1. معرفی
در سالهای اخیر، تقاضا برای خدمات مبتنی بر مکان (LBSs)، چه در داخل و چه در فضای باز، مورد توجه قرار گرفته است و تقاضای زیادی در صنعت و دانشگاه دارد [ 1 ]. استفاده موفقیت آمیز از سیستم موقعیت یابی ناوبری ماهواره ای (SNPS)، مانند سیستم موقعیت یابی جهانی (GPS) و سیستم ناوبری گالیله، راحتی زیادی را برای افراد مسافر فراهم می کند. با این حال، در محیط های داخلی یا پیچیده بیرونی، GPS نمی تواند LBS دقیق را ارائه دهد [ 2 ]. سنسورهای متعدد مجهز به یک گوشی هوشمند پیشرفت های جدیدی را برای LBS داخلی به ارمغان آورده است. با اندازه گیری با اندازه گیری سیگنال دریافتی، محلی سازی با Wi-Fi یا سیگنال مغناطیسی امکان پذیر می شود [ 3 ].
روشهای محلیسازی سنتی بر سیگنال زمان رسیدن (TOA)، تفاوت زمانی رسیدن (TDOA) و زاویه ورود (AOA) برای تعیین موقعیت تجهیزات کاربر (UE) متکی هستند. با این حال، تجهیزات ویژه ای برای تعیین زمان یا زاویه سیگنال رفت و برگشت مورد نیاز است. بنابراین، در بسیاری از کاربردها ناخوشایند و غیرعملی است. در مقابل، بیشتر روشهای تعیین موقعیت مبتنی بر اثر انگشت نیازی به تجهیزات یا زیرساخت اختصاصی ندارند و میتوان آن را تنها با یک گوشی هوشمند در همه جا پیادهسازی کرد. علاوه بر این، حسگرهای کم مصرف مجهز به تلفن هوشمند، حتی در صورت فعال بودن مداوم، انرژی بسیار کمتری را جذب میکنند [ 4 ].
همانطور که در شکل 1 نشان داده شده است، سیستم محلی سازی اثر انگشت پیشنهادی معمولاً از دو مرحله تشکیل شده است: فاز آفلاین و فاز آنلاین. در مرحله آفلاین، UE مجموعهای از نشانههای قدرت سیگنال دریافتی وایفای (RSSI) را از تمام نقاط دسترسی (APs) یا بزرگی سیگنال مغناطیسی در مکانهای شناخته شده، که به عنوان نقاط مرجع (RPs) شناخته میشوند، جمعآوری میکند تا پایگاه داده اثرانگشت بسازد. بنابراین، هر RP اثرانگشت خاص خود را دارد که شامل مکانهای شناخته شده و RSSI یا بزرگی سیگنال مغناطیسی دریافتی است. سپس، مدل یادگیری عمیق پیشنهادی برای آموزش با پایگاه داده اثر انگشت از پیش ساخته شده استفاده میشود. در مرحله آنلاین، از مدل یادگیری عمیق آموزشدیده برای تطبیق سیگنالهای دریافتی فعلی با پایگاهداده اثر انگشت استفاده میشود و مکان UE توسط بهترین برازش RP تعیین میشود [ 3 ، 5 ]].
رویکرد محلیسازی اولیه مبتنی بر اثر انگشت به K-Nearest Neighbor (KNN) برای یافتن RPهایی که به بهترین وجه با پایگاه داده اثر انگشت مطابقت دارند، متکی است. بعداً، الگوریتم بیزی، Weighted-K-Nearest Neighbors (WKNN) و Support Vector Machine (SVM) برای بهبود استحکام سیستم موقعیت یابی [ 6 ، 7 ، 8 ] پیشنهاد شده است. در [ 9 ] یک رویکرد محلی سازی زیرمنطقه داخلی مبتنی بر مغناطیسی با استفاده از یک الگوریتم یادگیری بدون نظارت پیشنهاد شد. یک رویکرد چند هاپ برای حل عدم دقت در مسئله محلی سازی [ 10 ] به کار گرفته شد.
با این حال، مشکل اصلی در دستیابی به محلیسازی اثر انگشت دقیق در نوسانات سیگنال است، مانند تأثیر نامطلوب محو شدن چند مسیره و تضعیف سیگنال توسط مبلمان، دیوارها و افراد. علاوه بر این، موقعیت یابی دقیق مستلزم جمع آوری RP های بیشتری است. بنابراین، حجم کار ساخت پایگاه داده اثر انگشت بسیار زیاد است. در نتیجه، چالش اصلی در بومیسازی مبتنی بر اثر انگشت این است که چگونه میتوان مدلی را توسعه داد که بتواند ویژگیهای قابل اعتماد استخراج کند و بهطور دقیق تعداد انبوهی از RPها را با سیگنالهای دارای نوسانات گسترده ترسیم کند [ 11 ].]. رویکردهای محلیسازی فوقالذکر دارای معماریهای یادگیری کم عمقی هستند که منجر به توانایی بازنمایی محدود میشود، بهویژه زمانی که با آن مسائل دادههای عظیم و پر سر و صدا سروکار داریم. موقعیت یابی با MFS نیز مشکل ساز است. تشخیص MFS هنگام در نظر گرفتن یک منطقه بزرگ به طور چشمگیری کاهش می یابد، که استفاده مستقیم از MFS را برای موقعیت یابی غیرممکن می کند.
در سال های اخیر، یادگیری عمیق چه در دانشگاه و چه در صنعت پیشرفت زیادی داشته است. یادگیری عمیق با لایه های چندگانه بر سایر تکنیک ها در تشخیص گفتار، طبقه بندی تصویر و غیره شکست خورده است [ 11 ، 12 ]]. بنابراین، در این کار، شبکه باقیمانده عمیق (Resnet) و یادگیری انتقال برای توسعه یک سیستم محلی سازی بسیار دقیق معرفی شده است. استفاده از MFS به تنهایی برای محلی سازی کافی نیست، زیرا در یک منطقه بزرگ قابل تشخیص نیست. بنابراین، با توجه به عملکرد فوقالعاده الگوریتم خوشهبندی پیک چگالی (DPC) در انتخاب ویژگی، یک الگوریتم خوشهبندی پیک چگالی جدید بر اساس الگوریتم فاصله مقایسه (CDPC) برای انتخاب چندین نقطه مرکزی از شدت میدان مغناطیسی (MFS) پیشنهاد میکنیم. آن را با سیگنال Wi-Fi ترکیب کرد تا استحکام سیستم محلی سازی پیشنهادی را بهبود بخشد. با توجه به عملکرد پیشرفته یادگیری عمیق در طبقه بندی تصاویر، Wi-Fi RSSI و نقاط مرکزی MFS برای ساخت پایگاه داده تصویر اثر انگشت به تصاویر تبدیل می شوند.
