

خلاصه
تعمیم اطلاعات جغرافیایی نه تنها شناخت و درک اشیاء و پدیده های واقع در فضا بلکه روابط و فرآیندهای بین آنها را نیز امکان پذیر می کند. اتوماسیون این فرآیند مستلزم رسمی سازی دانش نقشه برداری، از جمله اطلاعات در زمینه فضایی اشیا است. با این حال، این سؤال باقی میماند که کدام اطلاعات برای تصمیمگیریهای مربوط به تعمیم (در این مقاله: انتخاب) اشیاء حیاتی است. این مقاله قابلیت استفاده از سه روش مبتنی بر نظریههای مجموعههای خشن (نظریه مجموعههای خشن، نظریه مجموعههای ناهموار مبتنی بر تسلط، نظریه مجموعههای ناهموار فازی) را که تعیین ویژگیهای مرتبط با یک تصمیم را تسهیل میکنند، ارائه و مقایسه میکند. روش ها از انواع مختلف (سطوح اندازه گیری) ویژگی ها استفاده می کنند. نویسنده کاهشها و هستههای آنها (عناصر مشترک) را تعیین میکند که ارتباط ویژگیهای ناشی از بافت فضایی را نشان میدهد. روش تئوری مجموعههای خشن فازی کمترین کاربرد را نشان داد، در حالی که روشهای نظریه مجموعههای خشن و روشهای نظریه مجموعههای خشن مبتنی بر تسلط به نظر توصیه میشوند (بسته به سطح حاکم بر اندازهگیری).
کلید واژه ها:
مجموعه های خشن ؛ کاهش می دهد ; بافت فضایی ؛ RST ; DRST ; FRST
1. معرفی
1.1. تعمیم اطلاعات جغرافیایی
تعمیم فرآیندی است که بر درک فضای جغرافیایی [ 1 ] متکی است و نقشی حیاتی در حصول اطمینان از اینکه محتوای یک نقشه یا یک پایگاه داده فضایی به هدف خود در سطوح مشخصی از جزئیات (LoD) خدمت می کند، ایفا می کند [ 2 ]. هدف تعمیم استخراج اطلاعات مرتبط است (با حذف اطلاعاتی که خوانایی روندها و الگوها در داده ها را پنهان می کند) [ 3 ، 4 ]. رویکردهای جدیدتر (مانند [ 2 ]) اغلب تعمیم را با مدل سازی نقشه برداری، که به نقشه به عنوان مدلی از واقعیت مرتبط است، برابر می دانند [ 5 ].
یکی از چالش های اساسی کارتوگرافی مدرن، رسمی کردن اصول تعمیم است که برای اتوماسیون (حداقل جزئی) این فرآیند ضروری است [ 6 ، 7 ]. یکی از رویکردهای رسمیسازی قوانین تعمیم، مدلسازی شرط-عمل است (همراه با رویکردهای تعاملی، یعنی مدلسازی تعامل انسانی، و رویکردهای محدودکننده، یعنی مدلسازی مبتنی بر محدودیت) [ 1 ]. این فرآیند مستلزم انتخاب ویژگی هایی است که برای تصمیم گیری های تعمیم اساسی هستند.
فرآیند تعمیم اطلاعات جغرافیایی را می توان به مجموعه ای از فعالیت ها به نام عملگرهای تعمیم تقسیم کرد. شناخته شده ترین طبقه بندی عملگرهای تعمیم، طبقه بندی ارائه شده توسط شی و مک مستر [ 8 ] است که 12 عملگر تعمیم را متمایز می کند، به عنوان مثال، ساده سازی، هموارسازی، تجمع، نوع سازی و غیره. این مقاله به انتخاب اشیاء در میان عملگرهای تعمیم اشاره نمی کند. در عوض، به عنوان اولین مرحله (مرحله پیش پردازش) تعمیم، قبل از اجرای عملگرهای “مناسب” انجام شد. در طبقه بندی های دیگر، انتخاب را می توان به عنوان یک عملگر تعمیم، اغلب به صورت غیرمستقیم، به عنوان مثال، به عنوان حذف [ 9 ] نام برد.]. با این وجود، انتخاب فقط اولین مرحله تعمیم اطلاعات جغرافیایی نیست، بلکه بخشی از سایر عملگرها نیز می باشد. برای مثال، ساده کردن شکل یک خط به انتخاب گره های مناسب آن بستگی دارد. با توجه به نقش حیاتی انتخاب، تحقیق در این مقاله به انتخاب صحیح اشیاء جغرافیایی می پردازد.
1.2. منطق های خشن
منطق کلاسیک، که به صورت روزانه استفاده می شود، بر اساس سیستم دوتایی ارسطو 0-1 درست-کاذب [ 10 ]، در برخی موارد کافی نیست. این امر به ویژه در هنگام برخورد با اطلاعات متناقض یا ذاتاً متضاد، که اغلب با داده های واقعی اتفاق می افتد، صادق است. در پاسخ به نیاز به انجام عملیات منطقی رسمی بر روی چنین دادههایی، سیستمهای غیر کلاسیک متعددی ایجاد شدهاند، به عنوان مثال، منطق خشن [ 11 ] یا منطق فازی [ 12 ]. در بخش بعدی مقاله، نویسنده از منطق خشن و نظریه مجموعه های خشن استفاده می کند که پایه های آن توسط Zdzisław Pawlak [ 11 ] ایجاد شده است.
برخلاف نظریه مجموعههای کلاسیک، نظریه مجموعههای خشن فرض میکند که ممکن است سه حالت (و نه دو حالت مانند نظریه کلاسیک) از یک شی وجود داشته باشد – یک شی ممکن است: مطمئناً متعلق به یک مجموعه باشد، قطعاً به یک مجموعه تعلق ندارد، ممکن است یا ممکن است به یک مجموعه تعلق نداشته باشد [ 11 ].
یک جدول اغلب یک سیستم اطلاعاتی را در منطق تقریبی نشان میدهد، جایی که ردیفها با اشیاء جداگانه مطابقت دارند، در حالی که ستونها با ویژگیهایی که اشیاء را توصیف میکنند مطابقت دارند [ 13 ]. یکی از ویژگی ها را می توان به عنوان ویژگی تصمیم گیری مشخص کرد. بسته به نوع منطق تقریبی، صفات در سطوح اندازه گیری زیر ممکن است در جدول صفات ظاهر شوند:
نظریه مجموعههای ناهموار [RST]: ویژگیها اسمی هستند – مقادیر آنها میتواند اشیا را متمایز کند، اما ترتیب خاصی بین آنها وجود ندارد. به طور خاص، ویژگی ها می توانند از نوع بولی باشند که فقط می توانند دو مقدار (معمولاً 0 یا 1) داشته باشند [ 11 ، 13 ].
-
نظریه مجموعههای ناهموار مبتنی بر تسلط [DRST]: ویژگیها در مقیاس ترتیبی بیان میشوند که نظم خاصی را بین مقادیر خاص ویژگی ارائه میدهد [ 14 ، 15 ].
-
نظریه مجموعه های ناهموار فازی [FRST]: ویژگی ها به صورت اعداد (اعداد صحیح یا اعداد ممیز شناور) بیان می شوند. می توان نه تنها ترتیب، بلکه فاصله بین مقادیر فردی ویژگی ها را نیز مشخص کرد [ 16 ، 17 ].
ویژگی تصمیم در مقیاس اسمی (RST و FRST) یا مقیاس ترتیبی (DRST) بیان می شود. یک ویژگی تصمیم اغلب باینری است که در این تحقیق نیز وجود دارد: 1-یک شی در حین انتخاب انتخاب می شود، 0-یک شی غیر انتخابی.
1.3. کاهش می دهد
یکی از جالبترین ویژگیهای مجموعههای خشن این است که امکان تعیین کاهشها را فراهم میکنند. کاهش تصمیم یک زیرمجموعه حداقلی از ویژگیهای P⊆ C است که تقسیم اشیاء را به کلاسهای تصمیم ممکن میسازد، نه بدتر از اصلی (بر اساس مجموعه کاملی از ویژگیهای C). بنابراین، یک کاهش تصمیم مجموعه ای از ویژگی های P ⊆ C است که [ 15 ]:
-
تشخیص مجموعه C را برای تصمیم dec حفظ می کند، به عنوان مثال، اگر dec(x) ≠ dec(y) و x، y با C قابل تشخیص باشند، آنگاه با P نیز قابل تشخیص هستند.
-
تقلیل ناپذیر است، یعنی هیچ زیرمجموعه خاصی از مجموعه P مشخصه بالا را حفظ نمی کند.
ممکن است کاهش های زیادی برای یک جدول تصمیم وجود داشته باشد. با این حال، استفاده از هر یک از آنها حفظ کیفیت (یا کیفیت طبقهبندی، در مورد کاهشهایی که شامل ویژگی تصمیمگیری است) مجموعه کامل اصلی ویژگیها را تضمین میکند [ 15 ]. مجموعه ای از صفات تکرار شده در همه کاهش ها، هسته جدول نامیده می شود [ 18 ]. صفاتی که در تقلیل ها ظاهر می شوند اما به هسته تعلق ندارند، قابل مبادله نامیده می شوند، در حالی که ویژگی هایی که در هیچ کاهشی ظاهر نمی شوند، اضافی نامیده می شوند [ 15 ].
تعیین کاهش ها ممکن است هنگام محدود کردن تعداد ویژگی های مورد نیاز برای تصمیم گیری مفید باشد. با این وجود، کوتاه ترین کاهش همیشه بهترین نخواهد بود (از دیدگاه عملی مفیدترین). هزینه به دست آوردن مقادیر ویژگی های خاص (محاسبه شده بر اساس منابع مالی، زمان، خطر سلامت و غیره) اغلب یکسان نیست.
بسیاری از روش ها امکان تعیین کاهش ها را به طور کامل یا با استفاده از یکی از اکتشافی ها فراهم می کنند. تعیین کاهش ها در هر یک از منطق های خشن نیز متفاوت است:
-
RST – بر اساس رابطه غیرقابل تشخیص: دو شی غیر قابل تشخیص هستند اگر و تنها در صورتی که ویژگی های آنها یکسان باشد [ 13 ].
-
DRST- بر اساس رابطه تسلط: یک شی بر شی دوم تسلط دارد اگر و فقط در صورتی که مقادیر ویژگی های آن بزرگتر یا مساوی با دوم باشد (اما حداقل یک ویژگی باید بزرگتر باشد) [ 14 ].
