

خلاصه
کلید واژه ها:
رانش زمین ; زیرنویس تصویر ; دو زمانی LSTM ; تقسیم بندی معنایی
1. معرفی
- (1)
-
خطای انباشته: در فرآیند آموزش، شرح تصویر بسته به حقیقت زمین (GT) کلمه به کلمه ایجاد می شود. با این حال، در فرآیند پیشبینی، کلمه t فقط میتواند به کلمه t-1 تولید شده قبلی تکیه کند ، اگر کلمه t-1 نادرست باشد، ممکن است منجر به زنجیرهای نادرست در عنوان تصویر شود که باعث ایجاد یک خطای انباشته میشود.
- (2)
-
قسمتهای مختلف شرح تصویر اغلب بیشتر به ویژگیهای تصویر یا اطلاعات زمینه متکی است، اما بیشتر LSTM فعلی مبتنی بر توجه نمیتواند بین تصویر و اطلاعات زمینه انتخابی پویا و تطبیقی داشته باشد [ 26 ].
- (3)
-
مکان توجه ها به اندازه کافی دقیق نیست، یعنی توجه ها همیشه موقعیت واقعی زمین لغزش ها و اجساد آسیب دیده را دقیقاً تعیین نمی کنند، با وجود این، مکانیسم اصلاحی در روش های موجود وجود ندارد.
- (1)
-
ما یک LSTM دوزمانی جدید معرفی کردیم که از سه افت زبان، پیشبینی و توجه برای آموزش پارامترهای شبکه استفاده میکند تا خطای انباشته در فرآیند پیشبینی را کاهش دهد.
- (2)
-
ما یک دروازه معنایی پیشنهاد کردیم که شبکه را قادر میسازد تا به صورت پویا و تطبیقی به تصویر یا زمینه تکیه کند.
- (3)
-
ما یک مکانیسم اصلاح توجه جدید برای بهبود دقت مکان در تصاویر سنجش از دور ایجاد می کنیم.
2. مربوط به کار
2.1. تجزیه و تحلیل زمین لغزش بر اساس روش های سنتی
2.2. تجزیه و تحلیل زمین لغزش بر اساس شبکه های عصبی
3. پیشینه روش مورد استفاده
3.1. تقسیم بندی معنایی
3.2. زیرنویس تصویر
3.3. تلفیقی از تقسیم بندی معنایی و عنوان تصویر
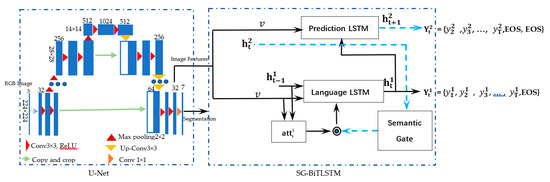
4. روش شناسی
4.1. نمودار جریان روش شناختی
4.2. معماری شبکه
4.3. U-Net و اشیاء جغرافیایی
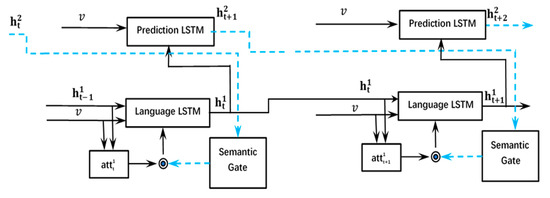
4.4. Bi-Temporal LSTM
در زمان اولیه، واحد حافظه زبان LSTM به شرح زیر است:
مقادیر اولیه گیت ورودی و دروازه فراموشی را می توان به صورت زیر محاسبه کرد:
ایکس10�01، ج1– 1�−11، ساعت1– 1ℎ−11را می توان به صورت زیر محاسبه کرد:
جایی که v�ویژگی تصویر سنجش از دور با ابعاد است 224 × 224 × 32224×224×32و w10�01بردار تعبیه کلمه اولیه با ابعاد 35 است.
LSTM دو زمانی از واحد حافظه ( ج10�01) و اطلاعات لایه پنهان ( ساعت10ℎ01) از زبان LSTM به عنوان مقادیر اولیه پیش بینی LSTM:
ایکس20�02از تعبیه می آید ( w11�11) خروجی از زبان LSTM در زمان اولیه:
مقادیر اولیه گیت ورودی و دروازه فراموشی را می توان به صورت زیر محاسبه کرد:
در زمان t: مقادیر دروازه ورودی، دروازه فراموشی و دروازه خروجی را می توان به صورت زیر محاسبه کرد:
جایی که مقدار ورودی ایکستی��را می توان به صورت زیر محاسبه کرد:
علاوه بر این، مقادیر سلول حافظه معنایی در زمان t را می توان به صورت زیر محاسبه کرد:
اطلاعات لایه پنهان ساعتتیℎ�در زمان t را می توان به صورت زیر محاسبه کرد:
در زمان t، ساعت1تیℎ�1، w1تی a n d ج1تی��1 ��� ��1ورودی به LSTM پیشبینی میشوند که باعث تولید میشود ساعت2t + 1ℎ�+12در زمان t + 1، از این رو، دروازه معنایی را می توان کنترل کرد. ارزش ورودی ایکستی��می توان با استفاده از:
مقادیر دروازه ورودی، دروازه فراموشی و دروازه خروجی را می توان به صورت زیر محاسبه کرد:
علاوه بر این، مقادیر واحد حافظه پیشبینی LSTM را میتوان به صورت زیر محاسبه کرد:
اطلاعات لایه پنهان ساعت2t + 1ℎ�+12در زمان t + 1 را می توان به صورت زیر محاسبه کرد:
فاز از عنصر ابتدای جمله (BOS) که معمولاً یک بردار صفر است شروع می شود و با عنصر انتهای جمله (EOS) به پایان می رسد. دنباله پیش بینی ساعت2t + 1ℎ�+12بستگی دارد به ساعت1تیℎ�1، بدین ترتیب y21�12در نیست Y2تی��2.
