

چکیده
کلید واژه ها:
چند مقیاس کانولوشن ; بینایی کامپیوتری ؛ تقسیم بندی معنایی ; سنجش از دور ؛ شبکه عصبی ؛ ISPRS Vaihingen
1. مقدمه
- (1)
-
یک ماژول ترکیبی چند مقیاسی جدید – ماژول ASMS (ماژول چند مقیاسی تطبیقی) پیشنهاد شده است که می تواند به طور تطبیقی ویژگی های چند مقیاسی از شاخه های مختلف را با توجه به ویژگی های اندازه تصاویر سنجش از دور ترکیب کند و اثر بخش بندی بهتری در مجموعه داده ها دارد. با اندازه های پیچیده و متغیر.
- (2)
-
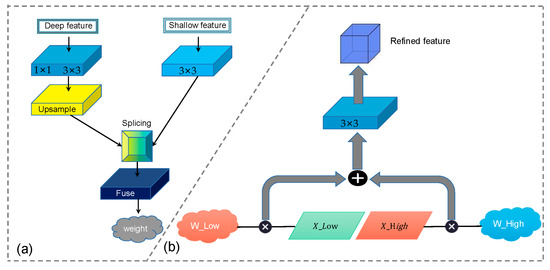
ما یک AFM (ماژول فیوز تطبیقی) طراحی کردیم که می تواند اطلاعات کم عمق تصاویر سنجش از راه دور را فیلتر و استخراج کند. این ماژول می تواند اطلاعات ویژگی های کم عمق و عمیق را به طور موثر ترکیب کند. پس از به دست آوردن وزن لایه های کم عمق و عمیق، این وزن ها در وزن اصلی نقشه ویژگی ضرب می شوند تا بر اطلاعات مفید موجود در نقشه ویژگی های کم عمق تأکید شود و نویزهای بی فایده را مهار کنند. به طوری که نقشه ویژگی عمیق می تواند اطلاعات دقیق تری را به دست آورد.
- (3)
-
نوع جدیدی از ساختار شبکه – شبکه وزنی تطبیقی (AWNet) پیشنهاد شده است که یک ساختار شبکه تعبیه شده با AMSM و AFM است. AWNet یکی از بهترین دقت ها را در مجموعه داده های ISPRS Vaigingen به دست آورد که به دقت کلی 88.35 درصد رسید.
2. کارهای مرتبط
2.1. تقسیم بندی معنایی
2.2. ماژول توجه
2.3. ادغام هرم فضایی و پیچش آتروس
3. مواد و روشها
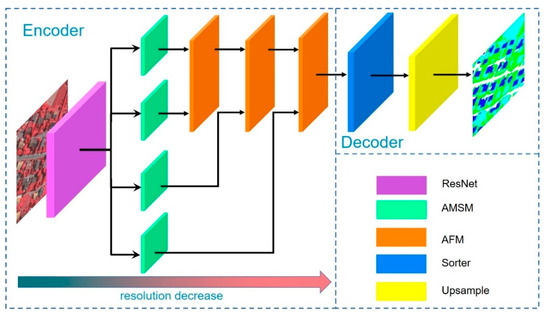
3.1. بررسی اجمالی
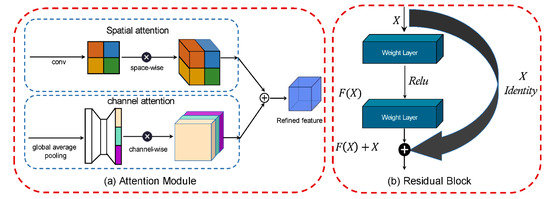
