

خلاصه
کلید واژه ها:
شبکه مکانی – زمانی ; یادگیری پیش بینی کننده ; افق LSTM ; ساختار عمودی ؛ معماری رمزگذار-رمزگشا
1. معرفی
2. کارهای مرتبط
3. مقدمات
هدف از یادگیری پیشبینیکننده برای دادههای مکانی-زمانی، پیشبینی پیشبینیهای آینده با استفاده از توالیهای مشاهده قبلی است. از دیدگاه ریاضی، این کار را می توان به عنوان یک مسئله تخمین احتمال در نظر گرفت. ما یک کلیپ ویدیویی (فرمت رایج دادههای مکانی-زمانی) را به عنوان یک هدف تحقیق میگیریم. این یک توالی زمانی است که به طور کلی از آن باز می شود t – J+ 1�−�+1به t + K�+�. با دادن مهر زمانی تی�، ایکسt – J+ 1, … ,ایکستی��−�+1,…,��(طول- جی�) نشان دهنده مشاهدات قبلی و ایکسt + 1, … ,ایکسt + K��+1,…,��+�(طول- ک�) مقادیر حقیقت پایه وضعیت آینده را نشان می دهد. در زمان معین t، هر مشاهده ایکس�، یک نمایش فضایی، می تواند با یک تانسور نمایش داده شود آرسی× م× N��×�×�، جایی که آر�به معنی ویژگی، سی� م�و ن�به ترتیب کانال، ارتفاع و عرض یک قاب را نشان می دهد. ماهیت پیشبینی، پیشبینی طول آینده است ک�دنباله بر اساس طول شناخته شده جی�توالی و برای به حداکثر رساندن احتمال پیش بینی پ�. پیش بینی ها ایکس^t + 1, … ,ایکس^t + k�^�+1,…,�^�+�به عنوان مقادیر تخمینی از حقیقت زمین استفاده می شود ایکسt + 1, … ,ایکسt + K��+1,…,��+�. این فرآیند را می توان توسط معماری رمزگذار-رمزگشا پیاده سازی کرد. بسیاری از مدلها برای یادگیری پیشبین از معماری رمزگذار-رمزگشا استفاده میکنند، از جمله FC-LSTM، ConvLSTM، ST-LSTM، Cause LSTM و مدل ما. ابتدا از رمزگذار برای رمزگذاری مشاهدات قبلی در حالت های میانی استفاده می شود و سپس از رمزگشا برای تولید نتایج پیش بینی بر اساس این حالت های میانی استفاده می شود. فرمول ها در فرمول (1) به صورت زیر آورده شده است:
LSTM برای پردازش توالی های زمانی مناسب است، که یک واحد سلولی بازگشتی با چهار ساختار دروازه در داخل است. طبق مقاله [ 27 ]، فرمول های اصلی LSTM در فرمول (2) در زیر نشان داده شده است:
جایی که σ�تابع فعال سازی سیگموئید است، ∙•و ∘∘به ترتیب محصول ماتمول و محصول هادامارد را نشان می دهند. با این حال، برای دادههای مکانی، محصول matmul تعداد زیادی اتصال اضافی (اتصالات کامل) ایجاد میکند تا همبستگیهای فضایی کارآمد را با کارایی بالا استخراج کند.
شی و همکاران با ترکیب لایه کانولوشن و لایه بازگشتی. ConvLSTM پیشنهادی [ 7 ]، که به طور گسترده در زمینه داده های مکانی-زمانی استفاده می شود زیرا همبستگی های مکانی و دینامیک زمانی به طور همزمان استخراج می شوند. ConvLSTM محصول matmul را با کانولوشن در سلول LSTM با اتصال کامل جایگزین می کند. فرمول های اصلی ConvLSTM در فرمول (3) در زیر نشان داده شده است:
جایی که σ�تابع فعال سازی سیگموئید است، ∗∗عملگر پیچیدگی و ∘∘محصول هادامارد را نشان می دهد. با این حال، شبکه تنها چهار لایه از واحدهای ConvLSTM را به صورت عمودی، مستقل از یکدیگر گام به گام پشته میکند، بنابراین لایه پایین ویژگیهای استخراجشده توسط لایه بالایی در زمان قبلی را نادیده میگیرد. پیشبینیها نمیتوانند روندهای کوتاهمدت را دریافت کنند و تمایل به فازی دارند.
