

چکیده
همه گیری کووید-19 یک چالش بزرگ برای جامعه به عنوان یک کل است و تجزیه و تحلیل تأثیر شیوع بیماری همه گیر و اقدامات کنترلی دولت بر الگوهای سفر ساکنان شهری می تواند کمک قدرتمندی به مدیران شهری برای تعیین سطح بالای پیشگیری از همه گیری باشد. سیاست ها و اقدامات ویژه پیشگیری از بیماری همه گیر. این مطالعه بررسی می کند که آیا استفاده از گروه های POI با الگوهای جریان عابر پیاده مشابه به عنوان واحد مطالعه به جای دسته های عملکردی POI مناسب تر است یا خیر. در این مطالعه، ما دادههای ساعت به ساعت جریان عابر پیاده مکانهای کلیدی در پکن را قبل، در طول و بعد از دوره پیشگیری و کنترل همهگیر شدید تجزیه و تحلیل کردیم و متوجه شدیم که الگوهای جریان عابر پیاده در دورههای مختلف با استفاده از یک شاخص خوشه بندی مرکب; ما نتایج خوشهبندی را از دو منظر تفسیر کردیم: گروههایی از الگوهای جریان عابر پیاده و دستههای عملکردی. نتایج نشان میدهد که بسته به مرحله خاص پیشگیری و کنترل همهگیری، تعداد الگوهای جریان منحصربفرد عابر پیاده از چهار مورد قبل از اپیدمی به دو مورد در مرحله کنترل دقیق کاهش یافته و سپس در طول از سرگیری اولیه کار به شش افزایش یافته است. محدودیتهای حرکتی با بیشتر بازدیدها همبستگی دارد و انتشار محدودیتها منجر به افزایش تنوع الگوهای منحصر به فرد جریان عابر پیاده در مقایسه با دوره قبل از محدودیت شد، حتی اگر تعداد کلی بازدیدها کاهش یافت، که نشان میدهد که محدودیت های اجتماعی به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی منجر شد. گروههای الگوهای جریان عابر پیاده و دستههای عملکردی نتایج نشان میدهد که بسته به مرحله خاص پیشگیری و کنترل همهگیری، تعداد الگوهای جریان منحصربفرد عابر پیاده از چهار مورد قبل از اپیدمی به دو مورد در مرحله کنترل دقیق کاهش یافته و سپس در طول از سرگیری اولیه کار به شش افزایش یافته است. محدودیتهای حرکتی با بیشتر بازدیدها همبستگی دارد و انتشار محدودیتها منجر به افزایش تنوع الگوهای منحصر به فرد جریان عابر پیاده در مقایسه با دوره قبل از محدودیت شد، حتی اگر تعداد کلی بازدیدها کاهش یافت، که نشان میدهد که محدودیت های اجتماعی به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی منجر شد. گروههای الگوهای جریان عابر پیاده و دستههای عملکردی نتایج نشان میدهد که بسته به مرحله خاص پیشگیری و کنترل همهگیری، تعداد الگوهای جریان منحصربفرد عابر پیاده از چهار مورد قبل از اپیدمی به دو مورد در مرحله کنترل دقیق کاهش یافته و سپس در طول از سرگیری اولیه کار به شش افزایش یافته است. محدودیتهای حرکتی با بیشتر بازدیدها همبستگی دارد و انتشار محدودیتها منجر به افزایش تنوع الگوهای منحصر به فرد جریان عابر پیاده در مقایسه با دوره قبل از محدودیت شد، حتی اگر تعداد کلی بازدیدها کاهش یافت، که نشان میدهد که محدودیت های اجتماعی به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی منجر شد. نتایج نشان میدهد که بسته به مرحله خاص پیشگیری و کنترل همهگیری، تعداد الگوهای جریان منحصربفرد عابر پیاده از چهار مورد قبل از اپیدمی به دو مورد در مرحله کنترل دقیق کاهش یافته و سپس در طول از سرگیری اولیه کار به شش افزایش یافته است. محدودیتهای حرکتی با بیشتر بازدیدها همبستگی دارد و انتشار محدودیتها منجر به افزایش تنوع الگوهای منحصر به فرد جریان عابر پیاده در مقایسه با دوره قبل از محدودیت شد، حتی اگر تعداد کلی بازدیدها کاهش یافت، که نشان میدهد که محدودیت های اجتماعی به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی منجر شد. نتایج نشان میدهد که بسته به مرحله خاص پیشگیری و کنترل همهگیری، تعداد الگوهای جریان منحصربفرد عابر پیاده از چهار مورد قبل از اپیدمی به دو مورد در مرحله کنترل دقیق کاهش یافته و سپس در طول از سرگیری اولیه کار به شش افزایش یافته است. محدودیتهای حرکتی با بیشتر بازدیدها همبستگی دارد و انتشار محدودیتها منجر به افزایش تنوع الگوهای منحصر به فرد جریان عابر پیاده در مقایسه با دوره قبل از محدودیت شد، حتی اگر تعداد کلی بازدیدها کاهش یافت، که نشان میدهد که محدودیت های اجتماعی به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی منجر شد. تعداد الگوهای جریان عابر پیاده منحصر به فرد از چهار مورد قبل از همه گیری به دو مورد در مرحله کنترل دقیق کاهش یافت و سپس در طول از سرگیری اولیه کار به شش افزایش یافت. محدودیتهای حرکتی با بیشتر بازدیدها همبستگی دارد و انتشار محدودیتها منجر به افزایش تنوع الگوهای منحصر به فرد جریان عابر پیاده در مقایسه با دوره قبل از محدودیت شد، حتی اگر تعداد کلی بازدیدها کاهش یافت، که نشان میدهد که محدودیت های اجتماعی به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی منجر شد. تعداد الگوهای جریان عابر پیاده منحصر به فرد از چهار مورد قبل از همه گیری به دو مورد در مرحله کنترل دقیق کاهش یافت و سپس در طول از سرگیری اولیه کار به شش افزایش یافت. محدودیتهای حرکتی با بیشتر بازدیدها همبستگی دارد و انتشار محدودیتها منجر به افزایش تنوع الگوهای منحصر به فرد جریان عابر پیاده در مقایسه با دوره قبل از محدودیت شد، حتی اگر تعداد کلی بازدیدها کاهش یافت، که نشان میدهد که محدودیت های اجتماعی به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی منجر شد.
کلید واژه ها:
رویدادهای بهداشت عمومی ؛ مناطق کلیدی شهری ؛ الگوهای تغییر جریان عابر پیاده خوشه بندی سری های زمانی
1. مقدمه
کووید-19، به عنوان یک اورژانس عمده بهداشت عمومی [ 1 ، 2 ]، بدون شک تأثیر زیادی بر شهرها [ 3 ، 4 ، 5 ، 6 ، 7 ، 8 ] به دلیل تراکم جمعیت بسیار بالا خواهد داشت [ 3 ، 4 ]. ، به ویژه در مورد الگوهای جریان عابر پیاده [ 9 ، 10 ]، که نشان دهنده تغییرات در تعداد افرادی است که از یک POI بازدید می کنند. برخی از پیشرفتهای مهم در تحقیق در مورد الگوهای جریان عابر پیاده، مانند شناسایی مناطق عملکردی شهری [ 11 ] و تشخیص ناهنجاریهای شهری در فعالیتهای انسانی [ 12 ] وجود داشته است.]. مطالعات در مورد تأثیر چنین رویدادهای عمومی عمده بر شهرها، مانند بازیابی سرزندگی شهری، توجه طیف وسیعی از محققان مرتبط را به خود جلب کرده است [ 13 ، 14 ، 15 ، 16 ]. بیشتر مطالعات در مورد واکنش شهری و بازیابی پس از بلایای بزرگ بر بلایای طبیعی متمرکز شده است [ 17 ، 18 ، 19 ]. برخلاف بلایای طبیعی، رویدادهای بهداشت عمومی به ساختمانها و تأسیسات شهری آسیب فیزیکی وارد نمیکنند، بلکه ترس و نگرانیهای درونی ایجاد میکنند که بر الگوهای سفر مردم تأثیر میگذارد.
برای جلوگیری از گسترش بیماری همه گیر از طریق تعامل فرد به فرد، دولت ها در سراسر جهان سیاست های قفلی را برای محدود کردن تحرک صادر کرده اند. آنها پس از بهبود وضعیت، سیاست بازگشایی را اجرا می کنند. با در نظر گرفتن پکن، می توانیم سه مرحله اجرای سیاست های مختلف را از 17 ژانویه 2020 تا 15 فوریه 2020 مشاهده کنیم. مرحله اول، مرحله عادی بدون COVID-19 است. مرحله دوم قرنطینه شدید با تعطیلی تمامی اماکن عمومی و مرحله سوم از سرگیری کار با بازگشایی تدریجی اماکن عمومی است. اثربخشی این سیاستها موضوعی معنادار برای مطالعه است [ 20 , 21 , 22]. سیاستهای محدودیت تحرک که محدودیتهای حرکتی غیرمتمایز را بر مناطق عملکردی شهری خاص یا دستههای عملکردی POI در مناطق مختلف تحمیل میکند، مشابه مواردی است که در پکن وجود دارد. یک فرض پنهان این رویکرد این است که دسته عملکردی POI یک مبنای معقول برای طبقه بندی است، یعنی POI های مشابه باید الگوهای جریان مشابهی داشته باشند. این فرض پنهان تأیید نشده است [ 23 ]، بنابراین سؤالات زیر مطرح می شود: آیا محدودیت های تحرک بر اساس مناطق عملکردی شهری یا دسته های عملکردی POI معقول است؟ آیا واحد اجرای بهتری برای محدودیت های حرکتی وجود دارد؟
