

خلاصه
کلید واژه ها:
تقسیم بندی معنایی ; تقسیم بندی منطقه آب ; رمزگذار – رمزگشا ; پیچیدگی قابل تفکیک عمیق ; شبکه باقی مانده
1. معرفی
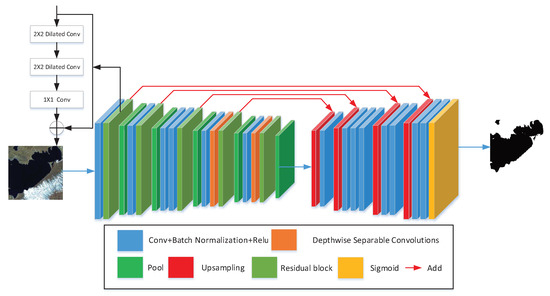
2. روش پیشنهادی
2.1. نمای کلی مدل
2.2. طراحی رمزگذار
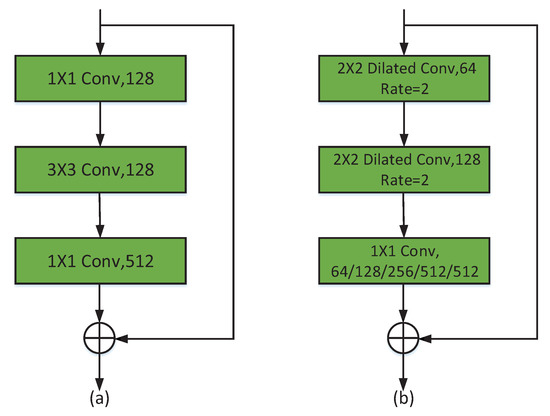
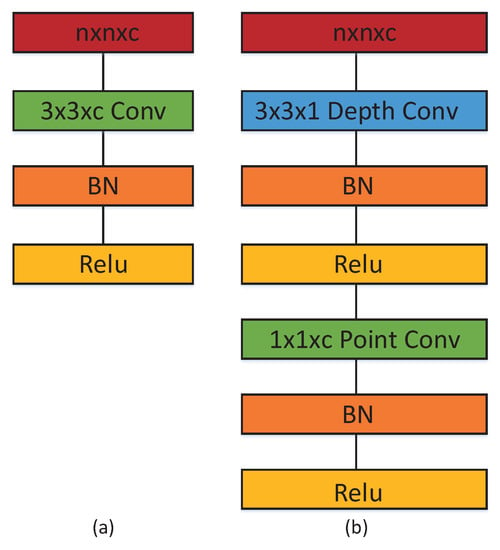
2.2.1. بلوک باقیمانده اصلاح شده
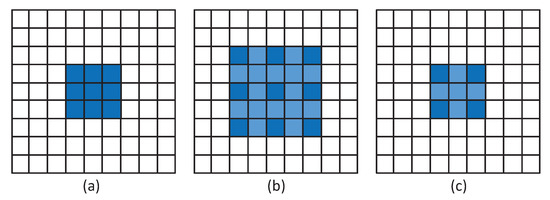
در مقایسه با SR-SegNet v1، SR-SegNet v2 3 × 3 هسته کانولوشن را در بلوک باقیمانده خود با 2 × 2 پیچش گشاد شده، با نرخ اتساع 2 جایگزین می کند. در شکل 2 b، شماره کانال اول 2 × 22×2لایه پیچیدگی دو برابر دومی است و هسته های کانولوشن 1×1 نهایی به ترتیب از کانال های 64، 128، 256، 512 و 512 برای پنج بلوک باقیمانده اصلاح شده در SR-SegNet استفاده می کنند. با توجه به معادله ( 1 )، میدان پذیرنده هسته کانولوشن 3×3 استاندارد 3 است که m اندازه میدان پذیرنده لایه قبلی، گام اندازه گام پیچیدگی و K اندازه هسته کانولوشن است.
معادله ( 2 ) برای محاسبه میدان پذیرنده یک پیچش گشاد شده است، که در آن نرخ نشان دهنده نرخ اتساع، اندازه هسته پیچشی K و اندازه هسته پیچشی با پیچش گشاد شده K است.دد.
