

خلاصه
تجزیه و تحلیل داده های جغرافیایی مبتنی بر هوش مصنوعی (هوش مصنوعی) توجه زیادی را به خود جلب کرده است. مجموعه داده های جغرافیایی چند بعدی هستند. دارای زمینه مکانی – زمانی در قالب های متفاوت وجود دارد. و نیاز به گردشهای کاری پیشرفته هوش مصنوعی دارد که نه تنها شامل آموزش و آزمایش الگوریتم هوش مصنوعی، بلکه پیشپردازش دادهها و پسپردازش نتایج نیز میشود. این پیچیدگی چالش بزرگی را در مورد مدیریت گردش کار تمام پشته هوش مصنوعی ایجاد می کند، زیرا محققان اغلب از مجموعه ای از عملیات دستی زمان بر برای مدیریت پروژه های خود استفاده می کنند. با این حال، هیچ یک از نرم افزارهای مدیریت گردش کار موجود، راه حل رضایت بخشی در مورد منابع ترکیبی، دسترسی کامل به فایل، جریان داده، کنترل کد و منشأ ارائه نمی دهد. این مقاله سیستم جدیدی به نام Geoweaver را برای بهبود کارایی مدیریت گردش کار هوش مصنوعی تمام پشته معرفی می کند. این برنامه از پیوند کلیه مراحل پیش پردازش، آموزش و آزمایش هوش مصنوعی و مراحل پس از پردازش در یک گردش کار خودکار واحد پشتیبانی می کند. برای نشان دادن کاربرد آن، ما یک مورد استفاده را ارائه می کنیم که در آن Geoweaver یادگیری عمیق پایان به انتها را برای نقشه برداری به موقع محصول با استفاده از داده های Landsat مدیریت می کند. ما نشان میدهیم که چگونه Geoweaver به طور موثری خستگی مدیریت اسکریپتها، کدها، کتابخانهها، نوتبوکهای Jupyter، مجموعه دادهها، سرورها و پلتفرمها را حذف میکند و زمان، هزینه و تلاشی را که محققان باید برای چنین گردشهای کاری مبتنی بر هوش مصنوعی صرف کنند، بسیار کاهش میدهد. مفاهیم نشان داده شده از طریق Geoweaver به عنوان یک بلوک مهم در آینده زیرساخت سایبری برای تحقیقات هوش مصنوعی عمل می کند. ما یک مورد استفاده را ارائه می کنیم که در آن Geoweaver یادگیری عمیق سرتاسری را برای نقشه برداری به موقع محصول با استفاده از داده های Landsat مدیریت می کند. ما نشان میدهیم که چگونه Geoweaver به طور موثری خستگی مدیریت اسکریپتها، کدها، کتابخانهها، نوتبوکهای Jupyter، مجموعه دادهها، سرورها و پلتفرمها را حذف میکند و زمان، هزینه و تلاشی را که محققان باید برای چنین گردشهای کاری مبتنی بر هوش مصنوعی صرف کنند، بسیار کاهش میدهد. مفاهیم نشان داده شده از طریق Geoweaver به عنوان یک بلوک مهم در آینده زیرساخت سایبری برای تحقیقات هوش مصنوعی عمل می کند. ما یک مورد استفاده را ارائه می کنیم که در آن Geoweaver یادگیری عمیق سرتاسری را برای نقشه برداری به موقع محصول با استفاده از داده های Landsat مدیریت می کند. ما نشان میدهیم که چگونه Geoweaver به طور موثری خستگی مدیریت اسکریپتها، کدها، کتابخانهها، نوتبوکهای Jupyter، مجموعه دادهها، سرورها و پلتفرمها را حذف میکند و زمان، هزینه و تلاشی را که محققان باید برای چنین گردشهای کاری مبتنی بر هوش مصنوعی صرف کنند، بسیار کاهش میدهد. مفاهیم نشان داده شده از طریق Geoweaver به عنوان یک بلوک مهم در آینده زیرساخت سایبری برای تحقیقات هوش مصنوعی عمل می کند.
کلید واژه ها:
هوش مصنوعی جغرافیایی ; زیرساخت سایبری ; گردش کار ژئوپردازش ; منشأ ؛ گردش کار پشته کامل ؛ سیستم های اطلاعات جغرافیایی (GIS) ; سنجش از دور
1. معرفی
هوش مصنوعی (AI) عمیقاً چشم انداز علمی را تغییر می دهد [ 1 ]. پذیرش تکنیکهای هوش مصنوعی انقلابی اساسی در نحوه جمعآوری، ذخیره، پردازش و تجزیه و تحلیل مجموعه دادههای قدیمی و فعلی ایجاد کرده است [ 2 ، 3 ، 4 ، 5 ]. ویژگیهای سودمند هوش مصنوعی، مانند کارایی در زمان اجرا، استفاده از منابع و اتوماسیون، این تکنیکها را نسبت به روالهای سنتی تحلیل علمی برای محققان جذابتر کرده است و بسیاری از دانشمندان/مهندسان در حال بررسی یا استفاده از تکنیکهای هوش مصنوعی در تحقیقات و صنعتی خود هستند. پروژه ها [ 6 ، 7 ، 8 ].
مکانیسم های داخلی مدل های هوش مصنوعی جادویی نیستند. این ترکیبی از سختافزار، نرمافزار و الگوریتمهایی است که رفتارهای معمول مغز انسان را هنگام رویارویی با مشکلات شبیهسازی میکند. یادگیری ماشینی یک رویکرد هوش مصنوعی محبوب است و در حل بسیاری از مشکلات علوم کامپیوتر موثر است. بسیاری از الگوریتم های اصلی جدید نیستند (به عنوان مثال، از دهه 1980) [ 9 ، 10 ، 11 ]. با این حال، تنها در سالهای اخیر پیشرفت سختافزارهایی مانند GPU (واحد پردازش گرافیک)، CPU (واحد پردازش مرکزی)، حافظه و دیسکهای ذخیرهسازی به مدلهای یادگیری ماشین اجازه داده است که دادههای بزرگ را در زمان نسبتاً کوتاهی هضم کنند [ 12 ، 13 ].]. هزینههای زمان محاسباتی کمتر و نتایج بهشدت بهبود یافته، استفاده گسترده از مدلهای یادگیری ماشین را با کاربرد در بسیاری از رشتههای علمی، از تشخیص گفتار [ 14 ] تحریک کرده است. ماشین های بدون راننده [ 15 ]; به شهرهای هوشمند [ 16 ]؛ خانه های هوشمند [ 17 ]; و بسیاری از زمینه های دیگر مانند کشاورزی، محیط زیست، تولید، حمل و نقل و دفاع [ 18 ، 19 ، 20 ]. رسانه های پرطرفدار این تصور را نشان می دهند که یادگیری ماشینی به طور مداوم در حال تغییر روش زندگی، کار و آرامش ما از جنبه های مختلف است.
دامنه کاربرد یادگیری ماشین به سرعت در تحقیقات جغرافیایی در حال گسترش است. در مطالعات اخیر، یادگیری ماشین برای استخراج اطلاعات از حجم عظیمی از دادههای جمعآوریشده در علوم زمین مؤثر بوده است [ 21 ، 22 ، 23 ، 24 ، 25 ]. مزایای یادگیری ماشینی میتواند از تلاشهای ما برای ایجاد بهترین درک پیشبینیکننده ممکن از نحوه عملکرد ژئوسیستم تعاملی پیچیده حمایت کند [ 23 ]]. برگن و همکاران اشاره کردند که استفاده از یادگیری ماشین در علوم زمین عمدتاً میتواند بر روی (1) انجام وظایف پیشبینی پیچیده که برای مدلهای عددی دشوار است، تمرکز کند. (2) مدل سازی مستقیم فرآیندها و تعاملات با شبیه سازی های عددی تقریبی. و (3) نشان دادن الگوها، ساختارها یا روابط جدید و اغلب پیش بینی نشده [ 23 ]. در آینده پیشبینیشده، یادگیری ماشین نقش کلیدی در تلاش برای درک بهتر تعاملات پیچیده بین زمین جامد، اقیانوس و جو خواهد داشت.
تحقیقات تحقیقاتی زیادی بر روی مجموعه داده های جغرافیایی در هر سه دسته انجام شده است. به عنوان مثال، تیمی از دانشمندان استرالیایی با تجزیه و تحلیل 15000 نمونه از رسوبات موجود در حوضه های دریایی، اولین نقشه دیجیتالی سنگ شناسی بستر دریا را ایجاد کردند [ 26 ]. آنها از مدل ماشین بردار پشتیبان (SVM) که یکی از پرکاربردترین مدل های یادگیری ماشینی است، برای ایجاد نقشه استفاده کردند ( شکل 1).) که قبلاً به تلاش بسیاری از افراد نیاز داشت. علاوه بر SVM، بسیاری از تکنیکهای یادگیری ماشین دیگر (مانند درخت تصمیم، جنگل تصادفی، بیز ساده، شبکههای عصبی) برای پیادهسازی هوش مصنوعی وجود دارد. یادگیری عمیق، یک منطقه مورد مطالعه زیرمجموعه محبوب یادگیری ماشین، شبکههای عصبی را با لایههای پنهان عمیق (مثلاً صدها لایه) یا لایههای پنهان گسترده با نورونهای زیاد مطالعه میکند. مدلهای معمولی یادگیری عمیق شامل شبکههای عصبی عمیق پیشخور [ 27 ]، شبکههای عصبی کانولوشنال [ 28 ]، شبکههای عصبی بازگشتی [ 14 ] و غیره است. یادگیری عمیق به طور فعال در مطالعات زمین شناسی استفاده شده است [ 7 ، 19]. برای مثال، لی و همکاران یک شبکه رمزگذار خودکار پشتهای را پیشنهاد کردند که ذاتاً همبستگیهای مکانی و زمانی را در نظر میگیرد و ثابت کرد که مدل آنها میتواند کیفیت هوای همه ایستگاهها را به طور همزمان پیشبینی کند [ 29 ]. برای پرداختن به چالشهای مدلهای حلوفصل ابری در نمایش فرآیندهای زیرشبکه، یادگیری عمیق برای شبیهسازیهای کوتاهمدت با هزینه محاسباتی کم استفاده میشود [ 30 ]. Rasp و همکارانش یک شبکه عصبی عمیق را آموزش دادند تا تمام فرآیندهای زیرشبکه جوی را در یک مدل آب و هوایی با یادگیری از یک مدل چند مقیاسی نشان دهد [ 30 ]. نتایج آنها امکان استفاده از یادگیری عمیق را برای پارامترسازی مدل آب و هوا نشان داد.
با این حال، دانشمندان همچنین اشاره میکنند که تکنیکهای هوش مصنوعی فعلی به تنهایی هنوز قادر به درک کامل پیچیدگی زمین نیستند [ 7 ]. مطالعه سیستمهای پیچیده مانند آب و هوا و محیط زیست نیازمند رویکرد ترکیبی هوش مصنوعی و مدلسازی فیزیکی عددی است که چالشهایی را برای ادغام هوش مصنوعی در علوم زمین ایجاد میکند. ترکیب این تکنیک ها ساده نیست. مدیریت و سادهسازی گردشهای کاری هوش مصنوعی ترکیبی در حال حاضر یک کار بسیار چالش برانگیز است.
پیشنهاد شده است که پنج مرحله کلی ( https://skymind.ai/wiki/machine-learning-workflow ) در گردش کار یادگیری ماشین وجود دارد: (1) تعریف هدف – شناسایی یک مشکل علم زمین و پیشنهاد یک راه حل بالقوه یادگیری ماشین ; (2) مطالعه امکان سنجی – تجزیه و تحلیل خطر شکست و مشکلات تنگنا. (3) طراحی مدل، آموزش، و ارزیابی آزمایشگاهی [ 31 ، 32 ]؛ (4) استقرار مدل، ارزیابی در تولید، و نظارت [ 33 ]؛ و (5) مدل نگهداری، تشخیص، اشتراک گذاری و قابلیت استفاده مجدد. در فاز 3 و 4، گردش کار پردازش هوش مصنوعی نه تنها شامل الگوریتم های هوش مصنوعی، بلکه شامل پیش پردازش و پس پردازش نیز می شود.https://towardsdatascience.com/workflow-of-a-machine-learning-project-ec1dba419b94). پردازش هوش مصنوعی فعلی با ترکیبی از نرم افزار، اسکریپت ها، کتابخانه ها و ابزارهای خط فرمان انجام می شود. متخصصان هوش مصنوعی اغلب با تکیه بر روشهای منحصربهفرد خود، جریانهای کاری خود را حفظ میکنند، روشهایی که معمولاً بدون اولویت زیادی برای دسترسی یا سهولت استفاده و درک دیگران ایجاد میشوند. از آنجایی که بسیاری از نهادهای متفاوت و پراکنده درگیر هستند، ساده کردن همه فرآیندها برای کمک به دانشمندان برای سازماندهی پروژه های یادگیری عمیق خود به شیوه ای قابل مدیریت و شفاف تبدیل به یک چالش می شود. در همین حال، اشتراکگذاری و استفاده مجدد از جریانهای کاری و نتایج AI ایجاد شده در میان جامعه زمینشناسی دشوار است، که منجر به کارایی پایین در آموزش و کاربرد مدل هوش مصنوعی در علوم زمین میشود. به دلیل عدم وجود جزئیات در مورد گردش کار و محیط های پلت فرم،
این مقاله یک چارچوب مدیریت گردش کار علمی را برای رسیدگی به این مسائل مربوط به گردش کار هوش مصنوعی و یک سیستم نمونه به نام Geoweaver برای اعتبار سنجی پیشنهاد می کند. ما سیستم را با استفاده از روشهای یادگیری عمیق برای نقشهبرداری پوشش زمین کشاورزی آزمایش کردیم. این وظیفه شامل سه سرور توزیعشده، پردازندههای گرافیکی، سه زبان برنامهنویسی، دهها ابزار دستوری، یک سیستم اطلاعات جغرافیایی (GIS)، یک جعبه ابزار یادگیری عمیق و چندین منبع داده عمومی است. Geoweaver به پزشکان این امکان را میدهد که همه این موجودیتها را در یک مکان مدیریت کنند و منشأ هر اجرا را در یک پایگاه داده جداگانه برای بررسی آینده ثبت کنند. نتایج ثابت میکند که این چارچوب میتواند مزایای بزرگی برای جامعه هوش مصنوعی برای ساخت، اجرا، نظارت، اشتراکگذاری، ردیابی، اصلاح، بازتولید، به ارمغان بیاورد. و از جریان های کاری هوش مصنوعی خود در یک محیط تک ماشینی یا یک محیط توزیع شده استفاده مجدد کنند. وجود Geoweaver می تواند به عنوان یک ابزار اساسی برای مدیریت گردش کار هوش مصنوعی در آینده عمل کند و کاربرد عملی هوش مصنوعی را در علوم زمین تقویت کند.