4.5. دروازه معنایی
- (1)
-
ما ماسکهای زمین لغزش و سایر اشیاء جغرافیایی را که با کلمه در زمان t مطابقت دارند به عنوان GT توجه زمانی که کلمه تولید شده یک اسم است، میپذیریم.
- (2)
-
GT توجه زمانی که کلمه تولید شده یک اسم نباشد 0 است، به این معنی که کلمه در حال حاضر شی سنجش از راه دور را در تصویر توصیف نمی کند.
در زمان t، ورودی ویژگی تصویر اصلی به صورت زیر بیان می شود:
فرمول های توجه عبارتند از:
دروازه معنایی به صورت زیر محاسبه می شود:
جایی که v�ویژگی تصویر سنجش از دور با ابعاد است 224 × 224 × 32224×224×32، k = 224 × 224، ساعت1t – 1ℎ�−11و ساعت2تیℎ�2اطلاعات لایه پنهان در زمان t − 1 و زمان t هستند. w1t – 1��−11زبان بردار تعبیه کلمه LSTM با ابعاد 512 در زمان t − 1 است، دبلیوs g���یک ماتریس وزنی از دروازه معنایی است و بs g���افست است.
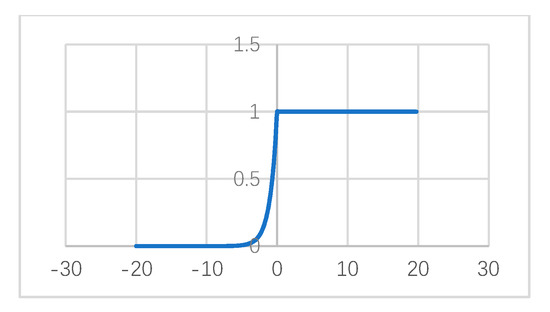
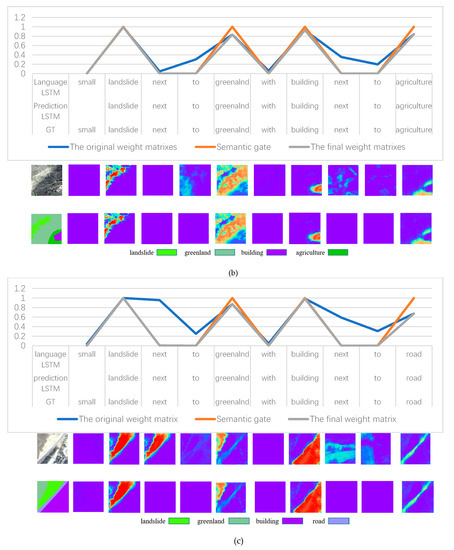
برای کنترل بهتر باز یا بسته شدن دروازه معنایی، از یک تابع فعال سازی سفارشی جدید استفاده کردیم که به شرح زیر تعریف شده است. ( شکل 7 )
- (1)
-
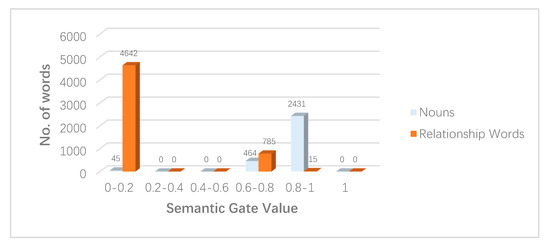
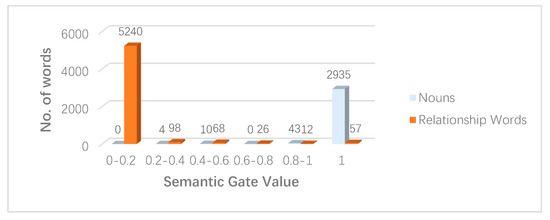
اگر ساعت2تیℎ�2از پیش بینی LSTM بردار جاسازی اسم است، پس دبلیومن1[ساعت2تی] +بمن1��1[ℎ�2]+��1≥ 0، f(دبلیومن1[ساعت2تی] +بمن1)�(��1[ℎ�2]+��1)= 1، بنابراین دروازه معنایی به طور کامل باز می شود. این کار تأثیر تصویر سنجش از راه دور را بر تولید کلمه در آن زمان به حداکثر میرساند.
- (2)
-
اگر ساعت2تیℎ�2از پیش بینی LSTM بردار جاسازی کلمات تابع (مثلاً روابط) است دبلیومن1[ساعت2تی] +بمن1��1[ℎ�2]+��1< 0، f(دبلیومن1[ساعت2تی] +بمن1)�(��1[ℎ�2]+��1)< 1، دروازه معنایی اطلاعات تصویر را مهار می کند، که باعث می شود LSTM بیشتر به اطلاعات زمینه تکیه کند.
4.6. عملکرد جامع از دست دادن
برای بهبود دقت مکان، این مقاله GT توجه را طراحی کرد. سپس، آنتروپی متقاطع بین ماسک شی و ماتریس توجه را به عنوان loss3 محاسبه می کنیم و آن را با Losses 1 و 2 در زمان t ترکیب می کنیم، به طوری که SG-BiTLSTM می تواند هم دقت مکان و هم توانایی را بهبود بخشد. به طور خودکار تصمیم می گیرید که چه زمانی روی تصویر بیشتر تمرکز کنید و چه زمانی بیشتر به بافت زبان تکیه کنید.
