1. معرفی
علوم محیطی همواره علاقه مند به پیش بینی دقیق توزیع مکانی پدیده های مختلف در خصوص خاک، آب، هوا و غیره بوده اند [ 1 ، 2 ، 3 ، 4 ]. در حال حاضر، افزایش تعداد دادههای دیجیتال (اینترنت اشیا، مدلهای ارتفاعی دیجیتال با دقت بالا (DEM)، تصاویر ماهوارهای) یک فرصت عالی برای نتایج پیشبینی بهبود یافته است.
در ابتدا، پیشبینی پدیدههای فضایی با استفاده از روشهای پیشبینی فضایی به دست آمد که عمدتاً در دو دسته زیر قرار میگرفتند: روشهای قطعی، مانند وزندهی معکوس فاصله یا نزدیکترین همسایگان، و موارد تصادفی، مانند مدلهای رگرسیون و تغییرات کریجینگ (مثلاً، معمولی). کریجینگ، کریجینگ جهانی و غیره). بعداً روشهای ترکیبی معرفی شدند [ 5 ، 6 ، 7] که تا حدی قطعی، تا حدی تصادفی بودند، مانند کریجینگ رگرسیون (RK) یا کریجینگ با رانش خارجی (KED). این روش ها سعی کردند مزایای هر دو جهان، قطعی و تصادفی را ترکیب کنند و به نتایج بهتری دست یابند. در حال حاضر، پیاده سازی های نوآورانه تر از روش های ترکیبی فوق الذکر به طور فزاینده ای استفاده می شود. آنها یادگیری ماشین (ML) را به عنوان بخش قطعی، همراه با کریجینگ باقیمانده های ML به عنوان بخش تصادفی معرفی می کنند [ 8 ، 9 ، 10 ، 11 ، 12]. این روش ها عمدتاً به دو دلیل در علوم زیست محیطی به طور گسترده مورد استفاده قرار می گیرند: دقت پیش بینی بهبود یافته و حذف بسیاری از محدودیت ها (مثلاً فرضیات آماری) که رگرسیون، کریجینگ و تغییرات آنها (RK، KED و غیره) نیاز دارند [ 9 ] ، 13 ].
معمولاً دانشمندان در مطالعات محیطی خود، مدلهای چندگانه ML را ارزیابی میکنند تا مدلی را بیابند که دقت پیشبینی را برای یک پدیده خاص به حداکثر میرساند [ 14 ، 15 ، 16 ، 17 ]. آنها از پیاده سازی های خاص ML (بسته ها، روش ها) استفاده می کنند و سعی می کنند بهترین هایپرپارامترها را برای مدل های خود تخمین بزنند که دقیق ترین نتایج را ایجاد می کند. با این حال، مشخص نیست که آیا پیاده سازی های مختلف ML همان مدل ML و روش های مختلف انتخاب فراپارامتر به طور قابل توجهی بر نتایج تأثیر می گذارد.
pH خاک یک پارامتر مهم خاک است که هم بر خصوصیات خاک و هم خود گیاهان تأثیر می گذارد. این تا حد زیادی بر رفتار عناصر شیمیایی تأثیر می گذارد و همراه با ماده آلی (OM)، مهمترین پارامتر تعیین کننده پارتیشن بندی فلزات و گونه زایی آبی در خاک است [ 18 ]. در ارتباط با عناصر غذایی [ 19 ] و ریز مغذی ها [ 20 ] از اهمیت ویژه ای در نظر گرفته می شود و این متغیر کلیدی است که بر رشد گیاه تأثیر می گذارد [ 21 ]. حاصلخیزی خاک را کنترل می کند، فرآیندهای بیوژئوشیمیایی خاک را تنظیم می کند و بر ساختار و عملکرد اکوسیستم های زمینی تأثیر می گذارد [ 22 ]. با توجه به توزیع مکانی آن، به نظر می رسد pH خاک تحت تأثیر ارتفاع زمین قرار می گیرد.23 ] و همبستگی متقاطع فضایی را با عناصر دیگر، مانند Fe خاک نشان میدهد [ 24 ]. بر اساس ویژگی های فوق، pH خاک به عنوان پارامتر ایده آل خاک برای مطالعه حاضر در نظر گرفته شد.
