1. مقدمه
فعالیت های جستجو و نجات افراد گمشده (SAR) فعالیت های حفاظت مدنی است که توسط تیم های جستجو و نجات انجام می شود. یک موضوع ممکن است تحت شرایط مختلف گم شود – مانند گردشگرانی که در مسیر پیاده روی سرگردان هستند، کودکانی که در مناطق وحشی سرگردان هستند، یا افراد مسن مبتلا به زوال عقل که از خانه سرگردان هستند. تنها در کرواسی، سرویس نجات کوهستان کرواسی بیش از 6000 مأموریت را از زمان تأسیس خود در 60 سال پیش انجام داده است [ 1 ]. هنگامی که شخصی گم می شود، حادثه یک فرد گم شده گزارش می شود، یک تیم SAR به روشی حساس جمع می شود و فعالیت هایی را با هدف یافتن فرد گمشده در اسرع وقت انجام می دهد. اعضای تیم SAR وظیفه دارند یک منطقه خاص را جستجو کنند و عملیات توسط مدیر SAR هدایت و هماهنگ می شود. هر حادثه و فعالیتی از این دست متفاوت است و چالش های خاص خود را دارد، اما تجربه و شهود تیم و مدیر SAR می تواند در شرایط بحرانی از اهمیت حیاتی برخوردار باشد. مدیران باتجربه SAR تصمیماتی اتخاذ خواهند کرد که منجر به موثرترین تکمیل کار می شود.
عملیات SAR خاص با نقطه برنامه ریزی اولیه (IPP) مشخص می شود، که نقطه اولیه ای است که در اطراف آن جستجو برای یک فرد گمشده برنامه ریزی شده است. معمولاً همان موقعیت جغرافیایی است که فرد گمشده آخرین بار در آنجا دیده شده است. این مکان اغلب به عنوان نقطه آخرین بازدید (PLS) شناخته می شود.. این مکان از گزارش فرد گم شده مشخص می شود زیرا شخصی که یک فرد را گم شده گزارش می دهد مکان آخرین باری که سوژه در آن دیده شده است را نیز می دهد. جهت جستجو، ناحیه فوکوس و فاصله از IPP مورد جستجو به عوامل مختلفی بستگی دارد و منوط به ارزیابی مدیر SAR است. مدیر SAR با تجربه تصمیماتی می گیرد که تیم را به سمت یافتن سریع فرد گمشده هدایت می کند. با این حال، تنها با تمرکز بر روی محتمل ترین مکان ها، می توان مکان واقعی فرد گم شده را از دست داد، زیرا همه رفتارها رایج ترین آنها نیستند. هدف تحقیق ارائه شده در این مقاله ساخت روش و ابزار نرم افزاری است که این تصمیمات را آسان تر می کند.
فناوری اطلاعات و ارتباطات (ICT) در تمام جنبه های فعالیت های انسانی نفوذ کرده است [ 2 ]. امروزه ابزارهای فناوری اطلاعات و ارتباطات نه تنها در بهبود بهره وری، ارتباطات، سبک زندگی و سفر استفاده می شوند، بلکه در حوزه مدیریت دولتی و امنیت عمومی نیز یافت می شوند [ 3 ]. در فعالیت های SAR، ابزار ICT، در شکل ابتدایی خود، به عنوان ابزار ارتباطی بین اعضای تیم استفاده می شود. ابزارهای ICT در شکل پیچیده تر خود می توانند به عنوان یک سیستم پشتیبانی تصمیم (DSS) نیز عمل کنند . DSS میتواند برای برنامهریزی بهینه فعالیتهای SAR سودمند باشد و پیشنهاداتی مبتنی بر دادهها، مدلها و هوش مصنوعی ارائه میدهد.
این مقاله روشی را ارائه میکند که در حین توسعه یک ابزار مبتنی بر فناوری اطلاعات و ارتباطات بهدست میآید که هدف آن استفاده از یک تیم برنامهریزی ماموریت جستجو و نجات برای ارزیابی منطقهای است که باید توسط تیم در حین جستجوی فرد گمشده اسکن شود. روش ما برای جستجو، جهت جستجو، ناحیه فوکوس و فاصله از IPP را پیشنهاد می کند. به عبارت دیگر، این روش ناحیهای با شکل نامنظم را به مدیر SAR پیشنهاد میکند که در آن فرد گمشده باید جستجو شود.
ما مراحل روش برای ساخت الگوریتم ها را شرح می دهیم – پیش پردازش داده ها، توسعه مدل های رگرسیون، کالیبراسیون مدل یادگیری انتقال، الگوریتم شبیه سازی و ساخت شکل پیشنهادی منطقه ای که باید جستجو شود. ما نتایج الگوریتمها – شکل منطقه پیشنهادی را با مکانهایی که فرد از روی سوابق بایگانی شده پیدا شد، مقایسه کردیم و نتایج را ارائه کردیم.
1.1. کار مرتبط
همانطور که قبلاً در مقدمه بیان شد، ابزارهای ICT می توانند چندین کار از فعالیت های سازمان یافته SAR را آسان کنند. در این کار ما بر نقش سیستمهای ICT در کار تعیین منطقه جستجو تمرکز خواهیم کرد. منطقه جستجو منطقه ای است که جستجوگران برای یافتن مکان جدید فرد گمشده غربالگری می کنند. رویکردهای مختلفی در تعیین منطقه جستجو وجود دارد.
اول، ما باید تشخیص دهیم که SAR می تواند در خشکی و دریا رخ دهد. هنگامی که فردی در دریا گم می شود، منطقه جستجو با توجه به جریان های دریا تعیین می شود، اما ویژگی های فضایی ساحل نزدیک نیز می تواند ورودی ارزشمندی برای تعیین منطقه جستجوی دقیق تر باشد، همانطور که در [ 4 ] پیشنهاد شده است.
