

خلاصه
الگوریتم های درخت تصمیم (DT) ابزارهای ناپارامتریک مهمی هستند که برای طبقه بندی پوشش زمین استفاده می شوند. در حالی که DT های مختلف برای طبقه بندی پوشش زمین Landsat اعمال شده اند، دقت طبقه بندی فردی و عملکرد آنها مقایسه نشده است، به ویژه در مورد اثربخشی آنها برای ایجاد آستانه های دقیق برای توسعه قوانین برای طبقه بندی پوشش زمین مبتنی بر شی. در اینجا، تمرکز بر مقایسه عملکرد پنج الگوریتم DT بود: Tree، C5.0، Rpart، Ipred و Party. این الگوریتمهای DT برای طبقهبندی ده طبقه پوشش زمین با استفاده از تصاویر Landsat 8 در استان Copperbelt زامبیا استفاده شدند. طبقه بندی با استفاده از تجزیه و تحلیل تصویر مبتنی بر شی (OBIA) از طریق توسعه مجموعه قوانین با آستانه های تعریف شده توسط DT ها انجام شد. عملکرد الگوریتمهای DT بر اساس موارد زیر ارزیابی شد: (1) دقت DT از طریق اعتبارسنجی متقابل. (2) دقت طبقه بندی پوشش زمین نقشه های موضوعی. و (3) خصوصیات ساختاری دیگر مانند اندازه نمودارهای درختی و توانایی های انتخاب متغیر. نتایج نشان میدهد که تنها مجموعههای قوانین توسعهیافته از الگوریتمهای DT با ساختارهای ساده و حداقل تعداد متغیرها، دقت طبقهبندی پوشش زمین بالایی را تولید میکنند (دقت کلی > 88٪). بنابراین، الگوریتمهایی مانند Tree و Rpart نتایج طبقهبندی بالاتری را در مقایسه با الگوریتمهای C5.0 و Party DT تولید کردند که متغیرهای زیادی را در طبقهبندی شامل میشوند. این دقت بالا به توانایی به حداقل رساندن بیش از حد برازش و ظرفیت رسیدگی به نویز در داده ها در طول آموزش توسط Tree و Rpart DT نسبت داده شده است. این مطالعه بینش جدیدی در مورد انتخاب رسمی الگوریتمهای DT برای توسعه مجموعه قوانین OBIA ایجاد کرد. بنابراین، الگوریتمهای Tree و Rpart میتوانند برای توسعه قواعد مورد استفاده قرار گیرند، زیرا آنها دقت طبقهبندی پوشش زمین بالایی را تولید میکنند و ساختار سادهای دارند. به عنوان راهی برای مطالعات آینده، عملکرد الگوریتمهای DT را میتوان با طبقهبندیکنندههای یادگیری ماشینی معاصر (مانند جنگل تصادفی و ماشین بردار پشتیبان) مقایسه کرد.

کلید واژه ها:
کاربری زمین ؛ سنجش از دور ؛ تجزیه و تحلیل مخلوط طیفی ; تشخیص تغییر ؛ تصاویر نوری ؛ آفریقا
چکیده گرافیکی
1. معرفی
تجزیه و تحلیل تصویر مبتنی بر شی (OBIA) به روشی مؤثر برای طبقه بندی پوشش زمین داده های سنجش از دور تبدیل شده است [ 1 ، 2 ]. برخلاف تجزیه و تحلیل سنتی مبتنی بر پیکسل، OBIA فرصتی را برای توسعه اشیاء گسسته ای ارائه می دهد که از طریق تقسیم بندی تصویر به اشیاء دنیای واقعی مربوط می شوند [ 3 ، 4 ]. فرآیند تقسیم بندی تغییرات طیفی در کلاس را کاهش می دهد و فرصتی را برای افزایش دقت طبقه بندی ارائه می دهد، به ویژه زمانی که در مقیاس مناسب انجام شود [ 5 ، 6 ].
توانایی ترکیب بافت، تراکم و سایر اطلاعات مربوط به شی با اطلاعات طیفی، OBIA را از سایر روشهای طبقهبندی مانند رویکردهای پیکسلی و زیرپیکسلی متمایز کرده است. در مقایسه با تجزیه و تحلیل تصویر مبتنی بر پیکسل، OBIA در کاهش اثرات نمک و فلفل بر روی نقشه های موضوعی موثر است [ 7 ، 8 ]. در حال حاضر تعدادی الگوریتم تقسیم بندی در eCognition Developer موجود است. با این حال، تقسیم بندی چند تفکیک پذیری رایج ترین روش مورد استفاده در طبقه بندی پوشش زمین است [ 1 ، 4 ، 9 ].
جدا از تقسیم بندی، یکی دیگر از مؤلفه های مهم OBIA طبقه بندی واقعی اشیاء قطعه بندی شده است [ 1 ، 2 ]. ماینت و همکاران [ 10 ] توضیح داد که دو راه برای تخصیص کلاس ها به اشیاء تقسیم شده وجود دارد: (1) به کارگیری دانش متخصص از طریق مجموعه قوانین. و (2) با استفاده از طبقه بندی خودکار. تحت دانش تخصصی، طبقه بندی با توسعه قواعد که بر اساس آستانه اطلاعات مربوط به شی مختلف است، انجام می شود. تحت رویکرد طبقهبندی خودکار، اشیاء بر اساس طبقهبندیکنندههای یادگیری ماشینی معاصر مانند Nearest Neighbor (NN)، جنگل تصادفی (RF)، ماشین بردار پشتیبان (SVM)، و طبقهبندی و درخت رگرسیون (CART) طبقهبندی میشوند. در eCognition Developer 9.1 [2 ، 11 ]. با این حال، تمرین توسعه قواعد با استفاده از آستانههای اطلاعات مرتبط با شیهای مختلف، یک روش معمول در طبقهبندی پوشش زمین OBIA است [ 1 ، 12 ].
راههای زیادی برای ایجاد آستانهها در طول توسعه مجموعه قوانین وجود دارد، مانند استفاده از دانش تخصصی، آزمون و خطا، و استفاده از درختهای تصمیم بازگشتی باینری (DTs) [ 10 ]. اگرچه یک روش معمول نیست، اجرای DT ها در ایجاد آستانه ها و توسعه نهایی قوانین مؤثر رسمی تر به نظر می رسد [ 2 ، 3 ، 13 ]. در اینجا، توجه به این نکته مهم است که بسته های آماری که برای توسعه قواعد استفاده شده اند به عنوان الگوریتم های DT نامیده می شوند [ 14 ].]. این الگوریتمها معمولاً به عنوان «جعبه سیاه» یا «جعبه سفید» شناخته میشوند که بستگی به این دارد که مترجم چقدر میتواند فرآیند را دنبال کند. الگوریتم های جعبه سیاه، مانند RF، به طور گسترده در طبقه بندی پوشش زمین، به ویژه با پیشرفت در تکنیک های یادگیری ماشین استفاده شده است [ 15 ]. از سوی دیگر، الگوریتمهای یادگیری ماشین ساده DT مانند Rpart، C5.0 و Tree نیز برای طبقهبندی پوشش زمین و ایجاد آستانهها در هنگام توسعه قواعد استفاده شدهاند [ 13 ].
DTهای ساده ابزارهای مفیدی برای ایجاد آستانههایی برای توسعه قوانین تصمیمگیری برای طبقهبندی پوشش زمین دادههای سنجش از دور هستند، زیرا آنها غیر پارامتری هستند و تفسیر آنها آسان است [ 10 ، 16 ]. در طول طبقهبندی، متغیرهای زیادی بر اساس اطلاعات طیفی و بافتی مرتبط با شی تولید میشوند که در صورت اعمال تکنیکهای مناسب مانند DTs، میتوانند برای توسعه مجموعههای قوانین مؤثر مورد استفاده قرار گیرند. بلژیک و همکاران [ 17 ] پیشنهاد کرد که DTها می توانند برای انتخاب تأثیرگذارترین متغیر و شناسایی آستانه برای کلاس های مختلف پوشش زمین مفید باشند، زیرا آنها ناپارامتریک هستند و بنابراین برای اکثر مناظر ایده آل هستند.