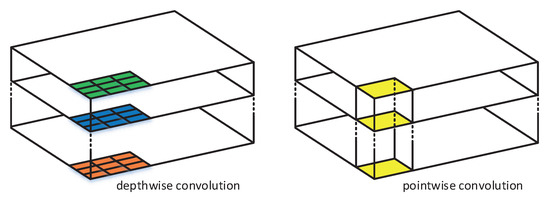
2.2.2. Depthwise Separable Convolution Construction
2.3. طراحی رمزگشا
3. آزمایش و تجزیه و تحلیل نتایج
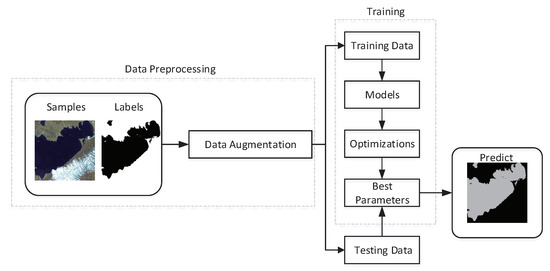
3.1. افزایش داده ها
3.2. معیارهای ارزیابی
برای ارزیابی عملکرد کمی مدلهای مختلف، چهار معیار ارزیابی انتخاب شدند: دقت، تاس، امتیاز F1 و Miou.
که در آن “AC” به عنوان تعداد پیکسل هایی که به درستی در یک تصویر طبقه بندی شده اند تعریف می شود. تاس برای اندازه گیری شباهت بین دو تصویر استفاده می شود. «دقت» نسبت پیکسلهای مثبت طبقهبندی شده به همه پیکسلهای مثبت پیشبینیشده است. «یادآوری» درصدی از پیکسلهای مثبت طبقهبندی شده به همه پیکسلهای مثبت واقعی است. “F1” ترکیبی از دقت و نرخ فراخوان است. و ‘Miou’ برای توصیف دقت تقسیم بندی استفاده می شود [ 37 ]. TP مثبت واقعی، TN منفی واقعی، FP مثبت کاذب و FN منفی کاذب است. فرمول های محاسبه در معادلات ( 3 )-(8) نشان داده شده است.
3.3. تنظیم و آموزش آزمایش
در این آزمایش، VGGNet به عنوان شبکه ستون فقرات استفاده شد، و وزنه های رسمی VGGNet منتشر شده توسط keras به عنوان وزنه های قبل از تمرین استفاده شد. DeconvNet، FCN32s، FCN16s و FCN8s به عنوان شبکه های مقایسه انتخاب شدند. در این مقاله، SR-SegNet v1 و SR-SegNet v2 پیشنهاد شده است. بلوک باقیمانده SR-SegNet v1 از پیچش های گشاد شده استفاده نمی کند، و بلوک باقیمانده SR-SegNet v2 از 2 × 2 پیچش گشاد شده با نرخ اتساع 2 استفاده می کند. در طول مرحله تمرین، بهینه ساز SGD [ 38] با نرخ یادگیری اولیه 0001/0 استفاده شد. تکانه روی 0.9 و کاهش وزن روی 0.0005 تنظیم شد. همه مدلها برای 300 دوره با اندازه کوچک 2 آموزش داده شدند. همه آزمایشها در ویندوز 10 با پردازنده AMD Ryzen 7 2700 (3.2 گیگاهرتز)، 16 گیگابایت حافظه (رم) و NVIDIA GeForce RTX 2070 انجام شد. 8 گیگابایت). پایتون 3.6 استفاده شد و آزمایش ها بر اساس چارچوب برنامه نویسی keras انجام شد. علاوه بر این، آنتروپی متقاطع به عنوان تابع از دست دادن شبکه عصبی، همانطور که در معادله ( 9 ) نشان داده شده است، استفاده شد. ایکس منمننمونه را نشان می دهد. p (x) و q (x) به ترتیب نشان دهنده دو توزیع احتمال مجزا از متغیر تصادفی x هستند . و n تعداد نمونه ها است.
