هزینه زیر است [ 53 ]:
جایی که d (1) فاصله فضایی بین جعبه مرزی پیشبینیشده از فیلتر کالمن (KF) و جعبه مرزی شناخته شده قبلی برای جسم است. فاصله بصری d (2) نشاندهنده کوچکترین فاصله کسینوس بین جعبههای مرزی اشیاء همسان در فریمهای متوالی است. i و j دو شی را در فریم های مختلف نشان می دهند. λ تأثیر فاصله ها را در فرآیند ردیابی تعیین می کند.
3.2. تطبیق رویداد با Edge
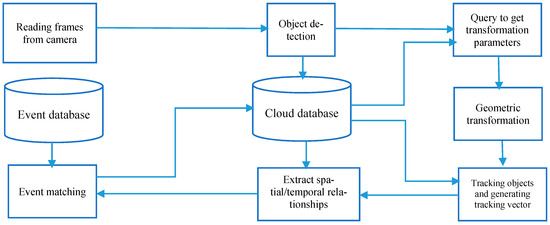
3.3. تطبیق رویداد با استفاده از رایانش ابری
4. اجرا
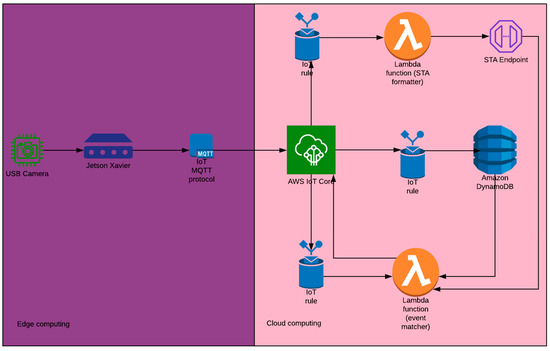
4.1. معماری اجرا شده
4.2. مدل STA
4.3. مدل تشخیص داده و شی
5. نتایج تجربی
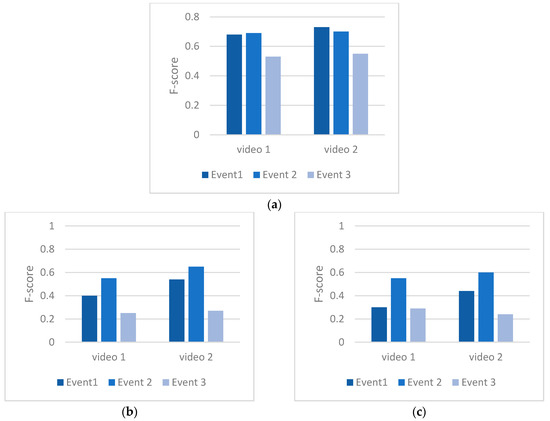
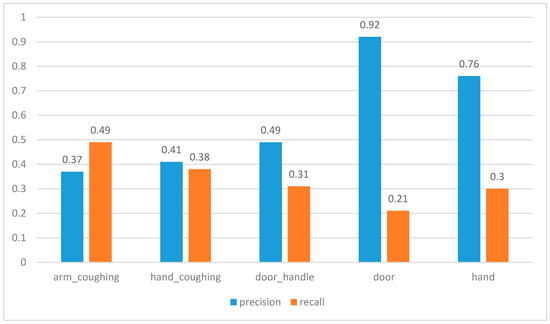
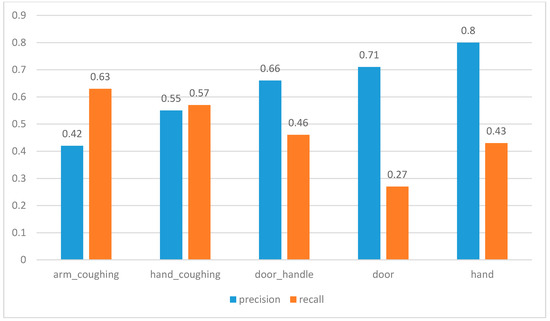
5.1. دقت تشخیص شی
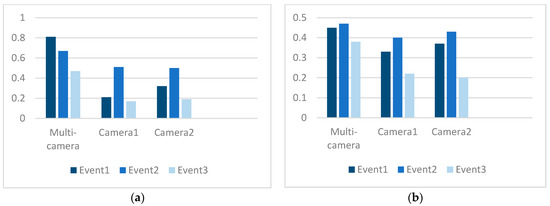
5.2. دقت تطبیق رویداد آنلاین
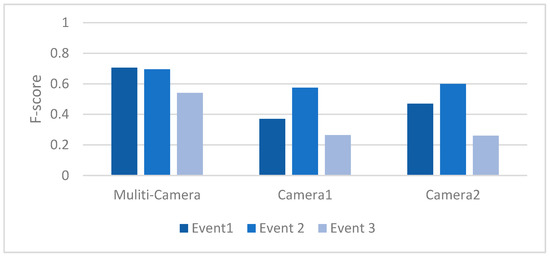
دقت تطبیق رویداد برای معماری لبه و محاسبات ابری یکپارچه در مقایسه با معماری که تمام فرآیندها را با محاسبه لبه با استفاده از تصاویر یک دوربین انجام میدهد، دقت تطبیق رویداد معماری را تعیین میکند. دقت تطابق رویداد بر اساس مقدار F-Score (معادله (3)) محاسبه شد. از آنجایی که این معیاری است که هم شامل دقت و هم یادآوری می شود، اطلاعات جامع تری در مورد تشخیص رویداد پیچیده ارائه می دهد.
