1. معرفی
پس از دههها افزایش مداوم عملکرد، سالهای اخیر شاهد کاهش رشد بهرهوری کشاورزی در اروپا بودهایم. علاوه بر این، کاهش تولید جهانی ممکن است تحت سناریوهای اقلیمی خاص مورد انتظار باشد [ 1 ، 2 ]. به طور همزمان، رشد جمعیت جهان، افزایش درآمد سرانه و افزایش تقاضا برای انرژی انتظار می رود تقاضا برای محصولات کشاورزی را افزایش دهد [ 3 ، 4 ]. همراه با افزایش خطرات ناشی از رویدادهای شدید آب و هوایی، این عوامل بر نیاز به نظارت به موقع و دقیق بر تولید محصول تاکید دارند. یک رویکرد رایج، استفاده از مدلهای پویا بیوفیزیکی است که رابط خاک-گیاه-اتمسفر را شبیهسازی میکند [ 5 ]]. این مدلها میتوانند تعاملات محیطی و مدیریت میدانی را شبیهسازی کنند، اما ظرفیت محدودی برای نمایش اطلاعات مکانی در مقیاسهای بزرگتر دارند.
برای رفع این اشکال، می توان تصاویر سنجش از دور و مدل های برش را ادغام کرد. سنجش از دور میتواند اطلاعات مکانی با وضوح بالا در مورد توسعه و سلامت گیاه را وارد فرآیند مدلسازی کند. افزایش دسترسی به داده های رایگان ماهواره ای به کاهش هزینه ها کمک می کند، به ویژه در هنگام جایگزینی اندازه گیری های میدانی سنتی یا کمپین های هوایی. فراوانی دادههای آرشیو Landsat و برنامه کوپرنیک توسط آژانس فضایی اروپا (ESA) ادغام دادههای ماهوارهای در مدلهای محصول را بیشتر تقویت میکند [ 6 ].
به دنبال کار اولیه دلکول و همکاران، تکنیکهای شبیهسازی دادههای مدل محصول را میتوان به سه گروه عمده طبقهبندی کرد: اجبار، کالیبراسیون مجدد، و بهروزرسانی [ 7 ]. اجبار به جایگزینی مقادیر شبیه سازی شده با داده های اندازه گیری شده اشاره دارد. این روش بسیار کارآمد و آسان برای پیاده سازی است، اما دارای معایب متعددی است. اول، به اندازهگیریهایی برای هر مرحله شبیهسازی نیاز دارد (مثلاً مشاهدات روزانه)، که اغلب در دسترس نیستند یا نیاز به درونیابی دارند. هنگام ادغام دادههای سنجش از دور نوری، به ویژه، پوشش ابری مکرر میتواند تعداد مشاهدات موجود را به شدت کاهش دهد، حتی با زمانهای کوتاهتر بازبینی مجدد در صورتهای فلکی مانند Sentinel-2. دوم، اجبار به طور موثر حلقه شبیه سازی را از بین می برد زیرا نتایج میانی را با ورودی های خارجی جایگزین می کند [8 ]. سوم، عدم قطعیت های اندازه گیری را در نظر نمی گیرد و بنابراین مستقیماً خطاها را به مدل منتقل می کند. با توجه به این اشکالات، چند مطالعه اخیر اجبار را در نظر گرفته اند.
روشی که اغلب به کار می رود کالیبراسیون مجدد است که گاهی اوقات به شروع مجدد و پارامترسازی مجدد تقسیم می شود. در اینجا، مقادیر اولیه و پارامترهای مدل محصول به طور مکرر با به حداقل رساندن یک تابع هزینه که فاصله بین متغیرهای حالت شبیهسازی شده و متغیرهای مشاهده شده را اندازهگیری میکند، تغییر میکنند [ 7 ، 9 ]. بنابراین کالیبراسیون مجدد مجموعه جدیدی از پارامترها یا مقادیر اولیه را به دست میآورد، بنابراین امکان شبیهسازی را فراهم میکند که شبیه مشاهدات بهتر باشد. اگرچه این روش اغلب پیش بینی های بازده مبتنی بر مدل را بهبود می بخشد، اما دو نقص دارد. اول، تنظیمات کالیبراسیون مجدد ممکن است غیر واقعی باشد یا ممکن است یک تنظیم پارامتر غیر قابل اعتماد را نشان دهد [ 9 ]]. دوم، کالیبراسیون مجدد میتواند از نظر محاسباتی سخت باشد، زیرا به چندین بار اجرای مجدد مدل نیاز دارد، که مانع از کاربردهای مقیاس بزرگتر میشود.
به روز رسانی، شبیه سازی را در طول شبیه سازی انجام می دهد، تنها زمانی که یک مشاهده در دسترس باشد، تداخل ایجاد می کند. بنابراین حتی با مشاهدات کم و نادر عملکرد خوبی دارد و زمان پردازش را در مقایسه با کالیبراسیون مجدد کاهش می دهد. علاوه بر این، به روز رسانی اجازه می دهد تا عدم قطعیت ها در هر دو شبیه سازی و داده های جذب شده برطرف شود [ 10 ]. با این حال، نیاز به تغییراتی در خود مدل (یعنی کد منبع) دارد و همه مدلها اجازه چنین تداخلی را نمیدهند. متداولترین تکنیکهای بهروزرسانی، فیلتر کالمن (گسترده)، فیلتر ذرات، و فیلتر کالمن مجموعه هستند [ 11 ، 12 ، 13 ، 14 ].
به دنبال تعریف کندی و اوهاگان، عدم قطعیت های مدل ممکن است به پارامتر، پارامتریک، عدم کفایت مدل، تغییرپذیری باقیمانده، مشاهده و عدم قطعیت کد طبقه بندی شوند [ 15 ]. در زمینه مدلسازی بیوفیزیکی، مرتبطترین منابع عدم قطعیتها عبارتند از عدم قطعیت پارامتر (خطاهای مربوط به تنظیمات پارامتر کمتر از حد بهینه)، عدم قطعیت پارامتری یا ورودی (خطاها در دادههای ورودی که شبیهسازی را انجام میدهند، به عنوان مثال، اندازهگیریهای آب و هوای روزانه)، عدم قطعیت کد (تقریبیها). و عدم دقت در اجرای مدل)، و عدم کفایت مدل (به عنوان مثال، تعصب مدل). عدم قطعیت های مربوط به اجراها و نارسایی ها معمولاً در طول توسعه مدل و مطالعات کالیبراسیون و حساسیت بعدی مورد توجه قرار می گیرند [ 16 , 17 ], 18 , 19 ]. با این حال، پارامترها و عدم قطعیت های ورودی، بسیار وابسته به کاربرد و زمینه هستند و باید به صورت جداگانه ارزیابی شوند.
بیشتر رویکردهای به روز رسانی قوی و سریع هستند، اما اغلب فاقد نمایش دقیق چنین عدم قطعیت هایی هستند. فیلتر کالمن، برای مثال، عدم قطعیتها در مدل و اندازهگیری را با یک اسکالر ساده (مثلاً انحراف استاندارد در اندازهگیریهای مکرر) یا یک ماتریس کوواریانس در حالتی که چندین متغیر بهروز میشوند، تقریب میزند [ 20 ]. این رویکرد امکان رسیدگی دقیق به منابع مختلف عدم قطعیت را نمی دهد. تکنیک هایی مانند مجموعه کالمن یا فیلتر ذرات فوق، ممکن است عدم قطعیت در پارامترها و حالت های مدل را به طور تصادفی به حساب آورند.
هم کالیبراسیون مجدد و هم به روز رسانی نیاز به حل یک مسئله بهینه سازی دارد که معمولاً غیرخطی است. برای چنین مسائلی می توان از چندین الگوریتم عددی استفاده کرد. در تکنیک به روز رسانی خود، ما از بهینه سازی ازدحام ذرات (PSO) به دلیل ظرفیت های بهینه سازی جهانی قابل اعتماد و انعطاف پذیری در ورودی ها و توابع هدف استفاده کردیم (به بخش 2.2.3 مراجعه کنید ). PSO کاربردهای مختلفی در سنجش از دور، اغلب در تقسیمبندی و طبقهبندی تصویر [ 21 ، 22 ، 23 ]، و همچنین در کاربردهای کشاورزی دیده است. به عنوان مثال، گوو و همکاران از این الگوریتم برای جفت کردن مدل بازتاب تاج پوشش PROSAIL با مدل کشت گندم بر اساس شاخصهای پوشش گیاهی استفاده کردند [ 24 ].]. دیگران آن را در ترکیب با طبقه بندی کننده ها و الگوریتم های متعدد برای طبقه بندی محصولات [ 25 ] استفاده کرده اند. با این حال، متداول ترین کاربرد، کالیبراسیون (دوباره) مدل های محصول مانند مدل مطالعات جهانی غذا (WOFOST) [ 26 ]، الگوریتم ساده برای تخمین عملکرد (SAFY) [ 27 ]، سیستم پشتیبانی تصمیم برای فناوری کشاورزی است. انتقال (DSSAT) [ 28 ، 29 ]، یا AquaCrop [ 30 ، 31 ].
بنابراین هدف اصلی این مطالعه اطمینان از افزایش انعطافپذیری مدیریت عدم قطعیت بود. تکنیک جدید پیشنهادی به کاربر اجازه میدهد تا عدم قطعیتهای متفاوتی را در فرآیند با حداقل محدودیت در نوع و تعریف آنها لحاظ کند. این تکنیک همچنین باید تا حد زیادی مستقل و خود کالیبره شود تا امکان استفاده مستقیم با حداقل تنظیمات قبلی را فراهم کند، بنابراین امکان جذب سریع مشاهدات سنجش از دور را فراهم می کند.