برای مقابله با نوسانات سیگنال، باید مدلی با توانایی یادگیری قوی طراحی شود. در این کار، یک رویکرد آموزش معماری سلسله مراتبی دو سطحی، شامل یک مرحله قبل از آموزش و مرحله تنظیم دقیق، برای به دست آوردن مدل یادگیری عمیق نهایی اتخاذ شده است. پس از اتمام ساخت مجموعه داده تصویر اثر انگشت، Resnet پیشنهادی ابتدا برای آموزش با مجموعه داده و بازگشت یک مدل از پیش آموزشدیدهشده به نام محلیساز درشت استفاده میشود. سپس، با استفاده از دانش قبلی از مدل از پیش آموزش دیده، یادگیری انتقال مبتنی بر لایه ادراک چندگانه (MLP) برای آموزش بیشتر با مجموعه داده و برگرداندن یک مدل دقیق تنظیم شده به نام محلیساز خوب استفاده میشود.
در طول مرحله آموزش، چندین رویکرد افزایش داده برای بهبود دقت محلی سازی اعمال می شود. تصاویر مجموعه داده اثر انگشت در ابعاد 224*224 استاندارد شده اند، بنابراین مدل می تواند به راحتی ویژگی های تصویر را یاد بگیرد. علاوه بر این، برخی از تصاویر 1.25 برابر بزرگ شده یا به طور تصادفی 15 درجه چرخانده می شوند. در نرمال سازی دسته ای، یک آیتم مومنتوم برای کاهش زمان ارتعاش و تسریع همگرایی مدل اضافه می شود. علاوه بر این، نرخ یادگیری (LR) به صورت پویا برای بهینه سازی بیشتر مدل تنظیم می شود. برای مرحله تطبیق، یک روش احتمالی برای نشان دادن دقت سیستم محلی سازی اعمال می شود.
مشارکت های اصلی این مقاله را می توان به صورت زیر خلاصه کرد: (1) الگوریتم CDPC یادگیری بدون نظارت ابتدا برای انتخاب نقاط مرکزی MFS استفاده می شود، که می تواند توزیع MFS را در هر RP نشان دهد. دقت موقعیت یابی را می توان با ترکیب سیگنال های Wi-Fi و MFS انتخابی بهبود بخشید. (2) متفاوت از مجموعه داده های معمولی، این MFS انتخاب شده و Wi-Fi RSSI به تصاویر تبدیل می شوند تا مجموعه داده تصویر اثر انگشت را برای محلی سازی تشکیل دهند. به منظور توسعه یک مدل با توانایی یادگیری قوی، Resnet و یک معماری آموزش سلسله مراتبی دو سطحی یادگیری انتقال مبتنی بر MLP برای بومیسازی پیشنهاد شدهاند. (3) با توجه به نقاط طبقه بندی متعدد، ما به صورت پویا تنظیم می کنیم LR را به صورت پویا تنظیم می کنیمو چندین رویکرد افزایش داده را برای افزایش توانایی تعمیم مدل شبکه عصبی عمیق (DNN) اتخاذ کرد. (4) برای تأیید اثربخشی سیستم موقعیتیابی پیشنهادی، آزمایش در هر دو محیط داخلی و خارجی واقعی انجام شد. این آزمایش نشان میدهد که سیستم موقعیتیابی پیشنهادی میتواند به محلیسازی با دقت بالا در محیطهای داخلی و خارجی دست یابد.
بقیه این مقاله به شرح زیر سازماندهی شده است: بخش 2 کارهای مرتبط را شرح می دهد. سیستم موقعیت یابی پیشنهادی در بخش 3 ارائه شده است . بخش آزمایشی در بخش 4 توضیح داده شده است . در نهایت، بخش 5 نتیجه گیری و کارهای آتی را شرح می دهد.
2. کارهای مرتبط
تقاضای زیاد برای LBS توسعه تکنیک های محلی سازی را تحریک کرده است. استقرار گسترده سیگنال های Wi-Fi و سیگنال های مغناطیسی می تواند تقریباً در تمام محیط های داخلی برای محلی سازی مفید باشد. بنابراین، علاقه زیادی را در بین محققان برانگیخته است [ 13 ].
سیستم های محلی سازی مبتنی بر اندازه گیری سنتی، مانند TOA و TDOA، می توانند مکان UE را تعیین کنند. با این حال، این رویکردها به انتشار سیگنال خط دید (LOS) نیاز دارند، زیرا رویکردهای محلی سازی به سه لایه بندی بستگی دارد. دقت محلی سازی در محیط های داخلی بسیار بدتر می شود، زیرا سیگنال اغلب توسط اشیا مسدود شده و شکسته می شود [ 14 ]. با این حال، محلی سازی مبتنی بر اثر انگشت می تواند بر این اشکالات غلبه کند، و ثابت شده است که عملکرد محلی سازی رضایت بخشی دارد [ 12 ]. بنابراین، تکنیک محلی سازی مبتنی بر اثر انگشت توجه گسترده ای را به خود جلب کرده است. اساساً سه نوع اثر انگشت وجود دارد: اثر انگشت بصری، اثر انگشت حرکتی و اثر انگشت سیگنال [ 3 ]]. تواناییهای بهبودیافته پردازش تصویر و ویدئو، تلفنهای هوشمند را قادر میسازد تا جستجوهای بصری عظیم را از تعداد زیادی پایگاهداده اثر انگشت بصری انجام دهند [ 15 ]. استفاده از Google Goggles و Vuforia Object Scanner نیز موفقیت آمیز بوده است. با پشتیبانی از حسگرهای حرکتی، مانند شتابسنجها و قطبنماهای الکترونیکی، تلفنهای هوشمند میتوانند دینامیک UE را در زمان واقعی شناسایی کنند. ایده اصلی محلیسازی اثر انگشت حرکتی ترکیب شتابسنج و اندازهگیریهای قطبنما و تطبیق آنها با پایگاهداده اثر انگشت حرکتی از پیش ساخته شده برای تعیین مکان UE است [ 16 ]. محلی سازی مبتنی بر اثر انگشت سیگنال سیگنال ها را می گیرد و آنها را با پایگاه داده اثر انگشت دارای برچسب جغرافیایی تطبیق می دهد تا مکان UE را تعیین کند [ 17 ].
