

CPRQ: پیشبینی هزینه برای جستجوهای محدوده در پایگاههای داده شی متحرک
چکیده
پیش بینی هزینه پرس و جو نقش مهمی در جابجایی پایگاه داده های شی ایفا می کند. پیشبینیهای دقیق به مدیران پایگاه داده کمک میکند تا بارهای کاری را به طور مؤثر برنامهریزی کنند و به استراتژیهای تخصیص بهینه منابع دست یابند. آثاری وجود دارد که بر پیشبینی هزینه پرس و جو تمرکز دارند، اما بیشتر آنها از روشهای تحلیلی برای به دست آوردن یک مدل پیشبینی هزینه مبتنی بر شاخص استفاده میکنند. با پیچیده تر شدن حجم کار سیستم مدیریت پایگاه داده، دقت می تواند به طور جدی به چالش کشیده شود.

متفاوت از کار قبلی، این مقاله روشی به نام CPRQ (پیشبینی هزینه محدوده پرس و جو) را پیشنهاد میکند که مبتنی بر تکنیکهای یادگیری ماشینی است. روش پیشنهادی شامل چهار مدل یادگیری است: مدل رگرسیون چند جملهای، مدل رگرسیون درخت تصمیم، مدل رگرسیون جنگل تصادفی، و مدل رگرسیون KNN (k-نزدیکترین همسایه). با استفاده از R-squared و MSE (میانگین مربعات خطا) به عنوان اندازه گیری، ما یک ارزیابی تجربی گسترده انجام می دهیم. نتایج نشان می دهد که CPRQ به دقت بالایی دست می یابد و مدل رگرسیون جنگل تصادفی بهترین عملکرد پیش بینی را به دست می آورد (R-squared 0.9695 و MSE 0.154 است).
کلید واژه ها:
پیش بینی هزینه ؛ محدوده پرس و جو ; پایگاه داده شی متحرک ; فراگیری ماشین
1. مقدمه
با گسترش فناوری های موقعیت یابی، حجم زیادی از داده های مکان جمع آوری می شود. مدیریت کارآمد چنین دادههایی مورد توجه بسیاری از سیستمهای مدیریت پایگاه داده قرار گرفته است. یک پایگاه داده شی متحرک (MOD) با اشیاء فضایی سروکار دارد که موقعیت آنها در طول زمان تغییر می کند [ 1 ]. نمونههای معمولی از اجسام متحرک تاکسی، هواپیما و کاربران تلفن همراه هستند. MOD ها به طور گسترده در بسیاری از کاربردها، مانند خدمات حمل و نقل [ 2 ، 3 ] و مدیریت ترافیک [ 4 ] مورد مطالعه قرار گرفته اند.
MOD ها تعداد زیادی عملگر را برای بازیابی داده ها فراهم می کنند. یک نوع پرس و جو رایج، پرس و جوی محدوده [ 5 ] نامیده می شود، به عنوان مثال، “همه ایستگاه های اتوبوس را که در فاصله ده مایلی محل پرس و جو قرار دارند را بیابید” – جستارهای k-Nearest Neighbor [ 6 ]. با توجه به ظهور کوئری ها در MOD ها، اخیراً یک کار مهم به تلاش مدل های هزینه تبدیل شده است که پیش بینی هزینه را برای پرس و جوها ارائه می دهند. پیشبینی هزینه اساساً از سه جنبه مفید است:
-
ارزیابی ساختار: برای انجام ارزیابی ساختار مبتنی بر هزینه، فرد رفتار پرس و جو را در مجموعه داده های ورودی مختلف و انواع پرس و جو بهتر درک می کند [ 7 ، 8 ].
-
نظارت بر فرآیند: می توان منابع بهینه را در طول برنامه ریزی پرس و جو با نظارت بر فرآیند انتخاب کرد و استراتژی های تخصیص منابع [ 9 ] را برای تعیین درخواست خاتمه یا تخصیص منابع به درخواست های دیگر با توجه به نتایج نظارت انجام داد، در نتیجه از هزینه های غیرضروری منابع جلوگیری کرد.
-
بهینه سازی پرس و جو: سیستم می تواند تخمین هزینه هدایت شده را برای بهینه سازی رویه اجرا [ 10 ] با در نظر گرفتن اطلاعات هزینه رفتارهای پرس و جو فضایی پیچیده قبل از شروع اجرا انجام دهد.
هدف این مقاله پیشبینی دقیق زمان CPU برای جستجوهای محدوده در MODها است. اگرچه حجم قابل توجهی از ادبیات در مورد پیش بینی هزینه پرس و جوهای محدوده [ 11 ، 12 ، 13 ، 14 ، 15 ] وجود دارد، این آثار بر اساس مدل های تحلیلی ساختارهای شاخص، مانند R-tree [ 16 ] و انواع آن [16] است. 17 ، 18 ]. با این حال، تلاش های قبلی دارای محدودیت های زیر است:
-
آنها بر استخراج فرمول های هزینه بر اساس تجربه و تخصص سیستم های مدیریت پایگاه داده تمرکز می کنند [ 14 ]، که ممکن است به طور جهانی قابل اجرا نباشد.
-
آنها فرضیات خاص یا ساده شده خاصی را در مورد مجموعه داده ها و پرس و جوها ایجاد می کنند تا تجزیه و تحلیل هزینه را آسان تر انجام دهند [ 19 ، 20 ]. بنابراین، به دلیل پیچیدگی روزافزون حجم کار سیستم های مدیریت پایگاه داده، دقت پیش بینی می تواند به طور جدی به چالش کشیده شود.
-
آنها سعی نمی کنند معیارهای هزینه بصری، مانند زمان CPU را پیش بینی کنند، و معیارهای مبتنی بر دیسک، مانند سربار دسترسی به دیسک را پیش بینی می کنند [ 11 ، 21 ]. با این حال، کاربران اغلب بیشتر نگران معیارهای هزینه قبلی هستند زیرا در عمل بیشترین تأثیر را بر تجربه کاربر دارند.
با انگیزه آن، ما روشی به نام CPRQ (C ost Prediction of Range Query) برای انجام پیشبینی زمان CPU پرسوجوهای محدوده در MOD پیشنهاد میکنیم. شکل 1معماری CPRQ را نشان می دهد. CPRQ از چند مرحله تشکیل شده است: جمعآوری داده، انتخاب و استخراج ویژگی، بردارسازی ویژگی، ساخت مدلهای پیشبینی، و پیشبینی مبتنی بر مدل. در ابتدا، ما یک مولد طرح پرس و جوی محدوده برای جمع آوری داده ها طراحی می کنیم. پس از استخراج ویژگی و برداری از پرس و جوهای محدوده، همه مدل های پیش بینی ساخته و آموزش داده می شوند تا رابطه بین ویژگی های پرس و جو و زمان CPU را تطبیق دهند. پس از تنظیم فراپارامترهای مدلهای پیشبینی در هنگام آموزش، از مدلهای یادگیری برای پیشبینی زمان CPU جستجوهای پیشبینینشده در آینده استفاده میشود. CPRQ از یک روش مبتنی بر یادگیری استفاده می کند که بر کاستی های ناشی از پیچیدگی تحلیل افزایش حجم کار غلبه می کند.
به طور خلاصه، مشارکت های اصلی ما به شرح زیر است:
-
ما مشکل پیشبینی پرسوجوهای محدوده را روی اشیاء متحرک رسمی میکنیم.
-
ما یک روش CPRQ برای پیشبینی زمان CPU کوئریهای محدوده پیشنهاد میکنیم. به طور خاص، ما ویژگی های پرس و جو را استخراج می کنیم و آنها را با استفاده از بردارها رمزگذاری می کنیم. یک مدل پیش بینی ساخته شده است.
-
ما مدل را در یک سیستم پایگاه داده توسعه پذیر SECONDO پیاده سازی می کنیم و آزمایش هایی را با استفاده از چهار مدل یادگیری انجام می دهیم: رگرسیون چند جمله ای، درخت تصمیم، جنگل تصادفی، KNN (k-نزدیک ترین همسایه). نتایج تجربی دقت بالای پیشبینی هزینه را برای پرسشهای محدوده نشان میدهد.