تحقیقات در مورد تأثیر اپیدمی بر تحرک در شهرها را می توان به سه بخش کلی تقسیم کرد: (1) مناطق مختلف به درجات مختلف تحت تأثیر قرار می گیرند: لی دریافت که فاصله اجتماعی بین گروه های مختلف بلوک های سرشماری و نقاط داغ شهری به طور قابل توجهی در طول شیوع تغییر کرده است. فاز هراس جمعیتی ناشی از [ 24 ]. چانگ و همکاران “سوپرهات اسپات” را در شهرها مورد مطالعه قرار دادند. آنها پیشنهاد کردند که نسبت عابران پیاده در نقاط داغ در شهرها یکی از مهم ترین شاخص های پاسخ شهری به همه گیری ها است [ 25 ]. وانگ و همکاران تأثیر اپیدمی و کنترل دولتی بر الگوهای بازدید ساکنان پارک را تحلیل کرد [ 26]. (2) گسترش اپیدمی و رفتار سفر: لی و همکاران. از تحلیل رگرسیون برای برازش رابطه بین حجم ترافیک یک منطقه و تعداد موارد COVID-19 در مناطق مختلف استفاده کرد [ 27 ]. پار و همکاران دریافتند که در حالی که حجم کلی ترافیک در حال کاهش بود، تغییرات بر اساس کلاس جاده متفاوت بود، و تأثیر بر حرکات بر اساس منطقه متفاوت بود [ 28 ]. (3) کنترل تحرک با از سرگیری منظم کار: چانگ و همکاران. دریافتند که محدود کردن بازدیدکنندگان به دو نوع POI، رستورانها و سالنهای ورزشی، گسترش موارد را پس از بازگشایی به حداقل میرساند [ 29 ، 30 ]. به عنوان هدف تحلیل فضایی، این مطالعات عمدتاً مناطق یا دسته های عملکردی POI را انتخاب کرده اند [ 31]، اما مناطق و دسته های عملکردی POI به عنوان متغیرهای توضیحی برای تغییرات در تحرک شهری کافی نیستند. برای مثال، فرض کنید دو رستوران وجود دارد که یکی در محل کار و دیگری نزدیک یک مرکز خرید است. در این صورت الگوی جریان رستوران در نزدیکی یک مرکز خرید به احتمال زیاد شبیه بازار است، و بهتر است که رستوران نزدیک یک مرکز خرید و خود مرکز خرید را به عنوان یک گروه الگو در سیاست بازگشایی مرحله زمانی در نظر بگیریم. ماهیت تحرک شهری در پاسخ به چنین شوکهایی موضوع هیچ تحلیل قبلی نبوده است و شوک اپیدمی و سیاستهای متعاقب آن یک آزمایش طبیعی برای تحرک شهری [ 32 ] است.
این مطالعات مقوله عملکردی یک POI و گروه الگوی جریان عابر پیاده از یک POI را یکسان میدانستند. با این حال، این دو مفهوم با یکدیگر مطابقت ندارند. هدف از این مطالعه گروه بندی همه POI ها از دیدگاه الگوی جریان عابر پیاده برای به دست آوردن الگوهای مختلف است. بنابراین، این مقاله به پرسشهای پژوهشی زیر میپردازد: POI با دستههای مختلف از نظر الگوهای جریان در مراحل مختلف همهگیری و سیاستها چه نوع ویژگیهایی را نشان میدهند؟ آیا الگوهای جریان POI در همان دسته عملکردی ثابت باقی می مانند؟ آیا محدودیتهای تحرک بر اساس مناطق عملکردی شهری یا دستهبندیهای عملکردی POI معقول است؟
در این مطالعه، POI ها بر اساس خوشه بندی سری های زمانی برای به دست آوردن مراحل مختلف الگوهای جریان عابر پیاده گروه بندی می شوند، و سپس رابطه ای بین الگوهای دوره های مختلف پیدا می کنیم و در مورد چگونگی تفاوت درجات بازیابی POI های مختلف بحث می کنیم. از نظر روششناسی، ما روشی را برای تعیین تعداد الگوهای جریان عابر پیاده POI در یک منطقه شهری پیشنهاد میکنیم. سپس تغییرات گروههای الگوی تحرک POI را در مقابل مراحل مختلف اپیدمی COVID-19 و سیاستهای محدودیت تحرک مرتبط مورد بحث قرار میدهیم ( شکل 1)). اهمیت مطالعه به اپیدمی ها محدود نمی شود. ماهیت این مطالعه این است که چگونه ساختار و عملکرد شهر، همانطور که توسط الگوهای جریان عابر پیاده POI آشکار میشود، تحت شرایط شوک ناگهانی تغییر میکند که محدودیتهای تحرک مختلفی را در انواع و مراحل مختلف تحمیل میکند. دوره این مطالعه موردی هر مرحله از تأثیر همه گیری را در بر می گیرد که تاکنون تنها در چند مطالعه محقق شده است. همچنین انواع سیاستهای محدودیت حرکتی در پکن، پایتخت چین را پوشش میدهد و آن را به یک مورد مناسب برای مطالعه تأثیر شرایط اضطراری عمومی بر تحرک شهری و پاسخ به سؤالات تحقیقاتی ما تبدیل میکند.
2. مواد و روش
2.1. داده ها
دادههای مجموعه آموزشی مربوط به جریان جمعیت در مناطق کلیدی شهری پکن در طول دوره اپیدمی از 17 ژانویه 2020 تا 15 فوریه 2020 است. دادهها شبکه تاریخی چند روزه زیر ساعتی (200 × 200 متر) تراکم جمعیت را ارائه میکنند. با استفاده از شاخص مردم برای نشان دادن تراکم جمعیت). شاخص اندازه گیری تعداد افراد در منطقه است که متناسب با تعداد افراد حاضر در منطقه در یک ساعت معین در یک روز خاص است. شاخص بزرگتر به این معنی است که افراد بیشتری در آن مکان حضور دارند و بالعکس.
داده ها شامل تقریباً تمام نقاط کانونی در داخل جاده کمربندی ششم پکن، همانطور که در شکل 2 نشان داده شده است ، و همچنین انواع کاربری زمین مقاصد مسافرتی در پکن را پوشش می دهد، که عمدتاً شامل شش دسته اصلی از POI های حمل و نقل، مراکز مراقبت پزشکی، POI های آموزشی است. , POI های تفریحی, POI های خرید و POI های ورزشی. همانطور که در جدول 1 نشان داده شده است، آنها همچنین به 14 زیرمجموعه با مجموع 997 مکان کانونی تقسیم می شوند .
تقسیم بندی دوره ها بر اساس اقدامات مختلف ادارات دولتی برای پیشگیری و کنترل COVID-19 و اطلاعیه های مربوطه صادر شده است. داده ها شامل دوره 17 ژانویه 2020 تا 15 فوریه 2020 است که در این مقاله به 3 دوره زمانی تقسیم شده است: دوره اول نشان دهنده مرحله قبل از پیشگیری و کنترل همه گیر است: 17 ژانویه 2020 در 00:00 تا 24 ژانویه 2020 در 00 :00 بخش دوم نشاندهنده مرحله پیشگیری و کنترل همهگیری است: 24 ژانویه 2020 ساعت 00:00 تا 10 فوریه 2020 ساعت 00:00 ساعت. دوره سوم نشاندهنده مرحله از سرگیری اپیدمی پس از کنترل منظم است: 10 فوریه 2020 در ساعت 0:00 ساعت تا 15 فوریه 2020 در ساعت 24:00 [ 33 ].
2.2. خوشه بندی سری های زمانی
با خوشهبندی همه کانونها بر اساس شاخصهای افراد ساعتی، میتوانیم POIها را پس از تعیین تعداد خوشهها گروهبندی کنیم و الگوها و ویژگیهای مربوط به بازدید را بیشتر استخراج کنیم.
با در نظر گرفتن فاز کنترل قبل از اپیدمی به عنوان مثال، هر مکان کانون به عنوان یک بردار N بعدی نشان داده شد، که در آن N نشان دهنده بازه زمانی این مرحله است. به عنوان مثال، مرحله کنترل قبل از اپیدمی از ساعت 0:00 در 17 ژانویه 2020 تا ساعت 0:00 در 15 فوریه 2020 است، بنابراین N برای این مرحله 168 است. روش خوشهبندی مورد استفاده، خوشهبندی K-means [ 34 ] بود. مقدار K در روش خوشهبندی K-means به عنوان یک فراپارامتر استفاده میشود که باید قبل از خوشهبندی به صورت تجربی تنظیم شود. از آنجایی که همه مکانهای کانونی که قرار است طبقهبندی شوند، در مجموع شامل 14 خوشه فرعی بر اساس دستههای عملکردی هستند، ما با تنظیم K روی 14 شروع کردیم. نتایج خوشهبندی در شکل 3 نشان داده شده است.
از آنجایی که POI در داده ها به طور مصنوعی به 6 دسته عملکردی اصلی و 14 دسته فرعی تقسیم شده است، تعداد الگوهای جریان عابر پیاده در ابتدا به 14 تنظیم شد، اما نتایج نشان می دهد که بیشتر POI های همان دسته در یک تحرک خوشه بندی نشده اند. گروه الگو نتایج نشان میدهد که دستههای عملکردی POI را نمیتوان به عنوان مبنایی برای تشخیص گروههای الگوهای جریان عابر پیاده در POI مشاهده کرد.
