

خلاصه
کلید واژه ها:
موقعیت داخلی ؛ میدان مغناطیسی ؛ شبکه عصبی کانولوشنال
1. معرفی
2. مواد و روشها
2.1. سنسورهای میدان مغناطیسی
2.2. پیش پردازش داده ها
2.2.1. بزرگی داده های میدان مغناطیسی
دادههای میدان مغناطیسی خام، که توسط سه مؤلفه در میکرو تسلا، که در بالا توضیح داده شد، تشکیل شدهاند، با استفاده از معادله ( 1 ) برای به دست آوردن بزرگی چنین دادههایی پردازش میشوند.
2.2.2. عادی سازی
برای جلوگیری از مقیاس بندی فضایی احتمالی به دلیل سنسورهای مختلف مورد استفاده، یک نرمال سازی Z برای هر یک از خوانش های میدان مغناطیسی که شامل امضای مغناطیسی هستند، با استفاده از معادله ( 2 ) اعمال می شود.zمن،دبه خواندن عادی اشاره دارد، rمن،داشاره به منتیساعتمشاهده امضا در بعد d ، μدمقدار میانگین امضا برای بعد d و استσدانحراف استاندارد امضا برای بعد d است.
2.2.3. گروه بندی انرژی
FFT را می توان به عنوان یک روش ساده تر و کارآمد برای محاسبه تبدیل فوریه گسسته (DFT) توصیف کرد، که به ما امکان می دهد سیستم های خطی را مشخص کنیم و اجزای فرکانس یک شکل موج نمونه برداری شده را شناسایی کنیم [ 28 ]. بنابراین، برای محاسبه DFT یک آرایه با یک الگوریتم سریع یا FFT، می توان از معادله ( 3 ) استفاده کرد.
جایی که z[ک]نشان دهنده بردار مقادیر برای تبدیل، ساعت=1،…،nکه در آن n طول y است، هایکسپ(-2πمن(ک-1)(ساعت-1)/n)یک ریشه n ام ابتدایی از 1 است و مقدار بازگشتی DFT تک متغیره نرمال شده از دنباله مقادیر z [ 29 ] است.
2.3. توضیحات مجموعه داده
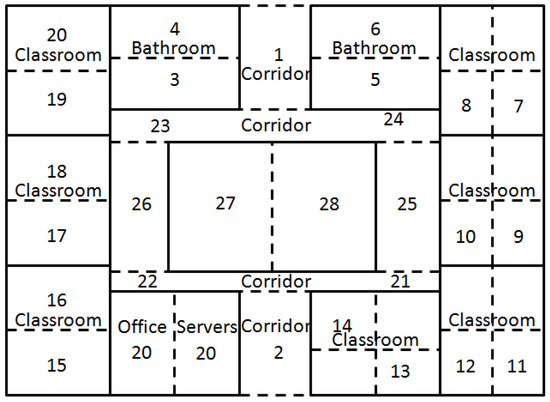
برای اطمینان از اعتبار آماری، حداقل تعداد امضاهای میدان مغناطیسی برای هر اتاق با استفاده از رابطه ( 4 )، همانطور که توسط Galvan-Tejada و همکاران پیشنهاد شده است، تعیین شد. [ 18 ]. در این معادله، نتیجه ای که با x نشان داده می شود، تعداد امضاها برای توسعه مدل است، N تعداد متغیرهای مورد استفاده برای آزمایش است. در این کار، N برابر با 33000 در نظر گرفته شده است (11 اتاق ضرب در 1000 نقطه داده میدان مغناطیسی منحصر به فرد، ضرب در سه سنسور مغناطیسی مختلف هر کدام). به معنای حداقل 16 امضا در هر اتاق.
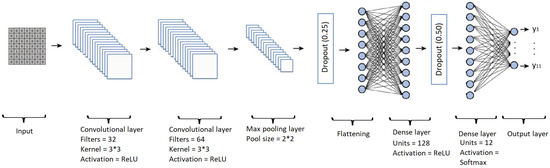
2.4. شبکه عصبی کانولوشنال
یک معماری سنتی ANN از لایه های N ، با یک بردار ورودی ایکس0، یک بردار خروجی تولید می کند ایکسn=f(دبلیوnایکسn-1+بn)، جایی که ایکسn-1بردار ورودی به است nتیساعتلایه. برای دستیابی به حداقل خطا بین خروجی مطلوب و واقعی، مجموعه ای بهینه از بردارهای وزنی، دبلیوnو بردارهای سوگیری، بn، مطابق معادلات ( 5 ) و ( 6 ) محاسبه می شود.