در عین حال، در نظر گرفتن جزئیات سطح پایین با حفظ اطلاعات معنایی سطح بالا برای دستیابی به تقسیم بندی معنایی دقیق تر، مهم است. به خصوص برای تصاویر سنجش از دور با وضوح بالا، اطلاعات دقیق تری نسبت به تصاویر طبیعی دارد. به طور کلی، شبکه های عمیق تر عملکرد بهتری خواهند داشت. با این حال، به دلیل ناپدید شدن گرادیان، نتایج آموزش رضایت بخش نخواهد بود، همانطور که در شکل 1 نشان داده شده است. این مشکل را می توان با استفاده از شبکه های عصبی باقیمانده، همانطور که در شکل 3 نشان داده شده است، حل کرد . مکانیسم بلوک های باقیمانده را می توان با فرمول زیر بیان کرد:
3.2. پیش فرآوری
قبل از آموزش رسمی، ما از ResNet-101 توسعه یافته از پیش آموزش داده شده برای پیش پردازش تصویر ورودی برای استخراج ویژگی های معنایی در محدوده جهانی استفاده کردیم. کل جریان ورودی معنایی را می توان به صورت زیر بیان کرد:
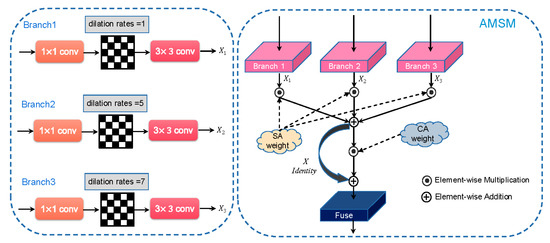
3.3. ماژول چند مقیاسی تطبیقی (AMSM)
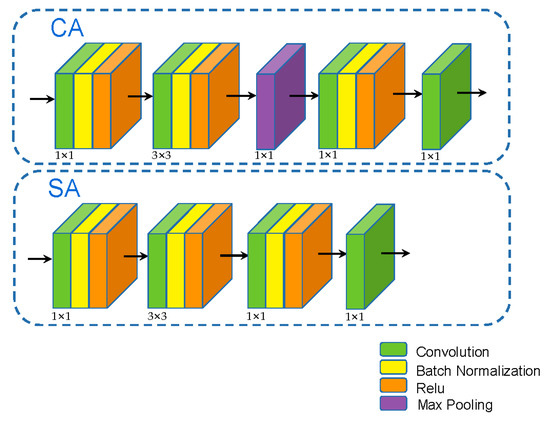
برای سه شاخه AMSM، هر شاخه با نرخ خالی متفاوتی مطابقت دارد تا وزنهای متفاوتی با توجه به اندازه تصویر سنجش از راه دور بدست آید. تصویر ورودی از یک ماژول توجه فضایی عبور می کند. تعداد کانال های خروجی این ماژول سه کانال می باشد. ما فرض کردیم که خروجی ایکسمن( i = 1, 2, 3) ویژگی هر لایه است و نتایج خروجی سه کانال به عنوان وزن فضاهای مربوطه در نظر گرفته می شود. سپس، همانطور که در قسمت سمت راست شکل 4 نشان داده شده است ، از مکانیسم توجه فضایی برای تولید وزن SA وزن [ 37 ] استفاده کردیم . پس از بدست آوردن وزن توجه فضایی، در هر شاخه ضرب شد تا همجوشی حاصل شود. شکل 5 روند به دست آوردن وزن توجه فضایی و وزن توجه کانال را نشان می دهد. تصویر ورودی از یک ماژول توجه کانال عبور می کند و توجه کانال برای غربالگری بیشتر استفاده می شود، با این فرض که هر لایه خروجی دارد. Yمن( i = 1، 2). سپس ویژگی فیوژن نمناز هر کانال توجه فضایی است
علاوه بر این، خروجی سه لایه اضافه شده و ذوب می شود و f(ایکس)اتصال پرش است.