الگوریتم خوشهبندی که ما استفاده کردیم یک روش یادگیری ماشین نیمه نظارت شده است زیرا تعداد خوشههای K یک فراپارامتر است که باید به صورت تجربی تنظیم شود و یک مقدار K معقول میتواند مجموعه دادهها را در زیر مجموعههای مختلف به درستی خوشهبندی کند [ 35 ]. از یک طرف، مقدار K صحیح می تواند الگوهای مختلف منطقه ای تغییرات جریان جمعیت را متمایز کند. از سوی دیگر، مقدار K صحیح را می توان برای آماده سازی کارهای پیشگیری از بیماری همه گیر و سایر ترتیبات کار کنترلی با توجه به الگوهای زمانی جریان جمعیت و ترتیب معقول نیروی انسانی و منابع مادی محدود پیشگیری از بیماری همه گیر استفاده کرد. اخیراً، بسیاری از محققان مطالعات عمیقی را در مورد مسئله انتخاب تعداد خوشههای K انجام دادهاند [ 36 ، 37]، که با توجه به اینکه داده ها دارای برچسب های خوشه بندی واقعی هستند، می توانند به دو نوع روش انتخاب و ارزیابی تقسیم شوند. یکی خوشه بندی داده ها با برچسب های دسته بندی واقعی است. مسئله انتخاب مقدار K از تفاوت طبقهبندی اشتباه نتایج در مقایسه با مقولههای واقعی شروع میشود [ 38 ]. نوع دیگر زمانی استفاده میشود که دادهها حاوی برچسبهای دستهبندی واقعی نباشند، و نقطه شروع این مسئله انتخاب مقدار K درجهای است که دادهها پس از خوشهبندی به درستی از هم جدا شدهاند. شاخص هایی مانند شباهت بین داده های یک دسته و تفاوت بین داده های دسته های مختلف یا شاخص های ترکیبی محاسبه شده از چند شاخص می توانند به عنوان مبنای انتخاب و قضاوت مورد استفاده قرار گیرند [ 39 ].
برای مشکل در این مقاله، اگرچه هر POI دارای یک دسته عملکردی واضح است، مانند مرکز حمل و نقل یا جاذبه توریستی، و یک دسته مکان خاص، مانند ایستگاه راه آهن، پارک و غیره، داده های مورد استفاده برای خوشه بندی داده های سری زمانی هستند. جریان عابر پیاده [ 40 ]؛ بنابراین، داده های سری زمانی، اگرچه مربوط به نوع کاربری زمین و نوع مکان است، اما هیچ ارتباط مستقیمی با مقوله ندارد. علاوه بر این، دادههای مسئله خوشهبندی در این مقاله حاوی برچسبهای دستهبندی واقعی نیستند، بنابراین برای انتخاب مقدار K، کلاس دوم روش توصیفشده در بالا را اعمال کردیم. برای خوشهبندی بدون برچسبهای واقعی، رایجترین روشهای انتخاب مقدار K در حال حاضر ضریب Silhouette، تمایز امتیاز CH، و تمایز شاخص DB هستند.
روش تفکیک ضریب Silhouette برای تشخیص بهینه بودن مقدار K انتخاب شده برای خوشه بندی با محاسبه ضریب Silhouette نتایج به دست آمده از خوشه بندی استفاده می شود. ضریب Silhouette که برای اولین بار توسط Peter J. Rousseeuw در سال 1987 ارائه شد، حاوی درجه تشابه داده های مشابه و درجه تفاوت بین خوشه های مختلف داده ها در نتایج خوشه بندی است و می توان از آن برای محاسبه شایستگی مقادیر مختلف K استفاده کرد. در نتایج خوشهبندی بر اساس میزان تجمع دادهها در توزیع فضای ویژگی در غیاب برچسبهای خوشهای واقعی دادهها [ 41]. این کار با محاسبه ضریب Silhouette مربوطه s(i) برای هر آیتم داده انجام می شود. s(i) از دو عبارت a(i) و b(i) تشکیل شده است که a(i) میانگین فاصله بین نمونه i و سایر نمونه ها در همان خوشه نمونه i است و b(i) نشان دهنده فاصله است. بین نمونه i و نمونه هایی از خوشه های دیگر. در جزئیات بیشتر، a(i) نشاندهنده فاصله بین نمونههای خوشهبندی شده در همان خوشه، یعنی درجه اختلاف درون خوشهای است. برای تمام نمونههای x از یک خوشه، a(x) مربوطه را محاسبه میکنیم. میانگین تمام مقادیر a(x) واریانس درون خوشه ای خوشه نشان داده می شود. با فرض اینکه نمونه j به همان خوشه A متعلق به نمونه i در نتیجه خوشه بندی باشد، داریم
آمن=∑j∈آ||من–j||22آn
جایی که آnتعداد نمونه ها در دسته A را نشان می دهد و ||من–j||22نشان دهنده مجذور فاصله اقلیدسی بین نمونه i و نمونه j است. مقدار a(i) کوچکتر نشان دهنده احتمال بالاتری است که i به دسته A تعلق دارد.
b(i) حداقل مقدار در فاصله متوسط نمونه i از نمونه های دیگر خوشه ها است:
بمن=دقیقهسی≠آ∑j∈سی||من–j||22سیn
جایی که سیnنشاندهنده تعداد نمونههای دسته C است. مقدار b(i) بزرگتر نشاندهنده احتمال بالاتری است که نمونه i به دسته A تعلق دارد. ضریب Silhouette s(i) نمونه i بر اساس درجه شباهت a(i) تعریف میشود. داده های مشابه و درجه تفاوت b(i) بین خوشه های مختلف داده ها:
سمن=1–آمنبمن، آمن<بمن0،آمن=بمنآمنبمن–1،آمن>بمن
برای نمونه i، ضریب Silhouette s(i) دارای محدوده [-1، 1] است. هر چه s(i) به 1 نزدیکتر باشد، احتمال اینکه نمونه i در دسته صحیح خوشه بندی شود، بیشتر است و هر چه s(i) به 1- نزدیکتر باشد، احتمال اینکه در دسته اشتباه خوشه بندی شود، بیشتر می شود. برای مقدار K انتخاب شده برای خوشهبندی، ضریب Silhouette مربوطه، میانگین s ضریب Silhouette همه نمونهها پس از خوشهبندی آنها در خوشههای K-many است. همانطور که با روش مقایسه برای نمونه های جداگانه، هر چه مقدار s مربوط به مقدار K بزرگتر باشد، هر چه نمونه ها در نتیجه خوشه بندی به یک خوشه نزدیکتر باشند، فاصله نمونه ها در خوشه های مختلف بیشتر باشد و انتخاب منطقی تر باشد. از مقدار K برای خوشه بندی. از آنجایی که مقدار میانگین ضریب Silhouette به عنوان پایه استفاده میشود، این روش به دادههای پرت بسیار حساس است که منجر به نتایج بالقوه غیر منطقی میشود. با توجه به نتایج درشکل 4 ، و بر اساس این فرض که هر چه مقدار بزرگتر باشد، نتیجه خوشه بندی بهتر است، الگوی جریان عابر پیاده باید بدون توجه به مرحله اپیدمی به دو نوع تقسیم شود.
تفکیک ضریب CH یکی دیگر از ضرایب رایج برای انتخاب مقدار K خوشه ها است و توسط کالینسکی و هاراباز در سال 1974 پیشنهاد شد، بنابراین ضریب کالینسکی-هاراباز [ 42 ] یا به اختصار ضریب CH نامیده می شود. ضریب CH مشابه ضریب Silhouette است و همچنین شامل دو جزء است، یکی نشان دهنده درجه نزدیکی بین نمونه های اختصاص داده شده به همان خوشه و دیگری نشان دهنده درجه پراکندگی بین نمونه های اختصاص داده شده به خوشه های مختلف [ 43 ]. درجه نزدیکی دبلیوکبین نمونه های یک خوشه با استفاده از مجموع مجذور فواصل اقلیدسی تک تک نمونه ها از همان خوشه تا مرکز خوشه و درجه پراکندگی محاسبه می شود. بکبین نمونهها از خوشهها با استفاده از مجموع مجذور فاصلههای اقلیدسی مرکز نمونهها از هر خوشه تا مرکز فضای نمونه کامل محاسبه میشود:
دبلیوک=∑q=1ک∑ایکس∈سیq||ایکس–ایکسq||22
بک=∑q=1کnq||ایکسq–ج||22
در رابطه (4)، K تعداد خوشه ها است، سیqمجموعه ای از نمونه های خوشه q است، ایکسqمرکز نمونه است سیq، nqتعداد نمونه ها در است سیq، و c مرکز فضای نمونه کامل است. سپس ضریب CH را می توان از آن محاسبه کرد دبلیوکو بک:
CHفهرست مطالب=بکدبلیوک×متر–کک–1
در رابطه (6) m تعداد کل همه نمونه ها و K تعداد خوشه ها است. هر چه نتیجه خوشه بندی بهتر باشد، کوچکتر است دبلیوکارزش و بزرگتر بکمقدار، با ضریب CH در نتیجه بزرگتر. بنابراین، هنگامی که ضریب CH به عنوان قضاوت استفاده می شود، یک مقدار بزرگتر نشان دهنده یک نتیجه خوشه بندی بهتر است.
در مقایسه با ضریب Silhouette، ضریب CH دارای مزایای پیچیدگی محاسباتی کم و سرعت محاسبات بسیار سریع است، اما دارای معایبی مشابه با ضریب Silhouette است. از آنجایی که محاسبه ضریب CH بر اساس فاصله اقلیدسی بین نمونهها است، میتواند اثر خوشهبندی را برای خوشهبندی مجموعه دادههای محدب بهتر منعکس کند، اما نمیتوان آن را برای فضای مجموعه داده سری زمانی غیرمحدب بهطور کامل اعمال کرد، زیرا مجموعه دادهها این کار را انجام میدهد. به قطعات بسیار ظریف تقسیم شود. برای قضاوت در مورد نتایج خوشه بندی باید همراه با سایر ضرایب استفاده شود. با توجه به نتایج در شکل 5و بر اساس این فرض که هر چه مقدار بزرگتر باشد، نتیجه خوشه بندی بهتر است، الگوی جریان عابر پیاده باید بدون توجه به مرحله اپیدمی به بیش از 10 گروه تقسیم شود.
شاخص DB یکی دیگر از شاخص های رایج برای تمایز نتایج خوشه بندی است که به عنوان شاخص صحت طبقه بندی نیز شناخته می شود و اولین بار توسط DL Davies و DW Bouldin در سال 1979 برای ارزیابی دقت نتایج خوشه بندی پیشنهاد شد [ 44 ]. در این مقاله، بعد فضای نمونه، بازه زمانی تغییر زمانی در جریان عابر پیاده است، همه نمونهها در خوشههای k- many و درجه تشابه قرار میگیرند. اسمننمونه های مشابه نیز در شاخص DB تعریف شده است:
