

چکیده
شهرهای توریستی محل دیدنی های تاریخی و میراث شهری بی بدیل هستند. اگرچه گردشگری مزایای مالی به همراه دارد، اما گردشگری انبوه بر شهرهای تاریخی فشار وارد می کند. بنابراین، «جذابیت» یکی از عناصر کلیدی برای توضیح پویایی گردشگری است. داده های جغرافیایی و مشارکتی کاربر، درک مبتنی بر شواهد از پاسخ مردم به این مکان ها ارائه می دهد. در این مقاله، ترکیبی از اطلاعات چندمنبعی در مورد آثار ملی، محصولات پشتیبان (یعنی جاذبهها، موزهها) و دادههای مکانی برای درک مکانهای میراث جذاب و عواملی که آنها را جذاب میکنند، استفاده میشود. ما عکسهای دارای برچسب جغرافیایی را از API Flickr بازیابی کردیم، سپس از خوشهبندی فضایی مبتنی بر چگالی برنامهها با الگوریتم نویز (DBSCAN) برای یافتن خوشهها استفاده کردیم. سپس خوشهها را با دادههای میراث آمستردام ترکیب کرد و دادههای ترکیبی را با حداقل مربع معمولی (OLS) و رگرسیون وزندار جغرافیایی (GWR) پردازش کرد تا جذابیت میراث و ارتباط محصولات پشتیبانی در آمستردام را شناسایی کند. نتایج نشان میدهد که درک جذابیت میراثها با توجه به انواع آنها و محصولات پشتیبان در محیط ساخته شده اطراف، بینشی برای افزایش جذابیت میراثهای غیرجذاب فراهم میکند. این ممکن است به کاهش بار گردشگری در مکان هایی که بیش از حد بازدید می شود کمک کند. ترکیب میراث کمتر جذاب با محصولات حمایتی تاثیرگذار قوی می تواند راه را برای گردشگری پایدارتر در آمستردام هموار کند. نتایج نشان میدهد که درک جذابیت میراثها با توجه به انواع آنها و محصولات پشتیبان در محیط ساخته شده اطراف، بینشی برای افزایش جذابیت میراثهای غیرجذاب فراهم میکند. این ممکن است به کاهش بار گردشگری در مکان هایی که بیش از حد بازدید می شود کمک کند. ترکیب میراث کمتر جذاب با محصولات حمایتی تاثیرگذار قوی می تواند راه را برای گردشگری پایدارتر در آمستردام هموار کند. نتایج نشان میدهد که درک جذابیت میراثها با توجه به انواع آنها و محصولات پشتیبان در محیط ساخته شده اطراف، بینشی برای افزایش جذابیت میراثهای غیرجذاب فراهم میکند. این ممکن است به کاهش بار گردشگری در مکان هایی که بیش از حد بازدید می شود کمک کند. ترکیب میراث کمتر جذاب با محصولات حمایتی تاثیرگذار قوی می تواند راه را برای گردشگری پایدارتر در آمستردام هموار کند.
کلید واژه ها:
داده های رسانه های اجتماعی مبتنی بر مکان ؛ داده های جغرافیایی شهری ; داده های فلیکر ؛ میراث ; تحلیل فضایی ; DBSCAN _ OLS ; GWR
1. مقدمه
گردشگری یکی از سریع ترین صنایع در حال رشد برای بسیاری از شهرها، به ویژه برای شهرهایی با ارزش های تاریخی قابل توجه است. در بسیاری از شهرهای تاریخی، مناطق خاصی به دلیل ساختمانها یا مکانهای میراثی قابل توجه، تبلیغات بیش از حد و امکانات و خدمات پشتیبانی برای بازدیدکنندگان بسیار جذاب میشوند [ 1 ، 2 ]. در مقابل، برخی از مناطقی که اهمیت میراثی دارند، ممکن است بازدیدکنندگان زیادی را جذب نکنند. اگرچه گردشگری مزایای اقتصادی ایجاد میکند، توزیع نامتوازن بازدیدکنندگان در شهرها میتواند منجر به اثرات منفی مانند ازدحام بیش از حد، از دست دادن ارزشهای فرهنگی و محلی و تخریب محیطزیست، چه در مناطق بیش از حد و چه در مناطقی باشد که نشان داده نمیشوند.
شهرهای تاریخی از میراث ملموس و ناملموس، بناها و مناظر فرهنگی تشکیل شده است [ 3 ]. ارائه دهندگان خدمات مانند هتل ها، رستوران ها و راهنمایان تور مکان های کاربردی را برای گردشگران شکل می دهند [ 4 ]. ترکیب مکان ها و خدمات تاریخی یک منطقه تاریخی جذاب را ایجاد می کند. بنابراین، علاوه بر موقعیت مکانی مکانهای میراث، خدمات و امکانات حمایتی (یعنی ایستگاههای حملونقل عمومی، امکانات خوردن و آشامیدن) نقش مهمی در جذابیت آنها دارند [ 5 ، 6 ]]. به عنوان مثال، مطالعه وونگ و اونگ (2012) نشان داد که تاریخ و فرهنگ، امکانات و خدمات در مکانهای میراث، تفسیر میراث، و جذابیت میراث عوامل متمایز برای بازدیدکنندگان میراث در ماکائو هستند. سایر عوامل متمایز بازدید از میراث، نحوه درک و تجربه گردشگران از یک مکان است [ 7]. از این نظر، بازدید از محیطهای اطراف میراث مانند ایستگاههای تراموا-مترو، مکانهای غذاخوری، محصولات محلی، جاذبهها، موزهها، بازارهای آزاد و غیره تأثیر میپذیرد. بنابراین، درک توزیع بازدیدکنندگان در سطح شهر و اینکه چه ویژگیهای محیط ساخته شده باعث جذب بازدیدکنندگان به این مکانها میشود، جنبههای مهمی برای توسعه سیاستهای پایدار در مدیریت بازدیدکننده است. در نتیجه می توان پیشنهاداتی برای جذابیت بیشتر مناطق گردشگری برای بازدیدکنندگان و در نتیجه توزیع یکنواخت بازدیدکنندگان در شهرها ارائه کرد.
فناوری های نوظهور در سال های اخیر شیوه بازیابی اطلاعات را به طرز چشمگیری تغییر داده اند. دادههای بزرگ از منابع جدید در دسترس، مانند شبکههای اجتماعی مبتنی بر مکان، حسگرها، که شامل طیف وسیعی از اطلاعات و شواهد مبتنی بر دادهها هستند [ 8 ]. این نوع داده عمدتاً شامل سه مفهوم کلیدی “3 V” است. حجم نشان دهنده مقدار زیادی از مقدار است. سرعت اندازه گیری سرعت رسیدن داده ها از منابع و تنوع در محدوده انواع داده ها است [ 9 ]. پس از آن، این مفهوم با افزودن صحت [ 10 ] به روز شد که نشان دهنده دقت و کاربرد داده ها و مقدار است [ 11 ]]، نشان دهنده پتانسیل داده های بزرگ است. چنین هجوم داده ها با اطلاعات مختلفی همراه است، مانند مکان بازدید مردم، نحوه حرکت آنها در شهر. بنابراین، دادههای بزرگ تازه در دسترس به منبعی ضروری برای مطالعات شهری و شیوههای برنامهریزی تبدیل شدهاند.
مطالعات میراث شهری و گردشگری شهری که از مجموعههای کلان داده جدید در دسترس استفاده میکنند، بر موضوعات مختلفی مانند مدیریت مقصد [ 3 ، 12 ]، فعالیتهای گردشگری در شهرهای تاریخی [ 13 ]، نقشهبرداری از ارزشهای تاریخی [ 14 ] و بررسی مکانهای تاریخی تمرکز کردهاند. 15 ]. این مطالعات نتیجه می گیرد که چنین داده هایی برای بررسی رابطه بین سایت های میراث و فعالیت های مردم مفید است.
مطالعات اخیر نشان می دهد که طیف گسترده ای از مجموعه داده ها از رسانه های اجتماعی [ 13 ، 16 ، 17 ، 18 ، 19 ، 20 ، 21 ، 22 ]، سیستم های موقعیت یابی جهانی (GPS) [ 23 ، 24 ، 25 ] و حسگرها می توانند درک بهتری ارائه دهند. رفتار و الگوهای بازدیدکنندگان در مقایسه با روش های سنتی مانند نظرسنجی. این مجموعه دادههای جدید در دسترس نیز برای مطالعات گردشگری و میراث به منظور درک الگوها و رفتار بازدیدکنندگان استفاده میشوند. کوتراس و همکاران [ 15] بر رفتار گردشگران با استفاده از دادههای شبکه اجتماعی مبتنی بر مکان در آتن تمرکز کردند و مطالعه آنها با استفاده از ویژگی مکانی-زمانی مجموعه دادههای فلیکر، تمرکز زمانی گردشگر را در هر POI، بازههای زمانی هفتگی، ماهانه و سالانه شناسایی کرد. دوکوتا و همکاران [ 16 ] از مجموعه داده های فلیکر و توییتر برای توضیح مناطق مورد علاقه گردشگری (TAOI) با خوشه بندی فضایی مبتنی بر چگالی برنامه های کاربردی با نویز (DBSCAN) استفاده کرد. یافتههای آنها نشان داد که ده کلمه کلیدی برتر همچنین بیشترین مکانها و فعالیتهای مرتبط با این مکانها را نشان میدهند. علاوه بر آن، آنها پیشنهاد کردند که داده های یکپارچه از منابع متعدد با در نظر گرفتن طرح های الگوریتم پردازش زبان طبیعی (NLP) نمرات بهتری برای تعریف TAOI ایجاد کند. گارسیا پالومرز و همکاران [ 17] بر شناسایی نقاط داغ گردشگران بر اساس شبکه های اجتماعی متمرکز شد و آنها فاش کردند که عکس های آپلود شده در اطراف بناهای تاریخی، جاذبه های گردشگری و موزه ها متمرکز شده اند. گنزارولی و همکاران [ 18 ] کارایی تریپ ادوایزر را بر کیفیت رستوران ها به عنوان بخشی از میراث فرهنگی ونیز تجزیه و تحلیل کرد و به این نتیجه رسید که رتبه بندی رستوران ها به شدت با کیفیت مورد انتظار بازدیدکنندگان در ونیز مرتبط است. مشخص شد که عکسهای گردشگران در مرکز شهر جمع شدهاند. با این حال، حرکات مردم محلی مانند پارک ها و مناطق تفریحی گسترش یافته است. ژیراردین و همکاران [ 19] مطالعه ای بر روی کمی سازی جذابیت شهری با استفاده از برچسب های عکس فلیکر و داده های شبکه AT&T، ردپای دیجیتال انجام داد و مشخص شد که جذابیت آب نماها در تابستان افزایش یافته است. Gede و همکاران [ 20 ] بر روی تجمع عکسهای مجموعه داده فلیکر در امتداد رودخانه دانوب متمرکز شد. آنها یک سری زمانی از داده ها را برای هر کاربر تشکیل دادند و تجزیه و تحلیل خوشه ای را اعمال کردند. نتایج نشان می دهد که نقاط متمرکز سیستم های مقصد به هم پیوسته در نظر گرفته می شوند، و مرزها توسط مرزها (به عنوان مثال، رومانی) تعریف می شوند. رانگ و همکاران [ 21] تغییرات فصلی در بازدید از قطب شمال را با مجموعه داده فلیکر توضیح داد. آنها نشان دادند که گردشگری تابستانی در مقایسه با سال 2006 تا 2016 چهار برابر بیشتر است و گردشگری زمستانی در فواصل زمانی مشابه 600 درصد افزایش یافته است. همچنین، آنها امکان توسعه یک سیستم هشدار اولیه را با فلیکر بررسی کردند. اما به دلیل کمبود اطلاعات امکان پذیر نبود. گونگ و همکاران [ 22 ] خصوصیات جمعیت را با مجموعه داده های رسانه های اجتماعی از توییتر و اینستاگرام در رویدادهای مقیاس شهر، یعنی بادبان 2015 و روز پادشاه 2016 توضیح دادند. آنها اطلاعات مربوط به جمعیت، مانند سن، جنسیت، توزیع زمانی، استفاده از کلمه، و غیره را تجزیه و تحلیل کردند. بر. دان و همکاران [ 23] بر جریان بازدیدکنندگان با GPS در هفته طراحی هلند برای توضیح منطقه مورد علاقه (AOI) متمرکز شد. بر اساس AOI، آنها رفتارهای مکانی و زمانی بازدیدکنندگان را با تحلیل شبکه تحلیل کردند. شوال و همکاران [ 24 ] روی وضعیتهای فعلی فناوریهای ردیابی در تحقیقات گردشگری متمرکز شد و مشخص شد که دادههای ردیابی دیجیتال مانند GPS، شبکه تلفن همراه، بلوتوث، دادههای رسانههای اجتماعی جغرافیایی کد شده داراییهای مهمی برای این تحقیقات به دلیل بعد مکانی و زمانی هستند. دوکا و همکاران [ 25] بر ایجاد پلت فرم داده باز مشابه ویکی پدیا استخراج شده از Booking، Facebook، Foursquare و Google Places مربوط به مکان های گردشگری در شهرهای اروپایی متمرکز شده است. مشخص شده است که گردشگران می توانند از این بستر برای ترتیب دادن سفرهای خود با در نظر گرفتن بهترین مکان های اقامتی، جاذبه های گردشگری، رویدادها و غیره بهره مند شوند.
