1. معرفی
با توجه به استفاده گسترده از سنسورهای ماهواره ای با زمان بازبینی کوتاه، اشکال مختلف تصاویر سنجش از دور به تعداد بی سابقه ای انباشته شده است. حجم زیادی از داده های تولید شده که امروزه در دسترس است، امکان استخراج اطلاعات پیچیده از این تصاویر را ضروری می سازد. بازیابی تصویر یک مکانیسم رایج استخراج اطلاعات است. اصل آن بازیابی تصاویر سازگار بصری از یک پایگاه داده از پیش تعریف شده، با توجه به مفهوم پرس و جو است [ 1 ، 2 ].
بازیابی تصویر سنجش از دور مبتنی بر محتوا (CBRSIR) یک کاربرد خاص از بازیابی تصویر بر روی مجموعه داده های تصویر سنجش از دور است. حالت کار سیستم CBRSIR را می توان به عنوان دو فرآیند اساسی خلاصه کرد، یعنی استخراج ویژگی و تطبیق تصویر. هدف از استخراج ویژگی یافتن و استخراج برخی از ویژگی های معرف و قوی از تصاویر است. روشهای سنتی استخراج ویژگی بر توصیفگرهای مصنوعی (مانند SIFT) [ 3 ] تکیه میکنند، که همچنین یک روش نمایش تصویر سنجش از دور پرکاربرد در کار RSIR (Remote Sensing Image Retrieval) است [ 4 ، 5 ].]. استخراج ویژگی های مصنوعی عمدتاً به برچسب های مصنوعی مرتبط با صحنه بستگی دارد. با این حال، طراحی برچسب ها نیاز به دانش حرفه ای کافی دارد و زمان بر است. در عین حال، کیفیت و در دسترس بودن برچسب ها به طور مستقیم بر عملکرد موتورهای جستجو تأثیر می گذارد. بنابراین، این روش استخراج ویژگی دارای عیوب خاصی است. از سوی دیگر، برخی از ویژگیهای تصاویر سنجش از دور نیز مانع از کاربرد مستقیم برخی از تکنیکهای رایج بازیابی تصویر (مانند تأیید هندسی، گسترش پرس و جو و غیره) میشود. تصویر سنجش از دور نه تنها یک هدف خاص بلکه یک یا چند هدف را نیز شامل می شود و همچنین دارای اطلاعات جغرافیایی غنی مانند ساختمان های دست ساز و مناظر طبیعی در مقیاس بزرگ مانند درختان، زمین های کشاورزی، علفزار و غیره است. به طور مشخص، تصویر سنجش از دور منطقه جغرافیایی نسبتاً وسیعی را پوشش میدهد و میتواند شامل تعداد مختلفی از اشیاء معنایی مختلف به طور همزمان باشد، که میتواند توسط منطقه در مقیاسهای مختلف ثبت شود. اگرچه برخی از مجموعه دادههای سنجش از راه دور متداول حاوی تصاویر زیادی هستند که به یک دسته معنایی تعلق دارند، این تصاویر کاملاً متفاوت هستند. به عنوان مثال، آنها ممکن است به طور قابل توجهی از نظر ظاهری متفاوت باشند یا از مناطق جغرافیایی مختلف منشأ بگیرند. علاوه بر این، سطح وضوح تصویر سنجش از دور و ارتفاع گرفتن تصویر مستقیماً بر اندازه شی مورد نظر و برخی جزئیات تأثیر می گذارد. به طور خلاصه، این ویژگی ها منجر به مشکلات و چالش های خاصی در RSIR شده است. اگرچه برخی از مجموعه دادههای سنجش از راه دور متداول حاوی تصاویر زیادی هستند که به یک دسته معنایی تعلق دارند، این تصاویر کاملاً متفاوت هستند. به عنوان مثال، آنها ممکن است به طور قابل توجهی از نظر ظاهری متفاوت باشند یا از مناطق جغرافیایی مختلف منشأ بگیرند. علاوه بر این، سطح وضوح تصویر سنجش از دور و ارتفاع گرفتن تصویر مستقیماً بر اندازه شی مورد نظر و برخی جزئیات تأثیر می گذارد. به طور خلاصه، این ویژگی ها منجر به مشکلات و چالش های خاصی در RSIR شده است. اگرچه برخی از مجموعه دادههای سنجش از راه دور متداول حاوی تصاویر زیادی هستند که به یک دسته معنایی تعلق دارند، این تصاویر کاملاً متفاوت هستند. به عنوان مثال، آنها ممکن است به طور قابل توجهی از نظر ظاهری متفاوت باشند یا از مناطق جغرافیایی مختلف منشأ بگیرند. علاوه بر این، سطح وضوح تصویر سنجش از دور و ارتفاع گرفتن تصویر مستقیماً بر اندازه شی مورد نظر و برخی جزئیات تأثیر می گذارد. به طور خلاصه، این ویژگی ها منجر به مشکلات و چالش های خاصی در RSIR شده است.
با توسعه بیشتر یادگیری عمیق، CBIR از «توصیفگر مصنوعی» ساده به «توصیفگر پیچیده» که میتواند از شبکههای عصبی کانولوشنال (CNNS) استخراج شود، توسعه یافته است [ 6 ، 7 ، 8 ]. شبکه عصبی کانولوشنال عمیق می تواند رابطه نگاشت بین ویژگی های سطح پایین و معناشناسی سطح بالا را ایجاد کند. با استخراج اطلاعات تصویر بسیار انتزاعی با معناشناسی سطح بالا، دقت RSIR پس از آموزش شبکه عصبی عمیق بهتر از RSIR بر اساس ویژگی های مصنوعی سنتی است [ 9 ، 10 ، 11 ].]. علاوه بر این، ویژگیهای عمیق را میتوان بهطور خودکار از دادهها بدون تلاش انسانی آموخت، که باعث میشود تکنیکهای یادگیری عمیق ارزش کاربردی بسیار مهمی در تحقیقات RSIR در مقیاس بزرگ داشته باشند. در میان آنها، یادگیری متریک عمیق (DML) یک فناوری است که یادگیری عمیق و یادگیری متریک را ترکیب می کند [ 12 ]. هدف DML یادگیری فضای جاسازی است که بردارهای تعبیه شده بین نمونه های مشابه را تشویق می کند تا نزدیکتر باشند، در حالی که نمونه های غیر مشابه از یکدیگر دور هستند [ 13 ، 14 ، 15 ].]. یادگیری متریک عمیق از توانایی تمایز CNNS برای جاسازی تصاویر در فضای متریک استفاده میکند، جایی که معیارهای معنایی بین تصاویر اندازهگیری شده میتواند مستقیماً توسط الگوریتمهای متریک ساده مانند فاصله اقلیدسی محاسبه شود، که فرآیند اجرای الگوریتم را سادهتر میکند. علاوه بر این، یادگیری متریک عمیق در بسیاری از حوزههای تصویر طبیعی، مانند تشخیص چهره [ 12 ]، ردیابی بصری [ 16 ، 17 ]، بازیابی تصویر طبیعی [ 18 ]، بازیابی مدل متقابل [ 19 ]، تعبیه چند چندگانه هندسی استفاده شده است. [ 20] و غیره. اگرچه تصاویر سنجش از دور کاملاً با تصاویر طبیعی معمولی متفاوت هستند، یادگیری متریک عمیق هنوز هم چشم انداز توسعه کاملی در CBRSIR دارد.
