1. معرفی
اطلاعات خاک با وضوح بالا، دقت و کامل بودن پوشش فضایی در یک منطقه بزرگ به طور فزاینده ای برای کاربردهای مدل سازی زمین شناسی، مانند مدل سازی اکولوژیکی، مدل سازی هیدرولوژیکی، مدیریت کشاورزی و مدیریت کاربری زمین ضروری است [ 1 ، 2 ، 3 ، 4 ]. نقشه برداری دیجیتالی خاک (DSM یا نقشه پیش بینی خاک) در حال حاضر کارآمدترین راه برای پیش بینی تغییرات فضایی خاک در یک منطقه است. 5 ]]. به طور معمول، DSM ابتدا یک رابطه کمی خاک-محیط (یا مدل) بر اساس نمونه های خاک (به عنوان مثال، نقاط مدل سازی) ایجاد می کند تا روابط بین خاک و متغیرهای محیطی (مانند تغییرات زمین شناسی، تغییرات آب و هوا، تغییرات توپوگرافی، و غیره) را مشخص کند. ، و سپس مدل را برای تخمین مقادیر ویژگی خاک در مکان های بازدید نشده اعمال می کند [ 5 ، 6 ، 7 ]. کامل بودن و دقت متغیرهای کمکی محیطی در یک منطقه برای اطمینان از کامل بودن و دقت نتیجه DSM مورد نیاز است.
اگرچه منابع دادهای بیشتر و بیشتر از متغیرهای کمکی محیطی متنوع DSM در دسترس است، اما وجود مقادیر نامعتبر (همچنین به عنوان دادههای گمشده یا خالی شناخته میشود، که معمولاً به عنوان مقدار NoData یا مقدار NA مشخص میشوند) در متغیرهای کمکی محیطی فردی در برخی مناطق طبیعی است. در یک منطقه، به ویژه در یک منطقه بزرگ. برای مثال، دادههای متغیر حاصل از مشاهدات سنجش از راه دور ممکن است شامل مناطق کمربند یا بلوکشکل با مقدار نامعتبر باشد، یا به دلیل خرابی حسگر یا پوشش ابری در طول مشاهده. بررسی نحوه برخورد صحیح با داده های نامعتبر متغیرهای کمکی محیطی برای انجام DSM در کل منطقه برای به دست آوردن یک نقشه کامل خاک مهم است.
در حال حاضر، دو طرح اصلی برای پرداختن به ارزش NoData متغیرهای کمکی محیطی برای DSM وجود دارد: طرح مکان یابی و طرح پر کردن فضای خالی. طرح پرش مکان ساده ترین و همچنین پرکاربردترین طرح است که به وسیله آن مکان های دارای مقادیر NoData از هر متغیر محیطی مورد بررسی به سادگی در طول DSM نادیده گرفته می شوند. این بدان معنی است که چنین مکان بازدید نشده ای در انتظار پیش بینی توسط DSM با مقدار خاک NoData در نقشه خاک پیش بینی شده مشخص می شود. بسیاری از روشهای DSM اغلب مورد استفاده مانند SoLIM [ 8 ] و الگوریتم جنگل تصادفی [ 9 ، 10 ]] از این طرح استفاده کنید. با این حال، برای سلولهایی با مقادیر NoData برای چند متغیر کمکی (مثلاً فقط یک متغیر کمکی) و مقادیر معتبر برای متغیرهای کمکی دیگر، طرح رد شدن مکان اطلاعات مفید بالقوه ارائهشده توسط مقادیر متغیر کمکی معتبر برای این سلولها را کاملا نادیده میگیرد. همچنین، توجه داشته باشید که هر یک از متغیرهای محیطی ممکن است دارای مقادیر NoData برای مناطق یا مکانهای مختلف باشد. این طرح ممکن است کامل بودن لایه های داده را بدتر کند، به عنوان مثال، منجر به ایجاد یک منطقه بزرگتر با NoData در نقشه خاک پیش بینی شده نسبت به هر لایه متغیر محیطی شود.
طرح پر کردن فضای خالی برای استفاده حداکثری از مقادیر کمکی معتبر و تضمین کامل بودن نتیجه DSM اتخاذ شده است. برای دستیابی به این هدف، طرح خالی پر کردن سلول ها را با مقدار NoData متغیر کمکی محیطی به عنوان یک مقدار معتبر با درون یابی اختصاص می دهد و سپس DSM را بر روی مجموعه داده پر از خلأ متغیرهای کمکی محیطی انجام می دهد. الگوریتمهای درون یابی که معمولاً برای طرح پر کردن فضای خالی استفاده میشوند، شامل تخصیص مقدار NoData متغیر کمکی پیوسته در یک سلول به عنوان مقدار متوسط مقادیر غیر NoData در پنجره مجاور آن 3×3 سلول (به روشی تکراری برای ناحیه پیوسته با NoData) یا مقدار متوسط مقادیر غیر NoData یک متغیر کمکی پیوسته کامل در منطقه مورد مطالعه، در حالی که مقدار NoData متغیر کمکی طبقهای را در یک سلول به حالت [11 ]. یک الگوریتم توسعه یافته و خاص DSM با طرح پر کردن فضای خالی توسط Hugelius و همکاران ارائه شد. (2013)، که در آن آنها پایگاه داده محتوای کربن آلی خاک دور قطبی شمالی را از طریق ایجاد تابعی بین غلظت کربن و چگالی ظاهری خاک ایجاد کردند، در حالی که مقدار NoData چگالی ظاهری خاک بر اساس مقدار متوسط وزن مخصوص ظاهری خاک در کل تخمین زده شد. منطقه مطالعه [ 12 ].
محدودیت طرح خالی پر کردن این است که دقت نتیجه DSM به دلیل خطاهای معرفی شده توسط الگوریتم تخمین مقدار متوسط یا درون یابی مورد استفاده، به ویژه خطاهای منتشر شده و انباشته شده در طول درونیابی تکراری اعمال شده در یک ناحیه پیوسته با NoData تحت تأثیر قرار می گیرد. [ 13]. توجه داشته باشید که الگوریتم های درون یابی مختلف بر اساس مفروضات مختلف توزیع (و حتی منابع) مقدار NoData در یک متغیر محیطی است که ممکن است اغلب درست نباشد. نتایج درون یابی برای یک منطقه و با مجموعه داده یکسان توسط الگوریتم های درون یابی مختلف ممکن است واگرا شوند. این وضعیت همچنین عملی بودن طرح پر کردن فضای خالی را محدود می کند، حتی قبل از در نظر گرفتن هزینه اضافی درونیابی در یک منطقه بزرگ.
