1. مقدمه
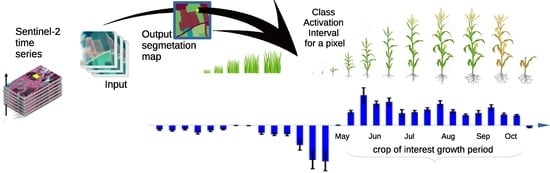
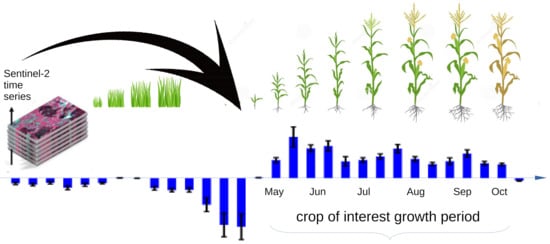
تولید بیشتر (غذا) با مصرف کمتر (مصرف منابع طبیعی) یکی از بزرگترین چالش هایی است که جامعه ما برای تضمین امنیت غذایی در سطح جهانی با آن مواجه است و بنابراین یکی از اولویت های اهداف توسعه توسعه پایدار سازمان ملل است. برای دستیابی به این هدف، تولیدات کشاورزی باید با برنامه ریزی پایدار حمایت شود و یکی از اولین اطلاعات مورد نیاز این است که محصولات در کجا و چه زمانی کشت می شوند. سنجش از دور ماهواره ای بهترین نامزد به عنوان منبع اطلاعاتی برای انجام نظارت بر محصول در سراسر جهان است، اما الگوریتم قدرتمند و قوی برای ارائه اطلاعات صریح زمانی و مکانی در مورد حضور محصول مورد نیاز است. Sentinel-2 (S2) یک ماموریت رصدی زمین کوپرنیک است که به طور سیستماتیک تصاویر نوری با وضوح مکانی بالا از زمین به دست می آورد. این ماموریت یک تغییر پارادایم در کیفیت و کمیت داده های دسترسی باز را معرفی می کند و عصر جدیدی را برای سیستم های نظارت بر زمین به ویژه برای بخش کشاورزی باز می کند. S2 داده های چند طیفی را با وضوح فضایی از 10 متر تا 60 متر فراهم می کند که به لطف مجموعه دو ماهواره می تواند 290 کیلومتر در هر اکتساب را با زمان بازنگری 5 روز پوشش دهد. با این حال، این مفهوم داده های بزرگ را معرفی می کند و بنابراین ما به مدل هایی نیاز داریم که توانایی بهره برداری از این حجم عظیم اطلاعات را داشته باشند. در این چارچوب، ما می خواهیم به نوآوری تحقیقاتی اختصاص داده شده برای انجام شناسایی محصول از تجزیه و تحلیل سری های زمانی تصاویر ماهواره ای Sentinel-2 کمک کنیم. هدف شناسایی رویکردی است که قادر به شناسایی (طبقه بندی) قابل اعتماد محصولات مختلف در یک منطقه معین با استفاده از یک شبکه عصبی کانولوشنال (3+2) بعدی برای تقسیم بندی معنایی باشد. روش همچنین جاهطلبی پیشبینی دورهای را دارد که در آن یک محصول معین واقعاً در یک فصل رشد میکند. ما مدلی مبتنی بر شبکههای هرمی ویژگیها (FPN) توسعه میدهیم که برای پردازش سریهای زمانی با هستههای سهبعدی یک منطقه کوچک مرتبط با هر نمونه ورودی، و می تواند به عنوان خروجی یک نقشه تقسیم بندی با استفاده از هسته های دوبعدی ارائه دهد. علاوه بر این، ما راه حلی را بررسی و پیشنهاد می کنیم تا بفهمیم چگونه CNN فواصل زمانی را که به تعیین فاصله فعال سازی کلاس خروجی (CAI) کمک می کند، شناسایی می کند. این راه حل به ما اجازه می دهد تا استدلال ارائه شده توسط CNN را در طبقه بندی یک پیکسل تفسیر کنیم. ما در آزمایشهای مختلف نشان میدهیم که شبکه ما قادر به شناسایی فواصل زمانی تبعیضآمیز در حوزه ویژگیهای ورودی است، با وجود اینکه CNN فقط برای حل یک کار طبقهبندی (یعنی راهحل فضایی) آموزش دیده است. بنابراین، با روش CAI خود، میتوانیم اطلاعاتی درباره «زمانی» که کلاس مرتبط با یک پیکسل در سری زمانی دادههای رصد زمین (EO) وجود دارد، ارائه دهیم. روش CAI برای تفکیک زمانی مفید می شود که محصولات تنها کشت شده باشند (مثلاً ذرت تابستانی) یا محصول دوم فصل (مانند گندم زمستانه به دنبال ذرت) باشد. در مورد دوم، ذرت معمولاً در اواخر فصل بعد از برداشت غلات و آماده سازی خاک کاشته می شود. توانایی ارائه چنین اطلاعاتی به شناسایی سیستمهای زراعی (تک یا دو محصول) در کنار کلاس محصولات ساده کمک میکند. به لطف CAI، اطلاعات مربوط به دوره کاشت، ایده ای از رقم کشت شده و مقصد محصولات (به عنوان مثال، ذرت برای سیلو یا علوفه) ارائه می دهد.