در مواردی که SAR در خشکی رخ میدهد، پیشبینی مکان جدید فرد گمشده به عوامل زیادی بستگی دارد که میتوان آنها را تقریباً به (الف) ویژگیهای فرد گمشده و (ب) ویژگیهای فضایی منطقه اطراف تفکیک کرد. در کارمان، ما با جستجوی یک فرد گمشده در محیطهای غیر شهری سر و کار داریم که اغلب به عنوان جستجو و نجات در بیابان [ 5 ] یاد میشود. پیشبینی منطقه جستجوی روششناختی بر اساس یک مدل است، در حالی که موضوع مدلسازی میتواند فرد گمشده یا منطقه باشد.
مدلی که رفتار افراد گمشده را توصیف میکند، معمولاً به سوابق بایگانی موارد و آمار قبلی متکی است. اولین تلاش مستند برای تجزیه و تحلیل رفتار افراد گمشده زمانی است که پدر لورنزو در آسایشگاه سنت گوتارد، صومعه ای در سوئیس، شروع به ضبط ماموریت های جستجو و نجات در کوه های آلپ سوئیس [ 6 ] در سال 1783 کرد. از آن زمان، چندین رکورد از گمشده وجود دارد. پایگاه داده های آرشیو جستجو و نجات افراد آمارهای گردآوری شده در کتاب [ 7 ] به عنوان اولین زمینه برای مدیریت جستجو مورد استفاده قرار گرفت. پایگاه داده بایگانی جدیدتر فعالیتهای قبلی SAR – پایگاه دادههای بینالمللی جستجو و نجات (ISRID) مبنایی برای تجزیه و تحلیل رفتار افراد گمشده در [ 8 ] است.
رفتار شخص گمشده به طور کامل در [ 8 ] مورد مطالعه قرار گرفته است. در [ 8 ] نویسنده مدلی از رفتار افراد گمشده را بر اساس آمار به دست آمده از پایگاه داده ISRID پیشنهاد می کند. این مدل از جداول فاصله اقلیدیان استفاده می کند و یک منطقه جستجو را با استفاده از روش شعاع نقطه ای در اطراف IPP پیشنهاد می کند.
با این حال، برای مطالعه موردی پارک ملی یوسمیتی، مدل پیشنهادی نتایج ضعیفی را نشان داده است، بنابراین آمار جدید تنها برای این منطقه در [ 9 ] ارائه شده است. ارزیابی مدل های رفتاری افراد گمشده در [ 10 ] انجام شد. نویسندگان جداول فاصله اقلیدسی را از [ 8 ] و مدل حوضه آبخیز از [ 9 ] مقایسه کردند و مدل جدیدی را بر اساس ترکیب دو مدل قبلی پیشنهاد کردند. همانطور که ما تفاوت های بین مدل مبتنی بر آمار بین المللی و مدل مبتنی بر آمار محلی را مشاهده می کنیم، می توانیم فرض کنیم که علاوه بر رفتار فرد گمشده، ویژگی های محلی زمین هنگام تخمین منطقه جستجو نیز باید در نظر گرفته شود.
تجزیه و تحلیل زمین به طور موثر با استفاده از سیستم های اطلاعات جغرافیایی (GIS) انجام می شود. سیستم های GIS به طور موثر اطلاعات متعددی را در مورد ویژگی های زمین مانند مدل رقومی ارتفاع، پوشش زمین، جاده ها، مکان های دیدنی و غیره دستکاری می کنند. در [ 11 ] نویسندگان یک نرم افزار پشتیبانی تصمیم گیری جستجو و نجات مبتنی بر GIS ارائه می دهند. این نرم افزار از مدلی بر اساس داده های عملیات قبلی استفاده می کند و احتمال یافتن یک موضوع را در بخش های مختلف منطقه جستجو محاسبه می کند. خروجی نرم افزار یک نقشه حرارتی است که با ترکیب ویژگی های تاثیرگذار زمین ساخته شده است. در [ 12 ] نویسندگان جنبه های زمین و فرد گمشده را ادغام کردند و از رویکرد بیزی برای پیش بینی رفتار افراد گمشده استفاده کردند.
برخلاف سیستمهای مشابه، که در آن منطقه جستجوی پیشنهادی منطقهای با بیشترین احتمال برای یافتن فرد گمشده با در نظر گرفتن آمار جستجوهای آرشیو شده است، ما یک رویکرد مبتنی بر شبیهسازی جدید را پیشنهاد میکنیم. روش ما مبتنی بر شبیهسازی همه رفتارها و مسیرهای ممکن راه رفتن است و منطقه جستجو را با تمام مکانهایی که فرد میتواند پس از تعجب از IPP در آن ساکن شود، پیشنهاد میکند.
دومین جنبه جدید تحقیق ما استفاده از روش های علم داده برای مدل سازی سرعت راه رفتن در زمین های غیر شهری است. روشهای علم داده قبلاً برای مدلسازی سرعت پیادهروی در مناطق شهری استفاده میشد. رگرسیون خطی ، به عنوان یک تکنیک رایج یادگیری ماشین در [ 13 ] برای پیشبینی سرعت راه رفتن استفاده شد. در [ 14 ] نویسندگان از یک مدل زمین نهفته برای پیشبینی مسیر پیمایش سوژه در حال حرکت استفاده کردند. در [ 15 ] نویسندگان از یادگیری انتقالی برای پیش بینی الگوهای حرکت جمعیت شهری استفاده کردند. با این حال، حرکت افراد گمشده در بیابان متفاوت است و نیاز به رویکردهای متفاوتی نسبت به مدل سازی حرکت شهری دارد.