در این مطالعه، ما یک روش جدید با یک طرح جدید برای غلبه بر محدودیتهای ذکر شده در طرحهای موجود برای مقابله با مقادیر NoData متغیرهای کمکی محیطی برای DSM پیشنهاد میکنیم. روش پیشنهادی DSM را برای هر سلول جداگانه با مقدار NoData یک متغیر کمکی با استفاده از مقادیر معتبر سایر متغیرهای کمکی روی این سلول و بدون درونیابی مقدار کمکی NoData انجام میدهد. با روش پیشنهادی، پوشش فضایی کامل نتیجه DSM را می توان تا حد امکان به دست آورد، در حالی که هیچ خطایی با درونیابی مقادیر NoData ایجاد نمی شود.
2. روش ها
2.1. ایده پایه
اگر مجموعه متغیرهای کمکی محیطی انتخاب شده بتواند شرایط محیطی را که با تغییرات فضایی خاک در یک منطقه مورد مطالعه (به عنوان پیش فرض اجرای DSM) متغیر است، مشخص کند، زیر مجموعه آن هنگام حذف مقادیر NoData و حفظ مقادیر معتبر در این مکان، باید همچنان برای توصیف رابطه خاک-محیط زیست و انجام پیشبینی خاک در این مکان تا حدی در دسترس باشد. در چنین مکانی، خاک را می توان بر اساس زیرمجموعه متغیرهای کمکی بدون مقدار NoData پیش بینی کرد. عدم قطعیت پیشبینی خاک که با نادیده گرفتن متغیرهای کمکی محیطی با مقدار NoData در هر مکان منفرد معرفی میشود، میتواند در سطح مکان نیز کمی شود. به طور کلی، هر چه متغیرهای کمکی محیطی به دلیل وجود NoData نادیده گرفته شوند، عدم قطعیت مربوطه بیشتر است. این طرح مانند فیلتری برای نادیده گرفتن ارزش NoData (یا NA) متغیرهای کمکی محیطی عمل می کند. بنابراین، در این مقاله، آن را به اختصار طرح FilterNA نامیدیم.
طرح FilterNA می تواند بر محدودیت های موجود در طرح های موجود برای مقابله با مقدار NoData متغیرهای کمکی محیطی برای DSM غلبه کند. بر خلاف طرح مکان یابی، طرح FilterNA می تواند خاک را در هر مکان با ارزش معتبر برای حداقل یک متغیر محیطی پیش بینی کند. بنابراین، کامل بودن پوشش فضایی نتیجه DSM توسط این طرح میتواند تا حد امکان تضمین شود، که شامل تمام سلولها با مقادیر معتبر برای هر متغیر محیطی مورد بررسی میشود. در همین حال، طرح FilterNA ناحیه NoData را برای هیچ متغیر محیطی درونیابی نمیکند. این بدان معناست که بر خلاف طرح خالی پر کردن، طرح FilterNA توزیع یا منبع مقدار NoData را در متغیرهای کمکی محیطی فرض نمیکند و همچنین هزینههای اضافی درون یابی ندارد.
طرح FilterNA به عنوان یک روش جدید برای مقابله با مقدار NoData متغیرهای کمکی محیطی برای DSM، همانطور که در زیر توضیح داده شده است، پیاده سازی شده است. چندین روش DSM در پیش بینی ویژگی های خاک در یک منطقه بزرگ استفاده شده است، مانند جنگل تصادفی [ 14 ، 15 ، 16 ]، کریجینگ رگرسیون [ 17 ، 18 ]، و کریجینگ تصادفی جنگل [ 19 ، 20 ]. این روش ها بر اساس آمار یا یادگیری ماشینی هستند که به مقدار زیادی نمونه خاک به عنوان نقاط مدل سازی نیاز دارند. در همین حال، اغلب نیاز است که نمونههای خاک توزیع خاصی داشته باشند تا به اندازه کافی رابطه خاک-محیط زیست را در کل منطقه مورد مطالعه نشان دهد [ 5 ]، 21 ]. با این حال، طبیعی است که نمونههای خاک موجود برای DSM با مساحت بزرگ به طور کامل الزامات ذکر شده در بالا را برآورده نکنند.
2.2. طراحی تفصیلی روش پیشنهادی
در این مطالعه، ما یک روش مبتنی بر طرح FilterNA همراه با یک روش DSM طراحی کردیم که در ابتدا توسط ژو و همکاران پیشنهاد شده بود. (1997) (یعنی مدل استنتاج زمین خاک، SoLIM) [ 8 ]، که می تواند با چند نمونه خاک هدفمند یا موقت (یعنی بدون طراحی خاص از قبل) کار کند [ 22 ، 23 ، 24 ]. SoLIM میتواند خاک را در هر مکان بازدید نشده بر اساس شباهتهای شرایط محیطی با نمونههای خاک موجود پیشبینی کند، که بر این فرض اساسی استوار است که هر چه شرایط محیطی دو مکان شبیهتر باشد (یک مکان بازدید نشده و یک نمونه خاک)، شبیهتر است. خاک در این دو مکان [ 24 ، 25 ] است]. SoLIM همچنین میتواند عدم قطعیت پیشبینی را در هر مکان، محاسبهشده بر اساس شباهت شرایط محیطی بین مکان و نمونههای خاک، کمی کند. این با موفقیت در نقشهبرداری پیشبینیکننده خاک در مناطق مختلف مورد مطالعه اعمال شده است [ 22 ، 26 ، 27 ]. در این تحقیق روش طراحی شده برای ترکیب طرح FilterNA با SoLIM SoLIM-FilterNA نامیده می شود. در حالی که SoLIM اصلی طرح مکان یابی را برای مقدار NoData متغیرهای کمکی محیطی اتخاذ می کند، روش SoLIM-FilterNA برای پیش بینی توزیع خواص خاک در آن مکان ها با مقدار NoData برای برخی از متغیرهای محیطی طراحی شده است.