اسمن=(1تیمن∑j=1تیمن||ایکسj–آمن||q)1q
در معادله (7) تیمنتعداد نمونه های خوشه i را در نتیجه خوشه بندی نشان می دهد، ایکسjنشان دهنده jامین نمونه در مجموعه نمونه های خوشه i و آمنمرکز نمونه ها در خوشه i را نشان می دهد. اسمننشان دهنده ریشه q ام میانگین گشتاورهای مرتبه q نمونه های خوشه i از مرکز خوشه است. اگر q مقدار 1 را بگیرد، اسمنمیانگین فاصله اقلیدسی بین هر نمونه و مرکز خوشه را نشان می دهد و اگر q مقدار 2 را بگیرد، اسمنانحراف معیار فاصله بین نمونه های خوشه و مرکز فضای نمونه برداری شده را نشان می دهد، که در آن می توان از فاصله 1 هنجاری یا فاصله 2 هنجاری، یعنی فاصله اقلیدسی، به عنوان اندازه گیری فاصله استفاده کرد. در محاسبه فضای نمونه غیر محدب با ابعاد بالا. اگرچه فاصله اقلیدسی انتخاب بهینه نیست، اندازه گیری فاصله پیش فرض عموماً فاصله اقلیدسی است [ 45 ].
شاخص DB به طور مشابه تفاوت بین خوشه ها، یعنی فاصله را تعریف می کند مij، بین مجموعه های نمونه از خوشه های مختلف:
مij=(∑ک=1ن||آکی–آkj||پ)1پ
مijنشان دهنده فاصله بین مجموعه نمونه در خوشه i و مجموعه نمونه در خوشه j است. آکیبعد k ام مرکز مجموعه نمونه در خوشه i است، آkjبعد k ام مرکز مجموعه نمونه در خوشه j است و N بعد کل نمونه ها است. شاخص DB بر اساس درجه شباهت است اسمناز نمونه های مشابه و فاصله مijبین مجموعه های نمونه در خوشه های مختلف، درجه تشابه را تعریف می کند آرijبین خوشه های مختلف:
آرij=اسمن+اسjمij
ترکیب شده با آرij، برای هر خوشه i، شاخص DB شباهت را محاسبه می کند آرirاز خوشه i به نزدیکترین خوشه r به آن خوشه، نشان داده شده است Dمن:
Dمن=حداکثرj≠منآرij
Dمننشان دهنده نزدیکترین درجه به خوشه دیگر برای خوشه i است. شاخص DB DBفهرست مطالبنتیجه خوشه بندی با محاسبه میانگین به دست می آید Dمنمقادیر برای مجموعه نمونه های همه خوشه ها:
DBفهرست مطالب=1ک∑من=1کDمن
K در معادله (11) عدد خوشهبندی K را نشان میدهد. شاخص DB نشاندهنده میزانی است که مرزهای خوشهبندی به وضوح در نتایج خوشهبندی مشخص نشدهاند، بنابراین هر چه مقدار آن کوچکتر باشد، تا حدی نتایج خوشهبندی نشاندادهشده بهتر است. از آنجایی که محاسبه شاخص DB شامل محاسبه شباهت بین هر دو خوشه است، زمانی که خوشههای پرت در نتایج خوشهبندی وجود داشته باشد، منطقی نیست. در این مورد، باید همراه با سایر ضرایب برای قضاوت در مورد صحت نتایج خوشه بندی استفاده شود. شاخص DB هدف مقایسه را از نمونهها به یک خوشه تبدیل میکند و بنابراین هنگام کمینه کردن به مقدار K کوچکتر تمایل دارد. DBفهرست مطالبکه در شکل 6 نیز قابل مشاهده است.
2.3. شاخص خوشه بندی مرکب
ترکیب ضریب Silhouette، ضریب CH و ضریب DB روش بهتری برای تعیین مقدار K خوشهبندی است. با توجه به مقدمه بالا، هرچه ضریب Silhouette و ضریب CH بزرگتر و ضریب DB کوچکتر باشد، نتایج خوشه بندی بهتری حاصل می شود، بنابراین پیشنهاد می کنیم این سه شاخص را در یک شاخص ترکیبی ترکیب کنیم. با توجه به مشکل ناهماهنگی در بزرگی ضرایب مختلف، پس از نرمال سازی همه ضرایب، ضریب Silhouette نرمال شده را به ضریب نرمال شده CH اضافه کردیم و سپس ضریب نرمال شده DB را کم کردیم تا شاخص مخلوط به دست آید. هر چه شاخص مختلط بزرگتر باشد، نتایج خوشه بندی بهتر است. برعکس، هرچه شاخص مختلط کوچکتر باشد، نتایج خوشه بندی بدتر است. در این صفحه،
ایکسجدید=ایکس–ایکسدقیقهایکسحداکثر–ایکسدقیقه
بنابراین، همه شاخصها مقادیری را در محدوده [-1، 1] میگیرند و از یکسان شدن ابعاد ضرایب مختلف در محاسبه اطمینان میدهند:
ثابتفهرست مطالب=سجدید+CHفهرست مطالبجدید–DBفهرست مطالبجدید
شاخص خوشهبندی ثابت دارای مزایای زیر است: این روش شباهت دادههای اصلی و دادههای خوشهای را در نظر میگیرد و تأثیر نقاط پرت در نتایج را بر انتخاب مقدار K کاهش میدهد.
از شکل 7 می توان دریافت که بر اساس این فرض که هرچه شاخص مختلط بزرگتر باشد، نتایج خوشه بندی بهتری خواهد داشت، الگوهای جریان POIها باید در مرحله پیش از اپیدمی به 4 گروه تقسیم شوند، مانند شکل 7 a. الگوهای جریان POI باید در طول اپیدمی به 2 گروه تقسیم شوند، مانند شکل 7 ب. و الگوهای جریان همه POIها باید در مرحله از سرگیری اولیه کار به 6 گروه تقسیم شوند، همانطور که در شکل 7 ج. تعداد زیر گروه های نشان داده شده در شکل 7با برآورد ما از وضعیت واقعی مطابقت دارد، جایی که الگوی جریان به دلیل COVID-19 و محدودیت های دولت در تحرک از چهار به دو کاهش یافت. در مرحله اولیه راهاندازی مجدد، مردم باید نیازهای سفر را برآورده کنند که قبلاً به دلیل محدودیتهای حرکتی برآورده نشده بود و تعداد الگوهای جریان عابر پیاده از دو به شش افزایش یافت.
3. نتایج و بحث
این بخش گروههای POI را برای مراحل مختلف الگوهای جریان عابر پیاده بهدستآمده از طریق الگوریتم خوشهبندی به تفصیل در بالا نشان میدهد و نتایج خوشهبندی را از دو منظر تفسیر میکند: گروههایی از الگوهای جریان عابر پیاده و دستههای عملکردی. این بخش تأثیر COVID-19 بر تحرک در دوره های مختلف و روابط بین الگوهای جریان عابر پیاده در دوره های مختلف از نتایج را تجزیه و تحلیل می کند.
3.1. نتایج
این بخش نتایج خوشهبندی جریان عابر پیاده در مکانهای هات اسپات پکن را در مراحل مختلف نشان میدهد و نتایج را به اختصار توضیح میدهد.
شکل 8 چهار الگوی جریان عابر پیاده را نشان می دهد که بر اساس شاخص خوشه بندی مختلط قبل از شروع اپیدمی به دست آمده است. رنگ های مختلف نشان دهنده دسته های عملکردی مختلف A از POI ها هستند. رابطه متناظر بین رنگ و POI را می توان در شکل 4 یافت . اولین گروه از POI ها نشان دهنده POI هایی با تعداد زیاد عابران پیاده و تمرکز بالا هستند. گروه دوم از POI ها نشان دهنده POI با تعداد کمتر عابران پیاده و تمرکز کمتر است. و گروه سوم و چهارم، POI با تعداد عابران پیاده و تمرکز فوق العاده بالا، عمدتاً ایستگاه های راه آهن و فرودگاه ها هستند. گروه چهارم POI تنها شامل یک POI است که مربوط به فرودگاه پایتخت پکن است.
شکل 9 نشان می دهد که الگوهای جریان عابر پیاده در همه POIها به جز گروه دوم POIهای فرودگاهی به دلیل سیاست محدودیت حرکتی دولت در طول همه گیری در گروه اول گروه بندی شدند. تقریباً همه POI الگوهای ترافیک کم و غلظت کم را نشان دادند، و اگرچه الگوی فرودگاه در گروه دوم همچنان بالا بود، در مقایسه با آنچه در شکل 8 نشان داده شده است، بیش از نصف کاهش یافت . از آنجایی که فرودگاه مهمترین مرکز حملونقل بینالمللی است، جریان عابر پیاده در فرودگاه در مقایسه با سایر POIها تحت تأثیر متفاوتی قرار گرفته است و همیشه به عنوان یک گروه الگوی جریان جداگانه در نظر گرفته شده است.
شکل 10نشان دهنده واگرایی الگوهای جریان عابر پیاده در شهر در مرحله از سرگیری اولیه در نتیجه سیاست بازگشایی دولت است. اولین گروه از POIها عمدتاً POIهای مراقبت پزشکی هستند، که می توان آنها را به عنوان کسانی که به سر کار بازمی گردند تفسیر کرد که باید قبل از برداشتن محدودیت توسط بیمارستان برای ویروس ها آزمایش شوند، بنابراین این نوع الگو از هم جدا شد. گروه دوم POI ها عمدتاً مراکز تفریحی و خرید در مجاورت هستند، زیرا ساکنان باید نیازهای ورزشی خود را که در زمان خانه و خرید روزانه ضروری برآورده نشده بود، جبران کنند. گروه سوم POI ها عمدتاً POI های دانشگاهی هستند و گروه چهارم عمدتاً POI های خرید بزرگ هستند که هر دو الگوهای جریان جزر و مدی قابل توجهی دارند. گروه پنجم POI فقط شامل سه POI است که عمدتاً به دلیل تراکم عابر پیاده بسیار بالاتر است. اگرچه سه POI از نظر نوع متفاوت هستند، الگوهای مشابه جریان عابر پیاده نشان دهنده اهمیت آنها در پیشگیری و کنترل اپیدمی ها است. گروه ششم POI فقط شامل یک POI است که مربوط به فرودگاه پایتخت پکن است.
3.2. بحث
