

خلاصه
کلید واژه ها:
شناسایی نهاد نامگذاری شده نمودار دانش ; یادگیری عمیق ؛ خطرات زمین شناسی
1. معرفی
-
تا جایی که ما می دانیم، این اولین کاری است که از تکنیک NER برای استخراج موجودیت های نامگذاری شده و ایجاد یک نمودار دانش برای ادبیات خطرات زمین شناسی استفاده می کند.
-
این مقاله یک مدل NER مبتنی بر یادگیری عمیق را پیشنهاد میکند که یک لایه BiGRU چند شاخه و یک مدل CRF را برای خطر زمینشناسی NER ترکیب میکند. این مدل از ساختار چند شاخه ای استفاده می کند. هر شاخه شامل یک لایه BiGRU با اعماق مختلف برای استخراج سطوح مختلف ویژگیها است و سپس ویژگیهای اولیه را با استفاده از مکانیسم توجه و ساختار باقیمانده افزایش میدهد.
-
این مقاله یک روش مبتنی بر الگو را برای ساخت یک مجموعه خطرات زمینشناسی در مقیاس بزرگ NER با هزینههای دستی کم پیشنهاد میکند.
2. کارهای مرتبط
3. مقدمات
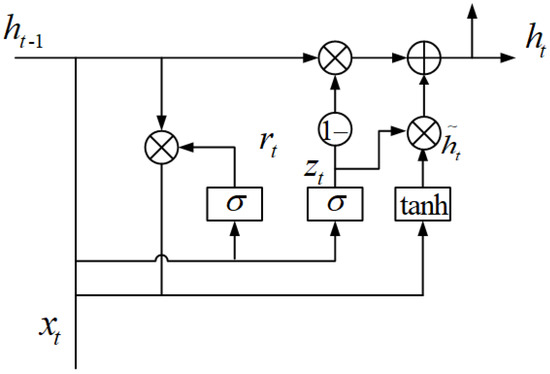
3.1. GRU
گیت ریست rتیو گیت آپدیت zتیبه صورت زیر تعریف می شوند:
جایی که σتابع فعال سازی سیگموئید [ 51 ] است. ساعتتیحالت ضمنی را نشان می دهد و به صورت زیر تعریف می شود:
که در آن ⊙ عملگر محصول عنصر دو بردار و ساعت˜تیحالت ضمنی نامزد را نشان می دهد و به صورت زیر تعریف می شود:
3.2. CRF
اجازه دهید جی=(V،E)یک گراف بدون جهت باشد، که در آن V مجموعه گره ها و E مجموعه یال ها است، و اجازه دهید Y=Yv|v∈Vمجموعه ای از متغیرهای تصادفی باشد Yvایندکس شده توسط گره v در V. با توجه به شرط X ، اگر هر متغیر تصادفی باشد Yvاز ویژگی مارکوف پیروی می کند:
سپس (ایکس،Y)یک CRF را تشکیل می دهد که X نشان دهنده دنباله مشاهده شده و تو∼vنشان دهنده تمام گره های همسایه u است که توسط گره v در نمودار G متصل شده اند .
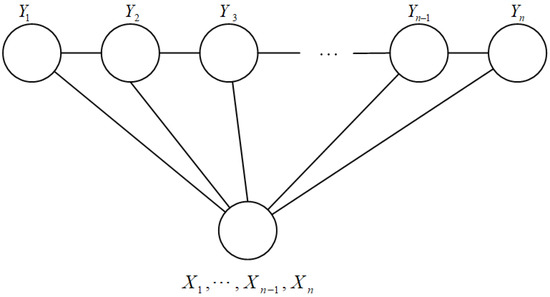
زنجیره خطی-CRF
زنجیره خطی-CRF [ 60 ]، همانطور که در شکل 2 نشان داده شده است، شکل رایج مدل CRF هستند. اجازه دهید ایکس=ایکس1،ایکس2،⋯،ایکسnتوالی مشاهده را نشان می دهد و y=y1،y2،⋯،ynمجموعه ای از حالات متناهی باشد، طبق نظریه پایه میدان تصادفی:
که در آن اصطلاحات به شرح زیر تعریف می شوند:
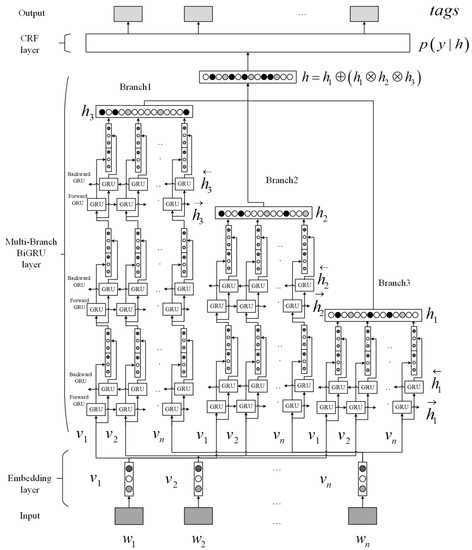
4. روش های پیشنهادی
-
ساخت پیکره مبتنی بر الگو. با توجه به اسناد ادبی اف={f1،f2،…،fن}جایی که fnn∈1،نسند n-ام است و پآتیتیهrnس پ={پمتر،پل،پد}جایی که پمتر، پل، پدالگوهایی برای مترهتیساعتoدس، لoجآتیمنon، و دآتیآ، به ترتیب. هدف روش ساخت پیکره مبتنی بر الگو ساختن یک نهاد با نام پیکره C است.