رایج ترین سیگنال های مورد استفاده سیگنال های Wi-Fi و سیگنال های ژئومغناطیسی هستند. هر سیگنال Wi-Fi دارای کنترل دسترسی رسانه منحصر به فرد خود (MAC) است، و توانایی پوشش سیگنال محدود آن (حدود 100 متر) سیگنال های Wi-Fi را قادر می سازد تا به طور گسترده در محلی سازی استفاده شوند [ 5 ]. با این حال، همانطور که در نشان داده شده است شکل 2 نشان داده شده استسیگنالهای Wi-Fi به دلیل نویزهای سیگنال اطراف، محو شدنهای متعدد و غیره میتوانند در محدوده وسیعی نوسان داشته باشند، که ممکن است مکانهای نزدیک را در سیستمهای موقعیتیابی مبتنی بر Wi-Fi گیج کند. بنابراین، جمع آوری سیگنال های Wi-Fi بیشتر با MAC های مختلف می تواند دقت موقعیت یابی بالاتری را ایجاد کند. سیستم های محلی سازی داخلی مبتنی بر Wi-Fi دارای عملکرد محلی سازی 5 تا 10 متر هستند. علاوه بر این، برای سیگنالهای با قدرت کم، فرآیند اسکن سیگنال Wi-Fi ممکن است چندین ثانیه طول بکشد تا تمام سیگنالهای Wi-Fi به دست آید.
میدان مغناطیسی در یک دوره طولانی نسبتاً پایدار است و در یک منطقه کوچک قابلیت تشخیص فضایی برجسته ای دارد [ 18 ]. این می تواند در هر ثانیه حدود 100 نقطه داده را توسط حسگرهای مجهز به گوشی هوشمند جمع آوری کند. محققان دریافتهاند که MFS در محیطهای داخلی از 20 تا 80 μT متغیر است. MFS در یک مکان مشخص، تغییرات مشابهی با مکانهای مجاور خواهد داشت. بنابراین، هنگام در نظر گرفتن یک منطقه بزرگ، تشخیص به طور چشمگیری کاهش می یابد. بنابراین، استفاده مستقیم از MFS برای موقعیت یابی غیرممکن است. این مقاله بحث میکند که آیا الگوریتم CDPC میتواند برای انتخاب نقطه مرکزی MFS برای افزایش دقت موقعیتیابی استفاده شود یا خیر.
در [ 19 ]، KNN برای یافتن بهترین تطابق از پایگاه داده اثر انگشت ساخته شده مورد استفاده قرار گرفت. با این حال، آزمایشها نشان داد که عملکرد چندان رضایتبخش نبود، زیرا سیستم به نویز سیگنال حساس بود. به منظور افزایش پایداری سیستم محلیسازی، رویکردهای بومیسازی فیلتر مبتنی بر بیزی در [ 20 ] پیشنهاد شد. با این حال، قابلیت ردیابی سیستم محلی سازی تحت تأثیر فیلتر قرار گرفت. یک سیستم محلی سازی مبتنی بر SVM که مشکل محلی سازی را به یک مسئله طبقه بندی تبدیل می کند در [ 21 ] پیشنهاد شد.]. با توسعه شبکه های عصبی (NN)، محققان از مدل های NN کم عمق برای محلی سازی استفاده کرده اند. با این حال، این مدل ها ساختارهای کم عمقی دارند و منجر به توانایی یادگیری محدود می شوند. بنابراین، نمی تواند مجموعه بزرگی از سیگنال های ارتعاشی عظیم را مدیریت کند و عملکرد محلی سازی خیلی خوب نیست [ 11 ]. افزایش قدرت محاسباتی کامپیوتر و کاربرد موفقیت آمیز یادگیری عمیق به محققان روش جدیدی برای بهبود عملکرد بومی سازی می دهد. یک مطالعه [ 22 ] کاربرد شبکه های عصبی کانولوشن را برای محلی سازی بررسی کرد. دیگری [ 11 ] از رمزگذار خودکار حذف نویز انباشته و DNN چهار لایه برای یادگیری ویژگی های قابل اعتماد استفاده کرد. به منظور افزایش بیشتر دقت محلی سازی، [ 23] اطلاعات وضعیت کانال (CSI) و یادگیری عمیق برای بومی سازی. SVM و DNN برای محلی سازی داخلی و خارجی استفاده شد [ 24 ]. با استفاده از شبکه عصبی کانولوشن، یک روش محلی سازی اثر انگشت بی سیم ترکیبی برای محلی سازی داخلی [ 25 ] پیشنهاد شد. با این حال، سخت افزار گران قیمت اضافی برای به دست آوردن اطلاعات CSI مورد نیاز است و حجم کاری پیش پردازش داده ها بسیار زیاد است. بنابراین، این رویکرد نامناسب و غیرعملی است [ 26 ].
این اثر در مقایسه با آثار دیگر سه تفاوت دارد. ابتدا، اندازهگیریهای سیگنال جمعآوریشده برای محلیسازی به تصویر مقیاس خاکستری اثر انگشت تبدیل شد. دوم، الگوریتم CDPC یادگیری بدون نظارت ابتدا برای یافتن نقاط مرکزی MFS استفاده میشود و این MFSهای انتخاب شده برای بهبود عملکرد محلیسازی مورد استفاده قرار میگیرند. سوم، در این کار، یک ساختار یادگیری عمیق سلسله مراتبی دو سطحی برای استخراج ویژگیهای کلیدی از سیگنالهای Wi-Fi و مغناطیسی عظیم و با نوسان گسترده استفاده میشود. علاوه بر این، یادگیری انتقال مبتنی بر MLP برای تنظیم دقیق بومی ساز درشت Resnet آموزش دیده برای به دست آوردن محلی ساز خوب معرفی شده است. علاوه بر این، سیستم محلی سازی ما به هیچ اطلاعات جهت گیری نیاز ندارد. بنابراین، هنگام بومی سازی، هیچ الزامات جهت گیری برای تلفن وجود ندارد. متفاوت از روشهای محلیسازی فوق، در این مقاله، روش پیشنهادی ما به سختافزار گرانقیمت اضافی متکی نیست و وظیفه بومیسازی تنها توسط یک گوشی هوشمند قابل تحقق است. بنابراین، سیستم محلی سازی پیشنهادی ما جهانی و مقرون به صرفه است.
