1. معرفی
به دنبال گسترش ابزارهای بسیار کارآمد LiDAR در دو دهه اخیر، رشد روزافزونی در استفاده از روشهای اسکن لیزری برای کاربردهای مختلف نقشهبرداری وجود داشته است. سیستم های رایج شامل ALS (اسکن لیزری هوابرد) همانطور که در مرجع [ 1 ]، TLS (اسکن لیزر زمینی) [ 2 ] و MLS (اسکن لیزری تلفن همراه) تأیید شده است، برای مثال به مرجع [ 3 ] مراجعه کنید. سیستم های نقشه برداری در حال ظهور شامل سیستم های اسکن لیزری شخصی و اسکن لیزری مبتنی بر پهپاد (وسیله هوایی بدون سرنشین) است. علاوه بر تکنیکهای اسکن لیزری، بازسازی 3 بعدی متراکم محیط ممکن است با روشهای مبتنی بر تصویر، به عنوان مثال، مرجع [ 4 ] انجام شود.] یا سیستمهای دوربین عمق، برای مثال، مرجع [ 5 ]، که معمولاً در زمینه های اسکن داخلی با آن مواجه می شوند. در نهایت، مجموعه دادههای ابر نقطهای نیز بهطور فزایندهای بهعنوان مجموعههای داده باز در دسترس هستند که معمولاً توسط آژانسهای نقشهبرداری ملی ارائه میشوند.
پیشرفت های ذکر شده منجر به افزایش قابل توجه استفاده از ابرهای نقطه ای و کاربرد آنها در روش ها و سیستم های تحلیلی متعدد شده است. توسعه الگوریتمهای پردازش ابر نقطهای، جنبههای جدیدی را نیز به ابرهای نقطهای معرفی کرده است، یعنی معناشناسی. طبقه بندی معنایی ابرهای نقطه ای ممکن است بسته به زمینه، ویژگی های متفاوتی داشته باشد. در MLS و دیگر ابرهای نقطهای زمینی (مثلاً مرجع [ 6 ])، بهعنوان گسترش طبقهبندی نقطهای وجود دارد که یک الگوی تثبیتشده با مجموعه دادههای ALS است. در اینجا، افزایش تعداد دستههای اشیاء و تغییر از یک کیس 2.5 بعدی به صحنههای سه بعدی بسیار دقیق، پیچیدگی را افزایش میدهد. در محیط های داخلی (به عنوان مثال، مرجع [ 7])، داده های ابر نقطه معنایی معمولاً با رباتیک مرتبط است و اغلب شامل شناسایی اشیاء منفرد است. در نهایت، امکان مرتبط کردن شناسههای اشیاء منفرد (مثلاً شناسههای ساختمان از سیستمهای اطلاعات جغرافیایی) با بخشهای ابر نقطهای پیشنهاد شده است [ 8 ].
ابرهای نقطه ای اغلب به عنوان پراکنده یا متراکم طبقه بندی می شوند [ 9 ] بسته به چگالی نقطه ای که در نمایش شی هدف استفاده می شود. با توجه به ذخیرهسازی آنها، ابرهای نقطهای از نظر دادهها به جای پراکنده هستند [ 10 ]، که به معنای مقادیر زیادی از دست رفته است. الوانکی و همکاران [ 11 ] اشاره می کند که تعداد زیادی ویژگی یا ویژگی های مختلف به هر نقطه در یک ابر نقطه مرتبط است. علاوه بر ایکسYزمختصات و مقادیر رنگ RGB، به عنوان مثال، ویژگی های اضافی مربوط به پالس لیزر برخوردی (به عنوان مثال، شدت، زاویه اسکن و داده های مربوط به بازگشت) و همچنین برخی از داده های معنایی، که معمولاً یک مقدار صحیح است که شی مورد نظر را طبقه بندی می کند، وجود دارد. . با این وجود، میتوان فرض کرد که تعداد کل ویژگیها در بیشتر موارد بسیار کمتر از 50 باقی میماند. از این نظر، ابرهای نقطهای را میتوان به صورت عمودی باریک توصیف کرد. به عنوان متضاد، در مرجع [ 10 ]، نویسندگان از اصطلاح “گسترده” برای مجموعه داده هایی استفاده می کنند که از صدها یا نه هزاران ویژگی مختلف تشکیل شده اند.
ذخیرهسازی فایلهای ابری نقطهای، هر چند از نظر تعداد نقاط بسیار زیاد باشند، نباید مشکلی ایجاد کند، زیرا ذخیرهسازی دیسک را میتوان عملاً رایگان در نظر گرفت [ 12 ]. علاوه بر این، تکثیر تدریجی درایوهای حالت جامد مبتنی بر فلش (SSD)، که فاقد قطعات متحرک هستند، به این معنی است که کل تأخیر دسترسی تصادفی (یعنی زمان جستجو + تأخیر چرخشی) حداقل خواهد بود [ 13 ، 14 ] . این بدان معناست که به دست آوردن زمان پاسخ سریع از یک پرس و جو ابر نقطه اساساً نیاز به کاهش آن دارد زمان انتقال داده است; یعنی زمان مورد نیاز برای بارگذاری داده ها از دیسک در حافظه. به طور دقیق تر، آنچه مورد نیاز است یک طرح نمایه سازی کارآمد برای مکان یابی سریع نقاط مورد نظر است. با یک ابر نقطه، شاخص از ایکسYزمختصات که اتفاقاً اطلاعات اصلی را نیز حمل می کنند.
با توجه به ماهیت ابرهای نقطه ای، دیدگاه پیشنهادی ون استروم و همکاران را به اشتراک می گذاریم. [ 15 ] از آنجایی که ابرهای نقطه دارای برخی ویژگی های مشترک با داده های شطرنجی و داده های برداری هستند، مفید است که آنها را به عنوان یک کلاس از هم در نظر بگیریم. توجه می کنیم که همانطور که در مرجع [ 16 ] اشاره شد، از آنجایی که داده های ابر نقطه ای با یک شبکه معمولی مرتبط نیستند، می توان آنها را به عنوان داده های بدون ساختار طبقه بندی کرد. علاوه بر این، ابرهای نقطه ای را می توان به عنوان مجموعه داده های عمدتا ایستا مشخص کرد [ توصیف کرد [ 17]؛ پس از پردازش و تمیز کردن، نیازی به اصلاح یا به روز رسانی آنها نیست. این عدم وجود یک مجموعه داده پویا به این معنی است که نیازهای پردازش داده ابرهای نقطهای بسیار متفاوت از یک پردازش مبتنی بر تراکنش فشرده است که شامل بهروزرسانیهای زیادی است [ 18 ]. به روز رسانی یک ابر نقطه ممکن است در نهایت در طول زمان مورد نیاز باشد، و می تواند به عنوان شامل تغییرات در مقیاس بزرگ یا کوچک طبقه بندی شود [ 19 ]. با این حال، نگرانی اصلی ما در استفاده از ابرهای نقطه، نحوه ارائه زمان پاسخ سریع حتی برای پرس و جوهای پیچیده (فقط خواندنی) است.
بنابراین برای استفاده از حجم وسیع داده در یک ابر نقطه، یک سیستم ذخیره سازی و بازیابی کارآمد مورد نیاز است. ما سه رویکرد اساسی برای ذخیرهسازی و مدیریت دادههای موجود در ابرهای نقطهای را شناسایی میکنیم: (1) رویکرد مبتنی بر فایل، (2) رویکرد سیستم مدیریت پایگاه داده رابطهای (RDBMS) و (3)، استفاده از دادههای بزرگ. ابزار.
انگیزه در اینجا استفاده از یک ابزار کلان داده خاص نیست، بلکه استفاده از داده های معنایی برای پارتیشن بندی موثر ابر نقطه است تا افزایش چشمگیری در سرعت پرس و جو ایجاد کند. ما دو پیادهسازی متفاوت از یک رویکرد مبتنی بر معنایی را ارائه میکنیم که بسته به استفاده از آن، دادههای ذخیرهشده در یک فایل یا در یک جدول واحد را کاهش میدهد. پیاده سازی اول از فایل ها و دایرکتوری ها برای ذخیره ابرهای نقطه استفاده می کند در حالی که اجرای دوم از یک RDBMS (PostgreSQL) استفاده می کند. اجرای دومی RDBMS با معیاری مقایسه میشود که از یک رویکرد سنتی (مسطح) RDBMS استفاده میکند. نتایج نشان داد که پیاده سازی RDBMS مبتنی بر معنایی ارائه شده به طور قابل توجهی سریعتر از معیار است.
بقیه مقاله به شرح زیر سازماندهی شده است: بخش 2 نگاهی عمیق به سه رویکرد ذکر شده قبلی برای مدیریت ابرهای نقطه میاندازد، در حالی که بخش 3 مجموعه دادههای نمونه و رویکرد طرحبندی دادهها را که برای دو پیادهسازی مختلف استفاده کردیم، ارائه میکند. رویکرد مبتنی بر معنایی بخش 4 بر نتایج بهدستآمده برای سه مجموعه داده تمرکز دارد و در نهایت، بحثی درباره نتایج و نتیجهگیریهای استنباطشده را میتوان در بخش 5 یافت .
2. سه رویکرد اساسی برای ذخیره ابرهای نقطه
2.1. رویکرد مبتنی بر فایل
به طور سنتی، ابرهای نقطه ای در فایل های باینری مانند فرمت معروف LAS یا فرمت فشرده آن LASzip [ 20 ] ذخیره می شدند. سپس فایل ها با برخی نرم افزارهای کاربردی خاص مانند LASTools پردازش می شوند. رویکرد مبتنی بر فایل، اساسی ترین تکنیک برای مدیریت ابرهای نقطه است، زیرا ذخیره سازی و بازیابی داده ها در قالب فایل اصلی انجام می شود. رویکرد مبتنی بر فایل، ابزارهای پرس و جو را از طریق سیستم مدیریت داده های ابر نقطه ای خود، که معمولاً به عنوان PCDMS شناخته می شود، فراهم می کند [ 16 ، 21 ].
با این حال، با پیشرفت فناوریهای جمعآوری دادهها برای ابرهای نقطهای، افزایش متناظری در اندازه ابر نقطه وجود دارد [ 22 ]. علاوه بر این، برنامههایی وجود دارند که شامل اسکن و نظارت لیزری میشوند (مانند برنامههایی که سیستمهای تونل را که بخشی از جادههای عمومی هستند نظارت میکنند) که در آن نیاز به نگهداری ابرهای نقطهای که قبلاً اسکن شدهاند نیز وجود دارد. در چنین مواردی، مقیاس پذیری به سرعت به یک مسئله تبدیل می شود [ 23 ]. از آنجایی که رویکردهای مبتنی بر فایل عموماً مبتنی بر فرمت فایل اختصاصی هستند، به اشتراک گذاری داده ها در بین برنامه های کاربردی مختلف سخت تر می شود [ 24 ]. در نهایت، برای کاربر برای اجرای پرس و جوهای ad-hoc، یک برنامه مبتنی بر فایل به سادگی کافی نیست [ 11 ، 25 ].
2.2. رویکرد RDBMS
علاوه بر رویکرد مبتنی بر فایل، ابرهای نقطه نیز می توانند در یک RDBMS مانند Oracle یا PostgreSQL ذخیره شوند. یکی از عوامل محرک در استفاده از RDBMS برای ذخیره ابرهای نقطه، سودمندی آنها در ارائه دسترسی به داده ها از طریق یک رابط کاربری قدرتمند، به عنوان مثال، SQL (زبان پرس و جو ساختاریافته) است [ 26 ]. پایگاه داده های رابطه ای به طور گسترده ای برای ذخیره ابرهای نقطه ای بزرگ مورد استفاده قرار می گیرند، همانطور که در مطالعه تطبیقی توسط ون اوستروم و همکاران تایید شده است. [ 15 ]. پایگاه های داده رابطه ای، طراحی شده توسط EF Codd [ 27]، داده ها را در جداول (روابط) با طرحی که روابط بین جداول را تعریف می کند، سازماندهی می کند. هر جدول از تعداد ثابتی از ویژگی ها (همچنین به عنوان ستون ها یا فیلدها شناخته می شود) تشکیل شده است و هر ورودی جدید یک ردیف جدید در جدول است که به طور منحصر به فرد توسط یک کلید اصلی شناسایی می شود [ 27 ]. کلید اولیه در یک RDBMS تقریباً همیشه بر اساس شاخص B-tree است که توسط Bayer و McCreight [ 28 ] ایجاد شده است. همانطور که در بخش 2.4 بحث شد ، شاخص B-tree واقعا برای نمایه سازی فضایی مناسب نیست، که می تواند پرس و جوهای ابر نقطه ای را که در یک RDBMS اجرا می شوند، کند کند، به ویژه زمانی که شاخص مورد نیاز در پرس و جو از قبل در حافظه نیست.
برای مقابله با این مشکل، استفاده از پسوندهای فضایی برای RDBMS رایج است، که منجر به چیزی می شود که به عنوان یک پایگاه داده شی-رابطه ای شناخته می شود که به کاربران اجازه می دهد تا انواع داده های انتزاعی خود را تعریف کنند [ 29 ]، مانند داده های اولیه هندسی. برای مثال، RDBMS PostgreSQL متنباز پیشرفته، که در حال حاضر در نسخه 11.X [ 30 ] است، میتواند از طریق پسوند PostGIS به دلیل Blasby [ 31 ] گسترش یابد. در PostGIS، ابرهای نقطه از طریق پسوند جداگانه «PC_PATCH» به دنبال کار رمزی [ 32 ] مدیریت میشوند.]. با «PC_PATCH»، PostGIS گروهها (یا وصلههای) از چند صد نقطه، عموماً در یک محل، تولید میکند، به طوری که هر ردیف در جدول به یک پچ اشاره میکند. در حالی که بازیابی یک گروه معین از نقاط می تواند بسیار سریع باشد، دسترسی به نقاط منفرد، ابتدا نیاز به باز کردن بسته بندی، یا منفجر کردن [ 32 ] وصله به نقاط اصلی دارد که به طور جداگانه ذخیره می شوند.
