1. مقدمه
مردم به طور مداوم در شهر رفت و آمد می کنند و به محل کار، مدرسه، امکانات ورزشی و سایر فعالیت های سرگرمی می روند. برنامه ریزی برای تحرک شهری نیازمند داده های مکانی و زمانی به روز در مورد شیوه های حمل و نقل فردی و جمعی است. حالتهای حملونقل فردی شامل «هر حالتی است که در آن تحرک نتیجه یک انتخاب شخصی و وسایلی مانند اتومبیل، پیادهروی، دوچرخهسواری یا موتورسیکلت است» [ 1 ]. حالت های حمل و نقل جمعی (یا حمل و نقل عمومی) شامل وسایل نقلیه مشترک و یک مسیر، برنامه و هزینه از پیش تعیین شده است. چنین حالت هایی شامل تراموا، اتوبوس، قطار، مترو و قایق های کشتی است.
دادههای تحرک شهری معمولاً توسط تعداد زیادی آژانس، برنامههای کاربردی و کاربران تولید و نگهداری میشوند. هر کدام نیازهای خاصی دارند و بنابراین سیاست خود را در مورد انتشار داده ها حفظ می کنند که می تواند باعث سطح بالایی از ناهماهنگی و ناهمگونی داده ها شود [ 2 ]. ادغام داده ها از چندین منبع ناهمگون در مورد شیوه های حمل و نقل مختلف یک چالش باقی مانده است [ 3 ، 4 ]، که مشکلاتی را برای شهروندانی که نیاز به جابجایی در سطح شهر دارند [ 5 ] منعکس می کند و مانع تصمیم گیری برنامه ریزان شهری به دلیل نداشتن دیدگاه یکپارچه می شود. کل شبکه حمل و نقل چندوجهی
مشکل دیگر در دستیابی به داده های شهری قابل اعتماد و به روز است. دو منبع اصلی برای چنین دادههایی وجود دارد: معتبر یا داوطلبانه. داده های معتبر معمولا توسط سازمان های دولتی با هزینه تولید بالا تولید می شوند، بنابراین بسیار قابل اعتماد هستند، اما به روز نگه داشتن آنها دشوار است [ 6 ، 7 ]. دادههای ارائهشده داوطلبانه از جمعیت بهعنوان تولیدکننده (یا حسگر)، اغلب بهصورت رایگان استفاده میکنند. قابلیت اطمینان اغلب یک مسئله است، اما دفعات بهروزرسانی میتواند زیاد باشد و در صورت وجود داوطلبان کافی، پوشش میتواند گسترده باشد. تکمیل و به روز رسانی داده های منبع رسمی با داده های داوطلبانه به طور فزاینده ای ضروری است، به ویژه در مکان هایی که زیرساخت کمی برای نگهداری داده های شهری دارند [ 6 ].
در مورد تحرک شهری، در دسترس بودن چنین منابع داده متنوعی که بیشتر آنها ریشه در نیازهای عملیاتی روزانه دارند و در بخشهایی از سیستم متمرکز شدهاند، با نیاز به دیدگاه یکپارچه از تحرک در تضاد است. با یک دیدگاه یکپارچه، ما قادر به تجزیه و تحلیل تحرک به عنوان یک کل، با در نظر گرفتن فرآیندهای در حال انجام و تحول مداوم آنها، و برنامه ریزی برای تکامل آنها می شویم.
در این مقاله، ما چارچوبی را برای یکپارچهسازی دادههای مکانی از منابع ناهمگن برای تولید مجموعه داده شبکه حملونقل شهری چندوجهی پیشنهاد میکنیم که میتواند در برنامههای مختلف محاسباتی شهری مورد استفاده قرار گیرد. برای تطبیق طرحواره، ما تبدیل هر طرحواره منبع را به یک مدل داده مفهومی فضایی استاندارد پیشنهاد میکنیم. برای تطبیق داده های مکانی، ما روشی را با استفاده از اطلاعات توپولوژیکی، هندسی و معنایی برای شناسایی تطابق بین اشیاء از مجموعه داده های مختلف ارائه می دهیم. سپس اشیاء منطبق با استفاده از تکنیکهای ترکیب دادهها در یک نمایش واحد ادغام میشوند، اما اشیایی که برای یک منبع داده خاص منحصر به فرد هستند، هر زمان که لازم باشد، گنجانده میشوند، زیرا منابع داده بیشتر مکمل یکدیگر هستند، نه از نظر موضوعی همپوشانی.
ما رویکرد خود را با استفاده از دادههای دنیای واقعی برای ایجاد مجموعه داده شبکه حملونقل شهری چندوجهی برای شهر بلو هوریزونته، در برزیل تأیید میکنیم. نتایج با ایجاد مسیرهای چندوجهی در میان نقاط تصادفی و مقایسه نتایج با مسیرهای ارائه شده توسط Google Maps ارزیابی میشوند. نتایج ما را قادر میسازد تا دادههای تحلیلی را با در نظر گرفتن کل شبکه شهری حملونقل چندوجهی به جای نماهای جدا شده از هر نوع حملونقل، تجزیه و تحلیل، شبیهسازی و محاسبه کنیم. ادغام دادههای داوطلبانه بهروز با منابع معتبر نیز میتواند برای شناسایی مناطقی که دادههای رسمی قدیمی هستند و برای بهینهسازی کار نقشهبرداری رسمی به روشی هدفمند استفاده شود.
ادامه این مقاله به شرح زیر سازماندهی شده است. بخش 2 مفاهیم و کارهای مرتبط را ارائه می کند. بخش 3 مدل داده شبکه حمل و نقل شهری چندوجهی ما را شرح می دهد. بخش 4 جزئیات فرآیند ساخت شبکه حمل و نقل چندوجهی از منابع متعدد با استفاده از تکنیک های یکپارچه سازی داده ها را شرح می دهد. مطالعه موردی با استفاده از رویکرد پیشنهادی برای Belo Horizonte در بخش 5 توضیح داده شده است . نتایج در بخش 6 ارائه و مورد بحث قرار گرفته است. در نهایت، بخش 7 مقاله را به پایان می رساند و مسیرهای کاری آینده را ارائه می دهد.
2. مفاهیم و کارهای مرتبط
ما ایجاد یک مجموعه داده شبکه حمل و نقل شهری چندوجهی را از منابع ناهمگن با استفاده از تکنیکهای یکپارچهسازی دادههای مکانی پیشنهاد میکنیم. چنین مجموعه داده ای را می توان با داده های منابع اضافی غنی کرد. به عنوان مثال، جنبههای مربوط به تجربه کاربر حملونقل عمومی را میتوان جمعسپاری کرد و دادههای حسگر مربوط به پویایی ترافیک را میتوان گنجاند. چارچوب ما شامل یک طرح مفهومی برای یک پایگاه داده فضایی است که به عنوان مرجعی برای تطبیق طرح واره استفاده می شود. سپس ادغام دادهها از منابع مختلف حول این طرح مفهومی سازماندهی میشود، و بنابراین ممکن است دادهها قبل از گنجاندن در مجموعه داده یکپارچه تبدیل شوند. تطبیق دادهها بین مجموعههای داده، در صورت نیاز، با توجه به شباهت هندسی بین اشیاء و همچنین جنبههای توپولوژیکی و معنایی انجام میشود. هنگامی که جفت های منطبق از اشیاء در نظر گرفته شده معادل یافت می شوند، آنها در مجموعه داده یکپارچه (Data Fusion) ادغام می شوند. اشیایی که در سایر مجموعه داده ها مطابقت ندارند نیز برای ادغام ارزیابی و تبدیل می شوند.
مجموعه داده حاصل، به دنبال طرح مفهومی پیشنهادی، می تواند در برنامه هایی استفاده شود که نیاز به دید یکپارچه از تحرک شهری، هم فردی و هم جمعی دارند. بقیه این بخش مفاهیم و کارهای مربوط به شبکه های حمل و نقل شهری چندوجهی و یکپارچه سازی داده های مکانی را ارائه می کند.
2.1. شبکه های حمل و نقل شهری چندوجهی
یک شبکه حمل و نقل شهری چندوجهی (MUTN) یک جزء ضروری در هنگام برخورد با تحلیل شهری است. Nes [ 8 ] حمل و نقل چندوجهی را به عنوان حمل و نقلی تعریف می کند که در آن حداقل از دو حالت مختلف استفاده می شود و مسافر باید از یک حالت به حالت دیگر انتقال دهد. به همین ترتیب، ماندلوی و تیل [ 9 ] و چن و همکاران. [ 10 ] هر زمان که جابجایی افراد یا کالاها شامل حداقل دو روش حمل و نقل از مبدأ تا مقصد باشد، حمل و نقل چندوجهی را مشخص می کند. زویجست و همکاران [ 11] MUTN را به عنوان مجموعه ای از زیرسیستم ها ببینید، که در آن هر یک نشان دهنده یک حالت انتقال است. اتصالات بین سیستم ها به عنوان نقاط مبادله در گره ها یا پایانه ها پیاده سازی می شوند. افراد فقط می توانند با استفاده از ترمینال به حالت دیگری تغییر کنند. با این حال، هنگامی که حالت های متعدد در دسترس هستند، و حالت ها توسط سازمان های مختلف مدیریت می شوند، اغلب هیچ نمای یکپارچه ای از کل سیستم وجود ندارد.
یک MUTN باید دادههای مربوط به شبکه خیابان و همچنین کل زیرساخت حملونقل (خیابانها، راهآهن، ایستگاههای اتوبوس) و خدمات حملونقل هر حالت (ماشین، پیادهروی، دوچرخهسواری، اتوبوس، مترو) را مدیریت کند. همچنین برای درک بهتر الگوها و تعاملات زندگی شهری، غنی سازی MUTN با داده های منابع داده های غیر متعارف، از جمله جمع سپاری، مطلوب است. به عنوان مثال، ژنگ و جرولیمینیس [ 12 ] یک مدل ترافیک چندوجهی با در نظر گرفتن محدودیت های پارکینگ با استفاده از یک نمودار اساسی ماکروسکوپی (MFD) برای تعریف استراتژی های قیمت گذاری پارکینگ برای کاهش ازدحام و هزینه های کلی سفر برای رانندگان ساختند. این کار بر روی مدلسازی عددی برای انتخاب مودال مورد استفاده متمرکز بود و با استفاده از یک شبکه حملونقل شهری شبیهسازیشده با در نظر گرفتن تنها اتومبیلها و اتوبوسها انجام شد. گیل [13 ] از داده های OpenStreetMap (OSM) برای ساخت MUTN برای فعال کردن تجزیه و تحلیل دسترسی استفاده کرد. داده های OSM برای حمل و نقل جمعی با داده های یک منبع رسمی (OpenOV) تکمیل شد، اما به شکل ساده شده، بدون در نظر گرفتن جزئیاتی مانند خطوط، خدمات و فرکانس آنها. جتلوند و همکاران [ 14 ] یک مدل داده عمومی برای داده های حمل و نقل، بر اساس استانداردهای ISO و INSPIRE، با تمرکز بر قابلیت همکاری داده ها، پیشنهاد کرد.
MUTN های حاصل از این کارها برای اهداف خاصی ساخته شده اند، در حالی که رویکرد ما مدل گسترده تری را پیشنهاد می کند که می تواند برای کاربردهای مختلف مورد استفاده قرار گیرد و می تواند داده های اضافی را ترکیب کند. همچنین با استفاده از روش های یکپارچه سازی داده ها، از داده های منابع مختلف و ناهمگن استفاده می کنیم که در بخش بعدی ارائه می شود.
2.2. یکپارچه سازی داده های مکانی
داده های مکانی نقش اساسی در فرآیند تصمیم گیری ایفا می کنند. تخمین زده می شود که حدود 80 درصد از کل اطلاعات مورد استفاده در فرآیند تصمیم گیری دارای ویژگی های فضایی است [ 15 ، 16 ] و استفاده صحیح از آن مستلزم تصمیم گیری بهتر است [ 17 ].
کنسرسیوم فضایی باز (OGC) یکپارچه سازی داده های مکانی را به عنوان «فرایند یکپارچه سازی دو یا چند مجموعه داده مجزا، که ویژگی های مشخصی مشترک دارند، در یک نتیجه یکپارچه فراگیر» تعریف می کند [ 18 ]. نتیجه یکپارچه سازی داده های مکانی فقط روی داده ها قرار نمی گیرد و با هم نمایش داده می شود. باید بین ویژگیها در مجموعههای داده مختلف ارتباط داشته باشد و آنها را در یک نمایش واحد ادغام کند، به امید یافتن دانش جدیدی که نمیتواند به تنهایی از مجموعه دادههای فردی مشتق شود [ 19 , 20 , 21 , 22]. منابع داده مورد استفاده در آثار ارجاع شده در مورد ادغام داده های مکانی را می توان به دو دسته طبقه بندی کرد: اطلاعات جغرافیایی رسمی (یا معتبر) و اطلاعات جغرافیایی داوطلبانه (VGI). دادههای رسمی عموماً توسط سازمانهای دولتی تولید میشوند، در حالی که دادههای VGI با مشارکت شهروندان و مشارکتکنندگان تولید میشوند. از جمله خدمات اولیه VGI، OpenStreetMap ( https://www.openstreetmap.org (دسترسی در 21 ژوئن 2021)) (OSM) و Waze ( https://www.waze.com (دسترسی در 21 ژوئن 2021)) هستند. هزینه بالای تولید برای ایجاد و نگهداری دادههای فضایی رسمی و در دسترس بودن فزاینده ابتکارات VGI، محققان و دولتها را تشویق کرده است تا به دنبال راههایی برای ادغام این منابع داده برای به دست آوردن مجموعه دادههای بهروزتر با هزینه تولید کمتر باشند [ 6 ]., 23 , 24 , 25 , 26 , 27 , 28 ].
ادغام داده های مکانی را می توان در سه وظیفه اصلی سازماندهی کرد [ 29 ]. اولین کار تطبیق طرحواره است که به دنبال ایجاد مطابقت معنایی بین کلاس های شی از مجموعه داده های مختلف است [ 30 ]. هنگامی که معناشناسی حل شد، وظیفه دوم، تطبیق داده ها، برای شناسایی اشیاء داده مربوطه انجام می شود. سومین و آخرین کار، که ادغام داده نامیده می شود، شامل حل تفاوت های شماتیک و نمایشی بین اشیاء همسان برای تولید یک نمایش منفرد و سازگار است. برخی از کارها تطبیق طرحواره و تطبیق دادهها را بهعنوان وظایف مستقل در نظر نمیگیرند، و پیشنهاد میکنند که آنها را بهعنوان مؤلفههای یک کار کلیتر در فرآیند یکپارچهسازی داده مشاهده کنید [ 31 ، 32 ، 33 ]، 34 ].
2.2.1. تطبیق طرحواره
تطبیق طرحواره شامل یافتن مطابقت های معنایی بین عناصر از طرحواره های مختلف است [ 30 ، 35 ]. تکنیکهای تطبیق طرحواره بر اطلاعات طرحواره (انواع داده، نام عناصر و ویژگیهای ساختاری) [ 36 ] ویژگیهای نمونههای شی یا اطلاعات خارجی، مانند هستیشناسیها و فرهنگ لغتها [ 2 ، 36 ، 37 ، 38 ، 39 ] متکی هستند.