2. داده های فضایی بزرگ و هوش مصنوعی
مدل های هوش مصنوعی ترکیبی از معادلات ریاضی جهانی هستند. از نظر تئوری، آنها را می توان در هر نوع مجموعه داده استفاده کرد و در اکثر سناریوهای علمی مناسب است. یکی از پیش نیازهای یک مدل هوش مصنوعی موفق یک مجموعه داده آموزشی بزرگ، کم سوگیری، دقیق و کامل است که به مجموعه داده های خام پیوسته و در مقیاس بزرگ نیاز دارد [ 34 ]. یافتن مجموعه دادههای آموزشی ایدهآل جمعآوریشده در قرن گذشته اغلب دشوار است، زیرا 90٪ از دادههای فعلی در جهان فقط در چند سال گذشته ایجاد شدهاند ( https://www.xsnet.com/blog/bid/205405/ the-vs-of-big data-velocity-volume-value-variety-and-veracity). هر روز، حجم عظیمی از دادهها از تلفنهای همراه، دوربینها، لپتاپها، ماهوارهها و حسگرها از سراسر جهان جمعآوری میشود و توسط امکانات دادهای تحت مدیریت دهها هزار موسسه، سازمان، آژانس و فرد ذخیره میشود [ 35 ]. اصطلاح “داده های بزرگ” حجم زیادی از داده ها را توصیف می کند، چه ساختار یافته (انواع داده به وضوح تعریف شده) و چه بدون ساختار (هر چیز دیگری) ( https://www.datamation.com/big-data/structured-vs-unstructured-data). html )، که توسط کسب و کارها به صورت روزانه جمع آوری می شود. دانشمندان چالش های کلان داده را در چندین “V” خلاصه کردند، از جمله حجم، سرعت، تنوع، صحت و ارزش [ 36 ]. صاحبان داده ها، ارائه دهندگان، یا نگهبانان سرمایه گذاری قابل توجهی برای توسعه راه حل هایی برای رفع این چالش ها انجام داده اند.37 ]. در دسترس بودن داده های بزرگ خبر خوبی برای برنامه های کاربردی هوش مصنوعی است، با این حال، استخراج مجموعه داده های آموزشی از داده های بزرگ مجموعه ای از چالش های مرتبط را ارائه می دهد [ 34 ].
در سال 2012، دولت ایالات متحده ابتکارات کلان داده را با بیش از 200 میلیون دلار سرمایه گذاری در تحقیق و توسعه برای بنیاد ملی علوم اعلام کرد [ 38 ]. نوآوری های تحقیقاتی اساسی در هر دو بخش بالادستی و پایین دستی داده ها انجام شده است، به عنوان مثال، مدل داده، ذخیره سازی، پرس و جو و استراتژی های انتقال، پارادایم محاسباتی و زیرساخت داده [ 39 ] که منجر به ایجاد گروهی از ابزارهای نرم افزاری شده است. ، کتابخانه ها و دستگاه های سخت افزاری. برخی از ابزارهای رایج عبارتند از Apache Hadoop [ 40 ]، Apache Spark [ 41 ]، HBase [ 42 ]، Hive [ 43 ]، MongoDB [ 44 ]، Google Earth Engine [ 45 ]]، Amazon S3 [ 46 ]، Amazon EC2، Jupyter Notebook [ 47 ] و غیره. این ابزارها با هم پردازش و تجزیه و تحلیل کارآمد مجموعه داده های بزرگ جمع آوری شده از کل جامعه بشری را امکان پذیر کرده اند. دست اندرکاران علوم زمین اولین پذیرندگان در زمینه داده های بزرگ و تجزیه و تحلیل به کمک هوش مصنوعی بوده اند، با نمونه های بسیاری از استفاده از تکنیک های کلان داده با موفقیت مشکلات علم اطلاعات جغرافیایی [ 48 ، 49 ، 50 ، 51 ].]. امروزه، هر دو بخش صنعتی و دانشگاهی چالشهای کلان داده را پذیرفته و نظریهها و فناوریهای جدیدی را برای کشف اطلاعات از دادههای فضایی بزرگ توسعه میدهند. بسیاری از روشهای تحلیل سنتی که برای استفاده در دادههای مقیاس کوچک ایجاد میشوند و نیاز به فرآیندهای دستی دارند، قادر به مقابله با حجم فزاینده دادههای مکانی موجود نیستند. این یک چالش بزرگ برای عملیات متعارف GIS برای پردازش چنین فراوانی از مجموعه داده های مکانی و ارائه اطلاعات به موقع به ذینفعان است [ 52 ]]. تکنیکهای هوش مصنوعی یک راهحل خودکار امیدوارکننده را ارائه میدهند: هوش مصنوعی به فرآیندهای دستی نیاز ندارد و میتواند دادههای مقیاس بزرگ را با استفاده از سختافزار مدرن خیلی سریع هضم کند. مهمترین چیز این است که ترافیک داده های زنده فوق العاده بر عملکرد عادی هوش مصنوعی به صورت روزانه تأثیر نمی گذارد. از هر جنبه، به نظر می رسد هوش مصنوعی یک راه حل ایده آل برای مسائل بزرگ داده های مکانی فعلی است.
با این حال، ویژگیهای مکانی-زمانی مجموعه دادههای جغرافیایی اغلب مشکلات بیشتری را برای مدلهای هوش مصنوعی ایجاد میکند تا با موفقیت یاد بگیرند و پیشبینی کنند. بر اساس تجربیات قبلی خود، به پنج دلیل نتیجه میگیریم که دادههای مکانی-زمانی نیاز به توجه بیشتری دارند:
- (1)
-
مشکل در کالیبره کردن مجموعه داده های آموزشی : این مشکل اغلب در داده های سنجش از راه دور رخ می دهد. وضوح فضایی اندازه هر پیکسل و چه مقدار از زمین را پوشش می دهد را تعیین می کند. به عنوان مثال، اگر مدلهای هوش مصنوعی از دادههای سنجش از دور به عنوان ورودی و دادههای جمعآوریشده از زمین به عنوان خروجی استفاده کنند، اگر تصاویر کمی جابهجا شوند، دقت میتواند به شدت تحتتاثیر قرار گیرد و در نتیجه نقاط نمونه زمین با پیکسلهای اشتباه مطابقت داشته باشند. تبدیل پروژه و الگوریتمهای نمونهگیری مجدد مورد نیاز است تا اطمینان حاصل شود که تطابق مکان بین ورودی و خروجی درست است. در غیر این صورت، همگرایی مدل بسیار سخت خواهد بود و مدل های آموزش دیده بی فایده هستند.
- (2)
-
مشکل در همگام سازی زمان مشاهده : بیشتر اطلاعات مکانی به زمان نیز حساس هستند. زمان مشاهده برای مرتبط ساختن رویدادهای مشاهده شده با علل محرک و پیامدهای احتمالی بعدی مهم است. در برخورد با داده های مکانی باید زمان دقیق مشاهده داده ها، دوره مشاهده تقریبی و مناطق زمانی (اگر مجموعه داده منطقه ای باشد) را در نظر داشته باشید. در بسیاری از مطالعات، گرانولهای با وضوح زمانی بالا به محصولات با وضوح بیشتر پردازش میشوند، به عنوان مثال، محصولات روزانه، هفتگی، دو هفتهای، ماهانه یا سالانه [ 32 ]. پردازش زمان می تواند از حداکثر، حداقل، میانگین، انحراف استاندارد و حتی برخی از الگوریتم های سفارشی استفاده کند.
- (3)
-
مشکل در کاهش سوگیری در مجموعه داده های آموزشی : بیشتر مجموعه داده های فضایی به طور طبیعی سوگیری دارند. به عنوان مثال، در کشاورزی داکوتای شمالی، هکتارهای رو به رشد کلزا بسیار کوچکتر از دانه سویا است و در مجموعه داده هایی که حاوی نمونه های سویا بیشتری نسبت به کلزا هستند، سوگیری ایجاد می کند. تعصب مشکلاتی را برای آموزش هوش مصنوعی ایجاد می کند، زیرا هوش مصنوعی در مجموعه داده های بی طرفانه دقت بسیار بهتری خواهد داشت. فرآیندهای اضافی برای کاهش سوگیری در مجموعه داده آموزشی مانند عادی سازی دسته ای یا محدود کردن اعداد نمونه نمایشی هر دسته در مجموعه داده های آموزشی نیاز است [ 53 ]]. با این حال، باید توجه داشت که سوگیری تنها دلیل عملکرد ضعیف برازش نیست و کاهش تعصب ممکن است باعث شود که مدل آموزشدیده در کلاسهای اصلی و بیش از حد در کلاسهای فرعی مناسب شود. دانشمندان همچنان به دنبال راه حل هایی برای ایجاد تعادل بین نمونه های کلاس اصلی و فرعی هستند.
- (4)
-
مشکل در درمان شکاف داده ها : شکاف های داده ناشی از مسائل مکانیکی، آب و هوا، ابر و دلایل انسانی در مجموعه داده های رصدخانه بلندمدت بسیار رایج است. یک مثال معمولی از خرابی مکانیک، شکاف در تصاویر Landsat 7 است که ناشی از شکست تصحیح خط اسکن از سال 2003 است. ابرها دلیل اصلی مسدود کردن ماهوارهها از رصد سطح زمین هستند. سوء رفتار توسط اپراتورهای دستگاه نیز می تواند باعث ایجاد شکاف در مجموعه داده ها شود. شکاف دادهها ممکن است منجر به از دست رفتن اطلاعات پدیدههای کلیدی شود و مدلهای هوش مصنوعی را نتوانند الگوها را ثبت کنند. چندین راه حل پیشنهادی برای پر کردن شکاف ها وجود دارد، اما نیاز به اختراع انسان دارد و زمان زیادی را می طلبد، که برای داده های بزرگ کارآمد نیست.
- (5)
-
مشکل در برخورد با مبهم بودن داده های مکانی-زمانی : داده های فازی، که مجموعه داده هایی هستند که از توصیف های کیفی به جای معیارهای کمی استفاده می کنند، در همه جا وجود دارند [ 54 ]. برای مثال،متن رسانههای اجتماعی [ 55 ] یک مکان مبهم مانند «سان فرانسیسکو» و زمان فازی مانند «دیروز» را در مورد برخی رویدادهای مشاهدهشده نشان میدهد. تجزیه و تحلیل مکانی-زمانی معمولاً به مکان دقیق (طول/طول جغرافیایی) و زمان (دقیق ساعت/دقیقه/ثانیه) نیاز دارد [ 56 ]. تغذیه اطلاعات مبهم در مدلهای هوش مصنوعی ممکن است مدلها را نادقیقتر کند. نحوه برخورد با داده های مکانی-زمانی فازی نیز مسئله مهمی است که امروزه هوش مصنوعی با آن مواجه است [ 57 ].