در اینجا، ما تأثیر COVID-19 بر تحرک شهری در دورههای مختلف و رابطه بین الگوهای جریان عابر پیاده در دورههای مختلف از نتایج خوشهبندی را تحلیل میکنیم.
از دیدگاه گروه های مختلف الگوهای جریان عابر پیاده، چندین الگوی همپوشانی جریان عابر پیاده وجود دارد که در شکل 8 a,b نشان داده شده است. الگوهای همپوشانی نشان میدهند که POI با دستههای عملکردی مختلف، در این مرحله، الگوهای جریان مشابهی دارند، همانطور که در شکل 8 الف نشان داده شده است، که عمدتاً شامل خرید، آموزش و مراقبتهای پزشکی میشود. تعداد زیاد عابران پیاده و تمرکز بالا به این معنی است که این POIها در شکل 8 a جذابیت بیشتر و عملکردهای خاص تری دارند. این POI ها نه تنها می توانند بازدیدکنندگان بیشتری را جذب کنند، بلکه بازدیدکنندگان تمایل بیشتری به بازدید از آنها در همان دوره دارند که باعث این خوشه جریان بالا و تمرکز بالا می شود. نکته جالب این است که منحنی جریان عابر پیاده در شکل 8 استb دقیقاً قسمت خالی نیمه پایینی شکل 8 a را پر کنید. تعداد کم عابران پیاده و غلظت کم به این معنی است که این POI ها در شکل 8 ب جذابیت کمتر و عملکردهای متنوع تری دارند، حتی اگر POI هایی از همان دسته در شکل 8 a,b وجود داشته باشد. با توجه به تعداد بسیار بالای عابران پیاده، تقریباً تمام محورهای ترافیکی در خوشه های سوم و چهارم قرار دارند و رفتار ثابتی در الگوی جریان دارند.
متفاوت از آنچه در شکل 8 است، با این تفاوت که الگوی جریان عابر پیاده در شکل 10 ب همچنان شامل چندین دسته عملکردی از POI است، الگوهای جریان سه گروه نشان داده شده در شکل 10 a,c,d خاص تر می شوند. از شکل 10 a,c,d می توان دید که رنگ های سه گروه برجسته تر از رنگ 10b هستند ، که نشان می دهد POI های چند منظوره که قبلاً انواع زیادی از جریان را جذب کرده بودند در این مرحله خاص تر شدند. با توجه به شاخص بالای افراد، فرودگاه همچنان به طور جداگانه گروه بندی می شود، همانطور که در شکل 10 f نشان داده شده است.
از منظر دسته های عملکردی POIها، شکل 11 الگوهای جریان را در دسته های عملکردی مختلف POI در طول دوره قبل از اپیدمی نشان می دهد. شکل عناصر در شکل نشان دهنده دسته های POI و رنگ های مختلف نشان دهنده الگوهای جریان متفاوت است. POI ترانزیت دارای بیشترین تعداد الگوها است و به دنبال آن Recreation POI قرار دارد و مورد خاص Sports POI است که فقط یک حالت جریان را شامل می شود. با توجه به نتایج ذکر شده در بالا، همانطور که در شکل 12 نشان داده شده است ، الگوهای جریان همه دسته های POI به جز فرودگاه ها در طول همه گیری در یک الگو فشرده شدند. شکل 13الگوهای جریان موجود در دسته های مختلف POI را در طول از سرگیری اولیه کار نشان می دهد. اگرچه تعداد عابران پیاده در همه دستههای POI در مقایسه با دوره قبل از اپیدمی کاهش قابل توجهی داشت، اما تعداد الگوهای جریان در همه دستههای POI نسبت به دوره قبل از همهگیری افزایش یافت. این نتیجه نشان میدهد که ساکنان نه تنها کمتر از قبل از همهگیری سفر میکنند، بلکه هنگام سفر کمتر تجمع میکنند که میتواند فاصله اجتماعی بین افراد را به میزان قابل توجهی افزایش دهد.
شکل 14 دسته های اصلی POI های موجود در گروه های POI مختلف را بر اساس الگوهای جریان عابر پیاده در مراحل مختلف نشان می دهد. از شکل 14 می توان دید که الگوهای جریان جمعیت دسته های مختلف POI در مراحل مختلف اپیدمی تنظیم شده است. مطابق با عقل سلیم، آنچه واضح است این است که تحت تأثیر اپیدمی، الگوهای جریان روزانه به یک الگوی جریان کم تردد و تجمع عابر پیاده از دوره قبل از اپیدمی تا اپیدمی فشرده شده است. عادت زنانه. نکته جالب این است که الگوهای تردد عابر پیاده بیشتر بود، اگرچه تعداد عابران پیاده پس از انتشار سیاست بازگشایی دولت به طور قابل توجهی کمتر از دوره قبل از اپیدمی بود. از شکل 14مشاهده می شود که اولین گروه از POI ها (خرید، آموزش، مراقبت های پزشکی) قبل از همه گیری در مرحله از سرگیری اولیه کار به سه گروه تقسیم شدند که مراقبت های پزشکی، خرید و آموزش به عنوان دسته های عملکردی اصلی POI بودند. این نشان میدهد که تحت تأثیر همهگیری، مردم فقط سفرهای ضروری را انجام میدهند، که الگوی تجمع در POIهای مختلف را متمایزتر میکند و منجر به تقسیم واضحتر شهر به مناطق عملکردی میشود. اولین دسته از POI های بازگشایی شده شامل دو دسته بود: حمل و نقل و خرید. قابل توجه ترین تغییرات در مراقبت های پزشکی و خرید بود. الگوهای جریان این دو دسته POI به وضوح از هم جدا شدند، که همچنین نشان می دهد که مراقبت های پزشکی و خرید مقاصد ضروری سفر در مرحله پس از اپیدمی بودند. دو گروه الگوی جریان POI از یک الگوی جریان به دو گروه جدا شدند. با در نظر گرفتن POIهای خرید، الگوی جریان به دو دسته تقسیم میشود: الگوی جریان عابر پیاده با تعداد عابران پیاده کم و تمرکز کم، و الگوی با تعداد زیاد عابران پیاده و تمرکز بالا. این نتیجه نشان می دهد که سیاست از سرگیری کار منجر به تغییر در الگوهای جریان خرید شده است. برخی از مکانهای خرید، ترافیک کم اما پیوسته دریافت میکنند، در حالی که برخی دیگر ترافیک آنی زیادی را دریافت میکنند، اما در بیشتر موارد تعداد کمی از افراد دریافت میکنند. اگرچه فروشگاههای خرید همه به عنوان خرید طبقهبندی میشوند، فروشگاههای مختلف از نظر الگوهای جریان یا تغییر الگوهای تحت تأثیر همهگیری یکسان نیستند. هنگام اجرای سیاست ها باید با این موارد به گونه ای متفاوت برخورد شود. با توجه به محدودیت داده ها،
همچنین می توان مشاهده کرد که گروه دوم (تفریح، آموزش، ورزش) در مرحله از سرگیری اولیه، مربوط به گروه دوم (تفریح، آموزش، خرید) قبل از اپیدمی است که در آن نوع اصلی POI Recreation است. این شامل پارکهایی در شهر با تعداد کم عابران پیاده و تمرکز کم است که نشاندهنده از سرگیری تدریجی تفریحات و سرگرمیهای فضای باز است. گروه سوم (Transit, Recreation) که در آن POI ترانزیت قسمت مرکزی قبل از اپیدمی بود، پس از همه گیری دیگر مشخص نیست، همچنین نشان می دهد که ترافیک درون شهری هنوز بهبود نیافته است. گروه Transit POI در پایین شکل 14بدون توجه به مرحله تأثیر همه گیر، با سایر POI ها گروه بندی نمی شود. این گروه از POI های ترانزیت شامل تنها یک POI، فرودگاه پایتخت، به دلیل تعداد زیاد و تمرکز عابران پیاده در فرودگاه است که توسط سایر POI ها قابل دسترسی نیستند، که در شکل 9 ، شکل 10 و شکل 11 نیز تایید شده است. برای POI های ورزشی، در مرحله اولیه اپیدمی، هیچ مشخصه الگوی جریان آشکاری وجود نداشت، بنابراین هیچ نقطه نقطه ورزشی در هر دسته از نتایج خوشه بندی وجود نداشت، اما در مرحله اولیه از سرگیری کار، الگوی جریان آن در دسته دوم نتایج، نشان می دهد که این بیماری همه گیر باعث می شود مردم به طور مداوم توجه بیشتری به ورزش برای بهبود مقاومت در برابر خود داشته باشند.
این مطالعه دارای محدودیتهایی است زیرا تجزیه و تحلیل به یک سری زمانی طولانی از دادههای جریان عابر پیاده از POI برای پشتیبانی نیاز دارد. با توجه به مقیاسهای زمانی و مکانی بزرگ درگیر، چنین دادههایی معمولاً باید توسط دولت یا ارائهدهندگان خدمات ارتباطات سیار جمعآوری شده و از طریق برنامههای کاربردی به دست آیند. ما دوره های مختلف اپیدمی را بر اساس اسناد اطلاع رسانی دولت تقسیم کردیم. این امر تأثیر آن را به یک تأثیر مستقیم ساده می کند، که در عمل مرحله به مرحله و مرحله به مرحله تأثیر می گذارد. این تمرکز تحقیقات بعدی خواهد بود. ما همچنین باید انواع دیگری از تجسم را در کارهای آینده در نظر بگیریم تا درک کاربر را بهبود ببخشیم [ 46 , 47 , 48 , 49 , 50]. با توجه به محدودیتهای دادهها، ما فقط جدایی از الگوهای جریان عابر پیاده را در طول دوره از سرگیری پیدا کردیم و دادههای جغرافیایی بیشتری برای توضیح علت این پدیده در کارهای آینده معرفی خواهند شد.