-
مدل عمیق و چند شاخه ای BiGRU-CRF برای NER. با توجه به اسناد ادبی اف={f1،f2،…،fن}جایی که fnn∈1،ننهمین سند و نهاد نامگذاری شده C است، مدل عمیق و چند شاخه ای BiGRU-CRF پیشنهادی با هدف استخراج مترهتیساعتoدس لoجآتیمنon، و دآتیآموجودیت هایی از F و یک نمودار دانش G می سازد.
4.1. ساخت بدنه مبتنی بر الگو
4.1.1. تعریف موجودات نامگذاری شده در ادبیات خطر زمین شناسی
4.1.2. اکتساب بذر مبتنی بر الگو
ما از این الگوها (عبارات منظم) برای مطابقت با جملات استفاده می کنیم اس={س1،س2،…،ساچ}در ادبیات F از مقالات در پایگاه داده Wanfang ( https://www.wanfangdata.com.cn ). کلماتی که با آن الگوها مطابقت دارند (عبارات منظم) P دانه های موجودیتی هستند که می خواهیم استخراج کنیم. پس از آن، به طور تصادفی 2000 دانه موجودیت را انتخاب می کنیم و به صورت دستی دانه های موجودیت را بررسی می کنیم تا دقت را با معادله زیر محاسبه کنیم:
جایی که nجتعداد دانههای موجودیت صحیح و n نشاندهنده تعداد کل دانههای موجودیت است. نتایج در جدول 3 نشان داده شده است. پس از بررسی دستی، همه موجودیتهای صحیح مجموعههای دانه موجودیت را تشکیل میدهند م={متر1،متر2،…،مترمن}، L={ل1،ل2،…،لجی}، و D={د1،د2،…،دک}.
4.1.3. MFM برای ساخت و ساز بدنه
- (1)
-
عناصر موجود در مجموعه seed موجودیت را مرتب کنید م={متر1،متر2،…،مترمن}، L={ل1،ل2،…،لجی}و D={د1،د2،…،دک}به طور جداگانه به ترتیب کاهش با توجه به طول.
- (2)
-
مجموعه بدنه C را به یک مجموعه خالی مقدار دهی اولیه کنید.
- (3)
-
برای هر جمله اسساعتساعت∈1،اچکه در اس={س1،س2،…،ساچ}، دانه ها را در مجموعه دانه های M ، L و D جستجو کنید. اگر دانه ای وجود دارد که توسط اسساعتو بدون برچسب است، سپس کلمات حاوی دانه را در برچسب گذاری کنید اسساعتبا تگ های موجودیت مربوطه
- (4)
-
پس از عبور از تمام مجموعه های دانه M ، L ، و D ، کلمات بدون برچسب باقی مانده در اسساعتبه عنوان “O” برچسب گذاری شده اند.
- (5)
-
برچسب را اضافه کنید اسساعتبه مجموعه پیکره C.
- (6)
-
وقتی بدون برچسب وجود ندارد اسساعتدر S ، برنامه به پایان می رسد و مجموعه مجموعه C را برمی گرداند .
| الگوریتم 1 MFM |
| ورودی: اسهnتیهnجهس اس={س1،س2،…،ساچ}، مهتیساعتoدساسههدس م={متر1،متر2،…،مترمن}، Loجآتیمنonاسههدس L={ل1،ل2،…،لجی}، Dآتیآاسههدس D={د1،د2،…،دک} خروجی: سیorپتوساسهتیسی
|
4.2. مدل BiGRU-CRF چند شاخه ای عمیق
4.2.1. لایه جاسازی
4.2.2. لایه BiGRU چند شاخه ای
4.2.3. لایه CRF
المانها ساعتتیکه در ساعت، جایی که t نشان دهنده t-امین عنصر در است ساعت، کاملا مستقل نیستند. مثلاً وقتی ساعتتی”B-MED” است، احتمال ساعتتی+1بدیهی است که “I-MED” بودن بسیار بیشتر از احتمال “B-DAT” بودن است. بنابراین، به جای درمان ساعتبه طور مستقل، ما از یک لایه CRF برای مدل سازی رابطه بین استفاده می کنیم ساعتو نتایج بهبود یافته را دریافت کنید. لایه CRF برای محاسبه احتمال شرطی اضافه می شود پ(y|ساعت)با معادله ( 9 )، که در آن y=y1،y2،⋯yتینشان دهنده دنباله های برچسب است.
جایی که γنشان دهنده دنباله های همه برچسب های ممکن است، t نشان دهنده احتمال انتقال برای یک دنباله ورودی داده شده است. ساعتاز جانب yمن-1به yمنو s امتیاز انتشار انتقال از خروجی لایه BiGRU به yمندر مرحله زمانی I.