هدف پژوهش حاضر چندگانه است. در مرحله اول، ما قابلیت های پیش بینی مدل های مختلف ML و غیر ML را با و بدون کریجینگ باقیمانده های آنها در پیش بینی pH خاک مقایسه می کنیم. مدلهای ML که ارزیابی میشوند عبارتند از جنگلهای تصادفی (RF)، کریجینگ جنگلهای تصادفی (RFK)، تقویت گرادیان (GB)، کریجینگ تقویتکننده گرادیان (GBK)، شبکههای عصبی (NN)، و کریجینگ شبکههای عصبی (NNK)، همراه با مدلهای غیرML رگرسیون خطی چندگانه (MLR)، کریجینگ معمولی (OK)، و کریجینگ رگرسیون (RK) به عنوان روشهای زمینآماری سنتی/هیبرید. در مرحله دوم، اثرات پیادهسازیهای مختلف (روشها و بستهها در R) همان مدلهای ML نیز ارزیابی میشوند. برای مدل RF از روش های رنجر و rf استفاده می شود. برای GB، xgbTree و xgbDART؛ و برای NN، nnet و avNNet. سرانجام،
2. مواد و روشها
2.1. مجموعه داده های خاک و متغیرهای کمکی محیطی
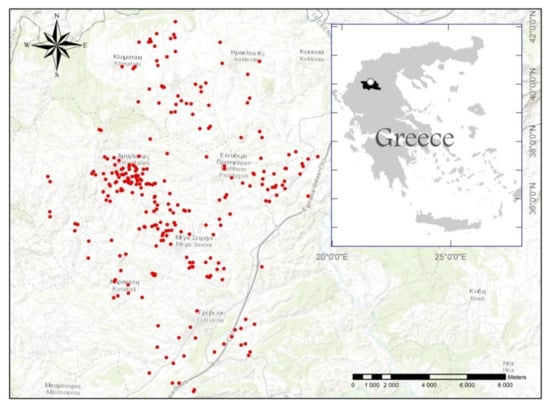
منطقه مورد مطالعه ( شکل 1 ) در واحد منطقه ای Grevena در شمال یونان واقع شده است و از عرض جغرافیایی 40°01’50.76″ شمالی تا 40°14’43.79″ شمالی و از طول جغرافیایی 21°17’30.06″ شرقی تا امتداد می یابد. 21°33’25.43 اینچ شرقی در سیستم ژئودتیک جهانی 1984 (WGS84). ارتفاع آن از حدود 500 متر از سطح دریا تا 900 متر شمالی تر است و منطقه تقریباً 270 کیلومتر مربع را پوشش می دهد .
بررسی خاک به مدت سه سال (2015، 2017 و 2018) عمدتاً در پاییز و اوایل زمستان هر سال انجام شد. به طور خاص، 266 نمونه خاک آشفته از مکانهای انتخاب شده بهطور تصادفی با استفاده از طرح نمونهبرداری تصادفی ساده (Soil Survey Division Staff, 2017) با مارپیچ خاک از عمق 0-30 سانتیمتری خاک سطحی بهدست آمد. در هر مکان، نمونه های معرف (2-3) نزدیک به یکدیگر گرفته شد و با هم ترکیب شدند تا یک نمونه مرکب ساخته شود. گیرنده های سیستم موقعیت یاب جهانی (GPS) برای شناسایی موقعیت های نمونه استفاده شد. حداقل فاصله بین دو نقطه نمونه برداری حدود 50 متر و میانگین فاصله بین نقاط 300 متر است.
در این مطالعه از متغیرهای کمکی خاک و متغیرهای کمکی محیطی استفاده شد ( جدول 1 ). با توجه به متغیرهای کمکی خاک، 266 نمونه خاک که از منطقه گرونا جمع آوری شد در آزمایشگاه موسسه منابع آب و خاک از نظر خاک رس (C)، سیلت (Si)، ماسه (S)، هدایت الکتریکی (EC)، آلی تجزیه و تحلیل شدند. ماده (OM)، نیتروژن (N)، فسفر (P)، پتاسیم (K)، منیزیم (Mg)، آهن (Fe)، روی (Zn)، منگنز (Mn)، مس (Cu) و بور (B) . علاوه بر این، تجزیه و تحلیل pH برای همان مکانها برای کالیبره کردن مدلها و ارزیابی نتایج پیشبینی انجام شد.
متغیرهای کمکی محیطی از نسخه دوم مدل ارتفاعی دیجیتال جهانی Aster (GDEM2) با استفاده از ماژول های نرم افزار SAGA-GIS مشتق شده اند. Aster از کاشی های 1°×1° (رزولیشن 30 متر) در سیستم ژئودتیک جهانی 1984 (WGS84) تشکیل شده است که برای این مطالعه به سیستم مرجع ژئودتیک یونان در سال 1987 (GGRS87) بازپخش شده است ( شکل 2 ).
2.2. نرم افزار
تجزیه و تحلیل آماری با استفاده از نرم افزار آماری R (نسخه 3.5.3) و بسته caret [ 25 ] اجرا شد. در مطالعه حاضر، بستهها و روشهای مختلفی در R از طریق caret استفاده شد: الف) xgboost همراه با روشهای xgbTree از بسته xgboost برای گیگابایت، ب) بستههای جنگلی تصادفی و رنجر برای RF، و ج) روشهای avNNet و nnet از بسته nnet برای NN. زمین آمار در مقاله فعلی با استفاده از بسته gstat پیاده سازی شده است. در نهایت از نرم افزار SAGA-GIS ( https://www.saga-gis.org/en/index.html ) برای تولید ویژگی های مختلف زمین استفاده شد.