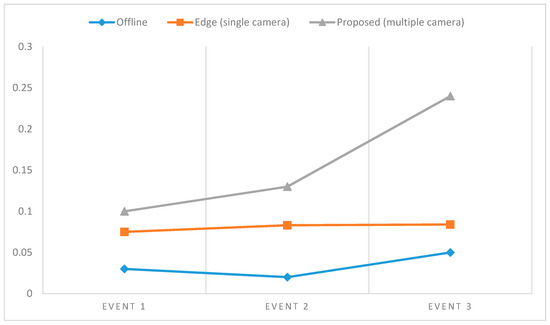
5.3. سرعت تشخیص رویداد آنلاین
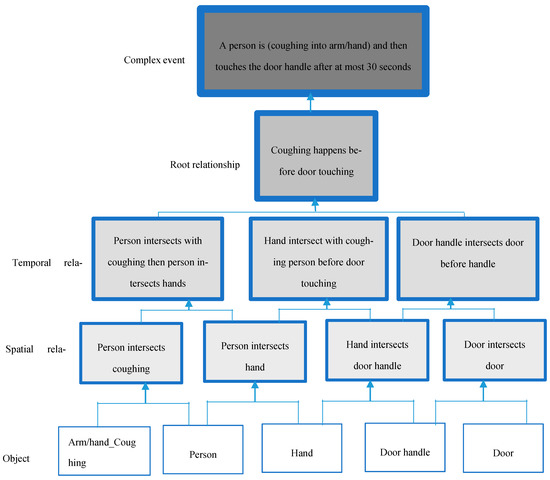
به منظور ارزیابی سرعت معماری توسعهیافته، تأخیر زمانی تطبیق رویداد برای تشخیص رویداد آفلاین با استفاده از لپتاپ و برای تشخیص رویداد آنلاین با Jetson Xavier با استفاده از پردازش تک دوربین و همچنین معماری یکپارچه در نظر گرفته شد. ما از رابطه (2) برای محاسبه تأخیر نسبی استفاده کردیم. در معادله، t زمانی است که به پایگاه داده ابری اطلاع داده شد، t f زمان خواندن فریم است، و t w زمانی است که به عنوان آستانه تعریف شده است (به عنوان مثال، سرفه کردن و سپس لمس کردن دستگیره در باید کمتر از دو دقیقه برای اینکه آن را به عنوان یک رفتار خطر تلقی کنیم) برای رویداد در پایگاه داده الگوی رویداد.
6. بحث
7. نتیجه گیری
پیوست اول
-
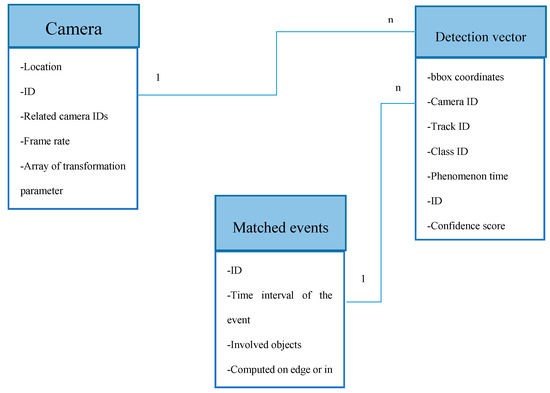
تعریف 1 (بردار رویداد). یک رویداد ذخیره شده در پایگاه داده رویداد یک بردار با عناصر زیر در نظر گرفته می شود:
-
O = آرایه ای از کلاس های شی شناسایی شده.
-
Sr = بردار رابطه فضایی که شامل بیان رابطه فضایی و کلاس های شی درگیر است.
-
Tr = بردار رابطه زمانی که شامل بیان رابطه زمانی و روابط فضایی درگیر است.
-
Rt = آرایه ای (بردار ریشه) از بردارها شامل روابط بین Tr. برای مثال، یک Rt به شکل زیر است:
-
Rt = [R 1 (Tr 1 ,Tr 2 ,relationship_expression1), …, Rn(Tr n−1 ,Tr n ,relationship_expression n )]
-
تعریف 2 (بردار شی تشخیص). شی شناسایی شده در هر فریم که شامل عناصر زیر است:
-
Bbox = مستطیل جعبه های محدود کننده شی یک آرایه است: [ x min , y min , width , height ];
-
Class = نام کلاس شی شناسایی شده.
-
Confidence = مقدار اطمینان احتمالی شی شناسایی شده.
