

چکیده
:
تجسم داده های جغرافیایی یک حوزه تحقیقاتی مهم در سیستم اطلاعات جغرافیایی وب (GIS) است. با توجه به مجموعه های فرعی دقیق و پایگاه داده جامع دانش، مدل سازی اطلاعات ساختمان (BIM) نقش مهمی در تحقیقات و صنایع زمین فضایی ایفا می کند. ادغام BIM و GIS به تجسم روان، ساخت سریع و مدیریت کارآمد داده های جغرافیایی کمک می کند. با این حال، روشهای بسیار کمی وجود دارند که میتوانند با حفظ یکپارچگی ساختار و ویژگیهای زیرمجموعه داخلی، انتقال داده و تجسم با کارایی بالا را برای مدلهای پیچیده BIM ارائه دهند. برای غلبه بر این مسئله، این مقاله یک روش تجسم مبتنی بر کاشیهای سهبعدی را برای مدلهای پیچیده BIM در بیننده مدل سهبعدی مبتنی بر وب پیشنهاد میکند. این روش برای تقسیمبندی مدل BIM بر اساس مونتاژ آن بدون سادهسازی مدل BIM، با استفاده از روش کاشیکاری برای مدلهای سهبعدی بر اساس درخت R تخریبشده، که اندازه کاشیها را به حساب میآورد، اتخاذ شده است. متعاقبا، ما “فیلتر ماسک” را معرفی می کنیم، یک روش سطحی از جزئیات که برای لایه بندی مدل BIM استفاده می شود. انجام یک سری آزمایش های کنتراست، نتیجه نشان می دهد که این روش کارآمد و امکان پذیر است، که به طور قابل توجهی عملکرد تجسم BIM پیچیده با داده های انبوه در صحنه جغرافیایی را بهبود می بخشد و ادغام مدل سازی اطلاعات ساختمان و سیستم اطلاعات جغرافیایی را تسهیل می کند. ” یک روش سطح جزئیات که برای لایه بندی مدل BIM استفاده می شود. انجام یک سری آزمایش های کنتراست، نتیجه نشان می دهد که این روش کارآمد و امکان پذیر است، که به طور قابل توجهی عملکرد تجسم BIM پیچیده با داده های انبوه در صحنه جغرافیایی را بهبود می بخشد و ادغام مدل سازی اطلاعات ساختمان و سیستم اطلاعات جغرافیایی را تسهیل می کند. ” یک روش سطح جزئیات که برای لایه بندی مدل BIM استفاده می شود. انجام یک سری آزمایش های کنتراست، نتیجه نشان می دهد که این روش کارآمد و امکان پذیر است، که به طور قابل توجهی عملکرد تجسم BIM پیچیده با داده های انبوه در صحنه جغرافیایی را بهبود می بخشد و ادغام مدل سازی اطلاعات ساختمان و سیستم اطلاعات جغرافیایی را تسهیل می کند.
کلید واژه ها:
مدل سازی اطلاعات ساختمان ; سطح جزئیات ؛ سازمان داده ها ; کاشی های سه بعدی
1. مقدمه
با توجه به پیشرفت های سریع در مدل سازی سه بعدی، مدل های سه بعدی دقیق تری در کاربردها و صنایع مختلفی از جمله برنامه ریزی و تحلیل شهری [ 1 ]، مدل سازی زمین مجازی [ 2 ] و سیستم های اطلاعات جغرافیایی سه بعدی (GIS) [ 3 ] استفاده می شود. ]. به طور خاص، در صنعت معماری، مهندسی و ساخت و ساز (AEC) [ 4 ]، مدل سازی اطلاعات ساختمان (BIM) [ 5 ]] برای دیجیتالی کردن خواص و عملکردهای مختلف مربوط به فرآیند ساخت استفاده می شود. مدل های BIM در ساخت اشیاء مختلف با خدمت به عنوان پایه ای قابل اعتماد برای مهندسان، معماران، مقامات و غیره برای تصمیم گیری کمک می کنند. بر اساس نقشه های طراحی، مجموعه های فرعی یک مدل BIM به صورت جداگانه از طریق یک فرآیند پیچیده ایجاد می شوند. این منجر به مدلی می شود که بسیاری از امکانات و ویژگی های داخلی را حفظ می کند. مدلهای BIM میتوانند شامل چندین ماژول ساختمان باشند و هر ماژول از چند مجموعه فرعی تشکیل شده است ( شکل 1)). کلاس های بنیاد صنعت (IFC) فرمت استاندارد بین المللی فعلی BIM است. به طور کلی، BIM در قالب IFC است. به عنوان یک استاندارد تبادل داده، IFC قصد دارد تمام اطلاعات در کل چرخه عمر ساختمان را در یک BIM یکپارچه کند، به طوری که همه نرم افزارهای موجود در چرخه عمر بتوانند اطلاعات را به اشتراک بگذارند و تبادل کنند. این از چهار لایه، از بالا به پایین، یعنی لایه دامنه/برنامه، لایه قابلیت همکاری، لایه هسته و لایه منبع تشکیل شده است. هندسه ها و ویژگی های زیر مجموعه ها در لایه منبع ذخیره می شوند. با توجه به مجموعه های فرعی استادانه و اطلاعات ساختمانی فراوان، این نوع مدل سه بعدی می تواند جلوه بصری عالی ایجاد کند. با این حال،
با توجه به این چالش ها، بسیاری از شرکت های GIS فرمت های داده ای را پیشنهاد کرده اند که می تواند جریان مدل های BIM را در خود جای دهد. در میان این شرکتها، Super Map، Cesium و ArcGIS هر کدام مشخصات قالب مدل سهبعدی باز خود را ارائه کردهاند، یعنی مدل فضایی سهبعدی (S3M)، کاشیهای سهبعدی، و لایههای صحنه سهبعدی نمایهشده (I3S). با این حال، تفاوت های قابل توجهی بین ساختارهای داده در این فرمت ها وجود دارد. 3D Tiles [ 6 ] از هر شکلی از ساختار داده های مکانی پشتیبانی می کند و آن را به انعطاف پذیرترین گزینه تبدیل می کند. از یک ساختار درختی برای مدیریت مدل سه بعدی استفاده می کند. درخت شاخص در فایل های json ذخیره می شود. داده های مکانی و داده های ویژگی مدل سه بعدی در فایل های کاشی ذخیره می شود. I3S [ 7] از پارتیشن های منظم (چهاردرخت و هشت درخت) و پارتیشن بندی وابسته به چگالی (R-tree) پشتیبانی می کند که با ترکیبی از فایل های json و فایل های باینری مشخص می شود. مدل سهبعدی کاشیکاری شده و در فایلهای باینری (.bin) ذخیره میشود، که توسط فایلهای فهرست به یک ساختار درختی سازماندهی شدهاند. S3M [ 8] یک ساختار داده است که توسط تحقیق و توسعه سفارشی شده است و دارای یک چارچوب قدرتمند است. در S3M، ساختار درختی نیز به عنوان زیرساخت داده های مکانی در نظر گرفته می شود. داده های مکانی در فایل های s3mb و داده های ویژگی در فایل های s3md ذخیره می شوند. این سه فرمت داده همگی مدل BIM را در نظر می گیرند، بنابراین می توانند با مدل BIM سازگاری بالایی داشته باشند. به عنوان مثال، از طریق یک سری فرمت های انتقالی، مانند فایل های باینری glTF و obj، می توان IFC را به کاشی های سه بعدی تبدیل کرد. با این حال، این تبدیل فقط تغییر در فرمت فایل است. در مقایسه با S3M، کاشی های سه بعدی یک استاندارد جامعه است که توسط کنسرسیوم فضایی باز (OGC) شناسایی شده است. فعالیت اجتماعی بالاتری دارد و نسبتاً بالغ تر و توسعه یافته تر است. در مقایسه با I3S، کاشی های سه بعدی انعطاف پذیری بیشتر، قابلیت سفارشی سازی بالاتر و قابلیت حمل و باز بودن بهتر را نشان می دهند.