2.3. رویکرد داده های بزرگ
قبل از اینکه نگاهی به رویکردهای کلان داده بیندازیم، تعریف مفهوم کلان داده مفید است. همانطور که توسط Zicari [ 33 ] اشاره شد، بهتر است دادههای بزرگ را از نظر ویژگیهای آن توصیف کنیم تا اندازه خالص آن، که انتظار میرود همچنان در حال رشد باشد. گروه تحقیقاتی گارتنر داده های بزرگ را از سه جنبه مشخص می کند که معمولاً به عنوان “3Vs” شناخته می شوند که عبارتند از حجم بالا (مقدار روزافزون داده های بزرگ)، سرعت بالا و تنوع بالا [ 34 ].]. سرعت فقط به سرعت تولید داده های جدید نیست، بلکه توصیف می کند که داده های دریافتی با چه سرعتی می توانند پردازش و در مخزن داده ذخیره شوند. از نظر تنوع، به این واقعیت اشاره دارد که داده های بزرگ از منابع مختلفی منشاء می گیرند، (علاوه بر رسانه های اجتماعی، داده ها ممکن است از طریق حسگرها یا دستگاه های هوشمند بیایند) و بنابراین ممکن است اشکال مختلفی به خود بگیرند: ساختاریافته، بدون ساختار یا نیمه ساختار. 35 ].
از آنجایی که دادههای ابر نقطهای معمولاً در زمان واقعی پردازش و پاک نمیشوند و از آنجایی که ماهیت عددی دارند، واقعاً نمیتوان گفت که دارای ویژگیهای کلان داده سرعت و تنوع است. بنابراین، ما ردپای ایوانز و همکاران را دنبال خواهیم کرد. [ 36 ] و برای اهداف ما، داده های بزرگ را صرفاً به عنوان هر داده فضایی تعریف می کنیم که حداقل یکی از سه ویژگی اساسی V در کل داده ها، یعنی حجم، سرعت یا تنوع را برآورده می کند. با توجه به این موضوع، دادههای ابر نقطهای ممکن است صرفاً بر اساس حجم زیاد آن به عنوان کلان داده طبقهبندی شوند.
سومین رویکرد برای مدیریت ابرهای نقطه ای شامل استفاده از ابزارهای کلان داده است که می تواند با توانایی آنها در مقیاس بندی با توزیع داده ها در یک خوشه از چندین گره مشخص شود [ 37 ]. از آنجایی که گلوگاه در برنامههای فشرده داده، عملیات ورودی/خروجی است، ابزارهای کلان داده تلاش میکنند تا این عملیات را موازی کنند تا هر گره از سهم دادههای موجود در دیسک محلی خود استفاده کند.
ابزارهای کلان داده را می توان اساساً در پایگاه های داده NoSQL و سیستم های مبتنی بر Hadoop گروه بندی کرد. پایگاه داده های NoSQL از چندین جنبه با پایگاه داده های رابطه ای سنتی تفاوت دارند. یک پایگاه داده NoSQL اساساً مدل رابطهای را حذف میکند، اغلب فاقد یک پیادهسازی کامل SQL است، و عموماً مفهوم ضعیفتری از سازگاری دادهها ارائه میکند: دادهها ممکن است همیشه بهروز نباشند، اگرچه در نهایت سازگار میشوند [ 38 ، 39 ].
پایگاه داده های NoSQL را می توان به چهار دسته اصلی به شرح زیر دسته بندی کرد:
-
کلید-مقدار ذخیره می شود که در آن مقادیر (که ممکن است کاملاً بدون ساختار نیز باشند، یعنی Blobs) تحت یک کلید منحصر به فرد ذخیره می شوند. مقادیر در جفت کلید-مقدار ممکن است انواع مختلفی داشته باشند و ممکن است در زمان اجرا بدون خطر ایجاد تضاد اضافه شوند [ 40 ]. در مرجع [ 41 ]، نویسندگان خاطرنشان میکنند که ذخیرههای کلید-مقدار بهگونهای تکامل یافتهاند که میتوان وجود یک مقدار را بدون دانستن کلید (جستجو مبتنی بر ارزش) آزمایش کرد.
-
فروشگاههای ستونگرا ، که بهعنوان فروشگاههای ستون گسترده نیز شناخته میشوند، دادهها را به صورت عمودی تقسیم میکنند تا مقادیر متمایز یک ستون معین بهطور متوالی در همان فایل ذخیره شوند [ 42 ]. ستون ها ممکن است بیشتر به خانواده ها گروه بندی شوند تا هر خانواده به طور پیوسته روی دیسک ذخیره شود. از این نظر، یک فروشگاه با ستون عریض را میتوان به عنوان توسعه فروشگاههای ارزش کلیدی در نظر گرفت. هر ستون-خانواده مجموعه ای از جفت های کلید-مقدار (تودرتو) است [ 41 ].
-
فروشگاه های اسناد . یک فروشگاه مبتنی بر سند از جفتهای کلید-مقدار استفاده میکند، جایی که مقدار اکنون به یک قالب نیمه ساختار یافته اشاره دارد که معمولاً یک قالب JSON یا JSON مانند است که در MongoDB یافت میشود [ 38 ، 39 ].
-
پایگاه داده های نموداری که در مدیریت داده ها با روابط بسیار عالی هستند [ 40 ]. یک مثال می تواند داده های شبکه های اجتماعی باشد. با استفاده از شبکه های عصبی کانولوشن در ابرهای نقطه [ 43 ]، نمودارها ابزار امیدوارکننده ای هستند، به ویژه در فرآیند طبقه بندی معنایی ابر نقطه. از آنجایی که پایگاه داده های گراف را می توان به عنوان یک کلاس برای خود در نظر گرفت، استفاده از آنها را با ابر نقاط در این کار بررسی نمی کنیم.
در مورد فروشگاه های مبتنی بر سند، MongoDB برای مدیریت ابرهای نقطه استفاده شده است [ 23 ]. با این حال، MongoDB عمدتاً برای تبدیل فایلهای LAS به مختصات محلی مورد استفاده قرار گرفت، جایی که هر کاشی ابر نقطهای (در مجموع بیش از 1300 کاشی) در یک سند ذخیره میشد که مجموعاً 400 میلیارد نقطه را نشان میداد [ 23 ]. MongoDB مشکل نمایهسازی را حل نمیکند، زیرا از یک شاخص B-tree [ 44 ] استفاده میکند تا محدودیتهای مشابهی که در RDBMS برای نمایهسازی 3D وجود دارد اعمال شود.
فروشگاه های ارزش کلیدی و ستون محور راه حل جالبی برای مدیریت ابرهای نقطه ای ارائه می دهند که همانطور که قبلاً ذکر شد به صورت عمودی باریک هستند. چند ویژگی غیر کلیدی (به عنوان مثال، غیر ایکسYزداده) را می توان در چند فایل ذخیره کرد تا ویژگی مورد نظر مانند رنگ های RGB یا شدت بسیار سریع قابل دسترسی باشد.
علاوه بر NoSQL، روش اصلی دیگر برای مدیریت داده های بزرگ، سیستم های مبتنی بر Hadoop، می تواند به (1) چارچوب های مبتنی بر Hadoop یا (2) سیستم های مبتنی بر SQL-on-Hadoop تقسیم شود. هر دو دسته از Hadoop، معادل متن باز MapReduce [ 45 ] استفاده می کنند. استفاده از Hadoop به معنای استفاده از الگوی MapReduce است که کاربر را از بار موازی کردن کار در دست خلاص می کند زیرا برنامه را به صورت موازی روی یک خوشه اجرا می کند [ 46 ]. نکته قابل توجه این است که اگرچه این خوشه از رایانه های شخصی از رایانه های شخصی به اصطلاح کالایی تشکیل شده است [ 45 ]]، هر گره در خوشه اغلب یک رایانه شخصی کالای رده بالا است، به این معنی که اگرچه به راحتی در فروشگاه های رایانه در دسترس است، اما از نظر حافظه معمولاً از سطح بالای طیف است زیرا بسیاری از پیاده سازی های کلان داده تمایل به مصرف انرژی دارند. [ 47 ].
با این وجود، سیستم مبتنی بر SQL-on-Hadoop توجه زیادی را به خود جلب کرده است [ 48 ، 49 ] زیرا مزایای SQL را در جستجوی داده ها ارائه می دهد. با این حال، Vo و همکاران. [ 17 ] توجه داشته باشید که چگونه رویکردهای مبتنی بر Hadoop زمانی که وظیفه به وضوح خود را به صورت موازی اجرا میکند، مانند برخورد با یک ابر نقطهای به عنوان گروهی از کاشیهای مستقل، بهترین کار را انجام میدهند. علاوه بر این، همانطور که در یک معیار [ 50 ] توضیح داده شد، اگرچه عملکرد و مقیاسپذیری بهتری در جستجوی یک ابر نقطه نسبت به PostgreSQL ارائه میدهد، نویسندگان دریافتند که پیکربندی یک سیستم مبتنی بر SQL-on-Hadoop (Spark SQL) برای عملکرد بهینه میتواند دلهرهآور باشد. و در واقع به حافظه زیادی نیاز دارد.
2.4. در مورد نمایه سازی داده های چند بعدی: شاخص B + Tree
در این بخش ما بر روی شاخص B + -tree تمرکز می کنیم.
هنگام ذخیره مقادیر تک بعدی در یک RDBMS، انتخاب طبیعی B-tree [ 28 ] یا به طور دقیق تر، یکی از بسیاری از انواع آن [ 51 ] است که به عنوان B + -tree شناخته می شود و به طور کلی به Wedekind نسبت داده می شود [ 52 ، 53 ] . مانند B-tree، B + -tree نیز از یک ریشه و از گره هایی تشکیل شده است که یا گره داخلی یا برگ هستند. هر گره عملاً یک صفحه دیسک است که معمولاً به عنوان یک بلوک دیسک شناخته می شود ، و بنابراین، مگر اینکه محتویات یک گره خاص که باید به آن دسترسی داشته باشید قبلاً خوانده شده باشد و در حافظه در به اصطلاح بافر pool باقی بماند [ 18 ].]، دسترسی به چنین گره ای به عملیات ورودی/خروجی دیسک نیز نیاز دارد. درخت B + با درخت B تفاوت دارد زیرا دادهها فقط در برگهای گرهها ذخیره میشوند. گره های داخلی، یا گره های غیر برگ، مقادیر مختلف کلید جستجو را نگه می دارند که به عنوان یک راهنما هنگام جستجو برای یک کلید خاص عمل می کنند. از آنجایی که این گرههای داخلی اطلاعات مربوط به خود دادهها را ذخیره نمیکنند، میتوانند تعداد بیشتری از مقادیر کلیدی مختلف را نسبت به B-tree در خود جای دهند [ 54 ]. ایده اساسی B-tree/B + -tree توسط خود طراحان به درستی بیان شده است [ 28 ]:
ما فرض میکنیم که خود ایندکس آنقدر حجیم است که تنها بخشهای کوچکی از آن را میتوان در یک زمان در فروشگاه اصلی نگهداری کرد.
اگرچه این فرض به اوایل دهه 1970 باز میگردد و حتی اگر بافرهای امروزی میتوانند بخشهای زیادی از حافظه را برای دادهها و شاخص تخصیص دهند [ 55 ]، ما متوجه شدیم که امروزه به طرز شگفتآوری برای ابرهای نقطهای که معمولاً به رایانه شخصی با حداقل 16 گیگابایت رم برای پردازش اولیه.
از آنجایی که نمیتوانیم به اینکه بتوانیم کل ابر نقطه را در حافظه نگه داریم تکیه کنیم، مشکل اصلی در مورد ابرهای نقطهای همان نمایهسازی است: چگونه میتوانیم شاخص را به اندازه کافی کوچک نگه داریم تا حداقل بخشهایی از آن در حافظه قرار گیرد؟ با RDBMS، میتوانیم دانهبندی شاخص [ 17 ] را از طریق گروهبندی نقاط ذکر شده در بلوکها یا وصلهها کاهش دهیم، اما همانطور که در منابع [ 15 ، 56 ] اشاره شد، هزینهای برای پرداخت وجود دارد. در مورد پرس و جوها، مفهوم این است که نقاط منفرد در یک بلوک برای پردازشگر پرس و جو نامرئی هستند تا زمانی که بلوک به نقاط اصلی منفجر شود.
ممکن است سعی شود از درخت B برای نمایه سازی نقاط در آن استفاده شود (ایکس،Y،ز)-فضا با استفاده از شاخص ترکیبی/ویژگی های پیوسته [ 57 ]. با این حال، همانطور که بایر و مارکل [ 58 ] اشاره کردند، استفاده از چند شاخص ثانویه و یک شاخص ترکیبی (یعنی همانطور که از طریق الحاق سه ویژگی که مقادیر X ، Y و Z را در خود نگه میدارند به دست میآید) هر دو منجر به شاخصهایی میشوند که دارای ویژگیهای خاص خود هستند. معایب خود از آنجایی که طبیعتاً، یک نمایه درخت B میتواند دادهها را فقط برای یک ویژگی واحد خوشهبندی کند، داشتن یک شاخص خوشهبندی شده روی یک کلید ترکیبی متشکل از دو ویژگی X و Y ، به طور مؤثر فقط از بعد اول X در هنگام بازیابی صفحات دیسک استفاده میکند. [ 58]. همین امر در استفاده از یک شاخص ثانویه برای هر مختصات صدق می کند.