یادگیری انتقالی [ 16 ] با موفقیت در یادگیری عمیق استفاده شده است. با این رویکرد، یک مدل شبکه عصبی با مجموعه بزرگی از دادهها از قبل آموزش داده میشود و ویژگیهای آموختهشده برای مشخص کردن مدل برای یک دامنه خاص که در آن امکان دستیابی به مجموعه دادهای به اندازه کافی بزرگ برای آموزش واقعی وجود ندارد، استفاده میشود. طبقه بندی کننده یا مدل از همین رویکرد می توان برای یادگیری انتقال مدل رگرسیون خطی استفاده کرد. در [ 17 ] روشی برای پالایش یک مدل رگرسیون خطی که در ابتدا برای یک دامنه آموزش داده شده است تا در حوزه دیگری استفاده شود، توضیح داده شده است.
اتوماتای سلولی (CA) [ 18 ] مدل های ریاضی ساده ای هستند که اغلب برای بررسی اثر خلاصه مجموعه اجزای ساده استفاده می شوند. سودمندی آنها در بسیاری از زمینه ها ثابت شده است. اتوماتای سلولی برای شبیه سازی ترافیک [ 19 ] و شبیه سازی پیاده روی عابران پیاده [ 20 ] استفاده شده است. اتوماتای سلولی مبتنی بر GIS برای شبیه سازی تغییر کاربری زمین [ 21 ] و شبیه سازی گسترش آتش [ 22 ] استفاده شده است. در حوزه حفاظت مدنی، اتوماتای سلولی برای شبیه سازی مسیرهای تخلیه در [ 23 ] استفاده شده است.
در [ 24 ] نویسندگان از مدل سازی مبتنی بر عامل برای محاسبه توزیع رفتارها و محاسبه توزیع فواصل افقی طی شده در زمان ثابت استفاده کردند.
1.2. روش پیشنهادی
تازگی کار ما از دو جنبه قابل توجه است. اولی یک رویکرد جدید و مبتنی بر شبیه سازی برای تعیین منطقه جستجو است. در سیستم های مشابه منطقه جستجو به عنوان محتمل ترین منطقه ای که فرد گمشده بر اساس آمار جستجوهای بایگانی شده پیدا می شود، پیشنهاد می شود. پیش بینی ما بر اساس شبیه سازی است. ما رفتار فرد گمشده را از نظر آماری قابل پیشبینی نمیدانیم، بلکه همه رفتارهای ممکن و تمام مسیرهای ممکن راه رفتن را شبیهسازی میکنیم تا به حداکثر مساحت از همه مکانهایی که فرد میتواند پس از سرگردانی از IPP در آن ساکن شود، دست یابد. تنها پارامتر رفتار فرد گمشده که ما فرض می کنیم سرعت پیش بینی شده راه رفتن در زمین با ویژگی های مختلف است.
دومین نوآوری روش پیشنهادی ما، مدل رگرسیون مبتنی بر یادگیری انتقال سرعت راه رفتن است. ما سوابقی از راه رفتن افراد گمشده نداریم، بنابراین نمی توانیم یک مدل یادگیری ماشینی برای پیش بینی سرعت راه رفتن فرد گمشده ایجاد کنیم. بنابراین، ما از مسیرهای موجود برای ایجاد مدلی برای پیشبینی سرعت راه رفتن در قسمتی از زمین استفاده میکنیم و از انتقال آن با مقیاسگذاری روی مدلی برای پیشبینی سرعت راه رفتن فرد گمشده استفاده میکنیم. رویکرد مبتنی بر یادگیری انتقال ما را قادر میسازد تا یک مدل سرعت راه رفتن فرد گمشده را بدون مقدار کافی داده برای یک مدل یادگیری ماشینی دقیق ایجاد کنیم. ما از دادههای ثبتشده پیادهروی در همان زمینی که میتوانستیم به دست آوریم، استفاده میکنیم، و آن سوابق GPX افرادی است که در جستجوی یک فرد گمشده هستند.
2. روش شناسی
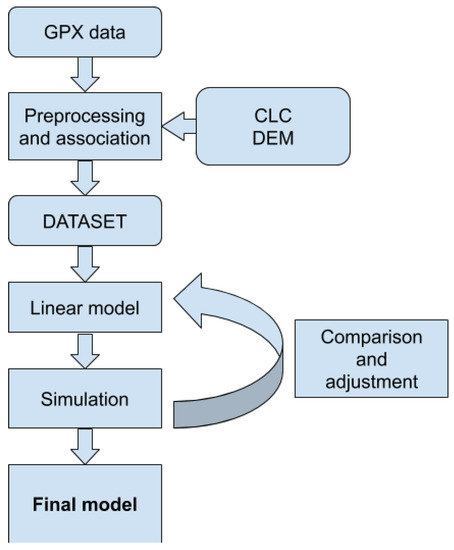
در این بخش، داده هایی را که استفاده کردیم و روش شناسی کار خود را شرح خواهیم داد. ابتدا، داده های جمع آوری شده از منابع مختلف که در قالب های مختلف بیان شده اند، پیش پردازش شدند. پیش پردازش برای ارتباط و ادغام داده ها همانطور که در شکل 1 نشان داده شده است انجام شد . نتیجه پیش پردازش یک مجموعه داده متصل است که برای آموزش مدل استفاده کردیم. آموزش در دو مرحله مدل پیش تمرین و کالیبراسیون مدل انجام شد. در نهایت، الگوریتمهایی را که برای پیشبینی منطقه جستجو استفاده میکنیم، توصیف میکنیم.