اگرچه مطالعات زیادی وجود دارد که ورودیهای سنجش از دور را با مدلهای کشت پویا ترکیب میکنند، مقایسه مستقیم دشوار است. ماهیت متنوع رویکردها شامل حسگرهای مختلف، متغیرهای ورودی، انواع محصول، مدلهای محصول، تنظیمات کالیبراسیون، مقیاسهای کاربردی (زمینی تا ملی یا حتی قارهای و جهانی) و مقادیر متفاوتی از دانش قبلی (مانند نمودارهای مطالعه دقیق با اندازهگیریهای منظم)، تشدید مقایسه مستقیم برای نشان دادن پتانسیل روش جدید، بنابراین تصمیم گرفتیم طرحهای بهروزرسانی چندگانه را برای مجموعه دادههای مشابه با تنظیمات مدل و کالیبراسیون یکسان اعمال کنیم. ما نتایج رویکرد جدید را با یک طرح بهروزرسانی ساده (جایگزینی مقادیر در شبیهسازی مدل به طور مستقیم) و همچنین فیلتر کالمن توسعهیافته (EKF) مقایسه کردیم. به عنوان مطالعه موردی،
بقیه مقاله از پنج قسمت تشکیل شده است. بخش 2 منطقه مورد مطالعه و داده های مورد استفاده را تشریح می کند و روش شناسی را معرفی می کند. ابتدا برخی از پیشینه روش شناختی را ارائه می کنیم و سپس توضیحی در مورد تکنیک به روز رسانی ارائه می دهیم. در بخش 3 ، ما نتایج را شرح می دهیم و در بخش 4 آنها را مورد بحث قرار می دهیم . در نهایت، بخش 5 یک نتیجه گیری و چشم انداز کوتاه ارائه می دهد.
2. مواد و روشها
2.1. مجموعه داده ها
2.1.1. منطقه مطالعه
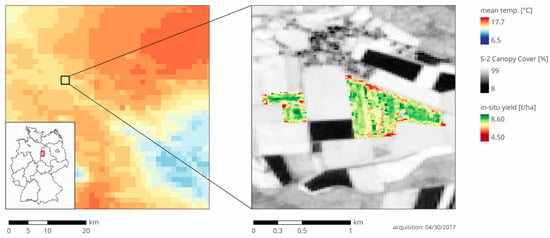
منطقه مورد مطالعه ما در مرکز آلمان در نزدیکی مرز ایالت های Niedersachsen و Sachsen-Anhalt واقع شده است ( شکل 1 را ببینید ). آب و هوا معتدل / اقیانوسی با تابستان های گرم و زمستان های مرطوب است (Cfb در طبقه بندی آب و هوای Koeppen-Geiger) [ 32 ]. این منطقه نسبتا گرم و خشک با میانگین دمای 8.2 درجه سانتی گراد و بارندگی سالانه 538 میلی متر در دوره مرجع آب و هوا 1960-1990 است [ 33 ]]. دادههای آبوهوای ما در سالهای 2016 و 2017 نشان داد که هر دو سال نسبتاً گرم (9.8 و 10.8 درجه سانتیگراد) بودند، در حالی که بارش در سال 2016 کم (436 میلیمتر) و در سال 2017 (679 میلیمتر) در مقایسه با میانگین بلندمدت زیاد بود. خاکهای منطقه معمولاً خاکهای استگنوسول و خاکهای قهوهای هستند که از بقایای یخی شنی و لومی منشأ میگیرند. علاوه بر این، خاک های رسی از لوم اسکلتی، لس شنی روی سنگ آهک، رندزینا و برخی از پادزول ها نیز وجود دارند [ 34 ].
2.1.2. داده های آب و هوا
سرویس هواشناسی آلمان (DWD) داده های آب و هوای روزانه را برای ایستگاه هواشناسی “Ummendorf” (11.18 درجه شرقی، 52.16 درجه شمالی) و همچنین مجموعه داده های آب و هوایی شطرنجی شده 1 × 1 کیلومتر مربع را برای کل آلمان ارائه کرد ( شکل 1 را ببینید ). داده های آب و هوا شامل دمای حداقل و حداکثر روزانه، مجموع بارش و تبخیر و تعرق مرجع بر اساس معادله پنمن-مونتیث [ 35 ] است. مجموعه دادههای شطرنجی بهعنوان ورودی مدل مورد استفاده قرار گرفت و مقدار محدودی از پویایی فضایی را معرفی کرد.
2.1.3. داده های پوشش سایبان
پایگاه داده ما شامل صحنههای Sentinel-2 Level-2A بین آگوست 2015 و نوامبر 2017 است که از نظر جوی تصحیح شدهاند. ما فقط صحنههایی با پوشش ابری معمولاً کم تا متوسط (تا 50 درصد) را در نظر گرفتیم. مجموعه داده شامل 116 صحنه است که تمام فصول رشد گندم زمستانی را برای هر دو دوره برداشت 2016 و 2017 پوشش می دهد. ما از پردازنده بیوفیزیکی پیاده سازی شده در جعبه ابزار ESA Sentinel-2 (S2TBX، نسخه 6.0.4) برای تولید پوشش تاج (CC) استفاده کردیم. ) نقشه های همه صحنه ها ( شکل 1 را ببینید ). پردازنده از شبکه های عصبی مصنوعی آموزش دیده بر روی مجموعه داده بزرگی از شبیه سازی های انتقال تابشی خواص تاج و برگ [ 36 ] استفاده می کند.]. مستندات پردازنده بیوفیزیکی SNAP برخی از شاخص های عملکرد نظری را ارائه می دهد. نویسندگان ادعا میکنند که خطای میانگین مربعات ریشه پایین (RMSE) 0.04 برای پیشبینیهای CC در مجموعه داده اعتبارسنجی آنها [ 36 ] است. در طول پیش پردازش، ما بیشتر یک تشخیص ابر و سایه ابر چند آستانه ای برای هر یک از میدان های آزمایشی خود انجام دادیم تا مشاهدات بالقوه آلوده را کنار بگذاریم. تعداد مشاهدات حاصل بسته به مکان بین سه تا 12 مورد در هر فصل رشد متغیر بود.
2.1.4. داده های بازده
دادههای مزرعه از طریق اندازهگیری عملکرد مبتنی بر GPS بر روی کمباینها در طول برداشت 30 مزرعه در سال 2016 و 32 مزرعه در سال 2017 بهدست آمد. اندازه گیری هایی که اغلب در شروع و پایان مراحل برداشت اتفاق می افتد. سپس نقاط باقیمانده را به نقشههای بازده 10×10 متر مربعی منطبق با مشاهدات Sentinel-2 تجمیع کردیم ( شکل 1 را ببینید ). میانگین بازده حاصل از همه مزارع با آمار عملکرد گزارش شده در سطح بخش مطابقت خوبی داشت [ 37 ، 38 ، 39]. بازده مشاهده شده در سطح پیکسل از 2.38 تا 9.60 تن در هکتار و میانگین بازده میدان از 3.90 تا 7.63 تن در هکتار متغیر بود. هیچ اطلاعاتی در مورد دقت اندازه گیری ارائه نشده است.
برای تجزیه و تحلیل بیشتر، ما یک مجموعه داده در سطح پیکسل و میدان ایجاد کردیم. ما هر دو را به طور تصادفی به 60 درصد کالیبراسیون (32 مشاهده میدانی، 23375 مشاهده پیکسل) و اعتبار 40 درصد (20 مشاهدات میدانی، 15584 مشاهده پیکسل) تقسیم کردیم.
2.2. پیشینه روش شناختی
2.2.1. توضیحات AquaCrop-OS
AquaCrop یک مدل محصول پویا است که توسط سازمان غذا و کشاورزی سازمان ملل متحد (FAO) توسعه یافته است. پاسخ عملکرد محصولات علفی را در یک مزرعه همگن با در نظر گرفتن پاسخ آب و اثرات تنش مختلف شبیه سازی می کند [ 40 ، 41 ، 42 ]. ورودیهای شبیهسازی روزانه، دادههای دمای حداکثر و حداقل، مجموع بارش و تبخیر و تعرق بالقوه است [ 43 ]. شبیهسازی در مقایسه با مجموعههای مدل پیچیده مانند سیستم پشتیبانی تصمیم برای انتقال فناوری کشاورزی (DSSAT) [ 44 ، 45 ]، به طور قابلتوجهی سادهتر شده است، با تمرکز بر قابلیت کاربرد مدل جهانی با محدوده بالقوه محدود دادههای موجود.
بخش مرکزی مدل تابع بهره وری محصول است که انباشت زیست توده را به بهره وری آب و تبخیر و تعرق برای بدست آوردن کل زیست توده تجمعی مرتبط می کند:
جایی که بتیکل زیست توده انباشته شده از است تی=0روز به تی=تی; کسبضریب تنش دمای هوا است. دبلیوپ∗آیا بهره وری آب به میانگین سالانه غلظت CO 2 نرمال شده است.تیrتیتعرق روزانه محصول است. و Eتیoتیتبخیر و تعرق بالقوه روزانه (هر دو بر حسب میلی متر) است.
AquaCrop اثرات تنش گرما، خشکسالی و سرما را از طریق ضرایب تنش نشان میدهد که میتواند بر توسعه تاج پوشش، هدایت روزنهای، پیری تاج پوشش یا توسعه شاخص برداشت تأثیر بگذارد. ضرایب تنش با سطح تنش به دنبال منحنی پاسخ محدب به مقعر تغییر می کند [ 41 ، 46 ]:
جایی که کستابع پاسخ استرس را توصیف می کند. اسrهلسطح استرس نسبی (≤ 1) است. و fسساعتآپهیک عامل شکل است که انحنای تابع را مشخص می کند.
متغیر حالت اصلی در مدل پوشش تاج پوشش است (CC؛ گاهی اوقات به عنوان بخشی از پوشش گیاهی، FVC یا FCOVER نامیده می شود) که مستقیماً تأثیر می گذارد. تیrتیدر رابطه (1) از طریق ضریب تعرق محصول:
جایی که سیسی∗پوشش سایبان فعلی (تنظیم شده برای اثرات میکرو صفت) است. کسیتیr،ایکسحداکثر ضریب تعرق محصول برای خاک خوب آبیاری شده و یک تاج پوشش کامل است. کسwنشان دهنده ضریب تنش آب خاک است. و کسیتیrضریب تعرق فعلی محصول به دست آمده است. بنابراین، CC یک متغیر مهم در انباشت زیست توده در معادله (1)، و در نتیجه، عملکرد است که از طریق یک شاخص برداشت (یعنی درصد زیست توده در بلوغ محصول) تعیین می شود.
