1. مقدمه
مجموعه داده های متشکل از مسیرهای وسیله نقلیه مبتنی بر سیستم ناوبری جهانی ماهواره ای (GNSS) برای مدیریت ترافیک، تشخیص تراکم ترافیک و برنامه ریزی حمل و نقل مفید هستند [ 1 ، 2 ، 3 ]. گیرنده های GNSS در همه جا به دلیل هندسه ماهواره، شرایط جوی و تضعیف سیگنال، اغلب دقت موقعیت یابی پایینی دارند. بنابراین، برنامه ها باید به اندازه کافی با داده های پر سر و صدا یا خطاهای مسیر برخورد کنند [ 4 ، 5 ].
کیفیت ضعیف مرتبط با نقاط ردیابی اغلب ناشی از یک حالت حسگر غیرعادی غیرمنتظره، تأثیر بازتاب چند مسیره در دره شهری است [ 6 ، 7 ]. اطلاعات جامع در مناطق شهری در مورد مسیر صحیح وسیله نقلیه به طور قابل توجهی به تطبیق نقشه، تجزیه و تحلیل رفتار رانندگی و سیستم های ناوبری خودرو کمک می کند تا از کارایی ترافیک موثر اطمینان حاصل شود [ 8 ]. بسیاری از روشهای استخراج مسیر برای تشخیص خطاهای واضح برای نقاط پر سر و صدا یا اشتباه در طول مسیرها و ارزیابی نزدیکیهای فضایی آنها پیشنهاد شدهاند [ 9 ، 10 ]]. با این حال، علاوه بر خطاهای صریح، بیش از 60 درصد از داده های مسیر تاکسی در فرکانس پایین برای صرفه جویی در هزینه های برق و پهنای باند ارتباطی در شهرهای بزرگ جمع آوری می شود [ 11 ]. یک بازه نمونه برداری از زمان یا فاصله زیاد ممکن است منجر به خطاهای ضمنی برای پیوندها در طول مسیرها شود، مانند پیوندهای جعلی متعدد نزدیک به یک چهارراه (یعنی میانبر به یک مسیر چرخشی)، دور از شبکه جاده [ 12 ، 13 ].
اکثر الگوریتم های فیلتر، نقاط پرت ردیابی را بر اساس معیارهای هندسی شناسایی می کنند [ 14 ]. اندازه گیری حرکت، مانند سرعت، جهت، و فاصله [ 15 ]. و ویژگی های زمین آماری چگالی نقطه [ 16 ]. مطالعات قبلی نشان داده است که از فیلترهای متوسط یا میانه ساده می توان برای تشخیص نقاط رانش بلوک های بلند استفاده کرد. به طور مشابه، فیلتر گاوسی نقاط پرت را با حذف بیش از حد در یک پنجره تحلیل با زمان یا فاصله ورودی کاهش می دهد [ 17 ]. با این حال، این الگوریتمها یک مسئله تضعیف را به ارث میبرند [ 18 ، 19]. برای غلبه بر مشکل تضعیف، فیلترهای کالمن از معادلات حالت سیستم خطی برای محاسبه حداقل واریانس در وضعیت سیستم و تخمین موقعیت بهینه نقاط ردیابی استفاده می کنند، اما فواصل نمونه برداری ناهموار مسیر ممکن است بر نتایج فیلتر تأثیر بگذارد [ 20 ، 21 ]. ]. فیلتر ذرات نیز موثر است، اما نیاز به تعریف یک آستانه فاصله پیچیده بین نقاط مکان دارد تا از فیلتر بیش از حد یا کمتر از آن جلوگیری شود [ 10 ، 22 ]. فیلترهای چگالی خط، درجه انحراف هر نقطه از یک ناحیه بسیار همگرا از نقاط را با توجه به یک آستانه جهانی از پیش تعیین شده بررسی می کنند [ 15 ]]. در مقایسه، روشهای تراکم هسته، با تشخیص بیروند، تشخیص خطمسیر کلاسیک (TRAOD)، و تشخیص خط بیرونی مسیر مبتنی بر چگالی (DBTOD)، یک رویکرد تعیین آستانه پیشرفته را برای تعیین پویا آستانه مناسب با زیرمجموعهای از مسیرها را امکانپذیر میسازد [ 16 ، 23 ، 24 ].
پیوندهای ردیابی غیرمنتظره اغلب به عنوان خطاهای “نرم” به دلیل مشکل فاصله نمونه گیری در نظر گرفته می شوند [ 25 ]. نرخ نمونهگیری بالا معمولاً منجر به خوشهبندی پیوندها، اغلب در پارکینگها یا چراغهای راهنمایی مجاور میشود. فواصل نمونه برداری زیاد به این معنی است که بیشتر نقاط ردیابی از بین رفته و عدم اطمینان زیادی در مسیرها ایجاد می شود. این نوع عدم قطعیت به شدت بر اثربخشی و کارایی فرآیندهای بعدی مانند نمایه سازی، پرس و جو و استخراج [ 26 ، 27 ] در طول تطبیق نقشه، استنتاج مسیر [ 28 ، 29 ]، یا تخمین زمان سفر [ 30 ] تأثیر می گذارد.]. یک لینک میانبر نشان دهنده یک وسیله نقلیه است که از یک تقاطع بدون دنبال کردن جاده عبور می کند. کمتر مطالعات موجود به این خطاهای ضمنی مربوط می شود. این موضوع، به دلیل فاصله طولانی نمونه برداری، به عنوان یک مشکل تطبیق نقشه در نظر گرفته شده است، که در آن یک مسیر به مجموعه ای از بخش ها یا بخش ها بر اساس سرفصل ها، تغییرات زاویه و سرعت تقسیم می شود [ 31 ]. این به نوبه خود به شناسایی بخشهای غیرعادی که از شبکه جادهای موجود خارج میشوند بر اساس شاخص ارزیابی کیفیت [ 15 ]، شباهتهای ساختاری [ 32 ، 33 ] یا فاصله هاوسدورف [ 34 ] کمک میکند.]. چنین رویکردهایی در طول تطبیق نقشه به جای پیوندهای منفرد در طول یک مسیر، بر بخشهای مسیر بزرگ تمرکز میکنند، به طوری که دقت فضایی موقعیتهای برش بین بخشهای مجاور و ویژگیهای هندسی و حرکتی بخشها کاملاً درشت است [ 35 ].