-
FRST – بر اساس رابطه شباهت: از نزدیکی مقادیر ویژگیهای خاص بین اشیا تعیین میشود (شباهت ممکن است مقادیری از 0 – نه مشابه، تا 1 – یکسان را بگیرد) [ 17 ].
1.4. اطلاعات زمینه فضایی
قطعات اطلاعات در مورد زمینه فضایی اشیاء منبعی از دانش ارزشمند ضمنی در داده های مکانی است [ 4 ]. برای قرن ها، این دانش به صورت بصری توسط گیرنده نقشه (اغلب یک نقشه کش باتجربه) خوانده می شد و به شیوه ای شهودی و اغلب ناخودآگاه استفاده می شد. علاوه بر این، درک مفاهیم فضایی (به عنوان مثال، نزدیک یا دور) ممکن است بسته به موقعیت مکانی متفاوت باشد [ 19 ، 20 ، 21 ]. هدف از خواندن نقشه، نوع و محدوده اطلاعات مورد استفاده را مشخص می کند. اطلاعات دیگر توجه یک کاربر معمولی نقشه و دیگر نقشه نگاری را که می خواهد داده ها را تعمیم دهد جلب می کند [ 22 , 23 , 24 .]
این مقاله بر استفاده از بافت فضایی به عنوان اطلاعات ضروری برای فرآیند انتخاب اشیا تمرکز دارد. این مقاله نمونه هایی از رسمی سازی اطلاعات بافت مکانی و همچنین روش انتخاب اطلاعات لازم را ارائه می دهد که کسب آنها از منظر تعمیم پایه مرتبط است. در این مقاله اطلاعات مربوط به بافت فضایی به شکلی از صفات اختصاص داده شده به اشیاء خاص رسمیت یافته است. همچنین راه های دیگری برای رسمی کردن بافت فضایی [ 25 ] وجود دارد مانند:
-
تجزیه و تحلیل زمین آماری: کریجینینگ و کوکریجینگ [ 26 ]، که به طور گسترده برای درونیابی استفاده می شود، به عنوان مثال، [ 27 ، 28 ].
-
اقتصادسنجی فضایی (مدل تاخیر مکانی، مدل خطای فضایی، آمار موران I و غیره، بر اساس همبستگی خودکار) [ 29 ] با تعاریف مختلف از ماتریس های همسایگی. گاهی اوقات به دلیل خودسری و ساده سازی بیش از حد فرآیندهای اجتماعی، اقتصادی و غیره مورد انتقاد قرار می گیرد [ 30 ];
-
پردازش الگوریتم ها به صورت محلی از طریق پنجره متحرک [ 31 ].
-
استفاده از نشانهشناسی، معنایی و هستیشناسی [ 32 ، 33 ] برای توصیف روابط آنها یا استفاده از بافت فضایی برای تأثیرگذاری بر مثلث نشانهشناختی [ 21 ].
-
تجزیه و تحلیل نمودار (به ویژه برای داده های شبکه) [ 34 ، 35 ];
-
مدل سازی عامل برای نمایش روابط و تعاملات بین اشیاء [ 36 ، 37 ].
با این حال، روش های دیگر در این مقاله به طور گسترده مورد تجزیه و تحلیل قرار نخواهند گرفت.
1.5. راف مجموعه تحقیقات و برنامه های فعلی
تعدادی از تحقیقات اساسی در مورد تئوری های مجموعه های خشن انجام شده است، مانند ارتباط مجموعه های خشن با آزمایشگران [ 38 ]. آنها همچنین رویکردهای بسیار جالبی با استفاده از مجراهای دوگانه مبتنی بر مجموعههای ناهموار فازی هستند که امکان کاهش ابعاد و اندازه دادهها را به طور همزمان فراهم میکنند [ 39 ]. اگرچه این تحقیقات دارای ماهیت نظری و ریاضی هستند، گروه وسیعی از تحقیقات دیگر وجود دارد که به پیاده سازی در زمینه های مختلف علم، صنعت و تجارت مربوط می شود.
پیاده سازی مجموعه های خشن در میان داده های مکانی عمدتاً اهداف طبقه بندی را پوشش می دهد. یک مثال می تواند کشف دانش و طبقه بندی شطرنجی پوشش زمین با استفاده از کاهش ها و قوانین ناهموار [ 40 ] باشد. سایر نویسندگان از مجموعههای خشن برای طبقهبندی تصاویر چند طیفی ماهوارهای با استفاده از روش انتخاب ویژگی و نشان دادن پتانسیل برای تصاویر چند طیفی و فراطیفی استفاده میکنند [ 41 ]. RST را می توان نه تنها برای تجزیه و تحلیل شطرنجی – در [ 42 ] قوانین تقریبی برای بهبود تصمیم گیری در مورد مکان رستوران ها در رستوران های زنجیره ای استفاده کرد. از سوی دیگر [ 43 ] از RST برای توصیف روابط مکانی-زمانی اوتروفیکاسیون در یک رودخانه بر اساس داده های پایش استفاده می کند.
نظریه های DRST و FRST برای داده های مکانی بسیار کمتر در کاربردهای فضایی محبوبیت دارند. روش DRST به عنوان مثال برای تعریف سطح امنیتی در مناطق شهر برزیلی Recife [ 44 ] استفاده شد. مثال دیگر استفاده از روش DRST برای شناسایی نوع صلاحیت مجدد به برخی ساختمان های مزرعه سنتی در ایتالیا است [ 45 ]. ترکیبی از مجموعههای فازی و خشن با موفقیت بهعنوان مثال در کاهش ویژگی برای طبقهبندی وب استفاده میشود [ 46 ]، که با این حال هیچ مرجع فضایی مستقیمی ندارد.
ادبیات محدودی وجود دارد که استفاده از مجموعههای خشن را مستقیماً در تعمیم کارتوگرافی توصیف میکند. یکی از آخرین رویکردها یک راه حل تقریبی برای تولید مقیاس اولیه در نقشههای تعاملی دیجیتال مبتنی بر توزیع شبکه جادهای و رفتارها و عملیات کاربران تاریخی در مکانهای مختلف ارائه میکند [ 47 ]. یک رویکرد جالب در مورد تعمیم در GIS در [ 48 ] ارائه شده است – نویسندگان یک ویژگی تصمیم فازی ناشناخته را پس از گسستهسازی ویژگیهای موجود با خوشهبندی k-means اضافه میکنند. سپس نویسندگان از RST برای کاهش ویژگی استفاده میکنند، که پتانسیل مجموعههای خشن را برای تجزیه و تحلیل دادههای مکانی نشان میدهد.
آخرین اما نه کم اهمیت، برخی از رویکردهای جدید نیز وجود دارد که به کاربرد عملی نظریههای مجموعههای خشن کمک میکند. یک مثال می تواند استفاده از کاهش های پویا با کاهش ویژگی مبتنی بر FRST باشد که می تواند برای کاربردهای عملی که داده ها به صورت تدریجی جمع آوری می شوند بسیار مفید باشد [ 49 ]. همچنین تحلیل هایی از نرم افزارهای مورد استفاده برای پردازش مشکلات مجموعه های خشن و عملکردهای آن وجود دارد. به نظر می رسد محبوب ترین بسته Rosetta، RSES، Rose2، WEKA و RoughSets در R [ 50 ] باشد. در این تحقیق آخرین مورد برای روش های RST و FRST و jMAF برای DRST استفاده شد.
1.6. اهداف اصلی مقاله
این مقاله رویکرد جدیدی را پیشنهاد میکند که شامل اطلاعات بافت مکانی به فرآیند تعمیم (انتخاب شی) میشود. ابتدا به رسمیت بخشیدن به اطلاعاتی که از هندسه و همسایگی اشیاء می آید، می پردازد. سپس نشان میدهد که چگونه میتوان از نظریههای مختلف مجموعههای ناهموار برای انتخاب ویژگی برای اهداف تعمیم استفاده کرد. همچنین ارزیابی هر یک از روش های مورد استفاده را ارائه می دهد و آنها را با هم مقایسه می کند. مطالعات ادبیات انجام شده توسط نویسنده نشان می دهد که این روش ها قبلا در این زمینه استفاده نشده است. بر اساس مطالعات انجام شده تنها روش RST پیش از این گهگاه در کارتوگرافی استفاده شده است. بنابراین هدف تحقیق بررسی این بود که آیا روشهای ناهموار مختلف (یعنی نظریه مجموعههای خشن، نظریه مجموعههای خشن مبتنی بر تسلط،
2. مواد و روشها
2.1. داده ها
این تحقیق بر روی داده های توپوگرافی انجام شد که برای نیازهای مطالعه حاضر در تصویر و شباهت پایگاه های رسمی توپوگرافی اروپا ایجاد و اصلاح شد. با این حال، در مقایسه با داده های واقعی، ساختار داده های مدل ساده شده است (به عنوان مثال، تعداد کمتری از ویژگی ها وجود دارد)، که تجزیه و تحلیل کیفی نتایج به دست آمده را تسهیل می کند (به ویژه کاهش می دهد).
از این رو، کلاس های اشیاء ایجاد شده در داده های مدل مطابق با:
-
ساختمان ها – اشیاء انسانی، اشیاء چند ضلعی.
-
بخش هایی از جاده ها – اشیاء انسانی، اشیاء خطی.
-
بخش هایی از جریان های آب – اشیاء طبیعی، اشیاء خطی.
دو منطقه آزمایشی تعریف شده است: یک منطقه کوچکتر، شکل 1 A (9.1 کیلومتر در 6.4 کیلومتر)، که از سطح جزئیات مربوط به نقشه های آنالوگ 1:10000 (LoD10k) به 1:50،000 (LoD50k) تعمیم داده شده است. و یک بزرگتر، شکل 1 B (24.6 کیلومتر در 22.2 کیلومتر)، که از سطح جزئیات مربوط به 1:50000 (LoD50k) به نقشه های 1: 250000 (LoD250k) تعمیم داده شده است، که در آن منطقه بزرگتر شامل منطقه کوچکتر است ( شکل 1). ). منطقه A شامل نمایشی از ساختمانها، جادهها و جریانهای آب در LoD10k است ( شکل 2 )، ناحیه B نشاندهنده جادهها و مسیرهای آب در LoD50k است ( شکل 3 ).
2.2. ویژگی های گنجانده شده است
برای تحقیق، سه گروه از ویژگی ها به اشیا اختصاص داده شد:
-
Native – ویژگی هایی که از ساختار پایگاه داده پدید می آیند، به عنوان مثال، عملکرد یک ساختمان. ابتدا در مرحله جمع آوری داده ها به اشیا اختصاص داده شد.