از آنجایی که تطبیق طرحواره ها در درجه اول تمرینی برای مدل سازی معناشناسی است، هستی شناسی ها اغلب در ادبیات استفاده می شوند. البکری و فیربایرن [ 36 ] روی Ordnance Survey و OpenStreetMap در سطح طرحواره (بر اساس XML) با استفاده از سه معیار کار کردند: شباهت نام بین کلاس ها، شباهت ساختاری بین طرحواره ها و شباهت نوع داده. معیارها در یک معیار شباهت وزنی برای حل منطبقات احتمالی ترکیب شدند، اما نتایج عالی به دست نیاوردند، بنابراین استفاده از هستیشناسیهای هدایتشدهتری را برای بهبود فرآیند یکپارچهسازی دادههای مکانی پیشنهاد میکنند. Du [ 39 ] از هستی شناسی ها برای ادغام داده های معتبر (Ordnance Survey) و crowdsourced (OpenStreetMap) در جاده ها استفاده کرد [ 40] و سایر داده های واقعی. روش آنها مجموعه داده های ورودی را به هستی شناسی تبدیل می کند و سپس آنها را در یک هستی شناسی جدید ادغام می کند. گوان و همکاران [ 37 ] از هستیشناسیها برای مطابقت با طرحوارههای زبان نشانهگذاری جغرافیایی (GML) استفاده کرد و این پیشنهاد را روی دادههای بزرگراهها و جادهها (در میان انواع دیگر دادهها، مانند ایالتها، شهرها، رودخانهها و دریاچهها) از کانادا و ایالات متحده آزمایش کرد. پرودوم و همکاران [ 2 ] یک فرآیند تفسیر معنایی را برای استنتاج یک هستی شناسی از طرح مجموعه داده بدون دانش قبلی اعمال کرد. سپس هستی شناسی تولید شده برای تطبیق طرحواره از طریق استفاده از تکنیک های تطبیق هستی شناسی استفاده می شود. رویکرد آنها برای تفسیر معنایی مبتنی بر کدگذاری جغرافیایی و پردازش زبان طبیعی است.
برای این کار، اگرچه تطبیق طرحواره مبتنی بر معنایی یا هستی شناسی امکان پذیر است، ما تصمیم گرفتیم تطبیق طرحواره را به صورت دستی انجام دهیم، با مقایسه مستندات در طرحواره هر منبع با طرح مفهومی پیشنهادی. در مورد دادههای انتقال، تطبیق طرحواره با استفاده از نمایشهای فضایی مشابه برای کلاسهای مهم شی تسهیل میشود.
2.2.2. تطبیق داده های مکانی
تطبیق داده های مکانی را می توان به عنوان مطابقت صحیح بین اشیاء داده های مختلف [ 26 ] تعریف کرد و یک نیاز برای یکپارچه سازی، مدیریت و ارزیابی کیفیت مجموعه داده های مکانی [ 34 ] است. همچنین می توان آن را پیوند [ 40 ]، همسویی [ 41 ] یا آشتی [ 42 ، 43 ] نامید.
طبقه بندی های زیادی برای تکنیک های تطبیق داده های مکانی در ادبیات وجود دارد [ 34 ، 44 ، 45 ، 46 ، 47 ، 48 ]. خاویر و همکاران [ 34 ] طبقه بندی گسترده ای را بر اساس دو معیار پیشنهاد کرد: سطح و مورد مطابقت. سطح به جایی اشاره دارد که در سلسله مراتب مدل سازی داده، تطابق رخ خواهد داد. سه گزینه ممکن است: طرحواره، ویژگی و داخلی. سطح طرحواره معادل مفاهیم تطبیق طرحواره ارائه شده در بخش 2.2.1 است. ویژگیروشهای تطبیق سطح در نظر میگیرند که تطبیق طرحواره از قبل کامل شده است، و برای یافتن مطابقت بین ویژگیها با استفاده از یک یا چند معیار تشابه تلاش میکنند. تطبیق سطح داخلی به مقایسه بخش هایی از ویژگی های هندسی مربوط می شود که برای ارزیابی کیفیت ضروری است [ 49 ، 50 ، 51 ]. مورد مکاتبات مربوط به اصل تطابق است و می تواند به صورت یک به یک (1:1)، یک به چند (1:N) و چند به چند (M:N) تعریف شود.
روشهای تطبیق ویژگی شامل جستجوی ویژگیهای کاندید برای تطبیق در مجموعه دادهها است بکه به یک ویژگی در مجموعه داده نزدیک هستند آو سپس شباهت هر ویژگی کاندید را برای مشخص کردن یک مسابقه بررسی کنید. از جمله تکنیک های رایج برای یافتن ویژگی های نامزد استفاده از بافرها [ 2 ، 28 ، 52 ، 53 ، 54 ، 55 ] و الگوریتم هایی برای یافتن نزدیک ترین همسایگان [ 47 ، 56 ] است. معیارهای تشابه را می توان به هندسی، توپولوژیکی، مبتنی بر ویژگی، زمینه محور و معنایی طبقه بندی کرد [ 34 ].
معیارهای هندسی از ویژگی های هندسی ویژگی هایی مانند موقعیت، طول، محیط، مساحت، شکل یا زاویه استفاده می کنند [ 57 ]. از جمله معیارهای مورد استفاده در این دسته عبارتند از: اقلیدسی [ 20 ، 58 ، 59 ، 60 ، 61 ، 62 ] ، هاسدورف [ 2 ، 45 ، 47 ، 63 ، 64 ، 65 ، 66 ] و Fréchet ، 6،6 ، 2 ، تشابه شکل اندازه گیری می شود [ 2 ، 49 ، 51]، و میزان همپوشانی بین ویژگی ها [ 2 ، 27 ، 69 ، 70 ].
متریک های توپولوژیکی روابط فضایی بین ویژگی ها را تجزیه و تحلیل می کند و بیشتر برای مطابقت با ساختارهای شبکه (گره-قوس) استفاده می شود. بسیاری از معیارهای مشخصه گراف استفاده می شود، مانند، درجه گره [ 71 ، 72 ]، مرکزیت [ 27 ، 73 ]، بین [ 73 ، 74 ، 75 ] و نزدیکی [ 73 ، 75 ].
معیارهای مبتنی بر ویژگی برای مقایسه ویژگیها بر اساس دادههای مرتبط غیرمکانی استفاده میشوند. این دسته از معیارهای شباهت به عملگرها برای مقایسه انواع داده های ویژگی متکی است. متداول ترین معیارهای مورد استفاده شامل مقایسه رشته ها هستند، مانند فاصله لونشتاین [ 76 ، 77 ] و فاصله همینگ [ 64 ].
معیارهای مبتنی بر زمینه از بافت جغرافیایی ویژگی ها برای کمک به تعیین شباهت آنها استفاده می کنند. بافت جغرافیایی به روابط بین یک ویژگی و سایر ویژگی های مرجع اشاره دارد. با استفاده از لیستی از نقاط شناخته شده (نقاط مشخص) که می تواند برای ساختن یک نمودار مجاورت [ 76 ]، یک مثلث دلونی یا یک نمودار ورونوی [ 54 ، 60 ] برای محاسبه شباهت بین ویژگی های کاندید استفاده شود، کار می کند.
معیارهای معنایی فاصله بین مفاهیم ویژگی ها را تعیین می کند، جایی که مفاهیم می توانند کلاس ها، روش ها یا ویژگی ها باشند [ 34 ]. مشکل در به کارگیری چنین روشهایی این است که معمولاً به برخی از نمایشهای رسمی دانش، مانند درخت هستیشناسی یا طبقهبندی نیاز است. هاستینگز [ 78 ] از کممعمولترین ابرمفهوم (LCS) در یک درخت طبقهبندی برای ارزیابی شباهت بین اصطلاحات gazetteer با شمارش تعداد گامهای (احتمالا وزندار) روی درخت لازم برای حرکت از یک مفهوم به مفهوم دیگر استفاده کرد.
تحقیقات زیادی در مورد استفاده از تکنیکها و روشها برای تطبیق دادههای مکانی در ادبیات موجود است. ما توجه خود را بر مواردی متمرکز می کنیم که شامل ادغام بین داده های معتبر و جمع سپاری داده های شهری و حمل و نقل است.
Mustiere و Devogele [ 58 ] NetMatcher را پیشنهاد کردند، یک فرآیند تطبیق ویژگی که از معیارهای شباهت هندسی، مبتنی بر ویژگی و توپولوژیکی برای یافتن و ارزیابی نامزدهای بالقوه برای تطابق، حتی با سطوح مختلف جزئیات استفاده میکند، بنابراین میتواند با یک به چند برخورد کند. و موارد مکاتباتی چند به چند.
لودویگ و همکاران [ 79 ] داده های جاده OSM را با مجموعه داده Navteq مقایسه کنید. آنها دادههای بخشهای جاده را از OSM تقسیم میکنند تا تعداد ویژگیها را در هر دو مجموعه داده یکسان کنند و سپس از عملیات بافر برای سهولت یافتن مکاتبات یک به یک استفاده میکنند. سپس، طول، دسته و نام ویژگیها به عنوان معیارهای شباهت برای یافتن بهترین نامزدها برای مطابقت استفاده میشود.
کوکولتسوس و همکاران [ 80 ] از یک رویکرد چند مرحلهای برای تطبیق ویژگیها، ترکیب معیارهای هندسی (فاصله، جهت، طول جادهها) و معیارهای مبتنی بر ویژگی (نام جادهها، انواع جاده) برای ارزیابی کامل بودن دادههای OSM در مورد مجموعه دادههای بررسی مهمات استفاده میکند. آنها از یک شبکه 1 کیلومتر مربعی برای برش دادن مجموعه داده ها استفاده می کنند و سپس هر سلول برای یافتن تطابق تجزیه و تحلیل می شود. ویژگی های داده های VGI، مانند ناهماهنگی های توپولوژیکی و اختصارات استفاده شده در نام ویژگی ها، ممکن است بر نتایج تأثیر بگذارد.
یانگ و همکاران [ 81] یک روش آرامش احتمالی اکتشافی برای تطبیق شبکههای جادهای از OSM و دادههای معتبر در سطح ویژگی ایجاد کرد. این روش با یک ماتریس احتمالی ساخته شده از معیارهای تشابه بر روی اشکال ویژگی شروع می شود و سپس ضرایب سازگاری نامزدهای همسایه را تا زمانی که ماتریس احتمالی در سطح جهانی سازگار شود، ترکیب می کند. سپس، جفتهای تطبیق یک به یک را پیدا میکند و سپس برای یافتن تطابقهای چند به یک گسترش مییابد. همچنین مطابقتهای تهی (سطح مکاتبات یک به ته یا 1:0) را شامل دادههایی میداند که منحصر به یکی از منابع هستند، احتمالاً در جاهایی که منبع دیگر قدیمی یا ناقص است. نتایج تطبیق دقت بالایی را تنها با استفاده از معیارهای تشابه هندسی نشان داد، اما این روش از نظر محاسباتی پرهزینه است.
فن و همکاران [ 24 ] از یک رویکرد مبتنی بر چند ضلعی برای تطبیق شبکههای جادهای در سطح ویژگی استفاده کرد. مرحله اول با چند ضلعی های بلوک شهری مطابقت دارد که مناطق همپوشانی را تأیید می کند. سپس بخشهای جادهای به حاشیه بلوکهای شهری اختصاص داده میشوند. آن بخشهای جادهای که به همان لبه یک جفت بلوک شهری همسان اختصاص داده میشوند، مطابقت در نظر گرفته میشوند. نتایج نرخ تطابق بالایی را نشان داد، اما با جادههایی که نمیتوان آنها را به یک بلوک شهری مجاور اختصاص داد، یا جادههای بدون عبور که یک چندضلعی بسته را تشکیل نمیدهند، مطابقت ندارد.
عبدالمجیدی و همکاران [ 66 ] رویکردهای مبتنی بر بخش و مبتنی بر گره را برای تطبیق جاده ها در سطح ویژگی مقایسه کرد. آنها رویکرد مبتنی بر گره را به دلیل کاهش هزینه محاسباتی انتخاب می کنند و آن را برای مدیریت روابط توپولوژیکی و سایر اجزای شبکه بهبود می بخشند. از معیارهای هندسی (جهت گیری و طول قطعه)، توپولوژیکی (بررسی پیوندها و همسایگان یک گره) و معیارهای تشابه مبتنی بر ویژگی (نام ویژگی) در فرآیند تطبیق استفاده شد. روش به دست آمده برای ارزیابی کامل بودن داده های OSM در رابطه با پایگاه داده راه های ملی سوئد استفاده می شود.
اولتئانو-ریموند و همکاران. [ 82 ] یک رویکرد تطبیق داده ها بر اساس تلفیق دانش با استفاده از نظریه باور ارائه می کند. آنها معیارهای هندسی (موقعیت، جهتگیری)، معنایی، مبتنی بر ویژگی (نام ویژگی) و شباهت زمینهای را در توابع باور مدلسازی میکنند تا جفتهای تطبیق صحیح را پیدا کنند.
در این کار، فرآیند تطبیق داده ها در سطح ویژگی رخ می دهد. برای ویژگیهای خط، فرآیند با ایجاد فهرستی از نامزدها برای تطبیق با یافتن ویژگیهایی از یک مجموعه داده که بافر یک ویژگی را در مجموعه داده دیگر قطع میکند، آغاز میشود. اگر یک ویژگی کاندیدایی برای تطبیق نداشته باشد به عنوان (تطابق تهی، یا یک به صفر) در نظر گرفته می شود. سپس، از فهرست برای یافتن جفتهای منطبق با کاردینالیتههای یک به یک، یک به چند (یا چند به یک) و چند به چند استفاده میشود. برای تأیید یک جفت، از معیارهای شباهت هندسی مانند نزدیکی گره، طول و شباهت زاویه قطعات استفاده می شود. برای ویژگیهای نقطه، ما همچنین فهرستی از تطابقهای احتمالی را با استفاده از درخت KD برای سرعت بخشیدن به جستجو ایجاد میکنیم. مسابقات با استفاده از هندسی (فاصله) تأیید می شوند، معیارهای تشابه معنایی (نوع ویژگی) و معیارهای تشابه مبتنی بر ویژگی (نام). برای تشابه نام از فاصله Levenshtein استفاده می شود. با این حال، ما یک درمان برای کاهش مشکلات در تطبیق نام معرفی می کنیم. نام ها به حروف کوچک تبدیل می شوند، نشانه گذاری می شوند، بر اساس حروف الفبا مرتب می شوند و به هم پیوسته می شوند. نشانهگذاری کاراکترهای نقطهگذاری را حذف میکند، و مرتبسازی امکان تطبیق دقیقتری را فراهم میکند، زمانی که نامها فقط در ترتیب کلمات متفاوت باشند (وضعیت رایج برای نامها در دادههای جمعسپاری).
2.2.3. ترکیب داده های مکانی
نتیجه کار تطبیق داده های مکانی مجموعه ای از جفت عناصر همسان از مجموعه داده های در حال ادغام است. گام بعدی استفاده از جفت های تطبیق شده در میان پایگاه های داده برای یافتن مقادیر واقعی زیربنایی در صورت تداخل است [ 83 ]. این مسئولیت مرحله ادغام داده های مکانی در فرآیند یکپارچه سازی داده های مکانی است [ 84 ، 85 ]. برای نشان دادن مشکلی که در تلفیق داده های مکانی با آن مواجه است، وضعیت زیر را در نظر بگیرید. دو شی جاده، آرآو آرباز مجموعه داده های مکانی مختلف با هندسه های کمی متفاوت و مقادیر مشابه برای ویژگی نام هستند. کدام جسم هندسه جاده واقعی را به بهترین شکل نشان می دهد؟ کدام یک دقیق ترین نسخه از نام جاده را دارد؟ خروجی مورد نظر یک شی جاده است که بهترین مطابقت واقعی را برای هر ویژگی در نظر گرفته شده دارد.
تکنیک های مورد استفاده در ترکیب داده ها را می توان به روش های مختلف [ 86 ] طبقه بندی کرد، مانند رابطه بین منابع داده [ 87 ]. در این مورد، منابع داده درگیر در فرآیند ادغام می توانند مکمل، اضافی یا همکاری باشند. شکل 1 نمای کلی این دسته ها را نشان می دهد. در ادغام دادههای مکمل ، منابع داده ورودی دیدگاههای متفاوتی از یک موضوع را نشان میدهند، به طوری که یکی میتواند اطلاعات موجود در دیگری را تکمیل کند و نسخه یکپارچه کاملتری از دادهها را تولید کند. در ادغام دادههای اضافی ، موضوع یکسان در منابع دادههای مختلف نشان داده میشود که میتوانند برای افزایش اعتماد به این دادهها متحد شوند. در تعاونیادغام داده ها، داده ها از منابع ورودی با اطلاعات جدیدی ترکیب می شوند که معمولاً پیچیده تر یا کامل تر از منابع اصلی هستند.
