1. معرفی
به منظور توسعه یک سیاست معقول و مطلوب برای بهبود ساختار شهر و تخصیص منابع شهری برای حمایت از توسعه پایدار شهر، برنامه ریزان شهری و سیاست گذاران باید درک خود را از توزیع کاربری زمین که بر الگوی فعالیت در زمان واقعی مردم تأثیر می گذارد، بهبود بخشند. درک توزیع کاربری زمین بسیار مهم است، زیرا دسته بندی های مختلف کاربری زمین، افراد متناسب مختلف را که اهداف فعالیت متفاوتی دارند جذب می کند و بنابراین بر تخصیص منابع شهری مانند حمل و نقل عمومی تأثیر می گذارد. علاوه بر این، اطلاعات توزیع کاربری زمین می تواند به برنامه ریزان شهری در یادگیری ساختار شهری در مقیاس خوب و چگونگی بهبود کارآمد آن توسط برنامه ریزان کمک کند. از این رو، فناوری طبقهبندی کاربری اراضی ریزدانه فضایی برای توسعه پایدار شهری مورد نیاز است. همانطور که در شهرهای مدرن، تعداد مجتمعهای ساختمانی در حال افزایش است، و رویکردهای طبقهبندی کاربری اراضی مرسوم مانند سنجش از دور برای شناسایی عملکردهای خاص مجتمعهای ساختمانی به خوبی قابل اجرا نیستند. به عنوان مثال، یک مجتمع ساختمانی گاهی اوقات شامل رستوران ها، دفاتر یا هتل هایی است که در اتاق ها یا طبقات مختلف قرار دارند. روشهای سنجش از دور مرسوم نمیتوانند عملکردهای خاص ساختمانهای بزرگ یا بلند مانند مجتمعها را به خوبی شناسایی کنند. اگرچه فناوریهای سنجش از دور هوایی میتوانند عملکردهای ساختمان را بهتر از فناوریهای سنجش از دور ماهوارهای طبقهبندی کنند، اما بسیار پرهزینه و زمانبر هستند. یک رویکرد کمهزینهتر اما جدید برای طبقهبندی کاربری زمین در سطحی دقیقتر مورد نیاز است (به عنوان مثال،
در گذشته، الگوهای فعالیت انسانی در بررسیهای سنتی خانوار مورد بررسی قرار میگرفت. با این حال، این راه زمان بر و هزینه بالایی است. با توسعه شبکه های اجتماعی و خدمات مبتنی بر مکان، تعداد برنامه های کاربردی رسانه های اجتماعی مانند Foursquare، Facebook، Twitter، Weibo و غیره همچنان در حال افزایش است. بنابراین، اطلاعات مبتنی بر مکان بهدستآمده از آن برنامهها به طور مکرر در بسیاری از زمینهها مورد استفاده قرار گرفتهاند و در نتیجه مزایای اجتماعی زیادی ایجاد کردهاند. این داده ها سهم قابل توجهی در تشخیص مرکز شهر [ 1 ]، سیستم های توصیه [ 2 ، 3 ، 4 ، 5 ] و الگوهای فعالیت انسانی [ 6 ، 7 ، 8 دارند.]. با توجه به فعالیت های مختلف ساکنان در نقاط مورد علاقه (POI) مختلف، از اطلاعات می توان برای نشان دادن عملکرد یا دسته فعالیت POI خاص استفاده کرد. در یک کلام، در
POI های مختلف، افراد ممکن است حرکات متفاوتی از خود نشان دهند (به عنوان مثال، در POI های مسکونی، افراد ممکن است هنگام بیدار شدن یا ترک خانه در صبح اعلام حضور کنند و سپس به خانه برگردند یا عصرها تلویزیون تماشا کنند، در حالی که، در مرکز خرید POI، افراد ممکن است هنگام خرید یا فعالیتهای سرگرمی در عصر یا آخر هفته بیشتر مراجعه کنند). این ممکن است به ما این امکان را بدهد که ساختار فعالیت داخلی انسانی برخی از مناطق عملکردی بزرگ را بررسی و اصلاح کنیم، جایی که تعدادی از POI های مشابه به شدت با داده های شبکه اجتماعی مبتنی بر مکان (LBSN) ترکیب شده اند.
با بلوغ
فناوری سنجش از دور، توانایی فناوری سنجش از دور برای گرفتن ویژگی های فیزیکی اجسام زمینی به طور فزاینده ای بهبود یافته است. بنابراین، فناوری سنجش از دور به عنوان یک رویکرد رایج یا حتی حیاتی برای طبقه بندی کاربری اراضی در نظر گرفته شده است. از لحاظ نظری، طبقه بندی کاربری زمین عمدتاً بر اساس فناوری سنجش از دور است که می تواند کاربری زمین را با ویژگی های طیفی و متنی تشخیص دهد [ 9 ، 10 ، 11 ]. با این حال، از آنجایی که روشهای سنتی تنها عوامل فیزیکی را در نظر میگیرند، عوامل اجتماعی توسط این روشها در نظر گرفته نشده است، که ممکن است به طور قابل توجهی بر دقت طبقهبندی کاربری اراضی تأثیر بگذارد [ 12 ].]. بنابراین، برای گردآوری ویژگیهای فیزیکی و عملکردهای اجتماعی سرزمینها، برخی از مطالعات تلاش کردند تا تصاویر سنجش از دور را با دادههای بزرگ جغرافیایی نوظهور تولید شده توسط انسان در زندگی روزمره در طبقهبندی کاربری زمین ترکیب کنند (مثلاً استفاده از دادههای تلفن همراه به عنوان مکملی برای تصاویر سنجش از دور. به طبقهبندی کاربری زمین [ 12 ]، طبقهبندی کاربری زمین با استفاده از دادههای سفر تاکسی و دادههای سنجش از دور برای بهبود دقت طبقهبندی [ 13 ]، ادغام دادههای رسانههای اجتماعی و دادههای سنجش از دور برای طبقهبندی کاربری زمین [ 14 ]، بهصورت داوطلبانه جمعآوری شد. دادههای اطلاعات جغرافیایی (VGI) مانند OpenStreetMap برای مدلسازی الگوهای کاربری زمین [ 15 ]، و حتی ترکیب تصاویر Landsat با POI برای
نقشهبرداری کاربری زمین [15].16 ]}. با این حال، امروزه تعداد زمینهای با کاربری مختلط به طور فزایندهای در حال رشد است و این زمینها گاهی اوقات آنقدر مخلوط هستند که نمیتوان با رویکردهای مرسوم مانند سنجش از دور (به عنوان مثال، زمینهای تجاری شامل مناطق عملکردی مختلفی مانند غذاخوری، هتل، سرگرمی، و غیره.). در این مورد، طبقه بندی های مرسوم کاربری زمین در سطح قطعه یا سطح منطقه نمی تواند تقاضای برنامه ریزی شهری مدرن را برآورده کند [ 17 ]. برای پرداختن به این موضوع، طبقهبندی کاربری اراضی یا مناطق کاربردی در مقیاس فضایی دقیقتر برای ارتقای برنامهریزی شهری مورد نیاز است. به عبارت دیگر، پالایش طبقهبندی مناطق عملکردی میتواند کمک بیشتری به برنامهریزی شهری ارائه دهد [ 17]. برای مثال، لانگ و لیو از دادههای POI برای اندازهگیری دقیق ترکیب کاربری زمین برای کاهش عدم تطابق بین برنامههای کاربری زمین شهری و کاربری واقعی زمین استفاده کردند [ 17 ]. می توان نشان داد که رویکرد مبتنی بر POI می تواند ترکیب کاربری زمین را نسبت به رویکرد سنتی مبتنی بر قطعه زمین اندازه گیری کند. علاوه بر این، مطالعات قبلی رویکردهای سنجش اجتماعی را به جای رویکردهای سنجش از دور برای طبقهبندی مناطق عملکردی یا قطعات کاربری زمین بر اساس تحرک و الگوهای فعالیت انسان پیشنهاد کردهاند [ 12 ]. با این حال، این مطالعات دارای دانه بندی فضایی محدودی هستند، زیرا انواع کاربری زمین پیش بینی شده بر اساس داده های رکورد تلفن همراه در سطح قطعه یا سطح منطقه هستند، در حالی که داده های کاربری زمین با دانه بندی دقیق تر، مانند داده های سطح POI یا سطح ساختمان ، قطعا در برنامه ریزی شهری کاربرد بیشتری دارند [17 ]. برای کم کردن این شکاف تحقیقاتی، ما سعی کردیم کاربری زمین را در مقیاسی دقیقتر بر اساس الگوهای تحرک و فعالیت انسانی که توسط دادههای LBSN منعکس میشوند، طبقهبندی کنیم. رویکرد سنجش اجتماعی پیشنهادی ما دارای مزایایی نسبت به سایر رویکردهای سنجش اجتماعی موجود است، از جمله هزینه کم و دانه بندی خوب.