-
Trackid = شناسه ای که هنگام اجرای ماژول ردیابی به هر شی اختصاص داده می شود.
| شبه کد 1—فرآیند تطبیق رویداد شروع می شود c = captureFrame() spatial_rel=[] temporal_rel=[] در حالی که c t = captureTime() det_obj = objectDetector(c) اگر det_obj.siz>0 برای هر رویداد از eventPatterns انجام دهید object_event = [] برای هر obj_pattern از event.object اگر det_obj در obj_pattern پایان را انجام دهید object_event.add (det_obj) اگر object_event.size() > 1 برای هر sr از event.Sr انجام دهید object1 = find(sr.object1.class,object_event) object2 = find(sr.object2.class,object_event) r = spatialRelation(object1,object2) اگر r درست است s = (sr,obj1,obj2,t) spatial_rel.add(s) انتهای انتهایی برای هر temporal_rel از event.Tr انجام دهید sr1 = find(temporal_rel.s1,spatial_rel) sr2 = find(temporal_rel.s2, spatial_rel) event_detected = temporalRelation(sr1.t,sr2.t) اگر event_detected True باشد انجام دهید T = (sr,obj1,obj2,t) temporal_rel.add(T) انتهای انتهایی برای هر root_vector از event.Rt انجام R1 = find( root_vector.T1,temporal_rel) R2 = find(root_vector.T2,temporal_rel) R = root_relationship(R1,R2) اگر R False است انجام دهید skipFrame() پایان پایان بازگشت رویداد پایان پایان پایان پایان پایان |
ضمیمه B
منابع
- بانرجی، اس. Wu, DO گزارش نهایی از کارگاه آموزشی NSF در مسیرهای آینده در شبکه های بی سیم . بنیاد ملی علوم: واشنگتن، دی سی، ایالات متحده آمریکا، 2013. [ Google Scholar ]
- فرانکوفسکی، جی. جرزاک، م. میلوستان، م. نواک، ت. Pawłowski، M. کاربرد سیستم پردازش رویداد پیچیده برای تشخیص ناهنجاری و نظارت بر شبکه. محاسبه کنید. علمی 2015 ، 16 ، 351-371. [ Google Scholar ]
- لی، اس. پسر، SH; Stankovic، JA خدمات تشخیص رویداد با استفاده از میان افزار سرویس داده در شبکه های حسگر توزیع شده. در پردازش اطلاعات در شبکه های حسگر ; Springer: برلین/هایدلبرگ، آلمان، 2003; ص 502-517. [ Google Scholar ]
- فن، اچ. چانگ، ایکس. چنگ، دی. یانگ، ی. خو، دی. تشخیص رویداد Hauptmann، AG Complex با شناسایی نماهای قابل اعتماد از ویدیوهای پاک نشده. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، ونیز، ایتالیا، 22 تا 29 اکتبر 2017؛ صص 736-744. [ Google Scholar ]
- وو، ای. دیائو، ی. Rizvi, S. پردازش رویداد پیچیده با عملکرد بالا در جریانها. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2006 در مدیریت داده ها، شیکاگو، IL، ایالات متحده، 27-29 ژوئن 2006. ص 407-418. [ Google Scholar ]
- کوگولا، جی. مارگارا، الف. پردازش جریان های اطلاعات: از جریان داده تا پردازش رویداد پیچیده. کامپیوتر ACM. Surv. (CSUR) 2012 ، 44 ، 1-62. [ Google Scholar ] [ CrossRef ]
- بوتاکووا، MA; Chernov، AV; شوچوک، PS; Vereskun، VD Complex پردازش رویداد برای تشخیص ناهنجاری شبکه در خدمات ارتباطی دیجیتال راه آهن. در مجموعه مقالات بیست و پنجمین انجمن مخابرات 2017 (TELFOR)، بلگراد، صربستان، 21 تا 22 نوامبر 2017؛ صص 1-4. [ Google Scholar ]
- Terroso-Saenz، F. والدس ولا، م. سوتومایر-مارتینز، سی. تولدو مورئو، آر. Gomez-Skarmeta، AF رویکرد مشارکتی برای تشخیص تراکم ترافیک با پردازش رویداد پیچیده و VANET. IEEE Trans. هوشمند ترانسپ سیستم 2012 ، 13 ، 914-929. [ Google Scholar ] [ CrossRef ]
- Mazon-Olivo، B. هرناندز روخاس، دی. مازا-سالیناس، ج. Pan، A. موتور قواعد و پردازشگر رویداد پیچیده در زمینه اینترنت اشیا برای کشاورزی دقیق. محاسبه کنید. الکترون. کشاورزی 2018 ، 154 ، 347-360. [ Google Scholar ] [ CrossRef ]
- لیو، ایکس. کائو، جی. تانگ، اس. Guo، P. تشخیص رویداد پیچیده متحمل به خطا در WSNs: مطالعه موردی در نظارت بر سلامت ساختاری. IEEE Trans. اوباش محاسبه کنید. 2015 ، 14 ، 2502-2515. [ Google Scholar ] [ CrossRef ]