در حالی که الگوریتمهای درخت تصمیم در مناطق مختلف مرتبط با طبقهبندی پوشش زمین مورد استفاده قرار گرفتهاند، این الگوریتمها بهطور جداگانه بر اثربخشی آنها در ایجاد آستانههایی برای توسعه قوانین برای طبقهبندی پوشش زمین OBIA ارزیابی نشدهاند. هدف اصلی این مطالعه انجام یک ارزیابی چند معیاره از پنج الگوریتم یادگیری ماشین مختلف DT بر اساس عملکرد آنها هنگام طبقهبندی تصاویر Landsat 8 بود. مقایسه عملکرد بر اثربخشی این پنج الگوریتم در مدیریت اندازههای مختلف دادهها و تفسیر ساده هر الگوریتم متمرکز بود.
2. مواد و روشها
2.1. سایت مطالعه
این مطالعه در استان کمربند مس زامبیا ( شکل 1 ) که در قسمت شمالی کشور واقع شده است (عرض جغرافیایی: 12.82 درجه جنوبی، طول جغرافیایی: 28.21 درجه شرقی) انجام شد. این منطقه سالانه بین 1000 تا 1200 میلیمتر بارندگی دریافت میکند و دمایی بین 7 تا 35 درجه سانتیگراد را تجربه میکند [ 18 ، 19 ]. معدن و کشاورزی عمده ترین فعالیت های اقتصادی در این حوزه است. این منطقه به شدت شهری است و دارای تراکم جمعیت (62.5 نفر در کیلومتر مربع) است [ 18 ، 20 ]]. در نتیجه عدم بهره وری معادن، اکثر مردم به کشت جابجایی در مقیاس کوچک اقدام می کنند که باعث تغییر سریع پوشش زمین، به ویژه تبدیل مناطق جنگلی به کشاورزی و سکونتگاه ها می شود. استان مس کمربند همچنین دارای بیشترین نسبت مزارع جنگلی در زامبیا است که متعلق به یک شرکت نیمه دولتی به نام شرکت جنگل و جنگل زامبیا (ZAFFICO) است [ 18 ].
2.2. مجموعه داده ها
تصاویر Landsat 8، همچنین به نام تصاویر Landsat مشاهده زمین (OLI) [ 21 ]، به دست آمده از وب سایت سازمان زمین شناسی ایالات متحده (USGS) ( https://glovis.usgs.gov ) در این مطالعه استفاده شد. تصاویر در سال 2016 گرفته شده اند و تصاویر سپتامبر انتخاب شده اند زیرا در این مدت منطقه مورد مطالعه فصل خشکی را تجربه می کند (یعنی بدون باران) و از این رو پوشش ابری کمتری دارد. لندست 8 دارای وضوح مکانی 30 متر، وضوح طیفی 11 باند، وضوح زمانی 16 روز و وضوح رادیومتری 12 بیت است. علاوه بر این، تصاویر Landsat 8 دارای نوار پانکروماتیک با وضوح فضایی 15 متر هستند [ 22 ، 23]. در این مطالعه از شش باند که از مرئی تا مادون قرمز متغیر است استفاده شد. جدای از تصاویر لندست، مدلهای ارتفاعی دیجیتالی ماموریت توپوگرافی رادار شاتل (SRTM) با وضوح فضایی 30 متر، برای پیش پردازش و به عنوان داده کمکی برای طبقهبندی استفاده شد.
در مجموع، 2600 نقطه تصادفی به طور تصادفی روی تصاویر Landsat با استفاده از بسته نرم افزاری ArcGIS 10.4 قرار گرفتند [ 24 ]. برای تخصیص کلاس ها به هر یک از 2600 نقطه، از دانش بصری و کارشناسی قبلی از طبقات مختلف پوشش زمین استفاده شد. به 2600 نقطه تصادفی یکی از 10 نوع پوشش زمین شناسایی شده در زمین اختصاص داده شد ( جدول 1 و جدول S1 ). این داده ها به آموزش DT (1000 نقطه نمونه)، طبقه بندی پوشش زمین (1000 نقطه نمونه) و نمونه ارزیابی دقت برای هر دو الگوریتم DT و نقشه پوشش زمین (600 نقطه نمونه) تفکیک شد. مجموعه داده به هر طبقه پوشش زمین با توجه به درصد مساحت تحت پوشش هر طبقه توزیع شد ( جدول 1 را ببینید ).
2.3. مواد و روش ها
2.3.1. پیش پردازش
پیش پردازش شامل تصحیح تصاویر از اثرات جوی و تغییرات توپوگرافی بود. این فرآیند اعداد دیجیتال (DN) را به مقادیر بازتاب زمین تبدیل می کند که برای تجزیه و تحلیل تصویر مفیدتر هستند. برای اطمینان از ثبات در طول تجزیه و تحلیل، همه تصاویر به سیستم پیشبینی جهانی عرضی Mercator (UTM) Zone 35S و World Geodetic System 84 (WGS 84) نمایش داده شدند. ATCOR 3 خودکار موجود در PCI Geomatics (PCI Geomatics، انتاریو، کانادا)، برای حذف مه، تصحیح جو و تصحیح توپوگرافی با ترکیب یک مدل ارتفاع دیجیتال 30 متری استفاده شد.
2.3.2. تقسیم بندی تصویر
تقسیم بندی اشیاء طیفی همگن ایجاد می کند که می تواند به اشیاء واقعی روی زمین مرتبط شود [ 25 ، 26 ]. تحقیقات گذشته چالشها را در ایجاد پارامترهای تقسیمبندی بهینه [ 2 ، 5 ] شناسایی کردند. بنابراین، پارامترهای تقسیمبندی که مقیاس (Sc)، شکل (Sh) و فشردهسازی (Cm) هستند معمولاً با استفاده از روشهای آزمون و خطا ایجاد میشوند [ 4 ، 25 ، 27 ]. Drǎguţ و همکاران. [ 5] یک روش رسمی برای ایجاد سطوح بهینه عوامل مقیاس با استفاده از ابزار تخمین پارامتر مقیاس (ESP) پیشنهاد کرد. برای این مطالعه، ابزار ESP برای Sc 12، برای Sh 0.2 و برای Cm 0.8 نشان داد. با این پارامترهای مقیاس، الگوریتم چند وضوح در eCognition Developer 9.1 (Trimble Navigation Ltd., Sunnyvale, California) برای تقسیمبندی تصاویر به اشیاء همگن طیفی استفاده شد.
2.3.3. انتخاب نمونه و استخراج ویژگی
پس از تقسیم بندی، مرحله بعدی انتخاب نمونه اشیاء با استفاده از 1000 نقطه آموزشی تصادفی و استخراج اطلاعات مربوط به شی بود. چندین مقدار ویژگی مرتبط با شی بر اساس شاخص های طیفی توسعه داده شد ( جدول 2)، مقادیر DEM، مقادیر طیفی هر باند، و ماتریس سطح خاکستری (GLCM). این فرآیند در eCognition Developer 9.1 با استفاده از ابزارهای «تخصیص کلاس بر اساس لایه موضوعی» و «تصویر طبقهبندی شده به نمونه» انجام شد. نمونه ها و اطلاعات مربوط به شی استخراج شده سپس به یک صفحه گسترده صادر شدند. برای ارزیابی عملکرد الگوریتمهای DT در طبقهبندی پوشش زمین، دقت DTها و دقت طبقهبندی نقشههای موضوعی نهایی در نظر گرفته شد. توجه به این نکته ضروری است که ما به دقت حاصل از اعتبارسنجی متقاطع DT ها پس از آموزش به عنوان دقت DT اشاره می کنیم در حالی که دقت نهایی نقشه های موضوعی که از ارزیابی دقت به دست آمده است، به عنوان دقت طبقه بندی پوشش زمین یا نقشه موضوعی نامیده می شود. دقت.