در مطالعه خود، ما فقط از بخش کوچکی از دادههای POI و بررسی ورود برای طبقهبندی کاربری زمین در سطح POI استفاده کردیم. به عبارت دیگر، ما کار دقیق تری را با انواع داده های کمتری به پایان رساندیم. به طور خاص، ما ابتدا الگوهای مکانی و زمانی رفتار و تحرک انسان را با استفاده از دادههای ورود از یک LBSN محبوب چینی به نام Sina Weibo بررسی کردیم و متعاقباً آن الگوها را برای پیشبینی دستهبندی POI برای اصلاح طبقهبندی کاربری زمین شهری در گوانگژو، چین به کار بردیم. رویکرد پیشنهادی ما میتواند به طور بالقوه برای طبقهبندی عملکردهای ساختمان بر اساس رفتار انسانی و حرکتی بازدیدکنندگان و ویژگیهای مکان ساختمانها اعمال شود.
ادامه این مقاله به شرح زیر سازماندهی شده است: بخش 2 منابع داده و منطقه مورد مطالعه را معرفی می کند. بخش 3 روش مورد استفاده در این مقاله را ارائه می دهد. بخش 4 نتایج تجربی و بحث را ارائه می کند. در نهایت، این مقاله نتیجه گیری و کارهای آتی را ارائه می کند.
شکل 1. نقشه منطقه گوانگژو، چین.
2. منطقه مطالعه و منابع داده
گوانگژو یک شهر اصلی در دلتای رودخانه مروارید، یکی از بزرگترین مناطق اقتصادی در چین است. در همین حال، Sina Weibo یکی از محبوب ترین LBSN ها با بیش از 400 میلیون کاربر در چین است. گوانگژو یکی از توسعه یافته ترین و پرجمعیت ترین شهرهای چین است. بنابراین، ما دادههای ورود سینا ویبو در شهر گوانگژو را به عنوان نمونهای برای نشان دادن روششناسی خود انتخاب کردیم.
2.1. منطقه مطالعه
گوانگژو، مرکز استان گوانگدونگ، در شمال دلتای رودخانه مروارید واقع شده است. گوانگژو همچنین یک شهر مهم در منطقه خلیج بزرگ گوانگدونگ-هنگ کنگ-ماکائو (GBA) است. بر اساس داده های باز و قابل اعتماد اداره ملی آمار چین، گوانگژو دارای تولید ناخالص داخلی حدود 325.16 میلیارد دلار در پایان سال 2018 است. گوانگژو به عنوان یکی از امیدوار کننده ترین شهرهای چین در نظر گرفته می شود، زیرا جمعیتی حدوداً داشت. 14.9 میلیون در پایان سال 2018 و قابلیت نوآوری با تکنولوژی بالا. گوانگژو از 11 ناحیه (بایون، کونگهوا، هایژو، هوادو، هوانگپو، لیوان، نانشا، پانیو، تیانهه، یوکسیو و زنگچنگ) تشکیل شده است که به شکل شکل 1 نشان داده شده است.
2.2. منبع اطلاعات
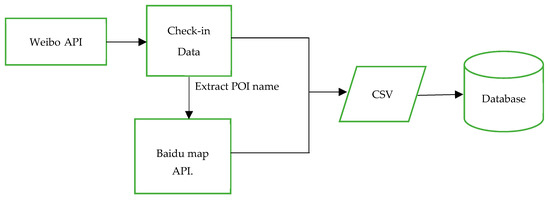
تعداد زیادی از کاربرانی که Weibo ارائه می کند به پایگاه داده ای فراوان برای استخراج ارزش اطلاعات فعالیت های انسانی تبدیل می شود. اطلاعات موجود در پایگاه داده شامل شناسه کاربر، زمان، جنسیت کاربر، سن کاربر، مکان، نام مکان، متن و نوع تلفن است، اما اطلاعات شخصی مانند نام کاربری، آدرس خانواده و حرفه در دسترس نیست. دادههای اعلام حضور که توسط کاربران فعال تولید میشود، مکانهای POI و تحرک و فعالیت روزانه کاربران را ثبت کرده است. این داده ها در رابط های برنامه نویسی کاربردی (API) Weibo موجود است. بنابراین ما آنها را از طریق APIهای Weibo به دست آوردیم. با این حال، با توجه به اطلاعات دسته بندی های مرتب شده در Baidu Map، که یک برنامه خدمات نقشه شبیه به Google Maps است، جامع تر از خدمات مکان Weibo است. بنابراین، ما دستههای POI ارائه شده توسط Weibo را با دستههای ارائه شده توسط Baidu map جایگزین کردیم. نحوه پیش پردازش داده ها در نشان داده شده استشکل 2 . در ابتدا، مجموعه داده check-in با فرمت json از طریق Weibo API جمع آوری شد. ثانیا، دستههای POI بهدستآمده از مجموعه دادههای check-in با دستههای بهدستآمده از Baidu Map API جایگزین شدند. در نهایت، بررسیها با دستههای POI جایگزین شده با یک فرم CSV در یک پایگاه داده ذخیره شدند.
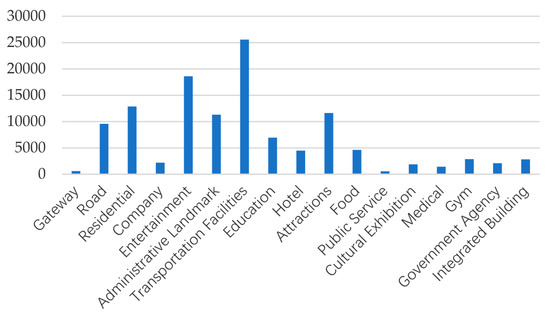
در محدودههای اداری گوانگژو، 134250 اعلام حضور توسط 74826 کاربر در 10408 مکان مجزا (POI) طی 28 هفته مداوم (از 1 مارس 2018 تا 16 سپتامبر 2018) از طریق APIهای Weibo جمعآوری شد. در بخش بعدی این مطالعه، الگوهای فعالیت های انسانی را بر اساس این مجموعه داده بررسی کردیم. پس از حذف بررسیهای بیفایده (مثلاً، کاربران اعلام حضور در برخی از POIهایی را که در سرویسهای مکان نقشه بایدو یافت نمیشوند، ارسال میکنند)، تعداد دستههای POI مختلف در بررسیهای باقیمانده مانند شکل 3 نشان داده شده است.
زمین های تجاری و مسکونی به فعال ترین مناطق برای فعالیت های روزمره انسان تبدیل شده اند. بنابراین، زمین ها به شدت مملو از انواع مختلف فعالیت های انسانی بود. با این حال، اکثر مطالعات قبلی در مورد طبقهبندی کاربری زمین نمیتواند تقاضای شناسایی انواع مختلف فعالیتهای انسانی زمینها برای کمک دقیق به برنامهریزان شهری را برآورده کند. بنابراین ما از یک رویکرد جدید برای اصلاح انواع کاربری تجاری و مسکونی با کمک دادههای حرکت افراد در LBSN استفاده کردیم. به طور خاص، ما چهار دسته بندی POI متعدد (مسکونی، سرگرمی، هتل، غذا) را که شامل زمین های تجاری و مسکونی به عنوان اهداف طبقه بندی اصلی مطالعه است، انتخاب کردیم. برخی دیگر از دستههای POI محبوب به دلایل مختلف در طبقهبندی در نظر گرفته نشدند: POI جادهها احتمالاً تعداد نسبتاً کمی از ورود و بازدیدکنندگان (کاربران Weibo) دارند، POIهای نشانههای اداری و جاذبهها با استفاده از روشهای دیگر مانند سنجش از راه دور، بررسیها در POI های حمل و نقل به راحتی قابل تشخیص هستند. امکانات در فرودگاه و ایستگاههای راهآهن متمرکز شدهاند، و POIهای گروه آموزشی در اطراف شهر کالج گوانگژو قرار دارند. بنابراین این دسته بندی های POI از طبقه بندی حذف شدند. مانند بنابراین این دسته بندی های POI از طبقه بندی حذف شدند. مانند بنابراین این دسته بندی های POI از طبقه بندی حذف شدند. مانندشکل 3 نشان می دهد، دسته بندی های POI باقی مانده برای طبقه بندی بسیار کم بودند، در غیر این صورت ممکن است منجر به دقت پیش بینی پایینی شده باشد.
