1. معرفی
تعمیم نقشه به دنبال تطبیق مجموعه داده های جغرافیایی دقیق برای تجسم در مقیاس کوچکتر است. در حال حاضر، این کار هنوز برای خودکارسازی بسیار چالش برانگیز است و نیاز به مداخله انسانی است. محققان برای چندین دهه تلاش کردند تا تعمیم نقشه را با طراحی عملگرهای هندسی مختلف [ 1 ] و فرآیندهای پیچیده برای هماهنگ کردن اپراتورهای فردی به روشی کارآمد [ 2 ] خودکار کنند. بنابراین، نیاز فعلی در مورد ارکستراسیون و اتوماسیون است [ 3 ]. یادگیری ماشینی یک راه حل اولیه برای غلبه بر روش های سنتی و به دست آوردن دانش نقشه نگاران انسانی در مورد نحوه هماهنگ سازی دگرگونی های هندسی بود [ 4 , 5 , 6 , 7]. به نظر می رسد محدودیت اصلی همه این رویکردها، ظرفیت یادگیری ماشینی برای تقلید از پیچیدگی استدلال انسانی، به ویژه در رابطه با روابط فضایی ضمنی (مثلاً ساختمان هایی که در امتداد یک جاده قرار دارند) باشد. با این حال، مانند بسیاری از زمینههای دیگر که از یادگیری ماشینی استفاده میشود، رویکردهای یادگیری عمیق ممکن است بتوانند بر این مشکلات غلبه کنند [ 8 ]. اولین تلاش ها برای تعمیم ساختمان ها با U-Net (یک شبکه عصبی کانولوشن برای تقسیم بندی تصویر) [ 9 ] نتایج بسیار امیدوارکننده ای را نشان داد [ 10 ].
برای فراتر رفتن از این تحقیق اساسی، میخواهیم این تکنیکهای جدید را در یک مورد کاربردی کلاسیک اما چالش برانگیز از تعمیم نقشه آزمایش کنیم: تعمیم جادههای کوهستانی. تعمیم جاده کوهستانی چالش برانگیزتر از ساده سازی ساختمان است، زیرا عملیات جابجایی، اعوجاج، و گاهی اوقات طرحواره سازی علاوه بر ساده سازی مورد نیاز است. در نتیجه، ما تصمیم گرفتیم بررسی کنیم که چگونه می توان این دانش را با رویکردهای یادگیری عمیق آموخت. این پارادایم جایگزین چالشهای تحقیقاتی جدیدی را معرفی میکند، مانند ایجاد یک مجموعه آموزشی تصویری اقتباسشده از مجموعه دادههای برداری، و ترکیبی از مسائل مربوط به علوم کامپیوتر و علم اطلاعات مکانی. در نهایت، یک چالش در ارزیابی خروجی یادگیری عمیق وجود دارد. در واقع، این رویکرد جایگزین تصاویر جدیدی ارائه می دهد که نمی توانند با روش های ارزیابی تعمیم سنتی مبتنی بر برداری ارزیابی شوند. ما هنوز انتظار نداریم که به نتایج بهتری نسبت به روش تعمیم کلاسیک دست یابیم، اما از این مثال به عنوان پایه ای برای کسب اطلاعات بیشتر در مورد چالش های ناشی از تعمیم یادگیری عمیق استفاده کنیم. رویکرد ما در استفاده از یادگیری عمیق در تعمیم نقشه، افزایش تدریجی پیچیدگی، مقابله با مسائلی است که حل آنها پیچیدهتر و پیچیدهتر است، بدون اینکه انتظار داشته باشیم سریعاً از تکنیکهای خودکاری که در طول سالها توسعه و بهینهسازی شدهاند، پیشی بگیریم. این مقاله یکی از اولین گامهای ما در این پیچیدگی فزاینده را شرح میدهد. اما برای استفاده از این مثال به عنوان پایه ای برای کسب اطلاعات بیشتر در مورد چالش های ناشی از تعمیم یادگیری عمیق. رویکرد ما در استفاده از یادگیری عمیق در تعمیم نقشه، افزایش تدریجی پیچیدگی، مقابله با مسائلی است که حل آنها پیچیدهتر و پیچیدهتر است، بدون اینکه انتظار داشته باشیم سریعاً از تکنیکهای خودکاری که در طول سالها توسعه و بهینهسازی شدهاند، پیشی بگیریم. این مقاله یکی از اولین گامهای ما در این پیچیدگی فزاینده را شرح میدهد. اما برای استفاده از این مثال به عنوان پایه ای برای کسب اطلاعات بیشتر در مورد چالش های ناشی از تعمیم یادگیری عمیق. رویکرد ما در استفاده از یادگیری عمیق در تعمیم نقشه، افزایش تدریجی پیچیدگی، مقابله با مسائلی است که حل آنها پیچیدهتر و پیچیدهتر است، بدون اینکه انتظار داشته باشیم سریعاً از تکنیکهای خودکاری که در طول سالها توسعه و بهینهسازی شدهاند، پیشی بگیریم. این مقاله یکی از اولین گامهای ما در این پیچیدگی فزاینده را شرح میدهد.
مقاله به شرح زیر سازماندهی شده است: بخش زیر وضعیت فعلی هنر است که استفاده از یادگیری عمیق در اطلاعات جغرافیایی و تعمیم را فهرست می کند و تحقیقات گذشته در مورد تعمیم جاده های کوهستانی را خلاصه می کند. بخش 3 روش پیشنهادی و مواد مطالعه به ویژه مجموعه داده های آموزشی و کالیبراسیون شبکه عصبی را ارائه می دهد. بخش 4 نتایج را نشان می دهد و تجزیه و تحلیل می کند. در نهایت، بخش 5 و بخش 6 برخی از نتایج را به دست می آورند و تحقیقات آینده را مورد بحث قرار می دهند.
2. کارهای مرتبط
تعمیم جاده های کوهستانی یک مشکل فرعی از تعمیم جاده است، زیرا جاده هایی با سری پیچ های سینوسی می توانند باعث ادغام نمادهای خاص شوند. تعمیم جاده را می توان به دو وظیفه تقسیم کرد، انتخاب و ساده سازی هندسی. مرحله انتخاب تصمیم میگیرد که کدام جادهها در نقشه نگه داشته شوند، و کدام جادهها حذف شوند [ 11 ، 12 ، 13 ]. در مرحله سادهسازی هندسی، هندسه جاده سادهسازی میشود [ 14 ]، صاف میشود، گاهی اوقات کاریکاتوری میشود [ 15 ]، یا حتی جابهجا میشود تا از درگیری با دیگر اشیاء نقشه جلوگیری شود. دو رویکرد اصلی برای این مرحله دوم وجود دارد: رویکرد جهانی و رویکرد تکراری [ 16]. در رویکرد جهانی، هندسه جاده به طور کلی بهینه شده است تا آن را صاف کند و مشکلات خوانایی نماد را حذف کند [ 17 ، 18 ]. در رویکرد تکراری، جاده از نظر سینوسی یا تضاد گرافیکی به بخشهای همگن تقسیم میشود و سپس بخش به بخش با عملگرهای مختلف تعمیم مییابد [ 16 ، 19 ]. تحقیق در مورد سطح تجزیه و تحلیل، یعنی تعریف دقیق جاده تعمیم یافته (یک شی از پایگاه داده منبع، بخش کوچکی از شی، گروهی از اشیاء) نیز در این کار تعمیم مهم است. به عنوان مثال، ر. [ 20 ] سعی کنید سکته مغزی مناسب را تعیین کنید [ 11] ورودی الگوریتمهای سادهسازی باشد، و چنین فرآیندی ممکن است برای تعریف واحدی که باید از آن یاد بگیریم (یعنی کل یک شی جاده، بخشی از یک شی یا گروههایی از اشیاء جاده) مرتبط باشد.
همانطور که در مقدمه ذکر شد، از آنجایی که هدف محققان در تعمیم نقشه، خودکار کردن کار نقشهبرداران انسانی بود، یادگیری ماشین برای به دست آوردن این دانش خاص مورد بررسی قرار گرفت [ 4 ]. یادگیری ماشینی را می توان برای یادگیری قوانین مورد استفاده توسط نقشه نگاران برای تصمیم گیری تعمیم [ 6 ]، یا برای یادگیری تبدیل ساختاری (هندسی و معنایی) بین نقشه اولیه و تعمیم یافته استفاده کرد [ 5 ]. با توجه به تعمیم جاده های کوهستانی، یک روش سنتی شناسایی برخی از اشکال جاده های معمولی و یادگیری الگوریتم سازگار با این شکل است [ 7 ]]. جاده ها بر اساس نیازشان به هموارسازی، کاریکاتور، جابجایی یا/یا ساده سازی واجد شرایط هستند. این جداسازی به ویژگیهای شکل جاده متکی است، و برخی از قوانین تبعیض نیز میتواند با رویکرد یادگیری ماشینی نشان داده شود [ 21 ]. علاوه بر این، یادگیری ماشین نیز برای انجام مرحله انتخاب تعمیم جاده استفاده می شود [ 22 ].