به طور خلاصه، اطلاعات مکان و زمان ذاتی دادههای مکانی-زمانی، و ابعاد بالای این دادهها، در مقایسه با سایر موارد استفاده سنتی، نیازمند توجه بیشتر مهندسان هوش مصنوعی است. مشکلاتی که در بالا برشمرده شد، حتی زمانی که با حجم کوچکی از داده ها سر و کار داریم، زمانی که داده های بزرگ درگیر می شوند، جدی تر می شوند. گلوگاه اصلی استفاده از هوش مصنوعی در دادههای مکانی، سازگاری بین الزامات مدلهای هوش مصنوعی و ساختار پیچیده دادههای فضایی بزرگ است. برای رسیدگی به این مسائل، ابزارها و نرمافزارهای تخصصی ضروری هستند و ممکن است تحت شرایط و ضوابط باز و اشتراکگذاری بهتر توسعه یابند، به طوری که کل جامعه دادههای بزرگ بتواند در راهحلها مشارکت داشته باشد، در حالی که از انواع دادهها، رابطها، و غیرقابل تعامل منحصربهفرد اجتناب شود. سازه های. این کار یکی از این تلاش ها برای ارائه یک نرم افزار متن باز به نام GeoWeaver به عنوان راه حلی برای چالش های ذکر شده است. در این نرم افزار، GeoWeaver قابلیت های کتابخانه ها و نرم افزارهای مختلف موجود، به عنوان مثال، GDAL (کتابخانه انتزاعی داده های جغرافیایی) /GRASS (سیستم پشتیبانی تجزیه و تحلیل منابع جغرافیایی) را برای کالیبراسیون یکپارچه می کند. USGS (سازمان زمین شناسی ایالات متحده) EarthExplorer Python مشتری برای دریافت مشاهدات در همان دوره. بسته آموزشی پایتون برای خوشه بندی و هموارسازی شکاف های داده، از جمله؛ و CUDA (معماری یکپارچه دستگاه محاسبه) DNN (شبکه عصبی عمیق) برای آموزش مدل با کارایی بالا و غیره. در مقایسه با نرم افزار مدیریت گردش کار موجود (WfMS)،
3. نرم افزار مدیریت گردش کار
نرمافزار مدیریت گردش کار (WfMS) یکی از نرمافزارهای ضروری برای کاربرد هوش مصنوعی دادههای بزرگ و شاید مهمترین نرمافزار در آینده قابل پیشبینی باشد [ 58 ، 59 ، 60 ، 61 ، 62 ]. در این بخش، ما پیشرفتهترین سیستمهای گردش کار را که ممکن است برای مدیریت گردشهای کاری هوش مصنوعی قابل استفاده باشند، بررسی کردیم. “جریان کار” یک اصطلاح بسیار کلی است و ممکن است به طرق مختلف تفسیر شود. به عنوان مثال، بسیاری از دانشمندان زمین اغلب یک نوت بوک Jupyter یا یک اسکریپت bash را به عنوان یک گردش کار معرفی می کنند [ 47 ]. کاربران GIS زنجیره ها را در ArcGIS ModelBuilder یک گردش کار می نامند [ 63 ]. تجار به خطوط تولید خود به عنوان یک گردش کار اشاره می کنند [ 64]. در محیط وب، زنجیره های خدمات وب، گردش کار هستند [ 59 ، 65 ، 66 ]. هیچ یک از این تفاسیر نادرست نیست. علیرغم تفاوتهای بزرگ در اشکال ظاهری، به اصطلاح گردشهای کاری توسط گروههای مختلف افراد، چندین مؤلفه کلیدی مشترک دارند:
3.1. فرآیند اتمی
به عنوان عناصر اساسی در یک گردش کار، فرآیندهای اتمی وظایفی هستند که بر روی آنها عمل می کنند و به نوعی داده ها را تبدیل یا ایجاد می کنند. اکثر سیستم های مدیریت گردش کار سنتی انتظار دارند که تمام فرآیندهای اتمی در یک گردش کار با انواع از پیش تعیین شده خاصی مطابقت داشته باشند. به عنوان مثال، ArcGIS ModelBuilder به ابزارهای ArcGIS (شامل ابزارهای سفارشی شده) به عنوان فرآیندهای اتمی اجازه می دهد [ 63 ]. مدیر فرآیند زبان اجرای فرآیند کسب و کار Oracle (BPEL) میتواند سرویسهای وب را با SOAP-WSDL (پروتکل دسترسی به اشیاء ساده – زبان توصیف خدمات وب) بنویسد [ 67 ]. اطلاعات مربوط به سایر WfMS ها را می توان در جدول 1 یافت. پیچیدگی نرم افزار علمی در زمینه علوم زمین، این انطباق را با فرآیندهای اتمی با عملکرد و دانه بندی متغیر می شکند. به عنوان مثال، پایتون به زبان و محیط غالب برای گردشهای کاری هوش مصنوعی تبدیل شده است [ 68]. جریان های کاری هوش مصنوعی نوشته شده در پایتون شامل فراخوانی های بسیاری از کتابخانه های پایتون و نوت بوک های Jupyter توزیع شده است. بیشتر محاسبات باید از راه دور روی سیستم هایی با پردازنده گرافیکی نصب شده یا قادر به اجرای کدهای بسیار موازی انجام شود. اسکریپتهای پوسته و خطوط فرمان دو فرآیند اتمی مهم دیگر برای تبدیل دادههای فضایی بزرگ به فرمت آماده هوش مصنوعی و نتایج پس از پردازش به محصولات با ارزش افزوده قابل درک هستند. دانه بندی فرآیندهای اتمی در جریان های کاری هوش مصنوعی بر اساس ترجیحات و عادات شخصی نویسندگان گردش کار به طور مداوم در حال تغییر است. شاغلین ممکن است تمایل داشته باشند که تمام منطق کسب و کار را در یک فرآیند اتمی عظیم جمع کنند، در حالی که برخی دیگر ترجیح می دهند منطق کسب و کار را به وظایف مجزا کوچکتر تبدیل کنند تا به جزئیات بیشتر در پیشرفت گردش کار دست یابند.
3.2. زنجیره عملکرد
به زبان ساده، یک گردش کار مجموعه ای از فرآیندهای مرتبط است [ 69 ]. برخی از فرآیندها (فرآیند پایین دست) به خروجی سایر فرآیندها (فرایند بالادستی) بستگی دارد. این وابستگی محرک اصلی ترکیب گردش کار است. پیوندهای بین فرآیندها معمولاً “جریان داده” نامیده می شوند. هنگامی که فرآیندها به یکدیگر زنجیر می شوند، WfMS به کاربران اجازه می دهد گردش کار را به صورت خودکار اجرا کنند و وضعیت بلادرنگ اجرا را بررسی کنند، که در مقایسه با اجرای دستی فرآیندهای جداگانه به صورت جداگانه، به مداخله انسانی بسیار کمتری نیاز دارد. برای تسهیل استفاده مجدد و تکرار، جوامع WfMS، به عنوان مثال، ائتلاف مدیریت گردش کار (WfMC) [ 70 ]، کنسرسیوم وب جهانی (W3C) [ 71 ]]، سازمان برای پیشرفت استاندارد اطلاعات ساختاریافته (OASIS) ( https://www.oasis-open.org/standards )، myExperiment [ 72 ]، کهکشان [ 73 ] و کپلر [ 74 ]]، مجموعه ای از زبان های گردش کار را پیشنهاد کرد که این پیوندهای گردش کار و فرآیندهای درگیر را توصیف و ضبط می کند. زبانهای استانداردی که معمولاً در بخش صنعتی استفاده میشوند عبارتند از BPEL (زبان اجرای فرآیند کسبوکار)، BPMN (مدل فرآیند تجاری و نمادگذاری)، زبان گردش کار رایج (CWL) و غیره. برای گردشهای کاری علمی، اکثر WfMS زبانهای خود را تعریف میکنند، مانند Taverna SCUFL2 (زبان جریان یکپارچه مفهومی ساده)، YAWL (یک زبان دیگر گردش کار)، Kepler و غیره. این زبانهای گردش کار، انتزاعها و مدلهای اطلاعاتی را برای فرآیندها ارائه میکنند. WfMS از این انتزاع ها و مدل ها برای اجرای گردش های کاری مربوطه استفاده می کند. با این حال، صدها WfMS توسعه یافته است، اما تنها تعداد انگشت شماری از زبان رایج گردش کار پشتیبانی می کنند. اکثر گردش های کاری ایجاد شده را نمی توان بین WfMS های مختلف به اشتراک گذاشت. از این رو،
3.3. کنترل خطا
یکی دیگر از اهداف مهم WfMS کنترل خطا است. پردازش کلان داده ممکن است روزها یا حتی ماه ها قبل از دستیابی به نتایج دلخواه اجرا شود. اجتناب ناپذیر است که استثنائات در طول چنین مدت محاسباتی طولانی رخ دهد. هر طراحی WfMS باید برای رسیدگی به وقوع خطا در اجرای گردش کار آماده باشد. با توجه به اتفاق رایج در محیطهای پردازش دادههای بزرگ که مؤلفهها به زبانهای برنامهنویسی مختلف نوشته میشوند و در پلتفرمهای مجازی توزیعشده اجرا میشوند، تحقق این امر میتواند چالشی دشوار باشد و به یک راهحل غیر ضروری نیاز است [ 75 ].]. استراتژیهای کنترل خطا معمولاً از دو مرحله تشکیل میشوند: ضبط خطا و مدیریت خطا. WfMS باید وضعیت هر فرآیند جداگانه را برای ثبت رویدادهای خطای احتمالی نظارت کند. این امر مستلزم آن است که فرآیندهای منفرد کانالی برای WfMS داشته باشند تا وضعیت بلادرنگ خود را مشاهده کند (مخصوصاً اگر فرآیند مدت زمان زیادی طول بکشد). هنگامی که یک خطا رخ می دهد، WfMS ممکن است آن را به یکی از سه روش مدیریت کند: (1) کل گردش کار را متوقف می کند، (2) فرآیند را دوباره اجرا می کند، یا (3) برای ادامه روند شکست خورده را رد می کند. در مورد کلان داده، یک راه حل توصیه شده این است که فقط فرآیندهای شکست خورده را مجدداً اجرا کنید تا از اتلاف زمان تکراری در فرآیندهای بالادستی که با موفقیت اجرا شده اند جلوگیری شود. با این حال، این ممکن است به موارد خاص بستگی دارد. برای آن دسته از خطاهای رایج مانند اختلال در شبکه، نشت حافظه، اتمام زمان، یا خرابی سخت افزار، WfMS باید راه حل های از پیش تعریف شده ای را برای کاهش تعامل ضروری کاربران ارائه دهد. در مطالعات اخیر، بسیاری از WfMS تلاش میکنند تا تشخیص و بازیابی خودکار خطا را بدون دخالت انسان انجام دهند. این ممکن است برای خطاهای اساسی قابل دستیابی باشد، در حالی که برای اکثر خطاهای با پیچیدگی بالا (در مرحله اشکال زدایی)، تجزیه و تحلیل و عملیات انسانی هنوز مورد نیاز است.
3.4. منشأ
با توجه به معماری های پیچیده رایج در یادگیری ماشین، به عنوان مثال، در شبکه های عصبی با گاهی اوقات صدها یا هزاران لایه وزن شده با پارامترهایی که برای انسان قابل تفسیر نیستند، تکنیک های هوش مصنوعی به بحران گسترده ای در تکرارپذیری، تکرارپذیری و تکرارپذیری کمک می کنند [ 76 ، 77 ]. , 78 , 79 , 80 ]. یک مفهوم کلیدی، اما اغلب اشتباه درک شده در این موضوعات، منشأ است [ 81 ، 82 ، 83 ، 84 ]]. سوابق منشأ با کیفیت بالا حاوی اطلاعات فرآیندی و شجره ای در مورد اینکه چه، چگونه، کجا و چه زمانی داده های جغرافیایی یا سایر داده ها به دست می آیند. سوابق اجزاء، ورودیها، سیستمها و فرآیندهایی که زمینه تاریخی را فراهم میکنند، همگی متعلق به چیزی هستند که میتوان آن را منشأ گذشتهنگر نامید. سوابق منشأ آیندهنگر مشابهی ممکن است برای فعالیتهای محاسباتی احتمالی آینده (اجرای گردش کار تصفیهشده) استفاده شود. دادههای مکانی ذاتاً از نظر قابلیت تکرار مشکلساز هستند (مثلاً به دلیل ناهمگونی مکانی [ 85 ])، و به نظر میرسد نیاز متناظر به اطلاعات منشأ جغرافیایی با کیفیت بالا بسیار زیاد است.
منشأ در دنیای تولید دادهها و دادههای مکانی بسیار مهم است و مزایای آن فراتر از چالشهای مرتبط با تکرارپذیری است و شامل کیفیت، شفافیت و اعتماد است [ 82 ، 83 ، 86 ، 87 ]. با این حال، سؤالات بی پاسخ جدی در مورد تضاد احتمالی بین منشأ، حریم خصوصی و مالکیت معنوی وجود دارد. علاوه بر این، توسعه استانداردهای منشأ برای گردش کار هوش مصنوعی به بلوغ نرسیده است. در گستره وسیعی، W3C توصیه ای برای یک مدل داده منشأ وب به نام PROV-DM (مدل داده منشأ) منتشر کرده است [ 71]، که یک مدل داده اصلی جهانی را برای تقریباً همه انواع اطلاعات منشأ تعریف می کند. با این حال، در مورد استفاده از چنین توصیهای برای ثبت منشأ تولید شده توسط جریانهای کاری هوش مصنوعی که دادههای مکانی بزرگ را در بر میگیرد، تردید وجود دارد. همچنین تحقیقات بیشتری برای حل مسائل مربوط به نمایش دادههای مرتبط با فشردهسازی منشأ، ذخیرهسازی، پرس و جو، بازنشستگی و غیره مورد نیاز است.
3.5. گردش کار پردازش داده های بزرگ
آموزش مدلهای هوش مصنوعی به مجموعه دادههای آموزشی بزرگی نیاز دارد که توسط گردش کار پردازش دادههای بزرگ به دست میآیند. با این حال، مدیریت گردشهای کاری پردازش دادههای بزرگ بسیار پیچیدهتر از مدیریت گردشهای کاری در مقیاس کوچک معمولی است. این بخش وضعیت فعلی مدیریت گردش کار پردازش کلان داده را بررسی میکند و چالشهایی را که امروز با آن روبرو هستیم، تحلیل میکند.
بسیاری از چارچوبهای پردازش دادههای بزرگ در پاسخ به انجام آزمایشهای محاسباتی در مقیاس بزرگ در علوم زمین استفاده شدهاند [ 88 ]. گردش کار علمی برای ترکیب محاسبات با عملکرد بالا سنتی با پارادایم های تجزیه و تحلیل داده های بزرگ استفاده می شود [ 89 ]]. آزمایشهای علمی فشرده محاسباتی معمولاً در مراکز داده بزرگ آزمایشگاههای ملی مانند DOE (دپارتمان انرژی)، آزمایشگاه ملی Oak Ridge، مرکز ابررایانهای سن دیگو، مرکز ملی کاربردهای ابر رایانه در دانشگاه ایلینوی در Urbana-Champaign و CISL انجام میشود. آزمایشگاه سیستم های محاسباتی و اطلاعاتی) ابر رایانه ها در NCAR (مرکز ملی تحقیقات جوی). این مراکز ابررایانه برخی از ابزارهای مشتری را برای مدیریت گردش کار آزمایشی خود از راه دور به کاربران ارائه می دهند، مانند Cylc [ 90 ]. به دلایل امنیتی و نگهداری، ابررایانهها میتوانند محیط محدودی را برای کاربران فراهم کنند تا آزمایشهای خود را انکوبه کنند.