2.3.4. الگوریتم های درخت تصمیم
DTها در طبقه بندی مبتنی بر تصویر استفاده شده اند، زیرا آنها غیر پارامتری هستند و به راحتی قابل تفسیر هستند [ 13 ، 14 ، 46 ]. در OBIA، ایجاد قوانین تصمیم گام مهمی در جهت طبقه بندی پوشش زمین است. با این حال، این مرحله نیاز به آستانه های مربوط به کلاس ها دارد که می توان با استفاده از روش های مبتنی بر دانش یا DT های ساده آن را ایجاد کرد. رویکرد مبتنی بر دانش می تواند پیچیده باشد، به ویژه زمانی که بسیاری از پوشش های زمین و متغیرهای تصمیم درگیر باشند. در اینجا، تمرکز بر روی DTهای بازگشتی باینری بود، که از متغیرهای پاسخ برای تقسیم درختان استفاده می کنند تا زمانی که امکان تقسیم بیشتر وجود نداشته باشد. عملکرد پنج الگوریتم DT ( جدول 3)، Rpart، Tree، Party، C5.0 و Ipred، در این مطالعه با استفاده از رویکرد چند معیاره [ 47 ] ارزیابی شد. ارزیابی شامل سه جزء بود: (1) ارزیابی دقت DTs دقت در خوشه بندی داده های آموزشی. (2) ارزیابی دقت طبقه بندی پوشش زمین. و (3) بررسی سادگی (مثلاً نمودار درختی و تعداد متغیرها) ساختار DTها.
2.3.5. ارزیابی دقت DT
الگوریتم های DT با استفاده از نمونه اطلاعات استخراج شده از نمونه ها آموزش داده شدند. پس از آموزش الگوریتمهای DT، یک مجموعه داده مستقل (600 امتیاز) برای اعتبارسنجی متقابل DTهایی که در طول آموزش تولید شدهاند استفاده شد. مقایسه با استفاده از نتایج پیشبینیشده از DTs و دادههای مستقل که به عنوان دادههای مرجع استفاده شد، انجام شد. دقت بر حسب درصد از مقایسه برای هر پنج الگوریتم DT به دست آمد. هنگامی که از اندازه های مختلف نمونه برای آموزش الگوریتم های DT استفاده شد، مقایسه ای در مورد دقت DT ها انجام شد. نمونه ها (یعنی 1000 نقطه نمونه) به ده نمونه در مضرب 100 تقسیم شدند. بنابراین، کوچکترین حجم نمونه 100 و بزرگترین حجم نمونه 1000 بود ( جدول 4).). این نمونه ها با تصادفی سازی و انتخاب تعداد مشخصی از نمونه ها ایجاد شدند. سپس از نمونههای مستقل برای ارزیابی دقت DTها نسبت به افزایش حجم نمونه استفاده شد. سپس از یک آزمون ناپارامتریک کروسکال-والیس برای ارزیابی تفاوت معنیدار بین دقت DT پنج الگوریتم به دلیل تلاشهای محدود طبقهبندی و غیرعادی بودن دادهها استفاده شد که توسط لی و همکاران پیشنهاد شده است. [ 2 ].
پس از انجام 10 طبقه بندی بر اساس حجم نمونه برای هر DT، بهترین نتیجه برای هر الگوریتم DT در تدوین قوانین برای طبقه بندی پوشش زمین استفاده شد. مجموعه قوانین از خلاصههای خروجی و نمودارهای DT توسعه داده شد. سپس مجموعه قوانین در درخت فرآیند 9.1 توسعهدهنده eCognition برای طبقهبندی پوشش زمین برای تولید نقشههای موضوعی برای پنج DT پیادهسازی شدند.
2.3.6. ارزیابی دقت نقشه موضوعی
طبقه بندی پوشش زمین تنها پس از انجام ارزیابی دقیق بر روی نقشه های موضوعی کامل می شود [ 1 ، 48 ، 49 ]. نمونه مستقل از 600 نقطه اعتبار سنجی تصادفی برای ساخت ماتریس های سردرگمی با مقایسه نقاط پوشش زمین طبقه بندی شده و مرجع استفاده شد. ماتریس های سردرگمی برای محاسبه دقت کاربران، تولیدکنندگان و کلی استفاده شد ( شکل 2 ). مناسب بودن پنج خروجی طبقه بندی پوشش زمین با استفاده از دقت کاربر و تولیدکننده مقایسه شد. دقت کلی نقشه های موضوعی با استفاده از دقت کلی انجام شد.
3. نتایج
3.1. دقت DT
الگوریتمهای DT با استفاده از نتایج پیشبینیشده در برابر یک نمونه مستقل از طریق اعتبارسنجی متقاطع آزمایش شدند. دقت DT از این ارزیابی نشان داد که C5.0 بالاترین (83٪) میانگین دقت DT را داشت، در حالی که حزب دارای کمترین دقت (77٪) بود ( شکل 3 ). با این حال، این تفاوت ها هنگام آزمایش با استفاده از آزمون ناپارامتریک Kruskal-Wallis ( p -value > 0.05) [ 50 ] از نظر آماری معنی دار نبودند.
نتایج حاصل از عملکرد الگوریتمهای DT با حجم نمونههای مختلف نشان میدهد که دقت فردی با افزایش حجم نمونه افزایش مییابد. شکل 4 نشان می دهد که C5.0 بالاترین دقت DT 88٪ را در هنگام استفاده از بزرگترین حجم نمونه 1000 داشت، در حالی که Rpart کمترین دقت 63٪ را در هنگام استفاده از کوچکترین حجم نمونه داشت.
3.2. دقت نقشه موضوعی
3.2.1. تعداد متغیرها و دقت طبقه بندی
کارایی الگوریتم های DT نیز با مقایسه متغیرهای مورد استفاده و دقت نقشه موضوعی نهایی ارزیابی شد. در این مطالعه 197 متغیر اولیه برای آموزش DTها در نظر گرفته شد. Rpart کمترین متغیرها را داشت (8)، در حالی که C5.0 از 35 متغیر برای ساخت یک DT استفاده کرد ( شکل 5 ). Tree و Ipred همچنین متغیرهای کمتری داشتند (کمتر از 15) و دقت طبقهبندی پوشش زمین بالای 85% را حفظ کردند. ساختار DT.
3.2.2. دقت طبقه بندی نقشه موضوعی
دقت کلی و ضریب کاپا، محاسبهشده از ماتریسهای سردرگمی، برای مقایسه دقت طبقهبندی OBIA حاصل از پنج الگوریتم DT استفاده شد. دقت تولید کننده (PA) و کاربر (UA) برای تعیین دقت طبقه بندی هر طبقه پوشش زمین در نظر گرفته شد. نقشه های موضوعی تغییراتی را در نتایج تولید شده نشان داد. الگوریتمهای C5.0 و Part دارای اجزای کوچک پوشش زمین، بهویژه در زمینهای بایر بودند، در حالی که نقشههای موضوعی برای Rpart، Tree و Ipred بخشهای پیوسته را برای زمینهای برهنه نشان دادند ( شکل 6 ).
نتایج نشان می دهد که نقشه موضوعی تولید شده با استفاده از الگوریتم درختی دارای بالاترین دقت کلی 89 درصد است، در حالی که نقشه موضوعی الگوریتم حزب کمترین دقت کلی را با 73 درصد دارد ( جدول 5 و شکل 6).). Rpart، Ipred و C5.0 به ترتیب دارای دقت کلی 88، 85، و 74 درصد بودند. طبقهبندی توسط الگوریتمهای DT با دقت کلی نسبتاً پایین، C5.0 و Party، دارای PA و UAهای بسیار پایینتری (59-43٪) برای کلاسهایی مانند زمینهای بایر و تالابها بود. زمین برهنه کمترین PA و UA، به ترتیب 74 و 62 درصد، برای الگوریتم Rpart و جنگل های اولیه کمترین PA را با 66 درصد داشتند در حالی که دقت UA 96 درصد بود. جنگلهای اولیه و ثانویه کمترین دقت کاربری و تولیدکننده (به ترتیب 39 و 37 درصد) را داشتند که نشاندهنده چالشهای موجود در جداسازی دو پوشش زمین است.