بایر و مارکل [ 58 ] به اصطلاح UB-tree را به طور خاص برای نمایه سازی داده های چند بعدی معرفی کردند. ایده اساسی UB-tree این است که از interleaving بیت استفاده شود تا ابتدا یک مقدار مختصات از چند بعد به یک مقدار صحیح تبدیل شود. سپس این مقدار به شاخص درخت B استاندارد تبدیل می شود. همانطور که مشخص است، رویکرد UB-tree عملاً مشابه روشی است که در استفاده از منحنیهای پرکننده فضا یافت میشود.
از آنجایی که منحنیهای پر کردن فضا به طور طولانی در ادبیات مورد بحث قرار میگیرند، برای مثال، منابع [ 16 ، 59 ، 60 ، 61 ]، نظریه را در اینجا ارائه نمیکنیم. ما فقط توجه می کنیم که استفاده از یک نمایش منحنی پرکننده فضای سه بعدی که از 128 بیت تشکیل شده است و با فرض دقت 1 سانتی متر، امکان ذخیره سازی یک منطقه به اندازه 2 × 10 را فراهم می کند. 6کیلومتر 2[ 50 ]. با این حال، ما دریافتیم که استفاده از 128 بیت از نظر محاسباتی بسیار گران است و بنابراین استفاده از ابزارهای دیگر نمایه سازی را انتخاب کردیم.
2.5. Semantic3D: یک طرح ابر نقطه معنایی ساده
از آنجایی که این کار با ابرهای نقطه سه بعدی است که با برچسب های معنایی تقویت شده اند [ 6 ، 62 ]، باید برای هر نقطه یک شناسه معنایی ذخیره کنیم. پ0در ابر نقطه طرح طبقه بندی، نشان داده شده است اسمنD، به طور مستقیم بر اساس طبقه بندی به اصطلاح Semantic3D به دلیل Hackel et al. [ 63 ] که در آن اسمنDمقادیری در محدوده 0 تا 8 می گیرد و بالاترین سطح موجودیت را تا چه نقطه ای نشان می دهد پ0از نظر معنایی متعلق به به عنوان مثال در آن طرح، اسمنDمقادیر 3 و 4 به ترتیب به پوشش گیاهی زیاد و کم اشاره دارد، در حالی که اسمنD= 5 دلالت بر یک ساختمان دارد [ 63 ]. به نقاطی که پس از فرآیند اسکن قابل طبقه بندی نیستند، مقدار داده می شود اسمنD= 0. ما همچنین فرض می کنیم که یک مقدار شدت I برای هر نقطه در دسترس است پ0(چون از ابرهای نقطه ای برای تجسم استفاده نمی کردیم، ترجیح دادیم مقادیر رنگ را لحاظ نکنیم ( آر،جی،ب) تا کارها را تسریع کند). به طور دقیق تر، به هر نقطه مرتبط است پ0، آن را ذخیره می کنیم (ایکس،Y،ز)مختصات، مقدار شدت I ، و برچسب معنایی یا شناسه کلاس، نشان داده شده است اسمنD.
در مورد معناشناسی، البته انتظار می رود که برخی از نقاط بخشی از سلسله مراتب موجودیت ها باشد. به عنوان مثال، یک نکته پ0ممکن است نشان دهنده دری باشد که بخشی از نما است که به نوبه خود بخشی از یک ساختمان است. با این حال، برای سادگی، و برای حفظ تمرکز بر روی طرح ارائه شده، ما در این مطالعه از تمام کلاسهای فرعی (مانند در و نما) صرفنظر کردیم. این بدان معنی است که طبقه بندی معنایی به این معنی است که هر نقطه طبقه بندی شده متعلق به یک کلاس معنایی واحد است، مشابه Weinmann و همکاران. (2017) [ 64 ]. بنابراین برای نکته ای که قبلا ذکر شد پ0، آن اسمنD=5، نشان دهنده موجودیت بالاترین سطح، به عنوان مثال، یک ساختمان است.
با توجه به ترتیب فایل، ما از Hackel و همکاران پیروی می کنیم. [ 63 ] و فرض کنید که یک مجموعه داده ابر نقطه معین از دو فایل جداگانه، یک فایل تشکیل شده است پoمنnتیس(ایکس،Y،ز،من)و یک فایل دیگر اسهمترآnتیمنجس(اسمنD). چون فایل اسهمترآnتیمنجس(برای اختصار می نویسیم اسهمترآnتیمنجسبه عنوان مختصر فایل اسهمترآnتیمنجس(اسمنD)و پoمنnتیسبه عنوان مختصر فایل پoمنnتیس(ایکس،Y،ز،من)) دقیقاً همان ترتیب و در نتیجه همان تعداد ردیف فایل را دارد پoمنnتیس، هیچ فهرست جداگانه ای برای فایل مورد نیاز نیست اسهمترآnتیمنجس.
ترتیبی که توضیح داده شد در واقع نمونه ای از طرح بندی ستون محور است. فایل اسهمترآnتیمنجسیک فایل تک ستونی است در حالی که فایل پoمنnتیس، که در مجموع از چهار ستون تشکیل شده است، نمونه ای از یک خانواده ستونی است [ 65 ] زیرا اطلاعات اساسی LiDAR را در یک موجودیت واحد گروه بندی می کند. برای راحتی، ما به ترتیب دو فایل فوق به عنوان فرمت Semantic3D اشاره می کنیم.
برای اینکه بتوانید به سرعت فایل ها را پیدا کنید اسهمترآnتیمنجسو پoمنnتیسحاوی داده های ابر نقطه ای متعلق به یک کلاس معنایی خاص است اسمنDما از دایرکتوری هایی استفاده می کنیم که در بخش 3.2 توضیح داده شده است، که در آن طرح بندی داده ای که با فرمت Semantic3D سازگار است و در عین حال امکان پرس و جوهای سریع را فراهم می کند، جزئیات می دهد. ما به این تکنیک جداسازی دادههای ابر نقطه بر اساس طبقهبندی معنایی هر نقطه از طریق اصطلاح عمومی Semantic Data Based Layout یا به سادگی SDBL اشاره میکنیم و جزئیات آن را به بخش 3.2 و بخش 3.3 موکول میکنیم . هنگام استفاده از رویکرد SDBL همراه با دایرکتوری ها، پرس و جوها باید به طور جداگانه برنامه ریزی شوند، و همانطور که در بخش 3.9 توضیح داده شد ، ما از Python استفاده کردیم.
همانطور که در بخش 3.3 نشان داده خواهد شد ، استفاده از رویکرد SDBL در هنگام استفاده از RDBMS نیز امکان پذیر است، البته بدون استفاده از دایرکتوری ها یا پایتون. در مورد ما، PostgreSQL گسترده ای را به عنوان RDBMS انتخاب کردیم. ما PostgreSQL را به عنوان RDBMS انتخاب کردیم زیرا به طور گسترده در دانشگاه با ابرهای نقطه استفاده می شود و یکی از معدود RDBMS هایی است که از مفهوم گروه بندی نقاط به وصله ها پشتیبانی می کند [ 32 ]. برای تمایز آسان بین این دو رویکرد، ما به استفاده از SDBL به صورت برنامهنویسی از طریق دایرکتوریها (و فایلها) به سادگی SDBL از طریق Python و به استفاده از SDBL از طریق RDBMS به عنوان SDBL از طریق PostgreSQL اشاره میکنیم.
3. مواد و روشها
ابتدا مجموعه دادههای ابر نقطه نمونه را توصیف میکنیم، سپس نگاهی عمیقتر به SDBL زیربنایی میاندازیم که در صورت استفاده از پایتون (و دایرکتوریها) یا از طریق PostgreSQL، درخواستهای سریع را امکانپذیر میکند.
3.1. ابرهای نقطه نمونه
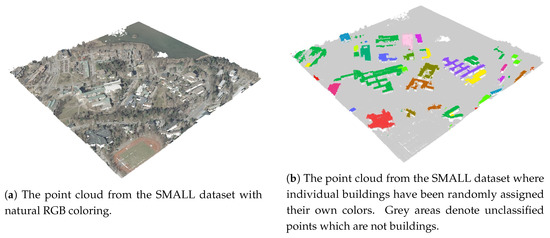
ما از سه ابر نقطه مختلف با اندازههای مختلف استفاده کردیم که کوچکترین مجموعه داده شامل چند صد هزار نقطه و بزرگترین آن تقریباً نیم میلیارد نقطه بود. مجموعه داده ها در اینجا به عنوان مجموعه داده های (i) SMALL، (ii) MEDIUM و (iii) LARGE نامیده می شوند و به طور خلاصه در جدول 1 توضیح داده شده اند.
مجموعه داده SMALL ( شکل 1 ) با توجه به استفاده از معنایی با دو مجموعه داده دیگر کمی متفاوت است. اسمنD. از آنجایی که فایل آن از طریق Semantic3D [ 63 ] به دست نمی آید و بیشتر ساختمان ها را نشان می دهد، اسمنDدر اینجا فقط دو مقدار متفاوت می گیرد، یعنی 0 (بدون طبقه بندی) یا یک مقدار صحیح بزرگ که نشان دهنده شناسه ساختمان مرتبط با هر نقطه است. با این حال، برای همسو بودن با معناشناسی طبقه بندی Semantic3D، فرض می کنیم که هر نقطه در مجموعه داده SMALL که به عنوان یک ساختمان طبقه بندی می شود، ابتدا با اسمنD=5و سپس با یک عدد صحیح بزرگ برای شناسایی یک ساختمان خاص همراه است. مجموعه داده SMALL نمونه برداری شد تا مجموعه داده ای به دست آید که به وضوح کوچکتر از مجموعه داده MEDIUM است. در بخش 4.1.1 ، ما از مجموعه داده SMALL اصلی، توسعه یافته و بدون نمونه برداری برای آزمایش پرس و جوهای پیچیده تر استفاده می کنیم. این مجموعه داده فقط در بخش 4.1.1 استفاده می شود و به عنوان مجموعه داده توسعه یافته SMALL نامیده می شود. بنابراین، اصطلاح مجموعه داده SMALL، هنگامی که به این صورت استفاده می شود، به مجموعه داده های کوچک نمونه برداری شده اطلاق می شود. مجموعه داده SMALL نمونه برداری شده در مجموع شامل 84 ساختمان است که هر کدام به طور متوسط تقریباً 500 امتیاز دارند و بقیه نقاط طبقه بندی نشده هستند. به غیر از این تفاوت طبقه بندی، سه مجموعه داده دارای ساختار فایل یکسانی هستند.
3.2. استفاده از SDBL از طریق پایتون
ما فرض می کنیم که هنگام پرس و جو ابرهای نقطه، کاربر به اشیاء متعلق به یک کلاس معنایی خاص، مانند یافتن ساختمان های خاص در یک مکان معین علاقه مند می شود. (لیستی از کاربردهای معنایی بالقوه ابر نقاط در مرجع [ 68 ] آورده شده است). با توجه به این موضوع، وقتی SDBL از طریق پایتون اعمال می شود، اساساً به این معنی است که طرح داده از دایرکتوری هایی استفاده می کند که کلاس های معنایی مختلف را منعکس می کند در حالی که پرس و جوها در پایتون نوشته می شوند. به طور دقیق تر، ابتدا داده ها را بر اساس کلاس های معنایی مختلف مرتب می کنیم، به طوری که برای هر برچسب معنایی متمایز اسمنD 0 تا 8، یک فهرست جداگانه با نام منD_اسمنDایجاد می شود و در مجموع نه دایرکتوری جداگانه ایجاد می شود.
به عنوان مثال، دایرکتوری با نام “ID_0” شامل یک فایل است پoمنnتیس، که شامل تمام نقاطی است که برچسب معنایی آنها اسمنDبرابر با 0 (نقاط طبقه بندی نشده)، در حالی که در پوشه ‘ID_5’، فایل است پoمنnتیسفقط حاوی نکاتی است که برچسب معنایی آنهاست اسمنD=5(یعنی ساختمان ها). شایان ذکر است که هنگام استفاده از SDBL از طریق پایتون و در نتیجه از طریق دایرکتوری ها، کلاس معنایی اسمنDخود نیازی به ذخیره در یک فایل ندارد، زیرا این اطلاعات قبلاً در نام دایرکتوری ID_ موجود است. اسمنD. به طور خلاصه، SDBL از طریق پایتون طرحی است که در آن فایل قبلاً ذکر شده است اسهمترآnتیمنجسغیر ضروری و اصلی شده است پoمنnتیسفایلی که حاوی تمام نقاط مجموعه داده بود اکنون به مجموعه جدیدی از تجزیه می شود پoمنnتیسفایل ها، با هر کدام پoمنnتیسفایلی که در زیر شاخه ای به نام ID_ قرار دارد اسمنDبه طوری که تمام نقاط در فایل پoمنnتیسمتعلق به همان طبقه معنایی است اسمنD. در نهایت، متذکر می شویم که برای رسیدگی به هر پرس و جوی خاص، معمولاً از کاربر انتظار می رود که حداقل کلاس معنایی را تأمین کند. با این حال، امکان استفاده از این تکنیک زمانی وجود دارد که شناسه معنایی یا اسمنDهمانطور که در بخش 4.3 مورد بحث قرار گرفت ناشناخته است ، اگرچه در چنین حالتی، SDBL برخی از مزیت های ذاتی خود را از دست می دهد که ممکن است منجر به جستجوهای کندتر شود.