2.1. شرح و منابع داده ها
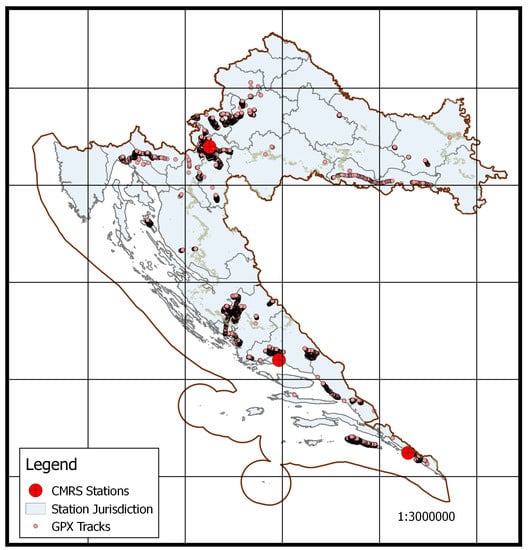
اساس مجموعه داده ما مجموعه ای از فایل های ارائه شده توسط سرویس نجات کوهستان کرواسی [ 1 ] بود. مجموعه ای از 1908 مسیر GPX برای تحقیق ما در دسترس قرار گرفت. مسیرهای GPX از سه بخش خدمات نجات کوهستانی – اسپلیت، کارلواچ و دوبرونیک جمع آوری شده است. مسیرها با استفاده از دستگاه های GPS مختلف که توسط افراد مختلف نگهداری می شد جمع آوری شد. مسیرها در مناطق وسیعی از سه شهر همانطور که در شکل 2 نشان داده شده است ثبت شده است. مسیرها در طول ماموریتهای جستجوی واقعی در گذشته در مورد حوادثی که بین سالهای 1999 و 2020 رخ داده بودند، ثبت و جمعآوری شدند. همه دادهها ناشناس بودند. GPX [ 25] فرمت تبادل GPS است—فرمت XML برای تبادل داده های GPS. یک مسیر GPX شامل یک سری نقاط است که هر کدام دارای مختصات جغرافیایی (طول و عرض جغرافیایی)، ارتفاع و زمان هستند. این مجموعه داده با دادههای مکانی جمعآوریشده از منابع دیگر که زمین این بخش را توصیف میکنند، بهویژه پوشش گیاهی – پوشش زمین Corine، CLC [ 26 ] و مدل ارتفاعی دیجیتالی زمین، DEM [ 27 ] غنیسازی شد و در مجموعه دادهها پردازش شد. دادههای CLC و DEM در قالب geotiff [ 28 ] بهدست آمدند، قالبی برای ذخیرهسازی دادههای شطرنجی مرجع جغرافیایی.
2.2. پیش پردازش داده ها
نمودار کامل داده های پیش پردازش در شکل 1 نشان داده شده است . مجموعه GPX شامل مجموعه ای از فایل های GPX است. هر فایل از یک دنباله راه رفتن یک نفر تشکیل شده است. یک مسیر GPX یک رکورد از یک سری نقاط جغرافیایی است که در آن شخصی که یک دستگاه GPS به تن دارد در حال راه رفتن بوده است. مسیرها پردازش و به بخشهایی تبدیل شدند. یک بخش راه رفتن بین دو نقطه از سطح زمین را توصیف می کند. هر بخش با نقاط شروع و پایان و همچنین زمان شروع و پایان توصیف می شود. از این اطلاعات میتوان به راحتی ویژگیهای لازم یک بخش را محاسبه کرد: طول مسافت، شیب زمین و سرعت بخش پیادهروی.
طول فاصله یک قطعه با استفاده از فرمول هارسین [ 29 ] برای محاسبه فاصله کروی بین دو نقطه در سطح زمین محاسبه شد. اگرچه طول متوسط یک قطعه تنها 6.7 متر است و فاصله کروی لازم نیست، ما از فرمولی استفاده کردیم که به عنوان یک روش معمول برای محاسبه فاصله استفاده می شود.
ما فرض می کنیم که فرد فاصله بین دو نقطه را در یک خط مستقیم طی کرده است با در نظر گرفتن دستگاه های GPS مورد استفاده به اندازه کافی دقیق بوده و نقاطی را ثبت کرده که به اندازه کافی نزدیک هستند. شیب زمین به عنوان قدر مطلق مماس زاویه به دست آمده به عنوان اختلاف ارتفاع و نسبت طول محاسبه شد. مقدار مطلق مطابق با [ 30 ] گرفته می شود]. در این اثر، نویسنده مدل سرعت پیاده روی در زمین های تپه ای را پیشنهاد کرده است. مدل به دست آمده نشان داد که سرعت به جای اینکه برای پیاده روی در سربالایی و سراشیبی تفاوت معنی داری داشته باشد به مقدار مطلق شیب بستگی دارد. یک رابطه مشابه در مجموعه داده های ما کشف شد، به طوری که تصمیم گرفته می شود که متغیر شیب زمین در مقدار مطلق مماس زاویه بیان شود.
سرعت راه رفتن به صورت میانگین سرعت افقی راه رفتن به سمت نقطه پایانی قطعه از نقطه شروع قطعه محاسبه می شود. بیشتر طول این بخش کمتر از 10 متر بود که میانگین آن 6.7 متر بود. در چنین قسمتی فرض می کنیم که راه رفتن یک خط مستقیم بود. تفاوت ارتفاع در محاسبه سرعت پیاده روی در نظر گرفته نمی شود. این سادهسازی برای اجرای نهایی نیز مفید است زیرا مدل در یک شبکه سلولی دو بعدی استفاده میشود و ما به مسافت پیمودهشده از مدل به عنوان فاصله روی نقشه و نه روی کره نیاز خواهیم داشت.