داده های تجربی POI های مختلف به طور سنتی با یک قانون فیلتر می شدند – بدون پردازش بیشتر یا تمام داده ها از آستانه مشابهی پیروی می کردند. با این حال، مشارکت کنندگان اصلی در بررسی بین زمین های تجاری و مناطق مسکونی، در واقع، متفاوت بودند. بنابراین ما روشی را برای مقابله با POI معمولی مسکونی (نوع مسکونی) و POI تجاری (دستههای غذا، سرگرمی و هتل) پیشنهاد کردیم. با توجه به توسعه هتل های خانوادگی، برخی از گردشگران ترجیح می دهند در طول سفر در مناطق مسکونی استراحت کنند. با این حال، الگوهای رفتاری مسافران با ساکنان متفاوت است. از نظر ما، مشارکت کنندگان اصلی در ورود به مناطق مسکونی ساکنان هستند، اگرچه ورود ساکنان با پذیرش گردشگران در مناطق مسکونی ترکیب شده است. و الگوی داده ورود به گردشگران تأثیر قابل توجهی در الگوی مسکونی رایج دارد. بنابراین، از دیدگاه ما، ابتدا میخواستیم دادههای تولید شده توسط گردشگرانی را که در مناطق مسکونی بررسی میکنند حذف کنیم. قوانین و مراحل حذف داده های ورود گردشگران تولید شده در مناطق مسکونی به شرح زیر ارائه شده است:
- (1)
-
کاربری که حداقل در پنج تاریخ مختلف ثبت نام کرده است.
- (2)
-
کاربری که اولین تاریخ ورودش با آخرین تاریخ ورودش بیش از یک هفته (7 روز) متفاوت است.
- (3)
-
کاربری که تعداد تجمعی ورودهایش بیشتر از 10 باشد. و
- (4)
-
در دادههای POI مسکونی، دادههای ورود ساکنین (کاربران دارای معیارهای 1 تا 3 هستند) ذخیره شد و سایر دادههای افراد غیر مقیم حذف شد.
در مقابل، پذیرش در مناطق تجاری توسط ساکنان و گردشگران انجام می شود. در همین حال، ویژگیهای زمانی رفتار ورود کاربر بین ساکنان و گردشگران در مناطق تجاری تفاوت ناچیزی دارد. بنابراین، ما عمداً، در POI های تجاری، ورود ساکنان و گردشگران در POI های تجاری را تشخیص ندادیم. با این حال، به نظر ما، ما می خواستیم نماینده ترین POI ها را از POI های تجاری به عنوان نمونه انتخاب کنیم. به عبارت دیگر، برای انتخاب POI های نماینده، آستانه ای از تعداد ثبت نام های فردی POI تعیین می کنیم. دلیل آن این است که POI های غیرنماینده از الگوی رایج تحت تأثیر تبلیغات تجاری پیروی نمی کنند. تا آنجا که ما می دانیم، تبلیغات به طور معمول و انبوه در چک-این های POI تجاری وجود دارد. قاعده تعیین آستانه برای تعداد ورودهای POI فردی به این صورت است: آستانه برای سرگرمی، غذا و هتل به ترتیب شش، چهار و دو است. در دادههای POI تجاری، دادههای POI مطابق با قانون ذخیره میشوند و سایر دادههای POI حذف میشوند. این قانون در مورد توازن بین مقادیر POI و نمایندگی در نظر گرفت. با توجه به اینکه تبلیغات کمتری در POI های مسکونی نسبت به موارد تجاری وجود دارد، بنابراین پس از حذف دستی اعلامیه های تبلیغاتی POI های مسکونی، هیچ آستانه ای برای POI مسکونی قائل نشدیم. و سایر داده های POI حذف شدند. این قانون در مورد توازن بین مقادیر POI و نمایندگی در نظر گرفت. با توجه به اینکه تبلیغات کمتری در POI های مسکونی نسبت به موارد تجاری وجود دارد، بنابراین پس از حذف دستی اعلامیه های تبلیغاتی POI های مسکونی، هیچ آستانه ای برای POI مسکونی قائل نشدیم. و سایر داده های POI حذف شدند. این قانون در مورد توازن بین مقادیر POI و نمایندگی در نظر گرفت. با توجه به اینکه تبلیغات کمتری در POI های مسکونی نسبت به موارد تجاری وجود دارد، بنابراین پس از حذف دستی اعلامیه های تبلیغاتی POI های مسکونی، هیچ آستانه ای برای POI مسکونی قائل نشدیم.
ما نتایج را بین قانون سنتی – بدون پردازش بیشتر یا تمام دادهها از آستانه یکسان – و قانون پیشنهادی در بالا برای تأیید دیدگاه ما مقایسه کردیم. پس از حذف دادههای بررسی POI طبق قوانین ذکر شده در بالا، مجموعه داده آزمایشی نهایی همانطور که جدول 1 نشان میدهد ارائه میشود. مجموعه دادهای که از قانون سنتی پیروی میکند – بدون پردازش بیشتر یا تمام دادهها از همان آستانه پیروی میکنند – نیز همانطور که جدول 1 نشان میدهد نمایش داده میشود.
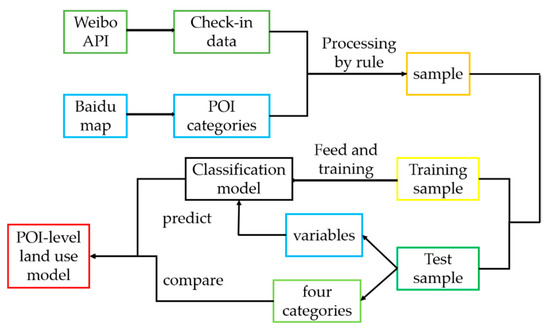
3. روش شناسی
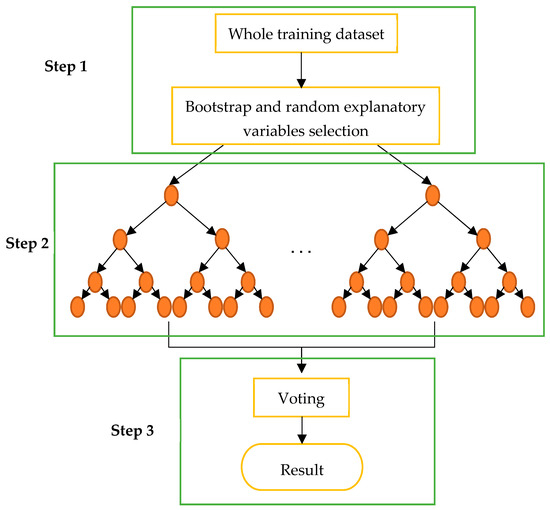
در مدل طبقهبندی کاربری زمین در سطح POI، ابتدا دستههای بررسی ورود به Weibo را با دستههای POI مربوطه استخراجشده از Baidu Map جایگزین کردیم. از آنجایی که مجموعه داده بهدستآمده از Weibo دادههای با کیفیت پایینی داشت، ما متعاقباً کیفیت دادهها را با قانون پیشنهاد شده در بخش 2.2 بهبود دادیم.. ما نمونه را به نمونههای آموزشی و آزمایشی پس از بهبود مجموعه دادهها جدا کردیم، که در آن نمونه آموزشی به مدل یادگیری طبقهبندی (به عنوان مثال، جنگل تصادفی و ماشین بردار پشتیبان) تغذیه شد تا یک مدل طبقهبندی بهینه را آموزش دهد، و نمونه آزمایشی عملکرد مدل آموزش دیده در فرآیند ساخت مدل طبقهبندی آموزشی، ما سه نوع مدل یادگیری ماشین را آموزش دادیم تا بهترین مدل برازش شده در این مطالعه را جستجو کنیم، زیرا مدلهای مختلف ویژگیهای متفاوتی دارند (به عنوان مثال، جنگل تصادفی میتواند تخمین دقت بیطرفانه تولید کند، و ماشین برداری را پشتیبانی کند. می تواند فضای بزرگ ویژگی [ 18 ]) را به تناسب مطالعات مختلف مدیریت کند. در نهایت، بهترین طبقهبندی کننده به عنوان مدل کاربری زمین در سطح POI در مطالعه انتخاب شد و گردش کار به صورت شکل 4 نشان داده شده است..