-
هندسی – ویژگی هایی که از هندسه، شکل، چگالی، یا قرارگیری متقابل اجسام در یک کلاس معین از اشیاء پدید می آیند، به عنوان مثال، تراکم ساختمان ها در شعاع 200 متری از یک ساختمان معین. با استفاده از ابزارهای تحلیلی مناسب محاسبه می شود.
-
رابطه ای – ویژگی هایی که موقعیت یک شی را نسبت به اشیاء طبقات دیگر توصیف می کنند، به عنوان مثال، فاصله ساختمان از نزدیکترین جاده. با استفاده از ابزارهای تحلیلی مناسب، با استفاده از هندسه و ویژگی های اشیاء طبقات دیگر محاسبه می شود.
بافت فضایی در درجه اول با ویژگی های هندسی و رابطه ای توصیف می شود. می توان تعداد نامحدودی از این ویژگی ها را تعیین کرد، اگرچه طبیعتاً همه آنها از منظر انتخاب شی مرتبط نیستند.
برخی از ویژگیهای پیشنهادی میتوانند از منظر دانش نقشهنگاری خبره مرتبط باشند و بنابراین، میتوانند دانش کارتوگرافی خبره را در مورد روابط بین اشیاء، که تاکنون به طور ضمنی در پایگاه داده ثبت شده است، رسمی کنند. از جمله این ویژگی ها عبارتند از: ویژگی های مربوط به متراکم شدن اشیاء (با شعاع متفاوتی که محله را مشخص می کند)، ویژگی هایی که ویژگی های یک سازه بزرگتر را توصیف می کنند (به عنوان مثال، یک رودخانه به جای بخشی از یک رودخانه و یک مسیر جاده به جای جاده). ، یا ویژگی هایی که فاصله ها را با سایر اشیاء (تعریف شده) توصیف می کنند. نویسنده در درجه اول استفاده از مقیاس های کمی را انتخاب کرده است. با این حال، می توان از مقیاس های کیفی برای توصیف روابط فضایی نیز استفاده کرد [ 51]. بخش نتایج شامل شرح مجموعه ای از ویژگی های مورد استفاده و ارتباط آنها با انتخاب ویژگی بر اساس رویکرد کاهش می باشد.
به دنبال دانش کارتوگرافی متخصص (تصمیم نویسنده)، به هر یک از اشیاء کلاس های تجزیه و تحلیل شده، مقدار مشخصه تصمیم k50 و/یا k250 که مطابق با تصمیم است، اختصاص یافت:
-
1-یک شی انتخاب شده برای سطح مشخصی از جزئیات،
-
0 – شیئی که برای سطح مشخصی از جزئیات انتخاب نشده است.
2.3. تغییر سطوح اندازه گیری
اولین مرحله، لازم برای تعیین کاهش های تصمیم، تنظیم سطوح اندازه گیری بود که در آن ویژگی ها به روش تقریبی مورد استفاده بیان می شد. برای دستیابی به این هدف، عملیات زیر انجام شد ( شکل 4 ):
-
تغییر دادههای پیوسته به کلاسهای ترتیبی – «کاهش» سطح اندازهگیری، که به دنبال روش بهینهسازی شکستهای طبیعی جنکس انجام میشود [ 52 ]. تعداد طبقات به صورت تجربی تعیین شد، به عنوان مثال، گسسته سازی مساحت ساختمان در متر مربع (استفاده شده در روش FRST) تا 5 کلاس ترتیبی (برای روش DRST).
-
تغییر دادههای ترتیبی به دادههای اسمی – «کاهش» سطح اندازهگیری. در حالی که این نیاز به هیچ اقدامی نداشت، تجزیه و تحلیل ترتیب طبقات را در نظر نگرفته بود، به عنوان مثال، 5 کلاسی که افزایش مساحت ساختمان (استفاده شده در روش DRST) را به عنوان 5 کلاس مختلف در روش RST تعریف میکنند، که در آن کلاس 1 در روش RST متفاوت است. از کلاس 2 به همان ترتیب از کلاس 5 (در روش RST).
-
تغییر دادههای اسمی به دادههای ترتیبی – «ارتقای» مصنوعی سطح اندازهگیری. تعیین یکنواختی طبقات ضروری بود که در برخی موارد کاملاً مشهود است (مثلاً دستههای مدیریت راه: از محلی به ملی)، در حالی که در موارد دیگر ذهنی (مثلاً ترتیب عملکرد ساختمانها). در نتیجه، داده های مناسب برای روش RST برای روش DRST تهیه شد.
-
تغییر دادههای ترتیبی به دادههای پیوسته – «ارتقای» مصنوعی سطح اندازهگیری. در حالی که هیچ اقدامی لازم نبود، اما به معنای پذیرش فاصله مصنوعی بین طبقات بود که ماهیت یکنواخت آنها تنها جنبه شناخته شده در مورد آن بود. معمولاً، فواصل بین کلاسها برابر بود، زیرا نحوه اتخاذ آنها بر نتیجه تأثیر میگذارد [ 53 ]. به عنوان مثال، دسته های ترتیبی مدیریت راه. از این روش برای تهیه داده های مختص روش DRST برای روش FRST استفاده شد.
باید توجه داشت که کاهش (“کاهش”) یا “ارتقا” مصنوعی سطح اندازه گیری پیامدهای خود را دارد. به دلیل کاهش سطح اندازهگیری، برخی از اطلاعات از بین میرود، مانند مقادیر دقیق یک ویژگی (مثلاً مساحت بر حسب متر مربع) یا ترتیب کلاسها. در مورد اول (گسسته سازی)، یک ذهنیت خاص از تقسیم مقادیر پیوسته به طبقات ترتیبی (در مورد تعداد و همچنین مکان های تقسیم) وجود دارد. یکی از الگوریتم های گسسته شناخته شده مبتنی بر توزیع داده ها (در این مقاله: روش شکست های طبیعی) ممکن است ذهنیت را محدود کند. سطح حتی بیشتر از ذهنیت گرایی در “ارتقای” مصنوعی سطح اندازه گیری ظاهر می شود. هنگامی که ترتیب طبقات غیر ترتیبی یا فواصل بین طبقات ترتیبی به صورت ذهنی اختصاص داده می شود، اطلاعات اضافی به مجموعه اضافه می شود که از تفسیر محقق از واقعیت ناشی می شود و – به عنوان یک عنصر ذهنی – بر نتیجه طبقه بندی (انتخاب) تأثیر می گذارد. این یکی از مواردی است که علاوه بر انتخاب ویژگیهای مدل، ویژگی ذهنی فرآیند تعمیم در روششناسی مورد مطالعه آشکار میشود. به طور طبیعی، فرد می تواند این عنصر را صرفاً با استفاده از سطوح اندازه گیری مناسب برای یک روش معین، یا با محدود کردن خود به “کاهش” سطوح اندازه گیری (و اجتناب از “ارتقای” آنها) محدود کند. با این حال، چنین اقداماتی امکان استفاده از برخی ویژگی های مرتبط در فرآیند تعمیم را کاهش می دهد. اطلاعات اضافی به مجموعه اضافه می شود که از تفسیر محقق از واقعیت ناشی می شود و به عنوان یک عنصر ذهنی بر نتیجه طبقه بندی (انتخاب) تأثیر می گذارد. این یکی از مواردی است که علاوه بر انتخاب ویژگیهای مدل، ویژگی ذهنی فرآیند تعمیم در روششناسی مورد مطالعه آشکار میشود. به طور طبیعی، فرد می تواند این عنصر را صرفاً با استفاده از سطوح اندازه گیری مناسب برای یک روش معین، یا با محدود کردن خود به “کاهش” سطوح اندازه گیری (و اجتناب از “ارتقای” آنها) محدود کند. با این حال، چنین اقداماتی امکان استفاده از برخی ویژگی های مرتبط در فرآیند تعمیم را کاهش می دهد. اطلاعات اضافی به مجموعه اضافه می شود که از تفسیر محقق از واقعیت ناشی می شود و به عنوان یک عنصر ذهنی بر نتیجه طبقه بندی (انتخاب) تأثیر می گذارد. این یکی از مواردی است که علاوه بر انتخاب ویژگیهای مدل، ویژگی ذهنی فرآیند تعمیم در روششناسی مورد مطالعه آشکار میشود. به طور طبیعی، فرد می تواند این عنصر را صرفاً با استفاده از سطوح اندازه گیری مناسب برای یک روش معین، یا با محدود کردن خود به “کاهش” سطوح اندازه گیری (و اجتناب از “ارتقای” آنها) محدود کند. با این حال، چنین اقداماتی امکان استفاده از برخی ویژگی های مرتبط در فرآیند تعمیم را کاهش می دهد. این یکی از مواردی است که علاوه بر انتخاب ویژگیهای مدل، ویژگی ذهنی فرآیند تعمیم در روششناسی مورد مطالعه آشکار میشود. به طور طبیعی، فرد می تواند این عنصر را صرفاً با استفاده از سطوح اندازه گیری مناسب برای یک روش معین، یا با محدود کردن خود به “کاهش” سطوح اندازه گیری (و اجتناب از “ارتقای” آنها) محدود کند. با این حال، چنین اقداماتی امکان استفاده از برخی ویژگی های مرتبط در فرآیند تعمیم را کاهش می دهد. این یکی از مواردی است که علاوه بر انتخاب ویژگیهای مدل، ویژگی ذهنی فرآیند تعمیم در روششناسی مورد مطالعه آشکار میشود. به طور طبیعی، فرد می تواند این عنصر را صرفاً با استفاده از سطوح اندازه گیری مناسب برای یک روش معین، یا با محدود کردن خود به “کاهش” سطوح اندازه گیری (و اجتناب از “ارتقای” آنها) محدود کند. با این حال، چنین اقداماتی امکان استفاده از برخی ویژگی های مرتبط در فرآیند تعمیم را کاهش می دهد. یا با محدود کردن خود به “تنزل” سطوح اندازه گیری (و اجتناب از “ارتقای” آنها). با این حال، چنین اقداماتی امکان استفاده از برخی ویژگی های مرتبط در فرآیند تعمیم را کاهش می دهد. یا با محدود کردن خود به “تنزل” سطوح اندازه گیری (و اجتناب از “ارتقای” آنها). با این حال، چنین اقداماتی امکان استفاده از برخی ویژگی های مرتبط در فرآیند تعمیم را کاهش می دهد.