در نهایت، مجموعه داده با داده های مربوط به پوشش زمین از منبع اضافی غنی می شود. در پیاده سازی خود از نقشه Corine Land Cover به دست آمده از سایت Copernicus [ 26 ] استفاده کردیم.
مراحل پیش پردازش داده های مورد استفاده در این کار در شکل 1 نشان داده شده است.
پس از پیش پردازش کل مجموعه داده، دادههایی را فیلتر کردیم که میتواند باعث سردرگمی در مدل شود، اما میتوان آن را به صورت اکتشافی رد کرد – مانند سرعت محاسبهشده پیادهروی بالاتر از 10 کیلومتر در ساعت، که در آن اختلاف زمانی بزرگتر از 20 ثانیه و مشابه بود. مجموعه داده ای که باقی مانده است شامل 1،432،740 بخش پیاده روی کاربران مختلف در زمین های مختلف است.
برای درک بهتر حجم و توزیع دادهها در مجموعه داده، دادهها را به گونهای تجسم کردیم که تعداد کاربرانی را که در همان بخش به عنوان رنگ راه میرفتند ارائه کردیم و نتیجه در شکل 2 نشان داده شده است . هرچه رنگ خط تیره تر باشد، مسیرهای GPS بیشتری در آن بخش ثبت می شود.
علاوه بر این، برای غنیسازی مجموعه داده، هر بخش را با اطلاعاتی در مورد پوشش زمین توصیف کردیم. در ابتدا، ما از طبقه بندی استاندارد پوشش زمین، Corine Land Cover [ 26 ] استفاده کردیم. کد پوشش زمین کورین یک کد سه رقمی است که طبقه و زیر کلاس های زمین را توصیف می کند. هنگام مشاهده میانگین سرعت پیاده روی در زمین، آن کدها برای هدف خطی بودن کافی نبودند، بنابراین پیش پردازش اضافی انجام شد. پس از مشاهده سرعت راه رفتن در زمین های خاص، ما یک جدول ترجمه از کدهای اصلی CLC به کدهای شناسایی پوشش زمین خود (LC id) ساختیم. کدهای CLC با استفاده از جدول ترجمه نشان داده شده در جدول 1 به یک شناسه LC ترجمه شدند .
در نهایت، ما یک مجموعه داده ساختیم که در آن هر ردیف نشان دهنده بخشی است که توسط یک شخص خاص راه میرود. یک بخش در یک ردیف با ویژگی های زیر توصیف می شود:
-
شناسه – شناسه منحصر به فرد نمونه داده
-
LC id – شناسه نوع پوشش زمین همانطور که در جدول 1 توضیح داده شده است
-
DEM – مقدار خوانده شده از فایل مدل رقومی ارتفاع مرتبط با نقطه شروع که نشان دهنده ارتفاع از سطح دریا بر حسب متر است.
-
شیب abs – مقدار مطلق مماس شیب که به صورت کسری از اختلاف ارتفاع عمودی (بر حسب متر) و فاصله افقی (بر حسب متر) محاسبه می شود.
-
dist wgs – طول بخش بین دو نقطه جغرافیایی در سیستم ژئودتیک جهانی بر حسب متر
-
d از شروع – فاصله، به عنوان مثال، موقعیت بخش در مجموعه از شروع مسیر GPX
-
سرعت 2d kmh-میانگین سرعت راه رفتن در بخش توسط کاربر خاص که بر حسب کیلومتر در ساعت بیان میشود
نمونه ای از داده ها از مجموعه داده در جدول 2 نشان داده شده است .
2.3. مدل رگرسیون خطی
رگرسیون خطی یک تکنیک یادگیری ماشینی است که برای پیشبینی مقدار یک متغیر وابسته پیوسته استفاده میشود، که اغلب به عنوان متغیر خروجی نامیده میشود، به عنوان ترکیب خطی مقادیر متغیر مستقل مدلسازی میشود، به عنوان متغیرهای توضیحی یا متغیرهای ورودی [ 31 ]. یک معادله رگرسیون ساده در سمت راست دارای یک برس و یک متغیر توضیحی با ضریب شیب است. یک رگرسیون چندگانه دارای چندین متغیر توضیحی در سمت راست است که هر کدام ضریب شیب خاص خود را دارند. معادله پیش بینی در معادله ( 1 ) نشان داده شده است:
جایی که y مقدار پیش بینی شده است، q0�0سوگیری یا رهگیری است، q1�1، q2�2,…, qn��، ضرایب شیب برای متغیرهای توضیحی هستند ایکس1�1، ایکس2�2,…, ایکسn��به ترتیب.
آموزش یک مدل رگرسیون خطی به تنظیم مقادیر ضرایب شیب ختم می شود تا مدل به بهترین شکل در داده های آموزشی قرار گیرد. در این کار، ما یک مدل رگرسیون خطی را برای پیشبینی زمان لازم برای پیادهروی بخشی از زمین بهعنوان ترکیبی خطی از مقادیر آموزش دادیم:
متغیر خروجی زمان پیاده روی قطعه زمین است. ما بیشتر زمان را پیشبینی میکنیم تا سرعت را زیرا زمان پیادهروی بعداً در شبیهسازی استفاده خواهد شد. با این حال، اگر طول فاصله ثابتی داشته باشیم، این دو متغیر با هم مرتبط هستند. پس از انجام نزول گرادیان برای برازش k-fold، مدلی با امتیاز در مجموعه قطار 0.4127 و در مجموعه آزمایشی 0.4120 دریافت کردیم.