فراتر از تکنیکهای سنتیتر یادگیری ماشین، استفاده از یادگیری عمیق برای تعمیم نقشه اخیراً وجود دارد، اما پتانسیل آن واقعی است [ 8 ]. از آنجایی که تعمیم نقشه یک مشکل گرافیکی است، تکنیکهای یادگیری عمیق باید بتوانند ساختارهای گرافیکی ضمنی، مانند روابط فضایی کلیدی را که برای یک تعمیم خوب نقشه ضروری هستند، یاد بگیرند. علاوه بر این، امکان واقعی ایجاد مجموعه داده های آموزشی بسیار بزرگ با استفاده از نقشه های تعمیم یافته موجود وجود دارد. در میان پروژه های تحقیقاتی اساسی با استفاده از یادگیری عمیق برای تعمیم نقشه، ر. [ 10] یک شبکه تقسیم بندی را برای تعمیم ساختمان ها در مقیاس های بزرگ پیشنهاد می کند. تقسیمبندی تصویر، طبقهبندی هر پیکسل در تصویر است، به عنوان مثال، تقسیمبندی پیکسلهای جادهها در تصاویر هوایی. فنگ و همکاران یک معماری U-Net، یک U-Net باقیمانده و یک معماری شبکه متخاصم مولد (GAN) را مقایسه کنید، معماری U-net باقیمانده در آزمایش آنها دقیق ترین است. کار بر روی انتقال سبک های نقشه در مقیاس های مختلف نیز می تواند به تعمیم نقشه مرتبط باشد. GAN پیشنهاد شده توسط [ 23 ] برای تولید نقشههای Google Maps مانند از دادههای OpenStreetMap میتواند جادههای بیاهمیت را زمانی که هدف نقشهای در مقیاس کوچک است حذف کند.
ساختن یک مدل یادگیری عمیق برای تعمیم جاده های کوهستانی نیاز به درک کمی از ارزیابی تعمیم دارد. تعمیم خوب جاده کوهستانی چیست؟ چگونه می توانیم کیفیت تصویری را که شامل چندین جاده تعمیم یافته است ارزیابی کنیم؟ ارزیابی تعمیم یک کار پیچیده است که معیارهای خوانایی، حفظ اطلاعات و رعایت برخی از محدودیت ها را ترکیب می کند [ 24 ، 25 ]. مفهوم ارزیابی جهانی و محلی نیز مهم است [ 26]: نقشهای با نقصهای کوچک روی همه اشیا با ارزیابی کلی میانگینگرا خوب نخواهد بود، در حالی که میتواند از نظر بصری کمتر از نقشهای با یک خطای بزرگ در یک جاده برای نقشهخوانها آزاردهنده باشد. این مهم است زیرا ارزیابی های یادگیری عمیق اغلب بر اساس میانگین دقت طبقه بندی است.
3. بخش بندی تصویر یادگیری عمیق برای تعمیم جاده کوهستانی
3.1. استفاده از مورد
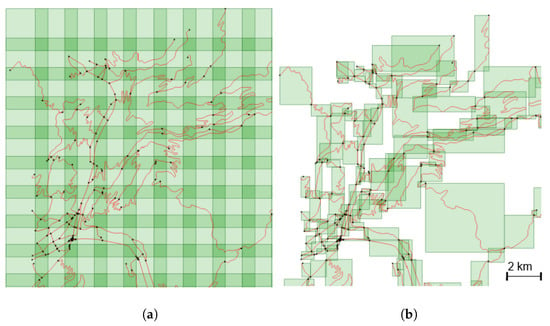
ما از دو مجموعه داده متفاوت از جادهها استفاده کردیم که بخش کوچکی (2155 کیلومتر مربع ) از کوههای آلپ در فرانسه را پوشش میدادند ( شکل 1 ). اولین مورد عصاره ای از پایگاه داده است که برای تهیه نقشه های توپوگرافی در مقیاس 1:25000 در IGN، آژانس ملی نقشه برداری فرانسه (NMA) استفاده می شود، و شامل 30،455 جاده به طول کل 5،253،248 کیلومتر است. مجموعه داده دوم عصاره ای از پایگاه داده است که برای تهیه نقشه مقیاس 1:250000 در IGN استفاده می شود، این مجموعه شامل 853 جاده به طول کل 1775205 کیلومتر است. این مجموعه داده دوم تنها جادههای مهم را نشان میدهد و شکل آنها برای تجسم بهتر پیچهای سینوسی ساده، هموار و اغلب طرحوارهسازی میشود. هدف از این مورد استفاده، تولید نقشه مقیاس 1:250000 از نقشه مقیاس 1:25000 بود.
این مجموعه داده ها به طور مستقل ساخته و مدیریت می شوند، بنابراین هیچ ارتباط مستقیمی بین جاده های مربوطه وجود ندارد و ویژگی های جاده مشابه نیستند.
مجموعه داده دوم از مجموعه اول توسط یک فرآیند تعمیم که ترکیبی از الگوریتم های خودکار و تصحیحات دستی توسط نقشه کشان بیست سال پیش [ 19 ] است، تولید شد و سپس به صورت دستی توسط نقشه نگاران به روز شد. مجموعه داده فقط شامل جاده های کوهستانی سینوسی نیست، بلکه شامل تمام جاده های منطقه است، بنابراین برخی از جاده های شهری در شهرها و یک بزرگراه در سراسر نقشه وجود دارد. ما مجموعه داده خود را بر اساس سینوسی به دو زیرگروه تقسیم کردیم ( شکل 2 )، به منظور آزمایش روشهای آموزشی مختلف، به عنوان مثال، آموزش با انواع جادهها و آموزش فقط با جادههای سینوسی، که تعمیم آن سختترین است. ما یک معیار ساده برای سینوسیت جاده انتخاب کردیم [ 7]: برای هر چند خط جاده، طول پایه (فاصله بین رئوس اول و آخر) را بر طول کل جاده تقسیم کردیم. این اندازه گیری به صورت درصد در شکل 2 نشان داده شده است: مقدار نزدیک به 100 هنگامی که جاده مستقیم است و نزدیک به 0 زمانی که بسیار سینوسی است.
به عنوان اولین قدم، ما نمی خواهیم در این مقاله، ساده سازی و انتخاب جاده را یاد بگیریم. به منظور شناسایی جاده ها از مجموعه داده منبع که در مجموعه داده خروجی نگهداری می شدند، یک پیش فرآیند تطبیق داده بین هر دو مجموعه داده ضروری بود. شکاف های بسیار زیادی بین جاده های مربوطه از هر دو مجموعه داده وجود داشت (اغلب چند صد متر)، بنابراین روش تطبیق جاده کلاسیک ما [ 27 ] ناموفق بود. در نتیجه، ما در نهایت تصمیم گرفتیم به صورت دستی جاده هایی را که در هر دو مجموعه داده وجود دارد مطابقت دهیم. از آنجایی که تطبیق دستی راه حل معقولی برای مناطق بزرگتر نخواهد بود، استفاده از روش های تطبیق داده های چند معیاره انعطاف پذیرتر باید مورد بررسی قرار گیرد [ 28 ].
3.2. تعمیم جاده های کوهستانی به عنوان یک مشکل یادگیری عمیق
هدف ما استفاده از یک شبکه عصبی کانولوشنال (CNN) بود، زیرا در تعمیم ساختمان ها موفق بود [ 10 ]. بنابراین، در این بخش، نحوه نمایش مشکل خود را با تصاویر به تفصیل شرح می دهیم. CNN شبکههایی هستند که برای وظایف پردازش تصویر، مانند طبقهبندی یا تقسیمبندی تصویر، سازگار شدهاند. در یک مدل تقسیم بندی، کلاس هر پیکسل توسط مدل تعیین می شود. در مورد ما، هر پیکسل در یکی از دو کلاس طبقه بندی می شود: جاده عمومی یا پس زمینه.
راه های ممکن دیگری برای مدل سازی تعمیم جاده به عنوان یک مسئله یادگیری عمیق وجود دارد، به عنوان مثال با استفاده از پیچیدگی نمودار [ 29 ]. اما ما فکر میکنیم که بخشبندی CNN سازگار است زیرا تمام اطلاعات لازم برای ترسیم نسخه تعمیمیافته یک جاده را میتوان در تصویر جاده گنجاند [ 8 ]. محدودیت های معمول تعریف شده برای تعمیم جاده های کوهستانی به شرح زیر است [ 16 ]:
-
ادغام (هنگامی که عرض نماد جاده برای مقیاس نمایش به اندازه کافی بزرگ باشد نباید هیچ نمادی وجود داشته باشد).
-
دانه بندی (جزئیات خطی که خیلی کوچک هستند و در مقیاس نمایش قابل مشاهده نیستند باید حذف شوند).
-
موقعیت (جاده تعمیم یافته باید نزدیک به جاده اولیه باشد).