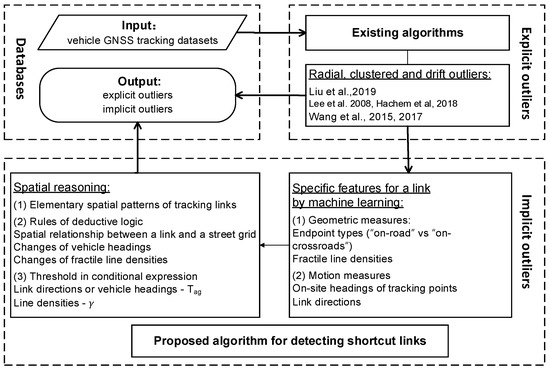
در این مطالعه، ما یک رویکرد یکپارچه برای تشخیص نقاط پرت پیوند در مسیرهای فاصله نمونهبرداری بزرگ در مناطق شهری ایجاد میکنیم. ما از الگوریتمهای موجود برای مدیریت نقاط پرت ظاهری پیوند با حداقل هزینه استفاده میکنیم و یک روش استدلال فضایی جدید برای تشخیص نقاط پرت پیوند میانبر ضمنی ناشی از فواصل نمونهبرداری طولانی پیشنهاد میکنیم. روش ما از پایگاه های اطلاعاتی کمکی (به عنوان مثال، شبکه های جاده ای) استفاده نمی کند. ما از یادگیری ماشینی برای تخمین مجموعهای از معیارهای هندسی و حرکتی خاص برای پیوندها استفاده میکنیم، که باید با مراجعه به شبکه جادهای اندازهگیری شوند. علاوه بر این، یک مجموعه ابتدایی از الگوهای فضایی که ساختارهای فضایی اولیه را برای پیوندهای ردیابی شبکه جاده منعکس میکنند، شناسایی میشوند تا از تعیین پیوندهای دورتر بر اساس معیارهای هندسی و حرکتی همه پیوندها پشتیبانی کنند. سرانجام،
2. مواد و روشها
2.1. تعریف پیوندهای ردیابی Outlier
مسیر GNSS وسیله نقلیه یک توالی مکان مهر زمانی از نقاط ردیابی ( xi , y i , t i ) است که در یک بازه نمونه برداری از زمان یا مسافت منظم توسط یک دستگاه GNSS نصب شده در یک وسیله نقلیه ثبت شده است. از طرف دیگر، مسیر را می توان به عنوان مجموعه ای از پیوندهای ردیابی در نظر گرفت که به عنوان بردارهایی تعریف می شوند که دو نقطه ردیابی متوالی را به هم متصل می کنند.
یک نقطه پرت نشان دهنده یک نقطه داده است که به طور قابل توجهی با حالت یا مقدار واقعی متفاوت است [ 36 ]. خط سیر تقریبی مسیری است که وسیله نقلیه از آن عبور می کند، که ممکن است به دلیل خطاهای اندازه گیری از مسیر حقیقتی زمین خودرو خارج شود. مطالعات قبلی عمدتاً خطاهای موقعیتیابی را در نظر گرفتهاند که باعث نوسانات فضایی در نقاط ردیابی میشوند و به همین ترتیب بر تطابق بین مسیرها و جادهها تأثیر میگذارند ( شکل 1 a). فواصل نمونه برداری طولانی تر یا فاصله ثبت شده توسط دستگاه موقعیت یابی منجر به کاهش کیفیت مسیر می شود، به عنوان مثال، ده ها ثانیه که معمولاً برای دستگاه موقعیت یابی تاکسی اتخاذ می شود، بر کیفیت مسیر نزدیک یک چهارراه تأثیر می گذارد ( شکل 1).ب) که در آن مسیر به عنوان یک خط میانبر ارائه می شود.
بر اساس این مفاهیم برای ردیابی پیوندها و جمعآوری دادههای خود، ما چهار نوع پرت را تعریف کردیم: شعاعی، رانش، خوشهای و میانبر.
- (1)
-
نقاط پرت شعاعی ( شکل 1 ج) روشنایی را تابش می کنند که در آن مرکز نشان دهنده مکان اولیه ای است که یک لاگر GNSS در صورتی که نتواند یک ثابت موقعیتی بدست آورد به آن باز می گردد. این نقاط پرت ممکن است به دلیل شرایط غیرعادی باشد که باعث اختلالات موقت در GNSS می شود.
- (2)
-
نقاط دورافتاده رانش ( شکل 1 د) به پیوندهای ردیابی با نقاط پایانی که از شبکه های جاده ای خارج می شوند به دلیل موقعیت یابی با کیفیت پایین اشاره دارد. این نقاط پرت ممکن است ناشی از اختلالات یونوسفر، لایه اتمسفر، یا تداخل چند مسیره باشد.
- (3)
-
نقاط پرت خوشه ای ( شکل 1 e) رشته های در هم تنیده ای را نشان می دهند که در آن تعداد زیادی از نقاط قرار گرفته از یکدیگر واگرا می شوند و در نتیجه پیوندها از یکدیگر عبور می کنند. دقت این نقاط ردیابی قابل قبول است و بیشتر در چهارراه ها، پارکینگ ها یا کنار جاده ها زمانی که وسیله نقلیه در علامت راهنمایی توقف می کند یا به طور موقت پارک می شود ظاهر می شوند.
- (4)
-
پرت های میانبر ( شکل 1 f) اغلب در چهارراه ها رخ می دهد. پیوند ردیابی میانبر مسیر چرخش خودرو را نشان می دهد که در آن هنگام عبور خودرو از یک تقاطع، تعداد کمی از نقاط ردیابی ثبت شده است. لینک های میانبر باعث عدم تطابق قابل توجهی بین مسیر واقعی و جاده می شوند زیرا تنها دو نقطه پایانی پیوند در جاده ها قرار دارند.
سه نوع اول پرت (که به عنوان نقاط پرت صریح نامیده می شود) به طور گسترده به عنوان مشکلات موقعیت یابی جغرافیایی شناسایی شده اند در حالی که آخرین نوع پرت ضمنی نامیده می شود، جایی که توجه کمتری به نقاط پرت میانبر شده است. به طور کلی، یک بازه نمونه برداری GNSS بزرگتر برای دستگاه منجر به نمایان شدن نقاط پرت لینک میانبر می شود.
ما یک رویکرد یکپارچه ( شکل 2 ) را بر اساس ترکیبی از تکنیک های فعلی برای رسیدگی به مشکلات مربوط به تشخیص نقاط پرت لینک فوق الذکر ایجاد کردیم. این امکان وجود دارد که یک پیوند به عنوان دو دسته متفاوت از نقاط پرت شناسایی شود، بنابراین نقاط پرت صریح ابتدا به ترتیب شعاعی ، خوشهای و رانش شناسایی میشوند و سپس فیلتر بر روی پرت ضمنی اعمال میشود.