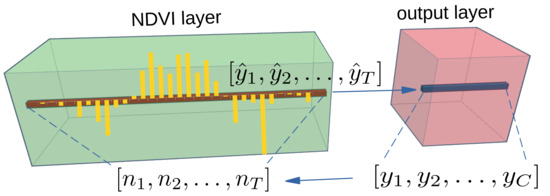
علاوه بر این، رویکرد پیشنهادی دارای اهمیت دوگانه است: نشان دادن ظرفیت شبکه برای تفسیر صحیح فرآیند فیزیکی مورد بررسی و ارائه اطلاعات اضافی به کاربر نهایی (به عنوان مثال، حضور محصول و پویایی زمانی آن. ارائه خروجی CAI است. روشی برای ارزیابی استحکام مدل برای هر طبقه معنایی، زیرا نمایشی صریح از دوره زمانی که احتمال کشت محصول در آن وجود دارد، چنین اطلاعاتی برای یک منطقه مورد مطالعه خاص میتواند توسط دانش تخصصی تأیید شود یا اطلاعات ارزش افزوده برای کاربر نهایی ارائه شود. شکل 1یک نمایش گرافیکی از اطلاعات CAI برای یک زیر مجموعه فضایی از داده های S2 تجزیه و تحلیل شده که در آن ذرت کشت می شود، ارائه می دهد. مقادیر پایین CAI در ابتدای سری های زمانی (دسامبر تا می) زمانی که بقایای محصول (دیگر محصول) وجود دارد رخ می دهد در حالی که مقادیر شاخص به طور قابل توجهی در دوره رشد مناسب (اردیبهشت تا سپتامبر) افزایش می یابد.
انواع مختلفی از شبکه های عصبی کانولوشنال (CNN) وجود دارد و همه آنها می توانند به بهبود سرعت و دقت بسیاری از وظایف بینایی کامپیوتر کمک زیادی کنند. به طور خاص، مدلهای سهبعدی CNN اغلب برای بهبود شناسایی اشیا در فیلمها یا حجمهای سه بعدی، مانند فیلمهای دوربینهای امنیتی [ 1 ] و اسکنهای پزشکی بافت سرطانی [ 2 ] استفاده میشوند.
بعد فضایی و زمانی تصاویر ماهواره ای Sentinel-2 شباهت های زیادی به ویدئو دارد. به همین دلیل، ما مدل هایی مشابه آنچه برای تجزیه و تحلیل فیلم ها استفاده می شود، اتخاذ می کنیم. در سالهای اخیر، دادههای مکانی-زمانی از طریق مدلهای CNN که از سه ایده اصلی پیروی میکنند پرداخته شده است: CNN 2D (مثلاً ConvNets دو جریانی [ 3 ] و شبکه بخش زمانی (TSN) [ 4 ])، CNN 3D (مثلا SFSeg [ 5 ] ] و ResNet 3D [ 6 ] و (2+1)D CNN (به عنوان مثال، P3D [ 7 ] و R(2+1)D [ 8]). پیشنهاد ما تا حدی از ایده CNN های سه بعدی استفاده شده برای مجموعه داده های ویدئویی پیروی می کند، اما در عین حال از هسته های دو بعدی (i) برای ایجاد نقشه های تقسیم بندی و (ii) برای پیش بینی فواصل فعال سازی کلاس ها در حوزه زمانی استفاده می کند.
اخیراً، سطوح عملکرد سیانانهای سهبعدی در زمینههای مختلف بهشدت بهبود یافته است [ 6 ] و علاوه بر این، حجم عظیمی از دادههای ماهوارهای رایگان [ 9 ] داریم که میتوانند به راحتی توسط مدلهای سهبعدی تفسیر شوند. با انگیزه موفقیت شبکه [ 10 ] 2D-FPN که برای تقسیم بندی معنایی چند کلاسه استفاده می شود، همچنین با موفقیت در داده های ماهواره ای برای تقسیم بندی معنایی از تصاویر RGB استفاده می شود [ 11 ]]، در این مقاله ما یک FPN (3+2)D برای تقسیمبندی معنایی چند کلاسه، بر اساس لایههای کانولوشن 3 بعدی و 2 بعدی ایجاد میکنیم. به ویژه مدلی که ما پیشنهاد کردیم برای تقسیمبندی معنایی محصولات به منظور بهبود دقت تشخیص خودکار محصول با اجرای قابلیتهای چند مقیاسی سهبعدی و افزایش وضوح مکانی و زمانی محصول موضوعی طراحی شد. این مدل برای تقسیمبندی معنایی محصولات به منظور بهبود دقت تشخیص محصولات با پیادهسازی قابلیتهای چند مقیاسی سه بعدی و افزایش وضوح مکانی و زمانی محصولات طراحی شده است.
شبکه هرمی ویژگی (FPN) بسیار شبیه یک شبکه عصبی کانولوشنال U شکل (U-Net) است [ 12 ]. مانند U-Net، FPN یک اتصال جانبی بین هرم پایین به بالا و هرم از بالا به پایین دارد. با این حال، در جایی که U-net به سادگی ویژگیها را کپی میکند و آنها را اضافه میکند، FPN قبل از اضافه کردن آنها، یک سطح پیچیدگی 1 × 1 اعمال میکند. این به هرم از پایین به بالا به نام “ستون فقرات” اجازه می دهد تا تقریباً هر چیزی باشد که ما می خواهیم. با توجه به این انعطاف پذیری بیشتر FPN، ما آن را انتخاب کرده و با مشکل خاص (3+2) بعدی خود تطبیق داده ایم. U-Net همچنین برای مسائل تقسیم بندی سه بعدی تطبیق داده شده است و با موفقیت برای بسیاری از مسائل تقسیم بندی دو بعدی و سه بعدی استفاده شده است [ 13 ]]. متأسفانه، ما نمیتوانیم مستقیماً با U-Net مقایسه کنیم، زیرا باید آن را تغییر دهیم تا بتوانیم همزمان روی یک ورودی سه بعدی و یک خروجی دو بعدی کار کنیم، اما دانستن اینکه FPN و U-Net دو بسیار هستند. مدل های مشابه و اینکه FPN در مقایسه با U-Net انعطاف پذیرتر است، ما تصمیم گرفته ایم که فقط با FPN کار کنیم.