فرمتهای دادهای که در بالا ذکر شد، پایه و اساس جریان مدل سهبعدی را ایجاد میکنند. جریان سریع به حداقل مقدار داده نیاز دارد که هر بار منتقل شود، که مستلزم سازماندهی منطقی تر مدل سه بعدی است. با این حال، فرمتهای دادهای که در بالا ذکر شد در سازماندهی کارآمد دادهها ناکام هستند. برای بهبود کارایی زمانبندی (بارگذاری مدل سهبعدی متناظر بر روی وب بر اساس شاخص آن) و ارائه مدلهای BIM در نمایشگر مدل سهبعدی مبتنی بر وب، لازم است هنگام استفاده از این قالبهای داده از سازماندهی کارآمد دادهها اطمینان حاصل شود. در حال حاضر، روش های سازماندهی داده ها برای مدل های BIM عمدتا به دو دسته طبقه بندی می شوند. دسته اول از مدل های سه بعدی استفاده می کند که می توانند بر اساس اطلاعات معنایی در سطح ثابتی از جزئیات (LOD) سازماندهی شوند ( شکل 2)آ). در اینجا، سطح جزئیات یک تکنیک تجسم است که می تواند بر اساس موقعیت و اهمیت آن برای بهبود کارایی رندر، کنترل کند که آیا شی باید رندر شود یا نه. [ 9 ] این روش فرآیند سازماندهی مدل های سه بعدی را ساده می کند. با این حال، فقط برای مدل های BIM با ساختارهای ساده، مانند ادارات و ساختمان های مسکونی مناسب است. اگر از این روش برای پردازش مدلهای BIM با ساختارهای پیچیده مانند پستها استفاده شود، تعداد زیاد زیرمجموعههای پیچیده به طور قابلتوجهی مقدار دادهها را برای هر LOD افزایش میدهد و تفاوتهای بین مجموعههای فرعی در همان سطح نادیده گرفته میشود. این منجر به کیفیت پایین تجسم می شود. دسته دوم از روشهای چهاردرخت، اکتری یا سادهسازی مدل برای سازماندهی مدلهای سه بعدی استفاده میکنند.شکل 2 ب). این روشها صافی جابهجاییهای افقی و زومهای عمودی در دیدگاه حاصل را به حساب میآورند. با این حال، هنگام استفاده از این روش ها، ساده سازی ها می توانند مدل سه بعدی را مخدوش کنند. برای چهار درخت و هشت درخت، تعادل حجم داده گره ها و عمق درخت شاخص می تواند دشوار باشد. علاوه بر این، این روشها ممکن است یک زیرمجموعه را به چندین قسمت جدا کنند، که الزامات حفظ یکپارچگی زیرمجموعه را نقض میکند و منجر به جلوههای بصری ضعیف در طول مرور میشود. روشهای بسیار کمی میتوانند تصویرسازی با کارایی بالا را برای BIM پیچیده با مقادیر بسیار زیاد داده ارائه دهند و در عین حال یکپارچگی زیرمجموعه را حفظ کنند.
بر اساس شکاف ها و محدودیت های روش های اصلی موجود در بالا، کاشی های سه بعدی را به عنوان مشخصات قالب و سزیوم را به عنوان پلت فرم تجسم و نمایشگر مدل سه بعدی برای استفاده در وب انتخاب کردیم. در این مطالعه، بر اساس کاشی های سه بعدی، یک روش تجسم با کارایی بالا برای BIM در بیننده مدل سه بعدی مبتنی بر وب، بدون ساده سازی مدل BIM توسعه داده شد. به طور خاص، این مطالعه دو سهم اصلی دارد: (1) در مورد مشکل عدم توانایی در حفظ یکپارچگی زیرمجموعه، ما یک روش کاشی کاری برای مدلهای سه بعدی مبتنی بر درخت R-تخریب شده پیشنهاد میکنیم. و (2) در مورد مشکل تجسم با کیفیت پایین، یک “فیلتر ماسک” معرفی شده و یک روش LOD بر اساس آن پیشنهاد شده است. هدف علمی این مطالعه تحقق تجسم با کارایی بالا مدلهای BIM با حجم داده بزرگ است.
2. آثار مرتبط
به دلیل ساختارهای پیچیده و مقادیر انبوه داده مدلهای BIM، رندر زمان واقعی در نمایشگر مدل سهبعدی مبتنی بر وب میتواند دشوار باشد. بنابراین، انتخاب یک قالب داده مدل سه بعدی مناسب و سازماندهی داده های بسیار کارآمد بر اساس آن فرمت ضروری است. کاشیهای سهبعدی که توسط سزیوم پیشنهاد شد، یک مشخصات باز برای تجسم محتوای فضایی سهبعدی عظیم ناهمگن است و ساختار دادههای سلسله مراتبی آن میتواند به جریان سریع و رندر دقیق دست یابد [ 6 ]]. با این حال، قوانین صریحی برای تجسم محتوا تعریف نمی کند. بنابراین، روش های سازماندهی و ساخت کاشی های سه بعدی بسته به اهداف و اشیاء متفاوت است. کارایی روش سازماندهی داده ها تأثیر قابل توجهی بر اثر رندر کاشی های سه بعدی در وب دارد [ 10 ]. در نتیجه، بسیاری از محققان روشهای مختلف سازماندهی دادهها را برای استفاده در کاشیهای سهبعدی، با توجه به ویژگیهای اشیاء مدلسازی شده، مطالعه کردهاند.
در مورد برخی از داده های سه بعدی، مانند مدل شهر سه بعدی [ 11 ]، مدل های عکاسی مایل [ 12 ]، داده های LiDAR ابر نقطه ای [ 13 ]، داده های آب و هوا [ 14 ] و داده های سیل [ 15 ]، استفاده از چهاردرخت رایج است. octrees یا شاخص های شبکه ای که با ساده سازی های مدل ترکیب شده اند تا آنها را سازماندهی کنند. از آنجایی که تراکم این داده ها نسبتاً کم است و ساختار مدل نسبتاً ساده است، این روش می تواند جلوه های بصری رضایت بخشی را ارائه دهد.
مدل BIM را می توان به دو دسته مدل BIM فدرال و یکپارچه و مدل BIM مستقل تقسیم کرد. هر دوی آنها از چندین ماژول تشکیل شده اند. هر زیر مجموعه در هر ماژول یک موجودیت مجزا است. بر اساس این ویژگیها، روش سازماندهی دادهها برای مدلهای BIM سهبعدی با روشی که در بالا توضیح داده شد متفاوت است و در عوض میتوان آن را به سه دسته طبقهبندی کرد. دسته اول روش مبتنی بر معنایی است. خو و همکاران (2020) [ 16 ] ساختمان های مسکونی را به چهار سطح، یعنی پی، کانتور خارجی، دیوارها و پنجره ها، و فضای داخلی جدا کرد [ 16 ]]. ساختار کاشیهای سهبعدی بهدستآمده شبیه یک فهرست پیوندی خطی بود که دارای یک گره شاخه با یک فرزند است. زمانی که ساختار مدل BIM نسبتاً ساده باشد، این روش میتواند به تجسمهای عالی دست یابد. با این حال، در ایجاد تجسم کارآمد برای مدل های پیچیده BIM شکست خورده است. دسته دوم روش های سازماندهی داده ها از چهار درخت یا اکتره استفاده می کنند. چن و همکاران (2018) [ 10 ] و کیم و همکاران. (2015) [ 17] octrees را برای سازماندهی مدل های ساختمانی سه بعدی بر اساس اطلاعات مکانی هر زیرمجموعه اتخاذ کرد. اگرچه اندازه کاشی های جداگانه کاهش یافت، اما عمق درخت شاخص افزایش یافت و زمانی که تعداد زیر مجموعه ها در مدل BIM افزایش یافت، مرور با تاخیر مواجه شد. دسته سوم روش های سازماندهی داده ها شامل ساده سازی مدل است. هو و همکاران (2019) [ 18 ] از الگوریتم متریک خطای چهارگانه برای کاهش اندازه یک مدل BIM استفاده کرد. آنها متعاقباً از الگوریتم بازسازی بردار معمولی مبتنی بر خوشهبندی برای تولید LOD استفاده کردند. چن و همکاران (2016) [ 19 ] یک الگوریتم خوشه بندی راس مربوط به بافت را به کار گرفت [ 20 ]] برای ساده سازی مدل پیچیده BIM، که حجم داده مورد استفاده برای انتقال شبکه و تجسم پیشرونده را کاهش داد. با این حال، هنگام استفاده از این روش، آستانه الگوریتم ساده سازی باید توسط کاربر تعیین شود. علاوه بر این، ویژگی های محلی مدل BIM ممکن است زمانی که مدل ساده می شود از بین برود، و این روش با مدل به عنوان یک موجودیت منفرد رفتار می کند، در نتیجه ویژگی های هر زیر مجموعه را نادیده می گیرد.