مطالعات قبلی پتانسیل داده های بزرگ مبتنی بر مکان و ارزش آنها را به عنوان منابعی برای درک الگوهای حرکتی و رفتار افراد نشان می دهد. بنابراین، برای تعیین نقطه مورد علاقه و مکان های جذاب، زیرا شامل دو عامل کلیدی اصلی است: فضا و زمان. در این مطالعات، ردپای دیجیتالی افراد توسط پلتفرمهای رسانههای اجتماعی مختلف مبتنی بر مکان، مانند فلیکر، توییتر و تریپ ادوایزر جمعآوری شد. با این حال، همانطور که در مطالعات موجود پیشنهاد شده است، فلیکر بر مطالعات مبتنی بر داده های بزرگ تسلط داشته است. دلیل اصلی می تواند این باشد که در سال 2005 تأسیس شد و پایگاه داده میلیون ها عکس را ارائه می دهد. در این مطالعات [ 13 , 16 , 17 , 18 , 19 , 20، 21 ، 22 ، 23 ]، میتوان مشاهده کرد که محققان از الگوریتمهای خوشهبندی مختلفی مانند همبستگی خودکار فضایی با Getis-Ord Gi*، حداکثر احتمال محدود (REML) و DBSCAN برای آشکار کردن نقاط داغ و مناطق جذاب استفاده میکنند.
مطالعات ذکر شده در بالا از مجموعه دادههای بزرگ جدید در دسترس برای درک الگوهای حرکتی و رفتار افراد و نشان دادن مکانهای جذاب در شهرها استفاده میکنند. با این حال، این مطالعات بیشتر تأثیر ویژگی های میراث و ویژگی های محیط ساخته شده را بر جذابیت مکان ها بررسی نمی کند. برای مثال، «امکانات-خدمات» عوامل تأثیرگذار بر جذابیت مکانهای میراث هستند [ 26 ]. بنابراین، اگر حرکات بازدیدکنندگان در اطراف امکانات و خدمات (مثلاً مکانهای خرید و غذاخوری) ردیابی شود، میتوان رابطه بین امکانات و رفتار بازدیدکنندگان را با روشهای آماری توصیف کرد [ 27 ].]. این رفتار رابطهای را میتوان با نقشهبرداری و تکنیکهای شبیهسازی نیز مشاهده کرد. مثال دیگر «ازدحام بیش از حد» است که با جذابیت میراث مرتبط است [ 26 ] و می توان آن را تحلیل کرد که آیا ازدحام بیش از حد بر مکان های میراث تأثیر می گذارد یا نه. از این نظر، داده های شبکه اجتماعی مبتنی بر مکان بزرگ نیز می تواند برای چنین اهدافی مورد استفاده قرار گیرد [ 28 ].
طبق دانش ما، این اولین مطالعه ای است که در آن تأثیر ویژگی های میراث و ویژگی های محیط ساخته شده بر جذابیت میراث با استفاده از داده های فلیکر و شهر در مورد میراث ها و خدمات و امکانات پشتیبانی ارزیابی می شود. در این تحقیق، ما تحلیل کردیم که میراث های عکاسی شده جذاب هستند و میراث های بدون عکس جذاب نیستند. با افزایش استفاده از رسانه های اجتماعی، افراد بیشتری تمایل به عکاسی و ترک ردپای دیجیتالی خود به صورت داوطلبانه دارند. از این نظر، ما تحقیقاتی را طراحی کردیم که عمدتاً مبتنی بر پلتفرمهای اشتراکگذاری عکس آنلاین (فلیکر) و زیر مجموعههای داده، مانند دادههای بنای تاریخی [ 29 ] و دادههای شهر آمستردام [ 30 ] بود.]. این تحقیق ابتدا با خوشه بندی داده های فلیکر از طریق الگوریتم DBSCAN به منظور شناسایی مناطق جذاب انجام شد. بعداً، دادههای شهر در مورد بناها و مکانهای میراثی با مناطق جذاب مطابقت داده شد. در فرض ما، انواع میراث مختلف مستعد عکاسی با فرکانس یکسان نیستند. به منظور جلوگیری از تعصب مکان، یک بافر ثابت 100 متری ایجاد کردیم (شکل 3a را ببینید) در اطراف نقاط مهمی که بیشترین عکسبرداریشدهها را نشان میدهند، سپس میراثها را شمارش کردیم. در نتیجه، میراثها به عنوان جذاب و غیرجذاب شناخته شدند. پس از آن ما رابطه بین این میراث ها و محصولات حمایتی را که می توانند به جذابیت کمک کنند، تجزیه و تحلیل می کنیم. علاوه بر این، ویژگیهای محیطی ساخته شده در اطراف این میراث، مانند تعداد کافهها، رستورانها، موزهها، ایستگاههای تراموا و مترو نیز به دادهها اضافه شد. سپس این مجموعه داده نهایی با استفاده از حداقل مربعات معمولی (OLS) و رگرسیون وزندار جغرافیایی (GWR) مورد تجزیه و تحلیل قرار گرفت. نتایج OLS به ما اجازه داد تا پارامترها را با تأثیر قابل توجهی بر جذابیت توضیح دهیم و این پارامترها را بر اساس تأثیرات بالقوه آنها برای تحقیقات بیشتر طبقه بندی کنیم. نتایج GWR با در نظر گرفتن موقعیت متغیرها بر جذابیت میراث، به درک بهتر عوامل مؤثر در درک بهتر کمک کرد.
پژوهش ما از چند جنبه دیدگاه های متفاوتی دارد. همانطور که در مطالعات فعلی که از دادههای رسانههای اجتماعی مبتنی بر مکان (به عنوان مثال، فلیکر، پانورامیو، توییتر، تریپادوایزر) استفاده کردهاند، بر آشکار کردن نقاط مورد علاقه و نقاط داغ در یک شهر تمرکز دارند. کارهای محدودی برای کشف جذابیت میراث با کلان داده های جدید در دسترس، مانند داده های فلیکر و شهر در مورد میراث و امکانات و خدمات انجام شده است. بنابراین، مقاله ما دارای دو مرحله است (1) یافتن مناطق جذاب در شهر و میراث هایی که در این مناطق هستند (2) درک اینکه چه چیزی این میراث ها را از نظر ویژگی های میراث و محیط ساخته شده اطراف جذاب می کند. ما آمستردام را به عنوان منطقه موردی برای این مطالعه انتخاب کردیم زیرا این شهر تاریخی است که در سالهای اخیر با مسائل گردشگری بیش از حد مواجه بوده است.
این مقاله به شرح زیر سازماندهی شده است: ابتدا روش جمع آوری داده ها و متغیرها توضیح داده شده است. سپس روشهایی که برای تجزیه و تحلیل دادهها استفاده میشوند معرفی میشوند. پس از این، یافته های مطالعه نشان داده می شود. این مقاله با بحث در مورد یافته ها و اثربخشی روش ها و پیشنهادات به سیاست گذاران به پایان می رسد.
2. داده ها و روش ها
روش شناسی ما در چهار بخش اصلی ساختار یافته بود، همانطور که در شکل 1 نشان داده شده است. ابتدا جمع آوری داده ها از منابع مختلف توضیح داده شده است. پس از آن، تجزیه و تحلیل خوشه با فرآیند DBSCAN توضیح داده شده است. پس از این، شناسایی میراث های جذاب ارائه می شود. سپس یک ماتریس داده جدید برای برآورد جذابیت میراث با رگرسیون وزندار جغرافیایی طراحی میشود.
2.1. جمع آوری و آماده سازی داده ها
آمستردام به عنوان یک مطالعه موردی انتخاب شد که یک مقصد گردشگری مهم است و هسته تاریخی آن توسط سازمان علمی و فرهنگی (یونسکو) در فهرست میراث جهانی (WHS) قرار گرفته است [ 31 ]. برای این مطالعه، سه مجموعه داده مختلف برای درک رابطه بین میراث و محصولات پشتیبانی در منظر شهری پردازش شد: مجموعه دادههای فلیکر، مجموعه دادههای آثار ملی، و مجموعه دادههای خدمات و امکانات شهر آمستردام.
Flickr API امکان دانلود مجموعه داده های بزرگ همراه با ابرداده را فراهم می کند. برای تعیین مناطق جذاب برای بازدیدکنندگان در زمان و مکان به کار گرفته شد. توجه داشته باشید که یک منطقه جذاب به مجموعه ای از تعداد زیادی عکس گرفته شده و برچسب گذاری شده در یک مکان اشاره دارد.
ابرداده 285130 عکس در محدوده مرزی بارگیری شد: مرز “minx”: 4.867080، “miny”: 52.357924، “maxx”: 4.933176، “maxy”: 52.390259. این مختصات نشان دهنده مرز منطقه مورد مطالعه است. قطعه کد با استفاده از زبان GO اجرا شد و مجموعه داده به عنوان یک فایل مقدار جدا شده با کاما (CSV) ذخیره شد. پایگاه داده فلیکر شامل زمان عکسبرداری، زمان آپلود، مکان (طول و عرض جغرافیایی) و توضیحات (برچسبها) عکسها است. مکان عکس ها را می توان به طور خودکار از دوربین آپلود کرد یا به صورت دستی روی نقشه تعیین کرد. در این تحقیق، اطلاعات جغرافیایی، طول جغرافیایی، مالک، تاریخ ثبت و URL حفظ شد. به دلیل حفظ حریم خصوصی داده ها، اطلاعات مربوط به کاربر، مانند نام، نام خانوادگی، وب سایت، شغل و زادگاه، تجزیه و تحلیل نشد. و نتایج حاوی اطلاعات شخصی نبود. ویژگی های داده های فلیکر در هر عکس را می توان در آن مشاهده کردضمیمه A , جدول A1 .