هنگامی که SoLIM-FilterNA پیشبینی خاک را مانند SoLIM در مکانهایی بدون مقدار NoData برای هر متغیر محیطی انجام میدهد، SoLIM-FilterNA طرح FilterNA را برای تخمین توزیع خواص خاک در مکانهایی با مقدار NoData برای یک یا چند متغیر کمکی محیطی با پیروی از روشی مشابه اتخاذ میکند. به عنوان SoLIM. در هر یک از این مکانها، SoLIM-FilterNA ارزش ویژگیهای خاک را به ارزش نمونههای خاک که بر اساس شباهتهای زیستمحیطی وزن میکنند، تخمین میزند که بر اساس متغیرهای کمکی محیطی با دادههای معتبر هم در مکان مورد نظر و هم در نمونه خاک جداگانه محاسبه میشود (یعنی به استثنای آن متغیرهای کمکی با NoData. ارزش در هر یک از مکان های درگیر).
جزئیات روش SoLIM-FilterNA به شرح زیر است. بدون از دست دادن کلیت، مثالی را در نظر بگیرید که تنها یک مقدار NoData در بردار متغیر محیطی e i در یک مکان بازدید نشده i وجود دارد و هیچ مقدار NoData در بردار متغیر محیطی ej در محل نمونه خاک j وجود ندارد ، همانطور که در نشان داده شده است. معادله 1):
که در آن n تعداد متغیرهای کمکی محیطی انتخاب شده برای DSM در منطقه مورد مطالعه است، و e i,m = NA نشان میدهد که مقدار m- امین متغیر کمکی محیطی NoData در مکان مورد نظر i است. شباهت محیطی ( Si ,j ) بین مکانهای i و j با حذف متغیر کمکی محیطی m محاسبه میشود، همانطور که در رابطه (2) نشان داده شده است:
که در آن E n ( i,j ) تابع شباهت در سطح متغیر برای محاسبه شباهت n- امین متغیر کمکی محیطی بین مکانهای i و j است. تابع تشابه سطح متغیر اغلب یک تابع فاصله Gower یا یک تابع گاوسی برای متغیرهای کمکی پیوسته (مانند ارتفاع، گرادیان شیب، دما، و غیره)، و یک تابع بولی برای متغیرهای کمکی طبقهای (مانند مواد مادر) است [ 22 ، 28 ]. ، 29 ]. P (…) تابع شباهت محیطی برای ادغام شباهتهای سطح متغیر هر یک از متغیرهای کمکی محیطی بین مکانهای i است.و j یک شباهت کلی شرایط محیطی بین i و j باشد. P (…) اغلب از یک حداقل عملگر [ 22 ، 28 ] استفاده می کند. محدوده مقدار S i,j [0، 1] است.
پس از اینکه مقادیر تشابه کلی شرایط محیطی بین مکان مورد نظر i و هر نمونه خاک به عنوان طرح فوق محاسبه شد، ارزش ویژگی خاک در مکان i (یعنی V i ) را می توان با یک معادله میانگین وزنی استفاده شده توسط SoLIM پیش بینی کرد. همانطور که در معادله (3) [ 22 ] نشان داده شده است:
که در آن k تعداد نمونههای خاک مورد استفاده به عنوان نقاط مدلسازی است، Vj مقدار ویژگی خاک j مین نمونه خاک است، آستانه S آستانه تشابه شرایط محیطی توسط کاربر است در صورتی که نقاط مدلسازی با شرایط محیطی بسیار متفاوت با مکان بهره i برای تخمین V i استفاده شد و تابع iif ( S i,j ≥ S آستانه , S i,j , 0) وقتی S i,j ≥ S i,j را برمی گرداند .آستانه S ، در غیر این صورت 0 را برمی گرداند. فقط آن نقاط مدل سازی با شرایط محیطی به اندازه کافی شبیه به مکان مورد علاقه برای محاسبه مقدار Vj استفاده می شود. اگر هیچ یک از نقاط مدلسازی شرایط محیطی مشابه با مکان بهره بزرگتر از آستانه تشابه نداشته باشد، تخمین خاک برای مکان با روش پیشنهادی NoData خواهد بود، که همان چیزی است که توسط SoLIM است. هنگامی که مقادیر خواص خاک در هر مکان بازدید نشده همانطور که در بالا ذکر شد تخمین زده میشود، میتوان با روش پیشنهادی نقشه خواص خاک منطقه مورد مطالعه را تهیه کرد.
عدم قطعیت معرفی شده توسط طرح FilterNA در هر مکان جداگانه را می توان بر اساس تعداد متغیرهای محیطی با مقدار NoData در یک مکان تعیین کرد. ساده ترین معادله بالقوه برای محاسبه چنین عدم قطعیتی باید نسبت بین تعداد متغیرهای کمکی محیطی با مقدار NoData و تعداد متغیرهای کمکی محیطی در نظر گرفته شود (یعنی n ). با این حال، چنین معادله ای به این معنی است که هر یک از متغیرهای کمکی محیطی دارای اهمیت یکسانی در DSM هستند که در عمل مورد سوال است. چندین عامل محیطی (به عنوان مثال، آب و هوا، مواد اولیه، زمین و پوشش گیاهی) مرتبط با توزیع فضایی خاک وجود دارد که می تواند در DSM به درجات مختلف در نظر گرفته شود [ 5 ].]. تعداد متغیرهای محیطی که عوامل محیطی فردی را کمیت می کنند ممکن است به طور چشمگیری در بین عوامل محیطی تغییر کند، جایی که اغلب همبستگی بین متغیرهای کمکی محیطی وجود دارد که همان یک عامل محیطی را کمیت می کنند [ 5 ]. به عنوان مثال، تعداد زیادی متغیرهای توپوگرافیک (مانند شیب شیب، انحناها، شاخص رطوبت توپوگرافی، و غیره) وجود دارد که فاکتور زمین را کمی می کنند و تا حدی با یکدیگر همبستگی دارند (به عنوان مثال، همبستگی بین شیب شیب و شاخص رطوبت توپوگرافیک). ) که به طور فراگیر در DSM در مقایسه با متغیرهای کمکی سایر عوامل محیطی استفاده می شوند [ 30]. در این شرایط، فرض کنید مجموعه متغیرهای کمکی محیطی که معمولاً در برنامههای کاربردی DSM استفاده میشود، شامل یک متغیر کمکی (یعنی نوع ماده اصلی) برای عامل ماده اصلی و بسیاری از متغیرهای توپوگرافیک برای عامل زمین است. در یک مکان، عدم قطعیت هنگام نادیده گرفتن نوع ماده اصلی باید بسیار بیشتر از نادیده گرفتن متغیر توپوگرافی (مثلاً شیب شیب یا شاخص رطوبت توپوگرافی) باشد.