3.4. ماژول فیوز تطبیقی (AFM)
4. آزمایشات
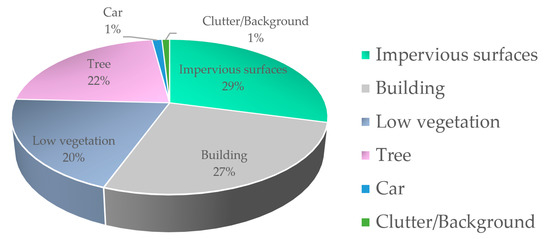
4.1. مجموعه آزمایش ها
امتیاز F1 یک شاخص بسیار مهم در مسائل طبقه بندی است. این نشانگر هم نرخ دقت و هم نرخ فراخوان را در نظر می گیرد و از درصد پیکسل هایی که دسته صحیح را پیش بینی می کنند به عنوان دقت کلی استفاده می کند. در بین آنها، هر دو مقدار بین 0 و 1 هستند. هر چه مقدار به 1 نزدیکتر باشد، دقت بالاتری دارد. دو پارامتر مورد استفاده برای محاسبه امتیاز F1 شامل یادآوری و دقت است که به صورت زیر تعریف می شوند:
در میان آنها، TP نشان دهنده تعداد دسته های C است که به درستی توسط مدل پیش بینی شده است. P نشان دهنده تعداد کل پیکسل های نمونه پیش بینی شده توسط مدل به عنوان دسته C است و C تعداد کل پیکسل های نمونه است. هنگامی که لازم است هم نرخ دقت و هم نرخ فراخوانی در نظر گرفته شود، می توان از شاخص امتیاز F1 مدل برای قضاوت در مورد مزایا و معایب مدل استفاده کرد. F1-socre دقت و فراخوانی مدل را نیز در نظر می گیرد که به صورت زیر تعریف می شود:
دقت کلی درصد پیکسل هایی با کلاس درست پیش بینی شده است و دقت به صورت تعریف می شود
4.2. پیش پردازش مجموعه داده ها
4.3. پیاده سازی
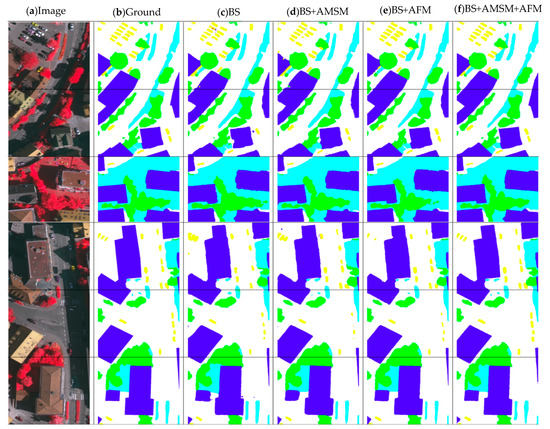
4.4. مطالعه Ablation برای ماژول های رابطه
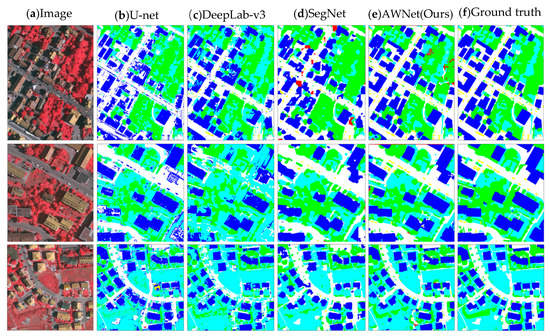
4.5. مقایسه با آثار موجود
5. نتیجه گیری و کار آینده
اختصارات
در این نسخه از اختصارات زیر استفاده شده است:
| AMSM | ماژول چند مقیاسی تطبیقی |
| AFM | ماژول فیوز تطبیقی |
| AWNet | شبکه وزنی تطبیقی |
| ASPP | ادغام هرم فضایی آتروس |
| لیسانس | خط پایه |
| RGB | قرمز-سبز-آبی |
| CNN | شبکه عصبی کانولوشنال |
| OA | دقت کلی |
منابع
- ون، دی. هوانگ، ایکس. لیو، اچ. لیائو، دبلیو. Zhang، L. طبقه بندی معنایی درختان شهری با استفاده از تصاویر ماهواره ای با وضوح بسیار بالا. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2017 ، 10 ، 1413-1424. [ Google Scholar ] [ CrossRef ]
- شی، ی. چی، ز. لیو، ایکس. نیو، ن. ژانگ، اچ. استفاده از زمین شهری و طبقه بندی پوشش زمین با استفاده از تصاویر سنجش از دور چند منبعی و داده های رسانه های اجتماعی. Remote Sens. 2019 , 11 , 2719. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ماتیکاینن، ال. Karila، K. نقشه برداری پوشش زمین مبتنی بر بخش از یک منطقه حومه شهر-مقایسه مجموعه داده های سنجش از دور با وضوح بالا با استفاده از درختان طبقه بندی و نقاط میدان آزمایشی. Remote Sens. 2011 ، 3 ، 1777-1804. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- خو، اس. پان، X. دروغ.؛ وو، بی. اتوبوس.؛ دونگ، دبلیو. شیانگ، اس. Zhang، X. استخراج خودکار از پشت بام ساختمان از تصاویر هوایی از طریق سلسله مراتبی RGB-D Priors. IEEE Trans. Geosci. Remote Sens. 2018 , 56 , 7369–7387. [ Google Scholar ] [ CrossRef ]
- لیو، دبلیو. یانگ، م. زی، ام. گوا، ز. دروغ.؛ ژانگ، ال. پی، تی. وانگ، دی. استخراج ساختمان دقیق از تصاویر DSM و پهپاد ذوب شده با استفاده از یک شبکه عصبی کاملاً پیچیده زنجیره ای. Remote Sens. 2019 , 11 , 2912. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لانگ، جی. شلهامر، ای. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015. [ Google Scholar ]