مجموعه داده فلیکر دانلود شده با حذف رکوردهای تکراری و نامعتبر پاک شد تا خطاهای مجموعه داده به حداقل برسد. الگوریتم دانلود فلیکر باید بارها اجرا می شد تا تمام داده های فلیکر از آمستردام بازیابی شود. با این حال، منجر به دادههای تکراری در برخی مکانها شد. داده های تکراری با پاک کردن همان URL ها حذف شدند. مهرهای زمانی عکسهای آپلود شده برای تقسیم کاربران به گردشگران و افراد محلی با در نظر گرفتن محدوده زمانی عکسها استفاده شد. همانطور که در ادبیات پیشنهاد شده است [ 15 ، 19]، طبقه بندی بین گردشگران و افراد محلی بر اساس فواصل تاریخی گرفته شده از عکس ها پردازش شد. مهرهای زمانی به دوره های 30 روزه تقسیم شدند. اگر یک کاربر بیش از یک عکس را در مدت 30 روز آپلود کند، آن کاربر به عنوان یک گردشگر در نظر گرفته می شود زیرا دوره های کوتاه تر توسط گردشگران ترجیح داده می شود. [ 13 ]. اگر دوره بیشتر از 30 روز باشد، آنها محلی محسوب می شدند. این ما را قادر می سازد تا خوشه های هر گروه کاربری را درک کنیم تا بتوانیم انواع خوشه ها را پیدا کنیم.
مجموعه داده پردازش نشده حاوی سوابق داده 28130 عکس بود. در مجموعه داده، مهرهای زمانی عکسها از سالهای 1927 و 2019 متفاوت است. عکسها قبل از سال 2007 گرفته شدهاند، به صورت دستی بررسی شدند. این عکسهای قدیمی در مجموعه دادهها نگهداری میشوند زیرا هنوز اطلاعات مکانی و زمانی را نشان میدهند. در نتیجه، عکس هایی که قبل از سال 2007 گرفته شده بودند، هم برای مردم محلی و هم برای گردشگران ادغام شدند. توزیع عکس ها در سال را می توان در ضمیمه A ، جدول A2 مشاهده کرد. سوابق داده های 93752 عکس متعلق به گردشگران و 191378 عکس متعلق به افراد محلی است. شکل 2a نشان دهنده یک عکس معتبر است که در تحقیق استفاده شده است. نمودار بالا تعداد عکس های گرفته شده توسط گردشگران و افراد محلی را قبل و بعد از فرآیند تمیز کردن نشان می دهد. نمودارهای پایین با درصد تعداد کاربران را نشان می دهد. اگرچه اکثر عکس ها توسط مردم محلی گرفته شده است، اما تعداد کاربران کمتر از گردشگران بوده است. برای مجموعه داده نهایی فلیکر، 12766 عکس از 1808 گردشگر و 25445 عکس از 654 نفر باقی مانده است. ۷۳ درصد عکسها توسط گردشگران و ۲۷ درصد توسط مردم محلی آپلود شده است. عکس های معتبر و توزیع کاربر ( شکل 2 الف) و توزیع فضایی عکس های فلیکر ( شکل 2 ب) در زیر آورده شده است. فایل داده نهایی شامل طول جغرافیایی، طول جغرافیایی، تاریخ گرفته شده و ستون های URL در هر رکورد عکس بود.
در شکل 2 ب مشاهده می شود که عکس های گردشگران عمدتاً در هسته شهری گرفته شده است، در حالی که عکس های افراد محلی محدوده وسیع تری از شهر را پوشش می دهند. داده های Flickr تمیز شده برای تجزیه و تحلیل خوشه ای برای شناسایی جذاب ترین مکان ها در آمستردام استفاده شد.
از دادههای آثار ملی برای تحلیل رابطه بین خوشههای عکس فلیکر و مناطق میراث شهری استفاده شد. هفت هزار و پانصد میراث در مجموعه آثار ملی آمستردام ثبت شده است که از سایت آژانس میراث فرهنگی وزارت آموزش، فرهنگ و علوم [ 29 ] دانلود شده است. همه داده ها در قالب شکل ارائه شد. بنابراین، امکان استفاده مستقیم از آنها در محیط نرم افزار GIS وجود داشت. هر شیء میراث دارای ویژگی های خاص خود است، از جمله مختصات، عملکرد، هدف (یعنی ساختمان، کلیسا، بنای تاریخی، شی)، کد پستی، نام خیابان، شهرداری و غیره.
برای تجزیه و تحلیل، 25 نوع میراث از پیش تعریف شده با توجه به عملکرد آنها به 14 دسته اختصاص داده شد. این کار به این دلیل انجام شد که برخی از انواع میراث در مجموعه داده ها نمایش کمتری داشتند، که می تواند بر نتایج تحلیل رگرسیون تأثیر بگذارد. بنابراین، میراثها با توجه به کارکردهایشان به گروههای متمرکزتری اختصاص یافتند. طبقه بندی میراث را می توان در جدول 1 مشاهده کرد.
در نهایت، داده های شهر آمستردام برای این مطالعه جمع آوری شد. این داده ها برای درک تأثیر امکانات شهری بر جذابیت میراث استفاده شد. داده های شهر شامل طیف گسترده ای از موضوعات، از جمله فضاهای عمومی، گردشگری، فرهنگ، زیرساخت ها، انرژی، جمعیت است. مجموعه داده با فرمت های مختلف ارائه می شود، به عنوان مثال، CSV، فایل word مایکروسافت (به عنوان مثال، docx، doc)، نشانه گذاری شی جاوا اسکریپت (JSON)، فرمت سند قابل حمل (PDF)، و با همکاری شهرداری آمستردام و شرکای آنها ایجاد شده است. همه داده ها باز و مناسب برای محققان هستند و به روز می شوند [ 30]. مجموعه دادههای خرید، توالت عمومی، محصولات محلی، ایستگاههای تراموا-مترو، غذاخوری، موزه، بازار آزاد و جاذبهها برای این مطالعه انتخاب شدند تا میزان تأثیر آنها بر میراث را توضیح دهند. این مجموعه داده ها حاوی اطلاعات موقعیت مکانی هر تاسیسات و خدمات در آمستردام است.
2.2. آنالیز خوشه ای
در این مطالعه، مکانهای جذاب با اعمال یک الگوریتم خوشهبندی بر روی مجموعه دادههای Flicker تمیز شده شناسایی شدند. تجزیه و تحلیل خوشه ای یک روش آماری برای ایجاد گروه و طبقه بندی اشیاء بر اساس برخی ویژگی ها است. این یک روش تجزیه و تحلیل بدون نظارت است. بنابراین، می توان آن را بدون آموزش داده اعمال کرد. خوشه بندی فضایی را می توان به عنوان تبدیل یک شی به خوشه هایی تعریف کرد که دارای مشخصات مشابه در گروه هایی هستند که می توانند به عنوان همگنی بالا تعریف شوند. با این حال، صلاحیت های متفاوت در بین سایر گروه ها که می توان آن را به عنوان ناهمگنی بالا پذیرفت. از این نظر، برای مطالعه ما، هر خوشه نشان دهنده نقاط مورد علاقه (POI) است، و مکان های متمرکز را می توان به عنوان مناطقی که بیشترین عکسبرداری شده را تعریف کرد [ 15 ].
ادبیات کنونی الگوریتمهای فراوانی برای خوشهبندی دارد، مانند K-means، فازی C-means، DBSCAN [ 32 ، 33 ، 34 ، 35 ، 36 ]. K-means یکی از روش های خوشه بندی محبوب است که در سال 1967 معرفی شد [ 32 ]. مقدار میانگین اشیاء در یک خوشه را به عنوان مرکز خوشه تعیین می کند. همچنین، این یک روش ساده است که پیچیدگی را محاسبه می کند [ 33 ]. K-means تعداد خوشه ها را از قبل به عنوان ورودی می طلبد که می تواند بر جنبه های خوشه ها تأثیر بگذارد. روش دیگر C-means فازی است که در سال 1973 توسعه یافت [ 34]، و عمدتاً برای تشخیص الگو استفاده می شود. هر دو روش، k-means و فازی c-means، تقریباً یک استراتژی را نشان می دهند. آنها بر اساس فاصله اقلیدسی به منظور تعیین شباهت بین اشیاء در نظر گرفته شده و مرکز خوشه [ 35 ] هستند. C-means فازی به انتخاب مراکز خوشه اولیه، کندی همگرایی حساس است و تمایل دارد در مقدار محلی بهینه گیر کند [ 36 ]. روش دیگر DBSCAN است که به طور گسترده در مطالعات برنامه ریزی شهری با داده های بزرگ استفاده می شود [ 15 ، 16 ، 33 ، 37 ]. این الگوریتمی است که مناطق با چگالی بالا را جستجو می کند. DBSCAN با دو پارامتر اجرا می شود. مناطق محله ( eps) و حداقل امتیاز ( MinPts ) در این مناطق. هنگام مقایسه روشها، k-means برای محققانی که بر روی یک مسئله بهینهسازی مکان تمرکز میکنند جذاب است، در حالی که DBSCAN بهتر است تجمع جغرافیایی را پیدا کند [ 33 ]. علاوه بر این، نقاط نویز، که در DBSCAN محاسبه می شوند، می توانند به عنوان مناطق کمتر جالب برای تجزیه و تحلیل بیشتر در نظر گرفته شوند.
برای این مطالعه، DBSCAN به عنوان الگوریتم خوشه بندی [ 38 ] انتخاب شد. خوشه ها را می توان به عنوان ویژگی های مشترک مشترک توضیح داد و نقاط نویز را می توان به عنوان مناطق با چگالی کم [ 39 ] توصیف کرد. الگوریتم با انتخاب یک نقطه هسته شروع میشود و به بزرگنمایی آن ادامه میدهد تا تمام نقاط چگالی قابل دسترسی از نقطه هسته. نقاطی که در هیچ خوشهای فهرست نشدهاند (نقطه چگالی قابل دسترس نیستند) به عنوان نقاط نویز اختصاص داده میشوند و تا زمانی که هیچ نقطهای باقی نماند به جستجو ادامه میدهند. خوشه ها به معیارهای مختلفی بستگی دارند. هسته، مرز، نویز، چگالی قابل دسترسی مستقیم و چگالی قابل دسترسی. نقطه مرکزی در مرکز خوشههای مبتنی بر چگالی است و آرایهای در درون eps و MinPts است.. نقطه مرزی در همسایگی نقطه مرکزی قرار دارد. نویز نقطه ای است که نه نقطه مرکزی است و نه نقطه مرزی. چگالی قابل دسترسی مستقیم (DDR) نقطه ای است که r چگالی مستقیم قابل دسترسی از s است. eps و MinPts متعلق به NEps ( ها ) و | NEps ( های )| ≥ MinPts . چگالی قابل دسترسی (DR) نقطه ای است که r از نقطه s قابل دسترسی است . eps و MinPts اگر دنباله ای از نقاط وجود داشته باشد r 1… rn , r 1 = s، rn = s به طوری که ri + 1 مستقیماً از ri قابل دسترسی است [ 39 ]. الگوریتم نواحی متراکم را پیدا می کند و خوشه هایی با شکل دلخواه ایجاد می کند [ 40 ].