به طور خلاصه، روش های موجود مستلزم پارتیشن بندی مدل های سه بعدی بر اساس اطلاعات معنایی یا مکان های مکانی و ایجاد LOD از طریق اطلاعات معنایی یا ساده سازی مدل است. این رویکردها تجسم کارآمدی را برای مدل های خاص BIM فراهم می کند. با این حال، اگر زیر مجموعه های دقیق تری در مدل BIM وجود داشته باشد، عملکرد این روش ها بدتر می شود.
3. روش شناسی
3.1. استراتژی برنامه ریزی برای کاشی های سه بعدی در سزیوم
سزیوم یک پلتفرم تجسم تعاملی است که به کاربران اجازه می دهد تجسم را شخصی کنند [ 21 ]. زمانبندیشده توسط سزیوم، کاشیهای سهبعدی را فقط میتوان در وب ارائه کرد [ 22 ]. پارامترهای زمانبندی زیادی در سزیوم وجود دارد که مستقیماً بر اثر رندر کاشی های سه بعدی تأثیر می گذارد. پارامترهای اصلی در زیر به تفصیل آمده است.
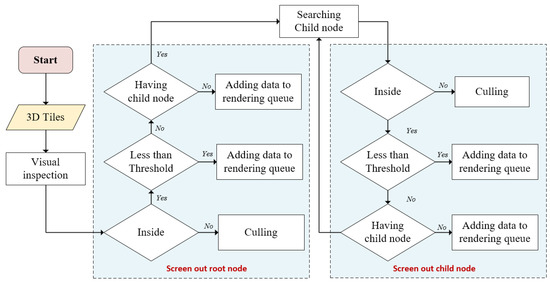
خطای فضایی صفحه ( SSE ) یک پارامتر ضروری برای رندر است. بر اساس تحقیقات قبلی (به معادلات (1) و (2) مراجعه کنید) [ 23 ]، اینکه آیا یک کاشی در کاشی های سه بعدی برنامه ریزی شده است به دو عامل اصلی بستگی دارد: حجم مرزی و خطای هندسی. حجم محدود کننده اندازه و نوع جعبه مرزی کاشی را مشخص می کند. در طول مرور، سزیم رابطه توپولوژیکی بین جعبه مرزی کاشی و نمای فروستوم را قضاوت می کند. اگر یک تقاطع وجود داشته باشد، قضاوت می کند که آیا خطای هندسی الزامات رندر را برآورده می کند یا خیر. علاوه بر این، خطای هندسی متریک انتخاب را تعیین می کند که نشان می دهد آیا یک کاشی خاص برنامه ریزی می شود یا خیر. هر چه کاشی بزرگتر باشد، برنامه ریزی آن کاشی آسان تر است.
اساسE=(g∗کد)
ک=(ساعتهمنgساعتتی2∗برنزه(fovy/2))
که در آن g خطای هندسی، d فاصله از نقطه دید تا کاشی، ارتفاع به ارتفاع صفحه و فووی نشان دهنده زاویه فرورفتگی دید است.
هنگام مرور، سزیوم ابتدا یک بازرسی بصری برای کاشیهای سهبعدی انجام میدهد، که بر اساس آن قضاوت میکند که آیا جعبه مرزی گره ریشه و نمای فروستوم تلاقی میکنند یا خیر. اگر آنها قطع کنند، گره ریشه مربوطه به صف درخواست اضافه می شود. متعاقباً، گرههای ریشه در صف درخواست بهطور متوالی مورد قضاوت قرار میگیرند تا مشخص شود که آیا آنها شرایط آستانه را برآورده میکنند یا خیر. به عبارت دیگر، این فرآیند تعیین می کند که آیا SSE گره ریشه کمتر از حداکثر خطای فضای صفحه نمایش (MaxSSE) است یا خیر. اگر کمتر از این مقدار باشد، گره ریشه مربوطه به صف رندر اضافه می شود. در غیر این صورت، گره ریشه مربوطه مورد بررسی قرار می گیرد تا مشخص شود که آیا گره فرزند دارد یا خیر. اگر این کار را نکرد، مستقیماً به صف رندر اضافه می شود. در غیر این صورت فرزندان آن در مرحله بعدی قضاوت می شوند. پردازش کودکان مانند گره های ریشه است. این فرآیند تا زمانی ادامه می یابد که تمام گره هایی که با تمام الزامات رندر مطابقت دارند پیدا شوند و پس از آن زمان بندی شوند. شایان ذکر است که کاشی های سه بعدی تنها زمانی برای رندر برنامه ریزی می شوند که هم حجم محدود و هم خطای هندسی الزامات رندر را برآورده کنند.
3.2. سازماندهی داده ها برای مدل های BIM
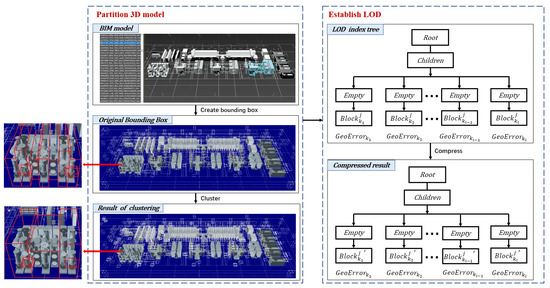
با تکیه بر روشهای سادهسازی مدل و/یا دادههای چند وضوحی، روشهای سنتی سازماندهی دادهها میتوانند یک مدل سهبعدی LOD تقسیمبندی شده بسازند. با این حال، دادههای چند وضوحی برای مدلهای BIM اغلب در دسترس نیستند و الگوریتمهای سادهسازی با اشکالات خاصی همراه هستند. بنابراین، به منظور دستیابی به تجسم های با کارایی بالا برای مدل های BIM در بیننده مدل سه بعدی مبتنی بر وب، به جای استفاده از الگوریتم های ساده سازی مدل پیچیده، این مطالعه هر زیر مجموعه مدل BIM را به عنوان سطح کانونی دانه بندی در نظر می گیرد. برای حفظ مدل اصلی BIM، یک روش سازماندهی داده های تک لایه بر اساس مجموعه های فرعی پیشنهاد شده است و SSE برای پردازش مدل BIM اتخاذ می شود.