- رونبرگر، او. فیشر، پی. Brox، T. U-Net: شبکه های کانولوشن برای تقسیم بندی تصویر زیست پزشکی. در مجموعه مقالات کنفرانس بین المللی محاسبات تصویر پزشکی و مداخله به کمک کامپیوتر، مونیخ، آلمان، 5 تا 9 اکتبر 2015. صص 234-241. [ Google Scholar ]
- ژو، جی. هائو، ام. ژانگ، دی. زو، پ. Zhang, W. Fusion روش مبتنی بر تقسیمبندی تصویر PSPnet برای ترکیب تصویر چند فوکوس. فوتون IEEE. J. 2019 ، 11 ، 1-12. [ Google Scholar ] [ CrossRef ]
- چن، L.-C.; پاپاندرو، جی. کوکینوس، آی. مورفی، ک. Yuille، AL DeepLab: Semantic Segmentation image with Deep Convolutional Nets، Atrous Convolution، و CRFهای کاملاً متصل. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 40 ، 834-848. [ Google Scholar ] [ CrossRef ]
- چن، ال. زو، ی. پاپاندرو، جی. شروف، اف. آدام، اچ. رمزگذار-رمزگشا با پیچیدگی قابل جداسازی آتروس برای تقسیم بندی تصویر معنایی. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018. [ Google Scholar ]
- پان، X. گائو، ال. ژانگ، بی. یانگ، اف. لیائو، دبلیو. برچسبگذاری معنایی تصاویر هوایی با وضوح بالا با شبکه هرمی متراکم. Sensors 2018 , 18 , 3774. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- یانگ، اف. فن، اچ. چو، پی. بلاش، ای. لینگ، اچ. تشخیص شی خوشه ای در تصاویر هوایی. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF 2019 در بینایی کامپیوتر (ICCV)، سئول، کره، 27 اکتبر تا 2 نوامبر 2019؛ صص 8310–8319. [ Google Scholar ]
- وو، اس. کیم، دی. چو، دی. Kweon، IS LinkNet: جاسازی رابطه ای برای نمودار صحنه. arXiv 2018 , arXiv:1811.06410. [ Google Scholar ]
- چن، ال سی; پاپاندرو، جی. شروف، اف. Adam, H. Rethinking Convolution Atrous for Semantic Image Segmentation. arXiv 2017 , arXiv:1706.05587. [ Google Scholar ]
- بدرینارایانان، وی. کندال، ا. Cipolla، R. SegNet: معماری رمزگذار-رمزگشای پیچیده پیچیده برای تقسیم بندی تصویر. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 2481-2495. [ Google Scholar ] [ CrossRef ]
- منیح، وی. هیس، ن. گریوز، ا. Kavukcuoglu، K. مدل های تکرارشونده توجه بصری. arXiv 2014 ، arXiv:1406.6247. [ Google Scholar ]
- لین، دی. جی، ی. لیشینسکی، دی. کوهن-اور، دی. Huang, H. درهم تنیدگی زمینه چند مقیاسی برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018. [ Google Scholar ]
- چنگ، بی. چن، L.-C.; وی، ی. زو، ی. هوانگ، ز. شیونگ، جی. هوانگ، تی. Hwu، W.-M.; شی، اچ. Uiuc، U. SPGNet: راهنمای پیشبینی معنایی برای تجزیه صحنه. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF 2019 در بینایی کامپیوتر (ICCV)، سئول، کره، 27 اکتبر تا 2 نوامبر 2019؛ صص 5217–5227. [ Google Scholar ]
- لین، جی. میلان، آ. شن، سی. Reid, I. RefineNet: شبکه های اصلاح چند مسیری برای تقسیم بندی معنایی با وضوح بالا. در مجموعه مقالات سی امین کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 22 تا 25 ژوئیه 2017؛ دوره 1396، صص 5168–5177. [ Google Scholar ]
- یو، سی. وانگ، جی. پنگ، سی. گائو، سی. یو، جی. سانگ، ن. یادگیری یک شبکه ویژگی متمایز برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس انجمن رایانه ای IEEE در مورد دید رایانه و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صفحات 1857–1866. [ Google Scholar ]