نقاط پرت شعاعی توسط فیلتر مسیر پردازش شدند که در آن یک استراتژی فیلتر قوی کالمن، بر اساس روش IGG III [ 37 ]، برای شناسایی نقاط پرت توسط باقیماندههای فاز خلفی و همچنین باقیماندههای استاندارد شده مشاهده با آستانه رد تحمل 500 استفاده شد. متر و خطای موقعیت یابی 10 متر [ 11 ]. نقاط پرت خوشه ای با استفاده از سرعت لحظه ای نقطه ردیابی (به دست آمده از داده های ردیف) پردازش شدند. با توجه به نتایج آماری، آستانه 2 متر بر ثانیه [ 38 ] تعیین شد. نقاط پرت رانش توسط یک تحلیل نوسانات بدون روند (DFA) فیلتر شدند [ 16 ، 18]، که در آن مقدار DFA در چگالی خط مسیرها با استفاده از نقاطی که دارای مقادیر چگالی بزرگتر از چگالی مشخص شده بودند، محاسبه شد، از طریق تجزیه و تحلیل DFA، چگالی 3.5 به عنوان آستانه انتخاب شد که رویدادهای شدید با نقاط چگالی کم در آن قرار گرفتند. بدون تأثیر بر روند همبستگی بلندمدت ردیابی حذف شد.
برای شناسایی نقاط پرت میانبر و تعیین شناسایی ساختاری، ما به طور کامل یک رویکرد مبتنی بر چگالی و آنتروپی را برای محاسبه ویژگیهای خاص پیوندهای میانبر طراحی کردیم. اندازهگیریهای هندسی و حرکتی توسط زمینآمار محاسبه میشوند که در آن رگرسیون منطقی، SVM (ماشین بردار پشتیبان) و درخت تصمیم برای قضاوت در مورد اینکه آیا یک نقطه ردیابی “روی جاده” یا “روی چهارراه” است، آزمایش شدند.
در ادغام این رویهها، عملکرد بهینه با حداقل هزینه با توجه به هدف شناسایی تمام نقاط پرت به دست آمد.
2.2. مدل سازی لینک ردیابی
2.2.1. اندازه گیری های هندسی و حرکتی یک پیوند ردیابی
پیوند ردیابی، برداری است که دو نقطه ردیابی مجاور (که به آنها نقاط انتهایی پیوند گفته می شود) را به هم متصل می کند. یک پیوند میانبر با دو نقطه پایانی، که اغلب در دو خط مختلف قرار دارند، یک نسخه بسیار ساده شده از یک مسیر چرخش خودرو منحنی در چهارراه به دلیل فاصله نمونه برداری طولانی است.
برای شناسایی پیوندهای میانبر در پیوندهای ردیابی که مسیر وسیله نقلیه را تعریف میکنند، معیارها یا ویژگیهای اساسی یک پیوند توسط یادگیری ماشینی برای پشتیبانی از تشخیص الگوی پیوند تخمین زده شد.
- (1)
-
مختصات پیوند نشان دهنده موقعیت جغرافیایی نقاط پایانی پیوند است. مختصات به صورت ( xi , y i , t i ) نشان داده می شود که در آن t i مهر زمانی است.
- (2)
-
نوع نقطه پایانی به محل یک نقطه پایانی، یعنی در جاده یا در یک چهارراه اشاره دارد. یک الگوریتم نوآورانه تعیین نوع نقطه پایانی در این مطالعه پیشنهاد شده است تا نقاط ردیابی را به دو نوع تقسیم کند (“روی جاده” در مقابل “روی چهارراه”).
- (3)
-
عنوان “در محل” یک نقطه ردیابی، جهت حرکت واقعی یک وسیله نقلیه را در یک شبکه جاده ای نشان می دهد. این با استفاده از تعداد مسیرهای پیوند ردیابی نزدیک، بدون نیاز به مجموعه داده های جانبی (مانند شبکه های جاده) تخمین زده می شود.
- (4)
-
جهت پیوند، عنوان پیوند است که به راحتی با استفاده از مختصات و مهرهای زمانی دو نقطه پایانی قابل محاسبه است. در یک مورد لینک میانبر، این جهت در واقع سرفصل وسایل نقلیه نیست.
- (5)
-
چگالی خط شکننده یک پیوند، چگالی فضایی پیوندهای ردیابی است که در یک پنجره جستجو در مرکز یک موقعیت شکننده در امتداد پیوند ردیابی پردازش شده قرار دارند. برای یک پیوند میانبر، دو نقطه پایانی در شبکه جاده قرار دارند، در حالی که بیشتر نقاط شکننده از جاده ها خارج می شوند. به طور پیش فرض، ما سه مقدار چگالی را محاسبه کردیم، یعنی در نقاط شروع، وسط و انتهای پیوند.
2.2.2. تعیین موقعیت نقاط ردیابی در شبکه راه ها بدون استفاده از پایگاه های اطلاعاتی جانبی راه ها
برای تشخیص اینکه آیا یک نقطه ردیابی در جاده یا در یک چهارراه قرار دارد، باید رابطه فضایی بین نقطه ردیابی و پوشش تقاطع را تجزیه و تحلیل کنیم. با این حال، مجموعه داده های شبکه جاده ای موجود (به عنوان مثال، OpenStreetMap) در قالب ویژگی های خط سازماندهی شده اند. استخراج تقاطع ها از یک نقشه شبکه خیابانی در مقیاس بزرگ نه تنها نیاز به کارهای اضافی دارد، بلکه با مشکلات فنی جدیدی مانند نحوه تعیین پوشش تقاطع ها نیز مواجه است. بنابراین، یک راهحل جایگزین که ویژگیهای هندسی مبتنی بر آنتروپی و چگالی اطلاعات پیشرفته را تنها بر اساس یک مجموعه داده مسیر محاسبه میکند تا نوع (“روی جاده” یا “روی چهارراه”) نقاط ردیابی را در این کار تشخیص دهد.
- (1)
-
اندازه گیری آنتروپی اطلاعات در یک نقطه ردیابی
پیوندهای ردیابی در جاده ها اغلب دارای دو جهت اصلی هستند که در مقابل یکدیگر قرار دارند و پیوندهای ردیابی در یک منطقه چهارراه معمولاً همه جهته هستند. با توجه به یک نقطه ردیابی، یک متریک آنتروپی اطلاعات برای تعیین کمیت توزیع جهت پیوندهای نزدیک به نقطه پیشنهاد شده است.
برای هر نقطه ردیابی در یک مسیر، ما یک پنجره جستجو با اندازه عرض جاده (مثلاً 20 متر) تعریف کردیم تا پیوندهای ردیابی را که با پنجره تلاقی می کنند بر اساس تجربه ما استخراج کنیم. بر اساس توزیع جهت این پیوندها، آنتروپی اطلاعات را در نقطه ردیابی به صورت زیر محاسبه کردیم.
ما آن را در نظر گرفتیم D={α1،α2،…،αمن،…،αمتر}،αمن∈[0،2π]مجموعه ای از مقادیر جهت برای پیوندهای انتخاب شده است که با یک پنجره در مرکز نقطه ردیابی پردازش شده تلاقی می کنند. ما یک دایره در مرکز این نقطه ردیابی را به طور مساوی به هشت بخش زاویه تقسیم کردیم و توزیع فرکانس جهات این پیوندها را محاسبه کردیم، F ={f1،…،fمن،…،f8}. پس از آن، آنتروپی اطلاعات، H ، به صورت زیر محاسبه شد:
جایی که fjنشان دهنده تعداد پیوندها با جهت هایی است که در بخش زاویه j قرار دارند.∑j=1nfjتعداد کل پیوندهای موجود در پنجره است. پjاحتمال است. شماره بخش، n، به طور پیش فرض روی 8 تنظیم شده بود.