ایجاد صفات به اصطلاح معکوس یکی از عناصر تطبیق ویژگی ها با روش های به کار گرفته شده بود. این به روش مجموعه خشن مبتنی بر تسلط (DRST) مربوط می شود، که یکنواختی ویژگی های شرطی را در یک تصمیم فرض می کند. به طوری که عمل مخالف نیز امکان پذیر است، یعنی انتخاب یک شی (dec ≥1) با ویژگی شرطی تعریف شده توسط علامت کمتر، لازم بود یکنواختی صفات شرطی معکوس شود. بنابراین، در روش DRST، هر صفت به دو صورت مستقیم و معکوس ظاهر می شود (با اضافه کردن “_i” به مخفف ویژگی مشخص می شود). تفسیر قوانین ایجاد شده مستلزم در نظر گرفتن جهت صفات است.
2.4. تعیین کاهش ها
با مشخصه هایی که به اندازه کافی آماده شده بودند، امکان تعیین تمام کاهش های تصمیم گیری ممکن با استفاده از سه روش خشن (RST، DRST، FRST) وجود داشت. از نرم افزار jMAF برای روش DRST با محاسبات کاهشی جامع بر اساس رابطه غالب استفاده شد. برای RST و FRST از بسته RoughSets زبان R استفاده شد – به ویژه تابع FS.all.reducts.computation . به اکثر پارامترها مقادیر پیش فرض اختصاص داده شد. فقط تابع تشخیص استفاده شده برای دو روش متفاوت است:
-
برای RST ویژگی ها می توانند یکسان یا متفاوت باشند (0 یا 1)
-
برای FRST از معیار تشابه/تحمل استفاده شد (طبق معادله بسته (1)):
آرآ(ایکس، y)=1- |آ(ایکس)-آ(y)||آمترآایکس – آمترمنn|.
از هر یک از مجموعهها در 4 تکرار، نمونههای طبقهبندی شده بهطور تصادفی انتخاب شدند که از بین آنها کاهندهها تعیین شدند. سپس برای هر یک از آنها موارد زیر تعیین شد:
-
تعداد کاهشهای تعیینشده (کاهشهای بیشتر – گزینههای بیشتر برای انتخاب زیرمجموعهای از ویژگیهای مؤثر بر تصمیم).
-
اندازه یک کاهش (کاهش های بزرگتر به معنای پیچیدگی بیشتر سیستم تصمیم گیری است).
-
اندازه هسته (نشان دهنده تعداد ویژگی های لازم برای تصمیم گیری صحیح)؛
-
ویژگی های هسته (نشان دهنده اطلاعات حیاتی برای تصمیم گیری، برای یک کلاس معین از اشیاء، طبق یک روش معین).
3. نتایج
3.1. ساختمان ها
3.1.1. ویژگی های
مجموعه ای شامل 476 ساختمان در منطقه A ایجاد شد. گروه بندی شده در چهار شهر و یک گروه کوچکتر به نمایندگی از یک لژ جنگلبان ( شکل 2 ). ویژگی های فهرست شده در جدول 1 برای ساختمان ها تعیین شده است. بهعلاوه، تصمیم (k50) ایجاد شد: ویژگیای که بیان میکند که آیا یک ساختمان معین 1 است – در حین انتخاب تا مقیاس 1:50،000 انتخاب شده است یا 0 – در طول انتخاب انتخاب نشده است.
ویژگی ها و سطوح اندازه گیری در نظر گرفته شده در این روش شناسی توسعه یافته متنوع است. بنابراین، سطوح اندازه گیری با روش ها تنظیم شد (طبق اطلاعات در بخش “تغییر سطوح اندازه گیری”). در روش DRST، ترتیب طبقات عینی بود (مثلاً در مورد ویژگی که تعداد طبقات را توصیف می کند) یا به روشی مصنوعی و ذهنی تحمیل شد:
-
تابع (o مقدار 1، out—2، res—3، c—4، i—5، p—6، rel—7 را می گیرد).
-
دسته (O مقدار 1، L—2، D—3 را می گیرد).
-
یک مرکز دولتی در شهر (n مقدار 1، L-2 را می گیرد).
برای روش FRST، گنجاندن ویژگی های طبقه بندی ممکن نبود. بنابراین، با در نظر گرفتن مفروضات ذکر شده در بالا، تنها ویژگی های عددی در ملاحظات بعدی گنجانده شدند.
3.1.2. کاهش می دهد
کاهش در زیرمجموعه های 300 ساختمان، چهار بار با نمونه گیری تصادفی طبقه بندی شده تعیین شد. جدول 2 تعداد و اندازه کاهش دهنده های تعیین شده با استفاده از روش RST را نشان می دهد . در تمام تکرارها، عملکرد ساختمان در هسته اصلی بود. در وسط تکرار – همچنین مکان در منطقه ساخته شده. مساحت ساختمان نیز مکررا ظاهر می شد. بنابراین، ویژگیهای بومی (تابع)، رابطهای (موقعیت در ناحیه ساختهشده)، و هندسی (منطقه) همگی مرتبط هستند. طول کاهش دهنده ها از 4 تا 7 عنصر متغیر بود. تعداد کاهش ها 8 تا 9 بود (به جز یک تکرار). شایان ذکر است که صرف نظر از طول یا تعداد کاهش دهنده های تعیین شده، هسته آنها بسیار قابل تکرار بود.
جدول 3 تعداد و اندازه کاهنده های تعیین شده با استفاده از DRST را نشان می دهدروش. وقتی با رویکرد RST مقایسه میشود، تعداد کاهشهای تعیینشده مرتبهای بالاتر است. بدون شک به دلیل روش اتخاذ شده است، اما دلیل دیگر ممکن است دو برابر بیشتر بودن صفات (صفات مستقیم و معکوس) باشد. همچنین ممکن است باعث افزایش اندازه کاهش دهنده ها شود (از 4-7 در روش RST به 5-11 در روش DRST). آنچه جالب است این است که هستههای کاهشدهندههای تعیینشده با استفاده از هر دو روش یکسان هستند (در همه تکرارها). در DRST، علاوه بر عملکرد یک ساختمان (یک تابع مهمتر – شانس بیشتر برای انتخاب شی) در هسته، یک ویژگی معکوس در مورد مکان ساختمان در منطقه ساخته شده وجود داشت (به عنوان مثال، اشیاء واقع در خارج از این منطقه شانس بیشتری برای انتخاب دارند).
کاهش تعیین شده با استفاده از روش FRST (در تمام تکرارها) با مجموعه کامل هشت ویژگی مطابقت دارد. بنابراین امکان محدود کردن این مجموعه وجود نداشت.
3.2. جاده ها
3.2.1. ویژگی های
یکصد و شصت و شش قطعه جاده که 76 مسیر در منطقه A و 141 بخش جاده که 49 مسیر در منطقه B را تشکیل می دهد ( شکل 2 و شکل 3 ) ایجاد شد. جاده ها در منطقه مشترک (A) همپوشانی دارند، اگرچه برای منطقه B فقط بخش هایی از جاده ها در نظر گرفته می شود (پس از انتخاب). به بخش های جاده ویژگی های فهرست شده در جدول 4 اختصاص داده شده است .
ویژگی «مسیر» مستقیماً به عنوان یک ویژگی شرطی در تعمیم استفاده نمی شود. این تنها به ترکیب بخشهای جادهها در مسیرهای جادهای کمک میکند. مسیرهای جاده به عنوان یک کل در نظر گرفته می شوند، به عنوان یک شی که نقاط را به هم متصل می کند و ارتباط بین آنها را تضمین می کند (بخش های جاده زمانی از هم جدا می شوند که هر یک از ویژگی ها تغییر کند یا زمانی که تقاطع با مسیر دیگری وجود دارد). ویژگی “route” همچنین تعیین یک ویژگی کلی تر از یک شی (مثلاً عرض متوسط مسیر) را برای یک بخش جاده امکان پذیر می کند.
علاوه بر این، تصمیمات (k50 و k250) مشخص شدند، به عنوان مثال، ویژگی مربوط به اینکه آیا یک بخش جاده معین: 1 – در مقیاس کوچکتر در طول انتخاب انتخاب شده است، 0 – انتخاب نشده است.
مشابه طبقات مورد بحث قبلی از اشیاء، همچنین لازم بود سطوح اندازه گیری را با روش های مورد استفاده برای بخش های جاده تنظیم کنید.
برای روش RST، صفات با مقادیر پیوسته و عدد صحیح گسسته شده اند. روش DRST از همان ویژگیها استفاده میکرد، اما آنهایی که در مقیاس طبقهبندی بیان میشوند باید مرتب شوند (تا حدی افزودن مصنوعی ارزش اطلاعاتی به ویژگیها است؛ اما، به عنوان مثال، دسته مدیریت جاده سلسله مراتبی است):
-
دسته مدیریت (O مقدار 1، L—2، D—3، P—4، N—5 را می گیرد).
-
کلاس (O مقدار 1، L—2، C—3، P—4، FT—5، E—6 را می گیرد).
-
روسازی (D مقدار 1، P—2، GM—3، Ma—4 را می گیرد).
روش FRST تقریباً از تمام ویژگی ها به شکل اصلی خود استفاده می کند، در حالی که ویژگی هایی مانند دسته، کلاس و ناحیه – مانند روش DRST – به شکل ترتیبی هستند.
3.2.2. LoD 1:10000 را به LoD 1:50000 کاهش می دهد
در هر تکرار، کاهش برای یک نمونه 110 شی تعیین شد. جدول 5 تعداد و اندازه کاهش های تعیین شده با استفاده از روش RST را نشان می دهد. در تمام تکرارها، هسته یکسانی به دست آمد: ویژگی مورد نیاز در هر کاهش تعداد تقاطع های یک مسیر معین با مسیرهای دیگر است. تعداد کاهشهای تعیینشده از 22 تا 24، و اندازه آنها از 4 تا 7 ویژگی متفاوت است (کوتاهترین کاهشها اکثریت هستند).
جدول 6 تعداد و اندازه کاهنده های تعیین شده با استفاده از روش DRST را نشان می دهد. تعداد کاهش دهنده های تعیین شده دو برابر بیشتر از روش RST است، اما اندازه آنها تقریباً مشابه روش قبلی است. هسته تعیینشده همچنین در تمام تکرارهای روشهای RST و DRST یکسان است و حاوی اطلاعاتی در مورد تعداد تقاطعهای مسیر است.