در نظر گرفتن یک نقشه ویژگی، f ، از یک لایه کانولوشن به اندازه w∗ساعت∗n، که در آن w و h به ترتیب نشان دهنده عرض و ارتفاع و n تعداد فیلترهای استفاده شده در لایه کانولوشن هستند. ادغام نقشه ویژگی، f ، با اندازه ادغام k و گام r یک آرایه سه بعدی، S را می دهد که در معادله ( 7 ) نشان داده شده است.
جایی که p به ترتیب p -norm و اشاره داردپ→∞حداکثر عملیات ادغام را نشان می دهد. g(ساعت،w،من،j،تو)=(r·من+ساعت،r·j+w،تو)یک تابع نگاشت از موقعیت های S تا f را نشان می دهد. سپس در معادله ( 8 )، محاسبه ای برای همبستگی لایه کانولوشن و لایه ادغام ارائه شده است.
جایی که θبه وزن هسته اشاره دارد، σ(·)به تابع فعال سازی واحد خطی اصلاح شده اشاره می کند (σ(ایکس)=مترآایکس(0،ایکس))، و o∈ن، N تعداد کانال های خروجی است [ 31 ، 32 ].
آموزش مدل
تابع فعال سازی، ReLU، یک تابع غیر سیگموئیدی را نشان می دهد که با معادله ( 9 ) تعریف شده است، که در آن x به مقدار مثبت به دست آمده اشاره دارد [ 33 ].
از سوی دیگر، هدف تابع فعالسازی Softmax تبدیل اعداد با نام لاجیت به احتمالاتی است که مجموع آنها به یک میرسد، و به عنوان خروجی یک بردار نشان دهنده توزیعهای احتمال فهرستی از نتایج بالقوه است. با معادله ( 10 ) محاسبه می شود، که در آن z یک بردار دلخواه با مقادیر واقعی است zjj = 1، …، n ، و n اندازه بردار است [ 34 ].
2.5. اعتبار سنجی مدل
برای تابع از دست دادن، آنتروپی متقاطع طبقه بندی شده است. این تابع برای داده های دسته بندی استفاده می شود، جایی که برای n کلاس، هدف برای هر نمونه یک بردار n بعدی است که در آن همه مقادیر صفر هستند، به جز شاخص مربوط به کلاس نمونه، که در آن مقدار یک است. سپس، هرچه خروجی های مدل به بردار با مقدار یک نزدیکتر باشد، ضرر کمتر می شود. بنابراین، این تابع توزیع پیشبینیها را که به صورت q در معادله ( 11 ) نشان داده شده است، با توزیع واقعی که به صورت q نشان داده شده است، مقایسه میکند، که در آن احتمال کلاس واقعی روی یک تنظیم میشود در حالی که برای بقیه کلاسها روی صفر
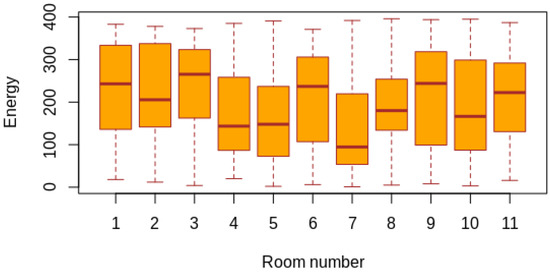
3. آزمایش ها و نتایج
-
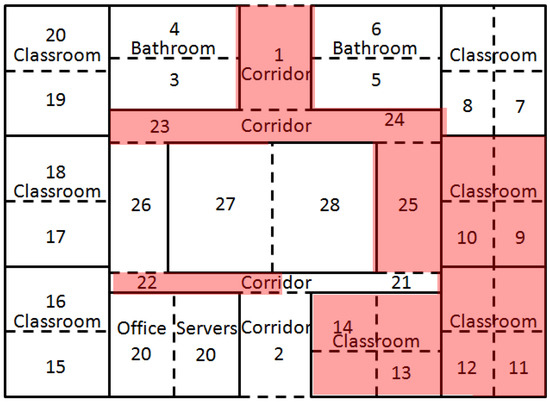
به طور کلی، جعبه هایی که نشان دهنده اندازه گیری انرژی هستند، تقارن را نشان نمی دهند س2در مرکز نیست
-
جعبه ها تفاوت بین ربعی مشابهی را نشان می دهند که با داشتن اندازه گیری های مشابه بین اتاق ها، همانطور که در بخش 2.3 ذکر شد، به توسعه پیچیدگی می بخشد.
