

خلاصه
شناخت صحنه های پس از زلزله نقش مهمی در نجات و بازسازی پس از زلزله دارد. برای غلبه بر اتکای بیش از حد به تفسیر بصری متخصص و عملکرد تشخیص ضعیف یادگیری ماشین سنتی در تشخیص صحنه پس از زلزله، این مقاله یک مدل تشخیص صحنه چندگانه پس از زلزله (PEMSR) را بر اساس روش یادگیری عمیق کلاسیک (SSD) پیشنهاد میکند. . در این مقاله، مجموعه دادههای صحنههای پس از زلزله برچسبگذاری شده با تقسیمبندی تصاویر سنجش از دور بدستآمده ساخته میشود که به شش دسته طبقهبندی میشوند: لغزش، خانهها، ویرانهها، درختان، گرفتگی و تالاب. با توجه به ناکافی بودن و عدم تعادل مجموعه داده اصلی، یادگیری انتقال و استراتژی تقویت و تعادل داده در مدل PEMSR استفاده می شود. برای ارزیابی مدل PEMSR، معیارهای ارزیابی دقت، یادآوری و امتیاز F1 در آزمایش استفاده می شود. نتایج آزمایش تجربی چندگانه نشان میدهد که مدل PEMSR عملکرد قویتری را در تشخیص صحنه پس از زلزله نشان میدهد. مدل PEMSR دقت تشخیص هر صحنه را در مقایسه با SSD با یادگیری انتقال و استراتژی تقویت داده بهبود می بخشد. علاوه بر این، میانگین زمان تشخیص مدل PEMSR تنها به 0.4565 ثانیه نیاز دارد، که بسیار کمتر از 8.3472s روش سنتی هیستوگرام گرادیان جهت دار + ماشین بردار پشتیبان (HOG+SVM) است. مدل PEMSR دقت تشخیص هر صحنه را در مقایسه با SSD با یادگیری انتقال و استراتژی تقویت داده بهبود می بخشد. علاوه بر این، میانگین زمان تشخیص مدل PEMSR تنها به 0.4565 ثانیه نیاز دارد، که بسیار کمتر از 8.3472s روش سنتی هیستوگرام گرادیان جهت دار + ماشین بردار پشتیبان (HOG+SVM) است. مدل PEMSR دقت تشخیص هر صحنه را در مقایسه با SSD با یادگیری انتقال و استراتژی تقویت داده بهبود می بخشد. علاوه بر این، میانگین زمان تشخیص مدل PEMSR تنها به 0.4565 ثانیه نیاز دارد، که بسیار کمتر از 8.3472s روش سنتی هیستوگرام گرادیان جهت دار + ماشین بردار پشتیبان (HOG+SVM) است.
کلید واژه ها:
بلایای زلزله ؛ تشخیص صحنه ؛ یادگیری عمیق ؛ روش کلاسیک SSD ؛ انتقال یادگیری
1. معرفی
زلزله یکی از مضرترین انواع بلایای طبیعی در جهان است. هر ساله تقریباً پنج میلیون زمین لرزه در سراسر جهان رخ می دهد که از این تعداد حدود ده یا بیست مورد آسیب جدی به بشریت وارد کرده است که منجر به خسارات زیست محیطی غیرقابل محاسبه و تلفات جانی و ثروتی شده است. زلزله 6.5 ریشتری لودیان در سال 2014 را به عنوان مثال در نظر بگیرید: باعث تلفات 617 نفر شد، حداقل 1024 رانش زمین با مساحتی معادل 100 متر مربع یا بیشتر و ده ها هزار ساختمان فروریخت [ 1 ، 2 ]. جمع آوری سریع و دقیق اطلاعات خسارت در مناطق زلزله زده برای نجات به موقع افراد گرفتار شده و بازسازی پس از زلزله از اهمیت قابل توجهی برخوردار است [ 3 ، 4 ]]. در کار امداد و نجات اضطراری لرزه ای، سنتی ترین روش، بررسی در محل توسط کارشناسان مربوطه است [ 5 ، 6 ]. با این حال، حجم کار بسیار زیاد است، و بهره وری پایین به دلیل گستردگی و تنوع مناطق فاجعه بار است [ 7 ]. اگر بازرسان با رانش زمین یا صحنه های گرفتگی مواجه شوند، دسترسی به موقع به مکان های فاجعه دشوار است. به دلیل راندمان پایین و عدم قطعیت، در حال حاضر برآوردن الزامات کاربردی ارزیابی سریع و نجات پس از زلزله امکان پذیر نیست.
با این حال، با توسعه سریع فناوریهایی مانند سنجش از راه دور ماهوارهای و وسایل نقلیه هوایی بدون سرنشین، توانایی به دست آوردن اطلاعات بلادرنگ در سطح زمین بهبود یافته است [ 8 ، 9 ]. تصاویر سنجش از دور را می توان به سرعت به دست آورد و می تواند جهان عینی را به طور جامع و شهودی منعکس کند، و منبع اطلاعاتی جدیدی برای تشخیص و ارزیابی سریع آسیب زلزله فراهم می کند [ 10 ، 11 ]. تحقیقات زیادی در مورد ارزیابی خطر بلایا بر اساس تصاویر سنجش از دور وجود دارد. جلنک و همکاران [ 12] به طور هم افزایی از تصاویر رادار Sentinel-1 و داده های نوری Sentinel-2 برای تجزیه و تحلیل تغییرات سطح پس از زلزله استفاده کرد و زلزله 7.8 ریشتری 2016 Kaikoura در نیوزیلند را به عنوان مثال در نظر گرفت. آنها از تداخل سنجی راداری برای ارزیابی اثرات زلزله از طریق محاسبه جابجایی های عمودی و تداخل نگاشتهای دیفرانسیل استفاده کردند. اولن و همکاران [ 13] روش جدیدی را برای تشخیص منطقه تحت تأثیر بالقوه (PAA) به دنبال یک رویداد خطر طبیعی بر اساس دادههای رادار باند C Sentinel-1 پیشنهاد کرد. روش پیشنهادی مبتنی بر سریهای زمانی انسجام است که تغییرپذیری طبیعی انسجام را در هر پیکسل در منطقه مورد نظر تعیین میکند و جایی که از دست دادن انسجام معنیدار آماری با مقایسه انسجام همرویداد پیکسل به پیکسل با توزیعهای انسجام زمانی رخ داده است. آنها عملکرد روش را در یافتن PPA در مورد زلزله سال 2017 ایران و عراق و یک منطقه مستعد رانش زمین در شمال غربی آرژانتین تأیید کردند. موندینی و همکاران [ 14] پیشنهاد کرد که استفاده از تصاویر باند C Sentinel-1 SAR می تواند مشکل کمبود تصاویر نوری قبل و بعد از لغزش را به دلیل پایداری ابر حل کند. آنها 32 مورد زمین لغزش جهانی را تجزیه و تحلیل کردند و نتایج نشان داد که تغییرات ناشی از زمین لغزش در دامنه SAR در حدود 84 درصد موارد بدون ابهام بود. روشهای تخصصی تفسیر بصری که به طور کامل از تصاویر با وضوح بالا استفاده میکنند، در زمینه ارزیابی، نجات و بازسازی پس از زلزله به جریان اصلی تبدیل شدهاند [ 15 ، 16 ، 17 ]. اما این روش ها از نظر منابع کارشناسی از ناکارآمدی و هزینه های بالایی رنج می برند. علاوه بر این، تفسیر نتایج به طور اساسی در بین متخصصان متفاوت است [ 18 ، 19 ].
