1. معرفی
این مطالعه بر یافتن یک روش ارزیابی برای تعیین کمیت تأثیر تکنیکهای فیلتر بر قابلیت اطمینان فضایی دادههای رسانههای اجتماعی (SMD) برای به دست آوردن مناسبترین، قابل اعتمادترین و دقیقترین SMD بر اساس موضوع برای استفاده از آن در رویکردهای مختلف متمرکز است. خطاهای متنی در مرحله فیلتر کردن برخورد با SMD منجر به تمرکز روی رویدادهای نامربوط، واکنش های نامربوط و مکان های نامربوط با توجه به رویداد می شود. این خطاها منجر به ایجاد نقشههای غیرقابل اعتماد یا نادرست مربوط به رویداد میشود – چیزی که در این مطالعه به عنوان دامنه از آن یاد خواهیم کرد. بسیاری از مطالعات قابلیت اطمینان SMD را بررسی کردهاند، عمدتاً آنهایی که در توییتر یافت میشوند [ 1 ، 2 ، 3]. پلت فرم توییتر به دلیل گزینه های برچسب گذاری جغرافیایی و استفاده گسترده در سراسر جهان به عنوان منبع SMD برای این مطالعه انتخاب شده است [ 4 ].
رسانههای اجتماعی دارای محتوای موضوعی متنوعی هستند که توسط حسگرهای انسانی منبع میشوند [ 5 ، 6 ، 7 ]. با این حال، جدا از وجود تعدادی پلتفرم جمعآوری داده مبتنی بر داوطلبانه، انگیزه مستقیمی برای مشارکت در تولید دادهها فراهم نمیکند [ 8 ، 9 ، 10 ]. این باعث می شود که تجزیه و تحلیل رسانه های اجتماعی با تجزیه و تحلیل داده های ساخت یافته متفاوت باشد. بنابراین، نیاز به فیلتر کردن چنین داده هایی برای بازیابی داده های مربوطه برای یک دامنه انتخابی وجود دارد.
برای تجزیه و تحلیل موضوع داغ درشت دانه، به عنوان مثال، اگر یک رویداد وحشتناک در یک شهر رخ داده باشد، نقاط دورافتاده غیر مرتبط ممکن است به راحتی با استفاده از رویکردهای خوشهبندی مبتنی بر چگالی از جریان دادهها فیلتر شوند [ 11 ، 12 ]. برعکس، فیلتر ریز دانه میتواند محتوای پر سر و صدا را برای تجزیه و تحلیل ریزدانه به شدت گسسته کند [ 13 ]. به عنوان مثال، نگاشت رخداد در طول و پس از یک رویداد وحشتناک و حذف دقیق ناهماهنگی ها توسط فیلتر ریز دانه به تولید نقشه های قابل اعتمادتر برای شناسایی مکان و تأثیر رویداد کمک می کند. این به نوبه خود می تواند از پاسخ های هماهنگ و دقیق و مدیریت اضطراری مورد نظر پشتیبانی کند.
اصطلاحات دقت، قابلیت اطمینان و اعتبار به طور کلی برای ارزیابی کیفیت SMD استفاده می شود. رابطه بین استخراج اطلاعات مکانی و حقیقت در تحلیل های رسانه های اجتماعی به عنوان دقت آن توسط [ 14 ، 15 ، 16 ، 17 ، 18 ] تعریف می شود. این مطالعات از مفهوم دقت برای تخمین مکانهای زندگی، کار یا سفر کاربران بر اساس فید رسانههای اجتماعی با استفاده از فاصله بین مکانهای دارای برچسب جغرافیایی و واقعی استفاده کردند. فاصله مورد استفاده در این مطالعات فاصله اقلیدسی است، یعنی فاصله بین دو نقطه یا در یک صفحه مسطح یا طول فضای سه بعدی که مستقیماً دو نقطه را با استفاده از قضیه فیثاغورث به هم متصل می کند [ 19 ].]. مفهوم قابلیت اطمینان بیشتر بر دقت درونی خود داده ها یا روشی که برای پردازش داده ها استفاده می شود همانطور که توسط لارنس [ 20 ] ذکر شده است، متمرکز است. این شامل بررسی رابطه بین نمرات آماری دو تحلیل احساسات متفاوت است. اعتبار اصطلاحی برای پاسخگویی منبع خبر در رسانه های جدید و سنتی است. برای اعتبار رسانههای اجتماعی، این شامل در نظر گرفتن مشخصات کاربر، شبکههای دوستی، و اعمال کاربران مانند توییتها، ریتوییتها، لایکها و نظرات است که توسط Castillo Ocaranza و همکاران پیشنهاد شده است. [ 21 ]. عباسی و لیو [ 22] اعتبار رسانه های اجتماعی را با اشاره به فعالیت های کاربران هماهنگ که با هم به عنوان یک بسته عمل می کنند، مورد توجه قرار دادند.
تا به امروز، مطالعات متعددی در مورد اعتبار [ 21 ، 22 ]، دقت [ 14 ، 15 ، 16 ، 17 ، 18 ] و قابلیت اطمینان [ 20 ، 23 ، 24 ] SMD انجام شده است، اما این موارد تا حدودی محدود هستند زیرا دارای فقط بر روی نتایج تجزیه و تحلیل متمرکز شده است، نه بر روی الگوریتم های فیلتر. با این حال، بیشتر اوقات، SMD بر اساس کلمات و هشتگ ها بر اساس رویداد قبل از تجزیه و تحلیل فیلتر می شود [ 25 ، 26 ، 27 ، 28 .]. با در نظر گرفتن ماهیت منفی محتوای حوزه فاجعه، تحلیل احساسات را می توان به عنوان رویکردی در نظر گرفت که می تواند برای دسترسی به محتوای مرتبط از منظر وسیع تری نسبت به نتایج فیلترینگ هشتگ و کیسه کلمات مورد استفاده قرار گیرد. بنابراین، تمرکز تنها بر روی تجزیه و تحلیل SMD منجر به نادیده گرفتن تکنیک های فیلتر می شود، بنابراین ارزیابی ها را به اشتباه هدایت می کند. بسته به درجات دقت و قابلیت اطمینان، که به عنوان جنبه های کیفیت [ 29 ] از الگوریتم فیلتر SMD نام برده می شود، کیفیت تحلیل ها تغییر می کند.
دو رویکرد برجسته در ادبیات با توجه به تحلیل احساسات وجود دارد [ 23 ، 24 ، 30 ]. روش اول از واژگان سوبژکتیویته استفاده می کند که شامل واژه نامه ای با امتیازات احساسی یا برچسب هایی برای هر کلمه یا عبارت است. این شامل اسکن اسناد یا عبارات برای تعیین نمره کل کلمه تشکیل دهنده از نظر قطبیت است. دومی یک رویکرد آماری تر است که از الگوریتم های مبتنی بر یادگیری بهره برداری می کند. با این حال، در مورد عبارات ریزدانه مانند آنهایی که در محتوای رسانه های اجتماعی یافت می شود، به خوبی کار نمی کند [ 31 ]. علاوه بر این، رویکردهای آماری ممکن است روی زبانهای آگلوتیناسیون و از نظر مورفولوژی غنی مانند ترکی، کرهای یا ژاپنی به خوبی کار نکنند [ 32 ]]. تلاشهای متعددی برای انجام و آزمایش تحلیلهای قطبی در زبان ترکی صورت گرفته است، که برخی از آنها بر اساس ترجمه واژگان ذهنی انگلیسی به ترکی [ 33 ، 34 ] هستند، در حالی که برخی دیگر به طبقهبندیکنندهها در سراسر موضوعات مفهومی [ 32 ] یا بر زبانشناختی تکیه میکنند. زمینه در ترکی [ 35 ]. استفاده از تجزیه و تحلیل احساسات می تواند با توجه به حوزه ای که برای آن استفاده می شود (به عنوان مثال، موضوعات خاص مانند بلایا، ستون های نظرات یا موسیقی) متفاوت باشد. در حالی که واژگان مستقل از دامنه رویکردهای سریع و مقیاس پذیر برای اهداف کلی ارائه می دهند، واژگان مبتنی بر دامنه در موضوعات و فرهنگ های خاص معتبر هستند [ 31 ]]. از نظر زبان مورد استفاده، غنای واژگان ذهنی به اندازه تکنیک ها و روش شناسی انتخاب شده مهم است. تعداد زیادی واژگان مختلف برای انگلیسی با محتوای کلمات غنی وجود دارد که قطبیت را با امتیاز [ 30 ]، با اختصاص دادن چندین احساس به هر عبارت [ 36 ، 37 ]، با برچسب زدن اصطلاحات به عنوان مثبت/خنثی/منفی [ 38 ، 39 ] و با امتیاز دادن به قدرت قطبیت هر عبارت از منفی به مثبت [ 30 ]. از سوی دیگر، بیشتر زبان های دیگر، از جمله ترکی، فاقد واژگان ذهنی جامع هستند. با این حال، تا جایی که ما می دانیم، چند واژگان برای زبان ترکی وجود دارد. دهخوارگانی و همکاران. [ 31] یک واژگان SentiTurkNet (STN) معادل ترجمه انگلیسی SentiWordNet [ 38 ] ایجاد کردند، در حالی که Ozturk و Ayvaz [ 40 ] یک واژگان ترکی متشکل از بیش از 5000 اصطلاح را تولید کردند که به عنوان اصطلاحاتی در استفاده مکرر روزانه مشخص شده است که به عنوان برچسب گذاری شده اند. مثبت، منفی یا خنثی این واژگان در این پژوهش با عنوان واژگان اوزتورک و آیواز (LOA) نامگذاری شده است. مطالعات قبلی در مورد محتوای ترکی شامل تجزیه و تحلیل احساسات مستقل از دامنه است و واژگان عمدتاً در متون طولانی اجرا می شود. از این رو، عملکرد مطالعات قبلی از نظر نحوه برخورد آنها با متون کوتاه از رسانه های اجتماعی با توجه به یک دامنه ناشناخته است.
تازگی این مطالعه توسعه روشی برای فیلتر SMD بر اساس ارتباط و دقت مکانی، با مقایسه تکنیکهای فعلی برای فیلتر کردن است. یکی دیگر از نتایج این مطالعه این است که ما یک شاخص شباهت فضایی برای تأیید صحت مکانی روش همراه با تکنیکهای فیلتر ایجاد کردهایم. SMD این مطالعه از دو رویداد تروریستی که در استانبول رخ داده است به دست آمده است. در نتیجه، داده های متنی توییت ها به زبان ترکی است. وجه تمایز دیگر این مطالعه ایجاد روش شناسی برای زبانی است که انگلیسی نیست. بیشتر مطالعات برای فیلتر کردن و تحلیل احساسات توییت ها به زبان انگلیسی مربوط می شود [ 30 , 41 , 42]. کشف شده است که استفاده از این تکنیکها بدون تنظیمات مناسب بر اساس رویداد یا زبان، به دلیل استفاده از پسوندها در انتهای کلمات و مقادیر زیاد همنام، میزان موفقیت بسیار کمی را برای زبانهای چسبنده مانند ترکی فراهم میکند [ 21 , 31 ، 33 ]. همانطور که Castillo Ocaranza، Mendoza و Poblete Labra [ 21 ] در مطالعه خود نشان می دهند، فیلتر کردن و اطمینان از اعتبار توییت ها به زبان اسپانیایی به دلیل امکان طبقه بندی های غیر مرتبط نیاز به برچسب گذاری دستی دارد.
این نوع موقعیت ها با توجه به فیلتر و زبان بر دقت و قابلیت اطمینان نقشه های حاصل (نقشه های رویداد، خطر یا خطر) تأثیر می گذارد. مطالعات قبلی عمدتاً بر محل وقوع رویداد از نظر جغرافیایی و میزان بزرگی آن متمرکز شدهاند، بدون در نظر گرفتن قابلیت اطمینان تکنیکهای ریز فیلتر مورد استفاده یا تأثیر قابلیت اطمینان فیلتر بر روی نقشهبرداری وقوع [ 1 ، 2 ، 3 ]. با این حال، کیفیت در نظر گرفته شده در این مطالعه بر اساس این است که چگونه SMD به درستی فیلتر شده است و چگونه این داده های فیلتر شده به درستی در ایجاد نقشه ها، هم از نظر فضایی و هم از نظر احساسی منعکس می شوند.
در این مطالعه دامنه انتخاب شده مربوط به حملات تروریستی است. رویدادهای انتخاب شده دو حمله از این قبیل در استانبول در سال 2016 بود و تمام توییتهای به دست آمده در رابطه با این حملات به زبان ترکی بود. برای بررسی اثرات دقت فیلتر بر روی نقشه ها از نظر جغرافیایی، نتایج هر تکنیک فیلتر با استفاده از یک روش عمومی نقشه برداری شد. تعیین دقت توییتهای فیلتر شده شامل استفاده از توییتهای برچسبگذاریشده دستی بهعنوان حقیقت پایه است، مانند گوپتا، لامبا، و کوماراگورو [ 2 ] و کاستیو اوکارانزا، مندوزا و پوبلته لابرا [ 21 ] که در تحقیقات خود استفاده کردند. سپس نقشه های مرتبط با هر تکنیک فیلتر بر اساس نقشه حقیقت زمینی مورد تجزیه و تحلیل قرار گرفت.
در این مرحله از مطالعه، از روشهای مختلف نمایهسازی شباهت استفاده شد و شاخص مشابهی جدیدی به نام شاخص Giz معرفی شد. شاخص Giz برای بررسی شباهتهای مقادیر، اندازهها و مجاورت اشیاء فضایی طراحی شده است که با استفاده از تکنیکی شامل درصد موفقیت با توجه به نقشه حقیقت زمینی فیلتر و نقشهبرداری شدهاند. تازگی شاخص تشابه جدید توسعه یافته توانایی آن در ارائه تقاطع فضایی، مجاورت و اندازه با هم است. به همین دلیل، می توان از آن برای بسیاری از مطالعات برای تشخیص دقت مکانی نقشه های تولید شده، تخمین زده، شبیه سازی شده یا پیش بینی شده با توجه به حقیقت استفاده کرد. در نهایت، نتایج حاصل از هر روش شاخص تشابه، از جمله شاخص جدید توسعه یافته Giz، با نقشه حقیقت زمین مقایسه شد. مقایسه بهترین ترکیب تکنیک فیلتر و شاخصهای شباهت را برای ایجاد نقشههای رویداد با توجه به SMD نشان داد. این مطالعه روشی را ارائه می دهد که می تواند برای فیلتر کردن SMD به طور دقیق و قابل اعتماد استفاده شود و روشی برای بررسی اثرات تکنیک های فیلتر بر روی دقت نقشه ارائه می دهد.