فرآیند کلی سازماندهی داده ها در شکل 4 نشان داده شده است . ابتدا، الگوریتم کاشی کاری “از پایین به بالا” را برای BIM انجام می دهد، که مجموعه های فرعی مدل BIM را به عنوان سطح دانه بندی در نظر می گیرد. در نتیجه، مدل BIM به چندین جعبه محدود تقسیم می شود. هر جعبه مرزی فقط شامل یک زیرمجموعه واحد است و جعبه مرزی i-ام نشان دهنده آن است بلoجککمن1. پس از آن، با توجه به آستانه حجم داده برای یک کاشی، بلoجککمن1بهطور پیوسته خوشهبندی میشود، که نیاز به محاسبه مجدد جعبه مرزی چندگانه دارد بلoجککمن1و حذف قبلی بلoجککمن1تا حجم داده های همه بلoجککمنjرسیدن به آستانه بعد، با توجه به ویژگی های هندسی از بلoجککمنj، جیهoErrorکمنو فیلترهای ماسک تنظیم شده است. در نهایت، دراکو [ 24 ]، که یک کتابخانه منبع باز است که توسط گوگل راه اندازی شده است، برای فشرده سازی استفاده می شود. بلoجککمنjو بدست آورید بلoجککمنj“. اینجا، بلoجککمنjهست کمنبلوک بعد از خوشه بندی j، جیهoErrorکمنخطای هندسی است کمنبلوک، و بلoجککمنj“فشرده است بلoجککمنj. در نتیجه، مدل BIM در مجموعه ای از کاشی های سه بعدی پارتیشن بندی شده با شاخص یک سطحی سازماندهی می شود.
3.2.1. روش کاشی کاری برای مدل های BIM
روش کاشی کاری پیشنهادی در اینجا یک بهبود نسبت به درخت R است. همانطور که در شکل 4 نشان داده شده است، مدل BIM از طریق خوشه بندی “پایین به بالا” تقسیم می شود .. مدل های BIM از مجموعه های فرعی متعددی مانند در و پنجره تشکیل شده اند. ابتدا، با توجه به حداقل مکعب های مرزی زیر مجموعه ها، مدل BIM به چندین بلوک مستقل تقسیم می شود. پس از آن، فاصله بین هر بلوک محاسبه می شود. در مرحله بعد، سیستم ارزیابی می کند که آیا مجموع وجوه موجود در دو نزدیکترین بلوک کمتر از آستانه است (فرمول (3)). اگر کمتر از آستانه باشد، حداقل مکعب های مرزی کلی محاسبه می شود و حداقل مکعب های مرزی هر یک حذف می شود. خوشه بندی تا زمانی ادامه می یابد که تعداد وجوه در هر بلوک به آستانه برسد. در طول پارتیشن بندی، تنها نتیجه نهایی کاشی کاری حفظ می شود. نتایج کاشی کاری از مراحل دیگر دور ریخته می شود. الگوریتم 1 به شرح زیر است:
| الگوریتم 1 روش کاشی کاری برای مدل BIM |
| ورودی: |
| مدل اصلی BIM م(v، vn، vتی، f) |
| مقدار دهی اولیه: |
| (1) مدل اصلی BIM را تجزیه و تحلیل کنید مو تعداد زیر مجموعه ها را تعیین کنید Objnum. |
| (2) رأس v ، مختصات بردار معمولی vn ، مختصات بافت vt ، و نمایه چهره f را در آرایه مربوطه زیرمجموعه Obj ذخیره کنید ( v ، vn ، vt ، f ). |
| (3) آرایه دو بعدی فاصله را راه اندازی کنید دیس_آرایهو آرایه یک بعدی از مینیمم مکعب های مرزی جعبه. |
| (4) با توجه به فرمول (3)، آستانه خوشه بندی را محاسبه کنید خوشه_آستانه. مدل کاشی کاری: |
| برای هر Oبjمن، حداقل مکعب مرز آن را محاسبه کنید بoایکسمن، و باریسنتر دبلیومن(محاسبه با فرمول (4)). |
| برای هر Oبjمن، فاصله را محاسبه کنید Dمنjبین خودش و دیگری Oبjjبر اساس دبلیومنو دبلیوj، و اضافه کنید Dمنjبه دیس_آرایه. |
| در حالی که اندازه از دیس_آرایهصفر نیست: |
| حداقل فاصله را بازیابی کنید Dمنjاز جانب دیس_آرایهو زیر مجموعه های مربوطه را بدست آورید Oبjمنو Oبjj. |
| اگر مجموع Oبjمن(f)و Oبjj(f)کمتر است از سیلتوستیهr_تیساعتrهسساعتoلد: |
| را به روز کنید بoایکسمنبه حداقل مکعب مرزی کلی Oبjمنو Oبjj، سازماندهی تمام داده های هندسی در Oبjj(v،vn،vتی،f)به Oبjمن(v،vn،vتی،f)، و حذف کنید بoایکسjو Oبjj |
| با توجه به فرمول (5)، باریسنتر کلی را دوباره محاسبه کنید دبلیومن. |
| حذف Djکه در Dمنس_آrrآyو فاصله را دوباره محاسبه کنید Dمنبین بoایکسمنو دیگر بoایکس. |
| دیگر: |
| حذف Dمنjو Djمنکه در Dمنس_آrrآy. |
| خروجی: |
| مدل BIM پارتیشن بندی شده Oبj(v،vn،vتی،f) |
سیلتوستیهrتیساعتrهسساعتoلد=م(f)Oبjnتومتر
ایکس“،y“،z“=(∑n=1مترایکسn1+ایکسn2+ایکسn33متر،∑n=1مترyn1+yn2+yn33متر،∑n=1مترzn1+zn2+zn33متر)
دبلیومن(ایکسمن،yمن،zمن)=(Oبjمن(f)∗ایکسمن+Oبjj(f)∗ایکسjOبjمن(f)+Oبjj(f)،Oبjمن(f)∗yمن+Oبjj(f)∗yjOبjمن(f)+Oبjj(f)،Oبjمن(f)∗zمن+Oبjj(f)∗zjOبjمن(f)+Oبjj(f))
3.2.2. روش LOD برای مدل های BIM
با توجه به مشخصات قالب برای کاشی های سه بعدی، خطای هندسی می تواند با تأثیر بر SSE کاشی، LOD مدل را کنترل کند. مدل مربوطه تنها زمانی باید ارائه شود که SSE کاشی با الزامات مطابقت داشته باشد. با این وجود، صرفاً وارد کردن نتایج کاشی کاری فوق الذکر در یک درخت شاخص به عنوان گره های برگ و تنظیم یک مقدار خطای هندسی خاص برای هر بلوک، همانطور که در شکل 5 الف نشان داده شده است، LOD را اجرا نمی کند. با توجه به استراتژی زمانبندی کاشیهای سهبعدی، حتی اگر SSE کاشی به طور قابلتوجهی بزرگتر از MaxSSE در فاصله مشاهده فعلی باشد، کاشی همچنان رندر میشود زیرا هیچ گره والد با دقت کمتری برای برنامهریزی وجود ندارد.
علاوه بر این، هنگامی که مدل اولیه می شود، سزیم مدل کلی BIM را بارگذاری می کند، حتی اگر خطای هندسی برخی بلوک ها به طور قابل توجهی از الزامات تجسم فراتر رفته باشد. در نتیجه، در طول مقداردهی اولیه، تعداد درخواستهای همزمان مشتری به شدت افزایش مییابد و مقدار زیادی از دادههای مدل سهبعدی باید آپلود و ارائه شوند. در نتیجه، تجسم مدل سه بعدی با تاخیر قابل توجهی مواجه خواهد شد که تجربه کاربر را بدتر خواهد کرد.