- Terroso-Saenz، F. والدس ولا، م. Skarmeta-Gomez، AF یک رویکرد پردازش رویداد پیچیده برای تشخیص رفتارهای غیرعادی در محیط دریایی. Inf. سیستم جلو. 2016 ، 18 ، 765-780. [ Google Scholar ] [ CrossRef ]
- جین، ایکس. یوان، پی. لی، ایکس. آهنگ، سی. جنرال الکتریک، اس. ژائو، جی. Chen, Y. حفظ حریم خصوصی کارآمد تشخیص شی نوع Viola-Jones از طریق نمایش تصویر پایه تصادفی. در مجموعه مقالات کنفرانس بین المللی IEEE 2017 در چند رسانه و نمایشگاه (ICME)، هنگ کنگ، چین، 10 تا 14 ژوئیه 2017؛ صص 673-678. [ Google Scholar ]
- چن، جی. Ran, X. یادگیری عمیق با محاسبات لبه: یک بررسی. Proc. IEEE 2019 ، 107 ، 1655-1674. [ Google Scholar ] [ CrossRef ]
- لی، جی. اوزسو، ام تی؛ سافرون، دی. Oria, V. MOQL: یک زبان پرس و جو شی چندرسانه ای. در مجموعه مقالات سومین کارگاه بین المللی سیستم های اطلاعات چندرسانه ای، سئول، کره، 22 تا 26 اکتبر 2018؛ ص 19-28. [ Google Scholar ]
- Kuo، TC; Chen، AL پردازش پرس و جو مبتنی بر محتوا برای پایگاه داده های ویدیویی. IEEE Trans. چند رسانه ای 2000 ، 2 ، 1-13. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عارف، و. حماد، م. Catlin، AC; الیاس، آی. غانم، ت. الماگرمید، ع. Marzouk, M. پردازش پرس و جو ویدیویی در بستر آزمایشی VDBMS برای تحقیقات پایگاه داده ویدیویی. در مجموعه مقالات اولین کارگاه بین المللی ACM در پایگاه داده های چند رسانه ای، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 7 نوامبر 2003. صص 25-32. [ Google Scholar ]
- لو، سی. لیو، ام. Wu, Z. Svql: یک زبان جستجوی توسعه یافته sql برای پایگاه داده های ویدئویی. بین المللی J. نظریه پایگاه داده. Appl. 2015 ، 8 ، 235-248. [ Google Scholar ] [ CrossRef ]
- کانگ، دی. بیلیس، پ. Zaharia, M. BlazeIt: بهینهسازی تجمع اعلانی و جستارهای محدود برای تجزیه و تحلیل ویدئویی مبتنی بر شبکه عصبی. arXiv 2018 , arXiv:1805.01046. [ Google Scholar ] [ CrossRef ]
- جین، پی. شوکلا، وی. سرینیواسان، ا. د کاسترو آلوز، آ. Hsiao، E. پشتیبانی از یک پرس و جو/نمای پارامتری در پردازش رویداد پیچیده. ثبت اختراع ایالات متحده شماره 8،713،049، 29 آوریل 2014. [ Google Scholar ]
- یداو، پ. Curry، E. VidCEP: چارچوب پردازش رویداد پیچیده برای تشخیص الگوهای فضایی-زمانی در جریانهای ویدیویی. در مجموعه مقالات کنفرانس بین المللی IEEE 2019 در مورد داده های بزرگ (داده های بزرگ)، لس آنجلس، کالیفرنیا، ایالات متحده آمریکا، 10 تا 12 دسامبر 2019؛ صص 2513-2522. [ Google Scholar ]
- مدیونی، جی. کوهن، آی. برموند، اف. هونگنگ، اس. نواتیا، R. تشخیص و تجزیه و تحلیل رویداد از جریان های ویدئویی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2001 ، 23 ، 873-889. [ Google Scholar ] [ CrossRef ]
- لی، ز. Ge, T. History آینه ای به آینده است: بهترین تلاش برای تطبیق رویداد پیچیده تقریبی با منابع ناکافی. Proc. VLDB Enddow. 2016 ، 10 ، 397-408. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فریروس، جی. پاردو، جی.ام. هورتادو، L.-F. سگرا، ای. اورتگا، آ. لیدا، ای. تورس، MI; Justo, R. ASLP-MULAN: پردازش گفتار و زبان صوتی برای تجزیه و تحلیل چند رسانه ای. فرآیندها طول. نات. 2016 ، 57 ، 147-150. [ Google Scholar ]
- یانگ، آ. ژانگ، سی. چن، ی. ژوانسون، ی. لیو، اچ. امنیت و حریم خصوصی سیستمهای خانه هوشمند مبتنی بر اینترنت اشیا و الگوریتمهای تطبیق استریو. IEEE Int. Things J. 2019 , 7 , 2521–2530. [ Google Scholar ] [ CrossRef ]
- کارتیک، آر. پرابهاران، AM; Selvaprasanth، P. استراتژی نظارت بر مرزهای امنیت بالا مبتنی بر اینترنت اشیا. آسیایی J. Appl. علمی تکنولوژی (AJAST) جلد. 2019 ، 3 ، 94-100. [ Google Scholar ]
- الساکران، HO سیستم اطلاعات ترافیک هوشمند مبتنی بر ادغام فناوری اینترنت اشیا و عامل. بین المللی J. Adv. محاسبه کنید. علمی Appl. 2015 ، 6 ، 37-43. [ Google Scholar ]
- ژانگ، اس. Yu, H. شناسایی مجدد شخص توسط شبکه های چند دوربینی برای اینترنت اشیا در شهرهای هوشمند. دسترسی IEEE 2018 ، 6 ، 76111–76117. [ Google Scholar ] [ CrossRef ]