3.1. درخت تصمیم
به عنوان یک روش یادگیری نظارت شده، درخت تصمیم به طور گسترده در طبقه بندی استفاده شده است. یک درخت تصمیم واحد، نمونهها را به مجموعهای از بخشهای منحصر به فرد متقابل در فضای ویژگی تقسیم میکند. به عنوان مثال، وجود دارد جیجیمجموعهای از مشاهدات، و هر مجموعهای از مشاهدات را تشکیل میدهد ککورودی هایی با یک مقدار پاسخ، مانند ( yمن،ایکسمن 1،ایکسمن 2, … ,ایکسمن ک�من،ایکسمن1،ایکسمن2،…،ایکسمنک) برای i = 1 ، 2 ، 3 ، … ، Jمن=1،2،3،…،جی. از نظر تشخیص دسته بندی POI، yمن�منمی تواند نشان دهنده دسته بندی برای هر کدام باشد منمن-امین نقطه نقطه، و ( ایکسمن 1،ایکسمن 2, … ,ایکسمن کایکسمن1،ایکسمن2،…،ایکسمنک) متغیرهایی را نشان میدهد که برای پیشبینی دستهبندی هر POI مرتبط هستند. در فرآیند طبقه بندی، درخت طبقه بندی به صورت بازگشتی POI ها را به دسته های مختلف تقسیم می کند. ککمتغیرهای توضیحی ورودی [ 19 ]. علاوه بر این، تکمیل این فرآیند معمولاً شامل بیش از یک زمان پارتیشن است. پس از تقسیم بندی تقسیم بندی شده، زیر منطقه دارای نمونه های کمتر و کمتری است. این روند تا رسیدن به معیارهای توقف ادامه دارد.
با توسعه درخت تصمیم، سه نوع درخت تصمیم وجود دارد که امروزه به طور گسترده مورد استفاده قرار میگیرند: تقسیمبندی تکراری 3 (ID3)، C4.5 (توسعهای از الگوریتم ID3 با استفاده از مفهوم آنتروپی اطلاعات)، و همچنین درخت طبقهبندی و رگرسیون. (CART) – و معیارهای طبقه بندی آنها با یکدیگر متفاوت است. با این حال، مدل جنگل تصادفی درخت طبقهبندی CART را به عنوان ماشین یادگیری پایه در این مطالعه اتخاذ کرد. طبقهبندی CART از کاهش میانگین در روش جینی برای اندازهگیری اهمیت متغیرهای مستقل بر اساس شاخص ناخالصی جینی برای تقسیم نمونههای آموزشی استفاده میکند. از کاهش شاخص ناخالصی جینی برای شناسایی مهم ترین متغیر توضیحی برای طبقه بندی بهینه در این مطالعه استفاده شد. میانگین کاهش شاخص ناخالصی جینی برای متغیر توضیحی منتخب نسبت به سایر متغیرهای مستقل بود. مثلا وجود دارد ککدسته بندی ها در یک مسئله طبقه بندی واقعی، و پکپکامکان دارد ککدسته -ام، بنابراین شاخص ناخالصی جینی را می توان به صورت زیر محاسبه کرد:
جایی که ایکسمنایکسمنیک متغیر کاندید را برای تقسیم نمونه های آموزشی نشان می دهد. از وقتی که جینی (ایکسمن)جینی(ایکسمن)برای هر متغیر توضیحی کاندید محاسبه شد، متغیر با کمترین شاخص ناخالصی جینی برای تقسیم نمونهها انتخاب شد.
3.2. جنگل تصادفی
اگرچه درخت تصمیم، با توسعه معیارهای طبقهبندی، به دقت نسبتاً بالاتری دست مییابد، مدل جنگل تصادفی (RF) از یک طبقهبندیکننده درخت تصمیم بهتر عمل میکند [ 20 ].]. مدل جنگل تصادفی با مقادیر زیادی درخت تصمیم تشکیل شده است. علاوه بر این، نتیجه نهایی محاسبه شده توسط جنگل تصادفی با آرای تولید شده از همه درختان تصمیم تعیین می شود. با این حال، بخشی از دلیل اینکه چرا الگوریتم جنگل تصادفی می تواند به طور گسترده مورد استفاده قرار گیرد و نتایج عالی به دست آورد، ویژگی تصادفی است. ویژگی تصادفی را می توان در دو جنبه نشان داد: نمونه آموزشی هر درخت تصمیم به طور جزئی و تصادفی از بین تمام نمونه های آموزشی انتخاب شده است و همچنین تصادفی بودن چندین متغیر توضیحی به دست آمده از کل متغیرهای مستقل. جنگل تصادفی از یک روش راهانداز برای استخراج نمونههای آموزشی بر اساس اصل تصادفی برای اطمینان از تنوع درختهای تصمیمگیری استفاده میکند. به عنوان مثال، فرض کنید یک مجموعه نمونه از اعداد وجود دارد نن، و روش ذکر شده در بالا انجام می شود n ( n < N )� (�<ن)زمان نمونه برداری مجدد روی مجموعه نمونه به عبارت دیگر، نمونه استخراج شده از هر درخت تصمیم ممکن است مانند سایر درختان تصمیم باشد. علاوه بر این، نمونههای خاصی که برای اندازهگیری دقت مدل در نظر گرفته میشوند، ممکن است در نمونه آموزشی درخت تصمیم ظاهر نشوند. علاوه بر این، برای هر درخت تصمیم، فرآیند تصادفی برای استخراج متغیرهای توضیحی تعداد k ( k < K )ک (ک<ک)در کل متغیرهای مستقل تعداد کک.
تصویر فرآیند کار RF به صورت شکل 5 نشان داده شده است . سه مرحله برای پیشبینی نمونهها در دستههای خاص وجود دارد. نمونه های آموزشی و ویژگی ها به طور تصادفی در درخت های تصمیم گیری مختلف در مرحله 1 انتخاب می شوند. مرحله 2 چندین درخت تصمیم را ایجاد می کند که از طریق آنها می توان تعداد را توسط مجری بهینه سازی کرد. نتایج هر درخت تصمیم ساخته شده توسط مرحله 2 با هم ترکیب می شوند تا نتیجه نهایی در مرحله 3 مشخص شود.
3.3. سایر مدل های مقایسه
برای تعیین مدلی که میتواند به بهترین نحو مقولههای POI را پیشبینی کند، مقایسه بین جنگل تصادفی (RF)، مدل ساده بیز (NBM) و ماشینهای بردار پشتیبان (SVM) در این مطالعه معرفی شد.
NBM یک الگوریتم مبتنی بر نظریه تصمیم بیزی است. به عبارت دیگر، تمام طبقه بندی های NBM به رابطه (2) بستگی دارد. به عنوان مثال، وجود دارد منمنانواع متمایز، (آ1،آ2, … ,آمن)(آ1،آ2،…،آمن)، و ببنمونه را نشان می دهد. NBM احتمال نمونه را محاسبه می کند ببمتعلق به هر نوع، که بر اساس مجموعه داده آموزشی است. نوع نهایی نمونه بببا بزرگترین احتمال تصمیم می گیرد.