ادامه مقاله به شرح زیر تدوین شده است. ما شروع به بحث در مورد کارهای مرتبط در بخش 2 می کنیم. در بخش 3 ، ما تعریف مشکل را ارائه می کنیم. ما استخراج ویژگی، بردارسازی و ساخت مدل پیشبینی CPRQ را در بخش 4 ارائه میکنیم. ارزیابی تجربی بر اساس پیشبینی چهار مدل یادگیری در بخش 5 ارائه شده است . ما کار خود را در بخش 6 مورد بحث قرار می دهیم . ما مقاله را در بخش 7 به پایان می رسانیم .
2. کارهای مرتبط
پیش بینی هزینه یک موضوع داغ در زمینه سیستم های مدیریت پایگاه داده است. کارهای مرتبط قابل توجهی روی پیش بینی هزینه پرس و جو انجام شده است [ 22 ، 23 ، 24 ، 25 ]. این مطالعات عمدتاً به دو دسته کلاسیک طبقه بندی می شوند: روش های تحلیلی و روش های یادگیری. معیارهای مختلفی برای پیشبینی هزینه وجود دارد که برای روشهای تحلیلی و/یا روشهای یادگیری قابل استفاده است. در مرحله بعد، ابتدا معیارهای رایج برای پیشبینی هزینه را معرفی میکنیم، سپس مطالعات تحقیقاتی مرتبط با روشهای تحلیلی و روشهای یادگیری را بهطور جداگانه نشان میدهیم.
در سیستم های مدیریت پایگاه داده، معیارهای مختلفی برای ارزیابی هزینه پرس و جو در جنبه های مختلف استفاده می شود. برای مثال، محققان میتوانند با مدلسازی مقدار حافظه [ 26 ] و فضای دیسک مصرفشده [ 27 ] بر روی یک سیستم مدیریت پایگاه داده هدف، برآورد هزینه پرس و جو را به دست آورند . زمان CPU به طور گسترده ای به عنوان یک متریک هزینه استفاده می شود [ 28 ، 29 ]، که در مقایسه با سایر معیارها، بازخورد پرس و جو را به کاربران ارائه می دهد که بصری تر است. برای پشتیبانی مؤثر از دادههای غیر سنتی (مثلاً اجسام متحرک)، ساختارهای شاخص مختلفی در MODها پیشنهاد شدهاند. بنابراین، معیارهای هزینه زیادی بر اساس ساختار شاخص [ 30 ] وجود دارد، مانند تعداد دسترسی به دیسک [ 11 ، 31 ] وجود دارد.] و انتخاب گره های شاخص [ 32 ].
روش های تحلیلی تکنیک رایج برای انجام پیش بینی هزینه در سیستم های مدیریت پایگاه داده بوده است [ 33 ، 34 ]. این روش از تخصص موجود در سیستمهای مدیریت پایگاه داده بهره میبرد و دانش را در مدلهای ریاضی با هدف ثبت نحوه ترسیم رفتارهای پرس و جو بر روی هزینه پرس و جو رمزگذاری میکند [ 35 ]. سان و همکاران یک برآوردگر هزینه مبتنی بر یادگیری سرتاسر برای برآورد هزینه پیشنهاد کنید [ 36 ]. برآوردگر ابرداده، عملیات پرس و جو و محمول پرس و جو را در یک مدل رمزگذاری می کند. تئودوریدیس و همکاران تمرکز بر استخراج فرمول های تحلیلی بر اساس R-tree برای تخمین هزینه (از نظر دسترسی به گره و دیسک) انتخاب و پیوستن پرس و جوها در پایگاه داده های فضایی [ 19 ]]. برخی از روش های تحلیلی برای کمک به تجزیه و تحلیل هزینه پرس و جو به بهینه ساز متوسل می شوند [ 20 ]. به عنوان مثال، مارکل و همکاران. یک بهینه ساز یادگیری LEO برای تخمین هزینه ارائه کنید [ 28 ]، که از یک حلقه بازخورد از آمار پرس و جو استفاده می کند.
روش های تحلیلی معمولاً بر فرضیات ساده شده در مورد نحوه اجرای پرس و جوها متکی هستند. بنابراین، ممکن است در سناریوهای واقعی که در آن چنین مفروضاتی مطابقت ندارند، صحت به چالش کشیده شود.
روش های یادگیری در طرف مقابل طیف قرار دارند، با توجه به اینکه نیاز به دانش کمی در مورد رفتار داخلی سیستم های مدیریت پایگاه داده هدف دارند. روش های یادگیری، سیستم مدیریت پایگاه داده را به عنوان یک جعبه سیاه در نظر می گیرند و برای استنتاج یک مدل رفتاری آماری بر رفتار واقعی تکیه می کنند [ 35 ]. با ظهور فناوری یادگیری ماشینی، دانشمندان بیشتر و بیشتری از فناوری های یادگیری برای پیش بینی هزینه استفاده می کنند [ 22 , 37 ]]. دو دلیل اصلی برای این روند وجود دارد. از یک طرف، پیچیدگی روزافزون سیستم های مدیریت پایگاه داده مدرن نشان دهنده حجم کار روزافزون برای ساخت مدل هزینه روش های تحلیلی است. از سوی دیگر، روش های تحلیلی مبتنی بر تجربه و دانش حرفه ای دیگر نمی تواند الزامات دقت را برآورده کند.
مطالعات زیادی در مورد پیشبینی هزینه بر اساس روشهای یادگیری ماشینی انجام شده است [ 38 ، 39 ]. روش های یادگیری به طور گسترده ای مورد استفاده قرار می گیرند، از جمله مدل های رگرسیون لجستیک [ 40 ]، مدل های جنگل تصادفی [ 37 ] و غیره Akdere et al. از یک ماشین بردار پشتیبان برای ساخت یک مدل پیشبینی جداگانه برای هر عملگر فیزیکی استفاده کنید و سپس نتایج پیشبینی آنها را برای ارزیابی زمان پرس و جو ترکیب کنید [ 41 ]. گوپتا و همکاران از درخت طبقه بندی باینری برای پیش بینی بازه زمانی تاخیر اجرای پرس و جو استفاده کنید. آنها تعامل و همزمانی پرس و جو را در نظر می گیرند [ 42]. علاوه بر استفاده از یک مدل واحد برای یادگیری رفتار پرس و جو، برخی از محققان سعی می کنند چندین روش یادگیری ماشینی را ارزیابی کنند. برای مثال ملاکار و همکاران. 11 روش یادگیری ماشینی را برای مدل سازی رفتار پرس و جو ارزیابی کنید [ 43 ].
روش های یادگیری برای مشکل پیش بینی هزینه امیدوار کننده هستند. با این حال، دقتی که آنها می توانند به آن دست یابند به شدت به بازنمایی مجموعه داده های مورد استفاده در مرحله آموزش اولیه بستگی دارد.
3. مقدماتی
ما پرس و جوی محدوده را در MOD ها رسمی می کنیم و ساختار شاخص SETI را که برای سرعت بخشیدن به اجرای پرس و جو استفاده می شود، معرفی می کنیم.
3.1. پرس و جوی محدوده
تعریف 1 (پرس و جوی محدوده).
با توجه به مجموعه ای از اجسام متحرک O، یک پنجره پرس و جو مستطیلی R، یک بازه زمانی تی=[تیل،تیr](تیل≤تیr)، یک جستجوی محدوده برمی گردد O”∈Oبه طوری که ∀o”∈O”:∃تی∈تی، o”R را در t قطع می کند.
ما از یک مثال برای نشان دادن پرس و جوهای محدوده استفاده می کنیم.
مثال 1.
سیستم مدیریت داده های یک شرکت لجستیکی خاص، اطلاعات چندین خودروی سریع السیر، از جمله اطلاعات مکان و اطلاعات زمان هر خودرو را هر روز ذخیره می کند. یک توزیع کننده خودرو می خواهد اطلاعات خودروهای سریع السیر را در پنجاه مایلی منطقه محلی برای ارسال لجستیک بازیابی کند. اجازه دهید Oبjساطلاعات چند خودروی سریع السیر، O اطلاعات یک خودرو، و t مهر زمانی یک خودرو در زمان رسیدن تا زمان حرکت باشد. R یک پنجره پرس و جو فضایی، متشکل از یک دایره با شعاع 50 مایلی از توزیع کننده را نشان می دهد. توزیع کننده بازه زمانی را تعیین می کند تی=[تیل،تیr](تیل≤تیr). پرس و جو محدوده را می توان به صورت زیر نوشت: اطلاعات O را برای هر خودرو از مجموعه اطلاعات بازگردانید Oبjساز چندین اتومبیل سریع، که در آن O اطمینان می دهد که یک مهر زمانی وجود دارد تی∈تیبه طوری که O در مهر زمان t با R قطع یا همپوشانی می کند.