برای غلبه بر اشکال معماری مستقل از لایه در ConvLSTM، وانگ و همکاران. یک معماری رمزگذار-رمزگشای جدید (PredRNN) [ 9 ] با جریان های حافظه زیگزاگی از لایه بالایی به لایه پایینی پیشنهاد کرد و یک واحد حافظه دوگانه به نام ST-LSTM با استفاده از توابع انتقال غیرخطی پیچیده طراحی کرد. PredRNN توانایی قوی در مدلسازی پویایی ویدیوهای کوتاهمدت دارد و پیشبینیهای واضحتری نسبت به ConvLSTM ایجاد میکند. معادلات کلیدی ST-LSTM در (4) به صورت زیر نشان داده شده است:
جایی که σ�تابع فعال سازی سیگموئید است، ∗∗عملگر پیچیدگی و ∘∘محصول هادامارد را نشان می دهد. براکت های مربع نشان دهنده الحاق و براکت های گرد نشان دهنده یک بخش کامل است. متأسفانه، مقادیر گرادیان به طور تصاعدی در فرآیند انتشار پس از انتشار کاهش می یابد. ST-LSTM پیچیده هنوز از مشکل ناپدید شدن گرادیان رنج می برد [ 23 ].
4. روش شناسی
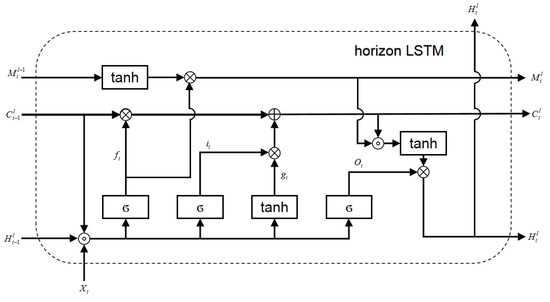
4.1. Horizon LSTM
معادلات کلیدی واحد Horizon LSTM در فرمول (5) به صورت زیر نشان داده شده است:
جایی که ∗∗عملیات پیچیدگی است، ∘∘محصول هادامارد از نظر عناصر است، σ�تابع سیگموئید است. براکت های مربع نشان دهنده الحاق ماتریس و براکت های گرد یک بخش کامل را نشان می دهند. W�1~4 پارامترهای فیلتر پیچیدگی را نشان می دهد، جایی که W�4 شکل 1 دارد ××1 فیلتر کانولوشن برای تنظیم خروجی نقشه ویژگی. همه متغیرهای حالت را می توان با یک تانسور چهار بعدی نشان داد که از حالت های دسته ای، عرض، ارتفاع و حالت های پنهان تشکیل شده است. همانطور که در فرمول 5 نشان داده شده است، تمام دروازه ورودی it��، دروازه مدولاسیون ورودی gt��، دروازه فراموشی ft��و دروازه خروجی ot��توابع هستند Xt��، Hlt−1��−1�، Clt−1��−1�. حافظه موقت Clt���تابع دروازه ورودی است it��، دروازه مدولاسیون ورودی gt��، دروازه فراموشی ft��و حالت های خروجی حافظه زمانی Clt−1��−1�در مهر زمان قبلی حافظه مکانی – زمانی Mlt���عملکرد دروازه فراموشی است ft��و حالت های خروجی حافظه مکانی-زمانی Ml−1t���−1در لایه زیرین حالت های مخفی خروجی Hlt���عملکرد دروازه خروجی است ot��، حافظه مکانی – زمانی Mlt���و حافظه موقت Clt���. در مقایسه با معادلات (4) در ST-LSTM، روش ما ساختارهای دروازه و عملیات پیچشی کمتری دارد که در معادلات (5) نشان داده شده است. ST-LSTM دارای دو دروازه ورودی است it��، دروازه مدولاسیون ورودی gt��، دروازه را فراموش کن ft��، در حالی که Horizon LSTM ما فقط یک دروازه ورودی دارد it��، دروازه مدولاسیون ورودی gt��، دروازه را فراموش کن ft��. بنابراین، Horizon LSTM ما ساختار مختصرتری نسبت به ST-LSTM دارد.