اگرچه مقدار امتیاز بهینه نیست، اما ما فرض میکنیم که این به دلیل سادهسازی است که با نادیده گرفتن متغیری که فردی را که در بخش راه میرود و ویژگیهای او توصیف میکند، ایجاد کردهایم. به دلیل ناشناس بودن داده ها، جنبه اطلاعات مربوط به یک شخص را نمی توان با استفاده از روش توصیف شده در این مقاله در مدل گنجاند. با این حال، ما فرض میکنیم که مدل تولید شده میانگینگیری سرعت راه رفتن را در خود جای داده است که میتواند به عنوان مبنایی برای کالیبراسیون با یادگیری انتقال استفاده شود.
2.4. کالیبراسیون مدل با آموزش انتقال
اطلاعات دقیق در مورد ردیابی افراد گمشده در دسترس نیست. ما نمیتوانیم دینامیک تغییر جهت را توسط سوژهای که بین IPP و مکان یافتن تعجب میکند، فرض کنیم. تنها اطلاعات موجودی که میتوانستیم برای اهداف تحقیقاتی بهدست آوریم، نقطه اولیه – IPP یا PLS و مکانی بود که فرد گمشده پیدا شد. هر دوی این نقاط با مختصات جغرافیایی توصیف شده اند. تعداد بسیار کمی از جفت نقطه جمع آوری شد – فقط 20 نمونه از داده ها. همه مکان های جمع آوری شده در جنگل ها یا مناطق روستایی قرار دارند. با تجزیه و تحلیل این مجموعه داده ها به این نتیجه رسیدیم که 50٪ از افراد گمشده در فاصله 1 کیلومتری از نقطه اولیه پیدا می شوند، در حالی که 75٪ از افراد گمشده در فاصله 2 کیلومتری از نقطه اولیه پیدا می شوند.
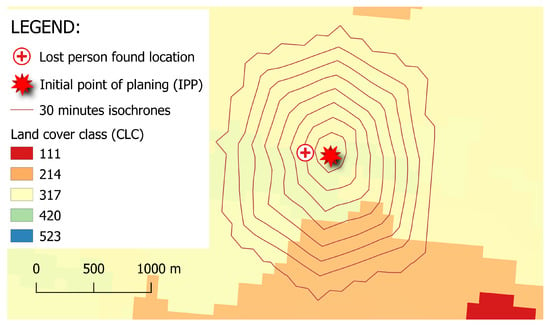
ما از مدل بخش قبل برای پیشبینی مسافتی که یک فرد در تمام جهات طی میکند استفاده کردیم. زمان شبیه سازی به طور مستقیم چهار ساعت برای پشتیبانی از جستجوی اولیه انتخاب شد. مسافت طی شده با استفاده از همان روش شبیه سازی اتوماتای سلولی که در بخش بعدی توضیح داده شد محاسبه می شود. نتیجه شبیهسازی بهعنوان همزمانها تجسم میشود – خطوطی که فواصل را به هم متصل میکنند که یک فرد مدلسازیشده میتواند همزمان از نقطه اولیه در هر جهتی راه برود. نتیجه یکی از شبیه سازی ها در شکل 3 نشان داده شده است، جایی که نقطه اولیه جستجو با یک ستاره برچسب گذاری شده است، مکانی که فرد پیدا می شود با یک صلیب برچسب گذاری شده است، و ایزوکرون هایی که هر 30 دقیقه گام به هم متصل می شوند با خطوط قرمز نشان داده شده اند. پس از بررسی نتایج شبیهسازی برای همه دادههای مجموعه داده بایگانی، مقایسه همزمانهای بهدستآمده با مکانی که فرد گمشده در آن پیدا میشود، و نادیدهانگاشتن موارد دورافتاده، پارامترهای مدل بهدستآمده را طوری تنظیم کردیم که مکان پیدا شدن فرد 75 درصد داده ها در داخل ایزوکرون های شبیه سازی قرار دارد. روند توصیف شده ساخت مدل نهایی در شکل 4 نشان داده شده است .
2.5. پیش بینی منطقه جستجو
همانطور که قبلا ذکر شد، پیش بینی منطقه جستجو با اجرای شبیه سازی پیاده روی در زمین اطراف نقطه اولیه جستجو انجام می شود. قبل از اجرای شبیهسازی، یک شبکه سلولی از ویژگیهای زمین اطراف نقطه اولیه آماده میکنیم. هر سلول 5 متر × 5 متر مساحت را پوشش می دهد، زیرا این دقیق ترین وضوح داده هایی است که استفاده می کنیم. ما یک شبکه با 400 سلول در هر جهت (بالا، پایین، چپ و راست) نقطه اولیه ایجاد می کنیم. دلیل انتخاب دقیقاً 400 سلول، پوشش حداکثر شعاع 2 کیلومتری است. هر سلول با ارتفاع از سطح زمین (dem) و شناسه پوشش زمین (LC id) از داده های GIS خوانده می شود. شبیه سازی در تیک های زمانی انجام می شود. در ابتدا، یک شخص در نقطه اولیه قرار دارد – IPP واقع در مرکز شبکه.فعال برای محاسبه برای هر 8 سلول اطراف همانطور که در شکل 5 نشان داده شده است ، ما زمان لازم برای رسیدن به سلول را محاسبه می کنیم. زمان لازم برای رسیدن به سلول، زمان راه رفتن 5 متر برای سلول های بالا، پایین، چپ و راست و 7.25 متر برای سلول های مورب است. هنگام تخصیص فاصله، فاصله ای را که اختلاف ارتفاع را در نظر می گیرد محاسبه نمی کنیم، زیرا اختلاف ارتفاع در سایر ویژگی ها – شیب و اختلاف ارتفاع – در نظر گرفته می شود. زمان راه رفتن قطعه با استفاده از مدل در قالب معادله ( 1 ) پیشبینی میشود.