در سالهای اخیر، توسعه یادگیری ماشین به غلبه بر برخی از این محدودیتها با ترویج استفاده از تشخیص و پردازش تصویر رایانهای کمک کرده است [ 20 ، 21 ]. علاوه بر این، با توسعه فناوری هایی مانند GPU و هوش مصنوعی، تشخیص تصویر از طریق روش های یادگیری عمیق کارآمدتر و دقیق تر شده است [ 22 ، 23 ]، که استفاده از یادگیری عمیق را برای تحقق تشخیص صحنه پس از زلزله امکان پذیر می کند. مراحل اصلی تشخیص تصویر معمولاً استخراج و طبقه بندی ویژگی ها است. در روزهای اولیه، تشخیص تصویر عمدتاً از روشهای سنتی استخراج ویژگیهای دستی، مانند تبدیل ویژگی تغییرناپذیر مقیاس (SIFT) استفاده میکرد [ 24 ]]، هیستوگرام گرادیان (HOG) [ 25 ] و مدل قطعات تغییر شکل پذیر (DPM) [ 26 ]، در ترکیب با طبقه بندی کننده هایی مانند ماشین بردار پشتیبان (SVM) [ 27 ] و جنگل تصادفی [ 28 ]. از آنجایی که هینتون [ 29 ] راه حلی برای مشکل ناپدید شدن گرادیان در آموزش شبکه عمیق ارائه کرد، یادگیری عمیق وارد دوره توسعه اساسی شد. پس از ارائه شبکههای عصبی کانولوشنال (CNN) [ 30 ] در سال 2012، یادگیری عمیق به طور انفجاری توسعه یافت. CNN به طور کامل توسعه یافته است و در بسیاری از زمینه های تحقیقاتی استفاده شده است. دو نوع معمولی از یادگیری عمیق برای تشخیص تصویر وجود دارد: روش هایی که بر اساس پیشنهاد منطقه هستند، مانند RCNN [ 31 ]، FAST-RCNN [32 ]، FASTER-RCNN [ 33 ] و R-FCN [ 34 ] و روش هایی که مبتنی بر رگرسیون هستند، مانند شما فقط یک بار نگاه می کنید (YOLO) [ 35 ] و آشکارساز MultiBox تک شات (SSD) [ 36 ]. روشهای نوع دوم سریعتر اما دقت کمتری نسبت به روشهای نوع اول دارند، زیرا جعبههای محدودکننده را در یک شبکه تولید میکنند. در مقایسه با YOLO، روش SSD نه تنها سرعت را بهبود می بخشد، بلکه دقت تشخیص را نیز بهبود می بخشد، که با سری RCNN قابل مقایسه است [ 36 ]. بنابراین، روش SSD در مدل ما اتخاذ شده است.
اخیراً بسیاری از محققان از روش های یادگیری عمیق برای تشخیص صحنه فاجعه استفاده کرده اند. دینگ و همکاران [ 37 ] یک تصویر گوگل پس از زلزله با وضوح فضایی 0.3 متر در شهرستان لودیان، استان یوننان چین را به عنوان نمونه در نظر گرفت و از یک مدل شبکه عصبی پیچش عمیق AlexNet از پیش آموزشدیده برای استخراج ویژگی، در ترکیب با یک طبقهبندی کننده SVM، برای درک پس از زلزله استفاده کرد. تشخیص صحنه سان و همکاران [ 38 ] یک شبکه عصبی کانولوشن را پیشنهاد کرد که با تقسیمبندی چند مقیاسی (CMSCNN) برای طبقهبندی تصاویر لرزهای با وضوح بالا ترکیب شد، که دقت بهبود یافته را متوجه شد. خو و همکاران [ 39] یک مدل هرم ویژگی متراکم با یک شبکه رمزگذار-رمزگشا (DFPENet) برای تشخیص زمین لغزش زمین لرزه ایجاد کرد و نتایج تجربی تشخیص دقیق، کارایی بالا و بین صحنهای بلایای زلزله را نشان داد. جی و همکاران [ 40 ] یک ویژگی CNN را با روش جنگل تصادفی پیشنهاد کرد. در مقایسه با CNN، این روش دقت شناسایی فروپاشی پس از زلزله را بهبود می بخشد و عملکرد استخراج ویژگی CNN بهتر از استخراج ویژگی بافت است. سونگ و همکاران [ 41] روشی را پیشنهاد کرد که از شبکه عصبی Deeplab v2 برای شناسایی اولیه مناطق ساختمانی آسیب دیده استفاده کرد و از روش خوشه ای تکراری خطی ساده (SLIC) برای استخراج دقیق مرزهای منطقه ساختمان های آسیب دیده از زلزله استفاده کرد. در نهایت، یک روش مورفولوژیکی ریاضی برای حذف نویز پسزمینه در این مقاله معرفی شد.
روش هایی که در بالا مورد بحث قرار گرفتند نتایج قابل توجهی در زمینه تشخیص صحنه پس از زلزله از طریق بهینه سازی ساختار شبکه و ادغام با سایر الگوریتم ها به همراه داشت. با این حال، این روش ها به ندرت کمبود داده را در نظر می گیرند و ممکن است با داده های ناکافی عملکرد خوبی داشته باشند. به خصوص در تشخیص تصویر سنجش از دور پس از زلزله، یک مانع اساسی فقدان نمونه های برچسب دار است. بنابراین، ایجاد یک مدل تشخیص صحنه پس از زلزله که بتواند تنها با مقدار کمی داده به خوبی عمل کند، مهم است.
در این مقاله، یک مدل تشخیص صحنه چندگانه پس از زلزله (PEMSR) بر اساس روش کلاسیک تشخیص SSD و یادگیری انتقال پیشنهاد شده است. این مدل سعی میکند تصاویر صحنههای پس از زلزله را جمعآوری کند و آنها را به صورت دستی برای ساخت یک مجموعه داده برچسبگذاری کند. برای از بین بردن تأثیر منفی یک مجموعه داده ناکافی، از تقویت داده و یادگیری انتقال [ 42 ] در این مدل استفاده می شود. علاوه بر این، نمونه برداری تصادفی بیش از حد برای غلبه بر مشکل عدم تعادل داده ها مورد استفاده قرار می گیرد. مدل PEMSR و سایر مدلها برای بررسی عملکرد مدل و تأثیرات افزایش دادهها و انتقال یادگیری بر روی مدل PEMSR ارزیابی و مقایسه میشوند.
2. مواد و روشها
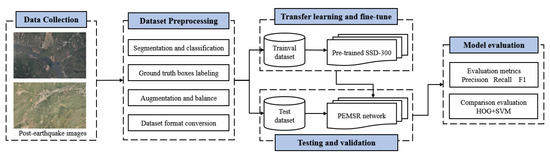
گردش کار مدل PEMSR در شکل 1 نشان داده شده است که دارای پنج جزء اصلی است: (1) جمع آوری داده ها. (2) پیش پردازش داده ها. (3) انتقال یادگیری با SSD. (4) آزمایش و اعتبار سنجی؛ و (5) ارزیابی مدل.
2.1. جمع آوری داده ها
در این مقاله، تصاویر گوگل از منطقه زلزله زده شهرستان لودیان، شهر ژائوتنگ، استان یوننان چین در تاریخ 7 آگوست 2014 با وضوح فضایی 0.3 متر به عنوان داده های خام برای شناسایی جمع آوری شده است. اطلاعات تفصیلی در جدول 1 ارائه شده است .
2.2. پیش پردازش داده ها
پس از به دست آمدن تصاویر، لازم است داده های خام پیش پردازش شوند تا بتوان آنها را برای آموزش شبکه تطبیق داد. مراحل اصلی پیش پردازش داده ها عبارتند از (1) تقسیم بندی و طبقه بندی داده ها. (2) برچسب زدن جعبه های حقیقت. (3) افزایش و تعادل داده ها. و (4) تبدیل فرمت مجموعه داده.