2. مواد و روشها
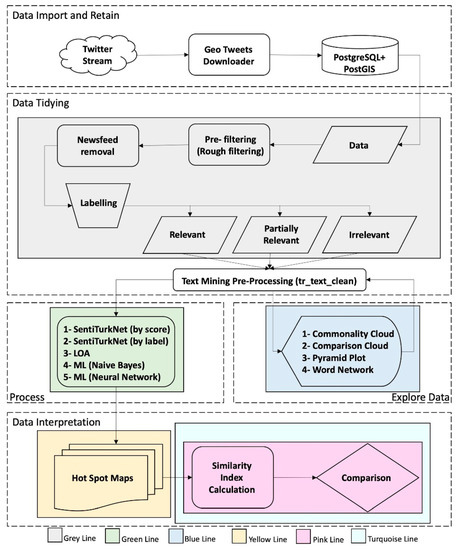
روششناسی این مطالعه با تجزیه و تحلیل اکتشافی دادههای توئیتر فیلتر شده برای ایجاد رویکردی برای فیلتر کردن دقیق دادههای مبتنی بر دامنه آغاز شد. به این ترتیب، پرت های پر سر و صدایی که به دامنه مرتبط نیستند، می توانند گسسته شوند. برای ایجاد رویکردی برای فیلتر کردن اختلافات با استفاده از تحلیل احساسات و تکنیک های یادگیری ماشین، گردش کار پایه علم داده [ 43 ]، که واردات → مرتب → درک (تجسم → مدل → تبدیل) → ارتباط است، دنبال شد، همانطور که در نشان داده شده است. شکل 1 . به طور مشابه، پردازش داده ها با در نظر گرفتن طبقه بندی علم داده (به دست آوردن → اسکراب → کاوش → مدل → تفسیر) همانطور که توسط میسون و ویگینز [ 44 ] پیشنهاد شده است، تفسیر می شود.
شکل 1 بخش هایی از روش را با واردات و حفظ بخشی به رنگ سفید نشان می دهد. قسمت مرتب کردن داده ها به رنگ خاکستری. بخش اکتشاف داده به رنگ آبی؛ بخش پردازش داده به رنگ سبز؛ و قسمت تفسیر داده ها به رنگ های زرد، صورتی و فیروزه ای. هر بخش از روش به صورت شماتیک با استفاده از شکل ها ( شکل 2 ، شکل 3 ، شکل 4 ، شکل 5 ، شکل 6 و شکل 7 ) توسعه یافته و در بخش های فرعی زیر توضیح داده شده است. با توجه به این، بخش 2.1. تکنیکی برای ارجاع جغرافیایی داده های به دست آمده از جریان توییتر با استفاده از Twitter API ارائه می دهد. این بخش با استفاده از جاوا همانطور که در Gulnerman و همکاران توضیح داده شده است. [ 45 ] به عنوان Geo Tweets Downloader (GTD). در بخش 2.2 ، جزئیات مرتب سازی داده ها به ترتیب پیش فیلتر کردن، تمیز کردن و برچسب گذاری برای تولید داده های صحت زمینی آورده شده است. در بخش 2.3 ، تکنیکهای کاوش دادهها مانند ابرهای کلمه، ابرهای مقایسه و دندروگرامهایی که برای این مطالعه استفاده میشوند توضیح داده شدهاند. این کاوش به توسعه عملکرد پیش پردازش متن کمک می کند که بخشی از قسمت مرتب کردن داده ها است. در بخش 2.4، روش انطباق رایج ترین تکنیک های طبقه بندی متن با فیلتر مبتنی بر دامنه وحشت معرفی شده است. در این بخش، دو واژگان احساسات متفاوت برای زبان ترکی و سه تکنیک مختلف یادگیری ماشینی برای فیلتر کردن خودکار محتوای مرتبط ارائه شده است. در بخش 2.5، روش تفسیر فضایی برای تعیین کمیت دقیق چگونگی تأثیر فیلتر متنی بر دقت فضایی نقشه های تولید شده معرفی شده است. این تفسیر شامل مراحل زیر است: 1-تولید یک نقشه هات اسپات برای داده های مرتبط با برچسب دستی (نقشه حقیقت زمین)، 2-تولید نقشه های نقطه هات برای هر تکنیک فیلتر برحسب نتایج مربوطه (نقشه پیش بینی شده) و 3-تعیین شباهت بین حقیقت زمین و نقشه های پیش بینی شده (اندازه گیری دقت فضایی). در این فرآیند کمی تشابه، شاخصهای شباهت فعلی (2.5.2) و یک ضریب شباهت جدید با عنوان Giz Index (2.5.3.) برای تفسیر کمی دقت فضایی نقشههای تولید شده استفاده میشوند. ویژگی هایی مانند مجاورت فضایی و اندازه خوشه فضایی توسط شاخص Giz در نظر گرفته می شوند اما توسط شاخص های فعلی در نظر گرفته نمی شوند. این توضیح داده شده و با داده های آزمون مقایسه شده استبخش 2.5.3 برای اثبات اینکه شاخص پیشنهادی برای تفسیر فضایی بهتر عمل می کند.
2.1. واردات و نگهداری داده ها
Geo Tweets Downloader (GTD) [ 45 ، 46 ]، یک برنامه دسکتاپ مبتنی بر جاوا که امکان فیلتر کردن را با استفاده از یک کادر فضایی محدود میکند و توئیتهای بدون برچسب جغرافیایی را حذف میکند، برای جمعآوری و فیلتر فضایی دادههای ترکی استفاده شد. GTD از API های توییتر استفاده می کند [ 47 ، 48] که توییت های وضعیت عمومی را در زمان واقعی ارائه می دهد. همچنین به پیکربندی با توجه به استفاده از PostgreSQL به منظور ذخیره داده های دارای برچسب جغرافیایی حفظ شده کمک می کند. با استفاده از GTD، داده های وضعیت عمومی به طور مداوم تا حد استفاده از API جمع آوری می شود. از آنجایی که توییت های جمع آوری شده دارای وضعیت عمومی و دارای برچسب جغرافیایی هستند، تعداد توییت هایی که در دوره مورد بررسی پست شده اند کمتر از حد معمول بوده است. با این حال، هدف و تکنیک مورد استفاده نیازی به ثبت همه توییتهای ارسال شده برای آزمایش این رویکرد ندارد، که شامل فیلترینگ بسیار مرتبط است.
2.2. مرتب سازی داده ها
تجزیه و تحلیل رسانه های اجتماعی با توجه به یک رویداد با دسترسی به داده های مربوطه شروع می شود. این بیشتر با جستجو در هشتگ های استفاده شده یا کلمات کلیدی احتمالی مرتبط با دامنه به دست می آید. این تمایل به ایجاد ترکیبی از داده ها دارد که اساساً تحت سلطه محتوای مرتبط است. با این حال، همچنان شامل نویز به شکل داده های غیر مرتبط است. بخش اول فرآیند مرتب سازی داده ها شامل فیلتر کردن داده های حفظ شده با استفاده از کلمات کلیدی احتمالی برای حوزه فاجعه مورد بررسی است. به دنبال این، توییتهای تولید شده توسط اخبار فیدها برای جلوگیری از هرزنامه یا پستهای غیرفردی گسسته میشوند. در بخش بعدی تمیز کردن دادهها، هر محتوای توییت به عنوان مرتبط، تا حدی مرتبط یا غیر مرتبط برچسبگذاری میشود تا اشتراکات و تفاوتهای محتوا در بخش کاوش بعدی بررسی شود.
-
محتوای مربوط به یک رویداد فاجعه به عنوان مرتبط علامت گذاری شده است.
-
محتوای مربوط به یک فاجعه به طور کلی، مانند انتقاد از یک حزب سیاسی یا خاطره یک رویداد فاجعهبار قدیمی، تا حدی مرتبط علامتگذاری میشود.
-
محتوای مربوط به زمینه بسیار متفاوت با یک رویداد فاجعهبار مانند «من امروز مثل یک بمب هستم» یا «من تا حد مرگ حوصلهام سر رفته است» بهعنوان غیرمرتبط علامتگذاری میشود.
خط خاکستری در شکل 1 در شکل 2 گسترش یافته است تا مراحل جریان داده را برای مرتب سازی داده ها نشان دهد. هر مرحله در شکل 2 نشان دهنده:
-
جدول داده های به دست آمده تولید می شود.
-
پیش فیلتر کردن با استفاده از کلمات کلیدی مبتنی بر دامنه (فیلتر کردن خشن).
-
حذف حساب Newsfeed از داده ها با استفاده از کلمات کلیدی مرتبط با رسانه؛
-
برچسبگذاری دستی به عنوان مرتبط، تا حدی مرتبط یا غیر مرتبط با دامنه؛
-
برچسب ها به جدول داده ها اضافه می شوند.
این فرآیند داده های از پیش فیلتر شده و برچسب گذاری شده را برای بخش کاوش داده فراهم می کند. در این فرآیند مرتب سازی داده ها، یک مرحله پاکسازی متن نیز وجود دارد که در نتیجه نتایج کاوش داده ها دوباره طراحی می شود. تابع tr_text_clean [ 49 ] با مراحل زیر ترکیب میشود:
این مرحله اولیه توکن سازی هر کلمه را به عنوان بخشی از فرآیندهای بعدی با توجه به متن کاوی آسان می کند. مراحل تمیز کردن به صورت بازگشتی با توجه به نتیجه بخش اکتشاف داده برای یافتن بهترین مراحل پیش پردازش برای زبان در این مطالعه تعیین شد. با توجه به این موضوع، قسمت پاکسازی متن با حذف مشکلات رمزگذاری زبان و با تصمیم به حفظ پسوندها دوباره طراحی شد. این به این دلیل است که پسوندها از نظر جفت کردن کلمه به کلاس مربوطه که در ابرهای کلمه bigram در بخش کاوش داده ها کشف می شود، متفاوت هستند. در حالی که این مرحله مرتب کردن برای تنظیم محتوای متن برای پردازش بیشتر مورد استفاده قرار گرفت، دادهها ممکن است شامل بینظمیهای متعددی مانند غلطهای املایی، اصطلاحات و اصطلاحات عامیانه باشد که میتواند عملکرد پردازش بیشتر را کاهش دهد.
2.3. کاوش داده ها
روشهای دادهکاوی اکتشافی برای شناسایی شباهتها و تفاوتهای بین توئیتهای مرتبط، تا حدی مرتبط و غیر مرتبط با برچسبگذاری دستی استفاده شد. ابرهای مشترک و مقایسه، یک طرح هرمی، و شبکه های کلمه برای به دست آوردن بینشی در مورد داده ها برای پردازش بیشتر تجسم شدند.
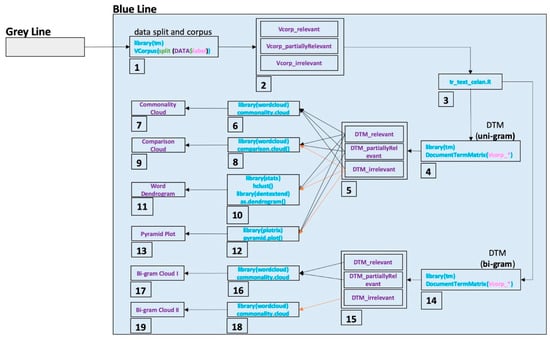
خط آبی در شکل 1 در شکل 3 گسترش یافته است تا مراحل جریان داده را برای اهداف اکتشاف داده نشان دهد. هر مرحله در شکل 3 نشان دهنده:
-
تقسیم داده ها از نظر نوع برچسب و تبدیل نوع داده از چارچوب داده به پیکره.
-
تخصیص داده های تقسیم شده به عنوان پیکره از نظر نوع برچسب.
-
تمیز کردن متن برای هر پیکره با استفاده از تابع tr_text_clean.
-
ایجاد ماتریس اصطلاح سند Uni-gram (DTM) برای هر مجموعه (هر عبارت دارای یک کلمه است).
-
تخصیص سه DTM برای داده های مرتبط، جزئی مرتبط و غیر مرتبط.
-
تعیین 100 کلمه پرتکرار در سه DTM.
-
نمودار ابر مشترک با اندازه کلمه متفاوت از نظر فراوانی کلمه.
-
شناسایی پنجاه اصطلاح متمایز رایج در DTMهای مرتبط و تا حدی مرتبط و غیر مرتبط.
-
ایجاد یک نمودار ابری مقایسه با عبارات متمایز تعیین شده در DTMs.
-
ایجاد یک شبکه کلمه بر اساس خوشه بندی سلسله مراتبی.
-
ایجاد یک نمودار دندروگرام کلمه برای آشکار کردن اصطلاح انجمن.
-
محاسبه درصد فراوانی اصطلاحات رایج از نظر DTMهای مرتبط و جزئی مرتبط و غیر مرتبط.
-
ایجاد نمودارهای هرمی با اصطلاحات رایج در DTM ها، به ترتیب با درصد اختلاف فرکانس.
-
ایجاد ماتریس اصطلاح سند Bi-gram (DTM) برای هر مجموعه (هر عبارت دارای دو کلمه است).
-
تخصیص سه DTM bigram برای دادههای مرتبط، جزئی مرتبط و غیر مرتبط.
-
تعیین 100 اصطلاح پرتکرار bigram در DTMهای مرتبط و جزئی مرتبط.
-
ایجاد یک نمودار ابر مشترک با اندازه نمودارهای مختلف از نظر فرکانس در DTMs.
-
تعیین 100 بیگرم متداول در DTMهای غیر مرتبط.
-
ایجاد یک نمودار ابری مشترک با اندازه نمودارهای مختلف از نظر فرکانس در DTMها.
اینها به کشف محتویات داده مرتبط، تا حدی مرتبط و غیر مرتبط کمک می کنند. جزئیات کار بسته های مورد استفاده در این فرآیند اکتشاف داده در بخش های فرعی زیر آورده شده است. در طول این کاوش، اهمیت پسوندها برای تبعیض از نظر ارتباط و تفاوتهای تداعی کلمه از نظر ارتباط مورد بررسی قرار گرفت. با توجه به این موضوع، ریشه کلمه در تابع پاکسازی متن اعمال نشد و کسری از نظر استفاده از پیش فیلترینگ یونیگرام آشکار شد.