2.3. رگرسیون کریجینگ
کریجینگ رگرسیونی یک روش زمین آماری ترکیبی است که رگرسیون خطی چندگانه بین متغیر خاک هدف و پارامترهای ثانویه را با روشهای زمین آماری (مثلا کریجینگ معمولی یا کریجینگ ساده) بر روی پسماندهای رگرسیون ترکیب میکند. هدف آن بهینهسازی پیشبینی ویژگیهای خاک در مکانهای بدون نمونه [ 26 ] بر اساس این فرض است که مولفه قطعی متغیر خاک هدف توسط مدل رگرسیون محاسبه میشود، در حالی که باقیماندههای مدل نشاندهنده مولفه متغیر مکانی اما وابسته [ 7 ] است. ].
به طور خاص، در مورد رگرسیون خطی چندگانه و کریجینگ معمولی، پیشبینی میشود ز^آرکسمنبرای سمنمکان ها مجموع پیش بینی رگرسیون است ز^آرسمنبرای مکان های مشابه و پیش بینی باقیمانده های رگرسیون ε^OΚ، همانطور که در معادله زیر مشاهده می شود.
در این معادله دو بخش مجزا وجود دارد. اولی، ز^آرسمن، جزء قطعی است و دومی، ε^OΚ، تصادفی است. این دو بخش مجزا امکان تفسیر مجزا از دو مؤلفه و کاربرد تکنیک های رگرسیون مختلف را فراهم می کند [ 6 ].
2.4. جنگل های تصادفی کریجینگ
جنگل تصادفی [ 27 ، 28 ] یک مدل یادگیری ماشینی مبتنی بر طبقهبندی و درختان رگرسیون [ 29 ] است که دقت پیشبینی را افزایش میدهد. در RF، مجموعه بزرگی از درختان بدون همبستگی، پر سر و صدا و تقریباً بیطرف ساخته شده و میانگینگیری میشوند تا واریانس مدل را کاهش داده و با ناپایداری مقابله کنند [ 30 ]. این با رشد چندین درخت با ترکیب تصادفی دوگانه به دست میآید: انتخاب تصادفی نمونهها در مجموعه داده آموزشی و ویژگیهای تصادفی مورد استفاده از یک مجموعه داده. مانند هر مدل یادگیری ماشینی، پارامترهایی وجود دارد که می توان آنها را بهینه کرد. در مورد بسته های Ranger/RandomForest، عمدتاً دو مورد وجود دارد: mtry و ntree ( جدول 2 ).
حتی اگر بسته به بستههای RF مورد استفاده، هایپرپارامترهای بیشتری وجود داشته باشد، این دو ارائه شده در اینجا بیشترین استفاده را دارند. بسته های مورد استفاده در مطالعه حاضر رنجر [ 31 ] و randomForest [ 32 ] بودند.
در نهایت، OK برای باقیمانده های RF اعمال شد ( ε^Oک) و سپس به نتایج پیش بینی RF اضافه می شود ز^آرافسمندر سمنمکان ها برای تخمین RFK طبق رابطه (2):
این شبیه معادله (1) است. با این حال، جزء قطعی ز^آرافسمن از جنگل های تصادفی به جای رگرسیون استفاده می کند.
2.5. افزایش گرادیان کریجینگ
در تقویت گرادیان [ 33 ]، چندین درخت تصمیم به صورت متوالی با استفاده از اطلاعات درختان موجود قبلی رشد می کنند. اگرچه هر درخت کوچک و با گره های پایانی کمی است، آنها موفق می شوند عملکرد کلی را با پرداختن به مشاهدات مشکل دار با خطاهای بزرگ افزایش دهند. به این ترتیب، آنها مدل را در مناطقی که عملکرد خوبی ندارد، بهبود میبخشند و در نتیجه یک مدل پیشبینی دقیقتر ایجاد میکنند. به طور خاص در مورد افزایش گرادیان، هر درخت با استفاده از یک الگوریتم نزول گرادیان که یک تابع تلفات مرتبط با کل مجموعه را به حداقل میرساند، به باقیماندههای مدل قبلی برازش داده میشود.
بسته های متعددی وجود دارد که می توانند GB (CatBoost، LightGBM، XGBoost، و غیره) را با پیاده سازی های مختلف و نتایج متفاوت انجام دهند. در مطالعه حاضر، “تقویت گرادیان فوق العاده” از بسته XGBoost [ 34 ] از طریق caret با اجرای دو روش مختلف استفاده شد: XgbDART و xgbTree. Extreme Gradient Boosting یک پیادهسازی کارآمد و مقیاسپذیر از چارچوب تقویت گرادیان در نظر گرفته میشود که در آن از رسمیسازی مدل منظمتر برای کنترل بیش از حد برازش و دستیابی به عملکرد بهتر استفاده میشود. برخی از مزایای آن به شرح زیر است:
-
یک تکنیک منظم سازی که به کاهش بیش از حد مناسب کمک می کند.