-
میانگین اندازهگیریها برای مناطق بین اتاقها مشابه نیست.
-
هیچ نقطه پرت وجود ندارد، که ثبات و قابلیت اطمینان در اندازه گیری ها را نشان می دهد.
4. بحث و نتیجه گیری
-
اثرانگشت میدان مغناطیسی را میتوان بهعنوان دادههای دوبعدی مشاهده کرد: حتی زمانی که دادههای میدان مغناطیسی بهعنوان یک نقطه داده منحصربهفرد در نظر گرفته میشوند، مجموعهای از نقاط یک اتاق را میتوان بهعنوان یک نقشه حرارتی داده دو بعدی در نظر گرفت که به ما امکان میدهد یک ILS با تکنیک های دو بعدی در این پیشنهاد، این نمایش های دو بعدی به عنوان یک تکامل طیفی پس از اعمال یک FFT، همانطور که در بخش نتایج ارائه شده است، مشاهده می شود، به این معنی که اطلاعات طیفی و خواص آنها به دلیل موارد فوق وجود دارد، به این معنی است که اثر انگشت جزئی به اندازه کافی وجود دارد. اطلاعاتی که می تواند اتاق را شناسایی کند.
-
CNN را می توان برای کار با داده های مغناطیسی استفاده کرد:در حال حاضر CNN به طور گسترده ای برای توسعه مدل های طبقه بندی در زمینه پردازش تصویر استفاده شده است. با این حال، برنامه ارائه شده در این کار، با داده های میدان مغناطیسی که به عنوان یک نقشه حرارتی دو بعدی دیده می شود، نشان داده شده است که پتانسیل استفاده از آن را به عنوان ورودی برای آموزش CNN به منظور توسعه ILS دارد. با توجه به نتایج بهدستآمده، طبقهبندی مکانهای داخلی بر اساس مدلسازی دادههای میدان مغناطیسی به ما امکان میدهد تا دقت آماری معنیداری را به دست آوریم. با این حال، CNN را میتوان به روشهای مختلفی بهبود بخشید، به عنوان مثال، تغییر عملکرد تلفات میتواند منجر به ارتقای عملکرد CNN برای این سناریوی خاص شود، همچنین یک NN عمیقتر میتواند AUC را برای ساختمانهای پیچیده افزایش دهد. با این اوصاف،
-
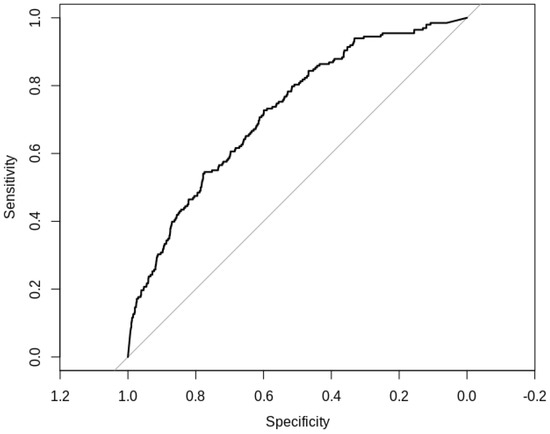
داده های میدان مغناطیسی اطلاعات کافی برای ایجاد یک ILS ارائه می دهند: چندین رویکرد شامل میدان مغناطیسی به عنوان منبع داده دوم برای تکمیل نوع دیگری از سیگنال است. با این حال، میدان مغناطیسی که به عنوان یک منبع داده دو بعدی در نظر گرفته می شود، اطلاعات کافی برای ایجاد یک ILS دارد و تقریباً 75٪ AUC را به دست می آورد. با این وجود، کاهش AUC در مجموعه کور می تواند منعکس کننده یک مشکل بیش از حد برازش باشد که باید مطالعه شود.