2.3.1. ابر مشترک
این تابع به عنوان بخشی از بسته «wordcloud» [ 50 ] در R مستقر میشود، در فرکانس یک عبارت اجرا میشود و متداولترین «n» تعداد عبارتها (کلمات) را همانطور که در آرگومان تابع تعیین میشود ترسیم میکند. برای این مطالعه، 100 عبارت برتر ترسیم شد تا نشان دهد کدام عبارت در مجموعه داده غالب است.
2.3.2. مقایسه ابر
همانند ابر مشترک، این تابع نیز به عنوان بخشی از بسته wordcloud [ 50 ] به کار گرفته می شود. برای یک ابر مقایسه، دو تکه داده مورد نیاز است تا بتوان اصطلاحات پرکاربرد را با هم مقایسه کرد. در این کار، برای دیدن اینکه کدام کلمات رایج در هر دو مجموعه داده برچسبگذاری شده بیشترین فراوانی را دارند، استفاده شد. این تابع بینش هایی را برای تجزیه و تحلیل احساسات ارائه می دهد که به امتیازدهی کلمات سازنده بدون هیچ وزنی بستگی دارد.
2.3.3. طرح هرمی
این تابع در بسته “plotrix” [ 51 ] مستقر شده است و برای نشان دادن تفاوت فرکانس در هر دو تکه استفاده می شود. تفاوت فرکانس با تقسیم حداکثر فرکانس مدت در مجموعه داده ها نرمال می شود و بر اساس تفاوت ها مرتب می شود. در این مطالعه، با استفاده از یک نمودار هرمی، 50 کلمه در مجموعه دادهها به تصویر کشیده شد که بالاترین میزان تفاوت را با یکدیگر دارند. این نمودار برای بیان وزن عباراتی که می تواند برای طبقه بندی مورد نظر استفاده شود، استفاده شد.
2.3.4. دندروگرام ورد
تابع “dist” و “hclust” از بسته “stats” [ 52 ] برای ایجاد یک شبکه کلمه به عنوان یک خوشه سلسله مراتبی، و بسته “dendextend” [ 53 ] برای تجسم و برجسته کردن اصطلاحات در یک دندروگرام استفاده شد. روش اقلیدسی در آرگومان های تابع “dist” برای تعیین فاصله بین عبارت ها قبل از فرآیند خوشه سلسله مراتبی استفاده شد. دندروگرام های مربوط، تا حدی مرتبط، و مجموعه های غیر مرتبط از داده ها برای تعیین تفاوت های ارتباط کلمه بیان شد.
2.4. پردازش داده ها
با توجه به بینش بهدستآمده از بخش کاوش دادههای روش، بخش پردازش با استفاده از تکنیکهای مختلف فیلتر بر اساس واژگان احساسات و یادگیری ماشین انجام شد. در سه تکنیک اول، واژگان ذهنی عمومی فعلی برای زبان ترکی [ 31 ، 40 ] برای طبقهبندی یک مجموعه داده تقریباً فیلتر شده بهعنوان مرتبط، تا حدی مرتبط یا غیر مرتبط مورد بهرهبرداری قرار گرفتند. تکنیکهای چهارم و پنجم از دادههای برچسبگذاری شده دستی استفاده کردند تا امکان ساخت طبقهبندیکننده یادگیری ماشینی برای فیلترهای ریزدانه را فراهم کنند.
یک دیدگاه مبتنی بر دامنه با بهرهبرداری از موارد مشابه قبلی ساخته شد. استفاده از واژگان سوبژکتیویته برای فیلتر کردن محتوای غیر مرتبط و پیشنهاد راهی برای مقابله با دادههای مبتنی بر دامنه ترور با توجه به زبان ترکی یک رویکرد کاملاً جدید از نظر تحلیل SMD بود. واژگان ذهنی برای جلوگیری از هرگونه سوء تفاهم در مورد کلمات ترکی استفاده شد. به عنوان مثال، کلمه “بمب” را می توان برای توصیف انفجار یک ابزار انفجاری یا به عنوان نام یک دسر محبوب در ترکیه استفاده کرد. به همین دلیل است که اطلاعات ارزشمند از پست ها نادیده گرفته نشد. تنها طبقهبندیهای مرتبط با استفاده از واژگان سوبژکتیویته برای انتخاب کلمات همنام مرتبط در زبان ترکی مورد هدف قرار گرفتند. با این حال، مزایای استفاده از پسوندهای کلمه را روشن می کند (به عنوان مثال،
از این منظر اول، قرار بود تمام محتوای مرتبط شامل احساسات منفی باشد، در حالی که محتوای غیر مرتبط مثبت در نظر گرفته شد. اولین واژگان عمومی به طور جامع برای ترکی، STN [ 31 ] است که دارای نزدیک به 15000 اصطلاح (uni /bi-gram) است. STN نمرات احساسات عبارت (از 0 تا 1) را برای هر برچسب احساسات (مثبت، منفی و هدف) و برچسب احساسات برنده را برای هر عبارت ارائه می دهد. در این مطالعه، تکنیک اول، کلمات تشکیلدهنده توییتها را در رابطه با برچسبهای احساسات برای هر عبارت اسکن کرد و محتوای هر توییت بر اساس بیشترین تعداد برچسبهای احساسات طبقهبندی شد.
تا آنجا که به تکنیک دوم مربوط می شود، امتیازات هر برچسب احساسی که از STN مشتق شده است در نظر گرفته شد و اصطلاحات اسکن شده برای هر توییت برای یافتن بیشترین وزن مربوط به آن محتوا خلاصه شد. بالاترین امتیاز، محتوای توییت را به عنوان مرتبط با بیشترین منفی، تا حدی مرتبط با بالاترین هدف و غیر مرتبط برای بالاترین مثبت طبقهبندی کرد.
تکنیک سوم از فرهنگ لغت دیگری برای زبان ترکی (LOA) که توسط Ozturk و Ayvaz [ 40 ] ایجاد شده است، استفاده کرد که به بیش از 5000 کلمه پرکاربرد روزانه بستگی دارد که از 5- تا 5+ توسط سه نفر نمره گذاری شده است. میانگین این سه به عنوان نمره قطبیت برای هر ترم پذیرفته شد. برای تکنیک سوم، توییتها برای مطابقت با اصطلاحات موجود در LOA اسکن شدند، و امتیازات کلمات منطبق برای طبقهبندی محتوا، با نمره منفی که مرتبط بودن، نمره صفر بهعنوان تا حدی مرتبط و یک نمره مثبت مشخص شد، جمعبندی شدند. نمره به عنوان نامربوط بودن
مطالعات کمی در مورد مقایسه بین فیلتر متن SMD [ 54 ، 55 ، 56 ، 57 ] وجود دارد، زیرا بسیاری از تکنیک های یادگیری ماشین برای SMD در نظر گرفته نمی شوند. همانطور که از آن مطالعات مشاهده میشود، رایجترین و کارآمدترین تکنیکهایی که میتوان با توجه به فیلتر کردن متن استفاده کرد عبارتند از Naive Bayes، Neural Network و Support Vector Machine [ 58 ، 59 ، 60 ، 61 ]. به همین دلیل است که این سه تکنیک در این مطالعه برای فیلتر SMD مبتنی بر دامنه در نظر گرفته شد.
برای تکنیک چهارم، از دیدگاه یادگیری ماشینی برای ایجاد یک طبقهبندی استفاده شد. طبقه بندی کننده ساده بیز (NB) [ 62] بر اساس روش تعیین احتمالی مورد استفاده قرار گرفت. طبق این روش، یک طبقهبندی کننده احتمال احتمال هر کلاس را روی یک مجموعه داده آموزشدیده در نظر میگیرد. سپس احتمال شرطی هر عبارتی را که در مجموعه داده آموزش دیده در رابطه با هر کلاس مشاهده می شود محاسبه می کند. طبقهبندیکننده این تحلیل را روی دادههای آزمایشی با ضرب احتمال برای هر عبارت اسکن شده برای هر توییت و همچنین ضرب احتمال احتمال هر کلاس انجام میدهد. در نهایت، طبقه بندی کننده احتمالات هر کلاس را مقایسه می کند و بالاترین را برای برچسب گذاری انتخاب می کند. این روش نرخ بروز را برای کلمات پرکاربرد در هر کلاس در نظر می گیرد. این از نظر عملکرد طبقه بندی با توجه به داده های تقریباً فیلتر شده سودمند است.
در تکنیک پنجم، طبقهبندیکنندههای شبکه عصبی (NN) آموزش داده شدند. بسته ‘nnet’ [ 63] برای مدل سازی طبقه بندی کننده ها استفاده شد. از نظر اصول NN، برای آموزش یک مجموعه داده، یک ماتریس اصطلاح سند (DTM) به عنوان سیگنال ورودی با برچسبهای کلاس پذیرفته میشود. سه طبقهبندی کننده با استفاده از یک مجموعه داده چند کلاسه آموزش داده میشوند. وزن لایه های پنهان از جلو شروع نمی شود و تمرین با 500 تکرار انجام می شود. در نظر گرفتن طبقه بندی متن با DTM یک مشکل خطی قابل تفکیک نیست، و هنگام طبقه بندی با یک طبقه بندی کننده NN به لایه های پنهان نیاز دارد. بنابراین، پارامتر لایه پنهان در طبقه بندی کننده به صورت 1، 2 و 3 مشخص می شود تا به طور تجربی بهترین شماره لایه پنهان تعیین شود. افزایش تعداد لایه پنهان دقت طبقه بندی بالایی را فراهم می کند، اما هزینه زمانی نیز ایجاد می کند. با این حال، هدف اصلی این مطالعه یافتن بهترین مناسب برای یک NN نبود. اما ارزیابی راههایی برای تعیین نتایج تکنیکهای فیلتر کردن سریعتر هنگام نقشهبرداری. با توجه به این، طبقهبندیکننده NN که عملکرد آماری قابل اعتمادی با دو لایه پنهان نشان میدهد در این بخش پردازش NN پذیرفته شد.
در بخش پردازش داده ها، واژگان احساسات و تکنیک های یادگیری ماشین عمدتاً برای فیلتر کردن داده های مبتنی بر دامنه استفاده شد. واژگان احساسی مورد استفاده برای استفاده در زبان ترکی بود. تکنیکهای یادگیری ماشینی مورد استفاده، آنهایی بودند که معمولاً برای طبقهبندی متن استفاده میشد [ 58 ، 59 ، 60 ، 61 ]. علاوه بر NB و NN، ماشین بردار پشتیبان (SVM) یکی دیگر از تکنیکهای محبوب مورد استفاده برای طبقهبندی متن است. به عنوان ششمین تکنیک، یک طبقهبندی کننده SVM آموزش داده شد. بسته ‘e1071’ [ 64] که یکی از توابع متفرقه دپارتمان آمار، TU Wien است، برای پیاده سازی طبقه بندی کننده مورد استفاده قرار گرفت. این بسته امکان آموزش یک طبقهبندی کننده SVM را با بردار کردن تعداد هر عبارت در هر سند با برچسبهای آموزشی فراهم میکند. از آنجایی که SVM نتایج موفقیتآمیزی را برای مسائل جداسازیپذیر خطی ارائه میدهد، هستههای مختلفی مانند چند جملهای، شعاعی و سیگموید برای طبقهبندیکنندههای SVM استفاده شد. اگرچه طبقهبندیکنندههای SVM به دلیل استفاده از مجموعه دادههای نامتعادل در این مطالعه به درجه بالایی از دقت دست یافتند، اما برای دو کلاس از سه کلاس به نتایج حساس صفر دست یافتند. بنابراین، تصمیم گرفته شد که SVM برای ارزیابی بیشتر در این مطالعه مناسب نیست.
خط سبز در شکل 1 در شکل 4 گسترش یافته است تا مراحل جریان داده برای پردازش داده را نشان دهد. هر مرحله در شکل 4 نشان دهنده موارد زیر است:
-
تقسیم داده ها به داده های روز رویداد و داده های آموزشی؛
-
تبدیل نوع داده از قاب داده به پیکره برای داده های روز رویداد.
-
تخصیص داده ها به عنوان پیکره برای داده های رویداد.
-
تمیز کردن متن برای پیکره رویداد با استفاده از تابع tr_text_clean.
-
ایجاد ماتریس مدت سند Uni-gram (DTM) برای پیکره پاک شده.
-
ایجاد قاب داده واژگان قطبیت sentiTurkNet.
-
ایجاد اصطلاحات پیوسته داخلی در داده های رویداد DTM و اصطلاحات در sentiTurkNet.
-
تجمیع مقادیر منفی، مقادیر عینی و مقادیر مثبت برای عبارات در هر سند.
-
تصمیمات قطبیت برای هر سند بسته به بزرگترین مقادیر هر مجموعه.
-
الحاق برچسب های قطبیت به داده های رویداد.
-
تخصیص داده های رویداد با برچسب های قطبی به عنوان داده STN_byScore.
-
شمارش برچسب های منفی (-1)، هدف (0) و مثبت (1) عبارات در هر سند.
-
تصمیم گیری قطبیت برای هر سند، بسته به بزرگترین شمارش.
-
الحاق برچسب های قطبیت به داده های رویداد.
-
انتساب داده های رویداد با برچسب های قطبیت به عنوان داده STN_byLabel.
-
ایجاد قاب داده واژگان قطبیت LOA.
-
پیوستن درونی عبارتها در دادههای رویداد DTM و عبارتها در LOA.
-
تجمیع امتیازات قطبیت اصطلاحات در هر سند.
-
تعیین برچسب های قطبیت بر اساس علامت (-، +) تجمع امتیاز قطبیت.
-
الحاق برچسب های قطبیت به داده های رویداد.
-
تخصیص داده های رویداد با برچسب های قطبی به عنوان داده LOA.
-
تبدیل نوع داده از چارچوب داده به پیکره برای داده های آموزشی.
-
تخصیص داده ها به عنوان مجموعه برای داده های آموزشی.
-
پاکسازی متن برای مجموعه آموزشی با تابع tr_text_clean.
-
ایجاد ماتریس اصطلاح سند Uni-gram (DTM) برای مجموعه آموزشی تمیز شده؛
-
مدل سازی یک طبقه بندی کننده ساده بیز با DTM آموزشی.
-
پیشبینی ارتباط DTM رویداد با طبقهبندیکننده ساده بیز.
-
الحاق یک برچسب پیش بینی به داده های رویداد.
-
تخصیص داده های رویداد با برچسب های پیش بینی به عنوان داده NB_pred.
-
مدل سازی یک طبقه بندی کننده شبکه عصبی با DTM آموزشی.
-
پیشبینی ارتباط رویداد DTM با طبقهبندی شبکه عصبی.