-
پشتیبانی از توابع هدف تعریف شده توسط کاربر و معیارهای ارزیابی؛
-
مکانیسم کارآمد هرس درختان بهبود یافته است.
-
چندین پیشرفت فنی مانند پردازش موازی، “تأیید متقابل داخلی” و مدیریت بهتر مقادیر از دست رفته.
پارامترهای متعددی وجود دارد که باید در این مدل تنظیم شوند ( جدول 3 ) و می توان آنها را به الف) پارامترهای کلی که نوع تقویت کننده را کنترل می کنند، ب) پارامترهای تقویت کننده خطی که عملکرد تقویت کننده خطی را کنترل می کنند طبقه بندی کرد. ج) پارامترهای تکلیف یادگیری که وظیفه یادگیری و هدف یادگیری مربوطه را مشخص می کند.
معرفی کریجینگ به عنوان بخش تصادفی (GBK) بر اساس معادله زیر محاسبه می شود:
روش OK بر روی باقیمانده های گیگابایت ( ε^Oک)، و نتایج OK به پیش بینی های گیگابایت اضافه می شود ز^جیبسمن.
2.6. شبکه های عصبی کریجینگ
شبکههای عصبی (یا شبکههای عصبی مصنوعی) ابزارهای قدرتمندی هستند که بر اساس مغز انسان مدلسازی شدهاند و از رویکرد یادگیری ماشینی برای تعیین کمیت و مدلسازی رفتار و الگوهای پیچیده استفاده میکنند. آنها وظایف را با در نظر گرفتن مثال ها انجام می دهند، به طور کلی بدون اینکه با قوانین خاص کار برنامه ریزی شوند. یک NN شامل مجموعه ای از واحدهای به هم پیوسته به نام نورون است که همبستگی های غیرخطی بین هر متغیر را تخمین می زند. نورونهای ورودی، که نشاندهنده متغیرهای پیشبینیکننده هستند، به یک یا چند لایه از نورونهای پنهان متصل میشوند، که سپس به نورونهای خروجی که نشاندهنده متغیر خاک هدف هستند [ 35 ] مرتبط میشوند.
برای NN در مطالعه حاضر، بسته nnet با دو روش مختلف استفاده شد: nnet و avNNet. بسته nnet [ 36 ، 37 ] نرمافزاری برای شبکههای عصبی پیشخور با یک لایه پنهان و برای مدلهای log-linear چندجملهای است. در یک NN feed-forward، اطلاعات تنها در یک جهت (به جلو) حرکت می کند. از گره های ورودی، از طریق گره های پنهان و به گره های خروجی. روش nnet دقیقاً این مدل را برای پیش بینی نتایج پیاده سازی می کند.
روش avNNet بسته nnet چندین مدل شبکه عصبی پیشخور را با برازش اعداد تصادفی مختلف دانهها جمعآوری میکند. در مورد رگرسیون، مانند آنچه در مطالعه حاضر استفاده شد، تمام مدلهای بهدستآمده برای پیشبینی با میانگینگیری نتایج حاصل از هر شبکه استفاده شد.
فراپارامترهای دقیق NN که در مطالعه حاضر تنظیم شدند، همراه با توضیحات آنها، در جدول 4 ارائه شده است. بیشتر آنها در هر دو روش به غیر از کیف که فقط در avNNet استفاده می شد، استفاده شد.
در نهایت، کریجینگ شبکه های عصبی (NNK) بر اساس معادله زیر است:
باقی مانده ها ε^Oک برای OK استفاده می شود و نتایج پیش بینی به پیش بینی NN اضافه می شود.
2.7. بهینه سازی هایپرپارامترها
هر مدل ML باید قبل از آموزش، هایپرپارامترهای خود را تعریف کند. این را می توان با استفاده از موارد زیر به دست آورد:
تنظیم را می توان به روش های مختلفی مانند جستجوی شبکه ای، جستجوی تصادفی، دنباله Sobol، دستی و موارد دیگر پیاده سازی کرد. جستجوی شبکه ای و جستجوی تصادفی بیشترین کاربرد را دارند. در جستجوی شبکه، هر ترکیبی از یک لیست از پیش تعیین شده مقادیر فراپارامترها تخمین زده می شود و برای ارزیابی مدل برای هر ترکیب استفاده می شود. با این حال، در مطالعه حاضر، جستجوی تصادفی انجام شد که در آن از ترکیبات تصادفی پارامترها از طیف وسیعی از مقادیر استفاده شد. جستجوی تصادفی در اینجا به دلیل نتایج بهبود یافته ای که طبق ادبیات ارائه می دهد ترجیح داده شد [ 38 ]. مدل با مجموعه پارامترهایی که بالاترین دقت را داشت بهترین در نظر گرفته شد و برای پیش بینی استفاده شد.