در نهایت، مدل با برآورد احتمال شرطی حداکثر [ 63 ] توسط معادله ( 10 ) آموزش داده می شود. دنباله ای که احتمال شرطی را فعال می کند پ(y|ساعت;تی،س)برای بدست آوردن حداکثر مقدار خروجی مدل است.
5. اجرا
6. نتایج تجربی
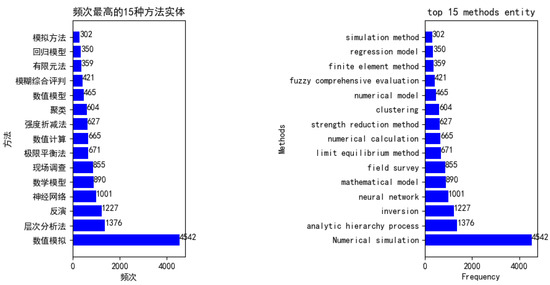
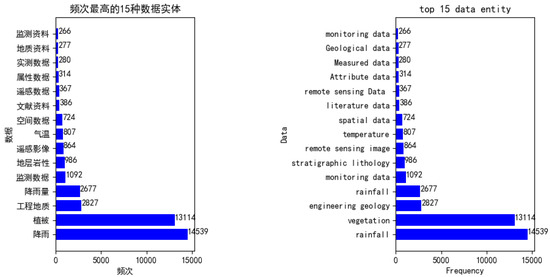
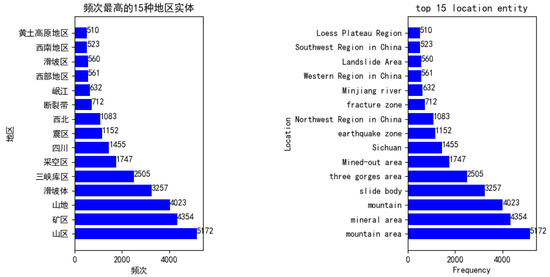
6.1. بدنه ساخته شده است
6.2. آموزش
6.3. نتایج
ما از P (دقت)، R (نرخ یادآوری)، و F (امتیاز F1)، که معیارهای ارزیابی پرکاربرد [ 31 ، 32 ، 33 ، 34 ، 65 ] در NER هستند، برای ارزیابی سه مدل ذکر شده استفاده کردیم. هرچه سه معیار ارزیابی بزرگتر باشد، تأثیر مدل بهتر است. P، R و F را می توان با سه فرمول زیر محاسبه کرد:
جایی که nپتعداد پیش بینی های مثبت واقعی را نشان می دهد. nتیکل پیشبینیهای مثبت، از جمله درست و نادرست را نشان میدهد. و nجتعداد کل پیشبینیها، اعم از مثبت و منفی را نشان میدهد.
-
مدل CRF مدلی است که توسط سبحانا و همکاران ارائه شده است. [ 38 ]، با استفاده از CRF برای NER در علوم زمین. ما از روش CRF به عنوان معیار خود استفاده کردیم. همانطور که در جدول 6 مشاهده می شود ، مدل CRF در ابتدا می تواند این مخاطرات زمین شناسی را شناسایی کند و به دقت متوسط 0.8210، نرخ فراخوان 0.7765 و امتیاز F1 79.81 دست یابد.
-
مدل BiLSTM-CRF مدلی پیشرفته در وظایف فعلی NER است [ 31 ]. این یک لایه LSTM دو طرفه و یک لایه CRF در بالا دارد. همانطور که در جدول 6 مشاهده می شود ، مدل BiLSTM-CRF در مقایسه با مدل CRF با میانگین دقت 0.9205، میانگین نرخ فراخوان 0.9419 و میانگین امتیاز F1 93.10 دارای برتری قابل توجهی در همه شاخص ها است. این به طور کامل نشان داد که مدل BiLSTM-CRF پس از افزودن یک لایه LSTM دو طرفه قبل از لایه CRF، استخراج ویژگی کارآمدتر و توانایی تشخیص دقیقتری دارد.
-
مدل عمیق و چند شاخه ای BiGRU-CRF مدل پیشنهادی با یک لایه BiGRU سه شاخه بود که از سه شاخه لایه های BiGRU انباشته با عمق های 1، 2 و 3 به ترتیب و یک لایه CRF در بالای آن تشکیل شده بود. همانطور که در جدول 6 مشاهده می شود ، مدل عمیق و چند شاخه ای BiGRU-CRF تقریباً در همه شاخص ها (به جز نرخ فراخوانی روش ها) در مقایسه با مدل CRF و مدل BiLSTM-CRF در بالا، با میانگین، برتری قابل توجهی داشت. دقت 0.9413، میانگین نرخ فراخوان 0.9425 و میانگین امتیاز F1 94.19. این به طور کامل نشان داد که مدل پیشنهادی پس از افزودن سه شاخه از BiGRU با عمقهای 1، 2 و 3، استخراج ویژگی کارآمدتر و توانایی تشخیص دقیقتری دارد.