- کومار، BV; کارنیرو، جی. Reid، I. یادگیری توصیفگرهای تصویر محلی با شبکههای کانولوشنال سیامی عمیق و سهگانه با به حداقل رساندن توابع تلفات جهانی. در مجموعه مقالات کنفرانس IEEE 2016 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لاس وگاس، NV، ایالات متحده آمریکا، 27 تا 30 ژوئن 2016؛ صص 5385–5394. [ Google Scholar ]
- دای، جی. چی، اچ. Xiong، Y. لی، ی. ژانگ، جی. متعجب.؛ Wei, Y. شبکه های کانولوشن قابل تغییر شکل. در مجموعه مقالات کنفرانس بین المللی IEEE 2017 در بینایی کامپیوتر (ICCV)، ونیز، ایتالیا، 22 اکتبر 2017؛ صص 764-773. [ Google Scholar ]
- ژانگ، آر. تانگ، اس. ژانگ، ی. لی، جی. یان، S. پیچیدگی های تطبیقی مقیاس برای تجزیه صحنه. در مجموعه مقالات کنفرانس بین المللی IEEE 2017 در بینایی کامپیوتر (ICCV)، ونیز، ایتالیا، 22 اکتبر 2017؛ صفحات 2050–2058. [ Google Scholar ]
- چنگ، جی. سان، ی. منگ، MQ-H. یک سیستم نگاشت معنایی متراکم مبتنی بر شبکه CRF-RNN. در مجموعه مقالات 2017 هجدهمین کنفرانس بین المللی رباتیک پیشرفته (ICAR)، هنگ کنگ، چین، 10 تا 12 ژوئیه 2017؛ صص 589-594. [ Google Scholar ]
- لیو، ز. لی، ایکس. لو، پی. لوی، سی.-سی. تانگ، X. تقسیم بندی تصویر معنایی از طریق شبکه تجزیه عمیق. در مجموعه مقالات کنفرانس بین المللی IEEE 2015 در بینایی کامپیوتر (ICCV)، سانتیاگو، شیلی، 7 تا 13 دسامبر 2015؛ صص 1377–1385. [ Google Scholar ]
- Ke، TW; هوانگ، جی جی؛ لیو، ز. Yu، SX میدان قرابت تطبیقی برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018. [ Google Scholar ]
- یو، سی. وانگ، جی. پنگ، سی. گائو، سی. یو، جی. سانگ، N. BiSeNet: شبکه تقسیم بندی دوطرفه برای تقسیم بندی معنایی زمان واقعی. ترانس. پتری نتس مدل های دیگر Concurr. 2018 ، 334-349. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- روآن، تی. لیو، تی. هوانگ، ز. وی، ی. وی، اس. ژائو، ی. شیطان در جزئیات: به سوی تجزیه دقیق انسانی تک و چندگانه. Proc. Conf. آرتیف AAAI. هوشمند 2019 ، 33 ، 4814–4821. [ Google Scholar ] [ CrossRef ]
- بیلینسکی، پ. Prisacariu، V. اتصالات میانبر رمزگشای متراکم برای تقسیم بندی معنایی تک گذر. در مجموعه مقالات کنفرانس IEEE/CVF 2018 در مورد دید رایانه و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 23 ژوئن 2018؛ صفحات 6596-6605. [ Google Scholar ]
- گوا، اچ. ژنگ، ک. فن، X. یو، اچ. وانگ، اس. سازگاری توجه بصری تحت تبدیل تصویر برای طبقهبندی تصویر چند برچسبی. در مجموعه مقالات کنفرانس IEEE/CVF 2019 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صص 729-739. [ Google Scholar ]
- سلواراجو، آر.آر. کگزول، ام. داس، ا. ودانتام، ر. پریخ، د. Batra, D. Grad-CAM: توضیحات تصویری از شبکه های عمیق از طریق محلی سازی مبتنی بر گرادیان. در مجموعه مقالات کنفرانس بین المللی IEEE 2017 در بینایی کامپیوتر (ICCV)، ونیز، ایتالیا، 22 تا 29 اکتبر 2017؛ صص 618-626. [ Google Scholar ]
- لی، بی. سان، ز. لی، کیو. وو، ی. انقی، اچ. تقسیم بندی مشترک شی عمیق گروهی با شبکه عصبی بازگشتی با توجه مشترک. در مجموعه مقالات کنفرانس بین المللی IEEE/CVF 2019 در بینایی کامپیوتر (ICCV)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صص 8518-8527. [ Google Scholar ]