جستجوی تصادفی از طریق بسته caret اجرا شد. در اینجا ذکر این نکته مهم است که به طور کلی، هایپرپارامترهایی که می توان از طریق caret بهینه سازی کرد معمولاً کمتر از پارامترهای واقعی است که بسته به تنهایی می تواند پشتیبانی کند. با این حال، آنها معمولاً مهمترین مواردی هستند که به طور قابل توجهی بر نتایج هر مدل تأثیر می گذارند. همراه با جستجوی تصادفی، همان مدلهای ML با مقادیر پیشفرض آموزش داده شدند و نتایج با هم مقایسه شدند.
2.8. ارزیابی خطا
266 نمونه مطالعه حاضر به طور تصادفی به دو مجموعه داده تقسیم شدند: مجموعه داده آموزشی (80٪ داده ها) که برای تخمین مدل ها استفاده شد و مجموعه داده آزمایشی (20٪ از داده ها) که برای ارزیابی مدل های مختلف استفاده شد. مدل ها. بهینهسازی پارامترهای مدلها با استفاده از تکنیکهای اعتبارسنجی متقاطع 10 برابری در مجموعه داده آموزشی اجرا شد.
معیارهای مختلف ( جدول 5 ) برای تخمین عملکرد مدل بر اساس تفاوت بین مشاهدات و پیشبینیهای مجموعه دادههای آزمایشی مورد استفاده قرار گرفت. ریشه میانگین مربعات خطا (RMSE) و میانگین خطای مطلق (MAE) بر اساس مقدار اندازه گیری شده برآورد شد. زسمنو پیش بینی آن ز^سمنبرای مکان ها سمناز نمونه ها مقادیر پایین تر RMSE و MAE با نتایج پیش بینی بهتر همراه است. همچنین ضریب تعیین (R2 ) که بیانگر میزان تغییرات توضیح داده شده توسط مدل است، برآورد شد. اصطلاحات SSE و SSTO به ترتیب نشان دهنده مجموع مربعات خطا و مجموع مجموع مربعات هستند. ضریب تعیین از 0 تا 1 متغیر است، جایی که برای 0 (صفر)، هیچ تغییری توسط مدل توضیح داده نمی شود و برای 1 (یک)، تمام تغییرات توسط مدل توضیح داده می شود.
3. نتایج
3.1. تجزیه و تحلیل داده های اکتشافی
متغیرهای کمکی خاک که در آزمایشگاه اندازه گیری شدند عبارت بودند از: خاک رس (C)، سیلت (Si)، ماسه (S)، هدایت الکتریکی (EC)، ماده آلی (OM)، نیتروژن (N)، فسفر (P)، پتاسیم. (K)، منیزیم (Mg)، آهن (Fe)، روی (Zn)، منگنز (Mn)، مس (Cu)، بور (B) و pH از 266 مکان در منطقه Grevena ( جدول 6 ). برخی از آنها، آنهایی که به طور قابل توجهی از حالت عادی منحرف شدند و به شدت بر باقیمانده های MLR تأثیر گذاشتند، به سیستم تبدیل شدند (EC، N، Fe، منگنز، مس، B و روی). بقیه بدون تغییر باقی ماندند زیرا آنها به طور قابل توجهی بر فرض نرمال بودن باقیمانده های MLR تأثیری نداشتند.
بر اساس تجزیه و تحلیل همبستگی پیرسون برای pH ( شکل 3 )، از نظر آماری همبستگی قوی با logFe وجود داشت. پ≤0.01، r=-0.8)و logMn پ≤0.01، r=-0.7و همبستگی متوسط با Mg و Si. به طور کلی، متغیرهای کمکی خاک همبستگی قویتری با pH نسبت به متغیرهای محیطی نشان دادند.
3.2. مدلسازی و تخمین پارامتر
کریجینگ رگرسیون بر روی مجموعه داده های آموزشی با ترکیب رگرسیون خطی چندگانه بین متغیر خاک هدف و پارامترهای ثانویه با کریجینگ معمولی بر روی باقیمانده های رگرسیون انجام شد (معادل 1).