4. نتیجه گیری
به عنوان یکی از بزرگترین رویدادهای بهداشت عمومی و ایمنی در سال های اخیر، COVID-19 تأثیر قابل توجهی بر کل جهان گذاشته است. همانطور که دولت ها اقدامات مربوط به پیشگیری، کنترل و ایزوله را معرفی کردند، بحران اپیدمی در اکثریت قریب به اتفاق مناطق کاهش یافت و همه جامعه به تدریج به عملکرد عادی بازگشت. تقریباً همه مناطق از عملیات عادی تا تأثیر ناگهانی اپیدمی بر بازگرداندن نظم تولید، این سه مرحله را که در بالا ذکر شد طی کردهاند. مردم الگوهای سفر متفاوتی را در مراحل زمانی مختلف اتخاذ میکنند، که منجر به الگوهای مختلف جمعآوری جریان عابر پیاده در POIهای مختلف میشود.
در نتیجه، این مطالعه مشارکت های زیر را انجام می دهد. یک کمک روشی برای به دست آوردن گروه های POI با الگوهای جریان عابر پیاده مشابه بر اساس خوشه بندی سری های زمانی است. روش ما می تواند به طور منطقی تعداد الگوهای جریان POI را در یک شهر در یک دوره معین محاسبه کند و بر این اساس گروه های POI با الگوهای مشابه را به دست آورد. مهمتر از آن، این مطالعه نشان داد که استفاده از گروههای POI با الگوهای جریان عابر پیاده مشابه به عنوان واحد مطالعه مناسبتر است تا دستهبندی عملکردی POI. سهم در کاربردها، تحلیل تغییرات تحرک شهری در شهرها تحت تأثیر شوکهای ناگهانی خاص از منظر الگوهای جریان است. برخلاف مطالعات قبلی که POI ها را بر اساس دسته بندی عملکردی متمایز می کردند، این مقاله دیدگاه جدیدی را برای تمایز گروهبندیها با استفاده از الگوهای جریان عابر پیاده POI ارائه میکند، که برای سیاستهای بازگشایی بر اساس منطقه و دوره کاربرد بیشتری دارد، و ما تأثیر COVID-19 را بر تقریباً کل فرآیند در پکن از ابتدا تا زمان از سرگیری اولیه کار در مرحله از سرگیری اولیه، تعداد عابران پیاده به طور قابل توجهی کمتر از قبل از همه گیری بود، اما تعداد الگوهای جریان بیشتر بود، که نشان می دهد محدودیت های اجتماعی منجر به تفاوت در الگوهای جریان POI و افزایش فاصله اجتماعی شده است. بنابراین، ما معتقدیم که سیاست اعمال محدودیتهای حرکتی بر اساس دستههای عملکردی POI محدود است. گروه بندی POI با توجه به ویژگی های تحرک آنها به عنوان واحد اساسی برای اجرای محدودیت های تحرک بهتر است.
مشارکت های نویسنده
Yihang Li تحقیق را انجام داد، داده ها را تجزیه و تحلیل کرد و مقاله را نوشت. لیان ژو بر این مطالعه نظارت داشت. هر دو نویسنده نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این تحقیق هیچ بودجه خارجی دریافت نکرد.
بیانیه در دسترس بودن داده ها
محدودیت هایی برای در دسترس بودن این داده ها اعمال می شود. داده ها به دلیل نگرانی های حفظ حریم خصوصی در دسترس عموم نیستند.
قدردانی
نویسندگان مایلند از هانگ یین در دانشگاه پکن و فو لی در دانشگاه پکن برای پیشنهادات و راهنمایی های فنی شان تشکر کنند. نویسندگان صمیمانه از نظرات داوران ناشناس و اعضای تیم تحریریه تشکر می کنند.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- لئونگ، ک. وو، جی تی. لیو، دی. Leung، GM موج اول COVID-19 انتقال و شدت در چین خارج از هوبی پس از اقدامات کنترلی، و برنامه ریزی سناریوی موج دوم: ارزیابی تاثیر مدل سازی. Lancet 2020 ، 395 ، 1382-1393. [ Google Scholar ] [ CrossRef ]
- چاکرابورتی، آی. Maity، P. شیوع COVID-19: مهاجرت، اثرات بر جامعه، محیط زیست جهانی و پیشگیری. علمی کل محیط. 2020 , 728 , 138882. [ Google Scholar ] [ CrossRef ]
- پاریک، م. بنگاش، MN; پاریک، ن. پان، دی. Sze، S. مینهاس، جی اس. حنیف، و. Khunti، K. قومیت و COVID-19: یک اولویت فوری تحقیقاتی بهداشت عمومی. Lancet 2020 ، 395 ، 1421-1422. [ Google Scholar ] [ CrossRef ]
- Dorn، AV; کونی، RE; Sabin، ML COVID-19 نابرابری ها را در ایالات متحده تشدید می کند. Lancet 2020 ، 395 ، 1243-1244. [ Google Scholar ] [ CrossRef ]
- Yancy، CW COVID-19 و آفریقایی آمریکایی ها. مربا. پزشکی دانشیار 2020 ، 323 ، 1891-1892. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- چوکوانیون، م. Reed, AL, Jr. نابرابری های بهداشتی نژادی و کووید-19-احتیاط و زمینه. N. Engl. جی. مد. 2020 ، 383 ، 201-203. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویلسون، سی. این نمودارها نشان میدهند که کووید-۱۹ چگونه محلههای کم درآمد شهر نیویورک را ویران میکند. زمان _ 2020. در دسترس آنلاین: https://time.com/5821212/coronavirus-low-income-communities/ (در 9 ژوئیه 2021 قابل دسترسی است).
- گارگ، اس. کیم، ال. ویتاکر، ام. اوهالوران، ا. کامینگز، سی. هلشتاین، آر. پریل، ام. چای، اس جی. کرلی، PD; آلدن، NB; و همکاران نرخ بستری شدن و ویژگیهای بیماران بستری با بیماری کروناویروس تایید شده آزمایشگاهی 2019—COVID-NET، 14 ایالت، 1 تا 30 مارس 2020. MMWR Morb. فانی. Wkly Rep. 2020 , 69 , 458–464. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- استایر، ای جی. برمن، ام جی; نرخ حمله Bettencourt، LMA COVID-19 با اندازه شهر افزایش می یابد. arXiv 2020 ، arXiv:2003.10376. [ Google Scholar ]
- سازمان بهداشت جهانی. سخنان افتتاحیه مدیر کل WHO در کنفرانس رسانه ای در مورد COVID-19. که. 2020. در دسترس آنلاین: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19– -11-مارس-2020 (دسترسی در 9 ژوئیه 2021).
- وو، ال. چنگ، ایکس. کانگ، سی. زو، دی. هوانگ، ز. لیو، ی. چارچوبی برای تجزیه با استفاده ترکیبی بر اساس امضاهای فعالیت زمانی استخراج شده از داده های جغرافیایی بزرگ. بین المللی جی دیجیت. زمین 2018 ، 13 ، 708–726. [ Google Scholar ] [ CrossRef ]
- چنگ، ایکس. وانگ، ز. یانگ، ایکس. خو، ال. لیو، ی. تشخیص و تفسیر چند مقیاسی ناهنجاریهای مکانی-زمانی فعالیتهای انسانی نشاندادهشده توسط سریهای زمانی. محاسبه کنید. محیط زیست سیستم شهری 2021 ، 88 ، 101627. [ Google Scholar ] [ CrossRef ]
- چوترای، وی. چند، R. بازیابی پس از فاجعه و آسیب پذیری مداوم: ده سال پس از ابر گردباد 1999 در اوریسا. گلوب. محیط زیست چانگ. 2012 ، 22 ، 695-702. [ Google Scholar ] [ CrossRef ]
- Olshansky، RB چگونه جوامع از فاجعه بهبود می یابند؟ مروری بر دانش فعلی و دستور کار برای تحقیقات آینده. در مجموعه مقالات چهل و ششمین کنفرانس سالانه انجمن مدارس دانشگاهی برنامه ریزی، کانزاس سیتی، MO، ایالات متحده آمریکا، 27 اکتبر 2005. [ Google Scholar ]
- کاتتون، ا. لمان، اس. González، MC درک قابلیت پیش بینی و کاوش در تحرک انسان. EPJ Data Sci. 2018 ، 7 ، 1-17. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- حامد مقدم، ح. رمضانی، م. صابری، م. آشکارسازی ویژگیهای نهفته شبکههای تحرک با دانهبندی درشت. علمی Rep. 2019 , 9 , 1-10. [ Google Scholar ]
- آلدریچ، دیپی این کسی است که میشناسید: عواملی که باعث بهبودی از فاجعه 11 مارس 2011 ژاپن شد. عمومی Adm. 2016 ، 94 ، 399-413. [ Google Scholar ] [ CrossRef ]
- روفت، س. تیت، ای. برتون، سی جی; معروف، AS آسیب پذیری اجتماعی در برابر سیل: بررسی مطالعات موردی و پیامدهای اندازه گیری. بین المللی J. کاهش بلایا. 2015 ، 14 ، 470-486. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وو، جی. لی، ن. زی، دبلیو. ژو، ی. جی، ز. شی، پی. بازیابی پس از فاجعه و تأثیر اقتصادی فجایع در چین. زمین Spectra 2014 ، 30 ، 1825-1846. [ Google Scholar ] [ CrossRef ]