در ادغام داده ها، به ویژه از نوع اضافی، لازم است از استراتژی های حل تعارض برای انجام انتقال یا ادغام اطلاعات بین ویژگی های ویژگی های جفت استفاده شود. استراتژی مورد استفاده به ویژگی های منابع داده، داده های موجود و خروجی مورد نظر بستگی دارد. Bleiholder و Naumann [ 85 ] یک طبقه بندی برای استراتژی های مقابله با تضادهای داده ها بر اساس سه استراتژی اصلی ارائه می دهند: ناآگاهی تعارض، اجتناب از تعارض و حل تعارض.
چارچوب ما وظایف ترکیب داده های مکانی را در زمان های مختلف انجام می دهد. هنگام ساخت شبکه خیابان، مقادیر مشخصه (نام جاده، طبقه بندی عملکردی، و عرض) که در یکی از مجموعه داده ها وجود ندارد و در دیگری در ویژگی های جفت وجود دارد، به روز می شوند، که ترکیب داده های اضافی را پیکربندی می کند. بخشهای خیابان منحصر به فرد از یک مجموعه داده، و همچنین اطلاعات دیگر (پارکینگ، حملونقل عمومی)، میتواند در نتیجه همجوشی (تلفیقی مکمل) گنجانده شود. در ایجاد شبکه چندوجهی، دادهها به گونهای سازماندهی میشوند که امکان مسیریابی در سراسر شبکه و حالتهای مختلف آن را فراهم کنند، که فرآیند همجوشی را به عنوان مشارکتی طبقهبندی میکند. شبکه حمل و نقل شهری چندوجهی به دست آمده امکان تجزیه و تحلیل و عملیات بر اساس یک دیدگاه یکپارچه از حمل و نقل شهری را فراهم می کند که اگر مجموعه داده ها به صورت مجزا استفاده شوند، دشوار یا غیرممکن خواهد بود. این چارچوب یک مدل داده مکانی را در طول فرآیند یکپارچه سازی داده ها و برای ذخیره نتایج پیشنهاد و استفاده می کند. مدل داده های مکانی در بخش زیر مورد بحث قرار می گیرد.
3. مدل داده شبکه حمل و نقل شهری چندوجهی
مدل شبکه حمل و نقل شهری چندوجهی (MUTN) زیرساخت یکپارچه حمل و نقل شهری را با در نظر گرفتن حالت های حمل و نقل فردی و جمعی نشان می دهد. حالت فردی شامل زیرساخت وسایل نقلیه شخصی یا مشترک (شامل تاکسی، اجاره، اشتراک خودرو، دوچرخه و غیره) و عابران پیاده است، در حالی که حالت حمل و نقل جمعی مسئول حمل و نقل عمومی مانند سیستم اتوبوس و مترو است. تفاوت بین آنها در این است که سیستم حمل و نقل عمومی معمولاً از یک ساختار از پیش تعیین شده پیروی می کند که در آن مسیرها، توقف ها و برنامه ها تعریف می شوند. چندین آژانس ممکن است مسئول مدیریت جایگزین های حمل و نقل عمومی باشند. شبکه برای هر حالت حمل و نقل به صورت جغرافیایی، با استفاده از مختصات مکانی، و توپولوژیکی، با استفاده از نمودارهای جهت دار نمایش داده می شود.
ما یک طرح مفهومی را معرفی می کنیم ( شکل 2 ) که به عنوان پایه ای برای یکپارچه سازی داده ها، از جمله تطبیق طرح، تطبیق داده ها و ادغام داده ها استفاده می شود. همه مجموعههای داده منبع باید مطابقت داده و در صورت لزوم تغییر شکل دهند تا با طرح پیشنهادی مطابقت داشته باشند. در ادامه، طرح پیشنهادی را با جزئیات شرح می دهیم.
کلاس Property ویژگی های هر ویژگی را با استفاده از یک طرحواره کلید-مقدار ذخیره می کند، جایی که کلید نمونه ای از کلاس PropertyType است که دارای یک نام و یک دامنه است که از طریق کلاس DataDomain داده می شود. به نوبه خود، کلاس DataDomain یک نام، یک نوع داده، و یک واحد (به عنوان مثال، کیلومتر در ساعت، متر، ثانیه، و سایر واحدهای اندازه گیری) برای تفسیر مقادیر مرتبط با دامنه دارد.
بلوک اصلی ساختار مدل MUTN کلاس ویژگی انتزاعی است. یک ویژگی یک شی در دنیای واقعی یا رابطه ای بین ویژگی ها را نشان می دهد. باید یک شناسه (fid) منحصر به فرد داشته باشد و متعلق به یک FeatureClass باشد. ویژگی ها ممکن است مجموعه ای از ویژگی ها را داشته باشند. FeatureClass شامل تمام انواع ویژگی های ممکنی است که مدل داده می تواند استفاده کند و اطلاعات مربوط به ویژگی های هر کلاس ویژگی را ذخیره می کند. یک ویژگی می تواند به عنوان یک رابطه، یک GeoFeature، یک NetFeature، یک ModeNetwork یا یک Multimodal Network تخصصی باشد.
در بسیاری از موقعیتها در مدلسازی، ما باید بین چندین ویژگی ارتباط برقرار کنیم تا هر یک بتواند در رابطه با دیگران نقشی داشته باشد. در این مواقع از کلاس های Relationship، RelatioshipRole، RelationshipType و Role استفاده می شود. RelationshipType و Role روابطی را برای هر یک از نقش های ممکن که یک ویژگی می تواند به عهده بگیرد، تعریف می کند. به عنوان مثال، یک محدودیت تبدیل ممنوع بین را در نظر بگیرید س1و س2بخش هایی که از تقاطع جاده عبور می کنند j1. این محدودیت را می توان به صورت زیر مدل کرد: باید یک RelationshipType ‘no_turn’ مرتبط با نقش های ‘from’، ‘via’ و ‘to’، یک نمونه جدید از کلاس Relationship با نوع ‘no_turn’ و سه نمونه جدید از کلاس RelationshipRole برای بخش ایجاد می شود س1، اتصال j1، و بخش س2در نقش های «از»، «از طریق» و «به» به ترتیب.
کلاس انتزاعی NetFeature نشان دهنده ویژگی هایی است که در ساختارهای توپولوژیکی به سایرین مربوط می شوند تا شبکه ها را تشکیل دهند. یک NetFeature می تواند یک اتصال، یک بخش، یک مسیر یا یک مسیر باشد. یک Junction مربوط به یک گره شبکه است، اما با یک نمایش جغرافیایی. کلاس Path برای نشان دادن یک مسیر از طریق شبکه حمل و نقل با استفاده از یک دنباله مرتب شده از Junctions استفاده می شود. کلاس Route برای نشان دادن یک سرویس حمل و نقل جمعی با برنامه ثابت، به عنوان مثال، خط اتوبوس یا مترو استفاده می شود. کلاس های Junction و Segment مبنای ایجاد ساختارهای شبکه به عنوان کلاس ModeNetwork هستند. در مدل داده پیشنهادی، شبکه ها به صورت نمودارهای جهت دار مدل می شوند. از نظریه گراف، گراف جهت دار به عنوان یک جفت مرتب تعریف می شود جی=(V،E)، که در آن V مجموعه ای از رئوس است و E مجموعه ای از یال ها است که به عنوان جفت های مرتب شده از رئوس تعریف می شوند. در مدل داده MUTN، یک ModeNetwork شبکه را برای یک حالت حمل و نقل به عنوان یک گراف جهت دار نشان می دهد که در آن رئوس و یال ها به ترتیب اتصالات و بخش ها هستند.
هر بخش به یک Junction شروع و به پایان می رسد که شناسه های آن در بخش به عنوان ویژگی های “منبع” و “هدف” آن ذخیره می شود. جهت جریان از طریق قطعه همیشه از منبع به هدف است. علاوه بر منبع و هدف، ویژگی های اجباری دیگری برای بخش ها وجود دارد، مانند طول، جهت گیری، هزینه. طول نشان دهنده اندازه هندسه قطعه بر حسب متر است. خصیصه جهت گیری زاویه جهت قطعه است که شرق را 0، شمال را 90، غرب را 180 و جنوب را 270 درجه در نظر می گیرد. ویژگی هزینه برای محاسبات مسیریابی استفاده می شود. مقدار پیشفرض این است که زمان عبور از بخش را بر حسب ثانیه ذخیره کنید. یک بخش می تواند به عنوان TransferSegment یا RouteSegment تخصصی شود. اولی برای نمایش بخش هایی استفاده می شود که انتقال های درون و بین وجهی را نشان می دهند. دومی برای نشان دادن مسیرها در شبکه های حمل و نقل جمعی استفاده می شود که در آن زمان حرکت و رسیدن مشخصی برای یک سرویس مشخص وجود دارد. ویژگی هندسه برای بخش های کلاس TransferSegment و RouteSegment ممکن است دقیقاً نشان دهنده مسیر دنیای واقعی نباشد. به عنوان مثال، گاهی اوقات مسیر دقیقی که اتوبوس طی می کند مشخص نیست، اما می توان توالی، موقعیت و فاصله بین توقف های آن در یک مسیر را تعیین کرد (یک وضعیت رایج در مشخصات تغذیه عمومی حمل و نقل (GTFS)https://developers.google.com/transit/gtfs/reference (دسترسی در 21 ژوئن 2021)) فایلها، زیرا مسیر اختیاری است). در این مورد، RouteSegment پیوند بین هر توقف در مسیر را نشان میدهد و یک جدول زمانی مرتبط دارد که اطلاعات مربوط به زمان رسیدن و خروج هر سرویس حملونقلی را که از بخش استفاده میکند ذخیره میکند. مشخصه isRealGeometry را می توان بررسی کرد تا مشخص شود که هندسه RouteSegment نشان دهنده مسیر واقعی است یا فقط انتقال بین توقف ها.
هر اتصال دارای یک هندسه نقطه است. Junction یک تقاطع بین بخش های شبکه را نشان می دهد. با این حال، ConnectionNode نقطهای را نشان میدهد که در آن امکان انتقال بین شبکههای حمل و نقل مختلف یا بین سرویسهای مختلف در یک شبکه وجود دارد، برای مثال، اتصال بین خطوط اتوبوس مختلف. یک اتصال می تواند از نوع تقاطع، ایستگاه یا انتقال باشد. یک ConnectionNode می تواند از نوع busStop، subwaystation، lightrailStation، railwaystation، parkingLot، parkAndRide، فرودگاه، ایستگاه اتوبوس بین شهری باشد. مبدا و مقصد نوع اتصال یک بخش، نوع آن را تعیین می کند. به عنوان مثال، فرض کنید هر دو اتصال منبع و هدف از نوع تقاطع هستند. در این صورت، بخش از نوع پیشفرض textitSegment خواهد بود. اگر یکی از نوع تقاطع متنی و دیگری از نوع انتقال یا ایستگاه باشد، نشان دهنده بخشی از نوع OuterTransfer است که نشان می دهد تغییری در نحوه حمل و نقل ایجاد خواهد شد. بخش های بین دو اتصال از نوع ایستگاه می توانند RouteSegment یا InterTransfer باشند. یعنی کاربر اتوبوس هنگام رسیدن به ایستگاه می تواند در همان خط اتوبوس ادامه دهد یا به خط دیگری تغییر مسیر دهد.
برای نمایش عناصری که لزوماً مستقیماً به شبکه حمل و نقل مرتبط نیستند، می توان از کلاس های PointFeature، LineFeature و AreaFeature استفاده کرد. به عنوان مثال، یک مرز شهر یا یک دریاچه می تواند نمونه های AreaFeature باشد. یک رودخانه را می توان به عنوان یک LineFeature مدل کرد. درختان، تیر چراغ ها، علائم راهنمایی و رانندگی، تصادفات را می توان به عنوان یک ویژگی نقطه ای نشان داد. اگرچه آنها لزوماً نیازی به اتصال به شبکه حمل و نقل ندارند، اغلب لازم است یک مکان شبکه به برخی از GeoFeature اختصاص داده شود. به عنوان مثال، هندسه اختصاص داده شده برای ثبت یک تصادف رانندگی ممکن است با Junction یا Segment مطابقت نداشته باشد. در این مورد، GeoFeatures ممکن است یک ویژگی NetLocation داشته باشد که بر اساس عناصر آن، مکانی را در شبکه حمل و نقل به آنها اختصاص می دهد. موقعیت می تواند مربوط به یک Junction یا یک Segment باشد. در مورد Junction مکان با موقعیت اتصال منطبق است، زیرا نمایش یک نقطه است. در مورد Segment، مکان اختصاص داده شده می تواند یک نقطه یا یک خط باشد. اگر مقدار NetLocation به یک بخش از شبکه اشاره می کند، باید یک موقعیت شروع و در صورت تمایل، یک موقعیت پایان ارائه شود. این مکان به عنوان یک موقعیت در امتداد خط Segment با استفاده از مقداری بین 0 (موقعیت شروع) و 1 (موقعیت پایان) ثبت می شود. به عنوان مثال، در یک قطعه با 100 متر، یک موقعیت شروع با مقدار 0.1 و موقعیت پایانی 0.5 نشان می دهد که GeoFeature از 10 متر، تا 50 متر، اندازه گیری شده از مبدا قطعه، در امتداد هندسه خط آن قرار دارد. اگر هیچ موقعیت پایانی اطلاع داده نشود، فرض می شود که مکان یک نقطه در امتداد بخش داده شده توسط موقعیت شروع است. از آنجایی که نمایندگی یک نقطه است. در مورد Segment، مکان اختصاص داده شده می تواند یک نقطه یا یک خط باشد. اگر مقدار NetLocation به یک بخش از شبکه اشاره می کند، باید یک موقعیت شروع و در صورت تمایل، یک موقعیت پایان ارائه شود. این مکان به عنوان یک موقعیت در امتداد خط Segment با استفاده از مقداری بین 0 (موقعیت شروع) و 1 (موقعیت پایان) ثبت می شود. به عنوان مثال، در یک قطعه با 100 متر، یک موقعیت شروع با مقدار 0.1 و موقعیت پایانی 0.5 نشان می دهد که GeoFeature از 10 متر، تا 50 متر، اندازه گیری شده از مبدا قطعه، در امتداد هندسه خط آن قرار دارد. اگر هیچ موقعیت پایانی اطلاع داده نشود، فرض می شود که مکان یک نقطه در امتداد بخش داده شده توسط موقعیت شروع است. از آنجایی که نمایندگی یک نقطه است. در مورد Segment، مکان اختصاص داده شده می تواند یک نقطه یا یک خط باشد. اگر مقدار NetLocation به یک بخش از شبکه اشاره می کند، باید یک موقعیت شروع و در صورت تمایل، یک موقعیت پایان ارائه شود. این مکان به عنوان یک موقعیت در امتداد خط Segment با استفاده از مقداری بین 0 (موقعیت شروع) و 1 (موقعیت پایان) ثبت می شود. به عنوان مثال، در یک قطعه با 100 متر، یک موقعیت شروع با مقدار 0.1 و موقعیت پایانی 0.5 نشان می دهد که GeoFeature از 10 متر، تا 50 متر، اندازه گیری شده از مبدا قطعه، در امتداد هندسه خط آن قرار دارد. اگر هیچ موقعیت پایانی اطلاع داده نشود، فرض می شود که مکان یک نقطه در امتداد بخش داده شده توسط موقعیت شروع است. اگر مقدار NetLocation به یک بخش از شبکه اشاره می کند، باید یک موقعیت شروع و در صورت تمایل، یک موقعیت پایان ارائه شود. این مکان به عنوان یک موقعیت در امتداد خط Segment با استفاده از مقداری بین 0 (موقعیت شروع) و 1 (موقعیت پایان) ثبت می شود. به عنوان مثال، در یک قطعه با 100 متر، یک موقعیت شروع با مقدار 0.1 و موقعیت پایانی 0.5 نشان می دهد که GeoFeature از 10 متر، تا 50 متر، اندازه گیری شده از مبدا قطعه، در امتداد هندسه خط آن قرار دارد. اگر هیچ موقعیت پایانی اطلاع داده نشود، فرض می شود که مکان یک نقطه در امتداد بخش داده شده توسط موقعیت شروع است. اگر مقدار NetLocation به یک بخش از شبکه اشاره می کند، باید یک موقعیت شروع و در صورت تمایل، یک موقعیت پایان ارائه شود. این مکان به عنوان یک موقعیت در امتداد خط Segment با استفاده از مقداری بین 0 (موقعیت شروع) و 1 (موقعیت پایان) ثبت می شود. به عنوان مثال، در یک قطعه با 100 متر، یک موقعیت شروع با مقدار 0.1 و موقعیت پایانی 0.5 نشان می دهد که GeoFeature از 10 متر، تا 50 متر، اندازه گیری شده از مبدا قطعه، در امتداد هندسه خط آن قرار دارد. اگر هیچ موقعیت پایانی اطلاع داده نشود، فرض می شود که مکان یک نقطه در امتداد بخش داده شده توسط موقعیت شروع است. در یک قطعه با 100 متر، یک موقعیت شروع با مقدار 0.1 و موقعیت پایانی 0.5 نشان می دهد که GeoFeature از 10 متر تا 50 متر، اندازه گیری شده از مبدا قطعه، در امتداد هندسه خط آن قرار دارد. اگر هیچ موقعیت پایانی اطلاع داده نشود، فرض می شود که مکان یک نقطه در امتداد بخش داده شده توسط موقعیت شروع است. در یک قطعه با 100 متر، یک موقعیت شروع با مقدار 0.1 و موقعیت پایانی 0.5 نشان می دهد که GeoFeature از 10 متر تا 50 متر، اندازه گیری شده از مبدا قطعه، در امتداد هندسه خط آن قرار دارد. اگر هیچ موقعیت پایانی اطلاع داده نشود، فرض می شود که مکان یک نقطه در امتداد بخش داده شده توسط موقعیت شروع است.