یک روش گام به گام برای انتخاب بهترین پیش بینی کننده های رگرسیون استفاده شد که در مطالعه ما C، OM، P، K، Mg، Devmean، Altitude، Aspect، logEC، logN، logFe، logMn و logZn بودند. معادله رگرسیون نهایی این بود:
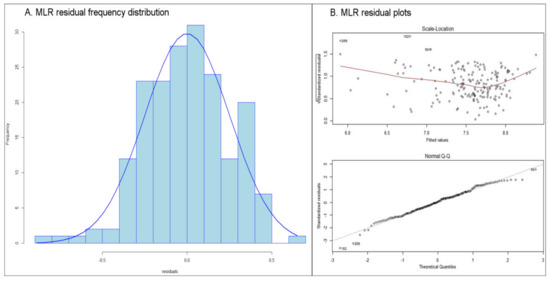
باقیمانده های رگرسیون توزیعی نزدیک به نرمال ارائه کردند، همانطور که در نمودار توزیع فرکانس باقیمانده ( شکل 4 الف) و نمودار Q-Q نرمال ( شکل 4 B، پایین) مشاهده می شود، دارای خطاهای انحراف استاندارد تقریباً ثابت (همسان سازی) ( شکل) 4 B، بالا). همچنین، آمار Shapiro-Wilk (W) برای باقیمانده ها محاسبه شد (W = 0.98588، p -value = 0.05638). بر اساس نتایج، برای سطح معنیداری 05/0، نمیتوان این فرضیه را رد کرد که باقیماندهها از جمعیتی میآیند که دارای توزیع نرمال هستند.
برای جنگلهای تصادفی، یک روش اعتبارسنجی متقاطع 10 برابری در مجموعه دادههای آموزشی برای انتخاب مقادیر فراپارامتر بهینه از طریق فرآیند تنظیم جستجوی تصادفی ( جدول 7 ) استفاده شد. مقدار پیشفرض mtry نزدیک به یک سوم کل متغیرهای مورد استفاده در RF [ 30 ] برآورد شد که در این مورد 8 بود.
تعداد درختان رشد کرده (num.trees در Ranger و ntree در RandomForest) از طریق caret قابل تنظیم نبود، بنابراین مقدار پیشفرض بستهها (500) برای هر دو مورد استفاده قرار گرفت. خط فاصله (سلول های خالی) در جدول 7 ، جدول 8 و جدول 9 برای نشان دادن فقدان یک فراپارامتر برای روش خاص استفاده شد. برای تخمین RFK برای هر بسته، از باقیمانده RF برای درونیابی OK استفاده شد و نتایج مطابق با رابطه (2) به RF اضافه شد.
تقویت گرادیان دارای انبوهی از فراپارامترها است که باید تعریف شوند ( جدول 8 ). برای مقادیر پیشفرض، پارامترهای پیشفرض کتابخانهها انتخاب شدند. در مورد مقادیر بهینه شده، فرآیند تنظیم جستجوی تصادفی با اعتبارسنجی متقاطع 10 برابری داده های آموزشی استفاده شد. در پایان، از باقیمانده GB برای OK استفاده شد و نتایج به منظور تخمین GBK برای هر روش (معادله (3)) اضافه شد.
در نهایت، در مورد NN، هایپرپارامترهای استفاده شده در جدول 9 ارائه شده است. مقادیر پیشفرض آنهایی بودند که کتابخانه پیشنهاد کرد. برای فراپارامترهای بهینهشده، «اندازه» و «واپاشی» از طریق یک فرآیند تنظیم جستجوی تصادفی با اعتبارسنجی متقاطع 10 برابر تنظیم شدند.
مشابه مدلهای قبلی ML، باقیماندههای NN برای OK استفاده شد و نتایج (معادله (4)) به منظور تخمین NNK اضافه شدند.
3.3. ارزیابی عملکرد
مدلهای مطالعه حاضر بر اساس تفاوت بین مشاهدات pH و پیشبینیهای آنها ارزیابی شدند. با توجه به نتایج پیشبینی، الگوریتمهای یادگیری ماشین (RF، GB، NN) دقت بهتری در هر متریک در مقایسه با MLR، RK یا OK نشان دادند ( جدول 10 ). برای مثال، RK (بهترین مدلهای غیرML) RMSE بالاتری را از تقریباً همه الگوریتمهای ML ارائه میکند، به غیر از NNnnD (NN با مقادیر پیشفرض آن). با جزئیات بیشتر، RMSE RK (0.336) در مقایسه با میانگین تمام مقادیر ML RMSE (0.289) 14٪ بیشتر بود و R 2 (0.626) RK 15٪ کمتر از میانگین R 2 همه مدل های ML (0.723) بود. . با مقایسه بهترین پیادهسازی هر مدل ML، RK کاهش 23% در RMSE و 25% افزایش در R2 را نشان داد .در مورد RFrgO (RMSE از 0.259، R2 از 0.781)، کاهش 22٪ در RMSE و 24٪ افزایش در R2 در مورد GBKxgbT (RMSE از 0.262، R2 از 0.778)، و در نهایت، 20 درصد کاهش در RMSE و 21 درصد افزایش در R2 در مورد NNnnO (RMSE از 0.268، R2 از 0.760). نتایج برای OK حتی بدتر بود. با این حال، این مورد انتظار بود، زیرا OK اطلاعات متغیرهای کمکی متعدد را که روشهای دیگر انجام میدهند، در خود جای نمیدهد.