در چارچوب DML، تابع ضرر نقش کلیدی ایفا می کند. با توسعه تحقیقات، تعدادی از توابع از دست دادن پیشنهاد شده است. کایا ام و همکاران [ 21 ] همراه با نتایج تحقیقات اخیر، اهمیت یادگیری متریک عمیق را آشکار کرد و مشکلات فعلی را که در این پرونده با آنها سروکار داشت، خلاصه کرد. برای مثال، از دست دادن کنتراست [ 22 ، 23 ] شباهت یا عدم تشابه بین نمونهها را نشان میدهد، در حالی که از دست دادن مبتنی بر سهگانه [ 12 ، 24 ]] رابطه بین نمونه های سه گانه را توصیف می کند. هر سه قلو شامل یک نمونه لنگر، یک نمونه مثبت و یک نمونه منفی است. به طور کلی به دلیل افزایش رابطه بین جفت نمونه مثبت و منفی، افت سه گانه بهتر از افت کنتراستیو است. تحقیقات اخیر با الهام از این موضوع، نمایش غنی تر اطلاعات ساختاریافته را در میان نمونه های متعدد [ 25 ، 26 ، 27 ، 28 ] در نظر گرفته اند و در بسیاری از کاربردهای عملی (مانند بازیابی تصویر و خوشه بندی تصویر) به عملکرد خوبی دست یافته اند. به طور خاص، وانگ و همکاران. [ 29] یک تابع از دست دادن یادگیری متریک را بر اساس رابطه زاویه ای سه گانه های محدود در نمونه های منفی پیشنهاد کرد که به آن “از دست دادن زاویه ای” می گویند. با این حال، پیشرفته ترین روش های DML هنوز محدودیت هایی دارند. اول از همه، متوجه میشویم که هنگام انتخاب نمونهها برای برخی از توابع از دست دادن، فقط از اطلاعات نمونه جزئی استفاده میشود و تفاوتها و جایگشتهای بین کلاسهای نمونه نادیده گرفته میشوند. در این حالت، نه تنها برخی از نمونه های غیر پیش پا افتاده هدر می روند، بلکه از اطلاعات مربوطه بین کلاس ها نیز به طور کامل استفاده نمی شود. در مرجع [ 30]، محقق از تمام نمونه های غیر پیش پا افتاده با تلفات غیر صفر (یعنی نقض محدودیت جفت پرس و جو) برای ساخت ساختاری با اطلاعات بیشتر برای یادگیری بردارهای جاسازی استفاده کرد تا از هدر رفتن اطلاعات ساختاری برخی موارد غیر پیش پا افتاده جلوگیری شود. نمونه ها. اگرچه اطلاعات بهدستآمده از این روش فراوان است، اما برخی از آنها اضافی هستند، که بار قابلتوجهی بر هزینههای محاسباتی و ذخیرهسازی دادهها وارد میکند. ثانیاً، توزیع مکانی نمونهها در کلاس در تلفات فوق در نظر گرفته نمیشود، بلکه فقط نمونههای مشابه تا حد امکان نزدیک ساخته میشوند. علاوه بر این، مشاهده می کنیم که تلفات قبلی برابر با هر نمونه مثبت است، یعنی تأثیر رابطه کمی بین نمونه های ساده و نمونه های سخت را بر بهینه سازی تلفات در نظر نمی گیرند. در حالت ایده آل، وزن بیشتری باید به نمونه سخت با درصد بیشتر داده شود. در مرجع [31 ]، نویسندگان افت یادگیری ساختار توزیع (DSLL) را پیشنهاد کردند، که در نظر میگیرد که ساختار فضایی نسبی حالت اولیه کلاسهای نمونه منفی با وزن دادن به کلاسهای نمونه منفی حفظ میشود. با این حال، تأثیر رابطه بین نمونه های مثبت و تعامل بین نمونه های مثبت و منفی بر ساختار فضایی را در نظر نمی گیرد. متدهای بالا برخی از ساختارهای شباهت و اطلاعات نمونه مفید را در کلاس از دست می دهند.
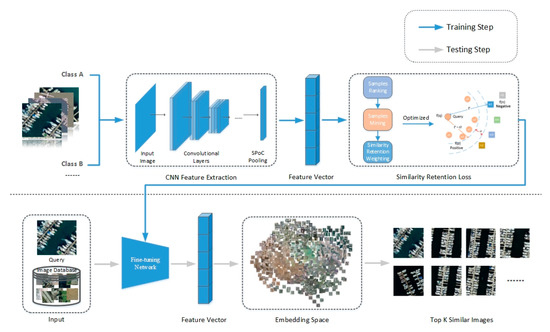
بر اساس مسائل فوق، این مقاله یک روش یادگیری متریک عمیق را بر اساس از دست دادن حفظ شباهت (SRL) پیشنهاد میکند. این روش در دو جنبه زیر بهبود یافته است. اولی استخراج نمونه ها بر اساس جفت های اطلاعاتی و دومی تخصیص وزن های نسبی مختلف به همه نمونه های انتخاب شده است. ابتدا، ما آستانهها و استراتژیهای انتخاب متفاوتی را برای نمونههای مثبت و منفی تعیین میکنیم تا اطمینان حاصل کنیم که نمونههای انتخاب شده هم نماینده و هم غیر زائد هستند. در عین حال، توصیه میکنیم در حین استخراج نمونه، توجه به حفظ اطلاعات ساختاری در کلاس نمونه مثبت شود. به طور خاص، ما فقط سعی میکنیم نمونههای یک کلاس را در یک آستانه فاصله مشخص، بدون اینکه آنها را به یک نقطه وادار کنیم، محدود کنیم. ثانیاً ما وزنهای دینامیکی را به نمونههای سخت انتخابی با توجه به نسبت نمونههای آسان به نمونههای سخت در کلاس اختصاص میدهیم و وزن از دست دادن ثبات رتبهبندی را بر اساس توزیع کلاسهای نمونه منفی وزن میکنیم. همانطور که در نشان داده شده است، ما یک معماری شبکه با تنظیم دقیق برای بازیابی تصویر سنجش از راه دور ایجاد می کنیم.شکل 1 . مشارکت های ما در این مقاله به شرح زیر است:
-
ما از دست دادن حفظ شباهت (SRL) را برای یادگیری متریک عمیق پیشنهاد می کنیم که با دو مرحله تکراری، استخراج نمونه ها و وزن های جفت، همانطور که در شکل 1 نشان داده شده است، تکمیل می شود . SRL حفظ ساختارهای شباهت را در داخل و بین کلاسها در نظر میگیرد که باعث میشود مدل در جمعآوری و اندازهگیری جفتهای اطلاعات کارآمدتر و دقیقتر شود و در نتیجه عملکرد بازیابی تصویر را بهبود بخشد.
-
ما یک آستانه بین نمونههای مشابه را یاد میگیریم تا توزیع دادهها را در کلاس حفظ کنیم، بهجای اینکه هر کلاس را به یک نقطه خاص در فضای جاسازی محدود کنیم. حفظ کارآمد اطلاعات در کلاس به گونه ای در نظر گرفته می شود که ویژگی های ساختار فضایی هر کلاس در فضای ویژگی حفظ شود.
-
با استفاده از یک شبکه تنظیم دقیق انتها به انتها، ما آزمایشهای گسترده و جامعی را بر روی مجموعه دادههای سنجش از راه دور PatternNet [ 11 ] و UCMD (UC Merced Land Use Dataset) [ 32 ] انجام دادهایم تا نظریه SRL را تأیید کنیم. نتایج نشان می دهد که روش ما به طور قابل توجهی بهتر از تکنولوژی پیشرفته است.
2. کارهای مرتبط
شبکه تنظیم دقیق برای بازیابی تصویر سنجش از دور شامل نمونهها، ساختار مدل شبکه و تابع از دست دادن است. این سه ترکیب یک سیستم کامل بازیابی تصویر را از طریق آموزش عمیق متریک تشکیل می دهند. در ادامه، کار مرتبط با مشارکت اصلی خود را حول این سه جنبه مورد بحث قرار خواهیم داد.
2.1. شبکه تنظیم دقیق
تنظیم دقیق شبکه یک روش جایگزین است که مستقیماً در یک شبکه از پیش آموزش دیده اعمال می شود. این روش توسط یک شبکه طبقه بندی از قبل آموزش دیده اولیه شده و سپس برای وظایف مختلف آموزش داده می شود. یادگیری ویژگی تصویر در مجموعه داده های مقیاس بزرگ (یعنی ImageNet) دارای قابلیت های تعمیم قوی است و می تواند به طور موثر به سایر مجموعه داده های مقیاس کوچک منتقل شود [ 33 ]. در فرآیند یادگیری انتقال CNN، مقدار خروجی لایه کاملا متصل باید در نظر گرفته شود [ 7 ]. با این حال، از آنجایی که مقدار ویژگی محلی تصویر بیان لایه کانولوشن نسبتاً بزرگ است [ 34 ]، ما معمولاً به جای لایههای کاملاً متصل از ویژگیهای لایه کانولوشن استفاده میکنیم.
ادغام یکی دیگر از مفاهیم اصلی در CNNS است و در واقع نوعی از نمونه برداری پایین است. لایه ادغام با کاهش ابعاد و انتزاع شی ورودی بصری از سیستم ورودی بصری تقلید می کند. این سه عملکرد زیر را دارد: تغییر ناپذیری ویژگی، کاهش ابعاد ویژگی و اجتناب از برازش بیش از حد. چند مدل ادغام عمومی وجود دارد که رایج ترین آنها ادغام مجموع است که توسط بابنکو و لمپیتسکی [ 35 ] پیشنهاد شده است و در ترکیب با سفید کردن توصیفگر به خوبی عمل می کند. متعاقباً، Kalantidis و همکاران. ادغام جمع وزنی پیشنهادی [ 36 ]، که می تواند به عنوان روشی برای انتقال یادگیری نیز دیده شود. طرح ترکیبی ترکیب خطی ترکیب حداکثر و مجموع R-Mac [ 37 ] است.]. یک ادغام ترکیبی جهانی برای بازیابی تصویر [ 38 ] پیشنهاد شده است که یک ادغام محلی استاندارد برای تشخیص اشیا است [ 39 ].