-
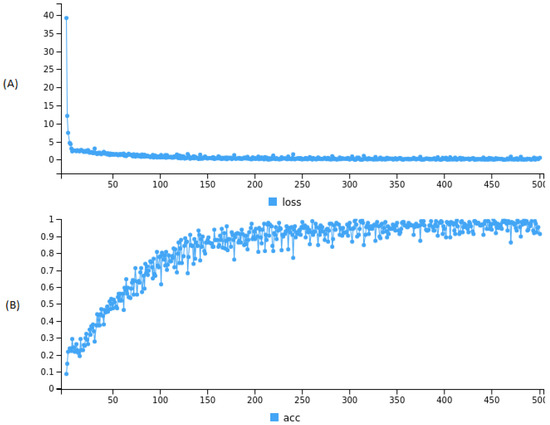
شبکههای عمیقتر و آموزش طولانیتر تناسب CNN را بهبود میبخشد: دقت CNN در طول 500 دوره پیشنهادی در این کار افزایش مییابد، به این معنی که ILS بهتر با کاهش معیار تلفات تکمیل میشود.
5. کار آینده
منابع
- گرونروس، اس. پلتونن، LM; سولوویف، وی. لیلیوس، جی. Salanterä، S. سیستم موقعیت یابی داخلی برای تجزیه و تحلیل مسیر حرکت در موسسات مراقبت های بهداشتی. فین. J. eHealth eWelf. 2017 ، 9 ، 112-120. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، ی. چنگ، دی. پی، تی. شو، اچ. Ge، X. ما، تی. دو، ی. او، ی. وانگ، ام. Xu, L. استنباط جنسیت و سن مشتریان در مراکز خرید از طریق داده های موقعیت یابی داخلی. در محیط و برنامه ریزی ب: تحلیل شهری و علوم شهر ; انتشارات سیج: لندن، انگلستان، 2019; پ. 2399808319841910. [ Google Scholar ]
- یونسکو، ال. بلو، ن. راچیرو، ن. Mazăre، A. Anghel, D. نظارت بر فرآیندهای تولید در صنعت خودرو با استفاده از سیستم مکان یابی داخلی. در سری کنفرانس های IOP: علم و مهندسی مواد ; انتشارات IOP: بریستول، انگلستان، 2016; جلد 145، ص. 022020. [ Google Scholar ]
- Galvan-Tejada، CE; گارسیا وازکز، جی پی. سیگنال های برنا، RF طبیعی یا تولید شده برای سیستم های مکان یابی داخلی؟ ارزیابی از نظر حساسیت و ویژگی. در مجموعه مقالات کنفرانس بین المللی IEEE 2014 در مورد الکترونیک، ارتباطات و کامپیوتر (CONIELECOMP)، Cholula، مکزیک، 26-28 فوریه 2014. صص 166-171. [ Google Scholar ]
- افوسی، مگابایت؛ ذوقی، MR موقعیت یابی داخلی بر اساس بهبود وزن KNN برای مدیریت انرژی در ساختمان های هوشمند. انرژی ساخت. 2020 ، 212 ، 109754. [ Google Scholar ] [ CrossRef ]
- کوی، دبلیو. لیو، کیو. ژانگ، ال. وانگ، اچ. لو، ایکس. Li, J. یک سیستم موقعیت یابی داخلی ربات متحرک قوی بر اساس Wi-Fi. بین المللی J. Adv. ربات. سیستم 2020 , 17 , 1729881419896660. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- خو، اچ. دینگ، ی. لی، پی. وانگ، آر. Li، Y. یک الگوریتم موقعیت یابی داخلی RFID بر اساس احتمال بیزی و K-نزدیکترین همسایه. Sensors 2017 ، 17 ، 1806. [ Google Scholar ] [ CrossRef ] [ PubMed ] [ نسخه سبز ]
- ژو، سی. یوان، جی. لیو، اچ. Qiu, J. بلوتوث موقعیت یابی داخلی بر اساس RSSI و فیلتر Kalman. سیم. پارس اشتراک. 2017 ، 96 ، 4115-4130. [ Google Scholar ] [ CrossRef ]
- Ni، LM; لیو، ی. Lau، YC; Patil، AP LANDMARC: سنجش مکان داخلی با استفاده از RFID فعال. در مجموعه مقالات اولین کنفرانس بین المللی IEEE در محاسبات و ارتباطات فراگیر، (PerCom 2003)، فورت ورث، TX، ایالات متحده، 23-16 مارس 2003. ص 407-415. [ Google Scholar ]
- کینگ، تی. لملسون، اچ. فاربر، ا. Effelsberg، W. Bluepos: موقعیت یابی با بلوتوث. در مجموعه مقالات سمپوزیوم بین المللی IEEE 2009 در مورد پردازش هوشمند سیگنال، بوداپست، مجارستان، 26-28 اوت 2009. صص 55-60. [ Google Scholar ]