در نهایت، کلاس MultimodalNetwork برای ترکیب چندین ModeNetworks، با استفاده از TransferSegments و ConnectionNodes برای ادغام همه حالتها در یک شبکه استفاده میشود. هر ModeNetwork داده ها را برای یک حالت حمل و نقل ذخیره می کند. یک انتقال بین حالتهای انتقال در ConnectionNode رخ میدهد که از طریق TransferSegment به ModeNetwork مرتبط است. هر ConnectionNode حاوی اطلاعات حالت انتقال ورودی (از حالت) و خروجی (toMode) است. یک ConnectionNode یک هزینه مرتبط برای انتقال حالت انتقال دارد. به این ترتیب، می توان هزینه یک سوئیچ درون یا بین مدال را تعیین کرد. به عنوان مثال، یک راننده (ModeNetwork؛ حالت = DRIVE) می تواند ماشین خود را در پارکینگ (ConnectionNode;fromMode = DRIVE;toMode = WALK) ترک کند و بقیه راه را (ModeNetwork؛ حالت = WALK) پیاده روی کند.
طرح مفهومی توصیف شده در این بخش باید به عنوان مبنایی برای فرآیند تطبیق طرح واره استفاده شود و اجرای آن می تواند نتایج تطبیق داده ها و وظایف یکپارچه سازی را از مجموعه داده های مختلف ذخیره کند. این طرح همچنین می تواند به عنوان مدلی برای ایجاد مجموعه داده های جدید مرتبط با حمل و نقل شهری استفاده شود. بخش زیر روشی را برای ساخت یک شبکه حمل و نقل شهری چندوجهی ارائه می دهد که می تواند با استفاده از طرح پیشنهادی برای کمک به تجزیه و تحلیل مشکلات مربوط به شهری ذخیره شود. سپس این روش برای ایجاد یک نمای یکپارچه برای شبکه شهری شهر بلو هوریزونته برزیل اعمال می شود.
4. ساخت شبکه حمل و نقل شهری چندوجهی
اولین قدم برای ساخت MUTN ایجاد یک شبکه خیابانی است که توسط عابران پیاده، دوچرخه ها و وسایل نقلیه استفاده می شود. این شبکه همچنین جایی است که اجزای زیرساخت حمل و نقل جمعی به هم متصل می شوند و می توان سایر GeoFeature ها را قرار داد. رویکرد ما این است که شبکه خیابانی را با استفاده از دادههای منابع مختلف بسازیم تا مجموعه داده کاملتر و بهروزتری به دست آوریم تا از آن به عنوان مبنایی برای ادغام دادههای حملونقل عمومی و سایر ویژگیهای جغرافیایی استفاده کنیم. نمای کلی مراحل ساخت شبکه چندوجهی در شکل 3 نشان داده شده است . باقیمانده این بخش هر فرآیند را با جزئیات ارائه می کند.
4.1. تعاریف اولیه
تعاریف زیر در توصیف فرآیند استفاده می شود:
-
مجموعه داده مرجع: این مجموعه داده مبنایی برای فرآیند یکپارچه سازی و ساخت شبکه حمل و نقل چندوجهی است. از طرح مفهومی پیشنهادی پیروی میکند و مجموعه دادهای است که دادههای آن در هنگام حل تضاد دادهها در یکپارچهسازی دادهها اولویت داده میشوند. معمولا، اما نه لزوما، باید یک مجموعه داده معتبر باشد.
-
مجموعه داده مکمل: حاوی داده هایی است که می تواند مجموعه داده مرجع را تکمیل، گسترش دهد، تصحیح یا به روز کند.
-
دادههای حمل و نقل جمعی: دادههای مربوط به مسیرها، توقفها و برنامههای زیرساخت حملونقل جمعی موجود در همان منطقه از مجموعه دادههای مرجع و تکمیلی. رایج ترین منابع فایل های GTFS هستند.
-
مجموعه داده های ویژگی ها: مجموعه داده های مختلفی که می توانند برای غنی سازی شبکه حمل و نقل چندوجهی منتج به استفاده از آن در برنامه های محاسباتی شهری استفاده شوند. این مجموعه داده ویژگی هایی را ارائه می دهد که به انتقال حالت حمل و نقل مربوط می شود، مانند پارکینگ ها یا نقاط اشتراک خودرو، برای فعال کردن مسیریابی چندوجهی.
4.2. تطبیق طرحواره برای مجموعه داده های مرجع و مکمل
طرح MUTN ارائه شده در این کار نشان می دهد که یک شبکه حمل و نقل به عنوان یک گراف جهت دار نمایش داده می شود. اولین گام کار تبدیل مجموعه داده های مرجع و مکمل به یک نمایش نمودار یکنواخت، به دنبال طرح پیشنهادی است. در شبکه حاصل، هر بخش باید در یک اتصال شروع و به پایان برسد. اگر انتقال از یک قطعه به قطعه دیگر امکان پذیر باشد، باید در هر تقاطع قطعه یک اتصال وجود داشته باشد. به عنوان مثال، در یک شبکه خیابانی، یک تقاطع جاده باید یک اتصال باشد، اما نقطه ای که یک جاده (بخش) یک تونل یا یک پل را قطع می کند، نمی تواند یک اتصال باشد، زیرا امکان انتقال وجود ندارد.
هر تقاطع باید نشان دهنده یک تقاطع یا بن بست باشد تا با طرح MUTN مطابقت داشته باشد. یک عملیات پاکسازی باید اتصالات بی فایده را شناسایی کند، به عنوان مثال، گره های عبوری که می توانند بدون تغییر توپولوژی شبکه حذف شوند. هنگامی که چنین گره هایی حذف می شوند، بخش های مجاور از نظر هندسی ادغام می شوند. این عملیات تنها در صورتی انجام می شود که ویژگی های بخش های مجاور با هم سازگار باشند. مجموعه ای از ویژگی ها در صورتی سازگار در نظر گرفته می شود که فقط در مقادیر مربوط به هندسه لبه (مثلاً طول) متفاوت باشد.
پس از فرآیند ساده سازی، دو ویژگی جدید به مجموعه داده ها، طول و جهت هر بخش اضافه می شود (یا به روز می شود). طول به اندازه هندسه قطعه، بر حسب متر است. جهت قطعه زاویه، بر حسب درجه، از محل اتصال منبع به محل اتصال هدف با در نظر گرفتن شرق = 0، شمال = 90، غرب = 180، جنوب = 270 درجه است.
باید امکان شناسایی حالت (یا حالتهای) حمل و نقل برای بخشها در همه مجموعه دادهها وجود داشته باشد. معمولاً این اطلاعات به عنوان یک ویژگی ذخیره می شود، در غیر این صورت کل مجموعه داده به یک حالت انتقال منفرد مربوط می شود.
هر مجموعه داده می تواند دارای تعداد دلخواه صفت برای هر دو بخش و اتصالات باشد. ما ترجیح دادیم در مطالعه موردی تطبیقهای دستی ایجاد کنیم، اما میتوان از تکنیکهای تطبیق طرحواره معنایی موجود استفاده کرد [ 88 ، 89 ، 90 ].
در نهایت، آخرین مرحله تبدیل تمام هندسه ها برای استفاده از سیستم مرجع مختصات یکسان (CRS) است. نتیجه تطبیق طرحواره ها نمودارها هستند، جیآرو جیسی، به ترتیب مجموعه داده های مرجع و مکمل را با ویژگی های آنها که به ویژگی های مدل داده MUTN نگاشت می شوند، نشان می دهد. ویژگیهای انحصاری از مجموعه داده تکمیلی نگهداری میشوند تا در صورت لزوم در فرآیند ترکیب دادهها مورد استفاده قرار گیرند. ویژگیهای رایج را میتوان در مرحله تطبیق دادهها برای بهبود نتایج تطبیق با تأیید یا رد جفتهای تطبیق بر اساس اطلاعات معنایی موجود استفاده کرد.
4.3. تطبیق داده ها برای داده های شبکه
فرآیند تطبیق داده ها با یافتن جفت های منطبق با افزایش کاردینالیته کار می کند. ما چهار کاردینالیته برای جفتهای منطبق تعریف کردیم: کامل، حاوی، درون و جزئی. شکل 4 به روشی ساده کاردینالیته های ممکن برای جفت های تطبیق را نشان می دهد. دسته پنجم، به نام null (کاردینالیتی یک به صفر)، برای ویژگی هایی استفاده می شود که در مجموعه داده دیگر مطابقت ندارند. این دسته برای ادغام داده های تکمیلی از اهمیت اساسی برخوردار است و به یک مجموعه داده اجازه می دهد تا محتوای دیگری را گسترش دهد تا کامل بودن نتیجه را بهبود بخشد. تطابق کامل (کاردینالیته یک به یک)، زمانی رخ می دهد که یک بخش از جیآرهمتای دقیقی دارد جیسیو بالعکس، به این معنی که محل اتصال منبع و هدف هر دو بخش از یک آستانه نزدیکتر است و هر دو هندسه مشابه هستند. در شکل 4 الف، بخش r1از جانب جیآرمطابقت کامل با بخش دارد ج1از جانب جیسی. تطابق حاوی زمانی رخ می دهد که یک بخش از جیسیدارای پیش بینی اتصالات منبع و هدف خود در همان بخش واقع شده است جیآر. در شکل 4 ب، بخش r2از جانب جیآردارای تطابق حاوی (یک به چند کاردینالیته) با بخشها ج2، ج3ه ج4. یک تطابق درونی (کاردینالیته چند به یک) به تطابق حاوی متقارن است. زمانی اتفاق می افتد که یک بخش وارد شود جیآردارای پیش بینی اتصالات منبع و هدف خود در یک بخش در داخل است جیسی. شکل 4 ج آن بخش را نشان می دهد r3و r4از جانب جیآردر مطابقت با ج5از جانب جیسی. یک تطابق جزئی (کاردینالیتی چند به چند) زمانی اتفاق میافتد که محل اتصال منبع و هدف یک بخش از جیآرپیش بینی های خود را در بخش های مختلف در جیسیو بخش های خبرنگار در جیسیهمچنین نمی تواند به یک بخش منفرد در ارتباط باشد جیآر. در شکل 4 بخش d r5مطابقت جزئی با بخش ها دارد ج6و ج7از جانب جیسی.
فرآیند تطبیق داده ها با لیستی از همه جفت های تطبیق نامزد ممکن شروع می شود ( Lمپ) از جانب جیآرو جیسی. بعد، Lمپبرای یافتن جفتهای تطبیق کامل تجزیه و تحلیل میشود، سپس شامل و در درون منطبقها میشود، و در نهایت، یالهای غیر همسان باقیمانده برای یافتن تطابق جزئی آزمایش میشوند. اگر اطلاعات معنایی در دسترس باشد، میتوان یک روش اضافی را برای بررسی قابلیت اطمینان جفتهای منطبق یافت شده و جستجوی سایر تطابقهای احتمالی در لبههای غیر همسان آغاز کرد.
4.3.1. ساخت مجموعه ای از نامزدها برای تطبیق
اولین گام در فرآیند یافتن لیست همه نامزدها برای مطابقت ( Lپم) ایجاد یک شاخص فضایی مبتنی بر R-Tree برای تسریع فرآیند است. ایندکس برای بخش های موجود در آن ایجاد می شود جیسی. سپس، بخشهای نزدیک را در آن جستجو میکنیم جیآر. هر بخش در جیآربافر می شود و برای جستجوی ایندکس برای بخش های موجود در آن استفاده می شود جیسیکه بافر بخش را قطع می کنند. همه بخش ها از جیسیکه بافر را قطع می کنند در آن درج می شوند Lپمهمراه با همتایان در جیآربه عنوان جفت تطبیق نامزد، با معیارهای زیر: تفاوت بین جهت گیری های بخش (در درجه) ( Dب، فاصله بین محل اتصال منبع هر دو بخش ( Dتوتو، فاصله بین اتصالات هدف هر دو بخش ( Dvv، فاصله بین اتصال منبع از جیآرو بخش هدف از جیسی( Dتوv، فاصله بین محل اتصال هدف از جیآرو محل اتصال منبع از جیسی( Dvتو)، یک پرچم نشان می دهد که آیا بافر قطعه از جیآرشامل بخش نامزد از جیسی( بجیتی) و نسبت اختلاف طول ( Lدr). تمام بخشهایی که هیچ تطابق نامزدی برای آنها یافت نشد (تطبیق تهی) بهعنوان انحصاری برای مجموعه داده خاص علامتگذاری میشوند و در مراحل تطبیق بعدی در نظر گرفته نمیشوند، اما میتوان از آن در فرآیند ادغام داده استفاده کرد.
در مراحل بعدی، برخی از معیارها برای هدایت فرآیند تطبیق محاسبه میشوند. آنها نزدیکی گره، شباهت طول، شباهت زاویه هستند.
نزدیکی گره
مجاورت گره برای بررسی اینکه آیا اتصالات مبدا و مقصد یک قطعه r به اندازه کافی به اتصالات مبدا و مقصد یک قطعه c نزدیک هستند ، با در نظر گرفتن تحمل فاصله استفاده می شود.تید. به این صورت تعریف می شود:
جایی که n1و n2محل اتصال در شبکه حمل و نقل هستند. دمنستی(n1،n2)تابعی برای محاسبه فاصله بین دو اتصال است، برای مثال فاصله اقلیدسی و تیدحداکثر فاصله برای در نظر گرفتن دو اتصال به عنوان یک تطابق ممکن است. هیچ ارزش ثابتی برای وجود ندارد تید، زیرا به دقت موقعیتی هر دو مجموعه داده بستگی دارد. به عنوان مثال، اگر هر دو مجموعه داده از دقت موقعیتی بالایی برخوردار باشند، می توان از آستانه 5 یا 10 متر برای تعیین اینکه آیا یک اتصال به اندازه کافی به دیگری نزدیک است استفاده کرد. اگر دقت پایین باشد، ممکن است لازم باشد از تلورانس بالاتری استفاده شود.