3.2. SETI
ما پیش بینی هزینه پرس و جوهای محدوده را بر اساس ساختار شاخصی به نام SETI (شاخص مسیر مقیاس پذیر و کارآمد) انجام می دهیم [ 44 ]. ما زمان CPU را بهعنوان هزینه اجرا تعیین میکنیم، زیرا هزینه اجرای منطقی برای اثرات پرسوجو در مقایسه با یک معیار فیزیکی برای تجربه کاربر، شهودی است. SETI از یک ساختار دو سطحی ساده برای جدا کردن نمایه سازی بعد مکانی و زمانی استفاده می کند. این مکانیسم بازیابی داده ها را نه تنها برای نمایه سازی مکانی، بلکه برای نمایه سازی زمانی بسیار کارآمد می کند. علاوه بر این، SETI این مزیت را دارد که یک ساختار نمایهسازی منطقی است که میتواند به راحتی بر ساختارهای نمایهسازی فضایی رایج مانند R-tree ساخته شود.
به طور خاص، SETI اشیاء فضایی را به تعدادی سلول فضایی غیر همپوشانی تقسیم میکند. یک سلول شامل بخش های مسیری است که به طور کامل در داخل سلول قرار دارند. هر بخش مسیر به صورت یک تاپل در یک فایل داده ذخیره میشود و صفحه داده فقط بخشهای مسیری را که به سلول فضایی یکسانی تعلق دارند نگهداری میکند. حداقل فاصله زمانی هر صفحه داده نشان دهنده بازه های زمانی تمام بخش های مسیر ذخیره شده در صفحه است. بازه های زمانی همه صفحات با استفاده از یک ساختار نمایه مانند R نمایه می شوند ∗-درخت این شاخصهای زمانی، شاخصهای پراکنده هستند، زیرا به جای یک ورودی برای هر بخش، تنها یک ورودی برای هر صفحه داده وجود دارد. اجسام متحرک معمولاً به ترتیب زمانی ذخیره می شوند. این ویژگی باعث می شود که SETI در هنگام بازیابی اشیاء متحرکی که با محدوده زمانی مشخص شده در یک پرس و جو همپوشانی دارند، از سایر ساختارهای شاخص بهتر عمل کند.
یک پرس و جو محدوده توسط یک جعبه پرس و جو سه بعدی، شامل یک جعبه گزاره زمانی و یک محدوده گزاره زمانی تشکیل می شود. بنابراین، دو مرحله برای انجام جستجوهای محدوده با استفاده از SETI وجود دارد: فیلتر مکانی و فیلتر زمانی . فیلتر فضایی برای انتخاب پارتیشنهای فضایی کاندید که با کادر محمول فضایی همپوشانی دارند اعمال میشود. فیلتر زمانی برای استخراج صفحات داده ای که طول عمر آنها با پیش بینی زمان همپوشانی دارد، استفاده می شود.
4. CPRQ
CPRQ یک تکنیک یادگیری آزمایش محور است که از دو مرحله اصلی تشکیل شده است: آموزش و آزمایش. در مرحله آموزش، مدل های پیش بینی از مجموعه داده های آموزشی به دست می آید که به صورت مجموعه ای از بردارهای ویژگی نمایش داده می شود. در مرحله آزمایش، مدلهای پیشبینی برای پیشبینی زمان CPU کوئریهای محدوده استفاده میشوند.
در این بخش، ابتدا ویژگی های پرس و جوی محدوده را تجزیه و تحلیل می کنیم، سپس ویژگی ها را در بردارها رمزگذاری می کنیم. در مرحله دوم، روش مدل سازی را معرفی می کنیم.
4.1. استخراج ویژگی و رمزگذاری
ابتدا ویژگی های طرح های پرس و جو را استخراج می کنیم و سپس ویژگی ها را در بردارها رمزگذاری می کنیم. چهار عامل اصلی بر هزینه پرس و جو تأثیر می گذارد، از جمله عملیات پرس و جو فیزیکی، محمول پرس و جو فضایی، محمول پرس و جو زمانی و داده. این ویژگی ها ویژگی های کلی پرس و جوهای محدوده هستند و برای استخراج ویژگی تقریباً تمام پرس و جوهای محدوده در سیستم های مدیریت پایگاه داده شی متحرک مختلف قابل استفاده هستند.
عملیات: عملیات ها عملگرهای فیزیکی هستند که در طرح های پرس و جو به کار می روند و عملیات های مختلف می توانند به طور قابل توجهی بر هزینه پرس و جو تأثیر بگذارند. را در نظر می گیریم منnتیهrسهجتیدبلیومنnدowو منnسمندهدبلیومنnدowاپراتورها بر اساس ساختار شاخص SETI. منnتیهrسهجتیدبلیومنnدowتمام بخش های مسیری که با پنجره جستجو تلاقی می کنند را برمی گرداند و منnسمندهدبلیومنnدowتمام بخش های مسیر را در پنجره جستجو برمی گرداند. هر عملیات را می توان به عنوان یک بردار تک داغ کدگذاری کرد.
رمزگذاری تک داغ [ 45 ] که به عنوان رمزگذاری موثر یک بیتی نیز شناخته می شود، از ثبات های N-bit برای کدگذاری N مقدار مختلف ویژگی استفاده می کند. هر مقدار دارای یک بیت ثبت مستقل است و تنها یک بیت ثبت در هر زمان معتبر است. به طور خاص، اگر مقدار ویژگی دارای m مقادیر مشخصه گسسته باشد، مشخصه بعد از عملیات رمزگذاری یک گرم یک بردار m بعدی است و ویژگی هر نمونه فقط می تواند یک مقدار داشته باشد، یعنی مختصات برداری مقدار است. 1 و بقیه 0 هستند.
محمول:یک گزاره یک فیلتر در یک پرس و جو است. گزارهها بر هزینههای پرس و جو تأثیر میگذارند، زیرا تعداد تاپلهایی که باید بازیابی شوند، با اعمال گزارههای مختلف تغییر میکند. یک پرس و جوی محدوده فقط یک بار انجام می شود، اما زمان CPU یک پرس و جو از کل زمان اجرا مشتق می شود، از جمله زمان فیلتر مکانی و زمان فیلتر زمانی. SETI از یک ساختار شاخص دو لایه برای جداسازی ابعاد زمانی و مکانی استفاده میکند، بنابراین محمولها را به دو بخش تقسیم میکنیم: محمولات مکانی و زمانی. برای طرح پرس و جو، یک گزاره فضایی یک مقدار عددی است و ما آن را با استفاده از اعداد ممیز شناور نرمال شده رمزگذاری می کنیم. برای گزاره زمانی، ابتدا کل بازه زمانی مجموعه داده ای را که باید بازیابی شود به دوره های زمانی مختلف تقسیم می کنیم و تعداد آیتم های داده در هر بخش تقریباً یکسان است. سپس،
داده ها: داده ها مجموعه ای از مجموعه داده های اشیاء متحرک هستند. به طور کلی، برای همان عملیات پرس و جو و محمول، هرچه مجموعه داده بزرگتر باشد، سربار محاسباتی و زمان پرس و جو متحمل می شود. ما از کدگذاری تک بیتی n برای نشان دادن n مجموعه داده استفاده می کنیم که هر کدام مربوط به یک بیت مهم است و بقیه بیت ها 0 هستند.