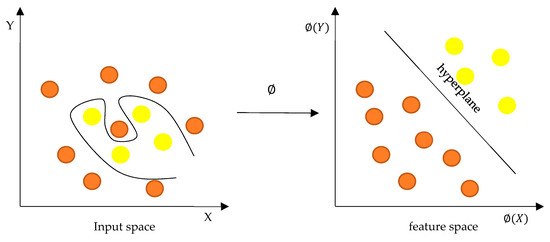
مدل SVM یک الگوریتم کلاسیک برای طبقه بندی و رگرسیون است. SVM می تواند با ساختن یک ابر صفحه در فضایی با ابعاد بالا که از تعداد زیادی ویژگی ساخته شده است، به بیشترین فاصله بین کلاس های مختلف دست یابد. یک نمودار ساده برای نشان دادن چگونگی حل مسئله طبقه بندی ارائه شده است که به صورت شکل 6 نشان داده شده است.. علاوه بر این، SVM را می توان به دو شکل خطی و غیر خطی برای مقابله با داده های خطی و غیر خطی تقسیم کرد. در وضعیت موارد خطی، مشکل طبقه بندی را می توان با یک تابع خطی که می تواند یک خط یا پلان در یک فضای یک بعدی یا دو بعدی باشد، حل کرد. بنابراین اگر تعداد ابعاد در نظر گرفته نشود، تابع خطی می تواند به عنوان یک ابر صفحه در نظر گرفته شود. با این حال، در وضعیت موارد غیر خطی، تقاضای حل مسائل طبقه بندی را نمی توان با توابع خطی برآورده کرد. بنابراین، تابع هسته ∅ ( x )∅(ایکس)برای انتقال فضای ورودی به فضای ویژگی در این شرایط معرفی شده است. در مقایسه ما، تابع پایه شعاعی رایج (RBF) به عنوان تابع هسته برای تشخیص دستههای POI در نظر گرفته میشود. عملکرد هسته RBF به صورت تعریف شده است ک(ایکسمنایکسj) =exp ( – γ ایکسمن–ایکسj)ک(ایکسمنایکس�)=انقضا(-� ایکسمن-ایکس�)که در آن ایکسمنایکسمنو ایکسjایکس�داده های ورودی است. γ = 1/2 σ _ _�=1/2�، σ�عرض باند است.
3.4. متغیرهای توضیحی
در این مطالعه، ویژگیهای ورود و ورود کاربران، ویژگیهای زمانی رفتار ورود کاربر، و ویژگیهای فضایی POI را در نظر گرفتیم. جدول 2متغیرهای توضیحی را فهرست می کند. ما فرض کردیم که (1) تعداد کاربران یا تعداد بررسیها احتمالاً از یک دسته POI به دسته دیگر بوده است. (2) نسبت ورود در بازههای زمانی مختلف روزانه (مثلاً صبح، ظهر، بعد از ظهر، عصر، و شب) یا بخشهای مختلف هفته (یعنی روزهای هفته و آخر هفته) احتمالاً از یک دستهبندی به دسته دیگر متفاوت است. (3) ناهمگونی مشارکت کاربران در حجم ورود، ناهمگونی مشارکت دورهها در حجم ورود در روزهای هفته، یا ناهمگونی مشارکت دورههای زمانی در حجم ورود در آخر هفته احتمالاً با یک تفاوت دارد. دسته POI به دسته دیگر. و (4) ویژگی های محیطی ساخته شده POI احتمالاً از یک دسته POI به دسته دیگر متفاوت است. متغیرهایی مانند آنتروپی کاربر (V3)، آنتروپی ورود در روزهای هفته (V8)،
هنگام محاسبه آنتروپی کاربر، آنتروپی ورود در روزهای هفته و آنتروپی ورود آخر هفته، پمنپمننشاندهنده نسبت اعلام حضورهای تولید شده توسط هر کاربر در ثبت ورود به این POI، نسبت اعلام حضورهای تولید شده در هر یک از چهار دوره زمانی هفته در این POI، و آنهایی است که در هر یک از چهار دوره زمانی آخر هفته در این POI ایجاد شده است. POI، به ترتیب.
4. نتیجه و بحث
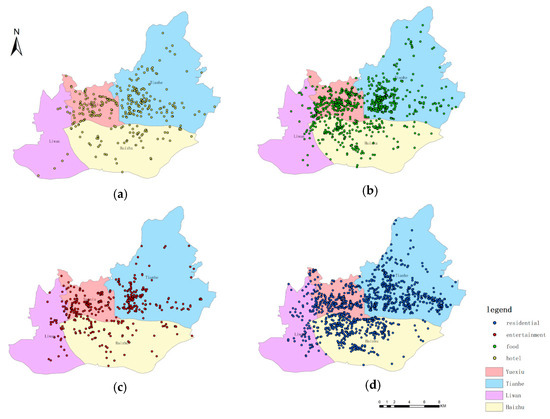
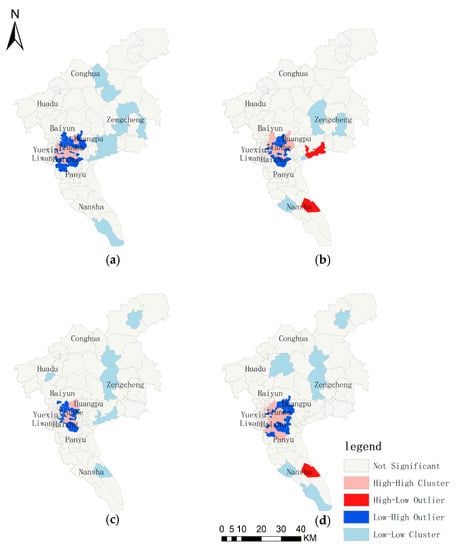
برای دادههای تجربی بهدستآمده از Weibo، ابتدا دادههای ورود را طبق قانون پیشنهادی در بخش 2.2 انتخاب کردیم . متعاقبا، ما چهار دسته POI را در چهار منطقه شهری اصلی گوانگژو (لیوان، هایژو، یوکسیو، تیانهه) با استفاده از مجموعه داده بدون فرآیند ترسیم کردیم، که در آن مجموعه POI تنها نشان دهنده POI ذخیره سوابق ورود است، نتیجه تجسم به صورت شکل 7 نشان داده شده است. اکثر POI ها، به عنوان نمایشگاه شکل 7در نواحی Tianhe، Yuexiu و Haizhu واقع شدهاند، جایی که میتوان شاهد نوسازی و رونق گوانگژو بود. علاوه بر این، POI های مواد غذایی و مسکونی توزیع نسبتاً همگنی را در سه منطقه ارائه می دهند، در حالی که POI های هتل و سرگرمی توزیع نسبی خوشه ای را در مناطق Tianhe و Yuexiu نشان می دهند. شکل 7ترکیب سطح بالایی از چهار دسته POI را نشان می دهد، به ویژه در مناطق Tianhe و Yuexiu. شایان ذکر است که Tianhe و Yuexiu به ترتیب شهر جدید و شهر قدیمی شهر هستند و همچنین پرجمعیت ترین مناطقی هستند که ترکیب کاربری سطح بالایی از زمین در آنها وجود دارد. از آنجایی که مکانهای چهار دسته POI احتمالاً الگوهای فضایی متفاوتی را نشان میدهند، ما بیشتر بررسی کردیم که آیا تعداد ورود به چهار دسته POI احتمالاً الگوهای فضایی مختلفی را نیز نشان میدهد یا خیر. بنابراین، ما از Moran’s I محلی برای تشخیص ویژگیهای خوشهبندی مقدار ورود به دستههای POI مختلف در سراسر شهر گوانگژو، پس از جدا شدن نقشه گوانگژو توسط مرزهای شهرها و جوامع، که در شکل 8 نشان داده شده است، استفاده کردیم . همانطور که در شکل 8نقشه های توزیع چهار دسته POI به طور کلی مشابه بودند، اما تفاوت های جزئی هنوز در منطقه محلی وجود داشت. این تفاوت ها ممکن است امکان تشخیص انواع مختلف POI را در مناطق با ترکیب بالا فراهم کند. علاوه بر این، توزیع خوشهای بالا از چهار نوع عمدتاً در مناطق اصلی شهری وجود داشت، به این معنی که اکثر کاربران ترجیح میدهند در این منطقه بررسی کنند و فعال باشند و ترکیب قابل توجهی از فعالیتهای مختلف انسانی در اینجا وجود دارد. وضعیت ترکیب سطح بالا نه تنها به این معنی است که لازم است انواع کاربری زمین را اصلاح کنیم، بلکه به این معنی است که جستجوی مرزهای آشکار برای جداسازی چهار دسته POI برای ما دشوار است، اگر فقط بر اساس نمایش شکل 7 و شکل 8 باشد.. بنابراین، در سطح توزیع فضا، ما حدس زدیم که انواع فعالیت های انسانی در چهار نوع POI قابل تشخیص نیست.
