

خلاصه
این مقاله بر روی مقایسه تکرار پایگاه داده با داده های مکانی در PostgreSQL و MySQL متمرکز شده است. تکرار پایگاه داده به معنای حل مشکلات مختلف با بارگذاری بیش از حد یک سرور پایگاه داده با نوشتن و خواندن کوئری ها است. مکانیسمهای تکثیر زیادی وجود دارد که قادر به مدیریت متفاوت دادهها هستند. معیارهایی برای مقایسه های عینی برای آزمایش و تعیین گلوگاه فرآیند تکرار تعیین شد. آزمایشها بر روی مجموعه دادههای فضایی برداری ملی واقعی، یعنی ArcCR500، Data200، زمین طبیعی و واحد پدولوژیک-اکولوژیکی تخمینی انجام شد. HWMonitor Pro برای نظارت بر پایگاه داده PostgreSQL، شبکه و بار سیستم استفاده شد. Monyog برای نظارت بر فعالیت MySQL (دادهها و پرسشهای SQL) در زمان واقعی استفاده شد. هر دو سرور پایگاه داده بر روی رایانه هایی با سیستم عامل مایکروسافت ویندوز اجرا می شدند. نتایج حاصل از آزمایشهای ارائهشده هر دو مکانیسم تکرار منجر به درک بهتر این مکانیسمها و تصمیمگیری آگاهانه برای استقرار آینده شد. نمودارها و جداول شامل داده های آماری هستند و مکانیسم های تکرار را در موقعیت های خاص توصیف می کنند. PostgreSQL با پسوند Slony با تکرار ناهمزمان، دسته ای از تغییرات را با سرعت انتقال بالا و بار بالای سرور همگام کرد. MySQL با تکرار همزمان، هر رکورد تغییر را با تأثیر کم بر عملکرد سرور و پهنای باند شبکه، همگام میکند. PostgreSQL با پسوند Slony با تکرار ناهمزمان، دسته ای از تغییرات را با سرعت انتقال بالا و بار بالای سرور همگام کرد. MySQL با تکرار همزمان، هر رکورد تغییر را با تأثیر کم بر عملکرد سرور و پهنای باند شبکه، همگام میکند. PostgreSQL با پسوند Slony با تکرار ناهمزمان، دسته ای از تغییرات را با سرعت انتقال بالا و بار بالای سرور همگام کرد. MySQL با تکرار همزمان، هر رکورد تغییر را با تأثیر کم بر عملکرد سرور و پهنای باند شبکه، همگام میکند.
کلید واژه ها:
پایگاه داده ; همانند سازی ؛ داده های مکانی ؛ MySQL ; PostgreSQL
1. معرفی
Replication فرآیند کپی و نگهداری اشیاء پایگاه داده [ 1 ] است. پایگاه داده های تکراری برای تغییرات نظارت می شوند و زمانی که تغییر ایجاد می شود همگام می شوند [ 1 ]. همانندسازی پایگاه داده به جای دسترسی به یک سرور مرکزی، یک کپی از داده ها را از بسیاری از سرورهای مختلف قابل دسترسی می کند، یا بسیاری از سرورها را قادر می سازد مانند یک (پردازش پرس و جوی موازی) رفتار کنند [ 1 ]. تکثیر پایگاه داده در مورد پیوستن انبارهای مختلف داده به یکی نیست که به عنوان انبار داده شناخته می شود [ 2 ، 3 ]. همانندسازی پایگاه داده کپی هایی از کل پایگاه داده یا فقط جداول خاص را در یک سرور پایگاه داده متفاوت ایجاد می کند و یک ارتباط بین آنها برای همگام سازی امن یک طرفه یا دو طرفه ایجاد می کند.4 ، 5 ]. سناریوهای معمولی وجود دارد که در آن از تکرار پایگاه داده استفاده می شود، به عنوان مثال، تأخیر کمتر ایمن برای ارتباطات از راه دور، ذخیره سازی داده های خام جداگانه و ذخیره سازی داده های کاربر، در دسترس بودن و عملکرد بالا ایمن. مکانیسمهای تکرار معمولاً برای برنامههای کاربردی وب (به عنوان مثال، وب حسگر و WebGIS)، یا بهعنوان ژئوپلیکاسیون برای تأخیر بین قارهای کمتر استفاده میشوند [ 6 ، 7 ]. Replication را می توان به طور نامناسب به عنوان مکانیزمی برای ایجاد پشتیبان گیری از داده ها در نظر گرفت. با این وجود، این کارکرد اصلی تکرارهای پایگاه داده نیست. ماهیت تکثیر پایگاه داده ایجاد یک محیط توزیع شده اضافی و به هم پیوسته است.
نگهداری تمام داده ها در یک سرور پایگاه داده به دلایل زیادی توصیه نمی شود: (الف) جدا نگه داشتن داده های خام و در دسترس عموم. (ب) تقسیم دادههای پردازش شده به بخشهای خاص برای کاربران خاص و (ج) نگهداری پایگاههای داده در یک مکان محلی برای به دست آوردن تأخیر کم پرس و جو [ 1 ، 4 ].
تکثیر پایگاه داده وسیله ای برای افزایش کارایی با تکنیک scale-out [ 8 و 9 ] است. افزایش تعداد سرورها می تواند به توزیع پیک ها و بارهای سنگین در بسیاری از سرورها کمک کند که می توانند به کاربران پاسخ دهند. تکنیک تکرار می تواند برای کاهش زمان تاخیر برای درخواست های کاربر استفاده شود [ 4 ، 10 ، 11 ].
واحد پایه تکرار یک گره است که نشان دهنده یک سرور پایگاه داده است. یک گره می تواند به عنوان یک سرور اصلی یا یک سرور برده عمل کند. هیچ نام استانداردی برای گرههای “master” و “slave” وجود ندارد و هر شرکتی میتواند برچسب متفاوتی برای آنها داشته باشد، به عنوان مثال، برای یک Master اینها شامل اصلی، ناشر و رهبر است، در حالی که برای یک Slave اینها شامل آماده به کار، مشترک و دنبال کننده است. . این نامها میتوانند با انواع مختلفی از منطق تکرار ارتباط داشته باشند، اما اغلب اوقات نامها همان رفتار فرآیند تکرار را بیان میکنند [ 12 ].]. سرور اصلی باید بر روی درج و به روز رسانی عبارات SQL تمرکز کند. سرور برده باید در درجه اول بر روی یک دستور انتخابی SQL کار کند. حداقل دو سرور برای ایجاد یک کلاستر تکرار مورد نیاز است. میتواند بسیاری از سرورهای اصلی (تکثیر چندگانه) برای همگامسازی دو طرفه، یا یک سرور اصلی با یک یا چند سرور برده برای همگامسازی یک طرفه از master به slave [ 13 ]، یا میتواند یک سرور اصلی در سرور وجود داشته باشد. حالت آماده به کار سرور آماده به کار در حالت آفلاین است و فقط تغییرات را از سرور اصلی دریافت می کند. سرور آماده به کار با عدم دسترسی به اولین سرور اصلی (مثلاً منطق نگهبان) فعال می شود.
یک تقسیم بندی معمولی بین انواع تکرار بین همگام در مقابل ناهمزمان و منطقی در مقابل تکرار فیزیکی وجود دارد [ 1 ، 14 ]. تکرار همزمان هر تغییر را فوراً همگام می کند و پس از تأیید توسط سرور برده، یک سرور اصلی تغییر داده دیگری را همگام می کند. تکرار ناهمزمان دسته ای از تغییرات را در یک مرحله زمانی مشخص، به عنوان مثال، یک ثانیه، یک دقیقه یا یک روز، همگام می کند. تقریباً هر شرکتی که راه حل های پایگاه داده ایجاد می کند، استراتژی های تکرار متفاوتی دارد، اما می توان آنها را در این دسته بندی های اساسی قرار داد. به عنوان مثال، پایگاه داده اوراکل دارای تکثیر نمای چند استاد و مادی شده است [ 1 ]. Microsoft SQL Server دارای عکس فوری، ادغام و تکرار تراکنش است [ 15]؛ MySQL شامل تکثیر مبتنی بر بیانیه، مبتنی بر ردیف و پایه مختلط [ 16 ] است و PostgreSQL به طور بومی (از نسخه 9.0) از تکرار جریان پشتیبانی می کند. بسیاری از پلاگین ها و نرم افزارهای شخص ثالث برای PostgreSQL در دسترس هستند که می توانند عملکردهای درخواستی را ارائه دهند (مانند Slony، PgCluster و Bucardo).
داده های مکانی در یک پایگاه داده به عنوان یک نوع مشخصه خاص مانند هندسه، شکل و جغرافیا ذخیره می شوند. اندازه یک ویژگی فضایی متفاوت است. کوتاه ترین طول یک نقطه است، در حالی که ویژگی های خط و چند ضلعی (خط بسته) دارای طول بر اساس تعداد نقاط لبه هستند.