2.3. برآورد جذابیت میراث
همانطور که در ادبیات پیشنهاد شده است، جذابیت میراث توسط عوامل متعددی شکل می گیرد، مانند فضای میراث، رویدادهای خاص، وضعیت حفاظت [ 41 ]، ارزش تاریخی میراث [ 26 ]، و پیشینه فرهنگی [ 7 ].]. در این مطالعه، با در نظر گرفتن محیط پیرامونی میراث، محصولات حمایتی مانند امکانات خرید، توالتهای عمومی، محصولات محلی، ایستگاههای تراموا-مترو، مکانهای غذاخوری، موزهها، بازارهای آزاد و جاذبهها برای درک میزان تأثیر این عوامل بر جذابیت میراث مورد تجزیه و تحلیل قرار گرفتند. . بنابراین، ابتدا خوشهها توسط الگوریتم DBSCAN در مکانهای عکس فلیکر شناسایی شدند. بعداً، این خوشهها با بافرهای 100 متری به منظور جلوگیری از سوگیری مکان گسترش یافتند. به دنبال آن، میراثهایی که در زیر مجموعههای بافر قرار میگیرند، بهعنوان میراث جذاب شناسایی شدند و بقیه بهعنوان میراث غیرجذاب برچسبگذاری شدند. سپس مجموعه دادههای میراث برچسبگذاریشده با مکانهای آنها با مجموعه دادههای ثانویه امکانات و خدمات از دادههای شهر آمستردام همراه شدند.
بر روی مجموعه داده نهایی، تجزیه و تحلیل OLS و GWR استفاده شد. تحلیل رگرسیون یک مدل آماری برای نشان دادن همبستگی بین یک متغیر وابسته و چند متغیر مستقل است. رگرسیون خطی بیشترین استفاده را در تحلیل جغرافیایی دارد. با این حال، تغییرات غیر ثابت را می توان در روش های ساده جهانی برازش، مانند OLS از دست داد. از سوی دیگر، GWR میتواند یک روش جایگزین برای تحلیل ارائه دهد تا تغییرات فضایی را در نظر بگیرد. GWR تغییرات محلی در برآورد ضریب را امکان پذیر می کند. بنابراین، ضریب رگرسیون با مقادیر مختلف برای هر مکان محاسبه می شود [ 42]. مزیت GWR این است که امکان شناسایی ویژگی های انتخاب شده از گروه بزرگی از معیارهای ممکن را با تأثیر قابل توجه بر ویژگی ها فراهم می کند و آنها را در راستای وزن آنها رتبه بندی می کند.
قبل از شروع OLS، چند خطی بودن بین متغیرها با نمرات عامل تورم واریانس (VIF) با پردازش ابزار رگرسیون اکتشافی در ArcGIS 10.8 بررسی شد. طبق تئوری، زمانی که امتیاز VIF بیشتر از 10 باشد، چند خطی بودن مشکلی برای تخمین است [ 43 ]. برای جلوگیری از تفسیرهای نادرست، محصولات محلی از ماتریس کم شدند. علاوه بر این، خود همبستگی فضایی توسط شاخص موران برای مشاهده چگونگی توزیع متغیرها بررسی شد. به عنوان آخرین مرحله، GWR برای مشاهده توزیع فضایی میراث های جذاب انجام شد. مجموعه ای از مدل ها با کمک ArcGIS 10.8 تجزیه و تحلیل شد.
3. نتایج
در این بخش ابتدا نتایج تحلیل خوشه ای را توضیح می دهیم. سپس، ما جذابیت میراث شناسایی را توصیف می کنیم. پس از این، نتایج OLS و GWR که برای درک جذابیت میراث مورد استفاده قرار گرفتند، توضیح داده میشوند. در نهایت، تشخیص مدل OLS و GWR ارائه شده است.
3.1. آنالیز خوشه ای
در این مطالعه، برای انتخاب پارامترهای ( MinPts و eps ) الگوریتم خوشهبندی DBSCAN، مقادیر مختلفی مورد آزمایش قرار گرفت و minPts = 125 برای گردشگران، minPts = 175 برای مجموعه دادههای محلی پس از چندین آزمایش تعیین شد. سپس، eps با استفاده از تابع kNN در زبان برنامهنویسی R محاسبه شد و بهترین خروجی eps 70 بود، هم برای مجموعه دادههای محلی و هم برای مجموعههای توریستی. دقیقه های کوچکترمنجر به خوشه های بیشتری می شود و این می تواند منجر به تجزیه و تحلیل فریبنده شود زیرا خوشه ها در هسته پخش شده اند. این آزمایش منجر به ایجاد 9 خوشه برای عکس های گردشگران و 12 خوشه برای عکس های افراد محلی شد. نتایج در شکل 3 الف با نقشه و شکل 3 ب با اعداد نشان داده شده است. خوشه های گردشگران و افراد محلی برای مراحل بعدی ترکیب شدند.
3.2. شناسایی میراث های جذاب
این مرحله با هدف شناسایی میراث های جذاب در شهر آمستردام، بر اساس خوشه های بیشتر مکان های عکاسی شده انجام شد. خوشههای موجود که بیشترین عکسبرداریشدهترین مکانها را در آمستردام نشان میدهند، برای ایجاد بافر پردازش شدند. بافر می تواند از سوگیری موقعیت مکانی که ممکن است برچسب های جغرافیایی عکس ها داشته باشند جلوگیری کند. به این معنا، 100 متر بافر ثابت در اطراف خوشه ها در ArcGIS 10.8 ایجاد شد. آنها یک چند ضلعی را در یک مجاورت مشخص از هر نقطه عکس نشان می دهند. پس از آن، میراث با مناطق حائل تقاطع شد. میراثهایی که در نواحی بافر قرار میگیرند ( شکل 3 الف)، بهعنوان جذاب در نظر گرفته میشوند، زیرا عکسهایی از اطراف آنها گرفته شده است. در غیر این صورت، میراث غیرمتقاطع به عنوان میراث غیرجذاب در نظر گرفته شد. شکل 4نشان دهنده تعداد میراثی است که در هر دسته میراث جذاب و غیرجذاب بوده است.
مطابق شکل 4 الف، جذاب ترین انواع میراث، ساختمان های منازل از جمله خانه های کانالی باریک بوده که به عنوان آثار ملی به ثبت رسیده و توجه بازدیدکنندگان را به خود جلب می کند. پس از آن، میراث فرهنگی-ورزشی از جمله میراث های هنری-فرهنگی و میراث ورزشی-تفریحی دومین نوع جذاب شناخته شد.
3.3. برآورد جذابیت میراث
به منظور تحلیل جذابیت میراث، عکسهای بومیها و گردشگران با هم ادغام شدند. برای نمونه نهایی، 118 میراث جذاب و 704 میراث غیرجذاب تشخیص داده شد. به منظور جلوگیری از سوگیری فضایی، میراث به سه گروه تجمیع شد. دلیل اصلی این است که برخی از انواع میراث کمتر ارائه شده بودند، مانند خرید (n = 4)، پذیرایی (n = 18)، حمل و نقل (n = 35)، از سوی دیگر، برخی از آنها بیش از حد در انبارها حضور داشتند (n = 327) ، ساختمان دولتی (n = 154)، یک کلیسا (n = 58). همانطور که در جدول 2 مشاهده می شودانواع میراث با توجه به کارکردهای میراث به سه گروه فرهنگی-علمی، تجاری-دولتی و تفریحی تقسیم شدند. به عنوان مثال، میراث های مرتبط با لذت، از جمله پذیرایی (به عنوان مثال، نقاط خوردن و نوشیدن) و مکان های تفریحی (به عنوان مثال، باغ و پارک)، به همان گروه اختصاص داده شد. خانهها باقی ماندهاند و میراثهای دستهبندی نشده از انواع میراث حذف شدند تا از استحکام دادهها اطمینان حاصل شود. همانطور که در شکل 4 نشان داده شده استخانهها از جذابترین میراثها به شمار میرفتند، زیرا اکثر میراثها بهعنوان خانه ثبت شده بودند. آنها در داده ها بیش از حد نشان داده شده بودند، و نتایج آزمایش می تواند سوگیری باشد. با این حال، نمی توان از تأثیرات خانه ها غافل شد. بنابراین، خانه ها به عنوان مسکونی تغییر نام داده و در رگرسیون به عنوان تسهیلات / خدمات پشتیبانی گنجانده شدند. خانه های کانالی باریک را می توان به دلیل میراث یونسکو یک عامل جذاب در نظر گرفت. می توان آن را به عنوان یک متغیر توضیحی مستقل برای توصیف تأثیر خانه های کانال بر جذابیت ارزیابی کرد. در نهایت، امکانات و خدمات پیرامونی میراث به عنوان متغیرهای مستقل به مجموعه دادهها اضافه شد: امکانات خرید، توالتهای عمومی، محصولات محلی، ایستگاههای تراموا-مترو، نقاط غذاخوری، موزهها، بازارهای آزاد و جاذبهها.44 ]. تعداد نقاط درون چند ضلعی های همسایگی به ماتریس داده اضافه شده شمارش شد. مجموعه داده نهایی برای تجزیه و تحلیل در ArcGIS 10.8 آپلود شد.
3.3.1. نتایج مدل جهانی (OLS)
تحلیل رگرسیون یک روش آماری رایج در تحقیقات فضایی برای ارزیابی رابطه بین متغیرهای توضیحی و پاسخ است. OLS یک مدل جهانی از متغیر را برای درک روابط بین برآوردگرها ارائه می دهد. بنابراین، OLS احتمالات برآوردگرها و قدرت ضرایب آنها را ارائه می دهد.
قبل از شروع با OLS، چند خطی بودن را بررسی کردیم. در خلاصه آمار چند خطی از ابزار رگرسیون اکتشافی ArcGIS 10.8 نشان داده شد که حداقل دو یا چند متغیر به شدت همبستگی دارند. هنگامی که مقادیر VIF بررسی شد، محصولات محلی و ایستگاه های تراموا مترو چند خطی کامل را نشان دادند. بنابراین، محصولات محلی از تجزیه و تحلیل رگرسیون به جای توقف های مترو تراموا حذف شدند، زیرا متغیرهای دیگر، مانند بازار آزاد و خرید، می توانند برای تخمین عوامل مرتبط با تجاری تجزیه و تحلیل شوند. جدول 3آمار توصیفی هر برآوردگر را با مقادیر میانگین، حداکثر، حداقل، انحراف معیار و امتیاز VIF نشان می دهد. به عنوان یک قاعده کلی، پارامترهای انتخاب شده (برآورنده ها) نباید همبستگی قوی داشته باشند. بنابراین، مقدار VIF باید زیر 10 باشد.
ما از مدل با استفاده از OLS با میراث جذاب به عنوان متغیر وابسته استفاده کردیم. متغیرهای مستقل به عنوان دو گروه انتخاب شدند. انواع میراث ( جدول 2. ) به عنوان میراث تجاری و تفریحی اضافه شد. سپس محصولات حمایتی پیرامون میراث (مانند میراث مسکونی، جاذبهها، مکانهای غذاخوری، موزهها، بازارهای آزاد، توالتهای عمومی، مکانهای خرید، و ایستگاههای تراموا) اضافه شدند. جدول 4 نتایج رگرسیون OLS را با R 2 تعدیل شده 0.384 نشان می دهد. تقریباً 39 درصد از واریانس ها ( جدول 5 را برای عملکرد مدل ببینید) توسط مدل نشان داده شده است.