مقالات اخیر توسط ژو و همکاران. [ 14 و 15 ] نشان دادهاند که واحدهای کانولوشنال لایههای مختلف شبکههای عصبی کانولوشنال (CNN) در واقع بهعنوان آشکارساز شی عمل میکنند، علیرغم اینکه هیچ نظارتی بر محل جسم ندارند. مقاله مشابهی [ 16 ] تکنیکی را برای شفافتر کردن CNN با افزودن «توضیحات بصری» به کلاس بزرگی از مدلها پیشنهاد میکند. آنها نشان دادند که شبکه میتواند قابلیت قابل توجه محلیسازی اشیاء خود را تا لایه نهایی حفظ کند، بنابراین به آن اجازه میدهد تا به راحتی مناطق تصویر متمایز را در یک پاس رو به جلو برای طیف گستردهای از فعالیتها شناسایی کند، حتی آنهایی که شبکه در ابتدا برای آنها آموزش ندیده بود. با الهام از نقشه های فعال سازی کلاس (CAM) پیشنهاد شده توسط ژو و همکاران. [14 ]، ما پیشنهاد میکنیم که FPN CNN (3+2) بعدی پیشنهادی را با مکانیزمی گسترش دهیم که امکان تجسم بازه زمانی سریهای زمانی را فراهم میکند که به تعیین کلاس برای هر پیکسل کمک میکند.
با FPN (3+2)D ما میخواهیم در پاسخ به سؤال « یک برش خاص کجاست » در داخل یک تصویر دقیقتر باشیم، اما نمیدانیم چگونه به سؤال « زمانی که آن برش وجود داشت » در داخل یک تصویر پاسخ دهیم. سری زمانی. به همین دلیل ما مکانیزمی را به شبکه اضافه کردهایم که پیشبینی میکند چه زمانی کلاس در سریهای زمانی ورودی وجود دارد، بدون اینکه نیازی به ارائه حقیقت بیشتر به شبکه باشد. به روشی مشابه آنچه در [ 14 ] اتفاق میافتد، جایی که شبکه برای درک « کدام ناحیه از تصویر ورودی » بیشتر در تعیین کلاس خروجی کمک میکند، ما راهحلی برای پیشبینی هر پیکسل پیشنهاد کردهایم. فاصله زمانییک کلاس خاص در مجموعه داده سری زمانی ورودی وجود دارد. دقیقاً همانطور که برای CAM اتفاق میافتد، جایی که میتوانیم بگوییم کدام ناحیه از تصویر در تعیین کلاس خروجی نقش داشته و در مورد کلاسهای دیگر چیزی نگوییم، از CAI برای تشخیص اینکه کلاس در سریهای زمانی ورودی چه زمانی فعال بوده است استفاده میکنیم بدون اینکه چیزی بگوییم. در مورد کلاس های دیگر در آن پیکسل. این بدان معناست که رویکرد ما روی هر پیکسلی که مدل به عنوان ورودی میبیند، چند کلاسه است، اما چند برچسبی نیست.
نوآوری هایی که در این مقاله پیشنهاد می کنیم به شرح زیر است:
-
ما یک مدل تقسیمبندی معنایی جدید مناسب برای سریهای زمانی سنجش از دور پیشنهاد میکنیم.
-
ما مکانیزمی را به CNN پیشنهادی اضافه میکنیم که به تجسم بازه زمانی سریهای زمانی کمک میکند که به تعیین کلاس برای هر پیکسل کمک میکند.
-
ما از حدود 4%وضعیت هنر در مجموعه داده های عمومی با سری های زمانی ماهواره ای.
2. روش پیشنهادی
روشی که ما در این مقاله پیشنهاد می کنیم از دو بخش ابتکاری اصلی تشکیل شده است، شبکه عصبی کانولوتیو که از پیچیدگی سه بعدی در سری های زمانی استفاده می کند و فاصله فعال سازی کلاس که برای درک زمانی که یک کلاس (مرتبط با یک پیکسل خروجی منفرد) با توجه به فعال است. سری زمانی تحلیل شده در ورودی
2.1. (3+2)D ویژگی های شبکه هرمی
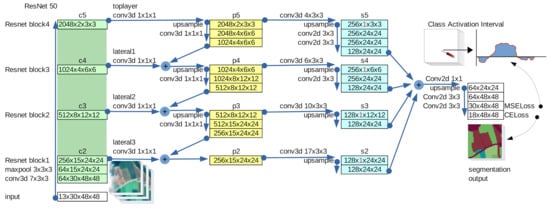
پیشرفتهای اخیر در بینایی کامپیوتر نشان میدهد که شبکههای هرمی ویژگیها (FPNs) [ 10 ] در تشخیص اشیاء در مقیاسهای مختلف بسیار مؤثر هستند، اما آنها همچنین ابزاری عالی برای بسیاری از مشکلات تقسیمبندی تصویر هستند [ 17 ، 18 ]. با این حال، FPN های سنتی برای تصاویر دو بعدی طراحی شده اند. در اینجا، ما یک شبکه FPN را پیشنهاد میکنیم که از هستههای سهبعدی در سریهای زمانی ورودی و تقریباً در کل شبکه استفاده میکند، به جز در آخرین لایههای نزدیک خروجی که در آن از هستههای دوبعدی استفاده میکنیم تا بتوانیم یک نقشه را قطعهبندی کنیم.