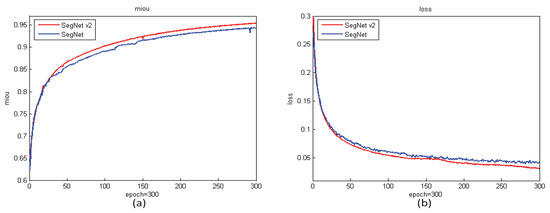
3.4. تجزیه و تحلیل نتایج
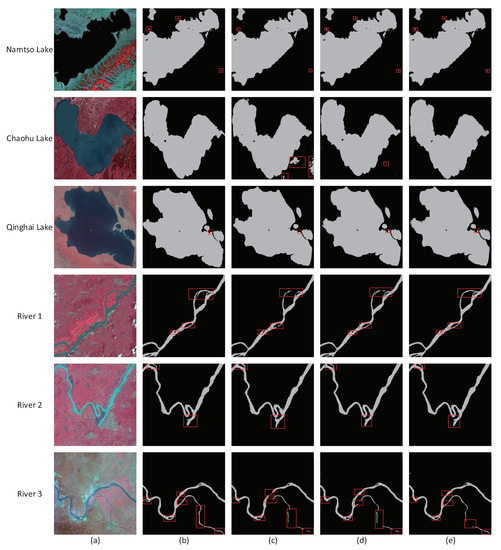
3.5. آزمایش تأیید
4. نتیجه گیری
منابع
- وان، دبلیو. شیائو، پی. فنگ، ایکس. لی، اچ. ما، ر. دوان، اچ. ژائو، ال. نظارت بر تغییرات دریاچه فلات چینگهای-تبت طی 30 سال گذشته با استفاده از داده های سنجش از دور ماهواره ای. چانه. علمی گاو نر 2014 ، 59 ، 1021-1035. [ Google Scholar ] [ CrossRef ]
- برو بالا.؛ بله، س. وی، کیو. تغییر یخ دریاچه در دریاچه Nam Co در فلات تبت در طول 2000-2013 و عوامل موثر. Prog. Geogr. 2015 ، 34 ، 1241-1249. [ Google Scholar ]
- McFeeters، S. استفاده از شاخص تفاوت عادی آب (NDWI) در ترسیم ویژگی های آب باز. بین المللی J. Remote Sens. 1996 ، 17 ، 1425-1432. [ Google Scholar ] [ CrossRef ]
- فریزر، پی. پیج، ک. تشخیص و ترسیم بدنه آب با داده های Landsat TM. فتوگرام مهندس Remote Sens. 2000 , 66 , 1461-1467. [ Google Scholar ]
- یوان، ایکس. Sarma، V. تشخیص و تقسیمبندی خودکار بدنه آب شهری از دادههای Sparse ALSM از طریق خوشهبندی مبتنی بر مدل مبتنی بر فضای محدود. IEEE Geosci. سنسور از راه دور Lett. 2011 ، 8 ، 73-77. [ Google Scholar ] [ CrossRef ]
- لو، اس. وو، بی. یان، ن. وانگ، اچ. روش نقشه برداری بدنه آب با تصاویر ماهواره ای HJ-1A/B. بین المللی J. Appl. زمین Obs. Geoinf. 2011 ، 13 ، 428-434. [ Google Scholar ] [ CrossRef ]
- ژانگ، اچ. جیانگ، کیو. Xu, J. استخراج خط ساحلی با استفاده از ماشین بردار پشتیبان از تصویر سنجش از دور. J. Multimed. 2013 ، 8 ، 175-182. [ Google Scholar ]
- فییسا، جی. میلبی، اچ. فنشولت، آر. پراید، S. شاخص استخراج خودکار آب: یک تکنیک جدید برای نقشه برداری آب های سطحی با استفاده از تصویر Landsat. سنسور از راه دور محیط. 2014 ، 140 ، 23-35. [ Google Scholar ] [ CrossRef ]
- مایکل، اس. وی، ال. Zhu، X. تشخیص خودکار خط ساحلی در دادههای پشت سر هم-X فیلتر نشده محلی. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE 2015 (IGARSS)، میلان، ایتالیا، 26 تا 31 ژوئیه 2015؛ ص 1036-1039. [ Google Scholar ]
- دو، ی. فنگ، جی. لی، ز. پنگ، ایکس. رن، ز. Zhu, J. روشی برای تشخیص بدنه آب های سطحی و تولید دم با چند هندسه TanDEM-X aata. IEEE J. Sel. بالا. Appl. زمین Obs. Remote Sens. 2008 , 12 , 151-161. [ Google Scholar ] [ CrossRef ]
- پارک، سی. جئون، جی. ماه، ی. Eom، I. تشخیص شکوفه جلبکی مبتنی بر تصویر با استفاده از تقسیمبندی مناطق آبی و شاخصهای احتمالی جلبک. IEEE Geosci. سنسور از راه دور Lett. 2019 ، 7 ، 8869–8878. [ Google Scholar ]
- وانگ، بی. وانگ، ک. لیائو، دبلیو. استخراج دریاچه فلات چینگهای-تبت بر اساس تقسیم بندی تصویر سنجش از دور. Remote Sens. Inf. 2018 ، 3 ، 117-122. [ Google Scholar ]