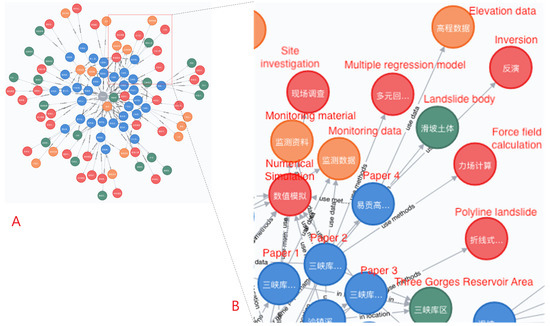
6.4. ساخت نمودار دانش
7. بحث
7.1. بحث های تعمیم پذیری
-
ساختار کاغذی در تمرین خود، بخشهای انتزاعی مقالهها را با نام شناسایی نهاد بررسی کردیم. بنابراین، روش ما هیچ الزام خاصی برای ساختار مقاله ندارد، تا زمانی که مقاله شامل یک بخش خلاصه کامل باشد.
-
زبان کاغذی از نظر زبان (مثلاً به زبان انگلیسی)، مدل باید به صورت زیر تنظیم شود: اولاً، چینی بر اساس کاراکترها است، در حالی که انگلیسی بر اساس کلمات است. بنابراین، برای گسترش روش خود به مقالات انگلیسی، باید الگوهای اکتساب بذر (در بخش 4.1.2 ) را بازسازی کنیم تا یک مجموعه آموزشی برای مدل بسازیم. ثانیاً، هنگام انجام وظایف NER به زبان چینی، یک کاراکتر مربوط به یک برچسب است، اما در انگلیسی، یک کلمه با یک برچسب مطابقت دارد. بنابراین، برای گسترش روش خود به مقالات انگلیسی، باید بردارهای حروف چینی را به واژه انگلیسی vectors در لایه جاسازی (در بخش 4.2.1 ) مدل عمیق و چند شاخه ای BiGRU-CRF تغییر دهیم.
7.2. بحث های توسعه پذیری
-
انعطاف پذیری برای تطبیق نمونه های جدید. هنگامی که یک مقاله جدید به پایگاه داده Wanfang اضافه می شود، مقالات جدید اضافه شده را می توان در سه مرحله زیر به گره ها و لبه ها پردازش کرد. مرحله اول: خزیدن بخش انتزاعی مقالات جدید از پایگاه داده Wanfang از طریق فناوری خزنده وب. مرحله دوم: استفاده از مدل عمیق و چند شاخه ای BiGRU-CRF برای شناسایی روش، داده ها و موجودیت های مکان. مرحله سوم: موجودیت به عنوان یک گره عمل می کند و اتصالات بین موجودیت ها و مقالات به عنوان لبه های نمودار دانش عمل می کند.
-
توسعه پذیری انواع موجودیت. در همان زمان، ما همچنین در مورد اینکه در صورت اضافه شدن انواع موجودیت جدید (مثلاً تئوری) روشهای ما باید چه تنظیماتی انجام دهند، بحث کردیم. اگر نوع موجودیت جدیدی اضافه شود، مدل عمیق و چند شاخه ای BiGRU-CRF باید به صورت زیر تنظیم شود: ابتدا باید الگوهای اکتساب بذر (مانند A) را به صورت دستی طراحی کنیم و مجموعه آموزشی را با استفاده از روش های ذکر شده بسازیم. در بخش 4.1.2 . دوم، به دلیل اضافه شدن انواع موجودیت های جدید، مقدار احتمال خروجی softmax آخرین لایه مدل ما باید از 7 تغییر کند (“O”، “I-LDS”، “I-MED”، “B” -LDS، «I-DAT»، «B-MED» و «B-DAT») تا 9 («O»، «I-LDS»، «I-MED»، «B-LDS»، «I -DAT، «B-MED»، «B-DAT»، «B-THE» و «I-THE») که در آن «THE» نهاد نظریه را نشان میدهد.