3. راه حل پیشنهادی
در این مقاله، ما یک محیط محلی سازی معمولی را با گوشی هوشمندی که اندازه گیری های RSSI و MFS را از AP های Wi-Fi و میدان های مغناطیسی اطراف دریافت می کند، در نظر گرفتیم. همانطور که در شکل 3 نشان داده شده است، هدف از محلی سازی یافتن مکان گوشی هوشمند از اندازه گیری سیگنال جمع آوری شده است. سیستم محلی سازی از شش ماژول کاربردی تشکیل شده است: جمع آوری داده، انتخاب داده، پیش پردازش داده، ساخت تصویر اثر انگشت، آموزش DNN و محلی سازی DNN. سنسورهای متعدد مجهز به تلفن های هوشمند امکان خواندن سیگنال های Wi-Fi و MFS را فراهم می کند. هدف از انتخاب داده ها استفاده از الگوریتم CDPC برای یافتن نقطه مرکزی MFS است و با ترکیب MFS انتخاب شده با Wi-Fi RSSI، می توان دقت محلی سازی را بهبود بخشید. اندازهگیریهای سیگنال به تصاویر تبدیل شدند تا مجموعه دادههای تصویر اثر انگشت را تشکیل دهند. علاوه بر این، اطلاعات محلی سازی شامل تصویر اثر انگشت و مکان آن است. هدف از پیش پردازش داده ها یافتن سیگنال هایی با قدرت بالا و سازگار ساختن آن برای تشکیل تصاویر اثر انگشت است. پس از ساخت پایگاه داده تصویر اثر انگشت، DNN پیشنهادی برای آموزش با آن استفاده شد. سپس، پایگاه داده پارامتر DNN مدل محلی سازی پیشنهادی را برای محلی سازی آنلاین ذخیره می کند. در فاز آنلاین، با استفاده از مدل DNN آموزش دیده، از تصویر اثر انگشت ساخته شده برای تطبیق با مجموعه داده های تصویر اثر انگشت برای تخمین مکان استفاده می شود. علاوه بر این، DNN مورد استفاده در این مقاله شامل آموزش انتقال مبتنی بر Resnet و MLP است. در بخشهای بعدی، مراحل پیادهسازی و الگوریتمهای مربوط به سیستم محلیسازی پیشنهادی را به تفصیل شرح خواهیم داد. پایگاه داده پارامتر DNN مدل محلی سازی پیشنهادی را برای محلی سازی آنلاین ذخیره می کند. در فاز آنلاین، با استفاده از مدل DNN آموزش دیده، از تصویر اثر انگشت ساخته شده برای تطبیق با مجموعه داده های تصویر اثر انگشت برای تخمین مکان استفاده می شود. علاوه بر این، DNN مورد استفاده در این مقاله شامل آموزش انتقال مبتنی بر Resnet و MLP است. در بخشهای بعدی، مراحل پیادهسازی و الگوریتمهای مربوط به سیستم محلیسازی پیشنهادی را به تفصیل شرح خواهیم داد. پایگاه داده پارامتر DNN مدل محلی سازی پیشنهادی را برای محلی سازی آنلاین ذخیره می کند. در فاز آنلاین، با استفاده از مدل DNN آموزش دیده، از تصویر اثر انگشت ساخته شده برای تطبیق با مجموعه داده های تصویر اثر انگشت برای تخمین مکان استفاده می شود. علاوه بر این، DNN مورد استفاده در این مقاله شامل آموزش انتقال مبتنی بر Resnet و MLP است. در بخشهای بعدی، مراحل پیادهسازی و الگوریتمهای مربوط به سیستم محلیسازی پیشنهادی را به تفصیل شرح خواهیم داد.
3.1. الگوریتم انتخاب داده پیشنهادی
برای اندازهگیری میدان مغناطیسی، الگوریتم CDPC یادگیری بدون نظارت برای انتخاب چندین نقطه مرکزی برای انعکاس بهتر توزیع MFS در هر RP استفاده میشود. ترکیب MFS انتخاب شده و Wi-Fi RSSI می تواند دقت سیستم محلی سازی را بهبود بخشد.
خوشهبندی با جستجوی سریع و یافتن پیکهای چگالی نماینده یک الگوریتم خوشهبندی چگالی است. ایده اصلی الگوریتم DPC بر دو فرض استوار است: (1) مرکز خوشه توسط چند نقطه با چگالی کمتر احاطه شده است. و (2) این مراکز فاصله نسبتاً بیشتری با نقاط چگالی بالاتر دارند [ 27 ].
این دو فرض، معیارهای مراکز خوشه ای را ارائه می دهند و معیارهای آزمون را برای مراکز بالقوه خوشه ای ارائه می دهند. دو پارامتر مهم، چگالی ρ�و فاصله نسبی δ�، قابل محاسبه است.
یک مجموعه داده خوشه بندی است ایکس= { x 1 ، x 2 ، … ، x n }ایکس={ایکس1،ایکس2،…،ایکس�}، جایی که x iایکسمن، 1 ≤ i ≤ n1≤من≤�بردار است با مترمترویژگی های. ایکسiایکسمنرا می توان به صورت بیان کرد x i = { x i 1 , x i 2 , … , x i m }ایکسمن={ایکسمن1،ایکسمن2،…،ایکسمنمتر}و فاصله اقلیدسی د( من ، ج )د(من،�)برای x iایکسمنو x jایکس�را می توان به صورت زیر نشان داد:
پس از محاسبه فاصله اقلیدسی، الگوریتم DCP را می توان با روش زیر انجام داد.
چگالی محلی را تعریف کنید ρمن�مننقطه داده منمن
جایی که دجدجفاصله قطع است و معمولاً براساس تجربه به عنوان پارامتر وارد شده به صورت دستی استفاده می شود.
فرض کنید N نقطه داده وجود دارد و فاصله بین هر نقطه است ند= (ن2)ند=(ن2). این فاصله ها به ترتیب صعودی مرتب شده اند. [ خطای پردازش ریاضی ]⌈ند×پ⌉موقعیت است [ خطای پردازش ریاضی ]دجبه این ترتیب، کجا [ خطای پردازش ریاضی ]پپارامتر درصد ورودی دستی است و [ خطای پردازش ریاضی ]⌈.⌉عملکرد سلولی است.
ایده از [ خطای پردازش ریاضی ]�من=∑من�(دمن�-دج)کشف تعداد نقاطی در فضای داده است که کمتر از [ خطای پردازش ریاضی ]دجاز نقطه داده [ خطای پردازش ریاضی ]من.
فاصله نسبی سنتی [ خطای پردازش ریاضی ]�: برای هر گره [ خطای پردازش ریاضی ]من، گره ای با چگالی بالاتر از [ خطای پردازش ریاضی ]�را می توان یافت. فاصله بین گره ها را محاسبه کنید [ خطای پردازش ریاضی ]منو [ خطای پردازش ریاضی ]�، و کوچکترین را تعریف کنید [ خطای پردازش ریاضی ]دمن�مانند [ خطای پردازش ریاضی ]�من. اگر گره [ خطای پردازش ریاضی ]منپس بیشترین چگالی را دارد [ خطای پردازش ریاضی ]�منحداکثر فاصله از آن نقطه تا نقاط دیگر است.