-
الحاق برچسب های پیش بینی به داده های رویداد.
-
تخصیص داده های رویداد با برچسب های پیش بینی به عنوان داده NNET.
این به ما داده های رویداد طبقه بندی شده را در نتیجه پنج تکنیک مختلف ارائه می دهد. دادههای طبقهبندیشده، از نظر تکنیکهای مختلف، بیشتر با روششناسی ارائهشده در بخش 2.5 برای تعیین کمیت تأثیر فیلتر کردن بر دقت مکانی پردازش میشوند.
اگر زبان با زبان این مطالعه متفاوت است، کاربران باید چندین مرحله نشان داده شده در روش را تغییر دهند. در مرحله مرتب سازی داده ها، داده ها باید به دلیل مشکلات رمزگذاری ناشی از کاراکترهای مختلف زبان ترکی رفع شوند. این عملیات مرتب سازی مختص زبان ترکی است و باید برای سایر زبان هایی که کدگذاری های متفاوتی دارند تغییر یابد. علاوه بر آن، حذف کلمه توقف قسمت تمیز کردن متن باید به زبان تعریف شده در صورت متفاوت بودن زبان با ترکی تغییر یابد. تغییر دیگری در قسمت مرتب کردن ممکن است افزودن فرآیند “ساقه کردن” باشد. این مطالعه “ساقه” را حذف کرد زیرا پسوندها به تبعیض ارتباط همانطور که در بخش اکتشاف داده کشف شد کمک می کنند. با این حال، عملیات “ساقه” می تواند به کشف محتوای بسیار مرتبط در زبان های دیگر کمک کند. در بخش پردازش دادهها، واژگان احساسات مربوط به زبان ترکی هستند و اگر فرآیند فیلتر کردن با واژگان احساسات زبان دیگری انجام شود، باید تغییر کنند.
دامنه در این مطالعه به عنوان حملات تروریستی تعریف شده است و قطعاً باید حاوی احساسات منفی باشد. همانطور که در بخش کاوش داده ها نیز کشف شد، داده های نامربوط حاوی احساسات مثبت هستند. به همین دلیل است که استفاده از واژگان احساسات می تواند برای این حوزه وحشت موفقیت آمیز باشد. این بدان معناست که از استفاده از واژگان احساسات برای تعیین ارتباط دامنه هایی که می توانند شامل انواع احساسات باشند، اجتناب شود. به عنوان مثال، در تحقیقات بازاریابی، دامنه ممکن است شامل احساسات مثبت، خنثی یا منفی باشد. بنابراین، استفاده از واژگان احساسات برای فیلتر کردن دادههای مرتبط قابل قبول نیست.
2.5. تفسیر فضایی SMD
متن کاوی دقیق برای فیلتر کردن دقیق اولین جنبه مرتبط با تولید نقشه های قابل اطمینان تر برای تحلیل های SMD مبتنی بر دامنه است. با این حال، به تنهایی برای تعیین دقت مکانی نقشه های تولید شده از SMD کافی نیست. برای تعیین اینکه چگونه تکنیکهای مختلف فیلترینگ بر دقت فضایی تأثیر میگذارند، این مطالعه یک روش تفسیر فضایی را پیشنهاد میکند. روش تفسیر شامل دو مرحله اصلی است – خوشه بندی فضایی و محاسبه شباهت فضایی. در بخش 2.5.1 ، جزئیات خوشهبندی فضایی برای نگاشت رخداد دادههای فیلتر شده که برای این مطالعه استفاده میشود، آورده شده است. در بخش 2.5.2 ، ضرایب جاری برای محاسبه شباهت فضایی معرفی شده است. در بخش 2.5.3ضریب شباهت فضایی جدید با عنوان شاخص Giz با مقایسه کمی شاخصهای معرفیشده قبلی نسبت به دادههای تست طراحی شده پیشنهاد شده است. نمرات شباهت بر حسب ضرایب شباهت انتخابی متفاوت است. بنابراین، تعیین اینکه کدام شاخص شباهت فضایی استفاده می شود، مهم است. در بخش 2.5.3 ، یک آزمون طراحی شده برای مقایسه شاخصهای شباهت استفاده میشود تا نشان دهد کدام شاخص مقدار شباهت قابل قبولی را برای مقایسههای نقشه بروز برمیگرداند.
2.5.1. خوشه بندی فضایی
تعدادی الگوریتم خوشه بندی فضایی [ 65 ] و روش های مورد استفاده برای تشخیص رویداد فضایی وجود دارد که نتایج آنها از نظر انتخاب الگوریتم و روش شناسی متفاوت است [ 12 ]. با در نظر گرفتن تضاد بین تکنیک های مختلف خوشه بندی و پارامترهای از پیش تعیین شده (مانند تعداد خوشه ها و حداقل تعداد مورد نیاز برای هر خوشه)، الگوریتم خوشه بندی فضایی Getis-Ord [ 66 ، 67 ] برای هر مجموعه داده برای مقایسه واریانس های فضایی انتخاب می شود. به دلیل روشهای فیلترینگ متفاوتی که قبلاً اعمال شده بود. در حین انجام تجزیه و تحلیل Hotspot بهینه واقع در جعبه ابزار آمار فضایی در ArcMap [ 68]، اندازه سلول بر حسب وضوح در سطح خیابان 500 متر تعریف می شود [ 69 ]، زیرا در نظر گرفته شده است که ریزدانه باشد، و روش تجمع به عنوان یک چند ضلعی شش ضلعی تعیین می شود تا به ما امکان استفاده از ظرفیت اتصال را بدهد. یک شکل شبکه خوشه ای [ 70 ]. این مرحله اول نقشههای Hotspot را برای روشهای فیلترینگ مختلف ارائه میکند، که به عنوان نقشههای پایه برای مرحله بعدی – محاسبه شباهت فضایی – عمل میکنند.
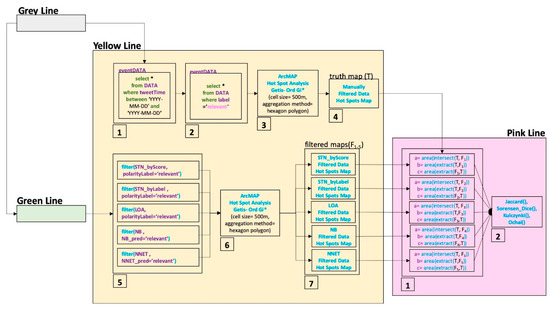
جزئیات نگاشت هات اسپات داده های فیلتر شده توسط قسمت خط زرد در شکل 5 آورده شده است. هر مرحله در شکل 5 نشان دهنده موارد زیر است:
-
فیلتر کردن داده ها بر حسب روز رویداد؛
-
انتخاب داده های مربوطه از نظر داده های برچسب گذاری شده دستی.
-
تولید یک نقشه هات اسپات برای داده های مرتبط فیلتر شده به صورت دستی.
-
تخصیص نقشه نقطه دسترسی فیلتر شده به صورت دستی به عنوان نقشه حقیقت زمینی (T).
-
انتخاب داده های مربوطه از نظر هر مجموعه داده طبقه بندی شده به طور خودکار.
-
تولید نقشه های هات اسپات برای هر مجموعه داده مربوطه که به طور خودکار فیلتر شده است.
-
تخصیص نقشههای نقاط دسترسی خودکار فیلتر شده به عنوان نقشههای فیلتر شده (F 1-5 ).
این حقیقت زمینی و نقشههای نقطه داغ داده فیلتر شده را برای محاسبه شباهت فضایی شرح داده شده در بخش فرعی ارائه میکند.
2.5.2. محاسبه تشابه فضایی
در زمینه های مختلف مانند زیست شناسی [ 71 ، 72 ]، اکولوژی [ 73 ] و بازیابی تصویر [ 74 ]، شاخص های شباهت متعددی پیشنهاد شده است. چوی و همکاران [ 75 ] یک نظرسنجی گسترده از بیش از 70 معیار شباهت از نظر تطابق مثبت و منفی و عدم تطابق زمانی که صحبت از مقایسه می شود ارائه می دهد. معیارهای تشابه نیز در حال استفاده هستند و برای مقایسه بین دو نقشه به منظور یافتن شباهتهای معنایی بین کاربری اراضی، طبقهبندی پوشش زمین، تغییرات زمانی و همپوشانیهای نقشه نقاط داغ [ 76 ، 77 ، 78 ] متفاوت است.]. در این مطالعه، شباهت بین نقشههای بروز با استفاده از ضرایب شباهت مورد آزمایش قرار گرفته است. شباهت نگاشت وقوع یک مورد خاص برای اقدامات مشابه است، زیرا وقوع بخش کوچکی از منطقه از پیش تعریف شده (مانند یک شهر، یک منطقه، یا یک منطقه) را پوشش می دهد. بنابراین، منطبقات منفی در محدوده مشاهده شده باید نادیده گرفته شوند تا از تشابه گمراه کننده زیاد به دلیل پوشش بالای مسابقات منفی جلوگیری شود. Arnesson و Lewenhagen [ 78 ] استفاده از چهار معیار تشابه کمی متفاوت را برای تعیین شباهتها یا تفاوتهای بین نقشههای نقاط مهم پیشنهاد میکنند. اینها شاخص جاکارد (1) [ 79 ]، شاخص سورنسن-دایس (2) [ 80 ، 81 ]، شاخص کولچینسکی (3) [82 ]، و شاخص Ochai (4) [ 72 ]، که هر کدام برای محاسبات شباهت استفاده می شوند. این معیارها امتیاز شباهت بین 0 و 1 را در مورد تعداد نقاط کانونی True-True (a)، True-False (b) و False-True (c) در مقایسه بین نقاط حقیقت و پیش بینی نشان می دهد. این شاخص ها منطبقات منفی را نادیده می گیرند (کاذب-کاذب (d)) [ 72 ، 78] که اولین نیاز برای محاسبات شباهت نگاشت بروز هستند. با این حال، این شاخصها بهطور خاص برای اهداف فضایی طراحی نشدهاند، با توجه به اینکه نزدیکی بین نقاط داغ ناهمخوان و منطبقهای مثبت را نادیده میگیرند. در این راستا، یک شاخص شباهت فضایی جدید برای کمی کردن قابلیت اطمینان نقشهبرداری وقوع با توجه به دادههای حقیقت زمینی فرموله شده است.
جزئیات محاسبه شاخص تشابه در خط صورتی در شکل 5 آورده شده است. هر مرحله در خط صورتی نشان دهنده:
این چهار امتیاز قابلیت اطمینان مکانی را از نظر معیارهای شباهت فعلی فراهم می کند. با این حال، کاربرد اقدامات با توجه به نقشهبرداری وقوع نامشخص است، زیرا اقدامات نزدیکی مناطق غیرتقاطع را در نظر نمیگیرند، حتی اگر همسایه باشند. به همین دلیل است که شاخص Giz به عنوان یک شاخص شباهت فضایی برای مطالعات نقشهبرداری بروز پیشنهاد شده است. در بخش فرعی بعدی، شاخص Giz فرموله می شود و یک آزمون مقایسه بین شاخص ها بر روی داده های آزمون ارائه می شود. این مقایسه برای توضیح واجد شرایط بودن شاخص Giz برای مقایسه نقشهبرداری بروز ارائه شده است، در حالی که سایرین برای هر شرایطی مناسب نیستند.
2.5.3. شاخص Giz
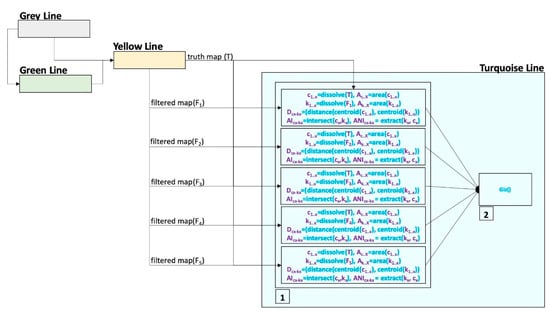
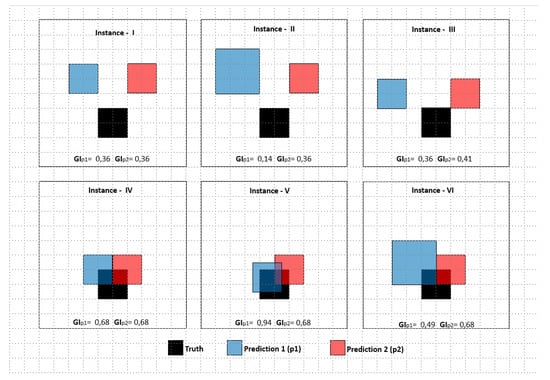
در یک زمینه فضایی، حذف منطبقات منفی اجازه می دهد تا نمایش دقیق تری از شباهت هات اسپات بین دو نقشه ارائه شود. در غیر این صورت، نتایج ممکن است تحت تسلط منطبقات منفی باشد و تقریباً برای همه مقایسه ها بیش از 99٪ شباهت داشته باشند. با این حال، استفاده از ضرایب برای اهداف فضایی دارای نقاط ضعفی است، مانند نادیده گرفتن اندازه خوشه های جداگانه و نزدیکی بین خوشه های غیر متقاطع. این ادعا در اینجا به قانون اول جغرافیای توبلر بستگی دارد، “همه چیز به هر چیز دیگری مربوط است، اما چیزهای نزدیک بیشتر از چیزهای دور مرتبط هستند”. بنابراین، فاصله و اندازه هر خوشه باید در نظر گرفته شود تا یک شاخص شباهت مکانی دقیق در مورد چیزهای نزدیکی که ممکن است بر یکدیگر تأثیر بگذارند ترسیم شود. یک شاخص شباهت فضایی جدید برای نشان دادن میزان شباهت دو نقشه به یکدیگر ایجاد شده است. این شاخص Giz Index نام دارد. این شاخص در فرمول ها و ارقام به عنوان GI نامیده می شود. این شاخص هر خوشه هات اسپات را در نقشه اول به عنوان حقیقت در نظر می گیرد (ج1..n ) و در نقشه دوم به عنوان پیش بینی (k 1..n ).
روش شناسی شاخص، مساحت هر خوشه را تشخیص می دهد (A c1..n، k1..n )، و در نظر می گیرد که آیا آنها برای تشکیل یک منطقه تقاطع (AI c1-k1 ) متقاطع می شوند یا برای تشکیل یک باقیمانده متقاطع نمی شوند. ناحیه تقاطع (ANI c1-k1 ) و فاصله بین خوشه ها (D c1-k1 ). شاخص Giz مطابق با معادله (5) برای تشابه خوشه منفرد فرموله شده است.