در میان مدلهای ML، RF دقت پیشبینی بالایی را نشان داد، با مدل RFrfO بهترین مدل با RMSE کوچک (0.259)، R 2 بالا (0.784) و MAE پایین (0.180). GB بسیار نزدیک بود، با GBKxgbT (RMSE: 0.262، R 2 : 0.778، MAE: 0.177) بهترین نتایج را در بین مدل های GB ارائه کرد. NN کمی بدتر عمل کرد و NNnnO بهترین مدل NN بود که امتیاز 0.268 در RMSE و 0.760 در R2 را کسب کرد . همانطور که در شکل 5 نیز مشاهده می شود، این خیلی از سایر مدل های ML دور نبود .
بهینهسازی فراپارامترها دقت پیشبینی را در مدلهای GB و NN بهبود بخشید. به خصوص در مورد NN، مقادیر پیشفرض منجر به مدلهای با کیفیت بسیار ضعیف شد، همانطور که از NNnnD مشاهده شد، که بدترین نتایج پیشبینی را داشتند (RMSE از 0.468، R 2 از 0.278، MAE از 0.312)، و NNavD (RMSE از 0.353، R 2از 0.618، MAE از 0.261)، دومین بدترین در بین تمام مدل های ML. در مورد RF، تنها چند فراپارامتر در بهینهسازی دخیل بودند و مقادیر پیشفرض نزدیک به مقادیر بهینهشده بودند. بنابراین، نتایج واقعا تحت تأثیر قرار نگرفت. مقادیر پیشفرض براساس پیشنهادهای ادبیات و مقادیر پیشفرض کتابخانهها بود که در مورد ما mtry = 8 و ntree = 500 بود، تقریباً مشابه مقادیر بهینهسازی (mtry = 9 و ntree = 500). در نتیجه، تنها تفاوتهای جزئی در نتایج مدلها بین فراپارامترهای پیشفرض و بهینهشده وجود داشت.
درون یابی کریجینگ باقیمانده ها تأثیر معنی داری بر نتایج نداشت. NN و RK را کمی بهبود بخشید، در حالی که برای RF، نتایج کمی بدتر شد. با جزئیات بیشتر، در مورد GB، کریجینگ باقیمانده ها، همانطور که در GBKxgbT مشاهده می شود، RMSE را تقریباً 6٪ و R 2 را 3.8٪ در مقایسه با GBxgbTO بهبود می بخشد، در حالی که RMSE GBKxgbD 4٪ و R 2 2.4 بهبود یافته است. % در مقایسه با GBxgbDO. با توجه به RF، کریجینگ باقیمانده منجر به افزایش جزئی در RMSE RFrgO به میزان 1.7٪ و کاهش R2 با 0.2٪ همانطور که در RFKrg مشاهده می شود، شد. به طور مشابه یک افزایش جزئی در RMSE RFrfO به میزان 1.7٪ و کاهش در R2 وجود داشت .0.4٪ (RFKrf). برای NN، معرفی OK به باقیمانده ها منجر به کاهش RMSE NNavO به میزان 8 درصد و افزایش R2 به میزان 7.5 درصد در مقایسه با NNKav شد، در حالی که استفاده از بسته nnet (NNnnO) در NN منجر به نتایج مشابهی شد. افزایش کمی در RMSE (1.3٪) و کاهش در R2 ( 0.7٪)، همانطور که در NNKnn دیده می شود. برای RK نیز با معرفی OK به باقیمانده ها 2.5% در RMSE و 3% در R2 بهبود یافت .
استفاده از پیادهسازیهای مختلف (بستهها/روشها) مدلهای ML یکسان منجر به تفاوتهای عمده در نتایج پیشبینی برای RF و GB نشد. در مورد RF، نتایج RFrgO و RFrfO مشابه بود، در حالی که در مورد GB (GBxgbTO و GBxgbDO)، تفاوتهای جزئی وجود داشت، با GBxgbTO که اندکی بهتر بود (RMSE 0.279، R2 از 0.750، MAE 0.190). ). در NN، تفاوت بین دو روش (NNnnO و NNavO) کمی بیشتر بود.
شایان ذکر است که در تنوع نتایج بین مدل های مختلف ML تفاوت وجود داشت. به طور خاص، نتایج RF کمترین تنوع (RMSE SD = 0.002، R 2 SD = 0.002) را در مقایسه با GB (RMSE SD = 0.32، R 2 SD = 0.017) و NN (RMSE SD = 0.189، R 2 SD = 0.078) داشتند. صرف نظر از بسته های مختلف استفاده شده، روش انتخاب فراپارامترها، یا گنجاندن (یا نه) OK از باقیمانده ها.
با توجه به R2 به طور کلی، مقادیر بالا ( شکل 5 ) ، بیش از 0.6 بود، به خصوص برای مدل های ML، جدا از NNnnD. بنابراین، مدلها بیشتر تغییرات کل pH را توضیح میدهند و به نظر میرسد که متغیرهای کمکی مورد استفاده به شدت بر pH خاک تأثیر میگذارند. MAE به طور مداوم مقادیر بسیار پایینی در مدلهای RF داشت که از 0.178 تا 0.184 متغیر بود. نتایج GB نزدیک بود، اما با تنوع بالاتر (0.177 تا 0.232)، و NN امتیاز بدتری داشت، با مقادیر بالاتر از 0.182 تا 0.312.