برای حل مشکلات ذکر شده در بالا، بر اساس استراتژی زمانبندی سزیم و مشخصات قالب کاشیهای سه بعدی، این مقاله یک استراتژی «فیلتر ماسک» را پیشنهاد میکند، همانطور که در شکل 5 نشان داده شده است.ب ایده اصلی این استراتژی به شرح زیر است. گره های والد خالی که گره های والد گره های برگ هستند به درخت شاخص اضافه می شوند. شناسه منبع یکنواخت (URI) گره والد خالی خالی است و خطای هندسی آن کمی بیشتر یا مساوی با خطای هندسی گره برگ مربوطه است. بنابراین، زمانی که دیدگاه دورتر شود و الزامات رندر گرههای برگ خاصی برآورده نشود، گرههای مادر خالی این گرههای برگ ارائه میشوند. از آنجایی که URIهای این گرههای والد خالی هستند، نیازی به آپلود مدلها نیست و برخی از مدلهای تجسمشده قبلی میتوانند بارگیری شوند. این به طور قابل توجهی بار حافظه رایانه را کاهش می دهد. در اینجا، گره والد خالی «فیلتر ماسک» است. بر اساس این استراتژی “Mask Filter”، روش LOD برای مدل های BIM به شرح زیر ساخته شده است.
ابتدا خطای هندسی منحصر به فرد هر بلوک با توجه به نتیجه کاشی کاری محاسبه می شود. همانطور که در فرمول (6) نشان داده شده است، دو برابر طول مورب حداقل مکعب های مرزی یک بلوک به عنوان خطای هندسی در نظر گرفته می شود:
جیهoمترهتیrمنج هrror=(ایکسمترآایکس–ایکسمترمنn)2+(Yمترآایکس–Yمترمنn)2+(زمترآایکس–زمترمنn)2×2
جایی که ایکسمترآایکس، Yمترآایکس، و زمترآایکسحداکثر مقدار بلوک را به ترتیب با محورهای X، Y و Z سیستم مختصات جغرافیایی نشان می دهد.
دوم، یک «فیلتر ماسک» جداگانه برای هر بلوک تنظیم شده است.
سوم، لایهها بهطور متوالی در فایل فهرست JSON کاشیهای سهبعدی سازماندهی میشوند، به طوری که «فیلتر ماسک» والد و بلوک فرزند است.
در حین مرور، با نزدیکتر شدن دیدگاه، گرههای برگ که خطاهای هندسی آنها آستانه را برآورده میکند، ارائه میشوند. در نتیجه، مدل با جزئیات بیشتری به نظر می رسد. برعکس، با دورتر شدن دیدگاه، گرههای برگ که خطای هندسی آنها آستانه را برآورده نمیکند، تخلیه میشوند و «فیلتر ماسک» برنامهریزی میشود. در نتیجه، مدل خشن تر به نظر می رسد. بنابراین، با توجه به ساختار ذخیره سازی داده، مدل ساخته شده با استفاده از این استراتژی تنها یک LOD دارد. از نظر تجسم، به اثر یک LOD سلسله مراتبی دست می یابد که روانی در مقیاس بندی را تضمین می کند.
در طول مقداردهی اولیه، از آنجایی که برخی از گره های برگ نمی توانند الزامات رندرینگ را در فاصله مشاهده اولیه برآورده کنند، «فیلتر ماسک» آنها به طور خودکار برنامه ریزی می شود. به این ترتیب، بار درخواست داده توسط مشتری به میزان قابل توجهی کاهش می یابد. از دیدگاه درخواستهای داده و سختافزار رایانه، «فیلتر ماسک» میزان درخواستهای دادهای همزمان را کاهش میدهد و امکان استفاده کارآمدتر از منابع سختافزاری رایانه را در مقایسه با روشهای دیگر فراهم میکند. در نهایت، از دیدگاه ساختار ذخیرهسازی داده، «فیلتر ماسک» به کاهش عمق درخت شاخص کمک میکند.
4. آزمایش ها و بحث
برای آزمایش عملکرد الگوریتم پیشنهادی، الگوریتمهای خود را در C++ روی ویندوز 10 64 بیتی پیادهسازی کردیم. آزمایشها بر روی یک رایانه DELL با یک Intel Core i7-9750H (Intel, Santa Clara, CA, USA), 16 انجام شد. رم گیگابایت (سامسونگ، شهر سئونگنام، استان گیونگگی، کره)، و کارت گرافیک NVIDIA GeForce GTX 1650.
آزمایش شامل دو بخش بود. ابتدا، عملکرد محاسباتی، عملکرد رندر، و اثر انتخاب و پرس و جو کاشی های سه بعدی ساخته شده با استفاده از روش پیشنهادی مورد آزمایش قرار گرفت. داده های تجربی، یعنی ویلاها، مسکن، ادارات و سه مدل پست در جدول 1 ارائه شده است. دوم، روش پیشنهادی با سه روش موجود مقایسه شد: octree (روش 1)، سادهسازی مدل (روش 2)، و اطلاعات معنایی (روش 3). همانطور که در جدول 1 نشان داده شده است، داده های تجربی آزمایش دوم Electric Power 3 بود .
4.1. کارایی
عملکرد روش پیش پردازش برای مدلهای BIM عمدتاً بر اساس عملکرد محاسباتی آزمایش شد، که ما آن را به عنوان زمان اجرای مورد نیاز برای تکمیل پیشپردازش تعریف کردیم. عملکرد رندر، که ما آن را به عنوان فریم در ثانیه (fps) در فواصل مختلف مشاهده در بیننده مدل سه بعدی مبتنی بر وب تعریف کردیم. و افکت انتخاب، که ما به این صورت تعریف کردیم که آیا زیرمجموعه های انتخاب شده کامل هستند یا خیر.
زمان اجرای مورد نیاز برای شش مدل پردازش در شکل 6 نشان داده شده است . مدل ها با استفاده از روش پیشنهادی و روش 1 فوق الذکر پردازش می شوند. شکل 6 نشان می دهد که با افزایش اندازه مدل، زمان اجرای هر دو روش افزایش می یابد. زمان کار ویلا، کوچکترین مدل، تنها تقریباً 2 ثانیه بود، در حالی که زمان کار Electric Power 3، بزرگترین مدل، کمتر از 5 دقیقه بود. اگرچه عملکرد کلی روش 1 کمی بهتر از روش پیشنهادی بود، تفاوت در زمان اجرا بین دو روش کم است (در عرض چند ثانیه). از این رو، روش ها نسبتاً کارآمد در نظر گرفته شدند.
عملکرد رندر مدل پردازش شده با دو روش در نمایشگر مدل سه بعدی مبتنی بر وب در شکل 7 نشان داده شده است . به طور خاص، این شکل نرخ فریم مرور مدل را هنگام پردازش توسط الگوریتمهای مختلف برای یک نقطه دید در فاصله 200 متر و 20 متر از مدل نشان میدهد. از شکل 7مشاهده می شود که عملکرد رندر روش پیشنهادی برای هر دو فاصله مشاهده بهتر از روش 1 بود. اگرچه افزایش اندازه مدل عملکرد رندر هر دو روش را کاهش داد، فریم بر ثانیه مدل پردازش شده با استفاده از روش پیشنهادی فقط نوسانات جزئی را نشان داد و عملکرد رندر بالا حفظ شد. برای روش پیشنهادی، فریم بر ثانیه همه مدلهای تجربی از 30 فراتر رفت، در حالی که فریم در ثانیه اکثر مدلهای تجربی تقریباً 50 است. وب به طور مداوم بلوک های جدید را ارائه می دهد و این مدل پیچیده تر می شود. از شکل 7، همچنین می توان مشاهده کرد که هنگام رندر مدل آفیس، عملکرد رندر هر دو روش کاهش یافته است. این به این دلیل است که جعبههای مرزبندی مجموعههای فرعی در مدل اداری تقریباً به یک اندازه هستند و طول مورب تقریبی منجر به خطای هندسی تقریبی میشود. در نتیجه، تعداد زیادی زیرمجموعه هنگام بزرگنمایی در سطح مشخصی بارگذاری میشوند که باعث کاهش روانی مرورگر میشود. در نتیجه، عملکرد رندر روش پیشنهادی عمدتاً به اندازه مدل و اینکه آیا زیر مجموعههای مدل از نظر هندسی متمایز هستند بستگی دارد.