7.3. بحث محدودیت ها و کار آینده
8. نتیجه گیری
پیوست اول

ضمیمه B
منابع
- واسوانی، ع. Shazeer، N. پارمار، ن. Uszkoreit، J. جونز، ال. گومز، AN; قیصر، Ł. Polosukhin، I. توجه شما تمام چیزی است که نیاز دارید. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صفحات 5998-6008. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صص 770-778. [ Google Scholar ]
- Chowdhury، GG پردازش زبان طبیعی. آنو. Rev. Inf. علمی تکنولوژی 2003 ، 37 ، 51-89. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- زو، ی. ژو، دبلیو. خو، ی. لیو، جی. Tan, Y. یادگیری هوشمند برای نمودار دانش نسبت به داده های زمین شناسی. علمی برنامه. 2017 ، 2017 ، 5072427:1–5072427:13. [ Google Scholar ] [ CrossRef ]
- بائر، اف. Kaltenböck, M. داده های باز پیوندی: ملزومات ; اد. تک رنگ/تک رنگ: وین، اتریش، 2011. [ Google Scholar ]
- Mihalcea، R. Tarau, P. Textrank: ایجاد نظم در متن. در مجموعه مقالات کنفرانس 2004 در مورد روشهای تجربی در پردازش زبان طبیعی، بارسلون، اسپانیا، 25-26 ژوئیه 2004. [ Google Scholar ]
- وانگ، سی. ما، ایکس. چن، جی. چن، جی. استخراج اطلاعات و ساخت نمودار دانش از ادبیات علم زمین. محاسبه کنید. Geosci. 2018 ، 112 ، 112-120. [ Google Scholar ] [ CrossRef ]
- لافرتی، جی. مک کالوم، ا. Pereira، FC زمینه های تصادفی شرطی: مدل های احتمالی برای تقسیم بندی و برچسب گذاری داده های توالی. در مجموعه مقالات هجدهمین کنفرانس بین المللی یادگیری ماشین (ICML 2001)، ویلیامزتاون، MA، ایالات متحده آمریکا، 28 ژوئن تا 1 ژوئیه 2001. ص 282-289. [ Google Scholar ]
- قدرت ها، DM کاربردها و توضیحات قانون Zipf. در مجموعه مقالات کنفرانس های مشترک در مورد روش های جدید در پردازش زبان و یادگیری زبان طبیعی محاسباتی، سیدنی، استرالیا، 11-17 ژانویه 1998. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 1998; صص 151-160. [ Google Scholar ]
- راموس، جی. استفاده از tf-idf برای تعیین ارتباط کلمه در جستارهای سند. در مجموعه مقالات اولین کنفرانس آموزشی در مورد یادگیری ماشین، Piscataway، NJ، ایالات متحده، 3-8 دسامبر 2003. جلد 242، صص 133–142. [ Google Scholar ]
- شی، ال. جیان پینگ، سی. جی، ایکس. استخراج اطلاعات اکتشافی توسط متن کاوی بر اساس شبکه های عصبی کانولوشنال-مطالعه موردی سپرده مس لالا، چین. دسترسی IEEE 2018 ، 6 ، 52286–52297. [ Google Scholar ] [ CrossRef ]
- چینچر، ن. رابینسون، P. MUC-7 تعریف وظیفه نهاد را نامگذاری کرد. در مجموعه مقالات هفتمین کنفرانس درک پیام، فراسکاتی، ایتالیا، 16 ژوئیه 1997; جلد 29. [ Google Scholar ]
- یتس، ای. کافرلا، م. بانکو، م. اتزیونی، او. برادهد، ام. Soderland, S. Textrunner: باز کردن استخراج اطلاعات در وب. در مجموعه مقالات فن آوری های زبان انسانی: کنفرانس سالانه بخش آمریکای شمالی انجمن زبان شناسی محاسباتی: تظاهرات، نیویورک، نیویورک، ایالات متحده آمریکا، 23 تا 25 آوریل 2007. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2007; صص 25-26. [ Google Scholar ]
- آگیشتاین، ای. گراوانو، ال. پاول، جی. سوکولووا، وی. Voskoboynik، A. Snowball: یک سیستم نمونه اولیه برای استخراج روابط از مجموعه های متنی بزرگ. در مجموعه مقالات کنفرانس بین المللی کتابخانه های دیجیتال، کیوتو، ژاپن، 13 تا 16 نوامبر 2000. [ Google Scholar ]
- فریبرگر، ن. Maurel, D. مبدل حالت محدود آبشار می کند تا موجودیت های نامگذاری شده را در متون استخراج کند. نظریه. محاسبه کنید. علمی 2004 ، 313 ، 93-104. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Sundheim، BM مروری بر نتایج ارزیابی MUC-6. در مجموعه مقالات ششمین کنفرانس درک پیام، کلمبیا، MD، ایالات متحده آمریکا، 6-8 نوامبر 1995; انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 1995; صص 13-31. [ Google Scholar ]
- چینچور، ن. بررسی اجمالی MUC-7. در مجموعه مقالات هفتمین کنفرانس درک پیام (MUC-7)، فیرفکس، VA، ایالات متحده آمریکا، 29 آوریل تا 1 مه 1998. [ Google Scholar ]