شباهت طول
شباهت از نظر طول در نظر می گیرد که صرفاً تعریف یک تلورانس بر اساس نسبت تفاوت در طول ها مناسب نیست. به عنوان مثال، اگر یک بخش r120 متر طول و یک قطعه است ج116 متر طول آنها ممکن است مطابقت داشته باشند، حتی با 20٪ اختلاف طول بین آنها. با این حال، اگر r11000 متر طول دارد و ج1800 متر طول دارد، احتمالاً 200 متر اختلاف آنقدر زیاد است که نمی توان آنها را یک مسابقه در نظر گرفت. اگر فقط یک مقدار مطلق را برای تفاوت در نظر بگیریم، همین اصل صادق است. فرض کنید برای در نظر گرفتن دو بخش از نظر طول مشابه از یک اختلاف تا 40 متر استفاده می شود. در این مورد، الف r1لبه با 10 متر و الف ج1لبه با 50 متر یک مسابقه در نظر گرفته می شود که مطلوب نیست. به این ترتیب، حد مطلق پایین تر و بالاتر برای اختلاف طول تعریف می شود، در حالی که مقادیر میانی به نسبت اختلاف طول بین بخش ها بستگی دارد. شباهت طول به صورت زیر تعریف می شود:
جایی که
و لrو لجبه ترتیب طول قطعات r و c هستند. را تیلمترآایکسو تیلمترمنnبه ترتیب حداکثر و حداقل مقدار تحمل فاصله مطلق هستند. و تیrآتیمنoمقدار تلورانس بر حسب نسبت بین است لrو لج.
شباهت زاویه
تشابه زاویه مشخص می شود که تفاوت زاویه جهت بخش های r و c کوچکتر از یک آستانه باشد. به این صورت تعریف می شود:
جایی که Dبزاویه بین قطعات r و c و است تیبمترآایکساختلاف آستانه (بر حسب درجه) برای مشابه بودن زاویه جهت هر دو بخش است. به عنوان مثال، الف تیبمترآایکس15 درجه به این معنی است که بخش هایی با اختلاف زاویه تا 15 درجه از نظر زاویه جهت مشابه در نظر گرفته می شوند.
4.3.2. پیدا کردن جفت های منطبق
فرآیند یافتن جفتهای منطبق به صورت مکرر عمل میکند و مطابق با اصلی بودن آنها جستجو میشود. ابتدا منطبقات کامل جستجو می شود، سپس موارد موجود و درون منطبق و در نهایت موارد جزئی جستجو می شود. نتایج تطبیق در فهرستهای هش که توسط بخش یا شناسه اتصال برای بازیابی کارآمد کلید میشوند، ذخیره میشوند.
تطابق کامل زمانی رخ می دهد که یک قطعه r وارد شودجیآر، با rسو rتیبه عنوان اتصالات منبع و هدف، به ترتیب، دقیقاً با یک قطعه c در مطابقت داردجیسی، با جسو جتیبه ترتیب به عنوان اتصالات منبع و هدف. لیست نامزدها Lپمبرای یافتن جفتهای تطبیق کامل استفاده میشود، که با بررسی مقادیر طول، شباهت زاویه و مجاورت گره مشخص میشوند، پسمنمتر(rس،جس)و پسمنمتر(rتی،جتی)، همه کوچکتر یا مساوی یک هستند. بخش هایی که این معیار را برآورده می کنند به عنوان تطابق کامل علامت گذاری می شوند. اگر یک قطعه r بیش از یک بخش نامزد داشته باشد جیسیبرای تطبیق کامل، یکی با بیشترین شباهت نام انتخاب می شود. در صورت تساوی جدید، بخش نامزد با کمترین فاصله انتخاب می شود. بخش های نامزد انتخاب نشده برای تطبیق جدید در دسترس هستند.
اگر یک جفت نامزد در آزمون تطبیق کامل مردود شود، تأیید برای انواع تطبیق حاوی و درون انجام میشود. A حاوی تطابق زمانی ایجاد می شود که یک قطعه r از آن باشدجیآرمربوط به یک یا چند بخش از جیسی، و این بخش ها در جیسیبه طور کامل با هندسه r مطابقت دارد ، بنابراین می توان گفت که r شامل بخش های از است جیسی. یک جفت قطعه ( r ، c )، که در آن r∈جیآرو ج∈جیسی، اگر r به طور دقیق حاوی c باشد، a حاوی تطبیق است ، و قطعه ای در r که با c مطابقت دارد (برنمایی c در r ) دارای Lسمنمترو بسمنمترکمتر یا مساوی یک ما تعریف کردیم که بخش r به شدت حاوی c if استجسو جتییک طرح ریزی معتبر در r داشته باشید ، و اگر طرح ریزی از جسدر r برابر است با rس، سپس پ(rس،جس)باید کمتر از یک باشد، و اگر طرح ریزی از جتیدر r برابر است با rتی، سپس پ(rتی،جتی)باید کمتر از یک یک یال می تواند فقط با یک بخش دیگر رابطه درونی داشته باشد. هنگامی که چندین نامزد ظاهر می شوند، جفت با کمترین فاصله انتخاب می شود.
برای یافتن منطبقات جزئی، بررسی می کنیم که آیا فقط یکی از اتصالات یک قطعه c ، جسیا جتی، یک برآمدگی در داخل قطعه r داشته باشید . با توجه به r“به عنوان بخشی از r که نمایانگر طرح ریزی c در r و ج“بخشی در c که نمایانگر طرح ریزی r در c است، اگر r“و ج“دارند Lسمنمترو بسمنمترکمتر از یک، سپس r و c تا حدی با یکدیگر مطابقت دارند.
4.3.3. انتخاب ویژگی های انحصاری از مجموعه داده های تکمیلی
پس از فرآیند تطبیق، جیسیویژگی هایی که مطابقت نداشتند (تطابق تهی). جیآربرای عملیات ادغام داده های احتمالی با جیآر. این عملیات در ادبیات ادغام نیز نامیده می شود [ 34 ، 61 ، 76 ، 91 ، 92 ]. ادغام داده های انحصاری یک مجموعه داده در دیگری امکان تکمیل داده ها در مجموعه داده مرجع و بهبود پوشش و کامل بودن آن را فراهم می کند. بخش بعدی جزئیات فرآیند همجوشی است.
4.4. ترکیب داده برای داده های شبکه
در این مرحله، ادغام داده ها به دو صورت انجام می شود: اضافی و مکمل. در ترکیب دادههای اضافی، ویژگیهای همسان میتوانند مقادیر ویژگیهای خود را بهروز کنند. به عنوان مثال، اگر دو بخش جاده مطابقت داشته باشند، مقدار مشخصه نام یک ویژگی می تواند برای به روز رسانی ویژگی دیگر استفاده شود. یکی از مشکلاتی که پیش میآید این است که چگونه میتوان مقدار ویژگی ویژگی را که از ادغام ویژگیها حاصل میشود، تعریف کرد. هیچ استراتژی واحدی وجود ندارد و موارد ممکن است بسته به ویژگیهای منابع داده و هدف از ادغام دادهها متفاوت باشد. هنگام برخورد با داده های معتبر و جمع سپاری، استراتژی پیش فرض استفاده از تکنیک اعتماد دوستان از دسته حل تعارض است (نگاه کنید به طبقه بندی تضاد داده ها در Bleiholder و Naumann [ 85 ]]) برای اولویت دادن به منبع داده معتبر. اگر مقدار در دادههای معتبر وجود نداشته باشد، میتوان از یک استراتژی اطلاعاتی از دسته اجتناب از تعارض برای گرفتن مقدار موجود از منابع دیگر، در صورت موجود بودن استفاده کرد.
تکنیکهای ترکیب دادههای تکمیلی برای تکمیل یک مجموعه داده با ویژگیهای سایر مجموعههای داده بدون مکاتبه (تطابقات تهی) استفاده میشوند. در این مورد، یک فرآیند کاملاً خودکار پیچیده است و ممکن است در معرض خطاهایی باشد که باید توسط انسان تأیید شود. در این کار، همجوشی تکمیلی در این مرحله در دو موقعیت استفاده میشود: اطلاعات مسیرهای رانندگی از دست رفته و شامل بخشهای متصل که هیچ مطابقی برای آنها یافت نشد.
برای شناسایی مسیرهای رانندگی گمشده، بخشهای جادهای که نامزدهای منطبقی برای آنها وجود دارد که نمیتوان آنها را مطابقت داد، تجزیه و تحلیل میشوند. به عنوان مثال، اگر به دلیل متریک شباهت زاویه، عدم تطابق وجود داشته باشد، و اختلاف زاویه نزدیک به 180 درجه باشد، آنگاه قطعه یک جهت رانندگی اشتباه در نظر گرفته می شود و یک بخش جدید درج می شود.
فرآیند ادغام دادهها برای شامل مجموعهای از بخشهای متصل که مطابقت ندارند بررسی میکند که آیا اتصالی از بخشهای تطبیق قبلی به هر بخش از مجموعه وجود دارد یا خیر. اگر اتصالات وجود داشته باشد، آنها در مجموعه داده مرجع درج می شوند و متصل می شوند. در غیر این صورت، اتصالات در مجموعه نزدیکتر از تحمل فاصله ( تیدبه عنوان پیش فرض) از یک اتصال یا بخش در مجموعه داده مرجع متصل می شوند. بخشهای جدیدی که برای اتصال مجموعههای بخشها ایجاد میشوند، یک پرچم ‘needs_review’ دریافت میکنند تا نشان دهد که نیاز به اعتبارسنجی بیشتری دارند.
4.5. ایجاد شبکه حمل و نقل جمعی
ایجاد یک مجموعه داده شبکه حمل و نقل جمعی دارای ویژگی هایی است که باید در نظر گرفته شود. اولاً، بر خلاف شبکه های حمل و نقل فردی، مسیرهای حمل و نقل جمعی با یک برنامه زمانی مشخص تعریف می شوند. دوم، مسیر فیزیکی واقعی که وسیله نقلیه در حمل و نقل جمعی طی می کند همیشه در دسترس نیست. با این حال، امکان جمع آوری داده ها در مورد خطوط و توالی توقف آنها وجود دارد. استانداردی که در حال حاضر برای انتشار اطلاعات حمل و نقل جمعی پذیرفته شده است، فایل های GTFS است.
مدل داده پیشنهادی امکان ساخت یک شبکه حمل و نقل عمومی با مسیرهای از پیش تعریف شده را از طریق کلاس های Connection Node، Route، RouteSegment و Timetable با نگاشت داده های GTFS به طرح پیشنهادی می دهد. یک مسیر مخفف مسیری است که از میان یک توالی توقف های حمل و نقل جمعی می گذرد. هر ایستگاه به عنوان یک ConnectionNode نشان داده می شود زیرا اجازه می دهد تا در حالت حمل و نقل تغییر ایجاد کند (WALK→BUS). فایل GTFS امکان گروه بندی توقف ها در ایستگاه ها را فراهم می کند. هنگام ساخت شبکه حمل و نقل جمعی برای مدل داده پیشنهادی، ایستگاه های همان ایستگاه در همان ConnectionNode که به عنوان یک ایستگاه نشان داده شده است، متحد می شوند. هنگام خروج از یک مسیر، کاربر می تواند حالت حمل و نقل را تغییر دهد (BUS→WALK) یا به مسیر دیگری متصل شود (BUS→BUS). برای فعال کردن مسیریابی بین وجهی، هر ConnectionNode که توسط چندین مسیر استفاده میشود، کپی میشود (یکی برای هر مسیر ممکن)، و TransferSegments از نوع InterTransfer ایجاد میشوند تا زمانی که یک کاربر حملونقل جمعی اتصال را برقرار میکند، تخصیص هزینه ایجاد میشود. اتصال ConnectionNode به شبکه حمل و نقل فردی با توجه به حالت حمل و نقل ممکن انجام می شود. به طور کلی، شبکه حمل و نقل جمعی از طریق TransferSegments از نوع OuterTransfer به شبکه عابر پیاده (خیابان) متصل می شود. برای هر RouteSegment، جدول زمانی مربوطه ایجاد میشود که حاوی اطلاعات روزها و زمانهای ورود و خروج خودرویی است که در مسیر خاصی حرکت میکند. و TransferSegments از نوع InterTransfer برای فعال کردن تخصیص هزینه زمانی که یک کاربر حمل و نقل جمعی اتصال برقرار می کند ایجاد می شود. اتصال ConnectionNode به شبکه حمل و نقل فردی با توجه به حالت حمل و نقل ممکن انجام می شود. به طور کلی، شبکه حمل و نقل جمعی از طریق TransferSegments از نوع OuterTransfer به شبکه عابر پیاده (خیابان) متصل می شود. برای هر RouteSegment، جدول زمانی مربوطه ایجاد میشود که حاوی اطلاعات روزها و زمانهای ورود و خروج خودرویی است که در مسیر خاصی حرکت میکند. و TransferSegments از نوع InterTransfer برای فعال کردن تخصیص هزینه زمانی که یک کاربر حمل و نقل جمعی اتصال برقرار می کند ایجاد می شود. اتصال ConnectionNode به شبکه حمل و نقل فردی با توجه به حالت حمل و نقل ممکن انجام می شود. به طور کلی، شبکه حمل و نقل جمعی از طریق TransferSegments از نوع OuterTransfer به شبکه عابر پیاده (خیابان) متصل می شود. برای هر RouteSegment، جدول زمانی مربوطه ایجاد میشود که حاوی اطلاعات روزها و زمانهای ورود و خروج خودرویی است که در مسیر خاصی حرکت میکند. شبکه حمل و نقل جمعی از طریق TransferSegments از نوع OuterTransfer به شبکه عابر پیاده (خیابان) متصل خواهد شد. برای هر RouteSegment، جدول زمانی مربوطه ایجاد میشود که حاوی اطلاعات روزها و زمانهای ورود و خروج خودرویی است که در مسیر خاصی حرکت میکند. شبکه حمل و نقل جمعی از طریق TransferSegments از نوع OuterTransfer به شبکه عابر پیاده (خیابان) متصل خواهد شد. برای هر RouteSegment، جدول زمانی مربوطه ایجاد میشود که حاوی اطلاعات روزها و زمانهای ورود و خروج خودرویی است که در مسیر خاصی حرکت میکند.
4.6. تطبیق GeoFeatures و حذف موارد تکراری
ویژگی های جغرافیایی می توانند در مدل داده های MUTN به صورت نقاط، خطوط یا چند ضلعی ظاهر شوند. وظیفه ادغام داده ها از منابع مختلف برای ویژگی ها پیچیده است. برای مثال، ویژگیهای جغرافیایی که به صورت نقاط نشان داده میشوند، هیچ ویژگی هندسی ندارند که بتواند موارد تکراری را فراتر از موقعیت خود شناسایی کند. بنابراین استفاده از معناشناسی در فرآیند تطبیق همیشه ضروری است. با این وجود، خودکارسازی کامل کار همچنان سخت است، زیرا ویژگیها دارای مجموعههای متفاوتی از ویژگیها هستند، ویژگیهایی که اطلاعات یکسانی را با نامها یا انواع دادههای مختلف نشان میدهند، مقادیر مشخصه ممکن است به زبانهای مختلف باشد، از جمله چالشهای مرتبط با تطبیق خودکار طرحواره. در این کار ما فقط با تطبیق PointFeature سروکار داریم.