2.2.1. تقسیم بندی و طبقه بندی داده ها
در این مرحله، تصاویری که دامنه وسیعی داشتند برای آموزش و آزمایش بیش از حد بزرگ بودند. از این رو، ما تصاویر را از طریق ArcGIS Desktop تقسیم کردیم تا صحنه های مفیدی برای آزمایش استخراج کنیم. هر تصویر نزدیک به 300*300 پیکسل برش داده می شود که برای پردازش بعدی راحت است. تصاویر تقسیمبندی شده بهصورت دستی بهعنوان شش نوع صحنه طبقهبندی میشوند: رانش زمین، خرابهها و گرفتگیهای ناشی از زلزله، همراه با صحنههای رایج، یعنی خانهها، برکهها و درختان. این شش نوع صحنه مجموعه داده اصلی ما را تشکیل می دهند. تعداد نمونه های هر نوع صحنه در جدول 2 مشخص شده است. با توجه به مقدار محدود داده در مجموعه داده اصلی، به منظور اطمینان از مجموعه داده آموزشی کافی برای جلوگیری از برازش بیش از حد و اطمینان از نتایج آزمایش، تصاویر بخشبندی شده به طور تصادفی به مجموعه داده trainval (آموزش و اعتبارسنجی) و مجموعه داده آزمایشی در یک مجموعه داده تقسیم میشوند. نسبت 4:1 از آنجایی که تصاویر اصلی برای ارائه خیلی بزرگ هستند، بخش هایی از تصاویر اصلی و تصاویر قطعه قطعه شده صحنه پس از زلزله در شکل 2 نشان داده شده است.
2.2.2. برچسب زدن جعبه های حقیقت زمینی
تصاویر طبقه بندی شده با برچسب گذاری دستی مناطق مورد علاقه (ROI) به عنوان دانش قبلی در آزمایش ضروری است. ROI هر تصویر توسط جعبه های حقیقت آبی رنگ مشخص می شود و فایل های TXT برای ثبت اطلاعات جعبه ها تولید می شوند، جایی که هر فایل TXT مربوط به یک تصویر است. فرمت فایل TXT به شرح زیر است:
-
شماره شی
-
نام کلاس x1min y1min x1max y1max
-
ClassName x2min y2min x2max y2max
تعداد جعبه های حقیقت زمینی و نام هر جعبه و محل آن در تصویر مربوطه ثبت می شود. یک مثال نتیجه برچسب زدن در شکل 3 ارائه شده است .
2.2.3. افزایش و تعادل داده ها
در روش یادگیری عمیق، نمونه های آموزشی کمتر ممکن است منجر به عملکرد یادگیری ناکافی مدل، تعمیم ضعیف مدل و برازش بیش از حد شود. برای غلبه بر مشکل دادههای نمونه ناکافی در آزمایش، از روش افزایش داده [ 43 ، 44 ] چرخش و آینهسازی برای به دست آوردن دادههای نمونه مشابه اضافی استفاده میکنیم. همانطور که در جدول 3 ارائه شده است، تبدیل آینه ای تعداد داده های نمونه اصلی را دو برابر می کند. تبدیل چرخش چرخش تصاویر اصلی به میزان 90، 180 و 270 درجه است که می تواند تعداد داده های نمونه اصلی را چهار برابر کند. در آزمایش، این مقاله دو روش افزایش داده را ترکیب کرده و از آنها برای افزایش حجم نمونه به 2، 4 و 8 برابر حجم نمونه اولیه استفاده می کند. در فرآیند تقویت دادهها، جعبههای حقیقت پایه برچسبگذاریشده به طور همزمان افزوده میشوند و فایلهای TXT حاشیهنویسی متناظر جدید نیز تولید خواهند شد.
علاوه بر این، عدم تعادل شدید در توزیع صحنه های اصلی وجود دارد که ممکن است بر عملکرد مدل تأثیر بگذارد. سه رویکرد اصلی برای مقابله با مشکلات عدم تعادل کلاس وجود دارد که میتوان آنها را به روشهای سطح داده، سطح الگوریتم و ترکیبی طبقهبندی کرد. برای بهبود مشکل عدم تعادل نمونه در مجموعه داده، از روش نمونه برداری تصادفی بیش از حد [ 38 ] برای تکرار و افزایش تعداد نمونه ها در کلاس های اقلیت در این مقاله استفاده شده است. جدول 4حجم داده ها را پس از افزایش داده ها و تعادل داده ها ارائه می دهد. تعداد صحنههای مجموعه داده افزایش مییابد و متوازنتر میشود. پس از هر تقویت داده، ما اطمینان حاصل کردیم که نسبت مجموعه داده trainval (آموزش و اعتبارسنجی) به مجموعه داده آزمایشی 4:1 است. پس از آخرین افزایش داده و تعادل، تعداد کل مجموعه داده trainval 4608 و تعداد کل مجموعه داده آزمایشی 1152 است.
2.2.4. تبدیل فرمت مجموعه داده
در این مقاله، همه آزمایشها بر اساس یک چارچوب منبع باز یادگیری عمیق، یعنی Caffe [ 45 ] است. Caffe نیاز دارد که فرمت داده های آموزشی LMDB باشد. بنابراین، لازم است قبل از آموزش، مجموعه داده را به فرمت LMDB تبدیل کنید. مراحل اصلی به شرح زیر است:
چهار پوشه جدید ایجاد کنید: Annotations، JPEGImages، ImageSets و Labels. همه تصاویر شماره گذاری شده و در پوشه JPEGImages ذخیره می شوند و فایل های برچسب TXT مربوطه در پوشه Labels ذخیره می شوند.
فایل های برچسب TXT را با استفاده از یک اسکریپت به فرمت XML تبدیل کنید و آنها را در پوشه Annotations ذخیره کنید.
یک اسکریپت برای تولید مجموعه داده trainval (آموزش و اعتبارسنجی) اجرا کنید و فایل های شناسایی مجموعه داده را آزمایش کنید و آنها را در پوشه اصلی ImageSets ذخیره کنید. از طریق این رویکرد، مجموعه داده به فرمت VOC تبدیل می شود.
برای تبدیل مجموعه داده VOC به فرمت LMDB، اسکریپت تبدیل را تغییر داده و اجرا کنید. Trainval قالب بندی شده (آموزش و اعتبارسنجی) و مجموعه داده های آزمایشی تولید و در پوشه LMDB ذخیره می شوند. پیش پردازش داده ها به پایان رسیده است.
2.3. انتقال آموزش با SSD
یادگیری انتقال دارای مزایای کم نیاز به داده، انعطاف پذیری و استحکام است که می تواند کارایی و دقت آموزش مدل PEMSR را بهبود بخشد. برای غلبه بر کمبود نمونه های برچسب دار کافی، این مقاله از یادگیری انتقال [ 42 ، 43 ، 46 ] با یک مدل از پیش آموزش دیده که از طریق آموزش SSD بر روی مجموعه داده PASCAL VOC به دست می آید، استفاده می کند. دو نوع ساختار SSD وجود دارد که بیشترین استفاده را دارند، از جمله SSD-300 و SSD-512. این مقاله SSD-300 را بهعنوان مدل پایه انتخاب میکند، که همچنین با اندازه تصاویر مجموعه داده ما 300*300 متناسب است. روش SSD-300 از دو جزء تشکیل شده است: یک شبکه عصبی کانولوشن عمیق مبتنی بر VGGNet- 16 ساختار شبکه [ 48] برای استخراج ویژگی اولیه هدف و یک شبکه تشخیص ویژگی چند مقیاسی. این شبکه نقشههای ویژگی چند مقیاسی و عملگرهای کانولوشن را ترکیب میکند تا جعبههای مرزی را با احتمال اینکه حاوی اشیاء مورد نظر باشند، تولید کند. سپس، نتایج تشخیص نهایی از طریق سرکوب غیر حداکثری (NMS) به دست میآید. مدل PEMSR ما مزایای این ساختار را به ارث برده و پارامترهای شبکه را با یادگیری از مجموعه دادههای صحنههای پس از زلزله تنظیم میکند.