اثرات انتخاب و پرس و جو از مدل پردازش شده با دو روش در جدول 2 نشان داده شده است. قسمت سبز در جدول نشان دهنده نتیجه ای است که با یک پرس و جو یا یک انتخاب باز می گردد. از جدول، مشهود است که روش پیشنهادی یکپارچگی هندسی زیرمجموعهها را تضمین میکند، صرف نظر از اینکه این زیرمجموعهها متعلق به اشیایی مانند نردهها (با مساحت وسیع) یا پستها (با تعداد زیاد وجه) هستند. با این حال، روش 1 فوق الذکر، که چهره ها را به عنوان حداقل واحدهای زیربخش در نظر می گیرد، مجموعه های فرعی را پارتیشن بندی می کند، که منجر به یک نتیجه پرس و جو ناقص می شود.
4.2. مقایسه تجسم ارائه شده توسط الگوریتم های مختلف
به منظور آزمایش برتری روش پیشنهادی، یک آزمایش کنتراست انجام شد که روش پیشنهادی را با سه روش جریان اصلی، یعنی روش 1، روش 2 [ 25 ] و روش 3 [ 16 ] مقایسه کرد. مدل Electric Power 3 برای دادههای تجربی انتخاب شد و مدل پردازش شده با چهار روش بر روی نمایشگر مدل سهبعدی مبتنی بر وب ارائه شد. پارامترهای باقیمانده، مانند MaxSSE [ 26 ]، روی همان مقادیر تنظیم شدند. پس از آن، LOD و روانی مرور مدل پردازش شده با روش های مختلف و در فواصل دید متفاوت مشاهده شد.
هنگامی که فاصله دید 1500 متر است، نقطه دید از مدل بسیار دور است. از شکل 8 ، مشخص است که مدل پردازش شده با روش پیشنهادی، شالوده مدل پست، دکل انتقال در مقیاس بزرگ و برخی زیرمجموعه های بزرگتر را نشان می دهد. طرح کلی برج انتقال دست نخورده باقی مانده است، همانطور که در کادر قرمز در شکل 8 الف نشان داده شده است. مدل پردازش شده توسط روش 1 فقط پایه و برج انتقال مدل پست را نشان می دهد. با این حال، همانطور که در کادر قرمز در شکل 8 نشان داده شده است، طرح کلی برج انتقال تا حد زیادی از بین رفته است.ب علاوه بر این، مدل پردازش شده توسط روش 2 پایه و برج انتقال و همچنین برخی از مجموعه های فرعی کوچکتر را نشان می دهد که بیش از حد جزئیات هستند. علاوه بر این، به دلیل سادهسازی مدل، طرح کلی برج انتقال به طور قابلتوجهی مبهم است، همانطور که در کادر قرمز در شکل 8 ج نشان داده شده است. علاوه بر این، مدل پردازش شده توسط روش 3 فقط پایه را نشان می دهد، و طرح کلی مدل تا حد زیادی وجود ندارد، همانطور که در کادر قرمز در شکل 8 d نشان داده شده است.
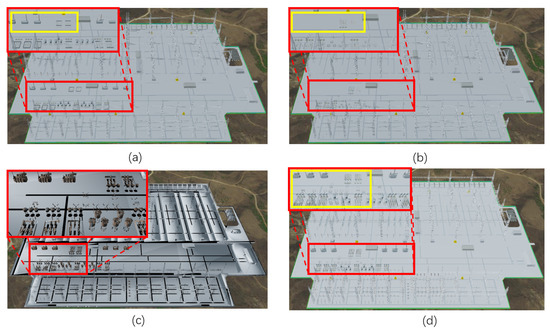
هنگامی که فاصله دید 300 متر است، مدل به طور دقیق کل پنجره تجسم را پوشش می دهد. همانطور که در شکل 9 نشان داده شده است ، مدل پردازش شده با استفاده از روش پیشنهادی، اصلاح مناسب را برای برخی از زیر مجموعه های با اندازه متوسط مانند ترانسفورماتورها نشان می دهد، همانطور که در کادر زرد در شکل 9 a نشان داده شده است. این یک دید واضح تر از جزئیات مدل ارائه می دهد. مدل پردازش شده با استفاده از روش 1 همچنین برخی از زیر مجموعه های تصفیه شده را نشان می دهد. با این حال، در مقایسه با روش پیشنهادی، جزئیات ارائه شده نسبتاً کمی هستند، همانطور که در کادر زرد در شکل 9 ب نشان داده شده است. علاوه بر این، مدل های پردازش شده توسط روش 2 و روش 3 هر دو تعداد بیشتری از زیر مجموعه های کوچکتر را ارائه می دهند، همانطور که در کادر قرمز در شکل 9 نشان داده شده است.c و کادر زرد رنگ در شکل 9 d به ترتیب، که باعث می شود قسمت هایی از مدل شلوغ به نظر برسند.
هنگامی که فاصله دید 50 متر است، نقطه دید به مدل نزدیک تر است. همانطور که از شکل 10 مشاهده می شود ، مجموعه های فرعی زیادی به مدل پردازش شده با روش پیشنهادی اضافه می شوند. جزئیات مدل غنیتر میشوند، در حالی که برخی از مجموعههای فرعی بیش از حد کوچک هنوز به طور مناسب نادیده گرفته میشوند، همانطور که در کادر قرمز در شکل 10 a نشان داده شده است. مدل پردازش شده توسط روش 1 نیز جزئیات غنی شده را نشان می دهد. با این حال، برخی از مجموعه های فرعی بسیار کوچک مانند رشته ها و جعبه های مقره نیز ارائه شده اند، همانطور که در کادر قرمز در شکل 10 ب نشان داده شده است. روش 2 و روش 3 هر دو جزئیات کاملی از مدل را ارائه می دهند و در نتیجه، مدل کلی نسبتاً آشفته است، همانطور که در کادر قرمز در شکل 10 نشان داده شده است.ج، د، به ترتیب.
همانطور که در شکل 11 نشان داده شده است، همانطور که دیدگاه به تدریج از 1300 متر به 50 متر دور می شود، نرخ فریم مرور مدل پردازش شده با روش های مختلف به طور مداوم در نوسان است .. برای روش پیشنهادی، در طول فرآیند مرور، نرخ فریم مرور از 40 تا 60 فریم در ثانیه در نوسان است. در فاصله 800 تا 500 متری، نرخ فریم مرور کاهش مییابد زیرا مجموعههای فرعی کوچک خاصی از مدل برنامهریزی شدهاند. فراتر از 300 متر، به دلیل کاشی کاری، برخی از بلوک های واقع در خارج از پنجره تجسم تخلیه می شوند و در نتیجه، نرخ فریم مرور افزایش می یابد. این نشان میدهد که روش پیشنهادی میتواند به روانی عالی در طول فرآیند مرور دست یابد. برای روش 1، نرخ فریم مرور در طول فرآیند مرور از 20 تا 40 فریم در ثانیه در نوسان بود. نوسانات در فریم بر ثانیه از 800 تا 500 متر و فراتر از 300 متر با نوسانات در هنگام استفاده از روش پیشنهادی سازگار بود. برای روش 2، نرخ فریم کلی مرور زیر 20 فریم بر ثانیه بود. یک مرحله سه سطحی مشهود در نوسان نرخ فریم وجود داشت که با بارگذاری مدل ساده شده ثانویه در فاصله 600-500 متر و پالایش شده ترین مدل در فاصله 260-200 متر مطابقت داشت. با این حال، تسلط مرور ضعیف بود. در نهایت، برای روش 3، نرخ فریم مرور از 10 تا 30 فریم در ثانیه در طول فرآیند مرور در نوسان بود، و نوسانات در بازه محلی با موارد استفاده از روش پیشنهادی سازگار بود. با این حال، روانی کلی مرور نسبتا ضعیف بود، در مقایسه با روش پیشنهادی. نرخ فریم مرور از 10 تا 30 فریم در ثانیه در طول فرآیند مرور در نوسان بود، و نوسانات در بازه محلی با موارد استفاده از روش پیشنهادی سازگار بود. با این حال، روانی کلی مرور نسبتا ضعیف بود، در مقایسه با روش پیشنهادی. نرخ فریم مرور از 10 تا 30 فریم در ثانیه در طول فرآیند مرور در نوسان بود، و نوسانات در بازه محلی با موارد استفاده از روش پیشنهادی سازگار بود. با این حال، روانی کلی مرور نسبتا ضعیف بود، در مقایسه با روش پیشنهادی.