3.2.3. سایر ویژگی های DT
ساختار هر الگوریتم نیز از نظر خروجی گرافیکی، خلاصه های مفید و توانایی تولید مجموعه قوانین به عنوان بخشی از خروجی در نظر گرفته شد. Rpart، Tree، C5.0 و Party دارای نمودارهای درختی به عنوان بخشی از خروجی خود هستند. برخلاف الگوریتمهای Rpart و Tree، C5.0 و Party نمودارهای درختی بزرگی تولید کردند که تفسیر آنها دشوار است. این به دلیل توانایی آنها در گنجاندن متغیرهای زیادی هنگام ساخت DT است. از سوی دیگر، Ipred با توسعه بسیاری از DT و بهبود دقت آنها، در صدد بهبود نتایج طبقه بندی است. تولید یک نمودار درختی منفرد دشوار است زیرا الگوریتم Ipred روی بسیاری از DTها به طور همزمان تمرکز می کند [ 51]. همه الگوریتمهای DT خلاصههایی را تولید میکنند که برای توسعه مجموعه قوانین مفید هستند. با این حال، C5.0 و Rpart قوانین جامعی را برای هر گره پایانه تولید می کنند.
4. بحث
4.1. دقت DT
مقایسه پنج الگوریتم DT نشان داد که دقت DT در بین این الگوریتمها تفاوت معنیداری ندارد. با این حال، C5.0 میانگین دقت DT بالایی را در اندازههای مختلف نمونه نشان داد. این یافته ها با یافته های پاورز و همکاران همخوانی دارد. [ 13 ]، که بیش از 88٪ دقت DT را با استفاده از الگوریتم C5.0 به دست آوردند. این را می توان به توانایی C5.0 در ادغام متغیرهای تصمیم بیشتر در توسعه یک DT از طریق تقویت و بسته بندی نسبت داد [ 52 ، 53 ]. بوستینگ با فرمولبندی مداوم درختهای مستقل که برای تصحیح خطاها در مدلهای نهایی استفاده میشوند، طبقهبندی را بهبود میبخشد، در حالی که در کیسهبندی، چندین درخت فرموله میشوند و درخت نهایی با رأی دادن به دقیقترین متغیرها و تقسیمبندی ایجاد میشود [ 46 ]., 47 , 53 ]. به غیر از C5.0، الگوریتمهای DT مانند Ipred و جنگل تصادفی نیز از کیسهبندی برای بهبود دقت طبقهبندی استفاده میکنند [ 51 ، 54 ، 55 ].
در ارزیابی عملکرد الگوریتمهای DT، استفاده از رویکرد چند معیاره مهم است. دفریز و همکاران [ 47 ] از یک رویکرد معیار چندگانه در ارزیابی عملکرد DT با در نظر گرفتن دقت، توانایی مدیریت نویز در دادهها، زمان محاسبه و ساختار الگوریتمها استفاده کرد. در حالی که الگوریتمها دقت DT پنج الگوریتم تفاوت معنیداری نداشتند، C5.0 میانگین دقت DT نسبتاً بالاتری نسبت به چهار DT دیگر داشت. با این حال، الگوریتم C5.0 به نویز در داده ها بسیار حساس است و ساختار بزرگتری دارند [ 55 ]. در مطالعه حاضر از 35 متغیر استفاده شد و 105 گره برای یک C5.0 DT در مقایسه با الگوریتم های دیگر مانند Rpart که دارای 10 متغیر و 12 گره بود، توسعه یافت.
الگوریتم DTها مانند Rpart و Tree که ساختارهای ساده ای دارند در انتخاب و کاهش تعداد متغیرهای پیش بینی کننده موثر هستند [ 46 ]. رودریگز-گالیانو و همکاران. [ 50 ] گزارش داد که دقت در بین الگوریتم های مختلف DT در نقشه برداری پوشش زمین در منطقه مدیترانه تفاوتی ندارد. با این حال، عملکرد این DT ها به نویز روی داده ها و اندازه نمونه حساس بود. بنابراین، عملکرد الگوریتم نباید تنها بر اساس دقت آماری انتخاب شود، بلکه باید بر اساس معیارهای متعددی که شامل چندین ملاحظات و دقت طبقهبندی نهایی نقشههای موضوعی است، انتخاب شود.
4.2. دقت طبقه بندی نقشه موضوعی
این مطالعه نشان داده است که الگوریتمهای DT ابزار مؤثری در توسعه قواعد تصمیمگیری برای نقشههای موضوعی پوشش زمین هستند. DTها در طبقه بندی پوشش زمین استفاده شده اند زیرا ماهیت آنها ناپارامتریک است و می تواند با تعدادی از داده های کمکی مانند مدل های رقومی ارتفاع (DEM)، شاخص های طیفی و داده های مکانی استفاده شود [ 56 ، 57 ]. به عنوان مثال، Im et al. [ 58 ] از دادههای تشخیص نور و محدوده (LiDAR) و OBIA در طبقهبندی پوشش زمین با استفاده از الگوریتم C5.0 DT استفاده کرد.
با استفاده از این DT ها می توان به دقت طبقه بندی نقشه موضوعی بالا دست یافت. با این حال، دقت از الگوریتمی به الگوریتم دیگر متفاوت است. به دلیل شباهت های طیفی بین برخی از طبقات مانند جنگل های اولیه و ثانویه، دقت آنها به اندازه سایر طبقات پوشش زمین (به عنوان مثال، جنگل های آب و مزرعه) بالا نبود. فیری [ 19 ] چالش های مشابهی را هنگام انجام طبقه بندی پوشش زمین در زامبیا گزارش کرد. شارما و همکاران [ 56] گزارش داد که دقت طبقهبندی پوشش زمین با استفاده از الگوریتمهای CART (بیش از 88 درصد) نسبت به روشهای طبقهبندی سنتی مانند حداکثر احتمال و ISODATA، که دقت کلی کمتر از 72 درصد را به دست آوردند، بهتر بود. با این حال، اکثر مطالعات گزارش کردهاند که سایر الگوریتمهای یادگیری ماشینی مانند ماشینهای بردار پشتیبان، جنگلهای تصادفی و شبکههای عصبی دقت طبقهبندی بالاتری نسبت به DTهای مورد استفاده در این مطالعه ایجاد کردهاند [ 52 ، 56 ، 57 ]. جدای از الگوریتم C5.0، الگوریتم های مبتنی بر CART، مانند Rpart و Tree، متداول ترین الگوریتم هایی هستند که به دلیل سادگی و قابلیت انتخاب و کاهش متغیرها برای طبقه بندی [ 16 ، 57 ] استفاده می شوند.
دقت بالای DT ناشی از اعتبارسنجی متقاطع ممکن است به دقت طبقهبندی پوشش زمین منجر نشود به دلیل: (1) بیش از حد و اشباع بودن الگوریتم. (2) توانایی مدیریت نویز روی داده ها؛ و (3) اندازه و ساختار الگوریتم [ 47 ]. برای مثال، C5.0 دارای میانگین دقت DT بالا مشابه سایر الگوریتمها بود. با این حال، دقت طبقه بندی پوشش زمین نسبتاً پایینی داشت ( جدول 2 ). این بزرگ است زیرا الگوریتم C5.0 مستعد ابتلا به نویز در داده ها است زیرا این الگوریتم توانایی قوی برای رسیدگی به موارد دورافتاده ندارد و بیشتر مستعد تطبیق بیش از حد است [ 47 , 55 ]]. DT های بزرگ باید هرس شوند تا اثرات بیش از حد برازش کاهش یابد. با این حال، هرس ممکن است بر دقت طبقه بندی تاثیر بگذارد [ 13 ].