-
صافی (خط تعمیم یافته باید صاف باشد)؛
-
حفظ شکل کلی (جاده تعمیم یافته باید شبیه جاده اولیه باشد).
-
خمهای سینوسی و حفظ سری خمها (وجود خمهای سینوسی یا سری خم باید حفظ شود، تا خطر حذف برخی از خمها در یک سری وجود داشته باشد).
تا زمانی که تصاویر استفاده شده در CNN جاده را با جزئیات کافی برای “دیدن” دانه بندی، ادغام یا خمیدگی به تصویر می کشند، CNN باید بتواند دانش ضمنی را برای تبدیل تصویر جاده و در عین حال رعایت این محدودیت ها بیاموزد. بنابراین، مجبور شدیم تصاویر زوجی بسازیم: یکی باید ورودی مدل و دیگری هدف، از جاده های برداری باشد. این فرآیند در زیر بخش زیر توضیح داده شده است.
3.3. ایجاد یک مجموعه داده یادگیری تطبیقی
تبدیل برداری به شطرنجی می تواند برخی از خطاها را ایجاد کند [ 30 ]، زیرا شطرنجی سازی همیشه باعث از دست رفتن اطلاعات در مقایسه با داده های برداری می شود. خطاها می توانند در ناحیه، محیط، شکل، ساختار، موقعیت و ویژگی های داده های شطرنجی شده رخ دهند، اما فقط خطاها در شکل، ساختار و موقعیت برای ما مرتبط هستند. افزایش وضوح تصویر شطرنجی میتواند این خطاها را به حداقل برساند، اما یک تصویر بزرگتر بر زمان محاسبه CNNها تأثیر میگذارد و همیشه نتایج نهایی را بهبود نمیبخشد. به عنوان مثال، طبقه بندی از [ 31] با اندازه 256 × 256 بهتر از اندازه 512 × 512 (با مقیاس ثابت) هستند. شبکه های عصبی کانولوشن برای کار بهینه با تصاویر مربعی با اندازه توان دو (مثلاً 128 × 128، 256 × 256 و غیره) طراحی شده اند. در نتیجه ما تصاویر 256 × 256 را انتخاب می کنیم که از نظر تجربی یک مصالحه خوب بین وضوح تصاویر و زمان محاسبه است. ما همچنین می توانیم توجه داشته باشیم که اندازه نمادها برای تعریف در طول شطرنجی مهم است. اندازه نماد یک مشکل کلاسیک در تعمیم شطرنجی است [ 32 ].
در نتیجه، ما تصمیم گرفتیم تصاویر 256 × 256 خود را با جاده های قرمز در پس زمینه سفید تولید کنیم. استفاده از یک تصویر رنگی، حتی اگر در حال حاضر فقط از یک رنگ استفاده شود، امکان افزودن بیشتر اطلاعات (مثلاً ساختمان ها یا رودخانه ها) را بدون تغییر معماری شبکه برای پذیرش تصاویر رنگی به عنوان ورودی فراهم می کند.
میتوانیم با تخصیص نمادهای عرض نسبت به اهمیت جاده، برخی اطلاعات اضافی را اضافه کنیم. ما مقادیر مشخصهای را که اهمیت جاده را در هر دو مجموعه داده تعیین میکنند، با عرض بر حسب پیکسل تطبیق دادیم، و این تطابق در جدول 1 خلاصه شده است.
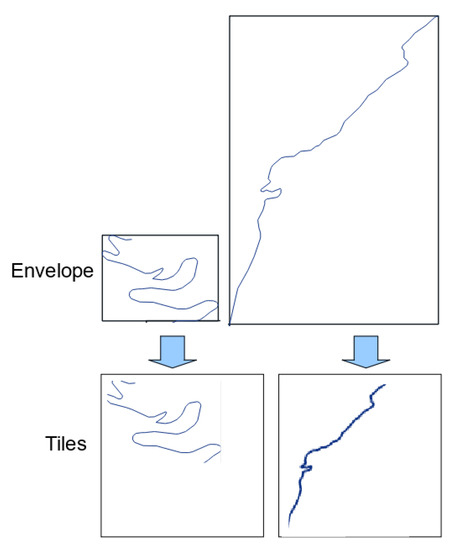
سپس، دو رویکرد (نشان داده شده در شکل 3 ) برای ایجاد تصاویر با کاشی کاری مجموعه داده پیشنهاد می کنیم:
-
برای کشیدن یک پنجره با اندازه ثابت روی منطقه مطالعه. این روش تصاویری را با مقیاس ثابتی از دادههای زیربنایی ایجاد میکند، اما میتواند کاشیهای بیربط (فقط بخش بسیار کوچکی از جاده) یا خالی تولید کند.
-
برای غلبه بر مشکل کاشی های نامربوط، می توانیم از اشیاء جاده به عنوان مبنایی برای هدایت ایجاد کاشی استفاده کنیم. در این روش کل هندسه یک جاده در کاشی قرار می گیرد و از آنجایی که اجسام جاده دارای طول های مختلف و گستردگی هندسی هستند، این فرآیند کاشی هایی می سازد که مقیاس های متفاوتی دارند.
لازم به ذکر است که در پایگاه داده اولیه، یک جاده جدید در هر تقاطع و در هر تغییر ویژگی جمع آوری می شود (به عنوان مثال، تغییر در تعداد خطوط یا در عرض جاده). به همین دلیل است که جاده ها همیشه در تقاطع ها ختم نمی شوند.
روش اول به دو پارامتر نیاز دارد: اندازه پنجره (یا وضوح) و نرخ همپوشانی که جابجایی پنجره را روی مجموعه داده تعریف می کند. روش دوم به هیچ پارامتری نیاز ندارد.
مشکلات مطرح شده توسط هر دو روش مشابه مسائل کلاسیک در تقسیم بندی داده ها برای تعمیم نقشه [ 33 ] است، جایی که هیچ راه حل کاملی وجود ندارد. در اینجا دو موضوع مهم وجود دارد که باید در نظر گرفته شود: ابتدا مقیاس تصاویر باید ثابت شود تا به شبکه کانولوشن کمک کند تا یاد بگیرد که مقیاس از تصویر ورودی به تصویر خروجی تغییر می کند. سپس، موضوع کلاسیک بهترین سطح تجزیه و تحلیل برای تعمیم وجود دارد [ 34 ]، که به ویژه هنگام برخورد با جاده های کوهستانی اهمیت دارد [ 16 ]. به عنوان مثال، کار بر روی سطح اشیاء جاده ای مجموعه داده دلخواه است، زیرا این اشیاء می توانند بسیار طولانی یا بسیار کوتاه باشند و همیشه از نظر شکل همگن نیستند. کار بر روی سکته های جاده ای [ 11] ممکن است انتخاب بهتری باشد، و/یا کار بر روی قسمتهایی از جادهها که از نظر سینووسیت یا ادغام نماد همگن هستند [ 16 ].
از آنجایی که هیچ یک از روش های پیشنهادی ایده آل نیست، تصمیم گرفتیم کاشی های تولید شده را پس از پردازش انجام دهیم. اولین فرآیند پس از آن شامل تمیز کردن کاشیهایی است که در محدوده محدوده مورد استفاده قرار دارند، زمانی که به دلیل اثرات لبه انتخاب، جادههایی از هر دو مجموعه داده ندارند. در مورد روش اول با کاشیهای با اندازه ثابت، کاشیهای نامربوط را که فاقد جاده هستند یا فقط بخش بسیار کمی از جادهها را شامل میشوند، حذف کردیم. سپس با توجه به روش دوم، سعی شد با اعمال یک عرض جاده ثابت شده با مقیاس (تصاویر در مقیاس های کوچکتر دارای نمادهای جاده باریک تر) اثر تغییر مقیاس را کاهش دهیم. همانطور که در شکل 4 نشان داده شده استهنگامی که جاده ها کوچکتر از کاشی هستند، عرض نماد بدون تغییر باقی می ماند، و عرض جاده 1 است، زمانی که وسعت جاده بیشتر از کاشی باشد، نسبت کاهش برای انتخاب عرض جاده ها به دنبال معادله ( 1 ) استفاده می شود. ).
پاکت حداقل مستطیل مرز موازی با محورهای X و Y اطراف جاده است. طول پاکت طول ضلع مستطیل موازی با محور X و عرض آن طول ضلع مستطیل موازی با محور Y است. شکاف یک فضای خالی کوچک است که در اطراف تصویر معرفی کردیم.
در نتیجه این فرآیندها با روش اول حدود 560 تصویر و با روش دوم 690 تصویر بدست می آوریم.
برای افزایش تعداد تصاویر برای آموزش، سه روش رایج وجود دارد [ 35 ] که تصاویر تغییر یافته را از تصاویر موجود ایجاد می کند: برش، آینه، و چرخش (به عنوان مثال، شکل 5 را ببینید ).