توسعه CC در طول فصل رشد بیشتر به صورت تجربی تعیین می شود. پس از ظهور محصول، CC ابتدا به صورت تصاعدی تا 50 درصد حداکثر افزایش می یابد. رشد آهسته تا رسیدن به حداکثر ادامه دارد. مقدار CC ثابت می ماند تا زمانی که یک فروپاشی نمایی در ابتدای پیری ایجاد شود [ 46 ]. این فرآیند در معادلات زیر خلاصه می شود:
جایی که سیسیپوشش سایبان جدید است. سیسیایکسحداکثر پوشش سایبان ممکن است. سیسیoپوشش اولیه سایبان در شروع رشد است. و سیجیسیو سیDسیبه ترتیب ضرایب رشد و کاهش تاج پوشش هستند. عملکرد خشک با اعمال شاخص برداشت (درصد) به ارزش زیست توده در بلوغ به دست می آید.
ما از نسخه منبع باز مدل به نام AquaCrop-OS استفاده کردیم، که به ما امکان می دهد تغییرات کد منبع لازم را برای رویه های به روز رسانی شرح داده شده در بخش 2.3 [ 47 ] انجام دهیم.
2.2.2. کالیبراسیون AquaCrop-OS
به دلیل فقدان اطلاعات در مورد انواع گندم زمستانه در مزارع آزمایشی یا نمونه برداری منظم در محل، دانش قبلی ما برای کالیبراسیون محدود بود. بنابراین ما بر یک کالیبراسیون تجربی پارامترهای مدل تکیه کردیم. این نیز شبیه سازی را عمومی تر و مستقل از شرایط میدانی خاص کرد.
AquaCrop-OS تعداد زیادی از پارامترهای محصول را ارائه می دهد که به پارامترهای محافظه کارانه تقسیم می شوند که قبلاً در بسیاری از محیط های مختلف و محیط های خاص کاربر به اثبات رسیده اند [ 43 ]. موارد اول در کالیبراسیون ما در اکثر موارد نادیده گرفته شدند، به جز ضرایب رشد و کاهش تاج (CGC و CDC، جدول 1 را ببینید ) به دلیل ارتباط خاص آنها در این زمینه. ما مدیریت آبیاری را در نظر نگرفتیم زیرا کشاورزی در منطقه مورد مطالعه ما منحصراً دیم است. به طور مشابه، ما فرض کردیم که مدیریت مزرعه به دلیل استانداردهای تکنولوژیکی بالا و سنت طولانی کشاورزی صنعتی در منطقه مورد مطالعه ما، “بهترین شیوه” را دنبال می کند.
ما یک تجزیه و تحلیل حساسیت را بر اساس تغییرات تکرار شونده به پارامترهای فردی انجام دادیم و تأثیر را بر عملکرد پیشبینیشده مشاهده کردیم. پارامترهای فهرست شده در جدول 1 را نشان داد که بیشترین ارتباط را برای پیشبینی عملکرد گندم زمستانه در منطقه مورد مطالعه ما دارند. ما مدل را با تغییر پارامترها به طور مکرر و به حداقل رساندن RMSE بازده کالیبره کردیم. فرآیند کالیبراسیون RMSE را از 2.305 تن در هکتار به 1.324 تن در هکتار در سطح مزرعه و از 2.264 تن در هکتار به 1.521 تن در هکتار در مجموعه داده های اعتبارسنجی در سطح پیکسل بهبود بخشید. تنظیمات پارامتر بهینه برای سطح پیکسل و میدان کاملاً مشابه بود، بنابراین تصمیم گرفتیم از یک مجموعه کالیبراسیون در هر دو مقیاس استفاده کنیم. جدول 1 فهرستی از تنظیمات کالیبراسیون را ارائه می دهد.
2.2.3. بهینه سازی ازدحام ذرات
بهینهسازی ازدحام ذرات یک الگوریتم بهینهسازی جهانی فراابتکاری است که بر اساس اصول هوش ازدحامی رفتار هوشمند پیچیدهای است که از عوامل فردی اولیه پدید میآید. به این ترتیب، آن بخشی از خانواده بزرگتر محاسبات تکاملی است [ 48 ، 49 ]. کندی و ابرهارت در ابتدا این الگوریتم را به دنبال تلاش های قبلی رینولدز در شبیه سازی حرکات واقع گرایانه گله های پرندگان طراحی کردند [ 50 ، 51 ].
ازدحام ذرات یک گروه (“ازدحام”) از راه حل های نامزد (“ذرات”) است که در طول زمان در فضای جستجوی چند بعدی حرکت می کنند (یعنی مراحل تکرار). هر ذره به عنوان یک بردار تصادفی با یک بردار سرعت اولیه تصادفی شروع می شود که حرکت آن را در فضای جستجو نشان می دهد. این سرعت در هر تکرار بر اساس قوانین خاصی به روز می شود و تناسب ذرات جدید به دست می آید. در نسخه اصلی، فرآیند تنها تحت تأثیر بهترین راه حل قبلی ذره (بهترین راه حل قبلی، pbest) و بهترین راه حل به دست آمده در همسایگی آن (همسایگی بهترین، nbest) است [ 48 ، 49]. این همسایگی با توپولوژی که نشان دهنده ارتباط بین ذرات در ازدحام است، توصیف می شود. توپولوژیهای مختلف زیادی در ادبیات استفاده میشوند، از جمله توپولوژیهای محلی بهترین، بهترین جهانی، و توپولوژیهای فون نویمان، اما همچنین توپولوژیهای پویا در طول فرآیند بر اساس زمان، فاصله اقلیدسی و نسبتهای تناسب به فاصله، در میان دیگران تغییر میکنند [ 52 ، 53 ]. برای بحث دقیق تر، خوانندگان می توانند به مقاله پولی و همکاران مراجعه کنند. [ 54 ].
معادلات زیر سرعت مرکزی و به روز رسانی موقعیت را توصیف می کنند (همه ضرب ها بر حسب عنصر هستند):
جایی که v⇀من(تی)بردار سرعت جدید (به روز شده) ذره است مندر مرحله زمانی تیو v⇀من(تی-1)بردار سرعت قبلی آن است. موقعیت های قبلی و جدید توسط ایکس⇀من(تی-1)و ایکس⇀من(تی)، به ترتیب. بهترین راه حل قبلی با نشان داده شده است پ⇀منو محله بهترین راه حل توسط پ⇀n. شرایط φ1و φ2به ضرایب pbest و nbest به ترتیب مراجعه کنید و ϵ1، ϵ2بردارهای تصادفی [ 48 ] هستند. می توان ضرایب pbest و nbest را به عنوان تمایل ذرات به حرکت مستقل یا “به سمت ازدحام” تفسیر کرد. بنابراین این دو عنصر ارتباط نزدیکی با اکتشاف و بهره برداری دارند.
رویکرد فراابتکاری آن PSO را از تکنیک های بهینه سازی مبتنی بر گرادیان متمایز می کند. PSO از اطلاعات مشتق دقیق یا تقریبی استفاده نمی کند. بنابراین نیازی به توابع هدف پیوسته یا قابل تمایز یا دانش قبلی در مورد تابع هزینه [ 55 ] ندارد. این باعث می شود که در مدیریت انواع مختلف ورودی ها و حتی ترکیبی از توابع پیوسته و گسسته بسیار انعطاف پذیر باشد. PSO همچنین در یافتن بهینه جهانی، حتی در فضاهای حل بسیار ناهمگن و پیچیده که توسط توابع آزمایشی مانند توابع جدول Ackley یا Holder شبیهسازی شده است، قابل اعتماد در نظر گرفته میشود [ 48 ، 56]. علاوه بر این، PSO با ورودیهای با ابعاد بالا بسیار خوب مقیاس میشود، زیرا تعداد ارزیابیهای عملکرد توسط اندازه ازدحام تعیین میشود، نه تعداد متغیرهای ورودی.
با این حال، PSO یک الگوریتم قطعی نیست، بلکه شامل عناصر تصادفی است. بنابراین فرآیند کاملاً قابل پیشبینی نیست، حتی شرایط شروع یکسان ممکن است به مراحل تکرار متفاوت و حتی به راهحلهای متفاوت به دلیل جزء تصادفی فرآیند منجر شود [ 54 ]. در نتیجه، تعیین پارامترهای خاص برنامه (مانند اندازه ازدحام، ضرایب، توپولوژی و غیره) به عهده کاربر است که همگرایی قابل اعتماد و سریع را تضمین می کند. علاوه بر این، برخلاف الگوریتمهای مربوط به نزول گرادیان که تحت مفروضات خاصی به حداقل محلی میرسند، همگرایی در روشهای PSO فقط در یک تنظیمات تصادفی معتبر است.
برای اطمینان از نتایج بهینه سازی سریع و قابل اعتماد، ما تعدادی از انواع مختلف PSO و تنظیمات را با هم مقایسه کردیم. این شامل اندازههای مختلف ازدحام، وزنهای اینرسی، ضرایب شناختی و اجتماعی، توپولوژیهای استاتیک و پویا (بهترین محلی، بهترین جهانی، نزدیکترین همسایه پویا، نسبت تناسب اندام به فاصله پویا، در میان دیگران) و همچنین توزیعهای مختلف برای نمونه برداری تصادفی برداری (یکنواخت، عادی، لوی).