در این مقاله، ابتدا از شبکه از پیش آموزشدیده برای تنظیم دقیق شبکه استفاده میکنیم، سپس جفتهای نمونه را از مجموعه دادههای تصویر سنجش از دور برای آموزش شبکه انتخاب میکنیم و در نهایت SRL پیشنهادی خود را برای وظیفه بازیابی تصویر سنجش از دور نهایی بهینه میکنیم. با مشاهده داده های سنجش از دور، متوجه می شویم که تصویر یک منطقه جغرافیایی بزرگ را پوشش می دهد و این منطقه حاوی اطلاعات پس زمینه غنی و تعداد متفاوتی از جفت های معنایی مختلف است. ما چندین روش متداول ادغام را مقایسه کردیم و مناسب ترین لایه ادغام SPoC (Sum-Pooled Convolutional Features) را به عنوان لایه تجمع انتخاب کردیم. این لایه همگرایی به عنوان آخرین لایه تنظیم دقیق شبکه عصبی کانولوشن برای ساختن سیستمی است که برای CBRSIR مناسب است.
2.2. استخراج نمونه سخت
یادگیری متریک مبتنی بر جفت نمونه معمولاً از تعداد زیادی نمونه جفت استفاده می کند، اما این نمونه ها اغلب حاوی اطلاعات اضافی زیادی هستند. این نمونه های اضافی عملکرد واقعی و سرعت همگرایی مدل را تا حد زیادی کاهش می دهند. بنابراین، استراتژی نمونهگیری نقش مهمی در اندازهگیری سرعت آموزش مدل یادگیری دارد. در از دست دادن متضاد، روش انتخاب نمونه های آموزشی ساده ترین است، یعنی انتخاب تصادفی جفت نمونه مثبت و منفی در داده ها. در ابتدا، برخی از تحقیقات در مورد یادگیری تعبیه شده تمایل به استفاده از آموزش جفت ساده در شبکه سیامی داشتند [ 23 ، 40 ]]. شبکه سیامی از دو شاخه محاسباتی تشکیل شده است که هر کدام شامل یک جزء CNN است. اما این روش سرعت همگرایی شبکه را کاهش می دهد.
به منظور حل این مشکل، روش های استخراج منفی سخت پیشنهاد شده و به طور گسترده مورد استفاده قرار گرفته است [ 12 ، 41 ، 42 ، 43 ]. شروف و همکاران [ 12 ]. یک طرح استخراج منفی سخت با کاوش سه قلوهای نیمه سخت پیشنهاد کرد. این طرح یک جفت پدر منفی را نسبت به مثبت تعریف می کند. با این حال، این روش استخراج منفی تنها تعداد کمی سه گانه نیمه سخت معتبر تولید می کند و آموزش شبکه معمولاً به نمونه های بزرگ نیاز دارد. هاروود و همکاران [ 41 ] چارچوبی به نام استخراج هوشمند برای جمع آوری نمونه ها از کل مجموعه داده پیشنهاد کرد. این روش هزینه های محاسباتی خارج از خط بالایی را به همراه خواهد داشت. Ge و همکاران [ 43] از دست دادن سه گانه سلسله مراتبی (HTL) را پیشنهاد کرد که یک درخت سلسله مراتبی از همه دسته ها می سازد و جفت های منفی سخت را از طریق حاشیه پویا جمع آوری می کند. در مرجع [ 42 ]، مشکل کاوی نمونه در یادگیری متریک عمیق مورد بحث قرار گرفت و یک کاوی نمونه وزن دار از راه دور برای انتخاب جفت نمونه های منفی پیشنهاد شد.
اگرچه تمام نمونههای داخل آستانه با روشهای فوق استخراج شدند، تفاوت بین کلاسهای نمونه منفی و تأثیر نمونههای اطراف بر روی نمونهها در نظر گرفته نشد. در این مقاله تنوع و تفاوت نمونه ها به طور کامل در نظر گرفته شده است. بر این اساس چندین نمونه مثبت و نمونه منفی از طبقات مختلف انتخاب می کنیم و فاصله نمونه ها را با توجه به توزیع نمونه های همسایه منفی تعیین می کنیم. ما یک روش استخراج نمونه سخت جدید را پیشنهاد میکنیم، یعنی انتخاب استراتژیهای استخراج مختلف برای انتخاب جفتهای نمونه مثبت و جفتهای نمونه منفی با مرتبسازی شباهت نمونه و اطلاعات کلاس. به این ترتیب، انتخاب نمونه هم نماینده و هم غیر زائد است، در نتیجه به همگرایی سریعتر و عملکرد بهتر مدل دست مییابد.
2.3. توابع از دست دادن برای یادگیری عمیق متریک
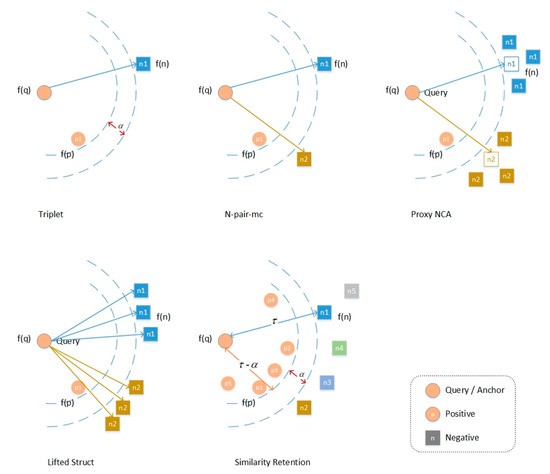
تابع ضرر نقش کلیدی در یادگیری متریک عمیق دارد. افزایش یا کاهش فاصله بین نمونه ها با تنظیم شباهت بین نمونه ها است. در مرجع [ 44 ]، توصیه میشود از سهقلوها بهعنوان نمونههای آموزشی برای یادگیری فضای ویژگی استفاده شود، جایی که شباهت جفتهای نمونه مثبت سهگانهها بیشتر از جفتهای نمونه منفی است. به طور خاص، فضای ویژگی وزن برابری را به جفت های نمونه انتخاب شده اختصاص می دهد. علاوه بر این، توابع از دست دادن چهارگانه مورد مطالعه قرار گرفته است، مانند از دست دادن هیستوگرام [ 45 ]. N-pair-mc [ 23] ویژگی های جاسازی شده را با استفاده از رابطه ساختاریافته بین چند نمونه می آموزد. هدف استخراج نمونه های منفی N-1 از دسته های N-1، یک نمونه منفی برای هر دسته و بهبود افت سه گانه با تعامل با نمونه ها و دسته های منفی بیشتر است. به طور مشخص، نمونه های انتخاب شده در از دست دادن جفت N نیز وزن یکسانی دارند. موشوویتز-آتیاس و همکاران. Proxy-NCA Loss [ 42 ] را پیشنهاد کرد که از یک پروکسی به جای نمونه اصلی برای حل مشکل نمونه برداری استفاده می کند. تخصیص پروکسی استاتیک یک پروکسی برای هر کلاس است و عملکرد آن بهتر از تخصیص پراکسی پویا است. با این حال، Proxy-NCA نمی تواند مقیاس پذیری DML را حفظ کند، بنابراین تعداد کلاس ها باید پیشنهاد شود. دونگ و همکاران یک افت انحراف دو جمله ای را پیشنهاد کرد [ 46] و از سوگیری دو جمله ای برای ارزیابی از دست دادن بین برچسب ها و شباهت استفاده کرد. هزینه انحراف دو جمله ای باعث می شود که مدل عمدتاً روی جفت های سخت تمرین کند، یعنی مدل بیشتر بر روی نمونه های منفی نزدیک به مرز تمرکز می کند. برخلاف افت لولا، افت انحراف دو جمله ای وزن های مختلفی را به جفت های نمونه بر اساس تفاوت فاصله آنها اختصاص می دهد. بعدها، سونگ و همکاران. Lifted Struct [ 25 ] پیشنهاد شد که ویژگی های تعبیه شده را با ترکیب تمام نمونه های منفی می آموزد. هدف Lifted Struct این است که جفت نمونه مثبت را تا حد ممکن نزدیک کند و همه نمونه های منفی را به موقعیتی دورتر از حاشیه فشار دهد.