در مورد ما، استفاده از تقویت برش (برش بخشی از تصویر) به نظر نمی رسد سازگار باشد: در کاشی های مبتنی بر شی، بخشی از زمینه (در اطراف شی) را از دست می دهیم، و در مورد کاشی های مقیاس ثابت. ، تصاویر مجموعه داده جدید مقیاس ثابتی ندارند. چرخش (90 ∘∘، 180 ∘∘، یا 270 ∘∘) و روش های تقویت آینه (بر اساس یک محور افقی یا عمودی) اثرات مشابهی بر روی تصویر دارند و مجموعه آموزشی را با تصاویر واقعی جاده ای جدید تقویت می کنند.
همچنین امکان افزایش تعداد تصاویر با تغییر پارامترهای کاشی کاری وجود دارد. در رویکرد مبتنی بر شی، در نظر گرفتن اشیاء کوچکتر از جاده های اولیه، به ویژه در مورد جاده های بسیار طولانی، اندازه مجموعه داده آموزشی را افزایش می دهد. در روش با اندازه ثابت، انتخاب یک پنجره کوچکتر یا استفاده از همپوشانی بزرگتر، اندازه مجموعه داده آموزشی را افزایش می دهد. این تقویتهای جایگزین برای ارزیابی سودمندی آنها در بخش 4 آزمایش و ارائه شدند.
اما افزایش دادهها مشکلات بازنمایی و همگنی را حل نمیکند، زیرا اگر تعداد جادههای غیر سینوسی از جادههای سینوسی در مجموعه داده اولیه بیشتر باشد، بسیار بیشتر خواهد شد، که در مورد استفاده ما چنین است.
3.4. انتخاب یک معماری شبکه عصبی
مسئله تعمیم به عنوان یک مشکل تقسیمبندی تصویر با یک تصویر به عنوان ورودی و طبقهبندی هر پیکسل در دو کلاس (جاده یا پسزمینه) به عنوان خروجی مدلسازی شد. بسیاری از معماری های شبکه مختلف در ادبیات برای حل این نوع مشکل وجود دارد [ 36]. شبکههای یادگیری عمیق، شبکههای عصبی با معماری عمیق، یعنی لایههای زیادی از نورونهای متصل هستند. هدف این شبکه ها یافتن پیش بینی کننده ای است که عملکرد خطا (از دست دادن) را به حداقل برساند. شبکههای عصبی کانولوشنال (CNN) نوع خاصی از شبکههای عصبی عمیق هستند و به دلیل توانایی آنها در پردازش دادههای ماتریسی، مانند تصاویر، در مقیاسهای مختلف، در کارهای تشخیص بصری و طبقهبندی مفید هستند. این شبکه ها از سیستم بینایی انسان الهام گرفته شده اند. اصول CNN بر پایه لایههای انحرافی متوالی است که فیلتری را روی تصویر اعمال میکند و لایههایی را با هم ترکیب میکند که اندازه یک تصویر را از طریق نمونهبرداری پایین کاهش میدهد.
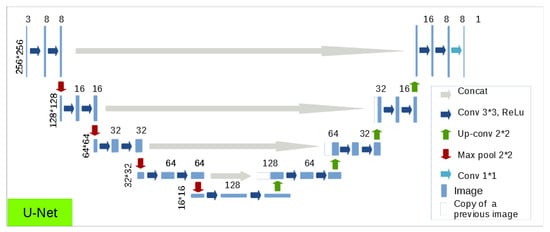
به دنبال نتایج اولین آزمایش در مورد تعمیم نقشه [ 10 ]، ما معماری U-Net را آزمایش می کنیم [ 9 ]. این شبکه ابتدا برای تقسیم بندی تصاویر پزشکی توسعه یافت. این شامل یک سری از لایههای کانولوشن و upconvolution به یک مسیر انقباضی است که از معماری معمولی یک شبکه کانولوشن پیروی میکند و یک مسیر گسترده (سمت راست) که اندازه فضایی ورودی را بازسازی میکند [ 37 ]. به منظور مدیریت اثرات مرزی، اتصالات پرش (الحاق) را معرفی می کند که لایه های قبلی را با لایه های عمیق تر شبکه پیوند می دهد. این شبکه توانست به نتایج تقسیم بندی بسیار خوبی در انواع مختلف برنامه ها دست یابد. پیاده سازی ما از این مدل در شکل 6 ارائه شده استاندازه هر تصویر در سمت چپ خط و تعداد کانال در بالای تصویر ارائه شده است. بسیار شبیه به تصویر اصلی است با این تفاوت که ما از تصاویر رنگی 256 × 256 پیکسل به عنوان ورودی استفاده کردیم.
که در شکل 6، تصویر اولیه عنصری به اندازه 256 × 256 در سه کانال در بالا سمت چپ است. در بالا سمت راست می توانید خروجی را مشاهده کنید که یک تصویر سیاه و سفید (یک کانال) با همان اندازه است. هر فلش نشان دهنده یک لایه عصبی است. ابتدا در رنگ آبی تیره لایه های پیچشی با فیلتری به اندازه 3×3 وجود دارد. چنین لایه هایی همیشه با یک تابع فعال سازی به نام واحد خطی اصلاح شده (ReLU) دنبال می شوند. در رنگ قرمز، لایه “max pooling” وجود دارد که امکان کاهش اندازه تصویر را فراهم می کند: فقط حداکثر مقدار را برای هر بلوک با اندازه 2 × 2 حفظ می کند. در رنگ سبز، لایه های کانولوشن بالا اندازه تصویر را افزایش می دهند. و تعداد کانال ها را کاهش دهید. در خاکستری، در هر سطح یک لایه الحاق اتصال پرش را انجام می دهد. در نهایت یک لایه کاملا متصل (آبی روشن) برای بدست آوردن نقشه تقسیم بندی ارائه می دهیم.
3.5. ارزیابی و ضرر
در این مقاله به دو نوع ارزیابی اشاره می کنیم: اول ارزیابی خودکار شبکه که امکان همگرایی مدل را در هر دوره فراهم می کند، این مقدار کمی تابع ضرر است. دوم، ارزیابی نهایی نتیجه که ارزیابی می کند که آیا مدل موفق به یادگیری کار شده است یا خیر. پاراگراف زیر معیارهای موجود را که برای هر دو ارزیابی در تقسیم بندی وجود دارد، ارائه می کند.
روشهای زیادی برای ارزیابی نتیجه یک تقسیمبندی در هوش مصنوعی وجود دارد، اکثر آنها اقتضای یک پیکسل کلاس بین کلاسهای پیشبینیشده و حقیقت پایه را در نظر میگیرند. همه روشهای ارزیابی تقسیمبندی، میزان تفاوت پیکسلها را در حقیقت و پیشبینی زمین اندازهگیری میکنند. با این وجود، انتخاب معیار مهم است، زیرا همه پیکسل ها اهمیت یکسانی در ارزیابی ندارند. به عنوان مثال، در یک کار تعمیم ساختمان [ 10 ]، تنها پیکسل های اطراف مرز ساختمان تعیین کننده هستند. نویسندگان [ 38] روش های مختلف ارزیابی را برای مشکلات تقسیم بندی مقایسه کنید. روش تقاطع بیش از اتحادیه (IOU) برای ارزیابی تقسیمبندیها با دو کلاس رایج است، زیرا نشاندهنده تقاطع روی اتحاد پیکسلها در کلاس جاده (در مورد استفاده ما) هم در پیشبینی و هم در حقیقت زمین است. از آنجایی که جادهها با چند پیکسل در هر تصویر نشان داده میشوند، معیاری که به کلاسهای نامتعادل حساس نیست، مفید خواهد بود، مانند ضریب تاس که نشاندهنده دو برابری تقاطع بیش از مجموع تعداد پیکسلها در کلاس جاده در هر دو پیشبینی است. و حقیقت را زمینه
این دو معیار می توانند برای مشکل تقسیم بندی ما مرتبط باشند و ما هر دو را در آزمایش های خود برای ارزیابی نتایج نهایی آزمایش کردیم. با این وجود، هر دو معیار واقعاً برای ارزیابی یک نتیجه تعمیم خوب به عنوان خروجی بخشبندی سازگار نیستند: یک تقسیمبندی خوب میتواند با مشکلات محلی مواجه شود که نتیجه کارتوگرافی بسیار بدی را نشان میدهد [ 26 ]. در مورد ما، تقسیم بندی به جای بزرگ کردن خم، تمایل به ایجاد حلقه در خم های سینوسی دارد (نتایج را در بخش زیر ببینید). این یک خطای تقسیم بندی بزرگ نیست زیرا تنها چند پیکسل اشتباه طبقه بندی شده اند، اما به وضوح یک اشتباه نقشه برداری مهم است. در نتیجه، ما یک ارزیابی تکمیلی با رتبهبندی بصری نتایج انجام دادیم.
در مورد تابع ضرر که به عنوان ارزیابی خودکار مدل عمل می کند، همان نکات اعمال می شود، زیرا ماهیت نامتعادل تصاویر ورودی و خروجی ما به خوبی توسط توابع از دست دادن پیش فرضی که در این مدل استفاده کردیم، منتقل نمی شود. تصور از دست دادن اقتباس شده برای نقشه کشی و تعمیم دیدگاهی است که توسط کار ما مطرح شده است.