رایانش ابری یکی دیگر از پارادایم های محبوب برای پردازش داده در مقیاس بزرگ امروزه است [ 91 ، 92 ، 93 ]. این مبتنی بر اشتراکگذاری منابع و مجازیسازی است تا محیطی شفاف، مقیاسپذیر و الاستیک را فراهم کند که میتواند در صورت تقاضا گسترش یا کاهش یابد [ 94 ]. با رایانش ابری، ماشینهای مجازی خوشهای، و همچنین چارچوبهای پردازش دادههای بزرگ مانند Hadoop و Spark، ممکن است برای ایجاد یک معماری پردازش کلان داده خصوصی با تلاش کم و اجتناب از نیاز به وارد شدن به صف برای تخصیص منابع، نمونهسازی و نصب شوند. 48]. ابزارهای نرم افزار کلان داده می توانند به طور خودکار موقعیت داده ها را اعمال کنند و انتقال داده ها را به حداقل برسانند و اجازه دهند گردش های کاری علمی به صورت موازی اجرا شوند. به عنوان مثال، فرض کنید وظیفه ای برای میانگین پتابایت داده های بارندگی جهانی از ساعتی به روزانه وجود دارد. WfMS می تواند به سازماندهی تمام فرآیندهای درگیر در روال ETL (استخراج، تبدیل، بارگذاری) در گردش کار MapReduce کمک کند [ 51 ، 95 ]. داده های بزرگ ابتدا هضم و به دسته های داده در سیستم های فایل توزیع شده مانند HDFS (سیستم فایل توزیع شده هادوپ) تقسیم می شوند [ 40 ]]. قرار است هر دسته به جفت های کلید/مقدار نگاشت شده و به گره های کاهش یافته برای اعمال الگوریتم های از پیش تعریف شده وارد شود. پردازش تمام دسته ها به صورت موازی انجام می شود. نتایج بیشتر به چند تایی کاهش یافته و در HDFS ذخیره می شوند. افراد می توانند از ابزارهایی مانند Apache Hive برای جستجوی داده ها از HDFS با استفاده از زبانی استفاده کنند که بسیار شبیه به SQL سنتی (زبان پرس و جوی ساختاریافته) است. Apache HBase یک پایگاه داده محبوب NoSQL است که در بالای HDFS اجرا می شود و از Hadoop برای مدیریت حجم زیادی از داده های ساختاریافته، نیمه ساختاریافته و بدون ساختار پشتیبانی می کند [ 42 ]. WfMS عمدتاً برای مدیریت دادهها و خطوط لوله داده استفاده میشود.
علاوه بر خانواده آپاچی، بسیاری دیگر از چارچوب های پردازش داده های بزرگ وجود دارد [ 96 ]. برای گردش کار علمی، پایتون امروزه نقش مهمی ایفا می کند. اکوسیستم کتابخانه های متعدد پایتون به دانشمندان این امکان را می دهد که آزمایش های خود را فقط با استفاده از کد پایتون مدیریت کنند. جامعه پانژئو یکی از بزرگترین میوههای گروههایی است که سعی میکنند از کتابخانههای پایتون برای مقابله با چالشهای کلان داده در علوم زمین استفاده کنند [ 97 ]. Pangeo یک نرم افزار نیست، بلکه یک محیط پایتون است که در آن افراد تمام کتابخانه های مورد نیاز را برای پردازش مجموعه داده های مقیاس بزرگ، به عنوان مثال پایگاه داده سنجش از راه دور اقیانوس جهانی، دریافت خواهند کرد. کتابخانه های اصلی برای پردازش موازی Xarray و Zarr هستند. در حال اجرا بر روی پلتفرم های ابری یا ابر رایانه ها، محیط Pangeo [ 97] امکان سنجی خود را در حل مسائل علوم زمین در مقیاس بزرگ از طریق پردازش حجم عظیمی از مشاهدات زمین انباشته شده در دهه های گذشته نشان داده است.
4. چارچوب
برای رویارویی با چالشهای بالا، ما یک چارچوب جدید برای مدیریت گردش کار ژئوپردازش مبتنی بر هوش مصنوعی در مقیاس بزرگ پیشنهاد میکنیم. این چارچوب برای کمک به دانشمندان برای مرتب کردن آزمایش هوش مصنوعی و بهبود اتوماسیون و قابلیت استفاده مجدد طراحی شده است. همانطور که در شکل 2 نشان داده شده است ، این چارچوب مبتنی بر اکوسیستم نرم افزاری موجود هوش مصنوعی و داده های فضایی بزرگ با ادغام بسیاری از سیستم های بالغ با هم در یک مکان برای تماس کاربران است. طراحی هسته با توجه به نهادهایی که با آنها سروکار دارند به سه ماژول تقسیم می شود. یعنی میزبان، فرآیند و گردش کار. جزئیات در زیر معرفی شده است.
4.1. میزبان
این ماژول پایه و اساس کل چارچوب و تفاوت عمده با WfMS های دیگر است. ورود به منابع موجود مانند سرورها، ماشینهای مجازی، نمونههای سرور Jupyter و پلتفرمهای محاسباتی شخص ثالث مانند Google Earth Engine و Google Colab را باز میکند. این ماژول کلاینت API (رابط برنامه نویسی برنامه) را ادغام می کند تا امکان دستکاری منابع هدف را فراهم کند. برای تسهیل پذیرش سریع و آسان پلتفرم، یک رابط آشنا برای کاربرانی که به ابزارهای رایج موجود عادت دارند توصیه می شود. به عنوان مثال، این ماژول می تواند شامل یک کنسول SSH (Secure Shell) برای دسترسی و تایپ خطوط فرمان به سرورهای راه دور (شامل سرورهای فیزیکی یا ماشین های مجازی ارائه شده توسط پلت فرم های ابری)، یک مرورگر فایل، و پنجره های ویرایش کد باشد.
یکی دیگر از عملکردهای مهم طراحی شده، به عهده گرفتن مدیریت محیط سیستم است. محیط سیستم در درجه اول مجموعه متغیرهایی است که تنظیمات فعلی را برای محیط اجرا تعریف می کند. محیط های سیستم به دلیل تنوع و سازگاری نسخه های کتابخانه های وابسته بسیار پیچیده هستند. تنظیم متغیرهای مسیر و محیط بسته به نسخه سیستم عامل ماشینها متفاوت است. متغیرهای محیطی اغلب بین سیستمها به دلیل عدم تطابق در محل نصب وابستگیها، یکی از دلایل اصلی مشکلات و اغلب مانعی برای تکرار آزمایش بر روی یک ماشین جدید، متفاوت است. برای مدیریت بهتر محیطها، نرمافزارهایی مانند مدیریت بستهها، مانند conda یا venv برای پایتون، که معمولاً برای توزیع بستهها استفاده میشوند، توسعه یافتهاند. محیط مجازی دایرکتوری است که شامل مجموعه خاصی از بسته های پایتون است. از طریق این ابزارهای مدیریتی، می توان محیط را توسط ماژول میزبان بازیابی کرد تا برنامه با موفقیت اجرا شود. یک جایگزین برای مدیریت مستقل همه متغیرهای محیطی، استفاده از فناوریهای کانتینریسازی (Docker و Kubernetes) است. کانتینرها میتوانند با حذف نیاز به نصب، مدیریت و بهرهبرداری از وابستگیهای محیط، محیطی آماده برای تولید برای استقرار برنامهها در کوتاهترین زمان فراهم کنند. یک جایگزین برای مدیریت مستقل همه متغیرهای محیطی، استفاده از فناوریهای کانتینریسازی (Docker و Kubernetes) است. کانتینرها میتوانند با حذف نیاز به نصب، مدیریت و بهرهبرداری از وابستگیهای محیط، محیطی آماده برای تولید برای استقرار برنامهها در کوتاهترین زمان فراهم کنند. یک جایگزین برای مدیریت مستقل همه متغیرهای محیطی، استفاده از فناوریهای کانتینریسازی (Docker و Kubernetes) است. کانتینرها میتوانند با حذف نیاز به نصب، مدیریت و بهرهبرداری از وابستگیهای محیط، محیطی آماده برای تولید برای استقرار برنامهها در کوتاهترین زمان فراهم کنند.
ماژول میزبان همچنین باید بتواند با سیستم عامل های شخص ثالث مانند سرور نوت بوک Jupyter و موتور Google Earth تعامل داشته باشد. با استفاده از API باز خود، ماژول میزبان می تواند پیام هایی را برای شروع فرآیندها در آن پلتفرم ها ارسال کند. این تابع به این چارچوب اجازه می دهد تا با پلتفرم های محاسباتی قدرتمند با کارایی بالا در حوزه عمومی ادغام شود. کاربران می توانند به راحتی گردش کار خود را از این پلتفرم ها به این چارچوب منتقل کنند.
4.2. روند
ماژول فرآیند شامل پنج زیر ماژول و یک پایگاه داده است. فرآیندهای اتمی پشتیبانی شده باید شامل اسکریپت ها، برنامه ها، دستورات یا کدهای پرکاربرد باشد. از آنجایی که آزمایشهای فعلی هوش مصنوعی معمولاً از Python استفاده میکنند، ماژول فرآیند حداقل باید از Python، Jupyter Notebook، اسکریپتهای پوسته (یعنی Bash) و SSH برای اجرای برنامههای سطح سیستم پشتیبانی کند. کتابخانه های هوش مصنوعی مانند DeepLearning4j، Keras [ 4 ]، PyTorch [ 98 ]، Caffe، Tensorflow [ 99] و غیره مستقیماً در فرآیندهای پایتون یا ژوپیتر قابل دسترسی هستند. ایجادکننده/ویرایشگر فرآیند گفتگویی است که در آن کاربران میتوانند فرآیندهای جدید ایجاد کنند یا فرآیندهای قدیمی را ویرایش کنند. باید یک ناحیه متنی برای رندر کردن اسکریپتهای شل، تکههای کد جاوا/پایتون و دستورات نرمافزار با رنگها برای خواندن بصری وجود داشته باشد. فرآیندهای جدید ایجاد شده باید در یک پایگاه داده (MySQL یا H2) ذخیره شوند. یک برنامهریز وظیفه مسئول زمانبندی درخواستهای اجرای فرآیند در لیست انتظار است و وظایف را با پلتفرمهای مناسب از مجموعه منابع اختصاص میدهد. یک فرآیند اجرا مسئول اتصال از طریق کانال های SSH و اجرای فرآیندها در پلتفرم های اختصاص داده شده است. اجرا باید ابتدا آخرین کد را به سرورهای راه دور منتقل کند و با ارسال دستورات کد را فعال کند. مانیتور فرآیند می تواند به تمام رویدادهای رخ داده در حین اجرا گوش داده و وضعیت بلادرنگ را گزارش دهد. پس از پایان اجرا، پیام های نتیجه به همراه ورودی ها و کدهای اجرا شده برای بررسی بعدی در پایگاه داده ذخیره می شوند. یک مدیر منشأ مسئول استعلام و تجزیه و تحلیل اطلاعات تاریخچه ذخیره شده اجرای هر فرآیند برای ارزیابی کیفیت داده یا بازیابی اجرای فرآیند از شکست است.
4.3. جریان کار
ماژول گردش کار دو عملکرد عمده را ارائه می دهد: (1) ترکیب جریان های کاری از فرآیندهای اتمی از ماژول فرآیند. و (2) مدیریت پرس و جو، ویرایش، اجرا، نظارت، و بازنشستگی گردش کار. مانند سایر سیستمهای گردش کار گرافیکی، خالق گردش کار باید یک پانل گرافیکی به عنوان بوم کار برای فرآیندهای drag-n-drop و پیوند آنها به یک گردش کار داشته باشد. یک رابط باید ایجاد شود تا به کاربران اجازه دهد گردش کار را بنویسند. بسیاری از پیشرفتهای اخیر در چارچوبهای جاوا اسکریپت، یعنی React، Angular، و Vue.js، و همچنین کتابخانههای جاوا اسکریپت مانند D3.js و CodeMirror وجود دارد که میتوانند به ساخت وبسایتها برای ارائه یک تجربه کاربری غنی از طریق رابطهای کاربری با ویژگیهای کامل کمک کنند. از طریق رابطها، افراد میتوانند فرآیندهای اتمی را بکشند و رها کنند و خطوطی را برای اتصال آنها به گردش کار ترسیم کنند. گردش کار ایجاد شده نشان دهنده دانش پردازش داده در مقیاس بزرگ است و در پایگاه داده ذخیره می شود. یک نوار ابزار باید برای مدیریت گردش کار، از جمله جستجوی گردش کار موجود، اجرا و نظارت بر گردش کار، و بررسی تاریخچه اجرای گردش کار ایجاد شود. ماژول گردش کار با نشان دادن رنگ های مختلف یا نشان دادن نوارهای پیشرفت، بازخوردهای بلادرنگ وضعیت فرآیند اعضا را ارائه می دهد. برای اشتراکگذاری دانش گردش کار، این ماژول همچنین باید به افراد اجازه دهد تا گردشهای کاری را صادر و وارد کنند (یا آپلود و دانلود کنند). کاربر باید بتواند گردش کار خود را از نمونه قدیمی صادر کند و گردش کار خود را به نمونه جدیدی وارد کند که در آن بتواند مستقیماً طبق معمول کار کند. یک نوار ابزار باید برای مدیریت گردش کار، از جمله جستجوی گردش کار موجود، اجرا و نظارت بر گردش کار، و بررسی تاریخچه اجرای گردش کار ایجاد شود. ماژول گردش کار با نشان دادن رنگ های مختلف یا نشان دادن نوارهای پیشرفت، بازخوردهای بلادرنگ وضعیت فرآیند اعضا را ارائه می دهد. برای اشتراکگذاری دانش گردش کار، این ماژول همچنین باید به افراد اجازه دهد تا گردشهای کاری را صادر و وارد کنند (یا آپلود و دانلود کنند). کاربر باید بتواند گردش کار خود را از نمونه قدیمی صادر کند و گردش کار خود را به نمونه جدیدی وارد کند که در آن بتواند مستقیماً طبق معمول کار کند. یک نوار ابزار باید برای مدیریت گردش کار، از جمله جستجوی گردش کار موجود، اجرا و نظارت بر گردش کار، و بررسی تاریخچه اجرای گردش کار ایجاد شود. ماژول گردش کار با نشان دادن رنگ های مختلف یا نشان دادن نوارهای پیشرفت، بازخوردهای بلادرنگ وضعیت فرآیند اعضا را ارائه می دهد. برای اشتراکگذاری دانش گردش کار، این ماژول همچنین باید به افراد اجازه دهد تا گردشهای کاری را صادر و وارد کنند (یا آپلود و دانلود کنند). کاربر باید بتواند گردش کار خود را از نمونه قدیمی صادر کند و گردش کار خود را به نمونه جدیدی وارد کند که در آن بتواند مستقیماً طبق معمول کار کند. ماژول گردش کار با نشان دادن رنگ های مختلف یا نشان دادن نوارهای پیشرفت، بازخوردهای بلادرنگ وضعیت فرآیند اعضا را ارائه می دهد. برای اشتراکگذاری دانش گردش کار، این ماژول همچنین باید به افراد اجازه دهد تا گردشهای کاری را صادر و وارد کنند (یا آپلود و دانلود کنند). کاربر باید بتواند گردش کار خود را از نمونه قدیمی صادر کند و گردش کار خود را به نمونه جدیدی وارد کند که در آن بتواند مستقیماً طبق معمول کار کند. ماژول گردش کار با نشان دادن رنگ های مختلف یا نشان دادن نوارهای پیشرفت، بازخوردهای بلادرنگ وضعیت فرآیند اعضا را ارائه می دهد. برای اشتراکگذاری دانش گردش کار، این ماژول همچنین باید به افراد اجازه دهد تا گردشهای کاری را صادر و وارد کنند (یا آپلود و دانلود کنند). کاربر باید بتواند گردش کار خود را از نمونه قدیمی صادر کند و گردش کار خود را به نمونه جدیدی وارد کند که در آن بتواند مستقیماً طبق معمول کار کند.