- چنگ، بی. کوی، اس. ما، ایکس. لیانگ، سی. تحقیق در مورد روش استخراج منطقه ساختمان شهری با تصویربرداری PolSAR با وضوح بالا بر اساس محلههای انتخاب محله تطبیقی برای حفظ جاسازی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 109. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Milosavljevic، A. شناسایی رسوبات نمک بر روی تصاویر لرزه ای با استفاده از روش یادگیری عمیق برای تقسیم بندی معنایی. ISPRS Int. J. Geo-Inf. 2020 ، 9 ، 24. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- سیمونیان، ک. Zisserman, A. شبکه های پیچیده بسیار عمیق برای تشخیص تصویر در مقیاس بزرگ. arXiv 2014 ، arXiv:1409.155. [ Google Scholar ]
- سگدی، سی. لوفه، اس. ونهوک، وی. عالمی، ع. Inception-v4، inception-resnet و تأثیر اتصالات باقیمانده بر یادگیری. در مجموعه مقالات سی و یکمین کنفرانس AAAI در مورد هوش مصنوعی، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 فوریه 2017. [ Google Scholar ]
- هوانگ، جی. لیو، ز. واندر ماتن، ال. Weinberger، KQ شبکه های کانولوشنال به هم پیوسته متراکم. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017. [ Google Scholar ]
- شیا، م. لی، ی. ژانگ، ی. ونگ، ال. لیو، جی. تشخیص ابر/برف تصاویر ابر ماهواره ای بر اساس شبکه توجه همجوشی چند مقیاسی. J. Appl. Remote Sens. 2020 , 14 , 032609. [ Google Scholar ] [ CrossRef ]
- لانگ، جی. شلهامر، ای. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. در مجموعه مقالات کنفرانس IEEE 2015 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015؛ صص 3431–3440. [ Google Scholar ]
- نه، اچ. هونگ، اس. هان، بی. یادگیری شبکه دکانولوشن برای تقسیم بندی معنایی. arXiv 2015 ، arXiv:1505.04366. [ Google Scholar ]
- بدرینارایانان، وی. کندال، ا. Cipolla، R. SegNet: یک معماری رمزگذار-رمزگشا کانولوشنال عمیق برای تقسیم بندی تصویر. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 2481-2495. [ Google Scholar ] [ CrossRef ]
- ژائو، اچ. شی، ج. Qi، X. وانگ، ایکس. شبکه تجزیه صحنه هرم جیا، جی. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 6230–6239. [ Google Scholar ]
- یو، اف. کلتون، V. تجمع بافت در مقیاس چندگانه توسط پیچیدگی گشاد شده. در مجموعه مقالات کنفرانس بین المللی در مورد بازنمایی های یادگیری 2016 (ICLR)، سان خوان، پورتوریکو، 2 تا 4 مه 2016. [ Google Scholar ]
- شیا، م. آهنگ، دبلیو. سان، ایکس. لیو، جی. هنوز.؛ Xu, Y. شبکه های کانولوشنال بهم پیوسته وزن دار برای یادگیری تقویتی. بین المللی ج. تشخیص الگو. آرتیف. هوشمند 2020 ، 34 ، 2052001. [ Google Scholar ] [ CrossRef ]
- Chollet، F. Xception: یادگیری عمیق با پیچیدگی های قابل جداسازی عمیق. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید کامپیوتری و تشخیص الگو (CVPR). IEEE، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صفحات 1800–1807. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE 2016 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016؛ صص 770-778. [ Google Scholar ]
- Xu, C. تحقیق و پیاده سازی تقسیم بندی عصبی بر اساس یادگیری عمیق. پایان نامه کارشناسی ارشد، دانشگاه پست و مخابرات پکن، پکن، چین، 2018. [ Google Scholar ]