4. نتایج و ارزیابی
4.1. پیاده سازی
ما آزمایش خود را با استفاده از پایتون 3 با کتابخانه Keras [ 39 ] انجام دادیم. این کد در پلتفرم Google Colaboratory با واحد پردازش گرافیکی موجود (GPU) برای مجوزهای استاندارد پیادهسازی شد. داده های کد و تصویر ما در هفته های آینده به عنوان بخشی از پلتفرم باز DeepMapGen https://github.com/umrlastig/DeepMapGen در دسترس خواهد بود . کد تولید تصاویر از مجموعه داده برداری بخشی از پلتفرم تعمیم متن باز CartAGEn https://github.com/IGNF/CartAGEn بود که در IGN [ 40 ] توسعه یافت.
در یادگیری عمیق، داده ها در سه مجموعه از هم جدا می شوند. مجموعه آموزشی مجموعه ای از تصاویر است که برای آموزش مدل استفاده می شود. در هر تکرار (یا دوره)، داده های اضافی، نه از مجموعه آموزشی، که مجموعه آزمایش نامیده می شود، برای ارزیابی و تنظیم مدل استفاده می شود. در نهایت، مجموعه ارزیابی در فرآیند آموزش استفاده نمی شود و در ارزیابی مدل آموزش دیده بر روی تصاویر جدید خدمت می کند. ما تصمیم گرفتیم مدل خود را بر روی 4٪ از مجموعه داده خود ارزیابی کنیم. این به طور غیرعادی کم است اما مجموعه داده اولیه ما کوچک بود (به بخش 3.1 مراجعه کنید) و ما می خواستیم آن را به اندازه کافی بزرگ نگه داریم تا آموزش موثری داشته باشیم. با این حال، این نسبت امکان نمایش بیشتر موقعیت ها را فراهم می کند. ما به طور تصادفی مجموعه داده خود را به یک مجموعه آموزشی و یک مجموعه ارزیابی جدا کردیم و این محدودیت را اضافه کردیم که کاشی های ارزیابی نباید همسایه های فضایی باشند. سپس داده های آموزشی به صورت تصادفی به مجموعه آموزشی واقعی و مجموعه آزمون تفکیک شدند. در نتیجه، 92 درصد از تصاویر ما برای آموزش استفاده شد.
در این آزمایش، باید یک تابع ضرر برای مدل انتخاب میکردیم. تابع ضرر خطای مدل را نشان می دهد و شبکه سعی می کند این تابع را به حداقل برساند. U-Net معمولاً با از دست دادن آنتروپی متقاطع باینری (BCE) پیاده سازی می شود. این تلفات با در نظر گرفتن خروجی نقشه احتمال برای هر پیکسل که یک جاده است محاسبه شد.
جایی که yمن�منبرچسب (1 برای جاده ها و 0 برای غیر جاده) پیکسل i است و p (yمن)پ(�من)احتمال پیش بینی شده پیکسل برای داشتن این برچسب.
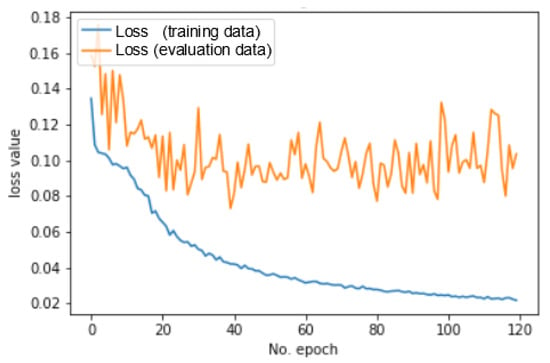
ما همچنین باید تعداد بهینه ای از دوره ها را تنظیم کنیم. یک دوره یک چرخه یادگیری است که تمام تصاویر آموزشی را در نظر می گیرد. شکل 7 تکامل از دست دادن شبکه را در مجموعه آموزشی و در مجموعه ارزیابی در طول دوره ها نشان می دهد. تعداد دوره ها باید نسبت به اندازه مجموعه آموزشی باشد تا از تناسب بیش از حد جلوگیری شود. از آنجایی که اندازه مجموعه داده آموزشی کوچک است، این تعداد دوره ها باید کوچک نگه داشته شوند.
برای تعیین مناسبترین لحظه برای توقف شبکه (یعنی تعداد دورهها)، میتوانیم مدل را در نقاط بازرسی هر 20 دوره ذخیره کنیم و نتیجه را برای این مدل فعلی مشاهده کنیم. تکامل زیان ارائه شده در شکل 7 روش دیگری برای ارزیابی تعداد بهینه دوره ها است. برای به دست آوردن بهترین نتایج، علیرغم رکود سریع کیفیت کمی بعد از دوره 50، تصمیم گرفتیم که آموزش را در 120 دوره متوقف کنیم، زیرا کیفیت بصری تصاویر پیشبینیشده پیشرفت میکند و تصاویر پیشبینیشده عموماً بهبودی فراتر از این را متوقف میکنند. آستانه.
منحنیهای زیان، و بهویژه این واقعیت که ضرر به شدت کاهش نمییابد، نشان میدهد که تابع ضرر میتواند کمتر از حد بهینه باشد، زیرا با بهبود بصری پیشبینی سازگار نیست. بنابراین، ما چندین تابع ضرر دیگر را که در کتابخانه Keras در دسترس بودند، و به خصوص خطای میانگین مربع که یکی دیگر از افت های رایج تقسیم بندی است، آزمایش کردیم. با این حال، این توابع نیز مطابقت نداشتند زیرا کیفیت جهانی طبقهبندی پیکسل را اندازهگیری میکردند، و نتایج با این توابع از دست دادن دیگر بدتر از از دست دادن آنتروپی متقاطع باینری بود. تحقیق برای ضرر تطبیقی چشم انداز مهم این کار است.
نکته مهم دیگری که باید به آن توجه کرد تفاوت بین مقادیر از دست دادن برای تصاویر آموزشی و اعتبارسنجی است. هرچه این منحنی ها بیشتر باشند، تناسب بیشتری وجود دارد. در این مورد، این تفاوت حدود 10 درصد بود در حالی که در مورد مجموعه دادههای کوچکتر (مثلاً هنگام استفاده از رویکرد کاشی کاری مبتنی بر شی، یا با نرخ همپوشانی کمتر بین کاشیها) مقادیر تلفات بسیار متفاوتی بین آموزش و ارزیابی داریم. این دوباره علاقه به انتخاب یک روش ساخت تصویر بهینه را نشان می دهد.
4.2. نتایج
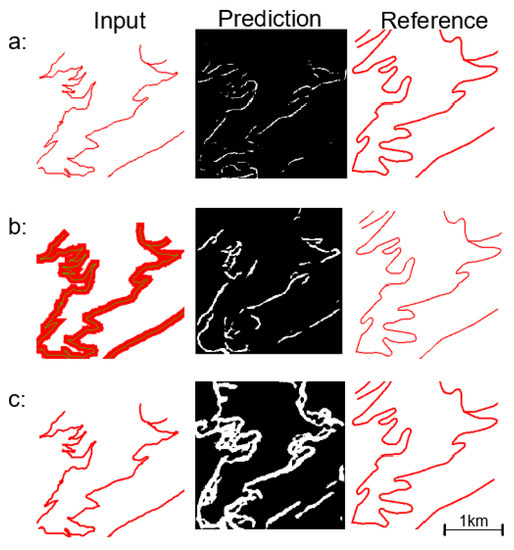
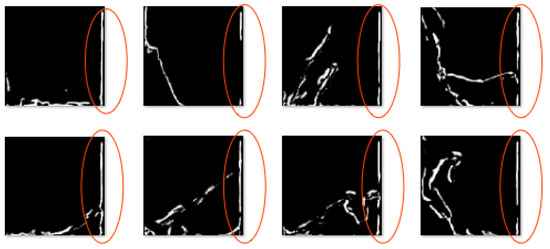
در این بخش، برخی از نتایج به دست آمده با تقسیمبندی U-Net تصاویر جادههای کوهستانی را ارائه میکنیم. مدل ما به دقت تقسیمبندی در مجموعه دادههای ارزیابی (و قطار) در حدود 60 درصد (80 درصد) با توجه به اندازهگیری Dice و 50 درصد (70 درصد) با توجه به اندازهگیری IOU میرسد. علاوه بر این، خطای اندازه گیری شده توسط تابع ضرر زیر 0.10 (0.03) کاهش می یابد. شکل 8برخی از نتایج به دست آمده بر روی تصاویر مجموعه اعتبار سنجی را نشان می دهد. شکل تصویر اولیه در سمت چپ، تصویر پیش بینی شده در وسط (سیاه و سفید) و تصویر حقیقت زمین در سمت راست را نشان می دهد. در بیشتر تصاویر، شکل جاده قابل تشخیص است و بسیار شبیه به تصویر تعمیم یافته است. همچنین اغلب صاف تر از تصویر اولیه است، حتی اگر گاهی اوقات از تصویر تعمیم یافته صاف تر باشد. خم ها در اکثر سری های خم سینوسی بزرگ می شوند، اما بزرگ شدن گاهی اوقات درست نیست، که می تواند منجر به حلقه ها یا خم های U شکل شود. در برخی موارد، در حقیقت زمین، جاده ها بین تصویر اولیه و تعمیم یافته جابجا می شوند تا از همپوشانی با اشیاء دیگر (رودخانه یا خط راه آهن) جلوگیری شود. از آنجایی که چنین دادههایی در تصاویر ما قابل مشاهده نیستند، مدل نمیتواند یاد بگیرد که چنین جابهجایی چه زمانی باید رخ دهد و در این تصاویر خراب میشود. علاوه بر این، روش ما اتصال شبکه را در داخل هر کاشی تضمین نمی کند و اغلب برخی از جاده ها در تصویر پیش بینی شده قطع می شوند. این یک اشکال جدی است که بعداً در مورد آن بحث شده استبخش 5 . گاهی اوقات، جادههایی در تصویر تعمیمیافته وجود دارند که در دادههای اولیه وجود ندارند، و این جادهها به وضوح توسط مدل تولید نمیشوند: گاهی اوقات، به عنوان مثال، تصویر چهارم در ستون سمت چپ، مدل هیچ جاده اضافی در همه؛ در موارد دیگر، به عنوان مثال، تصویر ششم از ستون دوم، مدل میتواند بخشهایی از جاده را اضافه کند که در دادههای اولیه نیستند، اما آنها واقعاً با حقیقت زمینی جادههای اضافی مطابقت ندارند. در نهایت تصویر سوم از ستون سمت راست، تولید یک بخش بسیار کوچک جدید از جاده را نشان می دهد که از لبه سمت راست تصویر پیروی می کند که نه در تصویر اولیه و نه در تصویر تعمیم یافته وجود ندارد.