- تیلچ، اس. Mautz, R. CLIPS – یک سیستم موقعیت یابی داخلی مبتنی بر دوربین و لیزر. J. Locat. مبتنی بر سرویس. 2013 ، 7 ، 3-22. [ Google Scholar ] [ CrossRef ]
- IndoorAtlas، L. فناوری مکان یابی داخلی مبتنی بر میدان مغناطیسی محیطی: آوردن قطب نما به سطح بعدی . IndoorAtlas Ltd.: Mountain View، CA، USA، 2012. [ Google Scholar ]
- پریانتا، NB سیستم مکان یابی داخلی کریکت. دکتری پایان نامه، موسسه فناوری ماساچوست، کمبریج، MA، ایالات متحده آمریکا، 2005. [ Google Scholar ]
- مجید، ک. Hranilovic، S. مرزهای عملکرد در موقعیت یابی غیرفعال داخل ساختمان با استفاده از نور مرئی. جی. لایتو. تکنولوژی 2020 ، 38 ، 2190-2200. [ Google Scholar ] [ CrossRef ]
- گوان، دبلیو. چن، اس. ون، اس. هو، دبلیو. تان، ز. Cen, R. سیستم محلی سازی داخلی ربات متحرک ROS بر اساس ارتباطات نور مرئی. arXiv 2020 ، arXiv:eess.SP/2001.01888. [ Google Scholar ]
- چانگ، CH; Lin، CY؛ وانگ، آر جی. Chou، CC استفاده از یادگیری عمیق و مدل سازی اطلاعات ساختمان در موقعیت یابی داخلی بر اساس صدا. در محاسبات در مهندسی عمران 2019: تجسم، مدلسازی اطلاعات و شبیهسازی ؛ انجمن مهندسین عمران آمریکا: Reston، VA، ایالات متحده آمریکا، 2019؛ صص 193-199. [ Google Scholar ]
- تونگ، YC; Shin, KG Echotag: برچسبگذاری دقیق مکان داخلی بدون زیرساخت با تلفنهای هوشمند. در مجموعه مقالات بیست و یکمین کنفرانس بین المللی سالانه محاسبات موبایلی و شبکه، پاریس، فرانسه، 7 تا 11 سپتامبر 2015. صص 525-536. [ Google Scholar ]
- Galvan-Tejada، CE; گارسیا وازکز، جی پی. استخراج و انتخاب ویژگی میدان مغناطیسی برنا، RF برای تخمین مکان داخلی. سنسورها 2014 ، 14 ، 11001-11015. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، بی. گالاگر، تی. Dempster، AG; Rizos, C. استفاده از میدان مغناطیسی به تنهایی برای موقعیت یابی داخل ساختمان چقدر امکان پذیر است؟ در مجموعه مقالات کنفرانس بین المللی IEEE 2012 در مورد موقعیت یابی داخلی و ناوبری داخلی (IPIN)، سیدنی، استرالیا، 13 تا 15 نوامبر 2012. صفحات 1-9. [ Google Scholar ]
- شائو، دبلیو. ژائو، اف. وانگ، سی. لو، اچ. محمد زاهد، ت. وانگ، کیو. لی، دی. استخراج اثر انگشت مکان برای موقعیت یابی داخلی بر اساس قدر میدان مغناطیسی. J. Sens 2016 , 2016 . [ Google Scholar ] [ CrossRef ]
- شن، GJ; ژائو، سی. ژائو، اف. مکان یابی داخلی با استفاده از ناهنجاری های میدان مغناطیسی. پتنت ایالات متحده 9,326,103, 26 آوریل 2016. [ Google Scholar ]
- اشرف، من. هور، اس. پارک، اس. Park, Y. DeepLocate: محلیسازی فضای داخلی مبتنی بر گوشی هوشمند با طبقهبندی کننده گروه شبکه عصبی عمیق. Sensors 2020 , 20 , 133. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- Farfade, SS; صابریان، ام جی; Li, LJ تشخیص چهره چند نمای با استفاده از شبکه های عصبی کانولوشنال عمیق. در مجموعه مقالات پنجمین کنفرانس بین المللی ACM در مورد بازیابی چند رسانه ای، شانگهای، چین، 23 تا 16 ژوئن 2015. صص 643-650. [ Google Scholar ]