سه تلفات را می توان از طریق فرمول های زیر محاسبه کرد، ضریب یک مقدار تجربی است که از آزمایش ها به دست می آید:
4.7. پیش بینی
- (1)
-
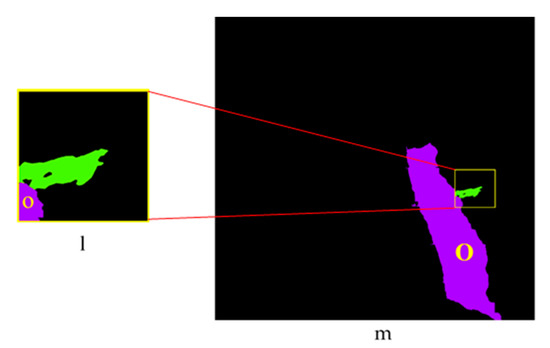
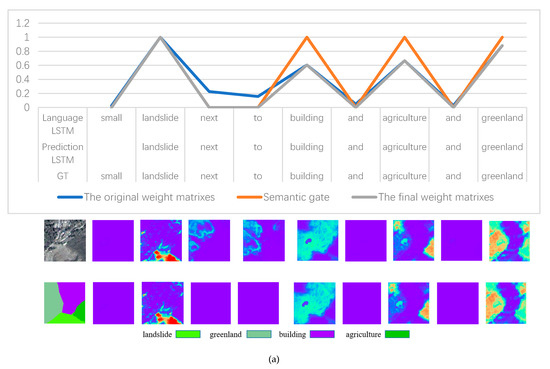
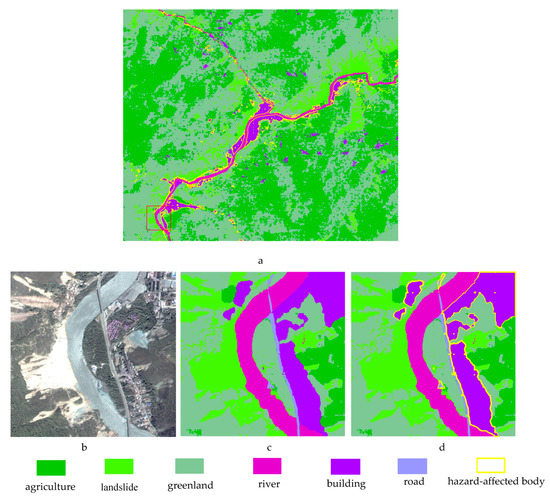
تبدیل رابطه از قسمت به کل شی: به هر پیکسل از نمونه پیشبینیشده 224 × 224 یک کانال به عنوان یک پرچم اضافه کردیم که اطلاعات مربوط به مجاورت پیکسل با لغزشها را ذخیره میکند. با مرور تمام نمونههای پیشبینیشده (وصلهها)، از یک جمله توضیح تصویری استفاده میکنیم (مثلاً شرح تصویر نمونه a: «لغزش کوچک در کنار ساختمان و کشاورزی و سرزمین سبز») برای یافتن اشیا (ساختمانها) مجاور زمین لغزش، سپس از ماتریس وزن فوکوس (به عنوان مثال، شکل 8 d,g) تولید شده توسط SG-BiTLSTM برای مکان یابی ماسک شی مربوطه استفاده کنید (به عنوان مثال، شکل 9متر). مقدار کانال اضافی پیکسل های بخشی از اشیاء (o در l) روی غیر صفر تنظیم شد، به طوری که رابطه فضایی در جمله عنوان می تواند بر روی پیکسل های بخشی از شیء نمایش داده شود.
- (2)
-
اجسام متاثر از خطر را شناسایی کنید: ما از برنامه stitching برای ادغام وصلههای نمونه پیشبینیشده با کل تصویر استفاده کردیم، سپس از هر شیء کامل (O) عبور کردیم تا قضاوت کنیم که آیا یک پرچم غیر صفر وجود دارد یا خیر. اگر وجود داشته باشد، کل شیء O در m بدن متاثر از خطر است.
- (3)
-
هر پیکسل در تصویر ادغام شده مربوط به همان نقطه مکانی تصویر اصلی است و مختصات مکانی آن قابل بازیابی است. به این ترتیب، بدن متاثر از خطر شناسایی شده می تواند اطلاعات مهمی مانند مکان، مرز و برچسب کلاس را برای واکنش اضطراری ارائه دهد.
5. آزمایش ها و تجزیه و تحلیل
5.1. معرفی منطقه تحقیق و نمونه
-
مقادیر میانگین هر باند از تصاویر a-c و e بالاتر از تصویر d است، به این معنی که شدت تابش تصاویر a-c و e بیشتر از تصویر d است.
-
میانگین انحراف مربع هر باند از تصاویر a-c بیشتر از تصاویر d و e است که نشان می دهد سلسله مراتب اطلاعات تصاویر a-c بهتر از تصاویر d و e است.
-
همگنی تصاویر a-c کمتر از تصاویر d و e است، به این معنی که تصاویر قبلی کنتراست بافت غنی تری نسبت به تصاویر دوم دارند و می توانند مرزهای واضحی را بین اشیاء جغرافیایی مختلف نشان دهند.