انتخاب مدیریت پایگاه داده مکانی (SDBMS) بر اساس معیارهای نشان داده شده در جدول 1 ایجاد شد. همه SDBMS از نوعی از تکثیر پایگاه داده پشتیبانی می کنند و محبوب ترین و پرکاربردترین پایگاه های داده بر این اساس هستند [ 17 ]]. این در مورد دپارتمان ژئوانفورماتیک در اولوموک، جمهوری چک نیز صادق است که از PostgreSQL یا MySQL در اکثر پروژه های تحقیقاتی و کلاس های دانشجویی خود استفاده می کند. علاوه بر این، در دپارتمان ژئوانفورماتیک PostgreSQL به عنوان پایگاه داده اولیه برای ArcGIS Enterprise، به ویژه برای سرور ArcGIS به عنوان ذخیرهسازی داده، استفاده میشود. PostgreSQL همچنین از پورتال ArcGIS توسط Esri استفاده می کند (همچنین در بخش استفاده می شود). MySQL در طراحی وب (مثلاً وردپرس، دروپال و ویکی پدیا) بسیار محبوب است. MongoDB محبوب ترین سیستم پایگاه داده NoSQL است که از ذخیره و پردازش پایه داده های مکانی (سه تابع پایه-geoIntersects، geoWithin و near) نیز پشتیبانی می کند. MongoDB از پشتیبانی قوی در برنامه های دسکتاپ GIS مانند PostgreSQL، MySQL، Oracle و سرور MS SQL برخوردار نیست.
مکانیسم تکرار مورد استفاده برای این آزمایش Slony-I v2.2.5 به عنوان پسوند برای PostgreSQL و تکرار جریان اصلی برای MySQL بود. خوشه تکرار شامل یک سرور اصلی و یک سرور برده بود که توسط PostgreSQL با استفاده از پسوند Slony ایجاد شد، که تکثیر master-slave، ناهمزمان، منطقی و مبتنی بر ماشه را فعال می کرد. خوشه تکرار (یک سرور اصلی و یک سرور برده) برای MySQL با استفاده از پخش بومی اصلی-برد، همزمان، منطقی، تکرار مبتنی بر بیانیه (SBR) ایجاد شد.
Slony از محرک های پایگاه داده برای جمع آوری وقایع رخ داده در یک جدول انتخاب شده استفاده می کند. جدول انتخاب شده با تکنیک ناشر/مشترک توسط Slonik Execute Script [ 18 ] پیکربندی شده است.]. در فایل پیکربندی، اطلاعات اتصال به همه پایگاههای داده در کلاستر تکرار، و مجموعههای جدولی که در فرآیند تکرار نقش دارند تنظیم میشود. Slony جداول منحصر به فردی را در PostgreSQL ایجاد می کند تا کل فرآیند تکرار را حفظ کند. رویدادها (توصیف شده بر اساس مبدا، نوع و پارامترها) در جدول “sl_event” ذخیره و در صف قرار می گیرند. دادهها برای تکرار توسط محرکها گرفته میشوند و در جداول “sl_log_1” و “sl_log_2” ذخیره میشوند. سپس، یک رشته “localListener” وجود دارد که به صورت دوره ای یک رویداد “SYNC” ایجاد می کند. این رویداد “SYNC” رشته “RemoteListener” را برای شروع همگام سازی در کلاستر تکرار می کند.
ایده تکرار مبتنی بر بیانیه MySQL این است که حداقل دو پایگاه داده یکسان وجود دارد که در آنها می توان دستورات اصلاحی را به جای انتقال داده های خام (به صورت Slony یا MySQL Replication مبتنی بر ردیف (RBR) اجرا کرد (به عنوان مثال، درج، به روز رسانی و حذف). ) do)، با SBR که فقط عبارت SQL را برای اصلاح پایگاه داده ارسال می کند. MySQL جریانی از عبارات SQL ایجاد می کند که در سرور اصلی تکمیل می شوند و سپس در سرور برده تکمیل می شوند [ 19 ]]. MySQL از سه رشته (Slony از دو رشته استفاده می کند) برای پردازش یک تکرار استفاده می کند. یک رشته “Binlog dump” محتوای لاگ باینری را از master به سرور برده ارسال می کند. رشته دوم، “Slave I/O” بر روی سرور برده اجرا می شود و از سرور اصلی می خواهد که به روز رسانی ها را ارسال کند. آخرین رشته، “Slave SQL” نیز بر روی سرور برده اجرا می شود و گزارش هایی را که قبلا توسط رشته “Slave I/O” نوشته شده بودند، می خواند و رویداد موجود در گزارش را اجرا می کند [ 20 ].
تکنیک های دیگری برای افزایش عملکرد و استحکام وجود دارد، مانند متعادل کردن بار یا در دسترس بودن بالا. این سه تکنیک برای سرویسهای داده (جغرافیایی) بسیار قوی و جهانی توصیه میشوند [ 4 ].
راه حل های زیادی برای ارزیابی عملکرد پایگاه داده مانند TPC-x (شورای عملکرد پردازش تراکنش)، SSB (معیار طرحواره ستاره) یا YCSB (معیار خدمات ابری یاهو!) وجود دارد. این تست ها عملکرد پایگاه های داده را به روش های مختلف ارزیابی می کنند: تعداد درج در ثانیه. زمان پاسخگویی برای تعدادی از کاربران؛ یا 50/50، 100/0، 0/100 خواندن و تست های به روز رسانی [ 11 ، 21 ، 22 ، 23 ، 24]. ارزیابی عملکرد خوشه تکرار فقط در مورد زمان پاسخ یک پایگاه داده نیست، بلکه در مورد زمان همگام سازی داده ها، بار کاری واحد پردازش مرکزی (CPU)، حجم کاری شبکه و تاثیر بر استفاده از منابع کامپیوتری برای خود تکرار [ 13 ]. معیارهایی برای مقایسه عینی تکرار پایگاه داده داده های مکانی تعیین شد. این معیارها منجر به نتایجی از مناسب بودن هر مکانیزم تکرار شد. معیار اصلی کل زمان پردازش یک فرآیند تکرار بود. فرآیندهای تکرار بسیار قابل اعتماد هستند، با میزان موفقیت 100٪. از این رو، میزان موفقیت به عنوان یکی از معیارهای ارزیابی در نظر گرفته نشد.
استفاده از مکانیسمهای تکرار نیز برای سناریوهای بلادرنگ مناسب است، به عنوان مثال، ذخیره و انتشار دادهها از شبکههای حسگر بیسیم (WSN) برای اندازهگیری شرایط محیطی. این نوع WSN مقدار کمی داده (معمولاً در حد 1 بیت تا ده ها کیلوبیت) تولید می کند. استفاده از یک مکانیسم تکثیر برای ایمن کردن دسترسی بالا به مشتریان، به شدت به بسیاری از درخواستهای ورودی در پایگاه داده و زمان ضربالاجل برای تکرار وابسته است. این محدودیت های یک پایگاه داده اصلی را می توان با تست های “درج در ثانیه” آزمایش کرد. مکانیسمهای تکرار برای ارائه پایگاه داده در دسترس مشتری (برای خواندن) با دادههای پردازش شده، به عنوان مثال، تکنیکهای کلان داده، تجزیه و تحلیل جریان یا داده کاوی مناسب هستند.
2. مواد و روشها
داده های مکانی در PostgreSQL 9.5 با پسوند PostGIS 2.3.3 و در MySQL 5.7.19 ذخیره شد. سرورهای پایگاه داده PostgreSQL و MySQL به هیچ سخت افزار تخصصی نیاز ندارند. آنها سرورهای نرم افزاری چند پلتفرمی هستند که از منابع کامپیوتری (کامپیوتر، نوت بوک، تلفن همراه، Apple MacOS، GNU Linux و Microsoft Windows) استفاده می کنند.
مزایای اصلی این سرورهای پایگاه داده به شرح زیر است:
-
آنها ذخیره و پردازش داده های مکانی را امکان پذیر می کنند.
-
آنها دارای اتصالات بومی به نرم افزار QGIS هستند.
-
آنها راه حل های مستقل با پلت فرم گسترده ای از کاربران هستند.
این دو سرور پایگاه داده حاوی مجموعه ای یکسان از لایه های برداری بودند. مجموعه داده های انتخاب شده معمولاً در مدیریت ایالت چک استفاده می شود. مجموعه داده ها شامل داده هایی از ArcCR500 v3.3 (مقیاس 1:500000، اطلاعات جغرافیایی و توپوگرافی در مورد چک)، Data200 (مقیاس 1:200000، بر اساس EuroRegionalMap، مدل جغرافیایی چک)، NaturalEarth v3.0.1 (مقیاس 1: 10 متر، شامل مقولههای فرهنگی، فیزیکی و شطرنجی برای کل زمین) و واحد خاکشناسی-اکولوژیکی تخمینی (EPEU) برای منطقه اولوموک نسخه 5.1.2018 (مقیاس 1:5000، ظرفیت مطلق و نسبی تولید زمین کشاورزی و شرایط برای حداکثر آن استفاده کارآمد). داده های مکانی در پایگاه های داده به عنوان داده های ویژگی در ویژگی های ساده OGC استاندارد برای SQL 1.2.1 ذخیره شدند. به عنوان فرمت باینری معروف (WKB).جدول 2 . لایه ها دارای تعداد رکوردهای متفاوتی از 1 تا 31280 و تعداد متفاوتی از نقاط لبه (15,092-3,725,023) هستند. این مقادیر برای مکانیسم تکرار ضروری هستند.