یک یا دو کاهش از 5 تا 7 طول عنصر با استفاده از روش FRST در هر تکرار تعیین شد ( جدول 7 ). در هسته، صفات زیر در تمام تکرارها تکرار می شود: (دسته، روسازی، عبور مسیر از مرکز شهر، تراکم جاده ها در مجاورت 500 متر، تعداد تقاطع های مسیر با مسیرهای دیگر). علاوه بر این، در دو تکرار، اطلاعاتی در مورد فاصله از یک بنای مذهبی در هسته وجود داشت. با این حال، در تکرارهایی که در آنها دو کاهش تعیین شده بود، فاصله از یک ساختمان عمومی یا فاصله از یک ساختمان عمومی یا مذهبی، به جای یکدیگر، ویژگی اضافی بود که به هسته می رسید.
3.2.3. LoD 1:50,000 را به LoD 1:250,000 کاهش می دهد
جدول 8 تعداد و اندازه کاهنده های تعیین شده با استفاده از روش RST را نشان می دهد. در تمام تکرارها، همان هشت کاهش دهنده بدون هسته مشترک تعیین شد. ویژگی های زیر کوتاه ترین کاهش را تشکیل می دهند: (دسته جاده، تراکم جاده ها در مجاورت 3000 متر). با این حال، در کاهشهای سه عنصری، ویژگیها (دسته راه، تعداد تقاطعهای مسیر با مسیرهای دیگر) ظاهر شد و بهطور متناوب، (طول مسیر) یا (گذر مسیر از میان). مرکز شهر) در حالی که تراکم جاده های مجاور حذف شده است. این کاهشهای تعیینشده نسبتاً کوتاه هستند و در مقایسه با نمونههای دیگر تحلیلشده در روش RST تعداد کمی از آنها وجود دارد.
برای روش DRST، همان هشت کاهش با 2 تا 5 عنصر در همه تکرارها تعیین شد و هسته ای وجود نداشت. کوتاه ترین، دو عنصر، کاهش شامل همان ویژگی های روش RST: (دسته جاده، تراکم جاده ها در مجاورت 3000 متر). در حالی که وزن دسته جاده کاملاً موجه به نظر می رسد، هیجان انگیز است که جاده هایی با تراکم بیشتر جاده های دیگر در مجاورت 3000 متر شانس بیشتری برای انتخاب در سطح مقیاس بالاتر داشته باشند.
به عنوان بخشی از روش FRST، امکان تعیین دو کاهش 4 یا 5 عنصری در تمام تکرارها وجود داشت ( جدول 9 ). موارد زیر در هسته تمامی تکرارها بودند: (دسته، سنگفرش، عبور مسیر از مرکز شهر) و در آخرین تکرار علاوه بر این (تراکم جاده ها در مجاورت 3000 متر). علاوه بر این، جدا از هسته اصلی، ویژگیهایی که بزرگترین شهر (از نظر منطقه) یا پرجمعیتترین شهر در مجاورت را توصیف میکنند، در کاهشها ظاهر شدند.
3.3. جریان های آب
3.3.1. ویژگی های
هنگام توسعه دادههای مدل، 51 بخش از جریانهای آب که 26 رودخانه را در منطقه A و 175 بخش از جریانهای آب را تشکیل میدهند که 83 رودخانه را در منطقه B تشکیل میدهند، ایجاد شد. در منطقه مشترک (A)، مسیرهای آب با یکدیگر همپوشانی دارند، در حالی که برای منطقه B فقط برخی از مسیرهای آبی در نظر گرفته می شود (پس از انتخاب). جدول 10 ویژگی های اختصاص داده شده به جریان های آب را نشان می دهد.
عدد هورتون-استرالر [ 54 ] ترتیب جریان را تعیین کرد. آمار مربوط به اطلاعات مربوط به کل رودخانهها برای بخشهایی از جریانهای آب متعلق به یک رودخانه معین بهطور میانگین (وزندار طول) میشود. بنابراین، آنها طول یا عرض متوسط رودخانه ها نیستند، زیرا خود رودخانه ها مستقیماً مدل سازی نشده اند.
ویژگی “رودخانه” به طور مستقیم به عنوان یک ویژگی شرطی در تعمیم استفاده نمی شود. با این حال، این ویژگی به ترکیب بخشهای جریانهای آب در رودخانهها کمک میکند، که بهعنوان یک شی واقعی در آن منطقه در نظر گرفته میشود (بخشها در صورت تغییر هر یک از ویژگیها یا زمانی که شاخههایی از رودخانهها وجود دارند از هم جدا میشوند). خصیصه river همچنین امکان تخصیص یک ویژگی کلی تری از یک شی (به عنوان مثال، طول کل رودخانه) را به بخش جریان آب می دهد.
علاوه بر این، تصمیمات (k50 و k250) مشخص شدند، به عنوان مثال، ویژگی مربوط به اینکه آیا یک بخش جریان آب معین: 1 – در مقیاس کوچکتر در طول انتخاب انتخاب شده است، 0 – انتخاب نشده است.
مشابه طبقات مورد بحث قبلی از اشیاء، همچنین لازم بود سطوح اندازهگیری را با روشهای مورد استفاده برای بخشهای جریان آب تنظیم کنیم.
برای روش RST (مانند ساختمان ها)، برخی از ویژگی ها نیاز به گسسته سازی دارند. روش DRST از همان ویژگیهای روش RST استفاده میکند، زیرا دادهها در ابتدا ترتیبی بودند. اما در روش FRST نیازی به گسسته سازی نبود. بنابراین، همان ویژگیهایی که در دو روش اول وجود داشت، استفاده شد – اما به شکل اصلی که در بالا توضیح داده شد.
3.3.2. LoD 1:10000 را به LoD 1:50000 کاهش می دهد
کاهش ها در 4 تکرار، هر بار برای زیر مجموعه ای از 35 شی تعیین شدند. جدول 11 تعداد و اندازه کاهش های به دست آمده با استفاده از روش RST را نشان می دهد. هسته در هیچ یک از تکرارها به دست نیامد. با این حال، کاهشهای تعیینشده برخی از نظمها را نشان دادند. در تمام تکرارها، کاهش دو عنصری تکرار شد (متوسط عرض رودخانه، تعداد گره های رودخانه). در تمام کاهشهای طولانیتر از سه عنصر (و در بیشتر کاهشهای سه عنصری)، حداقل یک ویژگی مرتبط با چگالی جریان آب رخ داد.
جدول 12 تعداد و اندازه احیا کننده های تعیین شده با استفاده از روش DRST را نشان می دهد. در مقایسه با رویکرد RST، تعداد کاهش های تعیین شده بسیار بیشتر بود (بیش از دو برابر تعداد). با این حال، اندازه آنها تفاوت قابل توجهی با اندازه های تعیین شده با استفاده از روش RST نداشت. در این مورد، کاهشهای کوتاه و دو عنصری یک بار در هر تکرار ظاهر میشوند. علاوه بر این، هر بار کاهش متفاوتی داشت – بهطور متوالی: (عرض متوسط رودخانه، معکوسترین شهر پرجمعیت در مجاورت)، (طول رودخانه، تعداد گذرگاهها با – حداقل – جادههای ناحیه)، (طول رودخانه، ترتیب آبراهه).
بسته به تکرار، 1 یا 2 کاهش با استفاده از روش FRST تعیین شد. طول آنها از 3 تا 4 ویژگی متغیر بود ( جدول 13 ). در تمام موارد، هسته شامل: (تعداد تقاطعهای بخش آبراهه با جادهها، تعداد تقاطعهای رودخانه با (حداقل) جادههای منطقهای) بود. علاوه بر این، دو تکرار شامل (تراکم جریان آب در مجاورت 1500 متر). در تکرارها با دو کاهش اختصاص داده شده به هر کدام، به جای یکدیگر، بزرگترین (از نظر منطقه) یا پرجمعیت ترین شهر در مجاورت جدا از هسته وجود داشت.
3.3.3. LoD 1:50,000 را به LoD 1:250,000 کاهش می دهد
کاهش در زیرمجموعه های 110 مقطع از آبراهه تعیین شد که چهار بار با استفاده از نمونه گیری تصادفی طبقه ای تعیین شد.
جدول 14تعداد و اندازه کاهش های تعیین شده با استفاده از روش RST را نشان می دهد. در تمام تکرارها، یک هسته غیر خالی تعیین شد که شامل 4 تا 6 ویژگی است. تنها ویژگی در هسته که در تمام تکرارها تکرار شد، ترتیب جریان آب بود. تعداد گذرگاهها با اشیاء دیگر نیز برای انتخاب بسیار مهم بود: در سه تکرار، آنها تقاطعهایی با بخش جریان آب و در یکی، تقاطعهایی با جادههای (حداقل) رده ناحیه با رودخانه بودند. چگالی جریانهای آب نیز حیاتی بود: مجاورت 3000 متر در هسته در سه تکرار، مجاورت 1500 متر در دو تکرار ظاهر شد. در 3 از 4 تکرار در هسته کاهش، عرض و طول رودخانه نیز ظاهر شد. کاهش های زیادی وجود نداشت (بسته به تکرار، 4 تا 7)، اما آنها بسیار طولانی بودند و از 6 تا 8 عنصر متغیر بودند.
جدول 15 تعداد و اندازه کاهنده های تعیین شده با استفاده از روش DRST را نشان می دهد. در مقایسه با رویکرد RST، تعداد کاهشهای تعیینشده چندین برابر بیشتر بود، در حالی که هستههای تعیینشده مشابه باقی ماندند. در این مورد، تنها عنصر هسته که در تمام تکرارها تکرار میشود، ترتیب جریان آب بود. طول و عرض بخش آبراهه نیز سه بار ظاهر شد، و همچنین تعداد معکوس تقاطع های مسیر آب با جاده ها (یعنی تعداد قابل توجهی از تقاطع ها با جاده ها برای انتخاب بخش مسیر مساعد نیست). کاهش های تعیین شده بسیار طولانی بودند (از 8 تا 16 عنصر).
در هر یک از تکرارها، تنها یک کاهش با استفاده از روش FRST تعیین شد. از 8 تا 10 عنصر تشکیل شده است. آن کاهش در همان زمان هسته اصلی هر تکرار را تشکیل می داد. ویژگی های اصلی موجود در همه تکرارها عبارتند از: (عرض متوسط رودخانه، طول رودخانه، ترتیب آبراهه، تعداد گره های رودخانه، بزرگترین (از نظر منطقه) شهر در مجاورت، تعداد تقاطع با جاده ها، تعداد تقاطع ها با جاده های (حداقل) رده ناحیه، تراکم آبراهه ها در مجاورت 1500 متر و تراکم آبراهه ها در مجاورت 3000 متر).