از آنتروپی اطلاعات می توان برای اندازه گیری پیچیدگی یک سیستم استفاده کرد. هر چه سیستم حالت های بیشتری داشته باشد، اطلاعات بیشتری در اختیار داشته باشد، آنتروپی بیشتر است [ 39 ]. بر اساس معادله (1)، آنتروپی اطلاعات مبتنی بر سرفصل نقاط ردیابی در جاده ها باید به طور قابل توجهی کمتر از تقاطع ها باشد. در حالی که عمدتاً دو جهت مخالف در یک جاده دو طرفه و یکی در یک جاده یک طرفه وجود دارد، جهت های بیشتری در یک تقاطع وجود دارد که چندین جاده با جهت های مختلف اغلب به آنها متصل می شوند.
- (2)
-
اندازه گیری گرادیان چگالی خط در یک نقطه ردیابی
چگالی خط در یک نقطه ردیابی، چگالی ویژگی های خط در همسایگی نقطه ردیابی پردازش شده است، که بر حسب بزرگی در واحد سطح از ویژگی های چند خطی که در شعاع اطراف هر سلول قرار می گیرند، محاسبه می شود. توجه می کنیم که تراکم خط یک نقطه روی چهارراه در بیشتر موارد بزرگتر از یک نقطه روی جاده است زیرا چهارراه ها جریان ترافیک بیشتری نسبت به جاده های متصل دارند. بنابراین، ما یک شاخص گرادیان چگالی خط را برای توصیف تفاوت بین تراکم خطوط در چهارراه و نقاط روی جاده پیشنهاد کردیم.
برای یک نقطه ردیابی معین، یک هسته فیلتر با استفاده از یک پنجره سلولی سه در سه تعریف شد. ابتدا یک سلول خاص در مرکز نقطه تعریف شد و هشت نزدیکترین همسایه با سلول فعلی تراز شدند. برای هر سلول، میانگین چگالی خط نقاط ردیابی که در آن وجود دارد را محاسبه کردیم. سپس گرادیان چگالی خط به صورت زیر محاسبه شد:
جایی که جیگرادیان چگالی خط در یک نقطه ردیابی است، دجمیانگین چگالی خط سلول مرکزی است و دمنمیانگین چگالی خط سلول همسایه است من، من=1…8. به طور کلی، گرادیان یک عدد مثبت در یک تقاطع است، در یک جاده باریک حول صفر در نوسان است و در ناحیه انتقال بین تقاطع و جاده منفی می شود.
- (3)
-
برچسب گذاری نقاط ردیابی با رگرسیون لجستیک
رگرسیون لجستیک برای قضاوت در مورد اینکه آیا یک نقطه ردیابی “روی جاده” یا “روی تقاطع” است بر اساس آنتروپی اطلاعات و گرادیان چگالی خط اتخاذ شد. آمار پیش بینی شامل رگرسیون غیرخطی احتمالی است. اجازه دهید ایکس=(ایکس1،ایکس2،⋯،ایکسn)بردار باشد با nمتغیرها و پ(Y=1|ایکس)با توجه به مقادیر مشخصه آن که به عنوان بردار ورودی x نشان داده شده است، احتمال وجود یک نقطه ردیابی “روی چهارراه” باشد. مدل رگرسیون لجستیک را می توان به صورت زیر بیان کرد:
جایی که g(ایکس)=β0+β1ایکس1+⋯+βnایکسn، β0رهگیری است و β=(β1،β2،⋯،βn)نشان دهنده ضرایب رگرسیون متغیرهای توضیحی است که باید با نمونه های آموزشی کالیبره شوند. محدوده از ایکستنظیم شد [0،1]و احتمال وقوع متغیر وابسته Y=1برآورد شد.
برای برآورد از تابع حداکثر درستنمایی استفاده شد β. اجازه دهید {y1،⋯،yمن،⋯،yمتر}باشد m مشاهدات از نمونه های آموزشی و yمن=0 نشان می دهد که نمونه یکم از نوع “در جاده” است، در حالی که yمن=1نشان دهنده “روی چهارراه” است. تابع احتمال از مترسپس مشاهدات را می توان به صورت زیر بیان کرد:
با اعمال لگاریتم های طبیعی در دو طرف رابطه (4)، یک تابع درستنمایی لگاریتمی به دست می آید که می توان از آن برای حل معادله استفاده کرد. βضرایب:
جایی که مترتعداد مشاهدات و nتعداد متغیرها است. را βضرایب با بیشینه سازی برآورد شد لوگاریتمLدر یک فرآیند تکراری بر اساس روش رایج نیوتن-رافسون.
2.2.3. تخمین عناوین “در محل” در دو نقطه پایانی یک پیوند
عناوین “در محل” در نقاط انتهایی یک پیوند ردیابی، جهت حرکت خودرو به جلو هستند. با این حال، ما در این مطالعه از عناوین در مجموعه دادههای خود استفاده نکردیم تا روش خود را برای آن دسته از منابع دادهای که فاقد معیارهای عنوان خودرو هستند، تضمین کنیم. در عوض، ما عنوان در سایت را بر اساس آمار زمین از پیوندهای ردیابی که با یک پنجره جستجو در مرکز نقطه پایان تلاقی می کنند، تخمین زدیم. همچنین می توان از شبکه خیابان برای برآورد استفاده کرد زیرا مسیر وسیله نقلیه همیشه با جهت جاده یکسان است. اگر نقاط پایانی در یک منطقه تقاطع قرار گیرند، عنوان در سایت خالی است.
با توجه به یک نقطه “روی جاده” که به یک پیوند ردیابی خاص با یک جهت متصل است αلمنnک، D={α1،α2،…،αمن،…،αمتر}،αمن∈[0،2π]مجموعه ای از جهت ها از مجموع m پیوند است که در یک پنجره جستجو در مرکز نقطه قرار دارد. تابع تشابه کسینوس به عنوان یک متریک برای اندازه گیری میزان مشابه بودن جهت دو پیوند استفاده شد، به شرح زیر:
جایی که یک مقدار کسینوس مثبت، سمن، نشان دهنده همان جهت متحرک (یک متقاطع با زاویه تند) و یک مقدار منفی نشان دهنده جهت مخالف (یک متقاطع با زاویه مبهم) است. در نتیجه، پیوندهای m در پنجره جستجو را می توان به دو گروه تقسیم کرد.