- سارا سعیدی، جی.ال. لیانگ، اس. هاوکینز، بی. چن، سی. کوریاس، آی. استارکوف، آی. مک دونالد، جی. آلزونا، م. بوتس، ام. محمدی جهرمی، م. و همکاران گزارش مهندسی خلبان OGC SCIRA ; کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2020. [ Google Scholar ]
- گارسیا، سی جی؛ Meana-Llorián، D.; G-Bustelo، BCP; لاول، JMC; گارسیا-فرناندز، ن. میدگار: تشخیص افراد از طریق بینایی کامپیوتری در سناریوهای اینترنت اشیا برای بهبود امنیت در شهرهای هوشمند، شهرکهای هوشمند و خانههای هوشمند. ژنرال آینده. محاسبه کنید. سیستم 2017 ، 76 ، 301-313. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چودری، آر. راویچاندران، ا. هاگر، جی. ویدال، آر. هیستوگرام های جریان نوری جهت دار و هسته های بینه کوشی در سیستم های دینامیکی غیرخطی برای تشخیص اعمال انسان. در مجموعه مقالات کنفرانس IEEE 2009 در مورد بینایی کامپیوتری و تشخیص الگو، میامی، FL، ایالات متحده آمریکا، 20-25 ژوئن 2009. صفحات 1932-1939. [ Google Scholar ]
- فن، اچ. لو، سی. زنگ، سی. فریانک، م. Que، Z. لیو، اس. نیو، ایکس. Luk, W. F-E3D: شتاب مبتنی بر FPGA یک شبکه عصبی کانولوشنال سه بعدی کارآمد برای تشخیص عمل انسان. در مجموعه مقالات سی امین کنفرانس بین المللی IEEE 2019 در مورد سیستم ها، معماری ها و پردازنده های خاص برنامه (ASAP)، نیویورک، نیویورک، ایالات متحده آمریکا، 15 تا 17 ژوئیه 2019؛ صص 1-8. [ Google Scholar ]
- سیمونیان، ک. Zisserman, A. شبکه های پیچیده بسیار عمیق برای تشخیص تصویر در مقیاس بزرگ. arXiv 2014 ، arXiv:1409.1556. [ Google Scholar ]
- هان، ی. ژانگ، پی. ژو، تی. هوانگ، دبلیو. Zhang، Y. با ConvNets دو جریانی برای تشخیص عملکرد در نظارت تصویری عمیقتر میشویم. تشخیص الگو Lett. 2018 ، 107 ، 83-90. [ Google Scholar ] [ CrossRef ]
- Girshick, R. Fast r-cnn. در مجموعه مقالات کنفرانس بین المللی IEEE در سال 2015 در بینایی کامپیوتر، سانتیاگو، شیلی، 7 تا 13 دسامبر 2015؛ ص 1440-1448. [ Google Scholar ]
- Ko، K.-E. سیم، ک.-بی. چارچوب پیچیده عمیق برای تشخیص رفتار غیرعادی در یک سیستم نظارت هوشمند مهندس Appl. آرتیف. هوشمند 2018 ، 67 ، 226-234. [ Google Scholar ] [ CrossRef ]
- گان، سی. وانگ، ن. یانگ، ی. یونگ، دی.-ای. Hauptmann, AG Devnet: یک شبکه رویداد عمیق برای شناسایی رویدادهای چندرسانه ای و بازگویی شواهد. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، سان خوان، روابط عمومی، ایالات متحده آمریکا، 17 تا 19 ژوئن 1997. صص 2568-2577. [ Google Scholar ]
- Xiong، Y. زو، ک. لین، دی. تانگ، ایکس. رویدادهای پیچیده را از تصاویر استاتیک با ترکیب کانالهای عمیق تشخیص دهید. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، سان خوان، روابط عمومی، ایالات متحده آمریکا، 17 تا 19 ژوئن 1997. صفحات 1600-1609. [ Google Scholar ]
- Jhuo، I.-H.; Lee, D. تشخیص رویداد ویدیویی از طریق یادگیری عمیق چند وجهی. در مجموعه مقالات بیست و دومین کنفرانس بین المللی شناسایی الگوی 2014، استکهلم، سوئد، 24 تا 28 اوت 2014. صص 666-671. [ Google Scholar ]
- وو، زی. جیانگ، ی.-جی. وانگ، ایکس. بله، اچ. Xue, X. ادغام چند کلاسه چند جریانی از شبکه های عمیق برای طبقه بندی ویدئو. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ACM در چند رسانه ای، آمستردام، هلند، 5 تا 19 اکتبر 2016؛ صص 791-800. [ Google Scholar ]
- حبیبیان، ع. منسینک، تی. Snoek، CG Composite کشف مفهومی برای تشخیص رویداد ویدیویی صفر شات. در مجموعه مقالات کنفرانس بین المللی بازیابی چند رسانه ای، گلاسکو، انگلستان، 1-4 آوریل 2014. صص 17-24. [ Google Scholar ]
- مظلوم، م. گاووس، ای. ون دو ساند، ک. اسنوک، سی. جستجوی بانکهای مفهومی آموزنده برای تشخیص رویداد ویدیویی. در مجموعه مقالات سومین کنفرانس ACM در کنفرانس بین المللی بازیابی چند رسانه ای، دالاس، تگزاس، ایالات متحده آمریکا، 16-19 آوریل 2013. صص 255-262. [ Google Scholar ]