با رعایت تلفات فوق، از دست دادن سه گانه و از دست دادن جفت N وزن یکسانی به جفت نمونه مثبت و منفی می دهد. بر خلاف آنها، افت انحرافی دوجملهای شباهت خود را در نظر میگیرد و اتلاف سازه بلند شده وزنها را برای جفتهای نمونه مثبت و منفی با توجه به شباهت نسبی منفی تعیین میکند. با این حال، این روش ها توزیع نمونه ها در کلاس و تفاوت بین کلاس های مختلف بین کلاس ها را نادیده می گیرند. در این کار، ما از دست دادن حفظ شباهت (SRL) را پیشنهاد می کنیم. همه نمونه ها به جز تصویر پرس و جو را بر اساس امتیاز شباهت فضای ویژگی های آموخته شده با پرس و جو مرتب می کنیم. سپس جفتهای نمونه انتخاب شده را با توجه به مرتبسازی ویژگی و برچسب، یعنی میزان نقض محدودیت هر جفت، وزن میکنیم. SRL از محدودیت های روش های سنتی با ادغام تعدادی از نمونه های سخت و کاوش در اطلاعات ساختارمند ذاتی جلوگیری می کند. برای جفت های نمونه منفی، فاصله باید تا حد امکان زیاد باشد، بنابراین هر چه تشابه بیشتر باشد، ضربه بیشتر و وزن بیشتر است. برای نمونه های مثبت، برعکس، هر چه تشابه کمتر باشد، باید توجه بیشتری شود و وزن بیشتر باشد. تصویر و مقایسه زیان های مختلف با انگیزه رتبه بندی و روش ما در ارائه شده است هر چه باید توجه بیشتری شود و وزن بیشتر شود. تصویر و مقایسه زیان های مختلف با انگیزه رتبه بندی و روش ما در ارائه شده است هر چه باید توجه بیشتری شود و وزن بیشتر شود. تصویر و مقایسه زیان های مختلف با انگیزه رتبه بندی و روش ما در ارائه شده استشکل 2 .
3. رویکرد پیشنهادی
هدف ما شناسایی تمام نمونه هایی است که با این تصویر پرس و جو مطابقت دارند از نمونه های دیگر در مجموعه داده، با توجه به هر تصویر پرس و جو از هر کلاس در مجموعه داده سنجش از دور. تنظیم X ={ (ایکسمن،yمن) }نi = 1ایکس={(ایکسمن،yمن)}من=1نبه عنوان داده ورودی، جایی که (ایکسمن،yمن)(ایکسمن،yمن)تصویر i را نشان می دهد که برچسب کلاس آن است yمنyمن.تعداد کلاس ها C است که در آن yمن∈ [ 1 , 2 , … , C ]yمن∈[1،2،…،سی]. اجازه دهید {ایکسجمن}نجi = 1{ایکسمنج}من=1نجمجموعه ای از تصاویر در کلاس c، که در آن تعداد کل تصاویر در کلاس c باشد نجنج.
3.1. نمونه برداری معدن
برای تصاویر پرس و جو، نمونه های مثبت و منفی آموزنده را استخراج می کنیم. نمونه پرس و جو داده شده است ایکسجمنایکسمنج، ما همه نمونه های دیگر را بر اساس شباهت آنها مرتب می کنیم ایکسجمنایکسمنج. پجمنپمنجمجموعه ای از همان کلاس تصویر query است که به صورت بیان می شود پجمن= {ایکسجj| j ≠ i }پمنج={ایکسjج|j≠من}، |پجمن| =نج– 1 |پمنج|=نج-1. نجمننمنجمجموعه ای از تصاویر دیگر است که با عنوان نجمن= {ایکسکj| k ≠ c , j ∈ [ 1 , 2 , … ,نک] }Nic={Xjk|k≠c,j∈[1,2,…,Nk]}، |نجمن| =∑k ≠ cنک|Nic|=∑k≠cNk. ما یک مجموعه داده متشکل از تاپل ها ایجاد می کنیم ( ایکسجمنXic، P (ایکسجمن)P(Xic)، N (ایکسجمن)N(Xic))، جایی که ایکسجمنایکسمنجتصویر پرس و جو را نشان می دهد، P (ایکسجمن)پ(ایکسمنج)مجموعه مثبتی است که از آن انتخاب شده است پجمن و N (ایکسجمن)پمنج و ن(ایکسمنج)مجموعه منفی انتخاب شده از است نجمننمنج. جفت های تصویر آموزشی از این تاپل ها تشکیل شده اند که هر تاپل مربوط به آن است | P (ایکسجمن) ||پ(ایکسمنج)|جفت نمونه مثبت و | N (ایکسجمن) ||ن(ایکسمنج)|جفت نمونه منفی
مجموعه نمونه مثبت P (ایکسجمن)پ(ایکسمنج). بر اساس ویژگی های مکانی نمونه ها، مشاهده می کنیم که نمونه های مثبت نزدیک به پرس و جو نه تنها اطلاعات مفید زیادی برای آموزش شبکه ندارند بلکه هزینه محاسبات نمونه ها را نیز افزایش می دهند. بنابراین، بر اساس فاصله توصیفگر CNN، از بین آنها انتخاب می کنیم پجمنPicتعداد ثابتی از نمونه های مثبت که کمترین شباهت را به تصویر پرس و جو دارند به عنوان نمونه های مثبت سخت برای تکرارهای آموزشی. انتخاب نمونه های مثبت سخت به پارامترهای CNN فعلی بستگی دارد و در هر دوره به روز می شود.
نمونه منفی N (ایکسجمن)N(Xic). از آنجایی که کلاس ها همپوشانی ندارند، نمونه های منفی را از کلاس هایی انتخاب می کنیم که با کلاس تصویر پرس و جو متفاوت هستند. ما فقط نمونههای منفی سخت [ 47 ، 48 ] را انتخاب میکنیم، یعنی نمونههای ناهماهنگ با شبیهترین توصیفگر به تصویر پرس و جو. K-نزدیکترین همسایهها از بین همه نمونههای ناسازگار انتخاب میشوند. در همان زمان، چندین نمونه مشابه در یک کلاس وجود دارد که منجر به افزونگی اطلاعات نمونه می شود. تعداد ثابتی از نمونه ها در هر کلاس مجاز است که تنوع بیشتری را در نمونه های منفی ایجاد می کند. انتخاب نمونه های منفی سخت به پارامترهای CNN فعلی بستگی دارد و در هر دوره چندین بار تجدید می شود.
3.2. وزن نمونه بر اساس کاهش
هدف الگوریتم ما این است که نمونههای مثبت را نسبت به هر نمونه منفی به تصویر پرس و جو نزدیکتر کند، در حالی که نمونههای منفی را به دورتر از یک مرز از پیش تعیینشده فشار میدهد. τ�. علاوه بر این، سعی می کنیم مرز نمونه مثبت را از مرز نمونه منفی با حاشیه جدا کنیم α�، یعنی نمونه های مثبت در داخل نمونه پرس و جو قرار دارند τ – α�-�فاصله از این رو، α�حاشیه بین نمونه های منفی و مثبت است.
برای هر تصویر پرس و جو، شباهت بین نمونه های مثبت و منفی انتخاب شده و شباهت آنها به نمونه پرس و جو متفاوت است. برای استفاده حداکثری از آنها، توصیه می کنیم آنها را با توجه به مقدار از دست دادن نمونه های انتخاب شده، یعنی میزان نقض محدودیت هر جفت نمونه، وزن کنید.