ما از میانگین جهت های هر گروه برای تقریب مسیر جاده استفاده کردیم. جهت متوسط با شباهت کسینوس مثبت، عنوان در محل برآورد شده در نقطه پایانی پردازش شده است. عناوین در سایت دو نقطه پایانی یک پیوند ردیابی به صورت نشان داده شده است βمن،من=0 یا 1. توجه داریم که عناوین «در محل» نقاط پایانی «روی چهارراه» محاسبه نشده است.
2.2.4. محاسبه چگالی خط در یک موقعیت شکسته یک پیوند ردیابی
چگالی خط، چگالی ویژگی های خط در یک پنجره جستجو است و بر حسب واحد طول در واحد مساحت محاسبه می شود. با توجه به یک پنجره جستجو با اندازه d ، تعداد کل نپیوندهای ردیابی انتخاب شد، جایی که لمنطول پیوند i را نشان می دهد . چگالی خط در مرکز پنجره را می توان به صورت زیر محاسبه کرد:
بر اساس این فرض که س={q1،…،qمن،…،qمتر}تعداد نقاط شکننده در امتداد یک پیوند ردیابی است، qمنI امین نقطه شکست در پیوند while استq1و qمتربه ترتیب نقطه شروع و پایان بخش هستند. پارامتر پ={ρ1،…،ρمن…،ρمتر}چگالی خط شکننده در نقطه است سدر امتداد پیوند ردیابی که با استفاده از رابطه (8) محاسبه می شود. در امتداد یک پیوند ردیابی، تعداد نامتناهی نقطه شکننده را می توان در تئوری تنظیم کرد. مدل ما به دو نقطه پایانی و حداقل یک نقطه شکننده نیاز دارد. برای کاهش حجم زیاد از محاسبه استفاده کردیم متر=3، که در آن نقطه شکستن نقطه میانی پیوند بود زیرا چگالی خط در این نقطه کمتر از سایر نقاط با احتمال زیاد است.
2.3. الگوریتم تشخیص لینک ردیابی میانبر
2.3.1. الگوهای فضایی پیوندهای ردیابی
یک پیوند ردیابی ممکن است الگوهای فضایی مختلفی را در شبکههای خیابان شهری به تصویر بکشد. بر اساس جابهجایی و ترکیب مکانهای دو نقطه پایانی در شبکه راهها، پیوندهای ردیابی را میتوان به سه الگوی فضایی اصلی گروهبندی کرد: (I) هر دو نقطه پایانی واقع در چهارراه، (II) یک نقطه پایانی در چهارراه و دیگری در چهارراه. جاده، و (III) هر دو نقطه پایانی در جاده ها.
با در نظر گرفتن ترکیبات احتمالی جهت پیوند، عنوان در محل نقاط پایانی و تراکم خط شکننده، سه گروه اصلی را می توان به چندین زیر گروه تقسیم کرد. الگوهای فضایی ابتدایی پیوندهای ردیابی پس از حذف موارد تکراری به دلیل چرخش، آینهکاری و چرخش در شکل 3 در مقایسه با نقشه خیابانی که به یک منطقه جاده و منطقه بلوک تقسیم شده است (نماینده منطقه غیر جاده) نشان داده شده است.
با توجه به مدل 9 تقاطع گسترشیافته (DE9M) (Egenhofer and Herring 1990)، دو نوع رابطه فضایی بین یک پیوند ردیابی و نقشه خیابان تقسیمبندی شده وجود دارد، به عنوان مثال، پیوند ممکن است کاملاً در یک منطقه جاده باشد یا با منطقه بلوک اولی یک پیوند معمولی نامیده می شود (I 1 ، II 11 ، II 21 ، و III 11 )، یعنی یک پیوند مستقیم در امتداد جاده، که با مسیر حقیقت زمینی وسیله نقلیه همپوشانی دارد. دومی پیوند میانبر پرت نامیده می شود (I 2 ، II 12 ، II 22 ، III 12 ، و III 20) که مسیر چرخش وسیله نقلیه بدون نقاط ردیابی در چهارراه است.
2.3.2. تشخیص نقاط پرت میانبر با استدلال فضایی
عادی یا غیرعادی بودن یک پیوند ردیابی به این بستگی دارد که دو نقطه پایانی پیوند در یک جاده باشند. با توجه به اینکه جادههای شهری مستقیم هستند یا جهتهای مسیر به شدت در یک فاصله معین از پیوند ردیابی با طول معقول تغییر میکند، میتوانیم سه معیار را برای استنباط اینکه آیا یک پیوند ردیابی بر اساس معیارهای هندسی و حرکتی پیوند یک میانبر برونبر است تعریف کنیم:
ترکیب دو نقطه پایانی پیوند بر اساس انواع نقطه.
توافق بین جهت پیوند و عناوین در محل دو نقطه پایانی؛
توافق بین چگالی خط شکننده پیوند.
شکل 4 تشخیص نقاط پرت پیوند (یا الگوهای فضایی) را از طریق استدلال فضایی نشان می دهد. چالش این است که تصمیم بگیرید آیا یک پیوند ردیابی ممکن است عادی تلقی شود یا یک میانبر.
اگر یک پیوند ردیابی به خوبی با جاده مطابقت داشته باشد، جهت پیوند باید نزدیک به عناوین در محل دو نقطه پایانی باشد و تمام تراکم خطوط شکننده پیوند نیز باید نزدیک به تراکم در دو نقطه پایانی باشد. بنابراین، دو ضریب اساسی، یعنی تیآgبرای تشابه جهت و γبرای شباهت چگالی خط شکننده، تعریف شد. محدوده این دو ضریب در بخش بحث مورد بحث قرار گرفته است. مقادیر پیشفرض آنها (به ترتیب 21 درجه و 64/0) از زمینآمار آزمایشهای طراحی نمونهگیری ذهنی ما برآورد شد.
3. نتایج
3.1. محدوده مطالعه و مجموعه داده
مجموعه داده مسیر مورد استفاده در آزمایشهای ما بر اساس دادههای GNSS از تاکسیهای منطقه شهری پکن، چین، شامل 12000 مسیر جمعآوریشده در 1 نوامبر 2012 بود. میانگین فاصله بین دو نقطه ردیابی متوالی ~219 متر و فواصل زمانی نمونهبرداری است. محدوده بین 12 تا 65 ثانیه ( شکل 5 ). این مجموعه داده نماینده پایگاههای داده مسیر نمونهبرداری پایین است که در شهرهای بزرگ به دست آمده است، که حاوی نویزهای مختلف است و اغلب باعث دشواری استنتاج مسیر، تطبیق نقشه یا استخراج قوانین ترافیک میشود.