سرور اصلی و سرور بر روی دستگاه (کامپیوتر یا نوت بوک) نصب نشده بودند. از این رو، اتصال بین سرورها نه تنها در لایه شبکه (توسط مدل شبکه TCP/IP) بود، بلکه سرورها از طریق لایه پیوند توسط یک کابل UTP به هم متصل شدند. سه اتصال ممکن بین سرورها تنظیم شد: اتصال از طریق روتر، اتصال مستقیم و اتصال محدود نرم افزار. اتصال مستقیم و از طریق روتر دارای حداکثر سرعت انتقال 100 مگابیت بر ثانیه بود. اتصال محدود دارای سرعت انتقال 10 مگابیت بر ثانیه بود. NetLimiter 4 برای نظارت و محدود کردن سرعت شبکه استفاده شد. در حال حاضر فناوری های مدرن قادر به کار با سرعت انتقال حداقل 10 گیگابیت در ثانیه هستند که حداکثر توانایی UTP Cat6A و Cat7 است. UTP Cat8 هنوز در دست توسعه است و 40 گیگابیت بر ثانیه تا 30 متر را ارائه می دهد.25 ]. حتی تلفنهای همراه در حال حاضر امکان انتقال دادهها را از طریق یک اتصال بیسیم از HSPA+، که گاهی اوقات بهعنوان 3.5G با حداکثر سرعت 10 مگابیت در ثانیه مشخص میشود، به 5G با حداکثر سرعت تا 10 گیگابیت در ثانیه میدهند [ 26 ]. اتصال Wi-Fi اجازه می دهد تا استاندارد IEEE 802.11b (منتشر شده در سال 1999) با سرعت 11 مگابیت در ثانیه ارتباط برقرار کند [ 27 ]. بنابراین 10 مگابیت در ثانیه کمترین سرعت انتقال داده است و فقط برای این آزمایش استفاده شده است. این محدودیت سرعت انتقال تفاوت بین انواع تکرار را نشان می دهد. محدودیت سرعت انتقال برای شرایط واقعیتر تعیین شد که در آن سرورهای پایگاه داده مجبور نیستند یک راهحل نرمافزاری یا سختافزاری در یک شبکه باشند و یک سرور سختافزاری میتواند به بسیاری از سرورهای نرمافزاری که پهنای باند اینترنت را به اشتراک میگذارند، سرویس دهد.
2.1. عملکرد سرور
عملکرد تکرار فقط در مورد استحکام نرم افزار نیست، بلکه به سخت افزار نیز مربوط می شود. همانطور که در جدول 3 نشان داده شده است، در این مطالعه از یک کامپیوتر شخصی و یک نوت بوک با عملکردهای متفاوت استفاده شد . فرآیند تکرار در هر دو پیکربندی زیر آزمایش شد: PC به عنوان یک سرور اصلی با نوت بوک به عنوان یک سرور برده و بالعکس. میزان تأثیر اتصال از طریق یک روتر 100 مگابیت در ثانیه، یک اتصال مستقیم 100 مگابیت در ثانیه بین سرورها و یک اتصال محدود 10 مگابیت در ثانیه آزمایش شد. پیش آزمون مکانیسم های همانندسازی نشان داد که CPU تأثیر قابل توجهی بر برخی از فرآیندهای تکرار دارد. برای نظارت، از HWMonitor Pro استفاده شد که میتواند یک فایل گزارش با نمودارهای نتایج میانگین بار CPU و بار یک هسته (برای پردازندههای چند هستهای) ایجاد کند.
2.2. روش تست
دو عملیات اولیه با داده های مکانی پردازش شد. اولین عملیات شامل به روز رسانی/ویرایش هندسه فضایی بود. عملیات دوم به روز رسانی/ویرایش مقادیر ویژگی بود. معیارهای اصلی نظارت شده، بارهای CPU، سرعت انتقال داده (بر حسب مگابیت در ثانیه) و زمان مورد نیاز برای کل تراکنش تکراری بودند. برای هر لایه فضایی، ده اندازه گیری برای هر کار برای هر پیکربندی خوشه (کامپیوتر به عنوان اصلی و نوت بوک به عنوان برده و بالعکس) و هر راه اندازی شبکه (با محدودیت 10 مگابیت در ثانیه، اتصال از طریق روتر، اتصال مستقیم) انجام شد. هیچ تغییر قابل توجهی در مقادیر اندازه گیری بیش از ده اندازه گیری وجود نداشت. همانطور که در جدول 3 نشان داده شده است، سرورهای پایگاه داده بر روی ویندوز 10 و مایکروسافت ویندوز 8.1 استاندارد اجرا می شوند.. حداکثر عملکرد رایگان در طول آزمایشها برای سرورهای پایگاه داده (مکث شده، به عنوان مثال، مایکروسافت ویندوز بهروزرسانی، اسکن آنتیویروس، هر نرمافزار دیگری) و برای نرمافزار نظارت (HWMonitor Pro و Monyog) ایمن شد.
اولین کار (به روز رسانی/ویرایش هندسه فضایی) در نرم افزار QGIS تکمیل شد، جایی که اتصال به سرور پایگاه داده اصلی برقرار شد. کل لایه با جابجایی هر نقطه یا نقطه لبه در یک لایه فضایی به موقعیت متفاوتی در همان زمان ویرایش شد. حرکت تصادفی بود، اما هر حرکت تمام نقاط لبه لایه چند ضلعی تأثیر قابل توجهی بر مختصات نقطه لبه در هندسه چند ضلعی دارد. کار دوم (بهروزرسانی/ویرایش مقادیر مشخصه) توسط یک پرس و جوی SQL خالص (UPDATE epeu SET b5 = 00100 WHERE gid <30001) در پایگاه داده اصلی انجام شد. یک ویژگی برای 30000 رکورد به روز شد. این مقدار به این دلیل انتخاب شد که مقادیر کمتری از رکوردها بهسرعت بهروزرسانی و تکرار شدند.
3. نتایج
این آزمایش برای انواع مختلف مکانیسمهای تکرار در SDBMS مختلف تکمیل شد تا دیدگاه گستردهتری در مورد مکانیسمهای تکرار ارائه شود. آزمایش تأیید کرد که تکرارهای پایگاه داده برای داده های مکانی مناسب هستند. رویکردهای مختلف با استفاده از PostgreSQL و MySQL تنوع مکانیسم تکرار را نشان میدهند و اینکه انتخاب رویکرد مناسب برای یک مورد خاص میتواند دشوار باشد. آزمایش با رویکردهای مختلف، مزایا و معایب مکانیسمهای تکرار Slony و SBR را برجسته میکند. ما سعی نمی کنیم دو رویکرد مشابه، به عنوان مثال، Slony و RBR را با هم مقایسه کنیم. تجزیه و تحلیل منجر به چندین نتیجه گیری مفید شد که می تواند برای به دست آوردن درک بهتری از تکرار داده های مکانی برای PostgreSQL و MySQL استفاده شود. این یافته ها در بخش زیر توضیح داده شده است.
ابتدا، میانگین بار CPU و بار هستههای CPU در طول تکرار لایه فضایی EPEU مورد آزمایش قرار گرفت. سپس سرعت انتقال در حین تکرار لایه فضایی EPEU محاسبه شد. در نهایت، زمان تکرار برای سایر لایههای فضایی و میانگین زمان تکرار تغییرات صفت محاسبه شد.
شکل 1 و شکل 2 بارهای CPU را در طول همگام سازی تغییرات لایه EPEU برای PostgreSQL و MySQL نشان می دهد.
پایگاه داده PostgreSQL با پسوند Slony ( شکل 1 ) به وضوح Slony را با استفاده از تکرار ناهمزمان نشان داد. Slony منتظر می ماند تا تغییرات در پایگاه داده اصلی تکمیل شود و پس از آن تغییرات با پایگاه داده Slave همگام سازی می شوند. MySQL از استریم، تکرار همزمان استفاده می کند. بنابراین، هر رکورد تغییر یافته (در این مورد، هر چند ضلعی) به سرعت به یک سرور برده به عنوان همان دستور اصلاح ارسال میشود که در سرور اصلی (تکثیر SBR) انجام میشود. برای PostgreSQL، یک پایگاه داده اصلی دارای بار متوسط CPU تا 33٪ در زمان ذخیره تغییرات در پایگاه داده است. PostgreSQL ابتدا تغییرات را در سرور اصلی تکمیل می کند و تمام داده ها را در یک جدول ذخیره می کند. هنگامی که سرور اصلی هیچ تغییری را حل نمی کند، Slony داده ها را به یک سرور برده (بخش میانیشکل 1 ). در طول همگام سازی تغییرات، CPU تقریباً در حالت بیکار است. PostgreSQL توسط رشتههای تکراری که دادهها را به سرور برده ارسال میکنند کند نمیشود. این مرحله (ارسال داده ها) پس از اتمام تغییرات در پایگاه داده اصلی انجام می شود.