بنابراین، در این مطالعه عدم قطعیت وارد شده توسط طرح FilterNA در محاسبه S i,j (یعنی عدم قطعیت _ NA i,j )) به صورت معادله (4) زیر طراحی شده است:
که در آن N تعداد عوامل محیطی انتخاب شده برای DSM در منطقه مورد مطالعه است، qتو(من)تعداد متغیرهای کمکی محیطی است که برای عامل محیطی u- ام در مکان مورد علاقه i و پتو(من،j)تعداد متغیرهای کمکی محیطی است که برای عامل محیطی u- ام با مقدار NoData در مکان مورد علاقه i یا نمونه خاک j استفاده می شود. محدوده مقدار Uncertainty_NA i,j [0، 1] است. هرچه Uncertainty_NA i,j بیشتر باشد، قابلیت اطمینان زیرمجموعه متغیرهای کمکی محیطی کمتر است، با نادیده گرفتن متغیرهای کمکی با مقدار NoData، در به تصویر کشیدن رابطه خاک و محیط زیست است.
عدم قطعیت پیشبینی روش پیشنهادی در مکان i (یعنی عدم قطعیت i در معادله (6) زیر) هم از عدم قطعیت پیشبینی بر اساس شباهتهای شرایط محیطی بین مکان i و نمونههای خاک پس از پردازش توسط طرح FilterNA و هم از عدم قطعیت معرفی شده ناشی میشود. با اعمال طرح FilterNA در مکان i (یعنی Uncertainty_NA i,j در معادله (5) زیر). اولی ترکیبی از عدم قطعیت بازنمایی نمونههای خاک در مکان مورد نظر i از نظر شرایط محیطی است (یعنی عدم قطعیت پیشبینی تعریف شده در SoLIM [ 31 ]).Uncertainty_Rep i در معادله (5) زیر) و قابلیت اطمینان اینکه زیرمجموعه متغیرهای کمکی محیطی با نادیده گرفتن آن متغیرهای کمکی با مقدار NoData همچنان میتواند رابطه خاک-محیط را به تصویر بکشد:
محدوده مقدار عدم قطعیت i [0، 1] است. چنین نقشههایی از عدم قطعیت i و Uncertainty_NA i میتوانند عدم قطعیت کلی نقشه ویژگی خاک تولید شده با روش پیشنهادی SoLIM-FilterNA در هر مکان و عدم قطعیت مربوطه معرفیشده توسط طرح FilterNA را نشان دهند.
3. مطالعه موردی
3.1. منطقه و داده های مطالعه
در این مقاله، روش پیشنهادی در نقشهبرداری پیشبینیکننده محتوای مواد آلی خاک (SOM) در لایه سطحی خاک در استان آنهویی (29°23’44″ شمالی – 34°39′5″ شمالی، 114°52′35″ شمالی استفاده شد. E – 119°39′37 E″)، چین. این منطقه به عنوان مطالعه موردی انتخاب شد، زیرا یک منطقه معمولی با توپوگرافی و شرایط آب و هوایی پیچیده است.
منطقه مورد مطالعه ( شکل 1 ) حدود 1.34 × 10 5 کیلومتر مربع بود .. زمین نسبتاً موج دار بود، با ارتفاعات از -92 متر تا 1806 متر، و شیب بین 0 تا 50 درجه. مناطق جنوبی و جنوب غربی منطقه مورد مطالعه کوهستانی با زمین ناهموار و متغیر بود، در حالی که منطقه شمالی دارای زمین نسبتا ملایم و بیشتر دشتی بود. شرایط اقلیمی در منطقه گذار بین اقلیم گرم معتدل و نیمه گرمسیری بود که در تابستان گرم و مرطوب و در زمستان خنک و خشک است. میانگین بارندگی سالانه بین 750 تا 2000 میلی متر و میانگین دما بین 14 تا 16 درجه سانتی گراد بود. مواد اولیه خاک در منطقه مورد مطالعه پیچیده و متنوع بود که شامل بازالت، گرانیت، پرکنیت، دیوریت، شیست، شیل، ماسه سنگ، کنگلومرا، گلسنگ، سنگ آهک، توف و غیره بود. کاربری اراضی عمدتاً شامل جنگل های سوزنی برگ،
در این مطالعه موردی، 478 نقطه نمونه خاک جمعآوریشده از منابع چندگانه با توزیع ناهموار به عنوان نقاط مدلسازی DSM استفاده شد، در حالی که 109 نقطه نمونه خاک دیگر از نمونهبرداری منظم (با شبکهای حدود 10 کیلومتر × 10 کیلومتر) و نمونهبرداری تصادفی جمعآوری شد. به عنوان امتیاز ارزیابی مستقل استفاده شد ( شکل 1 ).
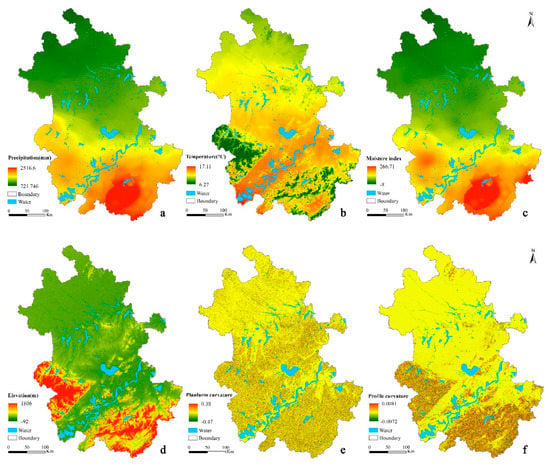
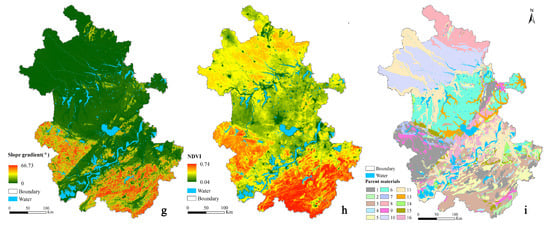
عوامل محیطی و متغیرهای کمکی محیطی مربوطه بر اساس دانش حوزه و مطالعات DSM موجود در این زمینه انتخاب شدند. برای SOM، شرایط آب و هوایی باید تأثیر زیادی داشته باشد. در همین حال، SOM نیز با توجه به دانش تخصصی خاک تحت تأثیر توپوگرافی و مواد مادر قرار می گیرد [ 5 ، 25 ، 27 ]]. بنابراین، عوامل محیطی اقلیم، زمین، ماده مادر و پوشش گیاهی در این مطالعه موردی در نظر گرفته شد. در مجموع 9 متغیر کمکی محیطی انتخاب شدند که شامل یک متغیر کمکی طبقه بندی شده (یعنی نوع ماده اصلی) و هشت متغیر کمکی پیوسته (یعنی میانگین بارندگی سالانه، دمای میانگین سالانه، شاخص رطوبت، ارتفاع، شیب شیب، انحنای پلانی، انحنای پروفیل، و شاخص گیاهی تفاوت عادی شده (NDVI)) ( جدول 1 ).