در بخش اول، معادله تشابه مناطق متقاطع (AI) را بررسی می کند. شباهت هوش مصنوعی با تقسیم نواحی متقاطع (AI c1-k1 ) خوشه (A c1 ) و ضرب آنها در فاصله نرمال شده بین خوشه ها (حقیقت زمین و پیش بینی) به دست می آید. این فاصله نرمال شده برای قسمت های متقاطع 1 در نظر گرفته می شود و برای ناحیه غیر متقاطع همیشه کمتر از 1 است. در همان زمان، با افزایش فاصله بین خوشه ها (c 1 – k 1 )، فاصله نرمال شده نسبت به ریشه مربع منطقه خوشه کاهش می یابد. در قسمت دوم، شباهت قسمت های غیر متقاطع با همان فرمول قسمت اول محاسبه می شود. شرایطی بر اساس اندازه های A وجود داردc1 و ANI c1-k1 ، که در آن نسبت مساحت در قسمت دوم فرمول معکوس شده است. برای مثال، اگر مساحت اولین خوشه (c 1) 4 واحد است و قسمت غیر متقاطع آن 10 واحد است، این نسبت به جای 10/4 به 4/10 تبدیل می شود.
جزئیات محاسبه Giz Index با خط فیروزه ای در شکل 6 آورده شده است. هر مرحله در شکل 6 نشان دهنده موارد زیر است:
این معیارهای شباهت را فراهم می کند که درجه شباهت را بسته به نزدیکی بین خوشه های نقشه حقیقت و خوشه های نقشه فیلتر شده وزن می کند.
شاخص Giz با توجه به داده های آزمایشی که در شکل 7 نمایش داده شده است، آزمایش شده و با شاخص های فعلی مقایسه می شود . داده های آزمون شامل شش نمونه است و هر نمونه دارای دو پیش بینی (p1، p2) و یک خوشه حقیقت است. دادههای آزمون برای نشان دادن جزئیات پاسخ شاخصهای شباهت بر حسب اندازههای مختلف خوشههای پیشبینی و فواصل بین خوشه پیشبینی و خوشه حقیقت ایجاد میشوند.
شباهت بین خوشه های پیش بینی (p1، p2) و خوشه حقیقت برای هر نمونه با استفاده از شاخص های فعلی و شاخص Giz پیشنهادی محاسبه می شود. نتایج شباهت بین 0 و 1 متفاوت است و در جدول 1 ارائه شده است. در سه مورد اول، هیچ خوشه متقاطعی وجود ندارد. بنابراین، نتایج شاخص های فعلی مقدار 0 را برمی گرداند. پیشبینی یا نزدیک به خوشه حقیقت یا دور از آن است. علاوه بر این، این شاخص ها اندازه خوشه غیر متقاطع را در این شرایط تقاطع صفر نادیده می گیرند. از سوی دیگر، شاخص Giz مقادیر شباهت متفاوتی را از نظر مجاورت و اندازه خوشههای غیر متقاطع برمیگرداند – در این موارد I، II و III. هنگامی که تفاوت در اندازه و فاصله بیشتر باشد، شاخص Giz (GI) نزدیک به 0 است. در غیر این صورت، به 1 نزدیکتر است. نمرات شاخصهای شباهت فعلی به اندازه ناحیه متقاطع در نمونههای IV، V و VI پاسخ میدهند. هنگامی که تقاطع به نسبت بالاتر باشد، نمرات فعلی بالاتر می شود، مانند GI. با این حال، مساحت باقیمانده خوشه صفر اضافه به افزایش تشابه دارد حتی اگر در قسمت های مجاور خوشه حقیقت قرار گیرند. با توجه به نتایج، بدیهی است که شاخصهای شباهت فعلی به طور کامل از قسمتهای غیرمتقاطع وقتی خوشهای متقاطع وجود ندارد، صرف نظر میکنند. بنابراین، شاخصهای فعلی ممکن است باعث تفسیر نادرست در مطالعات نقشهبرداری وقوع شوند، زیرا وقوع نزدیک به مناطق وقوع واقعی در تعیین منطقه وقوع دقیق ارزش دارد. به عبارت دیگر، وقوع رخدادهای نزدیک بر روی نقشه را می توان به عنوان نشانه هایی تعبیر کرد که نشان دهنده رویداد اصلی است. بنابراین برای تفسیر صحیح نقشه ها باید نزدیکی خوشه های غیر متقاطع و اندازه در نظر گرفته شود. بدیهی است که وقتی خوشه متقاطع وجود ندارد، شاخصهای شباهت فعلی به طور کامل از قسمتهای غیر متقاطع صرف نظر میکنند. بنابراین، شاخصهای فعلی ممکن است باعث تفسیر نادرست در مطالعات نقشهبرداری وقوع شوند، زیرا وقوع نزدیک به مناطق وقوع واقعی در تعیین منطقه وقوع دقیق ارزش دارد. به عبارت دیگر، وقوع رخدادهای نزدیک بر روی نقشه را می توان به عنوان نشانه هایی تعبیر کرد که نشان دهنده رویداد اصلی است. بنابراین برای تفسیر صحیح نقشه ها باید نزدیکی خوشه های غیر متقاطع و اندازه در نظر گرفته شود. بدیهی است که وقتی خوشه متقاطع وجود ندارد، شاخصهای شباهت فعلی به طور کامل از قسمتهای غیر متقاطع صرف نظر میکنند. بنابراین، شاخصهای فعلی ممکن است باعث تفسیر نادرست در مطالعات نقشهبرداری وقوع شوند، زیرا وقوع نزدیک به مناطق وقوع واقعی در تعیین منطقه وقوع دقیق ارزش دارد. به عبارت دیگر، وقوع رخدادهای نزدیک بر روی نقشه را می توان به عنوان نشانه هایی تعبیر کرد که نشان دهنده رویداد اصلی است. بنابراین برای تفسیر صحیح نقشه ها باید نزدیکی خوشه های غیر متقاطع و اندازه در نظر گرفته شود. از آنجایی که میزان وقوع نزدیک به نواحی وقوع واقعی در تعیین ناحیه وقوع دقیق ارزش دارد. به عبارت دیگر، وقوع رخدادهای نزدیک بر روی نقشه را می توان به عنوان نشانه هایی تعبیر کرد که نشان دهنده رویداد اصلی است. بنابراین برای تفسیر صحیح نقشه ها باید نزدیکی خوشه های غیر متقاطع و اندازه در نظر گرفته شود. از آنجایی که میزان وقوع نزدیک به نواحی وقوع واقعی در تعیین ناحیه وقوع دقیق ارزش دارد. به عبارت دیگر، وقوع رخدادهای نزدیک بر روی نقشه را می توان به عنوان نشانه هایی تعبیر کرد که نشان دهنده رویداد اصلی است. بنابراین برای تفسیر صحیح نقشه ها باید نزدیکی خوشه های غیر متقاطع و اندازه در نظر گرفته شود.
شاخص Giz از استنتاج های اکتشافی زمانی که معیار کمی بین 0 و 1 است، با در نظر گرفتن اندازه خوشه های فضایی و مجاورت آنها پشتیبانی می کند. اندازه و دقت مکان برای چندین موضوع که دامنه ها را تشکیل می دهند مهم است و شاخص Giz می تواند یک تفسیر مکانی سریع و خودکار از داده های تجزیه و تحلیل شده ارائه دهد. این شاخص همچنین می تواند برای نگاهی سریع به فرآیندهای اعتبارسنجی با توجه به داده های رسانه های اجتماعی در صورت وجود منابع داده ثانویه دیگری که می تواند به عنوان حقیقت پذیرفته شود، استفاده شود. شاخص Giz همچنین می تواند برای حوزه های مختلف مانند کنسرت ها، انتخابات و بازاریابی، علاوه بر بلایا، همانطور که در این مطالعه ذکر شد، استفاده شود. از تشابه مکانی معرفی شده در این تحقیق می توان برای مقایسه مکانی نقشه های شبیه سازی و نقشه های تخمینی استفاده کرد.
3. مطالعه موردی
3.1. واردات و نگهداری داده ها
در این مطالعه داده های 8 ماهه از ماه می تا دسامبر 2016 در رابطه با 10 حمله تروریستی رخ داده در ترکیه انتخاب شد. در طی آن دوره، توییتهای ارجاعشده جغرافیایی ضبط و با استفاده از GTD در پایگاه داده PostgreSQL درج شدند.
3.2. مرتب سازی داده ها
پیش فیلتر کردن تقریباً با استفاده از کلمات کلیدی مانند “حمله” (saldırı به ترکی)، “بمب” (بمب در ترکی) و “انفجار” (patlama در ترکی) انجام شد تا تکه های هدفمند داده با ترکیبی از مرتبط و غیر مرتبط ارائه شود. -محتوای مرتبط در هنگام فیلتر کردن، تمام ترکیبهای رمزگذاری حروف حساس به حروف و حروف ترکی برای بازیابی همه محتوای مرتبط ممکن مانند “saldırı”، “SALDIRI”، “Saldiri” و غیره در نظر گرفته شد.
به دنبال آن، 285 توییت از شش حساب خبری نیوزفید شناسایی و از داده های از پیش فیلتر شده حذف شدند، زیرا محتوای احتمالی با اخبار متنوع و غیر مرتبط ترکیب شده بود. پس از حذف، در مجموع 4395 توییت به صورت دستی با استفاده از سه برچسب طبقه بندی شدند: 1- مربوط (RL)، مربوط به حملات تروریستی تازه رخ داده. 2- تا حدی مرتبط (PR)، محتوای مرتبط از جمله ترور به طور کلی مانند انتقاد حزب سیاسی یا خاطرات یک رویداد تروریستی قدیمی؛ و 3- غیر مرتبط (IR)، محتویات کاملاً غیر مرتبط با یک حمله تروریستی، مانند «من عاشق دسر بمب هستم» یا «برو تیم برو، حمله کن و آنها را بزن». همانطور که عنوان شد، 934 توئیت غیر مرتبط، 799 توئیت تا حدی مرتبط و 2662 توییت مستقیماً به یک رویداد تروریستی مرتبط بودند. نقشههای هر مجموعه از توییتهای IR، PR و RL ایجاد و بر اساس ماه طبقهبندی شدند (شکل 8 ).
یکی از استنباطها هنگام برچسبگذاری این است که کاربران رسانههای اجتماعی با اعتراض به تروریستها، سرویسهای امنیتی، دولت و احزاب سیاسی به حملات تروریستی جدید واکنش نشان میدهند. با این حال، بسیاری از توییتها شامل تسلیت به خانوادههای قربانیان در رابطه با اطلاعات دست دوم بهدستآمده از جاهای دیگر مانند رسانههای سنتی/خبری است. تعداد بسیار کمی از کاربران اطلاعاتی را در مورد شاهد این حوادث به اشتراک می گذاشتند. در نتیجه، این استنباط ها عمدتاً نشان دهنده تکرار محتوای مشابه است. بنابراین، می توان گفت که استخراج اطلاعات دست اول درست مانند جستجوی سوزن در انبار کاه است. این اطلاعات دست اول، همانطور که در انگیزه این مطالعه ذکر شده است، برای نقشهبرداری وقوع در طول یا مدت کوتاهی پس از یک فاجعه از اهمیت بالایی برخوردار است.
قبل از تجزیه و تحلیل دادههای اکتشافی، متن توییتها پاک میشد تا از مشکلات بعدی در هنگام پردازش مجموعهای بهتر از کلمات جلوگیری شود. بنابراین، شکلک ها، علائم نگارشی، کلمات توقف در ترکی [ 83] و انگلیسی، اعداد و آدرسهای اینترنتی از توییتها حذف شدند و تمام مشکلات کدگذاری و حروف حل شد. علاوه بر این، نام شهرها و شهرستانها با توجه به ترکیه که ممکن است در این کار سوگیری ایجاد کند و در طبقهبندی محتوا مورد نیاز نبود، از متن حذف شد. استمینگ، که یکی از مراحل بعدی پاکسازی متن است، در این مطالعه نادیده گرفته شد. به این ترتیب، هدف حفظ تفاوت معنایی غنی با پسوندها در زبان ترکی بود. با استفاده از تابع tr_text_clean، پاکسازی متن این کار از یک سو با گنجاندن چندین تابع از بسته TM [ 84 ] و بسته ggrepel [ 85 ] و از سوی دیگر، توابع فرعی خود تعریف شده انجام شد. جزئیات عملکرد تمیز کردن tr_text_clean را می توان در [ 49 ] یافت] از نظر کاربرد آن در کارهای مشابه.
3.3. کاوش داده ها
کاوش دادهها برای دادههای مبتنی بر دامنه ترور ترکیه به صورت توصیفی با استفاده از ابرهای مشترک و مقایسه، یک نمودار هرمی و یک دندروگرام کلمه به منظور نشان دادن تفاوتهای بین اصطلاحات (کلمات) با توجه به دادههای مربوط به دامنه انجام شد.