3.3. استفاده از SDBL از طریق PostgreSQL
برای نشان دادن اینکه ایده اصلی در SDBL میتواند با یک RDBMS نیز استفاده شود، SDBL را از طریق PostgreSQL با استفاده از دقیقاً همان سه مجموعه داده پیادهسازی کردیم. بنابراین برای استفاده از طرحبندی داده با جداولی که شباهت به ایده اصلی پشت SDBL دارد، از پارتیشنبندی افقی یا ردیفی [ 69 ] برای تقسیم کردن دادهها به مجموعهای از جداول استفاده میکنیم.تی_اسمنDجایی که اسمنD=0،1،2،…،8به طوری که هر جدول تی_اسمنDنکات مربوط به یک کلاس معنایی واحد را ذخیره می کند. پارتیشن بندی ردیف، همچنین به عنوان تکه تکه شدن افقی شناخته می شود، تکنیکی است که با تقسیم سطرها به مجموعه ای از جداول تکه تکه شده با توجه به مقادیر رایج یک ویژگی پارتیشن بندی ، تعداد ردیف ها را در یک جدول بزرگتر کاهش می دهد . در مورد ما، مشخصه پارتیشن بندی، البته، چیزی جز ویژگی ID معنایی نیست اسمنDیعنی اولین جدول تکه تکه شده تی_0شامل ردیف هایی خواهد بود که فقط به آن اشاره دارند اسمنD=0، دومین جدول تکه تکه شده تی_1شامل سطرهایی خواهد بود که فقط به آن اشاره دارند اسمنD=1، و غیره. یک جدول پارتیشن بندی شده یا تکه تکه شده تیاسمنDبنابراین فقط از ردیف هایی تشکیل شده است که نشان دهنده نقاطی هستند که یک کلاس معنایی مشترک دارند اسمنD. هنگامی که مجموعه داده به مجموعه ای از جداول PostgreSQL تقسیم شد، نقاط مرتبط با ساختمان ها بازیابی می شوند. اسمنD=5برای مثال، در مجموعه داده MEDIUM معادل اجرای یک پرس و جوی ساده SQL مانند SELECT * FROM T_MEDIUM_5 است، زیرا همه نقاط مورد نیاز اکنون در جدول تکه تکه شده وجود دارند. تی_مEDمنUم_5.
3.4. پرس و جوهایی که استفاده شد
ما پنج پرس و جو برای سه مجموعه داده مختلف، همانطور که در جدول 2 و جدول 3 نشان داده شده است، اجرا کردیم . برای هر سه مجموعه داده، یک پرس و جو نقطه پایه (معانی) وجود داشت س1که شامل بازیابی تمام نقاط مرتبط با ساختمان ها بود. از آنجایی که مجموعه داده SMALL شامل شناسه های ساختمان بود، دو پرس و جو نقطه ای اضافی ( س1آو س1بهمانطور که در جدول 2 نشان داده شده است، که به دو شناسه ساختمان خاص برای این مجموعه داده اشاره شده است. به طور گذراً متذکر می شویم که در حالی که نویسندگان در مرجع [ 17 ] از عبارت point query برای نشان دادن پرس و جوی استفاده می کنند که یک نقطه واحد و ویژگی های آن را از ابر نقطه بازیابی می کند، ما از آن در مفهوم فضایی گسترده تر برای نشان دادن یک پرس و جو استفاده می کنیم. که به یک تطابق دقیق (برخلاف یک محدوده معین) برای یک ویژگی خاص نیاز دارد.
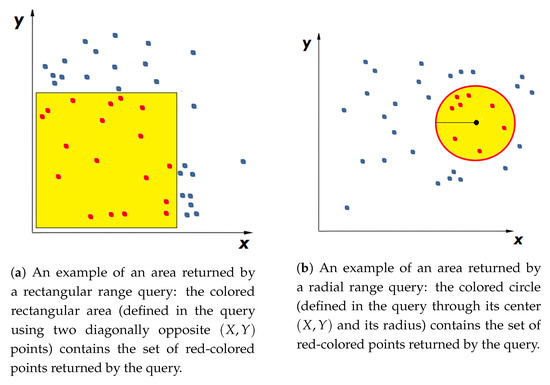
در مورد مجموعه داده های MEDIUM ( شکل 2 ) و LARGE ( شکل 3 )، یک پرس و جو محدوده س2آبرای محدود کردن بیشتر نتایج پرس و جو نقطه ای استفاده شد س1برای یافتن تنها نقاطی که مختصات X آنها بود >20. در مورد پرس و جو نقطه ای س2ب( جدول 3 )، به سادگی نقاطی را پیدا می کند که با آنها مرتبط است اسمنD=2(زمین طبیعی). برای هر سه مجموعه داده، دو پرس و جو محدوده (نشان داده شده در شکل 4 ) آزمایش شدند، یک پرس و جو مستطیلی س3و یک پرس و جو شعاعی س4. هر دوی این کوئری ها از مجموعه نتایج پرس و جو استفاده می کنند س1به عبارت دیگر، آنها فقط برای نقاطی که متعلق به ساختمان هستند اعمال می شوند. پرس و جو شعاعی س4به گونهای طراحی شده بود که برای هر سه مجموعه داده، مجموعهای از نقاط به وضوح کوچکتر از پرس و جو را برمیگرداند س3. در نهایت، برای اینکه احساس کنیم یک پرس و جو نقطه ای که شناسه معنایی را مشخص نمی کند، چگونه عمل می کند، یک پرس و جو نقطه ای اضافی را اجرا کردیم که یک نقطه واحد را از مجموعه داده LARGE همانطور که در بخش 4.3 شرح داده شده است، بازیابی می کند.
3.5. پرس و جو داده ها در SDBL با استفاده از پایتون
ما فرض می کنیم که یک طرح داده بر اساس SDBL از طریق Python برای یک مجموعه داده معین همانطور که قبلاً ذکر شد ایجاد شده است. اکنون هنگام استفاده از SDBL از طریق پایتون، تمام نقاطی را که بخشی از یک ساختمان هستند، یعنی آنهایی که دارای کلاس معنایی هستند، پرس و جو کنید. اسمنD=5، به معنای خواندن محتویات یک فایل واحد، یعنی فایل است پoمنnتیسکه در زیر شاخه ای با نام “ID_5” ذخیره می شود. گزیده ای مختصر از کد پایتون مورد نیاز در فهرست A1 پیوست A نشان داده شده است که در آن تابع get_sem_xyz_points دو پارامتر cur_dir و semanticID را می گیرد که به ترتیب به دایرکتوری والد طرح داده و کلاس معنایی اشاره دارد. با استفاده از پانداها [ 70 ] و بستههای پر [ 71 ]، تابع get_sem_xyz_points به سرعت زیرمجموعهای از ابر نقطه را میخواند (در خط 5) که در زیر مسیری که کاربر ارائه میکند ذخیره میشود. جتوr_دمنrو به دنبال آن زیر شاخه ‘ID_5’ (خط 3) از یک فایل باینری (به نام ‘xyz.fff’ همانطور که در خط 4 نشان داده شده است). بنابراین، برای به دست آوردن تمام نقاط مربوط به ساختمان ها، می توان به سادگی تابع get_sem_xyz_points را فراخوانی کرد (MyPath، ‘5’) که در آن MyPath به دایرکتوری حاوی مجموعه داده های ابر نقطه اشاره دارد. اعمال یک محدودیت و یافتن مجموعه نقاط مورد نظر از طریق تابع query pandas همانطور که در لیست A2 نشان داده شده است انجام می شود.
توجه داشته باشیم که برای مجموعه داده کوچک، زیرمجموعههای دیگری در زیر پوشه «ID_5» وجود دارد که هر زیرشاخه مطابق با یک شناسه ساختمان جداگانه مطابق با بخش 3.7 است. به منظور آزمایش اینکه چگونه زمانهای پرس و جو تحت تأثیر افزایش تعداد زیر شاخههای زیر فهرست «ID_5» قرار میگیرد، از مجموعه داده توسعه یافته SMALL استفاده کردیم. این آزمون، همراه با مجموعه داده توسعه یافته SMALL، به طور جداگانه در بخش 4.1.1 توضیح داده شده است .
3.6. پرس و جو از همان داده SDBL در PostgreSQL
پرس و جو با استفاده از SDBL از طریق PostgreSQL از طریق جداول تکه تکه شده همانطور که قبلا در بخش 3.3 بحث شد، انجام می شود . در حالی که مرسوم است که ویژگی پارتیشن بندی را در یک جدول تکه تکه حفظ کنیم، در صورتی که جداول باید بعداً در جدول اصلی بدون تکهتکه بازسازی شوند، در اجرای خود لازم ندانستیم که ستون را اضافه کنیم. اسمنD. بنابراین جداول تکه تکه شده هر کدام از چهار ویژگی تشکیل شده اند (ایکس،Y،ز،من). مجموعه داده SMALL، همانطور که قبلاً ذکر شد، از این جهت استثنا است که همه نقاط طبقه بندی شده به یک شناسه ساختمان خاص اشاره می کنند، بنابراین یک ستون ID معنایی باید در جدول T_5 گنجانده شود تا مقادیر صحیح بزرگی را که یک ساختمان خاص را مشخص می کند، نگه دارد. با این حال، از آنجایی که جدول مجموعه داده SMALL از نظر اندازه نسبتاً کوچک بود، یک شاخص استاندارد B-tree فقط بر روی ویژگی ها (ایکس،Y،ز)بدون توسل به ایجاد یک شاخص ثانویه کافی تلقی شد اسمنD.
شایان ذکر است تفاوت بین پارتیشن بندی افقی که به تازگی توضیح داده شده و رویکرد وصله (‘PC_PATCH’) [ 32 ] موجود در PostgreSQL (همچنین در Oracle به عنوان بلوک های ابری نقطه ای یافت می شود) را مورد توجه قرار می دهد. در حالی که وصله کردن، دانهبندی شاخص را با ایجاد گروههایی از نقاط هممحل کاهش میدهد، تکه تکهشدن افقی تعداد ردیفهای یک جدول را بدون تغییر دانهبندی شاخص کاهش میدهد. مهمتر از آن، تکه تکه شدن مکانیزمی برای دسترسی مستقیم به داده های معنایی در اختیار ما قرار می دهد، زیرا اگر همه ردیف ها/نقاط در جدول شناسه معنایی یکسانی داشته باشند، دیگر نیازی به تعیین آن ویژگی در یک پرس و جو وجود ندارد.
علاوه بر این، برای اینکه ایده بهتری در مورد سرعت رویکرد جداول PostgreSQL تکه تکه به دست آوریم، ما همچنین از یک نسخه PostGIS رویکرد تکه تکه شده علاوه بر رویکرد غیرقطعی اساسی استفاده کردیم که به عنوان معیاری برای پرس و جوهای PostgreSQL عمل می کرد. رویکرد معیار تکه تکه نشده از یک جدول پایه PostgreSQL که از پنج ستون تشکیل شده بود استفاده کرد (ایکس،Y،ز،من،اس)با یک شاخص ثانویه برای ستون S ، که به شناسه معنایی یا اسمنD.
در نهایت، برای مجموعه داده SMALL، ما همچنین یک رویکرد Patch-table مسدود شده را آزمایش کردیم که از PC_PATCH استفاده می کند. در این رویکرد، شناسه ساختمان به عنوان یک ویژگی گروهبندی عمل میکند، به طوری که هر پچ یا بلوک (84 مورد وجود دارد) از نقاطی (بهطور متوسط 500 امتیاز در هر پچ) تشکیل میشود که متعلق به همان شناسه ساختمان هستند. برای اینکه رویکرد Patch-table تا حد امکان سریع باشد، ستون شدت را حذف کردیم، به طوری که جدول به طور موثر فقط از چهار ستون تشکیل شده است: (ایکس،Y،ز)صفات و صفت معنایی اسمنD.
در ادامه، رویکردهایی را که برای آزمایش SDBL از طریق جداول PostgreSQL استفاده شدهاند، خلاصه میکنیم:
-
جدول تکه تکه شده: مجموعه داده به ردیف هایی تقسیم می شود به طوری که تمام نقاط یک جدول به یکسان تعلق دارند اسمنD. این شاخص یک ترکیب پایه B-tree است (ایکس،Y،ز)شاخص غیر خوشه ای در مجموع نه جدول تکه تکه شده برای مجموعه داده های MEDIUM و LARGE تولید می شود و فقط دو جدول تکه تکه شده ( اسمنD=0و اسمنD=5) برای مجموعه داده SMALL. ویژگی های موجود در جدول هر قطعه هستند (ایکس،Y،ز،من).
-
جدول تکه تکه شده PostGIS (فقط مجموعه داده های SMALL و MEDIUM) : اساساً مانند بالا، اما اکنون ویژگی ها (ایکس،Y،ز)و S (برای مجموعه داده کوچک) و (ایکس،Y،ز)و I (برای مجموعه داده MEDIUM). این چهار ویژگی در نوع PostGIS ‘Point’ گنجانده شده اند. برای مجموعه داده SMALL، شاخص از سه شاخص عملکردی مجزا تشکیل شده است که برای ویژگی های X ، Y و S هستند (اشاره به اسمنD). برای مجموعه داده MEDIUM، تنها دو شاخص عملکردی برای ویژگی های X و Y مورد نیاز است . این گزینه PostGIS فقط برای مجموعه داده های SMALL و MEDIUM آزمایش می شود و تنها دو جدول تکه تکه شده (آنهایی که واقعاً پرس و جو می شوند) برای هر مجموعه داده تولید می شود.