- چن، جی. او، س. چی، ز. فو، اچ. تشخیص لبخند در طبیعت با شبکه های عصبی کانولوشنال عمیق. ماخ Vis. Appl. 2017 ، 28 ، 173-183. [ Google Scholar ] [ CrossRef ]
- خان، ک. آتیک، م. خان، RU; سید، من. چانگ، TS یک چارچوب چند وظیفه ای برای طبقه بندی ویژگی های صورت از طریق تجزیه چهره به انتها و شبکه های عصبی کانولوشنال عمیق. Sensors 2020 , 20 , 328. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- الهمیانی، ف. Mahoor, M. بهبود اثر انگشت میدان ژئومغناطیسی داخلی برای محلی سازی ساعت هوشمند با استفاده از یادگیری عمیق. در مجموعه مقالات کنفرانس بین المللی IEEE 2018 درباره موقعیت یابی داخلی و ناوبری داخلی (IPIN)، نانت، فرانسه، 24 تا 27 سپتامبر 2018؛ صص 1-8. [ Google Scholar ]
- اشرف، من. هور، اس. Park, Y. کاربرد شبکههای عصبی کانولوشن عمیق و حسگرهای تلفن هوشمند برای محلیسازی فضای داخلی. Appl. علمی 2019 ، 9 ، 2337. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- برگلند، جی. یک تور با راهنما از تبدیل فوریه سریع. IEEE Spectr. 1969 ، 6 ، 41-52. [ Google Scholar ] [ CrossRef ]
- تیم اصلی R. R: زبان و محیطی برای محاسبات آماری . بنیاد R برای محاسبات آماری: وین، اتریش، 2019. [ Google Scholar ]
- گاناپاتی، دوم; پراکاش، س. دیو، آی آر. باکشی، اس. تشخیص گوش بدون محدودیت با استفاده از مدل شبکه عصبی کانولوشنال مبتنی بر مجموعه. در همزمانی و محاسبات: تمرین و تجربه . وایلی: هوبوکن، نیوجرسی، ایالات متحده آمریکا، 2020؛ پ. e5197. [ Google Scholar ]
- پرت، اس. اوچوا، ا. یداو، م. شتا، ع. Eldefrawy, M. Handwritten Digits Recognition با استفاده از شبکه های عصبی کانولوشن. جی. کامپیوتر. علمی Coll. 2019 ، 34 ، 40. [ Google Scholar ]
- های، جی. کیائو، ک. چن، جی. تان، اچ. خو، جی. زنگ، ال. شی، دی. یان، بی. متراکم کامل کانولوشن با زمینه چند مقیاسی برای تقسیمبندی خودکار تومور پستان. J. Healthc. مهندس 2019 , 2019 . [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- اشمیت هیبر، جی. رگرسیون ناپارامتریک با استفاده از شبکه های عصبی عمیق با تابع فعال سازی ReLU. arXiv 2017 , arXiv:1708.06633. [ Google Scholar ]
- کورتاس، آی. Paliouras, V. پیاده سازی سخت افزاری ساده شده تابع فعال سازی Softmax. در مجموعه مقالات هشتمین کنفرانس بین المللی IEEE 2019 در مورد مدارها و فناوری های سیستم های مدرن (MOCAST)، تسالونیکی، یونان، 13 تا 15 مه 2019؛ صص 1-4. [ Google Scholar ]
- شو، ی. بو، سی. شن، جی. ژائو، سی. لی، ال. Zhao، F. Magicol: محلیسازی فضای داخلی با استفاده از میدان مغناطیسی فراگیر و سنجش فرصتطلب WiFi. IEEE J. Sel. مناطق کمون. 2015 ، 33 ، 1443-1457. [ Google Scholar ] [ CrossRef ]
- کراس. 2015. در دسترس آنلاین: https://keras.io (دسترسی در 10 اکتبر 2019).


بدون دیدگاه