تنظیم دقیق یک مهارت مهم برای یادگیری انتقالی است. همانطور که در شکل 4 نشان داده شده است ، پارامترهای مدل PEMSR توسط پارامترهای مدل SSD-300 که روی مجموعه داده PASCAL VOC از قبل آموزش داده شده، مقداردهی اولیه می شوند. در عین حال، با توجه به مجموعه دادههای ورودی صحنههای پس از زلزله، وزن لایهها برای پیشبینی کلاس و تولید جعبههای مرزی تنظیم میشوند. در مرحله آموزش مدل، اندازه دسته روی 64، کاهش وزن روی 0.05، تکانه روی 0.9، تعداد تکرارها 24000 و نرخ یادگیری پایه بر روی 0.01 و تقسیم بر 10 تنظیم شده است. زمانی که تعداد تکرارها به 8000 و 16000 می رسد.
2.4. تست و اعتبارسنجی
مجموعه داده این مقاله به طور تصادفی به ده زیر مجموعه تقسیم می شود که هفت زیر مجموعه به عنوان مجموعه داده آموزشی، یک زیر مجموعه به عنوان مجموعه داده اعتبار و زیر مجموعه های باقی مانده به عنوان مجموعه داده آزمایشی استفاده می شود. پس از به دست آمدن مدل آموزشی PEMSR، اسکریپت آزمون اجرا شد و نتیجه آزمون به دست آمد. شکل 5 یک نتیجه تشخیص تست را نشان می دهد. در گوشه سمت چپ بالای کادر، نام کلاس و مقدار اطمینان مشخص شده است.
2.5. ارزیابی مدل
2.5.1. معیارهای ارزیابی
در این مقاله، دقت، فراخوان و F1 به عنوان معیارهای ارزیابی انتخاب شده است. دقت، نسبت تعداد نمونه های مثبتی است که به درستی به عنوان نمونه های مثبت شناسایی شده اند. این فراخوان نشان می دهد که آیا همه نمونه های مثبت شناسایی شده اند یا خیر. امتیاز F1 میانگین هارمونیک فراخوان و دقت است که یک معیار ارزیابی جامع تر است. مقدار بیش از 0.6 رضایت بخش در نظر گرفته می شود. این معیارها به صورت زیر محاسبه می شوند:
پrهجمنسمنon=تیپتیپ + fپ
rهجآلل=تیپتیپ + fn
اف1=2 ∗ پ ∗ آرپ + آر
جایی که تیپتعداد نمونه های مثبتی است که به درستی مثبت شناسایی شده اند، fپتعداد نمونه های منفی است که به اشتباه مثبت تشخیص داده شده اند، fnتعداد نمونه های مثبتی است که شناسایی نمی شوند، پمقدار دقت و آرمقدار یادآوری است.
2.5.2. مقایسه ارزیابی با روش HOG+SVM
برای مقایسه و ارزیابی بیشتر مدل PEMSR، این مقاله روش سنتی تشخیص هدف HOG+SVM را در این آزمایش در نظر میگیرد. HOG برای استخراج ویژگی و SVM برای طبقه بندی ویژگی ها استفاده می شود.
روش HOG+SVM [ 25 ، 27 ، 49 ، 50 ، 51 ] عمدتاً شامل مراحل زیر است:
- 1)
-
خاکستری شدن تصویر: تبدیل تصاویر RGB به مقیاس خاکستری.
- 2)
-
عادی سازی رنگ: فضای رنگ را با روش تصحیح گاما عادی کنید.
- 3)
-
محاسبه گرادیان: محاسبه گرادیان هر پیکسل از تصویر.
- 4)
-
تقسیم بندی سلول ها: تصویر را به سلول های کوچک 6 * 6 و هیستوگرام گرادیان آماری تقسیم کنید.
- 5)
-
توصیفگر بلوک: 2 * 2 سلول را در یک بلوک ترکیب کنید تا توصیفگر بلوک را بدست آورید.
- 6)
-
عادی سازی توصیفگر بلوک: کنتراست را برای هر بلوک عادی کنید و HOG ها را روی پنجره تشخیص جمع آوری کنید.
- 7)
-
طبقه بندی کننده SVM: بردار ویژگی HOG را به طبقه بندی کننده SVM ارسال کنید.
علاوه بر این، SVM استاندارد یک طبقهبندیکننده باینری برای تشخیص الگو است، و باید به یک طبقهبندی کننده چند کلاسه برای یادگیری یک مسئله چند کلاسه گسترش یابد. از این رو، این مقاله دو نوع صحنه پس از زلزله را برای تشکیل 15 طبقه بندی جدید ترکیب می کند. برای راحتی، شش نوع صحنه با A، B، C، D، E و F مشخص میشوند. هر آموزش بر روی نمونههای ناشناخته 15 نتیجه آموزشی را به همراه خواهد داشت. در آزمایش، بردار متناظر نمونه های ناشناخته بر روی 15 نتیجه آزمایش می شود. سپس، رای گیری برای طبقه بندی انجام می شود. روند کامل رای گیری به شرح زیر است:
-
اول، A = B = C = D = E = F = 0.
-
در طبقه بندی کننده (A, B)، اگر A برنده شود، A = A + 1. در غیر این صورت، B = B + 1;
-
در طبقه بندی (A, C)، اگر A برنده شود، A = A + 1. در غیر این صورت، C = C + 1.
-
در طبقه بندی کننده (D, F)، اگر D برنده شد، D = D + 1; در غیر این صورت، F = F + 1.
-
در طبقه بندی کننده (E, F)، اگر E برنده شد، E = E + 1. در غیر این صورت، F = F + 1.
-
در نهایت پس از 15 مقایسه، نتیجه طبقه بندی تصویر Max (A, B, C, D, E, F) است.
3. آزمایش ها و نتایج
این بخش به معرفی منطقه مورد مطالعه، آماده سازی محیط آزمایشی و روش های طراحی که در این مقاله استفاده شده است می پردازد. مجموعههای متعددی از آزمایشهای مقایسه و بهینهسازی برای شناسایی مدل بهینه PEMSR انجام شد.
3.1. منطقه مطالعه
این مقاله منطقه زلزله 6.5 ریشتری لودیان 2014 را به عنوان منطقه مورد مطالعه انتخاب کرد که با زمان و مکان زلزله مرتبط است. چندین ویژگی مهم منطقه مورد مطالعه وجود دارد. اولاً، شهرستان لودیان یک شهرستان فقیر در سطح ملی بود که در شمال شرقی یوننان، چین قرار داشت. شرایط اقتصادی محلی نسبتاً ضعیف و مقاومت لرزه ای ساختمان ها به طور کلی ضعیف بود، به طوری که هنگام وقوع زلزله، ساختمان های زیادی فروریختند. ثانیاً منطقه زلزله کوهستانی و مصادف با فصل بارندگی بوده و باعث بروز بلایای ثانویه جدی تری مانند رانش زمین و گل و لای شده است. این صحنهها در تصاویر سنجش از دور با پسزمینه پیچیدهتر واضحتر و معمولیتر هستند، بنابراین این مقاله منطقه زلزله لودیان را به عنوان منطقه مورد مطالعه انتخاب کرد.
3.2. آماده سازی و طراحی آزمایش
آزمایشات ما بر روی یک سیستم عامل اوبونتو 14.04 LTS (64 بیتی) انجام شده است. ما مدل را روی GTX 1080 با حافظه 8G آموزش می دهیم. سایر تنظیمات محیطی در جدول 5 ارائه شده است.
برای ارزیابی عملکرد مدل PEMSR و تأثیرات یادگیری انتقال، افزایش داده و تعادل بر روی مدل، این مقاله سه سطح آزمایش را طراحی کرد: اول، مقایسه با روشهای HOG+SVM و SSD اولیه برای ارزیابی عملکرد سه مدل در تشخیص صحنه پس از زلزله. دوم، پس از تقویت داده ها با 2، 4 و 8 بار، مقایسه عملکرد مدل PEMSR قبل و بعد از تقویت داده ها. و سوم، مقایسه عملکرد مدل قبل و بعد از تعادل داده ها.