شکل 2 نمونه ای از استخراج و کدگذاری ویژگی را نشان می دهد. طرح پرس و جو ” پرسش Obj IntersectWindow (SETIRect QueryRect 2011-11-30-12:00 2011-11-30-13:00) ” است، جایی که شی متحرک تنظیم می شود oبjشامل 2.5 میلیون نقطه داده، اپراتور است منnتیهrسهجتیدبلیومنnدow، اندازه پنجره SETI 400.0 و اندازه پنجره پرس و جو فضایی 100.0 است. طرح پرس و جو هر شی را در مجموعه شی متحرک برمی گرداند Oبjنمایه شده توسط SETI اسEتیمنآرهجتی، جایی که شی مورد نظر با پنجره پرس و جو مستطیلی فضایی تلاقی می کند ستوهryآرهجتیو فاصله زمانی 1390-11-30-12:00 تا 2011-11-30-13:00 . ما از رمزگذاری یک داغ برای رمزگذاری مجموعه داده ها و محمول استفاده می کنیم. به طور خاص، مجموعه داده در مثال شامل سه مجموعه داده فرعی است: 1.1 میلیون نقطه داده (1.1 M)، 2.5 میلیون نقطه داده (2.5 M) و 4.5 میلیون نقطه داده (4.5 M). سپس، می توانیم 2.5 M را که در مثال استفاده می کنیم، به عنوان 010 رمزگذاری کنیم. برای عملگر منnتیهrسهجتیدبلیومنnدowو منnسمندهدبلیومنnدow، برای رمزگذاری از یک بیت 0 و 1 استفاده می کنیم. برای محمول زمانی، ابتدا بازه زمانی مجموعه داده ای را که باید بازیابی شود به دوره های زمانی تقسیم می کنیم و تعداد آیتم های داده در هر دوره زمانی یکسان است. سپس، از رمزگذاری تک داغ برای رمزگذاری گزاره زمانی که در یک بازه زمانی معین قرار میگیرد، استفاده میکنیم. به طور خاص، اگر بازه زمانی از Oبj2011-11-30-07:00 2011-11-30-19:00 است و مرحله اطمینان از تعداد یکسان داده ها یک ساعت است، سپس 2011-11-30-07:00 را به 000000000001 و 2011 کدگذاری می کنیم. -11-30-19:00 تا 10000000000. بنابراین کدگذاری بازه زمانی 2011-11-30-12:00 2011-11-30-13:00 برای بازیابی در طرح استعلام 000000100000 می باشد.
ما از یک پایگاه داده شی متحرک مبتنی بر ماژول های جبری برای اجرای پرس و جو و جمع آوری داده ها استفاده می کنیم، بنابراین بردار ویژگی ماژول های جبری را می سازیم. ما یک مولد طرح پرس و جو برای تولید قالب های پرس و جو طراحی می کنیم. مولد طرح پرس و جو، حرکت اشیاء را در یک فضای دوبعدی با ویژگی های پرس و جو شبیه سازی می کند و هر قالب حاوی چندین مکان نگهدار است. یک ویژگی مربوط به یک مکان نگهدار در یک الگو است. جایگیرها را می توان با یک مقدار خاص جایگزین کرد. پرس و جوی محدوده به پرس و جوی اطلاق می شود که در آن متغیرهای مختلفی نمونه سازی می شوند.
4.2. مدل سازی
در این مقاله، ما یک پیشبینی هزینه انجام میدهیم که در آن زمان متریک هزینه CPU یک عدد واقعی است. یعنی، ما یک مشکل رگرسیون را در نظر می گیریم. اکنون به بررسی این میپردازیم که کدام نوع مدل رگرسیون را از نمونههای جمعآوریشده آموزش دهیم. فنآوریهای یادگیری ماشینی انواع مدلهای کاندید زیادی را ارائه میکنند، مانند مدل رگرسیون جنگل تصادفی، که برخی از آنها در کارهای قبلی در مورد پیشبینی هزینه پرس و جو مورد استفاده قرار گرفتند. انتخاب مدل های ما توسط دو عامل کلیدی بین سناریوی مشکل ما و سناریوهای قبلی هدایت می شود. اولاً، مدل می تواند خطاها را برای مجموعه داده های نامتعادل متعادل کند. ثانیاً، زمانی که تعداد ویژگیها و نمونهها خیلی زیاد نباشد، مدل میتواند دقت را حفظ کند. انواع ساده مدل یادگیری مبتنی بر نمونه عبارتند از رگرسیون چند جمله ای، درخت تصمیم، جنگل تصادفی و KNN با فاصله اقلیدسی. بعد،
رگرسیون چند جمله ای: یک نقطه شروع ساده رگرسیون خطی است. رگرسیون خطی به این معنی است که رابطه بین متغیرهای وابسته و متغیرهای مستقل خطی است. با این حال، اغلب بیش از یک متغیر مستقل وجود دارد که بر متغیر وابسته تأثیر می گذارد. مطالعه بین یک متغیر وابسته و یک یا چند متغیر مستقل را رگرسیون چند جمله ای می نامند. ما پیشبینی زمان CPU را برای پرس و جوی محدوده انجام میدهیم، یعنی متغیر پیشبینیشده تنها یک است، بنابراین متغیر وابسته زمان CPU است و متغیر مستقل شامل چندین ویژگی پرسوجو (عملیات، محمول و داده) است. با توجه به اینکه زمان CPU تحت تأثیر چندین ویژگی پرس و جو قرار می گیرد، ما از مدل رگرسیون چند جمله ای استفاده می کنیم.
درخت تصمیم: مدل رگرسیون درخت تصمیم یک مدل پیش بینی را در قالب یک ساختار درختی می سازد. مدل از چندین گره قضاوت تشکیل شده است. هر گره دارای دو یا چند شاخه است که مقادیر مشخصه آزمایش شده را نشان می دهد. هر گره داخلی حاوی تستی است که از قوانین if-else استفاده می کند تا مشخص کند که گره از کدام شاخه پیروی می کند. یک گره برگ نشان دهنده یک تصمیم در مورد هدف عددی است. بالاترین گره در درخت تصمیم، گره ریشه ای است که با بهترین پیش بینی مطابقت دارد. مقاله زمان CPU اجرای پرس و جو را پیش بینی می کند. ما مدل رگرسیون درخت تصمیم را با استفاده از بسته اسکلرن مدل DecisionTreeRegression پایتون می سازیم.
جنگل تصادفی: پیشرفت های مهم در دقت مدل از رشد مجموعه ای از درختان با درخواست از آنها برای رای دادن به مقدار پیش بینی شده در مدل رگرسیون جنگل تصادفی نشات گرفته است. یک جنگل تصادفی با گرفتن نمونه های مختلف از مجموعه داده های اصلی و سپس ترکیب خروجی های آنها، درختان رگرسیون ضعیف مختلف را ترکیب می کند. بنابراین، مدل رگرسیون پیشبینیکننده جنگل تصادفی، یک متا تخمینگر است که برخی درختهای رگرسیون را برای هر زیر نمونه از مجموعه داده برازش میدهد. علاوه بر این، مدل جنگل تصادفی از مقدار متوسط برای بهبود دقت پیشبینی و کنترل بیش از حد برازش استفاده میکند. مدل رگرسیون جنگل تصادفی، RandomForestRegressor، که ما استفاده کردیم توسط بسته sklearn پایتون ساخته شده است. مدل با مقادیر پیش فرض شروع می شود.
KNN: KNN k-نزدیکترین همسایه است، به این معنی که هر نمونه را می توان با k-نزدیکترین همسایه خود نشان داد. KNN زمان CPU را بر اساس k-نزدیکترین همسایگان نمونه جستجوی محدوده پیش بینی می کند. ما فاصله اقلیدسی را در فضای ویژگی برای تعیین زمان CPU در نظر می گیریم. ساختمان مدل KNN از دو مرحله تشکیل شده است. اولین گام این است که k نقطه های نزدیک به گره مورد پیش بینی را پیدا کنید. مرحله دوم این است که مقدار میانگین k گره ها را به عنوان مقدار پیش بینی شده نقطه پیش بینی شده در نظر بگیرید. ما مدل پیشبینی را با استفاده از رگرسیون KNN پایتون KNeighborsRegressor با مقادیر پیشفرض میسازیم. پس از تنظیم هایپرپارامترهای مدل، از مدل رگرسیون KNN برای پیش بینی زمان CPU استفاده می شود.
5. ارزیابی تجربی
5.1. برپایی
ارزیابی در یک سیستم پایگاه داده توسعه پذیر SECONDO [ 46 ] انجام می شود که از پرس و جوهای محدوده روی اشیاء متحرک پشتیبانی می کند. SECONDO توسط ماژول های جبر مقیاس پذیر است و رابط کاربری دوستانه ای دارد. کاربران می توانند ساختارهای داده و مدل های داده را توسعه دهند و آنها را در SECONDO ادغام کنند.