متغیرهای کمکی عامل آب و هوا (یعنی میانگین بارندگی سالانه و میانگین دمای سالانه) با وزن دهی معکوس فاصله (IDW) با مقادیر مشاهده در 35 ایستگاه هواشناسی (28 ایستگاه هواشناسی در داخل منطقه مورد مطالعه و هفت ایستگاه هواشناسی در فاصله 10 کیلومتری تا محدوده محدوده مورد مطالعه) از مرکز ملی اطلاعات هواشناسی. متغیرهای کمکی ضریب زمین بر اساس ماموریت توپوگرافی رادار شاتل (SRTM) DEM با وضوح 90 متر به دست آمد. شیب شیب، پلان فرم و انحنای پروفیل از DEM با SimDTA [ 32 ]، یک نرم افزار تجزیه و تحلیل زمین استخراج شد. NDVI از شاخص پوشش گیاهی طیفسنجی تصویربرداری با وضوح متوسط (MODIS) (با وضوح 250 متر) که از وبسایت دانلود شده است، به دست آمد.https://lpdaac.usgs.gov ). داده های مادی اصلی از نقشه زمین شناسی 1:500000 چین بود. فقط برای مواد اصلی، دادههای منبع NoData را برای برخی مکانها (نزدیک دریاچهها) نشان میدهد. تمام متغیرهای محیطی برای داشتن وضوح فضایی یکسان (یعنی 90 متر) مجدداً نمونه برداری شدند ( شکل 2 ). شاخص رطوبت و NDVI با الگوریتم دو خطی پیادهسازی شده در ArcGIS مجدداً نمونهبرداری شدند. دادههای ماده اصلی توسط حالت در یک پنجره 3 × 3، که در MATLAB انجام شد، نمونهگیری مجدد شد. مجموعه داده اصلی حاصل دارای 16302679 سلول با مقادیر معتبر در همه متغیرهای کمکی در منطقه مورد مطالعه بود.
3.2. طراحی تجربی
برای ارزیابی عملکرد روش پیشنهادی SoLIM-FilterNA، مجموعه داده های مختلف با توزیع متنوع NoData متغیرهای کمکی محیطی (به اصطلاح سناریوهای آزمایشی در این مقاله) بر اساس مجموعه داده اصلی ایجاد شد. از بین 9 متغیر کمکی محیطی، چهار متغیر توپوگرافی عامل زمین (به عنوان مثال، ارتفاع، شیب شیب، پلان فرم و انحنای پروفیل) بدون مقدار NoData در این آزمایش نگهداری شدند. این به دلیل این واقعیت بود که DEM برای استخراج متغیرهای توپوگرافی به طور فزاینده ای با کاملیت بالا (بدون مقدار NoData) و دسترسی در دسترس است. این تنظیم همچنین از وضعیت بالقوه داشتن سلول های NoData برای همه متغیرهای کمکی محیطی در آزمایش زیر جلوگیری کرد.
سناریوهای آزمایشی برای آزمایش با انتخاب تصادفی نقاط ارزیابی مستقل برای تنظیم مقدار NoData بر روی یک یا چند متغیر از پنج متغیر کمکی محیطی باقیمانده (با یک متغیر طبقهبندی و چهار متغیر پیوسته) به ترتیب در سطح سلول و سطح بلوک ایجاد شد. از میان هفت سناریو آزمایش در سطح سلول ( جدول 2 )، یک (به ترتیب متغیر پیوسته و متغیر طبقهای) و چندین (به ترتیب 2، 3، 4، 5، و 1-5) از پنج متغیر محیطی باقیمانده بودند. به طور تصادفی برای تنظیم مقدار NoData برای نمونه های ارزیابی مستقل انتخاب شده است. هفت سناریو در سطح سلول (یعنی T(V1C)، T(V1T)، T(V2)، T(V3)، T(V4)، T(V5) و T(Vr)؛ جدول 2 را ببینید.) با تنظیم مقدار NoData برای همه 109 نقطه ارزیابی مستقل ایجاد شد، و از آنها برای مقایسه عملکرد بین روش پیشنهادی SoLIM-FilterNA و روشهایی استفاده شد که میتوانند مقدار خاک را برای سلولهایی با مقدار NoData برای برخی از متغیرهای محیطی پیشبینی کنند (نگاه کنید به بخش 3.3زیر). علاوه بر این، یک سناریوی در سطح سلول (یعنی T(Vr-74cell)) با تنظیم مقدار NoData برای متغیرهای تصادفی انتخاب شده (1-5) در بین پنج متغیر کمکی محیطی بر روی 74 نقطه ارزیابی که به طور تصادفی از تمام نقاط ارزیابی مستقل انتخاب شده بودند، ایجاد شد. 70 درصد از تعداد). T(Vr-74cell) برای مقایسه عملکرد بین SoLIM-FilterNA و روش اتخاذ طرح مکان یابی، که نمی تواند ارزش ویژگی خاک را روی سلول ها با مقدار NoData متغیر محیطی پیش بینی کند، استفاده شد.
هنگامی که سناریوهای آزمایشی در سطح سلول، توزیع پراکنده ارزش NoData را در متغیرهای کمکی محیطی شبیهسازی کردند، سناریوهای آزمون سطح بلوک توزیع بلوکها را با NoData شبیهسازی کردند. چهار سناریو تست در سطح بلوک (یعنی T(Vr-buffer5)، T(Vr-buffer10)، T(Vr-buffer15)، و T(Vr-buffer25)؛ جدول 2 ) با گسترش تست در سطح سلول ایجاد شد. سناریوی T(Vr) برای تنظیم یک بافر (به ترتیب 5، 10، 15 و 25 سلول) برای هر یک از 109 نقطه ارزیابی در تنظیم مقدار NoData برای متغیرهای کمکی محیطی مربوطه با مقدار NoData. این سناریوهای آزمون سطح بلوک برای مقایسه عملکرد بین SoLIM-FilterNA و روشهایی که میتوانند ارزش خاک سلولها را با مقدار NoData برای بخشی از متغیرهای کمکی محیطی پیشبینی کنند، مورد استفاده قرار گرفتند.