در این مطالعه، دقت طبقهبندی پوشش زمین برای الگوریتمهای DT مانند Rpart و Tree بالا بود. این DTها همچنین دارای ساختار ساده، توانایی مقابله با نویز در داده ها و دقت پیش بینی آماری بالا بودند. الگوریتمهای سادهای که از حداقل تعداد متغیرهای تصمیم استفاده میکنند، ساختار سادهای دارند، کمتر اشباع میشوند و از این رو به راحتی قابل تفسیر هستند [ 56 ، 57 ]. در بین این الگوریتمهای DT، Rpart و C5.0 معمولاً در طبقهبندی پوشش زمین استفاده میشوند و معمولاً دقت طبقهبندی بالایی را ایجاد میکنند. پاورز و همکاران [ 13] هنگامی که از C5.0 برای ترسیم اختلالات صنعتی در مقیاس خوب استفاده شد، 88٪ دقت کلی را گزارش کرد. یکی دیگر از الگوریتم های DT که ساده و دارای دقت طبقه بندی بالایی است الگوریتم درخت است. با این حال، Rpart به Tree ارجحیت دارد زیرا انعطاف پذیرتر است و بسته های حمایتی زیادی در حال حاضر در نرم افزار آماری R موجود است [ 55 ]. هنگام کار با الگوریتمهای DT برای طبقهبندی پوشش زمین، تعیین اثرات پارامترهای مختلف تنظیم مانند تعداد متغیرها، تعداد شکافها، اندازه درخت و خطای مجاز مهم است زیرا میتوانند بر نتایج طبقهبندی تأثیر بگذارند [ 6 ، 50 ].]. مطالعات آینده میتواند بیشتر بر تأثیر پارامترهای تنظیم مختلف بر دقت طبقهبندی مناظر مختلف و دادههای سنجش از دور مختلف تمرکز کند.
4.3. انتخاب بهترین DT برای توسعه مجموعه قوانین
انتخاب الگوریتم DT ایده آل برای استفاده برای طبقه بندی پوشش زمین باید مهمترین هدف هنگام استفاده از این الگوریتم های DT برای ایجاد قوانین تصمیم گیری در طبقه بندی پوشش زمین OBIA باشد. مهم است که تمام ویژگیهای الگوریتمهای DT مانند دقت مدل، سادگی، توانایی مدیریت تعداد متغیرهای مختلف و اندازه مجموعه دادهها را در نظر بگیریم ( جدول 6 ). این را می توان با استفاده از یک رویکرد ارزیابی چند معیاره که توسط DeFries و همکاران پیشنهاد شده است، به دست آورد. [ 47 ]. تمرکز در این ارزیابی باید بر روی الگوریتمهای DT باشد که دارای دقت طبقهبندی بالا و ساختار ساده هستند و در برابر نویز در دادهها حساس نیستند و به راحتی قابل تفسیر هستند.
در این مطالعه، الگوریتمهای Tree و Rpart برای توسعه قواعد تصمیمگیری توصیه میشوند، بهویژه زمانی که تعداد بیشتری از متغیرها درگیر هستند، زیرا این الگوریتمها توانایی انتخاب تعداد کمی از متغیرهای تأثیرگذار برای طبقهبندی و در نتیجه دستیابی به سادگی و دقت طبقهبندی بالا را دارند [ 47 ، 56 ]. الگوریتم Ipred با Rpart و Tree در بیشتر عملکردهایش تفاوتی ندارد. با این حال، این الگوریتم بر اساس اصل بسته بندی ساخته شده است که دستیابی به سادگی و استخراج قوانین تصمیم گیری دشوار است زیرا چندین درخت تصمیم را تولید می کند. برای استفاده موفقیت آمیز از Ipred، یک تابع (nbagg = 1) که تولید یک DT را مشخص می کند می تواند استفاده شود [ 51]. C5.0 و Party باید زمانی استفاده شوند که هدف شامل متغیرهای پیش بینی کننده بیشتر و ایجاد دقت DT بالا در طول اعتبارسنجی متقابل باشد.
اگرچه دقت کلی بهدستآمده در این مطالعه بالا بود، اما دقت کاربر و تولیدکننده برای کلاسهای مشابه طیفی مانند جنگل اولیه و ثانویه پایین بود. بنابراین نیاز به تعریف کلاس ها به گونه ای است که از نظر طیفی مشابه باشند. علاوه بر این، روشهای دیگری مانند طبقهبندیکنندههای یادگیری ماشینی ناپارامتری، به عنوان مثال، جنگل تصادفی [ 15 ، 19 ، 59 ] و ماشین بردار پشتیبان [ 60 ، 61 ]، که ثابت کردهاند مؤثرتر هستند، میتوانند در طی طبقهبندی به ترتیب استفاده شوند. برای دستیابی به دقت بالاتر
مطالعه حاضر تنها یک مکان دارد و این پتانسیل را دارد که بر قابلیت انتقال و تعمیم نتایج تأثیر بگذارد. این می تواند چالشی برای مطالعات آینده باشد و نتایج حاصل از این مطالعه می تواند تعمیم با سطوحی از عدم قطعیت باشد. توجه به این نکته ضروری است که تعمیم، قابلیت انتقال و تکرارپذیری نتایج تا حد زیادی تحت تأثیر نوع DT مورد استفاده، حجم نمونه و نوع ویژگی های ورودی است.
5. نتیجه گیری ها
در این مقاله، مقایسه ای سیستماتیک از عملکرد پنج الگوریتم DT در طبقه بندی پوشش زمین با استفاده از Landsat 8 ارائه شده است. تمرکز اصلی بر انتخاب الگوریتمهای DT بود که دارای دقت طبقهبندی بالا، ساختار ساده و تفسیر آسان هستند، با استفاده از رویکرد معیارهای چندگانه پیشنهاد شده توسط DeFries و همکاران. [ 47]. در حالی که همه الگوریتمها دارای میانگین دقت DT بالایی بودند، مشخص شد که الگوریتمهای Tree و Rpart ساده، آسان برای تفسیر هستند و تحت تأثیر نویز مجموعه دادهها قرار نمیگیرند. نتایج حاصل از الگوریتم های Tree و Rpart DT دقت کلی بالای بیش از 86% را ایجاد می کند. الگوریتمهای C5.0 و Party با توجه به دقت کلی به همان اندازه خوب بودند. با این حال، آنها تعداد زیادی از متغیرهای تصمیم گیری را در خروجی ترکیب می کنند که اجرای آنها می تواند دشوار باشد و اثرات اضافه برازش و اشباع را نشان دهند. تجزیه و تحلیل بیشتر نشان داد که Rpart و Tree می توانند حداقل تعداد متغیرها را انتخاب کنند و از این رو قوانین ساده اما دقیق را حفظ کنند. بر اساس DT و دقت پوشش زمین و سایر جنبه های مهم مانند تعداد متغیر و سادگی ساختار DT، می توان استفاده از Rpart یا Tree را در ایجاد مجموعه قوانین برای طبقه بندی پوشش زمین OBIA از تصاویر Landsat 8 توصیه کرد. در آینده، مطالعات آینده میتوانند عملکرد این DTهای ساده را با طبقهبندیکنندههای یادگیری ماشینی معاصر مانند RF و SVM در مکانهای جغرافیایی مختلف در دورههای زمانی مختلف مقایسه کنند.