- رستگاری، م. دیبا، ع. پریخ، د. فرهادی، الف. پرسشهای چند ویژگی: ادغام یا عدم ادغام؟ در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، سان خوان، روابط عمومی، ایالات متحده آمریکا، 17 تا 19 ژوئن 1997. صص 3310–3317. [ Google Scholar ]
- دوبا، کاس؛ Cohn، AG; هاگ، دی سی؛ بهات، ام. Dylla, F. یادگیری مدل های رویداد رابطه ای از ویدئو. جی آرتیف. هوشمند Res. 2015 ، 53 ، 41-90. [ Google Scholar ] [ CrossRef ]
- کانگ، دی. ایمونز، جی. ابوزید، ف. بیلیس، پ. Zaharia, M. Noscope: بهینه سازی پرس و جوهای شبکه عصبی از طریق ویدئو در مقیاس. arXiv 2017 , arXiv:1703.02529. [ Google Scholar ] [ CrossRef ]
- حسیه، ک. Ananthanarayanan، G. بودیک، پ. ونکاتارامان، اس. باهل، ص. فیلیپس، م. Gibbons، PB; Mutlu، O. Focus: پرس و جو از مجموعه داده های ویدیویی بزرگ با تأخیر کم و هزینه کم. در مجموعه مقالات سیزدهمین سمپوزیوم USENIX در مورد طراحی و پیاده سازی سیستم های عامل (OSDI 18)، کارلزبد، کالیفرنیا، ایالات متحده آمریکا، 8 تا 10 اکتبر 2018؛ صص 269-286. [ Google Scholar ]
- چوچوتکائو، اس. یاماگوچی، اچ. هیگاشینو، تی. شیبویا، م. Hasegawa، T. EdgeCEP: پردازش رویداد پیچیده کاملاً توزیع شده در لبه های اینترنت اشیا. در مجموعه مقالات سیزدهمین کنفرانس بین المللی 2017 در مورد محاسبات توزیع شده در سیستم های حسگر (DCOSS)، اتاوا، ON، کانادا، 5 ژوئن 2017؛ صص 121-129. [ Google Scholar ]
- ردمون، جی. دیووالا، س. گیرشیک، آر. فرهادی، الف. شما فقط یک بار نگاه می کنید: یکپارچه، تشخیص شی در زمان واقعی. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، سان خوان، روابط عمومی، ایالات متحده آمریکا، 17 تا 19 ژوئن 1997. صص 779-788. [ Google Scholar ]
- ژائو، Z.-Q. ژنگ، پی. Xu، S.-t.; Wu, X. تشخیص شی با یادگیری عمیق: یک بررسی. IEEE Trans. شبکه عصبی فرا گرفتن. سیستم 2019 ، 30 ، 3212–3232. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گیرشیک، آر. دوناهو، جی. دارل، تی. Malik, J. Rich دارای سلسله مراتب برای تشخیص دقیق شی و تقسیم بندی معنایی هستند. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، سان خوان، روابط عمومی، ایالات متحده آمریکا، 17 تا 19 ژوئن 1997. صص 580-587. [ Google Scholar ]
- چن، اچ. وانگ، ی. وانگ، جی. Qiao, Y. Lstd: یک آشکارساز انتقال شات پایین برای تشخیص اشیا. در مجموعه مقالات سی و دومین کنفرانس AAAI در مورد هوش مصنوعی، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 5 فوریه 2018. [ Google Scholar ]
- هو، ایکس. وانگ، ی. چاو، ال.-پی. ردیابی خودرو با استفاده از مرتب سازی عمیق با فیلتر کردن مسیر با اطمینان کم. در مجموعه مقالات شانزدهمین کنفرانس بین المللی IEEE در سال 2019 در زمینه نظارت بر ویدئو و سیگنال پیشرفته (AVSS)، تایپه، تایوان، 18 سپتامبر 2019؛ صص 1-6. [ Google Scholar ]
- Punn، NS; Sonbhadra، SK; آگاروال، اس. نظارت بر فاصلهگذاری اجتماعی COVID-19 با شناسایی و ردیابی افراد از طریق تکنیکهای تنظیمشده YOLO v3 و Deepsort. arXiv 2020 ، arXiv:2005.01385. [ Google Scholar ]
- تیاگارجان، ر. پالا، اف. ژانگ، ایکس. بانو، بی. فوتبال: چه کسی توپ را در اختیار دارد؟ تولید تجزیه و تحلیل بصری و آمار بازیکن. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صفحات 1749-1757. [ Google Scholar ]
- کورنیاوان، ا. رمضلان، ع. Yuniarno، E. نظارت بر سرعت برای چندین وسیله نقلیه با استفاده از دوربین مدار بسته تلویزیون (CCTV). در مجموعه مقالات کنفرانس بین المللی 2018 مهندسی کامپیوتر، شبکه و چند رسانه ای هوشمند (CENIM)، سورابایا، اندونزی، 26 نوامبر 2018؛ صص 88-93. [ Google Scholar ]
- چمیلوسکا، ا. ماریانا، پ. مارسینیاک، تی. دابروفسکی، ا. Walkowiak, P. کاربرد هندسه تصویری در نگاشت چگالی بر اساس نظارت دوربین مدار بسته. در مجموعه مقالات پردازش سیگنال 2015: الگوریتم ها، معماری ها، ترتیبات و برنامه ها (SPA)، پوزنان، لهستان، 3 مه 2015. صص 179-184. [ Google Scholar ]