مشاهده کردیم که ضرایب انقباض Clerc [ 57 ] نسبت به وزنهای اینرسی یا مرزهای سرعت به تنهایی برتر بودند. بنابراین استفاده کردیم φ1= φ205/2 = و ضریب انقباض χ طبق [ 57 ] محاسبه می شود. ما همچنین مشاهده کردیم که اگرچه در هنگام استفاده از وزنهای اینرسی یا ضرایب انقباض لزوماً لازم نیست، vمترآایکسبه محدوده دینامیکی ورودی در برخی موارد سودمند بود، همانطور که در [ 58 ] پیشنهاد شد. توپولوژی های فون نویمان و نزدیکترین همسایه پویا عملکردهای کاملاً مشابهی را نشان دادند که اولی به دلیل کارایی محاسباتی بالاتر انتخاب شد. توزیعهای تصادفی مختلف تأثیر معنیداری در این زمینه نشان ندادند. اندازه ازدحام روی 20 تنظیم شد که یک مقدار رایج در ادبیات است. تعداد بیشتری از ذرات نتوانستند همگرایی را به طور قابل توجهی بهبود بخشند، اما به طور منطقی تعداد ارزیابی عملکرد را افزایش دادند و روند را کاهش دادند. جدول 2 سریع ترین و مطمئن ترین تنظیماتی را که به دست آورده ایم ارائه می کند. در برنامههای کاربردی ما، این پیادهسازی معمولاً به سرعت در عرض 10-15 تکرار به حد مطلوب همگرا میشود.
2.2.4. کمی سازی عدم قطعیت
ما منابع متعدد عدم قطعیت را، هم در مدل و هم در دادههای سنجش از دور در نظر گرفتیم. قبل از اینکه بتوان آنها را در روند به روز رسانی گنجاند، اینها باید کمیت شوند. ما نمیتوانیم خطاهای احتمالی اندازهگیری آب و هوا یا مسائل مربوط به ابزار را در نظر بگیریم. با این حال، ما میتوانیم واکنش شبیهسازیهای پوشش سایبان AquaCrop-OS را به اختلالات در ورودیهای آب و هوا و تنظیمات پارامتر اندازهگیری کنیم.
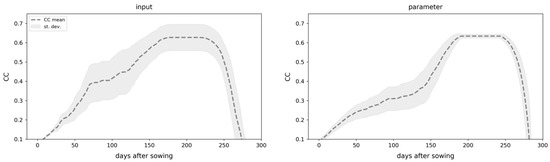
ما از طریق شبیه سازی مونت کارلو به این امر دست یافتیم. ابتدا، ما عدم قطعیت مربوط به ورودی را با برهم زدن تصادفی یک سری زمانی میانگین آب و هوای 10 ساله با نویز تصادفی گاوسی برآورد کردیم. بزرگی نویز با واریانس روزانه مشاهده شده در همان دوره 10 ساله تعیین شد. ما 10000 سری زمانی CC را از شبیهسازیهای AquaCrop-OS بر روی این مجموعه دادههای آب و هوایی تصادفی بهدست آوردیم. دوم، ما عدم قطعیت پارامترها را بر این اساس با نمونهبرداری تصادفی تنظیمات پارامتر از یک توزیع نرمال حول مقادیر کالیبرهشده در جدول 1 با انحراف استاندارد 1/10 محدوده کالیبراسیون ارزیابی کردیم. این امر تنوع کافی را در یک محدوده واقعی در اطراف تنظیمات کالیبره شده تضمین می کند. ما 10000 شبیه سازی مونت کارلو را به صورت تصادفی تمام پارامترهای فهرست شده در جدول 1 انجام دادیم.. هر دو عدم قطعیت مربوط به مدل در شکل 2 نشان داده شده است. سوم، ما عدم قطعیت ها را در داده های سنجش از دور تخمین زدیم. در اینجا، رویه ها در سطح میدان و پیکسل متفاوت است. در سطح میدان، ما از مجموعه ای از تمام مقادیر پیکسل CC در یک فیلد معین در تاریخ مشاهده استفاده کردیم. در سطح پیکسل، ما فقط از مقادیر در همسایگی 3 × 3 پیکسل استفاده کردیم ( شکل 3 را ببینید ).
با استفاده از این مجموعه دادهها، توابع چگالی احتمال (PDF) را ایجاد کردیم که احتمال تمام مقادیر CC ممکن (بین 0 و 1) هر منبع عدم قطعیت را نشان میدهد. ما از تخمین چگالی هسته با یک هسته گاوسی متقارن استفاده کردیم. آزمایشات نشان داد که پهنای باند باریک 0.02 بهترین نتایج را به همراه داشت. در نهایت، ما عدم قطعیت در شبیهسازی فعلی را با یک توزیع گاوسی حول مقدار CC شبیهسازیشده فعلی با استفاده از پهنای باند 0.2 نشان دادیم.
2.3. به روز رسانی متدولوژی
2.3.1. به روز رسانی ساده
طرح به روز رسانی ساده ای که ما استفاده کردیم، مقادیر CC شبیه سازی شده را مستقیماً با مشاهدات سنجش از راه دور بدون هیچ گونه پردازش اضافی و بدون در نظر گرفتن عدم قطعیت جایگزین کرد. در نتیجه، مقادیر CC شبیهسازیشده در نظر گرفته نشد و خطاها در دادههای سنجش از دور مستقیماً به مدل منتقل شدند.
2.3.2. به روز رسانی فیلتر کالمن
فیلتر کالمن از زمان اولین توصیف آن در [ 11 ]، به یکی از رایج ترین تکنیک های همسان سازی داده ها تبدیل شده است [ 20 ]. به طور مکرر یک مقدار تخمینی را با ترکیب اطلاعات از مقادیر اندازه گیری شده دریافتی، با در نظر گرفتن عدم قطعیت مربوط به اندازه گیری و ارزش تخمینی، به روز می کند. فیلتر کالمن یک مدل خطی را فرض می کند. گسترش آن به مدل های غیر خطی EKF است. در اینجا، خطیسازی تابع مدل غیرخطی اصلی برای بهروزرسانی عدم قطعیت (یعنی ماتریس کوواریانس) برآورد حالت مدل استفاده میشود [ 14 ، 59 ].
در مورد ما، ما یک مدل غیر خطی داریم، اما متغیر حالت اسکالر CC را مستقیماً جذب کردیم. بنابراین، هیچ مشاهده اضافی وجود ندارد. هر دو واقعیت روند EKF را ساده می کنند و به روز رسانی را از نظر محاسباتی بسیار کارآمد می کنند. با فرض اینکه برآوردهای متغیر حالت را داریم ایکسکو عدم قطعیت آن پکدر زمان گام فوری تیک. اکنون یک مقدار مشاهده جدید بدست می آوریم yک+1در لحظه بعدی تیک+1. سپس، EKF یک مرحله پیش بینی کننده برای حالت مدل انجام می دهد
با استفاده از مدل غیر خطی اصلی علاوه بر این، عدم قطعیت به صورت زیر پیش بینی می شود:
در اینجا، فرض می کنیم که مدل هیچ خطایی ندارد و از یک تقریب استفاده می کند افک≈f”(ایکسک)برای مشتق تابع مدل. در مورد ما، این مشتق نیز یک اسکالر است. اکنون سود کالمن به صورت زیر محاسبه می شود:
جایی که آرک+1عدم قطعیت در اندازه گیری است yک+1. اکنون، مرحله تصحیح تخمین های جدید وضعیت و عدم قطعیت آن را به صورت زیر محاسبه می کند:
ما تقریب مشتق مورد نیاز در رابطه (11) را با فرمول تفاضل محدود محاسبه کردیم:
این تقریب فقط از کمیت های قبلا محاسبه شده استفاده می کند. در مرحله اول جذب ( ک= 0)، یک تغییر برای جایگزینی مقدار مورد نیاز است ایکسک-1و f(ایکسک-1).
همانطور که قبلا ذکر شد، پس از محاسبه ابرها و سایههای ابر، مشاهدات باقیمانده خیلی مکرر نبودند. در صورت مشاهدات مکرر، عدم قطعیت به روز شده می تواند به طور مداوم در کل فرآیند EKF منتشر شود. با این حال، در مورد ما، ما اغلب با فاصله زمانی زیادی بین مشاهدات مواجه میشویم. این نشان میدهد که همسانسازی نمیتواند در هر مرحله زمانی مدل انجام شود. بنابراین، تابع fدر معادله (10) نه تنها یک گام مدل را نشان می دهد، بلکه ترکیبی از مراحل مدل را بین لحظه های زمانی بعدی خلاصه می کند. تیکو تیک+1جایی که اندازه گیری ها در دسترس هستند در نتیجه، تقریب مشتق در معادله (15) میانگینی از مشتق مدل در بازه [ تیک، تیک+1]. همانطور که در بخش 2.2.1 نشان داده شد ، AquaCrop-OS بسته به مراحل رشد و تأثیرات محیطی، به طور قابل توجهی در روشهای شبیهسازی متفاوت است. بنابراین، این نوع میانگین گیری از مشتق معقول به نظر می رسد. همانطور که در بالا ذکر شد، مشتق برای اولین مرحله جذب باید به روشی کمی متفاوت تقریب شود. در اینجا، ما از یک حالت در یک لحظه زمانی در بازه [ تی= 0، تی1] بجای ایکسک-1.
عدم قطعیت در حالت در ابتدا 0.2 در نظر گرفته شده است. عدم قطعیت در مقادیر اندازه گیری شده به عنوان انحراف استاندارد همه مقادیر CC در مکان و زمان مشاهده شده (یعنی تمام پیکسل های یک میدان در سطح میدان و پیکسل ها در همسایگی 3×3 در سطح پیکسل) برآورد شد.
2.3.3. طرح به روز رسانی جدید
شکل 4 مراحل اصلی پردازش روش جدید ما را نشان می دهد. آماده سازی داده های CC (سبز)، داده های آب و هوا (آبی)، و نقشه های عملکرد (زرد) در بخش 2.1 مورد بحث قرار گرفت و کمی سازی عدم قطعیت (آبی تیره) در بخش 2.2.4 پوشش داده شد . در این بخش و قسمت بعدی، جزئیات فرآیند واقعی به روز رسانی و ارزیابی دقت (خاکستری) را توضیح خواهیم داد.