برای شناسایی موارد تکراری، استراتژی این است که PointFeature های نزدیک به یکدیگر در فاصله تلورانس دلخواه و با نام های مشابه مقایسه شوند (همه GeoFeature ها باید دارای یک مقدار برای ویژگی name باشند، مقادیر null مجاز نیستند). فاصله لونشتاین یک معیار تشابه پرکاربرد برای مقایسه اسامی است. با این حال، نتایج آن به ترتیب ظاهر شدن کلمات در رشته ها، به نشانه گذاری، و به حروف کوچک یا بزرگ حساس است. مثلا یک مکان پ1به نام “Capitólio Estacionamento” و دیگری پ2با نام “Estacionamento Capitolio” دارای شباهت نرمال شده Levenshtein 0.58 است. دادههای جمعسپاری تنوع زیادی در ویژگیهایی دارند که کاربر میتواند آزادانه مقادیر آنها را ارائه دهد. برای به حداقل رساندن این تنوع و بهبود نتایج تطبیق، قبل از استفاده از فاصله Levenshtein، نام ها را از قبل پردازش می کنیم. ابتدا نام ها به حروف کوچک تبدیل می شوند و با نشانه گذاری رشته ها، علائم نگارشی حذف می شوند. سپس نشانه ها بر اساس حروف الفبا مرتب شده و به هم متصل می شوند. سپس فاصله لونشتاین محاسبه و نرمال می شود. شباهت نام، نسمنمتر، را می توان به صورت معادله ( 5 ) بیان کرد:
جایی که لهngتیساعتتابعی است برای برگرداندن تعداد کاراکترهای رشته نشان دهنده نام PointFeature و nآمتره“پردازش شده را نشان می دهد nآمترهاز ویژگی پس از تبدیل به کاراکترهای کوچک، نشانه گذاری، مرتب سازی و الحاق. اعمال کردن نسمنمتربه مثال قبلی از پ1و پ2منجر به مقدار 0.98 می شود.
ویژگی های نقطه ای پ1و پ2، با FeatureClass یکسان که به اندازه کافی به یکدیگر نزدیک هستند و با توجه به تلورانس معین نام های مشابهی دارند ( تیnآمتره، تکراری در نظر گرفته می شوند. اگر پسمنمتر(پ1،پ2)(معادله ( 1 )) کمتر از یک است، پ2به طور خودکار تکراری در نظر گرفته می شود. اگر نه، آن نکاتی که اسامی دارند نسمنمتر(پ1،پ2)با ارزش از تیnآمترهیا بیشتر تا فاصله تا فاصله تکراری در نظر گرفته می شوند دمتر(ضریب فاصله) برابر تید(تحمل فاصله). به طور رسمی، منسDتوپلمنجآتیه(پ1،پ2)تابع به صورت زیر تعریف می شود:
4.7. انتخاب ConnectionNodes
ConnectionNodes از GeoFeatures انتخاب می شوند. برای ایجاد شبکه حمل و نقل چندوجهی، انواع GeoFeatures را انتخاب می کنیم که می توان از آنها برای تغییر حالت حمل و نقل استفاده کرد. به عنوان مثال، پارکینگ ها را می توان در انتقال از حالت حمل و نقل اتومبیل به ریلی و بالعکس استفاده کرد.
4.8. ایجاد انتقال بین حالت های حمل و نقل
نقاطی که بهعنوان ConnectionNodes استفاده میشوند، بر اساس نحوه انتقالی که از آن انتقال به داخل و خارج میتواند رخ دهد، طبقهبندی میشوند. برای هر مجموعه، اتصالات با جستجوی نزدیکترین اتصال به موقعیت ConnectionNode و ایجاد یک TransferSegment از نوع OuterTransfer ایجاد می شود. برای مثال، مجموعهای از ConnectionNodes که برای انتقال از DRIVE به WALK استفاده میشوند، از طریق یک OuterTransfer ورودی به شبکه DRIVE و از طریق یک بخش OuterTransfer خروجی به شبکه WALK متصل میشوند.
4.9. اتصال GeoFeatures به شبکه حمل و نقل شهری چندوجهی
مدل داده MUTN به ما اجازه می دهد تا GeoFeatures را برای برنامه های مختلف ذخیره کنیم. برای کسانی که مستقیماً با مسیریابی مرتبط نیستند، نیازی به ایجاد Junction برای آنها نیست. در عوض، GeoFeatures ایجاد میشوند و کلاس NetLocation برای ذخیرهسازی جایی که در شبکه حملونقل میتوان به GeoFeature دسترسی داشت، استفاده میشود. به این ترتیب، مدل داده MUTN بدون پارتیشن بندی بیش از حد بخش ها برای ایجاد پیوند به GeoFeatures پایدار نگه داشته می شود.
5. مطالعه موردی
برای آزمایش اعتبار چارچوب، یک شبکه حمل و نقل شهری چندوجهی برای شهر برزیل بلو هوریزونته ساخته شد. داده ها از منابع مختلف برای ایجاد مسیرهای چندوجهی استفاده و ادغام شدند. از مجموعه داده های رسمی (مرجع) و جایگزین (مکمل) استفاده شد. مجموعههای داده در صورتی رسمی در نظر گرفته میشوند که ارائهدهنده آنها یک آژانس مرتبط با مدیریت دولتی باشد، در غیر این صورت به عنوان جایگزین در نظر گرفته میشوند. ابتدا، طرحوارههای مجموعه دادهها به طرح پیشنهادی MUTN نگاشت شدند. دوم، مجموعه دادهها با استفاده از تطبیق دادهها و تکنیکهای ادغام برای ساخت مجموعه داده شبکه حملونقل فردی یکپارچه شدند. سپس، فایل های GTFS برای ساخت مجموعه داده شبکه حمل و نقل جمعی استفاده شد. در نهایت، داده ها از منابع اضافی و ناهمگن برای ایجاد یکپارچه شدندگره های اتصال بین حالت های حمل و نقل. شبکه حمل و نقل شهری چندوجهی به دست آمده برای یافتن مسیرها در بین هشتاد نقطه با استفاده از حالت های حمل و نقل DRIVE ، WALK و TRANSIT استفاده شد. سپس مسیرهای ایجاد شده با مسیرهای معادل Google Maps مقایسه شدند. آزمایش ها بر روی یک رایانه لپ تاپ با پردازنده Intel Core i5-9300H، هارد دیسک 1 ترابایتی، 20 گیگابایت رم، PostgreSQL 11.7 (64 بیتی) با پسوندهای PostGIS (3.0.1) و hstore (1.5) فعال انجام شد. تمامی روش ها با استفاده از زبان پایتون (3.8.5) پیاده سازی شدند. شکل 5 نمای کلی از رویه های اجرا شده در مطالعه موردی را نشان می دهد.
بقیه این بخش مجموعه داده های مورد استفاده در مطالعه موردی را توصیف می کند و توضیح می دهد که چگونه آنها برای ساخت MUTN یکپارچه شدند. بخش 6 نتایج را مورد بحث قرار می دهد.
5.1. مجموعه داده ها
5.1.1. مجموعه داده های جایگزین
این کار از داده های OpenStreetMap، Yelp، Foursquare، Google Places و Facebook Places به عنوان مجموعه داده های جایگزین استفاده کرد.
OpenStreetMap ( https://www.openstreetmap.org/(دسترسی در 21 ژوئن 2021)) (OSM) یک پلت فرم نقشه برداری جمعی است که هر شخصی در جهان می تواند در آن مشارکت داشته باشد. دادههای OSM تنها با سه نوع مختلف شیء نمایش داده میشوند: گرهها، راهها و روابط. یک گره نشان دهنده یک نقطه جغرافیایی است. حداقل دارای یک شماره شناسه (osmid) و مختصات جغرافیایی به عنوان مقادیر طول و عرض جغرافیایی (EPSG = 4326) است. یک راه نمایانگر ویژگیهای خطی (خیابانها، رودخانهها) یا مرزهای منطقه (ساختمانها، جنگلها، دریاچهها) است و توسط فهرستی مرتب شده از 2 تا 2000 گره تشکیل میشود. هنگامی که راه یک مرز منطقه را نشان می دهد، اولین و آخرین گره باید از نظر مکانی منطبق شوند. منطقه می تواند جامد باشد (مثلاً یک ساختمان) یا نباشد (مثلاً یک دوربرگردان)، و برچسب های مرتبط با راه باید برای تعیین نوع آن بررسی شوند. روابط نشان دهنده یک رابطه بین دو یا چند عنصر OSM دیگر (گره ها، راه ها یا روابط دیگر) است. به عنوان مثال، یک مرز منطقه با یک سوراخ را می توان به عنوان یک رابطه بین دو روش نشان دهنده ناحیه نشان داد. یک رابطه لیست مرتبی از اشیایی است که در آن وجود دارد که اعضای رابطه نامیده می شوند.
ویژگیها در OSM از یک سیستم برچسبگذاری رایگان استفاده میکنند که امکان گنجاندن تعداد نامحدودی از ویژگیها را برای هر ویژگی فراهم میکند. این سیستم بسیار انعطاف پذیر است، اما پرس و جو و دستکاری داده ها را سخت تر می کند [ 13 ]. تگ ها به صورت جفت کلید-مقدار سازماندهی می شوند، اما هیچ قرارداد رسمی برای استفاده از آنها وجود ندارد. قواعد غیررسمی از استفاده جامعه، به شکل توافق نامه هایی برای استفاده از برخی کلیدها و مقادیر برای توصیف عناصر خاص پدیدار می شوند. اغلب، جامعه مشارکتکنندگان پیشنهادهایی را برای تأیید برچسبهای جدید ارائه میکنند، اما این امر استفاده مناسب یا جهانی از آنها را تضمین نمیکند. در پایان، “جمعیت” تعریف می کند که چه چیزی و چگونه از این عناصر استفاده شود.
دادههای OSM از Geofabrik ( https://download.geofabrik.de/south-america/brazil/sudeste.html (دسترسی در 7 ژوئیه 2020)) دانلود شد، سرویسی که میزبان عصاره OSM برای چندین منطقه است. دادههای مورد استفاده در این مطالعه موردی، تصویری فوری از 1 ژوئیه 2020 را نشان میدهند. دادهها فقط شامل اشیاء داخل چند ضلعی است که مرز شهر بلو هوریزونته را نشان میدهند. با این حال، با نگاهی به داده های حمل و نقل جمعی، چندین نقطه در مسیرهای اتوبوس خارج از محدوده رسمی شهر قرار دارند. به این ترتیب، ما از یک نسخه بافر شده چند ضلعی (لازم بود چند ضلعی اصلی را در 1200 متر گسترش دهیم) برای برش داده های اصلی استفاده کردیم. مجموعه داده های OSM حاصل که نشان دهنده شبکه راه است شامل 33348 بخش جاده به طول 7053116 متر است.
مکان های فیس بوک (DFP)، مکان های گوگل (DGP)، Yelp (DYP)، چهار ضلعی (DFS) و OSM (DOP) به عنوان منابع برای نقاط مورد علاقه استفاده شدند. همه سرویس ها API هایی را برای پرس و جوهای داده ارائه می دهند. با این حال، محدودیتهایی در مورد حجم کوئریهایی که میتوانند در یک زمان معین اجرا شوند (برای DFP، DGP، DYP و DFS) وجود دارد. مجموعه با جستجوی نقاط مرجع در فاصله 25 متری که به صورت شبکه ای در سراسر منطقه موجود توزیع شده است، جمع آوری شد. داده های هر سرویس برای حذف موارد تکراری پاکسازی شد (به بخش 4.6 مراجعه کنید ) و ذخیره شد. به عنوان مثال، تعداد نقاط نشان دهنده پارکینگ ها در ابتدا 1613 بود. پس از تمیز کردن و حذف موارد تکراری، تعداد کل به 1238 کاهش یافت ( جدول 1).). Facebook Places و Yelp با حجم نسبتاً کمی از داده ها کمک کردند. با این حال، برخی از آنها منحصر به فرد بودند، و بنابراین ما تصمیم گرفتیم آنها را از فرآیند یکپارچه سازی داده حذف نکنیم تا نتیجه کامل تری داشته باشیم.
5.1.2. مجموعه داده های رسمی
از چهار مجموعه داده رسمی استفاده شد. اولین مجموعه داده به نام “Classificação Viária” ( اچV، داده های مربوط به طبقه بندی عملکردی را برای هر بخش جاده ذخیره می کند. مجموعه داده دوم، به نام “Trecho Logradouro” ( تیL) شامل نام هر بخش جاده است. این دو مجموعه داده دارای محدودیت های یکپارچگی رابطه ای تعریف شده هستند، بنابراین اتصال اطلاعات هر دو مجموعه داده با استفاده از عملیات پایگاه داده رابطه ای ساده است. اچVتیL). مجموعه داده سوم، به نام “Circulação Viária” ( تیسی)، داده هایی در مورد شبکه خیابان های شهر دارد. هر بخش مربوط به یک مبدا و یک گره مقصد است. دادههای خیابان مربوط به یک نمودار جهتدار با استفاده از دو یال برای نشان دادن خیابانهای دوطرفه است که باعث میشود بسیاری از گرههای تکراری در تقاطعها برای نمایش مجوزهای چرخش استفاده شوند. هیچ راهی برای پیوند دادن یک بخش وجود ندارد تیسیبه یک بخش در اچVتیLفقط با استفاده از مقادیر ویژگی، بنابراین لازم است از عملیات تطبیق داده های مکانی برای ادغام داده ها از هر دو مجموعه داده استفاده شود. هر سه مجموعه داده بخشی از زیرساخت دادههای مکانی Belo Horizonte ( https://bhmap.pbh.gov.br/ (دسترسی در 9 ژوئیه 2020)) هستند که توسط مدیریت شهر ایجاد و مدیریت میشود.
مجموعه داده چهارم مجموعه ای از فایل های GTFS است که توسط اداره ترافیک شهر، BHTrans ( https://dados.pbh.gov.br/dataset/gtfs-estatico-do-sistema-convencional (در 3 ژوئیه 2020 قابل دسترسی است) ارائه شده است. داده های مورد استفاده از 29 جولای 2020، دارای 9328 توقف، 643 مسیر، 56771 سفر و 3202454 ورودی جدول زمانی برای هر سفر در هر ایستگاه است. جدول 1 نمای کلی از تعداد اشیاء نقطه و خط جمع آوری شده از مجموعه داده های رسمی و جایگزین و نتایج پس از روش های تطبیق طرحواره را نشان می دهد.
5.2. رویه های تطبیق طرحواره
فرآیند تطبیق طرحواره با ایجاد یک نمایش گراف جهت دار از مجموعه داده ها برای مطابقت با طرحواره MUTN پیشنهادی شروع می شود. این تیسیمجموعه داده در حال حاضر در قالب مناسب است، زیرا دارای یک بخش برای هر جهت، و هر بخش دارای یک اتصال منبع و مقصد است. با این حال، تیسیمجموعه داده دارای بخش هایی است که از همتای فیزیکی در دنیای واقعی پیروی نمی کنند، که برای نمایش چرخش های مجاز بین بخش ها استفاده می شود. از این بخش ها برای ساخت استفاده شد تیسیشبکه، اما در فرآیند تطبیق داده ها در نظر گرفته نشدند. پس از تطبیق طرحواره، تیسیمجموعه داده دارای 145625 گره (اتصالات) و 125554 خط (بخش) بود ( جدول 1 ).
ساختار شبکه برای نشان دادن اچVتیLباید ساخته می شد، زیرا فقط هندسه بخش ها در دسترس بود. یک اتصال برای هر تقاطع بخش ایجاد شد و بخش های مربوطه ویژگی های اتصال منبع و هدف خود را دریافت کردند. هیچ اطلاعاتی برای پی بردن به جریان ترافیک در داخل وجود نداشت اچVتیL. این مجموعه داده در درجه اول برای انتقال اطلاعات در مورد طبقه بندی عملکردی جاده، نام جاده ها و بخش های انحصاری عابر پیاده به مدل داده MUTN استفاده شد. پس از مطابقت طرحواره با اچVتیLمجموعه داده دارای 40287 نقطه (اتصال) و 111740 خط (بخش) بود ( جدول 1 را ببینید ).