3.2. اطلاعات عمومی در مورد نقاط پرت لینک شناسایی شده
بدون استفاده از پایگاههای اطلاعاتی کمکی (مثلاً شبکههای جادهای)، ما ابتدا مجموعه دادههای مسیر تاکسی را برای شناسایی نقاط پرت پیوند شعاعی، رانش و خوشهای پیش پردازش کردیم. سپس روش تشخیص میانبر اختصاصی برای تعیین نقاط پرت ضمنی با استفاده از رویکرد استدلال فضایی استفاده شد. همانطور که در جدول 1 فهرست شده است ، پیوندهای ردیابی ضعیف 38.2٪ از کل مجموعه داده آزمایشی را تشکیل می دهند. مقادیر پرت صریح 4.5٪ را تشکیل می دهند. مقادیر پرت ضمنی 33.7 درصد است. بیشتر نقاط پرت پیوند، پیوندهای خوشه ای هستند و به دنبال آن پیوندهای میانبر قرار دارند.
پیوندهای ردیابی برچسب گذاری شدند و بر روی نقشه ترسیم شدند ( شکل 6 ). نقشه نشان می دهد که پیوندهای معمولی منعکس کننده شبکه های مستقیم شبکه خیابان هستند. پیوندهای خوشهای بیشتر در چهارراهها ظاهر میشوند و برخی در نقاط داغ کنار جاده یا پارکینگها ظاهر میشوند. الگوهای پیوندهای میانبر، رادیکال و رانش، که به طور مشخص از جاده ها منحرف می شوند و با بلوک های مسکونی همپوشانی دارند، به هم ریخته هستند، به طوری که شبکه های خیابانی را نمی توان از این پیوندها متمایز کرد.
در میان تمام پیوندهای پرت، هر دو پیوند خوشه ای و میانبر سیگنال هستند. اولی به مکان های توقف کوتاه مدت یا پارک خودرو اشاره دارد در حالی که دومی تقاطع های جاده را نشان می دهد. پیوندهای شعاعی و رانش نشان دهنده نویز هستند. با این حال، آنها ممکن است برای تجزیه و تحلیل زمینه جغرافیایی که بر اساس آن نویز تولید شده است استفاده شود.
3.3. تصویر تفصیلی نقاط پرت لینک میانبر
ما منطقه Mudanyuan را برای تعیین ویژگیهای فضایی نقاط پرت پیوند میانبر انتخاب کردیم. جاده ها (رنگ نارنجی سویا) روی نقشه ( شکل 7 ) توزیع کنندگان ناحیه ای هستند که ترافیک را بین مناطق مختلف مسکونی، صنعتی و تجاری اصلی انجام می دهند.
در میان پیوندهای ردیابی در منطقه Mudanyuan، نقاط پرت لینک میانبر حدود 5.839٪ را تشکیل می دهند ( جدول 2 ). ما توجه می کنیم که تعداد نقاط پرت پیوند (III) بیشتر از سایر نقاط پرت است (I, II) زیرا پیوندهای “روی جاده” در مقایسه با پیوندهای “روی چهارراه” اکثریت را نشان می دهند.
بر اساس همپوشانی همه مجموعه دادههای ردیابی، شبکههای جادهای و تصاویر Google در این منطقه ( شکل 7 )، همه نقاط ردیابی از پیش پردازششده، نقاط باکیفیتی هستند که در محدودهای باریک در اطراف خیابانها و چهارراهها در نوسان هستند. شکل 7 نشان می دهد که نقاط ردیابی روی چهارراه و جاده به خوبی در فضا از هم جدا شده اند ( شکل 7 الف).
با این حال، خطوط مسیر بر اساس اتصال این نقاط متوالی با پیوندهای ردیابی، یک الگوی متقاطع پیچیده را ارائه می دهند ( شکل 7 ب). همه پیوندهای معمولی با هم یک شبکه خیابانی واضح را ارائه می دهند. در مقابل، نقاط پرت لینک میانبر، که در واقع مسیرهای چرخش وسیله نقلیه ساده شده هستند، به صورت سازماندهی نشده در نزدیکی چهارراه توزیع می شوند. الگوریتمهای استخراج پیشرفته برای این لینکهای میانبر میتوانند برای تشخیص تقاطعهای جادهای یا قوانین ترافیکی مورد استفاده قرار گیرند.
4. بحث
4.1. آیا آنتروپی اطلاعات به طور موثری جداسازی مکان نقاط ردیابی را در یک شبکه جاده ای توصیف می کند؟
نقاط ردیابی بر اساس رابطه فضایی بین نقاط ردیابی و شبکه جادهای بدون استفاده از پایگاه داده شبکه جادهای به دو دسته (“روی چهارراه” و “روی جاده”) گروهبندی شدند. برای تعیین تفاوت بین دو نوع نقطه از توصیفگر آنتروپی اطلاعات استفاده شد.
بر اساس معادله (1)، آنتروپی اطلاعات برای تمام نقاط ردیابی در منطقه Mudanyuan محاسبه شد. همانطور که در شکل 8 نشان داده شده است، مقادیر آنتروپی اطلاعات نقاط ردیابی “روی چهارراه” به طور قابل توجهی بالاتر از نقاط ردیابی “روی جاده” است. هر چه یک نقطه ردیابی از تقاطع های جاده دورتر باشد، آنتروپی اطلاعات آن کمتر است.
ما به طور تعاملی 11368 نقطه ردیابی نمونه را در سمت داخلی جاده کمربندی دوم پکن انتخاب کردیم که از میان آنها 8556 در خیابان ها و 2812 در تقاطع ها قرار دارند. بر اساس رابطه (1)، آنتروپی اطلاعات برای همه نمونه ها محاسبه شد. در یک آزمون جزوه، این نمونه ها به دو پوشه تقسیم شدند که یک پوشه شامل 9094 نمونه برای آموزش مدل رگرسیون لجستیک و دیگری شامل 2274 نمونه برای اعتبار سنجی بود.
اعتبار سنجی متقاطع K-fold برای آزمایش تنظیم پارامترها و عملکرد مدل رگرسیون لجستیک آموزش دیده استفاده شد. 11368 نقطه ردیابی نمونه به پنج تا تقسیم شده است که از این تعداد چهار تا برای آموزش و یک تا برای آزمایش است. نتایج پنج طبقه بندی مکرر در جدول 3 نشان داده شده است. نمرات کاپا بالا از 97.55 تا 98.72 بر اساس ماتریس سردرگمی نمونه های اعتبارسنجی به دست آمد ( جدول 3) که حاکی از سطح توافق خوبی برای رگرسیون لجستیک است که برای تشخیص نقاط ردیابی در تقاطعهای جادهها از نقاط ردیابی در جادهها با استفاده از توصیفگر آنتروپی اطلاعات و گرادیان چگالی خط استفاده میشود. استفاده از این طبقهبندیکننده رگرسیون لجستیک برای تمام نقاط ردیابی مجموعه دادههای آزمایشی نشان میدهد که نقاط “روی تقاطع” 24.70٪ از تمام نقاط ردیابی را تشکیل میدهند.