شکل 2 یک نمایش گرافیکی از مدل پایان به انتها پیشنهادی را نشان می دهد. سمت چپ ترین ستون نشان دهنده مسیر از پایین (داده های ورودی) به بالا است، یعنی محاسبات پیشخور ConvNet ستون فقرات. برای این مسیر پایین به بالا، یک مدل شناخته شده استفاده شده است و در شکل 2 ، ما از نسخه اصلاح شده ResNet 50 استفاده کردیم، اما آزمایش هایی را با مدل های دیگر انجام دادیم. برخلاف [ 10 ] که شبکه برای تصاویر بزرگ طراحی شده است، ما مدل را در برخی مکان ها تغییر می دهیم تا بتوانیم به طور کلی با تصویر کوچک کار کنیم (یعنی 48×48اندازه پیکسل در مورد خاص). به عنوان مثال، به عنوان ورودی، از یک اندازه هسته برابر با استفاده می کنیم (7،3،3)، با گام برداشتن =(1،1،1)و بالشتک =(3،1،1)، برای جلوگیری از رسیدن به بلوک ها ج4یا ج5( شکل 2 را ببینید ) با اندازه تصویر =1×1. لایه های صاف بعد از بلوک ها را برداشتیم پ4، پ3و پ2( شکل 2 را ببینید ) تا از تخریب بیش از حد سیگنال جلوگیری کنیم زیرا از تصاویر بسیار کوچک استفاده می کنیم.
اجازه دهید من∈آرب×تی×اچ×دبلیوسری زمانی با تصاویر T باشداچ×دبلیوبا کانال های B ، و اجازه دهیدy^=f(من)بخشی از شبکه باشد که تصویر I را به شاخص NDVI [ 19 ] تبدیل می کند (به معادله ( 2 ) مراجعه کنید) مرتبط با هر پیکسل. به این معنا که، y^∈آرتی×اچ×دبلیوخروجی آخرین لایه دوم به نام لایه NDVI است. خروجی نهایی yمن،j،جمدل، برای هر پیکسل محاسبه می شود (من،j)نقشه تقسیم بندی و برای هر کلاس ج∈سی، را می توان با عملیات پیچیدگی زیر بین یک هسته نوشت تی×ک×کو y^ارزش های:
بلوک های پایین به بالا و بالا به پایین ما به یک اندازه هستند تا از دست دادن اطلاعات بیش از حد از سری های زمانی جلوگیری شود. علاوه بر این، در بلوک معنایی قبل از خروجی، از هسته های سه بعدی به هسته های دو بعدی تغییر می کنیم. در نهایت، در لایه NDVI از یک تابع تلفات MSE برای پیشبینی شاخص گیاهی تفاوت عادی شده (NDVI) استفاده میکنیم.
جایی که ب8و ب4دو باند طیفی از ماهواره Sentinel-2 هستند که در آن هر پیکسل مربوط به یک منطقه جغرافیایی است. 10×10متر NDVI یک اندازه گیری رادیومتری از تابش فعال فتوسنتزی جذب شده توسط کلروفیل در برگ های سبز است و بنابراین، یک شاخص ساده برای ارزیابی حضور و کمیت پوشش گیاهی سبز در هدف مشاهده شده است. در نظارت بر کشاورزی، سری زمانی NDVI اجازه می دهد تا دوره کاشت، رشد گیاه و برداشت محصولات را دنبال کنید. به لطف این رگرسیون قبل از لایه طبقه بندی، شبکه باید بگوید که کدام مقادیر NDVI سری زمانی ورودی به تعیین فعال سازی کلاس کمک می کند. ما از این وابستگی سوء استفاده می کنیم تا بتوانیم فاصله فعال سازی کلاس (CAI) را که در بخش زیر توضیح داده شده است محاسبه کنیم.
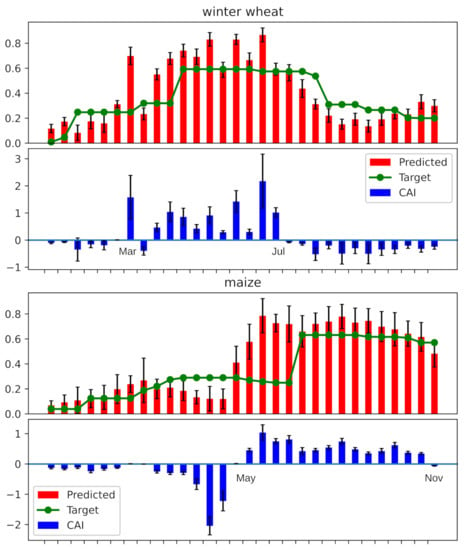
در شکل 3 ، دو نمونه از آنچه لایه NDVI در مرحله آموزش به عنوان هدف می بیند و آنچه در هر پیکسل پیش بینی می کند را نشان می دهیم (به عنوان میانگین و واریانس مقادیر تمام پیکسل های متعلق به آن کلاس نشان داده شده است). برای تولید مقادیر هدف، NDVI (معادله ( 2 )) را برای هر پیکسل با کلاس هدف یکسان محاسبه می کنیم و سپس همه این شاخص ها را در یک بردار واحد جمع می کنیم. تیمن،j=[تی1،تی2،⋯،تیتی]به طوری که تمام پیکسل ها (من،j)∈جهمان بردار را مرتبط کرده اند. برای جمع آوری تمام مقادیر NDVI یک کلاس، میانگین را به اضافه یک فیلتر حداکثر متحرک 1 بعدی با اندازه 5 محاسبه می کنیم و خروجی توسط یک تابع ReLU فیلتر می شود تا فقط مقادیر مثبت به دست آید. با نگاهی به مثال منحنی خط چین قرمز متوسط سیگنال NDVI در شکل 4 ، میتوان دوره رشد و برداشت را مشاهده کرد که پس از تابستان انجام شد و سپس، برداشت، چیز دیگری شروع به رشد کرد. از همان شکل می توان مشاهده کرد که مقادیر واقعی NDVI بسیار نویز هستند و رویدادهایی مانند عبور یک ابر می تواند منجر به خطاهای طبقه بندی شود. به همین دلیل ما تصمیم گرفتیم که مقادیر واقعی NDVI را با میانگین محاسبه شده NDVI خود جایگزین کنیم.