MySQL مقادیر بار CPU کمی بالاتر از حالت بیکار دارد ( شکل 2 ). پیک در حدود 30 درصد بار پردازنده می تواند نشانه ای از درخواست درخواست SQL یا تعداد بالاتر نقاط لبه در یک رکورد باشد. شکل 2 نشان می دهد که پایگاه داده slave نسبت به پایگاه داده اصلی، قدرت پردازشگر بیشتری مصرف می کند و این به دلیل قدرت کمتر CPU است. برای همین کار، CPU به منابع بیشتری نیاز دارد.
MySQL یک دستور با تغییر رکورد ایجاد می کند و این دستور تقریباً بلافاصله در یک گزارش باینری (با همکاری سه رشته) به سرور برده ارسال می شود. بنابراین، هر دو سرور به طور همزمان مشغول هستند و یک عبارت را اجرا می کنند. فرآیند تغییرات در لایه چند ضلعی EPEU زمان بیشتری می برد، اما قدرت CPU آنچنان نیاز ندارد.
3.1. بار هسته CPU
هر هسته CPU با همان روش، به عنوان بار متوسط CPU، نظارت شد. یک کامپیوتر با چهار هسته CPU به عنوان سرور اصلی برای نظارت استفاده شد. این آزمایش نشان میدهد که چگونه تک تک هستهها در فرآیند تکرار نقش داشتند. شکل 1 و شکل 2 میانگین بار CPU سرور اصلی و سرور را نشان می دهد. شکل 3 و شکل 4 هسته های CPU سرور اصلی را در طول فرآیند تکرار نشان می دهد.
شکل 3 بارهای هر هسته CPU را در طول ویرایش و ذخیره سازی داده ها و فرآیند تکرار بعدی نشان می دهد. نمودار به سه قسمت تقسیم شد (همان اندازه بار متوسط CPU در شکل 1 ). قسمت اول شکل 3 بارهای هسته دوم و چهارم CPU را نشان می دهد که روی ذخیره داده های ویرایش شده در QGIS کار می کردند. این فرض وجود دارد که هسته دوم از QGIS برای تغییرات داده استفاده می کند و هسته اول برای ذخیره داده ها در پایگاه داده استفاده می شود. قسمت میانی نشان دهنده فرآیند تکرار ارسال فایل های لاگ باینری توسط رشته Slony است. قسمت سوم وضعیت بیکار CPU را پس از کل فرآیند تکرار نشان می دهد.
شکل 4 استفاده از هسته های CPU را برای سرور اصلی MySQL نشان می دهد. بین میانگین بارهای هسته تفاوت معنی داری وجود نداشت. هر هسته در فرآیند تکرار شرکت کرد. پیکهای تک هستهای در شکل 4 همانند بارگذاری متوسط CPU در شکل 2 است (تقاضای پرس و جوی SQL یا تعداد بالاتر نقاط لبه در یک رکورد). قدرت کامل CPU استفاده نشد زیرا هر دستور SQL اصلاحی بلافاصله پس از رویداد اصلاح ماشه به سرور برده ارسال شد و به جای جایگزینی داده ها در جدول (همانطور که Slony و RBR انجام می دهند، دستور اصلاح را اجرا کرد).
3.2. سرعت انتقال
حداکثر یا متوسط سرعت انتقال به دست آمده، معیار نظارتی بعدی بود. شکل 5 و شکل 6 سرعت انتقال را برای تکرار از رایانه شخصی به عنوان سرور اصلی به نوت بوک به عنوان سرور برده برای PostgreSQL و MySQL نشان می دهد. شکل 7 و شکل 8 میانگین سرعت انتقال را برای سایر تنظیمات سرور نشان می دهد. این آزمایش تفاوت بین پیکربندی ها را در تقاضا برای پهنای باند و استحکام شبکه نشان می دهد.
یک نقطه مشخص در شکل 5 وجود دارد که در آن داده ها شروع به آپلود و دانلود از سرور اصلی به سرور می کنند. حداکثر سرعت انتقال 70 مگابیت در ثانیه ( شکل 7 ) برای پیکربندی با رایانه شخصی به عنوان سرور اصلی و از طریق اتصال از طریق روتر بود. یک روتر عمدتاً سرعت کمتری نسبت به حداکثر قابل دسترس (100 مگابیت در ثانیه) ایجاد می کند، زیرا با اتصال مستقیم بین سرورها به سرعت انتقال کامل 100 مگابیت در ثانیه رسیده است. PostgreSQL، پس از ذخیره تغییرات در یک پایگاه داده اصلی، سعی کرد داده ها را با حداکثر سرعت از طریق شبکه ارسال کند، همانطور که در شکل 5 و شکل 7 مشاهده می شود. در طرف مقابل MySQL است، با تکرار جریان، که در آن سرعت همگام سازی حدود 10 مگابیت در ثانیه بود ( شکل 6)و شکل 8 ). تفاوت بین سرعت انتقال توسط فناوریهای تکرار ایجاد شد، جایی که PostgreSQL با Slony از تکرار غیرهمزمان (ارسال دادههای خام پس از اتمام تمام تغییرات سرور اصلی) و MySQL از جریان، SBR، همزمان (ارسال جریان دستور اصلاح SQL و اجرای آنها در سرور برده) replication. پیک های انتقال برای MySQL ( شکل 6) توسط یک چندضلعی پیچیده تر با رکورد بزرگتر در لایه فضایی EPEU ایجاد شد. این نتایج نشان میدهد که پایداری شبکه، استحکام و پهنای باند چقدر نیازمند است. PostgreSQL دسته ای از همه تغییرات را در سرور برده همگام می کند. برخلاف آن، MySQL جریانی از دستورات اصلاح SQL را می فرستد تا در سرور برده به طور مداوم اجرا شوند، در حالی که در سرور اصلی تغییرات ایجاد می کنند.
3.3. زمان تکرار
یکی از معیارهای اصلی زمان تکرار از یک سرور به یک سرور برده است. PostgreSQL تغییرات را در یک فایل log بزرگ (“sl_log_1” یا “sl_log_2”) تکرار می کند و سعی می کند تا حد امکان از پهنای باند شبکه استفاده کند. MySQL تغییرات را به طور مداوم از ابتدا تکرار می کند، جایی که تغییرات در QGIS ایجاد می شود. زمان هر تکرار به دلیل فناوری تکرار مورد استفاده بسیار متفاوت بود. شکل 9 مقدار زمان صرف شده برای تکثیر گسترده ترین لایه فضایی EPEU را نشان می دهد. هر موقعیت ده بار اندازه گیری شد. نمودارهای جعبه، چارک اول و سوم، میانه و حداقل و حداکثر مطلق زمان صرف شده را نشان می دهند.
تفاوت معنی داری در زمان صرف شده بین این دو مکانیسم تکرار وجود داشت. تفاوت زمانی عمدتاً ناشی از رویکردهای همزمان و ناهمزمان مورد استفاده هر سرور پایگاه داده است. تکثیر همزمان هر تغییر رکورد را بلافاصله پس از ذخیره در یک پایگاه داده اصلی ارسال میکند، در حالی که تکرار ناهمزمان مقدار زیادی از تغییرات را ارسال میکند. Slony بین گرههای تکثیر در کمتر از 30 ثانیه هماهنگ شد، در حالی که MySQL تقریباً در 1700 ثانیه (56 برابر زمان بیشتر) برای همان مقدار داده و تغییرات همگامسازی شد.
شکل 10 و شکل 11 داده های آماری هر چهار پیکربندی سرور را برای یک لایه تکراری EPEU نشان می دهد.
تفاوت بین PostgreSQL و MySQL فقط از نظر زمان تکرار نبود، بلکه در واریانس اندازهگیریها نیز وجود داشت. اعداد خاص مربوط به شکل 10 و شکل 11 در جدول 4 نشان داده شده است. PostgreSQL، بر خلاف MySQL Replication، با سرعت انتقال محدودیت 10 مگابیت بر ثانیه افزایش زمان قابل توجهی داشت. شکل 12یک مقایسه بصری ارائه می دهد که میانگین زمان تکرار را برای هر شرایط نشان می دهد. از آنجایی که برنامه افزودنی تکرار Slony سعی می کند تا حد امکان از پهنای باند اتصال استفاده کند، محدودیت 10 مگابیت بر ثانیه زمان تکرار را بیش از حد طولانی می کند. روتر باعث ایجاد اختلاف زمانی بین رایانه شخصی (به عنوان سرور اصلی) متصل از طریق روتر و اتصال مستقیم می شود. این نتیجه کاهش سرعت انتقال از طریق روتر است. برای زمان تکرار با MySQL، محدودیتی در قدرت CPU سرور اصلی وجود دارد. هنگامی که یک نوت بوک سرور اصلی است و باید یک لایه ویرایش شده را به طور همزمان پردازش و ارسال کند، تکرار کندتر است. محدودیت سرعت انتقال برای MySQL مرتبط نیست. اساسی ترین تحلیل های آماری زمان تکرار در جدول 4 نشان داده شده است. میانگین زمانهای تکرار ممکن است برای PostgreSQL پایدارتر از MySQL به نظر برسد، اما با فرآیند تکرار بسیار سریعتر. هر دو سرور پایگاه داده دارای انحراف استاندارد در زمان کمتر از 5٪ بودند. فقط PostgreSQL با رایانه شخصی به عنوان پیکربندی سرور اصلی دارای انحراف استاندارد در زمان 12٪ بود.