توجه داشته باشید که در سناریوهای آزمایشی، تمام نقاط مدلسازی بدون تنظیم مقدار NoData برای متغیرهای کمکی محیطی نگهداری میشوند. این به این دلیل است که معمولاً برنامههای DSM واقعی فقط آن نقاط مدلسازی را بدون مقدار NoData برای متغیرهای کمکی محیطی طراحی و اتخاذ میکنند. روش پیشنهادی میتواند نقاط مدلسازی با مقدار NoData را برای متغیرهای کمکی محیطی به روشی مشابه پردازش مکانهای بازدید نشده با مقدار NoData برای متغیرهای کمکی محیطی مدیریت کند. ما معتقدیم که طراحی آزمایشی فعلی می تواند عملکرد روش پیشنهادی را به طور مناسب ارزیابی کند.
3.3. روش ارزشیابی
عملکرد SoLIM-FilterNA با عملکردهای SoLIM اصلی مقایسه شد که طرح پرش مکان را به سادگی از پیشبینی (با علامتگذاری NoData) سلولهای دارای مقدار NoData روی هر متغیر کمکی میگذراند، SoLIM با طرح پر کردن فضای خالی ترکیب میشود که انجام میدهد. پیش بینی پس از (به اصطلاح به طور خلاصه روش SoLIM-FillNA) و جنگل تصادفی (RF).
روش SoLIM-FillNA نگاشت SOM پیشبینیکننده را پس از پر شدن مقدار NoData هر متغیر کمکی در مجموعه داده مورد استفاده با درونیابی بر اساس یک پنجره همسایه 3×3 انجام داد. برای متغیرهای کمکی پیوسته، درون یابی با جایگزینی مقدار NoData با مقدار متوسط مقادیر معتبر در پنجره 3 × 3 به صورت تکراری انجام شد. برای متغیرهای طبقهای، مقدار NoData به طور مشابه با حالت در یک پنجره 3 × 3 جایگزین شد.
جنگل تصادفی [ 33 ]، یک روش یادگیری گروهی پرکاربرد، با موفقیت برای طبقه بندی، رگرسیون و سایر وظایف [ 34 ، 35 ] استفاده شده است و به طور فزاینده ای برای DSM اعمال می شود. الگوریتم RF مجموعهای از درختهای تصمیم را آموزش میدهد و از حالت کلاسها (طبقهبندی) یا میانگین پیشبینی (رگرسیون) درختهای منفرد، کلاس تولید میکند. RF می تواند پیش بینی را تحت شرایط با داده های از دست رفته در لایه های ورودی انجام دهد. در این مطالعه، ما از RF با فراخوانی بسته جنگل تصادفی پیادهسازی شده با زبان R استفاده کردیم. برای مقابله با مسئله ارزش NoData، rfImputeالگوریتم در بسته جنگل تصادفی برای اولین بار اجرا شد تا در ابتدا NoData را به عنوان مقدار میانگین برای متغیرهای پیوسته یا حالت برای متغیرهای طبقه بندی کند. سپس، به روشی تکراری، randomForest برای بدست آوردن ماتریس مجاورت از مجموعه داده ورودی پردازش شده بدون NoData فراخوانی شد. به نوبه خود، مقدار نسبت داده شده برای NoData بهروزرسانی میشود تا میانگین وزنی مقادیر معتبر با مجاورتها به عنوان وزن برای متغیرهای کمکی پیوسته یا دستهای با بیشترین میانگین مجاورت برای متغیرهای کمکی طبقهای باشد. پس از تکرار تعداد معینی از این فرآیند، یک مجموعه داده بدون NoData برای اجرای RF در دسترس خواهد بود. این روش استفاده از RF در مواقعی که داده های گمشده در حوزه های کاربردی مانند اپیدمیولوژیک وجود داشته باشد عملکرد خوبی نشان داده است [ 36 ]] و طبقه بندی پوشش زمین [ 37 ]. تا آنجا که ما می دانیم، عملکرد RF در برخورد با موضوع NoData در متغیرهای کمکی DSM به طور دقیق ارزیابی نشده است.
عملکرد هر روش تحت آزمون با استفاده از آمار کمی از تفاوتهای بین مشاهدات SOM و مقدار پیشبینی SOM هر نقطه ارزیابی مستقل، از جمله ریشه میانگین مربعات خطا (RMSE؛ معادله (7)) و میانگین خطای مطلق (MAE) ارزیابی شد. معادله (8) :
که در آن Vمنو V∧منبه ترتیب مقدار پیشبینیشده و مقدار ویژگی خاک مشاهدهشده در محل i هستند. nتعداد نمونه های ارزیابی است. ارزیابیهای مقایسهای در بین روشهای مورد آزمون دارای امتیاز مدلسازی یکسان و امتیاز ارزیابی مستقل یکسان بودند. توجه داشته باشید که SoLIM اصلی، با استفاده از طرح مکان یابی، NoData را روی آن سلول ها با مقدار NoData برای هر متغیر محیطی علامت گذاری کرد. این بدان معناست که خطای پیشبینی از SoLIM اصلی را نمیتوان برای آن نمونههای ارزیابی مستقل با مقدار NoData در هر متغیر محیطی محاسبه کرد. در بالا، آمار کمی برای SoLIM اصلی بر اساس نمونههای ارزیابی مستقل با مقادیر معتبر در هر متغیر کمکی محیطی (یعنی با سناریوی آزمایش در سطح سلول T (Vr-74cell)) محاسبه شد.