وجه مشترک برای uni/bi-grams و ابرهای مقایسه به تصویر کشیده شده است ( شکل 9) پس از اعمال چندین تابع تمیز کردن به هر سه تکه داده. ابر اشتراکی ترسیم شده برای یونی گرم (a) متداولترین عبارتها را در تمام تکههای برچسبگذاری شده نشان میدهد، که در آن قطعه مربوطه به دلیل تعداد نسبتاً بالای توییتها در مقایسه با سایر تکهها، بر فرکانس غالب است. این بدان معنی است که موضوعات داغی که در طول فاجعه با آنها سروکار دارند را می توان به راحتی با استفاده از ابر مشترک روی داده های تقریباً فیلتر شده تخمین زد. ابر مقایسه (b) متداولترین عبارتها را در هر دو بخش، از نظر توییتهای مرتبط/ جزئی مرتبط و توییتهای غیر مرتبط، نمایش میدهد. ابر مقایسه با ترسیم عبارات مکرر در مورد تکههای داده غیرمرتبط و مرتبط (جزئی یا کاملاً) نمای اکتشافی دقیقتری ارائه میکند (b). اصطلاحات این مطالعه به زبان ترکی و به انگلیسی ترجمه شده است. با کلمات داخل پرانتز کلمات ترکی واقعی هستند که در این تحقیق با آن مواجه می شوند. اولین استنتاج این است که تکهها شامل اصطلاحات رایجی مانند بمب (بمب)، انفجار (patlama) و حمله (saldırı) هستند. اصطلاحات متداول غیرمشابه شامل کلماتی مانند «دسر» (tatlı)، «انرژی» (enerji)، «رحمت» (rahmet)). استنباط دوم این است که برخی از رایج ترین کلمات در ابر مقایسه پسوندهای مختلفی گرفته اند. به عنوان مثال، «حمله» در قطعه مربوطه دارای پسوند اسمی است، در حالی که در قطعه غیر مرتبط بیشتر به عنوان یک فعل در حالت امری استفاده می شود. بنابراین، اینها با حذف ریشه در دوره پیش پردازش به عنوان اصطلاحات مختلف ارزیابی شدند. “انفجار” (patlama) و “حمله” (saldırı); اصطلاحات متداول غیرمشابه شامل کلماتی مانند «دسر» (tatlı)، «انرژی» (enerji)، «رحمت» (rahmet)). استنباط دوم این است که برخی از رایج ترین کلمات در ابر مقایسه پسوندهای مختلفی گرفته اند. به عنوان مثال، «حمله» در قطعه مربوطه دارای پسوند اسمی است، در حالی که در قطعه غیر مرتبط بیشتر به عنوان یک فعل در حالت امری استفاده می شود. بنابراین، اینها با حذف ریشه در دوره پیش پردازش به عنوان اصطلاحات مختلف ارزیابی شدند. “انفجار” (patlama) و “حمله” (saldırı); اصطلاحات متداول غیرمشابه شامل کلماتی مانند «دسر» (tatlı)، «انرژی» (enerji)، «رحمت» (rahmet)). استنباط دوم این است که برخی از رایج ترین کلمات در ابر مقایسه پسوندهای مختلفی گرفته اند. به عنوان مثال، «حمله» در قطعه مربوطه دارای پسوند اسمی است، در حالی که در قطعه غیر مرتبط بیشتر به عنوان یک فعل در حالت امری استفاده می شود. بنابراین، اینها با حذف ریشه در دوره پیش پردازش به عنوان اصطلاحات مختلف ارزیابی شدند. «حمله» در قطعه مربوطه دارای پسوند اسمی است، در حالی که در قطعه غیر مرتبط بیشتر به عنوان فعل در حالت امری استفاده می شود. بنابراین، اینها با حذف ریشه در دوره پیش پردازش به عنوان اصطلاحات مختلف ارزیابی شدند. «حمله» در قطعه مربوطه دارای پسوند اسمی است، در حالی که در قطعه غیر مرتبط بیشتر به عنوان فعل در حالت امری استفاده می شود. بنابراین، اینها با حذف ریشه در دوره پیش پردازش به عنوان اصطلاحات مختلف ارزیابی شدند.
علاوه بر ابر کلمه یکگرام، ابرهای کلمه بیگرم برای هر دو تکه رسم میشوند، چه استفاده از هر بیگرام میتواند در یکی یا هر دو فراگیر باشد ( شکل 9).ج، د). برای مثال، «رحمت خدا» (اللهتن رحمت) بیشترین فراوانی را در قسمت مربوطه (قصی یا کلی) دارد، در حالی که «مثل بمب آمدن» (بمبا گلییوروز) بیشترین بیگرم را در بخش غیرمعمول دارد. تکه مربوطه از منظر واژگان سوبژکتیو، ممکن است در نظر بگیریم که «خدا» را می توان مثبت نامید. با این حال، در ارتباط با “رحمت” به یک عبارت تسلیت تبدیل می شود که دارای احساسات منفی است. در همین راستا، “بمب” را می توان منفی یا مثبت درک کرد، در حالی که از سوی دیگر “مثل آمدن” یک احساس مثبت را بیان می کند، با “حمله” نشان دهنده احساسات منفی است. این کلمات «نفی کننده» نیستند که مستقیماً معنای قطبی شده ای مانند تأثیر «نه» را بر صفت ها معکوس کنند، مانند «خوب» و «خوب نیست». اهمیت تداعی کلمات را برای شناسایی احساسات صحیح نشان می دهد.
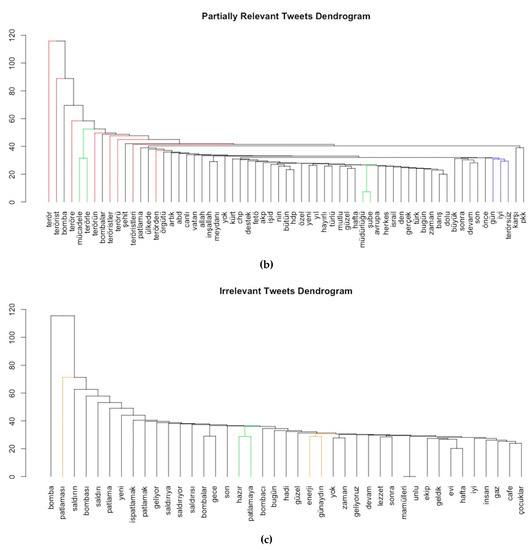
یک دندروگرام کلمه برای هر تکه تجسم می شود تا ارتباط کلمه در حال تغییر بین تکه ها مقایسه شود. چند نتیجه از دندروگرام ها وجود دارد. اولین مورد این است که چند شاخه برای کلمات مشابه با پسوندهای مختلف در دندروگرام یکسان، و همچنین در پسوندهای مختلف وجود دارد (مانند؛ terör، terörü، teröre و terörsüz و غیره که به رنگ قرمز در شکل 10 رنگ شده اند). این پسوندها سرنخی در مورد سایر قسمت های جمله ارائه می دهند. به عنوان مثال، “ترور” (teröre) می تواند با “لعنتی” (lanet) تکمیل شود تا “ترور لعنتی” ایجاد شود. به طور مشابه، در حالی که کلمه “terörsüz” به معنای “بدون وحشت” است، می توان آن را با عباراتی مانند “آرزوی یک روز بدون وحشت” تکمیل کرد (به رنگ آبی در شکل 10).). علاوه بر این، کلمه “انفجار” (patlama) در مجموعه داده مربوطه، مستقیماً با هیچ کلمه ای مرتبط نیست، در حالی که در بخش غیر مرتبط با “صبح بخیر” (günaydın)، “انرژی” (enerji) مرتبط است. و به عنوان “صبح بخیر!” من امروز یک انفجار انرژی داشته ام (به رنگ نارنجی در شکل 10 ). علاوه بر این، برگهای دندروگرامها کلمات مرتبطی مانند “آرزو” “سریع” “بهبود زخمیها” (“diliyorum”، “acil”، “şifalar”، “yaralılara”) را در دندروگرام مربوطه نشان میدهند. counter’ (‘mücadele’ به ترکی)، ‘تروریسم’ (‘terörle’)، ‘شاخه’ (‘şube’)، ‘دایرکتوری’ (‘müdürlüğü’) در توییت های تا حدی مرتبط، و ‘آماده’ (‘hazır’) , ‘منفجر شدن’ (‘patlamaya’) در مجموعه های غیر مرتبط (به رنگ سبز در شکل 10)). بنابراین، حفظ پسوندها و همچنین ارزیابی تداعی کلمات در یک سند برای تعیین احساس دقیق مهم است.
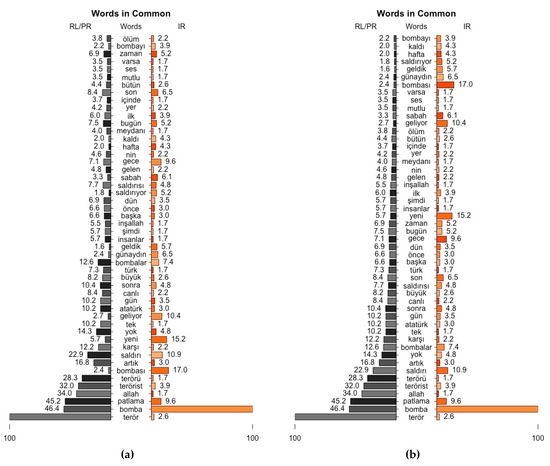
استفاده از نمودار هرمی نیز فرصت دیگری را برای کشف (ناهمسانی) از نظر فرکانس بین RL-PR و IR ارائه می دهد. اصطلاحات (“terör” در RL-PR، “bomba” در IR) که حداکثر فرکانس را در هر دو تکه دارند، 100 واحد در نظر گرفته میشوند و مقادیر فرکانس سایر عبارات با استفاده از نسبت نرخ نرمال میشوند، طبق معادله. (6). عادی سازی به منظور جلوگیری از تسلط اندازه های مختلف تکه ها به تکه های RL/PR و IR به طور جداگانه اعمال می شود.
نمودار هرمی مورد استفاده در این مطالعه 50 عبارت رایج را ترسیم می کند که دارای بالاترین اختلاف فرکانس بین تکه های RL/PR و IR هستند، که بر اساس تفاوت مقدار فرکانس ترم نرمال شده (ntfv) مرتب شده اند ( شکل 11 a) و مرتب شده توسط ntfv RL / تکه PR ( شکل 11ب). این نمودار از این جهت حائز اهمیت است که نشان میدهد اگرچه کلمات رایجی وجود دارد، اما هر کدام دارای نرخ فرکانس متفاوتی در تکههای مختلف هستند. به عنوان مثال، کلمات کلیدی مانند «terör»، «bomba» و «patlama» که برای فیلتر کردن خشن استفاده میشوند، بهطور شگفتانگیزی در پایین نمودار بهعنوان بالاترین ntfv برای قطعه RL/PR قرار میگیرند، در حالی که دارای 2.6، 100 هستند. و به ترتیب 9.6 ntfv برای قطعه IR. علاوه بر این، طرح امکان بررسی دقیق تر ntfv را با توجه به کلمات مشابه با پسوندهای مختلف، مانند “terör”، “terrorist”، “terörü”، “bomba”، “bombalar”، “bombas” فراهم می کند. ، و “bombayı”.
3.4. پردازش داده ها
دادههای کاوششده با استفاده از دو کتابخانه واژگان (STN و LOA) با سه فرآیند مختلف (نمره، برچسب امتیاز و برچسبهای قطبی) به منظور تعیین بهترین فرآیند فیلتر ریز دانه و عملکرد آن پردازش شدند. به طور کلی، قابلیتهای فیلتر حوزه وحشت واژگان سوبژکتیویته فعلی ترکیه قبل از اجرای تکنیکها با توجه به دو مورد از حوزه وحشت آشکار شد. در نتیجه، تمام دادههای خود برچسبگذاری شده با واژگان ذهنی فعلی در قالب STN و LOA پردازش شدند. این منجر به پیشبینی احساسات هر توییت با استفاده جداگانه از عباراتی با امتیاز در STN، برچسبهای قطبیت در STN و امتیازات در LOA شد. برای تعیین محتوای هر توییت – خواه منفی یا مثبت، یا هدف – تعداد برچسبها و مجموع امتیازات عبارتهای تشکیلدهنده هر توییت محاسبه شد. معیار مربوطه برای این امتیاز از نظر دقت کلی آن مطابق با معادله (7) انتخاب شد که نسبت موارد طبقه بندی شده صحیح به تعداد کل داده ها است.
این سه فرآیند به ترتیب نشان میدهند که 36%، 40% و 49% از نتایج برای فیلتر کردن دقیق هستند. با این حال، دو فرآیند اول STN منجر به غیرقابل اجرا بودن 37٪ (NA) و آخرین فرآیند (LOA) به غیرقابل اجرا بودن 5٪ (NA) شد ( جدول 2 a-c). بنابراین، یک نتیجه NA 37٪ می تواند به عنوان ناکافی بودن از نظر STN برای دامنه وحشت تفسیر شود، در حالی که LOA دارای قابلیت گسترده تری برای پوشش عبارات تنها با 5٪ نتایج NA است. این ممکن است نشان دهد که LOA کلمات بیشتری دارد که با اصطلاحات دامنه تلاقی می کنند. از سوی دیگر، دقت کلی برای هر دو واژگان به اندازه کافی با آن حوزه سازگار نیست تا امکان فیلتر کردن ریزدانه را فراهم کند.
مجموعه داده کاوششده شامل توییتهایی مربوط به چندین حمله تروریستی است که در ترکیه رخ داده است. دو مورد برای مقایسه تکنیک های فیلترینگ و قابلیت اطمینان نقشه برداری انتخاب شدند. در مورد اول، دادههای آزمایشی دادههای تقریباً فیلتر شدهای بودند که پس از حمله تروریستی که در نزدیکی ورزشگاه بشیکتاش وودافون (BVA) در منطقه بشیکتاش استانبول رخ داد، ایجاد شد. اطلاعات مورد دوم تقریباً پس از حمله تروریستی فرودگاه آتاتورک (ATA) فیلتر شد. این دو حمله تروریستی باعث تلفات و تلفات بسیاری شد و تهدیدی برای هزاران نفر در منطقه شهری ایجاد کرد. بسیاری از مردم ابراز تاسف کردند، تسلیت گفتند و نفرت خود را از این حملات ابراز کردند. بنابراین، تجزیه و تحلیل احساسات به عنوان راهی برای انجام فیلتر ریزدانه در نظر گرفته شد. هر دو مجموعه داده با توجه به سه واژگان و دو تکنیک مبتنی بر یادگیری ماشین پردازش شدند. سه تکنیک اول در مورد هر مورد از مجموعه داده ها استفاده شد. با این حال، این فرآیندها برخی از خروجی های بدون برچسب (NA) را برگرداندند، که از نظر دقت برای محاسبه نادیده گرفته شدند. ماتریس های سردرگمی اولین مجموعه از تکنیک ها در نمایش داده می شوندجدول 3 a-c برای BVA و جدول 4 a-c برای ATA. با توجه به فرآیند چهارم، یک طبقهبندی کننده ساده بیز برای همان رویدادها آموزش داده شد و آزمایش شد. بقیه دادههای تقریباً فیلتر شده و برچسبگذاری شده به عنوان یک مجموعه داده آموزشی برای ساخت یک طبقهبندی کننده ساده بیز استفاده شد. در نتیجه این فرآیند، طبقهبندی کننده تمام دادهها را با دقت 87 درصد برچسبگذاری کرد ( جدول 3d). این رویکرد با مجموعه داده دوم تولید شده پس از ATA آزمایش شد. رویداد ATA با دقت 84 درصد ( با استفاده از همین رویکرد منجر به دقت 84٪ ( جدول 3d) شد. فرآیند پنجم یک طبقهبندی شبکه عصبی (NN) بود که با استفاده از دادههای برچسبگذاری شده دستی آموزش داده شد. مدل داده های BVA و ATA را با دقت 61% و 70% طبقه بندی کرد ( جدول 4d,e) به ترتیب. یک پارامتر لایه پنهان به عنوان 1، 2 و 3 به منظور یافتن بهترین مدل برای NN اختصاص داده شد. در بخش پردازش NN، یک ساختار NN متشکل از دو لایه پنهان به دلیل عملکرد آماری قابل اعتماد آن اتخاذ شد.