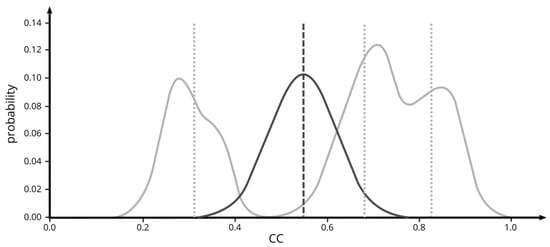
ایده اساسی در پشت رویکرد ما این است که تمام عدم قطعیت ها (مربوط به مدل و مشاهدات CC) را متعادل کنیم تا مقدار به روز شده را بدست آوریم. برای انجام این کار، ما همه عدم قطعیت ها را به صورت PDF نمایش دادیم (به بخش 2.2.4 مراجعه کنید ). سپس یک توزیع گاوسی بهینه فرضی به دست آوردیم، همانطور که با میانگین توصیف شد μو یک انحراف معیار σ، که تمام عدم قطعیت ها را از نظر فاصله آماری متعادل می کند ( شکل 5 را ببینید ). به عبارت دیگر، ما فرض کردیم که میانگین توزیعی که فاصلههای آماری را تا تمام فایلهای PDF به حداقل میرساند، با توجه به اطلاعات موجود، تخمین بهتری را در اختیار ما قرار میدهد. ما از PSO برای جستجوی میانگین و انحراف استاندارد این توزیع گاوسی بهینه استفاده کردیم.
عنصر مرکزی این تکنیک نمایش فاصله یا شباهت بین توزیعهای احتمال یا PDF مربوط به آنها است. تعدادی از معیارهای فاصله و واگرایی آماری در ادبیات پیشنهاد شده است. برخی از رایج ترین آنها عبارتند از فاصله هلینگر، واگرایی کولبک-لایبلر، و فاصله باتاچاریا [ 60 ، 61 ، 62 ].
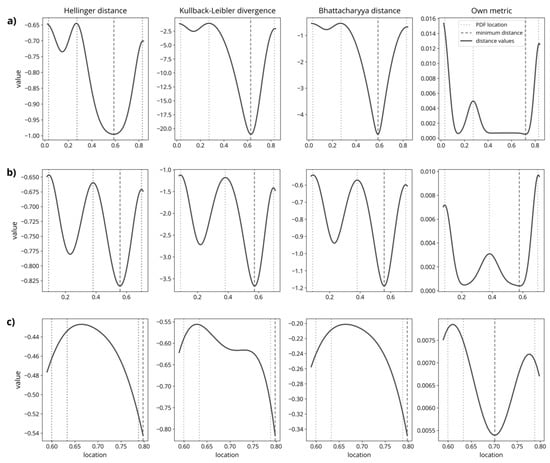
هنگام مقایسه محاسبات اندازهگیری فاصله آماری توزیع گاوسی بهینه با مجموعهای از فایلهای PDF عدم قطعیت، معیارهای مختلف رفتار مشابهی داشتند. شکل 6این را با موارد مثال نشان می دهد که در آن سه فایل PDF در مکان های مختلف و با انحرافات استاندارد متفاوت در نظر گرفته می شوند. مقادیر نشان داده شده برای معیارهای فاصله مختلف با استفاده از یک الگوریتم نیروی brute به دست آمد که توزیع بهینه انحراف استاندارد 0.05 را از 0.01 تا 0.99 در فضای جستجو منتقل می کند. با این حال، این موارد نمایشی بهشدت سادهتر شدهاند، زیرا فرض میکنند که همه فایلهای PDF توزیعهای گاوسی کاملاً متقارن هستند و انحراف استاندارد توزیع بهینه را ثابت نگه میدارند. علاوه بر این، این مورد مثال فقط سه فایل PDF را در نظر می گیرد در حالی که وضعیت به طور منطقی با در نظر گرفتن موارد بیشتر ناهمگن می شود.
شکل 6 a,b نشان میدهد که در مواردی که فایلهای PDF نسبتاً از هم فاصله دارند، سه معیار فاصله مشابه رفتار میکنند. اگرچه بزرگی ممکن است به طور قابل توجهی متفاوت باشد، اشکال کلی (تعداد و مکان بهینه محلی) کاملا مشابه هستند. با این حال، اگر موردی را در نظر بگیریم که سه فایل PDF نزدیک به یکدیگر قرار دارند، مشکلاتی به وجود می آید. در اینجا، همانطور که در شکل 6 نشان داده شده استج، هر سه فاصله نتوانستند حداقل مشخصی را در محدوده جستجو ایجاد کنند و در عوض قله ها یا فلات های منفرد را ایجاد کردند. این وضعیتی را با دو راهحل حداقلی بالقوه در نهایت ایجاد کرد. در جستجوی حداقل مقدار، الگوریتم به هر طرف اجرا می شود. در این مورد خاص که فقط توزیعهای نرمال گاوسی است، این معادل انتخاب کران بالا یا پایین به عنوان مقدار بهروز شده است. این ممکن است کاهش یابد، همانطور که در اجرای قبلی تلاش شد [ 63]، با استفاده از میانگین مجذور فاصله تخمینگر حداکثر درستنمایی (MLE) توزیع بهینه به MLEهای همه PDFهای عدم قطعیت. اما این رویکرد دو اشکال عمده دارد. اولاً، استفاده از MLE به عنوان یک شاخص برای موقعیت یک توزیع، تنها زمانی معرف آن است که توزیع یکوجهی و تقریباً نرمال باشد. دوم، یک مرحله پردازش اضافی برای تعیین MLE ها ضروری است. اگرچه به دست آوردن MLE ها یک مشکل بهینه سازی ساده است (به حداکثر رساندن مجموع احتمالات در تمام PDF ها)، به زمان پردازش اضافه می کند و یک منبع خطای بالقوه را معرفی می کند. با توجه به این اشکال، ما تصمیم گرفتیم از یک معیار متفاوت به شرح زیر استفاده کنیم:
جایی که foپتی(μ،σ)و fستومترتوزیع گاوسی بهینه تعریف شده توسط μو σو به ترتیب مجموع تمام فایل های PDF عدم قطعیت. علاوه بر این، qمنمقدار احتمال مجموع فایل های PDF عدم قطعیت است. اگرچه این تعریف حداقل دو معیار مهم یک متریک را نقض می کند، زیرا نه متقارن است و نه محدود به محدوده (0، 1) است، اما همچنان ممکن است برای سادگی به آن اشاره کنیم.
اساساً، این متریک احتمالات PDFهای عدم قطعیت را بر اساس فاصله آنها تا توزیع بهینه اندازه گیری شده در انحرافات استاندارد (نمرات z) وزن می کند. همانطور که در شکل 6 نشان داده شده است ، با استفاده از این معیار، میتوانیم از حداقل واضح در فضای جستجو اطمینان حاصل کنیم، حتی در مورد PDFهایی که بسیار نزدیک به یکدیگر قرار دارند.
علاوه بر این، به این احتمال پرداختیم که ممکن است همه فایلهای PDF ارتباط یکسانی برای بهروزرسانی نداشته باشند. بنابراین، با این فرض که پیدیافهایی که شبیهتر به مقدار CC شبیهسازیشده فعلی مدل هستند، یک وزنبندی را معرفی کردیم، نسبت به مواردی که متفاوتتر بودند. برای نشان دادن این موضوع، ما از فاصله هلینگر برای معرفی وزندهی به فایلهای PDF استفاده کردیم. ما وزنها را با محاسبه فاصله هلینگر برای هر PDF عدم قطعیت به یک توزیع گاوسی باریک حول مقدار CC شبیهسازیشده فعلی، به دنبال معادله به دست آوردیم:
جایی که پو سدو توزیع با پمنو qمنتوصیف احتمالات دو توزیع در نقطه من. فاصله هلینگر بین 0 (یکسان) تا 1 (بدون همپوشانی) است. ما از مقادیر فاصله به دست آمده برای ایجاد وزن های نمایی نرمال شده استفاده کردیم:
جایی که fمنPDF است که نشان دهنده عدم قطعیت مربوطه و fسمنمترتوزیع حول مقدار CC شبیه سازی شده است. مخرج مجموع تمام فواصل هلینگر را نشان می دهد و از جمع تا وحدت اطمینان می دهد. این بیشتر به ما اجازه می دهد تا معرفی کنیم α، یک ضریب ضربی ساده که مقدار وزن های با مقادیر بالاتر را تعیین می کند αمنجر به تاکید بیشتر بر PDFهای غیر مشابه (یعنی آنهایی که فاصله هلینگر بیشتری دارند). ترکیب معادله (16) با وزن های تعیین شده در رابطه (18) منجر به یک مسئله بهینه سازی به شکل زیر می شود:
با این حال، این تابع هدف ممکن است به فرآیند یافتن یک بهینه با انحراف معیار بسیار بزرگ منجر شود σ. اگرچه چنین توزیع بسیار مسطحی در واقع فاصله های آماری را به حداقل می رساند، اما راه حل مفیدی برای رویکرد ما نیست. اگر توزیع اساساً مسطح باشد، مقدار میانگین ممکن است در هر جایی در محدوده CC قرار گیرد بدون اینکه تأثیر قابل توجهی بر فاصله آماری داشته باشد. به عبارت دیگر، یک توزیع مسطح اجازه می دهد تا هر مقدار CC یک راه حل بهینه باشد. برای جلوگیری از این امر، جریمه کردیم σتوزیع گاوسی بهینه این منجر به مشکل بهینه سازی نهایی ما می شود:
سپس مقادیر بهینه را جستجو کردیم μو σبرای به حداقل رساندن معادله (20). با این حال، یک اشکال از نظر محاسبات این است که مقادیر حول بهینه معمولاً بسیار کوچک هستند و حداقل در مواردی که PDFها از هم دور هستند، مانند شکل 6 a,b، متمایز نیست. این امر تأکید بیشتری بر تنظیمات مناسب و قابلیت اطمینان بهینه ساز مورد استفاده دارد. با این حال، از لحاظ نظری نامحدود، اما در مشاهدات ما، محدوده مقدار کمی از این متریک، معرفی محدودیتها را در مقایسه با، برای مثال، واگرایی Kullback-Leibler با مقادیر مشاهدهشده بین 0.02 و بیش از 30 تسهیل میکند.