ما آزمایشها را روی سرور 64 بیتی اوبونتو 14.04 با پردازنده Intel Xeon(R) 1.90 گیگاهرتز، 31 گیگابایت رم سیستم و سیستمعامل لینوکس 4.4.0-31 انجام میدهیم. همه پرس و جوهای محدوده در SECONDO با یک مدل کاربر واحد اجرا می شوند و اندازه کش 512 مگابایت تنظیم شده است.
5.2. مجموعه داده ها و حجم کار
مجموعه داده های تجربی، مسیرهای تاکسی واقعی در پکن هستند که از [ 47 ] استخراج شده اند. جدول 1 آمار داده ها را نشان می دهد. مجموعه داده ها حاوی سوابق GPS از 10357 تاکسی از 2 فوریه تا 8 فوریه 2008 در پکن است. تعداد کل رکوردهای GPS حدود 15 میلیون و مسافت کل مسیرها به 9 میلیون کیلومتر می رسد. جدول 2 نمونه خاصی از مجموعه داده ها را نشان می دهد.
ما از مولد طرح پرس و جو بالا برای ایجاد موارد تست پرس و جو استفاده می کنیم. طرح پرس و جو یک الگو با یک زیرمجموعه خاص، یک محمول پرس و جوی خاص و یک داده خاص است که با مقادیر معینی برای تولید نمونه های پرس و جو نمونه سازی می شود. ما از سه مجموعه داده برای جمع آوری داده های آموزشی و آزمایشی استفاده می کنیم که شامل 1.1 میلیون، 2.5 میلیون و 4.5 میلیون نقطه داده است. برای سرعت بخشیدن به اجرای پرس و جو، از ساختار شاخص SETI استفاده می کنیم. ما SETI را بر اساس R-tree در آزمایش ها پیاده سازی می کنیم. ما هر طرح پرس و جو را سه بار اجرا می کنیم و میانگین زمان CPU را بر حسب ثانیه ثبت می کنیم. این کوئری ها حداقل یک نتیجه را نشان می دهند و در عرض یک ساعت اجرا می شوند.
جدول 3 جزئیات داده های آموزش و آزمایش را نشان می دهد. تقریباً 4117 پرس و جو از هر مجموعه داده وجود دارد. ما در مجموع 12350 رکورد به دست می آوریم و میانگین زمان CPU 3.3405 ثانیه است. شکل 3 توزیع زمان CPU 12350 رکورد را نشان می دهد. ما داده های جمع آوری شده را به دو زیرمجموعه مجزا تقسیم می کنیم: 70% برای داده های آموزشی، یعنی 8771 رکورد. و 30 درصد برای داده های آزمایشی، یعنی 3759 رکورد. ما از اعتبارسنجی متقاطع k -fold در مجموعه آموزشی استفاده می کنیم، جایی که k روی 5 تنظیم شده است. میانگین زمان CPU داده های آموزشی 3.3209 ثانیه است. شکل 4 توزیع زمان CPU مجموعه داده های آموزشی را نشان می دهد. میانگین زمان CPU داده های آزمایشی 3.3622 ثانیه است. شکل 5توزیع زمان CPU مجموعه داده های آزمایشی را نشان می دهد. ما از قالب طرح پرس و جو برای تولید نمونه های پرس و جو استفاده می کنیم. بنابراین، این خوشه هایی که در شکل 3 ، شکل 4 و شکل 5 ظاهر می شوند، نشان می دهند که ویژگی های پرس و جو مشابه هستند. به عنوان مثال، تنها با تغییر گزاره فضایی در قالب های پرس و جو، این پرس و جوها ویژگی های پرس و جو مشابهی دارند.
5.3. معیارها و اعتبارسنجی
ما از R-squared و MSE (میانگین مربعات خطا) به عنوان معیار خطا برای اندازه گیری دقت مدل های یادگیری استفاده می کنیم. R-squared یک معیار ارزیابی پرکاربرد برای ارزیابی مدلهای پیشبینی است که نزدیک به 1 است که نشاندهنده پیشبینی تقریباً کامل است. برای MSE، هرچه MSE کوچکتر باشد، دقت پیشبینی بهتر است. R-squared و MSE با استفاده از معادله زیر محاسبه می شوند که در آن yمنمقدار هدف حقیقت پایه برای نمونه i در مجموعه داده است، yمن¯میانگین است yمن، و yمن^مقدار پیش بینی شده مربوطه را برای نمونه مورد نظر نشان می دهد.
آر-سqتوآrهد=1-∑من=1متر(yمن^-yمن)2∑من=1متر(yمن¯-yمن)2
ماسE=1n∑من=1متر(yمن^-yمن)2
5.4. عملکرد مدل های یادگیری
ما دقت پیشبینی چهار مدل رگرسیون را ارزیابی میکنیم: رگرسیون چند جملهای (PM)، درخت تصمیم (DT)، جنگل تصادفی (RF)، و KNN. هنگام آموزش این چهار مدل، ما فراپارامترها را تنظیم می کنیم تا هر مدل را با بالاترین دقت به دست آوریم و سپس دقت پیش بینی چهار مدل را در مجموعه داده های آزمایشی مقایسه می کنیم.
جدول 4 پارامترهای فوق العاده ای را که هنگام آموزش مدل رگرسیون تنظیم می کنیم نشان می دهد: PM، DT، RF و KNN. برای مدل رگرسیون PM، دهgrههبرای تعیین ترتیب چند جمله ای مورد استفاده در رگرسیون چند جمله ای حاصل استفاده می شود. زمانی بهترین امتیاز را به دست می آوریم دهgrهه3 است. برای مدل های رگرسیون DT و RF، مترآایکس_دهپتیساعتحداکثر عمق درخت تصمیم را تعیین می کند. بهترین امتیاز زمانی به دست می آید که مترآایکس_دهپتیساعتدر مدل های رگرسیون DT و RF به ترتیب 9 و 9 می شود. ما فراپارامتر k را برای مدل رگرسیون KNN تنظیم می کنیم و k را روی 4 تنظیم می کنیم. شکل 6 تنظیم فراپارامترهای RF و k را در مدل های رگرسیون RF و KNN نشان می دهد.
نتایج مقایسه تجربی چهار مدل در شکل 7 و شکل 8 نشان داده شده است. در شکل 7 و شکل 8 ، متوجه می شویم که مقادیر R-squared همه بیشتر از 0.8 و مقادیر MSE همه کمتر از 1 مدل هستند. نتایج تجربی نشان میدهد که بین زمان CPU و رفتار پرسوجوی محدوده پرس و جو همبستگی وجود دارد. علاوه بر این، مدلهای یادگیری ماشینی با CPRQ میتوانند همبستگی را پیدا کنند و پیشبینی برآورد هزینه را به خوبی انجام دهند.
به طور خاص، مدل PM حداقل مقدار R-squared (0.8919) و حداکثر مقدار MSE (0.545) را به دست می آورد، که نشان دهنده نتیجه پیش بینی نسبتا ضعیف در مقایسه با سه مدل دیگر است. مقادیر R-squared و MSE مدل DT و RF تقریباً به همان روش با مقادیر برابر با 0.9649، 0.174 و 0.9695، 0.154 عمل می کنند. حداکثر مقدار مربع R و حداقل مقدار MSE نشان می دهد که مدل RF با بهترین دقت پیش بینی عمل می کند.
6. بحث
ما یک فناوری، CPRQ، برای پیشبینی هزینه جستجوی محدوده در سیستم مدیریت پایگاه داده شی متحرک با مدلسازی رفتار پرس و جو و زمان CPU، و ارزیابی تجربی چهار مدل رگرسیون با CPRQ پیشنهاد میکنیم. برای کارهای آینده، ما می خواهیم به برخی از کاستی هایی که در تحقیق ما وجود دارد، بپردازیم. یکی از محدودیت های اصلی CPRQ این است که این مدل زمان CPU را برای پرس و جوهای محدوده پیش بینی می کند در حالی که انواع مختلفی از پرس و جوها در مدیریت پایگاه داده شی متحرک وجود دارد. ما فناوری را برای گسترش سازگاری مدل با ادغام انواع مختلف پرس و جو برای پیش بینی هزینه پرس و جو تحت عملیات پرس و جو مختلف مطالعه می کنیم. یکی دیگر از معایب این است که CPRQ روشی مبتنی بر پیشرفت آموزش آفلاین است. مدلهای آفلاین میتوانند هزینههای پرس و جو را بهطور دقیق پیشبینی کنند، اما هرگونه پیشبینی نوع داده جدید باید مدل را دوباره آموزش دهد. ما یک کار در حال انجام برای یادگیری هزینه اجرای عملیات پرس و جو در زمان واقعی داریم که می تواند به صورت پویا دقت پیش بینی مدل را بهبود بخشد. بنابراین این موضوع در آینده نزدیک حل خواهد شد.