ما از دو تابع ضرر برای آموزش مدل استفاده کردیم، از دست دادن MSE برای یادگیری روند NDVI و از دست دادن Cross Entropy برای یادگیری برچسبهای کلاس مرتبط با هر پیکسل. بنابراین می توانیم باخت اول را برای یک امتیاز معرفی کنیم (من،j)مانند:
برای لایه آخر از یک تابع از دست دادن آنتروپی متقاطع استفاده کردیم که می توان آن را به صورت زیر نوشت
جایی که y∈آرسی×اچ×دبلیوو αجوزنه ای برای کلاس c است که برای متعادل کردن مجموعه تمرینی استفاده می شود. تابع زیان یک نمونه با جمع کردن تمام دو تلفات که قبلا توضیح داده شد به دست می آید:
اینجا، λیک اسکالر است که به عنوان یک فراپارامتر منظمسازی استفاده میشود که میتوان مقدار آن را برای نتایج بهتر بهینه کرد. توجه داشته باشید که معادله ( 5 ) شامل یک شاخص جدید برای مینی بچ می شود و سپس با استفاده از مجموع کاهش می یابد.
2.2. فواصل فعال سازی کلاس
در این بخش، ما روش تولید بازه فعال سازی کلاس (CAI) را با استفاده از یک شبکه عصبی کاملاً کانولوشنال (3+2)D توضیح می دهیم. CAI برای یک دسته خاص، فواصل متمایز استفاده شده توسط CNN برای شناسایی آن دسته را نشان می دهد (به چند نمونه در شکل 1 ، شکل 2 و شکل 3 و شکل 5 مراجعه کنید). روش مکان یابی این فواصل زمانی در شکل 5 نشان داده شده است . همانطور که در شکل 2 نشان داده شده است ، دو لایه کانولوشن با فیلترهای 2 بعدی ک×ک=3×3برای بدست آوردن دو لایه آخر که دو افت معادله ( 3 ) و ( 4 ) به آنها مرتبط است، استفاده شد. فرض کنید با کلاس های C و در نتیجه مطابقت هر پیکسل مشکل داریم(من“،j“)در ورودی، در خروجی یک بردار از عناصر داریم [y1،y2،⋯،yسی]. همانطور که در معادله زیر ( 6 )، هر یک از این عناصر توضیح داده شده استyجبه عنوان خروجی یک کانولوشن به دست می آید و بنابراین فقط به عناصر موجود در یک همسایگی بستگی دارد (من“،j“،0)⋯(من“+ک،j“+ک،تی)از لایه قبلی رسمی تر
با تجزیه و تحلیل معادله ( 6 ) مشخص میشود که وقتی برچسب c کلاس برنده به دست آمد، میتوان برای فهمیدن اینکه این مقدار خروجی به کدام بازه زمانی بستگی دارد، برگشت. بنابراین، برای دریافت فواصل فعال سازی کلاس در یک نقطه (من“،j“)، به این معنا که سیآمنمن“،j“=[nمن“،j“،1ج،⋯،nمن“،j“،تیج]باید به صورت زیر عمل کنیم
مثبت nمن“،j“،تیجمقادیر نشان می دهد که تاریخ t سری زمانی حاوی اطلاعات مفید برای تعیین کلاس است، در حالی که مقادیر منفی نشان می دهد که تاریخ t در تعیین کلاس کمکی نمی کند.
توجه داشته باشید که از دست دادن معادله ( 5 ) را می توان به صورت موازی محاسبه کرد، اما اگر بخواهیم هر برچسب کلاس خروجی به مقادیر NDVI بستگی داشته باشد، لایه NDVI باید قبل از لایه تقسیم بندی خروجی قرار گیرد. اگر دو لایه را به صورت موازی قرار دهیم، نمیتوانیم درباره وابستگی بین برچسب کلاس و فعالسازی NDVI با توجه به سری زمانی ورودی چیزی بگوییم و بنابراین نمیتوانیم CAI را محاسبه کنیم.
3. مجموعه داده
در آزمایشهای خود از مجموعه داده مونیخ استفاده شده در [ 20 ] که شامل بلوکهای مربعی است استفاده کردیم48×48پیکسل ها شامل 13 باند Sentinel-2 (به برخی از نمونه ها در شکل 6 مراجعه کنید). هر بلوک 480 متری از یک منطقه جغرافیایی مورد علاقه (102 کیلومتر × 42 کیلومتر) واقع در شمال مونیخ، آلمان استخراج شد. در آزمایشهای خود از تقسیم 0 مجموعه داده استفاده کردیم که شامل 6534 بلوک برای مجموعه آموزشی، 2016 بلوک برای مجموعه آزمایشی و 1944 بلوک برای مجموعه ارزیابی است.