2.3.4. تجزیه و تحلیل عملکرد
مقایسه طرحهای بهروزرسانی شامل سه موقعیت آزمایشی بود: تخمینهای سطح میدان، سطح پیکسل، و سطح انبوه پیکسل به میدان که در آن ما بازده را بر اساس پیکسل شبیهسازی کردیم و میانگین این تخمینهای فردی را با میانگین بازده مشاهدهشده مقایسه کردیم. رشته. ما این تجزیه و تحلیل را روی مجموعه داده اعتبارسنجی در سطح پیکسل انجام دادیم و بنابراین از همه پیکسل ها استفاده نکردیم. با این حال، اندازه بزرگ 40٪ از تمام پیکسل ها، نمونه ای از پیکسل ها را برای همه زمینه ها تضمین می کند. همانطور که قبلاً گفته شد، ما اندازهگیری در محل پوشش تاج پوشش یا نمونههای منظم زیست توده در این زمینه نداشتیم. بنابراین هدف ما بدست آوردن سری های زمانی CC واقع بینانه یا ایجاد مجدد توسعه زیست توده از نزدیک نبود. در عوض، مقایسه ما در درجه اول به ظرفیت بهبود پیشبینی بازده متکی است.
ما دو نسخه از روش خود را در نظر گرفتیم: یکی با یک مقدار ثابت (تعریف شده توسط کاربر) برای ضریب وزنی αو یک تطبیقی که به PSO اجازه می دهد به طور خودکار تعیین شود αدر این فرآیند آزمایشهای قبلی روی دادههای کالیبراسیون مقادیر بسیار بالایی را نشان داد αحدود 5-10 برای شبیه سازی در سطح میدانی سودمند بود، در حالی که در سطح پیکسل، مقادیر حدود 1-2 ارجحیت داشتند. در مقایسه خود، این تنظیمات را با نتایج بهدستآمده از وزندهی تطبیقی در محدوده پیوسته 1-10 مقایسه کردیم.
ما همچنین توانایی روش خود را برای ترکیب عدم قطعیت های مختلف با افزودن منابع عدم قطعیت یک به یک و مشاهده تأثیر بر عملکرد ارزیابی کردیم. ابتدا دادههای سنجش از راه دور را در بهروزرسانی معرفی کردیم، سپس عدم قطعیت مربوط به پارامتر و در نهایت مربوط به آب و هوا.
ما از سه معیار برای تجزیه و تحلیل نتایج استفاده کردیم. معیار اصلی برای عملکرد کلی در نتایج، RMSE بود.
جایی که yمنمقدار بازده مرجع و y^منمقدار پیش بینی شده است. برای تعیین سوگیری در نتایج، از میانگین درصد خطا (MPE) استفاده کردیم.
علاوه بر این، ما امتیازات R 2 را محاسبه کردیم .
جایی که y¯میانگین داده های مرجع است. برای ترکیب عدم قطعیت ذاتی که در هر نوع اندازهگیری بازده وجود دارد، ما همچنین از یک متریک درصد تطابق (یعنی شمارش مقادیر پیشبینیشده که در یک محدوده معین قرار میگیرند) حول مقدار مرجع مربوطه (در این مورد +/-20٪) استفاده کردیم. ).
3. نتایج
در این بخش، عملکرد پیشبینیهای عملکرد AquaCrop-OS را در سطح میدان، سطح پیکسل و سطح تجمع پیکسل به میدان توصیف میکنیم. مقادیر بسیار پایین R2 که در تمام آزمایشها مشاهده کردیم، برای تفسیر مفید نبودند و بنابراین از توضیحات حذف شدند. ما این موضوع را به طور خاص در بخش 3.4 و بحث ( بخش 4 ) تحلیل و بررسی می کنیم.
3.1. تخمین بازده در سطح میدان
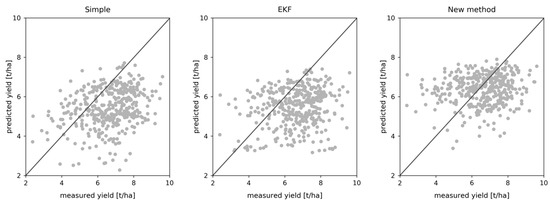
نتایج جدول 3 نشان میدهد که بدون جذب، AquaCrop-OS نتایج نسبتاً ضعیفی با RMSE 1.32 تن در هکتار و یک سوگیری کاملاً قابلتوجه، که در MPE 15.2٪ بیان میشود، تولید کرد که نشاندهنده تمایل مدل به تخمین بیش از حد عملکرد است. طرح به روز رسانی ساده هیچ تأثیری از نظر دقت نداشت، اما سوگیری را به یک دست کم گرفتن معکوس کرد. EKF با کاهش قابل توجهی از RMSE به 1.20 تن در هکتار و بایاس کمی کمتر عمل کرد.
روش جدید PSO ما مشابه یا بهتر از EKF با این دو عمل کرد αمقادیر 5 و 10 هنگام استفاده از هر سه عدم قطعیت. تنها استفاده از ورودیهای سنجش از راه دور منجر به تغییرات کوچکی در RMSE شد، اما بایاس را از مثبت به منفی در همه تنظیمات معکوس کرد، مشابه آنچه در بهروزرسانیهای ساده و EKF مشاهده کردیم. افزودن عدم قطعیتهای مربوط به پارامتر منجر به بهبود در RMSE و MPE شد، در حالی که افزودن بعدی ورودیهای مرتبط با آبوهوا نتایج را فقط اندکی تحت تأثیر قرار داد و گاهی اوقات MPE را کمی بدتر کرد. نسخه تطبیقی عملکرد قابل مقایسه ای داشت و حتی گاهی اوقات از نسخه های غیر تطبیقی بهتر عمل می کرد. به طور کلی، هنگام استفاده از هر سه عدم قطعیت، نتایج مدل تا 0.42 تن در هکتار در RMSE، 11.2٪ در MPE، و 15٪ از نظر pmatch بهبود یافتند.
همه نسخههای رویکرد ما در کاهش تعصب موفق بودند. این موضوع در نمودار پراکندگی شکل 7 نیز مشهود است. همچنین نشان دهنده تمایل روش جدید برای کاهش دامنه پیش بینی ها با اجتناب از نتایج کم < 5 تن در هکتار است.
3.2. تخمین بازده سطح پیکسل
جدول 4 نشان می دهد که در سطح پیکسل، مدل بدون به روز رسانی مجدداً RMSE بالایی تولید کرد و بایاس 12.7٪ را نشان داد. هر دو به روز رسانی ساده و EKF تعصب را به کمتر از برآورد -14.9٪ و -13.3٪ معکوس کردند. جالب توجه است که هر دو تکنیک عدم دقت را افزایش دادند.
روش جدید هنگام استفاده از سنجش از دور و عدم قطعیت های مربوط به پارامترها بهتر عمل کرد، در حالی که اضافه کردن عدم قطعیت مربوط به آب و هوا نتایج را به طور مداوم بهبود بخشید. با این حال، حتی بهترین نتایج فقط RMSE را حدود 0.09 تن در هکتار کاهش داد. با وجود آن، مجدداً توانست تعصب را به میزان قابل توجهی کاهش دهد. به نظر میرسد نسخه تطبیقی، عدم قطعیتهای مختلف را بهطور پیوستهتر ترکیب میکند، همانطور که با کاهش RMSE و MPE با هر عدم قطعیت اضافه نشان داده میشود. نمودار پراکندگی در شکل 8 این یافته ها را پشتیبانی می کند. همانطور که قبلا ذکر شد، روش جدید از طریق پیشبینیهای کمی بالاتر با محدوده کمی کوچکتر، سوگیری را کاهش داد.
3.3. تخمین بازده انباشته پیکسل به فیلد
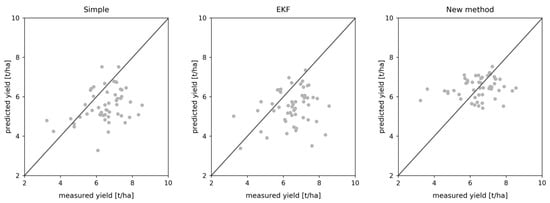
به طور کلی، نتایج تجمیع شده ( جدول 5) بهتر از آنهایی هستند که در سطح پیکسل هستند، که نشان دهنده مزایای تجمع است. با این حال، هنگامی که با نتایج سطح میدان مقایسه می شود، تفاوت ها آشکار می شود. بدون بهروزرسانی، مدل نتایج بهتری را در مجموع نسبت به سطح میدانی ایجاد کرد، در حالی که بهروزرسانی ساده تفاوت معنیداری را نشان نداد. با این حال، EKF در مقیاسهای جمعآوری بدتر از اجراهای میدانی عمل کرد که با RMSE بالاتر نشان داده شد. روش جدید، در مقایسه، نتایج مشابه یا بهتری را در انبوه در مقایسه با سطح میدان ارائه میکند و بایاس کمی کوچکتر است. نتایج برای تنظیمات مختلف عدم قطعیت به طور کلی مطابق با مشاهدات در بخشهای قبلی رفتار میکنند. در مقایسه با مدل بدون بهروزرسانی، ما فقط پیشرفتهای کوچکی را برای همه طرحهای بهروزرسانی مشاهده کردیم. باز هم نمودار پراکندگی در شکل 9دامنه کوچکتر، اما همچنین کاهش سوگیری در پیش بینی ها با استفاده از روش جدید در مقایسه با به روز رسانی ساده و EKF را نشان می دهد.