- لیو، اس. جانز، ای. دیویسون، AJ End-To-End Multi-Task Learning با توجه. در مجموعه مقالات کنفرانس IEEE/CVF 2019 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صفحات 1871-1880. [ Google Scholar ]
- لو، ایکس. وانگ، دبلیو. مک.؛ شن، جی. شائو، ال. Porikli, F. بیشتر ببینید، بیشتر بدانید: تقسیم بندی اشیاء ویدیویی بدون نظارت با شبکه های سیامی. در مجموعه مقالات کنفرانس IEEE/CVF 2019 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ صص 3618–3627. [ Google Scholar ]
- ژنگ، اچ. فو، جی. ژا، ز.-ج. Luo, J. به دنبال شیطان در جزئیات: یادگیری شبکه نمونه گیری توجه سه خطی برای تشخیص تصویر ریز. در مجموعه مقالات کنفرانس IEEE/CVF 2019 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 15 تا 20 ژوئن 2019؛ صفحات 5007–5016. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. arXiv 2015 , arXiv:1512.03385. [ Google Scholar ]
- وو، اس. پارک، جی. لی، جی.-ای. Kweon، IS CBAM: ماژول توجه بلوک کانولوشن. در مجموعه مقالات یادداشت های سخنرانی در علوم کامپیوتر ; Springer Science and Business Media LLC: برلین/هایدلبرگ، آلمان، 2018؛ صص 3-19. [ Google Scholar ]
- نصار، ع. لفور، اس. تطبیق نمونه چند نمای وگنر، JD با محدودیتهای نرم هندسی آموخته شده. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 687. [ Google Scholar ] [ CrossRef ]
- پان، X. شی، ج. لو، پی. وانگ، ایکس. Tang, X. Spatial as Deep: Spatial CNN for Traffic Scene Understanding. در مجموعه مقالات کنفرانس AAAI در زمینه هوش مصنوعی، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، 2 تا 7 فوریه 2018. [ Google Scholar ]
- ماگیوری، ای. تارابالکا، ی. چارپیات، جی. Alliez, P. برچسب گذاری تصویر هوایی با وضوح بالا با شبکه های عصبی کانولوشن. IEEE Trans. Geosci. Remote Sens. 2017 , 55 , 7092–7103. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ولپی، م. Tuia، D. برچسب گذاری معنایی متراکم تصاویر با وضوح زیر دسی متر با شبکه های عصبی کانولوشن. IEEE Trans. Geosci. Remote Sens. 2017 , 55 , 881–893. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژائو، اچ. شی، ج. Qi، X. وانگ، ایکس. شبکه تجزیه صحنه هرمی جیا، جی. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 1063-6919. [ Google Scholar ]
- ژو، ک. زی، ی. گائو، ز. میائو، اف. Zhang, L. FuNet: یک شبکه جدید استخراج جاده با ادغام داده های مکان و تصاویر سنجش از دور. ISPRS Int. J. Geo-Inf. 2021 ، 10 ، 39. [ Google Scholar ] [ CrossRef ]
- آهنگ، ا. کیم، ی. تقسیم بندی معنایی تصاویر سنجش از دور با استفاده از داده های بزرگ ناهمگن: انجمن بین المللی فتوگرامتری و سنجش از دور مجموعه داده های پتسدام و منظر شهری. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 601. [ Google Scholar ] [ CrossRef ]
- لیو، YF تحقیق در مورد الگوریتم تجزیه و تحلیل احساسات ویدئویی بر اساس یادگیری عمیق. در فارماکولوژی و سم شناسی پایه و بالینی ; وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2021؛ ص 183-184. [ Google Scholar ]
- کان، ک. یانگ، ز. لیو، پی. ژنگ، ی. Shene, L. مطالعه عددی جریان آشفته گذشته از یک پمپ جریان محوری دوار بر اساس یک روش مرزی غوطهور در سطح. تمدید کنید. انرژی 2021 ، 168 ، 960-971. [ Google Scholar ] [ CrossRef ]





بدون دیدگاه