4.2. آیا هدینگ در محل میتواند جایگزینی برای وسیله نقلیه در مسیر جاده باشد؟
برای پیوند ردیابی یک وسیله نقلیه، عنوان تخمینی “در محل” در نقاط انتهایی آن از لحاظ نظری معادل جهت جاده ای است که وسیله نقلیه در آن به جلو حرکت می کند، اما در واقع تفاوت هایی دارد. برای ارزیابی دقت سرفصل های برآورد شده در محل، آزمایش زیر در منطقه مودانیوان انجام شد: (1) چهار تقاطع در این منطقه وجود داشت که هر کدام دارای چهار راه (دو جهت ورود یا خروج از تقاطع) بودند، بنابراین عناوین حقیقت زمینی 25026 نقطه در جاده با توجه به موقعیت آنها به یکی از جهت های خطوط اختصاص داده شد، (2) خطاهای مطلق یا اختلاف عنوان بین عنوان های برآورد شده و حقیقت زمین محاسبه شد، و (3) تفاوت عنوان نشان داده شد. بر اساس آمار
بر اساس آمار، میانگین اختلاف سرفصل ها 2.2 درجه و انحراف معیار 6.58 درجه است که نشان دهنده نزدیک بودن سرفصل های محل به مسیر جاده است. توزیع چگالی تفاوتهای سرفصل نشاندهنده توزیع قانون قدرت است و صدک 95 روی منحنی تجمعی ~7 درجه است ( شکل 9 a)، که دقت بالای این روش را از نظر تخمین عناوین در محل تأیید میکند. این نتیجه نشان میدهد که پیوندهای ردیابی میانبر را میتوان با استفاده از عناوین تخمین زده شده در سایت به غیر از جهتهای جاده از پایگاه داده کمکی شبکه جاده شناسایی کرد.
برای بررسی بیشتر نقاط روی جاده با خطاهای بزرگ، 2281 نقطه در جاده با خطاهای بزرگتر از 7 درجه برای تولید یک نقشه حرارتی انتخاب شدند ( شکل 9 ب). نقشه نشان میدهد که بیشتر نقاط نادرست در نزدیکی تقاطعها قرار گرفتهاند، زیرا نمایش همه جانبه پیوندهای ردیابی در اطراف یک تقاطع بر تخمین جهتهای جادههای متصل تأثیر میگذارد.
4.3. چه زمانی سرفصل های سایت و مسیرهای پیوند یک پیوند یکسان در نظر گرفته می شوند؟
اگر جهت پیوند و عناوین سایت در دو نقطه پایانی مرتبط یکسان باشد، یک پیوند ردیابی باید به خوبی با یک جاده مطابقت داشته باشد. با این حال، به دلیل اشتباهات در تخمین سرفصل های موجود در سایت و محاسبه جهت پیوند، با وجود پیوندی که با جاده همپوشانی دارد، کاملاً برابر نیستند. بنابراین، یک آستانه مناسب ( تیآg) مورد نیاز است. اگر تفاوت آنها کمتر از آستانه باشد، جهت ها و سرفصل ها یکسان هستند.
در یک آزمایش نمونهگیری ذهنی، دو گروه از نمونههای پیوند برای آزمایش تفاوتها بین جهتهای پیوند و عناوین در محل در دو نقطه پایانی انتخاب شدند: پیوندهای عادی (III 11 ) و میانبر (III 20 ). اندازه گیری تفاوت بین عناوین در سایت و جهت پیوند به صورت تعریف شده است حداکثر(|αلمنnک-β0|، |αلمنnک-β1|).
برای پیوندهای معمولی، نشانگر حداکثر(|αلمنnک-β0|، |αلمنnک-β1|)بیشتر نزدیک به صفر است و هذلولی از یک تابع متقابل را نشان می دهد ( شکل 10 a1). این شاخص ~15 درجه در صدک 95 است ( شکل 10 a2). برای پیوندهای میانبر، این نشانگر ~24 درجه در صدک 5 است ( شکل 10 b2)، که با مقدار نظری 45 درجه در تضاد است. علاوه بر این، نمونه های دو گروه توزیع یکسانی ندارند ( p -value < 0.01 بر اساس آزمون من ویتنی U).
بر اساس این نتایج، ما از یک محدوده آستانه زاویه [ 15 ، 24 ] برای این نشانگر استفاده کردیم تا دو حالت را از هم جدا کنیم و پیشفرض را روی 20 درجه قرار دهیم. این مقدار نزدیک به مقدار آستانه (20 درجه) برای جدا کردن نقاط ضعیف در جاده تنظیم شد. تجزیه و تحلیل سایر موارد پیوند نتایج مشابهی را نشان داد.
4.4. چه زمانی تغییر در تراکم خطوط شکستنی در امتداد یک پیوند یک مورد معمولی یا میانبر در نظر گرفته می شود؟
تراکم خطوط در تمام موقعیت های شکننده یک پیوند ردیابی معمولی که در امتداد یک جاده توزیع شده است باید مشابه باشد. برای یک پیوند میانبر با تنها دو نقطه پایانی در یک شبکه جادهای، تراکم خطوط شکننده در موقعیتهای میانی که تاکسیها هرگز به آنها نمیرسند باید به طور قابلتوجهی کمتر از دو نقطه پایانی باشد.
بر اساس رابطه (8)، یک شاخص، به عنوان مثال، γ=دقیقه(ρمن،من=1…متر)/دقیقه(ρ1،ρمتر))، برای توصیف تغییر در تراکم خطوط شکننده در امتداد یک پیوند تعریف شد. در یک حالت ایده آل، نشانگر باید نزدیک به یک برای لینک های معمولی و صفر برای لینک های میانبر باشد. بنابراین به راحتی می توانیم لینک های میانبر را از لینک های معمولی تشخیص دهیم.
آزمایش نمونهگیری دیگری برای تعیین پراکندگی آن انجام شد γمقادیر شاخص با استفاده مجدد از دو گروه نمونه. بر اساس آمار چگالی خطوط شکننده، همانطور که در شکل 11 نشان داده شده است (a1,b1)، γاندیکاتور توزیع های متفاوتی را بین لینک های معمولی و لینک های میانبر و همچنین هیستوگرام های مختلف به دست می دهد ( p -value <0.01 بر اساس آزمون Mann-Whitney U). صدک پنجم برای پیوندهای معمولی 0.96 است ( شکل 11 a2) و صدک 95 برای پیوندهای میانبر ~0.31 است ( شکل 11 a2). بنابراین، γمحدوده روی [0.31، 0.96] و پیش فرض روی میانگین (0.64) تنظیم شد. تجزیه و تحلیل سایر موارد پیوند نتایج مشابهی را نشان داد.