- گونزالس-سوسا، ای. ورا رودریگز، آر. فیرز، جی. تومه، پی. اورتگا-گارسیا، جی. جبران تغییرپذیری با استفاده از تبدیل تصویری برای تشخیص چهره پزشکی قانونی. در مجموعه مقالات کنفرانس بین المللی 2015 گروه علاقه ویژه بیومتریک (BIOSIG)، دارمشتات، آلمان، 9 سپتامبر 2015; صص 1-5. [ Google Scholar ]
- میلر، ای. بانرجی، ن. Zhu, T. خانههای هوشمندی که عطسه، سرفه و لمس صورت را تشخیص میدهند. Smart Health 2020 , 19 , 100170. [ Google Scholar ] [ CrossRef ]
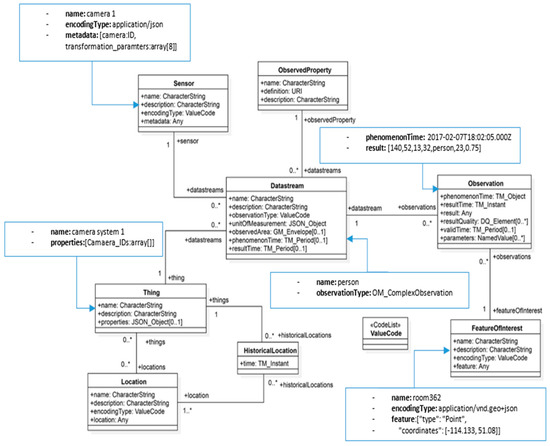
- لیانگ، SH. سعیدی، س. اوجاغ، س. هنرپرور، س. کیایی، س. جهرمی، م.م. Squires, J. یک معماری تعاملی برای اینترنت چیزهای COVID-19 (IoCT) با استفاده از استانداردهای فضایی باز – مطالعه موردی: بازگشایی محل کار. Sensors 2021 , 21 , 50. [ Google Scholar ] [ CrossRef ]
- Maeda، K. ارزیابی عملکرد کتابخانه های سریال سازی شی در قالب های XML، JSON و باینری. در مجموعه مقالات دومین کنفرانس بین المللی 2012 در زمینه فناوری اطلاعات و ارتباطات دیجیتال و کاربردهای آن (DICTAP)، بانکوک، تایلند، 16 مه 2018؛ صص 177-182. [ Google Scholar ]
- یغم زاده، ن. وانگ، ایکس. Dillig، I. انتقال خودکار داده های سلسله مراتبی به جداول رابطه ای با استفاده از برنامه نویسی به صورت مثال. Proc. VLDB Enddow. 2018 ، 11 ، 580-593. [ Google Scholar ] [ CrossRef ]
- شاسور، سی. لی، ی. Patel، JM ذخیرهسازی اسناد JSON در سیستمهای رابطهای را فعال میکند. در مجموعه مقالات WebDB، نیویورک، نیویورک، ایالات متحده آمریکا، 23 ژوئن 2013; ص 14-15. [ Google Scholar ]
- کوتسف، ا. شلید، ک. لیانگ، اس. ون در شاف، اچ. خلفبیگی، ت. گرلت، اس. لوتز، ام. جیرکا، س. Beaufils, M. گسترش INSPIRE به اینترنت اشیا از طریق SensorThings API. Geosciences 2018 ، 8 ، 221. [ Google Scholar ] [ CrossRef ][ Green Version ]
- لیانگ، اس. هوانگ، سی.-ای. Khalafbeigi, T. OGC SensorThings API Part 1: Sensing ; نسخه 1.0؛ کنسرسیوم فضایی باز: Wayland، MA، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- باتلر، اچ. دالی، م. دویل، ا. گیلیز، اس. هاگن، اس. شاوب، تی . فرمت جئوجسون ; کارگروه مهندسی اینترنت (IETF): ویلمینگتون، NC، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- هوربینسکی، تی. Cybulski, P. شباهت های عملکرد خدمات نقشه برداری وب جهانی در زمینه طراحی وب پاسخگو. Geod. کارتوگر. 2018 ، 67 ، 159-177. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هوربینسکی، تی. Lorek, D. استفاده از فایل های Leaflet و GeoJSON برای ایجاد نقشه وب تعاملی از وضعیت محیط طبیعی قبل از صنعتی شدن. جی. اسپات. علمی 2020 . [ Google Scholar ] [ CrossRef ]
- لین، تی.-ای. مایر، م. بلنگی، اس. هیز، جی. پرونا، پی. رامانان، دی. دلار، پی. Zitnick، CL مایکروسافت کوکو: اشیاء مشترک در زمینه. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر، گلاسکو، بریتانیا، 23 تا 28 اوت 2020؛ صص 740-755. [ Google Scholar ]
- میتال، آ. زیسرمن، آ. Torr، PH تشخیص دست با استفاده از چند پیشنهاد. در مجموعه مقالات BMVC، کلاورتون، بریتانیا، 8 سپتامبر 2020؛ پ. 5. [ Google Scholar ]
- بشیری، ف.س. لارز، ای. پیسیگ، پی. تفتی، AP MCIndoor20000: مجموعه داده تصویری کاملاً برچسبگذاری شده برای پیشبرد تشخیص اشیاء داخلی. داده مختصر 2018 ، 17 ، 71-75. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- کوزنتسوا، آ. رام، اچ. آلدرین، ن. Uijlings، J. کراسین، آی. پونت توست، جی. کمالی، س. پوپوف، اس. مالوچی، م. Kolesnikov، A. مجموعه داده تصاویر باز v4: طبقه بندی تصویر یکپارچه، تشخیص اشیا، و تشخیص ارتباط بصری در مقیاس. arXiv 2018 , arXiv:1811.00982. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- عبدالله، دبلیو ماسک R-CNN برای تشخیص اشیاء و تقسیمبندی نمونه در Keras و Tensorflow. 2017. در دسترس آنلاین: https://github.com/matterport/Mask_RCNN (در 18 دسامبر 2020 قابل دسترسی است).