-
جدول معیار تکه تکه نشده : مجموعه داده که اکنون از ویژگی ها تشکیل شده است (ایکس،Y،ز،من،اس)در یک جدول مسطح PostgreSQL (بدون PostGIS) و بدون استفاده از تکه تکه شدن وجود دارد. این جدول به عنوان یک معیار برای سایر تستهای PostgreSQL عمل میکند و از آنجایی که حاوی نقاطی از شناسههای معنایی مختلف است، یک شاخص درخت B اضافی در ویژگی اسمنDعلاوه بر کامپوزیت پایه B-tree ایجاد شد (ایکس،Y،ز)شاخص (غیر خوشه ای).
-
Patch-table : این رویکرد فقط با مجموعه داده SMALL استفاده می شود. وصله ها از نقاطی ایجاد می شوند که شناسه ساختمان یکسانی دارند و جدول از طریق یک شاخص GIST در نوع PCPOINT ایندکس می شود. Patch-table تک شامل چهار ویژگی است (ایکس،Y،ز،اس).
3.7. آماده سازی داده برای استفاده از SDBL از طریق پایتون
قبل از اینکه به نتایج بخش 4 نگاهی بیندازیم، پیشینه ای در مورد نحوه آماده سازی داده ها برای استفاده با SDBL ارائه می دهیم. به منظور آماده سازی مجموعه داده های ابر نقطه ای برای استفاده با SDBL از طریق پایتون، ما یک اسکریپت پایتون نوشتیم (همانطور که در بخش 3.9 مشخص شد ، ما از نسخه 3.7.1 پایتون استفاده کردیم) که برای هر یک از مجموعه داده ها، داده ها را به دایرکتوری ها تقسیم می کند. کلاس معنایی اسمنD. برای مجموعه داده های MEDIUM و LARGE، این به معنای ایجاد نه دایرکتوری (یکی برای هر کلاس معنایی) است. اسمنDدر محدوده 0 تا 8) و ایجاد فایل پoمنnتیس(ایکس،Y،ز،من)زیر هر دایرکتوری برای مجموعه داده SMALL، این مستلزم ایجاد دو دایرکتوری اصلی (یکی برای کلاس معنایی) است اسمنD=0و برای کلاس معنایی اسمنD=5) و سپس زیر پوشه «ID_5»، یک زیر شاخه «ID_BUILDING_ID» برای هر BUILDING_ID جداگانه ایجاد کنید (شامل یک فهرست جداگانه پoمنnتیسفایل برای ساختمان مورد نظر)، در مجموع 84 زیرمجموعه، تعداد ساختمان های مختلف در مجموعه داده SMALL.
برای هر مجموعه داده، پoمنnتیس-فایل ها به طور جداگانه بر روی دیسک تحت زیر شاخه مناسب با استفاده از فرمت پر باینری سریع [ 71 ] ذخیره می شوند. سپس این فایلها در صورت نیاز برای پرسوجوها در قالب داده پاندا بارگذاری میشوند. شاخص ضمنی ایجاد شده به طور خودکار توسط پانداها [ 70 ] کافی تلقی شد و از این رو هیچ شاخص صریحی ایجاد نشد.
زیرا در بخش 4.3 کوئری هایی را نیز آزمایش کردیم که شامل کلاس معنایی نبودند اسمنD، همچنین حداقل و حداکثر مختصات X ، Y و Z هر مجموعه داده را در یک فایل جداگانه ذخیره می کنیم (مجموعاً شش مقدار برای هر مجموعه داده). ذخیره این شش مقدار شدید به طور جداگانه به ما اجازه می دهد تا مجبور نباشیم همه 9 مقدار را بارگذاری کنیم پoمنnتیس-فایل زمانی که به دنبال نقطه خاصی هستید (ایکس،Y،ز). به عبارت دیگر، باید نقطه (ایکس،Y،ز)مواردی که در حال پرس و جو هستند در مینیمم و ماکزیمم های ذخیره شده قرار نگیرند، به سادگی می توانیم از بارگیری آن خاص صرف نظر کنیم. پoمنnتیس-فایل.
3.8. آماده سازی داده برای استفاده از SDBL از طریق PostgreSQL
در مورد آماده سازی داده ها برای PostgreSQL، ما از همان اسکریپت پایتون استفاده کردیم که برای پرس و جو SDBL از طریق پایتون استفاده شد. هنگامی که یک مجموعه داده خاص برای استفاده از پایتون آماده شد به طوری که همه نه پoمنnتیسفایل ها با استفاده از پکیج feather در فایل های مربوطه خود نوشته شده بودند، اسکریپت پایتون اجرا شد و گزینه ای از منو برای تبدیل مجموعه مناسب فایل ها به جداول PostgreSQL انتخاب شد. به طور دقیق تر، اسکریپت از بسته SQLAlchemy [ 72 ] برای تبدیل هر یک استفاده می کردپoمنnتیسفایل را در یک جدول تکه تکه شده PostgreSQL مربوطه قرار دهید. این جداول متعاقباً از طریق ستون ها نمایه شدند (ایکس،Y،ز).
به یاد بیاورید که مجموعه داده SMALL یک استثنا است زیرا جدول تکه تکه شده PostgreSQL حاوی یک ستون S برای نگه داشتن شناسه معنایی است ( اسمنD) که اکنون به شناسه ساختمان اشاره دارد. بنابراین، زمان آماده سازی برای مجموعه داده SMALL شامل زمان مورد نیاز برای ایجاد یک شاخص درخت B اضافی در ویژگی S با استفاده از pgAdmin است. با این حال، برای مجموعه داده های MEDIUM و LARGE، تمام آماده سازی داده ها برای جداول PostgreSQL تکه تکه شده از طریق اسکریپت پایتون انجام می شود.
در مورد جدول بنچمارک PostgreSQL بدون تکه تکه شدن، برای هر مجموعه داده، با استفاده از pgAdmin، نمایه شده در (ایکس،Y،ز)و با داده های جداول تکه تکه شده (با استفاده از SQL) پر شده است. سپس یک نمایه اضافی بر روی ستون S اضافه شد زیرا یک جدول تکه تکه نشده حاوی شناسه های معنایی مختلف است.
ما همچنین PostGIS را برای مجموعه داده های SMALL و MEDIUM (بدون «PC_PATCH») آزمایش کردیم. برای مجموعه داده SMALL، یک جدول PostGIS با چهار ویژگی ایجاد کردیم (ایکس،Y،ز،اس)و آن را با استفاده از تابع PC_MAKEPOINT(1,ARRAY[X,Y,Z,S]) با داده های یک جدول PostgreSQL تکه تکه شده پر کرد همانطور که در پیوست A در فهرست A5 نشان داده شده است. از آنجایی که S نشان دهنده شناسه ساختمان تا کدام نقطه است (ایکس،Y،ز)متعلق به، پس از پر کردن جدول مجموعه داده های کوچک PostGIS، یک شاخص عملکردی در سه ستون، یعنی X ، Y و S ایجاد شد.
در مورد استفاده از PostGIS با مجموعه داده MEDIUM، دو جدول PostGIS مختلف تولید شد که یکی از آنها تکه تکه شده بود. اسمنD=2و دیگری تکه تکه شده با اسمنD=5(این دو قطعه برای پرس و جوها کافی بود). این دو جدول شامل چهار ویژگی بودند (ایکس،Y،ز،من)و با استفاده از جدول تکه تکه شده PostgreSQL مناسب و تابع PC_MAKEPOINT(1,ARRAY[X,Y,Z,I]) پر شدند. هنگامی که این دو جدول PostGIS با داده های آنها پر شدند، یک شاخص عملکردی برای هر جدول فقط در دو ستون X و Y ایجاد شد.
ما توجه می کنیم که زمان آماده سازی SDBL از طریق PostgreSQL با استفاده از رویکرد جداول تکه تکه شده همانطور که در بخش 4 ارائه شده است، همیشه شامل ایجاد تمام قطعات جدول ممکن است. با این حال، برای سایر رویکردهای PostGIS، زمانهای آمادهسازی فقط شامل زمان ایجاد حداقل قطعاتی است که در واقع برای پرسوجوها مورد نیاز هستند.
در نهایت، ‘PC_PATCH’ فقط برای مجموعه داده SMALL آزمایش شد. این مستلزم ایجاد وصلهها با توجه به مقدار شناسه معنایی آن نقاطی است که در آنها قرار دارند اسمنD=5با استفاده از داده های یک قطعه جدول PostGIS. سپس جدول وصله ها با استفاده از شاخص GIST همانطور که در فهرست A3 نشان داده شده است نمایه شد.
3.9. نرم افزار و سخت افزار مورد استفاده
یک دسکتاپ Dell با کارایی بالا (Precision 5820) با 64 گیگابایت رم و 3.6 گیگاهرتز Xeon 6 هسته ای که روی ویندوز 10 64 بیتی اجرا می شود و مجهز به یک SSD داخلی 1 ترابایتی برای ذخیره سازی دیسک برای همه آزمایش ها استفاده شده است. نرم افزار طرح SDBL به طور کامل در پایتون 64 بیتی (Python 3.7.1) با استفاده از miniconda3 و استفاده از بسته های پاندا [ 70 ] و feather [ 71 ] نوشته شده است.
به عنوان یک RDBMS، ما از PostgreSQL 10.8، همراه با pgAdmin (نسخه 4.3) برای اجرای کوئری ها استفاده کردیم. برای ارزیابی عملکرد یک پرس و جو PostgreSQL، از “ابزار پرس و جو” در pgAdmin برای اجرای هر پرس و جو استفاده شد. با این حال، برای به دست آوردن یک زمان دقیق، برای هر پرس و جو دستور ‘EXPLAIN ANALYZE stmt ‘ را صادر کردیم، که در آن stmt کوئری است که اجرا شده است. زمان پرس و جو مجموع به دست آمده از زمان های برنامه ریزی و اجرا است و این مقادیر هستند که در جداول نتیجه گزارش می شوند، یعنی جدول 4 (داده های کوچک)، جدول 5 (مجموعه مجموعه داده متوسط)، جدول 6 (مجموعه داده بزرگ) و جدول 7(پرس و جوی ویژه بدون شناسه معنایی). پرس و جوهای داغ برای SDBL از طریق PostgreSQL در داخل پرانتز در این جداول نشان داده شده است، زمان گزارش شده برای پرس و جوی داغ میانگین سه اجرا برای پرس و جو پس از اولین اجرا است، به اصطلاح کوئری سرد.
4. نتایج
در بخشهای بعدی، برای هر یک از سه مجموعه داده، ابتدا نتایج را با استفاده از SBDL از طریق یک رویکرد Python ارائه میکنیم و سپس نتایج را هنگام استفاده از SBDL از طریق جداول تکهتکه شده PostgreSQL ارائه میکنیم. زمان لازم برای آماده سازی مجموعه داده برای پایتون در ستون اول و ردیف اول هر یک از جدول نتایج گزارش شده است ( جدول 4 ، جدول 5 و جدول 6 ).
4.1. نتایج برای مجموعه داده کوچک
زمان آماده سازی مجموعه داده SMALL هنگام استفاده از SDBL از طریق پایتون کمتر از 4 ثانیه یا 3885 میلی ثانیه طول می کشد همانطور که در جدول 4 نشان داده شده است و فقط کمی سریعتر از زمان آماده سازی برای استفاده از جدول تکه تکه شده PostgreSQL است. زمان آمادهسازی برای دومی، 4080 میلیثانیه، از زمان استفاده از اسکریپت پایتون برای تولید تنها دو جدول تکه تکه شده تشکیل شده است. اسمنD=0و اسمنD=5و آنها را بر روی صفات فهرست کنید (ایکس،Y،ز)(نیاز به 3810 میلی ثانیه). علاوه بر این، برای قطعه جدول اسمنD=5، ما از pgAdmin برای ایجاد یک شاخص ثانویه برای ویژگی S استفاده کردیم تا به سرعت شناسه های ساختمان را بازیابی کنیم، عملیاتی که فقط به 270 میلی ثانیه نیاز داشت.
در مورد زمان آمادهسازی دادهها برای جداول PostGIS تکه تکه شده (14555 میلیثانیه)، این زمان از زمان ایجاد دو قطعه جدول PostGIS تشکیل شده است. اسمنD=0و اسمنD=5(۶۰۵ میلیثانیه)، زمان پر کردن آنها با دادههای مربوطه (۲۲۵۷ میلیثانیه) از جداول PostgreSQL به همراه زمان مورد نیاز برای ساخت سه شاخص عملکردی روی ویژگیهای X ، Y و S (۱۱،۶۹۳ میلیثانیه) برای قطعه جدول. اسمنD=5فقط.
زمان آمادهسازی دادهها برای معیار غیرقطعی تقریباً 7 ثانیه (6919 میلیثانیه) است و از زمان ایجاد جدول (177 میلیثانیه)، زمان لازم برای افزودن یک ستون شناسه معنایی و نمایهسازی آن (759 میلیثانیه) تشکیل میشود. همراه با زمان پر کردن آن با داده ها (5983 میلی ثانیه) از دو جدول تکه تکه شده PostgreSQL.