ما یک آستانه استخراج نمونه مثبت سخت بین نمونه های مثبت و پرس و جو با توجه به ویژگی های توزیع فضایی نمونه ها تنظیم کردیم. فرض کنید فاصله بین نمونه ای که کمترین شباهت را با نمونه پرس و جو دارد و نمونه پرس و جو حاشیه باشد. نمونه های مثبت با فاصله از تصویر پرس و جو در محدوده [0، آستانه ] به عنوان نمونه های مثبت آسان با شباهت زیاد به پرس و جو تعریف می شوند، در حالی که نمونه های مثبت با فاصله در محدوده [ آستانه ، حاشیه] نمونه های سخت مثبت هستند. تأثیر بسیار زیاد نمونههای مثبت سخت در آموزش، تأثیر نمونههای منفی بر تغییرات گرادیان را تضعیف میکند، که نه تنها بر دقت شبکه تأثیر میگذارد، بلکه سرعت یادگیری را نیز کاهش میدهد. بنابراین در این کار از تعداد نمونههای مثبت سخت برای محدود کردن تأثیر نمونههای مثبت بر ضرر و جلوگیری از عدم تعادل در از دست دادن نمونههای مثبت و منفی در طول تمرین استفاده میشود. آستانه به عنوان تنظیم شده استτ – α�-�یعنی آستانه فاصله ویژگی نمونه مثبت و تصویر پرس و جو و تعداد نمونه ها را در پجمنپمنجبا فاصله ای بیشتر از τ – α�-�از پرس و جو به عنوان nمنnمن. با توجه به نمونه مثبت انتخاب شده ایکسجjایکسjج( ایکسجj∈ P (ایکسجمن)ایکسjج∈پ(ایکسمنج)) وزن آن w+ijwij+را می توان به صورت زیر محاسبه کرد:
برای جفتهای نمونه منفی، ما وزن کاهشی را بر اساس حفظ تشابه سفارش نمونه منفی پیشنهاد میکنیم. انتخاب نمونه های منفی پیوسته نیست، بلکه توسط دو عامل تعیین می شود – کلاس نمونه و شباهت با پرس و جو. از منظر کلاس، درجه تفاوت بین ویژگیهای کلی کلاسهای نمونه منفی مختلف و کلاسی که نمونه پرس و جو در آن قرار دارد متفاوت است، بنابراین سطح یادگیری نیز باید متفاوت باشد. در این زمان، حاشیه ثابت τ�نمی تواند خوب کار کند فرض کنید سه کلاس وجود دارد، C، ن1N1، ن2N2، که در آن C کلاس تصویر پرس و جو و ن1N1، ن2N2کلاس های نمونه منفی مختلف هستند. اگر تفاوت بین ن1N1و C به طور شهودی کوچکتر از بین آن است ن2N2و C، سپس فاصله بین ن1N1و C باید کوچکتر از آن بین باشد ن2N2و C. با این حال، زمانی که مقدار حاشیه به صورت تنظیم قبلی ثابت شود، اگر تنظیم بزرگتر باشد، مدل ممکن است نتواند بین آنها تمایز قائل شود. ن1N1و C خوب برعکس، اگر حاشیه کوچکتر تنظیم شود، ن2N2و C ممکن است به خوبی تشخیص داده نشود. در عین حال، شباهت بین نمونه های منفی و تصویر پرس و جو نیز متفاوت است، بنابراین تأثیر آن بر خود آموزش و هزینه محاسباتی مورد نیاز نیز متفاوت است. ما وزنهای متفاوتی را به هر کلاس نمونه منفی اختصاص میدهیم تا شباهت نسبی آنها را با نمونه پرس و جو حفظ کنیم و در عین حال اطمینان حاصل کنیم که ویژگیهای هر کلاس حفظ میشود. به طور خاص، با توجه به یک نمونه منفی انتخاب شده ایکسکjXjk( ایکسکj∈ N (ایکسجمن)Xjk∈N(Xic)) وزن آن w–ijwij-را می توان به صورت زیر محاسبه کرد:
جایی که rjrjموقعیت مرتب سازی نمونه منفی است ایکسکjایکسjکدر لیست نمونه منفی N (ایکسجمن)ن(ایکسمنج).
3.3. از دست دادن حفظ شباهت
برای هر پرس و جو ایکسجمنایکسمنج، هدف ما این است که از نمونه منفی آن را پدر بسازیم نجمننمنجاز نمونه های مثبت است پجمنپمنج، با حداقل اختلاف α�. بنابراین، نمونه هایی را از همان کلاس به حاشیه می کشیم τ – α�-�. ما مجموعه داده را در یک شبکه دو شاخه ای با معماری سیامی آموزش می دهیم. هر شاخه یک کلون از یک شاخه دیگر است، به این معنی که آنها دارای پارامترهای مشابه هستند.
به منظور گردآوری تمام نمونه های مثبت در پجمنپمنج، ما به حداقل می رسانیم:
به طور مشابه، برای فشار دادن نمونه های منفی به داخل نجمننمنجدور از مرز τ�، ما به حداقل می رسانیم:
جایی که ffیک تابع متمایز است که ما یاد گرفتیم، به طوری که شباهت بین پرس و جو و نمونه های مثبت در فضای ویژگی بیشتر از شباهت بین پرس و جو و نمونه های منفی است.
در SRL، ما با دو هدف کوچک شده به طور مساوی رفتار می کنیم و آنها را به طور مشترک بهینه می کنیم:
به منظور کاهش مقدار محاسبه و زمان محاسبه، به طور تصادفی I (I< نجنج) تصاویر از هر کلاس c به عنوان مجموعه تصویر پرس و جو Q ={{ایکسجq}منq= 1}سیc = 1س={{ایکسqج}q=1من}ج=1سیو تصاویر دیگر به عنوان کتابخانه عمل می کنند (تصویر پرس و جو انتخاب شده همچنین کتابخانه سایر تصاویر پرس و جو است). SRL شبکه به صورت زیر نمایش داده می شود:
3.4. یادگیری شبکه تنظیم دقیق بر اساس SRL
ما SRL خود را بر اساس یک شبکه دو شاخه با معماری سیامی پیاده سازی می کنیم. هر شاخه یک کلون از یک شاخه دیگر است، به این معنی که آنها دارای پارامترهای مشابه هستند. یادگیری تابع جاسازی عمیق بر اساس SRL در الگوریتم 1 نشان داده شده است. فرآیند آموزش و آزمایش شبکه در شکل 1 نشان داده شده است .
| الگوریتم 1 از دست دادن حفظ شباهت در شبکه تنظیم دقیق |
| 1: |
تنظیمات پارامترها: محدودیت فاصله τ�در مثال های منفی، حاشیه بین مثال های مثبت و منفی α�، تعداد کلاس های C، تعداد تصاویر در هر کلاس نج( c ∈ C )نج(ج∈سی)، تعداد کل تصاویر N =∑سیمننمنن=∑منسینمن، تعداد پرس و جو در هر کلاس I. |
| 2: |
ورودی: تابع تمایز ff، میزان یادگیری lr،
X ={ (ایکسمن،yمن) }نi = 1={{ (ایکسجمن) }نجi = 1}سیc = 1ایکس={(ایکسمن،yمن)}من=1ن={{(ایکسمنج)}من=1نج}ج=1سی، لیست پرس و جو Q ={{ایکسجq}منq= 1}سیc = 1س={{ایکسqج}q=1من}ج=1سی |
| 3: |
خروجی: به روز شده ff. |
| 4: |
مرحله 1: همه تصاویر را به داخل فوروارد کنید ffبرای به دست آوردن وکتور ویژگی جاسازی تصاویر. |
| 5: |
مرحله 2: رتبه بندی تکراری آنلاین و محاسبه ضرر. |
| 6: |
برای هر پرس و جو ایکسجqایکس�جانجام دادن |
| 7: |
سایر تصاویر را با توجه به شباهت با آن رتبه بندی کنید ایکسجqایکسqج |
| 8: |
نمونه های مثبت معدن P (ایکسجq)پ(ایکسqج). |
| 9: |
نمونه های منفی معدن N (ایکسجq)ن(ایکسqج). |
| 10: |
نمونه های مثبت را با استفاده از رابطه (1) وزن کنید. |
| 11: |
نمونه های منفی را با استفاده از رابطه (2) وزن کنید. |
| 12: |
محاسبه کنید Lپ(ایکسجq; f)Lپ(ایکسqج;f)با استفاده از رابطه (3). |
| 13: |
محاسبه کنید Lن(ایکسجq; f)Lن(ایکسqج;f)با استفاده از رابطه (4). |
| 14: |
محاسبه کنید LSRL(ایکسجq; f)LSRL(ایکسqج;f)با استفاده از رابطه (5). |
| 15: |
پایان برای |
| 16: |
محاسبه کنید LSRL( X ; f)LSRL(ایکس;f)با استفاده از رابطه (6). |
| 17: |
مرحله 3: محاسبه گرادیان و انتشار به عقب برای به روز رسانی پارامترهای ff. |
| 18: |
∇ f = ∂LSRL( X ; f) / ∂ f ∇ f=∂LSRL(ایکس;f)/∂ f |
| 19: |
f= f− lr ∗ ∇ f f=f-lr∗∇ f |
4. آزمایشات
4.1. مجموعه داده ها
این مقاله از دو مجموعه داده RSIR منتشر شده، PatternNet [ 11 ] و UCMD [ 32 ] برای ارزیابی از دست دادن حفظ شباهت (SRL) پیشنهادی ما برای یادگیری متریک عمیق استفاده میکند. PatternNet [ 11 ] یک مجموعه داده سنجش از دور در مقیاس بزرگ با وضوح بالا است که برای RSIR جمع آوری شده است. این شامل 38 کلاس است که هر کدام دارای 800 تصویر در اندازه 256 × 256 پیکسل است. این مجموعه داده تصاویری از شهرهای ایالات متحده است که از طریق Google Map API یا تصاویر Google Earth جمع آوری شده است. PatternNet شامل تصاویر با وضوح های مختلف است. حداکثر تفکیک مکانی حدود 0.062 متر و حداقل تفکیک مکانی حدود 4.693 متر است. تصویر نماینده هر کلاس از مجموعه داده PatternNet در شکل 3 به صورت بصری نشان داده شده است. UCMD [ 32] یک مجموعه داده پوشش زمین یا کاربری زمین است که به عنوان مجموعه داده معیار RSIR استفاده می شود. این شامل 21 کلاس با 100 تصویر 256 × 256 پیکسل در هر کلاس است. این تصاویر از تصاویر هوایی بزرگ دانلود شده توسط USGS (سازمان زمین شناسی ایالات متحده) با وضوح فضایی تقریباً 0.3 متر تقسیم شده اند. UCMD یک مجموعه داده بسیار چالش برانگیز با برخی از مقولههای همپوشانی بالا مانند مناطق مسکونی پراکنده، متوسط و متراکم است. تصویری نماینده از هر کلاس از مجموعه داده UCMD در شکل 4 به صورت بصری نشان داده شده است.