-
آنتروپی اطلاعات هر باند از تصاویر a-c بالاتر از تصاویر d و e است، که نشان می دهد محتوای اطلاعات تصاویر a-c غنی تر از تصاویر d و e است.
5.2. معرفی حالت های آموزشی
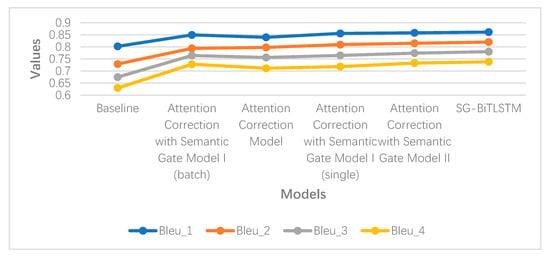
5.3. تحلیل دقت معنایی
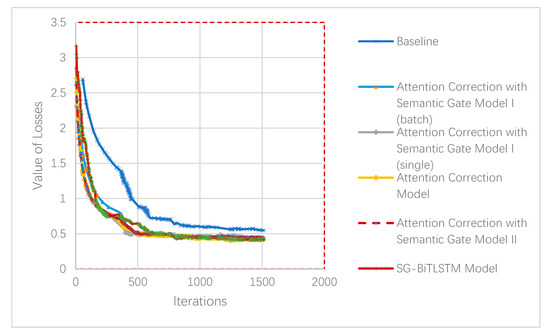
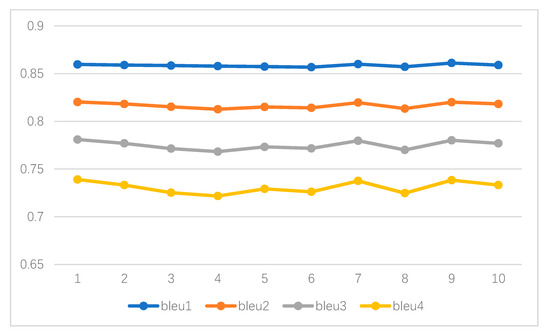
5.4. تحلیل پایداری مدل
6. بحث
6.1. تجزیه و تحلیل دقت موقعیت مکانی
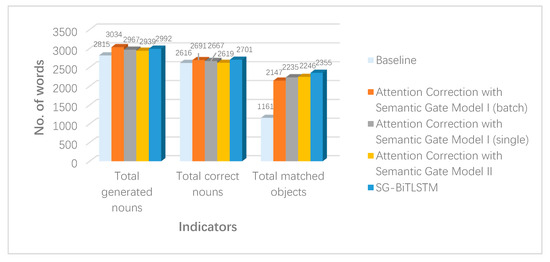
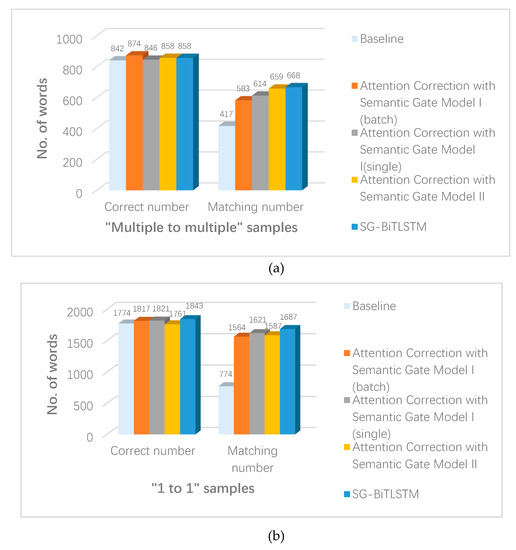
6.2. تجزیه و تحلیل مکان نمونه های “چند تا چندگانه” و “1 به 1”.
6.3. تحلیل دروازه معنایی
6.4. خلاصه
7. نتیجه گیری
منابع
- پیرالیلو، ST; شهابی، ح. جاریانی، ب. قربانزاده، ا. بلاشکه، تی. غلام نیا، ک. مینا، اس آر. Aryal, J. تشخیص زمین لغزش با استفاده از تقسیمبندی تصویر در مقیاس چندگانه و مدلهای مختلف یادگیری ماشین در هیمالیاهای عالی. Remote Sens. 2019 , 11 , 2575. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- روابده، ع. او، اف. موسی، ع. شیمی، NE; حبیب، الف. استفاده از یک سیستم تصویربرداری دیجیتال مبتنی بر وسیله نقلیه هوایی بدون سرنشین برای استخراج یک ابر نقطه سه بعدی برای تشخیص لغزش اسکارپ. Remote Sens. 2016 , 8 , 95. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- اسکایونی، م. لونگونی، ال. ملیلو، وی. پاپینی، ام. سنجش از دور برای تحقیقات زمین لغزش: مروری بر دستاوردها و چشم اندازهای اخیر. Remote Sens. 2014 , 6 , 9600–9652. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- سان، آر. گائو، جی. گونگ، ز. وو، جی. مروری بر روشهای تحلیل ریسک برای بلایای طبیعی. نات. خطرات 2020 ، 100 ، 571-593. [ Google Scholar ] [ CrossRef ]
- چن، ال. هوانگ، ی. بای، آر. چن، الف. ارزیابی ریسک بلایای منطقه ای چین بر اساس مدل ریسک جهانی. نات. خطرات 2017 ، 89 ، 647-660. [ Google Scholar ] [ CrossRef ]
- گائو، جی. سانگ، ی. شناسایی و برآورد خطر فاجعه جریان زمین لغزش-آوار در پردیسهای مدارس ابتدایی و راهنمایی در مناطق کوهستانی جنوب غربی چین. بین المللی جی. فاجعه. Res. 2017 ، 25 ، 60-71. [ Google Scholar ] [ CrossRef ]
- ژانگ، دبلیو. او، اچ. هوانگ، اچ. Cui, Y. HJ-1 Satellite’s Stable Operation 3 Anniversaries and Disaster Reduction Application. در مجموعه مقالات دومین کنفرانس بین المللی 2012 سنجش از دور، محیط زیست و مهندسی حمل و نقل، نانجینگ، چین، 1 تا 3 ژوئن 2012. صص 1-4. [ Google Scholar ]
- لیو، اس. وانگ، دی. لیانگ، اس. ارزیابی ریسک خطرات جغرافیایی در منطقه لس: مطالعه موردی شهرستان روئوآن در شهرستان هوآچی، استان گانسو، چین. J. Eng. جئول 2018 ، 26 ، 142-148. [ Google Scholar ]
- چی، دبلیو. Su, G. روش مبتنی بر سنجش از دور با وضوح بالا برای تعیین تغییرات خطر تلفات از زنجیره خطر زمینلرزه ناشی از زلزله. در مجموعه مقالات 2013 کنفرانس بین المللی سنجش از دور، محیط زیست و مهندسی حمل و نقل، نانجینگ، چین، 26 تا 28 ژوئیه 2013. [ Google Scholar ]
- یانگ، اچ. یو، بی. Luo, J. تقسیم بندی معنایی تصاویر با وضوح فضایی بالا با شبکه های عصبی عمیق. GIScience Remote Sens. 2019 ، 56 ، 749–768. [ Google Scholar ] [ CrossRef ]
- بیان، جی. ژانگ، ز. چن، جی. چن، اچ. کوی، سی. لی، ایکس. چن، اس. فو، کیو. ارزیابی ساده شده تنش آب پنبه با استفاده از تصویر حرارتی وسیله نقلیه هوایی بدون سرنشین با وضوح بالا. Remote Sens. 2019 , 11 , 267. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کاستیا، جی. Hay، GJ تجزیه و تحلیل تصویر مبتنی بر شی ; Springer: برلین، آلمان، 2008; صص 91-110. [ Google Scholar ]
- کوی، دبلیو. گائو، ال. وانگ، ال. لی، دی. مطالعه بر روی هستی شناسی جغرافیایی بر اساس تحلیل سنجش از دور شی گرا. در مجموعه مقالات کنفرانس بین المللی در مورد پردازش و تجزیه و تحلیل داده های مشاهده زمین، ووهان، چین، 28 تا 30 دسامبر 2008. [ Google Scholar ]