بر اساس نتایج، افزایش تعداد میراث تجاری، میراث تفریحی، جاذبهها، مکانهای غذاخوری، سرویسهای بهداشتی عمومی و ایستگاههای تراموا در یک محله، جذابیت میراث را بهطور چشمگیری افزایش داده است. هر دو نوع میراث (یعنی تجاری و تفریحی) قابل توجه بودند، به این معنی که این نوع میراث برای مردم جذاب بود. با توجه به محصولات حمایتی، افزایش تعداد جاذبه ها و توالت های عمومی در یک محله به طور قابل توجهی جذابیت میراث را افزایش می دهد. این نتیجه انتظار می رفت زیرا ترکیبی از میراث و خدمات به جذابیت مکان های تاریخی کمک می کند [ 5 ، 6 ]]. همچنین ممکن است به دلیل وجود میراث فرهنگی در این مناطق، خدمات و امکانات حمایتی ساخته شده باشد. از سوی دیگر، افزایش تعداد بازارهای آزاد و امکانات خرید که میتوان آنها را محل فروش قرار داد، جذابیت میراث را بهطور چشمگیری کاهش داد. بنابراین می توان استنباط کرد که میراث تجاری به عنوان یک نوع میراث برای مردم جذاب است. علاوه بر این، محصولات حمایتی تجاری به طور قابل توجهی جذابیت هر نوع میراث را کاهش دادند.
در این مطالعه از Moran’s I به عنوان معیار خودهمبستگی فضایی برای محاسبه میزان پراکندگی، تصادفی بودن و خوشهبندی دادهها استفاده شد. مقدار I موران با مقداری بین “1” و “-1” نشان داده می شود. بنابراین، “1” به معنای خود همبستگی فضایی کامل مثبت، “-1” همبستگی فضایی کامل منفی و “0” به معنای تصادفی فضایی کامل [ 45 ] است. مقدار I موران محلی مثبت بالا نشان میدهد که مقدار هدف انتخابشده شبیه به داخل همسایگی است و سپس مکانها خوشههای فضایی هستند، در حالی که یک مقدار Moran محلی منفی بالا نشاندهنده یک نقطه پرت فضایی بالقوه است که با مقادیر مکانهای داخل محله متفاوت است. [ 46 ].
برای تجزیه و تحلیل، باقی مانده از رگرسیون OLS با موران I با در نظر گرفتن مکان های همسایه مورد آزمایش قرار گرفتند. نتایج آزمون موران I نشان داد که باقیماندههای OLS تصادفی فضایی با Moran’s I = 0.003، که نزدیک به “0” بود، نشان داده شد. علاوه بر شاخص Moran’s I، z-score و p -value که بیانگر معناداری آماری هستند، محاسبه شد. نتایج حاصل از خود همبستگی فضایی نشان داد که امتیاز z از نظر آماری معنیدار نبود و باقیماندهها نشان داد که بهطور تصادفی توزیع شدهاند. توزیع خودهمبستگی فضایی را می توان در پیوست B ، شکل A1 مشاهده کرد.
همراه با رگرسیون OLS، ما همچنین آمار کونکر (BP) را که ثابت بودن را ارزیابی میکند، اندازهگیری کردیم. آماره کونکر (BP) (آمار دانشجویی کونکر بروش-پاگان) آزمونی است برای تعیین اینکه آیا متغیرهای مستقل در مدل با متغیر وابسته در فضای جغرافیایی رابطه دارند [ 47 ]. ما ثابت بودن جذابیت میراث را با آمار Koenker (BP) آزمایش کردیم. نتیجه معنی دار بود ( p <0.01). بنابراین، یک مدل رگرسیون وزندار جغرافیایی (غیر ایستایی) برای برآورد جذابیت میراث استفاده میشود. اطلاعات تشخیصی OLS را می توان در ضمیمه B ، جدول A3 مشاهده کرد.
3.3.2. نتایج مدل محلی (GWR)
آمار جهانی (OLS) که قبلاً برای توضیح جذابیت میراث در بالا استفاده کردیم، در سراسر منطقه مورد مطالعه تعمیم داده شد. با این حال، GWR یک مدال آماری است که بومیسازی مدلسازی رگرسیون را پوشش میدهد و با درگیر کردن مولفه فضایی، تجزیه و تحلیل جهانی را به محلی گسترش میدهد. برای GWR، پارامترهای زیر باید مشخص شوند. متغیر وابسته، متغیرهای توضیحی، نوع هسته و روش پهنای باند. در این مطالعه، ما همان متغیرهای توضیحی کلیدی را که با OLS استفاده شده بود، مشخص کردیم. معادله GWR برای هر ویژگی در ماتریس داده (متغیرهای وابسته و اکتشافی) با پهنای باند مشخص برای هر ویژگی هدف ساخته شده است. پهنای باند را می توان به صورت ثابت یا تطبیقی انتخاب کرد. ما یک هسته تطبیقی را مشخص کردیم، که به GWR اجازه می دهد تا با تکرار تعداد نزدیکترین همسایگان برای رگرسیون محلی، پهنای باند بهینه را در نظر بگیرد. نقشه خروجی GWR (بقایای GWR) را می توان در آن مشاهده کردشکل 5 . نتایج نشان داد که یک z-score – 0.264 که نشان می دهد باقیمانده های مدل تصادفی هستند (به پیوست B ، شکل A2 مراجعه کنید )، که نشان می دهد مدل GWR قادر به طبقه بندی متغیرها است.
ضرایب GWR با فواصل انحراف استاندارد با نقشه در شکل 6 نشان داده شده است ، از جمله میراث تجاری، میراث تفریحی، جاذبه ها، غذا خوردن، بازار آزاد، توالت عمومی، خرید و ایستگاه های تراموا-مترو. هر نقشه نشان دهنده متغیر توضیحی است و این ضرایب نشان می دهد که چگونه رابطه بین هر متغیر توضیحی در سراسر منطقه تغییر می کند. برای نقشه برداری از شکست های کلاس انحراف استاندارد استفاده شد. هنگامی که رابطه مثبت است، مناطق سبز تیره نشان می دهد که در آن ضرایب بزرگ بوده است. از سوی دیگر، با توجه به تأثیر بر جذابیت میراث، پیشبینیکنندههای منفی با رنگ قهوهای تیره نشان داده شد که ضرایب آن کم بود.
تأثیر مثبت قوی جاذبه ها در هسته تاریخی اطراف ایستگاه مرکزی آمستردام، De Oude Kerk، کلیسای سنت نیکلاس، Heineken Experience و Zoo Artis مشاهده شد. از سوی دیگر، پیشبینیکنندههای ضعیف در مناطق حاشیهایتر، مانند Het Schip، NSDM Werf و Sloterdijk قرار داشتند. تأثیر مثبت مکان های غذا خوردن به شدت در بخش شمالی، از جمله Het Stenen Hoofd، موزه چشم و کمی قوی در بخش جنوب غربی، مانند Occii و Westindische Buurt مشاهده شد. با این حال، آنها رابطه منفی در بقیه آمستردام به استثنای بخش های جنوب غربی، مانند Occii و Westindische Buurt نشان دادند. یک همبستگی منفی بین میراث جذاب و بازارهای باز در هسته تاریخی مشاهده شد. از سوی دیگر، بقایای توالتهای عمومی تأثیر مثبتی در هسته، منحصراً در بخش شمالی نشان دادند. باقی مانده از مکان های خرید به بخش شمالی منفی مشاهده شد. با این حال، آنها تأثیر مثبت کمی در اطراف باغ وحش Artis، Het Schip و NDSM Werf نشان دادند. آخرین برآورد این است که مکان توقف های تراموا-مترو به سمت شمال و جنوب شرقی به شدت مثبت بوده است. دلیل آن می تواند این باشد که ایستگاه مرکزی آمستردام در قسمت شمالی واقع شده است و می توان آن را مکان میراث جذابی برای بازدیدکنندگان یافت. آخرین برآورد این است که مکان توقف های تراموا-مترو به سمت شمال و جنوب شرقی به شدت مثبت بوده است. دلیل آن می تواند این باشد که ایستگاه مرکزی آمستردام در قسمت شمالی واقع شده است و می توان آن را مکان میراث جذابی برای بازدیدکنندگان یافت. آخرین برآورد این است که مکان توقف های تراموا-مترو به سمت شمال و جنوب شرقی به شدت مثبت بوده است. دلیل آن می تواند این باشد که ایستگاه مرکزی آمستردام در قسمت شمالی واقع شده است و می توان آن را مکان میراث جذابی برای بازدیدکنندگان یافت.
نتیجه GWR نشان داد که جاذبههای نزدیک به Damrak، Bloemenmarkt، موزه خانه رامبراند، Museumplein، De Oude Kerk، کلیسای سنت نیکلاس و کانالهای نمادین. توالتهای عمومی در اطراف ایستگاه مرکزی آمستردام و باغ وحش آرتیس، و ایستگاههای تراموا-مترو که مشابه جاذبهها هستند، به جذابیت میراث در هسته تاریخی کمک کردهاند. از سوی دیگر، بازارهای باز نزدیک به Zoo Artis، Melkweg، Vondelpark. موزههای اطراف ایستگاه مرکزی آمستردام، De Oude Kerk، کلیسای سنت نیکلاس؛ و مکان های خرید در بخش شمالی آمستردام باعث شد که میراث ها در هسته تاریخی جذابیت کمتری داشته باشند.
3.3.3. عملکرد مدل
تشخیص مدل را می توان با مقادیر R2 ، R2 تنظیم شده ، معیار اطلاعات Akaike (AICc) و مقادیر مجموع مجموع باقیمانده (RSS) انجام داد. R2 تغییر در متغیر وابسته را با عدد ممکن 0 و 1 نشان می دهد. مقادیر نزدیک به 1 نشان می دهد که مدل عملکرد بهتری دارد . R2 تعدیل شده 0.657 بود و نشان داد که GWR می تواند تقریباً 66 درصد از واریانس مدل را توضیح دهد. از سوی دیگر، OLS یک R 2 تنظیم شده 0.384 را انجام داد. AIC ها روش دیگری برای انتخاب مدل است که خوب بودن اندازه گیری برازش را توضیح می دهد. طبق تئوری، مقادیر AICc کمتر نسبت به مقادیر بالاتر ارجحیت دارند [ 48]. در حالی که OLS AICc 1500.634 را انجام داد، AICc GWR 1292.702 بود. RSS تغییرات غیرقابل توضیح را برجسته می کند که با 605.788 از OLS و 266.631 از GWR نشان داده شده است. جدول 5 عملکرد مدل را با R2 ، R2 تنظیم شده ، AICc و RSS نشان می دهد. اطلاعات دقیق تشخیصی OLS و GWR را می توان به ترتیب در ضمیمه B ، جدول A3 و جدول A4 مشاهده کرد.
4. نتیجه گیری
توسعه موفقیت آمیز مناطق میراث گردشگری با شناسایی جذابیت و حضور مقاصد همراه است. میراث ها و محصولات حمایتی آنها باید به درستی تعیین شوند. نتایج یک مطالعه ارائه شده است که شامل توزیع گردشگرانی است که از سایتهای میراث بازدید میکنند. متغیرهایی که بر بازدید تأثیر می گذارند با ترکیب مجموعه داده های جدید در دسترس و سایر منابع توضیح داده می شوند.