- Chieu، HL; Ng، HT شناسایی موجودیت نامگذاری شده: یک رویکرد آنتروپی حداکثر با استفاده از اطلاعات جهانی. در مجموعه مقالات نوزدهمین کنفرانس بین المللی زبان شناسی محاسباتی، تایپه، تایوان، 24 اوت تا 1 سپتامبر 2002. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2002; جلد 1، ص 1-7. [ Google Scholar ]
- بورثویک، ا. گریشمن، آر. رویکرد آنتروپی حداکثر برای شناسایی موجودیت نامگذاری شده. Ph.D. پایان نامه، دانشگاه نیویورک، نیویورک، نیویورک، ایالات متحده آمریکا، 1999. [ Google Scholar ]
- کوران، جی آر. کلارک، اس. NER مستقل از زبان با استفاده از یک برچسب آنتروپی حداکثر. در مجموعه مقالات هفتمین کنفرانس یادگیری زبان طبیعی در HLT-NAACL 2003، ادمونتون، AB، کانادا، 31 مه تا 1 ژوئن 2003. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2003; جلد 4، ص 164-167. [ Google Scholar ]
- هرست، MA; دومایس، ST; اوسونا، ای. پلات، جی. Scholkopf, B. ماشینهای بردار پشتیبانی. IEEE Intell. سیستم برنامه آنها 1998 ، 13 ، 18-28. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ایزوزاکی، اچ. Kazawa، H. طبقهبندیکنندههای بردار پشتیبانی کارآمد برای شناسایی موجودیت نامگذاریشده. در مجموعه مقالات نوزدهمین کنفرانس بین المللی زبان شناسی محاسباتی، تایپه، تایوان، 24 اوت تا 1 سپتامبر 2002. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2002; جلد 1، ص 1-7. [ Google Scholar ]
- کازاما، ج. ماکینو، تی. اوتا، ی. Tsujii, J. ماشینهای بردار پشتیبان تنظیم برای تشخیص موجودیت با نام زیست پزشکی. در مجموعه مقالات کارگاه ACL-02 در مورد پردازش زبان طبیعی در حوزه زیست پزشکی، فیلدادلفیا، PA، ایالات متحده، 11 ژوئیه 2002. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2002; جلد 3، صص 1-8. [ Google Scholar ]
- اکبال، ع. Bandyopadhyay, S. شناسایی موجودیت نامگذاری شده با استفاده از ماشین بردار پشتیبان: یک رویکرد مستقل از زبان. بین المللی جی الکتر. محاسبه کنید. سیستم مهندس 2010 ، 4 ، 155-170. [ Google Scholar ]
- ژو، جی. Su, J. شناسایی موجودیت نامگذاری شده با استفاده از برچسب تکه مبتنی بر HMM. در مجموعه مقالات چهلمین نشست سالانه انجمن زبانشناسی محاسباتی، فیلادلفیا، PA، ایالات متحده آمریکا، 7 تا 12 ژوئیه 2002. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2002; صص 473-480. [ Google Scholar ]
- ژائو، اس. شناسایی موجودیت نامگذاری شده در متون زیست پزشکی با استفاده از مدل HMM. در مجموعه مقالات کارگاه مشترک بین المللی در مورد پردازش زبان طبیعی در زیست پزشکی و کاربردهای آن. انجمن زبانشناسی محاسباتی، ژنو، سوئیس، 28-29 اوت 2004. صص 84-87. [ Google Scholar ]
- ژانگ، جی. شن، دی. ژو، جی. سو، جی. قهوهای مایل به زرد، CL افزایش تشخیص موجودیت با نام زیست پزشکی مبتنی بر HMM با مطالعه پدیده های خاص. جی. بیومد. آگاه کردن. 2004 ، 37 ، 411-422. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- مک کالوم، ا. لی، دبلیو. نتایج اولیه برای شناسایی موجودیت نامگذاری شده با فیلدهای تصادفی شرطی، القاء ویژگی و واژگان پیشرفته وب. در مجموعه مقالات هفتمین کنفرانس یادگیری زبان طبیعی در HLT-NAACL 2003، ادمونتون، AB، کانادا، 31 مه تا 1 ژوئن 2003. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2003; جلد 4، ص 188-191. [ Google Scholar ]
- Settles، B. شناسایی موجودیت با نام زیست پزشکی با استفاده از فیلدهای تصادفی شرطی و مجموعه ویژگی های غنی. در مجموعه مقالات کارگاه مشترک بین المللی در مورد پردازش زبان طبیعی در زیست پزشکی و کاربردهای آن، ژنو، سوئیس، 28-29 اوت 2004. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2004; صص 104-107. [ Google Scholar ]
- لی، دی. کیپر-شولر، ک. Savova، G. زمینههای تصادفی شرطی و ماشینهای بردار پشتیبان برای اختلال با نام شناسایی موجودیت در متون بالینی. در مجموعه مقالات کارگاه در مورد روندهای فعلی در پردازش زبان طبیعی زیست پزشکی، کلمبوس، OH، ایالات متحده، 19 ژوئن 2008; انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2008; ص 94-95. [ Google Scholar ]