در این مقاله، ما یک فاصله قابل مقایسه را برای بهبود فرضیه دوم DPC پیشنهاد میکنیم. الگوریتم DPC از نظر کمی مقایسه نمی کند [ خطای پردازش ریاضی ]�من. بنابراین، انتخاب یک متغیر جدید برای جایگزینی [ خطای پردازش ریاضی ]�مناندازه نسبی را در الگوریتم منعکس می کند. بر اساس شرایط فوق مبلغی [ خطای پردازش ریاضی ]زمنکه شبیه به [ خطای پردازش ریاضی ]�منبه صورت زیر تعریف می شود:
جایی که [ خطای پردازش ریاضی ]زمننشان دهنده فاصله از نقطه است [ خطای پردازش ریاضی ]منبه منطقه کم تراکم که مقدار بسیار مناسبی برای مقایسه است [ خطای پردازش ریاضی ]�من.
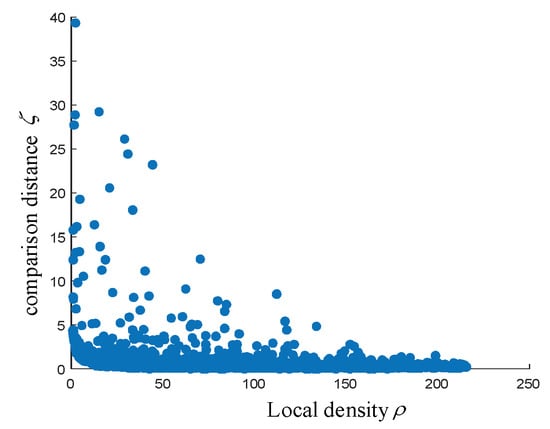
با این فرضیه مشخص می شود که نقطه ای با چگالی بیشتر و فاصله نسبی بیشتر، نقطه مرکز خوشه است. از این رو، محاسبات پس از هر نقطه از چگالی محلی است [ خطای پردازش ریاضی ]�و فاصله نسبی [ خطای پردازش ریاضی ]زمن. شکل 4 نمودار تصمیم گیری برای آزمایش های ما را نشان می دهد. [ خطای پردازش ریاضی ]�من=�من×زمنبرای یافتن چندین مقدار حداکثر محاسبه می شود. این مقادیر حداکثر به عنوان نقاط مرکزی استفاده می شود و توزیع کلی اندازه گیری مغناطیسی را منعکس می کند.
3.2. پیش پردازش داده ها
هدف از پیش پردازش داده ها یافتن سیگنال هایی با قدرت بالا و سازگار ساختن آنها با یک تصویر RGB است. به منظور از بین بردن اثر نامطلوب سیگنالهای Wi-Fi ضعیف بر محلیسازی، هشت سیگنال Wi-Fi قویتر را در هر RP انتخاب کردیم. در سیستم محلی سازی پیشنهادی ما، پایگاه داده اثر انگشت بر اساس تصویر ساخته شد. بنابراین، هدف از پیش پردازش داده ها تطبیق اندازه گیری سیگنال با یک تصویر بود. به طور کلی، یک تصویر RGB معمولی شامل سه ماتریس کانال است و مقادیر در ماتریس بین 0 تا 255 است. بنابراین، اندازه گیری Wi-Fi بر اساس [ خطای پردازش ریاضی ]�=|آراساسمن|.
3.3. ساخت تصویر اثر انگشت
متفاوت از کارهای دیگری که از داده های سیگنال خام برای ساخت پایگاه داده اثر انگشت استفاده می کنند [ 13 ، 16 ]، این مقاله روش جدیدی را برای ساخت مجموعه داده های تصویر اثر انگشت پیشنهاد می کند. با در نظر گرفتن تأثیر طول های مختلف داده و مجموعه های AP بر دقت محلی سازی، ماژول ساخت تصویر اثر انگشت، در هر شبکه، تمام تصاویر اثر انگشت را در اندازه و مجموعه AP یکسان عادی می کند. این ماژول هم در مراحل تمرین و هم در مراحل تطبیق استفاده می شود. تفاوت این است که در مرحله آموزش، تصاویر اثر انگشت برچسب گذاری می شوند و باید برچسب را در مرحله تطبیق پیش بینی کرد.
متفاوت از روش سنتی پردازش داده های توالی، ما داده های جمع آوری شده را برای استخراج ویژگی به تصاویر اثر انگشت تبدیل کردیم. دادههای حسگر جمعآوریشده شامل یک سری MFS، RSSI و چندین AP بود. به طور کلی، یک تصویر معمولی یک ماتریس سه کاناله است که به ترتیب دارای کانال های قرمز، سبز و آبی است. بنابراین، برای ساخت تصویر اثر انگشت، باید دادههای جمعآوریشده را دوباره مرتب کنیم.
در سیستم محلی سازی پیشنهادی، تصویر اثرانگشت ساخته شده باید به همان اندازه استاندارد شود. تصویر اثر انگشت [ خطای پردازش ریاضی ]افاز یک قسمت مغناطیسی تشکیل شده است [ خطای پردازش ریاضی ]افمترآ�و یک بخش Wi-Fi RSSI [ خطای پردازش ریاضی ]اف�سسمن. تصویر اثر انگشت را می توان به صورت زیر ساخت:
جایی که [ خطای پردازش ریاضی ]�تعداد نقاط مرکزی انتخاب شده توسط الگوریتم CDPC است و برابر است با تعداد اندازه گیری های RSSI جمع آوری شده در هر RP. [ خطای پردازش ریاضی ]کتعداد APهای شناسایی شده در مناطق محلی سازی است. بنابراین، MFS [ خطای پردازش ریاضی ]افمترآ�به صورت a ذخیره می شود [ خطای پردازش ریاضی ]1×�بردار تصویر اثر انگشت Wi-Fi RSSI به صورت یک ذخیره می شود [ خطای پردازش ریاضی ]ک×�ماتریس در این صفحه، [ خطای پردازش ریاضی ]افبرای تشکیل ماتریس های کانال قرمز، سبز و آبی استفاده می شود. بنابراین، تصویر اثر انگشت را می توان ساخت. سپس، از همین روش برای تشکیل مجموعه داده های تصویر اثر انگشت استفاده می شود.
3.4. مقدمه DNN پیشنهادی
در این مقاله، DNN پیشنهادی حاوی یک بومی ساز درشت مبتنی بر Resnet و یک بومی ساز خوب مبتنی بر یادگیری انتقال است. DNN مورد استفاده در سیستم محلی سازی ما می تواند به طور خودکار ویژگی های سیگنال را یاد بگیرد و می تواند تفاوت بین ویژگی های اثر انگشت را در نقاط طبقه بندی مختلف تشخیص دهد. با این حال، مجموعه داده جمع آوری شده نسبتا کوچک است، که دقت محلی سازی را کاهش می دهد. بنابراین، با الهام از ایده یادگیری انتقالی، یک استراتژی آموزش سلسله مراتبی دو سطحی اتخاذ شده است. ابتدا Resnet برای آموزش با پایگاه داده تصویر اثر انگشت استفاده می شود و مدل محلی سازی را رزرو کردیم. سپس MLP بعد از Resnet اضافه می شود و از مدل جدید برای آموزش انتقال استفاده کردیم.