- چیناتزی، م. دیویس، جی تی; عجلی، م. جیوانینی، سی. لیتوینووا، م. مرلر، اس. پیونتی، AP; مو، ک. روسی، ال. سان، ک. و همکاران تاثیر محدودیتهای سفر بر شیوع ویروس کرونای جدید (COVID-19) در سال 2019. Science 2020 , 368 , 395-400. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لاو، اچ. خسروی پور، و. کوکباخ، پی. Mikolajczyk، A. شوبرت، جی. بانیا، ج. خسروی پور، تی. تاثیر مثبت قرنطینه در ووهان بر مهار شیوع کووید-19 در چین. J. Trav. پزشکی 2020 ، 27 ، taaa037. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژانگ، ی. ژانگ، ا. وانگ، جی. بررسی نقش قطارهای پرسرعت، خدمات هوایی و اتوبوس در گسترش COVID-19 در چین. حمل و نقل Pol. 2020 ، 94 ، 34-42. [ Google Scholar ] [ CrossRef ]
- ژو، ی. نیش، ز. تیل، JC; لی، کیو. Li، Y. مکانهای بحرانی عملکردی در شبکه حملونقل شهری: شناسایی و تحلیل فضا-زمان با استفاده از مسیرهای تاکسی محاسبه کنید. محیط زیست سیستم شهری 2015 ، 52 ، 34-47. [ Google Scholar ] [ CrossRef ]
- لی، کیو. بسل، ال. شیائو، ایکس. فن، سی. گائو، ایکس. مصطفوی، الف. الگوهای متفاوت تحرکات و بازدید از نقاط دیدنی واقع در نقاط مهم شهری در سراسر کلان شهرهای ایالات متحده در طول کووید-19. R. Soc. علوم را باز کنید. 2020 ، 8 ، 201209. [ Google Scholar ] [ CrossRef ]
- مدلسازی شبکه Chang، S. Mobility نرخ بالاتر عفونت SARS-CoV-2 را در میان گروههای محروم توضیح میدهد و استراتژیهای بازگشایی را اطلاعرسانی میکند. MedRxiv 2020 . [ Google Scholar ] [ CrossRef ]
- وانگ، دی. گنگ، دی. اینس، جی. Wu, W. تأثیرات همهگیری COVID-19 بر بازدید از پارک شهری: یک تحلیل جهانی. جی. برای. Res. 2020 ، 32 ، 553-567. [ Google Scholar ]
- لی، اچ. پارک، اس جی. لی، GR; کیم، جی. Lee, JH رابطه بین روند شیوع COVID-19 و روند حمل و نقل در کره جنوبی. بین المللی ج. عفونی کردن. دیس 2020 ، 96 ، 399-407. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- پار، اس. ولشون، بی. رنه، جی. موری تویت، پی. Asce, AM; کیم، کی. تأثیرات ترافیکی همهگیری COVID-19: تجزیه و تحلیل سراسری جدایی اجتماعی و محدودیت فعالیت. صبح. Soc. مدنی مهندس 2020 , 21 , 04020025. [ Google Scholar ] [ CrossRef ]
- چانگ، اس. پیرسون، ای. Koh، PW; جراردین، جی. ردبرد، بی. گروسکی، دی. مدلهای شبکه Leskovec، J. Mobility برای COVID-19 نابرابریها را توضیح میدهند و بازگشایی را اطلاع میدهند. Nature 2021 ، 589 ، 82-87. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بنزل، اس جی؛ کولیس، ا. Nicolaides, C. رتبه بندی تماس های اجتماعی در طول همه گیری COVID-19: خطر انتقال و مزایای اجتماعی مکان های ایالات متحده. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2020 ، 117 ، 14642–14644. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- نیان، جی. پنگ، بی. سان، دی جی; ما، دبلیو. پنگ، بی. هوانگ، تی. تأثیر COVID-19 بر تحرک شهری در طول دوره پس از اپیدمی در کلان شهرها: از دیدگاه سفر تاکسی و نشاط اجتماعی. پایداری 2020 ، 12 ، 7954. [ Google Scholar ] [ CrossRef ]
- هانی رز، ج. آنگولوسکی، آی. بوهیگاس، جی. چیره، وی. داهر، سی. کونی-جندیک، سی. Oscilowicz, E. تاثیر COVID-19 بر فضای عمومی: مروری بر سؤالات در حال ظهور. 2020. در دسترس آنلاین: https://www.researchgate.net/publication/340819529_The_Impact_of_COVID-19_on_Public_Space_A_Review_of_the_Emerging_Questions (در 9 ژوئیه 2021 قابل دسترسی است).
- جنرال الکتریک، اچ. لیو، ن. مدلسازی مشکلات تصمیمگیری تخصیص مواد اضطراری بر اساس سناریوهای تکامل بیماریهای عفونی جدی: موردی از COVID-19. J. Ind. Eng. مهندس مدیریت 2020 ، 34 ، 214-222. [ Google Scholar ]
- احمد، م. سراج، ر. اسلام، اس ام اس الگوریتم k-means: بررسی جامع و ارزیابی عملکرد. Electronics 2020 , 9 , 1295. [ Google Scholar ] [ CrossRef ]
- پتیژان، اف. کترلین، ا. Gançarski، P. یک روش میانگین جهانی برای تابش زمانی پویا، با کاربردهایی برای خوشهبندی. تشخیص الگو 2011 ، 44 ، 678-693. [ Google Scholar ] [ CrossRef ]
- سها، ج. Mukherjee, J. CNAK: K-means به کمک شماره خوشه. تشخیص الگو 2021 ، 110 ، 107625. [ Google Scholar ] [ CrossRef ]
- کوتوری، ام. Blondel, M. Soft-DTW: تابع تلفات قابل تمایز برای سری های زمانی. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی یادگیری ماشین، سیدنی، استرالیا، 6 تا 11 اوت 2017؛ ICML: وین، اتریش، 2017; صفحات 1483-1505. [ Google Scholar ]
- صفری، ع. نبیل، ک. Biswajit، S. دقت طبقه بندی مبتنی بر یادگیری ماشینی کانال های سرویس رمزگذاری شده: تجزیه و تحلیل عوامل مختلف. J. Netw. سیستم مدیریت 2021 ، 29 ، 1-27. [ Google Scholar ] [ CrossRef ]
- فرانتی، پ. Sieranoja، S. چقدر می توان k-means را با استفاده از مقداردهی اولیه و تکرار بهتر بهبود بخشید؟ تشخیص الگو 2019 ، 93 ، 95-112. [ Google Scholar ] [ CrossRef ]
- پاپارریزوس، جی. Gravano، L. K-shape: خوشه بندی کارآمد و دقیق سری های زمانی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD در مدیریت داده ها، ملبورن، استرالیا، 31 مه تا 4 ژوئن 2015. انجمن ماشینهای محاسباتی: نیویورک، نیویورک، ایالات متحده آمریکا، 2015. صفحات 1855-1870. [ Google Scholar ] [ CrossRef ]
- Rousseeuw, PJ Silhouettes: کمکی گرافیکی برای تفسیر و اعتبارسنجی تحلیل خوشهای. جی. کامپیوتر. Appl. ریاضی. 1987 ، 20 ، 53-65. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کالینسکی، تی. Harabasz, J. روش دندریت برای تجزیه و تحلیل خوشه. اشتراک. آمار 1974 ، 3 ، 1-27. [ Google Scholar ]
- گومز آدورنو، اچ. المان، ی. ویلارینو آیالا، دی. سانچز-پرز، مایکروسافت؛ پینتو، دی. سیدوروف، جی. خوشه بندی نویسنده با استفاده از تحلیل خوشه بندی سلسله مراتبی. در مجموعه مقالات یادداشت های کاری کنفرانس و آزمایشگاه های انجمن ارزیابی (CLEF)، دوبلین، ایرلند، 11 تا 14 سپتامبر 2017. [ Google Scholar ]
- دیویس، دی ال. Bouldin، DW A Cluster Separation Measure. IEEE Trans. الگوی مقعدی ماخ هوشمند 1979 ، 2 ، 224-227. [ Google Scholar ] [ CrossRef ]
- شیائو، جی. لو، جی. Li, X. Davies Bouldin Index بر اساس مقداردهی اولیه سلسله مراتبی K-means. هوشمند داده آنال. 2017 ، 21 ، 1327–1338. [ Google Scholar ] [ CrossRef ]
- Hadjidemetriou، جنرال موتورز; ساسیداران، م. کوییلیس، جی. Parlikad، AK تأثیر اقدامات دولت و روند تحرک انسانی بر مرگهای ناشی از COVID-19 در بریتانیا. ترانسپ Res. بین رشته ای. چشم انداز 2020 ، 6 ، 100167. [ Google Scholar ]
- Cintia، P. رابطه بین تحرک انسان و قابلیت انتقال ویروس در طول همه گیری های Covid-19 در ایتالیا. arXiv 2020 ، arXiv:2006.03141. [ Google Scholar ]
- کریستوفانو، آر. مارسیلیو جونیور، دبلیو. Eler, D. PlaceProfile: بکارگیری تجزیه و تحلیل بصری و خوشه ای در مناطق نمایه بر اساس نقاط مورد علاقه. در مجموعه مقالات بیست و سومین کنفرانس بین المللی سیستم های اطلاعات سازمانی — جلد 1: ICEIS، Setúbal، پرتغال، 26-28 آوریل 2021؛ صص 506–514، ISBN 978-989-758-509-8. [ Google Scholar ] [ CrossRef ]
- D’Andrea، E. دوکانژ، پی. لوفرنو، دی. مارسلونی، اف. Zaccone، T. پروفایل هوشمند مناطق شهر بر اساس داده های وب. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 در محاسبات هوشمند (SMARTCOMP)، تائورمینا، ایتالیا، 18 تا 20 ژوئن 2018؛ ص 226-233. [ Google Scholar ] [ CrossRef ]
- کیم، دی. پانسه، سی. Sips, M. داده کاوی بصری مجموعه داده های فضایی بزرگ. در پایگاه های داده در سیستم های اطلاعات شبکه ای. DNIS 2003 ; یادداشت های سخنرانی در علوم کامپیوتر; بیانکی-برتوز، ن.، ویرایش. Springer: برلین/هایدلبرگ، آلمان، 2003; جلد 2822. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]