3.4. زمان تکرار لایه های فضایی دیگر
زمان تکرار سایر لایههای فضایی از همان روش استفاده شده برای آزمایش زمان تکرار لایه EPEU پیروی میکند. با این حال، آنها نقاط لبه، رکوردها و البته اندازه کمتری داشتند. از این رو، انجام همان تست بار CPU و سرعت انتقال مانند لایه EPEU بی ربط بود.
شکل 13 میانگین زمان تکرار (بر اساس ده اندازه گیری) را برای هر لایه و هر پیکربندی تکرار نشان می دهد. اگر روی زمان تکرار برای PostgreSQL تمرکز کنیم، میتوانیم ببینیم که توسعه زمانی مشخصی وجود دارد که به تعدادی از نقاط لبه (در جدول 2 ) با محدودیت سرعت 10 مگابیت در ثانیه بستگی دارد. لایه های دیگر تحت تأثیر تعداد نقاط لبه قرار گرفتند که آنها نیز ویرایش شدند (با حرکت به مکان دیگری در QGIS). از سوی دیگر، زمان تکرار MySQL ( شکل 14) به تعدادی رکورد تکیه کرد. با افزایش تعداد رکوردها، زمان تکرار افزایش یافت. این نتیجه ارسال هر تغییر رکورد تقریباً بلافاصله با تغییر رکورد در سرور اصلی به سرور برده است، جایی که اصلاح رکورد دوباره ایجاد شد (با اجرای دستور SQL).
هیچ تفاوتی بین لایههای فضایی نقطه، خط یا چند ضلعی برای مکانیسمهای تکرار PostgreSQL و MySQL وجود نداشت. شکل 13 و شکل 14 رفتارهای متضاد رایانه شخصی را به عنوان یک سرور برده نشان می دهد، جایی که برای PostgreSQL سریعترین تکرار بود، در حالی که برای MySQL کندترین تکرار بود. برای MySQL، تکرار SBR بیشتر از سرور اصلی نیاز دارد. این به این دلیل است که سرور اصلی باید داده ها را ذخیره کند و همزمان آنها را به سرور برده منتقل کند.
برای PostgreSQL، تفاوت های قابل توجهی بین پیکربندی سرورها وجود داشت. اگر سرور برده قدرتمندتر از سرور اصلی باشد، در آن صورت تکثیر سریعتر انجام می شود (پردازش سریعتر داده در ماشین سریعتر). تنظیمات خوشه تکرار MySQL تقریباً نتایج مشابهی را نشان داد (زمان تکرار برای رایانه شخصی با سرور اصلی، اتصال مستقیم و محدودیت 10 مگابیت در ثانیه).
3.5. زمان تکرار داده های ویژگی اعشاری
آخرین آزمایش برای اثبات تفاوت بین ویژگیها با فرمت دادههای مکانی و ویژگیهای با فرمت اعشاری انجام شد. البته در طول رکوردهای ویژگی تفاوت وجود دارد. داده های اعشاری یا متنی باید حداقل به سه قانون عادی سازی پایگاه داده رابطه ای اولیه پیشنهاد شده توسط Codd [ 28 ] احترام بگذارند. نتایج اندازه بسیار کوچکتری از رکورد صفت اعشاری یا متنی در مقایسه با ویژگیهای حاوی اطلاعات مکانی بود.
شکل 15 و شکل 16 میانگین زمان تکرار 30000 رکورد به روز شده در هر دو سرور پایگاه داده را نشان می دهد. برای PostgreSQL، تکثیر پایگاه داده رکوردهای ویژگی اعشاری با پیکربندی رایانه شخصی به عنوان سرور برده سریعترین سرعت را داشت. محدودیت سرعت برای PostgreSQL تاثیری بر زمان تکرار ندارد. در مقابل، MySQL تحت تأثیر محدودیت سرعت قرار گرفت و تقریباً پنج برابر کندتر از PostgreSQL بود. اتصال مستقیم یا محدودیت سرعت تأثیر ناچیزی بر تکرار داشت.
برای PostgreSQL، دوباره ثابت شد که یک سرور برده قدرتمندتر می تواند زمان فرآیند تکرار را کاهش دهد. برای MySQL، به نظر می رسد که برای تکرار ساختارهای داده کلاسیک به جای داده های مکانی بهینه شده است. محدودیت 10 مگابیت بر ثانیه تقریباً پنج برابر کندتر از اتصال مستقیم سرورها بود. میتوان فرآیند انتقال ویژگیهای اعشاری را بهینهسازی کرد: اجرا و سپس بهروزرسانی دادههای مکانی به سرور برده سریعتر بود. از این رو، محدودیت 10 مگابیت بر ثانیه همیشه کل فرآیند تکرار را کند می کند.
4. نتیجه گیری و بحث
این مطالعه با هدف توصیف و آزمایش راهحلهای تکثیر پایگاهداده موجود که عملکرد همانندسازی را روی دادههای مکانی ارائه میدهد، انجام شد. نتایج حاصل از آزمایشهای انجامشده از مکانیسمهای تکرار تأیید کرد که مکانیسمهای تکراری موجود در پایگاههای داده فضایی برای توزیع دادههای فضایی و حسگر وجود دارد. تکرارهای دادههای مکانی در مقایسه با تکرار انواع دادههای رایج، خاصتر بودند و به رویکرد خاصی نیاز داشتند.
این مقاله مقایسه ای از دو مکانیسم تکرار پایگاه داده برای PostgreSQL و MySQL را ارائه می دهد. این انتخاب بر اساس معیارهای نشان داده شده در جدول 1 بود. یکی از دلایل اصلی آزمایش PostgreSQL و MySQL بر روی اوراکل و مایکروسافت قیمت این راه حل ها بود. اوراکل به هیچ مجوز انحصاری برای Oracle Spatial و Graph از 5 دسامبر 2019 نیاز ندارد و در پایگاه داده Oracle گنجانده شده است. Oracle نسخه استاندارد 2 را با حداقل 21000 دلار ارائه می دهد. مایکروسافت SQL Server ارزان تر از Oracle است، اما همچنان 3717 دلار برای هر هسته است. هر دو سیستم خارج از محدوده دپارتمان ژئوانفورماتیک هستند. با این وجود، آزمایش پیشنهادی برای هر SDBMS قابل تکرار است.
هر دو سرور پایگاه داده (PostgreSQL و MySQL) در یک برنامه GIS معمولی هستند. ایجاد یک محیط قوی، ایمن و سریع باید بخشی از هر پروژه گسترده تر باشد. به جز برای تکرار، راهاندازی متعادلکننده بار و راهحلهای در دسترس بالا (مثلاً استفاده از PgPool برای PostgreSQL و روتر MySQL برای MySQL) باید در نظر گرفته شود. مقایسه در شرایط واقعی و بر اساس داده های مکانی واقعی انجام شد. دادههای مکانی از مجموعه دادههای در دسترس عموم و سرورهایی با عملکرد متفاوت استفاده شد. از نمودارهای تولید شده، می توان دریافت که مبادله بین یک سرور اصلی و یک سرور برده از رایانه شخصی به نوت بوک، نتیجه متفاوتی بر اساس عملکرد سرور اصلی یا سرور ایجاد می کند. ما همچنین رفتار را با محدودیت سرعت، تعداد متفاوتی از نقاط لبه یا رکوردها آزمایش کردیم.
زمانهای تکرار ( بخش 3.3 ) مربوط به سرعت انتقال ( بخش 3.2 ) و بار CPU ( بخش 3.1 ) و البته با تکنیک تکرار بود. PostgreSQL و MySQL از رویکردهای تکرار متفاوتی استفاده می کنند و این آزمایش نشان می دهد که هر تکنیک تکرار دارای مزایا و معایبی است.
PostgreSQL با پسوند Slony از تکرار منطقی ناهمزمان استفاده می کند و زمان تکرار به عملکرد سرور و پهنای باند اتصال بستگی دارد. Slony-I امکان تکرار یک یا چند جدول را در میان سرورهای PostgreSQL فراهم می کند. PostgreSQL میتواند پردازش دادههای بزرگتری را نسبت به MySQL انجام دهد و آن را در زمان کوتاهتری تکرار کند، اگرچه Slony میتواند ناسازگاری بین یک سرور اصلی و یک سرور برده برای مدت زمان معینی ایجاد کند (همگامسازی مرحله زمانی). سرورهای PostgreSQL باید اتصال عالی به یکدیگر و سخت افزار قدرتمندی داشته باشند. مزایای PostgreSQL با Replication Slony این است که Slony امکان تکرار بین نسخههای اصلی مختلف PostgreSQL و سیستمعاملهای مختلف را فراهم میکند و تنها برخی از جداول را به برخی از Slave کپی میکند (تکثیر آبشاری) [18 ]. معایب آن شامل این است که تنظیم آن سختتر است و همگامسازی تغییر در یک طرحواره دشوار است.