3.3. نتایج تجربی
3.3.1. مقایسه نتایج سه روش
روش HOG+SVM و روش SSD [ 36 ] پارامترهای اولیه با مدل PEMSR برای ارزیابی مقایسه مقایسه شده است. نتایج امتیاز F1 این روش ها در جدول 6 ارائه شده است. مطابق جدول 6نمرات F1 روش HOG+SVM فقط کمی بالاتر از روشهای SSD و PEMSR برای صحنههای ponding و درختی است، در حالی که امتیازات F1 برای صحنههای دیگر به مراتب کمتر از دو روش دیگر است. امتیاز F1 مدلهای SSD و PEMSR در خانهها، رانش زمین، خرابهها و برکهها از 60% فراتر میرود. نمرات درختان و گرفتگی به 60% نمی رسد که نیاز به بهبود بیشتر را نشان می دهد. علاوه بر این، میانگین زمان تشخیص هر دو روش SSD و PEMSR کمتر از 0.5 ثانیه است. این روش ها بسیار سریعتر از روش سنتی تشخیص HOG+SVM هستند. به طور خلاصه، روشهای یادگیری عمیق در کل از روش یادگیری ماشین سنتی بهتر عمل میکنند. با مقایسه عملکرد SSD و PEMSR، اگرچه روش SSD از نظر زمان تشخیص کمی سریعتر است.
3.3.2. مقایسه نتایج پس از افزایش داده ها
برای بهینه سازی مدل PEMSR، یک استراتژی افزایش داده در این مقاله استفاده شده است. نتایج امتیاز F1 که پس از افزایش 2، 4 و 8 بار داده ها به دست می آید در جدول 7 ارائه شده است. دقت تشخیص کلی مدل PEMSR با افزایش حجم نمونه ها افزایش می یابد، به ویژه برای درختان و صحنه های گرفتگی، که تنها بخش های کوچکی را در مجموعه داده اصلی اشغال می کنند. از طریق تقویت داده ها، دقت تشخیص هر صحنه بهبود یافته است و امتیازات F1 تمام صحنه ها بیش از 60٪ است. با این حال، این بدان معنا نیست که با افزایش حجم نمونه، عملکرد شناسایی به طور نامحدود بهبود می یابد. به عنوان مثال، برای داده های خرابه ها با افزایش چهار و هشت بار در جدول 7، مقدار داده ها افزایش یافت، اما امتیاز F1 اندکی کاهش یافت. اعتقاد بر این است که عملکرد تشخیص بهینه بر روی نمونههای خرابه نزدیک شده یا تحقق یافته است. بهترین عملکرد تشخیص توسط مدل PEMSR محقق می شود و بهبود آن از طریق افزایش داده ها دشوار است.
3.3.3. مقایسه نتایج پس از تعادل داده ها
عدم تعادل مجموعه داده ممکن است عملکرد مدل PEMSR را به سمت نمونه های اقلیت سوگیری کند. چندین آزمایش برای ارزیابی این فرضیه انجام شد. پس از استفاده از نمونهگیری بیش از حد تصادفی برای متعادلتر کردن نمونههای داده، نتایج امتیاز تشخیص F1 ارائه شده در جدول 8 به دست آمد. آنها بر روی نمونه های اصلی، تقویت شده و متعادل انجام می شوند. نتایج امتیاز F1 افزایش داده ها، دقت تشخیص بهینه در هر صحنه در آزمایش های تقویت قبلی است. پس از متعادل شدن نمونه ها، امتیازات F1 در حوضچه ها، درختان و صحنه های گرفتگی، که بخش های نسبتاً کوچکی از مجموعه داده قبلی را اشغال می کنند، به میزان قابل توجهی افزایش می یابد. آنها برای صحنه های دیگر به طور قابل توجهی تغییر نمی کنند.
3.3.4. مدل بهینه PEMSR
بر اساس نتایج آزمایشهای مقایسهای، مدل بهینه PEMSR به عنوان مدلی با افزایش دادهها با ضریب هشت و تعادل داده در نظر گرفته میشود. با توجه به شکل 6 ، مشاهده می شود که ارزش تلفات در 50 دوره اول به سرعت کاهش می یابد و سپس به تدریج صاف می شود تا همگرا شود. نتایج آزمون مدل بهینه PEMSR در شکل 7 ارائه شده است و دقت، فراخوانی و امتیاز F1 آن در جدول 9 ارائه شده است. همه این مقادیر در همه صحنه ها از 70 درصد و در صحنه لغزش از 90 درصد فراتر می روند. از این رو، عملکرد شناسایی رضایت بخشی محقق شده است.
4. بحث
مدل پیشنهادی PEMSR شش نوع تشخیص صحنه پس از زلزله را انجام می دهد. سپس، مدل بهینه می شود و عملکرد تشخیص بهبود می یابد. از طریق چندین آزمایش، مدل PEMSR دو مزیت را نشان میدهد. اول، مدل PEMSR مبتنی بر SSD با یادگیری انتقالی از روش HOG+SVM در تشخیص بهتر عمل می کند. دوم، تقویت و متعادل سازی داده ها بر مشکلات ناشی از مجموعه داده های ناکافی و نامتعادل غلبه می کند، که دقت مدل PEMSR را در تشخیص صحنه پس از زلزله بهبود می بخشد. علاوه بر این، این مدل شناسایی مناطقی را که شایستگی مطالعه بیشتر را دارند تسهیل می کند.
4.1. مدل PEMSR با یادگیری انتقالی از سایر روش ها بهتر عمل می کند
با توجه به جدول 6 ، مدل PEMSR کارایی تشخیص بالاتری را در مقایسه با روش یادگیری ماشین سنتی HOG+SVM نشان میدهد: میانگین زمان تشخیص مورد نیاز تنها 0.4565 ثانیه است، در حالی که روش HOG+SVM 8.3472 ثانیه و تشخیص کلی آن است. دقت بالاتر است استفاده از روش یادگیری انتقال منجر به بهبود قابل توجهی در کار آموزش یک مدل با نمونه های ناکافی می شود. مدل PEMSR که در این مقاله ارائه شده است مبتنی بر روش SSD است که از استراتژی یادگیری انتقال برای کاهش حجم دادههای نمونه آموزشی مورد نیاز استفاده میکند. به عنوان جدول 10نشان می دهد، دقت کلی برای هر نوع صحنه به دلیل استراتژی یادگیری انتقال بهبود یافته است، اگرچه میانگین زمان تشخیص در مقایسه با روش SSD کمی طولانی تر است. مدل PEMSR دقت کلی بهتری را از طریق یادگیری انتقال نشان میدهد.