3.4. عملکرد R 2
همانطور که قبلا ذکر شد ، ما به طور کلی مقادیر R2 پایین را در همه برآوردهای عملکرد مشاهده کردیم. این به ویژه شگفتانگیز است، زیرا حتی مقادیر خوب RMSE و MPE با مقادیر پایین R2 مرتبط بودند . نمودارهای پراکندگی در بخش های قبلی نیز نشان دهنده همبستگی کم بین مقادیر عملکرد پیش بینی شده و اندازه گیری شده است.
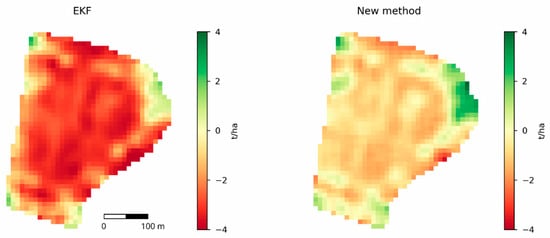
یک توضیح می تواند سوگیری نسبت به دست کم گرفتن شدید در برخی موارد و بیش از حد در برخی موارد باشد. این نوع سوگیری خود را در معیارهایی مانند MPE نشان نمی دهد، اما ممکن است با نگاه کردن به خروجی ها به صورت جداگانه آشکار شود. بنابراین، نتایج میدانهایی را با بدترین پیشبینیها بررسی کردیم. شکل 10 نمونه ای را برای بیش از حد و کم برآوردهای شدید در یکی از زمینه ها نشان می دهد. نتایج کلی با استفاده از بهروزرسانی EKF سوگیری آشکارتری نسبت به دست کمگرفتنها داشت (≤ -3 تن در هکتار). روش جدید همچنین خطاهای قابل توجهی ایجاد کرد، اما آنها تمایل داشتند کمی به طور مساوی توزیع شوند و در بیشتر موارد کمتر چشمگیر باشند. با این وجود، هر دو نتیجه روندهای مشابهی را با مناطق برآورد بیش از حد در نزدیکی بالا سمت چپ و راست و همچنین مرزهای پایین سمت چپ درشکل 10 . بخشهای باقیمانده عمدتاً دستکم گرفته شدند، بهویژه در نزدیکی مرکز و در مرز سمت راست میدان. این مسائل ممکن است با پیکسل های مختلط توضیح داده شوند و اغلب بازده پایین در نزدیکی مرزهای میدان مشاهده شده است که توسط مدل گرفته نشده است.
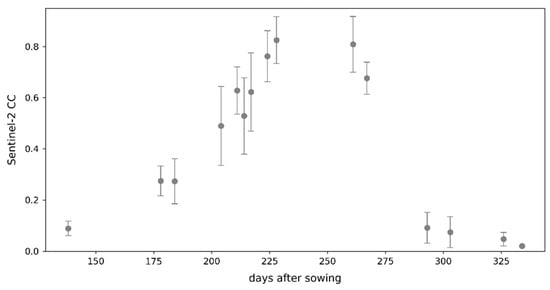
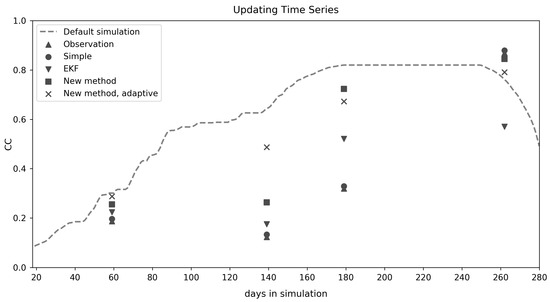
نمودار سری زمانی در شکل 11 ممکن است به دلایل رفتارهای مختلف تکنیک های به روز رسانی و همچنین مشاهدات Sentinel-2 CC اشاره کند. همانطور که قبلا ذکر شد، مشاهدات CC اغلب با آنچه که مدل AquaCrop-OS به طور پیشفرض شبیهسازی میکرد، بسیار متفاوت بود. در این مثال، مشاهدات بسیار کمتر از CC پیش بینی شده توسط مدل (بدون به روز رسانی)، به خصوص در مراحل رشد اولیه بود. بنابراین، بهروزرسانیهای EKF در بسیاری از موارد پایین بود، در حالی که روش جدید اغلب اصلاحات چشمگیر کمتری انجام میداد.
4. بحث
در این مطالعه، ما یک روش به روز رسانی جدید مبتنی بر PSO برای شبیه سازی عملکرد گندم با استفاده از مدل AquaCrop-OS معرفی کردیم. همانطور که قبلاً ذکر شد، مقایسه ما به نتایج طرحهای بهروزرسانی مختلف اعمال شده در سناریوی پیشبینی بازده یکسان میپردازد. ما اجراها را در مقیاس های مختلف مقایسه کردیم.
به طور کلی، روش جدید بهتر از یک به روز رسانی ساده و مشابه یا بهتر از رویکرد به روز رسانی EKF عمل کرد. به ویژه در کاهش تعصب در تخمین موفق بود و از این نظر از بهروزرسانی ساده و بهروزرسانی EKF بهتر عمل کرد. با این حال، EKF برای تصحیح خطاهای تصادفی در حالت مدل به جای خطاهای سیستماتیک طراحی شده است، بنابراین تقویت حالت یا تصحیح سوگیری ممکن است عملکرد آن را در این رابطه بهبود بخشد [ 64 ]. علاوه بر این، سایر تکنیکها مانند فیلتر کالمن یا بهروزرسانی فیلتر ذرات ممکن است بهتر به موارد غیرخطی در مدل بپردازند.
تنظیمات انتخاب شده برای به روز رسانی تا حد زیادی عملکرد را تعیین می کند. عامل وزنی αتأثیر قابل توجهی داشت و مقدار بهینه وابسته به مقیاس بود. این امر نیاز به آزمایش و کالیبراسیون قبلی توسط کاربر را ایجاد می کند که برای اکثر برنامه ها ایده آل نیست. تحقیقات بیشتر ممکن است بهترین روش را برای تنظیم نشان دهد α، که ممکن است به تعداد و/یا نوع فایلهای PDF عدم قطعیت یا مقیاس بستگی داشته باشد. با این حال، نسخه تطبیقی نتایج امیدوارکنندهای را از طریق خود تنظیم نشان داد α. عملکرد آن در مقایسه با سایر تنظیمات در همه مقیاسها بود، حتی اگر در بیشتر موارد، بهترین طرح بهروزرسانی نبود. به جای راهنمایی برای تنظیم دستی α، ممکن است ترجیح داده شود که روش درگیر در تابع هدف را بهبود بخشد.
مشاهدات دیگر در این زمینه این است که بالاتر است α(مقادیر پنج و بالاتر) در سطح زمین سودمند به نظر می رسید. ممکن است استدلال شود که مشاهدات سنجش از دور نسبت به شبیه سازی برتری دارند و بنابراین وزن بالاتر به طور خودکار منجر به بهبود قابل توجهی در پیش بینی ها می شود. با این حال، این تفسیر با نتایج ضعیف بهدستآمده در هنگام استفاده از عدم قطعیت مربوط به سنجش از راه دور به تنهایی یا در بهروزرسانی ساده در تضاد است. به احتمال زیاد دلیل آن در عدم قطعیت های مربوط به مدل نهفته است، که اغلب به طور معمول در اطراف یا نزدیک به مقدار CC شبیه سازی شده توزیع می شوند (کج می شوند)، در حالی که مشاهدات سنجش از دور به طور قابل توجهی متفاوت است. بنابراین، وزن بیشتری در عدم قطعیت مربوط به سنجش از دور لازم است تا بر دو توزیع مرتبط با مدل مشابه “بیشتر” شود. این تفسیر بیشتر توسط این واقعیت پشتیبانی می شود که سطح میدان به مقادیر α بالاتری نسبت به سطح پیکسل نیاز دارد. در پیادهسازی در سطح پیکسل، ما از همان فایلهای PDF عدم قطعیت مرتبط با مدل (بر اساس 10000 شبیهسازی هر کدام) استفاده کردیم، اما فقط همسایگی پیکسل را در نظر گرفتیم. به طور طبیعی، ناهمگونی در چنین نمونه کوچک و محدود فضایی بسیار کوچکتر است. بنابراین، توزیع عدم قطعیتهای مربوط به سنجش از دور در همسایگی پیکسلها نسبت به کل میدان باریکتر است و در نتیجه منجر به احتمال کمتری از همپوشانی با CC شبیهسازیشده فعلی AquaCrop-OS میشود. نتیجه این است که به اکثر پیشبینیهای سنجش از دور فاصله هلینگر 1 اختصاص داده میشود و بنابراین وزنهای بالاتری نسبت به سطح میدان دریافت میکنند، حتی با فاصله نسبتاً کوچک. ما از همان فایلهای PDF عدم قطعیت مرتبط با مدل (بر اساس 10000 شبیهسازی هر کدام) استفاده کردیم، اما فقط همسایگی پیکسل را در نظر گرفتیم. به طور طبیعی، ناهمگونی در چنین نمونه کوچک و محدود فضایی بسیار کوچکتر است. بنابراین، توزیع عدم قطعیتهای مربوط به سنجش از دور در همسایگی پیکسلها نسبت به کل میدان باریکتر است و در نتیجه منجر به احتمال کمتری از همپوشانی با CC شبیهسازیشده فعلی AquaCrop-OS میشود. نتیجه این است که به اکثر پیشبینیهای سنجش از دور فاصله هلینگر 1 اختصاص داده میشود و بنابراین وزنهای بالاتری نسبت به سطح میدان دریافت میکنند، حتی با فاصله نسبتاً کوچک. ما از همان فایلهای PDF عدم قطعیت مرتبط با مدل (بر اساس 10000 شبیهسازی هر کدام) استفاده کردیم، اما فقط همسایگی پیکسل را در نظر گرفتیم. به طور طبیعی، ناهمگونی در چنین نمونه کوچک و محدود فضایی بسیار کوچکتر است. بنابراین، توزیع عدم قطعیتهای مربوط به سنجش از دور در همسایگی پیکسلها نسبت به کل میدان باریکتر است و در نتیجه منجر به احتمال کمتری از همپوشانی با CC شبیهسازیشده فعلی AquaCrop-OS میشود. نتیجه این است که به اکثر پیشبینیهای سنجش از دور فاصله هلینگر 1 اختصاص داده میشود و بنابراین وزنهای بالاتری نسبت به سطح میدان دریافت میکنند، حتی با فاصله نسبتاً کوچک. ناهمگونی در چنین نمونه کوچک و محدود فضایی بسیار کوچکتر است. بنابراین، توزیع عدم قطعیتهای مربوط به سنجش از دور در همسایگی پیکسلها نسبت به کل میدان باریکتر است و در نتیجه منجر به احتمال کمتری از همپوشانی با CC شبیهسازیشده فعلی AquaCrop-OS میشود. نتیجه این است که به اکثر پیشبینیهای سنجش از دور فاصله هلینگر 1 اختصاص داده میشود و بنابراین وزنهای بالاتری نسبت به سطح میدان دریافت میکنند، حتی با فاصله نسبتاً کوچک. ناهمگونی در چنین نمونه کوچک و محدود فضایی بسیار کوچکتر است. بنابراین، توزیع عدم قطعیتهای مربوط به سنجش از دور در همسایگی پیکسلها نسبت به کل میدان باریکتر است و در نتیجه منجر به احتمال کمتری از همپوشانی با CC شبیهسازیشده فعلی AquaCrop-OS میشود. نتیجه این است که به اکثر پیشبینیهای سنجش از دور فاصله هلینگر 1 اختصاص داده میشود و بنابراین وزنهای بالاتری نسبت به سطح میدان دریافت میکنند، حتی با فاصله نسبتاً کوچک. α. این وضعیت ممکن است با تغییر پهنای باند هسته یا تجزیه و تحلیل مقیاسهای مختلف، تعداد پیکسلها و غیره برطرف شود تا احتمالاً یک رابطه بین تعداد فایلهای PDF یا اندازه نمونه و بهینه مشاهده شود. αارزش ها برای انتخاب رویکرد دیگر ممکن است استفاده از یک نسخه تطبیقی باشد که به نظر می رسید به طور کاملاً مؤثری با سطوح مختلف تنظیم می شود، که در عملکرد قابل مقایسه آن با نسخه های ثابت نشان داده شد.