دادههای OSM برای مطابقت با مدل دادههای MUTN به تغییراتی نیاز دارند. بخشهای جادهای که خیابانهای دوطرفه را در OSM نشان میدهند، برای ایجاد دو بخش یکطرفه کپی شده و معکوس شدند. یک ویژگی OSM way یک طرفه در نظر گرفته می شود اگر دارای یک برچسب یک طرفه با هر یک از مقادیر باشد: yes, true, 1 یا -1. در مورد مقدار -1، جهت بخش معکوس شد. اتصالات منبع و هدف به راحتی در مجموعه داده OSM در دسترس نیستند. هر راه در OSM دارای یک ویژگی گره است، که لیستی مرتب از همه کدهای گره است که هندسه راه را تشکیل می دهند. نمودار OSM ابتدا با استفاده از همه گره ها ساخته می شود و سپس برای حذف گره های میانی با پیروی از روش های شرح داده شده در بخش 4.2 ساده می شود . پس از تطبیق طرح واره، مجموعه داده OSM دارای 47458 نقطه (اتصال) و 127656 خط (بخش) بود (نگاه کنید بهجدول 1 ).
دادههای Foursquare، Google Places، Facebook Places، OSM و Yelp از مجموعه دادههای مربوطه خود انتخاب شدند و فقط آنهایی را فیلتر کردند که با مکانهای پارکینگ مطابقت داشتند. ما به صورت دستی مقادیر مشخصه مورد نیاز برای فیلتر کردن داده ها در هر مجموعه داده را به درستی شناسایی کردیم. به عنوان مثال، دادههای موجود در OSM با استفاده از برچسب مقدار amenity = parking فیلتر شدند. تعداد نقاط حاصل از هر مجموعه داده در جدول 1 نشان داده شده است .
5.3. تطبیق داده ها و تلفیق بین OSM و HVTL
روش تطبیق داده ها جفت های مربوطه از بخش ها را در مجموعه داده ها پیدا می کند. ابتدا، تطبیق بین مجموعه داده های OSM و HVTL به دنبال روش های ارائه شده در بخش 4.3.2 انجام می شود . جفت های تطبیق حاصل برای ترکیب داده ها بین مجموعه داده ها استفاده می شود. مجموعه داده OSM با اطلاعاتی در مورد نحوه حمل و نقل مجاز در هر بخش (برگرفته از برچسب ها) کمک می کند. مجموعه داده HVTL به عنوان منبعی برای بررسی اطلاعات نام بخش ها و طبقه بندی عملکردی استفاده شد. همچنین به عنوان منبع بخش های اضافی عابر پیاده استفاده می شد.
جدول 2 تعداد و طول کل (بر حسب متر) قطعات در هر مجموعه داده را نشان می دهد که بر اساس نوع تطبیق مطابقت داده شده اند. این اطلاعات میتواند پتانسیل هر مجموعه داده را برای داشتن دادههای تکمیلی یا اضافی نسبت به دیگری مشخص کند، اما نشان نمیدهد که آیا مطابقتها درست هستند یا نه (به بخش 5.5 مراجعه کنید ). تقریباً 69 درصد از بخش ها و طول کل OSM و 86 درصد از بخش ها و 91 درصد از طول کل بخش ها در HVTL مطابقت داشتند. نرخ بالای بخش ها و طول مطابقت داده شده در HVTL نشان می دهد که بیشتر به عنوان داده های اضافی در فرآیند یکپارچه سازی داده ها مشارکت خواهد داشت، در حالی که OSM اطلاعات تکمیلی بیشتری برای مشارکت دارد.
هنگامی که جفتهای تطبیق ایجاد شدند، فرآیند ادغام برای مجموعه دادهها انجام میشود. از سه ویژگی در فرآیند همجوشی استفاده شد: عرض ، سطح و نام که به ترتیب نشان دهنده عرض، طبقهبندی عملکردی و نام قطعه هستند. مجموعه داده OSM دارای بخش های کمی با مقدار عرض (115) بود. در این مورد، استراتژی ادغام تکیه بر داده های مجموعه داده HVTL بود. در صورت تفاوت در مقادیر، اگر همان بخش در بیش از یک جفت منطبق درگیر باشد، مقدار جدید برای عرض با میانگین مقادیر یافت شده محاسبه می شود. در مجموع 87532 بخش مقدار عرض آنها اختصاص داده شده یا به روز شده است.
در طول فاز تطبیق طرحواره، ویژگیهای هر مجموعه داده نشاندهنده مقدار سطح در مدل دادههای MUTN به مقادیر مربوطه نگاشت شدند. جدول 3 مطابقت های موجود در مقادیر را نشان می دهد. در مجموعه داده OSM، مقادیر موجود در جدول، محتویات برچسب ” بزرگراه ” را برای بخش ها نشان می دهد. در مجموعه داده HVTL، مقادیر محتوای ویژگی ‘ desc_class ‘ را نشان می دهند. استراتژی همجوشی اتخاذ شده در نظر گرفتن پایینترین سطح در صورت نابرابری برای غلبه بر محدودترین طبقهبندی از نظر سرعت مجاز در بخش بود. در پایان فرآیند، 2553 بخش مقادیر سطح خود را به روز کردند.
مجموعه داده OSM دارای 3438 بخش است که هیچ ارزشی برای ویژگی نام در میان آنهایی که دارای یک جفت متناظر هستند، ندارد. هنگام ادغام ویژگی name، استراتژی برای به روز رسانی مقادیر تنها زمانی اتخاذ شد که ارزش جفت مربوطه دارای شباهت کمتر از 80٪ باشد (معادله ( 5 )). در این مورد، مقدار نام مجموعه داده HVTL ترجیح داده می شود، زیرا یک منبع رسمی است ( به استراتژی ترکیبی به دوست خود اعتماد کنید ). برای تطابق جزئی یا حاوی، مقادیر مجموعه داده HVTL تنها زمانی در نظر گرفته میشوند که بیش از 50 درصد طول بخش مطابقت داشته باشد. در پایان فرآیند، 2813 بخش مقادیر جدیدی برای ویژگی name داشتند و 10599 بخش به روز شد.
آخرین روش در ادغام بین مجموعه داده های OSM و HVTL، درج بخش های عابر پیاده منحصر به فرد از HVTL بود. بخشها با مقادیر مشخصه «tipo_lograd» برابر با «VIA DE PEDESTRE» (پیادهرو)، «BECO» (کوچه)، یا «TRAVESSA» (یک خیابان باریک) شناسایی شدند. حتی اگر برخی از این بخشها میتوانست برای وسایل نقلیه موتوری استفاده شود، فقط برای استفاده عابران پیاده در نظر گرفته میشد. اطلاعات کافی در مجموعه دادههای HVTL وجود نداشت تا تضمین کند که آیا یک بخش میتواند توسط خودروها استفاده شود یا نه و جهت رانندگی صحیح آن کدام است.
در استراتژی فیوژن، بخشهای عابر پیاده انحصاری در HVTL که با یکی در OSM مطابقت نداشتند در اجزای متصل گروهبندی شدند. برای هر مؤلفه متصل، پیوندهایی شناسایی شدند که در فاصله تحمل بخشی از مجموعه داده OSM قرار داشتند. اگر وجود داشته باشد، بخش های مربوطه به هم متصل می شوند و کل گروه یکپارچه می شود. در غیر این صورت، تمام اجزای متصل نادیده گرفته می شوند. شکل 6بخشهایی از مجموعه دادههای OSM (به رنگ سیاه) و بخشهایی از HVTL که با موفقیت ادغام شدند (به رنگ سبز) و آنهایی که رد شدند (به رنگ قرمز) را نشان میدهد. در این فرآیند، 5591 بخش HVTL یافت شد که در 1219 جزء متصل گروه بندی شدند. مجموعه داده حاصل از همجوشی DSA نام داشت و دارای 136675 بخش، 51179 اتصال و طول کل 12694791 متر بود.
5.4. تطبیق داده ها و تلفیق بین DSA و TC
ادغام بین DSA و TC از همان رویه های مورد استفاده در ادغام بین OSM و HVTL پیروی می کند. ابتدا جفت های منطبق پیدا می شوند. در این مرحله فقط بخش های DSA (DSA د) که وسایل نقلیه موتوری را مجاز می کند در نظر گرفته شد زیرا در مجموعه داده TC فقط این نوع وجود دارد.
جدول 4 تعداد و طول کل (بر حسب متر) بخش هایی را نشان می دهد که بین DSA مطابقت داده شده اند د(فقط بخشهایی برای وسایل نقلیه موتوری) و مجموعه دادههای TC، که بر اساس نوع تطبیق متمایز میشوند. تقریباً 64٪ از بخش های DSA دو 96 درصد از بخش ها در HVTL مطابقت داشتند. DSA ددارای بیشتر بخشهای منطبق از نوع حاوی بود، که با نرخ بالای مطابقت درون در مجموعه داده TC مطابقت دارد. نتایج نشاندهنده تکه تکهشدن قابلتوجهتر بخشهای TC است، اما نرخ کلی بالای بخشهای همسان نشان میدهد که منبع دادههای اضافی برای فرآیند یکپارچهسازی دادهها است. این نتایج تطبیق نشان میدهد که مطابقتهایی در میان بخشهای مجموعه داده پیدا شده است، اما تأیید نمیکند که آیا به درستی مطابقت داشته است یا خیر. بخش 5.5 ارزیابی کمی فرآیند تطبیق را برای ارزیابی کیفیت تطابق ها ارائه می کند.
هنگامی که جفت های منطبق پیدا شدند، از آنها برای بررسی جهت رانندگی در DSA استفاده شد د. برای این منظور، ما تمام بخش ها را در DSA تجزیه و تحلیل کردیم دکه یک مسابقه داشتند، اما معادل آنها در جهت مخالف نبود. با استفاده از این رویکرد 1300 قطعه با جهت نادرست پیدا شد و از DSA حذف شد د. مجموعه داده DSA، با حذف بخش ها در جهت رانندگی اشتباه، DSB نام گرفت.
5.5. ارزیابی کمی نتایج تطبیق داده ها
برای ارزیابی کمی فرآیند تطبیق داده ها، ما یک تطبیق دستی از یک نمونه تصادفی از 400 ویژگی برای هر فرآیند، OSM-HVTL و DSA انجام دادیم. د-TC، و نتایج مربوطه را با هم مقایسه کرد این اندازه نمونه فاصله اطمینان 95% با حاشیه خطای کمتر از 5% را به ما می دهد. نمونه ها در QGIS با استفاده از ابزار انتخاب تصادفی انتخاب شدند. سپس، هر ویژگی انتخاب شده به صورت دستی با بازرسی بصری مطابقت داده شد. سپس نتایج با فرآیندهای تطبیق داده ها برای OSM-HVTL و DSA مقایسه شد د-TC از دو معیار ارزیابی استفاده شد، دقت و یادآوری که توسط معادلات ( 7 ) و ( 8 ) تعریف شدهاند:
جایی که مثبت واقعی ( تیپ) تعداد جفت های قطعه تصحیح شده مطابقت یافته است. مثبت کاذب ( افپ) تعداد جفت های بخش است که به اشتباه مطابقت دارند. منفی اشتباه ( افن) تعداد جفت های بخش است که توسط فرآیند تطبیق داده ها از دست رفته است. شهود این است که دقت به صحت و یادآوری کامل تطبیق مربوط می شود.
فرآیند تطبیق داده ها بین OSM و HTVL دقت 97.7% و فراخوانی 96.7% داشت. نتایج مربوط به تطابق بین DSA و TC به ترتیب 98.2% و 97.7% برای دقت و یادآوری بود.
5.6. ایجاد شبکه حمل و نقل جمعی از GTFS
اگرچه OSM می تواند جغرافیای حمل و نقل جمعی را نشان دهد، اما فاقد اطلاعاتی برای استفاده موثر برای برنامه ریزی مسیر است. به عنوان مثال، داده های OSM تنها 1457 ایستگاه اتوبوس دارند (گره های دارای برچسب بزرگراه = bus_stop)، در حالی که داده های GTFS برای Belo Horizonte دارای 9328 ایستگاه است. علاوه بر این، اگرچه پیشنهادهایی برای ذخیره داده های جدول زمانی در OSM وجود دارد، اما مشخص نیست که آیا جامعه از آن استقبال می کند یا خیر، زیرا برخی از اصول در مورد عدم درج ویژگی های زمانی و فصلی را نقض می کند. از این رو، ما به داده های GTFS برای ساخت مجموعه داده شبکه حمل و نقل جمعی برای ادغام در MUTN تکیه می کنیم.
پردازش فایلهای GTFS برای Belo Horizonte مراحل شرح داده شده در بخش 4.5 را دنبال میکند. برای هر ترکیب مسیر توقف، یک اتصال ایجاد می شود. سپس، TransferSegments برای اتصال هر Junction ایجاد می شود که نشان دهنده همان توقف است. به این ترتیب می توانیم TransferSegments بین مسیرها ایجاد کنیم.
برای هر بخش از یک مسیر، یک انتقال بین دو ایستگاه، یک RouteSegment ایجاد می شود. هر RouteSegment دارای یک شی جدول زمانی مرتبط با تمام زمانهای حرکت است که به آن مسیر بین دو ایستگاه اختصاص داده شده است (در GTFS، این به عنوان یک سفر نشان داده میشود). معمول است که فایلهای GTFS دادههای زمان حرکت کامل را برای هر ایستگاه ندارند، زیرا حضور آنها در اولین و آخرین ایستگاه فقط الزامی است. در این مورد، زمان حرکت تخمینی هر ایستگاه با استفاده از کل زمان صرف شده در مسیر بر اساس تعداد توقف ها درون یابی شد. سپس، هر شی جدول زمانی هر TransferSegment بین ConnectionNodes که نشان دهنده توقف های حمل و نقل جمعی است، با تمام زمان های حرکت از یک ایستگاه به ایستگاه دیگر و زمان پیمایش (بر حسب ثانیه) انجام می شود.
توقف حمل و نقل جمعی جایی است که تغییر در حالت حمل و نقل ممکن است رخ دهد، به این معنی که یک ConnectionNode در MUTN است. به این ترتیب، هر ایستگاه به نزدیکترین قسمتی متصل می شود که امکان حمل و نقل عابر پیاده را فراهم می کند. TransferSegments، هم ورودی و هم خروجی، برای هر ConnectionNode و نزدیکترین بخش عابر پیاده ایجاد می شود. اعداد حاصل از ایجاد شبکه حمل و نقل جمعی برای MUTN در جدول 1 نشان داده شده است. تعداد کل ConnectionNodes 35250 و TransferSegments 322122 بود.
5.7. ادغام ConnectionNodes در MUTN
ایجاد ConnectionNodes از دادههای پنج مجموعه داده استفاده کرد: OSM (DOP)، Yelp (DSY)، مکانهای Facebook (DFP)، Google Places (DGP) و Foursquare (DSF). نقاط از تمام مجموعه داده های شناسایی شده به عنوان پارکینگ انتخاب شدند. در مورد DOP، می توان پارکینگ هایی را نیز با استفاده از ویژگی های منطقه پیدا کرد. برای آنها، یک نقطه در داخل منطقه به طور خودکار ایجاد می شود تا پارکینگ را به عنوان ConnectionNode نشان دهد.
ادغام نقاط از دو معیار استفاده می کند (همانطور که در بخش 4.6 مشاهده می شود ): نزدیکی گره و شباهت نام. برای مطالعه موردی، از تحمل فاصله ( تید) از 5 متر. بنابراین اگر دو نقطه کمتر یا مساوی 5 متر از یکدیگر باشند، تکراری محسوب می شوند. در غیر این صورت، تا 20 متر ( دمتر=4، که به معنای چهار برابر تحمل است، شباهت نام ( نسمنمتر) اجرا می شود و هر دو نقطه با شباهت 0.8 ( تیnآمتره) یا بیشتر به عنوان تکراری در نظر گرفته می شوند. مقادیر برای تید، دمتر، تیnآمترهتجربی تعیین شدند.
پس از پردازش، 1238 ConnectionNode ایجاد شد. ادغام این نقاط در MUTN با استفاده از اطلاعات در مورد امکان تغییر حالت حمل و نقل در Tranfer Junctions انجام شد. ما پارکینگ ها را محلی برای تغییر از DRIVE (وسایل نقلیه موتوری) به WALK (عابر پیاده) در نظر گرفتیم. برای هر یک، ما نزدیکترین بخش را با حالت حمل و نقل DRIVE شناسایی می کنیم و آنها را با یک TransferSegment از نوع OuterTransfer (DRIVE → ConnectionNode) وصل می کنیم. به طور مشابه، نزدیکترین بخش را با حالت حمل و نقل WALK پیدا می کنیم و به ConnectionNode متصل می شویم (ConnectionNode → WALK).