4.2. معیارهای ارزیابی عملکرد
در این آزمایش، شباهت را با فاصله اقلیدسی اندازهگیری میکنیم و از میانگین دقت میانگین (mAP)، دقت بالای k ( P@k ) و فراخوانی بالا-k ( R@k ) برای ارزیابی عملکرد بازیابی تصویر استفاده میکنیم. .
4.3. راه اندازی آموزش
برای UCMD، ما استراتژی تقسیمبندی دادهها را اتخاذ میکنیم که بهترین عملکرد را در مرجع [ 10 ] ایجاد میکند، یعنی به طور تصادفی 50٪ نمونه از هر دسته را برای آموزش و 50٪ باقیمانده را برای آزمایش انتخاب میکنیم. برای PatternNet، ما از 80%/20% آموزش و تست استراتژی تقسیمبندی داده از [ 11 ] استفاده میکنیم.
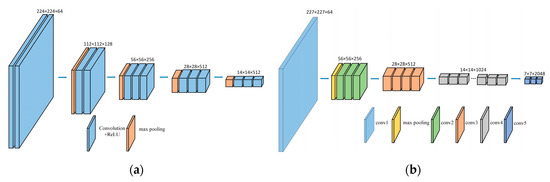
شکل 5 دو CNN استفاده شده توسط شبکه ما را نشان می دهد (نشان داده شده در شکل 1 )، که به عنوان شبکه های اساسی برای استخراج ویژگی استفاده می شوند، یعنی VGG16 [ 49 ] و ResNet50 [ 50 ]. ما از MatConvNet [ 51] برای تنظیم دقیق شبکه. برای CNN ها، فقط از لایه های کانولوشن برای استخراج ویژگی ها استفاده می شود. ما آخرین لایه ادغام شبکه های CNN را حذف می کنیم و از لایه های کانولوشنال دیگر به عنوان ساختار اصلی CNN خود استفاده می کنیم و سپس ادغام SPoC و تنظیم L2 را به ساختار شبکه جدید متصل می کنیم. در این آزمایش، شبکه بر اساس چارچوب PyTorch پیاده سازی شده است. پارامترهای هر شبکه را با استفاده از وزن های شبکه مربوطه که از قبل در ImageNet آموزش داده شده اند، راه اندازی کنید. ما شبکه را با بهینهساز Adam آموزش میدهیم، با کاهش وزن 5 × 10-4 ، تکانه 0.9، که با افزایش ابعاد تعبیهشده و تاپل تمرینی سایز 5 ثابت شد.
4.4. نتیجه و تجزیه و تحلیل
4.4.1. روش های ادغام
در این بخش، ما پیشرفتهترین روشهای ادغام را مقایسه میکنیم – حداکثر ادغام (MAC) [ 52 ]، ادغام متوسط (SPoC) [ 35 ] و ادغام میانگین تعمیمیافته (GeM) [ 33 ]. ما از اتلاف SRL برای آموزش شبکه روی مجموعه داده ها با نرخ یادگیری 5e-8 استفاده می کنیم. به جای تنظیم دقیق لایه ادغام آخرین لایه شبکه عصبی کانولوشن، از سه روش ادغام فوق استفاده می شود. از شکل 6 می توان نتیجه گرفتکه SPoC از MAC و GeM در همه مجموعه داده ها برتر است. به طور کلی، دو جنبه اصلی برای خطای استخراج ویژگی وجود دارد. اولی افزایش واریانس برآوردها به دلیل اندازه محدود همسایگی است. دلیل دوم این است که خطای پارامترهای لایه کانولوشن منجر به جبران میانگین برآورد شده می شود. ادغام SPoC میتواند اطلاعات پسزمینه تصویر بیشتری را با محاسبه میانگین مقدار مساحت تصویر حفظ کند تا از بروز خطای نوع اول بکاهد. این ویژگی منطقه جغرافیایی بزرگ مجموعه دادههای تصاویر سنجش از دور را برآورده میکند، اطلاعات پسزمینه غنی دارد و شامل تعداد متفاوتی از جفتهای معنایی مختلف است که باعث میشود اثر SPoC بهتر از سایر روشهای ادغام در بازیابی تصویر سنجش از دور باشد.
4.4.2. تاثیر حاشیه منفی
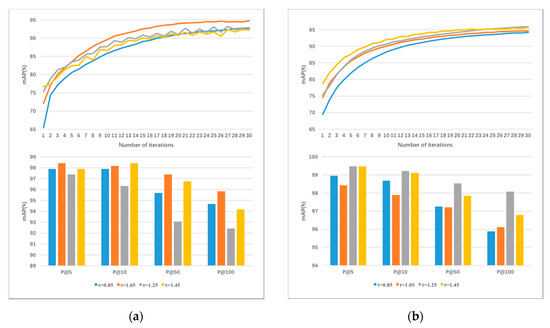
همانطور که در بخش 3.2 نشان داده شده است ، برای هر نمونه پرس و جو، SRL با تنظیم اندازه ساختار فضای نمونه منفی، سازگاری ترتیب تشابه ساختاری نمونه های منفی را تضمین می کند. از آنجایی که پارامتر محدودیت τ اندازه فضای منفی را تعیین میکند، آزمایشهایی را روی مجموعه داده انجام دادیم تا تاثیر پارامتر τ را تحلیل کنیم.
به منظور تطبیق آستانه τ با مجموعه داده PatternNet و بهبود عملکرد شبکههای مختلف، آزمایش مقدار 0.5-1.5 را انتخاب کرده و شبکه را با نرخ یادگیری 0.00001 آموزش میدهد. در نهایت، نتایج t = 0.85، 1.05، 1.25، 1.45 مطابق با آزمایش انتخاب شدند که در شکل 7 نشان داده شده است. نمودار نشان داده شده در شکل 7 a تحت VGG16 آموزش داده شده است، در حالی که شکل 7b نشان دهنده مجموعه داده به دست آمده تحت آموزش ResNet50 است. نتایج نشان می دهد که پارامتر بهینه τ برای شبکه VGG16 1.05 است، در حالی که برای ResNet50 1.25 است. همانطور که از نمودار مشاهده می شود، عملکرد شبکه با افزایش آستانه τ افزایش می یابد، اما زمانی که τ به یک آستانه خاص افزایش می یابد، مقدار کاهش می یابد. این به این دلیل است که وقتی مقدار آستانه کوچک است، فاصله بین پرس و جو و نمونه های منفی برای تشخیص آنها کافی نیست. با افزایش آستانه τ، نمونه های منفی با شباهت زیاد کاهش می یابند که بر اثر تمرین تأثیر می گذارد. نتایج نشان میدهد که وقتی آستانهها 05/1 (VGG6) و 25/1 (ResNet50) باشد، تفاوت بین نمونههای مثبت و منفی بهترین و نتایج مدل بهترین هستند. در آزمایش بعدی، آستانه τ = 1 را انتخاب کردیم.
4.4.3. تاثیر پارامتر α�
آستانه τ برای کنترل فاصله ای که نمونه های منفی دور می شوند استفاده می شود، در حالی که آستانه α�برای کنترل میزان تجمع نمونه های مثبت، یعنی فاصله بین نمونه های مثبت و منفی استفاده می شود. با تعیین آستانه α�، فاصله بین نمونه های مثبت و منفی را می توان با حفظ ساختار فضایی در بین نمونه های مثبت کشید. همانطور که در 4.4.2 توضیح داده شد، در VGG16، آزمایش آستانه را انجام دادیم α�تحت شرط τ = 1.05 و در ResNet50، τ = 1.25 را قرار می دهیم.
در آزمایش، مقادیر آستانه α�به ترتیب 0.2، 0.4، 0.6، 0.8 و 1.0 هستند. نتایج تجربی در شکل 8 نشان داده شده است. نتایج نشان می دهد که وقتی α = 1.0 را تنظیم می کنیم، بهترین نتیجه در VGG16 (a) به دست می آید. و در ResNet50 (b)، بهترین نتیجه در α = 0.6 به دست می آید. این به این دلیل است که وقتی α�کوچک است، فاصله بین نمونه های مثبت و منفی به اندازه کافی بزرگ نیست، به طوری که شبکه پس از آموزش نمی تواند آنها را به وضوح تشخیص دهد. برعکس، وقتی α�خیلی بزرگ است، ساختار فضایی داخل نمونه مثبت قابل حفظ نیست. بنابراین، شبکه تنها زمانی می تواند بهترین اثر را به دست آورد که مقدار α بتواند نمونه های مثبت و منفی را تشخیص دهد و ساختار فضای نمونه مثبت را حفظ کند.