4.5. برای اینکه رویکردهای مبتنی بر آنتروپی و چگالی عمل کنند، چند مسیر لازم است؟
بر اساس مجموعه داده مسیر ما در منطقه تقاطع Mudanyuan، به طور تصادفی به زیر مجموعههای مختلف با تراکم خطوط مختلف نمونهگیری مجدد کردیم تا اثرات چگالی خط نمونه بر روی متغیرهای توضیحی در رویکرد ما نشان داده شود. حجم نمونه این زیر مجموعهها از 31 تا 2873 متغیر بود.
آنتروپی و گرادیان چگالی خط مربوط به یک تقاطع، که با هم برای برچسب گذاری نقاط ردیابی استفاده می شوند، ابتدا بر روی این زیر مجموعه ها با استفاده از یک پنجره 35 متر × 35 متر محاسبه شدند. همانطور که چگالی خط نمونه بزرگتر می شود، مقدار دو متغیر افزایش می یابد تا زمانی که در چگالی خط 5 به حدی برسد ( شکل 12 (a1,b1)). تحت این نقطه عطف، رویکرد ما ممکن است نقاط ردیابی را به طور رضایت بخشی طبقه بندی نکند. دو پارامتر دیگر مورد استفاده در استدلال فضایی، که تفاوت بین عناوین در سایت و جهت پیوند و تغییر در تراکم خطوط شکننده در امتداد یک پیوند است، بر روی همان زیر مجموعههای داده محاسبه شد. این دو پارامتر در نمونه های با چگالی خط پایین به شدت تغییر می کنند. در چگالی خط 4، آنها تمایل دارند به تدریج همگرا شوند ( شکل 12(b1,b2)). ما حداکثر چگالی خط را در مقایسه دو نقطه عطف در نظر گرفتیم. اگر روی تعداد مسیرها حساب کنیم، برای دستیابی به خروجی قابل قبول، به حدود 407 رد خودرو توسط رویکرد ما نیاز است.
4.6. این روش تا چه اندازه می تواند انحنای جاده های شهری را بدون خطا داشته باشد؟
موقعیت های دیگری نیز وجود دارد که میانبرهای پیوند رخ می دهد، به عنوان مثال، در امتداد جاده های پر پیچ و خم. بنابراین، ما یک تست استحکام را برای ارزیابی میزان انحنا (به عنوان مثال، از نظر شعاع انحنا) در یک شبکه خیابان شهری انجام میدهیم. در مجموع 27 دایره متحدالمرکز که انحنای آنها از 0.001 m -1 تا 0.01 m -1 است برای شبیه سازی جاده ها ایجاد شد. در امتداد هر دایره، 600 مسیر GNSS وسیله نقلیه شبیه سازی شد که در آن نقاط ردیابی دارای خطاهای موقعیت یابی (0-15 متر)، فاصله زمانی نمونه برداری (12-65 ثانیه) و سرعت (36.5 کیلومتر در ساعت) هستند.
میانبرهای پیوند در تقاطع ها اگر عناوین “در محل” و جهت پیوند یکسان نباشند، شناسایی می شوند. طبق بخش 4.3 ، برای آن پیوندهای غیرمیانبر در جاده های مستقیم، اندازه گیری تفاوت بین سرفصل های محل و جهت پیوند، توزیع قانون قدرت را ارائه می دهد. ایکس1). بنابراین، ما برای پیوندهای شبیه سازی شده در هر دایره نیز همان اندازه ها را محاسبه کرده و توزیع آنها را بدست می آوریم ( ایکس2). اگر ایکس2بطور تصادفی بزرگتر از ایکس1، شعاع انحنای مربوط به ایکس2به عنوان یک مقدار آستانه برای تعیین پذیرش روش ما در نظر گرفته می شود. از آزمون U Mann-Whitney استفاده شد که در آن فرضیه صفر و جایگزین می باشد اچ0:ایکس1<ایکس2، اچ1:ایکس1≥ایکس2. همانطور که در جدول 4 نشان داده شده است ، دایره های دارای انحنا (<0.0068) و p -value (<0.0667) فرضیه های صفر را رد می کنند. بنابراین جاده های منحنی با شعاع انحنای بیش از 147 متر را می توان با روش ما پردازش کرد.
5. نتیجه گیری ها
در این مطالعه، مسیر وسیله نقلیه GNSS به عنوان مجموعه ای از پیوندهای ردیابی در نظر گرفته شد. علاوه بر پیوندهای معمولی، ما چهار نوع پرت (شعاعی، رانش، خوشهای و میانبر) را تعریف کردیم و یک رویکرد یکپارچه برای تشخیص این نقاط پرت پیشنهاد کردیم. به طور خاص، یک روش استدلال فضایی پیشرفته برای شناسایی میانبرهای پرت ضمنی توسعه داده شد. این رویکرد با استفاده از مجموعه داده مسیر تاکسی برای پکن از سال 2012 آزمایش شد. چهار نوع نقاط پرت با موفقیت شناسایی شدند. یافته های این مطالعه را می توان به شرح زیر خلاصه کرد:
-
روش تشخیص پرت پیشنهادی، که بر اساس یک چارچوب مفهومی پیوند ردیابی است، میتواند برای پردازش مجموعه دادههای مسیر خودرو بدون تکیه بر مجموعه دادههای شبکه جادهای استفاده شود. این به این دلیل است که نوع نقاط ردیابی توسط آن ویژگیهای مبتنی بر چگالی و آنتروپی از خود مجموعه داده مسیر تعیین میشود، و همچنین میتوان آن را با تطبیق مجموعه دادههای دسترسی باز، یعنی OpenStreetMap، به طور قطع تشخیص داد.
-
تشخیص پیوند میانبر بر اساس استدلال فضایی است. مجموعهای از الگوهای فضایی که پیوندهای عادی و میانبر را تعریف میکنند، شناسایی میشوند و به همین ترتیب، چندین معیار هندسی کلیدی یک پیوند ردیابی با درک ویژگیهای مسیر پیشنهاد میشوند. مقادیر آستانه پیشفرض این معیارها نیز با طراحی و تجزیه و تحلیل نمونهگیری ذهنی تعیین میشوند.
تحقیقات ما دیدگاه جدیدی را برای تشخیص نقاط پرت در مسیرها ارائه می دهد، و با این وجود محدودیت هایی وجود دارد. این رویکرد برای مناطق شهری که در آن شبکههای خیابانی به خوبی ارائه شدهاند، مناسب است، نه جادههای منحنی در مناطق کوهستانی، تقاطعهای بزرگراهها، یا تقاطعها در جادههای روستایی. رویکرد ما، که در آن چگالی، آنتروپی، و حتی سرفصلها بر اساس آمار است، به ویژگی چگالی خط در تقاطعها محدود میشود. در آینده، میخواهیم این مدل را در مجموعههای داده بیشتری اعمال کنیم که ممکن است الگوهای مختلف یا بینظمی مسیرها را در فضا نشان دهد و رویکرد را بیشتر بهبود بخشد.















بدون دیدگاه