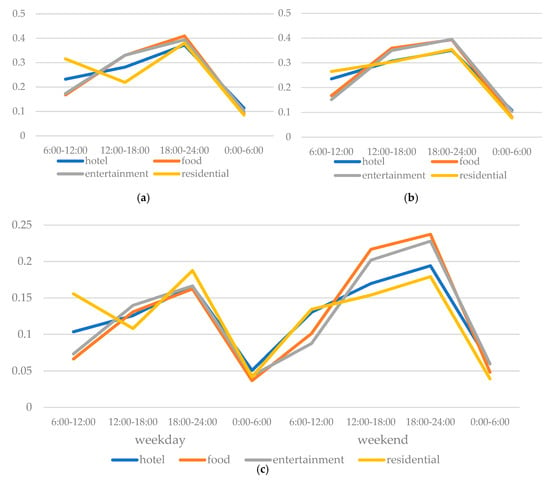
علاوه بر تفاوت در توزیع فضایی POI، اختلاف در الگوهای رفتار ورود کاربران (به عنوان مثال، تعداد ورود، الگوهای زمانی رفتار ورود، و غیره) همچنین میتواند به طور بالقوه به شناسایی دستهها کمک کند. به طور خاص، در این مطالعه، ما سعی کردیم ویژگیهای زمانی رفتار ورود انسان به طبقهبندی POI را وارد کنیم. به طور کلی، فعالیتهای انسان احتمالاً در زندگی روزمره منظم است (مثلاً افراد در ظهر یا عصر از غذا لذت میبرند، در مکانهای تفریحی در زمانهای غیر کاری استراحت میکنند و عصرها یا قبل از رفتن به سر کار در خانه میمانند). بنابراین، ابتدا مجموعه داده ورود به سیستم را به چهار دوره زمانی (6:00-12:00، 12:00-18:00، 18:00-24:00، 0:00-6:00) و دو روز تقسیم کردیم. انواع (روز هفته، آخر هفته).شکل 9 الف، ب. نمودارهای خطی ( شکل 9الف، ب) نشان می دهد که مردم ترجیح می دهند در صبح های روز (قبل از رفتن به سر کار) و عصرها (پس از اتمام کار) در خانه چک کنند و در بعدازظهرها یا شب های روز برای لذت بردن از غذا و سرگرمی بروند، در حالی که در آخر هفته، انسان الگوهای تحرک و فعالیت وضعیت نسبتاً بی نظمی را نشان می دهند (هر دسته POI منحنی فعال مشابهی را منعکس می کند). با این پدیده می توان تأیید کرد که مردم معمولاً برنامه روزانه منظمی برای کار و سرگرمی در روزهای هفته دارند، در حالی که به دلیل زمان و مکان آزاد بیشتر برای برنامه ریزی زندگی شخصی خود، مردم تمایل دارند برنامه روزانه کمتر منظمی در تعطیلات آخر هفته داشته باشند. متعاقباً، پس از تفکیک یک هفته به روزهای هفته و آخر هفته، توزیع ورودها را بین هشت دوره زمانی ترسیم کردیم. به طور دقیق تر، ورود در روزهای هفته و ورود به آخر هفته هر دو به طور متوسط بودند،شکل 9 ج)، مانند شکل 9 ج روشن شده است. علاوه بر اطلاعاتی که در شکل 9 a,b منعکس شده است، نمودار خط شکسته نشان میدهد که چکاینهای POI هتلها و محلهای مسکونی به سختی افزایش مییابد، در حالی که رشد قابلتوجهی در تعداد چکاین POIهای غذا و سرگرمی رخ میدهد. . بحثهای بالا نشان میدهد که ویژگیهای زمانی الگوی رفتار ورود انسان میتواند به شناسایی دستههای POI کمک کند. بنابراین، در نظر گرفتن ویژگی های زمانی در رفتار ورود در پیش بینی رده POI در نظر گرفته شد.
علاوه بر ویژگی های مکانی و زمانی، کیفیت نمونه ها نیز به طور قابل توجهی برای مدل سازی ضروری است. به منظور بررسی امکان سنجی قانون پیشنهادی برای فیلتر کردن نمونه ها در بخش 2.2 ، مقایسه بین سه قانون (قانون پیشنهادی، بدون فرآیند دیگر، آستانه مشابه) ذکر شده در بخش 2.2در ادامه انجام شد. ما از RF برای مدلسازی الگوی انواع POI در این مقایسه استفاده کردیم و دقت پیشبینی سه قانون (قانون پیشنهادی، بدون فرآیند بیشتر، آستانه مشابه) برای نمونه مدلسازی انتخابشده به ترتیب 76.75٪، 45.77٪ و 57.24٪ بود. . دقت پیشبینی نشان میدهد که قانون پیشنهادی برای فیلتر کردن نمونهها با اثربخشی بالاتری نسبت به دو قانون دیگر عمل میکند. بنابراین، میتوانیم حدس بزنیم که قانون عدم فرآیند دیگر ممکن است باعث دقت ضعیف به دلیل وجود احتمالی اعلام حضورهای جعلی شده باشد، در حالی که همان قانون آستانه دقت را افزایش میدهد، زیرا این قانون بخشی از بررسیهای جعلی را فیلتر میکند و نماینده کمتری است. داده های ورود به POI. بنابراین، مجموعه داده فیلتر شده توسط قانون پیشنهادی را در فرآیند زیر انتخاب کردیم.
به طور کلی، پارامترهای مدل بخش مهمی از بهینهسازی عملکرد مدل هستند و یک مدل بهینه برای دقت پیشبینی و همچنین کارایی مفید است. بنابراین، به منظور بهینه سازی مدل، بررسی تأثیر پارامترهای مدل بر عملکرد مدل بسیار مهم است. در این فرآیند، طبق گفته تان نوی و کاپاس [ 21]، حداکثر تعداد درختان تصمیم و متغیرهای تقسیم به عنوان پارامترهای اصلی برای بررسی مدل RF بهینه در این مطالعه انتخاب شدند. ما ابتدا مجموعه داده را به آموزش تفکیک کردیم و نمونههایی را به ترتیب برای آموزش و آزمایش دقت پیشبینی پیشبینی کردیم. ثانیاً، ما یک مدل تحت تعداد درختان تصمیم در محدوده یک تا 1000 در افزایش پنج ایجاد کردیم. به طور کلی، مقدار بیشتر درخت تصمیم باعث دقت پیشبینی بالاتر میشود، در حالی که محدودیت آن زمان صرف شده است. بنابراین، ما می خواستیم بین زمان مصرف شده و دقت پیش بینی تعادل ایجاد کنیم. به عنوان نمایشگاه شکل 10مشاهده کردیم که درختان ساختمانی بیش از حدود 280 منجر به افزایش عملکرد اضافی قابل توجهی نشدند، اما باعث کاهش جزئی دقت پیشبینی شدند. در نهایت، دقت پیشبینی نسبتاً پایدار در درخت فراتر از حدود 700 اتفاق افتاد. بنابراین، ما اندازه جنگل 700 را به عنوان یک مبادله منطقی بین زمان مصرف شده و دقت پیشبینی انتخاب کردیم. متعاقباً، ما مدل را تحت کمیت متغیرهای تقسیم از یک به 18 ساختیم (تعداد کل ویژگیهای انتخاب شده 19 بود). میتوانیم حدس بزنیم که عملکرد RF زمانی بهترین خواهد بود که حداکثر تعداد متغیرهای تقسیمکننده چهار باشد، همانطور که در شکل 10 نشان داده شده است.ب بنابراین ما چهار متغیر را به عنوان حداکثر تعداد متغیرهای تقسیم در مدل خود انتخاب می کنیم. از طریق آزمایش، ما دریافتیم که سایر پارامترهای RF تأثیر مثبت قابل توجهی برای دقت پیشبینی در مطالعه ندارند. بنابراین، در اینجا تأثیر سایر پارامترها را به تفصیل مورد بحث قرار نمی دهیم.
با استفاده از مجموعه داده ورود، ما همچنین تأثیرات متغیرهای توضیحی را برای پیشبینی دستههای POI بررسی کردیم. اهمیت متغیرهای توضیحی بر اساس شاخص ناخالصی جینی ذکر شده در بخش 3 محاسبه شد. روند محاسبه به شرح زیر است:
- (1)
-
با محاسبه جینی زیر گره m و جینی پس از تقسیم از m، اهمیت این متغیر توضیحی در گره m تفاوت بین آن است.
- (2)
-
با محاسبه اهمیت این متغیر توضیحی در زیر تمام گره های درخت به مرحله (1)، اهمیت این متغیر توضیحی در زیر این درخت حاصل جمع آن است.
- (3)
-
با محاسبه اهمیت این متغیر مستقل در زیر تمام درختان این مدل RF به صورت مرحله (2)، اهمیت این متغیر توضیحی در این مدل RF مجموع آن است.