علاوه بر این، روش پیشنهادی، روش 2 و روش 3 همگی قادر به شناسایی زیر مجموعه های کامل بودند. اگرچه روش 1 اندازه دادههای یک کاشی را تضمین میکند، اما قادر به شناسایی زیر مجموعههای کامل نبود.
به طور خلاصه، در فواصل دید متفاوت، روش پیشنهادی میتواند هر زیرمجموعه را با توجه به اندازه آن به صورت تطبیقی ارائه کند. بنابراین، میتواند زمانبندی هر زیرمجموعه را با دقت بیشتری کنترل کند و LOD را برجستهتر کند. با توجه به روش کاشی کاری، یکپارچگی زیرمجموعه و کانتور مدل بهتر از مدل های توسعه یافته قبلی حفظ می شود. علاوه بر این، روش LOD و الگوریتم فشرده سازی دراکو برای اطمینان از تجسم روان تر ترکیب شدند. در سراسر اعتبار سنجی تجربی ما، از نظر کیفیت تجسم و روانی مرور، روش پیشنهادی عملکرد برتری را نشان داد.
5. نتیجه گیری ها
برای ایجاد تجسمهای صاف از مدلهای پیچیده BIM در بیننده مدل سهبعدی مبتنی بر وب، این مقاله یک روش سازماندهی داده بسیار کارآمد بر اساس کاشیهای سهبعدی را پیشنهاد کرد. این روش مدل را ساده نمی کند. بر اساس حفظ مدل اصلی، مدل با توجه به مجموعههای فرعی مدل BIM و اندازه دادههای یک کاشی به چندین بلوک تقسیم میشود. پس از آن، مفهوم “فیلتر ماسک” برای دستیابی به LOD مدل معرفی می شود. از طریق چندین آزمایش کنتراست، ما نشان میدهیم که روش پیشنهادی در مقایسه با روشهای سنتی کارایی بالایی دارد. با توجه به عملکرد رندر، روش پیشنهادی به طور قابلتوجهی از الگوریتمهای سنتی بهتر عمل میکند، در نتیجه روانی مرور مدلهای پیچیده BIM را در بیننده مدل سهبعدی مبتنی بر وب بهشدت بهبود میبخشد. با توجه به تأثیر انتخاب و پرس و جو، روش پیشنهادی می تواند یکپارچگی زیر مجموعه های انتخاب شده را تضمین کند. در نتیجه، روش پیشنهادی میتواند به تجسم با کارایی بالا برای مدلهای BIM با حجم داده بزرگ در بیننده مدل سهبعدی مبتنی بر وب دست یابد. علاوه بر این، از طریق روش پیشنهادی، میتوانیم به راحتی با این مدلهای BIM در Web-3D GIS تعامل داشته باشیم، که انگیزه جدیدی به کاربرد یکپارچه BIM و Web-GIS میدهد.
با این وجود، جنبه های خاصی از این تحقیق بهینه سازی بیشتر را ایجاب می کند. ابتدا فقط یک پلتفرم آزمایشی روی رایانه شخصی در نظر گرفته شد. با توجه به محبوبیت دستگاه های تلفن همراه، تجسم مدل های سه بعدی در مقیاس بزرگ در دستگاه های تلفن همراه نیز باید در نظر گرفته شود. علاوه بر این، اگر اندازه بلوکهای بهدستآمده از طریق خوشهبندی یکسان باشد، بسیار مهم است که روشهایی را برای تنظیم خطای هندسی برای هر بلوک در نظر بگیریم، به طوری که تمایز هندسی بین هر بلوک افزایش یابد. در تحقیقات آینده، ما قصد داریم بر روی این جنبهها تمرکز کنیم تا عملکرد رندر و کاربرد این روش را بیشتر بهبود ببخشیم.
مشارکت های نویسنده
مفهوم سازی، ونشیائو ژان و جینگ چن. روش، Wenxiao ژان و Yuxuan چن. نرم افزار Wenxiao Zhan; اعتبارسنجی، Wenxiao Zhan، Yuxuan چن و جینگ چن. تحلیل رسمی، ونشیائو ژان و جینگ چن. تحقیق، Wenxiao Zhan و Yuxuan Chen. منابع، Yuxuan Chen; مدیریت داده ها، Yuxuan چن. نوشتن – آماده سازی پیش نویس اصلی، Wenxiao Zhan; نوشتن-بررسی و ویرایش، Wenxiao Zhan، Yuxuan Chen و Jing Chen. تجسم، Wenxiao Zhan; نظارت، جینگ چن. مدیریت پروژه، Wenxiao Zhan و Yuxuan Chen. همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
منابع مالی
این کار توسط برنامه ملی تحقیق و توسعه کلیدی چین (شماره کمک مالی 2018YFB0505302) تامین شده است.
بیانیه هیئت بررسی نهادی
قابل اجرا نیست.
بیانیه رضایت آگاهانه
قابل اجرا نیست.
بیانیه در دسترس بودن داده ها
داده های ارائه شده در این مطالعه به درخواست نویسنده مسئول در دسترس است. به دلیل محدودیتهای حریم خصوصی و اخلاقی، دادهها برای عموم در دسترس نیستند.
قدردانی
نویسندگان مایلند از داوران ناشناس و ویراستار تشکر کنند که نظرات و پیشنهادات آنها باعث بهبود این مقاله شد.
تضاد علاقه
نویسندگان هیچ تضاد منافع را اعلام نمی کنند.
منابع
- هاول، اس. هیپولیت، جی.-ال. جایان، بی. رینولدز، جی. Rezgui, Y. پشتیبانی از تصمیم گیری شهری سه بعدی مبتنی بر وب از طریق خدمات هوشمند و قابل همکاری. در مجموعه مقالات کنفرانس بین المللی شهرهای هوشمند IEEE 2016 (ISC2)، ترنتو، ایتالیا، 12 تا 15 سپتامبر 2016؛ صص 1-4. [ Google Scholar ]
- لیانگ، جی. گونگ، جی. لی، دبلیو. کاربردها و تأثیرات Google Earth: بررسی دههای (2006–2016). ISPRS J. Photogramm. Remote Sens. 2018 ، 146 ، 91-107. [ Google Scholar ] [ CrossRef ]
- کیو، جی. Chen, J. تجسم نقشه سه بعدی مبتنی بر وب با استفاده از WebGL. در مجموعه مقالات سیزدهمین کنفرانس IEEE 2018 در مورد الکترونیک صنعتی و کاربردها (ICIEA)، ووهان، چین، 31 مه تا 2 ژوئن 2018؛ صص 759-763. [ Google Scholar ]
- ازهر، S. مدل سازی اطلاعات ساختمان (BIM): روندها، مزایا، ریسک ها و چالش ها برای صنعت AEC. لیدرش مدیریت مهندس 2011 ، 11 ، 241-252. [ Google Scholar ] [ CrossRef ]
- هوپر، ام. برنامه ریزی خودکار پیشرفت مدل با استفاده از سطح توسعه. ساخت و ساز نوآوری. 2015 ، 15 ، 428-448. [ Google Scholar ] [ CrossRef ]
- 3DTiles. در دسترس آنلاین: https://github.com/AnalyticalGraphicsInc/3d-tiles/tree/master/specification#tile-format-specifications/ (دسترسی در 6 ژوئیه 2020).