هدف مقاله ما دو جنبه بود (1) یافتن مناطق جذاب در شهر و میراث هایی که در این مناطق هستند (2) درک اینکه چه چیزی این میراث ها را از نظر ویژگی های میراث و محیط ساخته شده اطراف جذاب می کند. نوآوری های این مطالعه را می توان با این دو جنبه اصلی توضیح داد. ابتدا، DBSCAN برای یافتن مناطق جذاب (یعنی مکانهایی که بیش از حد نشان داده شدهاند) با در نظر گرفتن تقسیمبندی گردشگران و افراد محلی توسط مجموعه دادههای فلیکر به کار گرفته شد. یک الگوریتم تقاطع برای استخراج میراث های همپوشانی به دست آمده از پایگاه داده آثار ملی در این مناطق استفاده شد. تجزیه و تحلیل خوشه ای برای طبقه بندی نقاط حساس مناسب بود. زمانی که ما مکانهای این خوشهها را بررسی کردیم، گردشگران معمولاً در اطراف موزهها (به عنوان مثال، Museumplein، موزه فیلم چشم، Heineken Experience و موزه Het Schip)، کلیساها (به عنوان مثال، De Oude Kerk و کلیسای سنت نیکلاس) و ایستگاه مرکزی آمستردام. مردم محلی در مناطق تفریحی (مانند Vondelpark، Zoo Artis، NDSM Werf، و Het Stenen Hoofd) و مکان های مسکونی (به عنوان مثال، Westindische Buurt و Sloterdijk) جمع شدند. میتوان گفت که مکانهای اصلی توریستی توسط گردشگران جذاب و مکانهای پنهان کمتر شناخته شده توسط مردم محلی کشف شد. تجزیه و تحلیل ما نشان داد که خانهها، میراث فرهنگی-ورزشی، و ساختمانهای صنعتی جذاب هستند. میتوان گفت که مکانهای اصلی توریستی توسط گردشگران جذاب و مکانهای پنهان کمتر شناخته شده توسط مردم محلی کشف شد. تجزیه و تحلیل ما نشان داد که خانهها، میراث فرهنگی-ورزشی، و ساختمانهای صنعتی جذاب هستند. میتوان گفت که مکانهای اصلی توریستی توسط گردشگران جذاب و مکانهای پنهان کمتر شناخته شده توسط مردم محلی کشف شد. تجزیه و تحلیل ما نشان داد که خانهها، میراث فرهنگی-ورزشی، و ساختمانهای صنعتی جذاب هستند.شکل 4 ). یکی از اهداف این مطالعه آشکارسازی نقاط میراث جذابی بود که میتوان آنها را به عنوان مکانهای بیش از حد توریستی شناسایی کرد. بنابراین، مجموعه داده های فلیکر برای توضیح مکان هایی که بیش از حد و کمتر ارائه شده اند مفید است. به دست آوردن دادههای بازدیدکنندگان از منابع سنتی، مانند نظرسنجیها، پرسشنامهها و تعداد بازدیدکنندگان از آژانسهای رسمی، میتواند در یک دوره معین گران و سخت باشد. این مطالعه ثابت میکند که دادههای رسانههای اجتماعی قادر به جذب فضایی توزیع بازدیدکنندگان هستند.
بر اساس یافتهها، خوشههای گردشگران در هسته تاریخی آمستردام جمع شدند، در حالی که افراد محلی در سایر نقاط شهر توزیع شدند ( شکل 3).). زیرا مهم است که بفهمیم چه چیزی میراث ها را جذاب می کند. بنابراین، بخش دوم مطالعه بر درک عمیق تر از جذابیت میراث برای توضیح جذابیت با ویژگی های میراث و محیط ساخته شده اطراف آن متمرکز شد. برای دستیابی به این هدف، از دو مدل رگرسیون OLS و GWR برای پیشبینی جذابیت میراث استفاده شد. مدلهای ما با موفقیت توسط OLS با واریانس 39.7% و GWR با واریانس 73.4% طبقهبندی شدند. در این دو مدل، ما از همان متغیرهای کلیدی توضیحی برای برآورد جذابیت میراث استفاده کردیم. نتایج OLS نشان داد که ویژگیهای میراث (به عنوان مثال، میراث تجاری و میراث تفریحی) و محصولات حمایتی (مانند جاذبهها، مکانهای غذاخوری، توالتهای عمومی و ایستگاههای تراموا) بر جذابیت تأثیر دارند.جدول 4 ). OLS یک آمار جهانی است و در کل منطقه مورد مطالعه اعمال شد. با این حال، GWR به ما اجازه داد تا آمار محلی را برای هر ویژگی تجزیه و تحلیل کنیم. طبق نتایج GWR، جاذبهها و ایستگاههای تراموا در اطراف Damrak، Bloemenmarkt، موزه خانه رامبراند، Museumplein، De Oude Kerk به جذابیت میراث بهعنوان پشتیبان محصولات در هسته تاریخی به طور مثبتی کمک میکنند. همانطور که در شکل 6 مشاهده می شودسایر محصولات حمایتی مانند مکان های غذاخوری در بخش شمالی و بخش جنوب غربی، بازارهای آزاد و مکان های خرید در شرق و غرب آمستردام را می توان برای کاهش فشار گردشگران در هسته تاریخی تبلیغ کرد. اگرچه آنها تأثیر زیادی بر جذابیت در هسته نداشتند، اما حضور آنها می تواند بقیه آمستردام را جذاب تر کند. سیاست گذاران، سازمان های مدیریت مقصد (DMOs)، و مراکز بازدیدکنندگان آمستردام می توانند توجه گردشگران را به این مکان ها جلب کنند. آنها می توانند مسیرهای جدیدی را برای بازدیدکنندگان ارائه دهند زیرا ایستگاه های تراموا-مترو قبلاً جذاب بوده اند. ترکیب میراث کمتر جذاب با محصولات حمایتی تاثیرگذار قوی، مانند ایستگاه های تراموا و مترو، می تواند راه را برای گردشگری پایدار در آمستردام هموار کند.
5. بحث
روشهایی (یعنی DBSCAN و GWR) که در این تحقیق به کار گرفته شد، میتواند برای پیشبینی جذابیت میراث سایر شهرهایی که در آینده در معرض توریسم بیش از حد قرار میگیرند نیز استفاده شود. ترکیب مجموعههای کلان داده جدید در دسترس از رسانههای اجتماعی، منابع داده باز، مانند دادههای شهر آمستردام و دادههای بنای تاریخی، امکان تحلیل عمیقتر را فراهم میکند. علاوه بر این، مدلهای جدیدی را میتوان با در نظر گرفتن متغیرهای اکتشافی اضافی توسعه داد، مانند مکانهای اقامتی که میتوان با ارتباط شبانهروزی تحلیل کرد، و سایر حالتهای سفر (به عنوان مثال، شاخص پیادهروی، اشتراک دوچرخه، ایستگاههای اتوبوس) را میتوان برای ارزیابی در نظر گرفت. تأثیر دسترسی به میراث بسته به شهر. علاوه بر این، ویژگیهای زمانی کلان دادههای جدید در دسترس را میتوان برای آینده مورد استفاده قرار داد زیرا میتواند بینش عمیقتری نسبت به پویایی گردشگری ارائه دهد. به عنوان مثال، فواصل ساعتی، روزانه، ماهانه و سالانه می تواند به درک بیشتر در مورد توزیع بازدیدکنندگان در شهرهای تاریخی کمک کند. با این داده ها می توان پیشنهادهای بهتری برای تبلیغ مکان ها ارائه داد.
این مطالعه محدودیت هایی دارد. در حال حاضر، عمدتا بر اساس مجموعه داده های فلیکر است که می توان آن را در هر زمان با چندین پارامتر دانلود کرد. به دلیل ماهیت این مجموعه داده های بزرگ تازه در دسترس، در هر زمان از روز به طور خودکار در حال رشد هستند. بنابراین، نتایج می توانند با مجموعه داده های مختلف تغییر کنند. به دلیل الگوریتم دانلود، برای داشتن بهترین داده ها باید بارها اجرا می شد و در برخی مکان ها داده های تکراری ایجاد می شد. پس از پردازش داده ها، حجم داده های مورد استفاده برای تجزیه و تحلیل کاهش یافت و نمی توان آن را کلان داده نامید. علاوه بر این، همه از رسانه های اجتماعی مانند فلیکر استفاده نمی کنند. بنابراین، نتایج ممکن است نماینده جمعیت نباشد. محدودیت دیگر این است که گردشگران با در نظر گرفتن فواصل زمانی عکسها به آنها اختصاص داده میشوند. همانطور که آستانه فواصل زمانی تنظیم می شود، تعداد گردشگران و افراد محلی در معرض تغییر است. در نهایت، برخی از میراثها ممکن است به اشتباه بهعنوان غیرجذاب شناخته شوند، زیرا از تعامل رسانههای اجتماعی دور بودند. تحقیقات بیشتر را می توان برای اعتبار سنجی متقابل با مقایسه با مجموعه داده های مختلف، مانند نظرسنجی ها، پرسشنامه ها و تعداد بلیط ها، برای تایید نتایج به کار برد. علاوه بر این، برای اعتبارسنجی نتایج تحقیق، می توان بحث را با گروه های متمرکز و کارشناسان انجام داد. می تواند به تسهیل توسعه جدید پیرامون میراث های غیرجذاب کمک کند تا آنها را جذاب کند. بنابراین می توان فشار گردشگری و ازدحام را در هسته تاریخی کاهش داد. تحقیقات بیشتر را می توان برای اعتبار سنجی متقابل با مقایسه با مجموعه داده های مختلف، مانند نظرسنجی ها، پرسشنامه ها و تعداد بلیط ها، برای تایید نتایج به کار برد. علاوه بر این، برای اعتبارسنجی نتایج تحقیق، می توان بحث را با گروه های متمرکز و کارشناسان انجام داد. می تواند به تسهیل توسعه جدید پیرامون میراث های غیرجذاب کمک کند تا آنها را جذاب کند. بنابراین می توان فشار گردشگری و ازدحام را در هسته تاریخی کاهش داد. تحقیقات بیشتر را می توان برای اعتبار سنجی متقابل با مقایسه با مجموعه داده های مختلف، مانند نظرسنجی ها، پرسشنامه ها و تعداد بلیط ها، برای تایید نتایج به کار برد. علاوه بر این، برای اعتبارسنجی نتایج تحقیق، می توان بحث را با گروه های متمرکز و کارشناسان انجام داد. می تواند به تسهیل توسعه جدید پیرامون میراث های غیرجذاب کمک کند تا آنها را جذاب کند. بنابراین می توان فشار گردشگری و ازدحام را در هسته تاریخی کاهش داد. می تواند به تسهیل توسعه جدید پیرامون میراث های غیرجذاب کمک کند تا آنها را جذاب کند. بنابراین می توان فشار گردشگری و ازدحام را در هسته تاریخی کاهش داد. می تواند به تسهیل توسعه جدید پیرامون میراث های غیرجذاب کمک کند تا آنها را جذاب کند. بنابراین می توان فشار گردشگری و ازدحام را در هسته تاریخی کاهش داد.
به طور کلی، مطالعه ما نشان می دهد که تجزیه و تحلیل جذابیت میراث ها با انواع آنها و محصولات حمایت کننده در محیط ساخته شده اطراف، چشم انداز ارزشمندی برای هدایت بازدیدکنندگان به مناطق کمتر شلوغ از نظر مکان های بیش از حد توریستی ارائه می دهد. این نشان می دهد که درک توزیع بازدیدکنندگان میراث می تواند نشان دهد که چه چیزی در شهرهای تاریخی جذاب یا غیرجذاب می شود. به منظور برداشتن بار گردشگری، شهرداری ها و سازمان های شهر تاریخی می توانند با توجه به توصیه های این پژوهش، نسبت به جذابیت بیشتر میراث های غیرجذاب اقدام کنند. برای تحقیقات آینده، محدودیتها را میتوان با در نظر گرفتن اعتبارسنجی متقاطع با سایر مجموعههای داده کاهش داد.