- کوریا، آی. فورنیه، اف. اسکاربوفسکی، I. مورد نامشخص کشف کلاهبرداری کارت اعتباری. در مجموعه مقالات نهمین کنفرانس بین المللی ACM در مورد سیستم های مبتنی بر رویداد توزیع شده، بارسلون، اسپانیا، 3 تا 7 ژوئیه 1995; ص 181-192. [ Google Scholar ]
- آدی، ع. بوتزر، دی. نچوشتی، گ. شارون، جی. پردازش رویداد پیچیده برای خدمات مالی. در مجموعه مقالات کارگاههای محاسباتی خدمات IEEE 2006، شیکاگو، IL، ایالات متحده آمریکا، 18 تا 22 سپتامبر 2006. صص 7-12. [ Google Scholar ]
- کابانیلاس ماسیاس، سی. کوریک، ا. دی سیچیو، سی. گوجهر، م. مندلینگ، جی. پرشر، جی. Simecka، J. ترکیب پردازش رویداد و ماشینهای بردار پشتیبانی برای پیشبینیهای انحراف خودکار پرواز. در مجموعه مقالات اولین کارگاه بینالمللی مدلسازی فرآیندهای بین سازمانی و اولین کارگاه بینالمللی مدلسازی رویداد و پردازش در مدیریت فرآیندهای کسبوکار که با شرکت Modellierung، وین، اتریش، 19 مارس 2014 برگزار شد. ص 45-47. [ Google Scholar ]
- چن، سی. فو، جی اچ. سانگ، تی. وانگ، P.-F. جو، ای. فنگ، M.-W. پردازش رویداد پیچیده برای اینترنت اشیا و کاربردهای آن. در مجموعه مقالات کنفرانس بین المللی IEEE 2014 در علوم و مهندسی اتوماسیون (CASE)، تایپه، تایوان، 19 اوت 2014. صص 1144-1149. [ Google Scholar ]
- نیلسن، اس. چمبرز، سی. Farr, J. سیستمها و روشها برای پردازش رویداد پیچیده اطلاعات خودرو و اطلاعات تصویر مربوط به یک خودرو. ثبت اختراع ایالات متحده شماره 8،560،164، 15 اکتبر 2013. [ Google Scholar ]
- بونینو، دی. De Russis، L. پردازش رویداد پیچیده برای افسران شهر: رویکرد بصری فیلتر و لوله. IEEE Int. Things J. 2017 , 5 , 775–783. [ Google Scholar ] [ CrossRef ]
- پنگ، اس. او، J. پردازش رویداد پیچیده تودرتو با زمینه آگاه کارآمد از طریق جریانهای RFID. در مجموعه مقالات کنفرانس بین المللی مدیریت اطلاعات عصر وب، نانچانگ، چین، 3 ژوئن 2016; صص 125-136. [ Google Scholar ]
- جدوبوم، AC; آری، ع. آدامو، ا. Gueroui، AM; محمدو، ع. Aliouat، Z. جمع آوری داده های بزرگ در شبکه های حسگر بی سیم در مقیاس بزرگ. Sensors 2018 , 18 , 4474. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- برونز، آر. دانکل، جی. ماسبروخ، اچ. Stipkovic، S. Intelligent M2M: پردازش رویداد پیچیده برای ارتباط ماشین به ماشین. سیستم خبره Appl. 2015 ، 42 ، 1235-1246. [ Google Scholar ] [ CrossRef ]
- بله، جی. لی، ی. خو، اچ. لیو، دی. چانگ، اس.-ف. Eventnet: یک کتابخانه مفهومی ساختار یافته در مقیاس بزرگ برای تشخیص رویدادهای پیچیده در ویدیو. در مجموعه مقالات بیست و سومین کنفرانس بین المللی ACM در چند رسانه ای، بریزبن، استرالیا، 26 تا 30 اکتبر 2015. صص 471-480. [ Google Scholar ]
- یداو، پ. Curry، E. VEKG: نمودار دانش رویداد ویدیویی برای نمایش جریانهای ویدیویی برای تطبیق الگوی رویداد پیچیده. در مجموعه مقالات اولین کنفرانس بین المللی 2019 در محاسبات نمودار (GC)، لاگونا هیلز، CA، ایالات متحده آمریکا، 25-27 سپتامبر 2019؛ ص 13-20. [ Google Scholar ]
- طوسیف، ک. حسین، جی. راجا، ج. جسمین، م. عارف، ای. مروری بر سیستمهای پردازش رویداد پیچیده برای دادههای بزرگ. در مجموعه مقالات چهارمین کنفرانس بین المللی 2018 در بازیابی اطلاعات و مدیریت دانش (CAMP)، کوتا کینابالو، اندونزی، 26 مارس 2018؛ صص 1-6. [ Google Scholar ]
- سعیدی، س. موسی، ع. El-Sheimy، N. مسیریابی شخصی آگاه از زمینه با استفاده از ترکیب حسگر تعبیه شده در گوشی های هوشمند. Sensors 2014 , 14 , 5742-5767. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- اوجاغ، س. سعیدی، س. Liang، SHL یک سیستم ردیابی تماس فرد به فرد و فرد به مکان COVID-19 بر اساس OGC IndoorGML. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 2. [ Google Scholar ]


بدون دیدگاه