4.2. افزایش و تعادل داده ها دقت مدل PEMSR را بهبود می بخشد
اکثر روش های یادگیری عمیق به داده های نمونه کافی نیاز دارند. در غیر این صورت، عملکرد تمرین ضعیف خواهد بود یا بیش از حد برازش اتفاق می افتد. در مدل PEMSR، از تقویت داده ها برای غلبه بر مشکل نمونه های اصلی ضعیف استفاده می شود. جدول 11نتایج امتیاز F1 هر صحنه پس از زلزله را برای هر آزمایش تقویتی ارائه می دهد. دقت تشخیص کلی مدل PEMSR با هر افزایش داده افزایش می یابد. با این حال، صحنه هایی با پیشرفت های بسیار جزئی مانند خرابه ها نیز وجود دارد. در این صحنه، عملکرد تشخیص نزدیک به عملکرد تشخیص بهینه مدل PEMSR است. نتیجه تشخیص خرابیها امتیاز F1 پایدار است، تنها با چند نوسان در هر آزمایش مختلف، و بهبود عملکرد از طریق افزایش دادهها دشوار است. مجموعه داده نامتعادل ممکن است مدل را به سمت کلاس اکثریت نمونه سوگیری کند، در حالی که تشخیص کلاس اقلیت نمونه رضایت بخش نیست. در حالی که صرفاً افزایش مقدار داده های آموزشی ممکن است به بهبود عملکرد مدل ادامه ندهد، ما استفاده از روش نمونه برداری بیش از حد را در افزایش داده ها برای متعادل کردن مجموعه داده در نظر می گیریم. نتایج نشان میدهد که وقتی مجموعه دادههای ما متعادل بود، عملکرد تشخیص مدل PEMSR بهطور قابلتوجهی بهبود مییابد، بهویژه در کلاسهایی از صحنههایی که نسبتهای کوچکی از مجموعه داده اصلی را اشغال میکنند، مانند حوض، درختان و گرفتگی. نتیجه گیری می شود که مدل PEMSR ما در صورت مواجهه با کمبود نمونه و عدم تعادل مزایایی را ارائه می دهد.
4.3. پیشرفت های آینده
همانطور که در این مقاله گزارش شده است، مدل PEMSR عملکرد تشخیص عالی را در تشخیص صحنه پس از زلزله انجام می دهد. با این حال، زمینه برای توسعه و کاربرد بیشتر وجود دارد. به عنوان مثال، این مقاله تأثیر وضوح تصویر بر عملکرد تشخیص را در نظر نمی گیرد. در آینده، آزمایشهای کنتراست از طریق تاری تصویر انجام خواهد شد و تأثیر وضوح بر عملکرد تشخیص مدل PEMSR بررسی خواهد شد. علاوه بر این، نمونههای این مقاله از یک منطقه لرزهخیز کوهستانی میآیند و تأثیر شناسایی مدل در ناحیه متراکم ساختمان شهری نیاز به تأیید بیشتری دارد. علاوه بر این، ما صحنه های رایج مانند خانه ها، درختان و حوض را به عنوان یک نمونه پس زمینه در نظر می گیریم و تأثیر آنها را در تشخیص مدل صحنه های ناشی از زلزله تحلیل می کنیم. در همان زمان، انواع بیشتری از صحنه های ناشی از زلزله اضافه شد، مانند ترک های زمین. در نهایت، استفاده از دانش اضافی از علم بلایا برای تحقق شناخت سلسله مراتبی صحنه های پس از زلزله موضوعی برای بررسی بیشتر است. به عنوان مثال، خرابه ها را می توان به کلاس های آسیب شدید و خفیف تقسیم کرد که ممکن است برای امداد رسانی و بازسازی پس از زلزله ارزشمندتر باشد.
5. نتیجه گیری ها
این مقاله یک مدل PEMSR را بر اساس روش تشخیص SSD کلاسیک پیشنهاد میکند که بر غلبه بر اتکای بیش از حد به تفسیر بصری متخصص و عملکرد تشخیص ضعیف یادگیری ماشین سنتی در تشخیص صحنه پس از زلزله متمرکز بود. در مدل، یک استراتژی یادگیری انتقال و تقویت داده برای غلبه بر نارسایی مجموعه داده استفاده می شود. علاوه بر این، یک روش نمونهگیری تصادفی برای غلبه بر عدم تعادل مجموعه داده استفاده میشود. نتایج چندین آزمایش مقایسه و بهینهسازی نشان میدهد که مدل عملکرد رضایتبخشی را در تشخیص صحنه پس از زلزله انجام میدهد و استراتژیهای یادگیری انتقال، تقویت دادهها و متعادلسازی دادهها عملکرد شناسایی مدل PEMSR را بهبود میبخشد. اگرچه فرصت های زیادی برای اکتشاف و توسعه بیشتر وجود دارد،
منابع
- لین، ایکس. ژانگ، اچ. چن، اچ. چن، اچ. لین، جی. تحقیقات میدانی در مورد ساختمانهای لرزهای آسیب دیده در زلزله لودیان ۲۰۱۴. زمین مهندس مهندس Vib. 2015 ، 14 ، 169-176. [ Google Scholar ] [ CrossRef ]
- Chong, X. استفاده از زمین لغزش های زمین لرزه ای برای تجزیه و تحلیل منبع و روند گسیختگی زمین لرزه لودیان 2014. J. Eng. جئول 2015 ، 23 ، 755-759. [ Google Scholar ]
- شیبایما، ا. هیسادا، ی. یک سیستم کارآمد برای به دست آوردن اطلاعات خسارت زلزله در منطقه آسیب دیده. در مجموعه مقالات سیزدهمین کنفرانس جهانی مهندسی زلزله، ونکوور، پیش از میلاد، کانادا، 1 تا 6 اوت 2004. [ Google Scholar ]
- عجمی، س. فتاحی، م. نقش سیستم های مدیریت اطلاعات زلزله (EIMS) در کاهش تخریب: مطالعه تطبیقی ژاپن، ترکیه و ایران. فاجعه قبلی مدیریت بین المللی J. 2009 , 18 , 150-161. [ Google Scholar ] [ CrossRef ]
- لی، اچ. شیائو، اس. Huo, L. بررسی آسیب و تجزیه و تحلیل سازه های مهندسی در زلزله Wenchuan. جی. ساخت. ساختار. 2008 ، 4 ، 10-19. [ Google Scholar ]
- سایسی، ع. Gentile, C. بررسی تشخیصی پس از زلزله یک برج بنایی تاریخی. J. Cult. میراث. 2015 ، 16 ، 602-609. [ Google Scholar ] [ CrossRef ]
- هوسکره، وی. نارازاکی، ی. Hoang، TA; Spencer, BF, Jr. به سوی بازرسیهای خودکار پس از زلزله با مدلهای آگاه از شرایط مبتنی بر یادگیری عمیق. arXiv 2018 , arXiv:1809.09195. [ Google Scholar ]
- دونگ، ی. لی، کیو. دو، ا. Wang, X. استخراج خسارات ناشی از زلزله Ms 8.0 Wenchuan در سال 2008 از داده های سنجش از دور SAR. J. آسیایی زمین علوم. 2011 ، 40 ، 907-914. [ Google Scholar ] [ CrossRef ]
- Eisenbeiss, H. یک وسیله نقلیه هوایی بدون سرنشین کوچک (UAV): نمای کلی سیستم و دریافت تصویر. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2004 ، 36 ، 1-7. [ Google Scholar ]
- لیو، J.-h. شان، X.-j. یین، جی.-ی. شناسایی خودکار ساختمانهای شهری آسیبدیده ناشی از زلزله با استفاده از اطلاعات سنجش از دور: با در نظر گرفتن زلزله 2001 بوج، هند، زلزله و زلزله 1976 تانگشان، چین، به عنوان مثال. Acta Seismol. گناه 2004 ، 17 ، 686-696. [ Google Scholar ] [ CrossRef ]