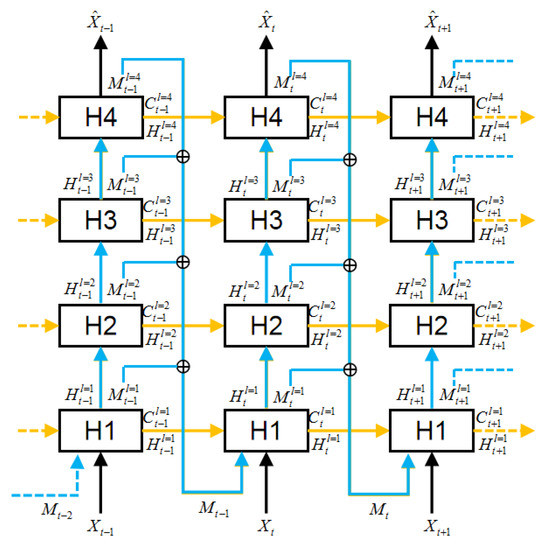
4.2. ساختار عمودی
معادلات کلیدی کل CostNet در فرمول (6) به شرح زیر ارائه شده است:
5. آزمایشات
5.1. انتقال مجموعه داده MNIST
5.1.1. پیاده سازی
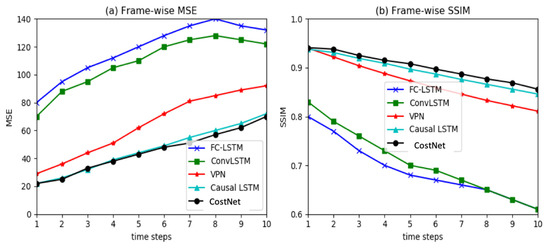
5.1.2. نتایج
5.2. مجموعه داده اکو رادار
5.2.1. پیاده سازی
5.2.2. نتایج
منابع
- وانگ، ام. ژانگ، ایکس. نیو، ایکس. وانگ، اف. Zhang، X. طبقهبندی صحنه تصویر سنجش از راه دور با وضوح بالا بر اساس resnet. J. Geov. مقعد فضایی. 2019 ، 3 ، 16. [ Google Scholar ] [ CrossRef ]
- وانگ، اس. ژونگ، ی. Wang, E. یک معماری پلتفرم GIS یکپارچه برای داده های بزرگ فضایی و زمانی. ژنرال آینده. محاسبه کنید. سیستم 2019 ، 94 ، 160-172. [ Google Scholar ] [ CrossRef ]
- لیو، ک. گائو، اس. کیو، پی. لیو، ایکس. یان، بی. Lu, F. Road2vec: اندازه گیری تعاملات ترافیکی در سیستم جاده های شهری از مسیرهای سفر عظیم. ISPRS Int. J. Geo Inf. 2017 ، 6 ، 321. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- لیو، ی. کائو، جی. ژائو، ن. یادگیری ماشین و زمین آمار را برای نقشه برداری با وضوح بالا از سطح زمین pm2 ادغام کنید. 5 غلظت. در تحلیل فضایی و زمانی آلودگی هوا و کاربرد آن در بهداشت عمومی ; الزویر: آمستردام، هلند، 2020؛ صص 135-151. [ Google Scholar ]
- لی، اچ. لیو، جی. ژو، ایکس. نقشه خوان هوشمند: چارچوبی برای درک نقشه توپوگرافی با یادگیری عمیق و روزنامه نگار. دسترسی IEEE 2018 ، 6 ، 25363–25376. [ Google Scholar ] [ CrossRef ]
- LeCun، Y. یادگیری پیش بینی. Proc. Speech NIPS 2016 . در دسترس آنلاین: https://drive.google.com/file/d/0BxKBnD5y2M8NREZod0tVdW5FLTQ/view (در 12 مارس 2020 قابل دسترسی است).