منابع
- کومار، آر. نندی، اس. آگاروال، آر. کوشواها، تحلیل دینامیک پوشش جنگل SPS و مدلسازی پیشبینی با استفاده از مدل رگرسیون لجستیک. Ecol. اندیک. 2014 ، 45 ، 444-455. [ Google Scholar ] [ CrossRef ]
- لی، ام. ما، ال. بلاشکه، تی. چنگ، ال. Tiede، D. مقایسه سیستماتیک تکنیک های مختلف طبقه بندی مبتنی بر شی با استفاده از تصاویر با وضوح فضایی بالا در محیط های کشاورزی. بین المللی J. Appl. زمین Obs. Geoinf. 2016 ، 49 ، 87-98. [ Google Scholar ] [ CrossRef ]
- پنا-باراگان، جی.ام. Ngugi، MK; کارخانه، RE; شش، J. شناسایی محصول مبتنی بر شی با استفاده از شاخصهای چندگانه پوشش گیاهی، ویژگیهای بافتی و فنولوژی محصول. سنسور از راه دور محیط. 2011 ، 115 ، 1301-1316. [ Google Scholar ] [ CrossRef ]
- کیندو، م. اشنایدر، تی. تکتای، دی. Knoke، T. تحلیل تغییر کاربری/پوشش زمین با استفاده از رویکرد طبقهبندی مبتنی بر شی در چشمانداز مونسا-ششمنی ارتفاعات اتیوپی. Remote Sens. 2013 , 5 , 2411–2435. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Drǎguţ، L. تاید، دی. Levick، SR ESP: ابزاری برای تخمین پارامتر مقیاس برای تقسیمبندی تصویر با وضوح چندگانه دادههای سنجش از راه دور. بین المللی جی. جئوگر. Inf. علمی 2010 ، 24 ، 859-871. [ Google Scholar ] [ CrossRef ]
- فیری، دی. مورگنروث، جی. Xu, C. چهار دهه مطالعه پوشش زمین و اتصال جنگل در زامبیا – یک رویکرد تجزیه و تحلیل تصویر مبتنی بر شی. بین المللی J. Appl. زمین Obs. Geoinf. 2019 ، 79 ، 97-109. [ Google Scholar ] [ CrossRef ]
- کلی، م. بلانچارد، SD; کرستن، ای. Koy، K. تصاویر سنجش از دور زمینی در حمایت از سلامت عمومی: راه های جدید تحقیق با استفاده از تجزیه و تحلیل تصویر مبتنی بر شی. Remote Sens. 2011 , 3 , 2321–2345. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فیری، دی. مورگنروث، جی. خو، سی. Hermosilla, T. اثرات روشهای پیش پردازش بر طبقهبندی پوشش اراضی Landsat OLI-8 با استفاده از OBIA و طبقهبندی جنگلهای تصادفی. بین المللی J. Appl. زمین Obs. Geoinf. 2018 ، 73 ، 170-178. [ Google Scholar ] [ CrossRef ]
- لی، ام. زنگ، س. وو، سی. دنگ، ی. تجزیه و تحلیل مخلوط طیفی مبتنی بر تقسیم بندی و مبتنی بر قانون برای تخمین نفوذناپذیری شهری. Adv. Space Res. 2015 ، 55 ، 1307-1315. [ Google Scholar ] [ CrossRef ]
- Myint، SW; گوبر، پ. برازل، ا. گروسمن کلارک، اس. Weng، Q. طبقهبندی بر پیکسل در مقابل شیء مبتنی بر استخراج پوشش زمین شهری با استفاده از تصاویر با وضوح فضایی بالا. سنسور از راه دور محیط. 2011 ، 115 ، 1145-1161. [ Google Scholar ] [ CrossRef ]
- فیری، دی. سیمواندا، م. Nyirenda، V. نقشه برداری از اثرات طوفان Idai در موزامبیک با استفاده از Sentinel-2 و رویکرد OBIA. اس افر. جی. جئوگر. 2020 . [ Google Scholar ] [ CrossRef ]
- لو، دی. Weng, Q. بررسی روش ها و تکنیک های طبقه بندی تصویر برای بهبود عملکرد طبقه بندی. بین المللی J. Remote Sens. 2007 , 28 , 823-870. [ Google Scholar ] [ CrossRef ]
- قدرت، RP; هرموسیلا، تی. Coops، NC; چن، جی. سنجش از دور و تکنیکهای مبتنی بر شی برای نقشهبرداری آشفتگیهای صنعتی در مقیاس خوب. بین المللی J. Appl. زمین Obs. Geoinf. 2015 ، 34 ، 51-57. [ Google Scholar ] [ CrossRef ]
- فیری، دی. مورگنروث، جی. Xu, C. تغییر طولانی مدت پوشش زمین در زامبیا: ارزیابی عوامل محرک. علمی کل محیط. 2019 ، 134206. [ Google Scholar ] [ CrossRef ]
- پوسانت، ا. روژیر، اس. Stumpf, A. نقشه برداری شی گرا از درختان شهری با استفاده از طبقه بندی جنگل تصادفی. بین المللی J. Appl. زمین Obs. Geoinf. 2014 ، 26 ، 235-245. [ Google Scholar ] [ CrossRef ]
- فروند، ی. میسون، ال. الگوریتم یادگیری درخت تصمیم متناوب. در مجموعه مقالات ICML، شانزدهمین کنفرانس بین المللی یادگیری ماشین، بلد، اسلوونی، 27 تا 30 ژوئن 1999. صص 124-133. [ Google Scholar ]
- بلژیک، م. Drăguţ، L. جنگل تصادفی در سنجش از دور: بررسی برنامهها و جهتهای آینده. ISPRS J. Photogramm. Remote Sens. 2016 ، 114 ، 24–31. [ Google Scholar ] [ CrossRef ]
- فیری، دی. فیری، ای. کاسوبیکا، ر. زولو، دی. Lwali، C. مفهوم استفاده از یک فاکتور فرم ثابت در مناطق تحت شرایط بارندگی و خاک مختلف برای Pinus kesiya در زامبیا. جنوب. برای. جی. برای. علمی 2016 ، 78 ، 35-39. [ Google Scholar ] [ CrossRef ]
- فیری، دی. پایش دینامیک پوشش زمین برای زامبیا با استفاده از سنجش از دور: 1972-2016. دکتری پایان نامه، دانشگاه کانتربری، کرایست چرچ، نیوزلند، 2019. [ Google Scholar ]
- کالابا، FK; کوین، CH; داگیل، ای جی؛ Vinya، R. ترکیب گلشناسی، تنوع گونهها و ذخیرهسازی کربن در زغالسنگ و آیشهای کشاورزی و پیامدهای مدیریتی در جنگلهای Miombo زامبیا. برای. Ecol. مدیریت 2013 ، 304 ، 99-109. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- فیری، دی. Morgenroth، J. تحولات در روش های طبقه بندی پوشش زمین Landsat: یک بررسی. Remote Sens. 2017 , 9 , 967. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- Wulder، MA; سفید، JC; لاولند، TR; Woodcock، CE; بلوارد، ع. کوهن، WB; Fosnight، EA؛ شاو، جی. ماسک، جی جی. روی، DP آرشیو جهانی لندست: وضعیت، تثبیت و جهت. سنسور از راه دور محیط. 2016 ، 185 ، 271-283. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- پورسانیدیس، د. کریسولاکیس، ن. Mitraka, Z. Landsat 8 در مقابل Landsat 5: مقایسه ای بر اساس نقشه برداری پوشش زمین شهری و حومه شهری. بین المللی J. Appl. زمین Obs. Geoinf. 2015 ، 35 Pt B ، 259–269. [ Google Scholar ] [ CrossRef ]
- ESRI. ArcGIS دسکتاپ. انتشار 10.4 ; موسسه تحقیقات سیستم محیطی: Relands، CA، ایالات متحده آمریکا، 2016. [ Google Scholar ]
- حسین، م. چن، دی. چنگ، ا. وی، اچ. Stanley, D. تغییر تشخیص از تصاویر سنجش از راه دور: از رویکردهای مبتنی بر پیکسل به رویکردهای مبتنی بر شی. ISPRS J. Photogramm. Remote Sens. 2013 ، 80 ، 91-106. [ Google Scholar ] [ CrossRef ]
- رسولی، ع. نقدی فر، ر. رسولی، م. پایش تغییرات خط ساحلی دریای خزر با استفاده از تکنیک های شی گرا. Procedia Environ. علمی 2010 ، 2 ، 416-426. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- ژاکین، ا. میساکووا، ال. Gay, M. یک رویکرد طبقه بندی مبتنی بر شی ترکیبی برای نقشه برداری پراکندگی شهری در محیط پیرامون شهری. Landsc. طرح شهری. 2008 ، 84 ، 152-165. [ Google Scholar ] [ CrossRef ]