4.4.4. تجزیه و تحلیل Ceteris Paribus
در این بخش به بررسی مزایای استفاده از روش تلفات ماندگاری مشابه نسبت به سایر تلفات سازه ای می پردازیم. برای این منظور، SRL پیشنهادی را در رویکرد خود با اتلاف سهگانه [ 44 ]، از دست دادن N-pair-mc [ 23 ]، Proxy-NCA Loss [ 42 ]، Lifted Struct Loss [ 25 ] و افت یادگیری ساختار توزیع جایگزین میکنیم. DSLL) [ 31 ]. سپس شبکه را دوباره آموزش میدهیم، ساختار شبکه (ResNet50) را یکسان نگه میداریم و به طور جداگانه برخی از پارامترهای فوقالعاده مانند کاهش وزن و نرخ یادگیری را دوباره تنظیم میکنیم. در آزمایش، ما از میانگین دقت میانگین (mAP)، دقت بالای k ( P@k ) و فراخوانی بالا-k ( R@k ) استفاده میکنیم.) برای ارزیابی عملکرد بازیابی تصویر. مجموعه داده UCMD مورد استفاده در آزمایش شامل 21 کلاس از 100 تصویر در هر کلاس است. 50 درصد از هر کلاس را به صورت تصادفی برای آموزش و 50 درصد باقیمانده را برای تست (یعنی 50 تصویر از هر کلاس) انتخاب می کنیم. با توجه به مشخصه کمی مجموعه داده UCMD، ما Recall را در بالای 25، 40، 50، 100 به عنوان یکی از معیارهای ارزیابی برای نتیجه آزمون انتخاب می کنیم. ما به طور تصادفی 80٪ از هر کلاس از تصاویر را از مجموعه داده PatternNet (شامل 38 کلاس، 800 تصویر در هر کلاس) به عنوان مجموعه آموزشی و 20٪ باقیمانده را به عنوان مجموعه تست انتخاب می کنیم (یعنی 160 تصویر از هر کلاس به عنوان آزمایش استفاده می شود. تنظیم). بنابراین ما Recall را در بالای 80، 100، 160، 200 به عنوان معیار ارزیابی برای نتیجه آزمایش مجموعه داده PatternNet انتخاب می کنیم. ما الگوریتم پیشنهادی را در وظایف بازیابی تصویر در مقایسه با الگوریتمهای پیشرفته از دست دادن یادگیری متریک ارزیابی میکنیم. عملکرد پس از آموزش در ارائه شده استجدول 1 و جدول 2 . همانطور که از جدول مشخص است، دقت روش ما بالاتر از سایرین است. هنگام استفاده از چارچوب شبکه ResNet50، در مقایسه با DSLL، SRL بهبود قابل توجهی +1.26٪ در mAP و +1.12٪ در R@50 در مجموعه داده UCMD ایجاد می کند. علاوه بر این، امضاهای SRL به افزایش +1.07٪ در mAP و +0.98٪ در R@160 در مجموعه داده PATTERNNET دست مییابند که از DSLL اخیراً منتشر شده پیشی میگیرد و mAP 99.41٪، P@10 از 100 و R@180 را به دست میآورد.از 99.96٪. به طور کلی، رویکرد ما موثرترین نشان داده شده است. این به این دلیل است که ما از روش جدیدی برای استخراج نمونه ها از طریق توزیع فضایی و محاسبه حفظ شباهت برای همه نمونه های انتخاب شده استفاده می کنیم.
4.4.5. نتایج کلی و نتایج هر کلاس
ما آزمایشهایی را روی مجموعه دادههای PatternNet و UCMD ارائه میکنیم، با حاشیه τ = 1.05 برای VGG16 و 1.25 برای ResNet50. در این آزمایش ما حاشیه را تعیین کردیم α = 1.0�=1.0برای VGG16 و 0.6 برای ResNet50. نتایج نهایی مجموعه داده های PatternNet و UCMD در جدول 3 نشان داده شده است. مشاهده می شود که در مقایسه با عملکرد پیشرفته، ویژگی های مبتنی بر SRL می توانند به عملکرد مطلوب دست یابند. هنگام استفاده از چارچوب شبکه VGG16، در مقایسه با MiLaN، SRL بهبود قابل توجهی +7.38٪ در mAP در مجموعه داده UCMD ارائه می دهد. علاوه بر این، SRL به افزایش +24.92٪ در mAP و +3.67٪ در P@10 در مجموعه داده PATTERNNET می رسد که از GCN (شبکه های کانولوشنال گراف) اخیراً منتشر شده پیشی می گیرد. هنگام استفاده از چارچوب شبکه ResNet50، در مجموعه داده UCMD، نتایج تجربی به رشد 8.38٪ در مقایسه با MiLaN در mAP و رسیدن به mAP 99.41٪، P@10 دست یافتند.از 100 و ارائه بیش از 73.11٪، 95.53٪ افزایش نسبت به GCN در مجموعه داده PATTERNNET. در همان زمان، متوجه شدیم که اگرچه اثر EDML (تقویت بازیابی تصویر سنجش از دور با شبکه یادگیری سهگانه عمیق متریک) [ 53 ] بر روی مجموعه داده PatternNet کمی بالاتر از SRL ما است، برای مثال، EDML به سودی از +1.40% و +0.14% در mAP در پایگاه داده PatternNet که به ترتیب در شبکه VGG16 و ResNet50 آموزش دیدند. اما بر اساس نتایج آزمایشی جامع، SRL ما بهترین است. ابتدا از نتایج ( جدول 3، روش ما می تواند به طور موثر دقت شبکه را در مجموعه داده UCMD بهبود بخشد (تعداد تصاویر در مجموعه داده کمتر است). مثال خاص – روش SRL به ترتیب 91/2+ و 15/2+ درصد در mAP بدست آمده پس از آموزش در شبکه VGG16 و شبکه ResNet50 به دست میآید که از نتیجه EDML بیشتر است. این نشان میدهد که روش ما برای مجموعه دادهها با تصاویر ناکافی دوستانهتر است، که در بازیابی تصویر بسیار معنادار است. دوم، ما متوجه میشویم که استراتژی کاوی نمونه اتخاذ شده توسط EDML، انتخاب تصادفی نمونههای مثبت از همان کلاس لنگر (به جز لنگر) و نمونههای منفی از هر کلاس دیگر است. این استراتژی دارای معایبی است. (1) تضمین نمایندگی نمونه ها دشوار است. (2) کار به دست آوردن نمونه سنگین است. (3) زمان همگرایی آموزشی را طولانی تر می کند. به منظور بررسی مزایای مدل الگوریتم SRL پیشنهادی از نظر سرعت آموزش، ما EDML را بازتولید کرده و زمان آموزش مدل را با مدل خود مقایسه میکنیم. ما آزمایش هایی را روی اینتل انجام می دهیم® i7-8700، 11 گیگابایت حافظه CPU، سیستم عامل اوبونتو 18.04LTS و استفاده از VGG16 و ResNet50 به عنوان شبکه اصلی برای محاسبه زمان آموزش. نتایج نشان می دهد که زمان آموزش 70 دوره پایگاه داده UCMD با استفاده از الگوریتم EDML در شبکه VGG16 و ResNet50 به ترتیب 9.8 ساعت و 27.8 ساعت است، در حالی که زمان آموزش مجموعه داده PatternNet به ترتیب 11.6 ساعت و 30.9 ساعت است. آموزش با SRL 8.2 ساعت (VGG16، UCMD)، 24.4 ساعت (ResNet50، UCMD)، 9.9 ساعت (VGG16، PatternNet) و 27.6 ساعت (ResNet50، PatternNet) طول کشید. به طور کلی، رویکرد ما موثرترین نشان داده شده است. به طور خلاصه، در هر دو مجموعه داده سنجش از دور مانند مجموعه داده UCMD و مجموعه داده PatternNet، روش ما به عملکرد پیشرفته یا قابل مقایسه جدیدی دست می یابد.
جالب است که بهترین عملکرد در PatternNet به طور قابل توجهی بهتر از UCMD است. یکی از دلایل احتمالی این است که داده محور یکی از ویژگی های اصلی یادگیری متریک عمیق است و عملکرد یادگیری ویژگی های نماینده تحت تأثیر میزان داده های آموزشی است. PatternNet نسبت به UCMD حجم داده بیشتری دارد، بنابراین شبکه اولی بهتر از دومی آموزش دیده است. نتایج تجسمی بازیابی تصویر PatternNet و UCMD آموزش دیده تحت شبکه ResNet50 در شکل 9 نشان داده شده است.