5. نمونه اولیه: Geoweaver
ما یک نمونه اولیه به نام Geoweaver [ 100 ، 101 ] برای اعتبار بخشیدن به چارچوب توسعه دادهایم. طراحی رابط در شکل 3 نشان داده شده است. این به سادگی از یک بوم فضای کاری، پانل منوی سمت راست، نوار ابزار ناوبری، نوار ابزار گردش کار، و پنجره خروج از سیستم تشکیل شده است. در پانل منوی سمت راست، سه پوشه وجود دارد: میزبان، فرآیند و گردش کار. هر پوشه دارای گره های فرزند است. در پوشه میزبان، هر گره فرزند یک ماشین است، یا یک سرور فیزیکی از راه دور یا یک ماشین مجازی. هر گره ماشین چهار دکمه را دنبال می کند: دکمه کنسول SSH، دکمه آپلود فایل، دکمه مرورگر/دانلود فایل و دکمه حذف میزبان. در پوشه فرآیند، چهار پوشه فرزند وجود دارد: اسکریپت های پوسته، کد پایتون، نوت بوک های Jupyter و پردازش های داخلی. هر پوشه شامل فرآیندها به همان زبان یا فرمت است. مکانیسم های اجرا برای پوشه های مختلف متفاوت است.
نرم افزار Geoweaver در ابتدا توسط برنامه ESIP (شرکای اطلاعات علوم زمین) Lab Incubator تامین شد و به عنوان یک نرم افزار منبع باز در Github ( https://esipfed.github.io/Geoweaver ) منتشر شده است. از مجوز MIT استفاده می کند که برای استفاده مجدد تجاری و غیر تجاری بسیار مجاز است.
6. مورد استفاده: نقشه برداری کشاورزی مبتنی بر هوش مصنوعی
ما Geoweaver را با استفاده از تصاویر Landsat و الگوریتمهای طبقهبندی یادگیری عمیق برای مطالعه تغییرات پوشش زمین و تأثیرات اجتماعی-اقتصادی مربوطه آزمایش کردیم [ 3 ، 5 ، 102 ، 103 ، 104 ، 105 ، 106 ، 107 ]. گردش کار هوش مصنوعی قبلاً در کار [ 5 ] منتشر شده است. ما گردش کار را در GeoWeaver تکرار میکنیم و آن را روی دادههای آزمایشی جدید اجرا میکنیم و نقشههای برش جدید را با موفقیت بازتولید کردیم [ 101 ] ( شکل 4 و شکل 5 ).
ابتدا، ما لایه داده های زمین زراعی (CDL) را از USDA (وزارت کشاورزی ایالات متحده) NASS (سرویس ملی آمار کشاورزی) [ 108 ] به عنوان داده مرجع برای پیش بینی مناطق و دوره های ناشناخته دانلود کردیم. در این گردش کار، LSTM (حافظه کوتاه مدت بلند مدت) [ 109 ] به عنوان روش طبقه بندی استفاده می شود. Landsat و CDL ابتدا در کاشی های کوچک تصاویر پیش پردازش می شوند (داده های نمونه را می توان در https://github.com/ZihengSun/Ag-Net-Dataset یافت ). چندین نوت بوک آموزشی Ag-Net Jupyter ( https://github.com/ESIPFed/Ag-Net ) وجود دارد. ما از محاسبات ابری (GeoBrain Cloud) استفاده کردیم [ 110 ، 111 ، 112] و پردازش موازی (NVIDIA CUDA GPU) [ 93 ، 113 ] برای مقابله با چالش پردازش تعداد زیادی پیکسل در تصاویر سنجش از راه دور (یک صحنه لندست 8 حاوی بیش از 34 میلیون پیکسل است) [ 114 ]. نقشه های طبقه بندی شده به نظارت، پیش بینی و تصمیم گیری کشاورزی کمک می کند [ 107 ، 115]. کل آزمایش مسائل مدیریتی زیادی را برای دانشمندان ایجاد می کند که نمی توانند آن ها را مدیریت کنند. ما باید با مشکلات در حفظ سازمان و ارتباطات شخصی، محدودیت های ارتباطی سخت افزاری و مشکلات پیکربندی آزاردهنده مقابله کنیم. ما شدیداً به یک راهحل نرمافزار مدیریتی نیاز داریم تا به مرتب کردن مراحل و فرآیندها کمک کند، و یک داشبورد کلی برای کار، مدیریت امکانات زیربنایی از طریق اینترنت، و ردیابی مسائل و منشأ در اختیار ما قرار دهد. در مورد ما، ما به آن برای ایجاد یک گردش کار ترکیبی بصری برای طبقهبندی مبتنی بر LSTM از تصاویر خام گرفته تا نقشههای پوشش زمین، اجرای گردش کار روی GeoBrain Cloud با Tensorflow و CUDA نیاز داریم [ 4 ، 99 ]، و منشأ آن را ردیابی کنیم. هر نقشه [ 116]، و نتایج را از طریق ایمیل یا رسانه های اجتماعی با دانشمندان دیگر به اشتراک بگذارید. نتایج نشان میدهد که گردش کار در GeoWeaver میتواند با موفقیت تصاویر Landsat را با دقت در مقایسه با نقشههای برش USDA طبقهبندی کند ( شکل 5 ).
در این آزمایش، Geoweaver به ما کمک کرد تا به طور انعطافپذیری دانهبندی فرآیندهای اتمی را در جریان کار تنظیم کنیم. ما با ترکیب تمام مراحل پردازش تصاویر Landsat با هم در یک فرآیند اتمی “پیش پردازش landsat” و ترکیب تمام مراحل پیش پردازش CDL در “پیش پردازش cdl”، گردش کار را برای مدیریت بهتر طراحی کردیم. ما کد را در یک فرآیند Shell ادغام کردیم که دانه بندی بیشتری دارد. فرآیند بزرگتر، کنار آمدن با موقعیت هایی مانند تغییر منبع داده را آسان تر می کند، به عنوان مثال، تغییر تصاویر ورودی از Landsat 8 به Landsat 5 (مشخصات باند متفاوت است). از طریق GeoWeaver، ادغام/تجزیه کد میتواند به راحتی با ایجاد فرآیندهای جدید و تقسیم یک مرحله بزرگ به قطعات یا ادغام مراحل خسته کننده در یک فرآیند بزرگ انجام شود. در مقایسه با سایر WfMS ها،
Geoweaver همچنین به ما در انتقال جریان کار بدون بازنویسی چیزی کمک کرد. ما چندین نمونه از Geoweaver را در GeoBrain Cloud در مورد محدودیتهای شبکه یا موقعیتهای تصادفی مانند قطع برق و خرابی سرور مستقر کردهایم. یک نمونه Geoweaver به سرور GPU دسترسی ندارد و یک نمونه Geoweaver دسترسی دارد. در ابتدا ما گردش کار را روی نمونه Geoweaver غیر GPU ایجاد کردیم. برای استفاده از GPU، گردش کار را همراه با کد فرآیند به عنوان یک بسته دانلود می کنیم و آن را با دسترسی GPU در نمونه Geoweaver آپلود می کنیم. در نمونه جدید به آرامی کار می کند و انتقال در مقایسه با انتقال دستی گردش کار از یک محیط به محیط دیگر بسیار صرفه جویی در زمان دارد. این همچنین نشان دهنده این واقعیت است که Geoweaver موانع بازتولید آزمایش در یک محیط جدید را کاهش می دهد.
در طول بازآفرینی گردش کار، راحت بود که Geoweaver توانست فرآیندهای ترکیبی نوشته شده به چندین زبان را زنجیرهای کند و آنها را روی چندین سرور راه دور اجرا کند. اسکریپت های دانلود و اسکریپت های پیش پردازش در شل نوشته شده اند. ag-net-train و ag-net-ready و ارزیابی-نتایج در پایتون هستند. فرآیند ShowCropMap یک فرآیند داخلی Geoweaver است که فایل های نتیجه را از سرورهای راه دور بازیابی می کند و آنها را به صورت بصری در رابط Geoweaver نمایش می دهد.
آموزش شبکه های عصبی به دلیل تنظیمات مکرر در مراحل پیش پردازش و پیکربندی شبکه عصبی ده ها بار تکرار شد. هر اجرای گردش کار، ناظر فرآیند و مدیر منشأ را شروع به جمعآوری و ثبت اطلاعات منشأ میکند. تمام موفقیتها و شکستها ذخیره میشوند و از طریق دکمه تاریخچه برای پرس و جو در دسترس هستند. جدول تاریخچه دارای یک ستون “وضعیت” است که چهار گزینه دارد: انجام شد، ناموفق، در انتظار، متوقف شد.. خطاها در گردش کار Geoweaver به درستی شناسایی و به طور کامل ثبت می شوند تا به کاربران اطلاع دهند. Geoweaver آنها را به روشی ثابت و یک مرحله ای در دسترس قرار می دهد، که با تجزیه و تحلیل منشأ ثبت شده و تنظیم سریع مدل های شبکه عصبی در وضعیت بهینه، از اجرای بیهوده گردش کار صرفه جویی می کند.
حجم کلی داده در آزمایش 9.5 ترابایت است (شامل داده های اصلی Landsat/CDL و محصولات داده نیمه تمام). پیش از این برای محققان این امر خسته کننده و چالش برانگیز بود که به صورت دستی فرآیند اجرا بر روی چنین مجموعه داده ای را نظارت کنند. Geoweaver بین سیستم ذخیره سازی فایل و کاربران از طریق ماژول میزبان خود مختصات می کند. این امکان را به کاربران می دهد تا به فایل ها در یک مکان دسترسی داشته باشند و آنها را مدیریت کنند و کاربران را راهنمایی می کند تا بدون گم شدن در دریای فایل های داده، روی الگوریتم ها تمرکز کنند. گردش کار کلان داده را می توان از طریق مرورگر وب نظارت کرد و قابل کنترل تر می شود. Geoweaver از ماژول در حال اجرا انعطافپذیر و ماژول مانیتورینگ بیدرنگ خود استفاده میکند تا به ما کمک کند از حالت آماده به کار مداوم و ترس از نشت حافظه GPU یا از دست دادن نقطه عطف بیشبرازش/کمتنظیم خلاص شویم. در آینده قابل پیشبینی، خدمات محاسباتی با کارایی بالا (مثلاً
7. بحث
دلایل متعددی وجود دارد که Geoweaver یک سیستم مدیریت گردش کار علمی توانا و جامع است. Geoweaver چندین مشکل کلیدی را در چشم انداز فعلی تحقیقات علمی هوش مصنوعی هدف قرار داده است. دانشمندان اغلب سوالات زیر را می پرسند: کد من کجاست؟ داده های من کجاست؟ چگونه می توانم نتایج تاریخی خود را پیدا کنم؟ چگونه چندین سرور، HPC و لپ تاپ را به طور همزمان مدیریت کنم؟ چگونه می توانم آزمایش خود را به یک گردش کار خودکار پیوند دهم؟ گردش کار هوش مصنوعی پیچیده و عظیم است. این شامل بسیاری از کتابخانهها، ابزارها، سیستمها، پلتفرمها، ماشینها یا حتی ابر رایانهها میشود. سیستم های گردش کار موجود در مدیریت چندین زبان برنامه نویسی، چندین سرور و مجموعه داده های متعدد کوتاهی می کنند. در اکثر سناریوها، گروه کوچکی از دانشمندان انتخاب های بسیار محدودی در ابزارهای مدیریت تحقیق دارند.
- (1)
-
گردش کار ترکیبی : Geoweaver می تواند به متخصصان هوش مصنوعی کمک کند تا هم از منابع عمومی و هم از منابع خصوصی استفاده کنند و آنها را با هم در یک جریان کاری ترکیب کنند. آمادهسازی مجموعه دادههای آموزشی به مجموعههای داده قدیمی و برنامههایی نیاز دارد که آنها را به قالب آماده هوش مصنوعی تبدیل میکنند. با این حال، امکانات آموزش مدل AI بیشتر در حوزه عمومی است، مانند نمونههای GPU آمازون EC2. اتصال پردازش داده های قدیمی با آموزش مدل هوش مصنوعی با استفاده از WfMS دیگر دشوار است. Geoweaver از ماژول میزبان و اتصال محاسباتی پویا استفاده می کند تا به دانشمندان اجازه دهد فرآیندهای اجرا شده بر روی سرورهای خصوصی و پلتفرم های عمومی را در یک گردش کار ترکیب کنند و مدیریت گردش کار ترکیبی را در یک مکان فعال کنند.
- (2)
-
دسترسی کامل به فایلهای راه دور : همانطور که در بالا ذکر شد، بیشتر فایلهای مرتبط با جریان کاری هوش مصنوعی در سرورهای راه دور/ ماشینهای مجازی ذخیره میشوند. کاربران همیشه از ابزارهایی که به آنها اجازه می دهد کنترل کامل و راحت بر روی فایل های واقعی داشته باشند، از جمله ایجاد فایل های جدید، مرور ساختار پوشه فایل ها، دانلود فایل ها و ویرایش فایل ها در محل، قدردانی می کنند. Geoweaver نه تنها یک سیستم گردش کار، بلکه یک سیستم مدیریت فایل از چندین سرور راه دور است.