MySQL از استریم بومی، تکرار منطقی همزمان استفاده میکند، جایی که عملکرد و پهنای باند اتصال آنقدر مهم نیست. تکرار به تعدادی رکورد ویرایش شده بستگی دارد زیرا تکرار همزمان هر رکورد را جداگانه همگام می کند. سرور اصلی یک گزارش باینری را با یک دستور (مکانیسم SBR) به سرور برده هنگام اجرا ارسال می کند. این لاگ های باینری را می توان برای ممیزی استفاده کرد. Monyog نشان می دهد که رکورد ابتدا از یک سرور برده حذف شده و سپس در یک رکورد جدید قرار داده شده است. اگرچه تکرار همزمان باید ثبات master-slave را تضمین کند، زمان صرف شده برای تکمیل تکرار بسیار بیشتر از PostgreSQL بود. اینکه آیا باید از این روش استفاده کرد یا نه، بسیار وابسته به موارد استفاده است. اگر نیازی به ثبات رکورد برای مدتی (به منظور ثبت تغییرات Slony finish در master و سپس ارسال آنها به سرور Slave) وجود نداشته باشد، مانند تجزیه و تحلیل طولانی مدت در سرور اصلی، تکرار Slony یک مزیت خواهد بود. روش دیگر (MySQL)، اگر بهتر است هر رکورد در سرور برده بلافاصله به عنوان یک رکورد در سرور اصلی، به عنوان مثال، نقشه برداری بلادرنگ (گذرنامه شهری درختان) همگام سازی شود.
به طور کلی، پیکربندی صحیح یک محیط توزیع شده کامل، از جمله تکرار پایگاه داده در همکاری با تکنیک های متعادل کننده بار و در دسترس بودن بالا، منجر به بهبود قابلیت اطمینان و در دسترس بودن داده ها در خوشه پایگاه داده برای مشتری (صفحه وب، دسکتاپ GIS) خواهد شد. این یک محیط توزیع شده را ایجاد می کند که در آن یک برنامه کاربردی می تواند مستقل از محل منابع به دیتا استور دسترسی پیدا کند. با افزایش تعداد گرههای تکرار، پیچیدگی سیستم افزایش مییابد، همانطور که نیازهای مدیریتی و شکنندگی بالقوه دادهها افزایش مییابد. مقایسه PostgreSQL با Replication Slony و MySQL بومی استریم تکرار تفاوت بین تکرار منطقی ناهمزمان و همزمان را نشان می دهد. Slony برای مجموعه داده های بزرگ مناسب تر است و می تواند ویرایش های گسترده داده را انجام دهد. MySQL یک تغییر داده را آهستهتر تکرار میکند، اما سازگاری دادهها را در کل کلاستر تکرار حفظ میکند. زمان تکثیر MySQL عمدتاً تحت تأثیر تعداد رکوردها و قدرت CPU سرور اصلی است. تکثیر MySQL به اندازه PostgreSQL به قدرت CPU نیاز ندارد و پهنای باند شبکه کمتر مورد نیاز است.
PostgreSQL با تکثیر پایگاه داده Slony را می توان در یک خوشه استفاده کرد، جایی که تغییرات زیادی در داده ها (نقاط لبه) ایجاد می شود، اما در آن مهم نیست که هر تغییری در کل خوشه به طور همزمان انجام شود (تأخیر از ثانیه به دقیقه). ). زمان تکرار Slony به قدرت سرور برده و تعداد نقاط لبه در داده های تکرار شده بستگی دارد.
برای کار همزمان بر روی یک ذخیره سازی گسترده پایگاه داده فضایی، جایی که هر متخصص GIS تجزیه و تحلیل طولانی مدت را تکمیل می کند، راه حل مناسب کار بر روی یک نسخه محلی از پایگاه داده و همگام سازی نتایج و تغییرات بین خود توسط تکرار پایگاه داده است. PostgreSQL با Slony در همه جا قابل استفاده است و توسط لایه های موجود اصلاح می شود. هر لایه در پایگاه داده فضایی یک جدول است و Slony طرحی را برای تکرار به طور خودکار تغییر نمی دهد. برای افزودن لایههای جدید در پایگاه داده، بهتر است از تکرار پخش جریانی PostgreSQL بومی یا تکرار MySQL SBR یا RBR استفاده کنید. Slony برای پایگاه داده در تولید مفید است، جایی که تغییراتی در داده ها وجود دارد (به روز رسانی، درج و حذف) و مقداری تاخیر بین سرور اصلی و slave بی ربط است. Replication Slony را می توان در یک شبکه حسگر استفاده کرد، که از فناوریهای شبکه گسترده کم توان (LPWAN) برای ارتباط استفاده میکند، که در آن انتقال دادهها با مهلتهای زمانی دقیق محاسبه نمیشود و لازم نیست هر رکورد بلافاصله یا نحوه دریافت آن در سرور اصلی تکرار شود. از سوی دیگر، همانندسازی MySQL SBR برای نشان دادن تغییرات فوری در دادههای مکانی مفید است. هر راه حلی برای ردیابی حرکت یا همکاری آنلاین بر روی یک مجموعه داده (به عنوان مثال، گذرنامه درختان با استفاده از تلفن های همراه) برای همگام سازی هر تغییر در مجموعه داده بین پایگاه های داده برای سازگاری ضروری است. همانندسازی MySQL SBR برای نشان دادن تغییرات فوری در داده های مکانی مفید است. هر راه حلی برای ردیابی حرکت یا همکاری آنلاین بر روی یک مجموعه داده (به عنوان مثال، گذرنامه درختان با استفاده از تلفن های همراه) برای همگام سازی هر تغییر در مجموعه داده بین پایگاه های داده برای سازگاری ضروری است. همانندسازی MySQL SBR برای نشان دادن تغییرات فوری در داده های مکانی مفید است. هر راه حلی برای ردیابی حرکت یا همکاری آنلاین بر روی یک مجموعه داده (به عنوان مثال، گذرنامه درختان با استفاده از تلفن های همراه) برای همگام سازی هر تغییر در مجموعه داده بین پایگاه های داده برای سازگاری ضروری است.
هر دو مکانیسم تکثیر در این آزمایش ثابت کردند که میتوانند حجم کمی از دادهها را بدون بارگذاری بیش از حد شبکه یا CPU مدیریت کنند و میتوانند تکثیر دادهها را به ترتیب ثانیه به پایان برسانند. در طول همکاری بلادرنگ، جایی که کاربران رکورد را به رکورد تغییر میدادند (ایجاد نقاط جدید، بهروزرسانی ویژگیهای رکورد)، هر دو مکانیسم تکرار توانستند یک محیط توزیع شده قدرتمند برای این نوع کار فراهم کنند.
عملاً، این مکانیسمهای تکرار عمدتاً برای این وظایف تحقیقاتی مورد استفاده قرار گرفتهاند [ 29 ، 30 ، 31 ]. هدف از استقرار مکانیسمهای تکرار برای این وظایف تحقیقاتی استفاده از مجموعه دادههای فضایی گسترده بود. از این رو، از مزایای شبکه پایگاه داده توزیع شده برای متعادل کردن بار بین پایگاه داده اصلی (برای نوشتن تغییرات) و پایگاه داده slave (برای حل مسائل تحلیلی) استفاده شد [ 5 ].
منابع
- اوربانو، آر. آرورا، ن. چان، ی. داونینگ، آ. الزبرند، سی. فنگ، ی. گالاگالی، ج. کلاین، جی. لیو، جی. لو، ای. و همکاران پایگاه داده Oracle Advanced Replication 11g ; Oracle: Redwood City, CA, USA, 2013; جلد 2. [ Google Scholar ]
- Samtani, G. ادغام B2B: راهنمای عملی برای تجارت الکترونیکی مشترک . World Scientific: سنگاپور، 2002; شابک 1-86094-326-8. [ Google Scholar ]
- اینمون، دبلیو. هاکاثورن، اچ. Richard, D. Using the Data Warehouse , 2nd ed.; جان وایلی و پسران: نیویورک، نیویورک، ایالات متحده آمریکا، 1996; ISBN 0471059668. [ Google Scholar ]
- اوزسو، MT; Valduriez, P. Principles of Distributed Database Systems ; Springer: نیویورک، نیویورک، ایالات متحده آمریکا، 2011; ISBN 9781441988331. [ Google Scholar ]
- پوهانکا، تی. پچانک، وی. Solanská، M. همگام سازی و تکرار Geodata در بستر Esri. در مجموعه مقالات پانزدهمین کنفرانس بین المللی ژئوکنفرانس علمی چند رشته ای SGEM 2015، آلبنا، بلغارستان، 18 تا 24 ژوئن 2015. جلد 1، ص 837–844. [ Google Scholar ]
- پوهانکا، تی. پچانک، وی. Hejlová، V. پایتون وب سرور برای تجسم داده های حسگر. در مجموعه مقالات شانزدهمین کنفرانس بین المللی ژئوکنفرانس علمی چند رشته ای (SGEM 2016)، آلبنا، بلغارستان، 30 ژوئن تا 6 ژوئیه 2016؛ جلد 1، ص 803-810. [ Google Scholar ]
- میستری، ر. Misner, S. معرفی مروری فنی Microsoft SQL Server 2014 ; Microsoft Press: Redmond، WA، USA، 2014; ISBN 9780735684751. [ Google Scholar ]
- تاکادا، M. سیستم های توزیع شده: برای سرگرمی و سود. در دسترس آنلاین: https://book.mixu.net/distsys/ (در 29 ژانویه 2019 قابل دسترسی است).