3.4.1. معرفی شبکه باقیمانده عمیق
الگوریتم DNN برای پیشبینی مکانهای تجهیزات کاربر (UE) پیشنهاد شده است. از آنجایی که ما مکانها را به برچسب تبدیل کردیم، نتایج پیشبینیشده شناسههای این برچسبها بود. علاوه بر این، محلیسازی پیشنهادی از یک بومیساز درشت مبتنی بر Resnet و یک بومیساز خوب مبتنی بر یادگیری انتقال تشکیل شده است.
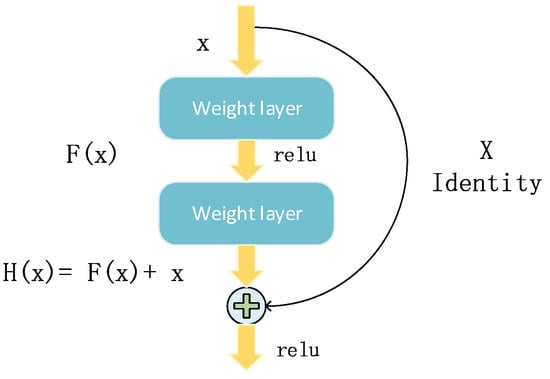
با توسعه یادگیری عمیق، محققان دریافته اند که با افزایش تعداد لایه های شبکه عصبی، توانایی یادگیری شبکه افزایش می یابد. با این حال، به دلیل مشکل بیش از حد برازش، توانایی تعمیم با عمیقتر شدن شبکه کاهش مییابد. این مشکل مدت هاست که محققان را به دردسر انداخته است. با تحقیقات بیشتر، [ 28 ] مدل باقیمانده عمیق را پیشنهاد کرد و با موفقیت توانایی یادگیری شبکه را بهبود بخشید. همانطور که در شکل 5 نشان داده شده است ، مدل باقیمانده با افزودن یک اتصال پرش ساخته شده است. یادگیری برای نقشه هدف [ خطای پردازش ریاضی ]اچ(ایکس)تبدیل می شود [ خطای پردازش ریاضی ]اچ(ایکس)=اف(ایکس)+ایکس، و یادگیری [ خطای پردازش ریاضی ]اف(ایکس)راحت تر از [خطای پردازش ریاضی ]اچ(ایکس). با تجمع چندین ماژول باقیمانده، مشکل تخریب DNN را می توان به طور موثر کاهش داد و عملکرد را بهبود بخشید.
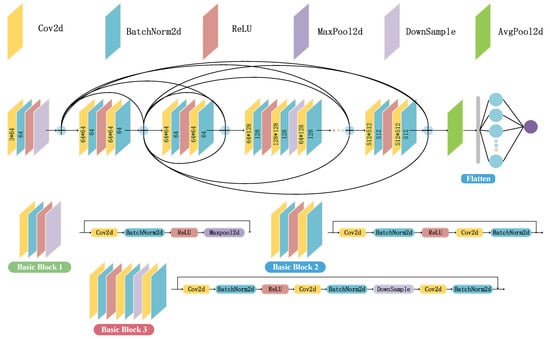
شکل 6 مدل Resnet پیشنهادی را نشان می دهد و از یک بلوک پایه 2، چهار بلوک پایه 2، سه بلوک پایه 3، یک لایه ادغام متوسط و یک لایه MLP تشکیل شده است. هر بلوک پایه یک ماژول باقیمانده است، و زمانی که بیش از حد برازش اتفاق میافتد، DNN برخی از بلوکهای باقیمانده را رد میکند و به آموزش ادامه میدهد. در این مقاله از SELU به عنوان تابع فعال سازی استفاده شده است. علاوه بر این، از دست دادن آنتروپی متقاطع به عنوان تابع تلفات استفاده می شود [ خطای پردازش ریاضی ]اس��تیحداکثرطبقه بندی. فرآیند محاسبه دقیق لایه های مختلف را می توان در [ 29 ] مشاهده کرد.
3.4.2. مقدمه آموزش انتقالی
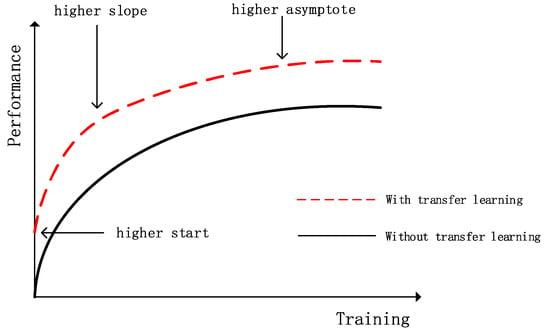
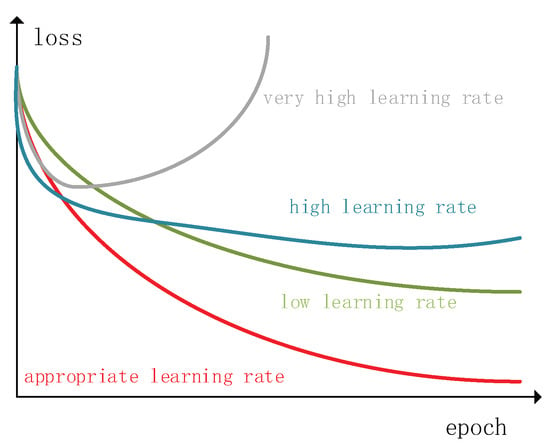
یادگیری انتقالی محاسن زیادی دارد. همانطور که در شکل 7 نشان داده شده است ، یادگیری انتقالی شروع بالاتر، شیب بالاتر و مجانبی بالاتر دارد. بنابراین، برای به دست آوردن بهترین مدل بومی سازی در این مقاله، یک مدل بومی ساز درشت مبتنی بر Resnet و مدل بومی ساز ظریف مبتنی بر یادگیری انتقال برای به حداکثر رساندن دقت بومی سازی استفاده شد. این دو مدل بومی ساز نیاز به آموزش جداگانه دارند. به طور خاص، Resnet ابتدا برای آموزش با مجموعه داده های تصویر اثر انگشت استفاده می شود. پس از تکمیل فرآیند آموزش، مدل Resnet آموزش دیده را رزرو کردیم و MLP را بعد از Resnet برای آموزش انتقال اضافه کردیم. مدل یادگیری انتقال مبتنی بر MLP از اطلاعات قبلی از Resnet آموزش دیده استفاده کرد تا دقت محلی سازی را به حداکثر برساند.