7. نتیجه گیری
پیش بینی هزینه های پرس و جو به مدیران پایگاه داده کمک می کند تا به طور موثر استراتژی های زمان بندی منابع بهینه را انجام دهند. این مقاله یک فناوری CPRQ را پیشنهاد میکند که با مدلسازی رفتار پرس و جو و زمان CPU، هزینه پرسوجوهای محدوده را در سیستم مدیریت پایگاه داده شی متحرک پیشبینی میکند. CPRQ ابتدا ویژگی های پرس و جو را استخراج می کند، ویژگی ها را در بردارها رمزگذاری می کند، و سپس مدل های یادگیری را متناسب با بردارها می سازد. ما یک روش استخراج ویژگی برای پرسشهای محدوده طراحی کردیم و چهار مدل رگرسیون را با CPRQ ارزیابی کردیم: مدل رگرسیون چند جملهای، مدل رگرسیون درخت تصمیم، مدل رگرسیون جنگل تصادفی، و مدل رگرسیون KNN.
ما از R-squared و MSE برای ارزیابی دقت پیشبینی مدل استفاده کردیم. R-squared و MSE مدل رگرسیون چند جمله ای، مدل رگرسیون درخت تصمیم، مدل رگرسیون جنگل تصادفی و مدل رگرسیون KNN به ترتیب 0.8919 و 0.545، 0.9649 و 0.174، 0.9695 و 0.154، 0.9333 و 0.25 بود. مدل رگرسیون جنگل تصادفی بالاترین دقت پیش بینی را به دست آورد. مقادیر R-squared چهار مدل بالای 0.89 و مقادیر MSE همه در داخل 0.6 بودند. نتایج تجربی نشان میدهد که CPRQ میتواند زمان CPU جستجوهای محدوده را به دقت پیشبینی کند.
منابع
- گوتینگ، RH; Schneider, M. Moving Object Databases ; الزویر: آمستردام، هلند، 2005. [ Google Scholar ]
- دینگ، ز. یانگ، بی. گوتینگ، RH; Li, Y. پایگاه داده شی متحرک مبتنی بر مسیر منطبق بر شبکه: مدل ها و برنامه ها. IEEE Trans. هوشمند ترانسپ سیستم 2015 ، 16 ، 1918-1928. [ Google Scholar ] [ CrossRef ]
- دینگ، ز. Guting، RH مدیریت اجسام متحرک در شبکه های حمل و نقل پویا. در مجموعه مقالات شانزدهمین کنفرانس بین المللی مدیریت پایگاه داده های علمی و آماری، جزیره سانتورینی، یونان، 21 تا 23 ژوئن 2004. ص 287-296. [ Google Scholar ]
- کهن، م. Ale, JM کشف تراکم ترافیک از طریق الگوهای جریان ترافیک ایجاد شده توسط مسیر حرکت اجسام. محاسبه کنید. محیط زیست سیستم شهری 2020 , 80 , 101426. [ Google Scholar ] [ CrossRef ]
- وانگ، اچ. Zimmermann, R. پردازش پرس و جوهای محدوده مبتنی بر مکان پیوسته بر روی اجسام متحرک در شبکه های جاده ای. IEEE Trans. بدانید. مهندسی داده 2010 ، 23 ، 1065-1078. [ Google Scholar ] [ CrossRef ]
- Iwerks، GS; صامت، ح. اسمیت، K. جستارهای پیوسته k-نزدیکترین همسایه برای نقاط متحرک پیوسته همراه با به روز رسانی. در مجموعه مقالات کنفرانس VLDB 2003، برلین، آلمان، 9 تا 12 سپتامبر 2003. صص 512-523. [ Google Scholar ]
- کائودی، ز. Quiané-Ruiz، JA; کنتراس روخاس، بی. پردو مزا، ر. ترودی، ع. Chawla، S. ML-based پرس و جو بهینه سازی چند پلت فرم. در مجموعه مقالات سی و ششمین کنفرانس بین المللی مهندسی داده IEEE 2020 (ICDE)، دالاس، TX، ایالات متحده، 20-24 آوریل 2020؛ صفحات 1489-1500. [ Google Scholar ]
- بورداکوف، AV; پرولتارسایا، وی. پلوتنکو، AD; ارماکوف، او. گریگورف، UA پیش بینی زمان اجرای پرس و جوی SQL با مدل هزینه برای پلتفرم Spark. IoTBDS 2020 ، 279-287. [ Google Scholar ] [ CrossRef ]
- صدیقی، ت. جیندال، ا. کیائو، اس. پاتل، اچ. Le, W. مدلهای هزینه برای پردازش پرس و جو دادههای بزرگ: یادگیری، مقاومسازی و یافتههای ما. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2020 در مدیریت داده ها، پورتلند، OR، ایالات متحده آمریکا، 14 تا 19 ژوئن 2020؛ صص 99-113. [ Google Scholar ]
- نگی، پ. مارکوس، آر. مائو، اچ. تتبول، ن. کراسکا، تی. Alizadeh, M. Cost-guided cardinality estimation: تمرکز روی جایی که اهمیت دارد. در مجموعه مقالات سی و ششمین کنفرانس بین المللی IEEE 2020 در کارگاه های مهندسی داده (ICDEW)، دالاس، تگزاس، ایالات متحده آمریکا، 20 تا 24 آوریل 2020؛ صص 154-157. [ Google Scholar ]
- پاپادوپولوس، آ. Manolopoulos, Y. عملکرد پرس و جوهای نزدیکترین همسایه در درختان R. در کنفرانس بین المللی نظریه پایگاه داده ; Springer: برلین/هایدلبرگ، آلمان، 1997; صص 394-408. [ Google Scholar ]
- محمد، س. هریس، EP; Ramamohanarao، K. بازیابی محدوده کارآمد پرس و جو برای توزیع های غیر یکنواخت داده. در مجموعه مقالات یازدهمین کنفرانس پایگاه داده استرالیا، ADC 2000 (شماره گربه PR00528)، کانبرا، استرالیا، 31 ژانویه – 3 فوریه 2000. ص 90-98. [ Google Scholar ]
- مک کارتی، ام. او، ز. Wang, XS ارزیابی پرس و جوهای محدوده با محمولات در اشیاء متحرک. IEEE Trans. بدانید. مهندسی داده 2013 ، 26 ، 1144-1157. [ Google Scholar ] [ CrossRef ]
- گوراوسکی، م. Bugdol، M. مدل هزینه برای X-BR-tree. در روندهای جدید در انبار داده و تجزیه و تحلیل داده ها ; Springer: برلین/هایدلبرگ، آلمان، 2009; صص 1-14. [ Google Scholar ]
- جی، ایکس. می، اچ. یانگ، اف. شائو، ز. Pan, J. ارزیابی هزینه و بهبود الگوریتم درج درخت سل. جی. کامپیوتر. روشهای علمی. مهندس 2018 ، 18 ، 445-458. [ Google Scholar ] [ CrossRef ]