حقیقت زمین یک تصویر دو بعدی است که شامل تقسیم بندی محصولات مختلف موجود در هر نمونه است، که در آن هر پیکسل دارای یک برچسب کلاس مرتبط است که از دو فصل رشد 2016 و 2017 به دست آمده است. داده های تقسیم بندی برای هر تاریخ سری زمانی نیست، بلکه با یک سال کامل مرتبط هستند، بنابراین در هر پیکسل، برچسب نشان دهنده محصول برداشت اعلام شده در آن سال است. 17 کلاس موجود در مجموعه داده در جدول 1 گزارش شده است. مجموعه داده حاوی اطلاعاتی درباره زمان حضور یک محصول (کاشت و رشد گیاه) و زمان غیبت آن (برداشت) در طول یک سال مشاهدات نیست. مجموعه دادهها به مجموعههای آموزشی، اعتبارسنجی و آزمون تقسیم شدند. مجموعه داده بسیار نامتعادل است و کاردینالیته دو مجموعه آخر در جدول 1 نشان داده شده است. کاردینالیته گزارش شده در مقاله [ 20 ] علیرغم استفاده از تقسیمات مشابه، با ما مطابقت ندارد، احتمالاً به این دلیل که از یک سری زمانی با تعداد نمونه های مختلف استفاده کردیم (30 نمونه در هر سری زمانی استخراج کردیم) یا به این دلیل که برخی از تقویت تصویر استفاده شده است. در مقاله آنها مجموعه داده اصلی را می توان از [ 21 ] دانلود کرد.
4. آزمایشات
ما سه گروه اصلی آزمایش را انجام دادهایم: در ابتدا، در بخش 4.1 ، برخی از تکنیکها را برای خنثی کردن اثر مجموعه دادههای نامتعادل آزمایش میکنیم. به عنوان آزمایش دوم، در بخش 4.2 ، مدل پیشنهادی را با ادبیات مقایسه میکنیم. در نهایت، در بخش 4.3 ، ما CAI تولید شده توسط مدل آموزش دیده را تجزیه و تحلیل می کنیم.
در آزمایشهای خود، از برخی معیارهای شناخته شده برای ارزیابی خوب بودن مدل خود استفاده کردیم. به طور خاص، ما عمدتاً از دقت کلی، کاپا [ 22 ]، یادآوری، دقت و ضرایب اندازه گیری F برای مقایسه نتایج خود با نتایج منتشر شده در [ 20 ] استفاده می کنیم.
ما هیچ آزمایش سیستماتیکی انجام ندادهایم تا بفهمیم بهترین مقدار برای تخصیص به فراپارامتر چیست. λبرای تابع ضرر تعریف شده در رابطه ( 5 ) و بنابراین ما این مقدار را بر روی λ=1. ما هر آزمایش را برای 300 دوره اجرا می کنیم. بهینه ساز SGD [ 23 ] است، با تکانه برابر با 0.9، کاهش وزن 0.001 و با نرخ یادگیری اولیه 0.01 و زمانبندی که از تابع کسینوس برای کاهش نرخ یادگیری پس از هر دوره استفاده می کند. تمام سری های زمانی مورد استفاده از 30 نمونه استخراج شده به طور تصادفی از هر یک از دو سال موجود تشکیل شده است.
مدل های آموزش دیده در pythorch-hub [ 24 ] و کد منبع برای اجرای آزمایش ها در یک مخزن gitlab [ 24 ] موجود است.
4.1. آزمایش های عدم تعادل طبقاتی
تقریباً همه مجموعه دادههای تقسیمبندی کاربری زمین مشکل غلبه برخی طبقات بر سایرین را دارند. اینکه کدام طبقات نسبت به سایرین غالب هستند، این بستگی به منطقه جغرافیایی، فصل و وسعت قلمرو مورد تجزیه و تحلیل دارد. علاوه بر این، به همین دلیل، تقسیم بندی چند طبقه برای مشکلات پوشش زمین از طریق تجزیه و تحلیل تصاویر ماهواره ای هنوز یک مشکل چالش برانگیز باقی مانده است. تعداد نمونهها از مجموعه داده آموزشی مورد استفاده برای تخمین گرادیان خطا در طول آموزش، اندازه دسته نامیده میشود و یک فراپارامتر مهم است که بر مدل آموزشدیده حاصل تأثیر میگذارد. اگر مجموعه داده نامتعادل باشد، تعداد پیکسلهای متعلق به هر کلاس که شبکه عصبی برای محاسبه گرادیان استفاده میکند به اندازه دسته بستگی دارد. اگر دسته خیلی بزرگ باشد، کلاسهای غالب کلاسهایی را که نمونههای بسیار کمی دارند، کاملاً خرد میکنند، در حالی که اگر دسته کوچک باشد، تعداد پیکسلهای هر کلاس متعادلتر است. به همین دلیل، در این آزمایش اول، ما به طور تجربی اثر اندازه دسته را به همراه دو تکنیک توزین کلاس تجزیه و تحلیل می کنیم.