یک ماتریس سردرگمی برای ارزیابی هر تکنیک فیلتر با نمرات دقت کلی، حساسیت (یادآوری)، ویژگی، PosPredValue (دقت)، F1، F2 و G-Mean (میانگین هندسی) رسم شد. این امتیازها جزئیات عملکرد فیلتر را نشان می دهد. در حالی که دقت عملکرد کلی فرآیند فیلتر کردن را نشان میدهد، اما در برخی شرایط به تنهایی کافی نیست، به عنوان مثال، یک امتیاز دقت بالا گمراهکننده میتواند برای کلاسهای داده نامتعادل به دلیل حساسیت صفر در همه کلاسها به غیر از کلاس اصلی مشاهده شود. 86]. داده هایی که در این مطالعه استفاده شد برای کلاس (R) مربوطه نامتعادل است، زیرا پیش فیلتر برای روز حملات تروریستی اعمال شد. اگرچه طبقهبندیکنندهها برای طبقهبندی چند کلاسه مدلسازی شدهاند، مهمتر است که کلاس اصلی (R) طبقهبندی شود. در این شرایط، معیارهای حساسیت، F1 و G-Mean توسط مطالعات مربوط به چنین دادهها و طبقهبندیکنندههایی [ 86 ، 87 ، 88 ] پیشنهاد شد. ].
بسته به نتایج ذکر شده در جدول 3 استنباط های مختلفی وجود دارد و جدول 4. اولین مورد این است که عملکرد طبقهبندیکننده Naïve Bayes در دو مجموعه داده به وضوح بهتر از چهار تکنیک دیگر از نظر دقت و حساسیت کلی، F1 و G-Mean برای کلاس مربوطه (R) است. رتبه بندی عملکرد در هر دو مجموعه داده از نظر دقت کلی یکسان است، که NB، NN، LOA، STN بر اساس امتیاز، و STN بر اساس برچسب قطبیت از بالاترین به پایین ترین است. رتبه کمی متفاوت است – که NB، LOA، NN، STN از نظر امتیاز، و STN با برچسب قطبیت برای BVA است – اما دوباره برای ATA از نظر امتیاز F1 مشابه است. این NB، NN، STN با برچسب قطبیت، STN بر اساس امتیاز، و LOA برای BVA و ATA از نظر امتیاز G-Mean است. از نظر تمام امتیازات، رتبه بندی عملکرد برای هر دو مجموعه داده بسیار مشابه است. این بدان معنی است که تکنیک های فیلتر دقیق و مستقل از داده ها هستند.
3.5. تفسیر فضایی بر روی SMD با فیلتر خوب
همانطور که در بالا ذکر شد، این مطالعه فیلتر محتوای ریز دانه مورد استفاده برای تولید نقشههای قابل اعتمادتر برای دامنههای خاص را بررسی کرد. هر مجموعه داده فیلتر شده به صورت متنی با استفاده از ماتریس های سردرگمی بررسی شد و این بخش از مطالعه دقت متنی توییت هایی را که می توان برای دامنه فاجعه استفاده کرد در نظر گرفت. با این حال، دقت فضایی توییتها باید تعیین شود تا قابلیت اطمینان کامل از نظر احساسات و مکان توییتها فراهم شود. برای تعیین دقت فضایی، این مطالعه دادههای برچسبگذاری شده دستی و فیلتر شده به صورت خودکار را در زمینه فضایی مقایسه کرد. الگوریتمهای خوشهبندی فضایی [ 65 ] و روشهای مختلفی برای تشخیص رویداد فضایی وجود دارد. نتایج از نظر انتخاب الگوریتم و روشهای مورد استفاده متفاوت است [12]. با توجه به تضادهای آشکار شده با استفاده از تکنیک های مختلف خوشه بندی و پارامترهای از پیش تعیین شده (مانند تعداد خوشه ها و حداقل تعداد مورد نیاز برای هر خوشه)، یک الگوریتم خوشه بندی فضایی Getis-Ord [ 66 ، 67 ] برای هر مجموعه داده برای مقایسه فضایی انتخاب شد. واریانس های ناشی از روش های مختلف فیلتر که قبلاً اعمال شده است.
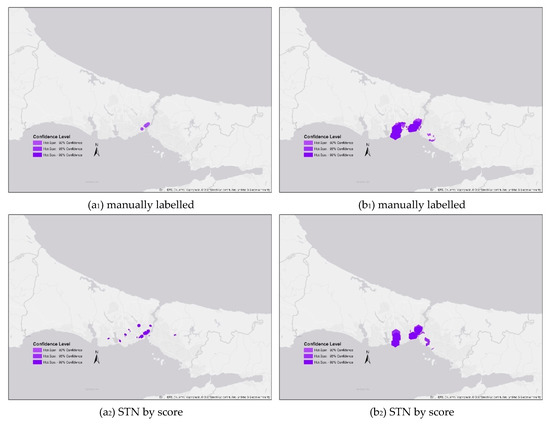
در حین انجام تجزیه و تحلیل Hotspot Optimized با استفاده از ArcMap [ 68 ]، اندازه سلول 500 متر تعریف شد. این نشان دهنده وضوح سطح خیابان [ 69 ] لازم برای اجازه دادن به تجزیه و تحلیل دقیق است. برای استفاده از ظرفیت اتصال یک شکل شبکه خوشه بندی [ 70 ]، چند ضلعی های شش ضلعی در روش تجمع انتخاب شدند. خط مرزی شهر استانبول – جایی که هر دو رویداد تروریستی در آن اتفاق افتاد – به عنوان مرز تحلیل در نظر گرفته شد. نتایج تجزیه و تحلیل یک روش اکتشافی برای شناسایی تفاوتها یا شباهتهای بین روشهای فیلتر کردن و دادههای برچسبگذاری شده دستی ارائه میدهد ( شکل 12 a 1 , b 1 ). نقاط داده با برچسب دستی برای BVA (a 1) و ATA (b 1 ) بدون در نظر گرفتن اعتبار داده های ارسال شده در رسانه های اجتماعی به عنوان حقیقت پایه در نظر گرفته می شوند. مقایسههای اکتشافی نقاط داغ را میتوان از نظر شباهت مکانهای خوشه، اندازه خوشه، تعداد خوشه و فاصله بین خوشهها ارزیابی کرد.
برای رویداد ATA، LOA (a 4 ) بیشتر از بقیه به نقشه حقیقت شبیه بود، در حالی که بعد از استفاده از Naïve Bayes، از نظر فیلتر کردن، دومین مورد دقیقتر بود. جالب اینجاست که وقتی از اندازه خوشه استفاده می شد، خوشه های فیلتر ساده بیز چندین برابر بزرگتر از حقیقت زمین بودند. حتی اگر از نظر مکان خوشه، فیلتر ساده بیز نتیجه دقیقی به دست می دهد – از آنجایی که شامل خوشه های پایه داخل می شود – از نظر اندازه خوشه، سطح دقت انتظارات را برآورده نمی کند، در حالی که فیلتر ساده بیز از نظر فیلتر کردن حرف اول را می زند. دقت.
برای رویداد BVA، هر دو نقطه فیلتر STN در چندین مکان دور پراکنده بودند، و STN بر اساس امتیاز (b 2 )، LOA (b 4 ) و Naïve Bayes (b 5 ) الگوی خوشه بندی مشابه تری را نشان می دهند. نقاط حساس با برچسب دستی (b 1 ). با این حال، خوشههای تولید شده توسط دادههای فیلتر شده با STN توسط برچسب قطبیت (b3 ) همگرایی متوسطی را با خوشههای پایه (b1 ) نشان میدهند.
نرخ شباهت هات اسپات برای هر رویداد، بر اساس شاخص های شباهت آنها فهرست شده است ( جدول 5 ). با توجه به این موضوع، نتایج از نظر شاخصهای انتخابی متفاوت است و در برخی نقاط، نتایج سایر شاخصها به شاخص Giz همگرا میشوند. از این موضوع می توان استنباط های متعددی کرد. اولین مورد این است که شاخص جاکارد (JI) زمانی که تقاطع به اندازه نقاط حساس در حقیقت زمین یا نقشه های فیلتر شده همگرا می شود، به خوبی عمل می کند ( شکل 12 a 4 , b 6 ). ثانیا، از آنجایی که شاخص سورنسون (SI) تقاطع را به صورت دو وزنی فرموله می کند، زمانی که سطح تقاطع به طور قابل توجهی بالا باشد، به شاخص Giz همگرا می شود ( شکل 12 a 5 ).,a 6 , b 3 , b 4 , b 5 ). کولچینسکی اهمیت یکسانی را برای نسبت قسمت تقاطع به حقیقت زمین یا نقشه فیلتر شده مشخص می کند و به شاخص Giz همگرا می شود، با نسبت تقاطع در هر دو نقشه مشابه است ( شکل 12 b 2 , b 4 , b 5 ). بنابراین، زمانی که ناحیه تقاطع به طور نامتناسب در نقشه های حقیقت و فیلتر شده، همانطور که در شکل 12 a 2 , a 5 نشان داده شده است، با امتیاز شاخص Giz همگرا نمی شود . علاوه بر این، شاخص Ochai نسبت تقاطع را به طور نمایی به کل مناطق کانونی در هر دو حقیقت زمین و نقشه های فیلتر شده در نظر می گیرد.شکل 12 a 6 , b 2 , b 4 , b 5 ). این وزن نمایی یک سوگیری از نظر اندازه تقاطع ایجاد می کند بدون اینکه در مورد فاصله بین مناطق غیر متقاطع اذیت شود. شاخص Giz امتیاز شباهت را از نظر تمام جنبه های مورد نیاز (اندازه خوشه، مجاورت فضایی، منطقه تقاطع فضایی و منطقه غیر متقاطع) برای مقایسه نقشه های وقوع محاسبه می کند.
آستانه تشابه برای استفاده از تکنیک های فیلترینگ و نقشه برداری 0.7 شناسایی شده است. با توجه به این موضوع، STN بر اساس امتیاز (STNScrPred) دارای آستانه بیش از 0.70 شباهت با توجه به JI و KI است، در حالی که برای LOA (LoaPred) دارای آستانه بیش از 0.90 بر اساس JI، KI، OI، و GI برای رویداد BVA ( جدول 5 a). برای رویداد ATA، به استثنای NN، همه نمایشهای نقشه نقطه نقطه شباهت معقولی بر اساس شاخصهای مختلف دارند ( جدول 5 ب).
با این حال، شاخص Giz به عنوان مناسب ترین شاخص شباهت برای این مطالعه پذیرفته شده است، زیرا بر خلاف شاخص های Jaccard، Sorensen-Dice، Kulczynski و Ochai شباهت فضایی را در بر می گیرد. نتایج شاخص Giz برای هر دو رویداد با در نظر گرفتن اندازه خوشههای فضایی و مجاورت آنها، استنباطهای اکتشافی را با معیارهای کمی بین 0 و 1 پشتیبانی میکند. این به این دلیل است که اندازه و دقت مکان برای مطالعاتی از جمله تحلیلهای فضایی، مانند مدیریت بلایا که شامل چنین تحلیلی است، مهم است. این شاخص می تواند تفسیر فضایی سریع و خودکار داده های تحلیل شده را ارائه دهد. وقتی صحبت از شاخص Giz به میان میآید، که به ما امکان میدهد دادهها را به صورت مکانی ارزیابی کنیم، شباهت کافی برای رویدادهای BVA با LOA و رویداد ATA با LOA، STN بر اساس امتیاز ارائه میدهد.
3.6. عواقب
همانطور که قبلا ذکر شد، روش پیشنهادی این مطالعه می تواند برای حوزه های مختلفی مانند انتخابات، بلایای طبیعی و بازاریابی نیز مورد استفاده قرار گیرد. به عنوان مثال، اگر دامنه انتخاباتی باشد، می توان از روش های زیر برای ترسیم واکنش های رسانه های اجتماعی استفاده کرد. اولین قدم فیلتر کردن صحیح SMD است. برای این مرحله کاربر باید کلمات کلیدی رویداد انتخاباتی مانند سیاست، حزب، مجلس، معاونت، نام احزاب، نام کاندیداها، انتخابات، رفراندوم و غیره را انتخاب کند. پس از این مرحله اول، SMD فیلتر شده شامل خواهد شد. توییت های غیر مرتبط یا تا حدی مرتبط به دلیل استفاده از همنام و استعاره. برای فیلتر کردن توییتهای غیر مرتبط و تا حدی مرتبط، بسته به تعداد توییتهای موجود، یک مجموعه داده آموزشی باید ذخیره شود و به صورت دستی به عنوان مرتبط، غیر مرتبط و تا حدی مرتبط برچسب گذاری شود. این مرحله را می توان به طور خودکار با استفاده از پلتفرم های وب مانند Kaggle و Mechanical Turk انجام داد.89 ، 90 ]. این مجموعه داده برچسبدار دستی یا مبتنی بر وب برای آموزش یک طبقهبندی کننده ساده بیز استفاده میشود، و این طبقهبندیکننده برای فیلتر کردن دانهریز SMD استفاده میشود. پس از فیلتر خودکار دانهریز، دادههای برچسبدار حاصله مربوطه را میتوان برای ایجاد نقشههای کانونی واکنش رسانههای اجتماعی، تغییرات در نقشههای واکنش، و توزیع موضوعی و مکانی واکنشها با استفاده از الگوریتم Getis-Ord* استفاده کرد. این نقشه می تواند بیشترین و کمترین نامزدها، احزاب، وعده ها و شکایات انتخاب کنندگان را در مناطق مختلف فضایی نشان دهد.
نقشه های واکنش زمانی را می توان با استفاده از شاخص Giz برای ارزیابی تفاوت ها از نظر مبارزات انتخاباتی بر اساس نامزدها یا احزاب مقایسه کرد. برای بررسی واکنش انتخاب کنندگان به وعده های نامزدها، می توان با استفاده از شاخص گیز، نقشه واکنش نامزدها یا احزاب قبل و بعد از جلسات را با هم مقایسه کرد.