- Xinggjian، S. چن، ز. وانگ، اچ. یونگ، دی.-ای. وانگ، دبلیو.-ک. وو، W.-C. شبکه lstm کانولوشن: یک رویکرد یادگیری ماشینی برای پخش بارش. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، مونترال، QC، کانادا، 12 تا 17 دسامبر 2015. ص 802-810. [ Google Scholar ]
- شی، ایکس. گائو، ز. لاوزن، ال. وانگ، اچ. یونگ، دی.-ای. وونگ، دبلیو-ک. وو، W.-C. یادگیری عمیق برای بارش در حال حاضر: یک معیار و یک مدل جدید. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صص 5617–5627. [ Google Scholar ]
- وانگ، ی. لانگ، م. وانگ، جی. گائو، ز. فیلیپ، SY Predrnn: شبکه های عصبی مکرر برای یادگیری پیش بینی با استفاده از lstms فضایی و زمانی. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صص 879-888. [ Google Scholar ]
- ژانگ، جی. ژنگ، ی. چی، دی. لی، آر. یی، X. مدل پیشبینی مبتنی بر DNN برای دادههای مکانی-زمانی. در مجموعه مقالات بیست و چهارمین کنفرانس بین المللی ACM SIGSPATIAL در مورد پیشرفت در سیستم های اطلاعات جغرافیایی، برلینگیم، کالیفرنیا، ایالات متحده آمریکا، 31 اکتبر تا 3 نوامبر 2016؛ ACM: Burlingame، CA، USA، 2016; صص 1-4. [ Google Scholar ]
- خو، ز. وانگ، ی. لانگ، م. وانگ، جی. KLiss، M. PredCNN: یادگیری پیشبینیکننده با پیچشهای آبشاری. در مجموعه مقالات بیست و هفتمین کنفرانس مشترک بین المللی هوش مصنوعی (IJCAI-18)، استکهلم، سوئد، 13 تا 19 ژوئیه 2018؛ صص 2940-2947. [ Google Scholar ]
- ژانگ، جی. ژنگ، ی. Qi، D. شبکههای باقیمانده مکانی-زمانی عمیق برای پیشبینی جریانهای جمعیتی در سطح شهر. در مجموعه مقالات سی و یکمین کنفرانس AAAI در مورد هوش مصنوعی، سانفرانسیسکو، کالیفرنیا، ایالات متحده آمریکا، 4 تا 10 فوریه 2017. [ Google Scholar ]
- اولیو، م. سلوا، جی. Escalera, S. شبکههای عصبی مکرر تاشو برای پیشبینی ویدیویی آینده. در مجموعه مقالات کنفرانس اروپایی بینایی کامپیوتر (ECCV)، مونیخ، آلمان، 8 تا 14 سپتامبر 2018؛ صص 716-731. [ Google Scholar ]
- رانزاتو، م. اسلم، آ. برونا، جی. متیو، ام. کولوبرت، آر. Chopra, S. مدلسازی ویدیویی (زبان): مبنایی برای مدلهای تولیدی ویدیوهای طبیعی. arXiv 2014 ، arXiv:1412.6604. [ Google Scholar ]
- لاتتر، دبلیو. کریمن، جی. Cox, D. شبکه های کدگذاری پیش بینی عمیق برای پیش بینی ویدیو و یادگیری بدون نظارت. arXiv 2016 , arXiv:1605.08104. [ Google Scholar ]
- کالچبرنر، ن. ون دن اورد، آ. سیمونیان، ک. دانیهلکا، آی. وینیالز، او. گریوز، ا. Kavukcuoglu، K. شبکه های پیکسل ویدئو. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی یادگیری ماشین – جلد 70 ; JMLR: سیدنی، استرالیا، 2017؛ صفحات 1771-1779. [ Google Scholar ]
- متیو، ام. کوپری، سی. LeCun, Y. پیشبینی ویدیوی چند مقیاسی عمیق فراتر از میانگین مربعات خطا. arXiv 2015 ، arXiv:1511.05440. [ Google Scholar ]
- جین، ا. ضمیر، ع. ساوارس، اس. Saxena، A. Structural-rnn: یادگیری عمیق در نمودارهای مکانی-زمانی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صص 5308–5317. [ Google Scholar ]
- تران، دی. بوردف، LD; فرگوس، آر. تورسانی، ال. Paluri، M. C3D: ویژگی های عمومی برای تجزیه و تحلیل ویدئو. CoRR abs/1412.0767 2014 ، 2 ، 8. [ Google Scholar ]