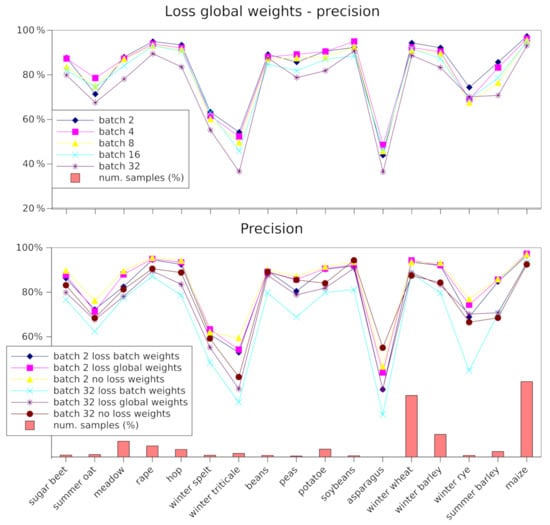
در این بخش، عملکرد مدل پیشنهادی را بدون لایه NDVI، با استفاده از تکنیکهای مختلف برای مقابله با اثر ناشی از مجموعه داده نامتعادل، تحلیل میکنیم. به طور خاص، ما از دو نوع مختلف استفاده می کنیم αجوزن تابع از دست دادن (به معادله ( 4 ) مراجعه کنید) که در زیر توضیح داده شده است، برای مقابله با اثر عدم تعادل کلاسهایی که در مجموعه داده داریم، و سپس آن را با وزن مقایسه میکنیم. αج=1برای تمام کلاس ها (بدون وزن). به عنوان مسیر پایین به بالا FPN پیشنهادی (3+2)D، در این آزمایشها از ResNet1 01 استفاده میکنیم.
در جدول 2 نتایجی از مدل داریم که فقط از آنتروپی متقاطع تعریف شده در رابطه ( 4 ) استفاده می کند اما بدون αجوزن (بدون وزن) و ما آن را با طرح وزن دهی (وزن دسته ای) مقایسه می کنیم که بر اساس «تعداد مؤثر نمونه» در هر دسته [ 25 ] اختصاص داده شده به αجوزن، و با استراتژی های وزن دهی بر اساس تعداد کل نمونه های موجود در هر کلاس (وزن جهانی) حتی به αجوزن. طرح وزن پیشنهادی در [ 25 ]، برای هر دسته از مجموعه آموزشی، تعداد نمونه های واقعی را محاسبه می کند. nجدر هر کلاس c . وزن موثر مورد استفاده در هر دسته با استفاده از یک فرمول ساده تعریف می شود αج=(1–β)/(1–βnج)، جایی که β∈[0،1)یک هایپر پارامتر است. در اوزان جهانی از وزنه استفاده می کنیم αج=حداکثرج(nج)/nج)برای هر کلاس، با استفاده از کل مجموعه آموزشی محاسبه می شود.
با تجزیه و تحلیل دقت کلی (OA)، کاپا، فراخوان وزنی (wR)، دقت (wP) و اندازه گیری F (w.F1) در جدول 2 و نمودارهای شکل 7 ، می بینیم که تکنیک های وزن دهی تابع از دست دادن منجر نمی شود. به هر گونه مزیت در این مجموعه داده. از سوی دیگر، باید توجه داشت که اندازه دسته (به ستون دوم با برچسب دسته در جدول 2 مراجعه کنید ) تأثیر زیادی بر نتیجه دارد و سپس اندازه دسته بسیار کوچک اجازه می دهد تا بهترین نتایج را به دست آورید. از جدول 1 می بینیم که کلاسی که کمترین تعداد پیکسل (ستون #pix) را در مجموعه اعتبارسنجی دارد، کلاس مارچوبه است. در حالی که در شکل 7 اثر وزن αجتابع از دست دادن و اثر اندازه دسته را می توان به عنوان تابعی از تعداد نمونه برای هر کلاس تجزیه و تحلیل کرد. تجزیه و تحلیل، به عنوان مثال، کلاس مارچوبه زمانی که وزن αج=1برای همه کلاس ها (نقشه بالای شکل 7 ) می بینیم که بهترین نتایج زمانی حاصل می شود که از اندازه کوچک باخ استفاده کنیم. در نتیجه این آزمایشها، در آزمایشهای دیگر از وزن استفاده نمیکنیم αج.
4.2. مقایسه ها
مجموعه داده های دامنه عمومی کمی در زمینه سنجش از دور وجود دارد، و به ویژه، مجموعه داده های عمومی تقسیم بندی چند طبقه، مناسب برای آموزش یک مدل عمیق، نادر هستند. در این بخش، نتایج مقایسه بین روش خود و نتایج مرتبط با تنها مجموعه داده عمومی موجود را نشان میدهیم [ 20 ]. علاوه بر این، ما یک تجزیه و تحلیل در مورد استفاده از ResNet های مختلف مورد استفاده به عنوان ستون فقرات بلوک پایین به بالا مدل پیشنهادی انجام دادیم. نتایج در جدول 3 گزارش شده است و نشان می دهد که با افزایش پیچیدگی بلوک پایین به بالا، دقت طبقه بندی بهبود می یابد. ما به دلیل در دسترس بودن سخت افزار محدود از مدل های پیچیده تر استفاده نکرده ایم، اما احتمالاً باید با استفاده از مدل های قدرتمندتر نتایج بهتری بگیریم.
در جدول 1 ، نتایج مقایسه انجام شده را با آنچه در مقاله روسبورم و کورنر [ 20 ] منتشر شده گزارش میکنیم و میتوانیم نتیجه بگیریم که مدل پیشنهادی ما از نقطه نظر همه معیارهای مورد استفاده در این مقایسه بهتر عمل میکند. اگرچه کاردینالیته در هر کلاس یکسان نیست، میتوانیم ببینیم که رفتار (3+2)D FPN هم در اعتبارسنجی و هم در مجموعه آزمایشی بسیار مشابه است.