- Guttman، A. R-trees: ساختار شاخص پویا برای جستجوی فضایی. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 1984 در مدیریت داده ها، بوستون، MA، ایالات متحده آمریکا، 18-21 ژوئن 1984. ص 47-57. [ Google Scholar ]
- سلیس، تی. روسووپولوس، ن. فالوتسوس، سی. R+-Tree: یک شاخص پویا برای اشیاء چند بعدی. در مجموعه مقالات سیزدهمین کنفرانس بین المللی پایگاه های داده بسیار بزرگ، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 1 تا 4 سپتامبر 1987. [ Google Scholar ]
- بکمن، ن. کریگل، اچ پی؛ اشنایدر، آر. Seeger, B. R*-tree: یک روش دسترسی کارآمد و قوی برای نقاط و مستطیل ها. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 1990 در مدیریت داده ها، آتلانتیک سیتی، نیوجرسی، ایالات متحده آمریکا، 23-25 مه 1990. صص 322-331. [ Google Scholar ]
- تئودوریدیس، ی. استفاناکیس، ای. Sellis, T. مدل های هزینه کارآمد برای پرس و جوهای فضایی با استفاده از درختان R. IEEE Trans. بدانید. مهندسی داده 2000 ، 12 ، 19-32. [ Google Scholar ] [ CrossRef ]
- لان، اچ. بائو، ز. پنگ، ی. نظرسنجی در مورد پیشرفت بهینه ساز پرس و جوی DBMS: تخمین کاردینالیتی، مدل هزینه، و شمارش طرح. اطلاعات علمی مهندس 2021 ، 6 ، 86-101. [ Google Scholar ] [ CrossRef ]
- جیتکاجورنوانیچ، ک. شلوار، ن. فولادگر، م. الماسری، ر. نظرسنجی در مورد تحقیقات پایگاه داده مکانی، زمانی و مکانی-زمانی و نمونه ای اصلی از کاربردهای مرتبط با استفاده از اکوسیستم SQL و یادگیری عمیق. J. Inf. مخابرات 2020 ، 4 ، 524-559. [ Google Scholar ] [ CrossRef ]
- باسو، دی. لین، کیو. چن، دبلیو. Vo، HT; یوان، ز. سنلارت، پی. برسان، اس. تنظیم پایگاه داده نادیده گرفته مدل هزینه منظم با یادگیری تقویتی. در معاملات در مقیاس بزرگ داده ها و سیستم های دانش محور ؛ Springer: برلین/هایدلبرگ، آلمان، 2016; جلد 28، ص 96–132. [ Google Scholar ]
- چاودهری، س. Narasayya، VR یک ابزار انتخاب شاخص کارآمد و هزینه محور برای Microsoft SQL Server . VLDB: آتن، یونان، 1997; صص 146-155. [ Google Scholar ]
- احمد، م. دوان، اس. ابولنگا، ع. بابو، اس. پیشبینی زمان تکمیل بارهای کاری پرس و جو دستهای با استفاده از مدلهای آگاه از تعامل و شبیهسازی. در مجموعه مقالات چهاردهمین کنفرانس بین المللی گسترش فناوری پایگاه داده، اوپسالا، سوئد، 21 تا 24 مارس 2011. صص 449-460. [ Google Scholar ]
- آن، اس. هان، اس. Al Husein, M. بهبود برآورد هزینه حمل و نقل برای ساخت و ساز پیش ساخته با استفاده از استخراج ویژگی داده های GPS در مقیاس بزرگ مبتنی بر حصار جغرافیایی و رگرسیون برداری پشتیبانی. Adv. مهندس به اطلاع رساندن. 2020 , 43 , 101012. [ Google Scholar ] [ CrossRef ]
- گاناپاتی، ا. کونو، اچ. دیال، یو. وینر، جی ال. فاکس، ا. جردن، م. پترسون، دی. پیشبینی معیارهای چندگانه برای پرسشها: تصمیمهای بهتری که توسط یادگیری ماشین فعال میشوند. در مجموعه مقالات بیست و پنجمین کنفرانس بین المللی IEEE در مهندسی داده، ICDE’09، شانگهای، چین، 29 مارس تا 2 آوریل 2009. IEEE: Piscataway, NJ, USA, 2009; صص 592-603. [ Google Scholar ]
- تئودوریدیس، ی. استفاناکیس، ای. Sellis, T. مدلهای هزینه برای جستارهای پیوستن در پایگاههای داده فضایی. در مجموعه مقالات چهاردهمین کنفرانس بین المللی مهندسی داده، اورلاندو، فلوریدا، ایالات متحده آمریکا، 23 تا 27 فوریه 1998. ص 476-483. [ Google Scholar ]
- مارکل، وی. لومان، جنرال موتورز; Raman, V. LEO: یک بهینه ساز پرس و جو خودکار برای DB2. سیستم آی بی ام J. 2003 , 42 , 98-106. [ Google Scholar ] [ CrossRef ]
- احمد، م. دوان، اس. ابولنگا، ع. بابو، اس. پیشبینی آگاهانه از تعامل زمانهای تکمیل حجم کاری هوش تجاری. در مجموعه مقالات بیست و ششمین کنفرانس بین المللی IEEE در سال 2010 در مهندسی داده (ICDE 2010)، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 1 تا 6 مارس 2010. صص 413-416. [ Google Scholar ]
- لو، ی. لو، جی. کنگ، جی. وو، دبلیو. شهابی، ج. الگوریتمهای کارآمد و مدلهای هزینه برای جستجوی کلیدواژه مکانی معکوس k-نزدیکترین همسایه. ACM Trans. سیستم پایگاه داده (TODS) 2014 ، 39 ، 1-46. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بوهم، سی. یک مدل هزینه برای پردازش پرس و جو در فضاهای داده با ابعاد بالا. ACM Trans. سیستم پایگاه داده (TODS) 2000 ، 25 ، 129-178. [ Google Scholar ] [ CrossRef ]
- جین، جی. آن، ن. Sivasubramaniam، A. تجزیه و تحلیل پرس و جوهای محدوده در داده های مکانی. در مجموعه مقالات شانزدهمین کنفرانس بین المللی مهندسی داده (Cat. No. 00CB37073)، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 28 فوریه تا 3 مارس 2000. صص 525-534. [ Google Scholar ]