سلول های اطراف مورد بازدید قرار می گیرند و برای فعال شدن در مرحله بعدی برچسب فعال می شوند. به سلول های فعال مقدار زمان صرف شده برای رسیدن به آنها از IPP اختصاص داده می شود. شبیه سازی در تکرار انجام می شود و زمان لازم برای رسیدن به هر سلول احاطه شده از تمام سلول های فعال را محاسبه می کند. اگر بتوان از بیش از یک سلول فعال به یک سلول دسترسی داشت، مقدار کمترین زمان برای رسیدن به IPP به سلول اختصاص داده می شود. شبیه سازی تا زمانی که تمام سلول ها بازدید شود اجرا می شود. پویایی این فرآیند در شکل 6 نشان داده شده است که در آن شکل (الف) وضعیت سلول ها را پس از 30 تیک و (ب) پس از 300 تیک نشان می دهد.
پس از انجام شبیهسازی، به هر سلول از شبکه یک مقدار اختصاص داده شده است – یک عدد مثبت که نشاندهنده زمان صرف شده برای رسیدن به سلول از سلول اولیه است. ما از ابزار gdal-contour [ 32 ] برای تبدیل نتایج بهدستآمده به فایل شکلی از همزمانهایی که هر 30 دقیقه به دست میآیند، استفاده میکنیم. شکل فایل تولید شده برای تجسم نتایج در هر نرم افزار استاندارد GIS، مانند QGIS [ 33 ] استفاده می شود.
3. نتایج و بحث
پیشآموزش یک مدل رگرسیون خطی با یک مجموعه آموزشی انجام شد که با پردازش مجموعه کاملی از آهنگهای GPX به آیتمهای بخش به دست میآید. علاوه بر این، مجموعه داده با داده های پوشش زمین DEM و Corine مرتبط بود. مجموعه نهایی به مجموعه های آموزشی و آزمایشی با نسبت 0.67/0.33 تقسیم می شود. چندین نمونه از مدل های رگرسیون مورد آزمایش قرار گرفتند. رگرسیون چند جمله ای با چندجمله ای 2 درجه نمرات کمی بهتر در مجموعه آموزش و آزمون ایجاد کرد. ما همچنین آزمایشی را با سایر مدلهای رگرسیون روی همان قطار و مجموعه داده آزمایشی انجام دادیم. نمرات حاصل در مجموعه آزمون در جدول 3 مقایسه شده است.
مدل Regressor درخت تصمیم برای سرعت راه رفتن بهترین نتایج را در یک مجموعه آزمایشی به دست آورد. با این حال، سود در نتایج امتیاز به اندازه کافی قابل توجه نبود تا استفاده از یک مدل پیچیده تر را توجیه کند، بنابراین تصمیم گرفتیم با مدل رگرسیون خطی ساده تر ادامه دهیم. انگیزه استفاده از رگرسیون خطی به این دلیل است که این مدل ساده به راحتی بین حوزه های موضوعات مختلف – جستجوگران و افراد گمشده – منتقل می شود. ما یک مدل رگرسیون خطی برای پیشبینی زمان راه رفتن یک قطعه همانطور که در رابطه ( 2 ) نشان داده شده است، به دست آوردیم:
جایی که:
| q0�0 |
4.786872732767515 |
| q1�1 |
0.013315859975442301 |
| q2�2 |
0.0019411657191748125 |
| q3�3 |
−16.319148163916193 |
| q4�4 |
−0.026739066247719285 |
| q5�5 |
0.5717657455052271 |
| و |
| Lسیمن d�سیمند |
ارزش شناسه پوشش زمین |
| دم |
ارتفاع از سطح دریا بر حسب متر |
| شکم |
مقدار مطلق مماس شیب قطعه |
| elev d |
تفاوت در ارتفاع بین و نقطه شروع |
| دور |
مسافت طی شده در متر |
|
در این معادله، پیشبینی از پیش تمرین شده زمان برای بخش راه رفتن ( من _ _هp tتیمنمترهپتی) به صورت ترکیبی خطی از مقادیر توضیحی محاسبه می شود. ما مقادیر دقیق ضریب شیب را برای تکرارپذیری مدل ارائه می دهیم. پس از کالیبراسیون معادله برای پیشبینی سرعت پیادهروی فرد از دست رفته همانطور که در بخش 2.4 توضیح داده شد ، ما عوامل زیر را برای سرعت راه رفتن فرد گمشده در قسمتی از زمین بهدست آوردیم:
|
| q0�0 |
1.1967181831918787 |
| q1�1 |
0.0033289649938605752 |
| q2�2 |
0.0004852914297937031 |
| q3�3 |
−4.079787040979048 |
| q4�4 |
−0.006684766561929821 |
| q5�5 |
0.14294143637630677 |
|
معادله ( 2 ) همراه با عوامل تصحیح شده نشان داده شده در جدول بالا در یک شبیه سازی مورد بهره برداری قرار گرفته است. ما یک اسکریپت نوشته شده در زبان برنامه نویسی پایتون [ 34 ] برای اجرای شبیه سازی ایجاد کردیم، در حالی که چندین تیک و گسترش ناحیه مشاهده شده را می توان به عنوان یک پارامتر تنظیم کرد. ما از کتابخانه Rasterio [ 35 ] برای تبدیل سلول شبکه به یک فایل tiff جغرافیایی مرجع و gdal-contour [ 32 ] برای بردار کردن نتایج به شکل فایل استفاده کردیم. شکل فایل به دست آمده منطقه ای را به ما می دهد که یک فرد گمشده بسته به زمان سپری شده از زمانی که فرد در نقطه اولیه دیده می شود، می تواند آن را بدست آورد. نمونه ای از شبیه سازی و پیش بینی ناحیه جستجو در شکل 7 نشان داده شده است.