همچنین توجه داشته باشید که روش SoLIM-FilterNA همان خطا (و در نتیجه همان مقدار آمار کمی فردی) را در یک نمونه ارزیابی مستقل ایجاد کرد، بدون توجه به اینکه این سناریو NoData در سطح سلول یا NoData در سطح بلوک داشت. با این حال، برای SoLIM-FillNA یا RF، خطاهای تولید شده در یک نمونه ارزیابی مستقل تحت سناریوی NoData در سطح سلول و سناریوی سطح بلوک، به ترتیب متفاوت بود. بنابراین، SoLIM-FilterNA با SoLIM اصلی از نظر آمار خطا تنها تحت سناریوی آزمایشی در سطح سلول T (Vr-74cell) مقایسه شد. بر اساس همان نقاط ارزیابی، SoLIM-FilterNA تحت سناریوهای تست سطح بلوک، همان RMSE و MAE را با SoLIM-FilterNA در سناریوی تست سطح سلولی T(Vr) تولید می کند، در حالی که SoLIM-FillNA یا RF این کار را نمی کند.
عدم قطعیت پیشبینی تولید شده توسط روش پیشنهادی نیز به صورت کمی و کیفی با مقایسه با مواردی که از SoLIM اصلی و SoLIM-FillNA بر اساس نمونههای ارزیابی مورد تجزیه و تحلیل قرار گرفت. عدم قطعیت پیشبینی از RF معمولاً از طریق فواصل اطمینان و آمار U-test [ 38 ، 39 ] محاسبه میشود که با عدم قطعیت پیشبینی روش SoLIM متفاوت است. در این آزمایش، ما عدم قطعیت پیشبینی از RF را با عدم قطعیت از روش SoLIM مقایسه نکردیم.
3.4. نتایج و بحث
3.4.1. تحت سناریوهای تست سطح سلولی
با توجه به مقادیر RMSE و MAE از هر روش تحت سناریوهای آزمایش در سطح سلول بر اساس نمونههای ارزیابی مستقل ( جدول 3روش SoLIM-FilterNA کمترین خطا را از نظر RMSE در بین موارد تحت آزمایش و همچنین کمترین MAE را بهجز MAE RF در سناریوی T(Vr) به دست آورد. با توجه به RMSE و MAE، خطاهای پیشبینی از SoLIM-FilterNA با تنظیم تعداد متغیرهای کمکی با مقدار NoData در هر نقطه در سناریوهای آزمایش در سطح سلول (یعنی دنباله T(V1C)/T(V1T)، T افزایش یافت. (V2)، T(V3)، T(V4)، تا T(V5))، در حالی که چنین پدیده ای در SoLIM-FillNA و RF وجود نداشت. چنین عملکردی از SoLIM-FilterNA معقول و بهتر از سایر روشهای آزمایششده بود، زیرا، به طور کلی، زمانی که متغیرهای کمکی محیطی کمتری میتوانند دادههای معتبری برای پیشبینی ارائه دهند، خطاهای پیشبینی باید بزرگتر باشند. به دنبال این پدیده، RMSE و MAE از SoLIM-FilterNA تحت سناریوی T(Vr) به طور منطقی بین آنهایی از SoLIM-FilterNA تحت سناریو T(V2) و T(V3) بودند، در حالی که چنین پدیده ای در SoLIM-FillNA و RF وجود نداشت. روش SoLIM-FillNA بزرگترین RMSE و MAE را در هر سناریوی آزمایشی در سطح سلول تولید کرد زیرا خطا در مقادیر متغیر کمکی محیطی توسط الگوریتم درون یابی پر شد.
تحت سناریوی T(Vr-74cell) در سطح سلول، SoLIM-FilterNA RMSE و MAE کمتری نسبت به SoLIM اصلی تولید کرد ( جدول 3 ). در همین حال، SoLIM-FilterNA میتواند مقادیر ویژگی خاک را روی سلولهایی با مقدار NoData برای برخی از متغیرهای کمکی محیطی پیشبینی کند، جایی که SoLIM اصلی ارزش NoData را در پیشبینی خاک تولید میکند. این نشان می دهد که SoLIM-FilterNA می تواند هم کامل بودن پوشش مکانی و هم دقت نتیجه DSM را تضمین کند.
3.4.2. تحت سناریوهای تست سطح بلوک
تحت سناریوهای تست سطح بلوک، روش SoLIM-FilterNA کمترین RMSE و MAE را در مقایسه با SoLIM-FillNA و RF تولید کرد ( جدول 4 ). RMSE و MAE از SoLIM-FillNA و RF با اندازه بافر اتخاذ شده برای تنظیم NoData در اطراف هر یک از نقاط ارزیابی افزایش یافت. RMSE و MAE از SoLIM-FillNA کمتر از RF در سناریوهای آزمایش سطح بلوک با بافرهای کوچکتر (یعنی 5 و 10 سلول) بودند، اما آنها بزرگتر از سناریوهای آزمایش RF در سطح بلوک با بافرهای بزرگتر بودند (یعنی ، سلول های 15 و 25) ( جدول 4). این پدیده ممکن است به این دلیل باشد که خطاها در مقادیر متغیرهای کمکی محیطی در مرکز یک بلوک NoData پر شده توسط الگوریتم درون یابی باید زمانی که بلوک کوچک است کوچکتر باشد. این نشان میدهد که SoLIM-FilterNA زمانی که ارزش NoData در متغیرهای کمکی محیطی بهعنوان بلوکهای پیوسته فضایی توزیع شد، بهتر از SoLIM-FillNA و RF عمل کرد.
3.4.3. عدم قطعیت پیش بینی
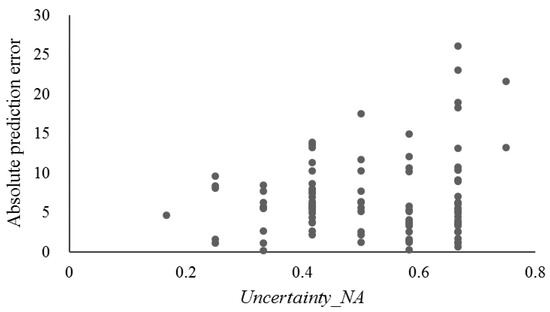
عدم قطعیت معرفی شده با استفاده از طرح FilterNA (یعنی Uncertainty_NA همانطور که در معادله (5) نشان داده شده است) به SoLIM-FilterNA تحت سناریوی تست سطح سلولی T(Vr) با رسم در برابر خطاهای پیشبینی مطلق نمونههای ارزیابی تجزیه و تحلیل شد ( شکل 3). ). به طور کلی، خطاهای پیشبینی مطلق با Uncertainty_NA افزایش یافت . این بدان معنی است که عدم قطعیت ایجاد شده با استفاده از طرح FilterNA را می توان به طور منطقی توسط SoLIM-FilterNA تعیین کرد.