جنبه دیگری از روش این مطالعه مربوط به نقشه برداری مبتنی بر رویداد برای تعیین اندازه و توزیع رویداد، برای یافتن خطرناک ترین، خطرناک ترین یا امن ترین مسیرهایی برای تخلیه است که توسط صاحبان توییت یا امن ترین مکان ها استفاده شده است. نمونه ای از چنین مواردی استفاده از این روش در حین و به دنبال وقوع زلزله برای ایجاد نقشه وقوع است. اولین گام، دوباره، از پیش تعیین کلمات کلیدی قبل از رویداد است. سپس در حین و پس از وقوع زلزله، SMD ها از قبل فیلتر می شوند. برای فیلتر کردن دانه ریز SMD پس از پیش فیلتر کردن، یک مجموعه داده آموزشی باید برای آموزش طبقهبندی کننده صرفهجویی شود، چه با برچسبگذاری دستی دادههای مرتبط، غیر مرتبط و تا حدی مرتبط، یا با استفاده از پلتفرمهای وب. به دنبال برچسب گذاری، مجموعه داده آموزشی برای آموزش طبقه بندی کننده های ساده بیز استفاده می شود. پس از طبقهبندی ساده بیز نظارت شده، تکنیکهای مدلسازی موضوع بدون نظارت مانند تحلیل معنایی پنهان (LSA)، LSA احتمالی (pLSA)، یا تخصیص دیریکله پنهان (LDA) میتوانند برای دستهبندی توییتهای گزارش رویداد استفاده شوند.91 ، 92]. اگر SMD بر اساس توییتهای متعدد حساب ربات برای دستکاری باز باشد، دادهها را میتوان بر اساس مکان و نام کاربری اصلاح کرد و در نتیجه منابع دستکاری و اثرات را میتوان به حداقل رساند. پس از این مرحله، یک الگوریتم Getis-Ord* می تواند برای ایجاد نقشه های وقوع بیشتر ساختمان های فروریخته موجود، اکثر افرادی که منتظر پاسخ هستند، یا امن ترین مکان ها یا مسیرها برای جمع آوری یا تخلیه استفاده شود. با استفاده از شاخص Giz میتوان نقشههای وقوع را با تماسهای اضطراری، نقشههای خطرات پیش از زلزله و طرحهای واکنش مقایسه کرد. به این ترتیب می توان خسارت ها و خطرات برآورد شده قبلی را اعتبارسنجی کرد و با استفاده از روش پیشنهادی، وضعیت فعلی موثر بر جریان اطلاعات را کنترل کرد. از این تفاوت می توان برای بهینه سازی طرح های واکنش سریع پس از زلزله استفاده کرد.
4. نتیجه گیری
دادههای رسانههای اجتماعی که توسط میلیاردها حسگر انسانی در سراسر جهان و تقریباً نیمی از کل جمعیت ترکیه تولید میشوند، بهعنوان منبع داده در حین و پس از یک فاجعه بسیار مهم هستند. این مطالعه نه تنها ارزش تکنیکهای فیلتر ریز دانه را در حوزه وحشت با توجه به زبان ترکی تعیین کرد، بلکه یک روش کمی را برای اطمینان از قابلیت اطمینان مکانی این دادههای فیلتر شده پیشنهاد میکند. با توجه به آن، مطالعه بر دو تحقیق اصلی متمرکز شد. استفاده از رویکردهای رایج برای فیلتر SMD مبتنی بر دامنه در زبان ترکی، و قابلیت اطمینان مکانی نقشههای بروز که با SMD فیلتر شده مبتنی بر دامنه تولید میشوند.
اولین پیامد در زمینه این مطالعه، پردازش توییتهای ترکی مربوط به دو حمله تروریستی با واژگان ذهنی فعلی و طبقهبندیکنندههای مبتنی بر یادگیری بود. به منظور توسعه روش برای فیلتر کردن خوب، در ابتدا، تجزیه و تحلیل های اکتشافی به صورت بازگشتی برای یافتن بهترین مراحل پیش پردازشی که برای زبان ترکی در این مطالعه به کار گرفته شد، انجام شد. بنابراین، قسمت پاکسازی متن با افزودن تثبیتهای رمزگذاری زبان، حفظ پسوندها به دلیل استفاده متفاوت از عبارات زوج در بیگرم طراحی شد. علاوه بر این، تحلیلهای اکتشافی تبعیض در احساسات، حتی برای کلمات رایج را نشان میدهد. اگرچه این استنباط از استفاده از واژگان ذهنی برای فیلتر کردن محتوای مرتبط پشتیبانی می کند، این همچنین ممکن است به این معنی باشد که استفاده مستقیم از نمره احساسات برای یک کلمه مشترک می تواند فرآیند فیلترینگ را به دلیل داشتن کلمه رایج دارای معانی منفی و مثبت هدایت کند. استنباط دیگر از تجزیه و تحلیل اکتشافی میزان استفاده از کلمات رایج از نظر طبقات مرتبط است. از آنجایی که میزان استفاده از کلمات رایج بین کلاسها متفاوت است، در نظر گرفته شد که اگر احتمال احتمال را در نظر بگیریم، طبقهبندی کننده باید در طبقهبندی ربط موفق باشد. نتایج بخش فیلتر برای هر دو مورد از این امر پشتیبانی می کند، زیرا Naïve Bayes بیش از 80٪ دقت کلی در هر دو مجموعه داده رویداد داشت. استنباط دیگر از تجزیه و تحلیل اکتشافی میزان استفاده از کلمات رایج از نظر طبقات مرتبط است. از آنجایی که میزان استفاده از کلمات رایج بین کلاسها متفاوت است، در نظر گرفته شد که اگر احتمال احتمال را در نظر بگیریم، طبقهبندی کننده باید در طبقهبندی ربط موفق باشد. نتایج بخش فیلتر برای هر دو مورد از این امر پشتیبانی می کند، زیرا Naïve Bayes بیش از 80٪ دقت کلی در هر دو مجموعه داده رویداد داشت. استنباط دیگر از تجزیه و تحلیل اکتشافی میزان استفاده از کلمات رایج از نظر طبقات مرتبط است. از آنجایی که میزان استفاده از کلمات رایج بین کلاسها متفاوت است، در نظر گرفته شد که اگر احتمال احتمال را در نظر بگیریم، طبقهبندی کننده باید در طبقهبندی ربط موفق باشد. نتایج بخش فیلتر برای هر دو مورد از این امر پشتیبانی می کند، زیرا Naïve Bayes بیش از 80٪ دقت کلی در هر دو مجموعه داده رویداد داشت.
فرآیند فیلتر کردن این مطالعه دارای سه تحلیل مبتنی بر واژگان و سه تحلیل مبتنی بر یادگیری ماشینی بر روی توییتهای ترکی مربوط به دو حمله تروریستی بود. اولین دو تحلیل مبتنی بر واژگان مبتنی بر STN [ 31 ] با تجزیه و تحلیل های مبتنی بر امتیاز و برچسب بود. سومین بر اساس واژگان اوزتورک و آیواز [ 40] که در مطالعه به عنوان LOA ذکر شد. همچنین سه تحلیل احساسات مبتنی بر یادگیری ماشین در این مطالعه اجرا شد که دو مورد اول بر اساس طبقهبندیکننده ساده بیز و طبقهبندیکننده شبکه عصبی، با یک لایه پنهان، دو لایه پنهان و سه لایه پنهان، به طور جداگانه انجام شد. آخرین تحلیل مبتنی بر یادگیری ماشین، ماشین بردار پشتیبان با هستههای چندجملهای، هستههای شعاعی و هستههای سیگموئید به طور جداگانه بود. در نتیجه این مطالعه، بالاترین موفقیت با استفاده از تکنیکهای Naïve Bayes با دقت بیش از 80% به دست آمد، در حالی که LOA با دقت بالای 60% به دومین میزان موفقیت دست یافت.
اگرچه Naïve Bayes بهترین نتایج را از نظر طبقه بندی ارائه می دهد، اما به مجموعه داده های آموزش دیده برای هر دامنه نیاز دارد. چنین داده های آموزش دیده ای ممکن است به راحتی جمع آوری نشود زیرا به رویدادهای فاجعه بزرگ بستگی دارد. به عنوان مثال استانبول به عنوان یکی از شلوغ ترین شهرهای جهان، در انتظار یک زلزله بزرگ است. با این حال، تا زمانی که یک زلزله مخرب رخ ندهد، امکان جمعآوری دادههای آموزشی وجود نخواهد داشت و این واقعیت آموزش طبقهبندی کننده برای همه زیر دامنههای فاجعه را به چالش میکشد. حتی واکنشهای کلی ممکن است برای همه انواع حوزههای فاجعه مانند «رحمت خدا» یا «آرزوی شفای عاجل برای مجروحان» رایج باشد. اگر مورد مطالعه فقط شامل یک حوزه خاص مانند وحشت در محدوده دامنه های فاجعه باشد، باید رویدادی برای جمع آوری و آموزش داده ها وجود داشته باشد.
دومین نتیجه در زمینه این مطالعه، کمی کردن تأثیر تکنیکهای فیلتر کردن بر قابلیت اطمینان فضایی دادههای رسانههای اجتماعی بود. با توجه به آن، این مطالعه شاخصهای شباهت فضایی کنونی را بررسی کرد و به جای آن یک شاخص جدید برای مقایسه توزیع فضایی دادههای فیلتر شده (پیشبینی) در مقابل دادههای برچسبگذاری شده دستی (حقیقت) پیشنهاد کرد. پس از ارزیابی روشهای فیلترینگ، نتایج فیلتر شده با استفاده از شاخصهای شباهت و دادههای حقیقت زمینی مورد ارزیابی قرار گرفتند. شاخص های شباهت شناخته شده با شاخص Giz که در این مطالعه توسعه یافته بود، مقایسه شدند. نتایج مقایسه شاخصهای تشابه بررسی شده در این مطالعه نشان میدهد که روشهای نمایهسازی بدون در نظر گرفتن روابط فضایی، تقاطع (غیر) را به صورت دودویی (0-1) میگیرند. با این حال، روابط فضایی مانند اندازه و مجاورت خوشه های غیر متقاطع باید برای تعیین شباهت فضایی صحیح در نظر گرفته شود. به همین دلیل، شاخص Giz با در نظر گرفتن اندازه خوشه های متقاطع و غیر متقاطع همراه با مجاورت فضایی بین خوشه های غیر متقاطع و خوشه های حقیقت زمین ایجاد شد.
این مطالعه با استفاده از تکنیکهای انتخابی مربوط به دادههای رسانههای اجتماعی، دقت 85 درصدی را برای رویداد BVA و بیش از 70 درصد را برای رویداد ATA، با توجه به متن و دادهکاوی مکانی به دست آورد. چنین دادههای فضایی دقیق فیلتر شده میتواند به عنوان دادههای کمکی عمل کند تا به ذینفعان اجازه دهد تا به سرعت وضعیت را پس از یک رویداد فاجعهآمیز، بهعنوان اطلاعرسانی در مورد وضعیت اضطراری، بهعنوان درخواست کمک یا برای تجمع عمومی، یا اطلاعرسانی مکانهای خطرناک تعیین کنند. .
نتایج این تحقیق یک شاخص شباهت فضایی جدید به نام Giz Index ارائه میکند و ترکیبی از تکنیکها و روشهای موجود و جدید توسعهیافته را برای فیلتر کردن دادههای توییتر برای یک دامنه با ارتباط بالا و تولید نقشه رویداد برای آن دامنه ارائه میکند و سپس به دست میآورد. دقت مکانی نقشه با توجه به داده های حقیقت زمینی. هنگامی که روابط فضایی در تجزیه و تحلیل SMD در نظر گرفته نمی شود، بحث در مورد قابلیت اطمینان SMD افزایش می یابد. بزرگترین مانع در استفاده از داده های رسانه های اجتماعی در تحلیل های علمی، قابلیت اطمینان SMD است. تعداد مطالعات پایایی کافی در زمینه متنی و فضایی SMD وجود ندارد. اینجاست که این مطالعه شاخصی برای قابلیت اطمینان مکانی ارائه میکند و محتوای متنی SMD را با استفاده از فیلتر مبتنی بر متن بر روی توییتها برای یک دامنه خاص ارزیابی میکند. به این ترتیب، ارزیابی عددی SMD را می توان با استفاده از روش های پیشنهادی ایجاد کرد.
این مطالعه از چند جنبه دارای محدودیت و محدودیت است. اولاً، این مطالعه اشتباهات املایی، اصطلاحات و اصطلاحات عامیانه را که ممکن است عملکرد تطبیق کلمات را با واژگان ذهنی کاهش دهد، نادیده می گیرد. تجزیه و تحلیل مبتنی بر واژگان وابسته به تنوع کلمه ای است که برای زبان استفاده می شود. اگر واژگان به نحوی غنی شود، نتایج می تواند با همان روش شناسی موفق تر باشد. ثالثاً، یک مجموعه داده قطار با برچسب دستی برای مدلسازی طبقهبندیکنندههای مبتنی بر یادگیری مورد نیاز است. برچسب گذاری دستی برای تکه های بزرگ داده امکان پذیر نیست. با این حال، این مشکل برچسبگذاری را میتوان با استفاده از پلتفرمهای وب مانند Kaggle و Mechanical Turk برای مطالعات بیشتر حل کرد [ 89 ، 90 ] حل کرد.]، با پتانسیل آنها برای ارائه داده های برچسب دار. چهارم، شاخص شباهت که برای مقایسه نگاشت وقوع با حقیقت زمینی طراحی شده است، بر روی نتایج رایج ترین روش خوشه بندی مورد آزمایش قرار می گیرد. در مطالعات بیشتر، اگر خوشه بندی به طور قابل توجهی بر نتایج تأثیر می گذارد، باید در سایر پیامدهای خوشه بندی به طور گسترده مورد بررسی قرار گیرد.
همچنین ذکر این نکته ضروری است که مطالعات کمی در این زمینه با توجه به زبان های غیر انگلیسی انجام شده است. این مطالعه روشی را ارائه میدهد که به ما امکان میدهد با زبانهای ادغامکننده، بهویژه ترکی، که اکثریت جمعیت آن به انگلیسی توییت نمیکنند، کار کنیم. در نتیجه، این مطالعه یک شاخص شباهت فضایی با توجه به جامعه ارائه میکند که به تقاطع فضایی، مجاورت و اندازه با هم میپردازد. این اولین مطالعه ای است که تکنیک های فیلترینگ را با توجه به SMD تجزیه و تحلیل مکانی می کند و روشی را ارائه می دهد که نه تنها به سازگاری دامنه و ارتباط معنایی می چسبد، بلکه قابلیت اطمینان فضایی SMD را در ارتباط با آنها نیز در نظر می گیرد.










بدون دیدگاه