شکل 9 نمرات ارزیابی مدل را با هر دو روش ارزیابی نشان می دهد: تاس و تقاطع روی اتحاد (IOU). آنها در هر دوره در مجموعه آموزشی و مجموعه ارزیابی (که برای آموزش مدل استفاده نمی شود) محاسبه شدند.
امتیاز ارزیابی بین دورههای متوالی ناپایدار است، بنابراین مقدار در پایان فرآیند نسبت به ارزیابی میانگین دورههای آخر (مثلاً میانگین 10 دوره گذشته) کمتر مرتبط است. دو معیار ارزیابی نتایج کمی بسیار ضعیفی را به دست میدهند. همانطور که در بخش 3.5 توضیح داده شد ، مقایسه پیکسل ها با یک مرجع برای ارزیابی تعمیم سازگار نیست. امتیاز پایین هر دو معیار را توضیح می دهد. ما همچنین مشاهده می کنیم که معیارها همیشه با درک کیفیت ما منسجم نیستند، اما به طور کلی یک شاخص خوب ارائه می دهند.
نتایج ارائه شده با استفاده از برخی پارامترها برای پیکربندی مدل به دست آمده است. کالیبراسیون پارامترها در زیر بخش زیر توضیح داده شده است. پارامترهای مورد استفاده برای استخراج کاشی ها به شرح زیر است:
-
اندازه کاشی 2.5 کیلومتر و یک پیکسل نشان دهنده 10 متر است.
-
نرخ همپوشانی بین کاشی ها 60 درصد است.
-
عرض جاده نشان دهنده سطح اهمیت است.
-
جادههای گنجانده شده تنها جادههایی هستند که در طول تطبیق پیش فرآیند مطابقت داشتند.
همه این پارامترها می توانند بر نتیجه تأثیر بگذارند. ما تأثیر این پارامترها را در بخش 4.3 مطالعه می کنیم .
4.3. پارامترهای مجموعه داده آموزشی
در این بخش، روش پیشنهادی برای ایجاد مجموعه داده آموزشی را ارزیابی میکنیم. جدول 2 نتایج این ارزیابی را خلاصه می کند.
4.3.1. آیا تطبیق داده ها قبل از فرآیند مفید است؟
ابتدا، زمانی که تصاویر اولیه شامل تمام جادههای مجموعه داده اولیه، حتی جادههایی که در فرآیند انتخاب حذف میشوند، نتایج تقسیمبندی را با نتایج استاندارد خود بدون آن جادههایی که با جادههای تعمیمیافته مطابقت ندارند، مقایسه میکنیم.
در شکل 10 می بینیم که حذف جاده های انتخاب نشده از تصویر اولیه راه حل بهتری به نظر می رسد اما نتایج در هر دو مورد برای این جاده کاملاً رضایت بخش نیست. میتوانیم توجه داشته باشیم که شبکه یاد گرفته است که جادههای بیاهمیت را حذف کند، اما این کار را به درستی انجام نداده است (بعضی از قسمتهای جاده باقی ماندهاند و یک جاده مهم در بالا تا حدی پاک شده است). انتخاب شبکه راه بر اساس معیارهای جهانی در شبکه است [ 12 ]، بنابراین ما انتظار نداریم که CNN بتواند نحوه انتخاب جاده های مهم را در یک عصاره بسیار کوچک از شبکه بیاموزد.
4.3.2. مقایسه روش های کاشی کاری
در این بخش سعی می کنیم دو رویکرد پیشنهادی برای تولید کاشی (مقیاس ثابت و مبتنی بر شی) را با هم مقایسه کنیم.
در شکل 11 مشاهده می کنیم که روش کاشی کاری در مقیاس ثابت نتایج بهتری نسبت به رویکرد مبتنی بر شی دارد. به نظر می رسد رویکرد مبتنی بر شی به طور سیستماتیک حلقه هایی را در پیچ ها ایجاد می کند و نمادهای جاده را بیش از حد بزرگ می کند (احتمالاً به دلیل مقیاس متفاوت آن است). این تفاوت می تواند به دلیل ساخت و روش فیلترینگ باشد. لازم به ذکر است که آموزش روی مجموعه داده های فیلتر نشده نتایج ضعیفی را با هر دو روش کاشی کاری ارائه می دهد.
ما فرض می کنیم که مشکل “حلقه” ناشی از ادغام در تصویر اولیه است که از “دیدن” شکل اولیه خط جلوگیری می کند. به همین دلیل است که یک نمایش مختلط از جاده ها در تصاویر ورودی امتحان شد: شکل خط به رنگ سبز با عرض 1 پیکسل نمایش داده می شود، که در بالای نماد قرمز بزرگتر که ادغام می شود، پوشانده می شود. شکل 12مقایسه ای از نتایج ارائه شده توسط این نمایش ترکیبی با روش مبتنی بر شی را ارائه می دهد. روش ترکیبی با تصویری مقایسه میشود که در آن عرض نماد بدون تغییر باقی میماند، و با تصویری که در آن عرض نماد اغراقآمیز است تا کاهش مقیاس به دلیل اندازه جاده را نشان دهد. این نشان میدهد که خوانایی شکل به لطف خطوط نازک سبز بهبود مییابد، و اثر “حلقه” را کاهش میدهد اما نتایج رضایتبخش باقی نمیماند. این مدیریت سری خم با ادغام سنگین نیاز به تحقیقات بیشتری دارد.
4.3.3. کالیبراسیون رویکرد کاشی کاری در مقیاس ثابت
همانطور که در بخش 3.3 توضیح داده شد ، مشکل اصلی این رویکرد، برش تصادفی جادهها، تخریب بافت (یعنی شکل جهانی جاده) است. بنابراین کالیبراسیونی که زمینه را تا حد امکان حفظ کند باید نتایج بهتری به همراه داشته باشد. اندازه کاشی ها پارامتری است که بر دو ویژگی تأثیر می گذارد: زمینه و تعداد تصاویر. ما این پارامتر را بر حسب اندازه زمین که با یک تصویر ۲۵۶ × ۲۵۶ پیکسل نشان داده شده است، اندازهگیری کردیم. انتخاب اندازه زیر 1 کیلومتر (زمینه کافی نیست) مرتبط نیست. در نتیجه، تمام پیکسل ها به عنوان “غیر جاده” طبقه بندی می شوند. برعکس، بیش از 5 کیلومتر، منطقه مورد مطالعه تحت پوشش برای داشتن تصاویر کافی (کمتر از 150) بسیار کوچک بود. مشاهده می کنیم که اندازه های بین 2.5 تا 3 کیلومتر برای وظایف ما مرتبط تر است.
شکل 13 برخی از نتایج آزمایشی را در مورد اندازه کاشی کاری که برای تأیید مشاهدات بصری خود انجام دادیم، نشان می دهد. وقتی مدل با مساحت های بزرگ (5×5 کیلومتر) آموزش داده می شود، می بینیم که صاف کردن به خوبی یاد نمی گیرد. ادغام خم های کوچک که با اندازه افزایش می یابد نتایج بدی به همراه دارد، بنابراین اندازه کاشی ها باید کوچک بماند تا ادغام نمادها در تصاویر ورودی به حداقل برسد.