- لیائو، LM؛ آهنگ، جی ال. وانگ، جی دی. شیائو، ZQ؛ روش Wang, J. Bayesian برای ساخت مجموعه داده های NDVI مکرر مشابه Landsat با ادغام MODIS و Landsat NDVI. Remote Sens. 2016 ، 8 ، 452. [ Google Scholar ] [ CrossRef ] [ نسخه سبز ]
- Zhu، XL; لیو، دی اس بهبود تخمین زیست توده بالای زمینی جنگل با استفاده از سری زمانی فصلی Landsat NDVI. ISPRS J. Photogramm. Remote Sens. 2015 ، 102 ، 222-231. [ Google Scholar ] [ CrossRef ]
- هیوت، ا. دیدان، ک. میورا، تی. رودریگز، EP; گائو، ایکس. Ferreira، LG مروری بر عملکرد رادیومتری و بیوفیزیکی شاخصهای پوشش گیاهی MODIS. سنسور از راه دور محیط. 2002 ، 83 ، 195-213. [ Google Scholar ] [ CrossRef ]
- Gitelson، AA; مرزلیاک، MN سنجش از دور غلظت کلروفیل در برگ های گیاه بالاتر. Adv. Space Res. 1998 ، 22 ، 689-692. [ Google Scholar ] [ CrossRef ]
- Sripada، RP; هاینیگر، RW; سفید، JG; عکسبرداری رنگی مادون قرمز هوایی Meijer، AD برای تعیین نیازهای نیتروژن اولیه در ذرت. آگرون. J. 2006 ، 98 ، 968-977. [ Google Scholar ] [ CrossRef ]
- آتزبرگر، سی. درویش زاده، ر. ایمیتزر، ام. شلرف، ام. اسکیدمور، آ. Le Maire, G. تجزیه و تحلیل مقایسه ای روش های مختلف بازیابی برای نقشه برداری شاخص سطح برگ مرتع با استفاده از طیف سنجی تصویربرداری هوابرد. بین المللی J. Appl. زمین Obs. Geoinf. 2015 ، 43 ، 19-31. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- تولد، GS; McVey, GR اندازه گیری رنگ چمن در حال رشد با اسپکتروفتومتر بازتابی. آگرون. J. 1968 , 60 , 640-643. [ Google Scholar ] [ CrossRef ]
- گوئل، NS; Qin، W. تأثیرات معماری تاج پوشش بر روابط بین شاخص های مختلف پوشش گیاهی و LAI و FPAR: یک شبیه سازی کامپیوتری. Remote Sens. Rev. 1994 , 10 , 309-347. [ Google Scholar ] [ CrossRef ]
- روندو، جی. استیون، ام. Baret, F. بهینه سازی شاخص های پوشش گیاهی با خاک. سنسور از راه دور محیط. 1996 ، 55 ، 95-107. [ Google Scholar ] [ CrossRef ]
- Huete، AR یک شاخص پوشش گیاهی با خاک (SAVI). سنسور از راه دور محیط. 1988 ، 25 ، 295-309. [ Google Scholar ] [ CrossRef ]
- Roujean, J.-L.; بریون، F.-M. برآورد PAR جذب شده توسط پوشش گیاهی از اندازهگیریهای بازتاب دو طرفه. سنسور از راه دور محیط. 1995 ، 51 ، 375-384. [ Google Scholar ] [ CrossRef ]
- کلید، سی. Benson، N. ارزیابی چشمانداز: سنجش از دور شدت، نسبت سوختگی نرمال شده و اندازهگیری شدت شدت، شاخص سوختگی مرکب. در FIREMON: Fire Effects Monitoring and Inventory System Ogden، یوتا: USDA Forest Service، Rocky Mountain Res. ایستگاه ؛ خدمات جنگلی USDA، ایستگاه تحقیقاتی کوه راکی: Ogden، UT، ایالات متحده آمریکا، 2005. [ Google Scholar ]
- گارسیا، ام ال. Caselles، V. نقشه برداری سوختگی ها و احیای جنگل های طبیعی با استفاده از داده های Thematic Mapper. Geocarto Int. 1991 ، 6 ، 31-37. [ Google Scholar ] [ CrossRef ]
- Segal, D. مبانی نظری برای تمایز مواد معدنی حاوی آهن آهن با استفاده از داده های Landsat MSS. در مجموعه مقالات سمپوزیوم بین المللی سنجش از دور محیط زیست، دومین کنفرانس موضوعی، سنجش از دور برای زمین شناسی اکتشافی 1982، Ft. Worth, TX, USA, 6-10 دسامبر 1982; جلد دوم، ص 949–951. [ Google Scholar ]
- ژا، ی. گائو، جی. Ni، S. استفاده از شاخص ایجاد تفاوت نرمال شده در نقشه برداری خودکار مناطق شهری از تصاویر TM. بین المللی J. Remote Sens. 2003 , 24 , 583-594. [ Google Scholar ] [ CrossRef ]
- سالومونسون، وی. Appel, I. برآورد پوشش کسری برف از MODIS با استفاده از شاخص تفاوت نرمال شده برف. سنسور از راه دور محیط. 2004 ، 89 ، 351-360. [ Google Scholar ] [ CrossRef ]
- Silleos، NG; الکساندریدیس، TK; گیتاس، IZ; پراکیس، K. شاخص های گیاهی: پیشرفت های انجام شده در تخمین زیست توده و پایش پوشش گیاهی در 30 سال گذشته. Geocarto Int. 2006 ، 21 ، 21-28. [ Google Scholar ] [ CrossRef ]
- گائو، B.-C. NDWI – یک شاخص تفاوت نرمال شده آب برای سنجش از راه دور آب مایع گیاهی از فضا. سنسور از راه دور محیط. 1996 ، 58 ، 257-266. [ Google Scholar ] [ CrossRef ]
- پونیا، م. جوشی، پ. Porwal، M. طبقه بندی درخت تصمیم از پوشش زمین کاربری برای دهلی، هند با استفاده از داده های IRS-P6 AWiFS. سیستم خبره Appl. 2011 ، 38 ، 5577-5583. [ Google Scholar ] [ CrossRef ]
- DeFries، RS; چان، JC-W. معیارهای چندگانه برای ارزیابی الگوریتم های یادگیری ماشین برای طبقه بندی پوشش زمین از داده های ماهواره ای. سنسور از راه دور محیط. 2000 ، 74 ، 503-515. [ Google Scholar ] [ CrossRef ]
- Congalton، RG; گرین، ک. ارزیابی دقت دادههای سنجش از راه دور: اصول و روشها . CRC Press/Taylor & Francis: Boca Raton, FL, USA, 2009; جلد 2. [ Google Scholar ]
- اولوفسون، پی. فودی، جنرال موتورز; هرولد، ام. Stehman، SV; Woodcock، CE; Wulder، MA شیوه های خوب برای تخمین مساحت و ارزیابی دقت تغییر زمین. سنسور از راه دور محیط. 2014 ، 148 ، 42-57. [ Google Scholar ] [ CrossRef ]
- رودریگز-گالیانو، وی اف. Chica-Rivas، M. ارزیابی روشهای مختلف یادگیری ماشین برای نقشهبرداری پوشش زمین از یک منطقه مدیترانه با استفاده از تصاویر چند فصلی Landsat و مدلهای زمین دیجیتال. بین المللی جی دیجیت. زمین 2014 ، 7 ، 492-509. [ Google Scholar ] [ CrossRef ]
- پیترز، آ. هاثورن، تی. Ipred: پیش بینی کننده های بهبود یافته. بسته R نسخه 0.9-6. 2017. در دسترس آنلاین: https://CRAN.R-project.org/package=ipred (در 6 ژوئن 2017 قابل دسترسی است).
- چان، JC-W. هوانگ، سی. DeFries، R. بهبود عملکرد الگوریتم برای طبقه بندی پوشش زمین از داده های سنجش از راه دور با استفاده از بسته بندی و تقویت. IEEE Trans. Geosci. Remote Sens. 2001 , 39 , 693-695. [ Google Scholar ]
- کوهن، م. استیو، دبلیو. Coulter, N. C50: C5.0 Decision Trees and Rule-based Models. بسته R نسخه 0.1.0-24. 2015. در دسترس آنلاین: https://CRAN.R-project.org/package=C50 (در 6 ژوئن 2017 قابل دسترسی است).