- گونگ، LX؛ وانگ، سی. وو، اف. ژانگ، جی اف. ژانگ، اچ. Li, Q. تشخیص آسیب ساختمان ناشی از زلزله با تصویربرداری نورافکن خیره شده توسط VHR TerraSAR-X پس از رویداد. Remote Sens. 2016 , 8 , 887. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جلنک، ج. کوپاچکووا، وی. Fárová، K. ارزیابی توزیع زمین لغزش پس از زلزله با استفاده از داده های نگهبان-1 و 2: مثال زلزله 7.8 مگاواتی 2016 در نیوزیلند. اقدامات. 2018 ، 2 ، 361. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- اولن، اس. بوکهاگن، ب. نقشه برداری مناطق آسیب دیده پس از رویدادهای مخاطره طبیعی با استفاده از سری زمانی انسجام نگهبان-1. Remote Sens. 2018 , 10 , 1272. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- موندینی، AC; سانتانجلو، ام. روچتی، ام. روزتو، ای. مانکونی، آ. تصاویر دامنه SAR Monserrat، O. Sentinel-1 برای تشخیص سریع زمین لغزش. Remote Sens. 2019 , 11 , 760. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- برونر، دی. لموئین، جی. Bruzzone، L. ارزیابی خسارت زلزله ساختمانها با استفاده از تصاویر نوری VHR و SAR. IEEE Trans. Geosci. Remote Sens. 2010 , 48 , 2403–2420. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ارلیش، دی. گوا، اچ. مولچ، ک. ما، جی. Pesaresi, M. شناسایی آسیب ناشی از زلزله ونچوان در سال 2008 از داده های سنجش از دور VHR. بین المللی جی دیجیت. زمین 2009 ، 2 ، 309-326. [ Google Scholar ] [ CrossRef ]
- لی، ز. جیائو، کیو. لیو، ال. تانگ، اچ. لیو، تی. نظارت بر خطرات زمینشناسی و بازیابی پوشش گیاهی در منطقه زلزلهزده ونچوان با استفاده از عکسبرداری هوایی. ISPRS Int. J. Geo-Inf. 2014 ، 3 ، 368-390. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یامازاکی، اف. کوچی، کی؛ کوهیاما، م. مورائوکا، ن. Matsuoka, M. تشخیص آسیب زلزله با استفاده از تصاویر ماهواره ای با وضوح بالا. در مجموعه مقالات IGARSS 2004. 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20-24 سپتامبر 2004; ص 2280-2283. [ Google Scholar ]
- وویگت، اس. اشنایدرهان، تی. توله، ا. گهلر، م. استاین، ای. مهل، اچ. ارزیابی سریع آسیب و نقشهبرداری وضعیت: یادگیری از زلزله 2010 هائیتی. فتوگرام مهندس Remote Sens. 2011 ، 77 ، 923-931. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Bishop، CM Pattern Recognition and Machine Learning ; Springer: برلین، آلمان، 2006. [ Google Scholar ]
- سیویکالپ، اچ. Triggs، B. تشخیص چهره بر اساس مجموعه تصویر. در مجموعه مقالات کنفرانس IEEE Computer Society در سال 2010 در مورد دید رایانه و تشخیص الگو، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 13 تا 18 ژوئن 2010. صص 2567-2573. [ Google Scholar ]
- مائو، بی. فضل الله، ز. م. تانگ، اف. کاتو، ن. آکاشی، او. اینو، تی. میزوتانی، ک. مسیریابی یا محاسبات؟ تغییر پارادایم به سمت انتقال بسته های شبکه کامپیوتری هوشمند مبتنی بر یادگیری عمیق. IEEE Trans. محاسبه کنید. 2017 ، 66 ، 1946-1960. [ Google Scholar ] [ CrossRef ]
- کوئلیو، IM; کوئلیو، وی. Luz، EJdS; اوچی، LS; Guimarães, FG; Rios، E. یک مدل مبتنی بر فراابتکاری یادگیری عمیق GPU برای پیشبینی سریهای زمانی. Appl. انرژی 2017 ، 201 ، 412-418. [ Google Scholar ] [ CrossRef ]
- ویژگی های تصویر متمایز Lowe، DG از نقاط کلیدی Scale-Invariant. بین المللی جی. کامپیوتر. Vis. 2004 ، 60 ، 91-110. [ Google Scholar ] [ CrossRef ]
- دلال، ن. Triggs، B. هیستوگرام گرادیان های جهت یافته برای تشخیص انسان. در مجموعه مقالات کنفرانس IEEE Computer Society در سال 2005 در مورد دید رایانه و تشخیص الگو (CVPR’05)، سن دیگو، کالیفرنیا، ایالات متحده آمریکا، 25 ژوئن 2005. [ Google Scholar ]
- فلزنزوالب، پ. مک آلستر، دی. رامانان، دی. در مجموعه مقالات کنفرانس IEEE 2008 در مورد بینایی کامپیوتری و تشخیص الگو، انکوریج، AK، ایالات متحده آمریکا، 23 تا 28 ژوئن 2008. صص 1-8. [ Google Scholar ]
- آنگولو، سی. RUIZ، FJ; ALEZ، LG; ORTEGA، JA چند طبقه بندی با استفاده از سه کلاس SVM. فرآیند عصبی. Lett. 2006 ، 23 ، 89-101. [ Google Scholar ] [ CrossRef ]
- بریمن، L. جنگل های تصادفی. ماخ فرا گرفتن. 2001 ، 45 ، 5-32. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هینتون، جنرال الکتریک؛ سالخوتدینوف، RR کاهش ابعاد داده ها با شبکه های عصبی. Science 2006 , 313 , 504-507. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- کریژفسکی، آ. سوتسکور، آی. هینتون، GE Imagenet طبقه بندی با شبکه های عصبی کانولوشن عمیق. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، دریاچه تاهو، NV، ایالات متحده، 3-6 دسامبر 2012. صص 1097–1105. [ Google Scholar ]
- گیرشیک، آر. دوناهو، جی. دارل، تی. Malik, J. Rich دارای سلسله مراتب برای تشخیص دقیق شی و تقسیم بندی معنایی هستند. در مجموعه مقالات کنفرانس IEEE در مورد دید کامپیوتری و تشخیص الگو، کلمبوس، OH، ایالات متحده، 24-27 ژوئن 2014. صص 580-587. [ Google Scholar ]
- Girshick, R. Fast r-cnn. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر، بوستون، MA، ایالات متحده آمریکا، 8 تا 10 ژوئن 2015. ص 1440-1448. [ Google Scholar ]
- رن، اس. او، ک. گیرشیک، آر. Sun, J. Faster r-cnn: به سمت تشخیص شی در زمان واقعی با شبکه های پیشنهادی منطقه. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، مونترال، QC، کانادا، 7-9 دسامبر 2015. ص 91-99. [ Google Scholar ]
- دای، جی. لی، ی. او، ک. Sun, J. R-FCN: تشخیص شیء از طریق شبکه های کاملاً پیچیده مبتنی بر منطقه. arXiv 2016 , arXiv:1605.06409. [ Google Scholar ]