از طریق این سه مرحله، ما اهمیت همه ویژگیها را در مدل خود محاسبه و رتبهبندی کردیم، که در جدول 3 نشان داده شده است.. بدیهی است که هر متغیر تأثیر متفاوتی بر پیشبینی دستههای POI دارد. متغیرهای V1 و V2 و همچنین V3 نقش مهمی در پیشبینی دستههای POI ایفا کردند. احتمالاً به این دلیل است که در مکانهای عمومی بزرگ مانند سرگرمی، تعداد کاربران و چکاینها به طور قابل توجهی بیشتر از مکانهایی مانند اقامتگاه و هتل است. بر این اساس، اطلاعات این متغیرها می تواند بخش بزرگی از POI را به طور منطقی طبقه بندی کند. در همین حال، متغیرهای V7 و V12 تأثیر کمتری بر مسائل پیشبینی طبقهبندی POI ارائه کردند. ما حدس می زنیم که دوره 0:00 تا 6:00 داده های ورود را تولید کرد که اندازه آن بسیار کوچک است تا نتایج آماری واضحی ایجاد کند و تأثیر مثبتی داشته باشد.
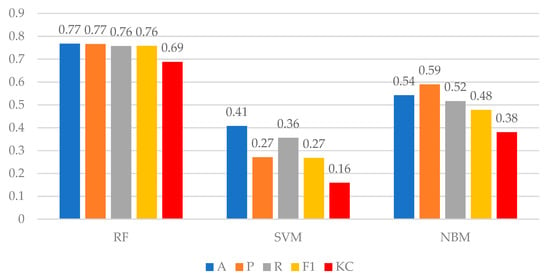
برای تعیین اینکه آیا مدل پیشنهادی میتواند به دقت نسبتاً بالایی در پیشبینی دستههای POI دست یابد، ما مقایسهای بین جنگل تصادفی (RF)، ماشین بردار پشتیبان (SVM) و مدل ساده بیز (NBM) انجام دادیم. اصول این مدل ها در بخش 3 نشان داده شده است. در همان قانون برای فیلتر کردن دادههای ورود و تقسیم مجموعه دادههای آموزشی و مجموعه دادههای آزمایشی، ما این مدلها را با استفاده از همان مجموعه داده آموزشی برازش کردیم. متعاقبا، ما از این مدلهای برازش برای پیشبینی دستههای POI استفاده کردیم. نتایج پیشبینی RF، SVM و NBM به ترتیب 76.75، 40.76 و 54.24 درصد بود که میتوان آن را به عنوان دقت سه مدل نیز مشاهده کرد. از منظر دقت، RF عملکرد پیشبینی بهتری نسبت به SVM و NBM در مطالعه ما نشان داد. با این حال، دقت به تنهایی نمی تواند عملکرد این مدل ها را به طور کامل نشان دهد. بنابراین ما از پنج شاخص ارزیابی طبقهبندی رایج، دقت (A)، دقت (P)، یادآوری (R)، امتیاز F1 (F1) و ضریب کاپا (KC) برای نشان دادن قابلیت سه مدل استفاده کردیم. ما این شاخص ها را با معادلات زیر محاسبه کردیم:
جایی که تینمنتینمننشان دهنده تعداد مواردی است که به درستی در دسته های i-ام پیش بینی شده اند. N نشان دهنده تعداد کل نمونه ها در مجموعه داده آزمایشی است. پنمنپنمنتعداد پیشبینیها در دستههای i را نشان میدهد. اسنمناسنمنتعداد کل نمونه های آزمایشی در دسته های i را نشان می دهد. پoپ�می توان با روش محاسبه دقت محاسبه کرد (و می توان گفت پoپ�دقت است)؛ و پهپهقابل محاسبه است په=∑منپنمن∗ اسنمنن∗ نپه=∑منپنمن∗اسنمنن∗ن.
مقایسه پنج شاخص رایج ارزیابی طبقه بندی بین سه مدل پس از محاسبه با معادلات فوق به صورت شکل 11 نشان داده شده است. علاوه بر این، نشانگرهای P، R و F1 که در شکل 11 نشان داده شده است، بیشتر تحت قاعده میانگین کلان محاسبه شدند. به عبارت دیگر، میانگین کلان، میانگین حسابی همه دسته ها بود. بدیهی است که RF عملکرد پیش بینی قابل توجهی بهتری نسبت به SVM و NBM از نظر پنج شاخص ارزیابی نشان داد. ما حدس زدیم که بهترین عملکرد RF و بهترین عملکرد بعدی NBM و به دنبال آن SVM در این مطالعه خواهد بود. بنابراین، ما RF را به عنوان مدل بهینه خود در تحقیق خود انتخاب کردیم. برای به دست آوردن یک دقت پیشبینی کلی، ما متعاقباً از RF برای به دست آوردن دقت کلی 72.21٪ در 10 پیشبینی در نمونههای مختلف آموزشی و آزمایشی استفاده کردیم.
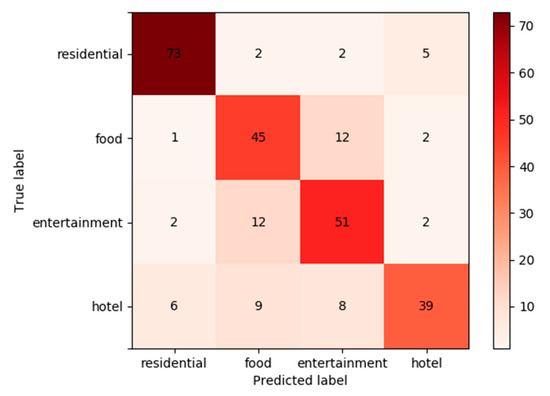
به منظور تجزیه و تحلیل بیشتر نتایج پیشبینی و کسب مفاهیم بهبود برای کارهای آینده، ماتریس سردرگمی تولید شده از پیشبینی مبتنی بر RF را که در شکل 12 نشان داده شده است، خروجی میدهیم.. بدیهی است که واحدهای مسکونی 89.02% R بالاتری داشتند، در حالی که غذا، سرگرمی و هتل ها به ترتیب تنها 75%، 76.12% و 62.9% Rs داشتند. نشان داده شده است که برخی از POI هتل ها به اشتباه برای اقامت، غذا و سرگرمی پیش بینی شده است. بر این اساس، ما حدس میزنیم که دلیل این امر این است که هتلها نه تنها از نظر الگوهای رفتاری ورود کاربران به اقامتگاهها شبیه هستند، بلکه از نظر ویژگیهای مکانی POI و الگوهای رفتاری ورود کاربران به غذا و سرگرمی نیز شبیه هستند. هتل های بزرگ دارای غذاخوری و امکاناتی مانند استخر و سالن های ورزشی هستند. بنابراین، این امر باعث تشابه ویژگی های مکانی و زمانی چک-این ها شد. علاوه بر این، برخی از POI های غذا و سرگرمی با یکدیگر اشتباه گرفته شدند. احتمالاً به این دلیل است که در فرآیند طبقه بندی اولیه، ما مراکز خرید بزرگ را به عنوان سرگرمی طبقه بندی کردیم، در حالی که ممکن است در یک مرکز خرید بزرگ چند غذاخوری وجود داشته باشد. در آینده، میتوانیم متغیرهای توضیحی دیگری را بررسی کنیم تا به وضوح این دستهبندیهای POI را برای بهبود دقت مدل تشخیص دهیم.