- LeCun، Y.; بنژیو، ی. هینتون، جی. یادگیری عمیق. طبیعت 2015 ، 521 ، 436-444. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- بنژیو، ی. سیمرد، پ. فراسکونی، پی. یادگیری وابستگی های طولانی مدت با نزول گرادیان دشوار است. IEEE Trans. شبکه عصبی 1994 ، 5 ، 157-166. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- ویلیامز، RJ; Zipser، D. الگوریتمهای یادگیری مبتنی بر گرادیان برای دورهای. در پس انتشار: نظریه، معماری، و کاربردها . انتشارات روانشناسی: برایتون، انگلستان، 1995; جلد 433. [ Google Scholar ]
- پاسکانو، آر. میکولوف، تی. Bengio، Y. در مورد دشواری آموزش شبکه های عصبی بازگشتی. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین، آتلانتا، GA، ایالات متحده آمریکا، 16-21 ژوئن 2013. ص 1310–1318. [ Google Scholar ]
- او، ک. ژانگ، ایکس. رن، اس. Sun, J. یادگیری باقیمانده عمیق برای تشخیص تصویر. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لاس وگاس، NV، ایالات متحده، 26 ژوئن تا 1 ژوئیه 2016. صص 770-778. [ Google Scholar ]
- LeCun، Y.; بوتو، ال. بنژیو، ی. هافنر، پی. یادگیری مبتنی بر گرادیان برای شناسایی اسناد به کار می رود. Proc. IEEE 1998 ، 86 ، 2278-2324. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- جردن، MI سفارش سریال: یک رویکرد پردازش موازی توزیع شده. در پیشرفت در روانشناسی ; Elsevier: آمستردام، هلند، 1997; جلد 121، ص 471–495. [ Google Scholar ]
- هوکرایتر، اس. Schmidhuber, J. حافظه کوتاه مدت طولانی. محاسبات عصبی 1997 ، 9 ، 1735-1780. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- دوست خوب، من. پوگت آبادی، ج. میرزا، م. خو، بی. وارد-فارلی، دی. اوزایر، س. کورویل، آ. Bengio، Y. شبکه های متخاصم مولد. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، مونترال، QC، کانادا، 8 تا 13 دسامبر 2014. صص 2672–2680. [ Google Scholar ]
- دنتون، EL; چینتالا، اس. مدلهای تصویر تولیدی Fergus, R. Deep با استفاده از هرم لاپلاسی شبکههای متخاصم. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، مونترال، QC، کانادا، 7 تا 12 دسامبر 2015. ص 1486-1494. [ Google Scholar ]
- اوه، جی. گوا، ایکس. لی، اچ. لوئیس، RL; سینگ، اس. پیشبینی ویدیویی شرطی عمل با استفاده از شبکههای عمیق در بازیهای آتاری. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، مونترال، QC، کانادا، 7 تا 12 دسامبر 2015. ص 2863-2871. [ Google Scholar ]
- جیا، ایکس. دی براباندر، بی. تویتلارس، تی. شبکه های فیلتر پویا Gool، LV. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، بارسلون اسپانیا، 5 تا 10 دسامبر 2016. صص 667-675. [ Google Scholar ]
- ویلگاس، آر. یانگ، جی. زو، ی. سون، اس. لین، ایکس. لی، اچ. یادگیری ایجاد آینده بلند مدت از طریق پیش بینی سلسله مراتبی. در مجموعه مقالات سی و چهارمین کنفرانس بین المللی یادگیری ماشین – جلد 70 ; JMLR: سیدنی، استرالیا، 2017؛ صص 3560–3569. [ Google Scholar ]
- سریواستاوا، ن. مانسیموف، ای. Salakhudinov, R. یادگیری بدون نظارت بازنمایی های ویدئویی با استفاده از LSTMs. در مجموعه مقالات کنفرانس بین المللی یادگیری ماشین، لیل، فرانسه، 6 تا 11 ژوئیه 2015. صص 843-852. [ Google Scholar ]