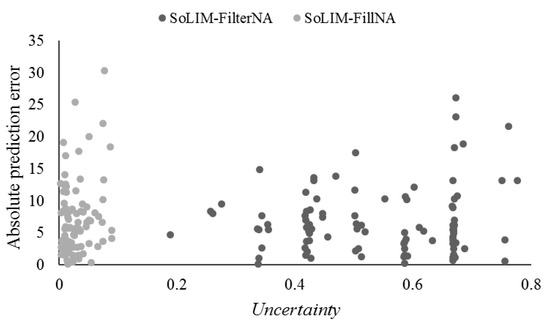
عدم قطعیت پیشبینی (یعنی عدم قطعیت i در معادله (6)، که ترکیبی از عدم قطعیت معرفیشده با استفاده از طرح FilterNA و عدم قطعیت پیشبینی بر اساس شباهتهای شرایط محیطی پس از پردازش توسط طرح FilterNA) تولید شده توسط SoLIM-FilterNA و SoLIM- FillNA بر اساس 109 نمونه ارزیابی مستقل تحت سناریوی تست سطح سلولی T(Vr) مقایسه شد ( شکل 4 ).
به طور کلی، عدم قطعیت پیشبینی از SoLIM-FilterNA میتواند به طور کامل نشان دهد که خطای پیشبینی مطلق از SoLIM-FilterNA با عدم قطعیت پیشبینی افزایش مییابد. در همین حال، عدم قطعیت پیشبینی از SoLIM-FillNA نمیتواند رفتار مشابه و معقولی را نشان دهد زیرا عدم قطعیت کمیسازیشده در SoLIM-FillNA عدم قطعیت معرفیشده توسط درونیابی برای پر کردن مقدار NoData متغیرهای کمکی محیطی را نادیده میگیرد. این نشان می دهد که عدم قطعیت پیش بینی را می توان به طور منطقی توسط SoLIM-FilterNA تعیین کرد.
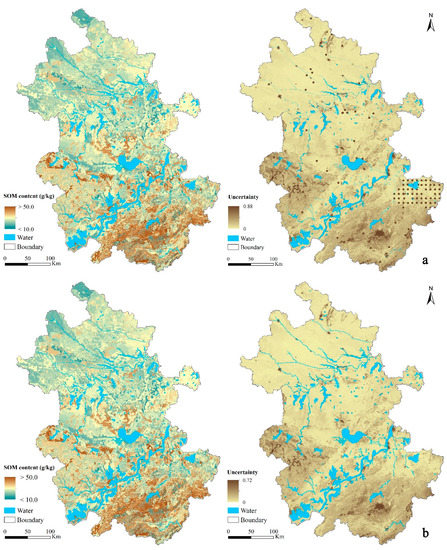
شکل 5 نقشه پیشبینی SOM و نقشه عدم قطعیت پیشبینی را نشان میدهد که توسط SoLIM-FilterNA، SoLIM-FillNA و SoLIM اصلی تحت سناریوی آزمون سطح بلوک T(Vr-buffer25) تولید شده است.
با مقایسه بصری بلوکها با NoData در سناریو، مقادیر عدم قطعیت پیشبینی از SoLIM-FilterNA در مکانهایی با NoData کمکی در سناریوی سطح بلوک بهطور قابلتوجهی بزرگتر از مقادیر تولید شده توسط SoLIM-FillNA با متغیرهای کمکی محیطی بدون مقدار NoData بود. عدم قطعیت پیشبینی SoLIM-FilterNA میتواند اطلاعات نشاندهنده بیشتری در مورد قابلیت اطمینان پیشبینی (به طور بالقوه دقت پیشبینی) از SoLIM-FilterNA نسبت به SoLIM-FillNA فراهم کند، زمانی که SoLIM اصلی نمیتواند در این مکانها پیشبینی کند.
4. نتیجه گیری و کار آینده
روش SoLIM-FilterNA که بر اساس طرح FilterNA ارائه شده در این مقاله طراحی شده است، میتواند مقادیر ویژگی خاک را برای هر سلول با مقدار NoData برای یک یا چند متغیر محیطی با استفاده از مقادیر معتبر سایر متغیرهای کمکی روی این سلول پیشبینی کند. روش پیشنهادی می تواند تضمین کند که پوشش فضایی نتایج DSM تا حد امکان کامل است. در همین حال، روش پیشنهادی عاری از مفروضات توزیع یا منبع مقدار NoData است و نه خطا دارد و نه زمان محاسبه اضافی که با درون یابی مقدار NoData معرفی شده است. بنابراین، محدودیتهای موجود در طرحهای موجود برای مقابله با مقدار NoData متغیرهای کمکی محیطی برای DSM قابل غلبه بر است. علاوه بر این، عدم قطعیت پیشبینی تولید شده توسط روش پیشنهادی SoLIM-FilterNA، عدم قطعیت معرفی شده با نادیده گرفتن متغیرهای محیطی با مقدار NoData در هر مکان جداگانه را در نظر میگیرد. چنین نتایج عدم قطعیت می تواند قابلیت اطمینان پیش بینی خاک با روش پیشنهادی را نشان دهد. همانطور که در نتایج تجربی نشان داده شده است، طرح FilterNA پیشنهادی، و همچنین روش پیشنهادی SoLIM-FilterNA، میتواند با مسئله ارزش NoData متغیرهای کمکی محیطی در DSM در یک منطقه بزرگ مقابله کند. کار آینده بر چگونگی ترکیب طرح FilterNA پیشنهادی با سایر روشهای DSM پرکاربرد در منطقه بزرگ متمرکز خواهد بود. و همچنین روش پیشنهادی SoLIM-FilterNA، میتواند با مسئله ارزش NoData متغیرهای کمکی محیطی در DSM در یک منطقه بزرگ مقابله کند. کار آینده بر چگونگی ترکیب طرح FilterNA پیشنهادی با سایر روشهای DSM پرکاربرد در منطقه بزرگ متمرکز خواهد بود. و همچنین روش پیشنهادی SoLIM-FilterNA، میتواند با مسئله ارزش NoData متغیرهای کمکی محیطی در DSM در یک منطقه بزرگ مقابله کند. کار آینده بر چگونگی ترکیب طرح FilterNA پیشنهادی با سایر روشهای DSM پرکاربرد در منطقه بزرگ متمرکز خواهد بود.






بدون دیدگاه