نتایج پرس و جو برای مجموعه داده کوچک، که در جدول 4 نیز نشان داده شده است ، از این نظر منحصر به فرد هستند که برای همه پرس و جوها، رویکرد جدول تکه تکه سریعتر از رویکرد پایتون است. به عنوان مثال، برای پرس و جو نقطه س2آ، رویکرد Python به 14.23 میلیثانیه برای بازیابی تمام 1386 نقطه موجود در یک فایل واحد (با شناسه ساختمان = 416793804) به حافظه نیاز دارد. در مقابل، پرس و جو PostgreSQL (فهرست A4 در ضمیمه A ) قادر است همان مجموعه نقاط را از یک جدول تکه تکه شده که شامل تمام نقاط مربوط به ساختمان ها در تنها 1.92 میلی ثانیه است بازیابی کند. ما این سرعت PostgreSQL را تا حدی به این واقعیت نسبت میدهیم که مجموعه نتایج در همه جستارها نسبتاً کوچک است، به این معنی که یک RDBMS میتواند با حداقل عملیات ورودی/خروجی دیسک به دادههای مورد نیاز دسترسی پیدا کند. با این حال، پرس و جو پایتون س2آاجرای آن نیز ساده است، زیرا عمدتاً شامل خواندن یک فایل باینری در حافظه است که در زیر شاخه MyPath\ID_5\416793804\ . به عبارت دیگر، نیازی به جستجوی صحیح نیست پoمنnتیسفایل، زیرا مکان آن از پیش تعیین شده از شناسه ساختمان است. شاید رویکرد Python کمی کندتر از رویکرد PostgreSQL تکهتکه شده باشد، صرفاً به دلیل سربار اضافی مرتبط با اسکریپت پایتون، که زمانی که زمانهای پردازش پرس و جو کم است، وارد عمل میشود.
رویکرد تکه تکه شده برای اکثر پرس و جوها به وضوح سریعتر از رویکرد غیرقطعی معیار است، به جز برای پرس و جوها س2آو س2بکه یک مجموعه نتیجه کوچک را برمی گرداند و برای آنها تفاوت بسیار کمی در زمان های پرس و جو وجود دارد. به عنوان مثال، برای پرس و جو س2آزمان پرس و جو برای جدول تکه تکه شده و جدول معیار به ترتیب 1.92 میلی ثانیه و 1.77 میلی ثانیه است.
در نهایت، ما همچنین استفاده از “PC_PATCH” را برای پرس و جو نقطه ای آزمایش کردیم س1با استفاده از کد موجود در فهرست A7. نتایج نشان میدهد که استفاده از وصلهها یا مسدود کردن به کندی میافزاید، در واقع ردیفی که «جدول وصله» در جدول 4 مشخص شده است، کندترین نتایج پرس و جو را دارد.
4.1.1. یک پرس و جو پیچیده تر با استفاده از مجموعه داده کوچک توسعه یافته
به یاد می آوریم که در مورد مجموعه داده SMALL، SDBL از طریق Python هر کدام را ذخیره می کند پoمنnتیسفایل برای شناسه ساختمان معین در زیر پوشه خود (علاوه بر ذخیره تمام شناسه های ساختمان در یک واحد بزرگتر پoمنnتیسفایل زیر پوشه “ID_5”). از آنجایی که دیدن اثر تعداد زیادی زیرمجموعه بر روی پرس و جوی پیچیده تر با استفاده از SDBL از طریق پایتون جالب است، ما به استفاده از نسخه توسعه یافته مجموعه داده SMALL متوسل شدیم. نسخه توسعهیافته شامل یک منطقه جغرافیایی بزرگتر با تراکم نقطه بالاتر است، که در مجموع شامل ۸،۹۷۱،۳۲۷ نقطه است که نشاندهنده ۱۹۴۰ شناسه ساختمانی مختلف است، که به نوبه خود از مجموع ۹۰۶،۹۲۶ نقطه تشکیل شدهاند. ما از یک پرس و جو استفاده کردیم که حداکثر مقدار مختصات Z را برای هر شناسه ساختمان در یک پایه پیدا می کند(ایکس،Y) محدوده در حالی که دو شناسه ساختمان خاص را حذف می کند. به طور دقیق تر، ما محدوده را تغییر دادیم ایکس≥ایکسمترمنnو Y≥Yمترمنnبا استفاده از پنج جفت مقادیر مختلف برای ایکسمترمنnو Yمترمنnهمانطور که در محدوده ها نشان داده شده است آر1– آر5در جدول 8 (در حالی که شناسه های ساختمان “416793804” و “416794274” به استثنای شناسه های ساختمان است. این به طور موثر منجر به پنج پرس و جو می شود.
هر یک از این پنج پرسوجو در سه پیادهسازی مختلف، با دو تنوع پایتون، به نامهای Python-with-groupby و Python-without-groupby و یک پیادهسازی جدا شده PostgreSQL اجرا شد. پرس و جوی SQL برای مورد جدول تکه تکه شده که ایکسمترمنn=378020 و Yمترمنn= 6,664,206 در فهرست 2 نشان داده شده است.
اگرچه هر دو پیاده سازی پایتون از SDBL از طریق پایتون استفاده می کنند، اما در نحوه دسترسی به داده ها متفاوت هستند. Python-with-groupby تابع گروه بای پانداها را بر روی یک دیتا فریم که با خواندن یک عدد بزرگتر به دست می آید، اعمال می کند.پoمنnتیسفایل زیر پوشه «ID_5» (قبل از اعمال تابع groupby ، تابع query pandas برای یافتن مجموعه منطبق از شناسههای ساختمان که متناسب با دادههای داده شده است استفاده میشود. (ایکس،Y)محدوده و دو شناسه ساختمانی نامطلوب حذف شدند). استفاده از pandas groupby در فهرست 1 نشان داده شده است. زمان آماده سازی برای هر دو پیاده سازی پایتون یکسان بود، 485 ثانیه، در حالی که زمان آماده سازی برای جدول تکه تکه شده PostgreSQL به طور مشابه برای مجموعه داده SMALL پایین نمونه به دست آمد و معلوم شد 119 است. س
فهرست 1. اعمال تابع pandas توسط groupby به مجموعه داده Pts_BlockXY که شامل مجموعه ای از نقاط در محدوده مورد نظر با دو ساختمان ناخواسته که در درخواست بخش 4.1.1 مشخص شده است حذف شده است.
1 Pts_Block_grouped = Pts_BlockXY.loc[Pts_BlockXY.groupby('s').z.idxmax()]
در مورد رویکرد Python-without-groupby، هر کدام را پردازش می کند پoمنnتیسفایلی که معیارهای پرس و جو را برآورده می کند، البته از خواندن آنها اجتناب می کند پoمنnتیسفایل هایی که مقادیر افراطی برای X و Y با داده شده مطابقت ندارد (ایکس،Y)محدوده همانطور که در بخش 3.7 توضیح داده شده است. این به طور موثر به این معنی است که اگر یکی از پنج پرس و جو در محدوده آرمنبرمی گرداند نمنشناسه های ساختمان، Python-without-groupby خوانده و پردازش خواهد شد نمن پoمنnتیسفایل ها. سه رویکرد پیاده سازی به طور خلاصه در زیر خلاصه شده است.
-
Python-with-groupby: از یک واحد استفاده می کند پoمنnتیسفایل زیر پوشه “ID_5” که در یک دیتافریم خوانده می شود. سپس دیتافریم از قبل پردازش میشود تا شناسههای ساختمانی که برای حذف در پرس و جو علامتگذاری شدهاند حذف شوند و فقط نقاطی در داخل دادهشده باشند. (ایکس،Y)محدوده گنجانده شده است. در نهایت، تابع groupby pandas به چارچوب داده بهدستآمده اعمال میشود تا مجموعه نهایی حداکثر نقاط مختصات Z ( Pts_Block_grouped در فهرست 1) برای هر شناسه ساختمان به دست آید.
-
Python-without-groupby: هر کدام را می خواند پoمنnتیسفایل از یک زیر پوشه جداگانه (زیر پوشه والد ‘ID_5’) که در داخل پوشه داده شده است (ایکس،Y)محدوده (و که به شناسه ساختمانی که برای حذف علامت گذاری شده تعلق ندارد) به یک دیتافریم موقت df . از df ، حداکثر مختصات Z محاسبه شده و به یک لیست اضافه می شود تا نتیجه نهایی به دست آید.
-
جدول تکه تکه شده: از یک جدول PostgreSQL استفاده می کند که شامل تمام نقاط (ردیف) مربوط به ساختمان ها است، با ساختار جدولی که برای مجموعه داده SMALL نمونه برداری شده یکسان است. جدول تکه تکه شده شامل 906926 ردیف است که تعداد نقاط مربوط به ساختمان ها در مجموعه داده توسعه یافته است.
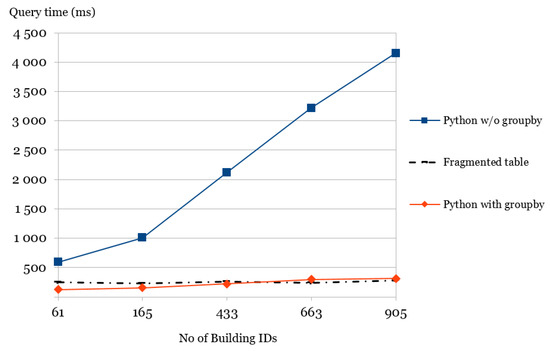
نتایج در جدول 8 و در قالب نمودار در شکل 5 نشان داده شده است. از جدول 8 ، مشاهده می شود که وقتی پرس و جو در مجموع 61 ساختمان را لمس می کند (یا به آن اشاره می کند)، هر سه پرس و جو در کمتر از 1 ثانیه کامل می شوند، با Python-with-groupby و پرس و جوهای جدول تکه تکه شده در عرض 300 میلی ثانیه (125 میلی ثانیه) تکمیل می شوند. و به ترتیب 250 میلی ثانیه). جدول همچنین نشان میدهد که وقتی 905 شناسه ساختمان برگردانده میشوند، جستارهای جدول Python-with-groupby و Fragmented هنوز در حدود 300 میلیثانیه (به ترتیب 310 و 280 میلیثانیه) تکمیل میشوند. با این حال، عملکرد کوئری Python-without-groupby به طور قابل توجهی کند شده است و بیش از 3 ثانیه (3220 میلی ثانیه) تکمیل می شود. این به این واقعیت نسبت داده می شود که پرس و جو در واقع نیاز به خواندن و پرس و جو 905 دارد پoمنnتیسفایل ها. همانطور که از نمودار مشاهده می شود ( شکل 5 )، بخش خطی که “Python without groupby” علامت گذاری شده است، به شدت به عنوان تعداد شناسه های ساختمان (و بنابراین تعداد پoمنnتیسفایلهای پردازش شده بیش از 165 است. این در تضاد با رویکرد Python-with-groupby است که همیشه میتواند تمام شناسههای ساختمان را فقط از یک واحد بخواند. پoمنnتیس فایل.
فهرست 2. پرس و جو پیچیده PostgreSQL با استفاده از مجموعه داده توسعه یافته SMALL برای یافتن بالاترین نقطه مختصات Z در بین هر ساختمان در یک منطقه (X,Y) معین ( ایکس≥378020 و ایکس≥6,664,206)، در حالی که دو شناسه ساختمان (ID = ‘41679380’ و ID = ‘416794274’). در بین پرس و جوهای پنج محدوده اجرا شده، این پرس و جو بیشترین تعداد شناسه ساختمان را به دست آورد که تعداد آنها 905 می باشد.
1 توضیح دهید تجزیه و تحلیل
2 MAX(Z) را از P2xyz_s_5 انتخاب کنید
3 WHERE X > = 378020 و Y > = 6664206
4 گروه با عدم ورود ( '416793804 ' , '
416794274 ' )
4.2. نتایج برای مجموعه داده های متوسط
برای مجموعه داده MEDIUM، نتایج در جدول 5 نشان داده شده است. داده ها در جداول PostgreSQL تکه تکه شده بارگیری می شوند (زمان مورد نیاز 43806 میلی ثانیه) با استفاده از یک اسکریپت پایتون به طور مشابه با مجموعه داده SMALL، با این تفاوت که شناسه معنایی دیگر در یک ستون جدول ذخیره نمی شود زیرا اکنون یک کلاس معنایی را نشان می دهد (مطابق با semantic3D [ 63 ]) و بنابراین همه نقاط/ردیفهای یک جدول یکسان هستند اسمنDارزش.
زمان آماده سازی جداول PostGIS تکه تکه شده (48791 میلی ثانیه) شامل زمان ایجاد و پر کردن قطعات PostGIS با ویژگی ها بود. (ایکس،Y،ز،من)با استفاده از دادههای مربوط به قطعات PostgreSQL (42755 میلیثانیه) و ایجاد دو نمایه عملکردی در X و Y برای قطعه با اسمنD=5(نیاز به 6036 میلی ثانیه). سایر قطعات به نمایه های عملکردی نیاز نداشتند زیرا هیچ اشاره ای به مختصات آنها در پرس و جوها نشده است.
با توجه به زمان آمادهسازی جدول بنچمارک PostgreSQL (274937 میلیثانیه)، این جدول شامل ایجاد یک جدول خالی با ستونها است. (ایکس،Y،ز،من،اس)(نیاز به 217 میلی ثانیه)، پر کردن جدول با داده های 9 جدول تکه تکه شده (251330 میلی ثانیه) و نمایه سازی آن در ویژگی اسمنD (23390 میلی ثانیه).