- (3)
-
جریان داده های پنهان : گردش کار تجاری مانند BPEL معمولاً محتوای گردش کار را به دو بخش تقسیم می کند: جریان کنترل و جریان داده. اولی توالی فرآیندهای درگیر را تعریف می کند و دومی انتقال داده را بین متغیرهای ورودی و خروجی تعریف می کند. هنگامی که داده ها بزرگ هستند و تعداد فایل ها پویا است، حفظ جریان داده ها توجه زیادی را می طلبد. Geoweaver میتواند محیطی آشنا برای افراد ایجاد کند تا بدون نگرانی در مورد جریان داده، گردش کار را ایجاد کنند. هر فرآیند مستقل است و جریان داده توسط منطق محتوای فرآیند مراقبت می شود.
- (4)
-
جداسازی کد-ماشین : یکی دیگر از ویژگی های Geoweaver این است که کد را از ماشین اجرا جدا می کند. با انجام این کار چند مزیت وجود دارد. کد در یک مکان مدیریت می شود و کنترل نسخه برای یکپارچگی بهتر کد بسیار ساده تر خواهد بود. Geoweaver به صورت پویا کد را در یک فایل روی سرورهای راه دور می نویسد و کد را اجرا می کند. پس از پایان فرآیند، Geoweaver کد را از سرورهای راه دور حذف می کند. با توجه به این واقعیت که سرورهای GPU معمولاً توسط چندین کاربر به اشتراک گذاشته می شوند، این مکانیسم بهتر از حریم خصوصی کد از سایر کاربران در همان دستگاه محافظت می کند.
- (5)
-
منشأ فرآیند گرا : جدا از معماری منشأ داده محور، Geoweaver از فرآیند به عنوان اشیاء اصلی برای ثبت منشأ استفاده می کند. اطلاعات ثبت شده نیز متفاوت است. در Geoweaver، ورودی ها محتوای کد اجرا شده و خروجی ها گزارش اجرا هستند. به جای ذخیره محصولات داده نیمه تکمیل شده، منشأ فرآیند گرا می تواند فضای دیسک را ذخیره کند و اطلاعات تاریخچه محصولات داده نهایی را غنی کند. منشأ فرآیند گرا می تواند مانع از بازتولید گردش کار شود که در غیر این صورت توسط تغییرات در کد ایجاد می شود.
8. نتیجه گیری
این مقاله یک چارچوب گردش کار علمی را برای رسیدگی به این مسائل مربوط به گردش کار هوش مصنوعی پیشنهاد میکند. یک سیستم نمونه اولیه به نام Geoweaver برای اعتبار سنجی پیاده سازی شده است. ما سیستم را با استفاده از طبقهبندی پوشش زمین کشاورزی مبتنی بر هوش مصنوعی آزمایش کردیم. این وظیفه شامل چندین سرور توزیعشده، پردازندههای گرافیکی، سه زبان برنامهنویسی، دهها ابزار فرمان، سیستم اطلاعات جغرافیایی، جعبه ابزار یادگیری عمیق و چندین منبع داده عمومی است. Geoweaver همه این موجودیت ها را در یک مکان قابل مدیریت می کند و منشأ هر اجرا را در یک پایگاه داده جداگانه برای بررسی آینده ثبت می کند. این مطالعه ثابت میکند که چارچوب پیشنهادی میتواند تسهیلات زیادی را برای جامعه هوش مصنوعی ایجاد کند، اجرا کند، نظارت کند، به اشتراک بگذارد، ردیابی کند، اصلاح کند، تکرار کند و از گردشهای کاری هوش مصنوعی خود در یک محیط تک ماشینی یا محیط توزیعشده استفاده کند.
منابع
- LeCun، Y.; بنژیو، ی. هینتون، جی. یادگیری عمیق. طبیعت 2015 ، 521 ، 436-444. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بنژیو، ی. یادگیری عمیق بازنمایی ها: چشم به راه. در مجموعه مقالات کنفرانس بین المللی آماری زبان و پردازش گفتار، لیوبلیانا، اسلوونی، 14 تا 16 اکتبر 2019. [ Google Scholar ]
- Sun, Z. برخی از مبانی یادگیری عمیق در کشاورزی. 2019 . [ Google Scholar ] [ CrossRef ]
- Sun، Z. شناسایی خودکار محصولات از Landsat توسط U-Net، Keras و Tensorflow. در دسترس آنلاین: https://medium.com/artificial-intelligence-in-geoscience/automatically-recognize-crops-from-landsat-by-u-net-keras-and-tensorflow-7c5f4f666231 (در 26 ژانویه 2020 قابل دسترسی است).
- سان، ز. دی، ال. Fang, H. استفاده از شبکه عصبی بازگشتی حافظه کوتاه مدت در طبقه بندی پوشش زمین در سری های زمانی لایه داده Landsat و Cropland. بین المللی J. Remote Sens. 2018 ، 40 ، 593-614. [ Google Scholar ] [ CrossRef ]
- یاسین، ز.ام. الشافعی، ع. جعفر، ع. عفان، HA; مدلهای مبتنی بر هوش مصنوعی Sayl، KN برای پیشبینی جریان: 2000-2015. جی هیدرول. 2015 ، 530 ، 829-844. [ Google Scholar ] [ CrossRef ]
- رایششتاین، ام. کمپز-والز، جی. استیونز، بی. یونگ، ام. دنزلر، جی. Carvalhais، N. یادگیری عمیق و درک فرآیند برای علم سیستم زمین مبتنی بر داده. Nature 2019 , 566 , 195. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- قربانزاده، ا. بلاشکه، تی. غلام نیا، ک. مینا، اس آر. تاید، دی. Aryal, J. ارزیابی روشهای مختلف یادگیری ماشین و شبکههای عصبی کانولوشنال یادگیری عمیق برای تشخیص زمین لغزش. Remote Sens. 2019 , 11 , 196. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هیرمن، PD; خازنی، ن. طبقه بندی داده های سنجش از راه دور چندطیفی با استفاده از شبکه عصبی پس انتشار. Geosci. Remote Sens. 1992 ، 30 ، 81-88. [ Google Scholar ] [ CrossRef ]
- شبکه های عصبی و زبان بریت، A. Kohonen. Brain Lang. 1999 ، 70 ، 86-94. [ Google Scholar ] [ CrossRef ]
- Pao, Y. شناسایی الگوی تطبیقی و شبکه های عصبی ; Addison-Wesley: بوستون، MA، ایالات متحده آمریکا، 1989. [ Google Scholar ]
- Gurney, K. مقدمه ای بر شبکه های عصبی . CRC Press: Boca Raton، FL، USA، 2014. [ Google Scholar ]
- فرانکیش، ک. رمزی، WM کتابچه راهنمای هوش مصنوعی کمبریج . انتشارات دانشگاه کمبریج: کمبریج، بریتانیا، 2014. [ Google Scholar ]
- گریوز، ا. محمد، ع.-ر. هینتون، جی. تشخیص گفتار با شبکه های عصبی عود کننده عمیق. در مجموعه مقالات کنفرانس بین المللی IEEE 2013 در مورد آکوستیک، پردازش گفتار و سیگنال (ICASSP)، ونکوور، BC، کانادا، 26 تا 31 مه 2013. [ Google Scholar ]
- سالاب، AE; عبدو، م. پروت، ای. Yogamani، S. چارچوب یادگیری تقویتی عمیق برای رانندگی خودمختار. الکترون. تصویربرداری 2017 ، 2017 ، 70–76. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Kök، İ. شیمشک، MU; Özdemir، S. یک مدل یادگیری عمیق برای پیش بینی کیفیت هوا در شهرهای هوشمند. در مجموعه مقالات کنفرانس بینالمللی IEEE 2017 درباره دادههای بزرگ (Big Data)، بوستون، MA، ایالات متحده آمریکا، 11–14 دسامبر 2017. [ Google Scholar ]
- آشپز، دی جی خانه شما چقدر هوشمند است؟ Science 2012 ، 335 ، 1579-1581. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وولودیموس، ا. دولامیس، ن. دولامیس، ا. Protopapadakis، E. یادگیری عمیق برای بینایی کامپیوتر: بررسی مختصر. محاسبه کنید. هوشمند نوروسک. 2018 , 2018 , 7068349. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- نجف آبادی، م.م. ویلانوستره، اف. خوش گفتار، TM; سلیا، ن. والد، آر. Muharemagic، E. کاربردها و چالش های یادگیری عمیق در تجزیه و تحلیل داده های بزرگ. J. Big Data 2015 , 2 , 1. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- دیلک، اس. چاکیر، اچ. آیدین، ام. کاربرد تکنیک های هوش مصنوعی برای مبارزه با جرایم سایبری: بررسی. arXiv 2015 ، arXiv:1502.03552. [ Google Scholar ] [ CrossRef ]
- Tsipis، K. 3Q: یادگیری ماشین و مدلسازی آب و هوا. موجود به صورت آنلاین: https://news.mit.edu/2019/mit-3q-paul-o-gorman-machine-learning-for-climate-modeling-0213 (در 7 ژوئن 2019 قابل دسترسی است).
- ستار، ع.م. ارطغرول، Ö.F. قره باغی، ب. مک بین، EA؛ Cao, J. مدل ماشین یادگیری افراطی برای مدیریت شبکه آب. محاسبات عصبی Appl. 2019 ، 31 ، 157-169. [ Google Scholar ] [ CrossRef ]
- برگن، کی جی. جانسون، PA; مارتن، وی. Beroza، GC یادگیری ماشینی برای اکتشاف مبتنی بر داده در علوم زمین جامد. Science 2019 , 363 , eaau0323. [ Google Scholar ] [ CrossRef ]
- واتسون، جی ال. تلسکا، دی. رید، م. Pfister، GG; مدلهای یادگیری ماشینی Jerrett, M. بهطور دقیق قرار گرفتن در معرض ازن را در طول رویدادهای آتشسوزی پیشبینی میکنند. محیط زیست آلودگی 2019 ، 254 ، 112792. [ Google Scholar ] [ CrossRef ]
- صیاد، یو. مصنف، ح. Al Moatassime, H. مدلسازی پیشبینی آتشسوزیها: یک مجموعه داده جدید و رویکرد یادگیری ماشین. آتش نشانی J. 2019 ، 104 ، 130-146. [ Google Scholar ] [ CrossRef ]
- Spina، R. داده های بزرگ و تجزیه و تحلیل هوش مصنوعی در علوم زمین: وعده ها و پتانسیل ها. GSA امروز 2019 ، 29 ، 42–43. [ Google Scholar ] [ CrossRef ]
- گلوروت، ایکس. Bengio، Y. درک دشواری آموزش شبکه های عصبی پیشخور عمیق. در مجموعه مقالات سیزدهمین کنفرانس بین المللی هوش مصنوعی و آمار، ساردینیا، ایتالیا، 13 تا 15 مه 2010. [ Google Scholar ]
- LeCun، Y. LeNet-5، شبکه های عصبی کانولوشن. در دسترس آنلاین: https://yann.lecun.com/exdb/lenet (در 21 فوریه 2020 قابل دسترسی است).
- لی، ایکس. پنگ، ال. هو، ی. شائو، جی. چی، تی. معماری یادگیری عمیق برای پیش بینی کیفیت هوا. محیط زیست علمی آلودگی Res. 2016 ، 23 ، 22408–22417. [ Google Scholar ] [ CrossRef ]
- راسپ، اس. پریچارد، ام اس; Gentine، P. یادگیری عمیق برای نشان دادن فرآیندهای زیرشبکه در مدلهای آب و هوایی. Proc. Natl. آکادمی علمی ایالات متحده آمریکا 2018 ، 115 ، 9684–9689. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- سان، ز. دی، ال. هوانگ، اچ. وو، ایکس. تانگ، دی کیو؛ ژانگ، سی. ویرجی، سی. نیش، اچ. یو، ای. Tan, X. CyberConnector: یک سیستم سرویس گرا برای تنظیم خودکار داده های رصد زمین چند منبعی برای تغذیه مدل های علم زمین. علوم زمین آگاه کردن. 2017 ، 11 ، 1-17. [ Google Scholar ] [ CrossRef ]
- سان، ز. دی، ال. نقدی، بی. Gaigalas, J. زیرساخت سایبری پیشرفته برای مقایسه و اعتبارسنجی مدلهای آب و هوایی. محیط زیست مدل. نرم افزار 2019 ، 123 ، 104559. [ Google Scholar ] [ CrossRef ]
- سان، ز. Di, L. CyberConnector COVALI: امکان مقایسه و اعتبارسنجی مدلهای علم زمین. در مجموعه مقالات خلاصههای نشست پاییز AGU، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 31 ژوئیه 2019. [ Google Scholar ]
- O’Leary، DE هوش مصنوعی و داده های بزرگ. IEEE Intell. سیستم 2013 ، 28 ، 96-99. [ Google Scholar ] [ CrossRef ]
- لی، جی. کائو، H.-A. یانگ، اس. نوآوری خدمات و تجزیه و تحلیل هوشمند برای صنعت 4.0 و محیط کلان داده. Procedia Cirp 2014 ، 16 ، 3-8. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ویکیپدیا. اطلاعات بزرگ. در دسترس آنلاین: https://en.wikipedia.org/wiki/Big_data (در 21 سپتامبر 2014 قابل دسترسی است).
- مانیکا، جی. داده های بزرگ: مرز بعدی برای نوآوری، رقابت و بهره وری. در دسترس آنلاین: https://www.mckinsey.com/Insights/MGI/Research/Technology_and_Innovation/Big_data_The_next_frontier_for_innovation (در 26 ژانویه 2020 قابل دسترسی است).