- کوی، دبلیو. لی، آر. یائو، ز. چن، جی. تانگ، اس. لی، کیو. مطالعه بر روی مقیاس تقسیم بندی بهینه بر اساس ابعاد فراکتال تصاویر سنجش از دور. J. دانشگاه ووهان. تکنولوژی 2011 ، 12 ، 83-86. [ Google Scholar ]
- کوی، دبلیو. ژنگ، ز. ژو، Q. هوانگ، جی. یوان، ی. کاربرد یک شبکه عصبی کانولوشن طیفی- فضایی موازی در طبقهبندی کاربری زمین سنجش از دور شی گرا. سنسور از راه دور Lett. 2018 ، 9 ، 334-342. [ Google Scholar ] [ CrossRef ]
- هی، GJ; مارسئو، دی جی; دوبه، پ. Bouchard، A. چارچوب چند مقیاسی برای تجزیه و تحلیل چشم انداز: تجزیه و تحلیل شی خاص و ارتقاء مقیاس. Landsc. Ecol. 2001 ، 16 ، 471-490. [ Google Scholar ] [ CrossRef ]
- چن، جی. هی، جی. St-Onge، B. چارچوب GEOBIA برای برآورد پارامترهای جنگل از Lidar Transects، Quickbird Imagery and Machine Learning: مطالعه موردی در کبک، کانادا. بین المللی J. Appl. زمین Obs. 2012 ، 15 ، 28-37. [ Google Scholar ] [ CrossRef ]
- Duynhoven، AV; Dragicevic، S. تجزیه و تحلیل اثرات وضوح زمانی و طبقه بندی اطمینان برای مدل سازی تغییر پوشش زمین با شبکه های حافظه کوتاه مدت بلند مدت. Remote Sens. 2019 , 11 , 2784. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، اچ. ژائو، ایکس. ژانگ، ایکس. وو، دی. Du, X. طبقهبندی پوشش زمین سری طولانی در چین از سال 1982 تا 2015 بر اساس یادگیری عمیق Bi-LSTM. Remote Sens. 2019 , 11 , 1639. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- او، تی. زی، سی. لیو، کیو. گوان، اس. لیو، جی. ارزیابی و مقایسه شبکههای جنگل تصادفی و A-LSTM برای شناسایی گندم زمستانه در مقیاس بزرگ. Remote Sens. 2019 ، 11 ، 1665. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- تیموری، ن. دیرمن، ام. Jorgansen، RN یک شبکه جدید فضایی-زمانی FCN-LSTM برای تشخیص انواع مختلف محصول با استفاده از تصاویر رادار چندموقت. Remote Sens. 2019 , 11 , 990. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چی، دبلیو. ژانگ، ایکس. وانگ، ن. ژانگ، ام. Cen, Y. یک شبکه عصبی کانولوشنال سه بعدی آبشاری طیفی-فضایی با یک شبکه حافظه کوتاه مدت کانولوشنال برای طبقهبندی تصاویر فراطیفی. Remote Sens. 2019 , 11 , 2363. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- مک.؛ لی، اس. وانگ، آ. یانگ، جی. Chen, G. ادی Nowcasting مبتنی بر مشاهده ارتفاع سنج با استفاده از یک شبکه Conv-LSTM بهبود یافته. Remote Sens. 2019 , 11 , 783. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چانگ، ی. Luo, B. شبکه عصبی LSTM کانولوشنال دو جهته برای وضوح تصویر فوق العاده سنجش از دور. Remote Sens. 2019 , 11 , 2333. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Gallego، AJ; گیل، پ. پرتوسا، ا. فیشر، تقسیم بندی معنایی RB تصاویر SLAR با رمزگذارهای خودکار انتخابی Convolutional LSTM. Remote Sens. 2019 , 11 , 1402. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لو، جی. شیونگ، سی. پریخ، د. سوچر، آر. دانستن زمان نگاه کردن: توجه تطبیقی از طریق یک نگهبان بصری برای شرح تصویر. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 375-383. [ Google Scholar ]
- دو، جی. یونس، AP; Bui، DT; ساهانا، م. چن، سی. زو، ز. وانگ، دبلیو. فام، BT ارزیابی مدلهای آماری چندگانه مبتنی بر GIS و دادهکاوی برای حساسیت زمین لغزش ناشی از زلزله و بارندگی با استفاده از Lidar DEM. Remote Sens. 2019 ، 11 ، 6. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- روی، جی. سها، س. عربامری، ع. بلاشکه، تی. Bui، DT یک رویکرد جدید گروهی برای نقشهبرداری حساسیت زمین لغزش (LSM) در منطقه دارجلینگ و کالیمپونگ، بنگال غربی، هند. Remote Sens. 2019 , 11 , 2866. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شن، سی. فنگ، ز. زی، سی. نیش، اچ. ژائو، بی. او، دبلیو. زو، ی. وانگ، ک. لی، اچ. بای، اچ. و همکاران اصلاح نقشه حساسیت زمین لغزش با استفاده از تداخل سنجی پراکنده مداوم در مناطق فعالیت های معدنی شدید در منطقه کارست در جنوب غربی چین. Remote Sens. 2019 , 11 , 2821. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پارک، جی. لی، سی دبلیو؛ لی، اس. لی، MJ نقشهبرداری و مقایسه حساسیت زمین لغزش با استفاده از مدلهای درخت تصمیم: مطالعه موردی منطقه جومونجین، کره. Remote Sens. 2018 , 10 , 1545. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- کدوی، روابط عمومی; لی، سی دبلیو; لی، اس. کاربرد مدلهای یادگیری ماشینی مبتنی بر مجموعه برای نقشهبرداری حساسیت زمین لغزش. Remote Sens. 2018 , 10 , 1252. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شائو، ایکس. ما، س. Xu, C. فهرستبندی مبتنی بر تصویر سیاره و نقشهبرداری حساسیت مبتنی بر یادگیری ماشین برای زمینلغزشهای ناشی از زمینلرزه توماکومای ژاپن 6.6 Mw6 2018. Remote Sens. 2019 , 11 , 978. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پراکاش، ن. مانکونی، آ. Loew, S. Mapping Landslides on EO Data: عملکرد مدل های یادگیری عمیق در مقابل مدل های یادگیری ماشین سنتی. Remote Sens. 2020 , 12 , 346. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- قربانزاده، ا. مینا، اس آر. بلاشکه، تی. تشخیص شکست شیب مبتنی بر پهپاد Aryal، J. با استفاده از شبکههای عصبی کانولوشنال یادگیری عمیق. Remote Sens. 2019 ، 11 ، 2046. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- شلهامر، ای. لانگ، جی. دارل، تی. شبکه های کاملاً پیچیده برای تقسیم بندی معنایی. IEEE Trans. الگوی مقعدی ماخ هوشمند 2017 ، 39 ، 640-651. [ Google Scholar ] [ CrossRef ]
- رونبرگر، او. فیشر، پی. Brox، T. U-Net: شبکه های کانولوشن برای تقسیم بندی تصویر زیست پزشکی. در محاسبات تصویر پزشکی و مداخله به کمک کامپیوتر – MICCAI 2015 ; نواب، ن.، هورنگر، ج.، ولز، دبلیو ام، فرانگی، اف.اف.، ویرایش. انتشارات بین المللی Springer: چم، سوئیس، 2015; جلد 9351، ص 234–241. [ Google Scholar ]
- هوانگ، جی. لیو، ز. ون در ماتن، ال. واینبرگر، شبکههای کانولوشن با اتصال متراکم KQ. در مجموعه مقالات کنفرانس IEEE 2017 در مورد دید رایانه و تشخیص الگو (CVPR)، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ ص 2261-2269. [ Google Scholar ]
- لی، ال. لیانگ، جی. ونگ، ام. Zhu, H. یک شبکه استفاده مجدد با ویژگی های چندگانه برای استخراج ساختمان ها از تصاویر سنجش از دور. Remote Sens. 2018 ، 10 ، 1350. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- یانگ، اچ. وو، پی. یائو، ایکس. وو، ی. وانگ، بی. Xu, Y. استخراج ساختمان در تصاویر با وضوح بسیار بالا توسط شبکه های متراکم توجه. Remote Sens. 2018 ، 10 ، 1768. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- سان، جی. هوانگ، اچ. ژانگ، ا. لی، اف. ژائو، اچ. Fu, H. ادغام شبکه های عصبی کانولوشن چند مقیاسی برای استخراج ساختمان در تصاویر با وضوح بسیار بالا. Remote Sens. 2019 , 11 , 227. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هوانگ، ز. چنگ، جی. وانگ، اچ. لی، اچ. شی، ال. Pan, C. استخراج ساختمان از تصاویر سنجش از راه دور چند منبعی از طریق شبکههای عصبی دکانولوشن عمیق. در مجموعه مقالات سمپوزیوم بین المللی علوم زمین و سنجش از دور IEEE 2016 (IGARSS)، پکن، چین، 10 تا 15 ژوئیه 2016؛ صفحات 1835–1838. [ Google Scholar ]