4.3. آزمایشهایی روی CAI و مطالعه فرسایش
برای ارزیابی کیفیت بازههای فعالسازی کلاسهای پیشبینیشده توسط شبکه، ما هیچ ارزش پایهای نداریم و بنابراین از کارشناسان نظر خواستیم. نتیجه تولید شده مطابق با دانش کارشناسان است. به عنوان مثال، از شکل 3 می توانیم ببینیم که چگونه برای CAI کلاس ذرت، مدل فاصله زمانی را که از ماه می تا ابتدای نوامبر می رود، پیش بینی کرده است، در حالی که برای گندم زمستانهاین مدل یک CAI را پیشبینی کرده است که از اواخر آوریل تا اوایل جولای ادامه مییابد، علیرغم اینکه مقادیر NDVI هنوز بالا هستند. این مقدار بالای NDVI معمولاً به دلیل حضور علف های هرز، رشد مجدد پس از برداشت و محصول بعدی است. در واقع، مدل در این دادههای پر سر و صدا و پیچیده، حوزه زمانی را شناسایی کرد که به طور منحصر به فردی با رشد گندم مرتبط است.
برای درک اینکه چگونه CAI با تغییر وصلهای که روی آن محاسبه میشود تغییر میکند، کلاس گندم زمستانه را در نظر گرفتهایم و همه بردارهای CAI را در کل مجموعه آزمایشی محاسبه کردهایم. ما در شکل 8 یک مقدار میانگین مجموع برای هر وصله نشان میدهیم، و میتوانیم ببینیم که چگونه بازه زمانی مرتبط با این کلاس با توجه به پچ تغییر نمیکند، حتی اگر میانگین مقادیر فعالسازی باشد. nمن،j،تیجکمی تغییر کند شبکه مورد استفاده در این آزمایش از Resnet 101 به عنوان بلوک پایین به بالا استفاده می کند و نتایج عددی در جدول 1 گزارش شده است.
برای درک تأثیر یادگیری شاخصهای NDVI با هدف پیشبینی CAI، ما همچنین یک مطالعه ابلیشن انجام دادیم که در آن از دست دادن MSE در طول آموزش حذف میکنیم و این نتیجه را با همان مدلی که از تابع ضرر استفاده میکند مقایسه میکنیم. از نتایج عددی گزارش شده در جدول 3 میتوان دید که ضرر MSE تأثیر زیادی بر عملکرد طبقهبندی ندارد.
5. نتیجه گیری ها
مدل پیشنهادی نشاندهنده یک روش کارآمد برای تولید نقشههای محصول با بهرهبرداری از اطلاعات مکانی-زمانی دادههای S2 است. FPN (3+2)D پیشنهادی وقتی روی دادههای Sentinel-2 اعمال میشود بسیار خوب عمل میکند و راهحل پیشنهادی را بیش از حد انجام میدهد. کار انجام شده دری را برای مطالعات جدید در زمینه درک الگوریتم های یادگیری عمیق در کاربردهای کشاورزی و محیطی باز می کند. ما در نظر می گیریم که روش توصیف شده نشان دهنده گامی رو به جلو برای درک رفتار مدل های یادگیری عمیق در کاربردهای کشاورزی است. ارائه مقادیر CAI در سطح پیکسل راهی برای ارزیابی استحکام تفسیر شبکه کلاس معنایی در نظر گرفته شده است. اگر دوره زمانی (یعنی زیرمجموعه سری های زمانی تصویر) که به عنوان اهمیت شبکه در نظر گرفته می شود، با روش های کشاورزی شناخته شده موافق باشد (یعنی دوره کاشت محصولات زراعی) می توان از صادرات پذیری روش در زمینه های دیگر اطمینان داشت. علاوه بر این، تکنیک پیشنهادی برای تفسیر بازه فعالسازی یک کلاس در حوزه زمانی بسیار نوآورانه است و میتواند با سایر حوزههایی که از مدلهای عمیق کاملاً پیچیده استفاده میکنند، تطبیق داده شود. علاوه بر این، در کنار سهم نوآورانه در حوزه تشخیص الگو، ما در نظر میگیریم که این نتایج دلگرمکننده میتواند کمک بسیار زیادی برای کاربر نهایی باشد. بهویژه تشخیص خودکار «مکان و زمان» محصولات کشاورزی یک حمایت اساسی از برنامهریزان و سیاستگذاران سرزمینی است. به ویژه در زمینه اروپا، سیاست مشترک کشاورزی (CAP) به حمایت از کشاورزان با ارائه یارانه بر اساس محصول کشت شده و انجام اقدامات کشاورزی مناسب اختصاص داده شده است. آژانس های پرداخت،https://esa-sen4cap.org/ ، مشاهده شده در 11 ژوئیه 2021). مدل تقسیمبندی پیشنهادی اطلاعات مکانی بسیار جالبی (که محصول کجاست) و زمانی (زمانی که کشت میشود) به عنوان پشتیبانی برای کاربران علاقهمند به نظارت بر پویایی محصول برای یک منطقه جغرافیایی معین فراهم میکند. برای کمک بیشتر به پایش محصولات با توجه به کشاورزی پایدار و شیوههای سازگار با آب و هوا، گام بعدی بالقوه این مطالعه، آزمایش امکان ارائه نشانههایی در مورد وضعیت زمین (چه مدت و برای چه مدت) قبل و بعد از کشت محصول برای شناسایی خاک خواهد بود. مدیریتی مانند وجود گیاهان پوششی و یا بقایایی که نشانگر اقدامات حفاظتی کشاورزی هستند. به این ترتیب، مدل باید برای هر پیکسل از نقشه تقسیمبندی خروجی، دارای چند برچسب و همچنین چند کلاسه شود.







بدون دیدگاه