پس از این مرحله ادغام، MUTN تقریباً کامل است، و لازم است هزینههای پیمایش را برای بخشها به هم مرتبط کنیم تا محاسبه مسیرهای چندوجهی را ممکن کند. رویکرد ما این بود که از زمان در ثانیه برای عبور از بخش به عنوان هزینه پیش فرض استفاده کنیم.
5.8. تخصیص هزینه به بخش ها
حداکثر سرعت و طول بخش برای محاسبه هزینه مورد نیاز است. فقط 5.72 درصد از بخش ها دارای مقدار حداکثر سرعت اختصاص داده شده هستند. برای بخشهایی که مقدار اختصاص داده شده ندارند، یک مقدار پیشفرض از طبقهبندی عملکردی بخش ( سطح ) به دست میآید. کد ترافیک برزیل ( https://www.planalto.gov.br/ccivil_03/leis/L9503Compilado.htm(در 7 آگوست 2020 قابل دسترسی است)) چهار طبقه بندی مختلف را برای جاده های شهری ایجاد می کند: ترافیک سریع، شریانی، جمع کننده و محلی. حداکثر سرعت هر کدام از آنها به ترتیب 80 کیلومتر در ساعت، 60 کیلومتر در ساعت، 40 کیلومتر در ساعت و 30 کیلومتر در ساعت است، در صورتی که سیگنالی وجود نداشته باشد که خلاف آن را نشان دهد. اگر از قبل یک نشانه سرعت برای بخش وجود داشته باشد، از کمترین مقدار استفاده می شود. با این حال، یک وسیله نقلیه همیشه با حداکثر سرعت مجاز جاده حرکت نمی کند و متغیرهای زیادی وجود دارد که بر سرعت آن تأثیر می گذارد، مانند نوع وسیله نقلیه، زمان روز، شرایط آب و هوایی و ساعات مدرسه. ما مقدار 65 درصد از حداکثر سرعت را برای محاسبات هزینه اتخاذ کردیم. این مقدار تخمینی بر اساس دادههای رادار BHTrans ( https://dados.pbh.gov.br/dataset/contagens-volumetricas-de-radares (در 7 اوت 2020) است.
برای عابران پیاده، میانگین سرعت راه رفتن 4.8 کیلومتر در ساعت استفاده شد [ 93 ]. بخشهای حملونقل جمعی از قبل زمان انتقال بین نقاط خود را در فایلهای GTFS بر حسب ثانیه دارند. این مقادیر به عنوان هزینه بخش ها استفاده شد. برای بخش هایی که نشان دهنده انتقال بین مسیرها در حمل و نقل جمعی هستند ( InterTransfers )، هزینه نیمی از فاصله بین حرکت ها در مسیر مقصد استفاده شد. برای مورد مطالعه، فقط پارکینگ ها به عنوان نقاط ممکن برای تغییر حالت حمل و نقل بین حالت های DRIVE و WALK ( OuterTransfers ) استفاده شد.). زمان صرف شده برای پارک خودرو بسته به مکان و زمان روز بسیار متفاوت است و تخمین دقیق آن دشوار است [ 94 ، 95 ]. برای مطالعه موردی، ما به طور تجربی هزینه 300 ثانیه را زمانی که یک انتقال اتفاق میافتد تعیین میکنیم.
5.9. مسیرهای چندوجهی با استفاده از MUTN
پس از تعریف هزینه های بخش، MUTN تمام اطلاعات لازم را برای تولید مسیرها با استفاده از حالت های مختلف حمل و نقل داشت. در مطالعه موردی، انتقال احتمالی بین حالتهای حملونقل از پیادهروی به حملونقل جمعی (و بالعکس)، و وسیله نقلیه شخصی به پیادهروی است. اولین مورد، وضعیت معمول یک کاربر حملونقل جمعی است که به یک ایستگاه میرود یا توقف میکند، سوار اتوبوس میشود و احتمالاً تا پایان سفر خط خود را تغییر میدهد. مورد دوم راننده ای را در نظر می گیرد که به مکانی مناسب برای پارک وسیله نقلیه خود در نزدیکی مقصد نیاز دارد.
امکان توقف وسیله نقلیه در خیابان ها در نظر گرفته نشد و فقط در پارکینگ های مشخصی وجود داشت. ما در نظر میگیریم که پارک کردن در خیابانها قبلاً توسط حالت حملونقل در نظر گرفته میشود، و فقط وسیله نقلیه شخصی را در نظر میگیریم (اگرچه ممکن است با توجه به زمان مورد انتظار برای یافتن یک مکان پارک در نزدیکی مقصد، جریمه زمانی اعمال شود). بنابراین، MUTN برای Belo Horizonte از مسیریابی برای DRIVE، WALK، TRANSIT و DW (رانندگی و پیاده روی) برای حالت های حمل و نقل وسیله نقلیه شخصی، عابر پیاده، حمل و نقل جمعی و وسیله نقلیه شخصی با نیاز به پارکینگ و پیاده روی تا مقصد پشتیبانی می کند. ، به ترتیب.
الگوریتم Dijkstra برای تعیین مسیرهای MUTN بهینه بر اساس هزینه های بخش استفاده شد. شکل 7 نمونههایی از مسیرهای ایجاد شده در شبکه MUTN را با در نظر گرفتن حالتهای DRIVE، WALK، TRANSIT و DW بین نقاط مشابه نشان میدهد (منبع: (600,421.4768275785, 7,784,595.199524326)؛ مقصد: (600,421.4768275785, 7,784,595.199524326).
6. نتایج و بحث
برای مقایسه نتایج بهدستآمده از مدلسازی و ادغام دادهها، مسیرهایی بین 80 نقطه در سراسر منطقه شهرداری ایجاد کردیم. هر نقطه نشان دهنده یک مکان در MUTN نزدیکترین به مرکز هر یک از واحدهای برنامه ریزی بلو هوریزونته است. واحدهای برنامه ریزی مناطقی هستند که از تجمیع بخش های سرشماری تشکیل می شوند که توسط اداره دولتی در موقعیت های مختلف مانند محاسبه شاخص های اجتماعی-اقتصادی (مانند کیفیت زندگی شهری، آسیب پذیری اجتماعی) و توزیع منابع بودجه مشارکتی استفاده می شود.
مسیرهای بین تمام جفت نقاط برای حالت های حمل و نقل WALK، DRIVE، TRANSIT با استفاده از MUTN و Google Maps محاسبه شد. Google Maps گزینه ای برای مسیرهای خودرویی که به دنبال پارکینگ در نزدیکی مقصد هستند، ندارد، بنابراین مقایسه آن با گزینه مسیریابی DW غیرممکن بود.
برای هر مسیر، زمان و مسافت با استفاده از MUTN و Google Maps محاسبه شد. سپس اختلاف فاصله ها و زمان ها محاسبه شد و در نهایت نسبت بین تفاوت ها و مقادیر مربوطه توسط MUTN به دست آمد. جدول 5 مقایسه نتایج را نشان می دهد. مقادیر جدول نشان دهنده میانگین مقادیر مطلق نسبت های زمان و مسافت است. تفاوت زمانی بین مسیرهای ایجاد شده از طریق MUTN و Google Maps 4.6٪، 7.3٪ و 17.5٪ برای حالت های حمل و نقل WALK، DRIVE و TRANSIT بود. به طور همزمان، اختلاف مسافت بین مسیرها 9.4%، 9.9% و 19.4% بود.
برای بررسی اینکه آیا فاصله بین نقاط تأثیر قابل توجهی بر تفاوت بین مسیرها دارد، نتایج را به ده گروه مجزا تقسیم کردیم که هر یک دارای 630±4عناصر، و میانگین های مربوطه را محاسبه کرد. جدول 5 نشان می دهد که کمترین تفاوت در گروه مسیرهایی با بیشترین فاصله بین مبدا و مقصد مشاهده می شود. در مقابل، مهمترین تفاوتها در گروه با فواصل کمتر برای هر شیوه حمل و نقل رخ داد. توضیح احتمالی برای این وضعیت این است که هر گونه تفاوت در مسیرها با در نظر گرفتن فاصله کم به طور قابل توجهی بر تفاوت بین آنها تأثیر می گذارد، در حالی که برای مسافت های طولانی تر، تغییرات کوچک در مسیرها تأثیر قابل توجهی ندارد.
در حالی که مسیرهای DRIVE و WALK در هر دو زمان و مسافت کمتر از 10٪ اختلاف داشتند، نتایج TRANSIT مقادیر بالاتری را به دست آورد، به ترتیب 17.5٪ و 19.4٪ از تفاوت برای مسافت و زمان. هنگام بررسی برخی از مسیرها با تفاوت معنیدارتر، مشاهده کردیم که در شرایط خاص، شبکه MUTN مسیرهای طولانیتری را نسبت به Google Maps دنبال میکند. شکل 8 a مسیری را نشان می دهد که در آن بیشترین تفاوت در فاصله نسبی رخ داده است. مسیر Google Maps از مسیری استفاده میکند که در آن هیچ ارتباط ظاهری در بخشهای نقشه وجود ندارد و طول مسیر 4394 متر را برمیگرداند. مسیریابی در شبکه MUTN فقط مسیرها را توسط بخش های متصل برمی گرداند ( شکل 8ب). طول مسیر برگشتی توسط MUTN 11183.68 متر بود. فرضیه دیگری برای توضیح تفاوت در مسیرهای TRANSIT ممکن است هزینه انتقال بین مسیرها یا هنگام ورود به شبکه حمل و نقل جمعی باشد که می تواند مسیرهای متفاوتی را از مسیرهای برگشتی توسط Google Maps برگرداند.
مدل داده پیشنهادی به عنوان یک چارچوب مرجع برای سازماندهی فرآیند و ادغام داده ها در ساختاری مناسب برای پردازش لازم کافی ثابت شد. نتیجه نهایی MUTN برای Belo Horizonte و داده های مرتبط 177 مگابایت فضای دیسک را اشغال کرد.
7. نتیجه گیری و کار آینده
در این کار، روشهای یکپارچهسازی دادههای مکانی و یک مدل داده برای ذخیره نتایج پیشنهاد شد. روش یکپارچه سازی داده های مکانی از مراحل تطبیق طرحواره، تطبیق داده ها و ادغام داده ها تشکیل شده است. در مرحله تطبیق طرح واره، مجموعه دادهها با طرحوارهها و سطوح جزئیات مختلف با مدل داده پیشنهادی سازگار میشوند. در مرحله تطبیق دادهها، جفتهای تطبیقی در مجموعه دادهها، با کاردینالیتههای مختلف، کامل (یک به یک)، حاوی و درون (یک به چند)، و جزئی (تعدادی به چند) یافت میشوند. بخش هایی که هیچ نامزد منطبقی ندارند شناسایی و به عنوان null علامت گذاری می شوندمسابقات. در مرحله ادغام داده ها، چنین تطابقات تهی را می توان در پایگاه داده یکپارچه گنجاند و ویژگی ها را می توان منتقل و ادغام کرد. هنگامی که مجموعه داده ها یکپارچه شدند، اطلاعات مربوط به حمل و نقل جمعی و انتقال بین روش های حمل و نقل، همچنین با استفاده از روش های یکپارچه سازی داده ها، گنجانده شد.
روش ها بر روی داده های دنیای واقعی برای شهر بلو هوریزونته آزمایش شدند. دادههای مجموعه دادههای معتبر و جمعسپاری در یک مجموعه داده چندوجهی، حاوی اطلاعاتی که امکان انجام مسیریابی و تحلیل چندوجهی را در محیط شهری فراهم میکند، ادغام شدند. مسیرهای ایجاد شده در این فرآیند با Google Maps مقایسه شدند و نتایج نزدیک را نشان دادند. برای مسیرهای مربوط به حملونقل جمعی که اختلاف قابلتوجهی را نشان میدهند، ما تشخیص دادیم که تفاوتها میتواند تا حدی با محدودیتهایی در Google Maps توضیح داده شود، که منجر به مسیرهایی میشود که از بخشهای ظاهراً جدا شده استفاده میکنند. فرضیه دیگری که برای تفاوت ها مطرح شد، مربوط به برآورد هزینه مورد استفاده در مدل MUTN است. از آنجایی که اطلاعات دقیقی در مورد نحوه دریافت نتایج Google Maps وجود ندارد، مقایسه دقیقتر دشوار است. با این اوصاف، نتایج بهدستآمده میتواند در چندین تحلیل شهری، مانند تحرک (زمان، هزینه، گزینههای حالت)، مطالعات دسترسی، و برنامهریزی حملونقل کمک کند. این روش عمومی است و می تواند برای ادغام مجموعه داده های مختلف استفاده شود، و فرآیند را می توان برای ادغام بیش از دو مجموعه داده زنجیره ای، همانطور که در مطالعه موردی نشان داده شده است.
محدودیت های شناسایی شده برای کار ما شامل (1) نیاز به ایجاد مقادیر مرجع برای آستانه در فرآیندهای یکپارچه سازی داده ها است. (2) مشکلات در تطبیق ویژگی ها با تفاوت های زیادی در سطح جزئیات. (3) مشکلات در به روز رسانی MUTN از تغییرات در مجموعه داده های اصلی، که نیاز به اجرای مجدد کل فرآیند یکپارچه سازی داده ها دارد. (4) عدم وجود یک رابط کاربر پسند برای استفاده از چارچوب. این محدودیت ها همچنین نشان دهنده مسیرهایی برای تحقیقات آینده است. فرآیند یکپارچه سازی داده ها به مطالعه بیشتر برای تعیین آستانه یا مقادیر تحمل در محاسبه معیارهای شباهت نیاز دارد. با این حال، ایجاد یک مقدار بهینه که مطابقت های صحیح را به حداکثر می رساند، مطابقت های نادرست را به حداقل می رساند یا از آن جلوگیری می کند.96 ]. به عنوان مثال، دادههای خیابانهای سازماندهیشده در شبکهای با دقت موقعیتی بالا، میتوانند آستانه کمتری برای شباهت زاویه نسبت به دادههای با دقت موقعیتی پایینتر یا با خیابانهایی که در یک الگوی خیابانی حلقهها و آبنبات چوبی توزیع شدهاند، داشته باشند. رویکرد فوری یافتن مقادیر به صورت تجربی خواهد بود [ 34]. رویکردی با استفاده از تکنیکهای یادگیری ماشین برای تعیین مقادیر بهینه برای آستانهها باید بررسی شود. یکی دیگر از نیازهای تحقیقاتی آینده یافتن راه هایی برای جلوگیری از اجرای مجدد فرآیند یکپارچه سازی داده ها در صورت اصلاح بخشی از داده های اصلی است. برای داده های OSM، ممکن است بتوان از ابرداده های تاریخچه ویرایش استفاده کرد و فقط تغییرات را در نمای داده یکپارچه گنجاند. یک مشکل فعلی در استفاده از چارچوب، فقدان یک رابط کاربر پسندتر و شهودی است. یکی از امکانها پیادهسازی افزونهای است که امکان دسترسی و استفاده از چارچوب را از ابزارهای منبع باز GIS مانند QGIS ( https://www.qgis.org/ (در 7 آگوست 2020) فراهم میکند).






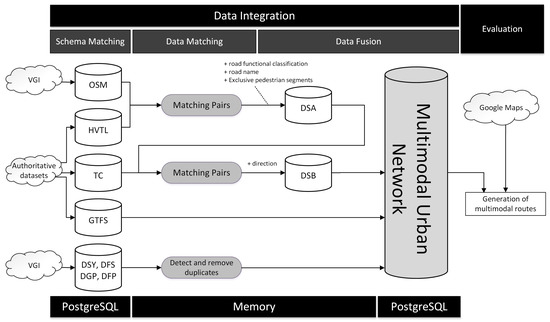





بدون دیدگاه