4. بحث
جدول 16 خلاصه ای از نتایج به دست آمده را نشان می دهد. می توان چندین قانون را در رابطه با روش های به کار گرفته شده و ویژگی های انتخاب شده در کاهش ها مشاهده کرد.
آنچه واقعاً شایان ذکر است این است که معمولاً کاهشهای بیشتری با استفاده از روش DRST نسبت به روش RST به دست میآید. دلیل ممکن است این باشد که روش DRST از ویژگیهای معکوس استفاده میکند، بنابراین تعداد ویژگیهای تحلیلشده دو برابر بیشتر بود. بنابراین تعداد ترکیبات ممکن و ارزشمند آنها نیز افزایش یافت. با این حال، باید تاکید کرد که در هر دوی این روشها اغلب ویژگیهای یکسانی نشان داده شد (هستههای کاهشدهنده تکرار شدند). فقط در نوع “معکوس” یا نه در روش DRST متفاوت است.
با روش FRST، تعداد کاهشهای یافت شده همیشه بسیار کوچک بود (1 یا 2)، در حالی که طول آنها کاملاً معنیدار بود (در یکی از انواع آزمایش، تعداد ویژگیهای مورد استفاده اصلاً کاهش پیدا نکرد).
در بیشتر انواع آزمایش، تعیین هستههای کاهشدهنده امکانپذیر بود که تجزیه و تحلیل ویژگیهای حیاتی را که بر تصمیمگیری برای انتخاب اشیاء از یک نوع خاص تأثیر میگذارند، امکانپذیر میسازد. هر جا که تعیین هستهها غیرممکن بود، اغلب (اما نه همیشه) ویژگیهای موجود در کاهشها تحلیل میشدند.
در زیر ویژگی های “مهم” آمده است. در پرانتز، تعداد رخدادهای کاهشی در هر روش، به ترتیب: RST + DRST + FRST آورده شده است. در موارد معدودی، ویژگیها بهعنوان حیاتی (تکرار شده) ذکر میشوند، حتی اگر خارج از هسته بودند و در همه کاهشها ظاهر نشدند (با علامتگذاری «خارج»). اطلاعات زیر برای انتخاب اشیاء بسیار مرتبط است:
-
برای ساختمان ها (10 k > 50 k): عملکرد ساختمان (4 + 4 + 4)، مکان در منطقه ساخته شده (2 + 2 + 4).
-
برای جاده ها (10 k > 50 k): تعداد تقاطع ها با جاده های دیگر (4 + 4 + 4)، دسته مدیریت، پیاده رو، گذر از شهر (0 + 0 + 4).
-
برای جاده ها (50 k > 250 k): دسته راه (خارج + بیرون + 3)، تراکم جاده ها در مجاورت 3000 متر (خارج + بیرون + 1)، سنگ فرش، گذر از شهر (0 + 0 + 3).
-
برای مسیرهای آبی (10 k > 50 k): تقاطع با جاده ها (0 + 0 + 4)، گذرگاه با جاده های (حداقل) رده ناحیه (0 + خارج + 4)، ویژگی مربوط به تراکم آبراهه ها (به جز + 0 + 2)، عرض متوسط رودخانه (خارج + خارج + 0).
-
برای مسیرهای آب (50 k > 250 k): ترتیب (4 + 4 + 4)، عرض، طول، تقاطع با جادهها (3 + 3 + 4)، تراکم آبراههها در مجاورت 3000 متر (3 + 2 + 4) تراکم آبراهه ها در مجاورت 1500 متر (2 + 2 + 4).
شایان ذکر است که بخش قابل توجهی از ویژگیهای نشاندادهشده در کاهشها، در تمام کلاسهای اشیاء و صرفنظر از سطح مقیاس، ویژگیهایی بهطور پیشفرض در ساختار پایگاه داده نیستند. در عوض، آنها از شناخت و تحلیل بافت فضایی (ویژگی های هندسی و رابطه ای) ناشی می شوند. مثال حیاتی تعداد تقاطع ها با جاده های دیگر برای تعمیم جاده ها 10 k > 50 k است. شکل 5به صورت بصری معنای حیاتی ویژگی را نشان می دهد که در کاهش دهنده ها نیز کشف شده است. معنای کشف دانش توسط مجموعههای ناهموار را نشان میدهد – نقشهبرها ممکن است بدانند که جادههای «اصلی» را انتخاب میکنند، اما ممکن است آگاه نباشند که اطلاعات مربوط به «کم و بیش اصلی» بودن جاده را میتوان با تعداد تقاطعها رسمیت بخشید. با سایر بخش های جاده به طور مشابه برای تعمیم 50 k > 250 k مثالی از ترتیب آبراهه ارائه شد ( شکل 6 ). در این مورد مشخص است که این اطلاعات خاص می تواند برای اهداف تعمیم استفاده شود [ 55] با این حال به درستی توسط قوانین خشن که دانش را به روش داده محور تأیید می کند، کشف می شود. این مثالها نشان میدهند که چگونه مجموعهها و کاهشهای خشن برای کشف دانش نقشهنگاری پنهان در دادهها و تصمیمهای متخصص مفید هستند – در هر دو مورد: زمانی که دانش ناشناخته است یا زمانی که فقط به تأیید و رسمیسازی مناسب نیاز دارد.
5. نتیجه گیری ها
امکان تعیین کاهش ها با استفاده از هر یک از سه روش ارائه شده وجود دارد. با این حال، کاهش در تعداد و اصلی از کاهش یا هسته های تعیین شده متفاوت است. روش FRST کمترین سودمندی را نشان داد زیرا اغلب یافتن تنها یک یا دو کاهش با تعداد قابل توجهی از ویژگیها را ممکن میسازد، در حالی که روشهای RST و DRST توصیه میشوند (بسته به سطح اندازهگیری حاکم).
همچنین باید به یاد داشته باشید که ویژگی ها را با سطوح اندازه گیری مورد استفاده در هر روش تنظیم کنید. بنابراین، سطوح غالب اندازهگیری ارزش در نظر گرفتن در دادههای تحلیلشده را دارند تا از ارتقا یا کاهش سطحهای اندازهگیری مملو از خطا جلوگیری شود.
همانطور که تجزیه و تحلیل نشان داد، استفاده از روشی برای تعیین کاهش ها ممکن است به مرتبط ترین ویژگی های اشیاء برای تعمیم منجر شود (در این مثال: انتخاب). صرف نظر از روش مورد استفاده، ویژگی هایی که زمینه فضایی اشیاء تعمیم یافته را توصیف می کنند ضروری هستند. رسمیسازی این ویژگیها به ویژگیها و انتخاب بعدی ویژگیها، هر دو عناصر مرتبط شناخت یک پایگاه داده فضایی هستند که از طریق یک مدل توصیف میشوند.
رسمیسازی ویژگیهایی که بافت فضایی را نشان میدهند، نیازمند تحلیلهای طراحیشده مناسبی است (که در سیستمهای اطلاعات جغرافیایی انجام میشود) که تلاش میکند تا شناخت کلاسیک را – تجربه شده توسط نقشهنگار با دانش و تجربه مناسب – جایگزین کند تا به ابزاری برای شناخت خودکار تبدیل شود.
آگاهی از اینکه کدام اطلاعات برای فرآیند تعمیم حیاتی است، اغلب از توانایی های نقشه نگاران خبره ای فراتر می رود که تصمیمات خود را به طور شهودی اتخاذ می کنند (حتی اگر آن ها را بر اساس دانش نقشه برداری و سال ها تجربه انجام می دهند). در این مثال، کاهشها مفید بودهاند: قادر به انتخاب زیرمجموعهها از مجموعه وسیعی از ویژگیها، یا حتی یک مجموعه کامل، برای رسیدن به تصمیم درست هستند. علاوه بر این، هستههای آنها بهخصوص اطلاعات مرتبط ضروری را سیگنال میدهند تا کیفیت تصمیمها به خطر نیفتد.
شایان ذکر است که این روش را می توان به عملگرهای تعمیم اطلاعات جغرافیایی به غیر از انتخاب اشیا، و همچنین به سایر جنبه های تحلیل داده های مکانی تعمیم داد. رسمی کردن اطلاعات بافت مکانی روی اشیاء نه تنها برای تعمیم اطلاعات جغرافیایی بلکه برای اهداف شناختی و تحلیلی بسیار مهم است. با این حال، ابزارهایی که انتخاب اطلاعات مربوطه (از یک نقطه نظر خاص) را تسهیل میکنند ارزشمند هستند – زیرا امروزه زیادهروی باعث مشکلات بیشتری نسبت به کمبود داده میشود. استفاده از چنین راه حل هایی در تجزیه و تحلیل و پردازش داده ها (از جمله داده های مکانی) و همچنین در سیستم های خبره ای که از تصمیم گیری پشتیبانی می کنند امکان پذیر است.