ارزیابی اهمیت متغیرهای کمکی ( شکل 6 ) نشان داد که آهن (Fe)، منگنز (Mn) و منیزیم (Mg) تأثیرگذارترین متغیرها برای هر دو RF و GB بودند. به طور خاص برای آهن (Fe)، تأثیر بالایی بر pH خاک بر اساس ادبیات مربوطه انتظار می رفت [ 18 ، 24 ]. در بین متغیرهای محیطی، ارتفاع برای هر دو مدل ML امتیاز بالاتری داشت.
4. بحث و نتیجه گیری
از نتایج مطالعه حاضر، بدیهی است که مدلهای ML در پیشبینی pH خاک، مانند MLR یا مدلهایی که از کریجینگ (RK یا OK) استفاده میکنند، بهتر از سایر روشها عمل کردند. علاوه بر این، استفاده از مدلهای ML آسان بود، بدون فرضیات آماری و الزاماتی که رگرسیون خطی و درونیابی کریجینگ نیاز دارند. با این حال، مدلهای ML به قدرت محاسباتی قابل توجهی همراه با دانش و توجه به فرآیند تنظیم مدلها نیاز دارند. به طور کلی، بر اساس نتایج، نویسندگان مطالعه حاضر تمایل دارند با این ادعا موافق باشند که “…کریجینگ به عنوان یک تکنیک پیش بینی فضایی ممکن است زائد باشد، اما دانش کامل زمین آمار و آمار به طور کلی بیش از هر زمان دیگری مهم است” [ 13 ] .
ارزیابی نتایج پیشبینی مدلهای مختلف ML نشان میدهد که GB و RF بهترین عملکرد را دارند و NN کمی دقت کمتری دارد. نتایج کمتر NN می تواند به دلیل این واقعیت باشد که NN به تعداد زیادی داده نیاز دارد تا بتواند پیش بینی های خوبی ایجاد کند، به عنوان مثال، 10 تا 100 برابر تعداد ویژگی ها یا 10 برابر تعداد ورودی ها [ 39 ، 40 ].]. 266 مکان مختلف و 23 متغیر ممکن است برای NN کافی نباشد تا قابلیت های پیش بینی خود را نشان دهد. همچنین، پیادهسازیهای مختلف یک مدل ML به تفاوتهای عمده برای RF و GB منجر نشد، در حالی که در NN، تفاوتها کمی بزرگتر بود. پیادهسازیهای مختلف مدلهای ML یکسان عمدتاً تغییرات جزئی از همان مدلهای ML را معرفی میکنند که ممکن است نتایج بهتری را ایجاد کنند، اما فقط در برخی موارد.
بهینهسازی فراپارامترها به دلیل افزایش تعداد پارامترها و تفاوت معنیدار بین مقادیر پیشفرض و بهینهشده، نتایج پیشبینی را در مدلهای GB و NN بهبود بخشید. بدیهی است که تنظیم دقیق و کامل آنها گامی تعیین کننده برای دستیابی به بهترین نتایج است. در مورد RF، هایپرپارامترها کم بود و مقادیر پیشفرض نزدیک به مقادیر بهینه شده بود که منجر به تفاوت جزئی در نتایج پیشبینی شد.
معرفی درون یابی کریجینگ باقیمانده های مدل های ML واقعاً نتایج را بهبود نمی بخشد. این مطابق با یافته های Henglet al. [ 41 ]، با بیان این که “…به عنوان یک قانون سرانگشتی، زمانی که یک مدل یادگیری ماشینی بیش از 60 درصد از تغییرات در داده ها را توضیح می دهد، احتمال اینکه کریجینگ ارزش تلاش محاسباتی را نداشته باشد.”
تفاوت در تنوع نتایج پیشبینی ML بر اساس یافتههای ذکر شده در بالا مورد انتظار بود. به طور کلی، RF بدون در نظر گرفتن بستهها یا روشهای مختلف، روشهای مختلف انتخاب فراپارامتر، یا حتی گنجاندن کریجینگ به باقیماندههای مدل ML، نتایج منسجمتری با تنوع کمتر نشان داد. این می تواند به عنوان یک مزیت در برخی موارد که ثبات یک الزام است در نظر گرفته شود. با این حال، افزایش تنوع نتایج پیشبینی سایر مدلهای ML نشان میدهد که آنها پتانسیل بهبود بیشتر دقت پیشبینی خود را دارند، به عنوان مثال، از طریق فرآیند تنظیم متفاوت یا استفاده از بستهها و پیادهسازیهای مختلف.








بدون دیدگاه