- ردمون، جی. دیووالا، س. گیرشیک، آر. فرهادی، الف. شما فقط یک بار نگاه می کنید: یکپارچه، تشخیص شی در زمان واقعی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صص 779-788. [ Google Scholar ]
- لیو، دبلیو. آنگلوف، دی. ایرهان، د. سگدی، سی. رید، اس. فو، سی.-ای. Berg, AC Ssd: آشکارساز چند جعبه ای تک شات. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر، آمستردام، هلند، 10-16 اکتبر 2016. ص 21-37. [ Google Scholar ]
- دینگ، ال. لی، اچ. هو، سی. ژانگ، دبلیو. Wang, S. Alexnet Feature Extraction and Multi-Kernel Learning برای طبقه بندی شی گرا. بین المللی قوس. فتوگرام حسگر از راه دور اسپات. Inf. علمی 2018 ، 42 ، 277-281. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، جی. هائو، ی. رانگ، جی. شی، س. Ren, J. آموزش عمیق ترکیبی و تقسیم بندی چند مقیاسی برای نقشه برداری سریع آسیب با وضوح بالا. در مجموعه مقالات آموزش عمیق ترکیبی و تقسیم بندی چند مقیاسی برای نقشه برداری سریع آسیب با وضوح بالا، اکستر، بریتانیا، 21 تا 23 ژوئن 2017. صص 1101–1105. [ Google Scholar ]
- خو، Q. اویانگ، سی. جیانگ، تی. فن، ایکس. چنگ، دی. arXiv 2019 ، arXiv:1908.10907. [ Google Scholar ]
- جی، م. لیو، LF; Buchroithner, M. شناسایی ساختمانهای فروریخته با استفاده از تصاویر ماهواره ای پس از زلزله و شبکه های عصبی کانولوشنال: مطالعه موردی زلزله 2010 هائیتی. Remote Sens. 2018 ، 10 ، 1689. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- آهنگ، دی. تان، ایکس. وانگ، بی. ژانگ، ال. شان، ایکس. Cui, J. ادغام روشهای تقسیمبندی سوپرپیکسلی و یادگیری عمیق برای ارزیابی ساختمانهای آسیب دیده در اثر زلزله با استفاده از تصاویر سنجش از دور تک فاز. بین المللی J. Remote Sens. 2020 , 41 , 1040–1066. [ Google Scholar ] [ CrossRef ]
- Xu، YL; زو، MM; لی، اس. فنگ، HX; Ma، SP; Che, J. تشخیص فرودگاه انتها به انتها در تصاویر سنجش از دور با ترکیب شبکههای پیشنهادی منطقه آبشاری و شبکههای تشخیص چند آستانه. Remote Sens. 2018 ، 10 ، 1516. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- چن، ز. ژانگ، تی. Ouyang، C. تشخیص هواپیمای سرتاسری با استفاده از آموزش انتقال در تصاویر سنجش از دور. Remote Sens. 2018 , 10 , 139. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- یان، ی. تان، ز. Su، N. یک استراتژی افزایش داده بر اساس نمونه های شبیه سازی شده برای تشخیص کشتی در تصاویر سنجش از دور rgb. ISPRS Int. J. Geo-Inf. 2019 ، 8 ، 276. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- جیا، ی. شلهامر، ای. دوناهو، جی. کارایف، اس. لانگ، جی. گیرشیک، آر. گواداراما، اس. Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv 2014 ، arXiv:1408.5093 v12014. [ Google Scholar ]
- ژائو، اچ. لیو، اف. ژانگ، اچ. لیانگ، Z. یادگیری انتقال ناهمگن مبتنی بر شبکه عصبی کانولوشن برای طبقه بندی صحنه سنجش از دور. بین المللی J. Remote Sens. 2019 , 40 , 8506–8527. [ Google Scholar ] [ CrossRef ]
- وانگ، ی. وانگ، سی. Zhang، H. ترکیب یک آشکارساز چند جعبه ای تک شات با یادگیری انتقال برای تشخیص کشتی با استفاده از تصاویر SAR نگهبان-1. سنسور از راه دور Lett. 2018 ، 9 ، 780-788. [ Google Scholar ] [ CrossRef ]
- سیمونیان، ک. زیسرمن، الف. شبکه های پیچیده بسیار عمیق برای تشخیص تصویر در مقیاس بزرگ. arXiv 2014 ، arXiv:1409.1556. [ Google Scholar ]
- دادی، اچ اس. Pillutla، GKM نرخ تشخیص چهره را با استفاده از ویژگیهای HOG و طبقهبندی کننده SVM بهبود بخشید. IOSR J. Electron. اشتراک. مهندس 2016 ، 11 ، 34-44. [ Google Scholar ] [ CrossRef ]
- برتوزی، م. بروگی، ع. دل رز، ام. فلیسا، م. راکوتومامونجی، ا. Suard، F. آشکارساز عابر پیاده با استفاده از هیستوگرام گرادیان های جهت دار و طبقه بندی کننده ماشین بردار پشتیبان. در مجموعه مقالات کنفرانس سیستم های حمل و نقل هوشمند IEEE 2007، سیاتل، WA، ایالات متحده آمریکا، 30 سپتامبر تا 3 اکتبر 2007. صص 143-148. [ Google Scholar ]
- کائو، ایکس. وو، سی. یان، پی. Li, X. طبقهبندی خطی SVM با استفاده از تقویت ویژگیهای HOG برای تشخیص وسیله نقلیه در ویدیوهای هوابرد در ارتفاع پایین. در مجموعه مقالات 2011 هجدهمین کنفرانس بین المللی IEEE در مورد پردازش تصویر، بروکسل، بلژیک، 11-14 سپتامبر 2011. ص 2421-2424. [ Google Scholar ]
شکل 1. گردش کار مدل PEMSR. مجموعه داده Trainval به معنی مجموعه داده آموزشی و اعتبار سنجی است.
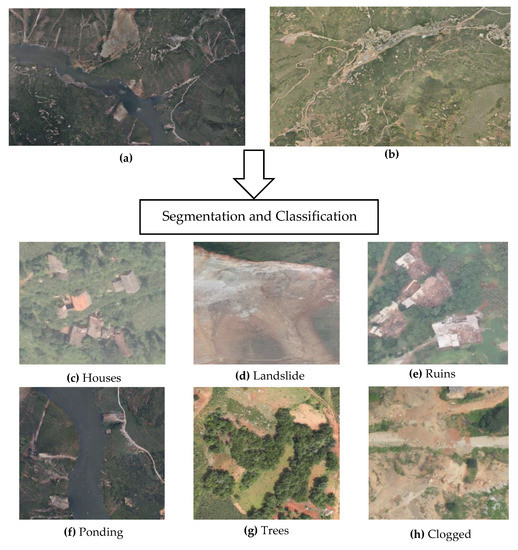
شکل 2. نتایج تقسیم بندی و طبقه بندی. تصویر ( الف ) بخشی از رودخانه نیولان و تصویر ( ب ) بخشی از کوه لانگتو است. صحنههای پس از زلزله تقسیمبندی شده و طبقهبندیشده: ( ج ) خانهها، ( د ) رانش زمین، ( ه ) ویرانهها، ( و) حوضبازی ، ( ز ) درختان و ( h ) گرفتگی.

شکل 3. نتیجه برچسب گذاری یک تصویر. جعبه های آبی نشان دهنده محل واقعی خانه ها هستند و اطلاعات آنها در یک فایل TXT ثبت می شود.
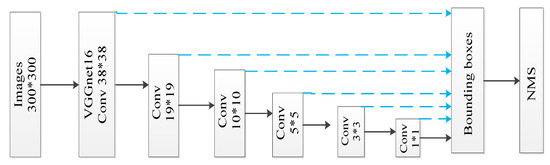
شکل 4. شبکه PEMSR پیشنهاد شده در این مقاله. فلش های سیاه نشان دهنده پارامترهای اولیه ثابتی هستند که در مجموعه داده PASCAL VOC آموخته شده اند و فلش های آبی نشان دهنده وزن هایی هستند که در مجموعه داده های این مقاله آموخته شده اند. اندازه نقشه های ویژگی در پنج لایه کانولوشنال بعدی 19، 10، 5، 3 و 1 است.

شکل 5. نمونه ای از نتیجه آزمایش.
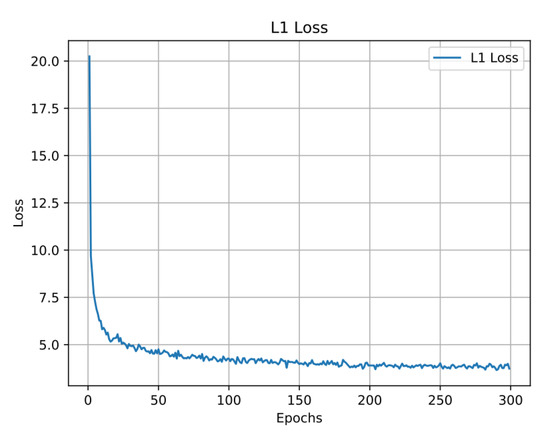
شکل 6. رابطه بین دوره ها و ارزش تلفات مدل PEMSR بهینه.

شکل 7. نمونه هایی از نتایج آزمون مدل PEMSR بهینه. از بالا به پایین صحنه هایی از خانه ها، رانش زمین، خرابه ها، گرفتگی، برکه و درختان نشان داده می شود.


بدون دیدگاه