منابع
- هری، ال. Weibel, R. مدلسازی فرآیند کلی تعمیم. در تعمیم اطلاعات جغرافیایی ; Elsevier Science BV: آمستردام، هلند، 2007; صص 67-87. [ Google Scholar ]
- Mackaness, W. درک فضای جغرافیایی. در تعمیم اطلاعات جغرافیایی: مدل سازی و کاربرد نقشه برداری ; Mackaness, W., Ruas, A., Sarjakoski, T., Eds.; Elsevier Science BV: آمستردام، هلند، 2007. [ Google Scholar ]
- Weibel, R. تعمیم داده های مکانی: اصول و الگوریتم های انتخاب شده. در مبانی الگوریتمی سیستم های اطلاعات جغرافیایی ; Springer: برلین/هایدلبرگ، آلمان، 1997; صص 99-152. [ Google Scholar ]
- Mackaness، W. بورگاردت، دی. Duchêne, C. تعمیم نقشه: بنیادی برای مدلسازی و درک فضای جغرافیایی. در چکیده اطلاعات جغرافیایی در جهان غنی از داده ; Springer: Cham, Switzerland, 2014; صص 1-15. [ Google Scholar ]
- بارانوفسکی، م. گوتلیب، دی. اولشفسکی، آر. جستجوی جوهر نقشهبرداری. پیشرفت در نقشه کشی و GIScience ; Peterson، WMP، Peterson، MP، Eds. انتشارات بین المللی اسپرینگر: چم، سوئیس، 2017; صص 525-536. [ Google Scholar ] [ CrossRef ]
- رگنولد، ن. تویا، جی. گولد، ن. Foerster، T. مدل سازی فرآیند، خدمات وب و ژئوپردازش. در چکیده اطلاعات جغرافیایی در جهان غنی از داده ; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; یادداشت های سخنرانی در اطلاعات جغرافیایی و نقشه برداری. Springer: Cham، Switzerland، 2014. [ Google Scholar ]
- Grünreich، D. توسعه تعمیم به کمک کامپیوتر بر اساس نظریه مدل نقشه برداری. Gis و تعمیم: روش شناسی و عمل . تیلور و فرانسیس: لندن، بریتانیا، 1995; صص 47-55. [ Google Scholar ]
- شی، کاس؛ مک مستر، RB تعمیم کارتوگرافی در یک محیط دیجیتال: چه زمانی و چگونه تعمیم دهیم. In Proceedings of the Auto-Carto، بالتیمور، MD، ایالات متحده آمریکا، 2-7 آوریل 1989; جلد 9، ص 56-67. [ Google Scholar ]
- راث، RE; برویر، کالیفرنیا؛ Stryker، MS گونهشناسی عملگرها برای حفظ طرحهای نقشه خوانا در مقیاسهای چندگانه. کارتوگر. چشم انداز 2011 ، 68 ، 29-64. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دگنان، م. منطق ارسطو. کتاب های فلسفی . 1994، جلد 35، صص 81-89. در دسترس آنلاین: https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1468-0149.1994.tb02858.x (دسترسی در 20 اکتبر 2019). [ CrossRef ]
- Pawlak, Z. ست های خشن. بین المللی جی. کامپیوتر. Inf. علمی 1982 ، 11 ، 341-356. [ Google Scholar ] [ CrossRef ]
- زاده، LA منطق فازی. کامپیوتر 1988 ، 21 ، 83-93. [ Google Scholar ] [ CrossRef ]
- پاولاک، ز. Grzymala-Busse، J.; اسلووینسکی، آر. ست های خشن زیارکو، دبلیو. اشتراک. ACM 1995 ، 38 ، 88-95. [ Google Scholar ] [ CrossRef ]
- گرکو، اس. ماتارازو، بی. Słowiński، R. نظریه مجموعه های خشن برای تجزیه و تحلیل تصمیم گیری چند معیاره. یورو جی. اوپر. Res. 2001 ، 129 ، 1-47. [ Google Scholar ] [ CrossRef ]
- اسلووینسکی، آر. گرکو، اس. Matarazzo، B. پشتیبانی تصمیم گیری مبتنی بر مجموعه خشن. در روش های جستجو ; Springer: Boston, MA, USA, 2014; صص 557-609. [ Google Scholar ]
- دوبوا، دی. پراد، اچ. مجموعه های فازی خشن و مجموعه های خشن فازی. بین المللی جی ژنرال سیست. 1990 ، 17 ، 191-209. [ Google Scholar ] [ CrossRef ]
- کورنلیس، سی. مارتین، جی اچ. جنسن، آر. Ślȩzak، D. انتخاب ویژگی با کاهشهای تصمیم فازی. در مجموعه مقالات کنفرانس بین المللی مجموعه های خشن و فناوری دانش، چنگدو، چین، 17-18 مه 2008. Springer: برلین/هایدلبرگ، آلمان، 2008; ص 284-291. [ Google Scholar ]
- Pawlak, Z. مجموعههای خشن: جنبههای نظری استدلال درباره دادهها . Kluwer Academic Publishing: Dordrecht، هلند، 1991. [ Google Scholar ]
- بوریگو، م. Coventry, K. Context بر انتخاب مقیاس برای شرایط مجاورت تأثیر می گذارد. تف کردن شناخت. محاسبه کنید. 2010 ، 10 ، 292-312. [ Google Scholar ] [ CrossRef ]
- فروندشوه، اس. Blades، M. توسعه شناختی مفاهیم فضایی NEXT، NEAR، AWAY و FAR. در جنبه های شناختی و زبانی فضای جغرافیایی ; Springer: برلین/هایدلبرگ، آلمان، 2013; صص 43-62. [ Google Scholar ]
- هان، جی. فوگلیارونی، پ. فرانک، AU; ناوراتیل، جی. یک مدل محاسباتی برای مفاهیم زمینه و فضایی. در داده های جغرافیایی در جهان در حال تغییر ; Springer: Cham, Switzerland, 2016; صص 3-19. [ Google Scholar ]
- تویا، جی. بوچر، بی. فالکت، جی. جارا، ک. اشتاینیگر، اس. مدل سازی روابط جغرافیایی در محیط های خودکار. در چکیده اطلاعات جغرافیایی در جهان غنی از داده ; Burghardt, D., Duchêne, C., Mackaness, W., Eds.; یادداشت های سخنرانی در اطلاعات جغرافیایی و نقشه برداری. Springer: Cham، Switzerland، 2014. [ Google Scholar ]
- موستیر، اس. Moulin, B. بافت فضایی در تعمیم کارتوگرافی چیست؟ بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2002 ، 34 ، 274-278. [ Google Scholar ]
- اشتاینیگر، اس. Weibel, R. روابط بین اشیاء نقشه در تعمیم نقشه برداری. کارتوگر. Geogr. Inf. علمی 2007 ، 34 ، 175-197. [ Google Scholar ] [ CrossRef ]
- Varanka، DE; کارو، هنگ کنگ محمولات رابطه فضایی در معناشناسی ویژگی توپوگرافی. در جنبه های شناختی و زبانی فضای جغرافیایی ; Springer: برلین/هایدلبرگ، آلمان، 2013; صص 175-193. [ Google Scholar ]
- استین، ا. کورستن، LCA کریجینگ جهانی و کوکریجینگ به عنوان یک روش رگرسیون. بیومتریک 1991 ، 47 ، 575-587. [ Google Scholar ] [ CrossRef ]
- کوماری، م. بایستا، ا. باکیمچاندرا، او. سینگ، CK مقایسه روشهای درونیابی فضایی برای نقشهبرداری بارش در هیمالیاهای هندی منطقه اوتاراکند. در رویکردهای زمین آماری و جغرافیایی برای توصیف منابع طبیعی در محیط زیست ; Springer: Cham, Switzerland, 2016; صص 159-168. [ Google Scholar ]
- Bockelmann، FD; پولس، دبلیو. کلیبرگ، یو. مولر، دی. Emeis، KC نقشه برداری محتوای گل و اندازه دانه متوسط رسوبات دریای شمال – یک رویکرد زمین آماری. مارس جئول. 2018 ، 397 ، 60-71. [ Google Scholar ] [ CrossRef ]
- Anselin، L. اقتصاد سنجی فضایی. همراهی با اقتصاد سنجی نظری. 2001، صص 310-330. در دسترس آنلاین: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.141.1868&rep=rep1&type=pdf (در 4 دسامبر 2019 قابل دسترسی است).
- پتروویچ، آ. مانلی، دی جی; ون هام، ام. آزادی از استبداد همسایگی: بازاندیشی تأثیرات بافت اجتماعی- فضایی. 2018. در دسترس آنلاین: https://www.econstor.eu/bitstream/10419/180434/1/dp11416.pdf (در 5 دسامبر 2019 قابل دسترسی است).
- هاس، تی. روشهای پنجره متحرک و منطقی تخمین رسوب اسید. مربا. آمار دانشیار 1990 ، 85 ، 950-963. [ Google Scholar ] [ CrossRef ]
- فو، جی. جونز، CB; Abdelmoty، گسترش جستجوی فضایی مبتنی بر هستی شناسی هوش مصنوعی در بازیابی اطلاعات. در مجموعه مقالات کنفرانس های بین المللی کنفدراسیون OTM “در حرکت به سوی سیستم های اینترنتی معنادار”، آگیا ناپا، قبرس، 31 اکتبر تا 4 نوامبر 2005. Springer: برلین/هایدلبرگ، آلمان، 2005; ص 1466-1482. [ Google Scholar ]
- وانوس، آر. ملکی، ج. بوجو، ا. وینسنت، سی. مدل سازی فعالیت های شی متحرک بر اساس قوانین هستی شناسی مسیر با در نظر گرفتن قوانین رابطه فضایی. در مدل سازی رویکردها و الگوریتم ها برای برنامه های کاربردی کامپیوتر پیشرفته ; Springer: Cham, Switzerland, 2013; ص 249-258. [ Google Scholar ]
- تامسون، آرسی Richardson, DE یک رویکرد نظریه گراف برای تعمیم شبکه جاده ای. در مجموعه مقالات هفدهمین کنفرانس بین المللی کارتوگرافی، بارسلون، اسپانیا، 3-9 سپتامبر 1995; صفحات 1871-1880. [ Google Scholar ]
- کرتین، تحلیل شبکه KM در علم اطلاعات جغرافیایی: بررسی، ارزیابی و پیش بینی کارتوگر. Geogr. Inf. علمی 2007 ، 34 ، 103-111. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تویا، جی. دوچن، سی. Taillandier، P. گفوری، ج. رواس، ع. Renard، J. سیستم های چند عاملی برای تعمیم نقشه برداری: بازخورد از تحقیقات گذشته و در حال انجام. گزارش پژوهشی؛ IGN (Institut National de l’Information Géographique et Forestière)؛ LaSTIG، équipe COGIT. hal-01682131. 2018. در دسترس آنلاین: https://hal.archives-ouvertes.fr/hal-01682131/document (در 4 دسامبر 2019 قابل دسترسی است).