- ویس، آر. زگورسکی، ال.-جی. دولت اوباما از ابتکار «داده های بزرگ» رونمایی کرد: 200 میلیون دلار سرمایه گذاری جدید در تحقیق و توسعه را اعلام کرد . خاموش علمی تکنولوژی مدیر سیاست خاموش پرس 2012 . [ Google Scholar ]
- یو، پی. جیانگ، L. BigGIS: چگونه داده های بزرگ می توانند GIS نسل بعدی را شکل دهند. در مجموعه مقالات سومین کنفرانس بینالمللی ژئوانفورماتیک 2014، پکن، چین، 11 تا 14 اوت 2014. صص 1-6. [ Google Scholar ]
- Borthakur, D. سیستم فایل توزیع شده هادوپ: معماری و طراحی. Hadoop Proj. وب سایت 2007 ، 11 ، 21. [ Google Scholar ]
- زهاریا، م. Xin، RS; وندل، پی. داس، تی. آرمبراست، ام. دیو، ا. منگ، ایکس. روزن، جی. ونکاتارامان، س. فرانکلین، ام جی آپاچی اسپارک: موتور یکپارچه برای پردازش کلان داده. اشتراک. ACM 2016 ، 59 ، 56-65. [ Google Scholar ] [ CrossRef ]
- George, L. HBase: راهنمای قطعی: دسترسی تصادفی به دادههای اندازه سیاره شما . O’Reilly Media, Inc.: Sevastopol, CA, USA, 2011. [ Google Scholar ]
- سوسو، ا. Sarma, JS; جین، ن. شائو، ز. چاکا، پ. آنتونی، اس. لیو، اچ. ویکوف، پی. Murthy, R. Hive: یک راه حل انبارداری بر روی یک چارچوب کاهش نقشه. Proc. VLDB Enddow. 2009 ، 2 ، 1626-1629. [ Google Scholar ] [ CrossRef ]
- Chodorow, K. MongoDB: The Definitive Guide: Powerful and Scalable Data Storage ; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2013. [ Google Scholar ]
- گولیک، ن. هنچر، م. دیکسون، ام. ایلیوشچنکو، اس. تاو، دی. Moore, R. Google Earth Engine: تجزیه و تحلیل جغرافیایی در مقیاس سیاره ای برای همه. سنسور از راه دور محیط. 2017 ، 202 ، 18-27. [ Google Scholar ] [ CrossRef ]
- واریا، ج. متیو، اس. مروری بر خدمات وب آمازون. در دسترس آنلاین: https://cabibbo.dia.uniroma3.it/asw-2014-2015/altrui/AWS_Overview.pdf (در 26 ژانویه 2020 قابل دسترسی است).
- کلایور، تی. راگان-کلی، بی. پرز، اف. گرنجر، BE; بوسونیر، ام. فردریک، جی. کلی، ک. همریک، جی بی. گروت، ج. Corlay, S. Jupyter Notebooks-فرمت انتشاراتی برای گردش کار محاسباتی قابل تکرار. در مجموعه مقالات بیستمین کنفرانس بین المللی انتشارات الکترونیکی، گوتینگن، آلمان، ژوئن 2016; صص 87-90. [ Google Scholar ]
- هاشم، IAT; یعقوب، ط. Anuar، NB; مختار، س. گانی، ع. Khan, SU ظهور “داده های بزرگ” در رایانش ابری: بررسی و باز کردن مسائل تحقیقاتی. Inf. سیستم 2015 ، 47 ، 98-115. [ Google Scholar ] [ CrossRef ]
- Ranjan, R. جریان پردازش کلان داده در ابرهای مرکز داده. IEEE Cloud Comput. 2014 ، 1 ، 78-83. [ Google Scholar ] [ CrossRef ]
- ممکن است.؛ وو، اچ. وانگ، ال. هوانگ، بی. رنجان، ر. زومایا، ا. جی، دبلیو. محاسبات داده های بزرگ سنجش از دور: چالش ها و فرصت ها. ژنرال آینده. محاسبه کنید. سیستم 2015 ، 51 ، 47-60. [ Google Scholar ] [ CrossRef ]
- راتور، MMU؛ پل، آ. احمد، ع. چن، BW; هوانگ، بی. Ji, W. معماری تحلیلی کلان داده در زمان واقعی برای کاربرد سنجش از دور. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2015 ، 8 ، 4610–4621. [ Google Scholar ] [ CrossRef ]
- سان، ز. یو، پی. لو، ایکس. ژای، ایکس. Hu, L. یک رویکرد مبتنی بر هستی شناسی وظیفه برای ژئوپردازش زنده در یک محیط خدمات گرا. ترانس. GIS 2012 ، 16 ، 867-884. [ Google Scholar ] [ CrossRef ]
- آیوف، اس. Szegedy, C. Batch normalization: تسریع آموزش عمیق شبکه با کاهش تغییر متغیر داخلی. arXiv 2015 ، arXiv:1502.03167. [ Google Scholar ]
- اشنایدر، ام. مدیریت عدم قطعیت برای پایگاه داده های داده های فضایی: انواع داده های فضایی فازی. در مجموعه مقالات سمپوزیوم بین المللی پایگاه های داده فضایی، هنگ کنگ، چین، 26-28 اوت 2013. [ Google Scholar ]
- Camponovo، ME; Freundschuh، SM ارزیابی عدم قطعیت در VGI برای پاسخ اضطراری. کارتوگر. Geogr. Inf. علمی 2014 ، 41 ، 440-455. [ Google Scholar ] [ CrossRef ]
- وتساوایی، ر.ر. گانگولی، ا. چاندولا، وی. استفانیدیس، ا. کلاسکی، اس. Shekhar, S. داده کاوی فضایی و زمانی در عصر داده های مکانی بزرگ: الگوریتم ها و کاربردها. در مجموعه مقالات اولین کارگاه بین المللی ACM SIGSPATIAL در مورد تجزیه و تحلیل برای داده های جغرافیایی بزرگ، ردوندو بیچ، کالیفرنیا، ایالات متحده آمریکا، 6 نوامبر 2012. [ Google Scholar ]
- کوسو، آی. بورگلت، سی. هولرمایر، ای. مجموعههای Kruse, R. Fuzzy در تجزیه و تحلیل دادهها: از مبانی آماری تا یادگیری ماشین. محاسبات IEEE. هوشمند Mag. 2019 ، 14 ، 31-44. [ Google Scholar ] [ CrossRef ]
- سان، ز. دی، ال. چن، آ. یو، پی. Gong, J. استفاده از گردشهای کاری مکانی برای پشتیبانی از تشخیص خودکار ویژگیهای پیچیده جغرافیایی از تصاویر با وضوح بالا. در مجموعه مقالات دومین کنفرانس بین المللی 2013 در مورد آگرو-ژئوانفورماتیک (Agro-Geoinformatics)، Fairfax، VA، ایالات متحده آمریکا، 12-16 اوت 2013. [ Google Scholar ]
- سان، ز. Yue, P. استفاده از وب 2.0 و خدمات پردازش جغرافیایی برای پشتیبانی از جریان های کاری زمین شناسی. در مجموعه مقالات 2010 هجدهمین کنفرانس بین المللی ژئوانفورماتیک، پکن، چین، 18 تا 20 ژوئن 2010. [ Google Scholar ]
- سان، ز. یو، پی. Di, L. GeoPWTManager: یک سیستم ژئوپردازش وب وظیفه گرا. محاسبه کنید. Geosci. 2012 ، 47 ، 34-45. [ Google Scholar ] [ CrossRef ]
- کوهن بولاکیا، س. بلحجامه، ک. کولین، او. شوپارد، جی. فرویدووکس، سی. گیگنارد، آ. هینسن، ک. لارمانده، پ. لو براس، ی. Lemoine, F. گردش کار علمی برای تکرارپذیری محاسباتی در علوم زیستی: وضعیت، چالش ها و فرصت ها. ژنرال آینده. محاسبه کنید. سیستم 2017 ، 75 ، 284-298. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تیلور، آی. دیلمن، ای. Gannon, D. Workflows for E-Science: Scientific Workflows for Grids ; Springer: برلین/هایدلبرگ، آلمان، 2006. [ Google Scholar ]
- آلن، DW آشنایی با ArcGIS ModelBuilder ; Esri Press: Redlands، CA، USA، 2011. [ Google Scholar ]
- هلویزا مارتینز، اس. نظارت و کنترل مبتنی بر فناوری گردش کار Tseng، MM برای فرآیندهای تجاری و مدیریت پروژه. بین المللی J. Proj. مدیریت 1996 ، 14 ، 373-378. [ Google Scholar ] [ CrossRef ]
- یو، پی. گونگ، جی. Di, LP تبدیل خودکار از توصیف معنایی به مشخصات نحوی برای زنجیره های خدمات پردازش جغرافیایی. در مجموعه مقالات وب و سیستمهای اطلاعات جغرافیایی بیسیم، ناپل، ایتالیا، 12 تا 13 آوریل 2012. [ Google Scholar ]
- سان، ز. دی، ال. Gaigalas, J. SUIS: ساده کردن استفاده از خدمات وب جغرافیایی در مدلسازی محیطی. محیط زیست مدل. نرم افزار 2019 ، 119 ، 228-241. [ Google Scholar ] [ CrossRef ]
- جوریک، MB; Krizevnik, M. WS-BPEL 2.0 for SOA Composite Applications with Oracle SOA Suite 11g ; Packt Publishing Ltd.: Birmingham, UK, 2010. [ Google Scholar ]
- Raschka، S. Python Machine Learning ; Packt Publishing Ltd.: Birmingham, UK, 2015. [ Google Scholar ]
- سان، ز. پنگ، سی. دنگ، م. چن، آ. یو، پی. نیش، اچ. Di, L. اتوماسیون تولید شاخص شرایط پوشش گیاهی سفارشی شده و در زمان واقعی از طریق گردش های کاری ژئوپردازش مبتنی بر زیرساخت سایبری. Sel. بالا. Appl. زمین Obs. Remote Sens. IEEE J. 2014 , 7 , 4512–4522. [ Google Scholar ] [ CrossRef ]
- WfMC، WPDIX Process Definition Language (XPDL)، استانداردهای WfMC . WFMC: واشنگتن، دی سی، ایالات متحده آمریکا، 2001. [ Google Scholar ]
- مورو، ال. Missier، P. بلحجامه، ک. بفار، آر. چنی، جی. کوپنز، اس. کرسول، اس. گیل، ی. گروت، پ. Klyne, G. Prov-dm: مدل داده های prov. بازیابی شده در جولای 2013 ، 30 ، W3C. [ Google Scholar ]
- گوبل، کالیفرنیا؛ بهگات، جی. آلکسیفس، اس. کریکشنک، دی. مایکلیدس، دی. نیومن، دی. بورکوم، م. بکهوفر، اس. روس، ام. Li, P. myExperiment: یک مخزن و شبکه اجتماعی برای به اشتراک گذاری گردش کار بیوانفورماتیک. Nucleic Acids Res. 2010 ، 38 ، W677–W682. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- گوکس، جی. نکروتنکو، آ. Taylor, J. Galaxy: یک رویکرد جامع برای حمایت از تحقیقات محاسباتی قابل دسترسی، تکرارپذیر و شفاف در علوم زیستی. ژنوم بیول. 2010 ، 11 ، R86. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- لوداشر، بی. آلتینتاس، آی. برکلی، سی. هیگینز، دی. جیگر، ای. جونز، ام. لی، EA; تائو، جی. ژائو، ی. مدیریت گردش کار علمی و سیستم کپلر. موافق محاسبه کنید. تمرین کنید. انقضا 2006 ، 18 ، 1039-1065. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- د کاروالهو سیلوا، جی. د اولیویرا دانتاس، AB; de Carvalho Junior, FH یک سیستم مدیریت گردش کار علمی برای هماهنگی اجزای موازی در ابری از خدمات پردازش موازی در مقیاس بزرگ. علمی محاسبه کنید. برنامه. 2019 ، 173 ، 95-127. [ Google Scholar ] [ CrossRef ]
- ACM، A. بررسی مصنوعات و نشان دادن. در دسترس آنلاین: https://www.acm.org/publications/policies/artifact-review-badging (در 19 فوریه 2020 قابل دسترسی است).
- Moreau, L. مبانی منشأ در وب . اکنون ناشران: هانوفر، MA، ایالات متحده آمریکا، 2010. [ Google Scholar ]
- McCaney، K. یادگیری ماشین در حال ایجاد یک بحران در علم است. در دسترس آنلاین: https://www.governmentciomedia.com/machine-learning-creating-crisis-science (در 26 ژانویه 2020 قابل دسترسی است).
- آکادمی های ملی علوم، مهندسی و پزشکی. تکرارپذیری و تکرارپذیری در علم ; انتشارات آکادمی ملی: واشنگتن، دی سی، ایالات متحده آمریکا، 2019. [ Google Scholar ] [ CrossRef ]
- دی، ال. یو، پی. Sun, Z. کشف ویژگی های پیچیده با پشتیبانی هستی شناسی در یک محیط وب سرویس. در مجموعه مقالات سمپوزیوم بین المللی IEEE 2012، علوم زمین و سنجش از دور (IGARSS)، مونیخ، آلمان، 22 تا 27 ژوئیه 2012. صص 2887-2890. [ Google Scholar ]
- میلر، دیدی شورش هوش مصنوعی پزشکی: آنچه پزشکان برای تمرین با ماشینهای هوشمند باید درباره دادهها بدانند. رقم NPJ. پزشکی 2019 ، 2 ، 1-5. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تولیس، جی. Cothren، JD; لنتر، DP; شی، ایکس. لیمپ، WF; لینک، RF؛ جوان، اس جی. Alsumaiti، T. Geoprocessing، Workflows, and Provenance. در کتابچه راهنمای خصوصیات، طبقه بندی و دقت داده های سنجش از دور . ثنکبیل، ص.، ویرایش. CRC Press: Boca Raton، FL، USA، 2015; ص 401-421. [ Google Scholar ]
- تولیس، جی. کورکوران، ک. هام، ر. کار، بی. ویلیامسون، ام. مفاهیم چند کاربر و تکرارپذیری گردش کار در برنامه های کاربردی sUAS. در کاربردهای سیستم های هواپیمای بدون سرنشین کوچک ; شارما، جی بی، اد. CRC Press: Boca Raton، FL، ایالات متحده آمریکا، 2019. [ Google Scholar ]
- یو، پی. سان، ز. گونگ، جی. دی، ال. Lu, X. یک چارچوب منشأ برای گردشهای کاری پردازش جغرافیایی وب. در مجموعه مقالات سمپوزیوم بین المللی زمین شناسی و سنجش از دور IEEE 2011 (IGARSS11)، ونکوور، BC، کانادا، 24-29 ژوئیه 2011. صص 3811–3814. [ Google Scholar ]
- گودچایلد، م. فاثرینگهام، اس. لی، دبلیو. Kedron، P. تکرارپذیری و تکرارپذیری در تحقیقات زمین فضایی: کارگاه SPARC. در دسترس آنلاین: https://sgsup.asu.edu/sparc/RRWorkshop (در 26 ژانویه 2020 قابل دسترسی است).