آخرین پارامتر رویکرد کاشی کاری با اندازه ثابت، نسبت همپوشانی بین کاشی ها است. این پارامتر امکان افزایش تعداد کاشی ها را فراهم می کند. آزمایش با مقادیر 40٪، 50٪ و 60٪ پیشرفت خوبی را در ارزیابی کیفی و کمی هنگامی که همپوشانی افزایش می یابد، نشان می دهد. علاوه بر این، این همپوشانی به ما اجازه میدهد تا زمانی که جادهها در چندین تصویر ظاهر میشوند، مقداری افزونگی داشته باشیم. ما معتقدیم که میتوانیم این نتایج طبقهبندی را در تصاویر مختلف ادغام کنیم تا تعمیم یک جاده را بهبود ببخشیم.
4.3.4. اهمیت سینوسیتی جاده
در این بخش، ما تأثیر عدم تعادل بین جادههای مستقیم که تعمیم آن آسان است و جادههای سینوسی نادری که تعمیم آن پیچیده است را مطالعه میکنیم. چندین سوال در رابطه با این عدم تعادل وجود دارد: آیا شبکه قادر است مناطقی را با جاده های عمدتاً مستقیم یا مناطقی که فقط جاده های بسیار پر پیچ و خم دارند را تعمیم دهد؟ اگر این مدل فقط روی کاشیهای حاوی جادههای بسیار پرپیچوخم آموزش داده میشد، در جادههای سینوسی بهتر کار میکرد؟ هنگام جداسازی داده ها بر اساس سینووسیت جاده ها، تعداد تصاویر را به میزان قابل توجهی کاهش می دهد اما همگنی را افزایش می دهد. بسته به روش کاشی کاری دو راه برای جداسازی جاده های سینوسی از غیر سینوسی پیشنهاد می کنیم. برای رویکرد مبتنی بر شی، معیار صرفاً پیچ خوردگی جاده ای است که کاشی روی آن متمرکز شده است. برای رویکرد با اندازه ثابت، ما از میانگین سینوسیتی جادهها در داخل کاشی استفاده میکنیم، وزن آن بر اساس طول جاده. برای این آزمایش، ما سینوسیته را با تقسیم طول پایه بر طول خط [7 ] و از آستانه 0.7 استفاده کردیم. نتایج به وضوح از کمبود تصاویر با جاده های سینوسی رنج می برد، اما آنها برای رویکرد مبتنی بر شی امیدوار کننده هستند. آزمایش این روش با تصاویر بسیار بیشتری از جاده های سینوسی جالب خواهد بود.
4.3.5. خلاصه
در این بخش فرعی، خلاصهای را برای نشان دادن بهترین رویکرد و پارامترها برای استخراج مجموعه داده آموزشی ارائه میکنیم. جدول 2 شامل ارزیابی هر آزمون از نظر مقدار تاس، مقدار IOU و مقایسه کیفی با وضعیت مرجع (REF) است. مقادیر جدول به شرح زیر است: اگر تصاویر پیشبینیشده از نظر بصری بهتر از پیشبینی مرجع باشند، رتبه بصری (+) ذکر میشود، اگر تصاویر پیشبینیشده بدتر از پیشبینی مرجع باشند، رتبه بصری (-) ذکر میشود. و اگر تصاویر پیش بینی شده مشابه پیش بینی مرجع باشد، رتبه بصری (=) ذکر می شود. تعداد تصاویر نیز جهت اطلاع داده شده است.
پیشبینی مرجع برای رویکردهای کاشیکاری با اندازه ثابت با لغزش از گوشه سمت چپ بالای منطقه یک کاشی مربع 2.5 کیلومتری با همپوشانی 40 درصد روی جادهها، با عرض نماد نشاندهنده اهمیت تولید میشود. برای رویکردهای مبتنی بر شی، هر تصویر جادهها را در وسعت یک جاده تعمیمیافته (با تقسیمبندی اولیه ویژگیهای جاده) نشان میدهد. و عرض جاده نشان دهنده تغییر اندازه (تغییر اندازه) تصویر است.
4.4. سودمندی غنی سازی و فیلتر کردن داده ها
فیلتر کردن به وضوح ضروری است، زیرا استفاده از تصاویر (تقریبا) خالی در فرآیند آموزش باعث از دست دادن پایدار و یادگیری بد می شود. یکی دیگر از فرآیندهای فیلتر ممکن حذف کاشیهایی است که موقعیتهای پیچیده و نه کوهستانی را نشان میدهند (مانند تبادل بزرگراه یا دوربرگردان). آزمایشهای ما نشان میدهد که این فیلتر کردن مفید نیست، زیرا نتایج مشابه هستند.
در یادگیری عمیق، اندازه مجموعه داده اغلب یک معیار موفقیت مهم است. هنگامی که مجموعه داده موجود محدود است، افزایش داده به ما امکان می دهد نتایج را بهبود ببخشیم. ما چندین روش برای تقویت مجموعه داده آموزشی در بخش 3.3 مورد بحث قرار دادیم و در اینجا تحلیلی از تأثیر چنین روشهایی بر نتایج مدل تقسیمبندی ارائه میکنیم. فرآیندهای تقویت زیر بر روی مجموعه داده آموزشی آزمایش شدند:
-
برش تصادفی افقی و عمودی 10٪ برای همه تصاویر.
-
برش تصادفی افقی و عمودی 20٪ برای همه تصاویر.
-
نیمی از تصاویر را به صورت تصادفی بچرخانید (90، 180 یا 270 درجه).
-
تمام تصاویر را به صورت تصادفی (90، 180 یا 270 درجه) بچرخانید.
-
تمام تصاویر را با سه زاویه (90، 180 و 270 درجه) بچرخانید.
اول، به نظر می رسد مجموعه داده تولید شده توسط روش مبتنی بر شی، بیشترین تأثیر را از محدودیت تعداد داده می گیرد. ما در جدول 3 اثر افزایش را ارائه می دهیم.
در رویکرد مبتنی بر شی، به نظر می رسد تبدیل محصول در اندازه کوچک تأثیر مثبتی بر نتایج دارد، بدون اینکه زمینه را بیش از حد پنهان کند، اطلاعات را افزایش می دهد. در همه موارد، به نظر می رسد تغییرپذیری ارزش ارزیابی افزایش می یابد. به نظر می رسد چرخش ارزش ارزیابی کمی را افزایش می دهد، بنابراین پیش بینی به مرجع نزدیک تر است. اما به نظر می رسد هنگامی که نتایج را به صورت بصری ارزیابی می کنیم، نویز نقطه سفیدی را در تصاویر ایجاد می کند.
سپس، در مورد روش کاشی کاری با اندازه ثابت، افزایش محصول گزینه خوبی نیست زیرا تصاویر را مخدوش می کند و زمینه اطراف جاده را کاهش می دهد ( جدول 4 ). افزایش با چرخش مرتبط است اما نتیجه را بهبود نمی بخشد. این نشان میدهد که مشکل مجموعه دادههای ما، کمیت کلی تصاویر نسبت به تنوع موقعیتهای قابل مشاهده در تصاویر است (ما فاقد جادههای سینوسی هستیم).
اگرچه همه آزمایشها نشان میدهند که افزایش دادهها ارزیابی کمی را بهبود میبخشد، شایان ذکر است که در این مورد استفاده، افزایش تعداد تصاویر همیشه مرتبط نیست و به نظر میرسد که تنوع بین دورهها را افزایش میدهد. افزایش تعداد تصاویر با تغییر روش کاشی کاری می تواند ارجح باشد.
5. بحث
حتی اگر ما انتظار نتایج پیشبینیشده را نداشتیم که به خوبی یا بهتر از مرجع باشد، نتایج در حال حاضر با این تعمیم مرجع بسیار فاصله دارند. در این بخش به بررسی خطاهای باقی مانده می پردازیم و سعی می کنیم دلایل آنها را توضیح دهیم. مشکل اصلی همان چیزی است که ما آن را مشکل “حلقه” می نامیم، که در شکل 11 نشان داده شده است ، جایی که بخش های جاده در پایه پیچ اضافه می شوند، خط را می بندند و یک حلقه را تشکیل می دهند. مشکل عمدتا زمانی رخ می دهد که مدل با داده های تولید شده با رویکرد مبتنی بر شی آموزش داده شود. ما میتوانیم به دو دلیل احتمالی این مشکل اشاره کنیم: فقدان تصاویری که جادههای بسیار پرپیچوخم را نشان میدهند و فقدان خوانایی یا وضوح این تصاویر.
مشکل دوم ظاهر نویز است. نادر اما قابل توجه است. ما این مشکل را در تمام آزمایشهای خود مشاهده میکنیم، زمانی که تعداد دورهها نسبتاً کم است (زیر 70)، زمانی که تعداد تصاویر برای آموزش کم است (زیر 150)، یا زمانی که اندازه واقعی نشاندادهشده توسط کاشی بسیار زیاد است (بالای 5). کیلومتر 2 ). ما دو نوع صدا را مشاهده می کنیم: لکه های سفید ( شکل 14 ) و ایجاد یک جاده ساختگی ( شکل 15 ).