- I3S. در دسترس آنلاین: https://docs.opengeospatial.org/cs/17-014r7/17-014r7.html/ (دسترسی در 7 آوریل 2021).
- S3M. در دسترس آنلاین: https://github.com/SuperMap/s3m-spec/tree/master/Specification/ (در 22 ژوئن 2021 قابل دسترسی است).
- یانگ، ال. ژانگ، ال. ما، جی. زی، جی. لیو، ال. تجسم تعاملی مدلهای ساختمان شهری با وضوح چندگانه با در نظر گرفتن شناخت فضایی. بین المللی جی. جئوگر. Inf. علمی 2011 ، 25 ، 5-24. [ Google Scholar ] [ CrossRef ]
- چن، ی. شورج، ا. رجبی فرد، ع. صبری، اس. از IFC تا کاشی های سه بعدی: یک راه حل منبع باز یکپارچه برای تجسم BIM ها بر روی سزیم. ISPRS Int. جی. ژئو. Inf. 2018 ، 7 ، 393. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مائو، بی. بان، ی. Laumert, B. Dynamic Online Visualization 3D Framework برای شبیه سازی انرژی در زمان واقعی بر اساس کاشی های سه بعدی. ISPRS Int. جی. ژئو. Inf. 2020 ، 9 ، 166. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- آهنگ، ز. لی، جی. استراتژی بارگذاری و زمانبندی کاشیهای پویا برای مدلهای فتوگرامتری مایل عظیم. در مجموعه مقالات سومین کنفرانس بین المللی IEEE 2018 در مورد تصویر، بینایی و محاسبات (ICIVC)، چونگ کینگ، چین، 27 تا 29 ژوئن 2018؛ صص 648-652. [ Google Scholar ]
- کولاویاک، م. کولاویاک، م. Lubniewski، Z. یکپارچه سازی، پردازش و انتشار داده های LiDAR در یک وب-GIS سه بعدی. ISPRS Int. جی. ژئو. Inf. 2019 ، 8 ، 144. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لو، ام. وانگ، ایکس. لیو، ایکس. چن، ام. بی، س. ژانگ، ی. Lao, T. تجسم بیدرنگ مبتنی بر وب داده های رادار آب و هوا در مقیاس بزرگ با استفاده از کاشی های سه بعدی. ترانس. GIS 2021 ، 25 ، 25-43. [ Google Scholar ] [ CrossRef ]
- هرمان، ال. راسناک، جی. Řezník، T. مدل سازی سیل و تجسم سیل ها از طریق داده های باز سه بعدی. در سمپوزیوم بین المللی سیستم های نرم افزاری محیطی ; Hřebíček, J., Denzer, R., Schimak, G., Pitner, T., Eds. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2017; صص 139-149. [ Google Scholar ]
- خو، ز. ژانگ، ال. لی، اچ. لین، Y.-H. یین، اس. ترکیب IFC و کاشی های سه بعدی برای ایجاد تجسم سه بعدی برای مدل سازی اطلاعات ساختمان. خودکار ساخت و ساز 2020 , 109 , 102995. [ Google Scholar ] [ CrossRef ]
- کیم، جی. هونگ، سی. Son, S. یک الگوریتم سبک وزن برای داده های BIM در مقیاس بزرگ برای تجسم در یک پلت فرم GIS مبتنی بر وب. ساختن. Inf. مدل. (BIM) Des. ساخت و ساز اپراتور 2015 ، 149 ، 355-367. [ Google Scholar ]
- Hu، Z.-Z. یوان، اس. بنگی، سی. ژانگ، J.-P. ژانگ، X.-Y.; لی، دی. Kassem, M. بهینهسازی هندسی مدلهای اطلاعات ساختمان در پروژههای MEP: الگوریتمها و تکنیکهایی برای بهبود ذخیرهسازی، انتقال و نمایش. خودکار ساخت و ساز 2019 ، 107 ، 102941. [ Google Scholar ] [ CrossRef ]
- چن، جی. لی، جی. لی، ام. تجسم پیشرونده مدل های سه بعدی پیچیده از طریق اینترنت. ترانس. GIS 2016 ، 20 ، 887-902. [ Google Scholar ] [ CrossRef ]
- چن، جی. لی، ام. لی، جی. الگوریتم خوشهبندی رئوس مرتبط با بافت بهبود یافته برای سادهسازی مدل. محاسبه کنید. Geosci. 2015 ، 83 ، 37-45. [ Google Scholar ] [ CrossRef ]
- Ziolkowska، JR; Reyes، R. مدلهای تجسم زمینشناسی و هیدرولوژیکی برای نمایش دیجیتال زمین. محاسبه کنید. Geosci. 2016 ، 94 ، 31-39. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کولاویاک، م. Kulawiak، M. کاربرد Web-GIS برای انتشار و تجسم سه بعدی داده های LiDAR با حجم بالا. در ظهور داده های بزرگ فضایی ; Ivan, I., Singleton, A., Horák, J., Inspektor, T., Eds. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2017; صص 1-12. [ Google Scholar ]
- Cozzi، PJ Visibility Driven Out-of-Core Hlod Rendering. پایان نامه کارشناسی ارشد، دانشگاه پنسیلوانیا، فیلادلفیا، PA، ایالات متحده آمریکا، 2008. [ Google Scholar ]
- دراکو در دسترس آنلاین: https://github.com/google/draco.html/ (در 21 ژوئیه 2020 قابل دسترسی است).
- Hoppe, H. پالایش مشهای پیشرو وابسته به نمایش. ACM SIGGRAPH 1997 ، 189-198. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Cesium3DTileset. در دسترس آنلاین: https://cesium.com/docs/cesiumjs-ref-doc/Cesium3DTileset.html/ (در 6 ژوئیه 2020 قابل دسترسی است).

شکل 1. مجموعه های فرعی یک مدل سه بعدی BIM.

شکل 2. سازماندهی داده برای BIM: ( الف ) سازماندهی داده مبتنی بر معناشناسی، و ( ب ) سازماندهی داده های چهار درختی.
شکل 3. استراتژی زمان بندی کاشی های سه بعدی.
شکل 4. فرآیند کلی برای سازماندهی داده های مدل BIM.

شکل 5. ساختار درخت شاخص: ( الف ) ساختار شاخص یک سطحی، و ( ب ) ساختار شاخص “فیلتر ماسک”.

شکل 6. عملکرد محاسباتی.

شکل 7. عملکرد رندر.

شکل 8. تجسم مدل در فاصله دید 1500 متر هنگام استفاده از: ( الف ) روش پیشنهادی، ( ب ) روش 1، ( ج ) روش 2، و ( د ) روش 3.
شکل 9. تجسم مدل در فاصله دید 300 متر هنگام استفاده از: ( الف ) روش پیشنهادی، ( ب ) روش 1، ( ج ) روش 2، و ( د ) روش 3.

شکل 10. تجسم مدل در فاصله دید 50 متر هنگام استفاده از: ( الف ) روش پیشنهادی، ( ب ) روش 1، ( ج ) روش 2، و ( د ) روش 3.

شکل 11. فریم بر ثانیه توسط روش ها در فواصل دید متفاوت فراهم می شود.


بدون دیدگاه