- Mazilu، MC Replication پایگاه داده. سیستم پایگاه داده J. 2010 ، I ، 33-38. [ Google Scholar ]
- مکریس، ع. تسرپس، ک. اسپیلیوپولوس، جی. Anagnostopoulos، D. ارزیابی عملکرد MongoDB و PostgreSQL برای دادههای مکانی-زمانی. در مجموعه مقالات کارگاه CEUR، لیسبون، پرتغال، 26 مارس 2019؛ جلد 2322. [ Google Scholar ]
- Kabakus، AT; کارا، آر. ارزیابی عملکرد پایگاههای اطلاعاتی در حافظه. J. King Saud Univ. محاسبه کنید. Inf. علمی 2017 ، 29 ، 520-525. [ Google Scholar ] [ CrossRef ]
- Aitchison, R. مقدمه ای بر DNS. در Pro DNS و BIND ؛ Apress: برکلی، کالیفرنیا، ایالات متحده آمریکا، 2005; صص 3-19. ISBN 1590594940. [ Google Scholar ]
- بل، سی. کیندال، م. Thalmann, L. MySQL High Availability ; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2014; ISBN 9780596807306. [ Google Scholar ]
- شونيگ، اچ.-ج. PostgreSQL Replication , 2nd ed.; Packt Publishing: Birmingham, UK, 2015; شابک 978-1-78355-060-9. [ Google Scholar ]
- گایر، سی. هابارد، جی. Byham, R. SQL Server Replication. در دسترس آنلاین: https://docs.microsoft.com/en-us/sql/relational-databases/replication/sql-server-replication (در 29 ژانویه 2019 قابل دسترسی است).
- تکرار MySQL. در دسترس آنلاین: https://dev.mysql.com/doc/refman/5.7/en/replication.html (در 29 ژانویه 2019 قابل دسترسی است).
- آنون. جامد IT: DB-Engines. در دسترس آنلاین: https://db-engines.com/en/ranking (در 29 مارس 2020 قابل دسترسی است).
- خواننده، S. Slony-I. در دسترس آنلاین: https://www.slony.info/ (در 26 فوریه 2020 قابل دسترسی است).
- شنلر، دی. Schwedl, U. MySQL Admin Cookbook: Replication and Indexing ; Packt Publishing: Birmingham, UK, 2011; ISBN 1849516146. [ Google Scholar ]
- آنون. MySQL :: MySQL 5.7 Reference Manual :: 16.2.2 Replication Implementation Details. در دسترس آنلاین: https://dev.mysql.com/doc/refman/5.7/en/replication-implementation-details.html (در 2 آوریل 2020 قابل دسترسی است).
- Tiwari, S. Professional NoSQL , 1st ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2011; شابک 978-0-470-94224-6. [ Google Scholar ]
- Boicea، A.; رادولسکو، اف. Agapin، LI MongoDB در مقابل اوراکل – مقایسه پایگاه داده. در مجموعه مقالات سومین کنفرانس بین المللی 2012 در مورد داده های هوشمند نوظهور و فناوری های وب، بخارست، رومانی، 19 تا 21 سپتامبر 2012. صص 330-335. [ Google Scholar ]
- آبرامووا، وی. برناردینو، جی. Furtado، P. کدام پایگاه داده NoSQL؟ Open J. Databases 2014 , 1 , 8. [ Google Scholar ]
- Dolgikh, M. Vysoká Dostupnost v Relačních Databázových Systémech ; دانشگاه ماساریک: برنو، جمهوری چک، 2014. [ Google Scholar ]
- پاندویت. آینده مس: کابل کشی رده 8 ; Panduit: Tinley Park, IL, USA, 2016. [ Google Scholar ]
- هیل، اس. 5G چقدر سریع است. در دسترس آنلاین: https://www.digitaltrends.com/mobile/how-fast-is-5g/ (در 29 ژانویه 2019 قابل دسترسی است).
- IEEE. 802.11b-1999 استاندارد IEEE برای فناوری اطلاعات – ارتباطات و تبادل اطلاعات بین سیستمها – شبکههای محلی و شهری – الزامات خاص – بخش 11: کنترل دسترسی متوسط LAN بیسیم (MAC) و لایه فیزیکی (PHY) Sp . IEEE: Piscataway، NJ، USA، 2000. [ Google Scholar ]
- Codd، FE عادی سازی بیشتر مدل رابطه ای پایگاه داده. سیستم پایگاه داده 1972 ، 6 ، 33-64. [ Google Scholar ]
- فیلیپوفوا، جی. پوهانکا، تی. ارزیابی زیست محیطی جنگل های دشت سیلابی اروپای مرکزی: مطالعه موردی از آبرفت رودخانه موراوا. لهستانی J. Environ. گل میخ. 2019 ، 28 ، 4511–4517. [ Google Scholar ] [ CrossRef ]
- پچانک، وی. ماچار، آی. پوهانکا، تی. اوپرشال، ز. پتروویچ، اف. شواجدا، ج. شالک، ال. Chobot، K. فیلیپوفوا، جی. کادلین، پی. و همکاران اثربخشی سیستم Natura 2000 برای حفاظت از انواع زیستگاه: مطالعه موردی از جمهوری چک. نات. حفظ کنید. 2018 ، 24 ، 21-41. [ Google Scholar ] [ CrossRef ]
- وروبلوا، ک. پوهانکا، تی. آیا حفاظت از محیط زیست جنگل های تحت سلطه راش اروپا کارآمد است؟ فرسنیوس محیط. گاو نر 2019 ، 28 ، 1218-1223. [ Google Scholar ]
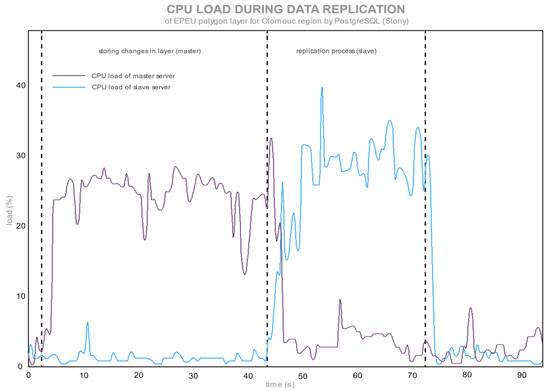
شکل 1. میانگین بار واحد پردازش مرکزی (CPU) در طول تکرار لایه واحد پدولوژیک-اکولوژیکی (EPEU) تخمین زده شده توسط PostgreSQL (Slony).
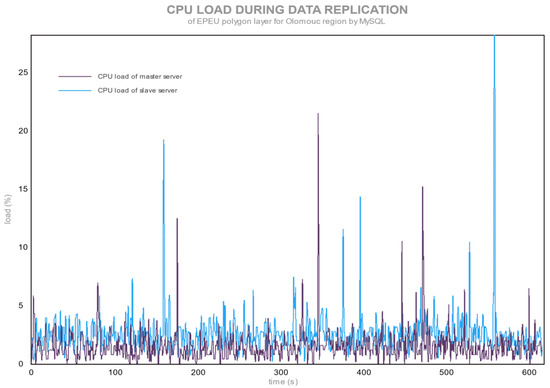
شکل 2. میانگین بار CPU در طول تکرار لایه EPEU توسط MySQL.
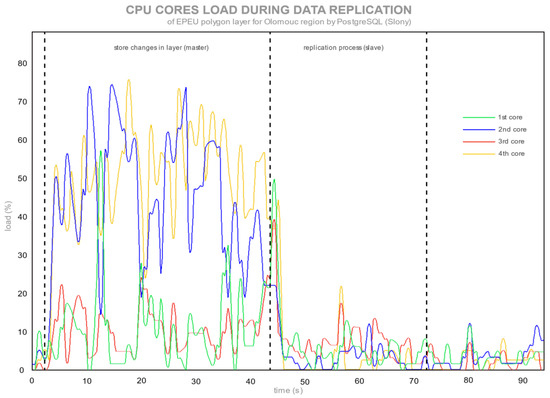
شکل 3. بار هسته CPU در طول تکرار لایه EPEU توسط PostgreSQL (Slony).