- دورو، دی سی؛ فرانکلین، SE; Dubé، MG مقایسه تحلیل تصویر مبتنی بر پیکسل و شی با الگوریتمهای یادگیری ماشین انتخاب شده برای طبقهبندی مناظر کشاورزی با استفاده از تصاویر SPOT-5 HRG. سنسور از راه دور محیط. 2012 ، 118 ، 259-272. [ Google Scholar ] [ CrossRef ]
- Lantz, B. Machine Learning with R , 1st ed.; Packt Publishing: بیرمنگام، بریتانیا، 2013. [ Google Scholar ]
- شارما، آر. قوش، ع. Joshi, P. رویکرد درخت تصمیم برای طبقه بندی داده های ماهواره ای سنجش از دور با استفاده از پشتیبانی منبع باز. J. Earth Syst. علمی 2013 ، 122 ، 1237-1247. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- شائو، ی. Lunetta، RS مقایسه ماشین بردار پشتیبان، شبکه عصبی و الگوریتمهای CART برای طبقهبندی پوشش زمین با استفاده از نقاط داده آموزشی محدود. ISPRS J. Photogramm. Remote Sens. 2012 ، 70 ، 78-87. [ Google Scholar ] [ CrossRef ]
- من، جی. جنسن، جی آر. هاجسون، ME طبقهبندی پوشش زمین مبتنی بر شی با استفاده از دادههای LiDAR با چگالی بالا. GIScience Remote Sens. 2008 ، 45 ، 209-228. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- رودریگز-گالیانو، وی اف. قیمیر، بی. روگان، جی. چیکا اولمو، م. Rigol-Sanchez، JP ارزیابی اثربخشی طبقهبندیکننده تصادفی جنگل برای طبقهبندی پوشش زمین. ISPRS J. Photogramm. Remote Sens. 2012 ، 67 ، 93-104. [ Google Scholar ] [ CrossRef ]
- کرانچیچ، ن. مداک، د. ژوپان، آر. Rezo، MJRS بردار پشتیبان ارزیابی دقت ماشین برای استخراج مناطق سبز شهری در شهرها. Remote Sens. 2019 , 11 , 655. [ Google Scholar ] [ CrossRef ][ نسخه سبز ]
- هوانگ، سی. دیویس، LS; Townshend، JRG ارزیابی ماشینهای بردار پشتیبان برای طبقهبندی پوشش زمین. بین المللی J. Remote Sens. 2002 ، 23 ، 725-749. [ Google Scholar ] [ CrossRef ]
شکل 1. مرزهای اداری استان مس کمربند زامبیا شامل رودخانه ها و شهرهای اصلی.
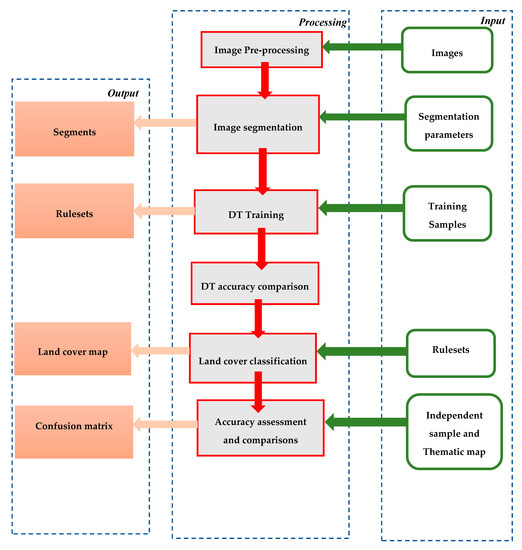
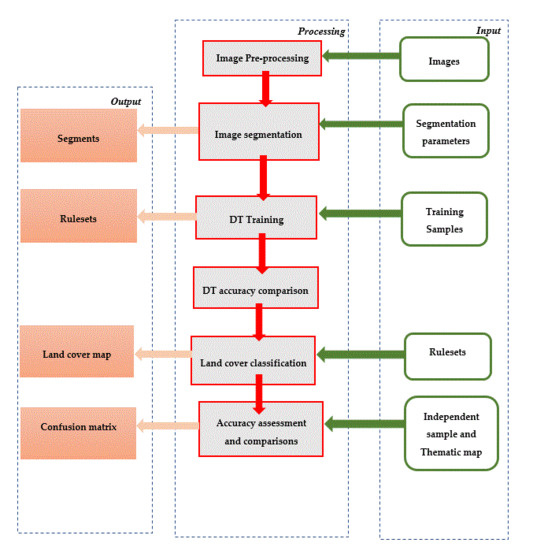
شکل 2. نمودار جریان مراحل استفاده شده در مطالعه.
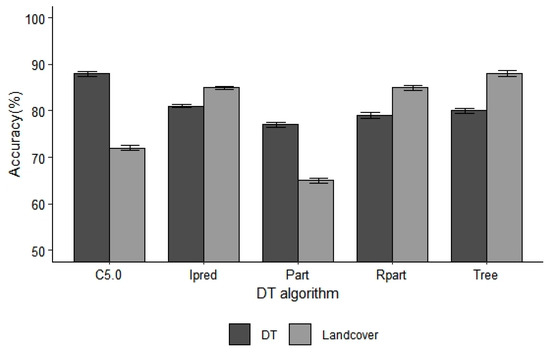
شکل 3. میانگین دقت DT پنج درخت تصمیم با استفاده از اعتبارسنجی متقاطع.
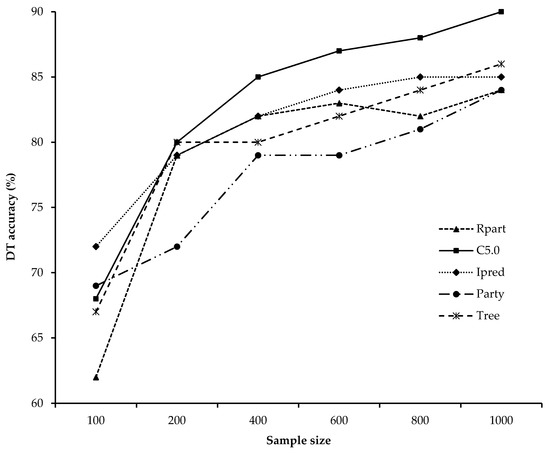
شکل 4. دقت الگوریتم های DT با افزایش حجم نمونه.
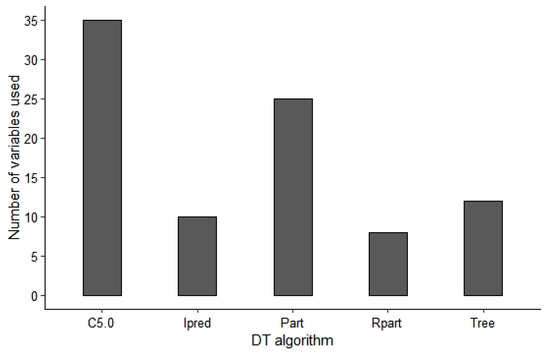
شکل 5. دقت طبقه بندی نقشه موضوعی (%) و تعداد متغیرهای مورد استفاده در طول طبقه بندی.
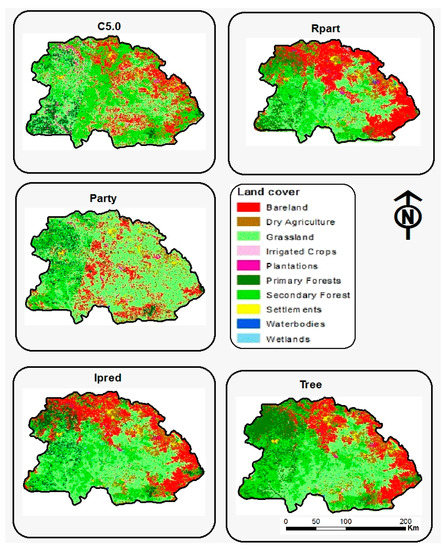
شکل 6. نقشه های طبقه بندی پوشش زمین با استفاده از مجموعه قوانین توسعه یافته از پنج الگوریتم DT.


بدون دیدگاه