- لامپ، جی. بالستروس، ام. سوبرامانیان، اس. کاواکامی، ک. Dyer, C. معماری های عصبی برای شناسایی موجودیت نامگذاری شده. arXiv 2016 , arXiv:1603.01360. [ Google Scholar ]
- چیو، جی پی؛ Nichols، E. شناسایی موجودیت نامگذاری شده با LSTM-CNN دو طرفه. arXiv 2015 ، arXiv:1511.08308. [ Google Scholar ] [ CrossRef ]
- Hammerton, J. شناسایی موجودیت نامگذاری شده با حافظه کوتاه مدت. در مجموعه مقالات هفتمین کنفرانس یادگیری زبان طبیعی در HLT-NAACL 2003، ادمونتون، AB، کانادا، 27 مه تا 1 ژوئن 2003. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2003; جلد 4، صص 172-175. [ Google Scholar ]
- ما، ایکس. Hovy، E. برچسبگذاری توالی انتها به انتها از طریق lstm-cnns-crf دو جهته. arXiv 2016 , arXiv:1603.01354. [ Google Scholar ]
- خو، ام. جیانگ، اچ. Watcharawittayakul, S. یک رویکرد تشخیص محلی برای شناسایی موجودیت نامگذاری شده و شناسایی ذکر. در مجموعه مقالات پنجاه و پنجمین نشست سالانه انجمن زبانشناسی محاسباتی (جلد 1: مقالات طولانی)، ونکوور، BC، کانادا، 30 ژوئیه تا 4 اوت 2017؛ جلد 1، ص 1237–1247. [ Google Scholar ]
- ژائو، دی. هوانگ، جی. لو، ی. Jia, Y. الگوریتم رمزگشایی مشترک برای شناسایی موجودیت نامگذاری شده. در مجموعه مقالات سومین کنفرانس بین المللی IEEE 2018 در مورد علم داده در فضای مجازی (DSC)، گوانگژو، چین، 18 تا 21 ژوئن 2018؛ ص 705-709. [ Google Scholar ]
- نگوین، TVT; موشیتی، آ. ریکاردی، جی. رتبهبندی مجدد مبتنی بر هسته برای استخراج موجودیت نامگذاری شده. در مجموعه مقالات بیست و سومین کنفرانس بین المللی زبانشناسی محاسباتی: پوسترها، پکن، چین، 23 تا 27 اوت 2010. انجمن زبانشناسی محاسباتی: استرودزبورگ، PA، ایالات متحده آمریکا، 2010; ص 901–909. [ Google Scholar ]
- سبحنا، ن. میترا، پ. Ghosh, S. تشخیص موجودیت نامگذاری شده بر اساس میدان تصادفی شرطی در متن زمین شناسی. بین المللی جی. کامپیوتر. Appl. 2010 ، 1 ، 143-147. [ Google Scholar ] [ CrossRef ]
- میکولوف، تی. کرفیات، م. بورگت، ال. چرنوک، جی. خودانپور، اس. مدل زبان مبتنی بر شبکه عصبی بازگشتی. در مجموعه مقالات یازدهمین کنفرانس سالانه انجمن بین المللی ارتباطات گفتار، ماکوهاری، چیبا، ژاپن، 26 تا 30 سپتامبر 2010. [ Google Scholar ]
- میکولوف، تی. کمبرینک، اس. بورگت، ال. چرنوک، جی. خودانپور، س. توسعه مدل زبان شبکه عصبی بازگشتی. در مجموعه مقالات کنفرانس بین المللی IEEE 2011 در مورد آکوستیک، گفتار و پردازش سیگنال (ICASSP)، پراگ، جمهوری چک، 22-27 مه 2011. صص 5528-5531. [ Google Scholar ]
- Gers، FA; اشمیدوبر، جی. کامینز، اف. یادگیری فراموش کردن: پیش بینی مستمر با LSTM. در مجموعه مقالات نهمین کنفرانس بین المللی شبکه های عصبی مصنوعی: ICANN’99، ادینبورگ، بریتانیا، 7 تا 10 سپتامبر 1999. [ Google Scholar ]
- ساک، اچ. ارشد، ا. Beaufays، F. معماریهای شبکه عصبی بازگشتی حافظه کوتاهمدت برای مدلسازی آکوستیک در مقیاس بزرگ. در مجموعه مقالات پانزدهمین کنفرانس سالانه انجمن بین المللی ارتباطات گفتار، سنگاپور، 14 تا 18 سپتامبر 2014. [ Google Scholar ]
- ساندرمایر، ام. شلوتر، آر. Ney, H. LSTM شبکه های عصبی برای مدل سازی زبان. در مجموعه مقالات سیزدهمین کنفرانس سالانه انجمن بین المللی ارتباطات گفتار، پورتلند، OR، ایالات متحده آمریکا، 9 تا 13 سپتامبر 2012. [ Google Scholar ]
- چو، ک. ون مرینبور، بی. گلچهره، سی. بهداناو، د. بوگارس، اف. شونک، اچ. Bengio، Y. آموزش نمایش عبارات با استفاده از رمزگذار-رمزگشا RNN برای ترجمه ماشینی آماری. arXiv 2014 ، arXiv:1406.1078. [ Google Scholar ]
- چانگ، جی. گلچهره، سی. چو، ک. Bengio، Y. ارزیابی تجربی شبکههای عصبی بازگشتی دروازهای در مدلسازی توالی. arXiv 2014 ، arXiv:1412.3555. [ Google Scholar ]
- چانگ، جی. گلچهره، سی. چو، ک. Bengio، Y. شبکه های عصبی بازگشتی بازخورد دروازه ای. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین، لیل، فرانسه، 6 تا 11 ژوئیه 2015؛ ص 2067–2075. [ Google Scholar ]