- وو، دبلیو. چی، ی. زو، اس. تاتمورا، جی. Hacigümüs، H. ناتون، JF پیش بینی زمان اجرای پرس و جو: آیا مدل های هزینه بهینه ساز واقعا غیر قابل استفاده هستند؟ در مجموعه مقالات بیست و نهمین کنفرانس بین المللی مهندسی داده IEEE 2013 (ICDE)، بریزبن، استرالیا، 8 تا 12 آوریل 2013. صص 1081-1092. [ Google Scholar ]
- هنداوی، ع.م. Mokbel، MF Panda: یک پردازشگر پرس و جوی مکانی-زمانی پیش بینی کننده. در مجموعه مقالات بیستمین کنفرانس بین المللی پیشرفت در سیستم های اطلاعات جغرافیایی، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 6-9 نوامبر 2012. صص 13-22. [ Google Scholar ]
- دیدونا، دی. کواگلیا، اف. رومانو، پی. Torre, E. افزایش استحکام پیشبینی عملکرد با ترکیب مدلسازی تحلیلی و یادگیری ماشین. در مجموعه مقالات ششمین کنفرانس بین المللی ACM/SPEC در مورد مهندسی عملکرد، آستین، تگزاس، ایالات متحده آمریکا، 28 ژانویه تا 4 فوریه 2015. صص 145-156. [ Google Scholar ]
- سان، ج. لی، جی. تخمینگر هزینههای مبتنی بر یادگیری سرتاسر. arXiv 2019 ، arXiv:1906.02560. [ Google Scholar ]
- Quoc، HNM؛ سرانو، ام. برسلین، جی جی. Phuoc، DL یک رویکرد یادگیری برای برنامه ریزی پرس و جو در داده های فضایی-زمانی اینترنت اشیا. در مجموعه مقالات هشتمین کنفرانس بین المللی اینترنت اشیا، سانتا باربارا، کالیفرنیا، ایالات متحده آمریکا، 15 تا 18 اکتبر 2018؛ صص 1-8. [ Google Scholar ]
- حسن، ر. گاندون، اف. یک رویکرد یادگیری ماشین برای پیشبینی عملکرد پرس و جوی sparql. در مجموعه مقالات کنفرانس های مشترک بین المللی IEEE/WIC/ACM 2014 در زمینه هوش وب (WI) و فناوری های عامل هوشمند (IAT)، ورشو، لهستان، 11 تا 14 اوت 2014. صص 266-273. [ Google Scholar ]
- وان، اس. ژائو، ی. وانگ، تی. گو، ز. عباسی، ق.ح. Choo، KKR نمایه سازی داده های چند بعدی و پردازش پرس و جو دامنه از طریق نمودار Voronoi برای اینترنت اشیا. ژنرال آینده. محاسبه کنید. سیستم 2019 ، 91 ، 382-391. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دوگان، جی. Cetintemel، U. پاپااممانوئیل، او. Upfal، E. پیش بینی عملکرد برای بارهای کاری همزمان پایگاه داده. در مجموعه مقالات کنفرانس بین المللی ACM SIGMOD 2011 در مدیریت داده ها، آتن، یونان، 12 تا 16 ژوئن 2011. صص 337-348. [ Google Scholar ]
- آکدره، م. Cetintemel، U. ریونداتو، م. آپفال، ای. مدل سازی و پیش بینی عملکرد پرس و جو مبتنی بر یادگیری Zdonik، SB. در مجموعه مقالات بیست و هشتمین کنفرانس بین المللی مهندسی داده IEEE 2012، واشنگتن، دی سی، ایالات متحده آمریکا، 1 تا 5 آوریل 2012. صص 390-401. [ Google Scholar ]
- گوپتا، سی. مهتا، ع. Dayal, U. PQR: پیشبینی زمان اجرای پرس و جو برای مدیریت بار کاری مستقل. در مجموعه مقالات کنفرانس بین المللی 2008 در محاسبات خودکار، شیکاگو، IL، ایالات متحده آمریکا، 2-6 ژوئن 2008. صص 13-22. [ Google Scholar ]
- ملاکار، پ. بالاپراکاش، پ. ویشوانات، وی. موروزوف، وی. کوماران، ک. محک زدن روشهای یادگیری ماشین برای مدلسازی عملکرد کاربردهای علمی. در مجموعه مقالات مدلسازی عملکرد IEEE/ACM 2018، محکگذاری و شبیهسازی سیستمهای رایانهای با عملکرد بالا (PMBS)، دالاس، TX، ایالات متحده آمریکا، 12 نوامبر 2018؛ صص 33-44. [ Google Scholar ]
- چاکا، معاون; Everspaugh، A.; Patel، JM فهرستبندی مجموعه دادههای مسیر بزرگ با SETI . CIDR: Asilomar، CA، USA، 2003. [ Google Scholar ]
- هریس، دی. Harris, S. طراحی دیجیتال و معماری کامپیوتر ; مورگان کافمن: برلینگتون، MA، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- لو، جی. Güting، RH Parallel secondo: یک سیستم عملی برای پردازش در مقیاس بزرگ اجسام متحرک. در مجموعه مقالات 2014 IEEE 30 کنفرانس بین المللی مهندسی داده، شیکاگو، IL، ایالات متحده، 31 مارس تا 4 آوریل 2014. صص 1190–1193. [ Google Scholar ]
- یوان، جی. ژنگ، ی. ژانگ، سی. زی، دبلیو. Xie، X. سان، جی. Huang, Y. T-drive: مسیرهای رانندگی بر اساس مسیرهای تاکسی. در مجموعه مقالات هجدهمین کنفرانس بین المللی SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، سن خوزه، کالیفرنیا، ایالات متحده آمریکا، 2 تا 5 نوامبر 2010. صص 99-108. [ Google Scholar ]
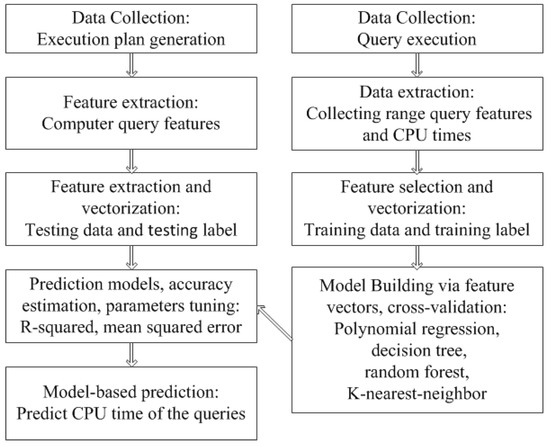
شکل 1. معماری CPRQ.
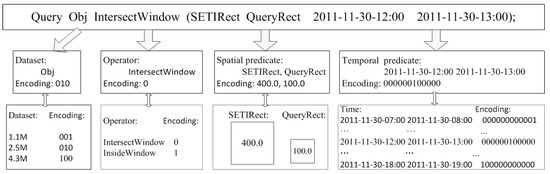
شکل 2. نمونه ای از استخراج و رمزگذاری ویژگی.
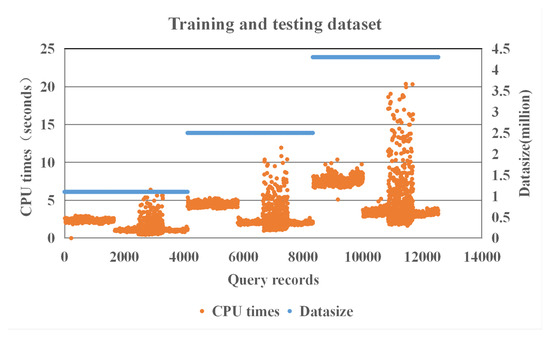
شکل 3. توزیع زمان CPU مجموعه داده های آموزش و آزمایش.
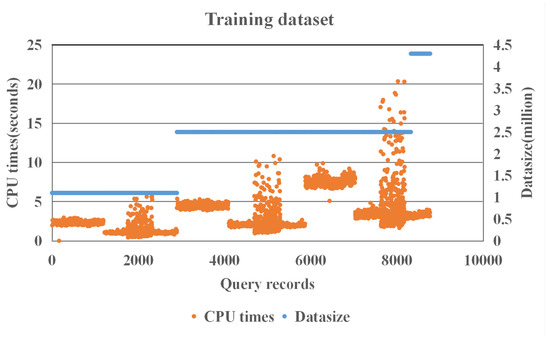
شکل 4. توزیع زمانی CPU مجموعه داده های آموزشی.
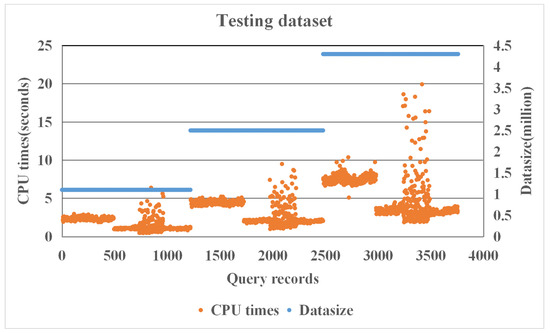
شکل 5. توزیع زمان CPU مجموعه داده های آزمایشی.
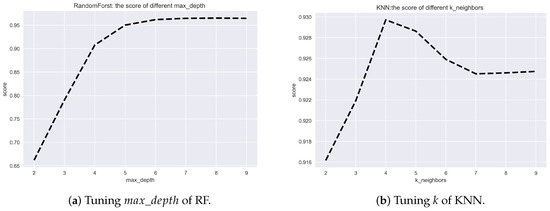
شکل 6. تنظیم فراپارامترها.
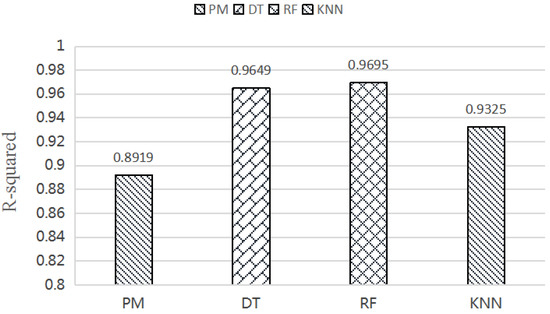
شکل 7. مقادیر مربع R رگرسیون چند جمله ای (PM)، درخت تصمیم (DT)، جنگل تصادفی (RF) و KNN.
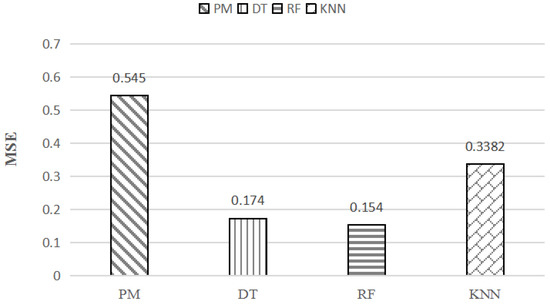
شکل 8. مقادیر MSE رگرسیون چند جمله ای (PM)، درخت تصمیم (DT)، جنگل تصادفی (RF) و KNN.


بدون دیدگاه