با توجه به پرس و جوهای واقعی، رویکرد Python و رویکرد PostgreSQL تکه تکه شده به وضوح از دو مدل حافظه کاملا متفاوت استفاده می کنند: اولی سعی می کند کل داده ها را در حافظه نگه دارد، در حالی که دومی صفحات داده مورد نیاز را در صورت نیاز از دیسک واکشی می کند. بنابراین جالب است بدانید که با مجموعه داده MEDIUM، اگرچه رویکرد Python هنوز نسبتاً سریع است، اما برای جستجوهای محدوده س3و س4، رویکرد جداول PostgreSQL حتی کمی سریعتر است. برای پرس و جو نقطه س2بکه به سادگی مجموعه بزرگی از ردیف ها را برمی گرداند، رویکرد پایتون به وضوح سریعتر است (93.39 در مقابل 595.43 میلی ثانیه). این احتمالاً به دلیل این واقعیت است که این جستجوی خاص از طریق خواندن های متوالی پردازش می شود که به حدود 40 دسترسی صفحه دیسک (با اندازه بلوک 8 K) ترجمه می شود تا تمام داده ها برای شناسه کلاس معنایی خوانده شود. اسمنD=2(جدول 337 مگابایت را اشغال می کند).
همانطور که انتظار می رفت، رویکرد جدول تکه تکه شده PostGIS، به وضوح کندتر از رویکرد PostgreSQL تکه تکه شده است، اما همچنین کندتر از رویکرد معیار غیرقطعی PostgreSQL (که داده ها را از تمام شناسه های معنایی ترکیب می کند) است. این حداقل تا حدودی به دلیل زمان اضافی مورد نیاز برای تبدیل نمایش نقطه باینری به قالبی قابل خواندن تر با کمک تابع PC_ASTEXT(pt) است که در فهرست A6 نشان داده شده است.
4.3. نتایج برای مجموعه داده بزرگ
ما داده ها را در جداول PostgreSQL تکه تکه بارگذاری کردیم به همان روشی که با مجموعه داده MEDIUM انجام شد، و اندازه بزرگ مجموعه داده به وضوح در زمان آماده سازی مورد نیاز، که اکنون کمی بیش از 1 بود، آشکار بود. ساعت 38 دقیقه، یا همانطور که در ثانیه در جدول 6 ، 5882 s نشان داده شده است.
زمان آمادهسازی برای جدول محکنشده PostgreSQL (9368 ثانیه)، مانند مجموعه داده MEDIUM، شامل ایجاد یک جدول خالی با ستونها بود. (ایکس،Y،ز،من،اس)و پر کردن آن با داده های نه جدول تکه تکه شده (که به 8923 ثانیه نیاز دارند) و نمایه سازی آن بر روی ویژگی S (یعنی، اسمنD) که به 445 ثانیه بیشتر نیاز دارد.
هنگام بررسی نتایج مجموعه داده LARGE در جدول 6 ، ما همان پدیده ای را تشخیص می دهیم که با مجموعه داده MEDIUM قبلی قابل مشاهده بود، به موجب آن رویکرد جدول تکه تکه شده سریع ترین زمان ها را برای جستارهای محدوده ارائه می کند. س3و س4اما برای سایر پرس و جوها به طور قابل توجهی کندتر است. آنچه قابل توجه است این است که اکنون رویکرد جدول بدون تکه تکه شدن به طور قابل توجهی کندتر از جداول تکه تکه شده است. بهعنوان مثال، زمانهای پرسوجوی PostgreSQL بدون تکهتکه و تکهتکه س320.25 در مقابل 3.64 s و برای پرس و جو هستند س4به ترتیب 14.24 در مقابل 5.65 ثانیه.
در مورد استفاده از SDBL از طریق پایتون برای پرس و جوهای نقطه ای که یک نقطه واحد را بدون مشخص کردن برمی گرداند اسمنDثابت کرد که دستیابی به آن نسبتاً آسان است. ما اسکریپت پایتون را طوری تغییر دادیم که یک نقطه به آن داده شود (ایکس،Y،ز)، هر نه معنایی را اسکن می کند پoمنnتیس برای نقطه مورد نیاز فایل کنید تا زمانی که پیدا شود. و همانطور که در بخش 3.7 ذکر شد ، ما از حداقل و حداکثر استفاده کردیم (ایکس،Y،ز)برای هر فایل شناسه معنایی به طوری که یک فایل تنها در صورتی در حافظه بارگذاری میشود که نقطه مورد پرسش در حداقل و حداکثر ذخیره شده جداگانه قرار داشته باشد.
به طور مشابه، برای استفاده از SDBL از طریق PostgreSQL برای پرس و جو از یک نقطه بدون مشخص کردن اسمنD، رویکرد جدول تکه تکه شده به سادگی از طریق استفاده از SQL Union-operator در پرس و جو، همانطور که در فهرست 3 نشان داده شده است، گسترش یافته است. در چنین حالتی، پرس و جو فرض می کند که نقاط بازیابی ممکن است در یک (یا چند) قطعه جدول باشند. و بنابراین هر نه ( اسمنD 0 تا 8) قطعات جدول باید پرس و جو شوند. با این حال، نتایج جدول 7 نشان می دهد که این یک پرس و جو پیچیده و کند پردازش نمی شود. برای مقاصد مقایسه، ما همچنین جدول تکه تکه نشده (از مجموعه داده بزرگ) را با استفاده از پرس و جو نقطه ای در فهرست 4 جویا شدیم. پرس و جو برای جدول تکه تکه شده کمی سریعتر از جدول تکه تکه نشده (45.5 میلی ثانیه) بود (29.5 میلی ثانیه).
فهرست 3. یک پرس و جو نقطه ای PostgreSQL که از عملگر UNION (محدوده 0 تا 8) برای یافتن یک نقطه معین بدون اطلاع از شناسه معنایی آن استفاده می کند.
1 توضیح دهید تجزیه و تحلیل
2 SELECT * FROM P2xyz_L_0 WHERE X = 42.552 AND Y = 94.641 AND Z = 2.531
3 UNION
4 SELECT * FROM P2xyz_L_1 WHERE X = 42.552 AND Y = 94.641 AND Z = 2.531
5 ……
6 UNION
7 SELECT * FROM P2xyz_L_8 WHERE X = 42.552 AND Y = 94.641 AND Z = 2.531
فهرست 4. یک پرس و جو نقطه ای PostgreSQL که مستقیماً به یک نقطه واحد از یک جدول غیرقطعی که شامل تمام نقاط مجموعه داده است دسترسی پیدا می کند.
1 توضیح تجزیه و تحلیل SELECT * FROM P2xyz_L WHERE X = 42.552
2 و Y = 94.641 و Z = 2.531
نتایج جدول 7 نشان می دهد که پرس و جو بدون شناسه معنایی مطمئناً می تواند به راحتی انجام شود. برای پیاده سازی پایتون، ما همچنین سعی کردیم یک نمایه واضح در آن ایجاد کنیم (ایکس،Y،ز)، اما زمان مورد نیاز برای ایجاد نمایه بسیار بیشتر از هر مزیتی بود زیرا ساخت نمایه و اجرای پرس و جو نقطه ای اکنون بیش از 47 ثانیه طول کشید (47710 میلی ثانیه) همانطور که در جدول 7 مشاهده می شود . اجرای همان پرس و جو نقطه ای در پایتون فقط با استفاده از نمایه ضمنی تولید شده توسط پانداها [ 70 ] رضایت بخش بود و به 7780 میلی ثانیه نیاز داشت.
5. بحث و نتیجه گیری
رویکرد SDBL با استفاده از دو فرمت کاملاً متفاوت ارائه شد، زیرا میتوان آن را از طریق پایتون و پانداها با استفاده از دایرکتوریها یا از طریق استفاده از PostgreSQL به عنوان یک RDBMS پیادهسازی کرد. SDBL از طریق پایتون را می توان به عنوان یک فروشگاه ستون محور ساده با پیچ و تاب اضافی مشخص کرد که نمایه سازی معنایی از طریق استفاده از دایرکتوری ها ارائه می شود. داده semantic3D [ 63 ] با کلاس معنایی ذخیره شده برای هر نقطه در یک فایل جداگانه (پرونده اسهمترآnتیمنجس) مفید است زیرا اطلاعات معنایی اندازه آن را افزایش نمی دهد پoمنnتیسفایل با داده های ابر نقطه واقعی. رویکرد SDBL via Python با حذف نیاز به فایل، این طرح معنایی را یک قدم جلوتر میبرد. اسهمترآnتیمنجسبه عنوان بزرگ پoمنnتیسفایل به کوچکتر تجزیه می شود پoمنnتیسفایل هایی که کلاس معنایی یکسانی دارند و در همان دایرکتوری که نام کلاس معنایی را در خود دارد ذخیره می شوند.
از سوی دیگر، SDBL از طریق رویکرد PostgreSQL اندازه یک جدول رابطهای را کاهش میدهد که دادههای ابر نقطهای را با تکهتکه کردن یک جدول بزرگتر به جدولهای کوچکتر با توجه به کلاس معنایی در خود نگه میدارد: یک جدول خاص در نهایت حاوی ردیفها یا نقاطی است که همه متعلق به همان شناسه معنایی دو رویکرد ارائه شده، SDBL از طریق Python و SDB از طریق PostgreSQL نیز با توجه به مدل حافظه خود متفاوت هستند. هنگام استفاده از SDBL از طریق پایتون، شیء اولیه داده کار، پانداس دیتا فریم است ، که اگرچه از نظر ساختار شباهت زیادی به یک جدول رابطهای دارد، اما با این وجود پایدار نیست. 73 ].]. به عبارت دیگر، این بر عهده برنامه نویس است که یک قالب داده مناسب را انتخاب کند (مانند بسته پر که ما استفاده کردیم) تا دیتافریم را برای استفاده بعدی روی دیسک ذخیره کند. بسته پانداها سرعت خود را از پردازش درون حافظه می گیرد، یعنی با تلاش برای حفظ تمام داده های مورد نیاز در حافظه. این در تضاد با استفاده از SDBL از طریق PostgreSQL است که سرعت خود را از توانایی مکان یابی سریع ردیف های داده صحیح و سپس انتقال بلوک های دیسک مورد نیاز از دیسک به حافظه می گیرد. در ادامه به طور خلاصه مزایا و محدودیتهای دو رویکرد SDBL را مورد بحث قرار میدهیم.
5.1. مزایای رویکرد SDBL ارائه شده
در حالی که تقسیم ابرهای نقطه بزرگ به فایلهای کوچکتر – که معمولاً به عنوان کاشیکاری [ 23 ] شناخته میشود، به عنوان وسیلهای برای بایگانی و توزیع دادههای ابر نقطه مفید است، زمان بارگذاری اضافی را تحمیل میکند که پرسوجوها را به طور قابل توجهی کند میکند [ 74 ]. علاوه بر این، کاشی کاری نمی تواند تضمین کند که نقاط متعلق به یک کلاس معنایی در یک فایل کاشی یکسان قرار می گیرند. در واقع، نقاط مختلف یک شی معنایی یکسان به کاشیهای جداگانه ختم میشوند که لبههای شی از مرزهای کاشی عبور کنند [ 75 , 76 ]]. رویکرد SDBL از طریق پایتون فایلهای مبتنی بر معنایی را حفظ میکند و بنابراین یکی از راههای غلبه بر این مشکل است. علاوه بر این، SDBL از طریق رویکرد Python، اگرچه به عنوان یک فروشگاه ستونگرا طبقهبندی میشود، پیادهسازی و نگهداری آن آسان است زیرا به هیچ ابزار داده بزرگ شخص ثالث (مثلا Hadoop) متکی نیست. در مقایسه با یک رویکرد مبتنی بر فایل مانند LAStools [ 77 ]، SDBL از طریق Python احتمالاً منجر به مجموعه بسیار کوچکتری از فایلها میشود، حتی اگر سلسله مراتبی در آن وجود داشته باشد، برای مرجع [ 77]. 15 ].] گزارش می دهند که مجموعه داده های آزمایشی آنها از بیش از 60000 فایل تشکیل شده است. علاوه بر این، SDBL از طریق پایتون به طور خاص برای پرس و جو از طریق کلاس های معنایی طراحی شده است، و نیازی به مکانیسم نمایه سازی اضافی نیست زیرا نمایه سازی از طریق سیستم عامل انجام می شود: پوشه های مختلف شامل کلاس های معنایی متفاوتی هستند. این ویژگیها به SDBL از طریق پایتون نسبت به راهحلهای مبتنی بر فایل برای پرسوجوهایی که معناشناسی نقش اساسی دارند، مانند در زمینههای رانندگی مستقل و برنامههای روباتیک صنعتی [ 78 ] یا هنگام استفاده از ناوبری داخلی یا BIM (مدلسازی اطلاعات ساختمان) مزیتی میبخشد. 79 ].
در مورد استفاده از SDBL از طریق PostgreSQL، بایر، پدر درخت B، به درستی اشاره کرده است [ 80 ] که مدل پایگاه داده رابطهای بهعنوان چنین از قبل دارای چند بعدی بودن است. یک رکورد از یک جدول داده شده با n ویژگی را می توان به عنوان نقطه ای در فضا با n بعد [ 80 ] مشاهده کرد. بنابراین، چالش استفاده از RDBMS برای ذخیره و دسترسی موثر ابرهای نقطه، اساساً بر این شاخص استوار است. به طور خاص، از آنجایی که نمیتوانیم فرض کنیم که مجموعه دادههای ابری نقطهای بزرگ در حافظه قرار میگیرد، میخواهیم حداقل این شاخص یا بیشتر آن در حافظه باشد تا سرعت جستجوها را افزایش دهد. در واقع، نویسندگان مرجع [ 56] به طور هدفمند تعداد ردیف های جدول را زیر چند میلیون نگه دارید.