می توان مشاهده کرد که لکه های سفید روی همه این تصاویر منظم نیستند و همیشه در مناطقی که جاده وجود ندارد ظاهر می شوند. این نویز را می توان به راحتی با استفاده از یک عملیات مورفولوژیکی پس از پردازش پردازش کرد.
در مورد جاده های اضافی ساختگی ( شکل 15 )، مشکل همیشه در یک سمت در تمام تصاویر مجموعه ارزیابی رخ می دهد، اما شکل جاده های اضافه شده همیشه یکسان نیست.
مشکل سوم، تغییر اتصال قابل مشاهده در تمام تصاویر ما است. این شامل چند پیکسل سیاه در وسط برخی جاده ها است که ارزیابی کمی را تغییر نمی دهد، اما به وضوح خوانایی جاده را کاهش می دهد. اگر تعداد دوره ها را افزایش دهیم، این مشکل کمتر وجود دارد، اما همچنان رخ می دهد. نمی توان با اعمال یک عملگر مورفولوژیکی روی تصویر خروجی در طول پردازش پس از پردازش، بدون آسیب رساندن به بقیه شکل جاده، آن را کاهش داد. سپس، تنها پس از فرآیندی که میتواند اتصال را دوباره برقرار کند، تبدیل جادهها به بردارها و استفاده از تکنیکهای بررسی اتصال از تعمیم شبکه جادهای است [ 12 ].]. برعکس، تصور میکنیم که میتوان تصاویر را بدون این مشکل با استفاده از معماری که ویژگیهای یک جاده، از جمله اتصال آن را یاد میگیرد، مانند شبکههای متخاصم (GAN) تولید کرد. GAN ها شامل یک ژنراتور است که یک تصویر تولید می کند (معمولا یک U-Net مانند آنچه در اینجا استفاده می شود)، و یک تفکیک کننده که یاد می گیرد جاده های واقعی و پیوسته را از خروجی های قطع شده مانند آنچه در اینجا به دست می آید، تشخیص دهد. در تحقیقات آتی در این راستا بررسی خواهیم کرد.
کار ما همچنین دارای محدودیت هایی است که خطا نیستند:
-
معیار ارزیابی و عملکرد زیان مرتبط باید بهبود یابد.
-
مجموعه داده ما اندازه محدودی دارد و شامل نمونه های کافی از سری های خمشی بسیار باریک و سینوسی نیست.
-
ما همچنین با محدودیت های زمان محاسبات و حافظه مواجه بودیم.
نمونه های فعلی ما حتی به سطح کیفی تحقیقات قبلی در مورد ساختمان ها نمی رسد [ 10]. همانطور که قبلا در مقاله توضیح داده شد، مقیاس در فرآیند تولید کاشی یک مشکل مهم است. به نظر می رسد که تصاویر آموزشی ما بسیار پیچیده تر از تصاویر آموزشی برای تعمیم ساختمان است که فقط شامل یک ساختمان یا یک بخش ساختمان می شود. تصاویر فعلی ما حاوی جزئیات بسیار زیادی هستند که تنها با چند پیکسل (فاض و شلوغ) نشان داده می شوند. این پیچیدگی در تصاویر ورودی ما حداقل سه نتیجه دارد: (1) برای آموزش مدل به مثالهای بیشتری نیاز داریم. (2) ما به تصاویر بزرگتر یا تصاویر با وضوح بهتر نیاز داریم. (3) اگر بخواهیم از تصاویری با چنین پیچیدگی استفاده کنیم، شبکه باید بسیار عمیق تر از تنظیمات فعلی ما باشد. اگر میخواهیم تصمیم کنونی خود را برای گنجاندن بخشهای مختلف جاده در یک تصویر حفظ کنیم، حداقل باید سعی کنیم ابعاد تصویر را افزایش دهیم. علاوه بر این، به عنوان مثال، برای یادگیری جابجایی جاده ها، فقط باید بدانیم که اشیاء نقشه دیگری در مجاورت نزدیک وجود دارد، ما به یک زمینه بزرگتر نیاز نداریم. ما در آزمایشات خود به دلیل مسائل محاسباتی و مدت زمانی که برای گسترش مجموعه داده اولیه با انجام یک داده دستی طولانی منطبق با پیش فرآیند نیاز است، محدود بودیم. در نتیجه ما هنوز این پیشرفت ها را آزمایش نکرده ایم.
6. نتیجه گیری و کار آینده
کار ما توانایی روش های یادگیری عمیق را برای دستیابی به وظایف تعمیم از تصاویر مشتق شده از داده های برداری، به عنوان یک کار تقسیم بندی نشان داده است. بنابراین، به دلیل پیچیدگی تعمیم جادههای کوهستانی و شکاف بزرگ مقیاس (1:25000 تا 1:250000) میتوان آن را بسط [ 10 ] در یک مسئله پیچیدهتر درک کرد. مدلی که ما پیشنهاد کردیم به درستی به عملیات هموارسازی، بزرگنمایی و کاریکاتور در اکثر موارد دست یافت، حتی اگر این موارد سادهتر باشند، یعنی مواردی که دارای نمادهای ادغام شده کمی هستند. مدل تقسیمبندی پیشنهادی نتایج بهتری نسبت به مرجع (یا حتی نزدیک) ایجاد نمیکند، اما نشان میدهد که بیشتر دانش پشت تعمیم میتواند توسط یک شبکه عصبی گرفته شود.
به منظور بهبود نتایج در مواقعی که جابجایی جاده مورد نیاز است، قصد داریم ویژگی های جغرافیایی دیگری را در تصاویر خود اضافه کنیم. از آنجایی که این جابجایی اغلب به دلیل همپوشانی با نمادهای یک رودخانه یا راه آهن مجاور ایجاد می شود، افزودن این اطلاعات در تصویر باید نتایج ما را بهبود بخشد. همچنین ممکن است بتوانیم این رودخانهها و راهآهنها را همزمان تعمیم دهیم.
علاوه بر این، ما علاقه چندین گزاره را در پردازش مجموعه داده آموزشی نشان دادیم، اما برخی از گزارههای دیگر قابل آزمایش هستند. به عنوان مثال، فرآیند انتخاب می تواند یکپارچه شود، و مقیاس ها و مجموعه داده های دیگر می تواند مورد استفاده قرار گیرد.
یکی از محدودیت های ما ارزیابی و تابع ضرر استفاده شده در مدل است. روش ارزیابی ما ترکیب کمی و کیفی است که ایده خوبی از کیفیت تعمیم ارائه می دهد. با این حال، یک اندازه گیری خودکار یکپارچه در شبکه عصبی ترجیح داده می شود. کار بیشتر باید روی این باشد که یک تصویر تعمیم یافته خوب از نظر طبقه بندی پیکسل چیست. به طور کلی تر، چگونه می توانیم خوانایی نقشه و حفظ شکل، و به طور کلی تر اصول ارزیابی تعمیم نقشه را به یک تابع از دست دادن ترجمه کنیم. تحقیقات در مورد ارزیابی ارزیابی شطرنجی را می توان برای مقابله با نتایج یادگیری عمیق گسترش داد. به عنوان مثال، معیارهای درهم ریختگی می تواند برای ارزیابی کیفیت خروجی یادگیری عمیق مفید باشد [ 41 , 42 ]]. فهرست معیارهای تعمیم خوب را میتوان به عنوان محدودیتهای روی پیکسلها و گروههای پیکسل رسمیت داد و رضایت آنها را اندازهگیری کرد. برای کار بیشتر، کیفیت نتایج تعمیم باید از طریق برخی از تست های کاربر ارزیابی شود.
دیدگاه دیگر، بررسی سایر معماریهای شبکه برای تعمیم جاده است. GAN ها (شبکه های متخاصم مولد) اغلب در تولید تصویر استفاده می شوند. علیرغم برتری نداشتن نسبت به U-Nets برای تعمیم سازی [ 10 ]، پتانسیل زیادی برای حل بیشتر محدودیت های پیش بینی های U-Net که به دست آوردیم دارد. GAN ها برای انتقال سبک در نقشه های چند مقیاسی [ 23 ، 43 ] استفاده شدند که مشکلی کاملاً شبیه به تعمیم نقشه است. اولین آزمایشهای ما با GANها موفقیتآمیز نبودند و در این مقاله ارائه نشدهاند، اما قصد داریم به آزمایش اینکه چگونه GANها میتوانند تصاویر تعمیمیافته را تولید کنند، ادامه دهیم.
در نهایت، پس فرآیند و ادغام جاده پیش بینی شده در یک نقشه نهایی یک مشکل مهم باقی مانده است. تبدیل شطرنجی به برداری باید مورد بررسی قرار گیرد، اما همچنین چگونه میتوانیم نتایج کاشیهای مختلف را که شامل جادههای یکسانی هستند ادغام کنیم.













بدون دیدگاه