همانطور که در شکل 8 نشان داده شده است ، در این مقاله، یادگیری انتقال مبتنی بر MLP برای تنظیم دقیق Resnet و افزایش بیشتر دقت محلی سازی استفاده می شود. ابتدا، Resnet برای آموزش با پایگاه داده تصویر اثر انگشت استفاده می شود. پس از اتمام مراحل آموزشی، مدلی از قبل آموزش دیده به نام coarse localizer به دست آوردیم. سپس مدل Resnet آموزش دیده را رزرو کردیم و بعد از آن MLP را اضافه کردیم. در نهایت، این مدل جدید ساخته شده برای آموزش بیشتر با پایگاه داده تصویر اثر انگشت استفاده شد. این مدل مبتنی بر یادگیری انتقالی بهعنوان مدل محلیسازی نهایی به نام محلیساز خوب استفاده شد.
4. نتایج تجربی
4.1. راه اندازی آزمایش ها
آزمایش ها در هر دو محیط داخلی و خارجی انجام شد که به صدها شبکه تقسیم شدند. شخصی راه می رفت و گوشی هوشمند مجهز به حسگرهای بی سیم را در دست داشت که می توانست MFS و RSSI را از محیط اطراف دریافت کند. در هر شبکه، یک سری از این اندازهگیریهای سیگنال در چهار تا شش مکان برای مقابله با بیثباتی سیگنال جمعآوری شد. علاوه بر این، این فرآیند پنج بار به فاصله پنج روز انجام شد. بنابراین، این اندازه گیری ها می توانند به طور کامل توزیع کلی سیگنال ها را منعکس کنند. در مرحله تطبیق، هدف یافتن مکان UE ها با مجموعه ای از داده های MFS و RSSI و مقایسه آن با مکان واقعی بود.
تعداد دوره های آموزشی به شدت بر عملکرد DNN تأثیر می گذارد. دوره های آموزشی بسیار کم، استخراج کامل ویژگی های مجموعه داده را برای مدل دشوار می کند. برعکس، دوره های آموزشی بیش از حد منجر به بیش از حد تناسب خواهد شد. به منظور حل این مشکل و به حداکثر رساندن دقت محلی سازی، مجموعه داده اثر انگشت به 60٪ مجموعه آموزشی، 20٪ مجموعه اعتبار سنجی و 20٪ مجموعه تست تقسیم شد. در هر دوره آموزشی، دقت محلی سازی جدیدی ایجاد خواهد شد. مدل DNN بهترین پارامترهای مدل دقت محلی سازی خود را ذخیره می کند. بنابراین مدل DNN به طور کامل آموزش داده خواهد شد و مدلی را با بهترین دقت بومی سازی به عنوان مدل نهایی انتخاب خواهیم کرد. برای افزایش بیشتر استحکام DNN پیشنهادی در این مقاله، چندین رویکرد افزایش داده اتخاذ شد. اولین، تصاویر اثر انگشت به 224*224 استاندارد شدند. دوم، بخشهایی از تصاویر اثر انگشت به اندازه 1.25 اندازه اصلی آن بزرگتر شدند، یا راه دیگر چرخاندن تصادفی تصاویر اثر انگشت به میزان 15 درجه بود. علاوه بر این، مومنتوم به نرمال سازی دسته ای اضافه شد تا سرعت تمرین افزایش یابد.
شکل 9 الف پلان طبقه داخلی را برای محلی سازی نشان می دهد و منطقه مورد نظر به 96 شبکه با اندازه 2 متر مربع تقسیم شده است. تعداد کل APهای جمع آوری شده 87 بود. بنابراین، ساختار DNN پیشنهادی شامل 137 واحد ورودی و 96 واحد خروجی بود. شکل 9 ب محیط آزمایشی در فضای باز را نشان می دهد که در یک باغ اجتماعی انجام شده است. محوطه فضای باز به 54 شبکه با اندازه 3 متر مربع تقسیم شد. تعداد کل APهای جمع آوری شده 161 بود. سیستم محلی سازی بر روی رایانه شخصی Dell با کارت گرافیک RTX2060 پیاده سازی شد. این قابلیت پردازش داده قدرتمندی در مقایسه با پلتفرم های گوشی های هوشمند دارد. مدلهای موقعیتیابی پیشنهادی، پیشپردازش دادهها و روشهای افزایش داده در Matlab و Pytorch پیادهسازی شدند.
4.2. تأثیر MFS و میزان یادگیری
LR یک فراپارامتر حیاتی در یادگیری عمیق است. در طول فرآیند آموزش، LR مناسب به افزایش توانایی اتصال و بهبود سرعت آموزش DNN کمک می کند. برعکس، LR نامناسب باعث همگرایی شبکه به حداقل محلی می شود و توانایی یادگیری را تا حد زیادی کاهش می دهد. با این حال، همانطور که در شکل 10 نشان داده شده است ، انتخاب یک LR مناسب دشوار است. علاوه بر این، یک LR ثابت ممکن است باعث شود که شبکه بین کوچکترین نقطه به عقب و جلو نوسان کند [ 29 ]. برای حل این مشکل، LR نیاز به تنظیم پویا برای بهبود همگرایی شبکه دارد. بنابراین، در این مدل DNN طراحی شده، LR اولیه 0.001 تنظیم شد و پس از هر 35 دوره، LR را به صورت پویا به نصف اندازه اصلی آن تنظیم کردیم.
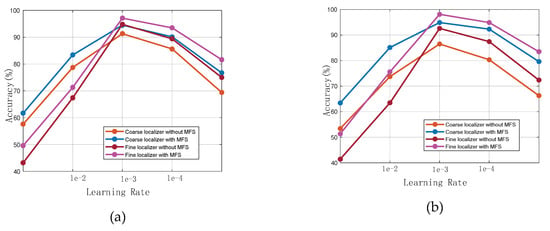
همانطور که در شکل 11 نشان داده شده است ، ما عملکرد بومی سازی بومی ساز پیشنهادی خود را با توجه به LR و MFS آزمایش کردیم. شکل 11 نشان می دهد که دقت محلی سازی زمانی به بالاترین حد خود رسید که برداشت LR 1 × 10-3 بود.. این یک LR مناسب برای DNN برای همگرایی به حداقل جهانی است. همچنین می توان مشاهده کرد که MFS به طور موثر به بهبود عملکرد محلی سازی هم برای محلی ساز درشت و هم برای محلی ساز خوب کمک می کند. این احتمالاً به این دلیل است که MFS انتخاب شده ویژگی های محلی سازی را غنی کرده است. محلی ساز خوب با LR نامناسب بدتر از محلی ساز درشت عمل کرد. این ممکن است به این دلیل باشد که شبکه قبلاً در ابتدای آموزش در حداقل محلی بود و همگرایی مؤثر دشوار بود. با LR مناسب، بومی ساز دقیق مبتنی بر یادگیری انتقال می تواند به طور موثر از اطلاعات قبلی بومی ساز درشت از پیش آموزش دیده برای دستیابی به عملکرد محلی سازی بهتر استفاده کند.