از طریق آزمایش، میتوانیم ببینیم که دقت کلی محاسبهشده با پیشبینی 10 برابری به 72.21 درصد رسیده است و بالاترین دقت پیشبینی فعلی میتواند به 76.75 درصد برسد. این بدان معناست که ما دقیقاً میتوانیم تقریباً سه چهارم دستههای کاربری زمین در سطح POI را در منطقه مورد مطالعه، گوانگژو پیشبینی کنیم. اگرچه دقت مطالعه قبلی که از یادگیری عمیق استفاده می کرد از روش ما فراتر رفت [ 22]، روش ما می تواند نتایج در مقیاس خوب به دست آورد و داده های مورد نیاز را با هزینه کمتر به دست آورد. رویکرد ما نسبت به سایر رویکردهای حس اجتماعی مزایایی دارد، از جمله هزینه کم و دانه بندی خوب. برنامهریز شهری میتواند مستقیماً از مدل ما برای یادگیری ساختار شهر در مقیاسی دقیقتر استفاده کند، اگر نیاز به درک دقیق ساختار شهری داشته باشد و بنابراین سیاست یا ساختارهای شهر را تغییر دهد تا تقاضای توسعه شهری را برآورده کند. آنها فقط باید متغیرهای مورد نیاز این روش را آماده کنند و این روش حتی به اندازه کافی انعطاف پذیر است تا داده های ورود به سیستم را با داده هایی مانند مسیریابی سیستم جهانی ناوبری ماهواره ای (GNSS) یا مکان های ضبط بلادرنگ در مناطق مورد مطالعه خود جایگزین کند. یافته دیگر در طول پردازش (به عنوان مثال، الگوهای مختلف ورود در روزهای هفته و آخر هفته، رفتار متفاوت ورود در دوره های مختلف روز، و توزیع فضایی ورود) می تواند به بهینه سازی تخصیص منابع برای مطابقت با ویژگی مکانی و زمانی یک شهر کمک کند. علاوه بر این، این روش ممکن است فرصتی را برای دستیابی به طبقهبندی کاربری اراضی در سطح ظریفتر در مناطق خاصی که فاقد دادههای POI هستند، فراهم کند. با این حال، کمبود طبقهبندی نظارت شده مانند RF نیاز مداخله اپراتور است [23]، که کارایی پردازش داده ها را در روش کاهش می دهد. بنابراین، در آینده میتوانیم مدلی برای بهبود کارایی پردازش دادهها قبل از طبقهبندی ایجاد کنیم. علاوه بر این، رویکرد پیشنهادی در این مطالعه احتمالاً کاربرد بالقوهای در طبقهبندی کاربری زمین در سطح ساختمان (به عنوان مثال، عملکرد ساختمانها) با توجه به تحرک انسان و رفتار فعالیت و ویژگیهای مکانی ساختمانها دارد. تحرک و رفتار فعالیت انسان را می توان با داده های رسانه های اجتماعی (به عنوان مثال، اعلام حضور، پست ها و تصاویر)، مسیرهای GNSS و سوابق تلفن همراه اندازه گیری کرد. مکان ساختمان ها را می توان از طریق برخی پروژه های نقشه برداری باز مانند OpenStreetMap به دست آورد.
5. نتیجه گیری ها
در مطالعه حاضر، ما یک روش جنگل تصادفی را برای تجزیه و تحلیل و پیشبینی دستههای POI برای اصلاح انواع کاربری زمین با استفاده از دادههای بررسی Weibo در گوانگژو، چین پیشنهاد کردیم. در این روش جنگل تصادفی، ما قاعدهای را با در نظر گرفتن ویژگیهای انواع POI برای فیلتر کردن دادههای ورود به سیستم برای به دست آوردن دادههای ورود نسبتاً نماینده POI پیشنهاد کردیم. این قانون با توجه به ملاحظات کمی در مورد ویژگیهای دستههای POI، تأثیر بهتری نسبت به قانون نشان میدهد. متعاقباً، ویژگیهای مکانی و زمانی دادههای ورود را بررسی کردیم. ویژگی توزیع فضایی که از بخش 4 یافت شد(داده های ورود به سیستم به طور قابل توجهی در مناطق اصلی شهری متمرکز شده است) وجود ترکیب کاربری سطح بالا و لزوم پالایش انواع کاربری زمین را نشان می دهد. اطلاعات دقیق تر از مناطق عملکردی به جای انواع کاربری زمین برای برنامه ریزان شهری برای طراحی بهتر ساختارهای فضایی و تخصیص منابع یک شهر ضروری است. ویژگی توزیع زمانی در همه زمانهای روز در طول روزهای هفته و آخر هفته نشان میدهد که دستههای POI مختلف عملکردها و انواع فعالیتهای متفاوتی را تعیین میکنند، در حالی که انواع فعالیتهای مختلف دارای ویژگیهای زمانی خاص هستند که از طریق آنها میتوانیم انواع POI مختلف را تشخیص دهیم. جدا از توزیع مکانی و زمانی ورود، ما همچنین تأثیر پارامترهای مدل را بر عملکرد مدل بررسی کردیم تا بتوانیم یک پارامتر مبادله نسبتاً بهینه را برای دستیابی به یک نتیجه پیشبینی بهتر انتخاب کنیم. علاوه بر این، ما مقایسه ای بین جنگل تصادفی (RF)، ماشین های بردار پشتیبان (SVM) و مدل ساده بیز (NBM) انجام دادیم، و نتایج نشان می دهد که RF دقت پیش بینی بالاتری در این مطالعه به دست آورد. در آزمایش ما، RF پیشنهادی ما بالاترین دقت 76.75٪ و دقت کلی 72.21٪ را به دست آورد. این نشان میدهد که ما میتوانیم مناطق عملکردی را در مقیاسی دقیقتر با شناسایی دستههای POI در مناطق با کاربری بسیار مختلط برای دستیابی به هدف پالایش انواع کاربریهای زمین شناسایی کنیم. و نتایج نشان میدهد که RF در این مطالعه به دقت پیشبینی بالاتری دست یافت. در آزمایش ما، RF پیشنهادی ما بالاترین دقت 76.75٪ و دقت کلی 72.21٪ را به دست آورد. این نشان میدهد که ما میتوانیم مناطق عملکردی را در مقیاسی دقیقتر با شناسایی دستههای POI در مناطق با کاربری بسیار مختلط برای دستیابی به هدف پالایش انواع کاربریهای زمین شناسایی کنیم. و نتایج نشان میدهد که RF در این مطالعه به دقت پیشبینی بالاتری دست یافت. در آزمایش ما، RF پیشنهادی ما بالاترین دقت 76.75٪ و دقت کلی 72.21٪ را به دست آورد. این نشان میدهد که ما میتوانیم مناطق عملکردی را در مقیاسی دقیقتر با شناسایی دستههای POI در مناطق با کاربری بسیار مختلط برای دستیابی به هدف پالایش انواع کاربریهای زمین شناسایی کنیم.
کار ما بخشی از شکافها را از طبقهبندی کاربری زمین در سطح قطعه تا طبقهبندی کاربری اراضی با وضوح بهتر پر میکند، که به تصمیمگیرندگان شهر اجازه میدهد الگوی شهر را در ساختار کاربری دقیقتر مشاهده کنند. این روش دیگری را برای تحقیق در مورد نواحی مرفه مركزی مركزی مركز و دهكده های شهری پیچیده ارائه می دهد. علاوه بر این، رویکرد پیشنهادی در این مطالعه میتواند به طور بالقوه برای شناسایی عملکرد ساختمانها با توجه به تحرک و رفتار فعالیت بازدیدکنندگان و ویژگیهای مکان ساختمانها اعمال شود.
با این حال، محدودیتهایی در این مطالعه وجود دارد، و بنابراین ما باید نحوه رسیدگی به آنها و بهبود بیشتر روش را در آینده در نظر بگیریم. اول از همه، دقت پیشبینیشده نسبتاً پایین POI هتل باعث شد مدل ما به عملکرد نسبتاً ضعیفی دست یابد. بنابراین، باید ویژگی بهتری برای بهبود دقت پیشبینیشده POI هتل پیدا کرد تا این مدل RF در آینده اصلاح شود. علاوه بر این، مدل ما فقط در چهار دسته POI ذکر شده در بالا کار می کند. این یک محدودیت در شهرهای با کاربری بسیار مختلط است، بنابراین توسعهپذیری مدل ما باید در کار بعدی اصلاح شود. به عبارت دیگر، کاربرد مدل را می توان به طبقه بندی دسته بندی های بیشتر POI تعمیم داد. علاوه بر این، ترکیب RF با سایر مدلهای یادگیری عمیق ممکن است یک راه عملی برای بهبود این روش باشد. به دلیل فقدان مجموعه داده متعلق به شهر دیگر، نمیتوانیم توانایی مدل خود را که در شهرهای دیگر استفاده شده است تأیید کنیم. جدای از آن، انواع دیگر دادهها، مانند دادههای توزیع بلادرنگ جمعیت، میتوانند در کارهای آینده برای بهبود عملکرد این مدل ادغام شوند. در نهایت، ما تلاش خواهیم کرد تا با استفاده از سایر دادههای حسگر اجتماعی مانند مسیرهای GNSS و سوابق تلفن همراه و دادههای ساختمان OpenStreetMap در آینده نزدیک، زمانی که دادههای حسگر اجتماعی در دسترس هستند، عملکرد ساختمانها را شناسایی کنیم.







بدون دیدگاه