پیوست اول

جدول A1. ویژگی های فلیکر در هر عکس
جدول A2. توزیع عکس در سال
ضمیمه B
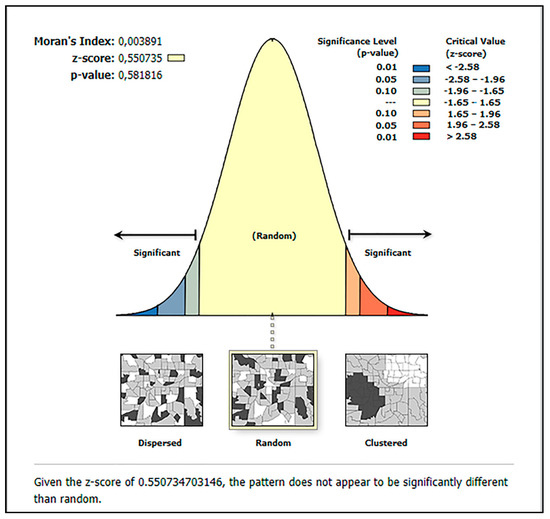
شکل A1. خود همبستگی فضایی با باقیمانده های OLS.
جدول A3. اطلاعات تشخیصی OLS
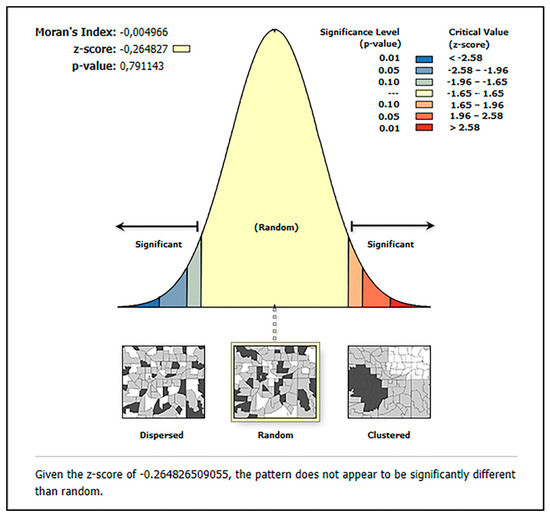
شکل A2. خود همبستگی فضایی با باقیمانده های GWR.
جدول A4. اطلاعات تشخیصی GWR.
منابع
- ون در بورگ، جی. کاستا، پی. گوتی، جی. گردشگری در شهرهای میراث اروپایی. ان تور. Res. 1996 ، 23 ، 306-321. [ Google Scholar ] [ CrossRef ]
- گارسیا هرناندز، م. de la Calle-Vaquero، M. یوبرو، سی. میراث فرهنگی و گردشگری شهری: مراکز شهرهای تاریخی تحت فشار. Sustainability 2017 , 9 , 1346. [ Google Scholar ] [ CrossRef ][ Green Version ]
- ون درزی، ای. برتوچی، دی. Vanneste، D. توزیع گردشگران در مقصدهای میراث شهری: تجزیه و تحلیل نقطه داغ/سرد داده های تریپ ادوایزر به عنوان پشتیبانی برای مدیریت مقصد. Curr. تور مسائل. 2018 ، 1–22. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اشورث، جی. صفحه، تحقیقات گردشگری شهری SJ: پیشرفت اخیر و پارادوکس های فعلی. تور. مدیریت 2011 ، 32 ، 1-15. [ Google Scholar ] [ CrossRef ]
- تو، اچ.-م. مدیریت میراث پایدار: بررسی ابعاد عوامل کشش و فشار. پایداری 2020 ، 12 ، 8219. [ Google Scholar ] [ CrossRef ]
- لی، ی. Lo, RLB کاربردی بودن ماتریس جذابیت بازار-استقامت: مطالعه موردی گردشگری میراث. تور. مدیریت 2004 ، 25 ، 789-800. [ Google Scholar ] [ CrossRef ]
- Trinh، TT; رایان، سی. بازدیدکنندگان از سایتهای میراث: انگیزهها و مشارکت – یک مدل و تحلیل متنی. J. Travel Res. 2017 ، 56 ، 67-80. [ Google Scholar ] [ CrossRef ]
- آهنگ، اچ. لیو، اچ. پیش بینی تقاضای گردشگران با استفاده از داده های بزرگ. در تجزیه و تحلیل در طراحی هوشمند گردشگری ; Xiang, Z., Fesenmaier, DR, Eds. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2017; صص 13-29. شابک 978-3-319-44262-4. [ Google Scholar ]
- لین، دی. مدیریت داده های سه بعدی کنترل سرعت و تنوع حجم داده ها. META Group Res. یادداشت 2001 ، 6 ، 1. [ Google Scholar ]
- بیر، م. Laney, D. اهمیت “داده های بزرگ”: یک تعریف ; گارتنر: استمفورد، سی تی، ایالات متحده آمریکا، 2012; در دسترس آنلاین: https://www.gartner.com/en/documents/2057415/the-importance-of-big-data-a-definition (در 31 دسامبر 2020 قابل دسترسی است).
- لی، جی. فناوریهای مرتبط با دادههای بزرگ، چالشها و چشماندازهای آینده. Inf. تکنولوژی گردشگری 2015 ، 15 ، 283-285. [ Google Scholar ] [ CrossRef ]
- کارایازی، اس.اس. دین، جی. de Vries, B. استفاده از داده های بزرگ جدید در دسترس برای میراث معماری شهری: طراحی یک سیستم توصیه برای مکان های میراث از طریق دریچه رسانه های اجتماعی. در Real Corp 2020: Shaping Urban Change Livable City Regions for the 21st Century، مجموعه مقالات بیست و پنجمین کنفرانس بین المللی برنامه ریزی شهری، توسعه منطقه ای و جامعه اطلاعاتی ، ویرایش اول؛ Schereng, M., Popovich, VV, Zeile, P., Elisei, P., Beyer, C., Ryser, J., Reicher, C., Eds. RWTH-دانشگاه آخن: آخن، آلمان، 2020؛ صص 553-563. شابک 978-3-9504173-9-5. [ Google Scholar ]
- Kadár, B. اندازه گیری فعالیت های توریستی در شهرها با استفاده از عکاسی دارای برچسب جغرافیایی. تور. Geogr. 2014 ، 16 ، 88-104. [ Google Scholar ] [ CrossRef ]
- گینزارلی، م. پریرا رادرز، آ. تلر، جی. نقشه برداری ارزش های منظر شهری تاریخی از طریق رسانه های اجتماعی. J. Cult. میراث. 2018 . [ Google Scholar ] [ CrossRef ]
- کوتراس، ع. نیکاس، IA; Panagopoulos، A. Towards to Developing Cities Smart: شواهدی از تجزیه و تحلیل GIS در مورد رفتار گردشگران با استفاده از داده های شبکه اجتماعی در شهر آتن. در گردشگری هوشمند به عنوان محرکی برای فرهنگ و پایداری ؛ Katsoni, V., Segarra-Oña, M., Eds. انتشارات بین المللی Springer: چم، سوئیس، 2019; ص 407-418. شابک 978-3-030-03909-7. [ Google Scholar ]
- دوکوتا، بی. میازاکی، اچ. Pahari, N. استفاده از محتوای تولید شده توسط کاربر برای توصیف مناطق مورد علاقه گردشگری. در مجموعه مقالات اولین کنفرانس بین المللی فناوری هوشمند و توسعه شهری 2019 (STUD)، چیانگ مای، تایلند، 13 تا 14 دسامبر 2019؛ صص 1-6. [ Google Scholar ]
- García-Palomares, JC; گوتیرز، جی. Mínguez, C. شناسایی نقاط داغ توریستی بر اساس شبکه های اجتماعی: تحلیل مقایسه ای کلان شهرهای اروپایی با استفاده از خدمات اشتراک عکس و GIS. Appl. Geogr. 2015 ، 63 ، 408-417. [ Google Scholar ] [ CrossRef ]
- گنزارولی، ع. د نونی، آی. van Baalen, P. Vicious Advice: تجزیه و تحلیل تأثیر TripAdvisor بر کیفیت رستوران ها به عنوان بخشی از میراث فرهنگی ونیز. تور. مدیریت 2017 ، 61 ، 501-510. [ Google Scholar ] [ CrossRef ]
- ژیراردین، اف. واکاری، ا. گربر، آ. بیدرمن، الف. کمی کردن جذابیت شهری از توزیع و تراکم ردپای دیجیتال. بین المللی جی. اسپات. زیرساخت داده Res. 2009 ، 4 ، 26. [ Google Scholar ]
- گد، م. Kadár, B. تجزیه و تحلیل جنبش های گردشگری در امتداد رودخانه دانوب بر اساس عکاسی فلیکر دارای برچسب جغرافیایی. Proc. بین المللی کارتوگر. دانشیار 2019 ، 2 ، 1-5. [ Google Scholar ] [ CrossRef ]
- رانج، کالیفرنیا؛ دایگل، آر.ام. هاوسنر، VH کمی سازی رونق گردشگری و ردپای فزاینده در قطب شمال با داده های رسانه های اجتماعی. PLoS ONE 2020 , 15 , e0227189. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گونگ، وی ایکس؛ دامن، دبلیو. بوزون، آ. Hoogendoorn، SP Crowd Characteration for Crowd Management با استفاده از داده های رسانه های اجتماعی در رویدادهای شهر. رفتار سفر. Soc. 2020 ، 20 ، 192-212. [ Google Scholar ] [ CrossRef ]
- دین، جی. بورگرز، آ. کایا، دی. Feng, T. جریان بازدیدکنندگان در یک رویداد فرهنگی در مقیاس بزرگ: ردیابی GPS در هفته طراحی هلند. IJGI 2020 ، 9 ، 661. [ Google Scholar ] [ CrossRef ]
- شوال، ن. آهاس، ر. استفاده از فناوری های ردیابی در تحقیقات گردشگری: دهه اول. تور. Geogr. 2016 ، 18 ، 587-606. [ Google Scholar ] [ CrossRef ]
- دوکا، ال. Marchetti، A. داده های باز برای گردشگری: مورد Tourpedia. جی. هاسپ. تور. تکنولوژی 2018 ، 10 ، 351-368. [ Google Scholar ]
- ونگ، LT-N. Ung, A. بررسی عوامل حیاتی گردشگری میراث ماکائو: گردشگران میراث فرهنگی هنگام بازدید از مکانهای میراث نمادین شهر به دنبال چه چیزی هستند. آسیا پک جی. تور. Res. 2012 ، 17 ، 231-245. [ Google Scholar ] [ CrossRef ]
- دین، جی. بورگرز، آ. فنگ، تی. تجربیات فوری ذهنی در طول رویدادهای فرهنگی در مقیاس بزرگ در شهرها: یک آزمایش برچسب گذاری جغرافیایی. پایداری 2019 ، 11 ، 5698. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- پالدینو، اس. بوجیک، آی. سوبولفسکی، اس. راتی، سی. گونزالس، MC مغناطیس شهری از طریق لنز عکاسی با برچسب جغرافیایی. EPJ Data Sci. 2015 ، 4 ، 5. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Ministrie van Onderwijs, C. en W. Rijksmonumenten-kaartlagen-Rijksmonumenten register-Rijksdienst voor het Cultureel Erfgoed. در دسترس آنلاین: https://www.cultureelerfgoed.nl/onderwerpen/rijksmonumentenregister/rijksmonumenten-kaartlagen (در 31 اوت 2020 قابل دسترسی است).
- Data En Informatie-Amsterdam. در دسترس آنلاین: https://data.amsterdam.nl/ (در 31 اوت 2020 قابل دسترسی است).