شکل 1. چارچوب مطالعه.

شکل 2. توزیع نقاط مهم در پکن.


شکل 3. نتایج خوشه بندی الگوهای در حال تغییر جریان عابر پیاده قبل از اپیدمی.

شکل 4. رابطه بین ضریب Silhouette و مقادیر K در مراحل مختلف اپیدمی.


شکل 5. رابطه بین ضریب CH و مقادیر K در مراحل مختلف اپیدمی.

شکل 6. رابطه بین شاخص DB و مقادیر K در مراحل مختلف اپیدمی.

شکل 7. رابطه بین شاخص خوشه بندی ثابت و مقادیر K در مراحل مختلف اپیدمی.

شکل 8. نتایج خوشه بندی چهار الگوی تغییر جریان عابر پیاده در مکان های کانونی پکن قبل از همه گیری.

شکل 9. نتایج خوشه بندی دو الگوی تغییر در جریان عابر پیاده در مکان های کانونی در پکن در طول اپیدمی.


شکل 10. نتایج خوشه بندی شش الگوی تغییر در جریان عابر پیاده در مکان های کانونی پکن در طول از سرگیری اولیه کار.

شکل 11. الگوهای تغییرات در جریان عابر پیاده در نقاط مختلف در پکن در طول دوره پیش از اپیدمی.

شکل 12. الگوهای تغییرات در جریان عابر پیاده در نقاط مختلف در پکن در طول اپیدمی.

شکل 13. الگوهای تغییرات در جریان عابر پیاده در نقاط مختلف در پکن در طول از سرگیری اولیه کار.
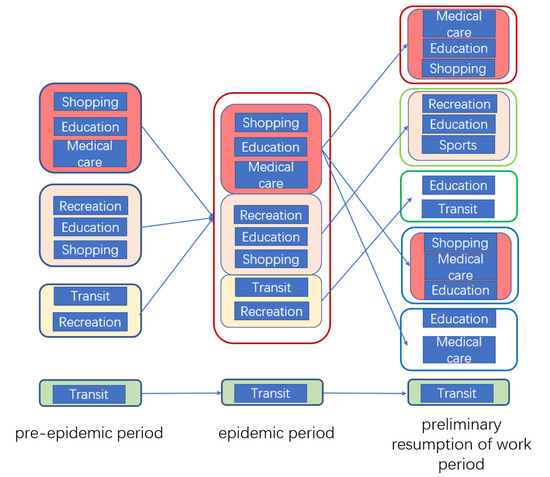
شکل 14. تغییر الگوهای جریان ترافیک در نقاط حساس شهری در مراحل مختلف.


بدون دیدگاه