- دوبیدی، د. سرمانت، پ. تامپسون، جی. دیبا، ع. فیاض، م. شارما، وی. حسین کرمی، ع. مهدی ارزانی، م. یوسف زاده، ر. ون گول، ال. و همکاران استدلال زمانی در ویدیوها با استفاده از واحدهای تکراری دردار کانولوشن. در مجموعه مقالات کنفرانس IEEE در کارگاه های آموزشی بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 22 ژوئن 2018؛ صص 1111-1116. [ Google Scholar ]
- LeCun، Y.; بنژیو، ی. هینتون، جی. یادگیری عمیق. Nature 2015 , 521 , 436. [ Google Scholar ] [ CrossRef ]
- Schmidhuber, J. یادگیری عمیق در شبکه های عصبی: یک مرور کلی. شبکه عصبی 2015 ، 61 ، 85-117. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- گریوز، ا. محمد، ع. هینتون، جی. تشخیص گفتار با شبکه های عصبی عود کننده عمیق. در مجموعه مقالات کنفرانس بین المللی IEEE 2013 در مورد آکوستیک، گفتار و پردازش سیگنال ونکوور، BC، کانادا، 26-31 مه 2013. ص 6645–6649. [ Google Scholar ]
- Hecht-Nielsen، R. نظریه شبکه عصبی پس انتشار. در شبکه های عصبی برای ادراک ; الزویر: آمستردام، هلند، 1992; صص 65-93. [ Google Scholar ]
- بنژیو، ی. سیمرد، پ. فراسکونی، پی. یادگیری وابستگی های طولانی مدت با نزول گرادیان دشوار است. IEEE Trans. شبکه عصبی 1994 ، 5 ، 157-166. [ Google Scholar ] [ CrossRef ]
- پاسکانو، آر. میکولوف، تی. Bengio، Y. در مورد دشواری آموزش شبکه های عصبی بازگشتی. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین، آتلانتا، GA، ایالات متحده آمریکا، 16-21 ژوئن 2013. ص 1310–1318. [ Google Scholar ]
- Ratnaparkhi، A. مدل حداکثر آنتروپی برای برچسب گذاری بخشی از گفتار. در مجموعه مقالات کنفرانس روشهای تجربی در پردازش زبان طبیعی، فیلادلفیا، PA، ایالات متحده آمریکا، 17-18 مه 1996. [ Google Scholar ]
- باوم، LE; پتری، تی. استنتاج آماری برای توابع احتمالی زنجیره های مارکوف حالت محدود. ان ریاضی. آمار 1966 ، 37 ، 1554-1563. [ Google Scholar ] [ CrossRef ]
- ژنگ، اس. جایاسومانا، اس. رومرا-پاردس، بی. واینیت، وی. سو، ز. دو، دی. هوانگ، سی. Torr، PH زمینه های تصادفی شرطی به عنوان شبکه های عصبی بازگشتی. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، سانتیاگو، شیلی، 7 تا 13 دسامبر 2015. صص 1529-1537. [ Google Scholar ]
- مسیح، PF; الشعیر، MEA; اتلینگر، اف. تاتاوارتی، اس. بیکل، ام. بیلیچ، پ. رمپفلر، ام. آرمبراستر، ام. هافمن، اف. D’Anastasi، M. و همکاران تقسیمبندی خودکار کبد و ضایعه در CT با استفاده از شبکههای عصبی کاملاً پیچیده و میدانهای تصادفی شرطی سهبعدی. در مجموعه مقالات کنفرانس بین المللی محاسبات تصویر پزشکی و مداخله به کمک رایانه، آتن، یونان، 17 تا 21 اکتبر 2016. صص 415-423. [ Google Scholar ]
- هوبرگ، تی. روتنشتاینر، اف. فیتوسا، RQ; Heipke, C. زمینه های تصادفی شرطی برای طبقه بندی چند زمانی و چند مقیاسی تصاویر ماهواره ای نوری. IEEE Trans. Geosci. از راه دور. Sens. 2015 ، 53 ، 659-673. [ Google Scholar ] [ CrossRef ]
- لی، ک. آی، دبلیو. تانگ، ز. ژانگ، اف. جیانگ، ال. لی، ک. هوانگ، ک. هادوپ شناسایی موجودیت با نام زیست پزشکی با استفاده از فیلدهای تصادفی شرطی. IEEE Trans. توزیع موازی سیستم 2015 ، 26 ، 3040-3051. [ Google Scholar ] [ CrossRef ]
- ساتن، سی. McCallum، A. مقدمه ای بر زمینه های تصادفی شرطی. پیدا شد. Trends ® Mach. فرا گرفتن. 2012 ، 4 ، 267-373. [ Google Scholar ] [ CrossRef ]
- مارش، ای. Perzanowski، D. MUC-7 ارزیابی فناوری IE: مروری بر نتایج. در مجموعه مقالات هفتمین کنفرانس درک پیام (MUC-7)، فیرفکس، ویرجینیا، 29 آوریل تا 1 مه 1998. [ Google Scholar ]
- قدردانی، T. CRF++: یک جعبه ابزار CRF دیگر. در دسترس آنلاین: https://crfpp.sourceforge.net/ (در 22 دسامبر 2019 قابل دسترسی است).
- Elkan، C. مدل های لاگ خطی و زمینه های تصادفی شرطی. معلم خصوصی یادداشتهای CIKM 2008 ، 8 ، 1-12. [ Google Scholar ]
- سریواستاوا، ن. هینتون، جی. کریژفسکی، آ. سوتسکور، آی. Salakhutdinov, R. Dropout: راهی ساده برای جلوگیری از برازش بیش از حد شبکه های عصبی. جی. ماخ. فرا گرفتن. Res. 2014 ، 15 ، 1929-1958. [ Google Scholar ]
- نادو، دی. Sekine, S. بررسی شناخت و طبقه بندی موجودیت نامگذاری شده. Lingvisticae Investig. 2007 ، 30 ، 3-26. [ Google Scholar ]



بدون دیدگاه