- گالاندا، م. Weibel, R. چارچوبی مبتنی بر عامل برای تعمیم بخش فرعی چند ضلعی. در پیشرفت در مدیریت داده های مکانی ; Springer: برلین/هایدلبرگ، آلمان، 2002; صص 121-135. [ Google Scholar ]
- لازو-کورتز، ام اس; مارتینز-ترینیداد، جی اف. Carrasco-Ochoa، JA; سانچز-دیاز، جی. در مورد رابطه بین کاهش دهنده های مجموعه خشن و آزمایش کننده های معمولی. Inf. علمی 2015 ، 294 ، 152-163. [ Google Scholar ] [ CrossRef ]
- مک پارتالین، ن. جنسن، آر. Diao، R. مجراهای دوگانه مجموعه فازی برای کاهش داده ها. IEEE Trans. سیستم فازی 2019 . [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Sikder، IU یک رویکرد مجموعه ای با دقت متغیر برای کشف دانش در طبقه بندی پوشش زمین. بین المللی جی دیجیت. زمین 2016 ، 9 ، 1206-1223. [ Google Scholar ] [ CrossRef ]
- پسوا، آسا؛ استفانی، اس. Fonseca، LMG انتخاب ویژگی و طبقهبندی تصویر با استفاده از نظریه مجموعههای خشن. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE 2011، ونکوور، BC، کانادا، 24 تا 29 ژوئیه 2011. ص 2904-2907. [ Google Scholar ]
- چن، ال. تسای، سی. چارچوب داده کاوی بر اساس تئوری مجموعه خشن برای بهبود تصمیمات انتخاب مکان: مطالعه موردی یک رستوران زنجیره ای. تور. مدیریت 2016 ، 53 ، 197-206. [ Google Scholar ] [ CrossRef ]
- Yan, HY; ژانگ، XR؛ دونگ، جی اچ. شانگ، ام اس؛ شان، ک. وو، دی. یوان، ی. وانگ، ایکس. منگ، اچ. هوانگ، ی. و همکاران اکتساب قاعده رابطه مکانی و زمانی اتروفیکاسیون در رودخانه دانینگ بر اساس نظریه مجموعه های خشن Ecol. اندیک. 2016 ، 66 ، 180-189. [ Google Scholar ] [ CrossRef ]
- فیگوایردو، سی. Mota, C. یک مدل طبقه بندی برای ارزیابی سطح امنیت در یک شهر بر اساس GIS-MCDA. ریاضی. مشکل مهندس 2016 ، 2016 ، 3534824. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Ottomano Palmisano، G. لوئیسی، ر. روجیرو، جی. روچی، ال. بوگیا، ا. روما، آر. Dal Sasso، P. استفاده از فرآیند شبکه تحلیلی و رویکرد مجموعه خشن مبتنی بر تسلط برای صلاحیت مجدد پایدار ساختمانهای مزرعه سنتی در جنوب ایتالیا. سیاست کاربری زمین 2016 ، 59 ، 95-110. [ Google Scholar ] [ CrossRef ]
- جنسن، آر. Shen, Q. کاهش مشخصه فازی خشن با کاربرد به طبقه بندی وب. سیستم مجموعه های فازی 2004 ، 141 ، 469-485. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یان، سی. یانگ، ال. گارتنر، جی. زو، س. لیو، ایکس. تولید مقیاس نقشه اولیه هوشمند بر اساس قوانین ناهموار. عرب جی. ژئوشی. 2019 ، 12 ، 109. [ Google Scholar ] [ CrossRef ]
- لی، دبلیو. کیو، جی. وو، زی. لین، ز. Li, S. کاربرد مجموعه های خشن در تعمیم GIS. در مجموعه مقالات کنفرانس بین المللی مجموعه های خشن و فناوری دانش، بنف، AB، کانادا، 9 تا 12 اکتبر 2011. Springer: برلین/هایدلبرگ، آلمان، 2011; صص 347-353. [ Google Scholar ]
- یانگ، ی. چن، دی. وانگ، اچ. تسانگ، ای. ژانگ، دی. کاهش ویژگی افزایشی مبتنی بر مجموعه ناهموار فازی از دادههای پویا با رسیدن نمونه. سیستم مجموعه های فازی 2017 ، 312 ، 66-86. [ Google Scholar ] [ CrossRef ]
- عباس، ز. Burney، A. بررسی بسته های نرم افزاری مورد استفاده برای تجزیه و تحلیل مجموعه های خشن. جی. کامپیوتر. اشتراک. 2016 ، 4 ، 10-18. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فوگلیارونی، پ. ویزر، پی. هوبل، اچ. جستجوی پیکربندی فضایی کیفی. تف کردن شناخت. محاسبه کنید. 2016 ، 16 ، 272-300. [ Google Scholar ] [ CrossRef ]
- Jenks، GF طبقهبندی دادههای بهینه برای نقشههای Choropleth . گروه جغرافیا، دانشگاه کانزاس مقاله گاه به گاه شماره 2; گروه جغرافیا، دانشگاه کانزاس: لارنس، KS، ایالات متحده آمریکا، 1977. [ Google Scholar ]
- Fiedukowicz، A. ساخت سیستم تداخل فازی برای تعمیم اطلاعات جغرافیایی – انتخاب بخش های جاده. اطلاعات جغرافیایی پول 2013 ، 12 ، 53-62. [ Google Scholar ] [ CrossRef ]
- Strahler، AN تحلیل کمی ژئومورفولوژی حوزه آبخیز. Eos Trans. صبح. ژئوفیز. اتحادیه 1957 ، 38 ، 913-920. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Mackaness، WA; ریش، KM استفاده از نظریه گراف برای پشتیبانی از تعمیم نقشه. کارتوگر. Geogr. Inf. سیستم 1993 ، 20 ، 210-221. [ Google Scholar ] [ CrossRef ]
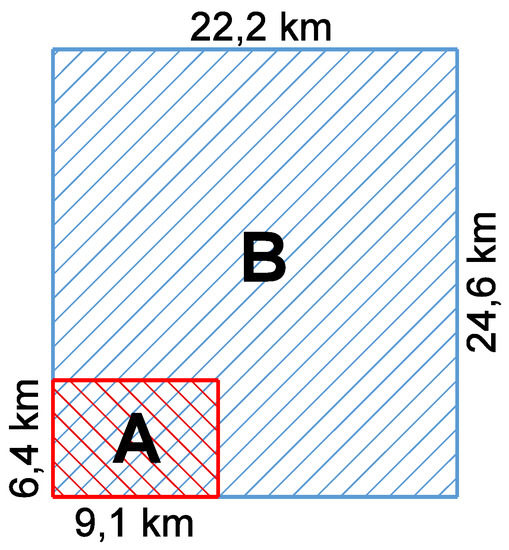
شکل 1. ابعاد و موقعیت متقابل مناطق داده مدل: ( A ) 1:10 000 منطقه داده، ( B ) 1:50 000 منطقه داده.
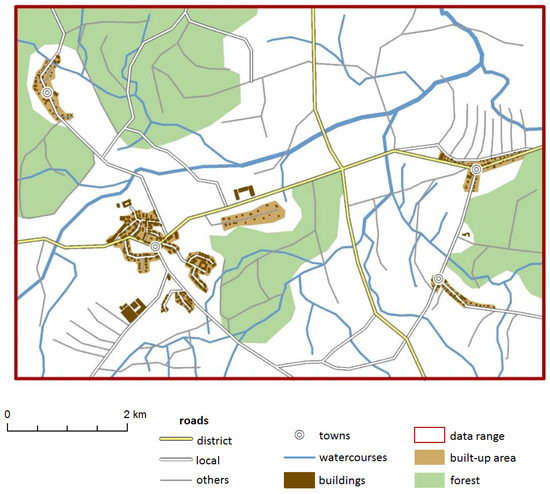
شکل 2. داده های مدل در ناحیه A نشان داده شده در شکل 1 (مشاهده شده در ArcMap ESRI). منبع: کار خود
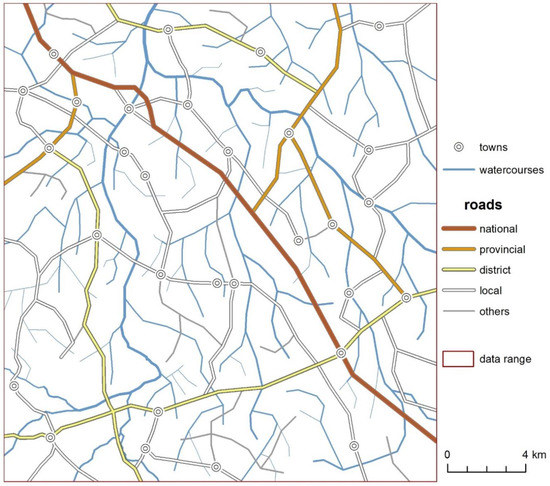
شکل 3. داده های مدل در ناحیه B نشان داده شده در شکل 1 (مشاهده شده در ArcMap ESRI). منبع: کار خود

شکل 4. تغییر سطوح اندازهگیری: فلشهای سمت چپ به معنای «کاهش» سطح اندازهگیری، فلشهای سمت راست به معنای «ارتقا» (اغلب مصنوعی) سطح اندازهگیری است.
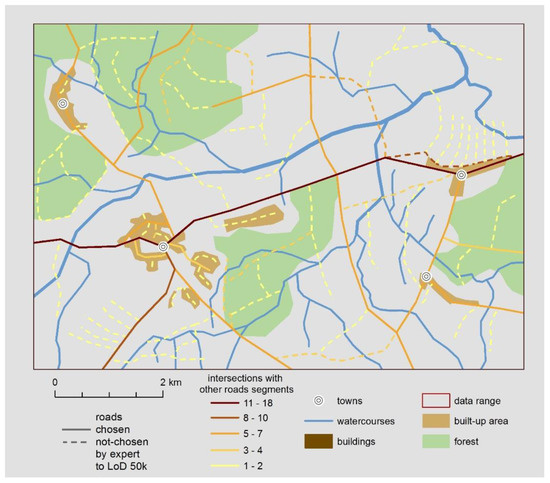
شکل 5. انتخاب متخصص جادههای 10 k > 50 k (خطوط جامد) در کنار ویژگی جادهها که تعداد تقاطعها را با سایر بخشهای جاده توصیف میکند (ویژگی هندسی)، اهمیت ویژگی کشف شده را نیز در کاهشها نشان میدهد.
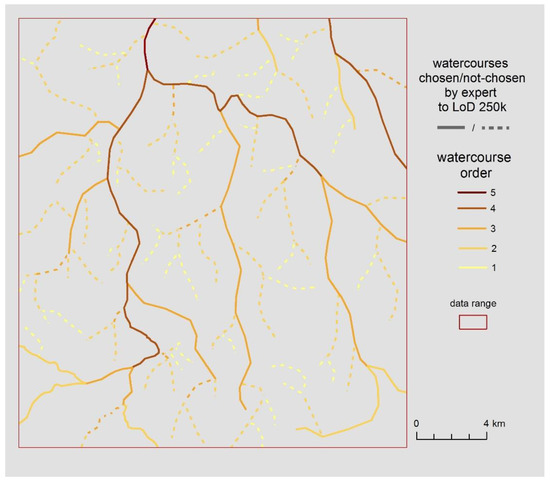
شکل 6. انتخاب خبره جریانهای آب 50 k > 250 k (خطوط جامد) در کنار هم قرار گرفتهاند (ویژگی هندسی)، که بهطور بصری اهمیت ویژگی کشفشده را در کاهشها نشان میدهد.


بدون دیدگاه