4.3. تأثیر تعداد مختلف نورون ها و لایه های پنهان
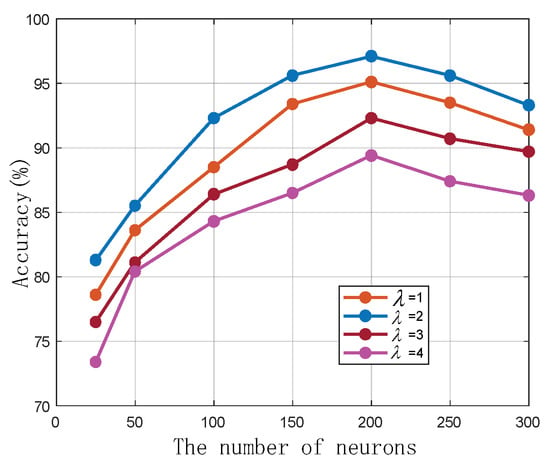
تعداد نورون ها و لایه های پنهان به شدت بر DNN تأثیر می گذارد. بنابراین، ما تأثیر آنها را بر عملکرد بومیسازی مقایسه کردیم. [ خطای پردازش ریاضی ]�تعداد لایه های پنهان را نشان می دهد. شکل 12 نشان می دهد که با افزایش تعداد نورون ها، دقت محلی سازی ابتدا افزایش یافته و سپس کاهش می یابد. روند نزولی مشخص نبود. با این حال، این مورد در هنگام آزمایش با تعداد لایه های پنهان نبود. دقت محلیسازی زمانی که DNN عمیقتر میشود بدتر میشود، زیرا لایههای بیش از حد، انتشار گرادیانها بین هر لایه پنهان را دشوار میکند. بهترین عملکرد محلی سازی با دو لایه MLP پنهان و 200 نورون در هر لایه پنهان به دست آمد.
4.4. تأثیر نرخ های مختلف ترک تحصیل
برای جلوگیری از مشکل overfitting، یک لایه dropout بین هر لایه MLP استفاده شد. در طول مرحله آموزش، لایه حذف به طور تصادفی نورون های ورودی را روی 0 قرار می دهد. به این ترتیب، می تواند تعداد ویژگی های میانی را کاهش دهد و در نتیجه افزونگی را کاهش دهد، یعنی متعامد بودن بین هر ویژگی را افزایش دهد. جدول 1 تأثیر نرخ های مختلف ترک تحصیل را بر عملکرد بومی سازی نشان می دهد. مشاهده می شود که دقت محلی سازی زمانی که نرخ ترک تحصیل 0.6 بود به اوج 97.1% رسید. با این حال، اگر MLP دارای یک لایه حذفی نبود، بهترین دقت محلی سازی 94.7٪ بود که کمتر از بهترین نتیجه است. این به این دلیل است که مشکل بیش از حد برازش رخ داده است. بنابراین، برای حل مشکل اضافه برازش، از یک لایه dropout استفاده شد.
4.5. تأثیر نرخ یادگیری پویا و روش های افزایش داده ها
به منظور افزایش بیشتر توانایی تعمیم مدل DNN. LR به صورت پویا تنظیم شد و چندین روش افزایش داده به کار گرفته شد. جدول 2 تأثیر روش های LR پویا و افزایش داده ها را بر دقت محلی سازی نشان می دهد. مشاهده می شود که این دو روش به طور قابل توجهی توانایی تعمیم DNN را بهبود می بخشد.
4.6. مقایسه با سایر الگوریتم ها
به منظور ارزیابی الگوریتم پیشنهادی با سایر الگوریتمها، آزمایشهای مختلفی انجام شد. شکل 13عملکرد بومی سازی الگوریتم پیشنهادی را با سایر الگوریتم های یادگیری موجود نشان می دهد. دادههای Wi-Fi خام جمعآوریشده و MFS انتخابشده برای ساخت اثر انگشت استفاده شد و به عنوان ورودیهای GRNN، KNN، WKNN، SVM و MLP استفاده شد. شایان ذکر است که مجموعه داده تصویر اثر انگشت با اندازه گیری سیگنال خام جمع آوری شده ساخته شده است. سپس، این الگوریتم های یادگیری برای آزمایش های مقایسه ای مورد استفاده قرار گرفتند. هنگام استفاده از SVM چند کلاسه برای موقعیت یابی، هسته گاوسی به عنوان تابع هسته استفاده می شود، با مقیاس هسته روی sqrt(P)/4، که در آن P تعداد پیش بینی کننده ها است. برای GRNN، ما ضریب هموارسازی آن را روی 1 قرار دادیم. برای SVM، 80٪ از مجموعه داده برای آموزش و 20٪ باقی مانده برای پیش بینی استفاده شد. MLP شامل سه لایه پنهان است. الگوریتم CNN شامل یک لایه کانولوشن است، یک لایه عادی سازی دسته ای، یک تابع فعال سازی ReLU و دو لایه پیشخور. نتایج آزمایش نشان داد که بومی ساز پیشنهادی نسبت به سایر رویکردهای بومی سازی برتری دارد. این به این دلیل است که مدلهای دیگر ساختار کم عمقی داشتند که منجر به توانایی یادگیری محدود میشد. محلیساز پیشنهادی ساختار عمیقی داشت و میتوانست برای استخراج ویژگیهای قابل اعتماد از مجموعه بزرگی از نمونههای سیگنال در نوسان به خوبی عمل کند.
5. نتیجه گیری ها
در این مطالعه، ما یک رویکرد آموزش سلسله مراتبی دو سطحی را ارائه کردهایم که شامل یک چارچوب یادگیری عمیق برای محلیسازی داخلی و خارجی با Wi-Fi و انگشت نگاری مغناطیسی است. با استفاده از یادگیری بدون نظارت، الگوریتم CDPC می تواند نقاط مرکزی MFS را برای ساخت پایگاه داده تصویر اثر انگشت با اندازه گیری های Wi-Fi انتخاب کند. سپس، Resnet برای آموزش با پایگاه داده تصویر اثر انگشت و دریافت محلیساز درشت استفاده میشود. به منظور افزایش عملکرد بومی سازی، بومی ساز دقیق یادگیری انتقال مبتنی بر MLP برای اصلاح نتایج بومی سازی بر اساس دانش قبلی از بومی ساز درشت آموزش دیده استفاده می شود. ما سیستم محلی سازی پیشنهادی خود را در مناطق داخلی و خارجی ارزیابی کرده ایم. نتایج تجربی مختلف برتری سیستم محلی سازی ما را نشان داده اند.










بدون دیدگاه