- مرکز، UWH قرن هفدهم کانال حلقه منطقه آمستردام در داخل Singelgracht. در دسترس آنلاین: https://whc.unesco.org/en/list/1349/ (دسترسی در 26 دسامبر 2020).
- مک کوئین، جی. چند روش برای طبقه بندی و تحلیل مشاهدات چند متغیره. Multivar. Obs. 1967 ، 1 ، 17. [ Google Scholar ]
- لی، آی. کای، جی. لی، ک. کاوش عکس های دارای برچسب جغرافیایی از طریق روش های داده کاوی. سیستم خبره Appl. 2014 ، 41 ، 397-405. [ Google Scholar ] [ CrossRef ]
- دان، JC یکی از بستگان فازی فرآیند ISODATA و استفاده از آن در تشخیص خوشه های فشرده و خوب جدا شده. نول 1973 ، 3 ، 32-57. [ Google Scholar ] [ CrossRef ]
- مای، دی اس؛ Ngo، LT نیمه نظارتی فازی C-Means Clustering برای تشخیص تغییر از تصویر ماهواره ای چندطیفی. در مجموعه مقالات کنفرانس بین المللی IEEE 2015 در مورد سیستم های فازی (FUZZ-IEEE)، استانبول، ترکیه، 2 تا 5 اوت 2015؛ صص 1-8. [ Google Scholar ]
- وینکلر، آر. کلاون، اف. Kruse, R. مسائل فازی c-Means خوشه بندی و الگوریتم های مشابه با مجموعه داده های با ابعاد بالا. در چالش های رابط تجزیه و تحلیل داده ها، علوم کامپیوتر و بهینه سازی ؛ Gaul, WA, Geyer-Schulz, A., Schmidt-Thieme, L., Kunze, J., Eds. Springer: برلین/هایدلبرگ، آلمان، 2012; صص 79-87. شابک 978-3-642-24465-0. [ Google Scholar ]
- کیسیلویچ، اس. کرستایچ، م. کیم، دی. آندرینکو، ن. Andrienko, G. تجزیه و تحلیل مبتنی بر رویداد از فعالیت ها و رفتار افراد با استفاده از مجموعه عکس های دارای برچسب جغرافیایی Flickr و Panoramio. در مجموعه مقالات چهاردهمین کنفرانس بین المللی 2010 تجسم اطلاعات، لندن، انگلستان، 26-29 ژوئیه 2010; ص 289-296. [ Google Scholar ]
- استر، ام. کریگل، اچ.-پی. Xu, X. الگوریتم مبتنی بر چگالی برای کشف خوشهها در پایگاههای داده فضایی بزرگ با نویز. در مجموعه مقالات دومین کنفرانس بین المللی کشف دانش و داده کاوی (KDD-96)، پورتلند، OR، ایالات متحده آمریکا، 2 تا 4 اوت 1996. جلد 96، ص 226–231. [ Google Scholar ]
- باترا ناگپال، پ. احلوات من، ص. مطالعه تطبیقی الگوریتم های خوشه بندی مبتنی بر چگالی. بین المللی جی. کامپیوتر. Appl. 2011 ، 27 ، 44-47. [ Google Scholar ] [ CrossRef ]
- گوتز، ام. بودنشتاین، سی. Riedel, M. HPDBSCAN: DBSCAN بسیار موازی. در مجموعه مقالات کارگاه یادگیری ماشین در محیطهای محاسباتی با کارایی بالا-MLHPC ’15، آستین، TX، ایالات متحده آمریکا، 15-20 نوامبر 2015. 2015; صص 1-10. [ Google Scholar ]
- کمپیاک، جی. هالیوود، ال. بولان، پ. McMahon-Beattie, U. The Heritage Tourist: An Understanding of Visitor Experience at Heritage Attractions. بین المللی جی. هریت. گل میخ. 2017 ، 23 ، 375-392. [ Google Scholar ] [ CrossRef ]
- براندون، سی. فاثرینگهام، اس. چارلتون، ام. عدم ایستایی فضایی مدلسازی رگرسیون جغرافیایی وزندار. JR Stat. Soc. سر. D 1998 , 47 , 431-443. [ Google Scholar ] [ CrossRef ]
- وولدریج، اقتصاد سنجی مقدماتی JM: رویکردی مدرن. آموزش نلسون 2012 ، 910 ، 94-99. [ Google Scholar ]
- Statistiek, CB voor de Wijk-En Buurtkaart. 2020. در دسترس آنلاین: https://www.cbs.nl/nl-nl/dossier/nederland-regionaal/geografische-data/wijk-en-buurtkaart-2020 (در 3 نوامبر 2020 قابل دسترسی است).
- موران، یادداشت های PAP در مورد پدیده های تصادفی پیوسته. Biometrika 1950 , 37 , 7. [ Google Scholar ] [ CrossRef ]
- فو، WJ; جیانگ، پی کی. ژو، جنرال موتورز؛ Zhao، KL با استفاده از Moran’s I و GIS برای مطالعه الگوی فضایی تراکم کربن بستر جنگل در یک منطقه نیمه گرمسیری جنوب شرقی چین. Biogeosciences 2014 ، 11 ، 2401-2409. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رگرسیون OLS چگونه کار می کند-ArcGIS Pro | مستندات. در دسترس آنلاین: https://pro.arcgis.com/en/pro-app/tool-reference/spatial-statistics/how-ols-regression-works.htm (در 19 نوامبر 2020 قابل دسترسی است).
- آکایک، اچ. نظریه اطلاعات و بسط اصل احتمال حداکثری. در منتخب مقالات هیروتوگو آکایکه ; Parzen, E., Tanabe, K., Kitagawa, G., Eds. Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 1998; صص 199-213. شابک 978-1-4612-1694-0. [ Google Scholar ]
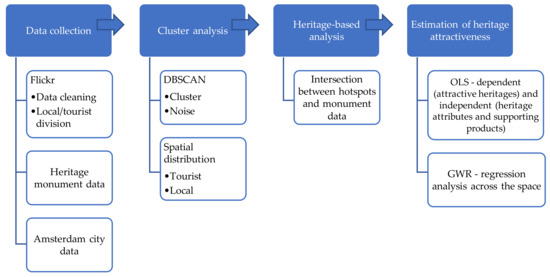
شکل 1. نمودار جریان روشی مورد استفاده در فرآیند داده.
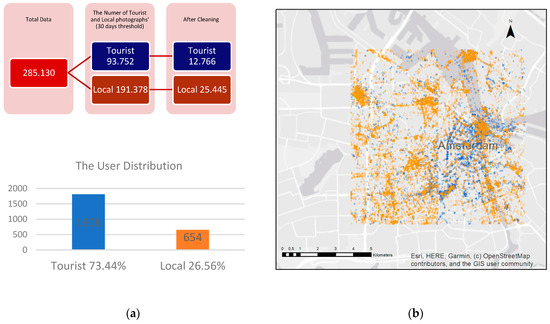
شکل 2. ( الف ) عکس های معتبر و توزیع کاربر. ( ب ) عکس های فلیکر.
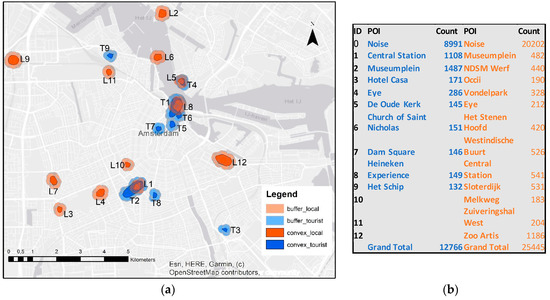
شکل 3. توزیع خوشه ها (نقاط مورد علاقه (POI)) برای توریست ها و محلی: ( الف ) نقشه; ( ب ) تعداد عکسها در هر نقطه نقطه.
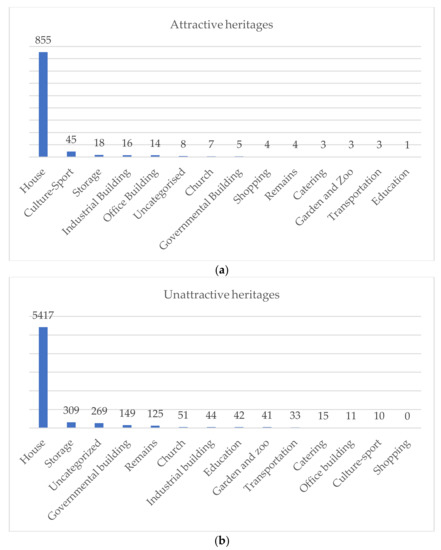
شکل 4. توزیع میراث در هر نوع: ( الف ) جذاب. ب ) غیر جذاب.
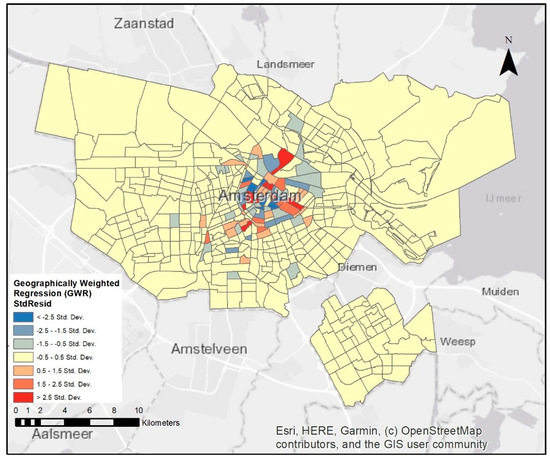
شکل 5. توزیع فضایی پسماندهای رگرسیون وزنی جغرافیایی (GWR).
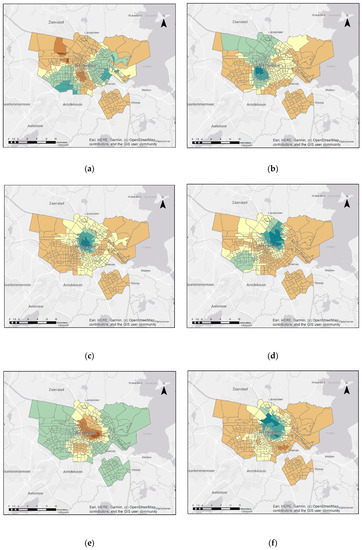
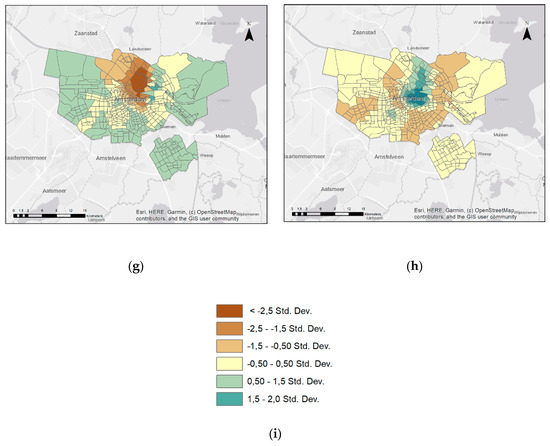
شکل 6. باقیمانده های GWR برای هر متغیر توضیحی: ( الف ) میراث تجاری. ( ب ) میراث تفریحی؛ ج ) جاذبه ها؛ ( د ) مکان های غذا خوردن؛ ( ه ) بازارهای آزاد؛ ( و) توالت های عمومی. ( ز ) مکان های خرید؛ ( ح ) ایستگاه های تراموا-مترو؛ ( من ) راهنما.


بدون دیدگاه