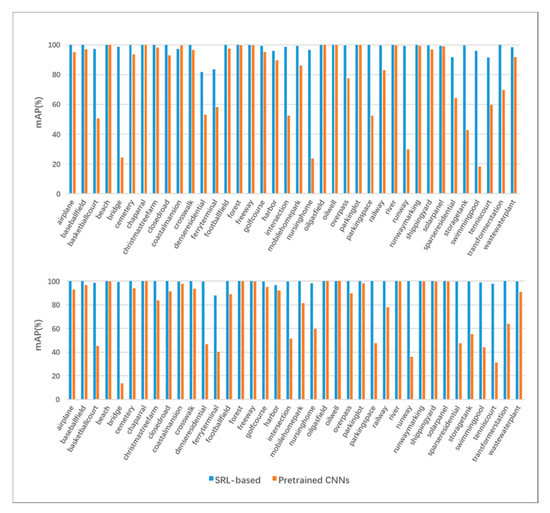
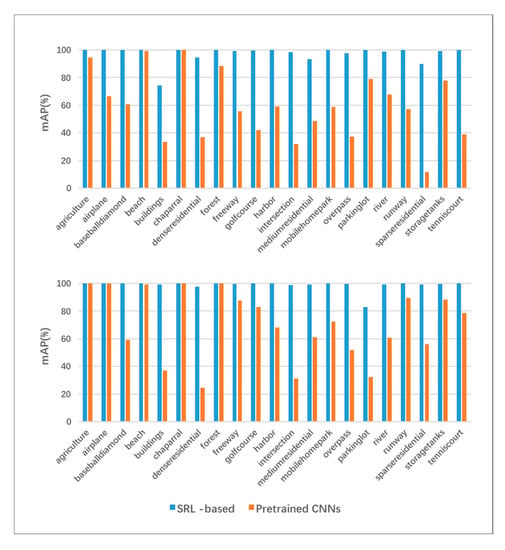
برای نتایج هر کلاس، نتایج خاصی از ارزیابی mAP که با VGG16 و ResNet50 در مجموعه دادههای PatternNet و UCMD در مقایسه با CNNهای از پیش آموزشدیده انجام شده است، در جدول 4 و جدول 5 نشان داده شده است. مشاهده می شود که نتایج هر کلاس آموزشی بر اساس SRL نسبت به قبل از تمرین بهبود یافته است. عملکردهای mAP بر اساس ویژگیهای عمیق مختلف VGG16 (بالا) و ResNet50 (پایین) به ترتیب در شکل 10 و شکل 11 نشان داده شدهاند. به طور کلی، برای هر کلاس، ویژگی های مبتنی بر SRL نسبت به ویژگی های از پیش آموزش داده شده در هر دو مجموعه داده برتری دارند. همانطور که در جدول 4 ارائه شده استبه طور کلی، تقریباً برای هر کلاس، ویژگیهای مبتنی بر SRL از ویژگیهای از پیش آموزشدیده بهتر عمل میکنند. ویژگی های از پیش آموزش داده شده مبتنی بر VGG16 در بازیابی تصاویر ساختمان ها، تقاطع ها و مسکونی پراکنده، با میانگین mAP 25.68 درصد، بسیار کمتر از همتای خود، با 87.4 درصد برای ویژگی های مبتنی بر SRL در مجموعه داده UCMD، مشکل خاصی دارند. . در همین حال، در مجموعه داده PatternNet، ویژگیهای مبتنی بر VGG از پیش آموزشدیده، در مناطق مسکونی متراکم، تقاطعها و پارکینگ، با میانگین mAP 29.35 درصد، تا 93.8 درصد برای ویژگیهای مبتنی بر SRL، مشکل خاصی دارند. ویژگیهای از پیش آموزشدیده مبتنی بر ResNet50 در کلاسهایی مانند پل، تقاطع خانه سالمندان و باند پرواز ضعیف عمل میکنند، با میانگین mAP 26%. این مقدار برای ویژگی مبتنی بر SRL 98.38٪ در مجموعه داده UCMD است. در حالی که در مجموعه داده PatternNet هستید، ویژگی های از پیش آموزش دیده عملکرد خوبی در پل، زمین تنیس و پایانه کشتی ندارند، با میانگین mAP 28.27٪، در حالی که 95.11٪ برای ویژگی های مبتنی بر SRL، که بیشتر عملکرد برتر ویژگی های مبتنی بر SRL را برای CBRSIR نشان می دهد. همانطور که می توان ازشکل 10 و شکل 11 که ویژگی های مبتنی بر SRL عملکرد بسیار بهتری نسبت به ویژگی های از پیش آموزش داده شده برای همه کلاس ها دارند. در همان زمان، نتایج در PatternNet بهتر از UCMD در هر دو شبکه است و ResNet50 عملکرد بهتری از VGG16 برای هر دو مجموعه داده داشت.
5. نتیجه گیری ها
در این کار، ما یک یادگیری متریک عمیق بر اساس از دست دادن حفظ شباهت برای بازیابی تصویر پیشنهاد میکنیم و آن را در CBRSIR، که یک فناوری کلیدی برای استفاده مؤثر از کیفیت رو به رشد تصاویر سنجش از راه دور است، اعمال میکنیم. SRL ویژگی های تصویر تصاویر سنجش از دور (فقط تصاویر ترکیبی RGB) را ترکیب می کند و الگوریتم را از سه جنبه زیر بهبود می بخشد – روش تجمیع ویژگی، استراتژی استخراج نمونه بر اساس انتخاب جفت اطلاعات و محاسبه وزن نسبی جفت های نمونه مختلف، بنابراین برای دستیابی به بازیابی دقیق تصویر. ابتدا، ما پیشنهاد می کنیم از روش ادغام SPoC برای تجمیع ویژگی های کانولوشن استخراج شده توسط شبکه برای انطباق با تصاویر سنجش از دور با یک منطقه جغرافیایی بزرگ و اطلاعات پس زمینه غنی استفاده کنیم. دوم، ما مفهوم حفظ شباهت را پیشنهاد می کنیم. با یادگیری توزیع نمونه در اطراف هر نمونه، جفت های منفی را از تصویر پرس و جو به فواصل مختلف جدا می کنیم. در عین حال، ما یک آستانه درون کلاسی برای هر کلاس یاد می گیریم تا از فشرده سازی ویژگی های نمونه های مثبت به یک نقطه جلوگیری کنیم و ساختار نمونه های مثبت را تضمین کنیم. سوم، ما از شباهت به عنوان معیار استفاده می کنیم و آستانه ها و استراتژی های انتخاب متفاوتی را برای انتخاب نمونه های مثبت و منفی تعیین می کنیم. به این ترتیب، الگوریتم می تواند اطمینان حاصل کند که انتخاب نمونه هم نماینده است و هم اضافی نیست. ما یک آستانه درون کلاسی برای هر کلاس یاد می گیریم تا از فشرده سازی ویژگی های نمونه های مثبت به یک نقطه جلوگیری کنیم و ساختار نمونه های مثبت را تضمین کنیم. سوم، ما از شباهت به عنوان معیار استفاده می کنیم و آستانه ها و استراتژی های انتخاب متفاوتی را برای انتخاب نمونه های مثبت و منفی تعیین می کنیم. به این ترتیب، الگوریتم می تواند اطمینان حاصل کند که انتخاب نمونه هم نماینده است و هم اضافی نیست. ما یک آستانه درون کلاسی برای هر کلاس یاد می گیریم تا از فشرده سازی ویژگی های نمونه های مثبت به یک نقطه جلوگیری کنیم و ساختار نمونه های مثبت را تضمین کنیم. سوم، ما از شباهت به عنوان معیار استفاده می کنیم و آستانه ها و استراتژی های انتخاب متفاوتی را برای انتخاب نمونه های مثبت و منفی تعیین می کنیم. به این ترتیب، الگوریتم می تواند اطمینان حاصل کند که انتخاب نمونه هم نماینده است و هم اضافی نیست.
ما روش را روی دو مجموعه داده در دسترس عموم آزمایش می کنیم و بهترین عملکرد را در هر دو مجموعه داده به دست می آوریم. برای اثبات اثربخشی از دست دادن حفظ شباهت برای یادگیری متریک عمیق در بازیابی تصویر کافی است. مهمتر از آن، روش ما همچنین میتواند در تحقیقات اطلاعات جغرافیایی، مانند هوش ترافیک جادهای شهری، آزمایشهای محیطی، تشخیص بلایای طبیعی، نقشهبرداری پوشش گیاهی، برنامهریزی شهری و تحقیق در مورد بازیابی تصویر سنجش از دور با وضوح بالا، اعمال شود.









بدون دیدگاه