- فین، سی. دوست خوب، من. Levine, S. یادگیری بدون نظارت برای تعامل فیزیکی از طریق پیشبینی ویدیویی. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، بارسلون، اسپانیا، 5 تا 10 دسامبر 2016. صص 64-72. [ Google Scholar ]
- Patraucean، V. هاندا، ا. Cipolla, R. رمزگذار خودکار ویدئوی فضایی-زمانی با حافظه قابل تمایز. arXiv 2015 ، arXiv:1511.06309. [ Google Scholar ]
- ویلگاس، آر. یانگ، جی. هونگ، اس. لین، ایکس. لی، اچ. تجزیه حرکت و محتوا برای پیشبینی توالی ویدیویی طبیعی. arXiv 2017 , arXiv:1706.08033. [ Google Scholar ]
- وانگ، ی. گائو، ز. لانگ، م. وانگ، جی. Yu, PS PredRNN++: به سوی حل معضل عمیق در زمان در یادگیری پیشبینی فضایی-زمانی. arXiv 2018 , arXiv:1804.06300. [ Google Scholar ]
- وندریک، سی. پیرسیاوش، ح. Torralba، A. تولید ویدئو با پویایی صحنه. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، بارسلون، اسپانیا، 5 تا 10 دسامبر 2016. صص 613-621. [ Google Scholar ]
- لو، سی. هیرش، ام. Scholkopf, B. شبکه های مکانی-زمانی انعطاف پذیر برای پیش بینی ویدئو. در مجموعه مقالات کنفرانس IEEE در مورد دید رایانه و تشخیص الگو، هونولولو، HI، ایالات متحده آمریکا، 21 تا 26 ژوئیه 2017؛ صص 6523-6531. [ Google Scholar ]
- Denton، EL یادگیری بدون نظارت بازنمایی های جدا شده از ویدئو. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صص 4414-4423. [ Google Scholar ]
- باتاچارجی، پی. Das, S. معیارهای مبتنی بر انسجام زمانی برای پیشبینی فریمهای ویدئویی با استفاده از شبکههای متخاصم مولد چند مرحلهای عمیق. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 4 تا 9 دسامبر 2017؛ صص 4268-4277. [ Google Scholar ]
- Chollet، F. Keras: کتابخانه یادگیری عمیق پایتون. در دسترس آنلاین: https://keras.io/#support (در 12 مارس 2020 قابل دسترسی است).
- آبادی، م. آگاروال، ا. برهم، پ. برودو، ای. چن، ز. سیترو، سی. کورادو، جی اس. دیویس، ا. دین، جی. دوین، ام. تنسورفلو: یادگیری ماشینی در مقیاس بزرگ در سیستمهای ناهمگن. arXiv 2016 , arXiv:1603.04467. [ Google Scholar ]
- Kingma، DP; Ba, J. Adam: روشی برای بهینه سازی تصادفی. arXiv 2014 ، arXiv:1412.6980. [ Google Scholar ]
- Ba، JL; کیروس، جی آر. نرمال سازی لایه هینتون، جنرال الکتریک. arXiv 2016 , arXiv:1607.06450. [ Google Scholar ]
- بنژیو، اس. وینیالز، او. جیتلی، ن. Shazeer, N. نمونه برداری زمان بندی شده برای پیش بینی توالی با شبکه های عصبی مکرر. در مجموعه مقالات پیشرفتها در سیستمهای پردازش اطلاعات عصبی، مونترال، QC، کانادا، 12 تا 17 دسامبر 2015. صص 1171-1179. [ Google Scholar ]
- وانگ، ز. بوویک، AC; شیخ، HR; Simoncelli، EP ارزیابی کیفیت تصویر: از دید خطا تا شباهت ساختاری. IEEE Trans. فرآیند تصویر 2004 ، 13 ، 600-612. [ Google Scholar ] [ CrossRef ] [ PubMed ][ نسخه سبز ]
- وانگ، ی. ژانگ، جی. زو، اچ. لانگ، م. وانگ، جی. یو، PS Memory در حافظه: یک شبکه عصبی پیش بینی برای یادگیری غیر ایستایی مرتبه بالاتر از دینامیک مکانی-زمانی. در مجموعه مقالات کنفرانس IEEE در مورد بینایی کامپیوتری و تشخیص الگو، لانگ بیچ، کالیفرنیا، ایالات متحده آمریکا، 16 تا 20 ژوئن 2019؛ ص 9154–9162. [ Google Scholar ]





بدون دیدگاه