- شیا، م. لیو، دبلیو. خو، ی. وانگ، ک. Zhang، X. شبکه توجه باقیمانده گشاد شده برای تفکیک بار. محاسبات عصبی Appl. 2019 ، 31 ، 8931–8953. [ Google Scholar ] [ CrossRef ]
- لیو، پی. لیو، ایکس. لیو، ام. شی، س. یانگ، جی. خو، X. Zhang, Y. استخراج ردپای ساختمان از تصاویر با وضوح بالا از طریق شبکه عصبی کانولوشنال آغاز باقیمانده فضایی. Remote Sens. 2019 , 11 , 830. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- آیوف، اس. Szegedy، C. نرمال سازی دسته ای: تسریع آموزش عمیق شبکه با کاهش تغییر متغیر داخلی. در مجموعه مقالات سی و دومین کنفرانس بین المللی یادگیری ماشین (ICML)، آتلانتا، GA، ایالات متحده آمریکا، 6 تا 11 ژوئیه 2015؛ صص 448-456. [ Google Scholar ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE Imagenet طبقه بندی با شبکه عصبی کانولوشن عمیق. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی (NIPS)، دریاچه تاهو، ND، ایالات متحده، 5-8 دسامبر 2015. صص 1097–1105. [ Google Scholar ]
- سندلر، ام. هوارد، آ. زو، ام. ژموگینوف، آ. Chen, L. MobileNetV2: باقیمانده های معکوس و گلوگاه خطی. در مجموعه مقالات کنفرانس IEEE 2016 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، سالت لیک سیتی، UT، ایالات متحده آمریکا، 27 تا 30 ژوئن 2016؛ ص 4510–4520. [ Google Scholar ]
- پان، پ. وانگ، ی. لو، ی. ژو، جی. تقسیمبندی خودکار نئوپلاسم نازوفارنکس در تصویر MR بر اساس مدل U-net. جی. کامپیوتر. Appl. 2019 ، 39 ، 1183-1188. [ Google Scholar ]
- رونبرگر، او. فیشر، پی. Brox، T. U-Net: شبکه های کانولوشن برای تقسیم بندی تصاویر زیست پزشکی. در مجموعه مقالات هجدهمین کنفرانس بین المللی محاسبات تصویر پزشکی و مداخله به کمک رایانه (MICCAI)، مونیخ، آلمان، 5 تا 9 اکتبر 2015؛ صص 234-241. [ Google Scholar ]
- شیا، م. کیان، جی. ژانگ، ایکس. لیو، جی. Xu, Y. تقسیم بندی رودخانه بر اساس شبکه باقی مانده توجه قابل جداسازی. J. Appl. Remote Sens. 2019 , 14 , 32602. [ Google Scholar ] [ CrossRef ]
- شیا، م. ژانگ، ایکس. لیو، دبلیو. ونگ، ال. Xu, Y. یادگیری محدودیتهای ویژگی چند مرحلهای برای تخمین سن. IEEE Trans. Inf. پزشکی قانونی امن. 2020 ، 15 ، 2417-2428. [ Google Scholar ] [ CrossRef ]
- پولاک، م. ژانگ، اچ. Pi، M. یک معیار ارزیابی برای تقسیمبندی تصویر چندین شی. تصویر Vis. محاسبه کنید. 2009 ، 27 ، 1223-1227. [ Google Scholar ] [ CrossRef ]
- Bottou, L. یادگیری ماشینی در مقیاس بزرگ با نزول گرادیان تصادفی. در مجموعه مقالات COMPSTAT ; Springer: برلین/هایدلبرگ، آلمان، 2010; صص 177-186. [ Google Scholar ]
- شیا، م. ژانگ، سی. وانگ، ی. لیو، جی. لی، سی. تصمیم گیری مبتنی بر حافظه: مدل مدار عصبی اسپکینگ. شبکه عصبی جهان 2019 ، 29 ، 135–149. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- LeCun، Y.; بوزر، بی. دنکر، جی. هندرسون، دی. Jackel, L. تشخیص ارقام دستنویس با یک شبکه پس انتشار. Adv. عصبی Inf. روند. سیستم 1990 ، 396-404. [ Google Scholar ]




بدون دیدگاه