کاهش تعداد کل نقاط/ردیف ها در جدول از طریق تقسیم بندی یکی از راه های دستیابی به این هدف است. علاوه بر این، تکه تکه کردن یک جدول بر اساس شناسه معنایی آن، احتمال اینکه نقاطی که در محل مشترک قرار دارند به طور پیوسته روی دیسک ذخیره شوند، افزایش میدهد و در نتیجه سرعت بازیابی دادهها را افزایش میدهد. و همانطور که نتایج برای مجموعه دادههای MEDIUM و LARGE نشان داد، رویکرد PostgreSQL تکهتکه شده به وضوح سریعتر از رویکرد PostgreSQL تکهتکهنشده برای همه پرسوجوها است. برای مجموعه داده SMALL، پرس و جوهای نقطه ای س2آو س2ببرای جدول PostgreSQL تکه تکه نشده کمی سریعتر از جداول تکه تکه شده PostgreSQL است، اما این تفاوت کوچک ممکن است به عدم دقت اندازه گیری نسبت داده شود مانند سایر پرس و جوها در مجموعه داده SMALL ( س1، س3و س2آ) رویکرد جداول تکه تکه شده به وضوح سریعتر از رویکرد جداول تکه تکه شده است.
اگر نیاز قانعکنندهای به استفاده از RDBMS برای ذخیرهسازی یک ابر نقطه وجود ندارد، استفاده از SDBL به صورت برنامهنویسی با پایتون (همراه با بستههای پاندا و پر) و دایرکتوریها باید نتایج رضایتبخشی را ارائه دهد. استفاده از دایرکتوری ها و نامگذاری آنها بر اساس اسمنDیک راه سریع برای مکان یابی داده ها بر اساس کلاس های معنایی فراهم می کند. مزایا این است که نمایه سازی اکنون به طور موثر توسط سیستم عامل زیربنایی که مسئول مدیریت فایل و دایرکتوری است مراقبت می شود. ایده استفاده از دایرکتوری ها به عنوان مکانیزم نمایه سازی از کار قبلی ما گرفته شده است [ 81 ].
5.2. محدودیت های رویکرد SDBL ارائه شده
اگرچه ما از ویژگی های رنگ استفاده نکردیم (آر،جی،ب)، رویکرد ارائه شده در واقع استفاده از آنها را محدود نمی کند. البته شامل کردن ویژگیهای رنگی منجر به فایلها/جدولهای کمی بزرگتر میشود و از این رو این احتمال وجود دارد که سرعت جستجوهای مربوط به مجموعه دادههای بزرگ کاهش قابل توجهی داشته باشد. در واقع، پیادهسازی فعلی برای مجموعه داده MEDIUM (که از رنگها استفاده نمیکرد) با موفقیت در پیکربندی تنها با 8 گیگابایت رم اجرا شد، البته با زمان پرس و جو بسیار کندتر.
در حالی که رویکرد ارائه شده بر این فرض ساخته شده است که هر پرس و جو شامل شناسه معنایی است، می توان آن را برای پرس و جوهای نقطه ای که مشخص نمی کنند اعمال کرد. اسمنDهمانطور که در بخش 4.3 نشان داده شد . از این نظر، ما هیچ مانع بزرگی را در استفاده از SDBL در برنامه های مختلف پیش بینی نمی کنیم. با این حال، اگر SDBL از طریق Python با مجموعهای از چندین پرسوجو استفاده شود که در آن هر پرسوجو به شناسه معنایی متفاوتی اشاره میکند، این نشان میدهد که برای هر کوئری، دادهها باید از یک فایل در قالب داده پاندا (در حافظه) بارگیری شوند. به منظور یک پرس و جو. اگرچه SDBL باید در اینجا مفید باشد زیرا اندازه فایل ها را کاهش می دهد، اما اسکریپت پایتون باید هر یک را بارگیری کند. پoمنnتیسفایل از دیسک به منظور اجرای یک پرس و جو. از آنجایی که فرمت Semantic3D در مجموع از 9 کلاس معنایی استفاده می کند، بدون زیر سلسله مراتب، حداکثر تعداد پoمنnتیسبنابراین از نه فایل تجاوز نخواهد کرد.
نتایج برای نوع پرس و جو پیچیده تر با استفاده از مجموعه داده توسعه یافته SMALL در بخش 4.1.1 نشان می دهد که اگر تعداد نسبتاً زیادی (مثلاً بیش از 100) از پoمنnتیسفایلها خوانده میشوند، عملکرد پایتون از طریق SDBL به سرعت به یک رویکرد مبتنی بر فایل تبدیل میشود، به این معنی که مزایای بهدستآمده از رویکرد مجموعه داده پانداهای مبتنی بر حافظه از بین میرود. با این حال، در مورد زیر سلسله مراتب و یک پرس و جو که به تعداد زیادی از زیر کلاس های معنایی (یعنی شناسه های ساختمان) دسترسی دارد، می توان این وضعیت را به راحتی با استفاده از یک بزرگتر اصلاح کرد. پoمنnتیسفایلی که در پوشه والد قرار دارد و حاوی تمام نقاط زیر پوشه است. این رویکرد به طور موثر روشی است که برای پرسش Python-with-groupby استفاده می شود ( بخش 4.1.1 ). همچنین باید هنگام استفاده از پرس و جوهایی که شامل نقاط در کلاس های معنایی مرزی (مانند ساختمان و زمین زیر آن) هستند، مفید باشد.
باید چنین باشد پoمنnتیسفایلها بسیار بزرگ میشوند (مثلاً بیش از 200 میلیون ردیف)، زمانهای پرسوجو را میتوان با تقسیم کردن کلاسهای شناسه معنایی مورد نظر به یک زیر سلسله مراتب سریعتر انجام داد، که به نوبه خود میتواند در زیرمجموعههای مربوطه ذخیره شود. بنابراین، برای مثال، طبقه معنایی ساختمانها را میتوان در زیر سلسله مراتب سقفها و نماها طبقهبندی کرد، همانطور که در مرجع [ 82 ] انجام شد. این ترتیب باید مفید باشد، مشروط بر اینکه پرس و جو نیاز به دسترسی به اشیاء معنایی خاص داشته باشد و دقت شود که از مشکل دسترسی به تعداد زیاد جلوگیری شود. پoمنnتیسفایل ها در یک پرس و جو همانطور که قبلا بحث شد. استفاده از یک سلسله مراتب فرعی همچنین می تواند برای مقابله با این واقعیت استفاده شود که توزیع شناسه های معنایی احتمالاً برای کلاس های معنایی مختلف نابرابر است [ 78 ].
در نهایت، از آنجایی که این مطالعه به استفاده از راهحلهای یک گره بهراحتی قابل استقرار محدود بود، ما آزمایش نکردیم که SBDL چگونه از پردازش موازی سود میبرد.
5.3. نحوه ارتباط رویکرد SDBL ارائه شده با کار قبلی
Cura و همکاران در مقالات خود [ 56 ، 83 ] در مورد ایجاد یک سرور ابر نقطه ای. گروه بندی ابرهای نقطه ای را بر اساس ویژگی های مختلف، از جمله داده های معنایی در نظر بگیرید. نویسندگان خاطرنشان میکنند که اگر برای مثال دادههای ساختمان با هم گروهبندی شوند، باید مراقب بود که گروه خیلی بزرگی نداشته باشیم زیرا یافتن یک نقطه خاص مستلزم خواندن کل گروه است [ 56 ]. مزیت استفاده از SDBL از طریق پایتون این است که داده های مربوط به فعال است اسمنDبه احتمال زیاد در حافظه است به عنوان مثال، اگر کاربر پرس و جوی مربوط به ساختمان ها را صادر کند، مجموعه داده ساختمان در حافظه باقی می ماند (به عنوان یک چارچوب داده پانداها) تا زمانی که کاربر شناسه معنایی را به هدف دیگری مانند پوشش گیاهی بالا تغییر دهد. (اسمنD=3).
کورا و همکاران [ 56 ] از یک RDBMS (PostgreSQL و PostGIS) استفاده کنید که در آن تعداد نقاط از طریق وصله کاهش می یابد و به طراحی جالب آنها به عنوان PCS اشاره کنید.، مخفف Point Cloud Server. با این حال، برخلاف SDBL ما از طریق PostgreSQL، استفاده از PCS مستلزم این نیست که تمام نقاط یک پچ متعلق به یک کلاس معنایی باشند. علاوه بر این، SDBL از طریق PostgreSQL از وصله ها استفاده نمی کند یا نقاط را فشرده نمی کند. جالب اینجاست که PCS از شاخصهای کاربردی استفاده میکند تا امکان جستجوی تکههای نقاط را بدون انفجار آنها فراهم کند. هر زمان که یک وصله جدید تولید می شود، چندین شاخص عملکردی در ویژگی های مختلف محاسبه شده و در یک “فرمت ساده” (با دقت کمتر و در نتیجه فضای کمتر) در پایگاه داده ذخیره می شود. سپس نادیده گرفتن کل نقاط (به عنوان مثال، آنهایی که ساختمان نیستند) بدون انفجار آنها ممکن می شود [ 56 ]]. با این حال، هنگامی که یک پچ مناسب پیدا می شود، برای بازیابی، قطعاً نقاط آن باید منفجر شوند. زمانهای پرس و جو گزارششده برای رویکرد PCS، فرآیند یافتن یک وصله را از بازیابی و باز کردن واقعی آن جدا میکند [ 56 ] و بنابراین زمانهای ارائهشده مستقیماً با رویکرد ما قابل مقایسه نیستند.
ون اوستروم و همکاران [ 15 ] یک معیار بزرگ و دقیق در مورد پرس و جو از ابرهای نقطه بسیار بزرگ انجام داد که شامل استفاده از PostgreSQL (بدون وصله) و PostGIS با وصلهها است. در یکی از جستارهای مستطیلی خود (پرس و جو شماره 2) در مجموعه داده ‘210M’، (210,631,597 امتیاز) با استفاده از PostgreSQL با وصله ها و بدون هیچ ویژگی اضافی علاوه بر آن (ایکس،Y،ز)، نویسندگان زمان جستجوی داغ را 2.15 ثانیه گزارش کردند (نویسندگان از یک سرور قدرتمند با 128 گیگابایت رم و پردازنده های 2 × 8 هسته ای Intel Xeon استفاده کردند) برای یک پرس و جو که 563108 امتیاز را برگرداند. در مقابل، SDBL ما از طریق پرس و جو مستطیلی تکه تکه شده PostgreSQL که 945357 امتیاز را در 1.39 ثانیه برای مجموعه داده بزرگ (در مجموع نزدیک به نیم میلیارد امتیاز) برگرداند. جای تعجب نیست که زمانهای پرس و جو که برای رویکرد تکهتکهشده PostgreSQL یافتیم، با زمانهای پرس و جو برای یک پرس و جو مشابه با استفاده از PostGIS با وصلههایی که در یک پلتفرم سختافزاری قدرتمندتر اجرا میشوند، رقابتی است. از این گذشته، از آنجایی که SBDL از طریق پرس و جو PostgreSQL فرض می کند که همه نقاط در ناحیه مستطیلی به یک کلاس معنایی تعلق دارند، بنابراین می تواند از جدول تکه تکه شده استفاده کند که از نظر ردیف بسیار کوچکتر است (فقط 8903،
در مرجع [ 25 ]، پوکس و همکاران. چارچوبی را برای Smart Point Cloud یا SPC تعریف کنید که معناشناسی را از جغرافیایی در چارچوبی از سه کلاس جدا می کند. SPC از یک طرح طبقه بندی معنایی جالب استفاده می کند که در آن هر نقطه اگر به زمین یا سایر مرزها مانند دیوارها و سقف ها مربوط باشد در سطح 0 طبقه بندی می شود. هنگامی که نقطه بخشی از یک شی است O1که بر روی زمین قرار می گیرد (مانند میز)، در سطح 1 طبقه بندی می شود و اگر شی O1به عنوان میزبان برای یک شی دیگر عمل می کند O2، سپس آن شی O2به عنوان اولین مهمان شناخته می شود و در سطحی بلافاصله بالاتر طبقه بندی می شود، یعنی در این مورد سطح 2 [ 25 ]. چنین طرحی باید برای تقسیم بندی ابر نقاط داخلی [ 79 ] بسیار مفید باشد و برای مثال می تواند با استفاده از SDBL از طریق پایتون پیاده سازی شود.
در مرجع [ 84 ]، Poux توضیح میدهد که چگونه یک ابر نقطه میتواند پردازش شود تا دادههای معنایی استخراج شود و آنها را در پایگاه دادههای ابر نقطهای (PostgreSQL V.9.6) برای جستوجوهای معنایی ذخیره کند. نویسنده نشان می دهد که چگونه یک پرس و جو نقطه SQL نام شی را که میزبان نقطه داده شده است، برمی گرداند. با این حال، تاکید کار بر طبقه بندی معناشناسی یک ابر نقطه به طور موثر است (منطقه ای از 68 اتاق تنها در 59 دقیقه تجزیه و تحلیل و طبقه بندی می شود) به جای پرس و جو.
5.4. دستورالعمل های آینده
جالب است که SDBL ارائه شده را از طریق پایتون و از طریق یک رویکرد PostgreSQL با یک مجموعه داده ابر نقطه واقعی دنیای واقعی که سلسله مراتب شناسه معنایی را در بر می گیرد، آزمایش کنید. به عنوان مثال، اگر ساختمانها بیشتر به سقف و نما طبقهبندی شوند، این به سادگی نیاز به استفاده از دو زیرمجموعه اضافی برای SBDL از طریق رویکرد Python و استفاده از دو جدول تکه تکهشده اضافی برای SBDL از طریق رویکرد PostgreSQL دارد. می توان انتظار داشت که زمان پرس و جو به طور قابل توجهی کندتر نشود و آزمایش این فرض باید برای یک پروژه تحقیقاتی آینده امیدوار کننده باشد.






بدون دیدگاه