- ناصری، م. لودویگ، SA ارزیابی اعتماد گردش کار با استفاده از مدلسازی مارکوف پنهان و دادههای منشأ. در منشأ داده و مدیریت داده در علوم الکترونیک ; Springer: برلین/هایدلبرگ، آلمان، 2013; صص 35-58. [ Google Scholar ]
- Roemerman, S. Four Reasons Data Provenance برای Analytics و AI حیاتی است. در دسترس آنلاین: https://www.forbes.com/sites/forbestechcouncil/2019/05/22/four-reasons-data-provenance-is-vital-for-analytics-and-ai/ (دسترسی در 23 دسامبر 2019) .
- سان، ز. دی، ال. تانگ، دی. Burgess, AB Advanced Geospatial Cyber Infrastructure برای پوسترهای یادگیری عمیق. در مجموعه مقالات نشست پاییز AGU، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 9 تا 13 دسامبر 2019. [ Google Scholar ]
- کاینو-لورس، اس. لاپین، آ. کارتررو، جی. Kropf, P. بکارگیری پارادایم های کلان داده در یک گردش کار علمی در مقیاس بزرگ: درس های آموخته شده و جهت گیری های آینده. ژنرال آینده. محاسبه کنید. سیستم 2018 . [ Google Scholar ] [ CrossRef ]
- الیور، اچ جی; شین، م. Sanders, O. Cylc: موتور گردش کار برای سیستم های دوچرخه سواری. J. نرم افزار منبع باز. 2018 ، 3 ، 737. [ Google Scholar ] [ CrossRef ]
- آرمبراست، ام. فاکس، ا. گریفیث، آر. یوسف، AD; کاتز، آر. کونوینسکی، ا. لی، جی. پترسون، دی. رابکین، ا. Stoica، I. نمایی از محاسبات ابری. اشتراک. ACM 2010 ، 53 ، 50-58. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، ز. دی، ال. هیو، جی. ژانگ، سی. نیش، اچ. یو، پی. جیانگ، ال. تان، ایکس. گوا، ال. Lin, L. GeoFairy: به سوی یک سرویس یک مرحله ای و مبتنی بر مکان برای بازیابی اطلاعات مکانی. محاسبه کنید. محیط زیست سیستم شهری 2017 ، 62 ، 156-167. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تان، ایکس. دی، ال. دنگ، م. هوانگ، اف. بله، X. شا، ز. سان، ز. گونگ، دبلیو. شائو، ی. هوانگ، سی. تجمیع خدمات زمین فضایی مبتنی بر عامل به عنوان یک سرویس در ابر: مطالعه موردی پاسخ سیل. محیط زیست مدل. نرم افزار 2016 ، 84 ، 210-225. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- بهاردواج، س. جین، ال. جین، اس. محاسبات ابری: مطالعه زیرساخت به عنوان یک سرویس (IAAS). بین المللی J. Eng. Inf. تکنولوژی 2010 ، 2 ، 60-63. [ Google Scholar ]
- رید، دی. Dongarra, J. محاسبات Exascale و کلان داده. اشتراک. ACM 2015 ، 58 ، 56-68. [ Google Scholar ] [ CrossRef ]
- مشارکت کنندگان، W. Big Data. در دسترس به صورت آنلاین: https://en.wikipedia.org/w/index.php?title=Big_data&oldid=925811014 (در 14 نوامبر 2019 قابل دسترسی است).
- آرنت، AA; هامان، ج. راکلین، ام. تان، ا. Fatland، DR; جوگین، جی. گاتمن، ED; ستیوان، ال. هندرسون، ST Pangeo: ابزارهای جامعه برای تجزیه و تحلیل داده های علوم زمین در ابر. در مجموعه مقالات خلاصههای نشست پاییز AGU، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 31 ژوئیه 2019. [ Google Scholar ]
- کتکار، ن. مقدمه ای بر پایتورچ. در یادگیری عمیق با پایتون ؛ Springer: برلین/هایدلبرگ، آلمان، 2017; صص 195-208. [ Google Scholar ]
- آبادی، م. برهم، پ. چن، جی. چن، ز. دیویس، ا. دین، جی. دوین، ام. قماوت، س. ایروینگ، جی. ایزارد، ام. تنسورفلو: سیستمی برای یادگیری ماشینی در مقیاس بزرگ. در مجموعه مقالات OSDI، ساوانا، GA، ایالات متحده آمریکا، 2-4 نوامبر 2016. ص 265-283. [ Google Scholar ]
- سان، ز. Di, L. Geoweaver: یک سیستم نمونه اولیه مبتنی بر وب برای مدیریت گردشهای کاری ترکیبی جغرافیایی شبکههای عمیق توزیعشده در مقیاس بزرگ. 2019 . [ Google Scholar ] [ CrossRef ]
- سان، ز. دی، ال. نیش، اچ. Burgess, AB; سینگ، ن. زیرساخت سایبری یادگیری عمیق برای تقسیم بندی معنایی محصول. در مجموعه مقالات AGU Fall Meetin، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 31 ژوئیه 2019. [ Google Scholar ]
- سان، ز. نیش، اچ. دی، ال. یو، پی. تان، ایکس. Bai, Y. توسعه یک سیستم مبتنی بر وب برای طبقه بندی نظارت شده تصاویر سنجش از دور. GeoInformatica 2016 ، 20 ، 629-649. [ Google Scholar ] [ CrossRef ]
- سان، ز. نیش، اچ. دی، ال. Yue, P. تحقق طبقه بندی خودکار بدون پارامتر تصاویر سنجش از دور با استفاده از مهندسی هستی شناسی و تکنیک های زیرساخت سایبری. محاسبه کنید. Geosci. 2016 ، 94 ، 56-67. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، ز. نیش، اچ. دنگ، م. چن، آ. یو، پی. Di, L. Regular Shape Similarity Index: یک شاخص جدید برای استخراج دقیق اجسام منظم از تصاویر سنجش از دور. Geosci. Remote Sens. 2015 , 53 , 3737–3748. [ Google Scholar ] [ CrossRef ]
- شما، ام سی. سان، ز. دی، ال. Guo, Z. یک روش نیمه خودکار مبتنی بر وب برای حاشیه نویسی معنایی دبیرستان ها در تصاویر سنجش از دور. در مجموعه مقالات سومین کنفرانس بین المللی آگروژئوانفورماتیک (آگروژئوانفورماتیک 2014)، پکن، چین، 11 تا 14 اوت 2014. صص 1-4. [ Google Scholar ]
- سان، ج. دی، ال. سان، ز. شن، ی. Lai, Z. پیشبینی عملکرد سویا در سطح شهرستان با استفاده از مدل عمیق CNN-LSTM. Sensors 2019 , 19 , 4363. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- سان، ز. دی، ال. نیش، اچ. گوا، ال. یو، ای. تانگ، جی. ژائو، اچ. گیگالاس، جی. ژانگ، سی. Lin, L. زیرساخت سایبری پیشرفته برای پایش خشکسالی کشاورزی. در مجموعه مقالات هشتمین کنفرانس بین المللی 2019 در مورد آگرو-ژئوانفورماتیک (آگرو-ژئوانفورماتیک)، استانبول، ترکیه، 16 تا 19 ژوئیه 2019؛ صص 1-5. [ Google Scholar ]
- هان، دبلیو. یانگ، ز. دی، ال. مولر، R. CropScape: یک برنامه کاربردی مبتنی بر وب برای کاوش و انتشار محصولات دادههای زمینهای زراعی جغرافیایی ایالات متحده برای پشتیبانی تصمیم. محاسبه کنید. الکترون. کشاورزی 2012 ، 84 ، 111-123. [ Google Scholar ] [ CrossRef ]
- هوکرایتر، اس. Schmidhuber, J. حافظه کوتاه مدت طولانی. محاسبات عصبی 1997 ، 9 ، 1735-1780. [ Google Scholar ] [ CrossRef ]
- ژانگ، سی. دی، ال. سان، ز. لین، ال. یوجین، جی. گایگالاس، جی. بررسی خدمات پردازش وب مبتنی بر ابر: مطالعه موردی در مورد اجرای CMAQ به عنوان یک سرویس. محیط زیست مدل. نرم افزار 2019 ، 113 ، 29–41. [ Google Scholar ] [ CrossRef ]
- گیگالاس، جی. دی، ال. Sun، Z. زیرساخت سایبری پیشرفته برای فعال کردن جستجوی مجموعه داده های آب و هوایی بزرگ در THREDDS. ISPRS Int. J. Geo Inf. 2019 ، 8 ، 494. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، سی. دی، ال. سان، ز. یوجین، جی. هو، ال. لین، ال. تانگ، جی. رحمان، MS یکپارچه سازی سرویس پردازش وب OGC با محیط محاسبات ابری برای داده های رصد زمین. در مجموعه مقالات ششمین کنفرانس بین المللی 2017 در زمینه آگرو-ژئوانفورماتیک، فیرفکس، VA، ایالات متحده آمریکا، 7 تا 10 اوت 2017; صص 1-4. [ Google Scholar ]
- تان، ایکس. گوا، اس. دی، ال. دنگ، م. هوانگ، اف. بله، X. سان، ز. گونگ، دبلیو. شا، ز. Pan, S. سرویس جغرافیایی مبتنی بر عامل موازی به عنوان سرویس (P-AaaS) در ابر. Remote Sens. 2017 , 9 , 382. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- روی، DP; ولدر، ام. لاولند، تی. Woodcock، C.; آلن، آر. اندرسون، ام. هلدر، دی. آیرونز، جی. جانسون، دی. کندی، R. Landsat-8: علم و چشم انداز محصول برای تحقیقات تغییرات جهانی زمینی. سنسور از راه دور محیط. 2014 ، 145 ، 154-172. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، ز. دی، ال. ژانگ، سی. نیش، اچ. یو، ای. لین، ال. تان، ایکس. گوا، ال. چن، ز. Yue, P. ایجاد زیرساخت سایبری برای تسهیل نظارت بر خشکسالی کشاورزی. در مجموعه مقالات ششمین کنفرانس بین المللی 2017 در زمینه آگرو-ژئوانفورماتیک، فیرفکس، VA، ایالات متحده آمریکا، 7 تا 10 اوت 2017; صص 1-4. [ Google Scholar ]
- سان، ز. یو، پی. هو، ال. گونگ، جی. ژانگ، ال. Lu, X. GeoPWProv: درهم آمیختن نقشه و فراداده وجهی برای تجسم و ناوبری منشأ. Geosci. Remote Sens. 2013 , 51 , 5131–5136. [ Google Scholar ]
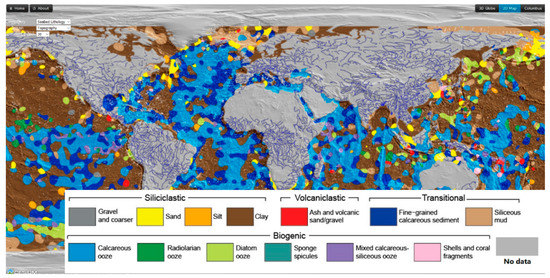
شکل 1. نقشه لیتولوژی بستر دریا توسط ماشین بردار پشتیبان (SVM) (عکس از وب سایت gplates ( https://portal.gplates.org/cesium/?view=seabed )).
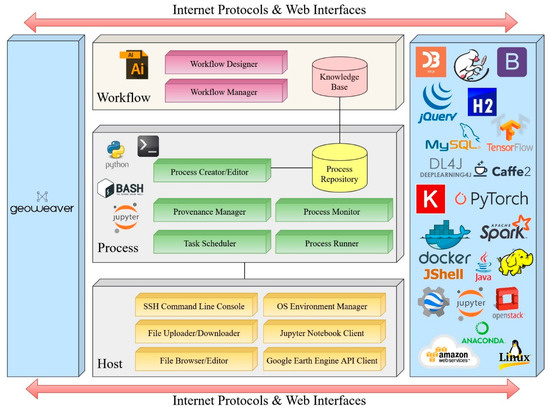
شکل 2. چارچوب مدیریت گردش کار پیشنهادی هوش مصنوعی (AI). API، رابط برنامه نویسی برنامه. (سیستم عامل: سیستم عامل)
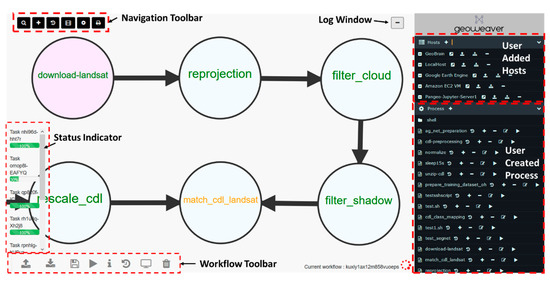
شکل 3. Geoweaver.
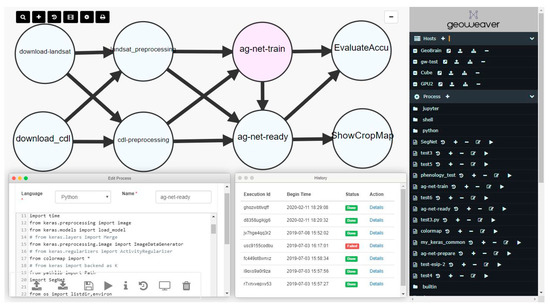
شکل 4. گردش کار GeoWeaver ایجاد شده برای نقشه برداری برش.
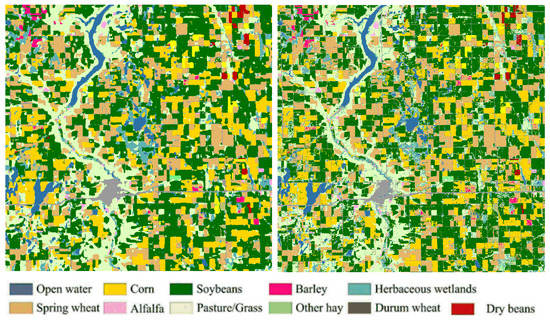
شکل 5. نقشه محصول بازتولید شده توسط GeoWeaver (سمت چپ) در مقایسه با نقشه وزارت کشاورزی ایالات متحده (USDA) (راست).


بدون دیدگاه