ناحیه حاصل به شکل نامنظم است و شکل آن به پیکربندی زمین اطراف بستگی دارد. این بدان معنی است که در جهت هایی که زمین به گونه ای پیکربندی شده است که فرد باید آهسته تر راه برود، منطقه ای که باید جستجو شود کوچکتر است. ناحیه جستجوی تعریف شده به این شکل دقیق تر از رویکرد سنتی است – تعیین شعاع دایره در اطراف نقطه اولیه جستجو که در آن هر جهت احتمالاً یکسان است، در حالی که هنوز منطقه ای را که احتمال یافتن فرد گمشده کم است
برای ارزیابی نتایج، شبیهسازی را برای 20 مکان از دادههای آرشیو شخص گمشده SAR اجرا کردیم و مکان پیدا شدن فرد و ایزوکرونهای حاصل از شبیهسازی را مقایسه کردیم. از 20 مورد، 4 نفر خارج از منطقه پیش بینی شده با روش ما پیدا شدند. برای نه شبیهسازی، فرد گمشده در اولین همزمان، در شش مورد در 2. ایزوکرون، و برای 1 مورد، فرد در داخل خط 3. همزمان پیدا میشود. این در جدول 4 خلاصه شده است.
این روش بر اساس تقریبهای زیادی استوار است و از جنبههای متعددی مانند ویژگیهای جسمی و روانی فرد گمشده، شرایطی که در آن فرد گم میشود، شرایط کمکی مانند آب و هوا و دید نادیده گرفته میشود. با این حال، مدل و تکنیک پیشبینی میتواند به مدیران SAR کمک کند تا تأثیر ویژگیهایی مانند پوشش زمین و شیب زمین را در حرکت افراد گمشده درک کنند و به آنها کمک کند تا در مورد شکل و وسعت منطقه جستجو تصمیم بگیرند در حالی که همچنان بر تجربه و شهود تکیه میکنند. منطقه پیش بینی شده را می توان در نرم افزار GIS بیشتر تحلیل کرد.
در محدوده این مقاله، ما به مشکل زمان محاسبه و پیچیدگی نمی پردازیم زیرا در درجه اول بر پیش بینی شکل و اندازه منطقه جستجو که می تواند به صورت آفلاین انجام شود تمرکز می کنیم.
4. نتیجه گیری و کار آینده
این مقاله روشی را برای ساختن یک سیستم نرم افزاری پیشنهاد و نشان می دهد که می تواند به عنوان بخشی از یک سیستم پشتیبانی تصمیم در مدیریت اقدامات عملیاتی جستجو و نجات استفاده شود. ما نرم افزاری را که با استفاده از روش پیشنهادی ایجاد کرده ایم ارائه می کنیم. هدف این سیستم پیشنهاد یک منطقه جستجو است – منطقه ای از زمین در جایی که فرد گمشده به احتمال زیاد پیدا خواهد شد. ما حدس می زنیم که بهترین منطقه جستجوی پیشنهادی شکل منظمی ندارد، اما بی نظمی آن به پیکربندی زمین اطراف و همچنین پوشش زمین بستگی دارد. ما یک مدل رگرسیون خطی را پیشنهاد میکنیم که بر روی دادههای ردیابی GPS جمعآوریشده از مأموریتهای جستجو و نجات قبلی با ردیابی حرکت امدادگران آموزش دیده است. سرعت پیاده روی قطعه زمین به صورت رگرسیون خطی با امتیاز در مجموعه قطار 0.4127 و امتیاز در مجموعه آزمایشی 0.4120 مدل شده است.
الگوریتمی برای پیشبینی منطقه جستجو مبتنی بر شبیهسازی خودکار سلولی راه رفتن از نقطه اولیه و تعیین حداکثر مسافتی است که یک فرد گمشده میتواند در یک بازه زمانی از پیش تعریفشده طی کند. زمانهای رسیدن به مکانها را در فاصله 2 کیلومتری از نقطه اولیه محاسبه میکنیم و برای هر 30 دقیقه خطوط همزمان ایجاد میکنیم. اگر سوژه 30 دقیقه بیشتر راه رفته باشد، هر ایزوکرون حداکثر منطقه ای را نشان می دهد که ممکن است در آن پیدا شود. مدل حاصل، منطقه جستجو را بر اساس پیکربندی زمین توصیف شده با کلاس پوشش زمین، ارتفاع بالاتر از سطح دریا و شیب زمین در جهت راه رفتن پیشبینی میکند. منطقه حاصل را میتوان در نرمافزار پشتیبانی تصمیمگیری مبتنی بر GIS گنجاند و با توجه به جادهها، حوزههای آبخیز، بیشتر مورد تجزیه و تحلیل قرار گرفت.
سایر ویژگی ها را می توان در اصلاحات آینده مدل در نظر گرفت. دادههای سنجش از دور و دادههای سایر منابع (مانند دادههای آبوهوا) برای غنیسازی مجموعه دادههای آموزشی در تلاش برای دستیابی به دقت بهتر در مدل پیشبینی استفاده خواهد شد.
مدلی که ویژگی های فرد گمشده را در نظر بگیرد می تواند دقت مدل را به میزان قابل توجهی بهبود بخشد. یکی از جهت گیری های کار آینده استخراج ویژگی های رفتار فرد از مسیرهای GPS به دست آمده با استفاده از تبدیل فضای پنهان است. تکنیکهای مدلسازی پیچیدهتر برای پیشبینی حرکت افراد گمشده در کارهای آینده مورد بررسی قرار خواهند گرفت.
علاوه بر این، توجه بیشتری به بهینه سازی عملکرد شبیه سازی به منظور دستیابی به قابلیت استفاده در زمان واقعی با نتایج سریع تر داده خواهد شد.








بدون دیدگاه