- کروملینک، اس. کووا، م. یانگ، م. Vosselman, G. کاربرد یادگیری عمیق برای ترسیم مرزهای مرئی کاداستر از تصاویر سنجش از دور. Remote Sens. 2019 ، 11 ، 2505. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، تی. تانگ، اچ. ارزیابی جامع رویکردها برای استخراج منطقه ساخته شده از تصاویر Landsat Oli با استفاده از نمونه های عظیم. Remote Sens. 2019 , 11 , 2. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فو، ی. لیو، ک. شن، ز. دنگ، ج. گان، م. لیو، ایکس. لو، دی. وانگ، ک. نقشه برداری از سطوح غیرقابل نفوذ در کمربندهای انتقال شهر به روستا با استفاده از تصاویر GF-2 چین و CNN های عمیق مبتنی بر شی. Remote Sens. 2019 , 11 , 280. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لی، دبلیو. دونگ، آر. فو، اچ. Yu, L. تشخیص درخت نخل روغنی در مقیاس بزرگ از تصاویر ماهواره ای با وضوح بالا با استفاده از شبکه های عصبی کانولوشنال دو مرحله ای. Remote Sens. 2019 ، 11 ، 11. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- ژانگ، دی. وانگ، دی. گو، سی. جین، ن. ژائو، اچ. چن، جی. لیانگ، اچ. لیانگ، دی. استفاده از شبکه عصبی برای شناسایی شدت سوختگی سر فوزاریوم گندم در محیط مزرعه. Remote Sens. 2019 , 11 , 2375. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ایتان، ال. تایر، دبلیو. نیکلاس، ک. چاد، دی. وو، اچ. هود، ال. ربکا، جی. مایکل، الف. فنوتیپ کمی سوختگی برگ شمالی در تصاویر پهپاد با استفاده از یادگیری عمیق. Remote Sens. 2019 , 11 , 2209. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پانبونیوئن، تی. جیتکاجورنوانیچ، ک. لااویرووجونگ، س. سرستاساتیرن، پ. Vateekul، P. Semantic Semantic Segmentation on Remote Sensing Images using an Enhanced Global Convolutional Network با توجه کانال و یادگیری انتقال خاص دامنه. Remote Sens. 2019 ، 11 ، 83. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- مو، ال. غمیسی، پ. Zhu، XX شبکههای عصبی بازگشتی عمیق برای طبقهبندی تصاویر فراطیفی. IEEE Trans. Geosci. Remote Sens. 2017 , 55 , 3639–3655. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وو، اچ. پراساد، S. شبکه های عصبی بازگشتی کانولوشن برای طبقه بندی داده های فراطیفی. Remote Sens. 2017 , 9 , 298. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ندیکومانا، ای. Minh، DHT؛ بغدادی، ن. کورو، دی. Hossard، L. شبکه عصبی بازگشتی عمیق برای طبقه بندی کشاورزی با استفاده از SAR Sentinel-1 چند زمانی برای Camargue، فرانسه. Remote Sens. 2018 , 10 , 1217. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- لیو، بی. یو، ایکس. یو، ا. ژانگ، پی. Wan, G. طبقهبندی طیفی- فضایی تصاویر فراطیفی بر اساس شبکههای عصبی مکرر. سنسور از راه دور Lett. 2018 ، 9 ، 1118–1127. [ Google Scholar ] [ CrossRef ]
- لیو، کیو. ژو، اف. هنگ، آر. یوان، X. یادگیری ویژگی های طیفی-فضایی مبتنی بر LSTM دو جهته برای طبقه بندی تصاویر فراطیفی. Remote Sens. 2017 , 9 , 1330. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ما، ا. فیلیپی، AM; وانگ، ز. یین، زی. طبقهبندی تصویر فراطیفی با استفاده از شبکههای عصبی عمیق بازگشتی مبتنی بر اندازهگیریهای شباهت. Remote Sens. 2019 , 11 , 194. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وینیالز، او. توشف، ا. بنژیو، اس. Erhan, D. نمایش و بگویید: A Neural Image Caption Generator. در مجموعه مقالات کنفرانس IEEE 2015 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015؛ صص 3156–3164. [ Google Scholar ]
- کارپاتی، ا. لی، F.-F. ترازهای بصری- معنایی عمیق برای تولید توضیحات تصویر. در مجموعه مقالات کنفرانس IEEE 2015 در مورد بینایی کامپیوتری و تشخیص الگو (CVPR)، بوستون، MA، ایالات متحده آمریکا، 7 تا 12 ژوئن 2015؛ صص 3128–3137. [ Google Scholar ]
- خو، ک. با، ج. کیروس، آر. چو، ک. کورویل، آ. سالاخوتدینوف، ر. زمل، آر. Bengio، Y. نمایش، حضور و گفتن: ایجاد شرح تصویر عصبی با توجه بصری. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین، لیل، فرانسه، 6 تا 11 ژوئیه 2015؛ صفحات 2048–2057. [ Google Scholar ]