با توجه به عدم قطعیت ها، تمام نسخه های روش جدید موفق شدند PDF های مختلف را با موفقیت ترکیب کنند. تنها استفاده از عدم قطعیت سنجش از دور منجر به نتایج ضعیفی شد، احتمالاً به دلیل نحوه مدیریت وزن: در صورت داشتن تنها یک ورودی عدم قطعیت، به آن توزیع همیشه وزن 1 اختصاص داده می شود (معادله (18) را ببینید). انتظار می رود نتایج به نتایج یک به روز رسانی جایگزین ساده نزدیک باشد زیرا PDF مربوط به سنجش از راه دور تنها مورد در نظر گرفته شده است. سپس یک توزیع بهینه به دست آمده به وضوح نزدیک به پیکسل مشاهده شده یا مقدار میانگین CC میدان قرار می گیرد. در صورت توزیع نرمال واقعی مقادیر، باید یکسان باشد.
همانطور که انتظار می رفت، اضافه کردن عدم قطعیت مربوط به مدل همیشه نتایج را بهبود می بخشد، به جز اضافه کردن PDF آب و هوا، که قادر به افزایش مداوم عملکرد نبود. یک دلیل احتمالی می تواند شباهت دو توزیع باشد که در شکل 2 نشان داده شده است. افزودن فایلهای PDF بدون قطعیت خاص پارامتر به جای PDF یکپارچه ممکن است جایگزین بهتری در آینده باشد. این همچنین اهمیت انتخاب نوع عدم قطعیت مربوطه و کمی سازی صحیح آن را برجسته می کند. با این حال، ممکن است برای اطمینان از ادغام مناسب همه فایلهای PDF، تحقیقات بیشتری لازم باشد. این وظیفه با بهبود بهینه سازی ارتباط نزدیکی دارد α، اما ممکن است شامل افزایش همسایگی 3 × 3 پیکسل با یک مستطیل یا دایره بزرگتر باشد.
مشاهدات دیگر این بود که مقادیر R2 عموماً در تمام تحلیلها، روشها و مقیاسها ضعیف بودند. بررسی ما نشان داد که بسیاری از زمینه ها دارای مناطقی بودند که بیش از حد و دست کم برآورد شده بودند. این نقاط پرت مکرر ممکن است باعث کاهش مقادیر R2 شود ، حتی در مواردی که مقادیر RMSE و MPE نسبتاً خوبی دارند. به نظر میرسد روش جدید کمتر از بهروزرسانی EKF بازده را دستکم میگیرد، اما روند کلی مشابهی را نشان داد.
در این زمینه، ما همچنین نمیتوانیم احتمال سوگیری قابل توجهی را در خود دادههای Sentinel-2 CC رد کنیم. خطاهای کم ذکر شده در گزارش اصلی در مورد الگوریتم نشان دهنده عملکرد خوب است [ 36 ]. با این حال، مجموعه دادههای مورد استفاده برای آموزش و اعتبارسنجی شبکههای عصبی مصنوعی در الگوریتم از شبیهسازیهای انتقال تابشی بهجای دادههای تجربی درجا بهدست آمدهاند، بنابراین ممکن است برای همه موقعیتها نماینده نباشند. این واقعیت که R 2 پایین استمقادیر در تمام نتایج بهروزرسانی وجود داشت، بیشتر نشان میدهد که آنها احتمالاً به خود روشهای بهروزرسانی ارتباطی ندارند، اما به مسائلی در ورودیهای CC یا دادههای بازده درجا مرتبط هستند. این بیشتر با این واقعیت پشتیبانی می شود که پیش بینی های سطح پیکسل بسیار بدتر بودند و به روز رسانی ساده به خصوص ضعیف عمل می کرد. بنابراین دادههای سطح پیکسل ممکن است غیرقابل اعتماد باشند. با افزایش جزئیات در فرآیند (یعنی تعداد شبیهسازیهای فردی در هر زمینه)، روند گستردهتر ثبت میشود، اما پیشبینیهای عملکرد پیکسلی منفرد مطابقت ندارند. با این وجود، از آنجایی که هیچ اندازه گیری خارجی در محل در منطقه مورد مطالعه ما در دسترس نبود، ما نتوانستیم کیفیت را به طور قطعی تأیید کنیم.
در نهایت، AquaCrop-OS همچنین ممکن است عدم قطعیت های ناشناخته ای را معرفی کند. حتی با کالیبراسیون دقیق، مقیاس کردن چنین مدلی برای نشان دادن شرایط در تعدادی از زمینههای توزیع شده در یک منطقه بزرگ دشوار است، چه رسد به مقیاسهای فضایی مختلف.
علاوه بر سوالات مربوط به عملکرد، الزامات پیش پردازش برای برنامه ها مهم است. رویکرد در پیاده سازی که در اینجا توضیح داده شده است نیاز به پیش پردازش گسترده دارد. با این حال، تکنیک ما در مورد نوع نمایش عدم قطعیت انعطافپذیر است، برنامههای کاربردی آینده نیازی به تکیه بر رویکرد محاسباتی فشرده مانند شبیهسازیهای مونت کارلو و تخمین چگالی هسته ندارند. در عوض، اگر دانش قبلی در مورد ویژگیهای مدل در دسترس باشد، برای مثال، روابط عملکردی ساده ممکن است نشان دهنده عدم قطعیت باشد.
5. نتیجه گیری ها
ما روشی را برای بهروزرسانی متغیرهای مدل در طول شبیهسازی، با در نظر گرفتن عدم قطعیتها در مدل و دادههای جذب شده، ارائه کردیم. ما روشی را برای جذب داده های سنجش از دور در یک مدل محصول پویا برای بهبود تخمین عملکرد توصیف کردیم. ثابت شد که این روش با سایر تکنیکهای بهروزرسانی موجود قابل مقایسه است، اما بهویژه قادر به کاهش تعصب در برآوردها بود و توانست منابع مختلف عدم قطعیتها را ترکیب کند.
ما این فرآیند را به طور خاص برای برنامه در مطالعه خود شرح دادیم. با این حال، این اصل به راحتی به سایر مدل ها یا متغیرهای مدل قابل انتقال است. انعطافپذیری آن در مورد نمایش عدم قطعیتها همچنین امکان انطباق با موقعیتهای مختلف را فراهم میکند که شبیهسازی مونت کارلو ممکن است امکانپذیر نباشد. دانش قبلی در مورد مدل مورد نظر امکان نمایش عدم قطعیت ها را با یک رابطه عملکردی ساده یا مجموعه ای از توزیع ها فراهم می کند.
ممکن است تحقیقات بیشتری برای تجزیه و تحلیل رفتار تکنیک در مورد تعداد مختلف عدم قطعیت ها و بهبود بالقوه در ترکیب آنها در طرح به روز رسانی مورد نیاز باشد. علاوه بر این، بهبود معیارهای فاصله، تابع هدف، و وزن نیز ممکن است به عنوان قابل استفاده در مجموعه دادههای مختلف سنجش از دور و اندازههای همسایگی پیکسل مورد توجه باشد. همچنین می توان پیشرفت های مربوط به توزیع بهینه را تجزیه و تحلیل کرد، به عنوان مثال، با اضافه کردن چولگی یا کشیدگی. علاوه بر این، مقایسههای اضافی با سایر تکنیکهای بهروزرسانی غیرخطی مانند فیلتر کلمن ممکن است بینشهای ارزشمندی ارائه دهد.






بدون دیدگاه