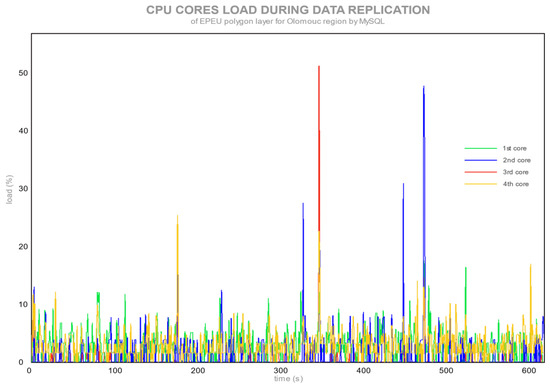
شکل 4. بار هسته CPU در حین تکرار لایه EPEU توسط MySQL.
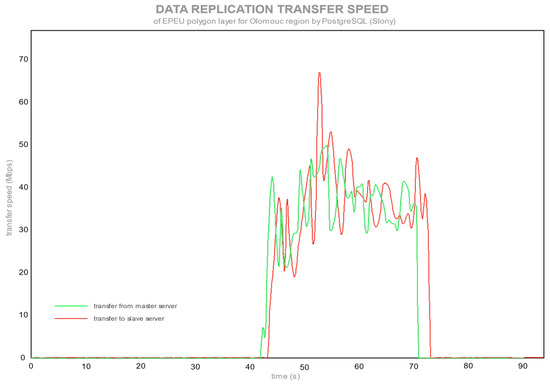
شکل 5. سرعت انتقال تکرار لایه EPEU توسط PostgreSQL (Slony).
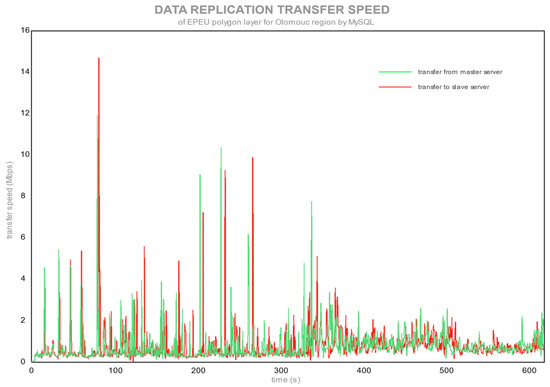
شکل 6. سرعت انتقال تکرار لایه EPEU توسط MySQL.
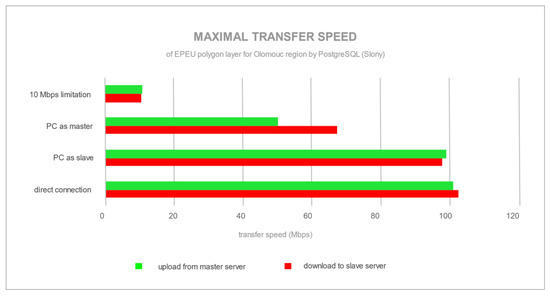
شکل 7. میانگین سرعت تکرار لایه EPEU برای پیکربندی های مختلف خوشه توسط PostgreSQL (Slony).
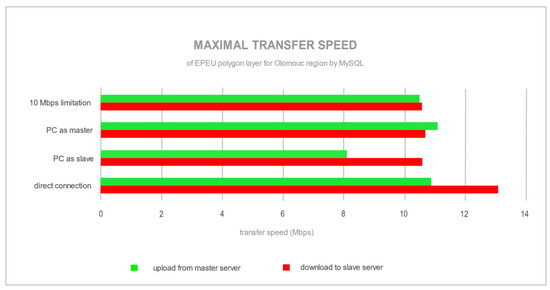
شکل 8. میانگین سرعت تکرار لایه EPEU برای پیکربندی های مختلف خوشه توسط MySQL.
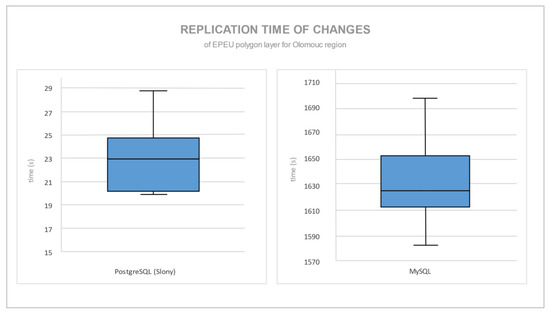
شکل 9. زمان تکرار تغییرات لایه EPEU.
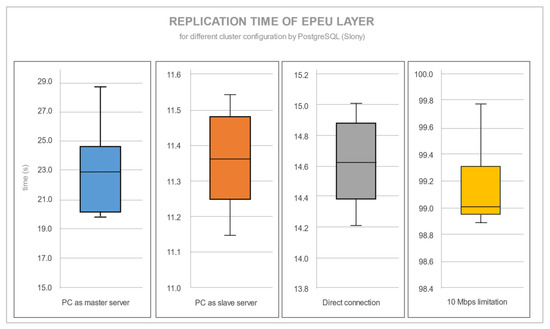
شکل 10. زمان تکرار لایه EPEU برای پیکربندی های مختلف خوشه توسط PostgreSQL (Slony).
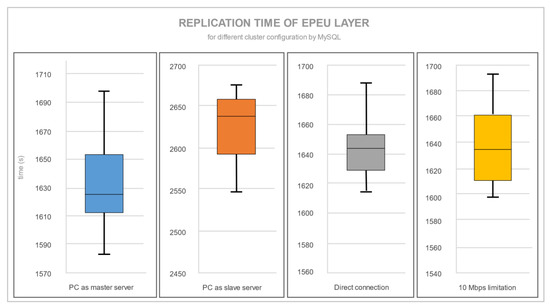
شکل 11. زمان تکرار لایه EPEU برای پیکربندی های مختلف خوشه توسط MySQL.
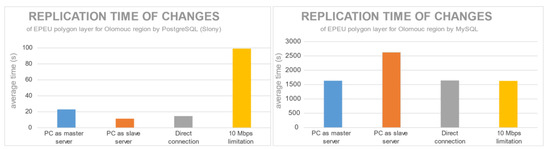
شکل 12. میانگین زمان تکرار لایه EPEU برای هر دو محلول تکرار.
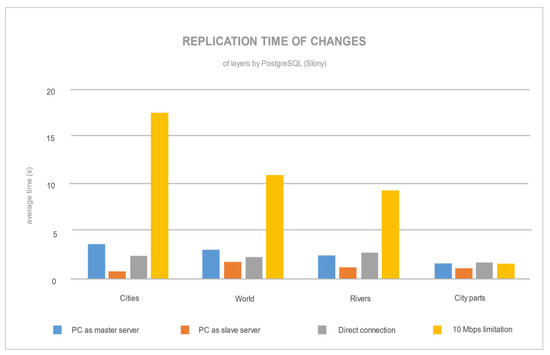
شکل 13. میانگین زمان تکرار لایه ها با پیکربندی های خوشه های مختلف توسط PostgreSQL (Slony).
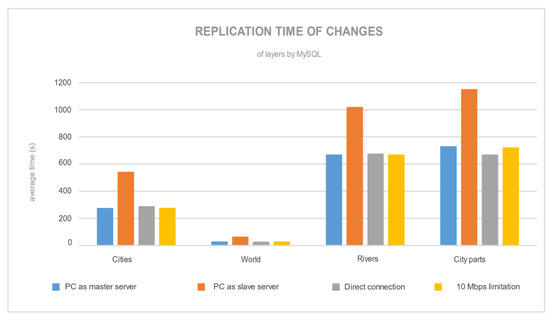
شکل 14. میانگین زمان تکرار لایه ها با پیکربندی خوشه های مختلف توسط MySQL.
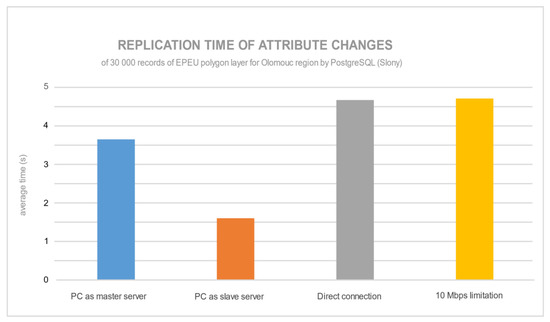
شکل 15. میانگین زمان تکرار لایه ها با پیکربندی های خوشه های مختلف توسط PostgreSQL (Slony).
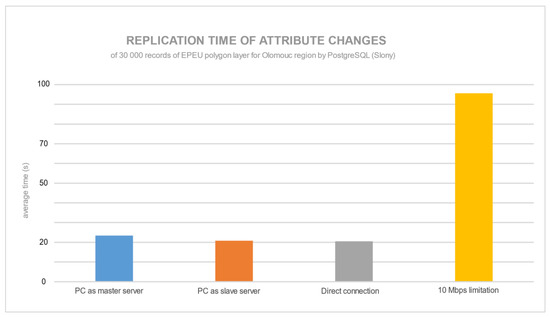
شکل 16. میانگین زمان تکرار لایه ها با تنظیمات خوشه های مختلف توسط MySQL.


بدون دیدگاه