- کو، بی. لی، ایکس. تائو، دی. لو، ایکس. درک معنایی عمیق تصویر سنجش از دور با وضوح بالا. در مجموعه مقالات کنفرانس بین المللی 2016 کامپیوتر، اطلاعات و سیستم های مخابراتی (CITS)، کونمینگ، چین، 6 تا 8 ژوئیه 2016؛ صص 1-5. [ Google Scholar ]
- شی، ز. Zou, Z. آیا ماشینی میتواند توصیفات زبانی انسانمانند را برای تصویر سنجش از راه دور ایجاد کند؟ IEEE Trans. Geosci. Remote Sens. 2017 , 55 , 3623–3634. [ Google Scholar ] [ CrossRef ]
- لو، ایکس. وانگ، بی. ژنگ، ایکس. لی، ایکس. کاوش مدلها و دادهها برای تولید عنوان تصویر سنجش از دور. IEEE Trans. Geosci. Remote Sens. 2018 , 56 , 2183–2195. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- وانگ، بی. لو، ایکس. ژنگ، ایکس. لیو، دبلیو توضیحات معنایی تصاویر سنجش از دور با وضوح بالا. IEEE Geosci. سنسور از راه دور Lett. 2019 ، 99 ، 1274-1278. [ Google Scholar ] [ CrossRef ]
- ژانگ، ایکس. وانگ، ایکس. تانگ، ایکس. ژو، اچ. Li, C. توضیحات نسل برای تصاویر سنجش از دور با استفاده از مکانیسم توجه ویژگی. Remote Sens. 2019 , 11 , 612. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هو، آر. رورباخ، م. دارل، تی. تقسیم بندی از عبارات زبان طبیعی. در مجموعه مقالات کنفرانس اروپایی بینایی رایانه، آمستردام، هلند، 11 تا 14 اکتبر 2016. [ Google Scholar ]
- لیو، سی. لین، ز. شن، ایکس. یانگ، جی. لو، ایکس. Yuille، A. تعامل چندوجهی مکرر برای بخش بندی تصویر ارجاع دهنده. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتری (ICCV)، ونیز، ایتالیا، 22 اکتبر 2017. [ Google Scholar ]
- چن، دی. جیا، اس. لو، ی. چن، اچ. لیو، تی. گروهبندی از طریق متن برای ارجاع بخشبندی تصویر. در مجموعه مقالات کنفرانس بین المللی IEEE در مورد عکس محاسباتی (ICCP)، توکیو، ژاپن، 15 تا 17 مه 2019. [ Google Scholar ]
- لو، اچ. لین، جی. لیو، ز. لیو، اف. تانگ، ز. Yao, Y. توجه بصری مبتنی بر تقسیم بندی ویدیویی SegEQA برای پاسخگویی به سؤالات تجسم یافته. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر (ICCV)، سئول، کره، 27 اکتبر تا 2 نوامبر 2019؛ صفحات 9967–9976. [ Google Scholar ]
- پیتر، ا. او، X. کریس، بی. دیمین، تی. مارک، جی. استفان، جی. ژانگ، L. توجه از پایین به بالا و بالا به پایین برای شرح تصاویر و پاسخگویی به سؤالات تصویری. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، سالت لیک سیتی، UT، ایالات متحده آمریکا، 18 تا 23 ژوئن 2018. [ Google Scholar ]
- لی، ک. ژانگ، ی. لی، ک. لی، ی. Fu, Y. استدلال معنایی بصری برای تطبیق تصویر-متن. در مجموعه مقالات کنفرانس بین المللی IEEE در بینایی کامپیوتر (ICCV)، سئول، کره، 27 اکتبر تا 2 نوامبر 2019؛ صص 4654–4662. [ Google Scholar ]
- کوی، دبلیو. وانگ، اف. او، X. ژانگ، دی. خو، X. یائو، ام. وانگ، ز. Huang, J. بخش بندی معنایی چند مقیاسی و تشخیص روابط فضایی تصاویر سنجش از دور بر اساس یک مدل توجه. Remote Sens. 2019 , 11 , 1044. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- چن، جی. ونگ، کیو. هی، GJ; He, Y. تجزیه و تحلیل تصویر مبتنی بر شی جغرافیایی (GEOBIA): روندهای در حال ظهور و فرصت های آینده. GIScience Remote Sens. 2018 ، 55 ، 159-182. [ Google Scholar ] [ CrossRef ]
- بلاشکه، تی. Strobl، J. مشکل پیکسل ها چیست؟ برخی از پیشرفت های اخیر در ارتباط با سنجش از دور و GIS. Z. Geoinformationssysteme 2001 ، 14 ، 12-17. [ Google Scholar ]
- چن، ام. ژو، دبلیو. یوان، T. GF-1 ارزیابی کیفیت تصویر و کاربردهای بالقوه برای طبقه بندی کاربری زمین در منطقه معدن. جی. ژئومات. علمی تکنولوژی 2015 ، 32 ، 494-499. [ Google Scholar ]
- وو، اچ. کلارک، ک. شی، دبلیو. نیش، ال. لین، ا. ژو، جی. بررسی حساسیت مقیاس فضایی در شبیهسازی زنجیره مارکوف سلولی اتوماتای سلولی تغییر کاربری زمین. بین المللی جی. جئوگر. Inf. علمی 2019 ، 33 ، 1040–1061. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]









بدون دیدگاه